基于Redis的4种延时队列实现方式
延时队列是一种特殊的消息队列,它允许消息在指定的时间后被消费。在微服务架构、电商系统和任务调度场景中,延时队列扮演着关键角色。例如,订单超时自动取消、定时提醒、延时支付等都依赖延时队列实现。
Redis作为高性能的内存数据库,具备原子操作、数据结构丰富和简单易用的特性,本文将介绍基于Redis实现分布式延时队列的四种方式。
1. 基于Sorted Set的延时队列
原理
利用Redis的Sorted Set(有序集合),将消息ID作为member,执行时间戳作为score进行存储。通过ZRANGEBYSCORE命令可以获取到达执行时间的任务。
代码实现
public class RedisZSetDelayQueue {private final StringRedisTemplate redisTemplate;private final String queueKey = "delay_queue:tasks";public RedisZSetDelayQueue(StringRedisTemplate redisTemplate) {this.redisTemplate = redisTemplate;}/*** 添加延时任务* @param taskId 任务ID* @param taskInfo 任务信息(JSON字符串)* @param delayTime 延迟时间(秒)*/public void addTask(String taskId, String taskInfo, long delayTime) {// 计算执行时间long executeTime = System.currentTimeMillis() + delayTime * 1000;// 存储任务详情redisTemplate.opsForHash().put("delay_queue:details", taskId, taskInfo);// 添加到延时队列redisTemplate.opsForZSet().add(queueKey, taskId, executeTime);System.out.println("Task added: " + taskId + ", will execute at: " + executeTime);}/*** 轮询获取到期任务*/public List<String> pollTasks() {long now = System.currentTimeMillis();// 获取当前时间之前的任务Set<String> taskIds = redisTemplate.opsForZSet().rangeByScore(queueKey, 0, now);if (taskIds == null || taskIds.isEmpty()) {return Collections.emptyList();}// 获取任务详情List<String> tasks = new ArrayList<>();for (String taskId : taskIds) {String taskInfo = (String) redisTemplate.opsForHash().get("delay_queue:details", taskId);if (taskInfo != null) {tasks.add(taskInfo);// 从集合和详情中移除任务redisTemplate.opsForZSet().remove(queueKey, taskId);redisTemplate.opsForHash().delete("delay_queue:details", taskId);}}return tasks;}// 定时任务示例public void startTaskProcessor() {ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);scheduler.scheduleAtFixedRate(() -> {try {List<String> tasks = pollTasks();for (String task : tasks) {processTask(task);}} catch (Exception e) {e.printStackTrace();}}, 0, 1, TimeUnit.SECONDS);}private void processTask(String taskInfo) {System.out.println("Processing task: " + taskInfo);// 实际任务处理逻辑}
}
优缺点
优点
- 实现简单,易于理解
- 任务按执行时间自动排序
- 支持精确的时间控制
缺点
- 需要轮询获取到期任务,消耗CPU资源
- 大量任务情况下,
ZRANGEBYSCORE操作可能影响性能 - 没有消费确认机制,需要额外实现
2. 基于List + 定时轮询的延时队列
原理
这种方式使用多个List作为存储容器,按延迟时间的不同将任务分配到不同的队列中。通过定时轮询各个队列,将到期任务移动到一个立即执行队列。
代码实现
public class RedisListDelayQueue {private final StringRedisTemplate redisTemplate;private final String readyQueueKey = "delay_queue:ready"; // 待处理队列private final Map<Integer, String> delayQueueKeys; // 延迟队列,按延时时间分级public RedisListDelayQueue(StringRedisTemplate redisTemplate) {this.redisTemplate = redisTemplate;// 初始化不同延迟级别的队列delayQueueKeys = new HashMap<>();delayQueueKeys.put(5, "delay_queue:delay_5s"); // 5秒delayQueueKeys.put(60, "delay_queue:delay_1m"); // 1分钟delayQueueKeys.put(300, "delay_queue:delay_5m"); // 5分钟delayQueueKeys.put(1800, "delay_queue:delay_30m"); // 30分钟}/*** 添加延时任务*/public void addTask(String taskInfo, int delaySeconds) {// 选择合适的延迟队列String queueKey = selectDelayQueue(delaySeconds);// 任务元数据,包含任务信息和执行时间long executeTime = System.currentTimeMillis() + delaySeconds * 1000;String taskData = executeTime + ":" + taskInfo;// 添加到延迟队列redisTemplate.opsForList().rightPush(queueKey, taskData);System.out.println("Task added to " + queueKey + ": " + taskData);}/*** 选择合适的延迟队列*/private String selectDelayQueue(int delaySeconds) {// 找到最接近的延迟级别int closestDelay = delayQueueKeys.keySet().stream().filter(delay -> delay >= delaySeconds).min(Integer::compareTo).orElse(Collections.max(delayQueueKeys.keySet()));return delayQueueKeys.get(closestDelay);}/*** 移动到期任务到待处理队列*/public void moveTasksToReadyQueue() {long now = System.currentTimeMillis();// 遍历所有延迟队列for (String queueKey : delayQueueKeys.values()) {boolean hasMoreTasks = true;while (hasMoreTasks) {// 查看队列头部任务String taskData = redisTemplate.opsForList().index(queueKey, 0);if (taskData == null) {hasMoreTasks = false;continue;}// 解析任务执行时间long executeTime = Long.parseLong(taskData.split(":", 2)[0]);// 检查是否到期if (executeTime <= now) {// 通过LPOP原子性地移除队列头部任务String task = redisTemplate.opsForList().leftPop(queueKey);// 任务可能被其他进程处理,再次检查if (task != null) {// 提取任务信息并添加到待处理队列String taskInfo = task.split(":", 2)[1];redisTemplate.opsForList().rightPush(readyQueueKey, taskInfo);System.out.println("Task moved to ready queue: " + taskInfo);}} else {// 队列头部任务未到期,无需检查后面的任务hasMoreTasks = false;}}}}/*** 获取待处理任务*/public String getReadyTask() {return redisTemplate.opsForList().leftPop(readyQueueKey);}/*** 启动任务处理器*/public void startTaskProcessors() {// 定时移动到期任务ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(2);// 移动任务线程scheduler.scheduleAtFixedRate(this::moveTasksToReadyQueue, 0, 1, TimeUnit.SECONDS);// 处理任务线程scheduler.scheduleAtFixedRate(() -> {String task = getReadyTask();if (task != null) {processTask(task);}}, 0, 100, TimeUnit.MILLISECONDS);}private void processTask(String taskInfo) {System.out.println("Processing task: " + taskInfo);// 实际任务处理逻辑}
}
优缺点
优点
- 分级队列设计,降低单队列压力
- 相比Sorted Set占用内存少
- 支持队列监控和任务优先级
缺点
- 延迟时间精度受轮询频率影响
- 实现复杂度高
- 需要维护多个队列
- 时间判断和队列操作非原子性,需特别处理并发问题
3. 基于发布/订阅(Pub/Sub)的延时队列
原理
结合Redis发布/订阅功能与本地时间轮算法,实现延迟任务的分发和处理。任务信息存储在Redis中,而时间轮负责任务的调度和发布。
代码实现
public class RedisPubSubDelayQueue {private final StringRedisTemplate redisTemplate;private final String TASK_TOPIC = "delay_queue:task_channel";private final String TASK_HASH = "delay_queue:tasks";private final HashedWheelTimer timer;public RedisPubSubDelayQueue(StringRedisTemplate redisTemplate) {this.redisTemplate = redisTemplate;// 初始化时间轮,刻度100ms,轮子大小512this.timer = new HashedWheelTimer(100, TimeUnit.MILLISECONDS, 512);// 启动消息订阅subscribeTaskChannel();}/*** 添加延时任务*/public void addTask(String taskId, String taskInfo, long delaySeconds) {// 存储任务信息到RedisredisTemplate.opsForHash().put(TASK_HASH, taskId, taskInfo);// 添加到时间轮timer.newTimeout(timeout -> {// 发布任务就绪消息redisTemplate.convertAndSend(TASK_TOPIC, taskId);}, delaySeconds, TimeUnit.SECONDS);System.out.println("Task scheduled: " + taskId + ", delay: " + delaySeconds + "s");}/*** 订阅任务通道*/private void subscribeTaskChannel() {redisTemplate.getConnectionFactory().getConnection().subscribe((message, pattern) -> {String taskId = new String(message.getBody());// 获取任务信息String taskInfo = (String) redisTemplate.opsForHash().get(TASK_HASH, taskId);if (taskInfo != null) {// 处理任务processTask(taskId, taskInfo);// 删除任务redisTemplate.opsForHash().delete(TASK_HASH, taskId);}}, TASK_TOPIC.getBytes());}private void processTask(String taskId, String taskInfo) {System.out.println("Processing task: " + taskId + " - " + taskInfo);// 实际任务处理逻辑}// 模拟HashedWheelTimer类public static class HashedWheelTimer {private final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);private final long tickDuration;private final TimeUnit unit;public HashedWheelTimer(long tickDuration, TimeUnit unit, int wheelSize) {this.tickDuration = tickDuration;this.unit = unit;}public void newTimeout(TimerTask task, long delay, TimeUnit timeUnit) {long delayMillis = timeUnit.toMillis(delay);scheduler.schedule(() -> task.run(null), delayMillis, TimeUnit.MILLISECONDS);}public interface TimerTask {void run(Timeout timeout);}public interface Timeout {}}
}
优缺点
优点:
- 即时触发,无需轮询
- 高效的时间轮算法
- 可以跨应用订阅任务
- 分离任务调度和执行,降低耦合
缺点:
- 依赖本地时间轮,非纯Redis实现
- Pub/Sub模式无消息持久化,可能丢失消息
- 服务重启时需要重建时间轮
- 订阅者需要保持连接
4. 基于Redis Stream的延时队列
原理
Redis 5.0引入的Stream是一个强大的数据结构,专为消息队列设计。结合Stream的消费组和确认机制,可以构建可靠的延时队列。
代码实现
public class RedisStreamDelayQueue {private final StringRedisTemplate redisTemplate;private final String delayQueueKey = "delay_queue:stream";private final String consumerGroup = "delay_queue_consumers";private final String consumerId = UUID.randomUUID().toString();public RedisStreamDelayQueue(StringRedisTemplate redisTemplate) {this.redisTemplate = redisTemplate;// 创建消费者组try {redisTemplate.execute((RedisCallback<String>) connection -> {connection.streamCommands().xGroupCreate(delayQueueKey.getBytes(), consumerGroup, ReadOffset.from("0"), true);return "OK";});} catch (Exception e) {// 消费者组可能已存在System.out.println("Consumer group may already exist: " + e.getMessage());}}/*** 添加延时任务*/public void addTask(String taskInfo, long delaySeconds) {long executeTime = System.currentTimeMillis() + delaySeconds * 1000;Map<String, Object> task = new HashMap<>();task.put("executeTime", String.valueOf(executeTime));task.put("taskInfo", taskInfo);redisTemplate.opsForStream().add(delayQueueKey, task);System.out.println("Task added: " + taskInfo + ", execute at: " + executeTime);}/*** 获取待执行的任务*/public List<String> pollTasks() {long now = System.currentTimeMillis();List<String> readyTasks = new ArrayList<>();// 读取尚未处理的消息List<MapRecord<String, Object, Object>> records = redisTemplate.execute((RedisCallback<List<MapRecord<String, Object, Object>>>) connection -> {return connection.streamCommands().xReadGroup(consumerGroup.getBytes(),consumerId.getBytes(),StreamReadOptions.empty().count(10),StreamOffset.create(delayQueueKey.getBytes(), ReadOffset.from(">")));});if (records != null) {for (MapRecord<String, Object, Object> record : records) {String messageId = record.getId().getValue();Map<Object, Object> value = record.getValue();long executeTime = Long.parseLong((String) value.get("executeTime"));String taskInfo = (String) value.get("taskInfo");// 检查任务是否到期if (executeTime <= now) {readyTasks.add(taskInfo);// 确认消息已处理redisTemplate.execute((RedisCallback<String>) connection -> {connection.streamCommands().xAck(delayQueueKey.getBytes(),consumerGroup.getBytes(),messageId.getBytes());return "OK";});// 可选:从流中删除消息redisTemplate.opsForStream().delete(delayQueueKey, messageId);} else {// 任务未到期,放回队列redisTemplate.execute((RedisCallback<String>) connection -> {connection.streamCommands().xAck(delayQueueKey.getBytes(),consumerGroup.getBytes(),messageId.getBytes());return "OK";});// 重新添加任务(可选:使用延迟重新入队策略)Map<String, Object> newTask = new HashMap<>();newTask.put("executeTime", String.valueOf(executeTime));newTask.put("taskInfo", taskInfo);redisTemplate.opsForStream().add(delayQueueKey, newTask);}}}return readyTasks;}/*** 启动任务处理器*/public void startTaskProcessor() {ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);scheduler.scheduleAtFixedRate(() -> {try {List<String> tasks = pollTasks();for (String task : tasks) {processTask(task);}} catch (Exception e) {e.printStackTrace();}}, 0, 1, TimeUnit.SECONDS);}private void processTask(String taskInfo) {System.out.println("Processing task: " + taskInfo);// 实际任务处理逻辑}
}
优缺点
优点:
- 支持消费者组和消息确认,提供可靠的消息处理
- 内置消息持久化机制
- 支持多消费者并行处理
- 消息ID包含时间戳,便于排序
缺点:
- 要求Redis 5.0+版本
- 实现相对复杂
- 仍需轮询获取到期任务
- 对未到期任务的处理相对繁琐
性能对比与选型建议
| 实现方式 | 性能 | 可靠性 | 实现复杂度 | 内存占用 | 适用场景 |
|---|---|---|---|---|---|
| Sorted Set | ★★★★☆ | ★★★☆☆ | 低 | 中 | 任务量适中,需要精确调度 |
| List + 轮询 | ★★★★★ | ★★★☆☆ | 中 | 低 | 高并发,延时精度要求不高 |
| Pub/Sub + 时间轮 | ★★★★★ | ★★☆☆☆ | 高 | 低 | 实时性要求高,可容忍服务重启丢失 |
| Stream | ★★★☆☆ | ★★★★★ | 高 | 中 | 可靠性要求高,需要消息确认 |
总结
在实际应用中,可根据系统规模、性能需求、可靠性要求和实现复杂度等因素进行选择,也可以组合多种方式打造更符合业务需求的延时队列解决方案。无论选择哪种实现,都应关注可靠性、性能和监控等方面,确保延时队列在生产环境中稳定运行。
相关文章:

基于Redis的4种延时队列实现方式
延时队列是一种特殊的消息队列,它允许消息在指定的时间后被消费。在微服务架构、电商系统和任务调度场景中,延时队列扮演着关键角色。例如,订单超时自动取消、定时提醒、延时支付等都依赖延时队列实现。 Redis作为高性能的内存数据库&#x…...

时序预测 | Matlab实现基于VMD-WOA-ELM和VMD-ELM变分模态分解结合鲸鱼算法优化极限学习机时间序列预测
时序预测 | Matlab实现基于VMD-WOA-ELM和VMD-ELM变分模态分解结合鲸鱼算法优化极限学习机时间序列预测 目录 时序预测 | Matlab实现基于VMD-WOA-ELM和VMD-ELM变分模态分解结合鲸鱼算法优化极限学习机时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab…...

静态测试:软件质量保障的第一道防线
在软件测试领域,静态测试往往是被低估却极其重要的环节。与动态测试不同,静态测试不需要执行代码,而是在软件开发早期阶段就能发现潜在问题。本文将深入探讨静态测试的概念、方法、优势以及如何在项目中有效实施。 什么是静态测试࿱…...

星露谷物语 7000+ 大型MOD整合包
衣服美化、家具美化、地图美化、人物肖像美化 全地图装修存档、人物美化、扩展包、环境美化、家具、动植物、通用前置包、新增NPC、功能、服装发饰妆 帽子发型农场小镇美化大型玩法拓展实用功能mod 动漫人物形象MOD 地点/动物/地图/功能/机械/家具/建筑/界面美化/扩展/农场/食谱…...
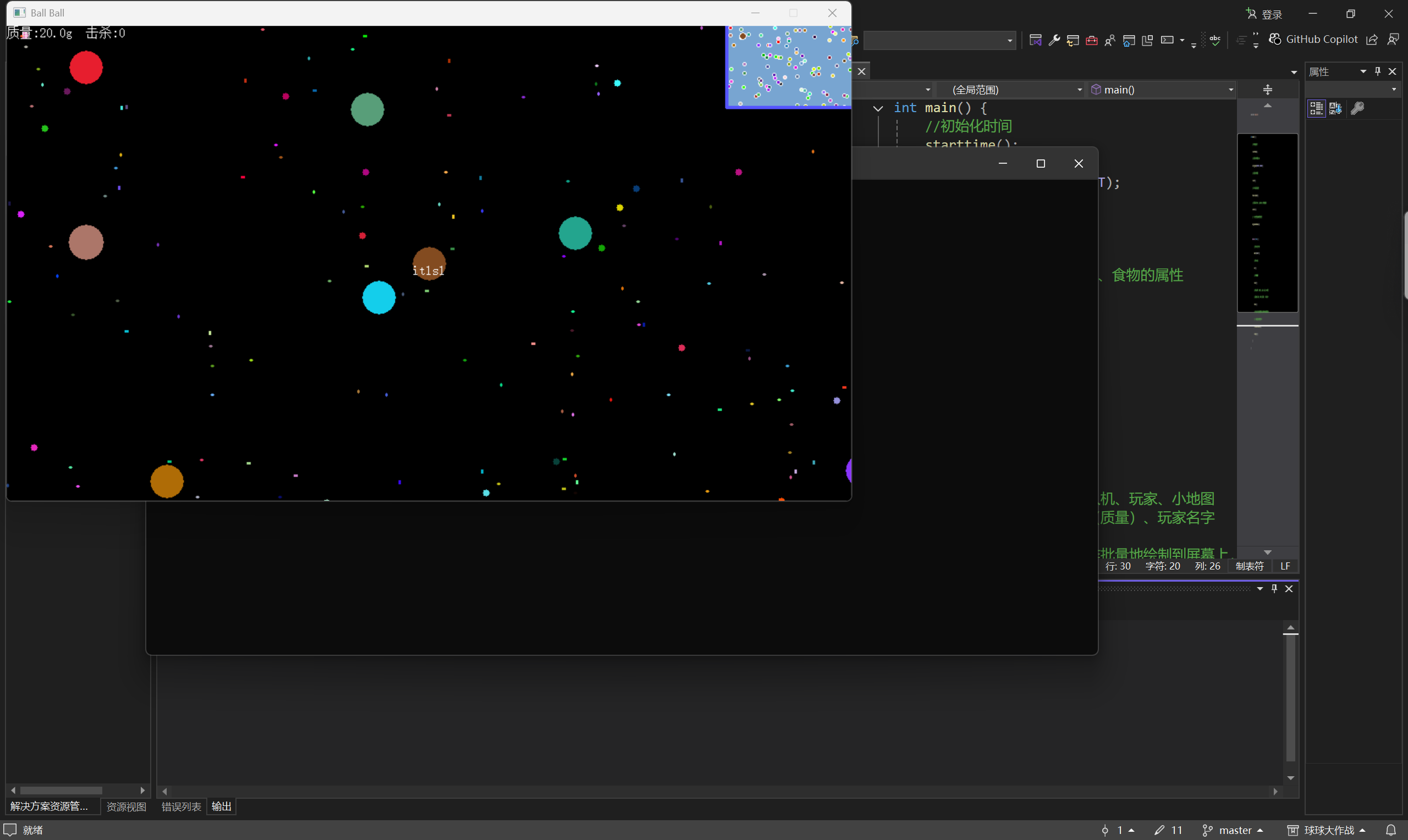
基于EasyX库开发的球球大作战游戏
目录 球球大作战 一、开发环境 二、流程图预览 三、代码逻辑 1、初始化时间 2、设置开始界面大小 3、设置开始界面 4、让玩家选择速度 5、设置玩家小球、人机小球、食物的属性 6、一次性把图绘制到界面里 7、进入死循环 8、移动玩家小球 9、移动人机 10、食物刷新…...
《系统分析师-第三阶段—总结(一)》
背景 采用三遍读书法进行阅读,此阶段是第三遍。 过程 第一章 第二章 总结 在这个过程中,对导图的规范越来越清楚,开始结构化,找关系,找联系。...

AI——K近邻算法
文章目录 一、什么是K近邻算法二、KNN算法流程总结三、Scikit-learn工具1、安装2、导入3、简单使用 三、距离度量1、欧式距离2、曼哈顿距离3、切比雪夫距离4、闵可夫斯基距离5、K值的选择6、KD树 一、什么是K近邻算法 如果一个样本在特征空间中的k个最相似(即特征空…...

L2-006 树的遍历
L2-006 树的遍历 问题描述格式输入格式输出样例输入样例输出评测用例规模与约定解析参考程序难度等级 问题描述 给定一棵二叉树的后序遍历和中序遍历,请你输出其层序遍历的序列。这里假设键值都是互不相等的正整数。 格式输入 输入第一行给出一个正整数N࿰…...

java线程池原理及使用和处理流程
实际测试使用如下: package com.study;import java.util.concurrent.*;/*** 线程池作用:* 1、线程的复用* 2、资源管理* 3、任务调度* --------------执行过程--------------* 第1-3个任务进来时,直接创建任务并执行* 第4-8个任务进来时&…...

用 NLP + Streamlit,把问卷变成能说话的反馈
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...
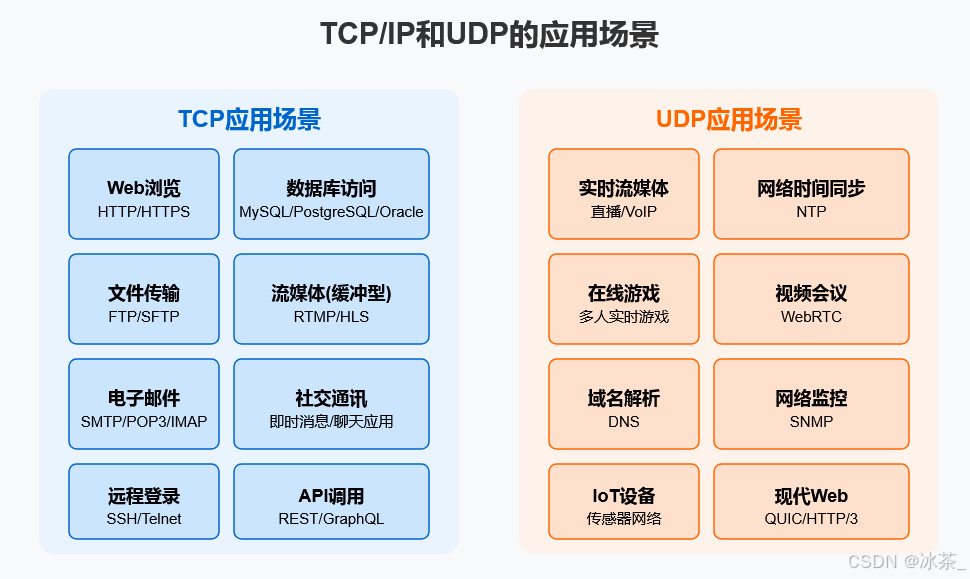
TCP/IP和UDP协议的发展历程
TCP/IP和UDP协议的发展历程 引言 互联网的发展史是人类技术创新的辉煌篇章,而在这一发展过程中,通信协议发挥了奠基性的作用。TCP/IP(传输控制协议/互联网协议)和UDP(用户数据报协议)作为互联网通信的基础…...
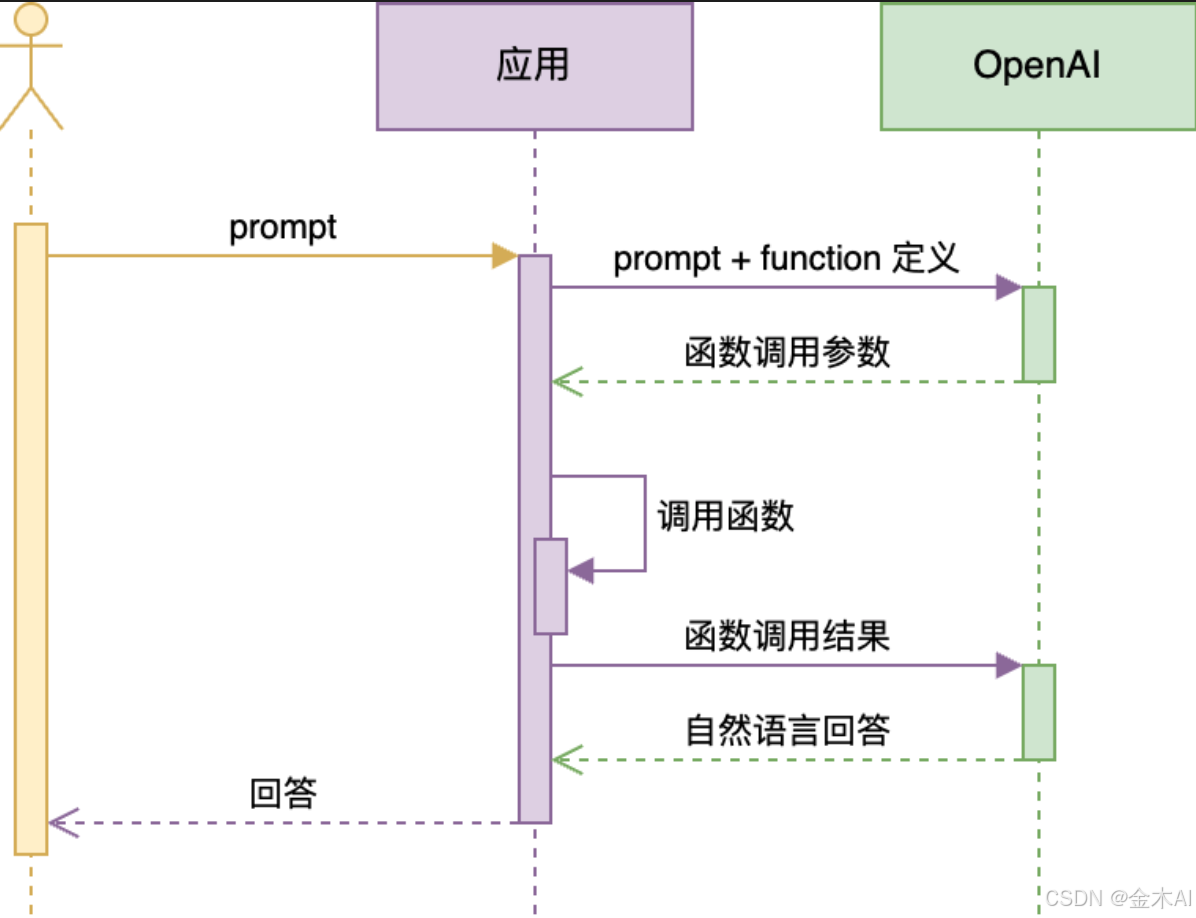
Function Calling的时序图(含示例)
🧍 用户: 发起请求,输入 prompt(比如:“请告诉我北京的天气”)。 🟪 应用: 将用户输入的 prompt 和函数定义(包括函数名、参数结构等)一起发给 OpenAI。 …...
)
DICOM通讯(ACSE->DIMSE->Worklist)
DICOM 通讯协议中的 ACSE → DIMSE → Worklist 这条通讯链路。DICOM 通讯栈本身是一个多层的协议结构,就像 OSI 模型一样,逐层封装功能。 一、DICOM 通讯协议栈总体架构 DICOM 通讯使用 TCP/IP 建立连接,其上面封装了多个协议层次…...
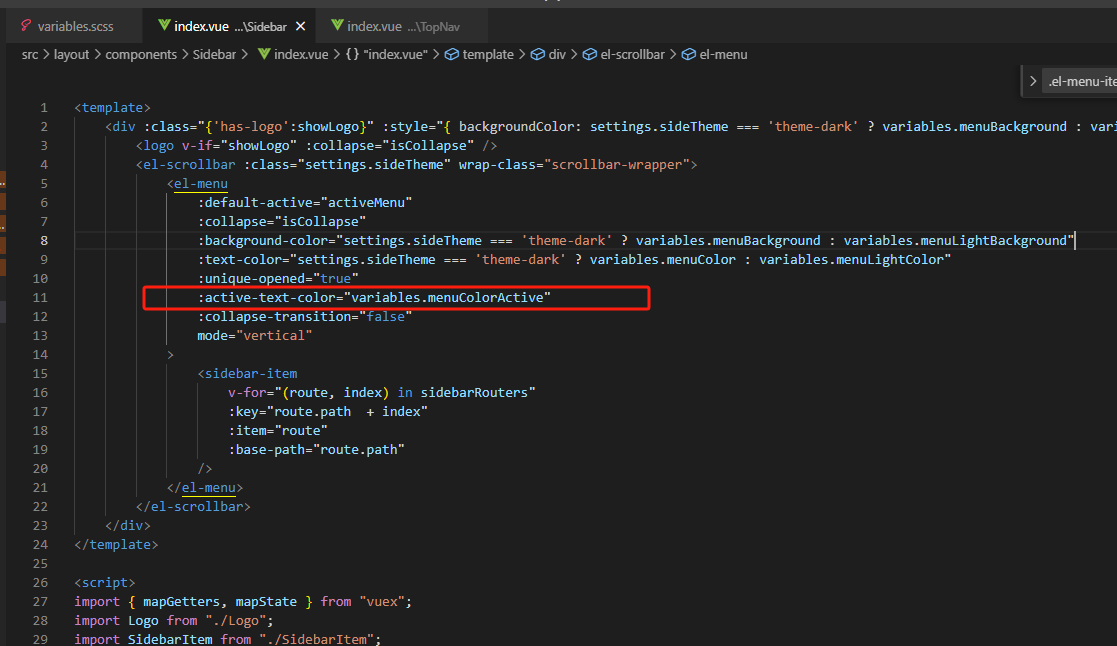
若依框架修改左侧菜单栏默认选中颜色
1.variables.sacc中修改为想要的颜色 2.给目标设置使用的颜色...
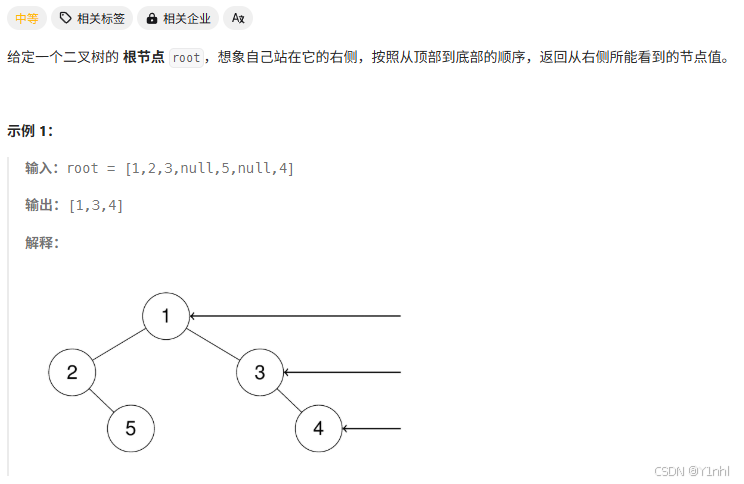
搜广推校招面经七十八
字节推荐算法 一、实习项目:多任务模型中的每个任务都是做什么?怎么确定每个loss的权重 这个根据实际情况来吧。如果实习时候用了moe,就可能被问到。 loss权重的话,直接根据任务的重要性吧。。。 二、特征重要性怎么判断的&…...
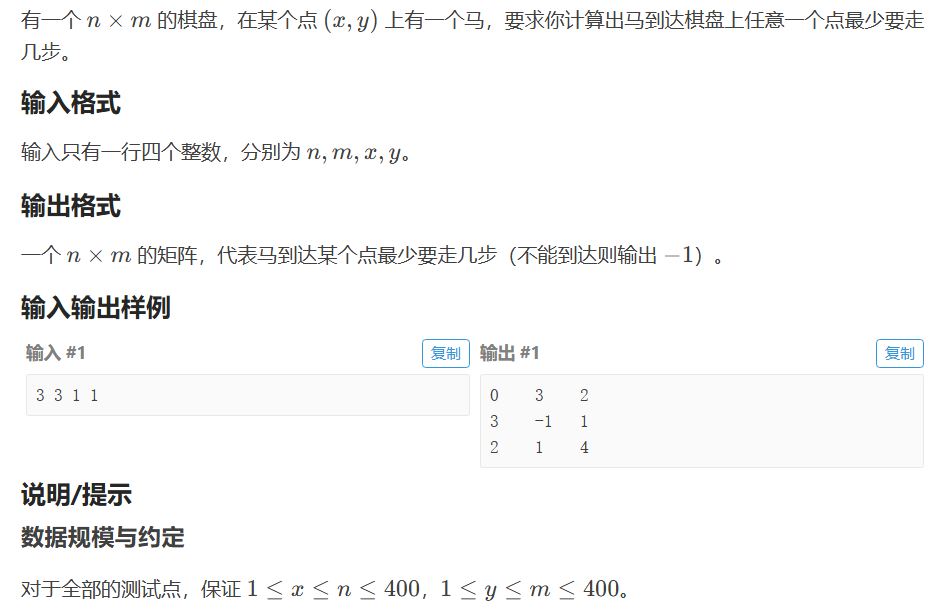
广搜bfs-P1443 马的遍历
P1443 马的遍历 题目来源-洛谷 题意 要求马到达棋盘上任意一个点最少要走几步 思路 国际棋盘规则是马的走法是-日字形,也称走马日,即x,y一个是走两步,一个是一步 要求最小步数,所以考虑第一次遍历到的点即为最小步数ÿ…...
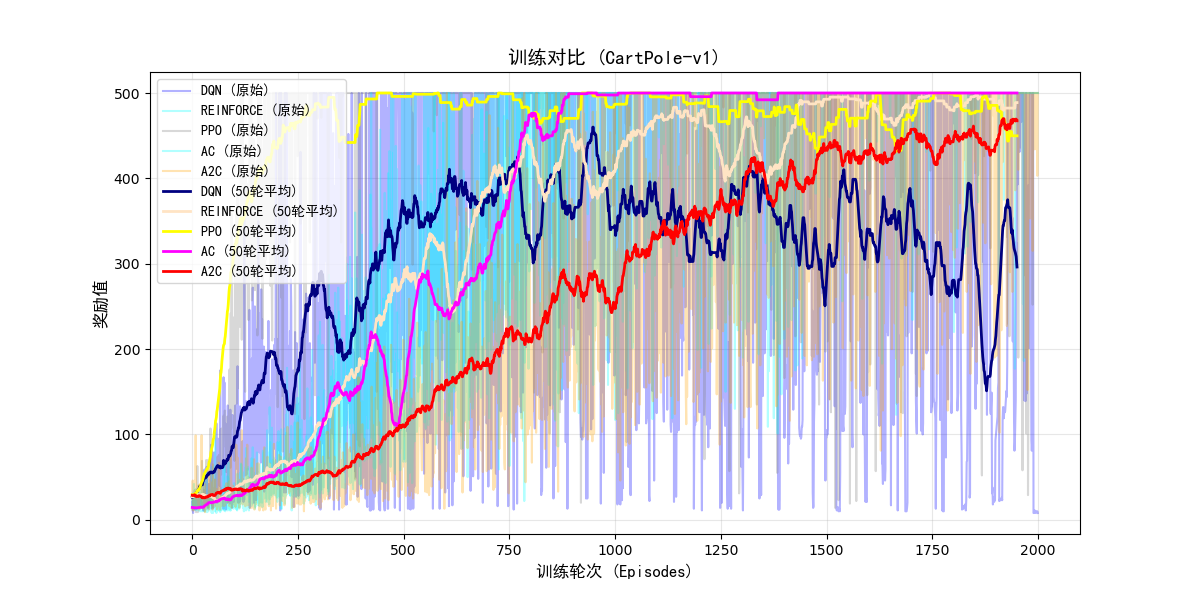
强化学习算法系列(六):应用最广泛的算法——PPO算法
强化学习算法 (一)动态规划方法——策略迭代算法(PI)和值迭代算法(VI) (二)Model-Free类方法——蒙特卡洛算法(MC)和时序差分算法(TD) (三)基于动作值的算法——Sarsa算法与Q-Learning算法 (四…...

Vue3 + TypeScript中provide和inject的用法示例
基础写法(类型安全) typescript // parent.component.vue import { provide, ref } from vue import type { InjectionKey } from vue// 1. 定义类型化的 InjectionKey const COUNTER_KEY Symbol() as InjectionKey<number> const USER_KEY Sy…...
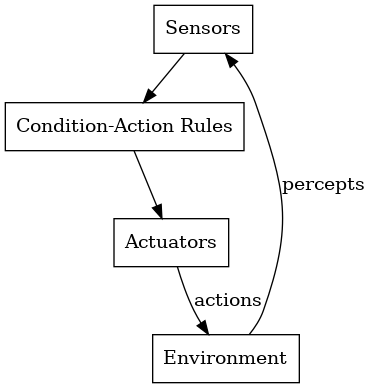
AI Agents系列之AI代理架构体系
1. 引言 智能体架构是定义智能体组件如何组织和交互的蓝图,使智能体能够感知其环境、推理并采取行动。本质上,它就像是智能体的数字大脑——集成了“眼睛”(传感器)、“大脑”(决策逻辑)和“手”(执行器),用于处理信息并采取行动。 选择正确的架构对于构建有效的智能…...

3个实用的脚本
1. Linux 系统清理临时文件脚本 该脚本用于清理系统中 /tmp 目录下超过 7 天的临时文件。 #!/bin/bash# 清理 /tmp 目录下超过 7 天的文件 find /tmp -type f -atime 7 -exec rm -f {} \;# 清理 /var/tmp 目录下超过 7 天的文件 find /var/tmp -type f -atime 7 -exec rm -f {…...
2025海外代理IP测评:Bright Data,ipfoxy,smartproxy,ipipgo,kookeey,ipidea哪个值得推荐?
近年来,随着全球化和跨境业务需求的不断扩大“海外代理IP”逐渐成为企业和个人在多样化场景中的重要工具。无论是进行数据采集、广告验证、社交媒体管理,还是跨境电商平台运营,选择合适的代理IP服务商都显得尤为重要。然而,市场上…...

条款13:以对象管理资源
什么是资源?内存?没错但是内存只是我们需要管理众多资源的一种,资源还包括数据的连接,文件描述符,互斥锁,网络套接字,不管哪种资源他都是从系统中获取的,当你不在需要他的时候是要还…...
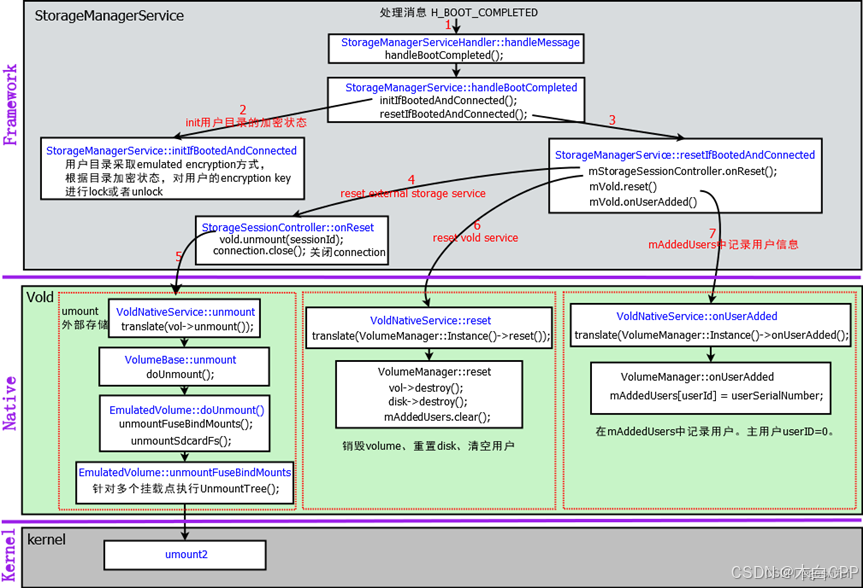
Android守护进程——Vold (Volume Daemon)
简介 介绍:Vold 是用来管理 android 系统的存储设备,如U盘、SD卡、磁盘等移动设备的热插拔、挂载、卸载、格式化 框架结构:Vold 在系统中以守护进程存在,是一个单独的进程。处于Kernel和Framework之间,是两个层级连接…...
vue3+vite 实现.env全局配置
首先创建.env文件 VUE_APP_BASE_APIhttp://127.0.0.1/dev-api 然后引入依赖: pnpm install dotenv --save-dev 引入完成后,在vite.config.js配置文件内加入以下内容: const env dotenv.config({ path: ./.env }).parsed define: { // 将…...
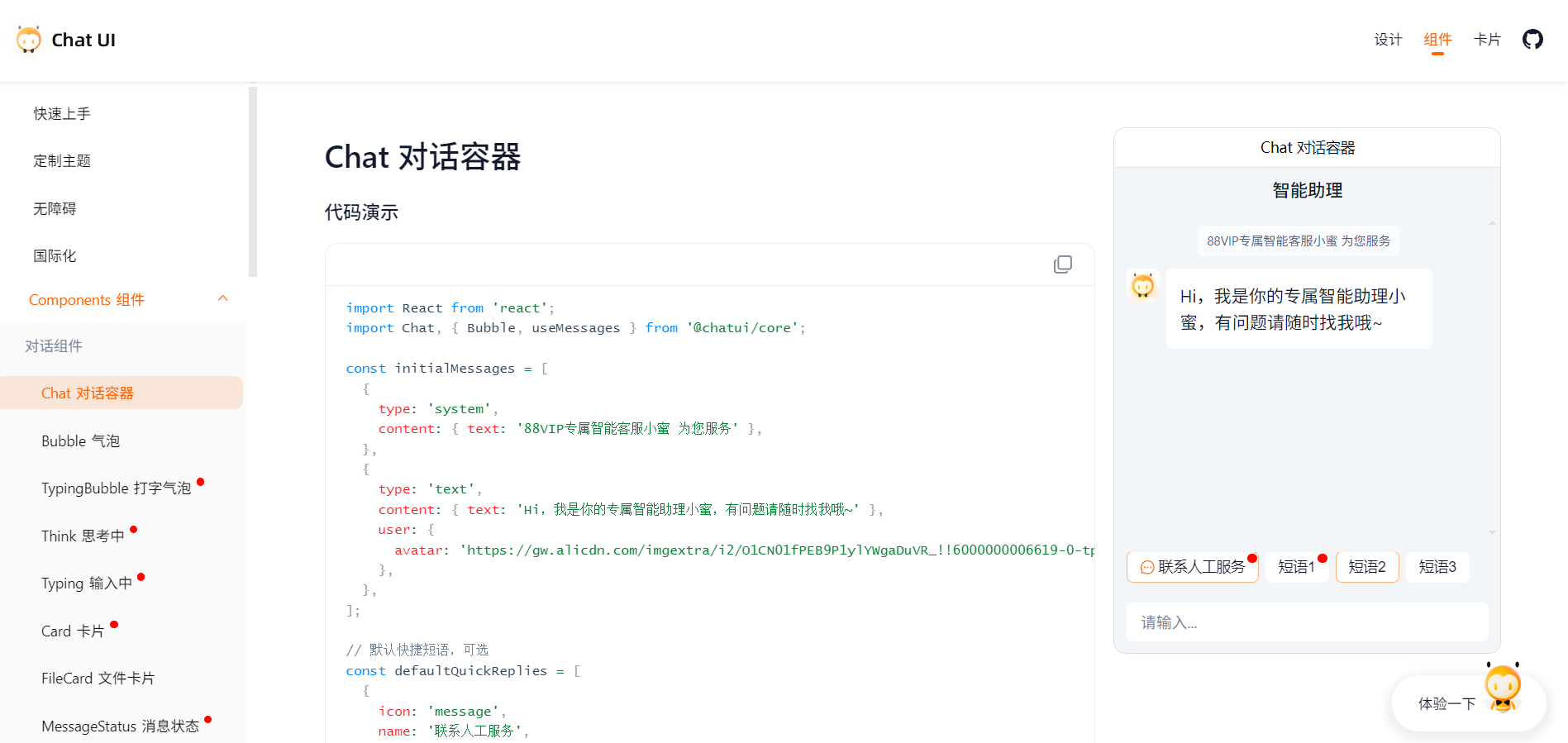
AI 组件库是什么?如何影响UI的开发?
AI组件库是基于人工智能技术构建的、面向用户界面(UI)开发的预制模块集合。它们结合了传统UI组件(如按钮、表单、图表)与AI能力(如机器学习、自然语言处理、计算机视觉),旨在简化开发流程并增强…...

【AI模型学习】关于写论文——论文的审美
文章目录 一、“补丁法”(Patching)1.1 介绍1.2 方法论1.3 实例 二、判断工作的价值2.1 介绍2.2 详细思路2.3 科研性vs工程性 三、novelty以及误区3.1 介绍3.2 举例 看了李沐老师的读论文系列后,总结三个老师提到的有关课题研究和论文写作的三…...

OpenCV day6
函数内容接上文:OpenCV day4-CSDN博客 , OpenCV day5-CSDN博客 目录 平滑(模糊) 25.cv2.blur(): 26.cv2.boxFilter(): 27.cv2.GaussianBlur(): 28.cv2.medianBlur(): 29.cv2.bilateralFilter(): 锐…...

AI的出现,是否能替代IT从业者?
一、技术能力的边界:AI 能做什么? 自动化基础任务 代码生成:GitHub Copilot、天工 AI 等工具可自动生成 80% 以上的重复性代码,例如根据自然语言描述生成完整的网站前端代码。测试与运维:AI 驱动的测试工具能自动生成测…...
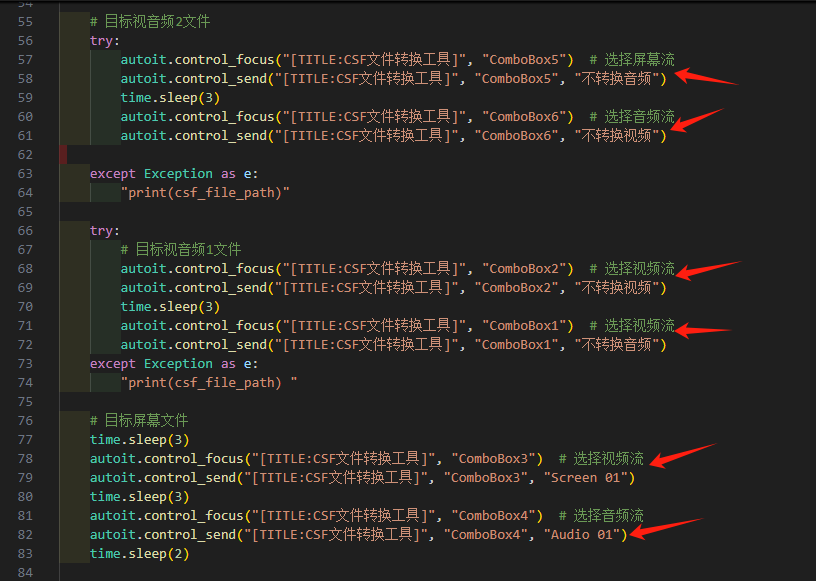
【AI飞】AutoIT入门七(实战):python操控autoit解决csf视频批量转换(有点难,AI都不会)
背景: 终极目标:通过python调用大模型,获得结果,然后根据返回信息,控制AutoIT操作电脑软件,执行具体工作。让AI更具有执行力。 已完成部分: 关于python调用大模型的,可以参考之前的…...

MARA/MARC表 PSTAT字段
最近要开发一个维护物料视图的功能。其中PSTAT字段是来记录已经维护的视图的。这里记录一下视图和其对应的字母。 MARA还有个VPSTA(完整状态)字段,不过在我试的时候每次PSTAT出现一个它就增加一个,不知道具体是为什么。 最近一直…...