【学习笔记】Py网络爬虫学习记录(更新中)
目录
一、入门实践——爬取百度网页
二、网络基础知识
1、两种渲染方式
2、HTTP解析
三、Request入门
1、get方式 - 百度搜索/豆瓣电影排行
2、post方式 - 百度翻译
四、数据解析提取三种方式
1、re正则表达式解析
(1)常用元字符
(2)常用量词
(3)贪婪匹配和惰性匹配
(4)re模块
(5)re实战1:自定义爬取豆瓣排行榜
(6)re实战2:爬取电影天堂
一、入门实践——爬取百度网页
from urllib.request import urlopenurl = "http://www.baidu.com"
resp = urlopen(url)with open("mybaidu.html", mode="w",encoding="utf-8") as f:# 使用with语句打开(或创建)一个名为"mybaidu.html"的文件# 打开模式为写入("w"),编码为UTF - 8("utf-8")# 文件对象被赋值给变量f# with语句确保文件在代码块结束后会自动关闭f.write(resp.read().decode("utf-8"))
这段代码的功能是从百度首页获取HTML内容,并将其保存到本地文件"mybaidu.html"中
爬取结果 ↓(被禁了哈哈)

二、网络基础知识
1、两种渲染方式
服务器渲染:
- 在服务器就直接把数据和html整合在一起,统一返回给浏览器在页面源代码中能看到数据
客户端渲染:
- 第一次请求只要一个html骨架
- 第二次请求拿到数据,进行数据展示在页面源代码中,看不到数据
2、HTTP解析
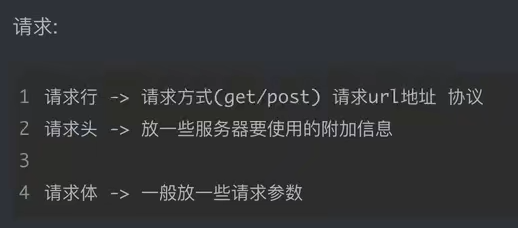
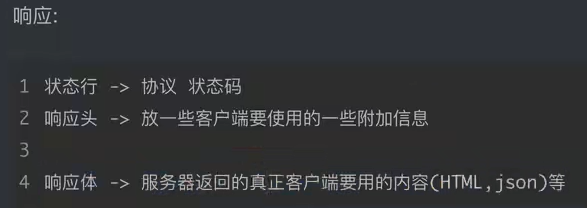
请求头中最常见重要内容(爬虫需要)
- User-Agent身份标识:请求载体的身份标识(用啥发送的请求)
- Referer防盗链:(这次请求是从哪个页面来的?反爬会用到)
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
响应头中一些重要的内容
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
- 各种莫名其妙的字符串(这个需要经验了,一般都是token字样,防止各种攻击和反爬)
三、Request入门
1、get方式 - 百度搜索/豆瓣电影排行
import requests
query = input("请输入想查询的内容!")
url = f"https://www.baidu.com/s?wd={query}"resp = requests.get(url)dic = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit"
}resp = requests.get(url=url, headers=dic) #伪装成浏览器
print(resp.text)
resp.close()
爬了一下百度,成功啦!
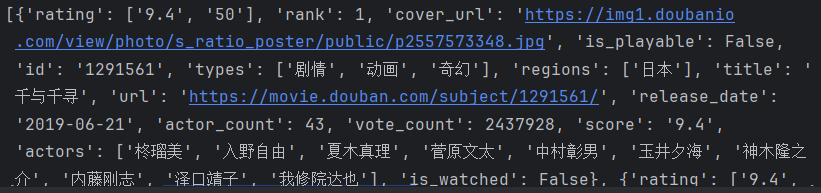
import requestsurl = f"https://movie.douban.com/j/chart/top_list"parm= {"type": 25,"interval_id": "100:90","action":"","start": 0,"limit": 20,
}dic={
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit"
}resp = requests.get(url=url,params=parm,headers=dic)
print(resp.json())
resp.close()
2、post方式 - 百度翻译
发送post请求,发送的数据必须放在字典里,通过data参数进行传递
import requests
s = input("请输入想查询的内容!")
url = f"https://fanyi.baidu.com/sug"dat = {"kw":s
}
resp = requests.get(url)#发送post请求,发送的数据必须放在字典里,通过data参数进行传递
resp = requests.post(url=url,data=dat)
print(resp.json())
resp.close()

四、数据解析提取三种方式
上述内容算入门了抓取整个网页的基本技能,但大多数情况下,我们并不需要整个网页的内容,只是需要那么一小部分,这就涉及到了数据提取的问题。
三种解析方式:
- re解析
- bs4解析
- xpath解析
1、re正则表达式解析
正则表达式是一种使用表达式的方式对字符串进行匹配的语法规则
抓取到的网页源代码本质上就是一个超长的字符串,想从里面提取内容,用正则再合适不过
在线正则表达式测试
(1)常用元字符
. 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线 \s 匹配任意的空白符 \d 匹配数字 \n 匹配一个换行符 \t 匹配一个制表符 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \W 匹配非字母或数字或下划线 \D
匹配非数字 \S 匹配非空白符 a|b 匹配字符a或字符b () 匹配括号内的表达式,也表示一个组 [...] 匹配字符组中的字符 [a-zA-Z0-9] [^...] 匹配除了字符组中字符的所有字符
(2)常用量词
* 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次
(3)贪婪匹配和惰性匹配
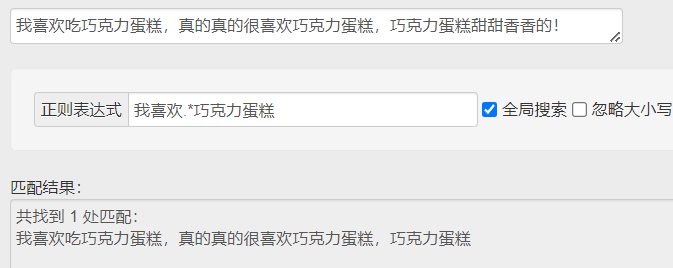
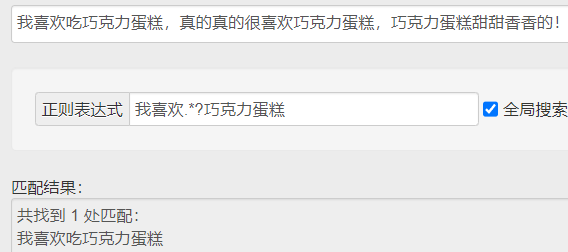
.* 贪婪匹配(尽可能多的匹配) .*? 惰性匹配(尽可能少的匹配)
↑ 贪婪匹配就是尽可能长地匹配
↑ 惰性匹配就是尽可能短地匹配
(4)re模块
- findall:匹配字符串中所有符合正则的内容
- finditer:匹配字符串中所有内容【返回的是迭代器】,从迭代器中拿到内容要.group
import re#findall:匹配字符串中所有符合正则的内容 list = re.findall(r"\d+","我的学号是20250102,他的学号是20240105") print(list)#finditer:匹配字符串中所有内容【返回的是迭代器】,从迭代器中拿到内容要.group it = re.finditer(r"\d+","我的学号是20250102,他的学号是20240105") for i in it:print(i.group())
- search:找到一个结果就返回,返回的结果是match对象,拿数据要.group()
- match:从头开始匹配
- 预加载正则表达式
import re#search:找到一个结果就返回,返回的结果是match对象,拿数据要.group() s = re.search(r"\d+","我的学号是20250102,他的学号是20240105") print(s.group())#match:从头开始匹配 m = re.search(r"\d+","20250102,他的学号是20240105") print(s.group())#预加载正则表达式 obj = re.compile(r"\d+") #相对于把头写好,后面直接补上字符串 ret = obj.finditer("我的学号是20250102,他的学号是20240105") for i in ret:print(i.group())
- ?P<起的别名>正则表达式:给提取的内容起别名,例如?P<name>.*?,给.*?匹配到的内容起别名name
s = """ <div class='cat'><span id='1'>凯蒂猫</span></div> <div class='dog'><span id='2'>史努比</span></div> <div class='mouse'><span id='3'>杰瑞</span></div> <div class='fish'><span id='4'>小鲤鱼</span></div> """obj = re.compile(r"<div class='(?P<class>.*?)'><span id='(?P<id>.*?)'>(?P<name>.*?)</span></div>",re.S) #re.S:让.能匹配换行符 result = obj.finditer(s) for it in result:print(it.group("id") +" "+ it.group("class") +" "+ it.group("name"))
(5)re实战1:自定义爬取豆瓣排行榜
通过request拿到页面源代码,用re正则匹配提取数据

import re
import csv
import requests#request获取页面源代码
url = "https://movie.douban.com/top250?start=%d&filter="
num = int(input("请问您想要查询豆瓣电影Top榜单前多少页的信息:"))for i in range(0,num): #第1页=0*25,第二页=1*25…… range范围[a,b)i=i*25
new_url = format(url%i) #用值i替换url中的变量,形成新的urldic = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit"
}
resp = requests.get(url=new_url,headers=dic)
page_content = resp.text#re提取数据
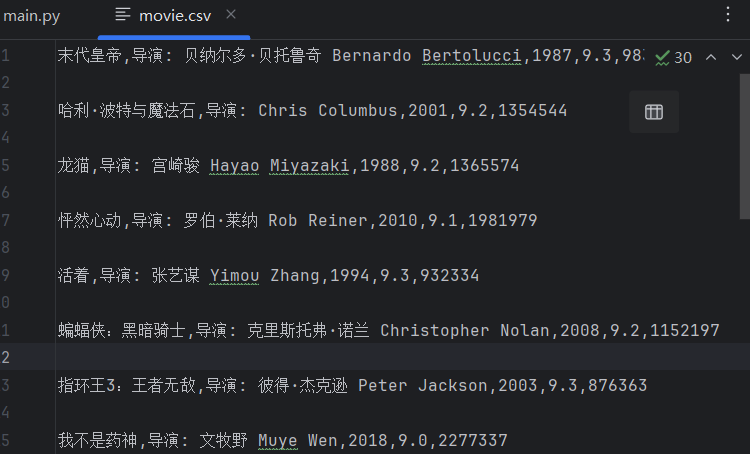
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>'r'.*?<p>(?P<daoyan>.*?) .*?<br>(?P<year>.*?) .*?'r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>'r'.*?<span>(?P<people>.*?)人评价</span>',re.S)res = obj.finditer(page_content)
f = open("movie.csv","a",encoding="utf-8")
csvWriter = csv.writer(f) #将文件转为csv写入
for item in res:dic = item.groupdict() #把获取的数据转换成字典dic['year'] = dic['year'].strip() #去除字符串首尾的指定字符dic['daoyan'] = dic['daoyan'].strip()csvWriter.writerow(dic.values())f.close()
resp.close()
print("over!")
(6)re实战2:爬取电影天堂


import re
import csv
from urllib.parse import urljoinimport requests#request获取页面源代码
domain_url = "https://dydytt.net/index.htm"dic = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 SLBrowser/9.0.6.2081 SLBChan/103 SLBVPV/64-bit"
}
resp = requests.get(url=domain_url,headers=dic,verify=False)
resp.encoding = "gb2312"
main_page_ct = resp.text#re匹配数据
obj1 = re.compile(r"最新电影更新.*?<ul>(?P<url>.*?)</ul>",re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'>",re.S)
obj3 = re.compile(r'<title>(?P<name>.*?)</title>'r'.*?磁力链下载器:<a href="(?P<down>.*?) target="_blank" title="qBittorrent">',re.S)res1 = obj2.finditer(main_page_ct)f = open("dyttmovie.csv","a",encoding="utf-8")
csvWriter = csv.writer(f) #将文件转为csv写入#1.提取页面子链接
res2 = obj2.finditer(main_page_ct)
child_href_list = []
for i in res2:#拼接子页面连接child_url = urljoin(domain_url,i.group('href'))child_href_list.append(child_url)#2.提取子页面内容
for i in child_href_list:child_resp = requests.get(url=i,headers=dic,verify=False) #获取子页面urlchild_resp.encoding = 'gb2312'res3 = obj3.search(child_resp.text) #提取子页面数据tdic = res3.groupdict()csvWriter.writerow(tdic.values()) #存入文件f.close()
resp.close()
print("over!")
相关文章:
【学习笔记】Py网络爬虫学习记录(更新中)
目录 一、入门实践——爬取百度网页 二、网络基础知识 1、两种渲染方式 2、HTTP解析 三、Request入门 1、get方式 - 百度搜索/豆瓣电影排行 2、post方式 - 百度翻译 四、数据解析提取三种方式 1、re正则表达式解析 (1)常用元字符 ࿰…...

Python + Playwright:编写自动化测试的避坑策略
Python + Playwright:编写自动化测试的避坑策略 前言一、告别 `time.sleep()`,拥抱 Playwright 的智能等待二、选择健壮、面向用户的选择器,优先使用 `data-testid`三、严格管理环境与依赖,确保一致性四、分离测试数据与逻辑,灵活管理数据五、采用 POM 等设计模式,构建可…...

电脑开机启动慢的原因
硬件老化或故障 机械硬盘老化:电脑使用时间较长,机械硬盘的读写速度会逐渐下降。这是因为机械硬盘内部的盘片和磁头在长期使用后,可能会出现磨损、坏道等问题,导致数据读取速度变慢,从而影响开机时系统文件的加载速度&…...
旅游资源网站登录(jsp+ssm+mysql5.x)
旅游资源网站登录(jspssmmysql5.x) 旅游资源网站是一个为旅游爱好者提供全面服务的平台。网站登录界面简洁明了,用户可以选择以管理员或普通用户身份登录。成功登录后,用户可以访问个人中心,进行修改密码和个人信息管理。用户管理模块允许管…...

C语言链接数据库
目录 使用 yum 配置 mysqld 环境 查看 mysqld 服务的版本 创建 mysql 句柄 链接数据库 使用数据库 增加数据 修改数据 查询数据 获取查询结果的行数 获取查询结果的列数 获取查询结果的列名 获取查询结果所有数据 断开链接 C语言访问mysql数据库整体源码 通过…...

WiFi“管家”------hostapd的工作流程
目录 1. 启动与初始化 1.1 解析命令行参数 1.2 读取配置文件 1.3 创建接口和 BSS 数据结构 1.4 初始化驱动程序 2. 认证和关联处理 2.1 监听认证请求 2.2 处理认证请求 2.3 处理关联请求 3. 数据转发 3.1 接收客户端数据 3.2 转发数据 4. 断开连接处理 4.1 处理客…...

中间件--ClickHouse-9--MPP架构(分布式计算架构)
1、MPP 架构基础概念 MPP(Massively Parallel Processing 大规模并行处理) 是一种分布式计算架构,专门设计用来高效处理大规模数据集。在这种架构下*,数据库被分割成多个部分,每个部分可以在不同的服务器节点上并行处理*。这意味着ÿ…...

分布式计算领域的前沿工具:Ray、Kubeflow与Spark的对比与协同
在当今机器学习和大数据领域,分布式计算已成为解决大规模计算问题的关键技术。本文将深入探讨三种主流分布式计算框架——Ray、Kubeflow和Spark,分析它们各自的特点、应用场景以及如何结合它们的优势创建更强大的计算平台。 Spark批量清洗快,…...

每天学一个 Linux 命令(20):find
可访问网站查看,视觉品味拉满: http://www.616vip.cn/20/index.html find 是 Linux 系统中最强大的文件搜索工具之一,支持按名称、类型、时间、大小、权限等多种条件查找文件,并支持对搜索结果执行操作(如删除、复制、执行命令等)。掌握 find 可大幅提升文件管理效率…...

使用Service发布应用程序
使用Service发布应用程序 文章目录 使用Service发布应用程序[toc]一、什么是Service二、通过Endpoints理解Service的工作机制1.什么是Endpoints2.创建Service以验证Endpoints 三、Service的负载均衡机制四、Service的服务发现机制五、定义Service六、Service类型七、无头Servic…...
Winform发展历程
Windows Forms (WinForms) 发展历程 起源与背景(1998-2002) Windows Forms(简称WinForms)是微软公司推出的基于.NET Framework的GUI(图形用户界面)开发框架,于2002年随着.NET Framework 1.0的…...

【Hadoop入门】Hadoop生态之Flume简介
1 什么是Flume? Flume是Hadoop生态系统中的一个高可靠、高性能的日志收集、聚合和传输系统。它支持在系统中定制各类数据发送方(Source)、接收方(Sink)和数据收集器(Channel),从而能…...
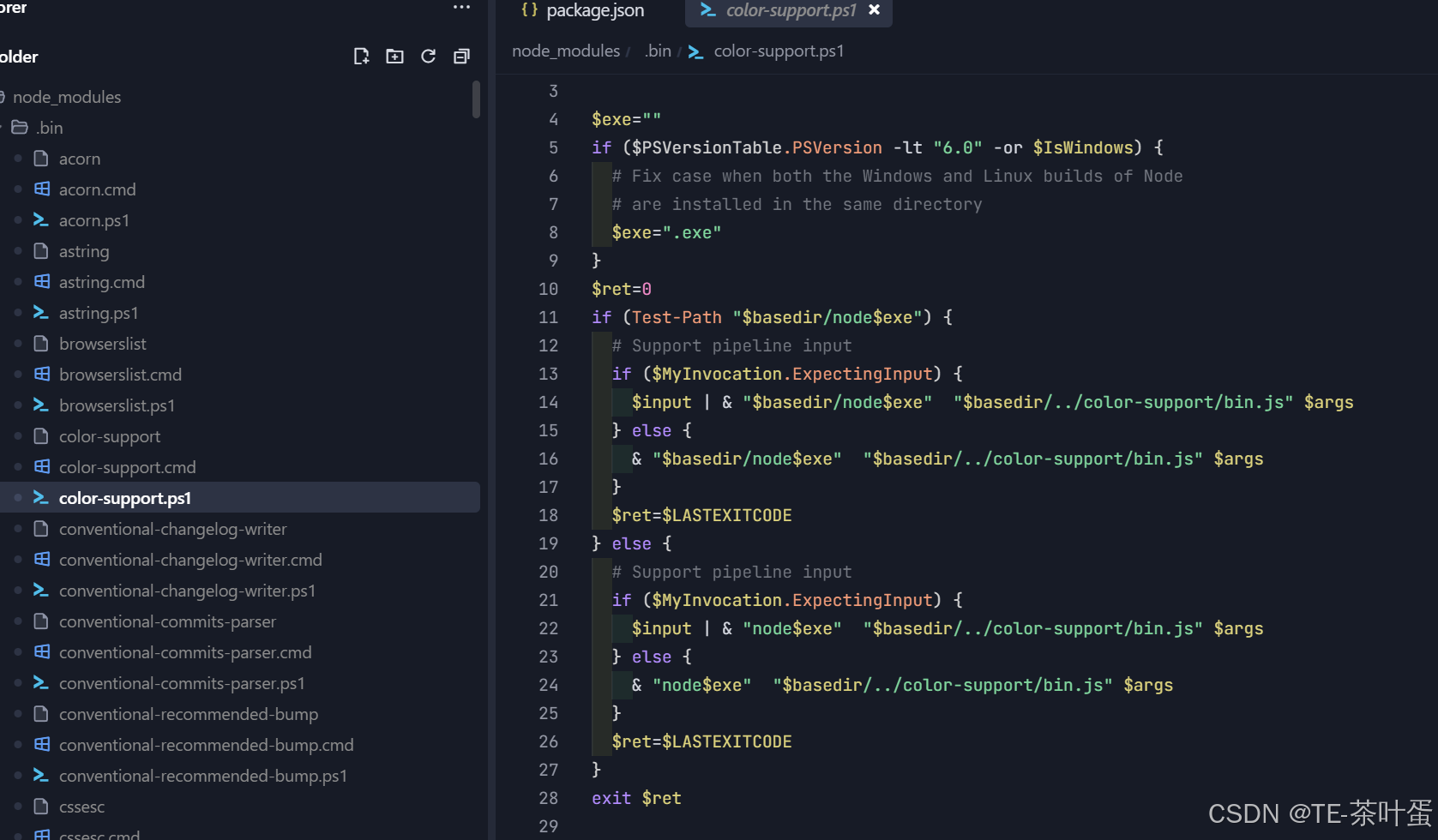
npx 的作用以及延伸知识(.bin目录,npm run xx 执行)
文章目录 前言原理解析1. npx 的作用2. 为什么会有 node_modules/.bin/lerna3. npx 的查找顺序4. 执行流程总结1: 1. .bin 机制什么是 node_modules/.bin?例子 2. npx 的底层实现npx 是如何工作的?为什么推荐用 npx?npx 的特殊能力…...

本地部署DeepSeek-R1(Dify升级最新版本、新增插件功能、过滤推理思考过程)
下载最新版本Dify Dify1.0版本之前不支持插件功能,先升级DIfy 下载最新版本,目前1.0.1 Git地址:https://github.com/langgenius/dify/releases/tag/1.0.1 我这里下载到老版本同一个目录并解压 拷贝老数据 需先停用老版本Dify PS D:\D…...
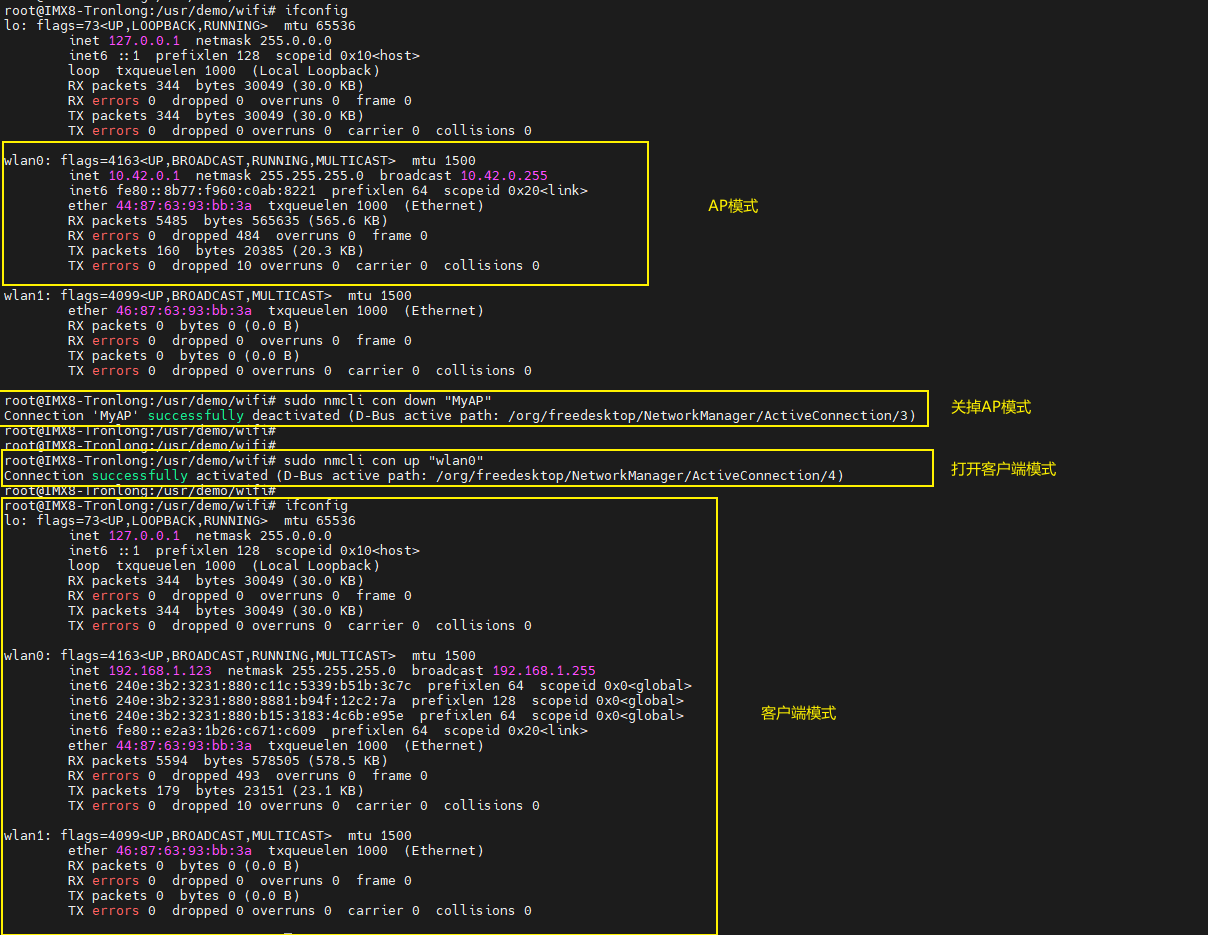
【ubuntu】在Linux Yocto的基础上去适配Ubuntu的wifi模块
一、修改wifi的节点名 1.找到wifi模块的PID和VID ifconfig查看wifi模块网络节点的名字,发现是wlx44876393bb3a(wlxmac地址) 通过udevadm info -a /sys/class/net/wlx44876393bba路径的命令去查看wlx44876393bba的总线号,端口号…...

25软考新版系统分析师怎么备考?重点考哪些?(附新版备考资源)
软考系统分析师(高级资格)考试涉及知识面广、难度较大,需要系统化的复习策略。以下是结合考试大纲和历年真题整理的复习重点及方法: 一、明确考试结构与分值分布 1.综合知识(选择题,75分) 2…...
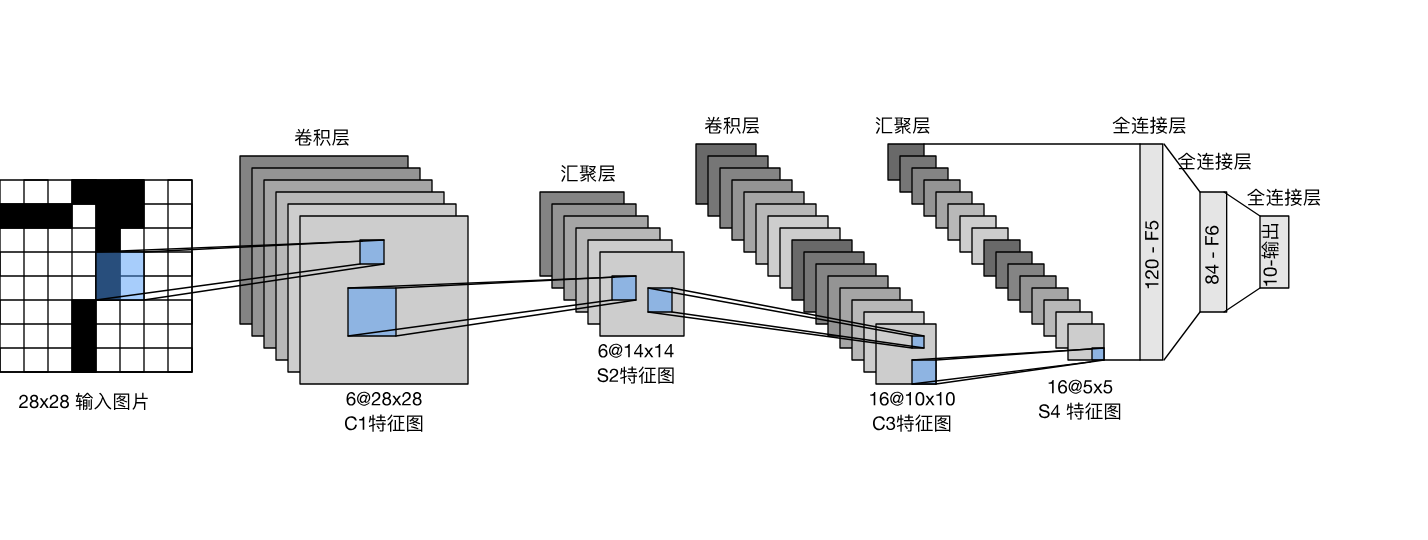
PyTorch入门------卷积神经网络
前言 参考:神经网络 — PyTorch Tutorials 2.6.0cu124 文档 - PyTorch 深度学习库 一个典型的神经网络训练过程如下: 定义一个包含可学习参数(或权重)的神经网络 遍历输入数据集 将输入通过神经网络处理 计算损失(即…...

Edge浏览器安卓版流畅度与广告拦截功能评测【不卡还净】
安卓设备上使用浏览器的体验,很大程度取决于两个方面。一个是滑动和页面切换时的反应速度,另一个是广告干扰的多少。Edge浏览器的安卓版本在这两方面的表现比较稳定,适合日常使用和内容浏览。 先看流畅度。Edge在中端和高端机型上启动速度快&…...

Docker 和 Docker Compose 使用指南
Docker 和 Docker Compose 使用指南 一、Docker 核心概念 镜像(Image) :应用的静态模板(如 nginx:latest)。容器(Container) :镜像的运行实例。仓库(Registry…...

【设计模式】观察者
观察者模式 1 简介 观察者模式是观察者对象们通过注册到被观察者对象中,从而使被观察者发生变化时能通知到观察者,避免硬编码,使用写死的代码逻辑调用通知,从而实现解耦效果。 2 基本代码逻辑 观察者 class IObserver { publ…...
vue3环境搭建、nodejs22.x安装、yarn 1全局安装、npm切换yarn 1、yarn 1 切换npm
vue3环境搭建 node.js 安装 验证nodejs是否安装成功 # 检测node.js 是否安装成功----cmd命令提示符中执行 node -v npm -v 设置全局安装包保存路径、全局装包缓存路径 在node.js 安装路径下 创建 node_global 和 node_cache # 设置npm全局安装包保存路径(新版本…...
安卓开发一个完整的登录页面-支持密码登录和手机验证码登录)
(二十五)安卓开发一个完整的登录页面-支持密码登录和手机验证码登录
下面将详细讲解如何在 Android 中开发一个完整的登录页面,支持密码登录和手机验证码登录。以下是实现过程的详细步骤,从布局设计到逻辑实现,再到用户体验优化,逐步展开。 1. 设计登录页面布局 首先,我们需要设计一个用…...

【java 13天进阶Day05】数据结构,List,Set ,TreeSet集合,Collections工具类
常见的数据结构种类 集合是基于数据结构做出来的,不同的集合底层会采用不同的数据结构。不同的数据结构,功能和作用是不一样的。数据结构: 数据结构指的是数据以什么方式组织在一起。不同的数据结构,增删查的性能是不一样的。不同…...
)
水污染治理(生物膜+机器学习)
文章目录 **1. 水质监测与污染预测****2. 植物-微生物群落优化****3. 系统设计与运行调控****4. 维护与风险预警****5. 社区参与与政策模拟****挑战与解决思路****未来趋势** 前言: 将机器学习(ML)等人工智能技术融入植树生物膜系统ÿ…...
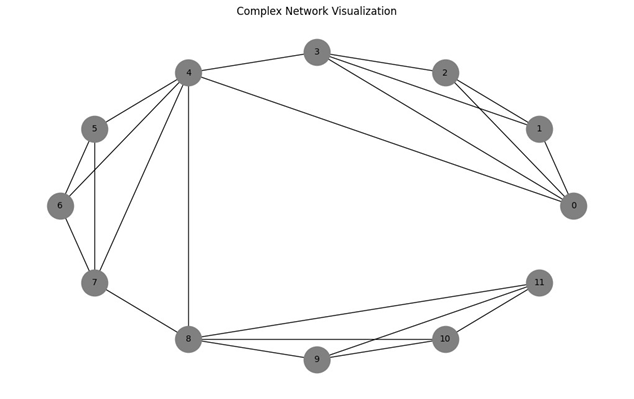
Python人工智能 使用可视图方法转换时间序列为复杂网络
基于可视图方法的时间序列复杂网络转换实践 引言 在人工智能与数据科学领域,时间序列分析是一项基础且重要的技术。本文将介绍一种创新的时间序列分析方法——可视图方法,该方法能将时间序列转换为复杂网络,从而利用复杂网络理论进行更深入…...
spring:加载配置类
在前面的学习中,通过读取xml文件将类加载,或他通过xml扫描包,将包中的类加载。无论如何都需要通过读取xml才能够进行后续操作。 在此创建配置类。通过对配置类的读取替代xml的功能。 配置类就是Java类,有以下内容需要执行&#…...

使用Pydantic优雅处理几何数据结构 - 前端输入验证实践
使用Pydantic优雅处理几何数据结构 - 前端输入验证实践 一、应用场景解析 在视频分析类项目中,前端常需要传递几何坐标数据。例如智能安防系统中,需要接收: 视频流地址(rtsp_video)检测区域坐标点(point…...

从零搭建一套前端开发环境
一、基础环境搭建 1.NVM(Node Version Manager)安装 简介 nvm(Node Version Manager) 是一个用于管理多个 Node.js 版本的工具,允许开发者在同一台机器上轻松安装、切换和使用不同版本的 Node.js。它特别适合需要同时维护多个项目ÿ…...

金融数据库转型实战读后感
荣幸收到老友太保科技有限公司数智研究院首席专家林春的签名赠书。 这是国内第一本关于OceanBase数据库实际替换过程总结的的实战书。打个比方可以说是从战场上下来分享战斗经验。读后感受颇深。我在这里讲讲我的感受。 第三章中提到的应用改造如何降本。应用改造是国产化替换…...

代码审计系列2:小众cms oldcms
目录 sql注入 1. admin/admin.php Login_check 2. admin/application/label/index.php 3. admin/application/hr/index.php 4. admin/application/feedback/index.php 5. admin/application/article/index.php sql注入 1. admin/admin.php Login_check 先看一下p…...