python-各种文件(txt,xls,csv,sql,二进制文件)读写操作、文件类型转换、数据分析代码讲解
1.文件txt读写标准用法
1.1写入文件
要读取文件,首先得使用 open() 函数打开文件。
file = open(file_path, mode='r', encoding=None)file_path:文件的路径,可以是绝对路径或者相对路径。mode:文件打开模式,'r'代表以只读模式打开文件,这是默认值,‘w’表示写入模式。encoding:文件的编码格式,像'utf-8'、'gbk'等,默认值是None。
下面写入文件的示例:
#写入文件,当open(file_name,'w')时清除文件内容写入新内容,当open(file_name,'a')时直接在文件结尾加入新内容
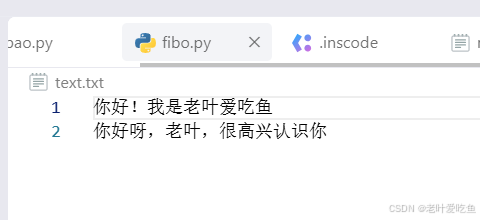
file_name = 'text.txt'
try:with open(file_name,'w',encoding='utf-8') as file:file.write("你好!我是老叶爱吃鱼")file.write("\n你好呀,老叶,很高兴认识你")
except Exception as e:print(f'出错{e}')
系统会判断时候会有text.txt文件,没有的话会创建文件,加入写入内容,示例ru
1.2读取文件
下面是读取文件示例:
#读取文件
try:with open(file_name,'r',encoding='utf-8') as file:print(file.read())
except Exception as e:print(f'出错时输出{e}')
#打印出:你好!我是老叶爱吃鱼 你好呀,老叶,很高兴认识你1.2.1 readline() 方法
readline() 方法每次读取文件的一行内容,返回一个字符串。
# 打开文件
file = open('example.txt', 'r', encoding='utf-8')
# 读取第一行
line = file.readline()
while line:print(line.strip()) # strip() 方法用于去除行尾的换行符line = file.readline()
# 关闭文件
file.close()
1.2.2 readlines() 方法
readlines() 方法会读取文件的所有行,并将每行内容作为一个元素存储在列表中返回。
# 打开文件
file = open('example.txt', 'r', encoding='utf-8')
# 读取所有行
lines = file.readlines()
for line in lines:print(line.strip())
# 关闭文件
file.close()
1.2.3 迭代文件对象
可以直接对文件对象进行迭代,每次迭代会返回文件的一行内容。
# 打开文件
file = open('example.txt', 'r', encoding='utf-8')
# 迭代文件对象
for line in file:print(line.strip())
# 关闭文件
file.close()2. 二进制文件读取
若要读取二进制文件,需将 mode 参数设置为 'rb'。
# 以二进制只读模式打开文件
with open('example.jpg', 'rb') as file:# 读取文件全部内容content = file.read()# 可以对二进制数据进行处理,如保存到另一个文件with open('copy.jpg', 'wb') as copy_file:copy_file.write(content)
3. 大文件读取
对于大文件,不建议使用 read() 方法一次性读取全部内容,因为这可能会导致内存不足。可以采用逐行读取或者分块读取的方式。
3.1 逐行读取
# 逐行读取大文件
with open('large_file.txt', 'r', encoding='utf-8') as file:for line in file:# 处理每行内容print(line.strip())
3.2 分块读取
# 分块读取大文件
chunk_size = 1024 # 每次读取 1024 字节
with open('large_file.txt', 'r', encoding='utf-8') as file:while True:chunk = file.read(chunk_size)if not chunk:break# 处理每个数据块print(chunk)4.Excel表格文件的读写
4.1读取excel
import xlrd
import xlwt
from datetime import date,datetime# 打开文件
workbook = xlrd.open_workbook(r"D:\python_file\request_files\excelfile.xlsx", formatting_info=False)
# 获取所有的sheet
print("所有的工作表:",workbook.sheet_names())
sheet1 = workbook.sheet_names()[0]# 根据sheet索引或者名称获取sheet内容
sheet1 = workbook.sheet_by_index(0)
sheet1 = workbook.sheet_by_name("Sheet1")# 打印出所有合并的单元格
print(sheet1.merged_cells)
for (row,row_range,col,col_range) in sheet1.merged_cells:print(sheet1.cell_value(row,col))# sheet1的名称、行数、列数
print("工作表名称:%s,行数:%d,列数:%d" % (sheet1.name, sheet1.nrows, sheet1.ncols))# 获取整行和整列的值
row = sheet1.row_values(1)
col = sheet1.col_values(4)
print("第2行的值:%s" % row)
print("第5列的值:%s" % col)# 获取单元格的内容
print("第一行第一列:%s" % sheet1.cell(0,0).value)
print("第一行第二列:%s" % sheet1.cell_value(0,1))
print("第一行第三列:%s" % sheet1.row(0)[2])# 获取单元格内容的数据类型
# 类型 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
print("第二行第三列的数据类型:%s" % sheet1.cell(3,2).ctype)# 判断ctype类型是否等于data,如果等于,则用时间格式处理
if sheet1.cell(3,2).ctype == 3:data_value = xlrd.xldate_as_tuple(sheet1.cell_value(3, 2),workbook.datemode)print(data_value)print(date(*data_value[:3]))print(date(*data_value[:3]).strftime("%Y\%m\%d"))
4.2 设置单元格样式
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name # 设置字体名字对应系统内字体
font.bold = bold # 是否加粗
font.color_index = 5 # 设置字体颜色
font.height = height # 设置字体大小# 设置边框的大小
borders = xlwt.Borders()
borders.left = 6
borders.right = 6
borders.top = 6
borders.bottom = 6style.font = font # 为样式设置字体
style.borders = bordersreturn style
4.3写入excel
writeexcel = xlwt.Workbook() # 创建工作表
sheet1 = writeexcel.add_sheet(u"Sheet1", cell_overwrite_ok = True) # 创建sheetrow0 = ["编号", "姓名", "性别", "年龄", "生日", "学历"]
num = [1, 2, 3, 4, 5, 6, 7, 8]
column0 = ["a1", "a2", "a3", "a4", "a5", "a6", "a7", "a8"]
education = ["小学", "初中", "高中", "大学"]# 生成合并单元格
i,j = 1,0
while i < 2*len(education) and j < len(education):sheet1.write_merge(i, i+1, 5, 5, education[j], set_style("Arial", 200, True))i += 2j += 1# 生成第一行
for i in range(0, 6):sheet1.write(0, i, row0[i])# 生成前两列
for i in range(1, 9):sheet1.write(i, 0, i)sheet1.write(i, 1, "a1")# 添加超链接
n = "HYPERLINK"
sheet1.write_merge(9,9,0,5,xlwt.Formula(n + '("https://www.baidu.com")'))# 保存文件
writeexcel.save("demo.xls")5.cvs文件的读写操作
5.1读取cvs文件
# 读取 CSV 文件
def read_from_csv(file_path):try:with open(file_path, 'r', encoding='utf-8') as csvfile:reader = csv.reader(csvfile)print("读取到的 CSV 文件内容如下:")for row in reader:print(row)except FileNotFoundError:print(f"错误: 文件 {file_path} 未找到!")except Exception as e:print(f"读取文件时出错: {e}")5.2写入cvs文件
# 写入 CSV 文件
def write_to_csv(file_path, data):try:with open(file_path, 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)# 写入表头writer.writerow(['Name', 'Age', 'City'])# 写入数据行for row in data:writer.writerow(row)print(f"数据已成功写入 {file_path}")except Exception as e:print(f"写入文件时出错: {e}")6.SQL文件读取
import sqlite3
import pandas as pd# 连接到SQLite数据库
conn = sqlite3.connect('example.db')# 读取数据库表
query = "SELECT * FROM table_name"
data = pd.read_sql(query, conn)
print(data.head())# 关闭连接
conn.close()7.cvs、xls、txt文件相互转换
一般情况下python只会对cvs文件进行数据处理,那么对于很多文件属于二进制文件不能直接处理,那么需要将二进制转为cvs文件后才能处理,如xls是二进制文件需要对xls文件转为cvs文件,操作数据后再转成xls文件即可
7.1xls文件转cvs文件
import pandas as pddef xls_to_csv(xls_file_path, csv_file_path):try:df = pd.read_excel(xls_file_path)df.to_csv(csv_file_path, index=False)print(f"成功将 {xls_file_path} 转换为 {csv_file_path}")except Exception as e:print(f"转换过程中出现错误: {e}")# 示例调用
xls_file = 'example.xls'
csv_file = 'example.csv'
xls_to_csv(xls_file, csv_file)7.2cvs文件转xls文件
import pandas as pddef csv_to_xls(csv_file_path, xls_file_path):try:df = pd.read_csv(csv_file_path)df.to_excel(xls_file_path, index=False)print(f"成功将 {csv_file_path} 转换为 {xls_file_path}")except Exception as e:print(f"转换过程中出现错误: {e}")# 示例调用
csv_file = 'example.csv'
xls_file = 'example.xls'
csv_to_xls(csv_file, xls_file)7.3txt文件转cvs文件
import pandas as pddef txt_to_csv(txt_file_path, csv_file_path):try:# 假设 txt 文件以空格分隔,根据实际情况修改 sep 参数df = pd.read_csv(txt_file_path, sep=' ', header=None)df.to_csv(csv_file_path, index=False, header=False)print(f"成功将 {txt_file_path} 转换为 {csv_file_path}")except Exception as e:print(f"转换过程中出现错误: {e}")# 示例调用
txt_file = 'example.txt'
csv_file = 'example.csv'
txt_to_csv(txt_file, csv_file)7.4csv文件转txt文件
import pandas as pddef csv_to_txt(csv_file_path, txt_file_path):try:df = pd.read_csv(csv_file_path)df.to_csv(txt_file_path, sep=' ', index=False, header=False)print(f"成功将 {csv_file_path} 转换为 {txt_file_path}")except Exception as e:print(f"转换过程中出现错误: {e}")# 示例调用
csv_file = 'example.csv'
txt_file = 'example.txt'
csv_to_txt(csv_file, txt_file)相关文章:
python-各种文件(txt,xls,csv,sql,二进制文件)读写操作、文件类型转换、数据分析代码讲解
1.文件txt读写标准用法 1.1写入文件 要读取文件,首先得使用 open() 函数打开文件。 file open(file_path, moder, encodingNone) file_path:文件的路径,可以是绝对路径或者相对路径。mode:文件打开模式,r 代表以…...

[250418] 智谱 AI 发布新一代模型,同时推出新域名 Z.ai
目录 智谱开源 GLM-4-32B-0414 系列 AI 模型开源赋能,加速 AI 应用落地性能卓越,比肩顶尖模型应用广泛,赋能各行各业 智谱开源 GLM-4-32B-0414 系列 AI 模型 国内人工智能领军企业智谱华章正式开源新一代 GLM-4-32B-0414 系列大语言模型&…...
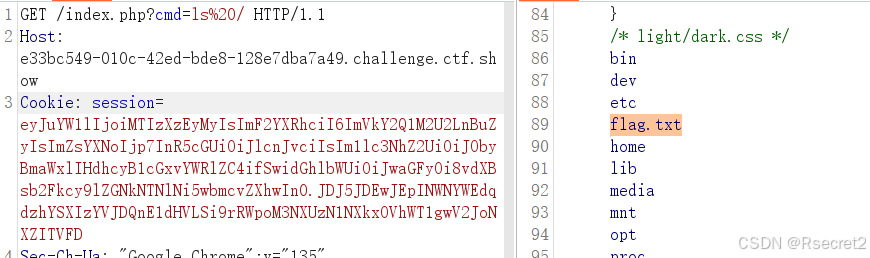
ctfshow-大赛原题-web702
因为该题没有理解到位,导致看wp也一直出错,特此反思一下。 参考yu22x师傅的文章 :CTFSHOW大赛原题篇(web696-web710)_ctfshow 大赛原题-CSDN博客 首先拿到题目: // www.zip 下载源码 我们的思路就是包含一个css文件,…...
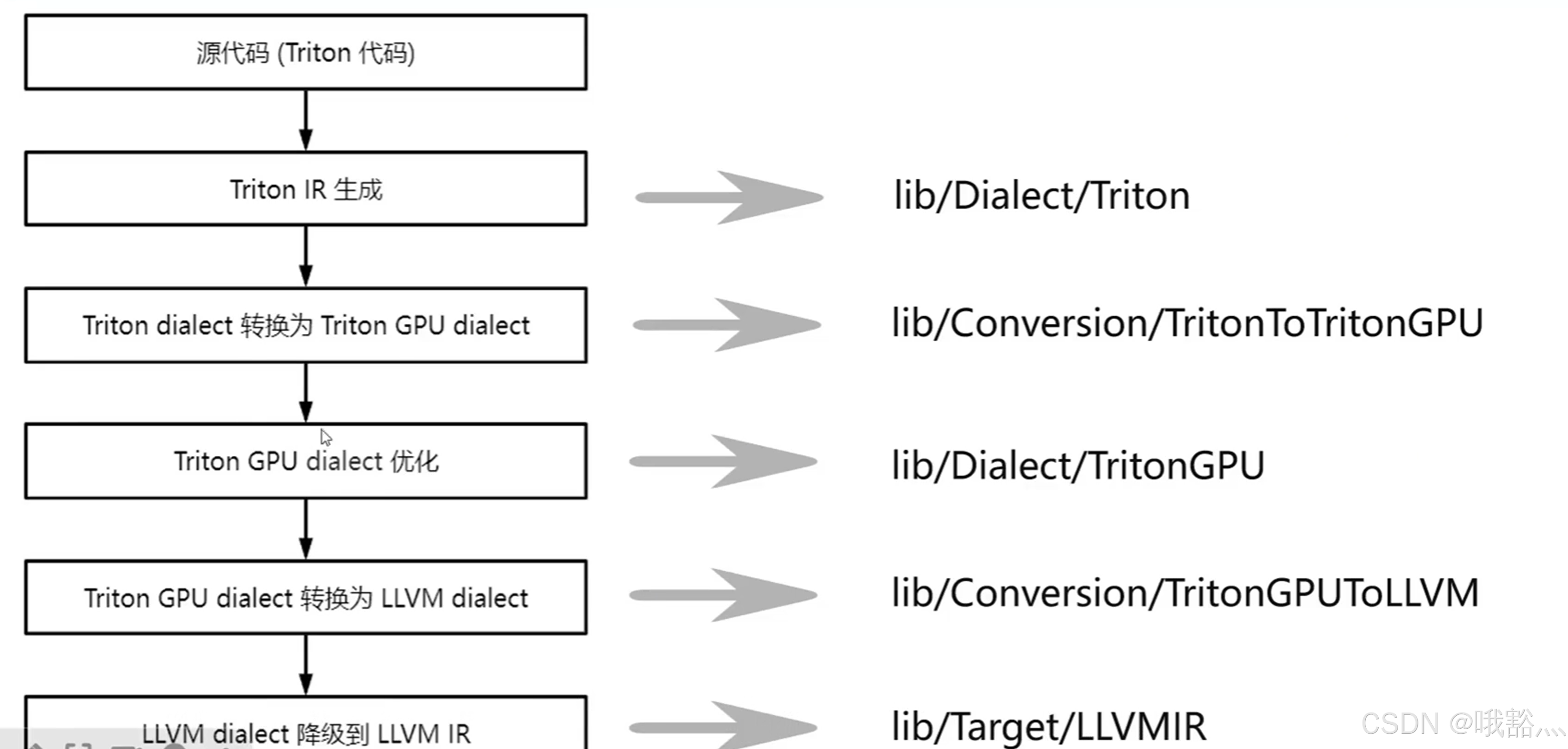
Triton(2)——Triton源码接结构
1 triton 3.0.0 源码结构 triton docs/:项目文档 cmake/:构建配置相关 bin/:工具、脚本 CmakeLists.txt:cmake 配置文件 LSCENSE README.md Pyproject.toml:python 项目配置文件 utils/:项目配置文…...
容器docker入门学习
这里写目录标题 容器容器的软件厂商 dockerdocker引擎 虚拟化虚拟化技术 docker安装详解1、安装检查2、安装yum相关的工具3、安装docker-ce软件4、查看docker版本5、启动docker服务6、设置docker开机启动7、查看有哪些docker容器运行进程8、查看容器里有哪些镜像9、下载nginx软…...

Android——动画
帧动画 帧动画就是很多张图片,一帧一帧的播放,形成的一个动画效果。 frame.xml <?xml version"1.0" encoding"utf-8"?> <animation-list xmlns:android"http://schemas.android.com/apk/res/android">&l…...

HarmonyOS NEXT开发教程:全局悬浮窗
今天跟大家分享一下HarmonyOS开发中的悬浮窗。 对于悬浮窗,可能有的同学会想到使用层叠布局是否可以实现,将悬浮窗叠在导航栏组件Tabs上,像这样: Stack({alignContent:Alignment.BottomEnd}){Tabs({barPosition:BarPosition.End…...
)
守护进程及gdb调试(新手简略版)
一、守护进程 守护进程(Daemon Process)是一种在后台运行的特殊进程,它独立于控制终端,并且在系统启动时自动运行,通常用于执行一些系统级的任务或提供特定的服务。以下是关于守护进程的详细定义和特点: …...

解锁元生代:ComfyUI工作流与云原生后端的深度融合
目录 蓝耘元生代:智算新势力崛起 ComfyUI 工作流创建详解 ComfyUI 初印象 蓝耘平台上搭建 ComfyUI 工作流 构建基础工作流实操 代码示例与原理剖析 云原生后端技术全景 云原生后端概念解析 核心技术深度解读 蓝耘元生代中两者的紧密联系…...
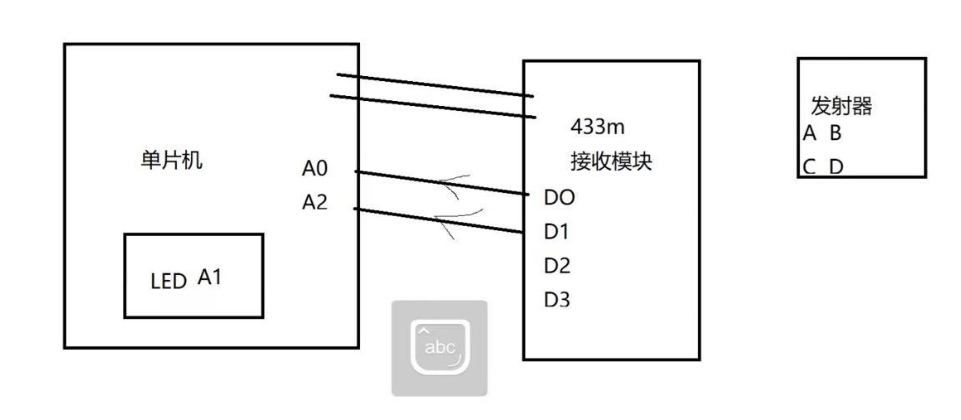
STM32 基本GPIO控制
目录 GPIO基础知识 编辑IO八种工作模式 固件库实现LED点灯 蜂鸣器 按键基础知识 编辑继电器 震动传感器 433M无线模块 GPIO基础知识 GPIO(General-Purpose input/output,通用输入/输出接口) 用于感知外部信号(输入模式)和控制外部设备&…...

汽车免拆诊断案例 | 2019款大众途观L车鼓风机偶尔不工作
故障现象 一辆2019款大众途观L车,搭载DKV发动机和0DE双离合变速器,累计行驶里程约为8万km。车主进厂反映,鼓风机偶尔不工作。 故障诊断 接车后试车,鼓风机各挡位均工作正常。用故障检测仪检测,空调控制单元&#x…...

FastAPI与SQLAlchemy数据库集成
title: FastAPI与SQLAlchemy数据库集成 date: 2025/04/17 15:33:34 updated: 2025/04/17 15:33:34 author: cmdragon excerpt: FastAPI与SQLAlchemy的集成通过创建虚拟环境、安装依赖、配置数据库连接、定义数据模型和实现路由来完成。核心模块包括数据库引擎、会话工厂和声…...
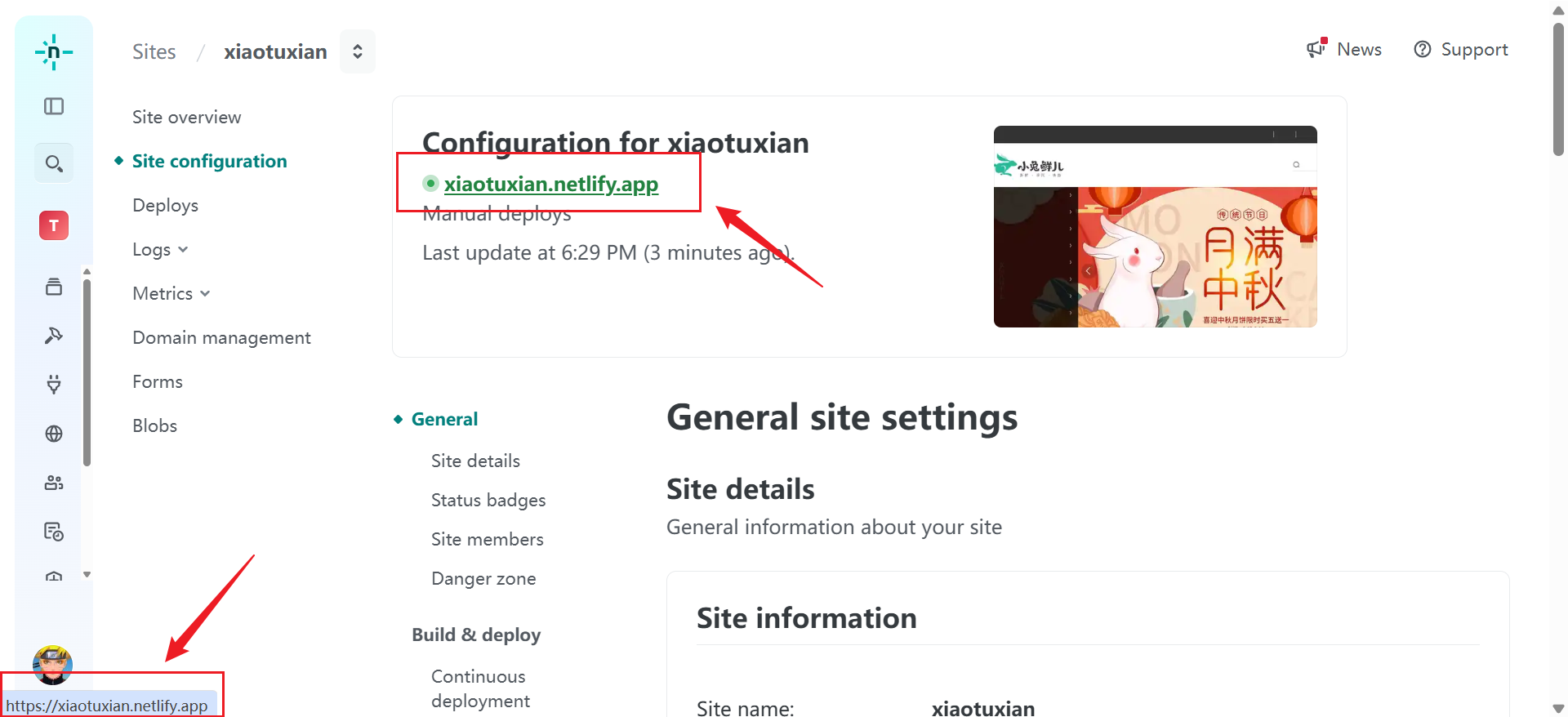
免费将静态网站部署到服务器方法(仅支持HTML,CSS,JS)
原视频链接:把HTML免费部署到网站上,实现别人也能访问的教程来啦QAQ_哔哩哔哩_bilibili 注意:仅支持HTML、CSS、JS。不支持Vue等框架。 1.打开网站www.wordpress.org 点击红框按钮 点击红框按钮下载wordpress模板文件并解压。 将自己编写的…...

4.Rust+Axum Tower 中间件实战:从集成到自定义
摘要 深入探讨 Rust 中 Axum Tower 中间件生态系统,包含实用集成与自定义示例。 一、引言 在 Rust 的 Web 开发领域,Axum 是一个轻量级且功能强大的 Web 框架,而 Tower 中间件生态系统为 Axum 提供了丰富的扩展能力。中间件在 Web 应用中扮…...

51单片机实验一:点亮led灯
目录 一、实验环境与实验器材 二、实验内容及实验步骤 1.用keil 软件创建工程,C文件编写程序,编译生成hex文件编辑 2.用STC烧写hex文件,点亮第一个LED灯 3.使用法2,点除第一个以外的LED灯 一、实验环境与实验器材 环境&am…...
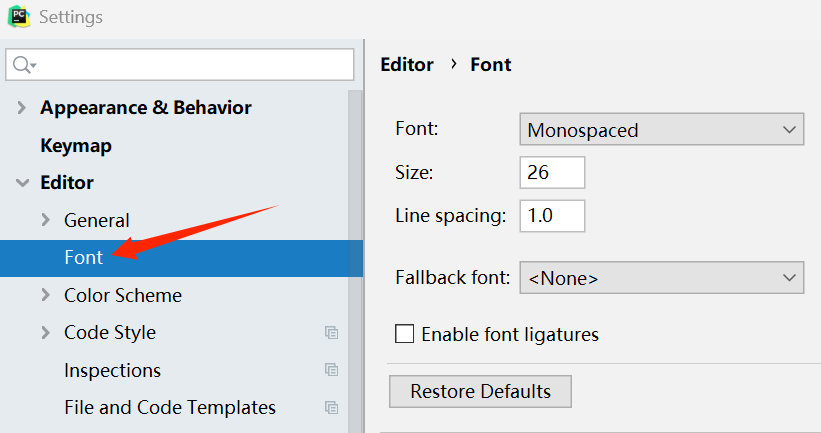
PyCharm 开发工具 修改字体大小及使用滚轮没有反应
PyCharm 开发工具 修改字体大小及使用滚轮没有反应 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是PyCharm 开发工具。前后每一小节的内容是有学习/理解关联性,希望对您有用~ PyCharm 开发工具 修改字体大小…...

AndroidStudio编译报错 Duplicate class kotlin
具体的编译报错信息如下: Duplicate class kotlin.collections.jdk8.CollectionsJDK8Kt found in modules kotlin-stdlib-1.8.10 (org.jetbrains.kotlin:kotlin-stdlib:1.8.10) and kotlin-stdlib-jdk8-1.6.21 (org.jetbrains.kotlin:kotlin-stdlib-jdk8:1.6.21) D…...
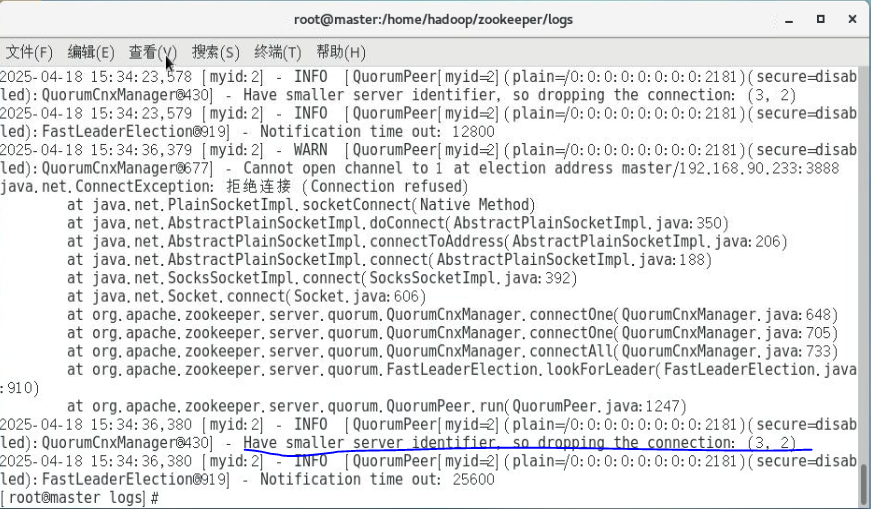
zookeeper启动报错have small server identifier
解决方案: 1、查看myid是否有重复 2、查看server.X 与myid的X是否一致 3、启动顺序为myid从小到大的服务器顺序...

1.Framer Motion 中 motion/react 和 motion/react-client 的用法和区别
背景知识:服务器端渲染 (SSR) 和客户端渲染 (CSR) 在最新的 Motion for React(原 Framer Motion)12.x 及更高版本中,官方提供了两个入口模块:motion/react 和 motion/react-client。二者对外 API 完全一致,…...

Django 结合 Vue 实现简单管理系统的详解
以下是一个 Django 结合 Vue 实现简单管理系统的详细步骤及示例代码: 项目整体架构思路 后端:使用 Django 搭建 RESTful API,负责数据的存储和处理。前端:使用 Vue 构建用户界面,通过调用后端 API 实现数据的展示、添加、修改和删除等操作。步骤 1:创建 Django 项目和应…...

简易 Python 爬虫实现,10min可完成带效果源码
目录 准备工作 编写爬虫代码 运行爬虫 查看结果 遇到的问题及解决 总结 前言和效果 本文记录了使用 Python 实现一个简单网页爬虫的过程,目标是爬取 quotes.toscrape.com 的名言和作者,并将结果保存到文本文件。以下是完整步骤,包含环境…...
)
ArcPy工具箱制作(下)
在上一篇博客中,我们已经初步了解了如何制作ArcPy工具箱,包括工具箱的基本概念、准备工作、脚本编写以及将脚本转换为工具箱的步骤。今天,我们将继续深入探讨ArcPy工具箱的制作,重点介绍一些进阶技巧和优化方法. 一、优化工具箱的…...

492Q 型气缸盖双端面铣削组合铣床总体设计
一、引言 492Q 型气缸盖是发动机的重要组成部分,其双端面的加工精度对发动机的性能和可靠性有着重要影响。设计一款适用于 492Q 型气缸盖双端面铣削的组合铣床,能够提高加工效率和质量,满足发动机生产的需求。 二、总体设计要求 加工精度&…...

YOLO学习笔记 | YOLOv11的改进方向与应用领域
YOLOv11作为目标检测领域的前沿模型,其改进方向和应用领域在多个研究中得到了广泛探索。以下从改进策略和应用场景两个维度进行综合总结: 一、YOLOv11的改进方向 1. 骨干网络(Backbone)优化 Swin Transformer替换:通过引入层次化特征表示和移位窗口自注意力机制,解决了视…...
【学习笔记】Py网络爬虫学习记录(更新中)
目录 一、入门实践——爬取百度网页 二、网络基础知识 1、两种渲染方式 2、HTTP解析 三、Request入门 1、get方式 - 百度搜索/豆瓣电影排行 2、post方式 - 百度翻译 四、数据解析提取三种方式 1、re正则表达式解析 (1)常用元字符 ࿰…...

Python + Playwright:编写自动化测试的避坑策略
Python + Playwright:编写自动化测试的避坑策略 前言一、告别 `time.sleep()`,拥抱 Playwright 的智能等待二、选择健壮、面向用户的选择器,优先使用 `data-testid`三、严格管理环境与依赖,确保一致性四、分离测试数据与逻辑,灵活管理数据五、采用 POM 等设计模式,构建可…...

电脑开机启动慢的原因
硬件老化或故障 机械硬盘老化:电脑使用时间较长,机械硬盘的读写速度会逐渐下降。这是因为机械硬盘内部的盘片和磁头在长期使用后,可能会出现磨损、坏道等问题,导致数据读取速度变慢,从而影响开机时系统文件的加载速度&…...
旅游资源网站登录(jsp+ssm+mysql5.x)
旅游资源网站登录(jspssmmysql5.x) 旅游资源网站是一个为旅游爱好者提供全面服务的平台。网站登录界面简洁明了,用户可以选择以管理员或普通用户身份登录。成功登录后,用户可以访问个人中心,进行修改密码和个人信息管理。用户管理模块允许管…...

C语言链接数据库
目录 使用 yum 配置 mysqld 环境 查看 mysqld 服务的版本 创建 mysql 句柄 链接数据库 使用数据库 增加数据 修改数据 查询数据 获取查询结果的行数 获取查询结果的列数 获取查询结果的列名 获取查询结果所有数据 断开链接 C语言访问mysql数据库整体源码 通过…...

WiFi“管家”------hostapd的工作流程
目录 1. 启动与初始化 1.1 解析命令行参数 1.2 读取配置文件 1.3 创建接口和 BSS 数据结构 1.4 初始化驱动程序 2. 认证和关联处理 2.1 监听认证请求 2.2 处理认证请求 2.3 处理关联请求 3. 数据转发 3.1 接收客户端数据 3.2 转发数据 4. 断开连接处理 4.1 处理客…...