解锁元生代:ComfyUI工作流与云原生后端的深度融合
目录
蓝耘元生代:智算新势力崛起
ComfyUI 工作流创建详解
ComfyUI 初印象
蓝耘平台上搭建 ComfyUI 工作流
构建基础工作流实操
代码示例与原理剖析
云原生后端技术全景
云原生后端概念解析
核心技术深度解读
蓝耘元生代中两者的紧密联系
工作流对云原生后端的需求
云原生后端对工作流的支撑
代码层面的集成示例
总结
蓝耘元生代:智算新势力崛起

在当下人工智能蓬勃发展的时代浪潮中,蓝耘元生代宛如一颗耀眼新星,强势跻身于智能计算领域的前沿。其品牌建设承载着对前沿技术深度整合与创新应用的宏伟愿景,致力于为各行业打造出高效、智能且极具竞争力的解决方案。而在这一宏大布局里,平台所实现的工作流(ComfyUI)创建与云原生后端之间的紧密联系,宛如中枢神经系统,成为推动整个品牌在技术赛道上飞速驰骋的核心动力。深入剖析二者关联,不仅有助于理解蓝耘元生代的技术精髓,更能洞察其为品牌在复杂多变的市场环境中构筑坚实壁垒的关键所在。
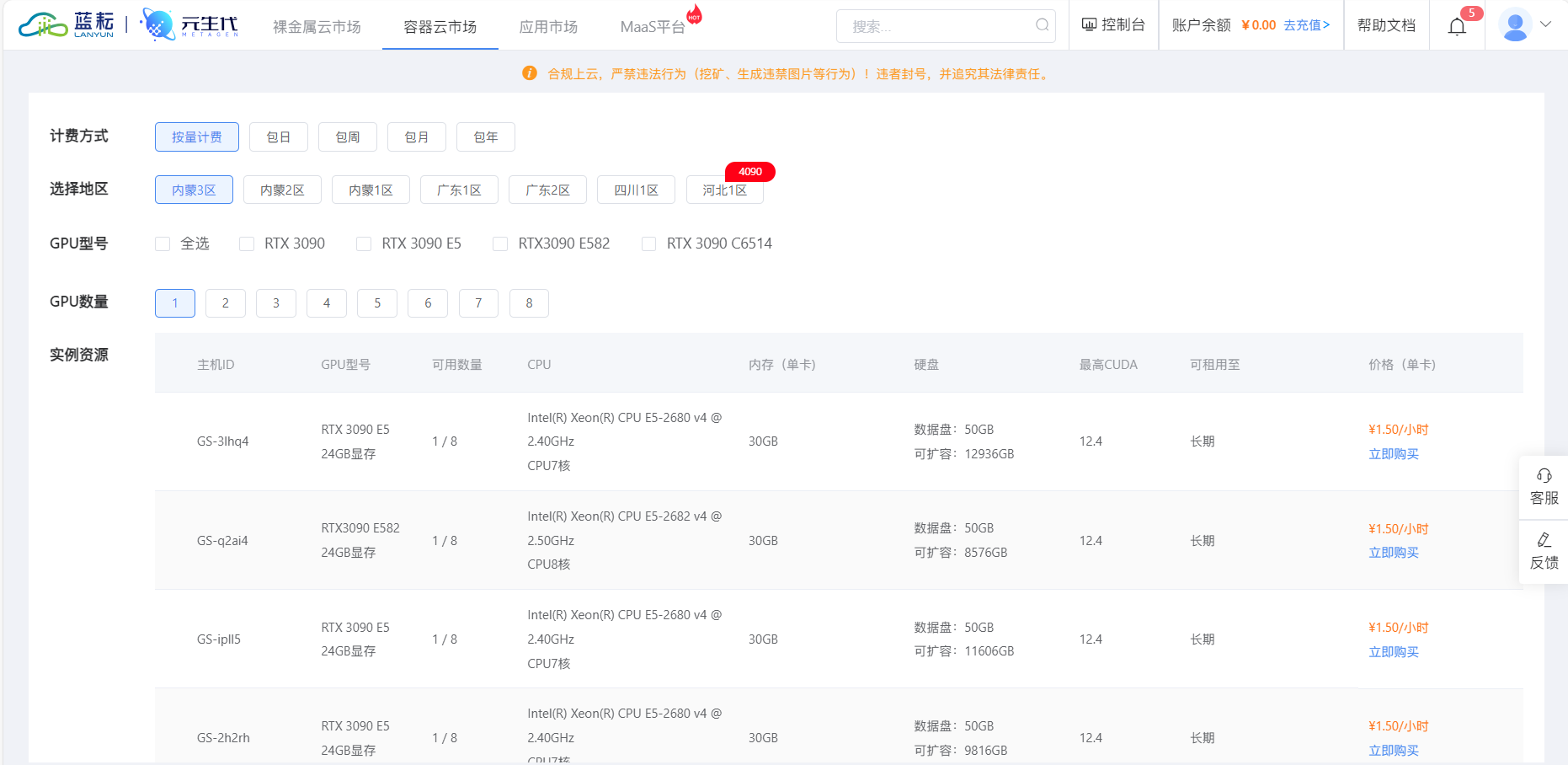
2024 年 11 月 28 日,蓝耘科技在杭州隆重举行以 “智算蓝图,耘领未来” 为主题的战略与产品发布会,正式推出 “元生代” 智算云平台,这一举措在人工智能领域引起了广泛关注。“元生代” 智算云平台基于 Kubernetes 原生云设计,充分整合了大规模 GPU 算力资源,具有卓越的性能和强大的功能。它实现了从数据准备、代码开发、模型训练到推理部署等全场景覆盖,为用户提供了一站式的 AI 研发解决方案,能够高效赋能用户 AI 研发全流程,大大降低了 AI 开发的门槛,让中小开发者也能轻松接入与世界顶级 AI 巨头相媲美的算力服务 ,真正推动了人工智能技术的普及和应用。
在当今竞争激烈的人工智能市场中,蓝耘元生代凭借其独特的优势脱颖而出。它拥有强大的算力调度能力,无论是裸金属调度还是容器调度,都能满足不同用户的多样化需求。裸金属调度给予用户更多的自由发挥空间,使其能够根据自身需求灵活配置资源;容器调度则依托方便快捷的调度能力,帮助纳管伙伴闲置的算力资源,实现资源的高效利用,能够在分钟级打造一个自己品牌的算力平台,极大地提高了资源的利用率和运营效率。
元生代还搭建了丰富的应用市场,预集成了如 Stable Diffusion 等热门模型的容器化封装,方便开发者快速验证业务场景,加速项目的开发进程。同时,它支持用户自助上传镜像,为开发者在社区打造个人 IP、开辟变现渠道提供了便利条件,进一步激发了开发者的创新活力和创造力。其 AI 协作开发模块更是充分考虑了团队协作场景,通过前台、中台和后台的全面协同,帮助开发者高效完成从数据准备到模型训练与部署的全流程。前台为开发工程师集成了常用的开发套件、存储调用、镜像仓库及高灵活度的资源调度,并进行了一系列后台优化,如计算网络轨道调优、NUMA 亲和性调度、分布式缓存等,可实现将自定义任务运行于同一组 Leaf 交换机上,有效提高了训练效率;中台主要为用户的运维团队提供集群基础设施级别的监控指标,帮助运维人员更好地追踪训练任务各个阶段的资源使用水位线,进一步优化资源分配,提高训练效率;后台则为非技术人员提供运营和财务等相关功能,确保整个项目的顺利运营和管理。
蓝耘元生代在人工智能发展浪潮中占据着重要地位,其推出的 “元生代” 智算云平台为用户提供了强大的算力支持和一站式的 AI 研发解决方案,推动了人工智能技术的普及和应用。而在其品牌建设过程中,平台实现工作流(如 ComfyUI)的创建与云原生后端之间存在着紧密的联系,这种联系对于提升平台的性能、用户体验以及推动人工智能的发展具有重要意义,接下来我们将深入探讨它们之间的内在关联。
ComfyUI 工作流创建详解
ComfyUI 初印象
ComfyUI 是一款基于 Python 的图形界面工具,在 AI 绘图领域展现出独特魅力。它以直观的节点连接方式构建工作流,用户无需编写复杂代码,就能轻松实现各种 AI 绘图任务 ,大大降低了技术门槛,让更多艺术创作者和爱好者能够投身于 AI 绘画的奇妙世界。
与传统的 AI 绘图工具相比,ComfyUI 具有诸多优势。它的模块化设计极为灵活,将复杂的 AI 绘图流程拆解为一个个独立的节点,每个节点都有明确的功能,如加载模型、处理文本提示词、采样去噪等。用户可以像搭建积木一样,根据自己的需求自由组合这些节点,构建出个性化的工作流。这种高度自定义的特性,使得用户能够深入控制图像生成的每一个环节,实现更加精细和独特的创作效果。ComfyUI 还具有出色的效率表现。一旦用户确定了一个有效的工作流,就可以将其保存并重复使用,就像建立了一条高效的生产流水线,只需调整输入的文本提示词、参数等内容,就能快速生成一系列符合预期的图像,特别适合需要批量生成图像的场景,如游戏素材制作、插画创作等,极大地提高了工作效率。
蓝耘平台上搭建 ComfyUI 工作流
在蓝耘平台部署 ComfyUI 工作流,首先需登录蓝耘专属控制台,在资源管理界面精准定位到虚拟机实例板块。这里,用户要仔细筛选符合 ComfyUI 运行配置需求的虚拟机,如具备高性能 GPU、充足内存及存储的机型,为后续工作流的顺畅运行筑牢硬件根基。接下来进入镜像部署环节,在镜像仓库中搜索并选定官方认证的 ComfyUI 镜像,点击部署按钮后,平台会依据镜像预设参数,自动完成基础环境搭建,包括 Python 环境配置、依赖库安装等。完成镜像部署后,通过 SSH 连接工具,输入虚拟机的 IP 地址、用户名及密码,成功建立连接。此时,便正式踏入了 ComfyUI 的工作流构建环境。
登录与注册:打开浏览器,访问蓝耘 GPU 智算云平台官网(https://cloud.lanyun.net//#/registerPage?promoterCode=0131 )。新用户需先进行注册,注册成功后即可享受免费体验 18 小时算力的优惠。登录后,用户将进入蓝耘平台的控制台,在这里可以看到丰富的功能模块,如容器云市场、应用市场等 。
构建基础工作流实操
以构建一个简单的 AI 图像生成基础工作流为例,首先要加载大模型节点。在 ComfyUI 的节点库中找到对应大模型节点,如 Stable Diffusion 模型节点,双击添加到工作流画布。选中该节点,在右侧属性栏中配置模型路径、权重文件等关键参数,确保模型能够准确加载。紧接着,配置正负词 CLIP 文本编码器节点,将其与大模型节点通过数据连接线相连。在正负词文本框内输入如 “美丽的自然风光”(正词)、“模糊、杂乱”(负词)等描述,以此引导模型生成符合预期的图像。随后,连接 KSampler 节点,该节点负责图像生成过程中的采样操作。在其属性设置中,调整采样步数、采样方法(如 DDIM、PLMS 等)、噪声强度等参数,这些参数直接影响图像生成的质量与风格。最后,连接图像输出节点,设置好输出路径与图像格式(如 PNG、JPEG),至此,一个基础的 AI 图像生成工作流搭建完成,点击运行按钮,即可见证图像生成的全过程。
完成上述步骤后,一个基础的 ComfyUI 工作流就搭建完成了。用户只需在相应的提示词框中输入想要生成图像的正负词,设置一些其他风格参数,然后点击右边的 Queue Prompt(添加提示词队列),就可以等待 ComfyUI 按照工作流的设定,逐步生成心仪的图片。在生成过程中,用户可以通过高亮的工作框,清晰地看到每个流程运转到的节点位置,直观了解图像生成的进度和过程 。
代码示例与原理剖析
从代码层面深入剖析,以 Python 伪代码来模拟工作流节点的定义与连接逻辑。假设定义一个简单的图像数据输入节点:
class ImageInputNode:def __init__(self):self.output_data = Nonedef set_input(self, input_path):# 实际代码中应包含读取图像数据的逻辑,如使用PIL库self.output_data = input_path再定义一个图像数据处理节点,例如图像缩放节点:
class ImageResizeNode:def __init__(self):self.input_data = Noneself.output_data = Nonedef set_input(self, input_data):self.input_data = input_datadef process(self):if self.input_data:# 模拟图像缩放处理逻辑,这里仅为示意width, height = self.input_data.sizenew_width = width // 2new_height = height // 2self.output_data = self.input_data.resize((new_width, new_height))在工作流构建时,通过以下代码模拟节点连接:
input_node = ImageInputNode()
resize_node = ImageResizeNode()input_node.set_input("input_image.jpg")
resize_node.set_input(input_node.output_data)
resize_node.process()在这个示例中,ImageInputNode负责读取图像数据,ImageResizeNode从输入节点获取数据并进行缩放处理。实际的 ComfyUI 工作流节点连接更为复杂,涉及多种数据类型、处理逻辑及参数传递,但原理与此类似,各节点按照设定的逻辑顺序,依次对数据进行处理与传递,最终实现整个工作流的既定目标。
云原生后端技术全景
云原生后端概念解析
云原生后端是一种基于云计算技术和理念构建的后端系统架构,其设计与运行紧密依托云计算环境,旨在充分挖掘云计算的潜力,实现应用程序的灵活部署、高效扩展和可靠运行 。在云原生后端架构中,应用程序及其依赖项被精心打包到容器中,这些容器就像是一个个独立的 “小盒子”,里面装着运行应用所需的一切,从代码、运行时环境到各类库和配置文件,确保应用在不同的环境中都能以一致的方式运行 。
以一个电商应用为例,传统的后端架构可能将所有功能模块紧密耦合在一起,部署在物理服务器上。当业务量突然增加时,很难快速扩展资源以应对高并发,而且不同环境(开发、测试、生产)之间的配置差异可能导致各种兼容性问题。而采用云原生后端架构,电商应用的各个功能模块,如商品管理、订单处理、用户服务等,会被拆分成独立的微服务,并分别打包成容器 。这些容器可以轻松地在不同的云环境中部署,无论是公有云、私有云还是混合云。当促销活动导致订单处理模块的流量激增时,云原生后端能够自动快速地增加该模块对应的容器实例数量,实现弹性伸缩,确保系统稳定运行,同时在不同环境中的一致性也极大地降低了开发和运维的难度 。
核心技术深度解读
1.容器化(Docker):容器化技术是云原生后端的基石,而 Docker 则是其中的佼佼者。Docker 通过 Linux 内核的 Namespaces 和 Cgroups 特性来实现资源的隔离和限制 。Namespaces 提供了进程、网络、挂载点、用户等资源的隔离,就像为每个容器打造了一个独立的小世界,容器内的进程无法感知到容器外的其他进程和资源,保证了容器之间的相互隔离 。Cgroups 用于限制、记录和隔离进程组所使用的物理资源,如 CPU、内存、磁盘 I/O 等,确保每个容器不会过度占用资源 。
在实际应用中,开发人员可以使用 Dockerfile 来定义镜像的创建过程。例如,对于一个基于 Python Flask 框架的 Web 应用,其 Dockerfile 可能如下:
# 使用Python官方镜像作为基础镜像
FROM python:3.10-slim# 设置工作目录
WORKDIR /app# 复制项目文件到容器内
COPY. /app# 安装项目依赖
RUN pip install -r requirements.txt# 暴露应用端口
EXPOSE 5000# 定义容器启动时执行的命令
CMD ["python", "app.py"]通过这个 Dockerfile,开发人员可以轻松构建一个包含该 Web 应用及其所有依赖的 Docker 镜像。这个镜像可以在任何支持 Docker 的环境中运行,无论是开发人员的本地机器,还是生产环境的云服务器,都能保证应用的一致性运行 。
2. 微服务架构:微服务架构将应用程序拆分为多个小型、独立的服务单元,每个服务专注于执行特定的业务功能 。这些服务遵循单一职责原则,具有高度的自治性,它们之间通过轻量级的通信机制(如 HTTP API、消息队列等)进行交互 。以一个在线教育平台为例,它可以拆分为用户管理服务、课程管理服务、订单服务、直播服务等多个微服务 。用户管理服务负责处理用户的注册、登录、信息修改等功能;课程管理服务负责课程的添加、编辑、删除、展示等操作;订单服务处理用户购买课程的订单流程;直播服务则专注于实现课程直播的功能 。每个微服务都可以独立开发、测试、部署和扩展,不同的团队可以负责不同的微服务,提高了开发效率和系统的可维护性 。当某个微服务需要升级或修改时,不会影响其他服务的正常运行 。例如,如果课程管理服务需要添加新的课程类型,开发团队可以独立对该服务进行开发和部署,而不会对其他服务造成干扰 。
3. Kubernetes(K8s):Kubernetes 是业界标准的容器编排平台,犹如一个智能的指挥官,负责管理和调度容器集群,确保服务的高可用性和可扩展性 。它可以根据资源需求和负载情况,自动分配容器到合适的节点上运行 。Kubernetes 支持自动扩展、负载均衡和滚动更新等重要功能 。在一个大型的电商系统中,在促销活动期间,订单量会急剧增加,Kubernetes 可以根据预设的规则,自动快速地增加订单处理服务的容器副本数量,以应对高并发的订单处理需求 。当活动结束后,它又能自动减少容器副本数量,避免资源浪费 。在进行服务升级时,Kubernetes 的滚动更新功能可以逐步替换旧版本的容器为新版本,确保服务在升级过程中不中断,用户几乎感知不到服务的更新过程 。
4. 持续集成 / 持续部署(CI/CD):持续集成 / 持续部署通过自动化构建、测试和部署流程,实现快速迭代和持续交付,大大缩短了开发周期 。持续集成强调开发人员频繁地将代码合并到主干分支,每次合并都会触发自动构建和测试,确保代码的质量 。持续交付则是自动将通过测试的代码部署到预生产环境,准备随时发布到生产环境 。持续部署进一步自动化,将通过测试的代码直接部署到生产环境 。在一个移动应用开发项目中,开发人员每天多次提交代码到代码仓库,每次提交都会触发 CI 流程 。CI 工具(如 Jenkins、GitLab CI/CD 等)会自动拉取代码,进行编译、单元测试、集成测试等操作 。如果测试通过,代码会被自动部署到预生产环境进行进一步的测试和验证 。当一切准备就绪,通过 CD 流程,代码可以快速、可靠地部署到生产环境,让用户及时体验到新功能和修复的问题 。
蓝耘元生代中两者的紧密联系
工作流对云原生后端的需求
在蓝耘元生代的 AI 绘图业务场景中,ComfyUI 工作流的运行对云原生后端有着多方面的迫切需求。随着用户对 AI 绘图的热情不断高涨,蓝耘元生代平台上的绘图任务量呈爆发式增长,这就要求云原生后端具备强大的资源动态分配能力 。当大量用户同时发起复杂的 AI 绘图任务时,每个任务对计算资源(如 GPU、CPU、内存等)的需求各不相同,而且任务的执行时间也长短不一 。云原生后端需要能够实时监测这些任务的资源需求变化,像一位智能的资源管家,根据任务的优先级、复杂程度等因素,动态地为每个 ComfyUI 工作流分配最合适的资源 。对于一些紧急且资源需求大的商业项目绘图任务,云原生后端要优先保障其所需的 GPU 资源,确保任务能够高效完成,避免因资源不足而导致任务卡顿或失败 。
高并发处理能力也是云原生后端不可或缺的。在蓝耘元生代平台上,每天都有成千上万的用户同时使用 ComfyUI 工作流进行 AI 绘图,这就产生了极高的并发请求 。云原生后端需要像一座坚固的桥梁,能够稳定地承载这些高并发请求,确保每个用户的绘图任务都能得到及时响应 。它需要具备高效的网络通信机制,快速地接收和处理用户的请求数据,同时要合理地分配计算资源,避免因并发过高而导致系统崩溃 。如果云原生后端无法处理高并发,就会出现用户请求长时间等待、绘图任务无法及时启动等问题,严重影响用户体验 。
服务弹性扩展能力同样至关重要。当蓝耘元生代平台迎来流量高峰,如举办 AI 绘图比赛、推出热门绘图活动时,平台上的 ComfyUI 工作流数量会急剧增加 。此时,云原生后端需要像一个灵活的变形金刚,能够根据实际的工作负载,自动快速地扩展服务资源 。它可以通过增加容器实例的数量,为更多的 ComfyUI 工作流提供运行环境,确保平台在高负载情况下依然能够稳定运行 。当流量高峰过去,云原生后端又能自动缩减资源,避免资源的浪费,降低运营成本 。如果云原生后端不具备弹性扩展能力,在流量高峰时,平台就会出现运行缓慢、甚至无法响应的情况,导致用户流失 。
云原生后端对工作流的支撑
云原生后端通过多种关键技术,为 ComfyUI 工作流在蓝耘元生代平台上的高效稳定运行提供了坚实支撑 。
容器化部署 ComfyUI 是云原生后端的重要举措。通过将 ComfyUI 及其依赖项打包成 Docker 容器,实现了环境的一致性和隔离性 。每个容器就像是一个独立的小世界,里面包含了 ComfyUI 运行所需的所有组件,从 Python 运行环境、各种依赖库,到 ComfyUI 的代码和配置文件 。这样,无论在开发、测试还是生产环境中,ComfyUI 都能以相同的方式运行,避免了因环境差异而导致的兼容性问题 。在开发阶段,开发人员可以在本地的 Docker 容器中进行 ComfyUI 的开发和测试,确保代码在各种环境中的一致性 。当将 ComfyUI 部署到生产环境时,只需要将相同的 Docker 镜像推送到生产服务器上运行即可 。容器的隔离性还保证了不同的 ComfyUI 工作流之间不会相互干扰,一个工作流出现问题,不会影响其他工作流的正常运行 。
利用微服务架构优化工作流模块,也是云原生后端的一大优势。云原生后端将 ComfyUI 工作流中的各个功能模块,如模型加载、图像生成、后处理等,拆分成独立的微服务 。每个微服务都专注于实现一个特定的功能,具有高度的自治性 。这些微服务之间通过轻量级的通信机制(如 HTTP API、消息队列等)进行交互 。以模型加载微服务为例,它专门负责从存储中读取各种 AI 绘图模型,并将其加载到内存中,供其他微服务使用 。当图像生成微服务需要使用模型时,只需通过 HTTP API 向模型加载微服务发送请求,获取所需的模型即可 。这种微服务架构使得每个模块都可以独立开发、测试、部署和扩展,提高了开发效率和系统的可维护性 。如果需要优化图像生成微服务的算法,开发团队可以独立对其进行修改和部署,而不会影响其他微服务的正常运行 。
借助 Kubernetes 实现资源调度,是云原生后端保障 ComfyUI 工作流高效运行的关键。Kubernetes 就像是一个智能的指挥官,负责管理和调度容器集群 。它可以根据 ComfyUI 工作流的资源需求和负载情况,自动分配容器到合适的节点上运行 。当一个 ComfyUI 工作流需要大量的 GPU 资源进行图像生成时,Kubernetes 会根据集群中各个节点的 GPU 资源使用情况,将该工作流对应的容器调度到 GPU 资源充足的节点上 。Kubernetes 还支持自动扩展、负载均衡和滚动更新等重要功能 。在高并发情况下,Kubernetes 可以根据预设的规则,自动快速地增加 ComfyUI 工作流相关容器的副本数量,实现负载均衡,确保每个工作流都能得到及时处理 。在进行 ComfyUI 版本升级时,Kubernetes 的滚动更新功能可以逐步替换旧版本的容器为新版本,确保服务在升级过程中不中断,用户几乎感知不到服务的更新过程 。
代码层面的集成示例
在云原生环境中部署 ComfyUI 工作流,涉及到一系列的配置和代码实现,以下是一些关键的示例。
Kubernetes 配置文件是部署 ComfyUI 工作流的重要依据,以下是一个简单的 Kubernetes Deployment 配置文件示例:
apiVersion: apps/v1
kind: Deployment
metadata:name: comfyui-deployment
spec:replicas: 3selector:matchLabels:app: comfyuitemplate:metadata:labels:app: comfyuispec:containers:- name: comfyui-containerimage: your-comfyui-image:latestports:- containerPort: 8080resources:requests:memory: "512Mi"cpu: "0.5"limits:memory: "1Gi"cpu: "1"在这个配置文件中,apiVersion指定了 Kubernetes API 的版本 。kind表明这是一个 Deployment 资源,Deployment 用于定义和管理一组 Pod 的副本 。metadata.name为该 Deployment 指定了名称为comfyui - deployment 。spec.replicas设置为 3,表示期望创建 3 个 Pod 副本,以提高服务的可用性和处理能力 。spec.selector.matchLabels定义了选择器,用于选择与标签app: comfyui匹配的 Pod 。spec.template.metadata.labels则为 Pod 模板添加了相同的标签,确保 Pod 能够被正确选择 。在spec.template.spec.containers部分,定义了容器的相关信息 。name为容器指定了名称comfyui - container 。image指定了要使用的 ComfyUI Docker 镜像,这里假设镜像名为your - comfyui - image:latest,其中latest表示镜像的版本标签 。ports部分定义了容器要暴露的端口,这里将容器的 8080 端口暴露出来,以便外部可以访问 ComfyUI 服务 。resources.requests和resources.limits分别定义了容器对内存和 CPU 资源的请求量和限制量 。请求量表示容器期望获得的资源量,限制量则防止容器使用过多的资源,影响其他容器的正常运行 。这里请求 512Mi 内存和 0.5 个 CPU 核心,限制为 1Gi 内存和 1 个 CPU 核心 。
在云原生环境中,服务注册与发现是实现微服务之间通信的关键机制 。以使用 Consul 作为服务注册与发现工具为例,以下是一个简单的 Python 代码示例,展示如何在 ComfyUI 相关微服务中实现服务注册:
import consul
import time# 初始化Consul客户端
c = consul.Consul()# 服务名称和地址
service_name = 'comfyui - model - loader'
service_address = '10.0.0.10'
service_port = 8081# 注册服务
try:c.agent.service.register(name=service_name,address=service_address,port=service_port,check=consul.Check.tcp(service_address, service_port, '10s'))print(f'{service_name} 已成功注册到Consul')
except Exception as e:print(f'服务注册失败: {e}')# 保持服务运行
try:while True:time.sleep(1)
except KeyboardInterrupt:# 注销服务c.agent.service.deregister(service_name)print(f'{service_name} 已从Consul注销')
在这段代码中,首先导入了consul库,用于与 Consul 服务器进行交互 。然后初始化了一个 Consul 客户端c 。接着定义了要注册的服务名称service_name、服务地址service_address和服务端口service_port 。在try块中,使用c.agent.service.register方法将服务注册到 Consul 服务器 。其中,check参数定义了一个健康检查,这里使用 TCP 检查,每 10 秒检查一次服务是否正常运行 。如果服务注册成功,会打印提示信息 。在while True循环中,使用time.sleep(1)让程序保持运行状态 。当用户通过键盘中断程序时,会进入except KeyboardInterrupt块,使用c.agent.service.deregister方法将服务从 Consul 服务器注销,并打印注销提示信息 。通过服务注册与发现,其他微服务(如图像生成微服务)可以通过 Consul 服务器轻松找到模型加载微服务的地址和端口,实现相互之间的通信和协作 。
总结
蓝耘元生代品牌建设进程中,ComfyUI 工作流与云原生后端宛如车之两轮、鸟之双翼,紧密交织、相辅相成。ComfyUI 工作流凭借其强大的可视化构建能力,为业务流程创新提供了无限可能,而云原生后端则以卓越的资源管理、高效运维与灵活扩展特性,为工作流的稳定运行与持续发展保驾护航。这种深度融合,不仅为蓝耘元生代在智能计算领域构筑了坚实的技术护城河,更推动着其在品牌价值塑造、市场份额拓展等方面大步迈进。在未来的技术演进与市场竞争中,持续深化二者融合,不断探索创新应用场景,必将助力蓝耘元生代在智能计算的星辰大海中,乘风破浪,驶向更加辉煌的彼岸。
相关文章:

解锁元生代:ComfyUI工作流与云原生后端的深度融合
目录 蓝耘元生代:智算新势力崛起 ComfyUI 工作流创建详解 ComfyUI 初印象 蓝耘平台上搭建 ComfyUI 工作流 构建基础工作流实操 代码示例与原理剖析 云原生后端技术全景 云原生后端概念解析 核心技术深度解读 蓝耘元生代中两者的紧密联系…...
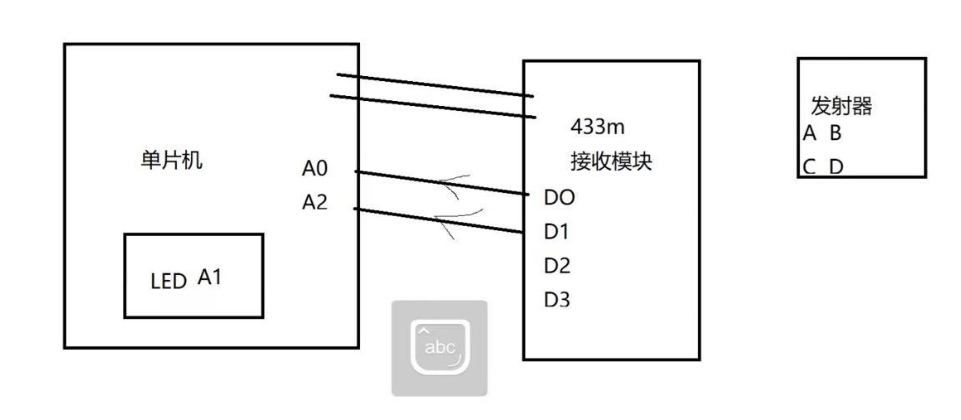
STM32 基本GPIO控制
目录 GPIO基础知识 编辑IO八种工作模式 固件库实现LED点灯 蜂鸣器 按键基础知识 编辑继电器 震动传感器 433M无线模块 GPIO基础知识 GPIO(General-Purpose input/output,通用输入/输出接口) 用于感知外部信号(输入模式)和控制外部设备&…...

汽车免拆诊断案例 | 2019款大众途观L车鼓风机偶尔不工作
故障现象 一辆2019款大众途观L车,搭载DKV发动机和0DE双离合变速器,累计行驶里程约为8万km。车主进厂反映,鼓风机偶尔不工作。 故障诊断 接车后试车,鼓风机各挡位均工作正常。用故障检测仪检测,空调控制单元&#x…...

FastAPI与SQLAlchemy数据库集成
title: FastAPI与SQLAlchemy数据库集成 date: 2025/04/17 15:33:34 updated: 2025/04/17 15:33:34 author: cmdragon excerpt: FastAPI与SQLAlchemy的集成通过创建虚拟环境、安装依赖、配置数据库连接、定义数据模型和实现路由来完成。核心模块包括数据库引擎、会话工厂和声…...
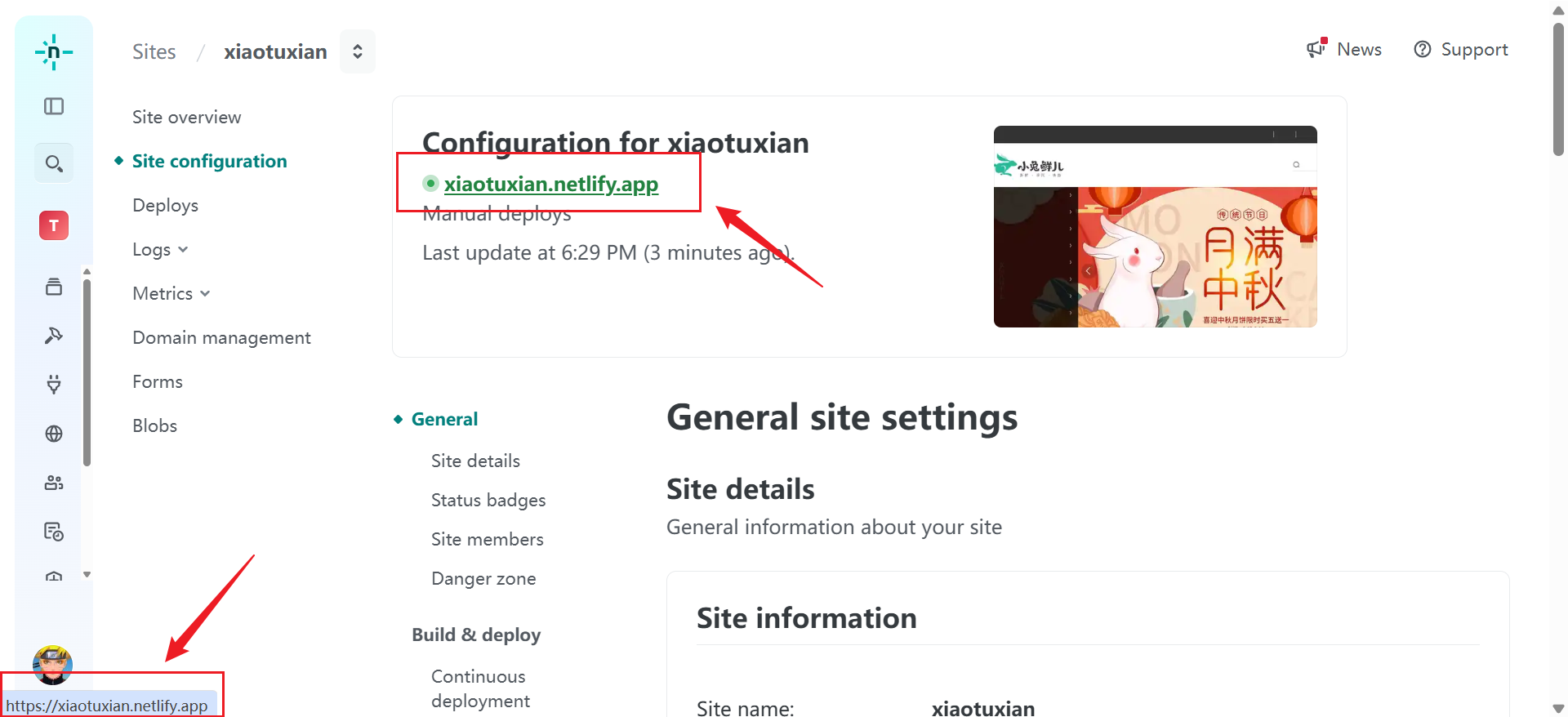
免费将静态网站部署到服务器方法(仅支持HTML,CSS,JS)
原视频链接:把HTML免费部署到网站上,实现别人也能访问的教程来啦QAQ_哔哩哔哩_bilibili 注意:仅支持HTML、CSS、JS。不支持Vue等框架。 1.打开网站www.wordpress.org 点击红框按钮 点击红框按钮下载wordpress模板文件并解压。 将自己编写的…...

4.Rust+Axum Tower 中间件实战:从集成到自定义
摘要 深入探讨 Rust 中 Axum Tower 中间件生态系统,包含实用集成与自定义示例。 一、引言 在 Rust 的 Web 开发领域,Axum 是一个轻量级且功能强大的 Web 框架,而 Tower 中间件生态系统为 Axum 提供了丰富的扩展能力。中间件在 Web 应用中扮…...

51单片机实验一:点亮led灯
目录 一、实验环境与实验器材 二、实验内容及实验步骤 1.用keil 软件创建工程,C文件编写程序,编译生成hex文件编辑 2.用STC烧写hex文件,点亮第一个LED灯 3.使用法2,点除第一个以外的LED灯 一、实验环境与实验器材 环境&am…...
PyCharm 开发工具 修改字体大小及使用滚轮没有反应
PyCharm 开发工具 修改字体大小及使用滚轮没有反应 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是PyCharm 开发工具。前后每一小节的内容是有学习/理解关联性,希望对您有用~ PyCharm 开发工具 修改字体大小…...

AndroidStudio编译报错 Duplicate class kotlin
具体的编译报错信息如下: Duplicate class kotlin.collections.jdk8.CollectionsJDK8Kt found in modules kotlin-stdlib-1.8.10 (org.jetbrains.kotlin:kotlin-stdlib:1.8.10) and kotlin-stdlib-jdk8-1.6.21 (org.jetbrains.kotlin:kotlin-stdlib-jdk8:1.6.21) D…...
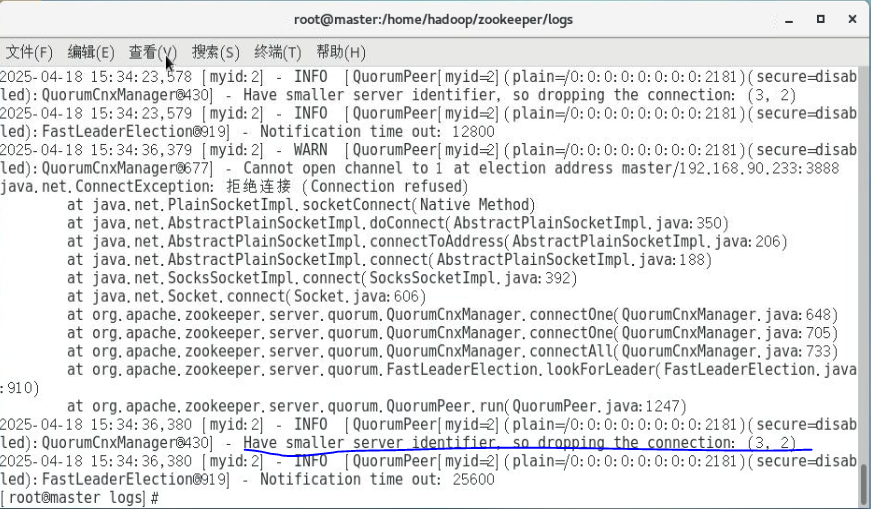
zookeeper启动报错have small server identifier
解决方案: 1、查看myid是否有重复 2、查看server.X 与myid的X是否一致 3、启动顺序为myid从小到大的服务器顺序...

1.Framer Motion 中 motion/react 和 motion/react-client 的用法和区别
背景知识:服务器端渲染 (SSR) 和客户端渲染 (CSR) 在最新的 Motion for React(原 Framer Motion)12.x 及更高版本中,官方提供了两个入口模块:motion/react 和 motion/react-client。二者对外 API 完全一致,…...

Django 结合 Vue 实现简单管理系统的详解
以下是一个 Django 结合 Vue 实现简单管理系统的详细步骤及示例代码: 项目整体架构思路 后端:使用 Django 搭建 RESTful API,负责数据的存储和处理。前端:使用 Vue 构建用户界面,通过调用后端 API 实现数据的展示、添加、修改和删除等操作。步骤 1:创建 Django 项目和应…...

简易 Python 爬虫实现,10min可完成带效果源码
目录 准备工作 编写爬虫代码 运行爬虫 查看结果 遇到的问题及解决 总结 前言和效果 本文记录了使用 Python 实现一个简单网页爬虫的过程,目标是爬取 quotes.toscrape.com 的名言和作者,并将结果保存到文本文件。以下是完整步骤,包含环境…...
)
ArcPy工具箱制作(下)
在上一篇博客中,我们已经初步了解了如何制作ArcPy工具箱,包括工具箱的基本概念、准备工作、脚本编写以及将脚本转换为工具箱的步骤。今天,我们将继续深入探讨ArcPy工具箱的制作,重点介绍一些进阶技巧和优化方法. 一、优化工具箱的…...

492Q 型气缸盖双端面铣削组合铣床总体设计
一、引言 492Q 型气缸盖是发动机的重要组成部分,其双端面的加工精度对发动机的性能和可靠性有着重要影响。设计一款适用于 492Q 型气缸盖双端面铣削的组合铣床,能够提高加工效率和质量,满足发动机生产的需求。 二、总体设计要求 加工精度&…...

YOLO学习笔记 | YOLOv11的改进方向与应用领域
YOLOv11作为目标检测领域的前沿模型,其改进方向和应用领域在多个研究中得到了广泛探索。以下从改进策略和应用场景两个维度进行综合总结: 一、YOLOv11的改进方向 1. 骨干网络(Backbone)优化 Swin Transformer替换:通过引入层次化特征表示和移位窗口自注意力机制,解决了视…...
【学习笔记】Py网络爬虫学习记录(更新中)
目录 一、入门实践——爬取百度网页 二、网络基础知识 1、两种渲染方式 2、HTTP解析 三、Request入门 1、get方式 - 百度搜索/豆瓣电影排行 2、post方式 - 百度翻译 四、数据解析提取三种方式 1、re正则表达式解析 (1)常用元字符 ࿰…...

Python + Playwright:编写自动化测试的避坑策略
Python + Playwright:编写自动化测试的避坑策略 前言一、告别 `time.sleep()`,拥抱 Playwright 的智能等待二、选择健壮、面向用户的选择器,优先使用 `data-testid`三、严格管理环境与依赖,确保一致性四、分离测试数据与逻辑,灵活管理数据五、采用 POM 等设计模式,构建可…...

电脑开机启动慢的原因
硬件老化或故障 机械硬盘老化:电脑使用时间较长,机械硬盘的读写速度会逐渐下降。这是因为机械硬盘内部的盘片和磁头在长期使用后,可能会出现磨损、坏道等问题,导致数据读取速度变慢,从而影响开机时系统文件的加载速度&…...
旅游资源网站登录(jsp+ssm+mysql5.x)
旅游资源网站登录(jspssmmysql5.x) 旅游资源网站是一个为旅游爱好者提供全面服务的平台。网站登录界面简洁明了,用户可以选择以管理员或普通用户身份登录。成功登录后,用户可以访问个人中心,进行修改密码和个人信息管理。用户管理模块允许管…...

C语言链接数据库
目录 使用 yum 配置 mysqld 环境 查看 mysqld 服务的版本 创建 mysql 句柄 链接数据库 使用数据库 增加数据 修改数据 查询数据 获取查询结果的行数 获取查询结果的列数 获取查询结果的列名 获取查询结果所有数据 断开链接 C语言访问mysql数据库整体源码 通过…...

WiFi“管家”------hostapd的工作流程
目录 1. 启动与初始化 1.1 解析命令行参数 1.2 读取配置文件 1.3 创建接口和 BSS 数据结构 1.4 初始化驱动程序 2. 认证和关联处理 2.1 监听认证请求 2.2 处理认证请求 2.3 处理关联请求 3. 数据转发 3.1 接收客户端数据 3.2 转发数据 4. 断开连接处理 4.1 处理客…...

中间件--ClickHouse-9--MPP架构(分布式计算架构)
1、MPP 架构基础概念 MPP(Massively Parallel Processing 大规模并行处理) 是一种分布式计算架构,专门设计用来高效处理大规模数据集。在这种架构下*,数据库被分割成多个部分,每个部分可以在不同的服务器节点上并行处理*。这意味着ÿ…...

分布式计算领域的前沿工具:Ray、Kubeflow与Spark的对比与协同
在当今机器学习和大数据领域,分布式计算已成为解决大规模计算问题的关键技术。本文将深入探讨三种主流分布式计算框架——Ray、Kubeflow和Spark,分析它们各自的特点、应用场景以及如何结合它们的优势创建更强大的计算平台。 Spark批量清洗快,…...

每天学一个 Linux 命令(20):find
可访问网站查看,视觉品味拉满: http://www.616vip.cn/20/index.html find 是 Linux 系统中最强大的文件搜索工具之一,支持按名称、类型、时间、大小、权限等多种条件查找文件,并支持对搜索结果执行操作(如删除、复制、执行命令等)。掌握 find 可大幅提升文件管理效率…...

使用Service发布应用程序
使用Service发布应用程序 文章目录 使用Service发布应用程序[toc]一、什么是Service二、通过Endpoints理解Service的工作机制1.什么是Endpoints2.创建Service以验证Endpoints 三、Service的负载均衡机制四、Service的服务发现机制五、定义Service六、Service类型七、无头Servic…...
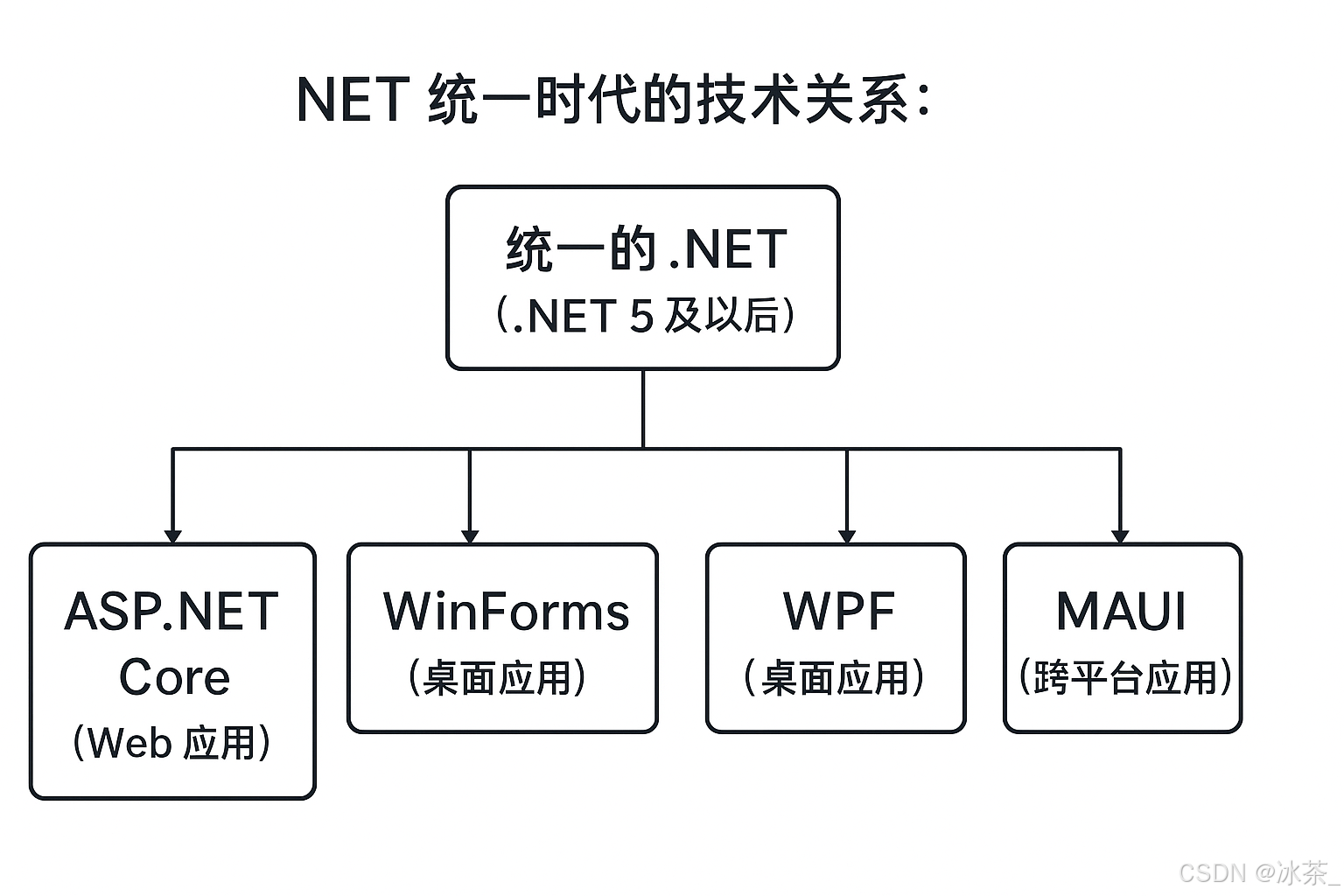
Winform发展历程
Windows Forms (WinForms) 发展历程 起源与背景(1998-2002) Windows Forms(简称WinForms)是微软公司推出的基于.NET Framework的GUI(图形用户界面)开发框架,于2002年随着.NET Framework 1.0的…...

【Hadoop入门】Hadoop生态之Flume简介
1 什么是Flume? Flume是Hadoop生态系统中的一个高可靠、高性能的日志收集、聚合和传输系统。它支持在系统中定制各类数据发送方(Source)、接收方(Sink)和数据收集器(Channel),从而能…...
npx 的作用以及延伸知识(.bin目录,npm run xx 执行)
文章目录 前言原理解析1. npx 的作用2. 为什么会有 node_modules/.bin/lerna3. npx 的查找顺序4. 执行流程总结1: 1. .bin 机制什么是 node_modules/.bin?例子 2. npx 的底层实现npx 是如何工作的?为什么推荐用 npx?npx 的特殊能力…...

本地部署DeepSeek-R1(Dify升级最新版本、新增插件功能、过滤推理思考过程)
下载最新版本Dify Dify1.0版本之前不支持插件功能,先升级DIfy 下载最新版本,目前1.0.1 Git地址:https://github.com/langgenius/dify/releases/tag/1.0.1 我这里下载到老版本同一个目录并解压 拷贝老数据 需先停用老版本Dify PS D:\D…...