图灵奖得主LeCun:DeepSeek开源在产品层是一种竞争,但在基础方法层更像是一种合作;新一代AI将情感化

图片来源:This is World
来源 | Z Potential
Z Highlights:
-
新型的AI系统是以深度学习为基础,能够理解物理世界并且拥有记忆、推理和规划能力的。一旦成功构建这样的系统,它们可能会有类似情感的反应,但这些情感是基于对结果的预期,而不是像愤怒或嫉妒这样的情感。
-
仅仅通过文本训练人工智能,我们永远无法达到人类的水平。让系统理解现实世界以及理解现实世界本身是非常困难的。
-
分层规划的思想非常重要。智能系统需要能够进行分层规划,而目前我们还不知道如何让机器做到这一点。这是未来几年面临的一个重大挑战。
-
人工智能的进步是建立在彼此合作的基础上的,这就是如何实现意义和技术进步的方式。
Yann LeCun,法国计算机科学家,被认为是现代深度学习之父之一。2018年,他获得了被称为“计算机界的诺贝尔奖”的图灵奖。他目前是纽约大学的教授,也是Meta(前Facebook)的首席AI科学家。本次访谈他分享了自己对人工智能现状以及未来发展的看法。
深度学习的崛起与AI面临的挑战
Matt Kawecki:您能莅临这里真是我们的荣幸。我的第一个问题是关于您在谷歌学术上被引用了50万次的研究。您与Jeffrey Hinton共同开展的深度学习研究为何能成为游戏规则的改变者?
Yann LeCun:您大概指的是我和杰夫·辛顿(Jeff Hinton)2015年在《Nature》杂志上发表的一篇论文。这并非新成果,它基本上是一份宣言或综述,旨在告知广大科学界和研究人员,有一套新的技术效果显著,这是其发挥作用的领域清单,这是未来的发展方向。那篇论文实际上并没有新的成果。新的成果以及大多数其他引用都可追溯到我在20世纪80年代和90年代所做的工作。
Matt Kawecki:你还记得它开始走红的那个时刻吗?那个成为历史转折点的时刻,你意识到“天哪,这是史上最受欢迎的研究成果之一”?
Yann LeCun:实际上这种热潮发生了两次。第一次是在80年代末,当时我们开始使用多层神经网络方法(我们现在称其为深度学习)取得非常好的成果,用于图像识别等任务。当时我们还无法识别复杂的图像,更多的是像手写字符这类简单的图像,但效果非常好。我们开始取得这些成果时,我非常兴奋,因为这可能会彻底改变我们进行纸张识别的方式,最终改变计算机视觉,甚至更广泛的人工智能领域。所以在80年代末到90年代中期出现了一波热潮。
然后在90年代中期,由于我们当时开发的技术需要大量的数据进行训练。那时候还没有互联网,所以我们只能为少数应用获取到好的数据,比如手写识别、字符识别和语音识别。这需要当时非常昂贵的计算机,是一项巨大的投资。所以90年代中期对这方面的兴趣就消失了。然后在21世纪00年代末期,热度又慢慢回升。大约在2013年,深度学习的热度彻底爆发。2013年是关键的一年,研究界意识到深度学习确实效果显著,而且可以应用于很多不同的领域。从那以后,它的发展速度一直非常快。
Matt Kawecki:今天的AI是否能像人类一样拥有情感,比如愤怒、嫉妒等?
Yann LeCun:不会。目前的AI系统在很多方面仍然非常“愚蠢”。我们被它们出色的语言操控能力所迷惑,误以为它们很聪明,但它们并不理解物理世界,也没有我们这种持久的记忆,它们无法真正推理和规划。这些都是智能行为的关键特征。我们正在研究一种新型的AI系统,基于深度学习,能够理解物理世界、拥有记忆、推理和规划能力。一旦我们成功构建这样的系统,它们可能会有类似情感的反应,比如恐惧或兴奋,但这些情感是基于对结果的预期,而不是像愤怒或嫉妒这样的情感。
Matt Kawecki:关于意识呢?
Yann LeCun:意识是另一回事。我们甚至无法准确定义什么是意识,更不用说测量它了。
Matt Kawecki:您曾经说过机器学习“很糟糕”,现在您对AI的发展有何看法?
Yann LeCun:我们正在努力开发新的机器学习系统,使其能像人类和动物一样高效学习。我可以简要介绍一下过去几十年机器学习的发展历程。目前有三种主要的机器学习范式:监督学习、强化学习和自监督学习。
监督学习(supervisor learning)是最经典的一种。训练监督学习系统的方法是,比方说让一个系统识别图像。你给它看一张图片,比方说一张桌子,然后告诉它这是一张桌子,这就是监督学习,因为你告诉它正确答案是什么。这就是计算机的输出,如果你在表格上写了别的东西,那么它就会调整内部结构中的参数,从而使它产生的输出更接近你想要的输出。如果你继续用大量的桌子、椅子、汽车、猫和狗的例子来做这件事,最终系统会找到一种方法来识别你训练它的每张图片,同时也能识别它从未见过的与你训练它的图片相似的图片。这就是所谓的泛化能力。
在强化学习(reinforcement learning)中,你不会告诉系统正确的答案是什么,你只会告诉它,它得出的答案是好是坏。在某种程度上,这可以解释人类和动物的某种学习方式。你试着骑自行车,但你不知道怎么骑,过了一会儿你摔倒了,于是你知道自己做得不好,然后你稍微改变了一下策略。最终,你学会了如何骑自行车。然而事实证明强化学习的效率极低。如果你想训练一个系统下棋、下围棋或打扑克或类似的东西,强化学习确实很有效,因为你可以让这个系统和自己下几百万、几千万盘棋,但它在现实世界中并不奏效。如果你想训练一辆汽车自动驾驶,你不可能用强化学习来训练它,因为它会撞车上千次。如果你想训练机器人学会抓东西,强化学习可以是解决方案的一部分,但它不是完整的答案,也不够充分。
因此,还有第三种学习形式,叫做自监督学习(self-surpervised learning),这也是最近自然语言理解和聊天机器人取得进步的原因。在自我监督学习中,你不需要训练系统完成任何特定任务,你只需要训练它捕捉输入的结构。因此,将其用于文本(例如语言)的方式是,你获取一段文本,以某种方式对其进行破坏,例如删除一些单词然后来预测缺失的单词。例如你截取了一段文本,而文本中的最后一个单词不可见,于是你训练系统预测文本中的最后一个单词,这就是大型语言模型的训练方式。每个聊天机器人都是这样训练的。从技术上讲,虽然有些不同,但这是基本原理。这就是所谓的自我监督学习。你不用训练系统完成任务,只需训练它学习输入的内部依赖关系。这种方法取得了惊人的成功。如果你让系统合适地使用监督学习或强化学习来正确回答问题,那么系统最终就能真正理解语言,并能理解问题。因此,这就是业界每个人都在研究的东西,但如果你想让系统理解物理世界,这种模式是行不通的。
Matt Kawecki:少了点什么?
Yann LeCun:是的,只是物理世界比语言更难理解。语言是智能,因为只有人类才能操纵语言,但事实证明语言很简单,因为它是一连串离散的符号。字典中可能出现的单词数量是有限的,你永远无法训练一个系统准确预测下一个会出现什么单词,但你可以训练它为字典中的每个单词打分或者为字典中的每个单词出现在那个位置的概率打分。你可以通过这种方式处理预测中的不确定性,但你无法训练一个系统来预测视频中将要发生的事情。我已经尝试了20年。很多人都有这样的想法:如果你能训练一个系统来预测视频中将要发生的事情,那么这个系统就会隐含地理解这个世界的底层结构。直觉物理学或者说物理直觉。如果我拿起一个物体,然后放手,它就会掉下来。很明显重力会把你的物体吸向地面。人类婴儿大概在九个月大的时候就学会了这一点。
Matt Kawecki: 或许当今人工智能发展的限制并非在于人工智能本身,而在于我们对现实的认知,我们无法超越已知的范围。我们不知道引力是如何产生的,也不知道量子世界是如何转变为经典世界的。
Yann LeCun:但这其实是个简单的问题。因为你的猫或者狗在短短几个月内就能了解重力。猫在这方面真的很厉害。它们能够规划复杂的动作,攀爬各种东西,跳跃,显然它们对所谓的直觉物理学有着非常良好的直觉理解。我们还不知道如何用计算机来复制这一点。这是人工智能研究人员所说的莫拉维克悖论的又一个例子。莫拉维克是一位机器人专家,他指出计算机可以下棋、解决数学难题等等,但它们却无法像动物那样做物理动作,比如操纵物体、跳跃等等。
这个悖论的另一个例子是,离散对象和符号的空间很容易被计算机处理,但现实世界太复杂了,适用于一种情况的技术在另一种情况中却行不通。一种很好的方式来想象这一点是,通过我们的感官,比如视觉或触觉,传递给我们的信息量,与通过语言获得的信息量相比,绝对是巨大的。这或许能解释为何我们有能通过律师资格考试、能解决数学问题或写出好文章的语言模型聊天机器人,但我们仍然没有家用机器人,仍然没有能完成猫狗都能完成的任务的机器人,仍然没有完全自动驾驶的五级自动驾驶汽车,更不用说像任何17岁少年那样在大约20个小时的练习后就能学会驾驶的自动驾驶汽车了。显然,我们遗漏了什么重要的东西。我们所遗漏的是如何训练一个系统去理解像视觉这样复杂的感官输入。
Matt Kawecki:如果我们想让机器像人类和动物那样专业地学习,这有必要吗?
Yann LeCun:没错,如果我们想要制造出具有类似于动物和人类的智能、具备常识,甚至在某种程度上拥有意识等特质的机器,能够真正解决复杂世界中的问题,我们就得解决这个问题。让我给您做个简单的计算。一个典型的大型语言模型是用大约2万亿个token进行训练的。Token差不多相当于单词。一个token通常用三个字节来表示。20或30万亿个token,每个标记占三个字节,那就是大约10的14次方字节,也就是1后面跟14个零。这是互联网上所有公开文本的总量。我们任何人读完这些材料都需要几十万年的时间。这是海量的信息,但再看看通过视觉系统传入我们大脑的信息量。在生命的头四年里,这个量是差不多的。一个四岁的孩子醒着的时间总共约16000小时。通过视神经传入大脑的信息量大约是每秒2兆字节。算一下,大概是10到14次方字节。差不多是一样的。四年里,一个小孩所接触到的信息量或数据量就和最大的语言模型一样多。这说明,仅仅通过文本训练人工智能,我们永远无法达到人类的水平。让系统理解现实世界以及理解现实世界本身是非常困难的。
信息、意识与人工智能的未来:从熵到机器人技术的十年
Matt Kawecki:在您的LinkedIn和Facebook上,您将人工智能与熵联系在一起。我们很难理解您所写的内容,您可以简单解释一下吗?
Yann LeCun:我一直对此很着迷,因为有一个大问题,它是计算机科学、物理学、信息论以及许多不同领域诸多问题的根源所在,那就是如何量化信息。一条消息中包含多少信息?我多次提到的观点是,一条消息中的信息量并非一个绝对的量,因为它取决于解读这条消息的人。从传感器、别人对你说的话或其他任何东西中能提取出多少信息,这取决于你如何解读。所以信息量可以用绝对的术语来衡量,这种观点可能是错误的。
任何信息度量都与解读该信息的特定方式相关。这正是我想要表达的观点,而且这会产生非常深远的影响,因为如果不存在绝对的信息度量方式,那就意味着物理学中有很多概念实际上并没有客观定义,比如熵。熵是对物理系统状态的无知程度的度量。当然,这取决于你对系统的了解程度。我一直痴迷于寻找定义熵、复杂性或信息含量的相对性的好方法。
Matt Kawecki:难道您不觉得我们用于训练人工智能模型的全球数据库已经饱和了吗?在2000年,当时仅有25%的数据被数字化。如今,所有数据都已实现数字化。
Yann LeCun:我们还差得远呢。有大量的文本知识尚未数字化。也许在很多发达国家,很多知识已经数字化,但大部分并不公开。例如,有大量医疗数据没有公开。在世界许多地区,还有许多文化数据、历史数据无法以数字形式获取。即使是数字形式,也不是扫描文件的形式,所以不是文本。所以这并不正确,仍然有很多数据存在。
Matt Kawecki:这是对现实本质的质疑,因为、我们不知道人脑中的物质是如何转化为意识的,所以我们没有这方面的数据,但也许将来我们会做到这一点。
Yann LeCun:我们不应该纠结于意识这个问题。
Matt Kawecki:全世界都被这个问题迷住了。
Yann LeCun:世界上有些地方对这个问题非常着迷。坦白说,这有点像一个“咬文嚼字”的现象,我们之所以找不到一个关于意识的明确定义,可能是因为我们问错了问题。举个例子。在18世纪,人们发现了17世纪的一个现象——视网膜上的成像。光线通过虹膜进入眼睛,如果有晶状体,视网膜上形成的图像是倒置的。当时的人们完全困惑:为什么我们看到的世界是正立的,尽管视网膜上的图像是倒置的?这对他们来说是个谜。现在我们知道,这个问题本身是没有意义的。这只是你大脑解释图像的方式,图像在视网膜上形成的方向并不重要。意识有点像这个情况。它是我们无法定义的东西,它存在,但却无法真正抓住它的本质。
Matt Kawecki:这是让我们成为不同个体的原因吗?
Yann LeCun:那不一样。诸多因素塑造了我们彼此之间的差异。我们有着各自独特的经历,学习着不同的知识,在迥异的环境中成长,甚至连大脑的神经连接也存在细微差别。每个人身上都带有独特的印记,这是进化的需要,旨在确保我们各不相同,因为我们是社会性动物。如果部落中的成员在各方面都毫无二致,那么群体的优势将无从谈起。然而,正是因为我们各有不同,我们才能发挥各自的优势,将不同的专长汇聚在一起,从而形成强大的合力,这是进化的结果,进化通过不同的大脑神经线路、神经递质、荷尔蒙以及其他生理机制的微妙调整,塑造了我们独特的个性和能力。
Matt Kawecki:自由推理抽象思维模型是怎么回事?我们能否期待您的实验室也开发出类似的东西?
Yann LeCun:从观察中提炼出抽象表示的问题是深度学习的核心。深度学习的本质就是学习表示。事实上,深度学习领域的一个主要会议叫做“国际学习表示会议”(International Conference on Learning Representations),这个会议是我参与创办的。这说明了学习抽象表示这个问题在人工智能(尤其是深度学习)中的重要性。如果你希望系统能够进行推理,你还需要另一组特性,也就是推理或规划的能力。这不仅仅是基于机器学习的AI,而是自20世纪50年代以来经典AI的核心。
推理的本质是寻找问题解决方案的过程。
例如,如果我给你一份城市列表,然后让你找出经过所有这些城市的最短路线,你会思考并说:“我应该先去附近的城市,这样总路线会尽可能短”,所有可能的路线构成了一个巨大的搜索空间,也就是所有城市排列组合的集合。像GPS这样的算法会在这个空间中搜索最短路径。所有的推理系统都基于这种思想:在可能的解决方案空间中搜索符合目标的结果。
当前的系统(比如像o1、R1这样的大型语言模型)是以一种非常原始的方式完成这个任务的。它们在所谓的“token空间”中操作,也就是输出的空间。它们基本上会让系统生成大量不同的token序列(或多或少是随机的),然后让另一个神经网络检查所有这些假设序列,找出看起来最好的一个并输出。这种方式非常低效,因为它需要生成大量输出,然后再筛选出好的结果。这并不是我们人类的思考方式。我们不会通过生成大量动作、观察结果,然后找出最好的一个来思考。
如果我让你想象一个漂浮在你面前的立方体,然后让你将这个立方体绕垂直轴旋转90度,接着让你描述旋转后的立方体是否和原来一样。你会回答“是”,因为你知道立方体旋转90度后仍然是立方体,而且你从同一个视角看它,结果是一样的。这就是我们人类推理的方式,而不是通过生成大量可能性来筛选。
Matt Kawecki:您是说那是自由推理的幻觉?
Yann LeCun:因为你是在你的心理状态下进行推理,而不是在你的输出行动空间里进行推理。
Matt Kawecki:在物理世界里。
Yann LeCun:或者无论你的输出状态是什么,你是在一个抽象的空间中进行推理。我们拥有这些关于世界的心理模型,它们让我们能够预测世界上会发生什么、操纵现实,并提前预测我们行动的后果。如果我们能够预测行动的后果(比如将一个立方体旋转90度或其他任何操作),那么我们就可以规划一系列行动,以达到特定的目标。
每当我们有意识地完成一项任务时,我们的全部注意力都会集中在它上面,我们会思考需要采取哪些行动序列来完成这项任务。比如组装宜家家具、用木头搭建东西,或者日常生活中任何需要我们动脑筋的事情。这类任务需要我们进行规划,而且大多数时候我们是分层规划的。
例如,假设你现在决定从纽约回到罗马。你知道你需要去机场并搭乘飞机。这时你就有了一个子目标:去机场。这就是分层规划的核心——你为最终目标定义子目标。你的最终目标是去罗马,而子目标是去机场。那么,在纽约怎么去机场呢?你需要走到街上,打车去机场。怎么走到街上呢?你需要离开这栋楼,乘电梯下楼,然后走出去。怎么去电梯呢?你需要站起来,走到门口,开门等等。到了某个程度,你会细化到一个足够简单的目标,以至于你不需要再规划,比如从椅子上站起来。你不需要规划,因为你已经习惯了,可以直接去做,而且你已经掌握了所有必要的信息。所以,这种分层规划的思想非常重要。智能系统需要能够进行分层规划,而目前我们还不知道如何让机器做到这一点。这是未来几年面临的一个重大挑战。
Matt Kawecki:这就是为什么你在达沃斯花了那么多时间谈论机器人技术。你谈到即将到来的机器人十年。机器人技术经历了无数次寒冬。这次为什么不同?
Yann LeCun:机器人在今天被大量使用,但它们被用在......
Matt Kawecki:廉价的传感器、更好的模拟器还是什么?
Yann LeCun:机器人可以执行相对简单的任务,并能以非常简单的方式实现自动化。所以制造机器人可以在工厂里给汽车喷漆、组装零件等,只要所有东西都摆放在正确的位置,这些机器人基本上就是自动装置。但如果是另一项工作,比如驾驶。我们还没有像人类一样可靠的自动驾驶汽车。我们有这样的公司,但他们使用的传感器比人类的传感要复杂得多。
Matt Kawecki:马斯克不是说特斯拉将在未来五年内实现五级自动驾驶吗?
Yann LeCun:过去八年来,他一直这么说。在过去八年里,他一直说这将在明年发生,但显然没有。你显然不能再相信他的话了,因为他一直都是错的。要么是他认为是对的,结果却是错的,要么就是他在撒谎。这是他激励团队年复一年实现遥不可及的目标的一种方式,但对于工程师或科学家来说,被他们的CEO告知你的整个职业生涯都在致力于解决的问题我们明年就要解决它,实际上是非常困难的。
Matt Kawecki:因此您认为这是我们这个时代最大的挑战,如何将人工智能、机器人技术和传感器结合起来?
Yann LeCun:如果我们能够建立起能够理解物理世界、拥有持久记忆、能够推理和规划的人工智能系统,那么我们就拥有了可以为机器人提供动力,使其比现有的机器人更加灵活的人工智能的基础。在过去的一两年里,有很多机器人公司成立了。他们制造人形机器人之类的东西,所有的演示都令人印象深刻,但这些机器人都非常愚蠢。它们不能做人类能做的事,不是因为它们没有体能,而是因为它们不够聪明,无法应对现实世界。因此,很多公司都寄希望于人工智能能在未来3到5年内取得快速发展,这样当它们准备好大规模销售这些机器人并大规模制造它们时,它们就会足够聪明。他们确实会足够聪明,因为人工智能已经取得了进步。这是一个很大的赌注,所以我无法告诉你这是否会在未来三五年内发生,但我们很有可能在人工智能方面取得重大进展,从而在未来十年内实现更灵活的机器人,就像我已经说过的,未来十年是机器人技术的十年。
Matt Kawecki:看看今天的人工智能发展以及日复一日夜复一夜的进步,您会感到惊讶吗?
Yann LeCun:其实并没有。让我感到惊讶的是,这个领域的发展并不是连续的,而是断断续续的。20世纪80年代和90年代有很多进展,但之后却停滞了一段时间。到了2000年代,虽然也有一些进展,但这些进展并不明显,大多数人并没有意识到我们正在取得突破。直到2013年左右,这些进展变得显而易见,整个领域突然爆发,许多人才开始投身其中,许多公司也开始投资。由于更多的关注和资源投入,进展开始加速。基于我的预测,我会以为从20世纪80年代开始,进展会更加连续和平稳,但现在这样是断断续续地爆发。
开源与全球合作:从DeepSeek到Stargate
Matt Kawecki:今天,全世界都在谈论中国的新型DeepSeek,它是开源的并且比美国人便宜得多。您不觉得为时已晚吗?
Yann LeCun:有一点需要明确:如果一项研究或开发成果被公开发布,也就是说相关的技术通过论文、白皮书或报告等形式公开,并且代码是开源的,那么全世界都会从中受益。不仅仅是开发者个人或团队会获得声望和认可,可能还会吸引投资等,但真正受益的是整个世界。这就是开放式研究和开源软件的魔力。
我个人,包括Meta公司整体,一直是开放式研究和开源的坚定支持者。每当一个实体通过开放式研究和开源发布一些东西时,整个开源社区都会从中受益。人们可能会把这件事描述成一种竞争,但实际上它更像是一种合作。问题是:我们是否希望这种合作是全球范围的?我的答案是肯定的,因为世界上每个地方都会产生好想法。
例如,Llama是Meta发布的第一个大型语言模型(LLM)。当然,它并不是第一个LLM,之前我们也发布过一些,但它们并没有引起太多关注。Llama是在巴黎研发的。这个实验室是位于巴黎的FAIR实验室,那里有100多名研究人员。巴黎实验室和我们在蒙特利尔的实验室都产出了很多优秀的成果。研究社区确实是全球化的,每个人都做出了贡献。没有任何一个实体能够垄断好想法,这就是为什么开放合作能让这个领域发展得更快。我们之所以大力支持开放式研究和开源,是因为当你与其他科学家交流时,整个领域会进步得更快。
现在,行业中有一些人过去曾实践开放式研究,但现在却闭门造车。比如OpenAI和Anthropic(Anthropic从未开放过),它们把一切都保密。谷歌则从部分开放转向了部分封闭,虽然它们仍然在做一些开放式研究,但更多是基础性和长期的研究。这很遗憾,因为很多人实际上把自己排除在了全球研究社区之外,没有参与其中,也没有为进步做出贡献。过去10年人工智能领域进展如此迅速,正是因为开放式研究的存在。
Matt Kawecki:大家都这么认为吗?
Yann LeCun:当然,这是事实。这不是观点,而是事实。让我举个例子,几乎整个人工智能行业都在构建或至少在研发阶段使用PyTorch软件来构建系统。PyTorch是开源的。它是由我在Meta的同事开发的。几年前,PyTorch的所有权转让给了Linux基金会。Meta不再拥有它,它仍然是主要贡献者,但并不控制它,而是由一个开发者社区控制。微软、Nvidia,包括所有人。每个人都在使用PyTorch,整个学术界、研究界都在使用PyTorch。在所有出现在科学文献中的论文中,有70%都提到了PyTorch。因此人工智能的进步是建立在彼此合作的基础上的,这就是如何实现意义和技术进步的方式。
Matt Kawecki:如果不是DeepSeek,也许美国的Stargate项目会改变一切。
Yann LeCun:不会。
Matt Kawecki:您不认为这是人类历史上最大的项目吗?
Yann LeCun:关于DeepSeek,我还想说一点:这是一项很棒的工作。参与其中的人提出了非常好的想法,他们做了一些非常出色的工作。这并不是中国第一次在创新领域做出卓越贡献。
我们一直知道中国在计算机视觉等领域的进展非常突出。虽然中国在大语言模型方面的贡献是最近才显现的,但在计算机视觉领域,中国有着悠久的传统。看看顶级计算机视觉会议,一半的参会者都来自中国。那里有很多优秀的科学家和非常聪明的人。所以,无论是美国、欧洲还是世界其他地区,都没有垄断好想法的能力。DeepSeek的想法很可能在几周内就会被复现,并可能被整合到美国、欧洲等地未来发布的版本中。现在它已经成为全球知识的一部分。这就是开源和开放式研究的美妙之处。在产品层面,这是一种竞争,但在基础方法层面,它更像是一种合作。
现在我们来谈谈Stargate。所有参与人工智能的公司都看到了一个不远的未来:数十亿人将每天使用AI助手。比如我现在戴的这副眼镜,它内置了摄像头,是由Meta开发的。你可以通过它与AI助手对话,向它提问,甚至可以通过摄像头识别植物种类等。我们可以预见的未来是人们会戴着智能眼镜,或者使用智能手机和其他智能设备,在日常生活中随时随地使用AI助手。这些助手会在日常生活中帮助他们。这意味着将会有数十亿用户每天多次使用这些AI助手。为了实现这一点,你需要非常庞大的计算基础设施,因为运行一个大语言模型或AI系统并不便宜,需要大量的计算能力。Meta今年在基础设施上的投资大约在600亿到650亿美元之间,主要用于AI。微软也宣布将投资800亿美元,而Stargate的500亿美元投资是分5到10年完成的,而且我们还不清楚这笔资金的来源。所以,这些投资的规模其实与微软和Meta正在做的事情并没有太大差别。
大部分投资是用于推理(inference),也就是运行AI助手来服务数十亿用户,而不是用于训练大型模型。训练大型模型实际上相对便宜。所以金融市场最近对DeepSeek的反应——比如“现在我们可以更便宜地训练系统,所以不再需要那么多计算机了”——是完全错误的。
Matt Kawecki:所以更多的是回归常态?
Yann LeCun:训练会变得更有效率一些,但结果是我们只是去训练更大的模型,最终大部分基础设施和大部分投资都用于实际运行模型,而不是训练它们。这就是投资所在。
卷积神经网络与AI未来:从技术突破到多领域发展
Matt Kawecki:我们的观众有一个问题。您提出了一种替代Transformer架构的方案,而Transformer是大型语言模型(LLM)中最重要的部分。JEPA模型与Transformer有何不同?
Yann LeCun:JEPA(ZP注:Joint Embedding Predictive Architecture,联合嵌入预测架构)实际上是一种宏观架构,而不是Transformer的替代品。你可以在JEPA中使用Transformer。你可以在其中安排不同的模块,这些模块可以是Transformer,也可以是其他东西。JEPA和Transformer并不是对立的概念,它们是正交的,可以共存。
JEPA真正要替代的是当前主流的大型语言模型架构,这些架构在业界被称为自回归解码器架构或Transformer。OpenAI称它们为GPT(通用Transformer)。
GPT是一种特定的架构,它使用我之前描述的自监督学习技术进行训练:输入一个符号序列(比如文本或单词序列),然后训练系统。系统的组织方式是,为了预测输入中的某个单词,它只能查看该单词左侧的内容。这种架构被称为因果架构。如果你训练一个系统,输入一段文本并让它复现这段文本,那么实际上你是在隐式地训练它预测文本中的下一个单词。因此,你可以用这个系统自回归地生成一个接一个的单词,这就是大型语言模型的工作原理。
现在,试着将这种方法应用到现实世界中。比如你想训练一个机器人来规划任务或预测世界上会发生什么,这种方法就不奏效了。如果你用视频帧代替单词,将这些帧转换为类似token的东西,然后尝试训练系统来预测视频中接下来会发生什么,这种方法效果很差。原因是世界上发生的很多事情根本无法预测。在高维空间(比如视频)中,表示“你无法准确预测接下来会发生什么”这一事实,本质上是一个数学上难以处理的问题。而在离散空间(比如文本)中,这是可能的——你无法准确预测下一个单词是什么,但可以预测所有可能单词的概率分布。
然而,对于视频,我们不知道如何表示所有可能视频帧的分布。因此,那些在文本、DNA序列和蛋白质上效果很好的技术,在视频或其他自然信号上并不适用。JEPA就是针对这个问题提出的解决方案。它的核心思想是:不在输入空间中进行预测,而是训练系统学习输入的抽象表示,然后在该表示空间中进行预测。事实证明,这是一种更好的问题表述方式。
例如,如果我用摄像机拍摄我们所在的房间,将摄像机对准一个位置,然后慢慢转动摄像机,最后停下来,问系统“接下来视频中会发生什么”。系统可能会预测摄像机会继续转动,但你无法预测摄像机旋转后视野中的所有细节。比如房间里有一株植物,墙上可能有一幅画,可能有人坐在那里。系统无法预测这些人会是什么样子,也无法预测植物的种类或地板的纹理。这些细节根本无法预测。如果你训练一个系统去预测这些细节,它会花费大量资源去尝试预测那些无法预测的东西,最终失败。
Matt Kawecki:Yann LeCun实验室最伟大的成就是什么?
Yann LeCun:其实并没有一个叫“Yann LeCun实验室”的地方。这个问题有点难回答。不过,我最出名的成就是卷积神经网络(Convolutional Neural Networks,简称CNN)。这是一种受视觉皮层结构启发的特殊架构,专门用于处理图像、视频、音频、语音等自然信号。现在,这种技术已经无处不在。比如,如果你的车有驾驶辅助系统,现在欧盟销售的所有新车都必须配备这种系统,至少要有自动刹车功能。
Matt Kawecki:这是您的实验室的成果吗?
Yann LeCun:这些系统都使用了卷积神经网络。这是我在1988年发明的技术,也是我最著名的贡献。最早的卷积神经网络应用是字符识别、手写识别、读取邮政编码、读取支票金额等,这些应用在90年代初就已经开始了。大约从2010年开始,卷积神经网络的应用迅速扩展。当你和手机对话时,语音识别系统的前几层通常就是卷积神经网络。手机上的一些应用,比如拍一张植物的照片然后问它这是什么植物,或者识别昆虫种类,甚至听鸟叫声识别鸟类,这些功能背后都是卷积神经网络在发挥作用。
Matt Kawecki:您是欧洲人。您认为在美国和中国的人工智能竞赛中,欧洲的位置在哪里?
Yann LeCun:欧洲可以发挥非常重要的作用,但欧洲最困难的是...
Matt Kawecki:执行条例?
Yann LeCun:欧盟肯定存在这类问题。例如,我现在戴着的眼镜,它的一个应用就是翻译通过摄像头的图像,这样我就可以用波兰语看菜单,或者你用波兰语跟我说话,菜单就会有翻译。
Matt Kawecki:这种眼镜不可以用吧。
Yann LeCun:由于法规的不确定性,除了视觉功能外,这种眼镜在欧洲是可用的。我甚至不清楚法规是否会将其定为非法,法规只是说不清楚。但我想说的是,欧洲拥有巨大的资产和优势,首先是人才。数学家,计算机科学家,工程师,物理学家等等。人工智能领域的许多顶尖科学家,无论他们在世界的哪个地方工作,都来自欧洲。我来自欧洲并在美国待了很长时间。
Matt Kawecki:您是欧洲人,目前还住在巴黎?
Yann LeCun:不,我住在纽约,但我经常去巴黎。
Matt Kawecki:最后一个问题。我记得在诺贝尔奖新闻发布会上,我问过Jeffrey Hinton一个问题:如果能回到过去,你会做出不同的选择吗?回顾你在AI发展中的研究,是否有让你感到遗憾的事情?我也想问你同样的问题。
Yann LeCun:我不知道Jeff当时是怎么回答的,但我可以猜一下他的答案。让我先说说我的回答吧。我的答案是:在很长一段时间里,我对我们现在称为“自监督学习”的东西并不感兴趣,因为这个问题被错误地表述了。事实上,我和Jeff Hinton讨论过很多年,我一直推动监督学习,而他告诉我,最终我们需要弄清楚如何实现他所说的“无监督学习”(现在是一种特定形式的自监督学习)。直到2000年代中期,我才改变了看法。这可能晚了10年,所以我应该更早对这个问题产生兴趣。但问题是,从90年代中期到2000年代初,神经网络和深度学习领域并没有太多进展,因为整个世界对这些完全不感兴趣。我们不得不做其他事情——我研究过图像压缩,开发了一个叫djvu的系统,我听说它在波兰,甚至整个东欧,还挺受欢迎的。如果我能改变一件事,那就是我会更早关注自监督学习。不过,我对事情的发展总体上还是很满意的。另外,我可能会在90年代末更积极地推动社区对神经网络和机器学习的兴趣,这样就不会出现所谓的“深度学习寒冬”。
我猜Jeff可能会提到的一件事是,他在两年前改变了想法。他职业生涯的目标一直是弄清楚大脑皮层的学习算法。他一直认为,反向传播(backpropagation,这是今天训练神经网络的主要技术,他和我都与此有关)并不是大脑使用的机制,因为反向传播在生物学上并不太合理。因此,在过去四年里,他每隔两年就会提出一种新的机器学习方法。但两年前,他放弃了,他说:“也许大脑不使用反向传播,但反向传播效果非常好,也许这就是我们需要的。它甚至可能比大脑使用的任何机制都更有效”。然后他退休了,基本上可以说是宣布胜利了。
Matt Kawecki:我想问您的最后一个问题是,您为什么支持Ataraxis--一家波兰裔美国初创企业,利用纽约大学的人工智能预测乳腺癌。您是董事会成员并且您是顾问。
Yann LeCun:首先,深度学习的医学应用前景非常广阔。深度学习方法已经在诊断领域得到应用,比如通过乳腺X光片诊断乳腺癌等。我有一位年轻的同事,Krzysztof Geras,他现在是医学院放射学系的教授,非常优秀。最近他说:“机会太多了,我打算和几个朋友一起创业”。他们找到我,问我是否愿意担任顾问。我知道他们的科研工作非常出色,所以觉得这家公司很有前途,也很好奇他们能做出什么成果。他们的应用范围很广,主要是利用深度学习进行诊断,尤其是影像诊断,但不止于此。事实上,他们希望直接从测量数据跳到治疗方案,而不仅仅是诊断。这非常有前景,也非常吸引人,这就是为什么我支持他们”。
Matt Kawecki:非常感谢您抽出宝贵的时间,您的光临是我们的荣幸,谢谢。
原文:Father of AI:AI Needs PHYSICS to EVOLVE | prof. Yann LeCun
https://www.youtube.com/watch?v=RUnFgu8kH-4
编译:Julie Qiao
相关文章:
图灵奖得主LeCun:DeepSeek开源在产品层是一种竞争,但在基础方法层更像是一种合作;新一代AI将情感化
图片来源:This is World 来源 | Z Potential Z Highlights: 新型的AI系统是以深度学习为基础,能够理解物理世界并且拥有记忆、推理和规划能力的。一旦成功构建这样的系统,它们可能会有类似情感的反应,但这些情感是基…...

从GET到POST:HTTP请求的攻防实战与CTF挑战解析
初探HTTP请求:当浏览器遇见服务器 基础协议差异可视化 # 典型GET请求 GET /login.php?username=admin&password=p@ssw0rd HTTP/1.1 Host: example.com User-Agent: Mozilla/5.0# 典型POST请求 POST /login.php HTTP/1.1 Host: example.com Content-Type: application/x…...

SQL-exists和in核心区别、 性能对比、适用场景
EXISTS和IN的基本区别。IN用于检查某个值是否在子查询返回的结果集中,而EXISTS用于检查子 查询是否至少返回了一行数据。通常来说,EXISTS在子查询结果集较大时表现更好,因为一旦找 到匹配项就会停止搜索,而IN则需要遍历整个结果集。 在 SQL 中,EXISTS 和 IN 都可以用于…...

Charles 安装与使用详解:实现 App 与小程序 HTTPS 抓包
在日常的移动端开发、接口调试或逆向分析中,我们经常需要抓取移动 App 或微信小程序的 HTTP/HTTPS 请求。Charles 是一款经典强大的代理抓包工具,凭借简单的界面和强大的功能,成为了 macOS 抓包的首选工具之一。 本文将详细介绍 Charles 的安…...
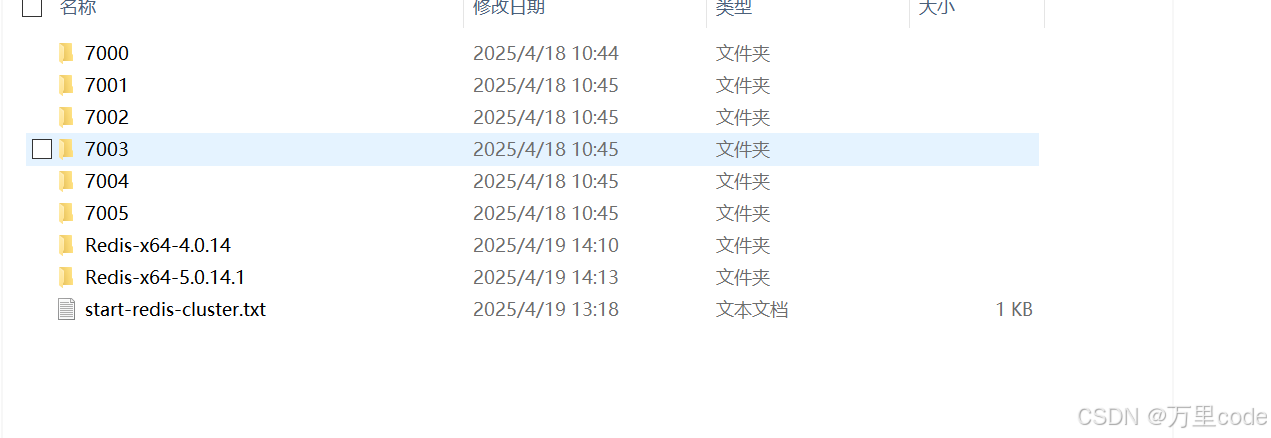
使用Redis5.X部署一个集群
文章目录 1.用Redis5.x来创建Cluste2. 查看节点信息 nodes3. 添加节点 add-node4.删除节点 del-node5.手动指定从节点 replicate6.检查集群健康状态 check 建议使用5.x版本。 首先,下载Redis,根据自己的环境选择版本。 一键启动Redis集群文件配置。 ech…...
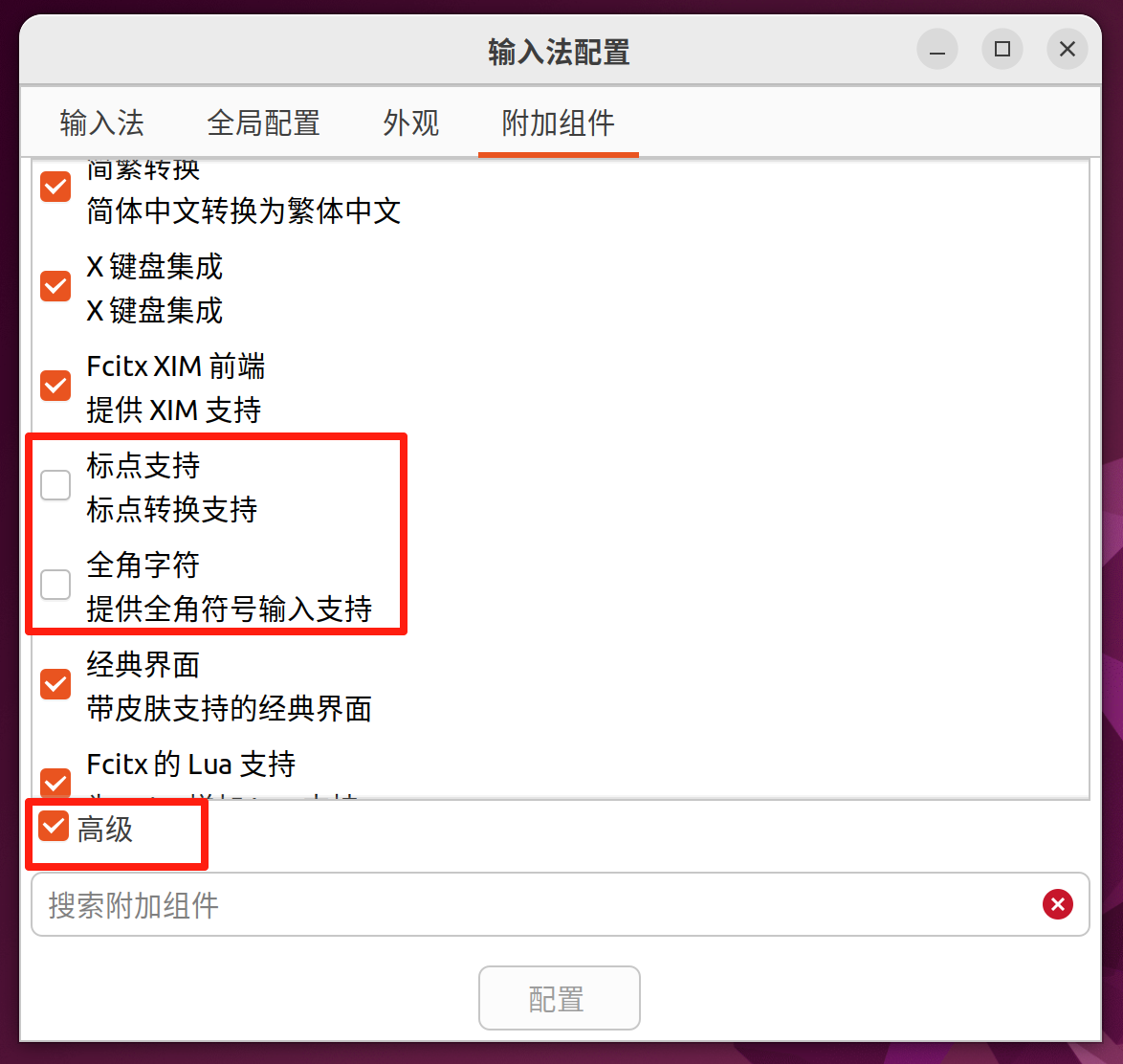
Ubuntu Linux 中文输入法默认使用英文标点
ubuntu从wayland切换到x11, 然后安装fcitx(是fcitx4版本)和 fcitx-googlepinyin, 再sudo dpkg -i 安装百度输入法deb包. 在fcitx配置中, 附加组件,打勾高级, 取消打勾标点支持和全角字符. 百度输入法就可以默认用英文标点了. 而google拼音输入法的问题是字体大小没法保存,每…...

Mermaid 是什么,为什么适合AI模型和markdown
什么是 Mermaid? Mermaid 是一个基于 JavaScript 的开源绘图和图表工具,允许用户通过简单的文本语法创建图表。它支持生成流程图、时序图、类图、甘特图等多种类型的可视化内容,并直接从类似 Markdown 的代码中渲染。Mermaid 因其与 Markdow…...

Java漏洞原理与实战
一、基本概念 1、序列化与反序列化 (1)序列化:将对象写入IO流中,ObjectOutputStream类的writeobject()方法可以实现序列化 (2)反序列化:从IO流中恢复对象,ObjectinputStream类的readObject()方法用于反序列化 (3)意义:序列化机制允许将实现序列化的J…...

第十届团体程序设计天梯赛-上理赛点随笔
2025.4.19来到军工路580号上海理工大学赛点参加cccc 校内环境挺好的,校内氛围也不错;临走前还用晚餐券顺走一袋橘子 再来说说比赛 首先是举办方服务器爆了,导致前10分钟刷不出题,一个多小时还上交不了代码 然后就是我用py总有几…...

考公:数字推理
文章目录 1.真题12 312 530 756 ()-3 3 1 12 17 ()356 342 333 324 ()30 28 27 25 () 2215105 1494 1383 1272 ()2 3 8 21 46 ()4/25 1/4 4/9 1 ()39 416 630 848 ()5 8 11 17 () 10714 21 40 77 () 229 2.数字推理方法2.1 差值法2.2 比值法(乘法关系)2.…...
config.txt常用音频配置)
树莓派超全系列教程文档--(32)config.txt常用音频配置
config.txt常用音频配置 板载模拟音频(3.5mm耳机插孔)audio_pwm_modedisable_audio_ditherenable_audio_ditherpwm_sample_bits HDMI音频 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 板载模拟音频(3.5mm耳机…...

面试专栏-02-MySQL知识点(第二部分)
6、锁 1、分类: 全局锁:锁住数据库中的所有表表级锁:每次操作锁住整张表行级锁:每次操作锁住对应行的数据 2、全局锁 加锁后,整个实例只能进行读取操作,从而保证数据的完成性和一致性。 特点ÿ…...

55、⾸屏加载⽩屏怎么进⾏优化
答: (1)使⽤CDN 减⼩代码体积,加快请求速度; (2)SSR通过服务端把所有数据全部渲染完成再返回给客⼾端; (3) 路由懒加载,当⽤⼾访问的时候,再加载相应模块; (4) 使⽤外…...

python函数之间嵌套使用yield
假设一种场景,函数 A 可以在获得函数 B 的返回值(即一个生成器对象)后,再次对其进行 yield 操作。这是因为 Python 的生成器是可迭代的,你可以在一个生成器中迭代另一个生成器,并将其结果逐个 yield 出去。…...
【MySQL数据库入门到精通】
文章目录 一、SQL分类二、DDL-数据库操作1.查询2.创建数据库3.删除数据库4.使用数据库 三、DDL-表操作1.查询 一、SQL分类 根据功能主要分为DDL DML DQL DCL DDL:Date Definition Language数据定义语言:定义数据库,表和字段 DML:Date Manipulatin Lan…...
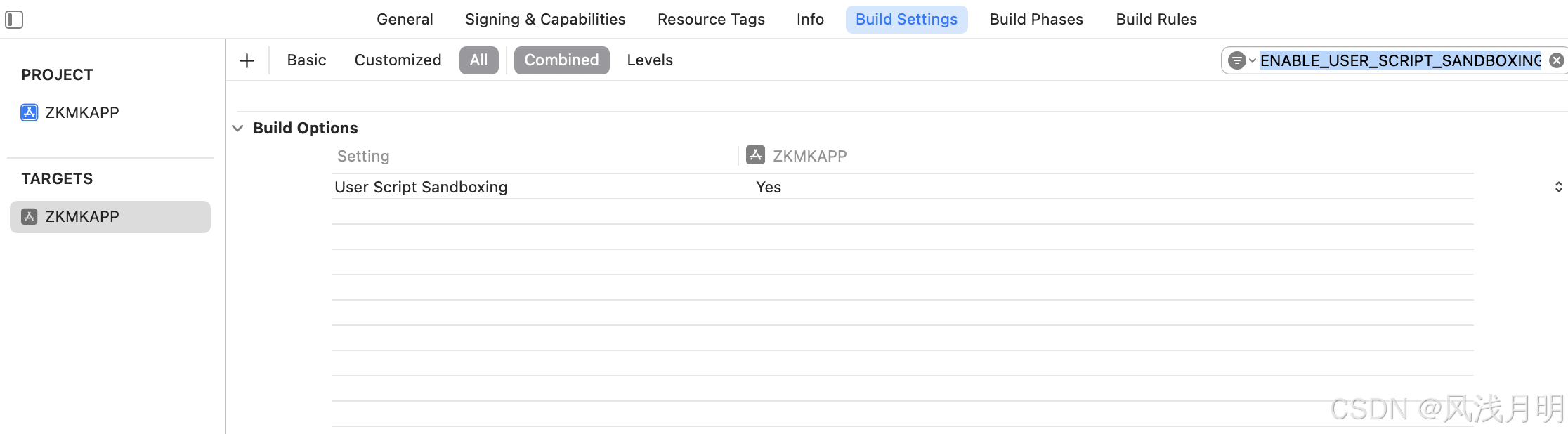
[Swift]pod install成功后运行项目报错问题error: Sandbox: bash(84760) deny(1)
操作: platform :ios, 14.0target ZKMKAPP do# Comment the next line if you dont want to use dynamic frameworksuse_frameworks!# Pods for ZKMKAPPpod Moyaend pod install成功后运行报错 报错: error: Sandbox: bash(84760) deny(1) file-writ…...

游戏引擎学习第233天
原地归并排序地方很蒙圈 game_render_group.cpp:注意当前的SortEntries函数是O(n^2),并引入一个提前退出的条件 其实我们不太讨论这些话题,因为我并没有深入研究过计算机科学,所以我也没有太多内容可以分享。但希望在过去几天里…...
卷积神经网络基础(二)
停更好久的卷积神经网络基础知识终于开始更新了哈哈,今天主要介绍的是误差反向传播法。 目录 一、计算图 1.1 用计算图求解 1.2 局部计算 1.3 为什么采用计算图 二、链式法则 2.1 计算图的反向传播 2.2 链式法则 2.3 链式法则和计算图 三、反向传播 3.1 …...
探索大语言模型(LLM):定义、发展、构建与应用
文章目录 引言大规模语言模型的基本概念大规模语言模型的发展历程1. 基础模型阶段(2018年至2021年)2. 能力探索阶段(2019年至2022年)3. 突破发展阶段(以2022年11月ChatGPT的发布为起点) 大规模语言模型的构…...

树莓派超全系列教程文档--(33)树莓派启动选项
树莓派启动选项 启动选项start_file ,fixup_filecmdlinekernelarm_64bitramfsfileramfsaddrinitramfsauto_initramfsdisable_poe_fandisable_splashenable_uartforce_eeprom_reados_prefixotg_mode (仅限Raspberry Pi 4)overlay_prefix配置属…...

PTA:模拟EXCEL排序
Excel可以对一组纪录按任意指定列排序。现请编写程序实现类似功能。 输入格式: 输入的第一行包含两个正整数 n (≤105) 和 c,其中 n 是纪录的条数,c 是指定排序的列号。之后有 n 行,每行包含一条学生纪录。每条学生纪录由学号(6…...

Python 爬虫解决 GBK乱码问题
文章目录 前言爬取初尝试与乱码问题编码知识科普UTF - 8GBKUnicode Python中的编码转换其他编码补充知识GBKGB18030GB2312UTF(UCS Transfer Format)Unicode 总结 前言 在Python爬虫的过程中,我尝试爬取一本小说,遇到GBK乱码问题&a…...

Scala与人工智能:融合多范式编程的AI开发利器
在人工智能(AI)技术飞速发展的今天,编程语言的选择直接影响着算法实现效率与系统可扩展性。Scala,作为一门融合面向对象(OOP)与函数式编程(FP)的多范式语言,凭借其独特的…...

解决echarts饼图label显示不全的问题
解决办法 添加如下配置: labelLayout: {hideOverlap: false},...

JCST 2025年 区块链论文 录用汇总
Conference:Journal of Computer Science and Technology (JCST) CCF level:CCF B Categories:交叉/综合/新兴 Year:2025(截止4.19) JCST 2024年 区块链论文 录用汇总 1 Title: An Understandable Cro…...
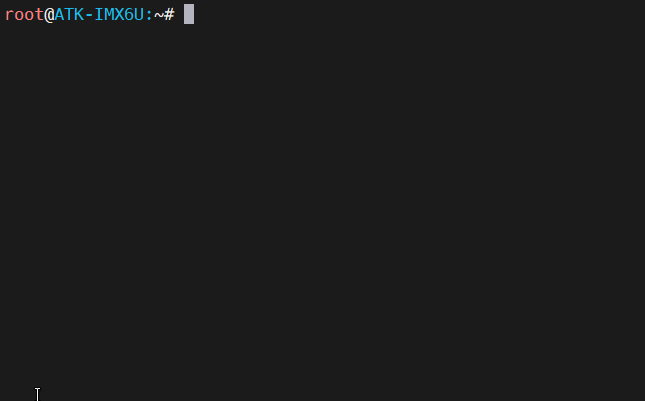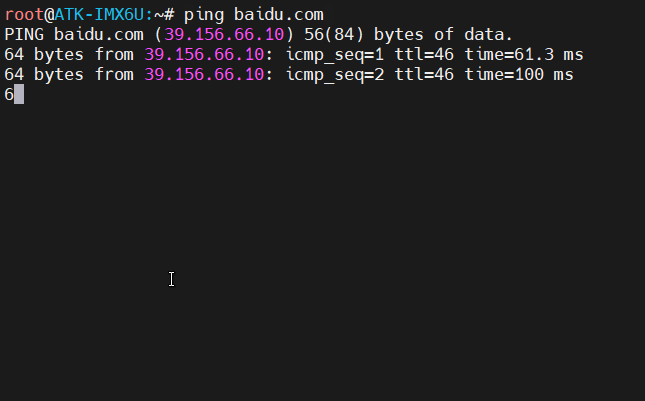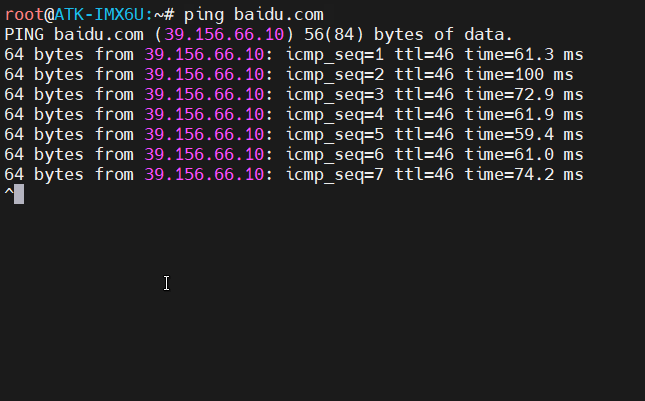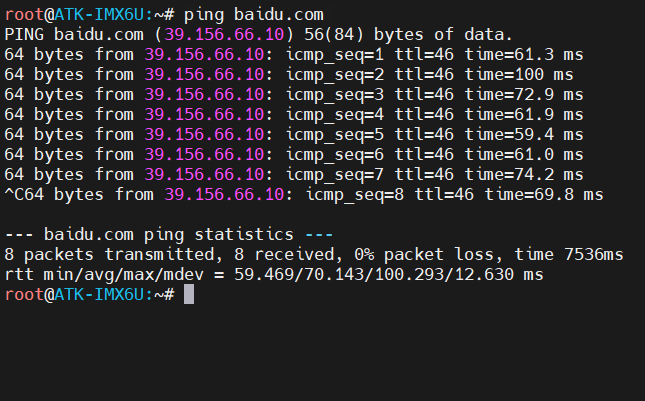
不带无线网卡的Linux开发板上网方法
I.MX6ULL通过网线上网 设置WLAN共享修改开发板的IP 在使用I.MX6ULL-MINI开发板学习Linux的时候,有时需要更新或者下载一些资源包,但是开发板本身是不带无线网卡或者WIFI芯片的,尝试使用网口连接笔记本,笔记本通过无线网卡连接WIFI…...
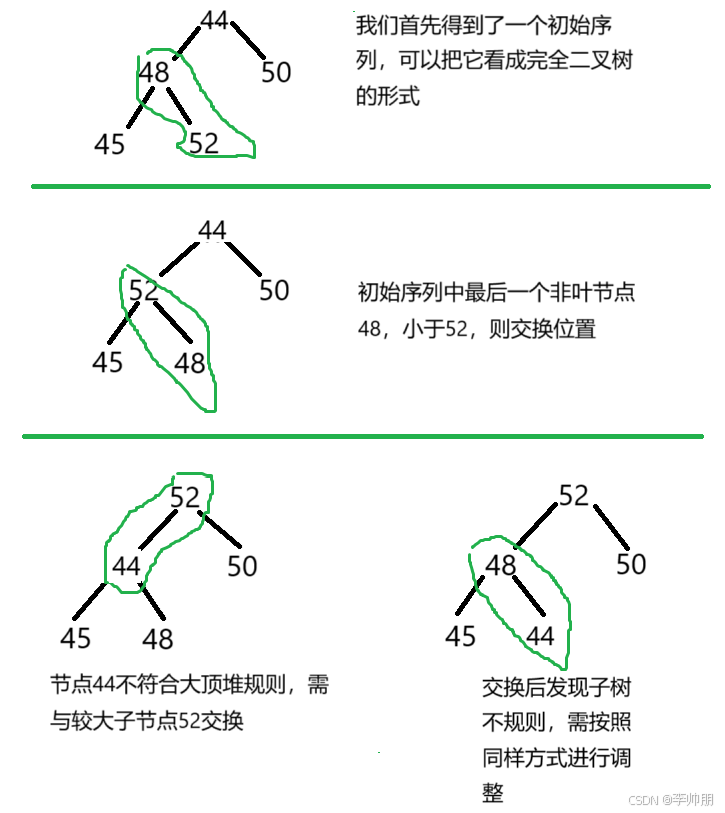
选择排序(简单选择排序、堆排序)
简单选择排序(Selection Sort) 1. 算法思想 它通过多次遍历数组,每次从未排序部分中选择最小(或最大)的元素,将其放到已排序部分的末尾(或开头),直到整个数组有序。 2.…...

velocity模板引擎
文章目录 学习链接一. velocity简介1. velocity简介2. 应用场景3. velocity 组成结构 二. 快速入门1. 需求分析2. 步骤分析3. 代码实现3.1 创建工程3.2 引入坐标3.3 编写模板3.4 输出结果示例1编写模板测试 示例2 4. 运行原理 三. 基础语法3.1 VTL介绍3.2 VTL注释3.2.1 语法3.2…...

word选中所有的表格——宏
Sub 选中所有表格()Dim aTable As TableApplication.ScreenUpdating FalseActiveDocument.DeleteAllEditableRanges wdEditorEveryoneFor Each aTable In ActiveDocument.TablesaTable.Range.Editors.Add wdEditorEveryoneNextActiveDocument.SelectAllEditableRanges wdEdito…...

13.第二阶段x64游戏实战-分析人物等级和升级经验
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:12.第二阶段x64游戏实战-远程调试 效果图: 如下图红框,…...