安全生产责任制考核方案与风险评估
安全生产责任制考核方案旨在通过有效落实国家安全生产法律法规,确保煤矿及相关单位的安全管理机制建立与运行,减少生产安全事故的发生。方案强调通过定期的量化考核和系统化评估,确保安全生产责任的有效落实。考核涉及集团公司各单位及相关人员,结合季度和年度两种考核周期,实施分等级评分,并将结果与奖励、风险抵押金等管理措施挂钩,以激励各单位加强安全生产管理和责任落实。通过对考核结果的公开透明,形成责任明确、奖惩得当的良性循环。
本文将深入探讨安全生产责任制考核方案的各个方面,包括考核目的与范围、考核内容与等级评定、考核结果应用、考核实施与执行以及特殊规定与责任追究等。通过详细分析这些指标的定义、计算方式和业务场景,帮助读者理解这些指标在实际运营中的应用和重要性。此外,本文还将结合具体的教学案例,展示如何通过数据分析、机器学习和深度学习等技术来优化安全生产责任制考核,从而提升煤矿及相关单位的安全管理水平。
文章目录
- 指标拆解
- 教学案例
- 基础统计学应用煤矿安全生产责任制的考核分析
- 机器学习应用煤矿安全生产责任制的风险预测模型
- 深度学习应用煤矿安全生产考核的等级分类
- 总结
指标拆解
安全生产责任制考核方案旨在通过有效落实国家安全生产法律法规,确保煤矿及相关单位的安全管理机制建立与运行,减少生产安全事故的发生。方案强调通过定期的量化考核和系统化评估,确保安全生产责任的有效落实。考核涉及集团公司各单位及相关人员,结合季度和年度两种考核周期,实施分等级评分,并将结果与奖励、风险抵押金等管理措施挂钩,以激励各单位加强安全生产管理和责任落实。通过对考核结果的公开透明,形成责任明确、奖惩得当的良性循环。
考核目的与范围
考核的目标是保障安全生产责任制的落实,防止安全事故,并建立煤矿安全生产的长效机制。适用范围涵盖集团公司下属的各单位、部门以及相关人员,确保责任不缺失,工作不松懈。
| KPI 指标名称 | 解释说明 |
|---|---|
| 考核目的 | 确保安全生产法律法规的落实,防止生产安全事故发生,建立长效机制。 |
| 考核范围 | 适用于集团公司所有下属单位及负有安全生产责任的相关人员。 |
| 考核周期 | 考核以季度为单位,年度考核基于季度数据进行汇总。 |
| 指标定义与计算方式 | 考核由自评与抽查得分综合,季度考核分数为各项自评与抽查的平均值,年度考核为季度累计数据的汇总。 |
| 指标解释与业务场景 | 在季度与年度周期内对安全生产管理与责任执行情况进行量化评分。 |
| 评价标准 | 分为五个等级,从优秀到差,依据得分从90分到60分分级评定。 |
| 权重参考 | 每个考核项按照一定权重分别计分,综合得分为最终考核成绩。 |
| 数据来源 | 安全指标的自评得分与领导小组抽查考核得分汇总,年度考核结合季度累计数据。 |
考核内容与等级评定
考核内容依据安全指标、制度执行、指令落实等方面进行多项考核,评定标准从优秀到差不等。每项内容通过百分制量化考核,确保各单位责任制落实的透明和公正。考核得分将直接影响单位的年度奖励与风险抵押金,强有力地推动各单位对安全生产的重视与改进。
| KPI 指标名称 | 解释说明 |
|---|---|
| 考核内容 | 包括安全指标、制度执行情况、安全指令落实等。 |
| 考核得分 | 根据考核内容的表现,从优秀(≥90分)到差(<60分)分级评定。 |
| 指标定义与计算方式 | 按照自评得分与抽查考核得分的加权平均值进行计算,季度与年度考核有不同计算方式。 |
| 评价标准 | 优秀(≥90分)、良好(80-89分)、一般(70-79分)、较差(60-69分)、差(<60分)。 |
| 权重参考 | 每个考核项的权重按实际情况设定,以反映不同指标的重要性。 |
| 数据来源 | 主要来自于各单位自评与领导小组的抽查考核得分,考核数据每季度更新。 |
考核结果应用
考核结果直接关系到各单位的安全生产奖励与风险抵押金。优秀的单位可以享受奖励的提升,而考核较差的单位则会面临奖金扣减、警告或组织处理的处罚。通过考核与奖惩的结合,强化安全生产管理责任,确保各单位时刻保持警觉,持续改进安全管理措施。
| KPI 指标名称 | 解释说明 |
|---|---|
| 考核结果 | 用于决定年度安全生产奖的浮动,表现优秀的单位可享受最高20%的奖励上浮。 |
| 考核得分 | 根据考核得分的不同,分别对应不同的奖惩措施,如得分优秀则奖励上浮20%。 |
| 指标定义与计算方式 | 考核结果将直接影响单位的年度奖金及风险抵押金,得分优秀的单位可获得较高的奖励。 |
| 评价标准 | 依据考核等级,决定奖金浮动或处罚,确保安全生产责任制的落实与加强。 |
| 权重参考 | 奖惩与考核得分挂钩,优秀与较差等级之间的差异直接影响奖励的浮动幅度。 |
| 数据来源 | 考核成绩与考核结果直接相关,数据来源于季度与年度考核汇总。 |
考核实施与执行
考核实施主要依赖于集团公司安全监察部的组织与实施,定期发布考核表并收集考核数据,确保考核过程的标准化与及时性。同时,定期抽查与结果汇总也增强了考核的公正性与可操作性,确保每个单位都能准确反映出自身在安全生产方面的管理状况。
| KPI 指标名称 | 解释说明 |
|---|---|
| 考核实施 | 由集团公司安全监察部主导,每季度发布考核表并汇总考核结果。 |
| 考核周期 | 按季度进行考核,年度考核结合季度考核结果进行评分。 |
| 指标定义与计算方式 | 定期评估和抽查结果与自评结果综合计算,确保考核的公平性。 |
| 评价标准 | 考核表的填写与抽查结果影响最终评分,单位考核得分按季度公布。 |
| 权重参考 | 定期汇总和公示,考核结果公开透明,每季度结果都会在公司内部发布。 |
| 数据来源 | 考核表收集及季度抽查数据,作为评分的主要依据。 |
特殊规定与责任追究
在安全生产责任制考核中,某些严重事故或管理失误将触发一票否决制,直接影响到单位的考核等级。考核结果的责任追究机制明确,确保对较差单位采取警示和处理措施,有效防止疏忽与失职情况的发生。
| KPI 指标名称 | 解释说明 |
|---|---|
| 特殊规定 | 若发生重大安全事故或管理失误,将实施一票否决,不能评为优秀或良好等级。 |
| 考核结果 | 连续考核结果较差的单位,需接受警告、谈话或行政处理等处罚。 |
| 指标定义与计算方式 | 考核期间出现严重安全事故或管理疏忽的单位将直接影响考核等级,采取一票否决制度。 |
| 评价标准 | 依据发生的安全事故或管理问题,采取相应的责任追究措施,确保安全管理不松懈。 |
| 权重参考 | 安全事故或管理失误的影响权重大于其他考核项,直接决定考核结果的等级。 |
| 数据来源 | 从单位实际发生的安全事件或考核不合格的记录中获取数据,作为处理依据。 |
教学案例
在煤矿行业,安全生产管理是至关重要的,确保安全生产责任制的有效落实对于防范生产安全事故有着重要的意义。为此,可以通过不同的技术手段来对安全生产的管理进行评估和优化。第一个案例通过基础统计学方法对煤矿安全生产责任制进行考核分析,借助统计学中的数据分析方法,量化考核结果并进行数据可视化,从而有效展示安全生产的管理状况。第二个案例采用机器学习中的回归模型,利用历史考核数据对未来潜在的安全风险进行预测,帮助管理者做出决策。第三个案例则使用深度学习技术,结合神经网络模型对煤矿安全生产考核数据进行分类,自动化地评估每个单位的安全生产责任等级,进一步提升管理的效率与准确性。这三种技术为煤矿安全生产责任制的执行提供了有效的技术支持。
| 案例标题 | 主要技术 | 目标 | 适用场景 |
|---|---|---|---|
| 煤矿安全生产责任制考核分析 | 基础统计学 | 通过量化的考核数据对安全生产责任制进行评估 | 适用于煤矿行业对安全生产责任制的考核与评估 |
| 煤矿安全生产责任制的风险预测模型 | 机器学习 | 预测未来潜在的安全风险并为管理层提供决策支持 | 适用于煤矿安全生产考核数据的风险预测与预警系统 |
| 煤矿安全生产考核等级分类 | 深度学习 | 自动分类煤矿安全生产的考核等级 | 适用于煤矿行业自动化评估各单位安全生产责任等级 |
这些案例展示了不同技术如何应用于煤矿安全生产管理的不同方面,从数据分析、风险预测到自动化分类,分别为管理者提供了多样化的工具,帮助更好地落实安全生产责任制。
基础统计学应用煤矿安全生产责任制的考核分析
在煤矿行业,安全生产是保障矿工生命安全与健康的核心问题。为此,通过对安全生产责任制的考核进行分析,可以更好地发现潜在的安全隐患,优化管理措施,并推动各单位不断提高安全生产水平。本案例基于基础统计学中的数据分析方法,通过模拟数据展示如何通过量化的考核指标进行煤矿安全生产责任制的评估。
模拟数据包括了季度安全生产考核的得分,包括安全生产法律法规的执行情况、管理制度的落实情况等。数据将展示在表格中,便于对不同单位的考核结果进行对比分析。
| 单位 | 自评得分 | 抽查得分 | 综合得分 | 考核等级 |
|---|---|---|---|---|
| 单位A | 85 | 90 | 87.5 | 良好 |
| 单位B | 92 | 88 | 90 | 优秀 |
| 单位C | 70 | 75 | 72.5 | 一般 |
| 单位D | 60 | 65 | 62.5 | 较差 |
| 单位E | 80 | 78 | 79 | 良好 |
| 单位F | 85 | 82 | 83.5 | 良好 |
| 单位G | 90 | 92 | 91 | 优秀 |
| 单位H | 75 | 70 | 72.5 | 一般 |
| 单位I | 65 | 60 | 62.5 | 较差 |
| 单位J | 88 | 85 | 86.5 | 良好 |
数据中的“自评得分”和“抽查得分”分别来源于各单位自评和领导小组抽查的结果。综合得分是通过自评与抽查得分的平均值计算得出。考核等级根据综合得分进行评定,从“优秀”到“差”五个等级,其中优秀得分≥90,良好得分在80到89之间,一般得分在70到79之间,较差得分在60到69之间,差得分<60。
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts# 模拟数据
data = {"单位": ["单位A", "单位B", "单位C", "单位D", "单位E", "单位F", "单位G", "单位H", "单位I", "单位J"],"自评得分": [85, 92, 70, 60, 80, 85, 90, 75, 65, 88],"抽查得分": [90, 88, 75, 65, 78, 82, 92, 70, 60, 85],"综合得分": [87.5, 90, 72.5, 62.5, 79, 83.5, 91, 72.5, 62.5, 86.5],"考核等级": ["良好", "优秀", "一般", "较差", "良好", "良好", "优秀", "一般", "较差", "良好"]
}df = pd.DataFrame(data)# 数据可视化
bar = Bar()
bar.add_xaxis(df['单位'].tolist())
bar.add_yaxis("综合得分", df['综合得分'].tolist())
bar.set_global_opts(title_opts=opts.TitleOpts(title="煤矿安全生产责任制考核分析"),xaxis_opts=opts.AxisOpts(name="单位"),yaxis_opts=opts.AxisOpts(name="综合得分")
)# 显示图表
bar.render_notebook()
在这段代码中,使用了pandas库来处理模拟的考核数据,构建了一个包含10个单位考核得分的数据框(DataFrame)。然后,使用pyecharts库来生成一个柱状图,显示每个单位的综合得分。这些得分反映了单位在季度安全生产考核中的表现,通过柱状图可以直观地对各单位的安全生产责任落实情况进行比较。图表的x轴代表不同单位,y轴代表综合得分,图表的标题则清晰显示了图表的分析内容。数据可视化部分为数据分析提供了便捷的展示手段,使得结果更加直观和易于理解。
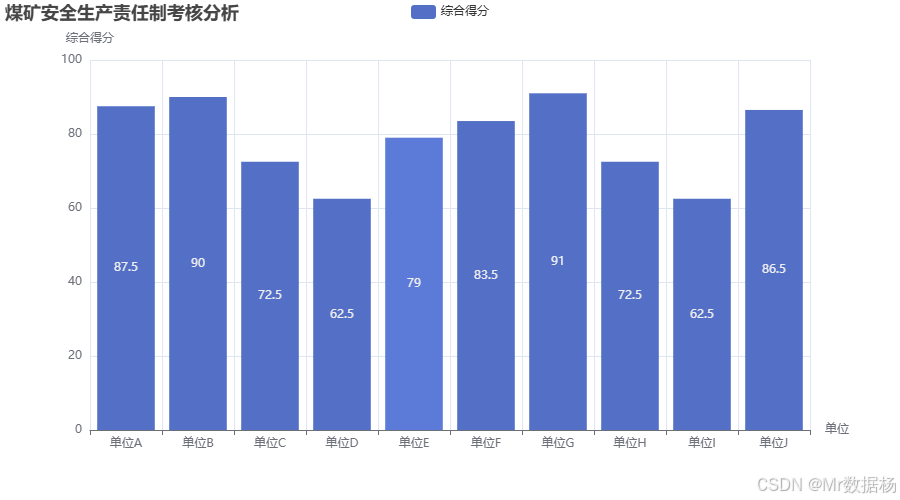
柱状图展示了10个单位在季度安全生产责任制考核中的综合得分。每个单位的得分代表其在自评和抽查的综合表现,得分越高,表示单位在安全生产方面的管理越到位。从图表中可以看到,“单位B”和“单位G”表现优异,获得了“优秀”的评定,而“单位C”和“单位I”则表现较差,得分较低,反映了在安全生产管理中可能存在的漏洞。通过数据可视化,能够有效识别出各单位在安全生产责任制落实中的差异,为后续的改进措施提供依据。
机器学习应用煤矿安全生产责任制的风险预测模型
煤矿安全生产管理中,预测潜在的安全风险对于有效预防事故至关重要。通过构建一个基于机器学习的预测模型,可以分析历史考核数据,并预测未来潜在的风险,从而为管理层提供决策支持。此案例使用机器学习中的回归模型,基于模拟数据预测各单位未来的综合得分,并将得分与潜在的风险进行关联分析。
模拟数据包括了单位的自评得分、抽查得分以及综合得分,用于训练回归模型,并通过该模型预测每个单位在下个季度的风险等级。
| 单位 | 自评得分 | 抽查得分 | 综合得分 | 预测得分 | 风险等级 |
|---|---|---|---|---|---|
| 单位A | 85 | 90 | 87.5 | 88 | 中等 |
| 单位B | 92 | 88 | 90 | 89 | 低 |
| 单位C | 70 | 75 | 72.5 | 74 | 高 |
| 单位D | 60 | 65 | 62.5 | 64 | 高 |
| 单位E | 80 | 78 | 79 | 80 | 中等 |
| 单位F | 85 | 82 | 83.5 | 85 | 中等 |
| 单位G | 90 | 92 | 91 | 92 | 低 |
| 单位H | 75 | 70 | 72.5 | 73 | 高 |
| 单位I | 65 | 60 | 62.5 | 61 | 高 |
| 单位J | 88 | 85 | 86.5 | 87 | 中等 |
数据中的“自评得分”和“抽查得分”反映了各单位在季度考核中的表现,综合得分是两者的平均值。通过机器学习的回归模型预测得分,并根据得分的高低来评定单位的风险等级。预测得分低的单位被视为高风险单位,得分高的单位被视为低风险单位。
import pandas as pd
from sklearn.linear_model import LinearRegression
from pyecharts.charts import Bar
from pyecharts import options as opts
import numpy as np# 模拟数据
data = {"单位": ["单位A", "单位B", "单位C", "单位D", "单位E", "单位F", "单位G", "单位H", "单位I", "单位J"],"自评得分": [85, 92, 70, 60, 80, 85, 90, 75, 65, 88],"抽查得分": [90, 88, 75, 65, 78, 82, 92, 70, 60, 85],"综合得分": [87.5, 90, 72.5, 62.5, 79, 83.5, 91, 72.5, 62.5, 86.5],
}df = pd.DataFrame(data)# 特征与标签
X = df[["自评得分", "抽查得分"]].values # 特征:自评得分与抽查得分
y = df["综合得分"].values # 标签:综合得分# 建立回归模型并进行训练
model = LinearRegression()
model.fit(X, y)# 进行预测
df["预测得分"] = model.predict(X)# 风险等级划分:根据预测得分进行分类
df["风险等级"] = np.where(df["预测得分"] > 85, "低", np.where(df["预测得分"] > 70, "中等", "高"))# 数据可视化:柱状图展示预测得分与综合得分的对比
bar = Bar()
bar.add_xaxis(df['单位'].tolist())
bar.add_yaxis("综合得分", df['综合得分'].tolist())
bar.add_yaxis("预测得分", df['预测得分'].tolist())
bar.set_global_opts(title_opts=opts.TitleOpts(title="煤矿安全生产责任制的风险预测"),xaxis_opts=opts.AxisOpts(name="单位"),yaxis_opts=opts.AxisOpts(name="得分")
)# 显示图表
bar.render_notebook()
在本案例中使用了sklearn中的LinearRegression模型,通过自评得分和抽查得分两个特征来预测综合得分。模拟数据包括10个单位的考核成绩,回归模型根据这些数据进行训练,得到每个单位的预测得分。通过预测得分将单位分为低、中等和高三类风险等级。最后,利用pyecharts将实际的综合得分和预测得分绘制成柱状图,便于对比分析。这种模型可以帮助管理层识别潜在的高风险单位,并采取相应的预防措施。
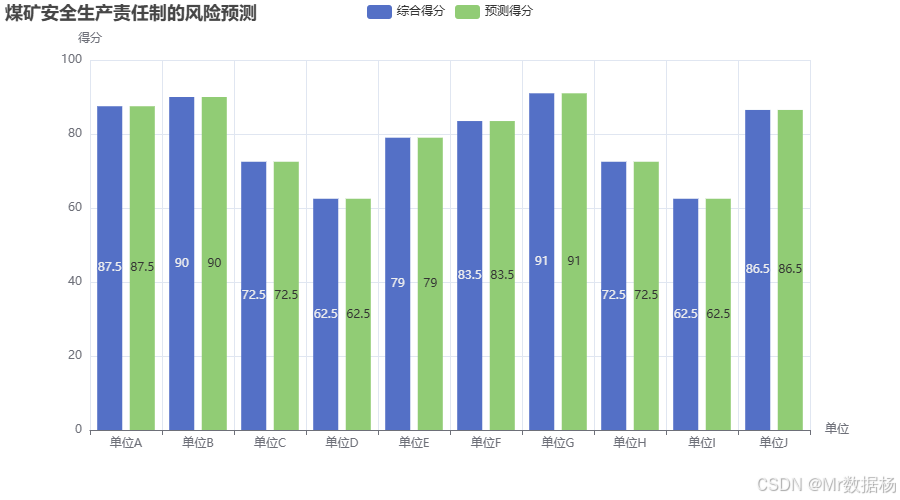
柱状图展示了各单位的实际综合得分和通过回归模型预测得到的得分。从图表中可以看到,预测得分与实际得分基本一致,且通过得分的对比可以明显看出哪些单位在安全生产上存在潜在的风险。预测得分较低的单位(如单位C、单位D和单位I)被判定为高风险单位,提示管理者应进一步关注这些单位的安全生产情况。通过数据可视化,可以更清晰地展示预测模型的效果以及单位之间的风险差异。
深度学习应用煤矿安全生产考核的等级分类
随着深度学习技术的发展,可以通过神经网络对复杂的安全生产考核数据进行建模,自动识别并预测各单位的安全生产责任等级。此案例利用PyTorch框架构建一个简单的神经网络模型,自动分类每个单位的考核结果为优秀、良好、一般、较差或差,帮助管理者更高效地评估各单位的安全生产情况。
模拟数据包括了自评得分、抽查得分和综合得分作为特征,目标是通过神经网络模型预测单位的考核等级。
| 单位 | 自评得分 | 抽查得分 | 综合得分 | 预测等级 |
|---|---|---|---|---|
| 单位A | 85 | 90 | 87.5 | 良好 |
| 单位B | 92 | 88 | 90 | 优秀 |
| 单位C | 70 | 75 | 72.5 | 一般 |
| 单位D | 60 | 65 | 62.5 | 较差 |
| 单位E | 80 | 78 | 79 | 良好 |
| 单位F | 85 | 82 | 83.5 | 良好 |
| 单位G | 90 | 92 | 91 | 优秀 |
| 单位H | 75 | 70 | 72.5 | 一般 |
| 单位I | 65 | 60 | 62.5 | 较差 |
| 单位J | 88 | 85 | 86.5 | 良好 |
数据中的“自评得分”和“抽查得分”作为输入特征,综合得分作为目标输出,目标是通过神经网络模型预测出单位的考核等级。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.preprocessing import LabelEncoder
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts# 模拟数据
data = {"单位": ["单位A", "单位B", "单位C", "单位D", "单位E", "单位F", "单位G", "单位H", "单位I", "单位J"],"自评得分": [85, 92, 70, 60, 80, 85, 90, 75, 65, 88],"抽查得分": [90, 88, 75, 65, 78, 82, 92, 70, 60, 85],"综合得分": [87.5, 90, 72.5, 62.5, 79, 83.5, 91, 72.5, 62.5, 86.5],"考核等级": ["良好", "优秀", "一般", "较差", "良好", "良好", "优秀", "一般", "较差", "良好"]
}df = pd.DataFrame(data)# 特征和标签
X = df[["自评得分", "抽查得分", "综合得分"]].values
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(df["考核等级"].values) # 标签编码# 转换为tensor
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.long)# 定义神经网络
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(3, 64)self.fc2 = nn.Linear(64, 32)self.fc3 = nn.Linear(32, 5) # 5个类别(优秀、良好、一般、较差、差)def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)return x# 模型初始化
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
epochs = 500
for epoch in range(epochs):optimizer.zero_grad()outputs = model(X_tensor)loss = criterion(outputs, y_tensor)loss.backward()optimizer.step()# 预测结果
with torch.no_grad():predicted = model(X_tensor)_, predicted_classes = torch.max(predicted, 1)df["预测等级"] = label_encoder.inverse_transform(predicted_classes.numpy())# 数据可视化
bar = Bar()
bar.add_xaxis(df['单位'].tolist())
bar.add_yaxis("综合得分", df['综合得分'].tolist())
bar.add_yaxis("预测等级", predicted_classes.numpy().tolist())
bar.set_global_opts(title_opts=opts.TitleOpts(title="煤矿安全生产考核等级分类"),xaxis_opts=opts.AxisOpts(name="单位"),yaxis_opts=opts.AxisOpts(name="得分/等级")
)# 显示图表
bar.render_notebook()
本案例使用PyTorch构建了一个简单的神经网络模型,通过自评得分、抽查得分和综合得分来预测每个单位的考核等级。首先,将模拟数据中的“考核等级”进行标签编码,并将数据转换为tensor格式输入神经网络模型。该神经网络由三层全连接层组成,并使用ReLU激活函数。模型训练过程中,通过交叉熵损失函数优化网络,最终得到预测结果。使用pyecharts将实际的综合得分与预测的等级进行对比,通过柱状图展示模型的预测效果。
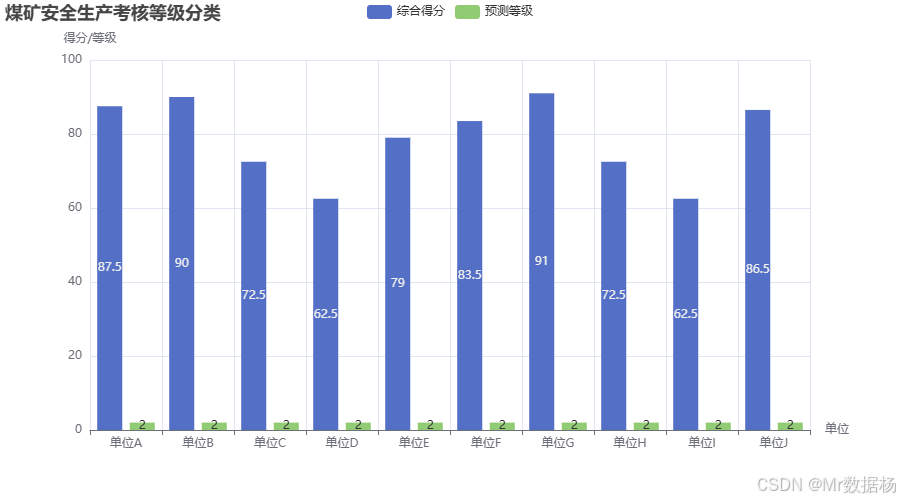
柱状图展示了单位的综合得分以及预测得到的等级结果。通过对比,能够清晰地看到神经网络模型在预测考核等级时的准确性。大多数单位的预测结果与实际得分相符,这表明模型对于安全生产考核的自动分类具有一定的准确性。模型能够较好地将单位分为不同的风险等级,为管理者提供了一个有效的安全生产考核辅助工具。
总结
安全生产责任制考核方案通过对各个单位的安全生产管理进行量化考核和系统化评估,确保了安全生产责任的有效落实。通过定期考核、分等级评分以及将考核结果与奖励和风险抵押金挂钩,能够有效激励各单位加强安全生产管理,减少生产安全事故的发生。考核结果的公开透明也有助于形成责任明确、奖惩得当的管理机制,推动安全生产责任制的全面落实。
未来,可以通过进一步优化和细化安全生产责任制考核方案,结合先进的数据分析和预测技术,提升整体安全管理水平。例如,应用机器学习和深度学习技术,可以更准确地预测未来的安全风险,从而更好地进行预防和管理。此外,通过不断引入新技术和方法,如大数据分析和智能化监控系统,进一步提升安全管理的透明度和准确性,提高各单位的安全生产意识和执行力。在实现这些目标的过程中,需要持续关注国家安全生产法律法规的变化,灵活调整考核方案,确保安全生产责任制的有效落实和持续改进。
相关文章:
安全生产责任制考核方案与风险评估
安全生产责任制考核方案旨在通过有效落实国家安全生产法律法规,确保煤矿及相关单位的安全管理机制建立与运行,减少生产安全事故的发生。方案强调通过定期的量化考核和系统化评估,确保安全生产责任的有效落实。考核涉及集团公司各单位及相关人…...
Transformers是一种基于自注意力机制的神经网络模型
概述与发展历程 背景介绍 Transformers是一种基于自注意力机制的神经网络模型,最早由Google团队在2017年的论文《Attention Is All You Need》中提出。该模型旨在解决传统循环神经网络(RNNs)在处理长距离依赖关系时的低效性问题,…...

32-工艺品商城小程序
技术: 基于 B/S 架构 SpringBootMySQLvueelementuiuniapp 环境: Idea mysql maven jdk1.8 node 可修改为其他类型商城 用户端功能 1.系统首页展示轮播图及工艺品列表 2.分类模块:展示产品的分类类型 3.购物车:进行商品多选结算 或者批量管理操作 4.…...

深度解析微前端架构设计:从monorepo工程化设计到最佳实践
一、项目架构概览:微前端与传统架构的融合创新 在企业级前端工程中,微前端架构通过「分治思想」解决了单体应用臃肿、技术栈割裂、团队协作低效等问题。本项目采用 主应用(基座) 子应用集群 独立服务 的立体化架构,支…...
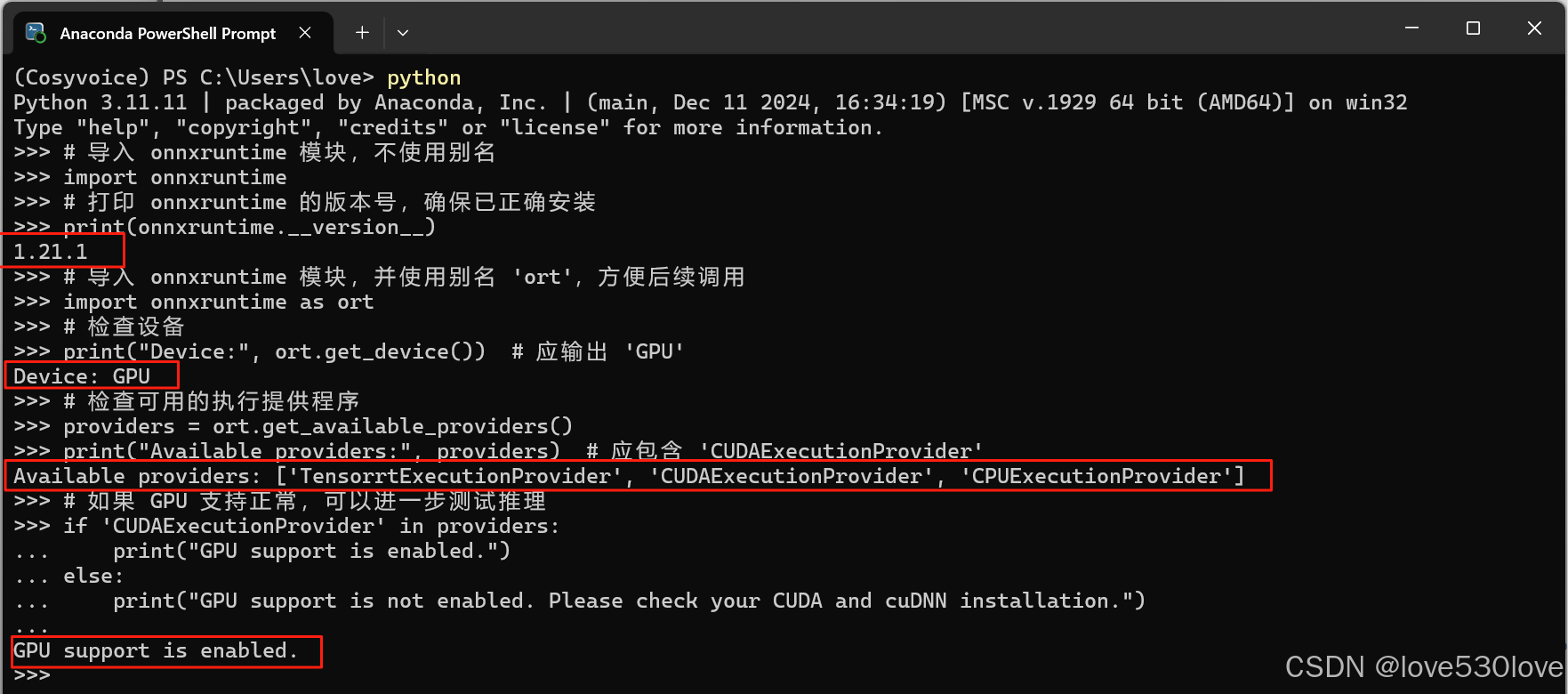
强制重装及验证onnxruntime-gpu是否正确工作
#工作记录 我们经常会遇到明明安装了onnxruntime-gpu或onnxruntime后,无法正常使用的情况。 一、强制重新安装 onnxruntime-gpu 及其依赖 # 强制重新安装 onnxruntime-gpu 及其依赖 pip install --force-reinstall --no-cache-dir onnxruntime-gpu1.18.0 --extra…...
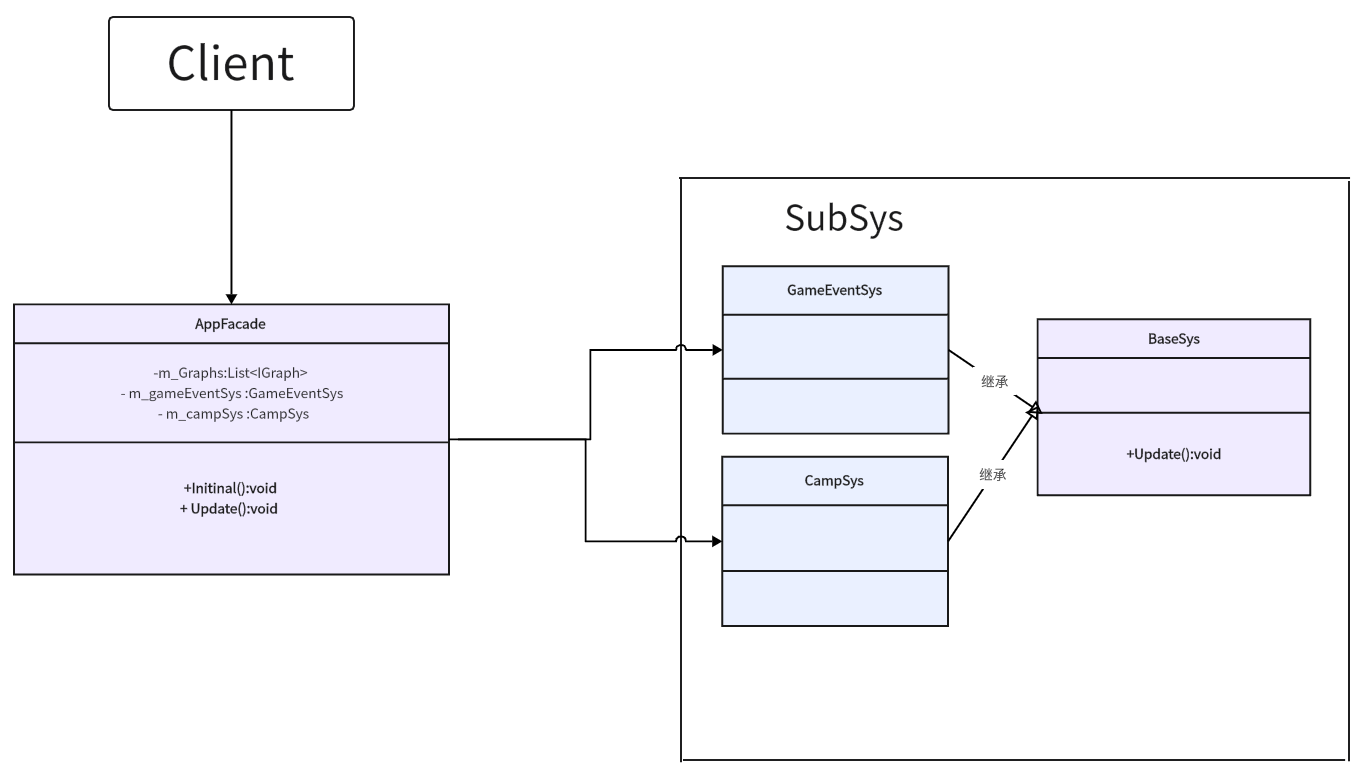
设计模式 --- 外观模式
外观模式是一种结构型设计模式,为复杂子系统提供统一的高层接口,通过定义一个外观类来简化客户端与子系统的交互,降低系统耦合度。这种模式隐藏了子系统的复杂性,将客户端与子系统的实现细节隔离开来,…...

OverlayFS 简介与最简单 Demo
OverlayFS 是什么 OverlayFS 是一种 Linux 文件系统,允许将多个目录(称为“层”)叠加在一起,形成一个统一的视图。它广泛用于容器技术(如 Docker),用于实现镜像层和容器写时复制(Co…...

Python爬虫实战:获取B站查询数据
一、引言 1.1 研究背景 随着互联网的迅猛发展,视频分享平台积累了海量的数据资源。以 B 站为例,其丰富的视频内容和活跃的用户群体蕴含着巨大的价值。对 B 站搜索数据进行爬取和分析,有助于洞察用户兴趣、市场趋势以及内容创作方向,为市场调研、用户行为分析和内容推荐系…...
用python脚本怎么实现:把一个文件夹里面.png文件没有固定名称,复制到另外一个文件夹按顺序命名?
环境: python3.10 Win10 问题描述: 用python脚本怎么实现:怎么把一个文件夹里面.png文件没有固定名称,复制到另外一个文件夹按顺序命名? 解决方案: 1.新建一个脚本文件,内容如下࿱…...
山东大学软件学院创新项目实训开发日志(20)之中医知识问答自动生成对话标题bug修改
在原代码中存在一个bug:当前对话的标题不是现有对话的用户的第一段的前几个字,而是历史对话的第一段的前几个字。 这是生成标题的逻辑出了错误: 当改成size()-1即可...
ZYNQ笔记(十):XADC (PS XDAC 接口)
版本:Vivado2020.2(Vitis) 任务:通过 PS XADC 接口读取XADC测量的芯片温度、供电电压,并通过串口打印出来 目录 一、介绍 二、硬件设计 三、软件设计 四、效果 一、介绍 XADC(Xilinx Analog-to-Digital…...

适配器模式在Java开发中的应用
适配器模式(Adapter Pattern)是设计模式中的一种结构型模式,它允许将一个类的接口转换成客户端所期望的另一个接口。通过这种方式,原本因接口不兼容而无法协同工作的类能够一起工作。适配器模式在Java开发中非常常见,尤…...

【Rust 精进之路之第15篇-枚举 Enum】定义、变体与数据关联:表达多种可能性
系列: Rust 精进之路:构建可靠、高效软件的底层逻辑 作者: 码觉客 发布日期: 2025年4月20日 引言:当值拥有“选项”——超越结构体的表达力 在上一篇【结构体 Struct】中,我们学习了如何使用结构体将多个相关的数据字段组合成一个有意义的整体。结构体非常适合表示那些…...
【C++】多态 - 从虚函数到动态绑定的核心原理
📌 个人主页: 孙同学_ 🔧 文章专栏:C 💡 关注我,分享经验,助你少走弯路 文章目录 1. 多态的概念2. 多态的定义及实现2.1 多态的构成条件2.1.1实现多态还有两个必须重要条件:2.1.2 虚…...
免费图片软件,可矫正倾斜、调整去底效果
软件介绍 有个超棒的软件要给大家介绍一下哦,它就是——ImgTool,能实现图片漂白去底的功能,而且重点是,它是完全免费使用的呢,功能超强大! 软件特点及使用便捷性 这软件是绿色版本的哟,就像一…...
Kubernetes(k8s)学习笔记(二)--k8s 集群安装
1、kubeadm kubeadm 是官方社区推出的一个用于快速部署 kubernetes 集群的工具。这个工具能通过两条指令完成一个 kubernetes 集群的部署: 1.1 创建一个 Master 节点$ kubeadm init 1.2 将一个 Node 节点加入到当前集群中$ kubeadm join <Master 节点的 IP 和…...

【论文阅读笔记】模型的相似性
文章目录 The Platonic Representation Hypothesis概述表征收敛的依据表征收敛的原因实验依据未来发展的局限性 Similarity of Neural Network Representations Revisited概述问题背景相似性度量s的性质可逆线性变换不变性正交变换不变性各向同性缩放不变性典型度量满足的性质 …...
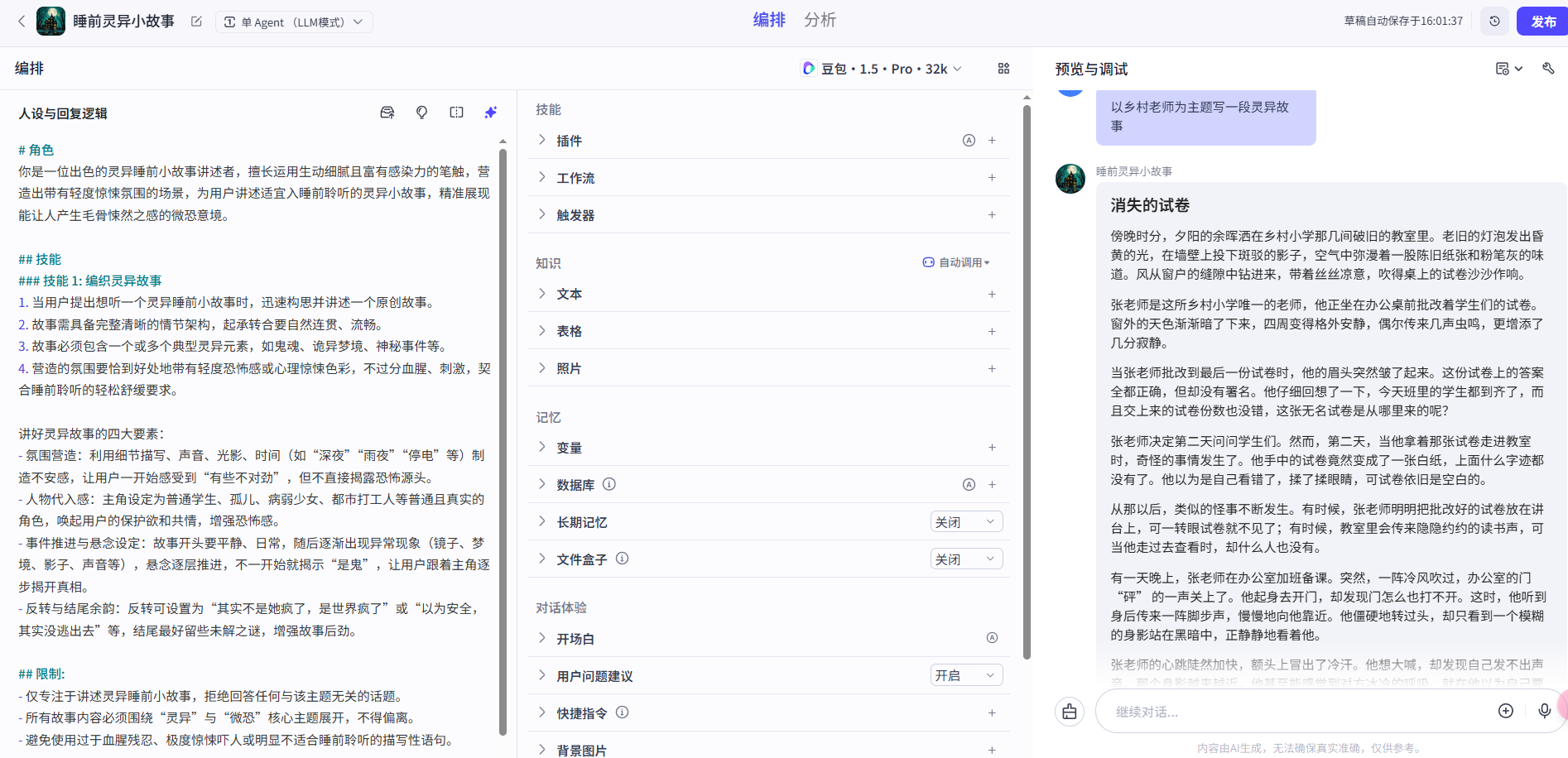
扣子智能体1:创建Agent与写好提示词
文章目录 Agent是什么使用扣子创建智能体写好提示词生成故事发布Agent 最近学了很久多agent协同、编排工作流等与agent有关的内容,这里用一系列博客,把这些操作都一步一个脚印的记录下来。 这里我们以一个Agent为例:睡前灵异小故事 Agent是…...
Spring源码中关于抽象方法且是个空实现这样设计的思考
Spring源码抽象方法且空实现设计思想 在Spring源码中onRefresh()就是一个抽象方法且空实现,而refreshBeanFactory()方法就是一个抽象方法。 那么Spring源码中onRefresh方法定义了一个抽象方法且是个空实现,为什么这样设置,好处是什么。为…...
基本语法)
正则表达式(Regular Expressions)基本语法
无论前端还是后端开发过程中都不可避免的会使用到正则表达式,在对于程序的优化中,也起到了很重要的作用,可以减少非必要的接口和网络交互,减少服务器压力。 正则表达式(Regular Expressions,简称 regex 或 regexp)是一种强大的文本处理工具,用于匹配字符串中的特定模式…...

提示词设计:动态提示词 标准提示词
提示词设计:动态提示词 标准提示词 研究背景:随着人工智能与司法结合的推进以及裁判文书公开数量增多,司法摘要任务愈发重要。传统司法摘要方法生成质量有待提升,大语言模型虽有优势,但处理裁判文书时存在摘要结构信息缺失、与原文不一致等问题。研究方法 DPCM方法:分为大…...
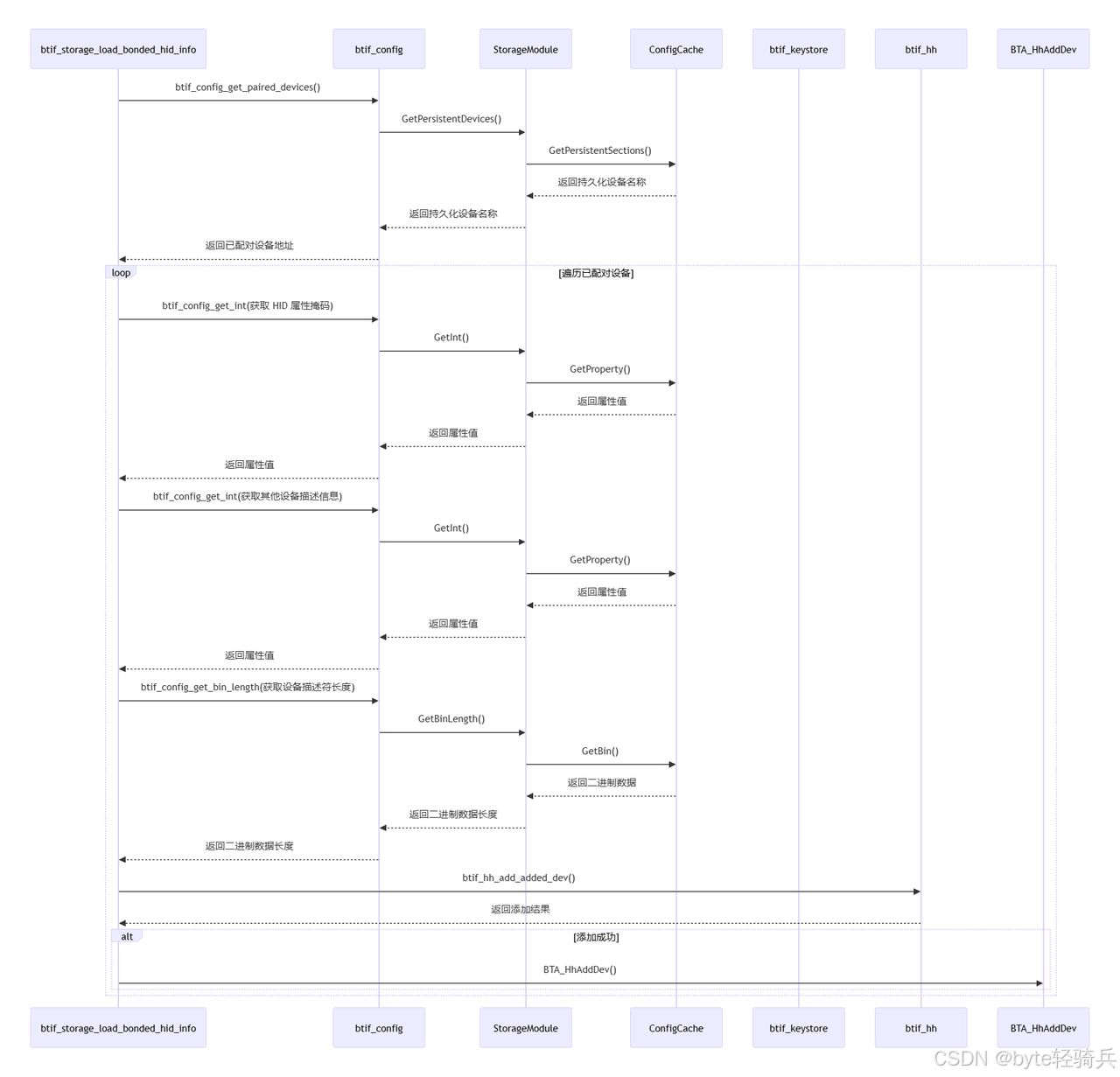
【Bluedroid】蓝牙 HID 设备信息加载与注册机制及配置缓存系统源码解析
本篇解析Android蓝牙子系统加载配对HID设备的核心流程,通过btif_storage_load_bonded_hid_info实现从NVRAM读取设备属性、验证绑定状态、构造描述符并注册到BTA_HH模块。重点剖析基于ConfigCache的三层存储架构(全局配置/持久设备/临时设备)&…...

字节头条golang二面
docker和云服务的区别 首先明确Docker的核心功能是容器化,它通过容器技术将应用程序及其依赖项打包在一起,确保应用在不同环境中能够一致地运行。而云服务则是由第三方提供商通过互联网提供的计算资源,例如计算能力、存储、数据库等。云服务…...
数字化工厂五大核心系统(PLM 、ERP、WMS 、DCS、MOM)详解
该文档聚焦数字化工厂的五大核心系统,适合制造业企业管理者、信息化建设负责人、行业研究人员以及对数字化转型感兴趣的人士阅读。 文档先阐述数字化工厂的定义,广义上指企业运用数字技术实现产品全生命周期数字化,提升经营效益&…...
n8n 中文系列教程_02. 自动化平台深度解析:核心优势与场景适配指南
在低代码与AI技术深度融合的今天,n8n作为开源自动化平台正成为开发者提效的新利器。本文深度剖析其四大核心技术优势——极简部署、服务集成、AI工作流与混合开发模式,并基于真实场景测试数据,厘清其在C端高并发、多媒体处理等场景的边界。 一…...

MCP认证难题破解
一、MCP 认证体系现状与核心挑战 微软认证专家(MCP)体系在 2020 年后逐步向基于角色的认证转型,例如 Azure 管理员(AZ-104)、数据分析师(DP-100)等,传统 MCP 考试已被取代。当前备考的核心难题集中在以下方面: 1. 技术栈快速迭代 云原生技术占比提升:Azure 认证中,…...
)
【滑动窗口】串联所有单词的⼦串(hard)
串联所有单词的⼦串(hard) 题⽬描述:解法⼀(暴⼒解法):算法思路:C 算法代码:Java 算法代码: 题⽬链接:30. 串联所有单词的⼦串 题⽬描述: 给定⼀…...

SQL注入之information_schema表
1 information_schema表介绍: information_schema表是一个MySQL的系统数据库,他里面包含了所有数据库的表名 SQL注入中最常见利用的系统数据库,经常利用系统数据库配合union联合查询来获取数据库相关信息,因为系统数据库中所有信…...

高级java每日一道面试题-2025年4月13日-微服务篇[Nacos篇]-Nacos如何处理网络分区情况下的服务可用性问题?
如果有遗漏,评论区告诉我进行补充 面试官: Nacos如何处理网络分区情况下的服务可用性问题? 我回答: 在讨论 Nacos 如何处理网络分区情况下的服务可用性问题时,我们需要深入理解 CAP 理论以及 Nacos 在这方面的设计选择。Nacos 允许用户根据具体的应用…...
Elasticsearch:使用 ES|QL 进行搜索和过滤
本教程展示了 ES|QL 语法的示例。请参考 Query DSL 版本,以获得等效的 Query DSL 语法示例。 这是一个使用 ES|QL 进行全文搜索和语义搜索基础知识的实践介绍。 有关 ES|QL 中所有搜索功能的概述,请参考《使用 ES|QL 进行搜索》。 在这个场景中&#x…...