【论文阅读笔记】模型的相似性
文章目录
- The Platonic Representation Hypothesis
- 概述
- 表征收敛的依据
- 表征收敛的原因
- 实验依据
- 未来发展的局限性
- Similarity of Neural Network Representations Revisited
- 概述
- 问题背景
- 相似性度量s的性质
- 可逆线性变换不变性
- 正交变换不变性
- 各向同性缩放不变性
- 典型度量满足的性质
- 中心核对齐(CKA)
- 核心思想
- 数学表示
- 点积相似性
- 线性回归
- Hilbert-Schmidt Independence Criterion (HSIC):
- 典型相关分析(CCA)
- CKA的原理和关联
The Platonic Representation Hypothesis
原文链接
概述
论文提出了柏拉图表征假设(Platonic Representation Hypothesis),认为随着AI模型(特别是深度神经网络)的规模、数据和任务多样性增加,不同模型的表征方式正在收敛到一个共享的、反映现实统计模型的表征,称之为柏拉图表征。这种表征类似于柏拉图《洞穴寓言》中描述的理想现实,捕捉了生成观测数据的世界事件联合分布。
表征收敛的依据
(1)单模态收敛:不同架构、训练目标和数据集的神经网络表征趋于对齐。例如,研究通过模型拼接(model stitching)和核对齐度量(如CKA、互近邻)发现,训练于ImageNet和Places-365的视觉模型具有相似的表征。
(2)跨模态收敛:视觉模型和语言模型的表征在更大规模和更高性能下趋于对齐。例如,使用Wikipedia图像-文本数据集(WIT)测量,性能更强的语言模型与视觉模型的表征对齐度更高。
(3)与现实的对齐:神经网络的表征与人类视觉系统的表征表现出一致性,可能是因为两者面临相似的任务和数据约束。表征对齐度与下游任务性能(如Hellaswag、GSM8K)正相关,表明对齐的表征更接近现实的统计模型。
表征收敛的原因
随着数据和任务的扩展,满足这些约束的表示量必须按比例变小,模型被迫学习更通用的表征(Contravariance principle)
数据规模和模型性能之间存在幂律关系(Hestness等人,2017)。这意味着,有了足够的数据,表征应该收敛到一个具有不可约误差的非常小的解集。
多任务目标可能比单任务目标(例如ImageNet分类)更有效,因为它们对表示施加了更多的任务约束,导致更小、更高质量的解决方案空间
对比学习目标(如InfoNCE)通过学习点互信息(PMI)捕获数据间的统计结构,促进表征对齐现实分布。
一些假说:
(1)简单性偏差假说:较大的模型对拟合相同数据的所有可能方法的覆盖范围更大。然而,深度网络的隐含简单性偏差鼓励更大的模型找到这些解决方案中最简单的一个。
(2)容量假说:与较小的模型相比,较大的模型更有可能收敛到共享表示。
(3)Occam’s razor:如果有两个模型都能解释数据,优先选择更简单的那个(参数更少、假设更少)。简单模型通常泛化能力更强,减少过拟合风险。
实验依据
(1)视觉-视觉对齐实验 (Vision-Vision Alignment):验证不同视觉模型的表示是否趋同,以及这种趋同是否与模型性能相关。
(2)跨模态对齐实验 (Cross-Modal Alignment):验证视觉模型和语言模型的表示是否趋同,以及这种对齐是否随着模型性能提升而增强。
(3)颜色共现实验 (Color Cooccurrence Experiment):验证视觉和语言模型是否通过共现关系学习到相似的表示,具体以颜色表示为例。
(4)字幕密度实验 (Caption Density Experiment):验证更密集的图像字幕是否提高视觉-语言表示对齐。
未来发展的局限性
(1)模态差异:不同模态的传感器可能捕捉不同信息(如触觉无法捕捉颜色),可能限制完全趋同。
(2)任务特定性:某些任务可能需要特定的表示,阻碍通用表示的形成。
(3)实际约束:现实中数据和计算资源的有限性可能限制模型逼近柏拉图表示。
Similarity of Neural Network Representations Revisited
原文链接
概述
论文主要探讨了如何比较和分析深度神经网络的表示(representations),提出了一种新的相似性度量方法——中心核对齐(Centered Kernel Alignment, CKA),并将其与传统方法如canonical correlation analysis (CCA)进行了对比。
问题背景
给定两个神经网络的激活矩阵 X ∈ R n × p 1 X \in \mathbb{R}^{n\times p_1} X∈Rn×p1, Y ∈ R n × p 2 Y \in \mathbb{R}^{n\times p_2} Y∈Rn×p2, n n n是样本数, p 1 , p 2 p_1, p_2 p1,p2是神经元数。假设矩阵已中心化且 p 1 ≤ p 2 p_1 \le p_2 p1≤p2,目标是设计和分析一个标量相似性度量 s ( X , Y ) s(X, Y) s(X,Y),用于比较神经网络内部和跨网络的表示,以帮助可视化和理解深度学习中不同变因的影响。
相似性度量s的性质
在探索最合理的度量 s s s的过程中,科学家提出了许多 s s s应满足的性质的假设,并基于此提出了许多理论。然而,这些理论都有一定的局限性。
可逆线性变换不变性
定义:若相似性度量 s ( X , Y ) = s ( X A , Y B ) s(X,Y) = s(XA,YB) s(X,Y)=s(XA,YB),其中 A , B A,B A,B是任意满秩矩阵,则该度量对可逆线性变换不变。
直观理解:在全连接层 f ( X ) = σ ( X W + β ) f(X) = \sigma(XW+\beta) f(X)=σ(XW+β)中,激活 X X X右乘可逆矩阵 A A A,同时权重 W W W左乘 A − 1 A^{-1} A−1,不会改变网络输出。因此,某些研究(如Raghu et al., 2017)认为相似性度量应对可逆线性变换不变。
局限性:当表示维度 p ≥ n p \ge n p≥n时,度量无法区分高维表示的差异。许多神经网络(尤其是卷积网络)的层神经元数量远超训练数据点数量(如Springenberg et al., 2015);此外,神经网络训练对输入或激活的线性变换敏感。例如,梯度下降首先沿输入协方差矩阵的最大特征值方向收敛(LeCun et al., 1991),批归一化(Ioffe & Szegedy, 2015)也表明尺度信息对训练至关重要。因此,忽略尺度信息的度量(如CCA)会丢失关键信息。
正交变换不变性
定义:若 s ( X , Y ) = s ( X U , Y V ) s(X, Y)=s(XU, YV) s(X,Y)=s(XU,YV),其中 U , V U, V U,V是正交矩阵(满足 U T U = I U^TU=I UTU=I),则度量对正交变换不变。
解决的问题:
(1)正交变换保留欧几里得距离和标量积,适合捕捉表示的几何结构。
(2)当表示维度 p ≥ n p \ge n p≥n时,正交变换不变的度量仍然有效,克服了可逆线性变换不变性的局限。
(3)正交变换不变性包含排列不变性,适应神经网络的对称性(Chen et al., 1993)。
将 X , Y X,Y X,Y进行QR分解,即 X = Q X R X , Y = Q Y R Y X = Q_XR_X, Y=Q_YR_Y X=QXRX,Y=QYRY, Q ∈ R n × p Q \in \mathbb{R}^{n \times p} Q∈Rn×p是列正交矩阵( Q T Q = I Q^TQ=I QTQ=I), R X ∈ R p × p R_X \in \mathbb{R}^{p \times p} RX∈Rp×p是上三角矩阵。
我们可以构造新度量 s ′ ( X , Y ) = s ( Q X , Q Y ) s'(X,Y)=s(Q_X, Q_Y) s′(X,Y)=s(QX,QY),则 s ′ s' s′具有可逆线性变换不变性。
各向同性缩放不变性
定义:若 s ( X , Y ) = s ( α X , β Y ) s(X, Y)=s(\alpha X, \beta Y) s(X,Y)=s(αX,βY),其中 α , β ∈ R + \alpha, \beta \in \mathbb{R}^{+} α,β∈R+,则度量对各向同性缩放不变。
直观理解:各向同性缩放仅改变表示的整体尺度,不影响其相对结构,因此度量应对其不变。
若度量同时对正交变换和非各向同性缩放(即特征维度的独立缩放)不变,则等价于对可逆线性变换不变(由奇异值分解可推导)。因此,论文关注对各向同性缩放不变但对非各向同性缩放敏感的度量。
典型度量满足的性质

中心核对齐(CKA)
核心思想
论文提出与其直接比较两个表示 X ∈ R n × p 1 X \in \mathbb{R}^{n \times p_1} X∈Rn×p1和 Y ∈ R n × p 2 Y \in \mathbb{R}^{n \times p_2} Y∈Rn×p2的特征向量,不如比较它们各自的表示相似性矩阵(RSMs),即样本间的内积矩阵 X X T XX^T XXT和 Y Y T YY^T YYT。这种方法受神经科学的启发(Kriegeskorte et al., 2008a),通过样本间的相似性结构间接比较表示。
数学表示
点积相似性
样本间内积矩阵的元素 ( X X T ) i j (XX^T)_{ij} (XXT)ij表示第 i i i个样本和第 j j j个样本在表示 X X X中的相似性。比较 X X T XX^T XXT和 Y Y T YY^T YYT的相似性等价于比较特征间的内积:
⟨ vec ( X X ⊤ ) , vec ( Y Y ⊤ ) ⟩ = tr ( X X ⊤ Y Y ⊤ ) = ∥ Y ⊤ X ∥ F 2 \left\langle\operatorname{vec}\left(X X^{\top}\right), \operatorname{vec}\left(Y Y^{\top}\right)\right\rangle=\operatorname{tr}\left(X X^{\top} Y Y^{\top}\right)=\left\|Y^{\top} X\right\|_{F}^{2} ⟨vec(XX⊤),vec(YY⊤)⟩=tr(XX⊤YY⊤)= Y⊤X F2
其中 ∣ ∣ ⋅ ∣ ∣ F ||\cdot||_F ∣∣⋅∣∣F是Frobenius范数。
线性回归
R LR 2 = ∥ X ^ − X ∥ F 2 ∥ X ∥ F 2 R_{\text{LR}}^2 = \frac{\|\hat{X} - X\|_F^2}{\|X\|_F^2} RLR2=∥X∥F2∥X^−X∥F2
其中 X ^ \hat{X} X^是 Y Y Y对 X X X的线性拟合。
局限性:不对称,仅衡量单向拟合能力;对正交变换和各向同性缩放不变,但忽略双向相似性。
Hilbert-Schmidt Independence Criterion (HSIC):
HSIC(Gretton et al., 2005)是衡量两个核矩阵 K K K和 L L L相关性的统计量。对于线性核 K = X X T K=XX^T K=XXT和 L = Y Y T L=YY^T L=YYT,HSIC为:
HSIC ( K , L ) = 1 ( n − 1 ) 2 t r ( K H L H ) \text{HSIC}(K,L)=\frac{1}{(n-1)^2}tr(KHLH) HSIC(K,L)=(n−1)21tr(KHLH)
其中 H n = I n − 1 n 1 1 T H_n=I_n - \frac{1}{n}11^T Hn=In−n111T是中心化矩阵。
对中心化的 X X X和 Y Y Y,HSIC等价于跨协方差矩阵的Frobenius范数的平方:
HSIC ( K , L ) = ∥ cov ( X ⊤ , Y ⊤ ) ∥ F 2 \text{HSIC}(K,L)=\left\|\text{cov}(X^{\top}, Y^{\top})\right\|_{F}^{2} HSIC(K,L)= cov(X⊤,Y⊤) F2
典型相关分析(CCA)
R CCA 2 = ∑ i = 1 p 1 ρ i 2 p 1 = ∥ Q Y ⊤ Q X ∥ F 2 p 1 , ρ ~ CCA = ∑ i = 1 p 1 ρ i p 1 = ∥ Q Y ⊤ Q X ∥ ∗ p 1 R_{\text{CCA}}^2 = \frac{\sum_{i=1}^{p_1} \rho_i^2}{p_1} = \frac{\|Q_Y^\top Q_X\|_F^2}{p_1}, \quad \tilde{\rho}_{\text{CCA}} = \frac{\sum_{i=1}^{p_1} \rho_i}{p_1} = \frac{\|Q_Y^\top Q_X\|_*}{p_1} RCCA2=p1∑i=1p1ρi2=p1∥QY⊤QX∥F2,ρ~CCA=p1∑i=1p1ρi=p1∥QY⊤QX∥∗
其中 ρ i \rho_i ρi是典型相关性(canonical correlations), ∥ ⋅ ∥ ∗ \|\cdot\|_* ∥⋅∥∗是核范数。
局限性:对可逆线性变换不变,忽略尺度信息;在高维表示或条件数大时不稳定(Golub & Zha, 1995)。
变体SVCCA通过截断奇异值分解保留固定方差比例的成分(Raghu et al., 2017),仅在保留子空间不变时对可逆线性变换不变,但仍受限于CCA的本质。
变体PWCCA对CCA进行加权,与线性回归密切相关,但不对称且鲁棒性有限。
ρ PW = ∑ i = 1 c α i ρ i ∑ i = 1 c α i , α i = ∑ j ∣ ⟨ h i , x j ⟩ ∣ \rho_{\text{PW}} = \frac{\sum_{i=1}^c \alpha_i \rho_i}{\sum_{i=1}^c \alpha_i}, \quad \alpha_i = \sum_j |\langle \mathbf{h}_i, \mathbf{x}_j \rangle| ρPW=∑i=1cαi∑i=1cαiρi,αi=∑j∣⟨hi,xj⟩∣
CKA的原理和关联
HSIC对各向同性缩放不不变,因此通过归一化得到CKA:
CKA ( K , L ) = HSIC ( K , L ) HSIC ( K , K ) HSIC ( L , L ) \text{CKA}(K, L) = \frac{\text{HSIC}(K, L)}{\sqrt{\text{HSIC}(K,K)\text{HSIC}(L, L)}} CKA(K,L)=HSIC(K,K)HSIC(L,L)HSIC(K,L)
CKA的值在 [ 0 , 1 ] [0,1] [0,1]内,1表示完全相似,0表示完全不相似。
对于线性核,CKA等价于:
CKA ( X X ⊤ , Y Y ⊤ ) = ∥ Y ⊤ X ∥ F 2 ∥ X ⊤ X ∥ F ∥ Y ⊤ Y ∥ F \text{CKA}(XX^\top, YY^\top) = \frac{\|Y^\top X\|_F^2}{\|X^\top X\|_F \|Y^\top Y\|_F} CKA(XX⊤,YY⊤)=∥X⊤X∥F∥Y⊤Y∥F∥Y⊤X∥F2
当 X X X与 Y Y Y中心化时,CKA与CCA有以下关系:
R CCA 2 = CKA ( Q X Q X ⊤ , Q Y Q Y ⊤ ) p 2 p 1 R_{\text{CCA}}^2 = \text{CKA}(Q_X Q_X^\top, Q_Y Q_Y^\top) \sqrt{\frac{p_2}{p_1}} RCCA2=CKA(QXQX⊤,QYQY⊤)p1p2
CKA通过特征值加权(反映方差贡献)改进了CCA,强调重要子空间的作用。
线性回归 R L R 2 R^2_{LR} RLR2与CKA的关系为:
R LR 2 = CKA ( X X ⊤ , Q Y Q Y ⊤ ) p 1 ∥ X ⊤ X ∥ F ∥ X ∥ F 2 R_{\text{LR}}^2 = \text{CKA}(XX^\top, Q_Y Q_Y^\top) \frac{\sqrt{p_1} \|X^\top X\|_F}{\|X\|_F^2} RLR2=CKA(XX⊤,QYQY⊤)∥X∥F2p1∥X⊤X∥F
CKA对称地处理两个表示,而线性回归是不对称的。
CKA的优越性有:
(1)对称性:平等对待两个表示。
(2)加权机制:通过特征值加权,强调重要子空间。
(3)灵活性:支持线性核和非线性核(如RBF核),适应不同表示结构。
(4)鲁棒性:在高维表示和数据点不足时仍有效。
(5)实践:实验证明,CKA能可靠识别不同初始化、不同架构和不同数据集下网络层的对应关系,准确率接近99%。
相关文章:
【论文阅读笔记】模型的相似性
文章目录 The Platonic Representation Hypothesis概述表征收敛的依据表征收敛的原因实验依据未来发展的局限性 Similarity of Neural Network Representations Revisited概述问题背景相似性度量s的性质可逆线性变换不变性正交变换不变性各向同性缩放不变性典型度量满足的性质 …...
扣子智能体1:创建Agent与写好提示词
文章目录 Agent是什么使用扣子创建智能体写好提示词生成故事发布Agent 最近学了很久多agent协同、编排工作流等与agent有关的内容,这里用一系列博客,把这些操作都一步一个脚印的记录下来。 这里我们以一个Agent为例:睡前灵异小故事 Agent是…...
Spring源码中关于抽象方法且是个空实现这样设计的思考
Spring源码抽象方法且空实现设计思想 在Spring源码中onRefresh()就是一个抽象方法且空实现,而refreshBeanFactory()方法就是一个抽象方法。 那么Spring源码中onRefresh方法定义了一个抽象方法且是个空实现,为什么这样设置,好处是什么。为…...
基本语法)
正则表达式(Regular Expressions)基本语法
无论前端还是后端开发过程中都不可避免的会使用到正则表达式,在对于程序的优化中,也起到了很重要的作用,可以减少非必要的接口和网络交互,减少服务器压力。 正则表达式(Regular Expressions,简称 regex 或 regexp)是一种强大的文本处理工具,用于匹配字符串中的特定模式…...

提示词设计:动态提示词 标准提示词
提示词设计:动态提示词 标准提示词 研究背景:随着人工智能与司法结合的推进以及裁判文书公开数量增多,司法摘要任务愈发重要。传统司法摘要方法生成质量有待提升,大语言模型虽有优势,但处理裁判文书时存在摘要结构信息缺失、与原文不一致等问题。研究方法 DPCM方法:分为大…...
【Bluedroid】蓝牙 HID 设备信息加载与注册机制及配置缓存系统源码解析
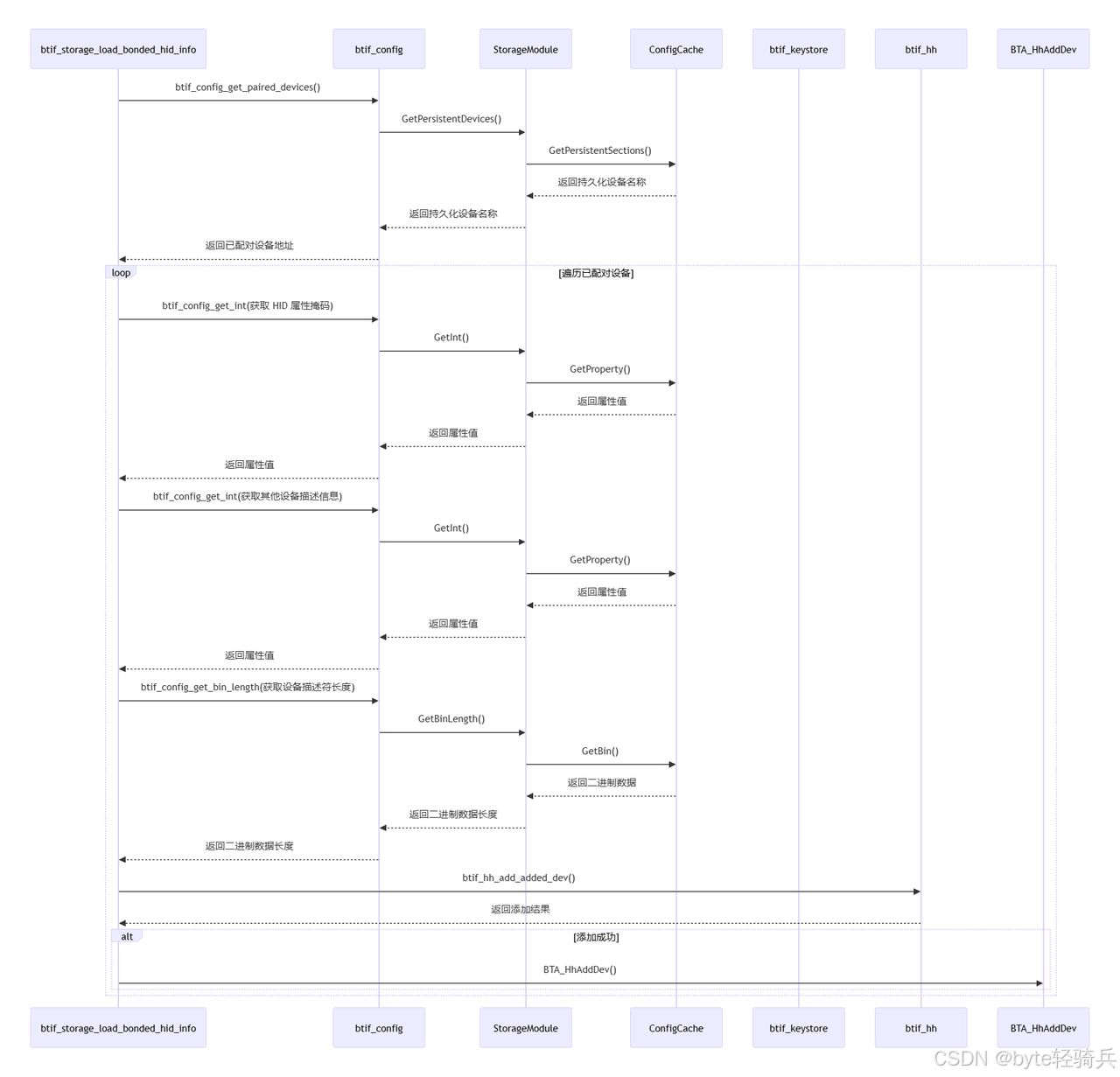
本篇解析Android蓝牙子系统加载配对HID设备的核心流程,通过btif_storage_load_bonded_hid_info实现从NVRAM读取设备属性、验证绑定状态、构造描述符并注册到BTA_HH模块。重点剖析基于ConfigCache的三层存储架构(全局配置/持久设备/临时设备)&…...

字节头条golang二面
docker和云服务的区别 首先明确Docker的核心功能是容器化,它通过容器技术将应用程序及其依赖项打包在一起,确保应用在不同环境中能够一致地运行。而云服务则是由第三方提供商通过互联网提供的计算资源,例如计算能力、存储、数据库等。云服务…...
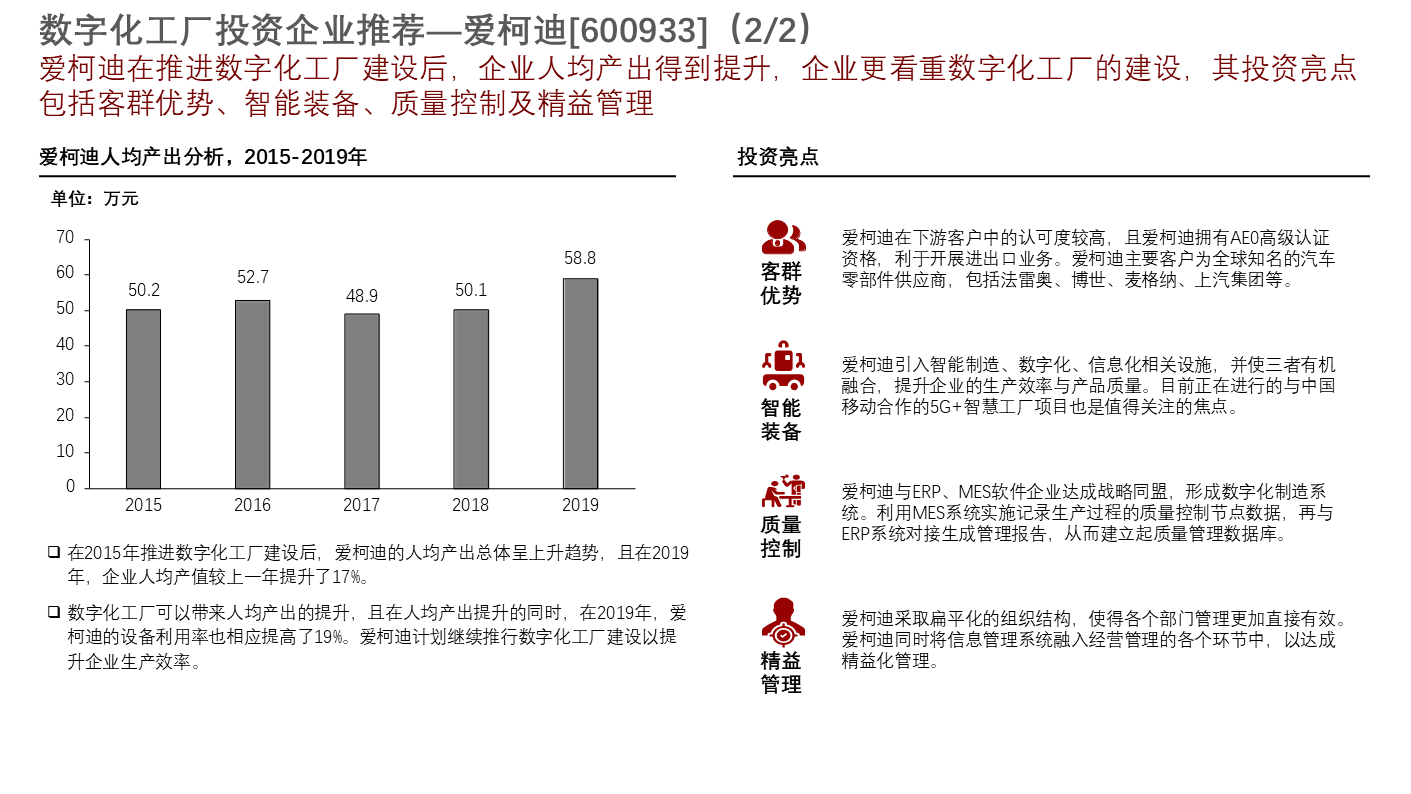
数字化工厂五大核心系统(PLM 、ERP、WMS 、DCS、MOM)详解
该文档聚焦数字化工厂的五大核心系统,适合制造业企业管理者、信息化建设负责人、行业研究人员以及对数字化转型感兴趣的人士阅读。 文档先阐述数字化工厂的定义,广义上指企业运用数字技术实现产品全生命周期数字化,提升经营效益&…...
n8n 中文系列教程_02. 自动化平台深度解析:核心优势与场景适配指南
在低代码与AI技术深度融合的今天,n8n作为开源自动化平台正成为开发者提效的新利器。本文深度剖析其四大核心技术优势——极简部署、服务集成、AI工作流与混合开发模式,并基于真实场景测试数据,厘清其在C端高并发、多媒体处理等场景的边界。 一…...

MCP认证难题破解
一、MCP 认证体系现状与核心挑战 微软认证专家(MCP)体系在 2020 年后逐步向基于角色的认证转型,例如 Azure 管理员(AZ-104)、数据分析师(DP-100)等,传统 MCP 考试已被取代。当前备考的核心难题集中在以下方面: 1. 技术栈快速迭代 云原生技术占比提升:Azure 认证中,…...
)
【滑动窗口】串联所有单词的⼦串(hard)
串联所有单词的⼦串(hard) 题⽬描述:解法⼀(暴⼒解法):算法思路:C 算法代码:Java 算法代码: 题⽬链接:30. 串联所有单词的⼦串 题⽬描述: 给定⼀…...

SQL注入之information_schema表
1 information_schema表介绍: information_schema表是一个MySQL的系统数据库,他里面包含了所有数据库的表名 SQL注入中最常见利用的系统数据库,经常利用系统数据库配合union联合查询来获取数据库相关信息,因为系统数据库中所有信…...

高级java每日一道面试题-2025年4月13日-微服务篇[Nacos篇]-Nacos如何处理网络分区情况下的服务可用性问题?
如果有遗漏,评论区告诉我进行补充 面试官: Nacos如何处理网络分区情况下的服务可用性问题? 我回答: 在讨论 Nacos 如何处理网络分区情况下的服务可用性问题时,我们需要深入理解 CAP 理论以及 Nacos 在这方面的设计选择。Nacos 允许用户根据具体的应用…...
Elasticsearch:使用 ES|QL 进行搜索和过滤
本教程展示了 ES|QL 语法的示例。请参考 Query DSL 版本,以获得等效的 Query DSL 语法示例。 这是一个使用 ES|QL 进行全文搜索和语义搜索基础知识的实践介绍。 有关 ES|QL 中所有搜索功能的概述,请参考《使用 ES|QL 进行搜索》。 在这个场景中&#x…...

R语言之.rdata文件保存及加载
在 R 中,.rdata 文件是通过 save() 函数创建的。 使用 save() 函数可以将一个或多个 R 对象保存到 .rdata 文件中。使用 load() 函数可以将 .rdata 文件中的对象恢复到当前工作环境中。 1.创建并保存对象到.rdata 假设有一个基于 iris 数据集训练的线性回归模型&a…...
)
二进制和docker两种方式部署Apache pulsar(standalone)
#作者:闫乾苓 文章目录 1、二进制安装部署Pulsar(standalone)1.1 安装配置JDK1.2 下载解压pulsar安装包1.3 启动独立模式的Pulsar 集群1.4 创建主题测试1.5 向主题写入消息测试1.6 从主题中读取消息测试 2.docker安装部署Pulsar(standalone)2.1 使用docker 启动Pul…...
MySQL表与表之间的左连接和内连接
前言: 在上个实习生做的模块之中,在列表接口,涉及到多个表的联表查询的时候总会出现多条不匹配数据的奇怪的bug,我在后期维护的时候发现了,原来是这位实习生对MySQL的左连接和内连接不能正确的区分而导致的这种的情况。 表设置 …...

RAG知识库中引入MCP
MCP(Memory, Context, Planning)是一种增强AI系统认知能力的框架。将MCP引入RAG知识库可以显著提升系统的性能和用户体验。下面我将详细介绍如何实现这一整合。 MCP框架概述 MCP框架包含三个核心组件: Memory(记忆):存储和管理历史交互和知识Context(上下文):理解当…...
)
TDengine 性能监控与调优实战指南(二)
四、TDengine 性能调优实战 4.1 硬件层面优化 硬件是 TDengine 运行的基础,其性能直接影响着 TDengine 的整体表现。在硬件层面进行优化,就如同为高楼大厦打下坚实的地基,能够为 TDengine 的高效运行提供有力支持。 CPU:CPU 作…...

低代码开发平台:企业数字化转型的加速器
一、引言 在数字化时代,企业的转型需求日益迫切。为了在激烈的市场竞争中保持领先地位,企业需要快速响应市场变化、优化业务流程、提升运营效率。然而,传统的软件开发模式往往面临开发周期长、成本高、灵活性差等问题,难以满足企业…...

【AI图像创作变现】02工具推荐与差异化对比
引言 市面上的AI绘图工具层出不穷,但每款工具都有自己的“性格”:有的美学惊艳但无法微调,有的自由度极高却需要动手配置,还有的完全零门槛适合小白直接上手。本节将用统一格式拆解五类主流工具,帮助你根据风格、控制…...
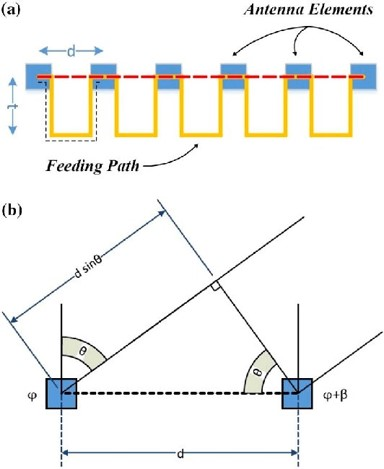
相控阵列天线:原理、优势和类型
本文要点 相控阵列天线 (Phased array antenna) 是一种具有电子转向功能的天线阵列,不需要天线进行任何物理移动,即可改变辐射讯号的方向和形状。 这种电子转向要归功于阵列中每个天线的辐射信号之间的相位差。 相控阵列天线的基…...

【HD-RK3576-PI】Ubuntu桌面多显、旋转以及更新Logo
硬件:HD-RK3576-PI 软件:Linux6.1Ubuntu22.04 在基于HD-RK3576-PI硬件平台运行Ubuntu 22系统的开发过程中,屏幕方向调整是提升人机交互体验的关键环节。然而,由于涉及uboot引导阶段、内核启动界面、桌面环境显示全流程适配&#x…...

树莓派超全系列教程文档--(36)树莓派条件过滤器设置
树莓派条件过滤器设置 条件过滤器[all] 过滤器型号过滤器[none] 过滤器[tryboot] 过滤器[EDID*] 过滤器序列号过滤器GPIO过滤器组合条件过滤器 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 条件过滤器 当将单个 SD 卡(或卡图像&am…...

【Rust 精进之路之第3篇-变量观】`let`, `mut` 与 Shadowing:理解 Rust 的变量绑定哲学
系列: Rust 精进之路:构建可靠、高效软件的底层逻辑 作者: 码觉客 发布日期: 2025-04-20 引言:为数据命名,Rust 的第一道“安全阀” 在上一篇文章中,我们成功搭建了 Rust 开发环境,并用 Cargo 运行了第一个程序,迈出了坚实的一步。现在,是时候深入了解构成程序的基…...

wordpress独立站的产品详情页添加WhatsApp链接按钮
在WordPress外贸独立站的产品展示页添加WhatsApp链接按钮,可以帮助客户更方便地与你联系。以下是实现这一功能的步骤: 方法一:使用HTML代码添加按钮 编辑产品展示页 进入WordPress后台,找到需要添加WhatsApp按钮的产品展示页。…...
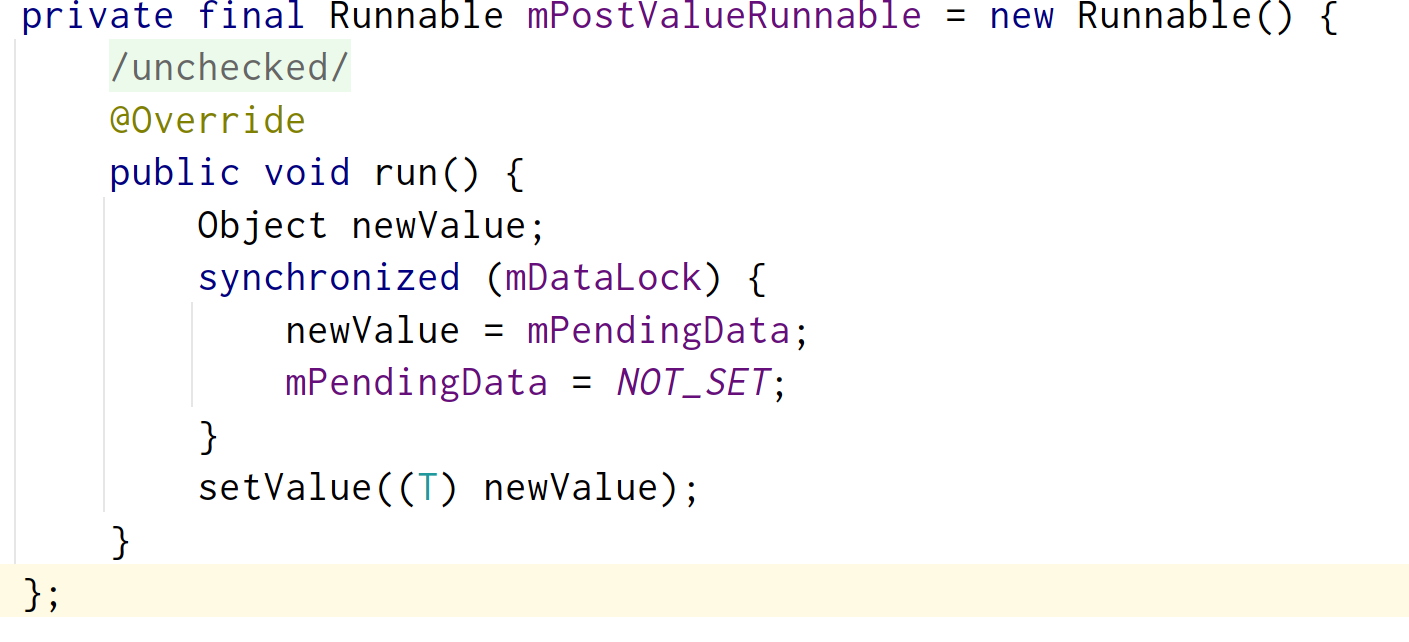
jetpack之LiveData的原理解析
前言 在一通研究下,我打算LiveData的解析通过从使用的方法上面切入进行LiveData的工作原理分析😋。感觉这样子更能让大家伙理解明白,LiveData的实现和Lifecycle分不开,并且还得需要知道LiveData的使用会用到什么样的方法。所以&a…...

Viper配置管理笔记
一、什么是 Viper? Viper 是 Go 语言的一个强大工具,就像一个超级管家,专门负责帮你打理程序的各种配置。它能把配置文件(比如 JSON、YAML、TOML 等格式)里的内容读出来,还能监控配置文件的变化࿰…...

go+mysql+cocos实现游戏搭建
盲目的学了一段时间了,刚开始从Box2d开始学习,明白了很多,Box2d是物理模型的基础,是我们在游戏中模拟现实的很重要的一个开源工具。后来在朋友的建议下学习了cocos,也是小程序开发的利器,而golang是一款高效…...
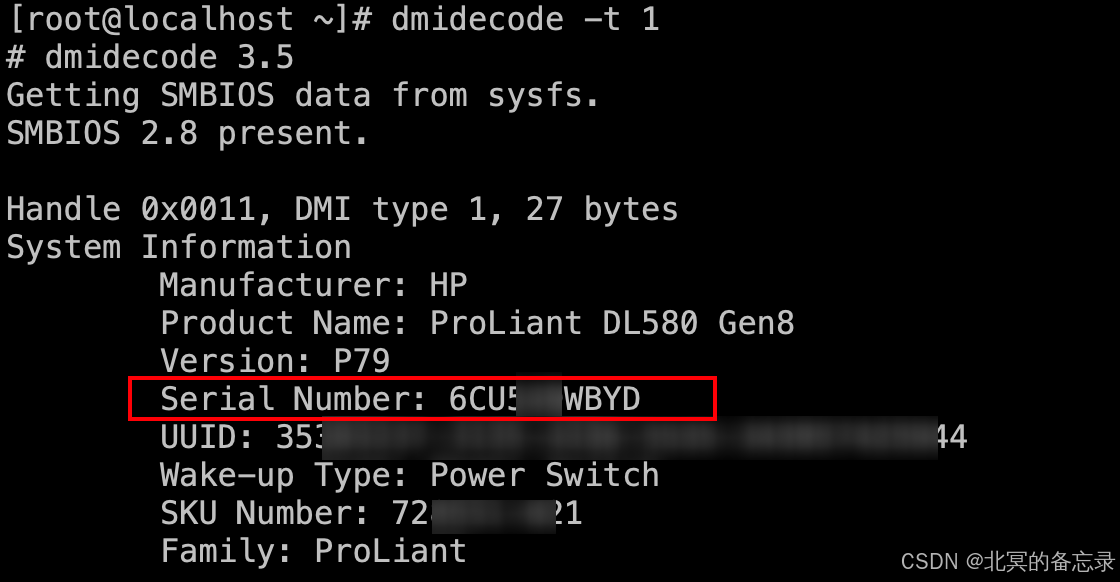
【微知】服务器如何获取服务器的SN序列号信息?(dmidecode -t 1)
文章目录 背景命令dmidecode -t的数字代表的字段 背景 各种场景都需要获取服务器的SN(Serial Number),比如问题定位,文件命名,该部分信息在dmi中是标准信息,不同服务器,不同os都能用相同方式获…...