python-将文本生成音频
将文本生成音频通常需要结合 文本转语音(TTS,Text-to-Speech) 工具或库来实现,比如 Google TTS (gtts)、Amazon Polly、Microsoft Azure TTS 等。
一、使用 Google TTS (gtts) 将文本生成音频
gtts 是一个简单易用的 Python 库,它使用 Google Translate 的 TTS API,将文本转化为音频。
安装gtts:
pip install gtts
将文本转换为音频文件
以下是使用 gtts 将一段文本保存为音频文件的代码:
from gtts import gTTS
# 定义文本和语言
text = "你好,欢迎使用文本转语音功能。这是一个示例。"
language = "zh" # 中文
# 转换文本为音频
tts = gTTS(text=text, lang=language)
tts.save("text_to_audio.mp3") # 保存为音频文件
print("音频文件已保存为 text_to_audio.mp3")
二、使用 pyttsx3 来支持离线 TTS
如果需要离线处理文本转语音,可以使用 pyttsx3 库,它支持多种 TTS 引擎。
安装 pyttsx3
pip install pyttsx3
使用 pyttsx3 转换文本
以下是示例代码:
import pyttsx3
# 初始化 TTS 引擎
engine = pyttsx3.init()
# 设置语音属性
engine.setProperty('rate', 130) # 语速
engine.setProperty('volume', 1.0) # 音量
# 定义文本内容
text = "这是一个离线文本转语音的示例,我们使用 pyttsx3 来完成。"
engine.save_to_file(text, "offline_text_to_audio.wav") # 保存音频文件
# 执行生成语音
engine.runAndWait()
print("离线音频文件已保存为 offline_text_to_audio.wav")
pyttsx3与gtts 库的介绍
1、pyttsx3 是一个 Python 库,用来实现 文本转语音(TTS, Text-to-Speech) 的功能,支持多种不同的 TTS 引擎,可以离线运行,且操作简单易用。它可以用来生成音频文件或直接播放语音。以下是 pyttsx3 的常用使用方式和操作技巧。
- 安装 pyttsx3
在使用 pyttsx3 之前,需要安装它。可以通过以下命令安装:
pip install pyttsx3
- 常用用法
(1) 基本文本转语音
pyttsx3 默认会使用操作系统支持的语音引擎来播放语音,以下是最简单的使用方式:
import pyttsx3# 初始化 TTS 引擎
engine = pyttsx3.init()
# 输入需要转化的文本
text = "这是一个简单的文本转语音示例。谢谢使用 pyttsx3 库!"
# 使用说话功能
engine.say(text) # 通过 TTS 播放音频
# 执行语音合成任务
engine.runAndWait() # 等待语音播放完成
运行这段代码后,会直接播放一段语音。
(2) 保存语音到文件
如果需要将语音保存到音频文件(如 .wav),可以使用 save_to_file() 方法:
import pyttsx3
# 初始化 TTS 引擎
engine = pyttsx3.init()
# 输入需要转化的文本
text = "这是保存语音到文件的示例,请注意文件格式是 .wav。"
# 保存语音到文件
engine.save_to_file(text, 'output.wav') # 保存为 .wav 文件
# 执行语音合成任务
engine.runAndWait()
print("语音文件已保存为 output.wav")
(3) 设置语音属性
pyttsx3 允许设置语速、音量和语音类型(如男性或女性声音)等属性。
设置语速
默认语速可能较快,可以通过 setProperty(‘rate’, value) 来调整速度:
import pyttsx3
engine = pyttsx3.init()
# 设置语速,默认值约为 200,值越小语速越慢
engine.setProperty('rate', 150)
engine.say("语速已调慢,这是调整后的语速示例。")
engine.runAndWait()
设置音量
音量值范围为 0.0 到 1.0,可以通过 setProperty(‘volume’, value) 来设置:
engine = pyttsx3.init()
# 设置音量,范围在 0.0 至 1.0
engine.setProperty('volume', 0.8)
engine.say("这是设置音量的示例,现在的音量是 80%。")
engine.runAndWait()
设置语音类型(男性或女性)
通过获取 voices 属性来选择不同的语音(男性或者女性):
voices = engine.getProperty('voices')
# 设置为男性声音
engine.setProperty('voice', voices[0].id) # 声音库第一个索引通常为男性
engine.say("这是男性语音的示例。")
# 设置为女性声音
engine.setProperty('voice', voices[1].id) # 声音库第二个索引通常为女性
engine.say("这是女性语音的示例。")
engine.runAndWait()
(4) 获取引擎属性
可以通过 pyttsx3 的属性查询功能,获取当前语音引擎的状态:
print("当前语速:", engine.getProperty('rate'))
print("当前音量:", engine.getProperty('volume'))
voices = engine.getProperty('voices')
print("支持的语音类型:")
for i, voice in enumerate(voices):print(f"{i}: {voice.name}")
这段代码会输出当前语速、音量以及所有支持的语音类型。例如:
当前语速: 200
当前音量: 1.0
支持的语音类型:
0: Microsoft David Desktop - English (United States)
1: Microsoft Zira Desktop - English (United States)
可以选择合适的语音类型进行设置。
(5) 多段文本连续播放
如果需要播放多段文本,可以将多个 engine.say() 放在一起,让它依次播放:
engine.say("第一个文本")
engine.say("第二个文本")
engine.say("第三个文本")
engine.runAndWait() # 按顺序播放所有文本
- 异常处理
(1) 引擎初始化失败问题
如果 .init() 方法报错,可能是语音引擎未正确安装,可以尝试:
确保你的操作系统支持TTS引擎(例如 Windows 内置的语音支持)。
在 Linux 上可以安装 espeak 作为语音引擎:
sudo apt-get install espeak
pip install pyttsx3
(2) 输出不支持指定格式
默认保存文件格式为 .wav,如果需要保存为其他格式(如 .mp3),需要额外工具(如 ffmpeg)来转化。
4. 使用场景
pyttsx3 可以应用于以下场景:
文本播报:自动朗读文章、通知等。
生成语音文件:可以批量生成语音,从而服务于语料生成场景。
多语言支持:虽然库本身支持多语言,但不同系统配置可能限制语言类型(例如中文播报需要配置相应的 TTS 引擎)。
离线语音处理:不依赖在线 API,适合高安全性需求的场景。
5. 注意事项
pyttsx3 是离线语音库,因此适合简单的场景,如果需要更自然的语音,建议尝试在线 TTS 服务(例如 Google Cloud Text-to-Speech、Amazon Polly 等)。
在多语言场景下:
如果系统设置的语音引擎不支持某些语言,可能需要安装其他引擎。
可以尝试切换语音类型,或者改用支持更广泛语言的工具(如 gTTS)。
通过pyttsx3 可以快速实现离线文本转语音,具有高度的灵活性。你可以根据实际需求调整语速、音量和语音类型,同时能够将语音保存到文件中以供后续使用。如果有进一步的定制需求,可以结合其他音频处理工具(如 ffmpeg)完成一些高级效果。
gtts (Google Text-to-Speech) 是一个 Python 库,它调用 Google Translate 的 TTS API,将输入文本转换为语音,并生成 .mp3 文件或直接播放音频。它简单易用,且支持多种语言,非常适合轻量级的文本到语音转换需求。
以下是 gtts 的常用使用方式及详细说明
- 安装 gtts
可以通过 pip 安装 gtts:
pip install gtts
- 常用用法
(1) 将文本转换为语音并保存为文件
这段代码演示了如何将一段文本转换为语音并保存为 .mp3 文件:
from gtts import gTTS
# 定义文本内容
text = "你好,欢迎使用 gtts 进行文本转语音。希望你喜欢这个示例!"
# 定义语言(中文为 "zh")
language = "zh"
# 创建 TTS 对象
tts = gTTS(text=text, lang=language)
# 保存为 MP3 文件
tts.save("output.mp3")
print("语音已保存为 output.mp3 文件")
运行后,音频文件 output.mp3 会保存到当前目录。
(2) 播放生成的语音
可以直接播放生成的语音。如果使用其他库(比如 playsound)播放 gtts 生成的音频:
from gtts import gTTS
from playsound import playsound # 安装 playsound:pip install playsound
# 定义文本内容
text = "你好,这是一个直接播放音频的示例。"
# 定义语言(中文为 "zh")
language = "zh"
# 创建 TTS 对象
tts = gTTS(text=text, lang=language)
# 保存为临时的 MP3 文件
tts.save("temp_audio.mp3")
# 播放 MP3 文件
playsound("temp_audio.mp3")
在运行后,语音文件会直接播放。
- 高级使用
(1) 支持不同语言
gtts 支持 Google Translate 提供的多种语言。以下是切换不同语言的示例:
from gtts import gTTStext_en = "Welcome to use gtts. This is an English example." # 英文文本
text_fr = "Bonjour, ceci est un exemple en français." # 法文文本
# 分别定义语言
language_en = "en" # 英文
language_fr = "fr" # 法文
# 转换文本为语音
tts_en = gTTS(text=text_en, lang=language_en)
tts_fr = gTTS(text=text_fr, lang=language_fr)
# 保存音频
tts_en.save("english.mp3")
tts_fr.save("french.mp3")
print("英语和法语语音文件已保存")
(2) 拼接多个文本段生成语音
如果需要为多个段落生成一个音频,可以拼接文本并统一转换语音:
from gtts import gTTS# 多段文本
text1 = "这是第一段文字。"
text2 = "这是第二段文字,我将它们合并生成语音。"# 拼接文本
final_text = text1 + " " + text2
# 定义语言
language = "zh"
# 转换为语音
tts = gTTS(text=final_text, lang=language)
tts.save("merged_audio.mp3")
print("拼接文本的语音文件已保存为 merged_audio.mp3")
(3) 更改声音的速度
gtts 本身不支持直接调整语速,但可以使用 ffmpeg 或其他工具对生成的音频文件进行后处理以降低或提高速度。
降低语速:
ffmpeg -i output.mp3 -filter:a "atempo=0.8" slower_output.mp3
提高语速:
ffmpeg -i output.mp3 -filter:a "atempo=1.5" faster_output.mp3
(4) 从文件读取文本并生成语音
有时需要从文本文件中读取内容,将其转化成语音:
from gtts import gTTS
# 从文件中读取文本
with open("input.txt", "r", encoding="utf-8") as file:text = file.read()
# 定义语言
language = "zh"
# 转换为语音
tts = gTTS(text=text, lang=language)
tts.save("file_audio.mp3")
print("从文本文件生成的音频已保存为 file_audio.mp3")
(5) 设置 TTS 的慢速模式
gtts 允许使用 slow=True 参数对语音进行慢速设置:
from gtts import gTTS
text = "这是一个慢速语音播放示例。"
language = "zh"
# 将语速设置为慢速
tts = gTTS(text=text, lang=language, slow=True)
tts.save("slow_audio.mp3")
print("慢速语音文件已保存为 slow_audio.mp3")
- 获取支持的语言列表
可以使用 gtts.lang.tts_langs() 来获取所有支持的语言列表:
from gtts.lang import tts_langs
languages = tts_langs()
print("支持的语言列表:")
for lang_code, lang_name in languages.items():print(f"{lang_code}: {lang_name}")
部分输出示例:
en: English
zh: Chinese
fr: French
de: German
es: Spanish
- 常见问题与解决办法
(1) 网络连接问题
gtts 依赖 Google Translate TTS API,需要联网。如果提示 ConnectionError 或 Timeout,请检查网络连接。
(2) 中文语音生成问题
若生成的中文语音无法正常播报:
确保语言代码为 “zh”,即使用简体中文。
检查输入文本是否为有效的 UTF-8 编码。
(3) 播放音频的问题
如果音频保存成功,但无法播放,可以使用 ffmpeg 或其他音频播放器检查音频文件是否损坏。
6. 使用场景扩展
(1) 为应用程序生成提示音
将简短的提示消息转化为语音,用于应用程序的欢迎页面、错误提示等。
(2) 批量生成语音
遍历多个文本文件或文本段,批量生成语音文件。
示例:
texts = ["欢迎使用我们的程序。", "读取完毕,请执行下一步操作。", "已完成处理。"]for i, text in enumerate(texts):tts = gTTS(text=text, lang="zh")tts.save(f"audio_{i+1}.mp3")print("批量语音文件已生成")
(3) 自定义背景音
与 ffmpeg 结合,将语音文件与背景声音混合:
ffmpeg -i text_audio.mp3 -i background_music.mp3 -filter_complex amix=inputs=2:duration=shortest mixed_audio.mp3
相关文章:

python-将文本生成音频
将文本生成音频通常需要结合 文本转语音(TTS,Text-to-Speech) 工具或库来实现,比如 Google TTS (gtts)、Amazon Polly、Microsoft Azure TTS 等。 一、使用 Google TTS (gtts) 将文本生成音频 gtts 是一个简单易用的 Python 库&a…...

[王阳明代数讲义]语言模型核心代码调研
语言模型核心代码调研 基于Consciciteation的才气张量持续思考综述将文本生成建模为才气张量网络扩散过程,实现非自回归推理通过才气张量的群-拓扑流形交叉注意力实现多模态推理,将输入压缩到低维空间持续迭代提出「条件计算提前终止」机制,…...
算了和周日一块写了 4月20日日记)
4月19日记(补)算了和周日一块写了 4月20日日记
周六啊 昨天晚上又玩的太嗨了。睡觉的时候有点晚了,眼睛疼就没写日记。现在补上 实际上现在是20号晚上八点半了。理论上来说应该写今天的日记。 周六上午打比赛啦,和研究生,输了,我是替补没上场。没关系再练一练明天就可以变强…...

trivy开源安全漏洞扫描器——筑梦之路
开源地址:https://github.com/aquasecurity/trivy.git 可扫描的对象 容器镜像文件系统Git存储库(远程)虚拟机镜像Kubernetes 在容器镜像安全方面使用广泛,其他使用相对较少。 能够发现的问题 正在使用的操作系统包和软件依赖项…...
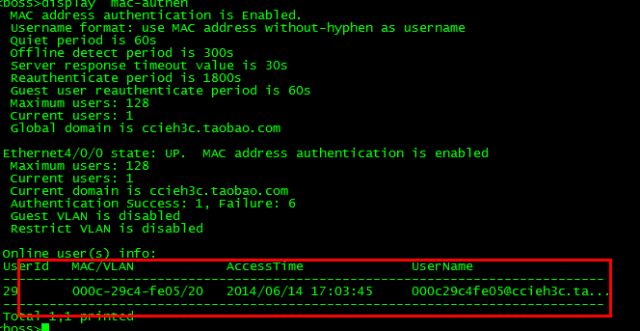
【实战中提升自己】内网安全部署之dot1x部署 本地与集成AD域的主流方式(附带MAC认证)
1 dot1x部署【用户名密码认证,也可以解决私接无线AP等功能】 说明:如果一个网络需要通过用户名认证才能访问内网,而认证失败只能访问外网与服务器,可以部署dot1x功能。它能实现的效果是,当内部用户输入正常的…...
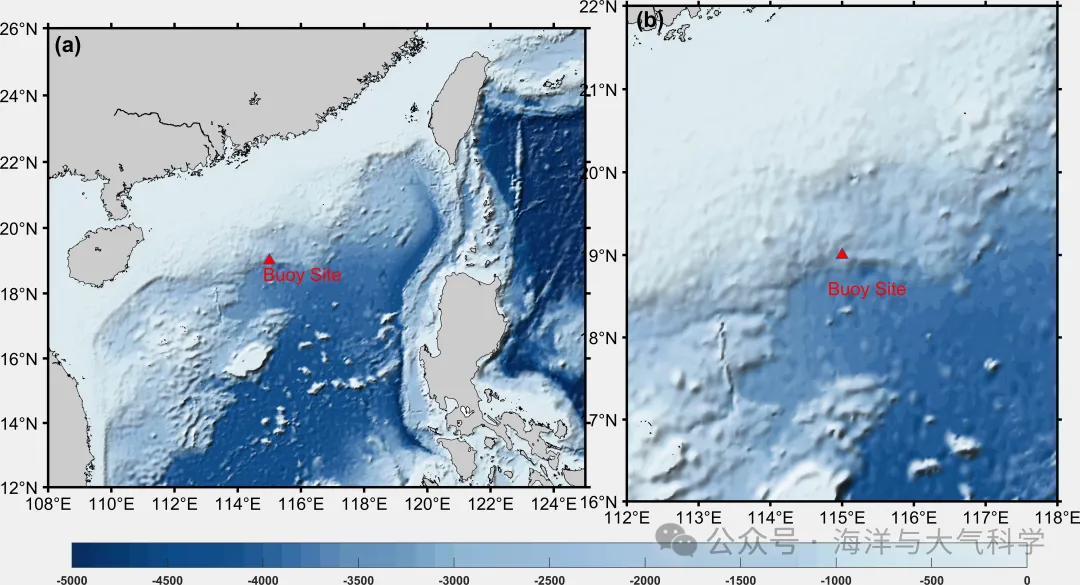
[matlab]南海地形眩晕图代码
[matlab]南海地形眩晕图代码 请ChatGPT帮写个南海地形眩晕图代码 图片 图片 代码 .rtcContent { padding: 30px; } .lineNode {font-size: 12pt; font-family: "Times New Roman", Menlo, Monaco, Consolas, "Courier New", monospace; font-style: n…...
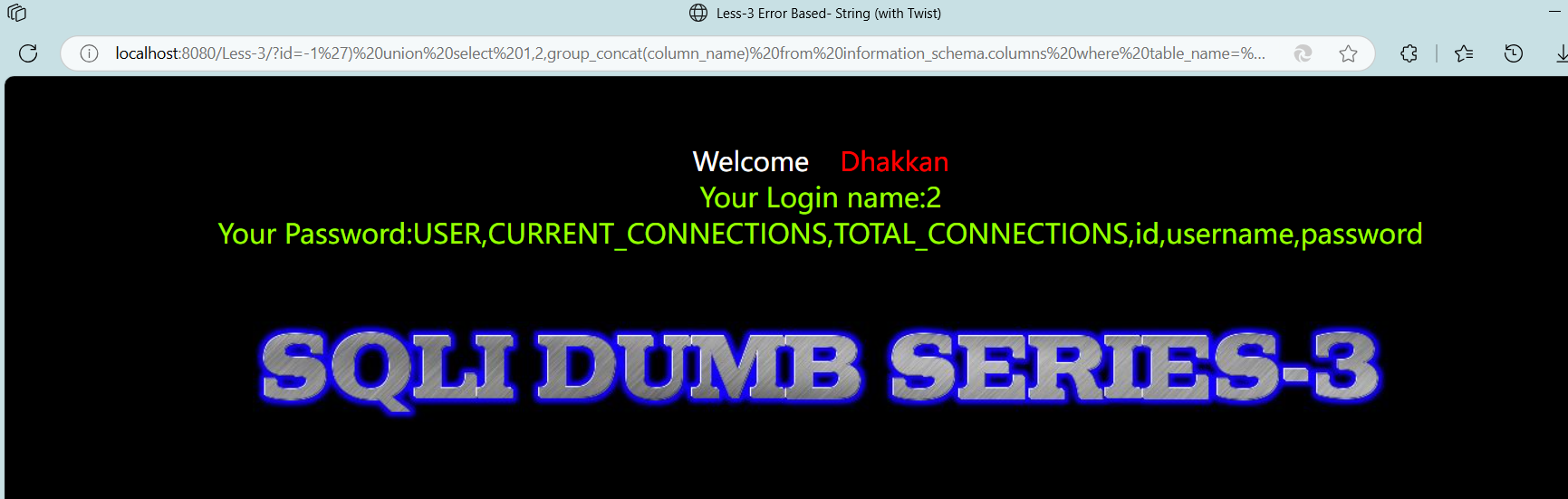
Web安全和渗透测试--day6--sql注入--part 1
场景: win11家庭版,edge浏览器 , sqlin靶场 定义: SQL 注入(SQL Injection)是一种常见的网络安全攻击方式,攻击者通过在 Web 应用程序中输入恶意的 SQL 代码,绕过应用程序的安全机…...
预测及治疗方案制定中的应用研究)
大模型在胆管结石(无胆管炎或胆囊炎)预测及治疗方案制定中的应用研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的 1.3 国内外研究现状 二、胆管结石相关理论基础 2.1 胆管结石概述 2.2 临床表现与诊断方法 2.3 传统治疗方法 三、大模型技术原理与应用优势 3.1 大模型基本原理 3.2 在医疗领域的应用潜力 3.3 用于胆管结石预测的可…...

MIT6.S081-lab4
MIT6.S081-lab4 注:本篇lab的前置知识在《MIT6.S081-lab3前置》 1. RISC-V assembly 第一个问题 Which registers contain arguments to functions? For example, which register holds 13 in main’s call to printf? 我们先来看看main干了什么: …...

精通 Spring Cache + Redis:避坑指南与最佳实践
Spring Cache 以其优雅的注解方式,极大地简化了 Java 应用中缓存逻辑的实现。结合高性能的内存数据库 Redis,我们可以轻松构建出响应迅速、扩展性强的应用程序。然而,在享受便捷的同时,一些常见的“坑”和被忽视的最佳实践可能会悄…...
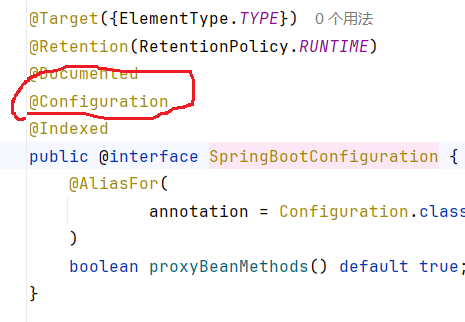
[SpringBoot]快速入门搭建springboot
默认有spring基础,不会一行代码一行代码那么细致地讲。 SpringBoot的作用 Spring Boot是为了简化Spring应用的创建、运行、调试、部署等而出现的。就像我们整个SSM框架时,就常常会碰到版本导致包名对不上、Bean非法参数类型的一系列问题(原出…...
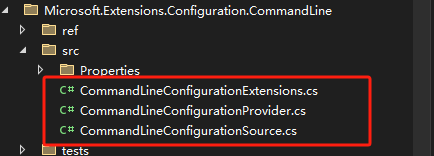
理解.NET Core中的配置Configuration
什么是配置 .NET中的配置,本质上就是key-value键值对,并且key和value都是字符串类型。 在.NET中提供了多种配置提供程序来对不同的配置进行读取、写入、重载等操作,这里我们以为.NET 的源码项目为例,来看下.NET中的配置主要是有…...

C++面试八股文:智能指针
一、了解哪些智能指针? 回答:智能指针是用于管理动态分配的内存,行为类似于指针,但又具有自动管理内存的能力,所以称为智能指针。 首先说一下 auto_ptr和unique_ptr,它们都是独占式指针,同一时…...

nohup命令使用说明
文章目录 如何在后台运行程序呢?如何正常运行代码重定向呢?nohup: ignoring input 如何在后台运行程序呢? 使用nohup命令即可, nohup python dataset/ReferESpatialDataset.py >>dataset_20250417.log 2>&1 &n…...
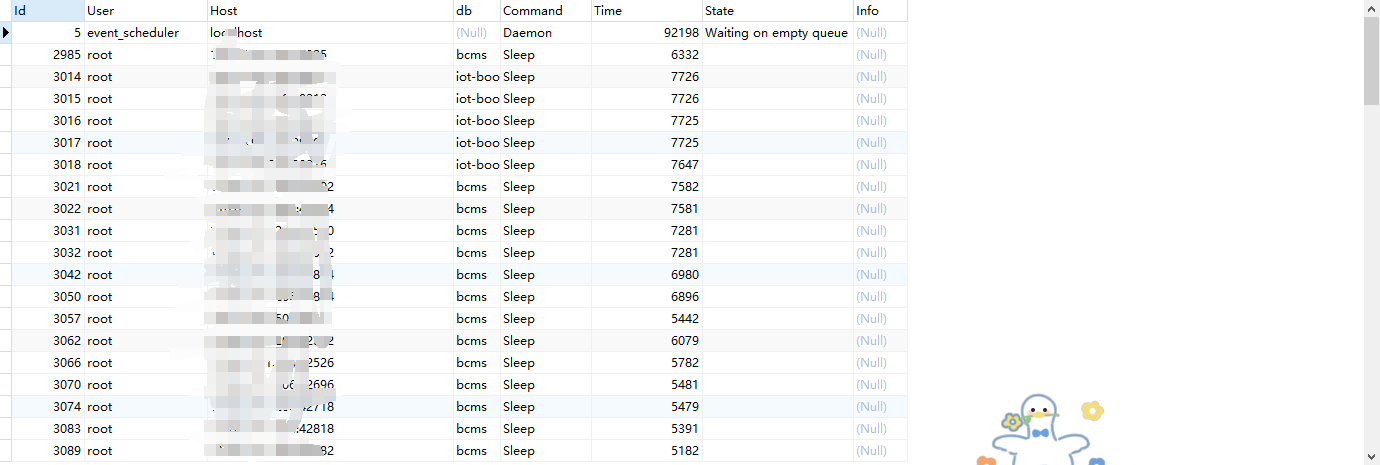
MYSQL “Too Many Connections“ 错误解决
1.查询当前连接数 show status like "Threads_connected"; 2.查询数据库最大连接数 show variables like "max_connections" 3.查询所有活动连接 show processlist; 4.根据查询结果观察是否有长时间未被释放的连接 参数解释 : 字段说明id连接的唯一…...

Linux `init 6` 相关命令的完整使用指南
Linux init 6 相关命令的完整使用指南—目录 一、init 系统简介二、init 6 的含义与作用三、不同 Init 系统下的 init 6 行为1. SysVinit(如 CentOS 6、Debian 7)2. systemd(如 CentOS 7、Ubuntu 16.04)3. Upstart(如 …...
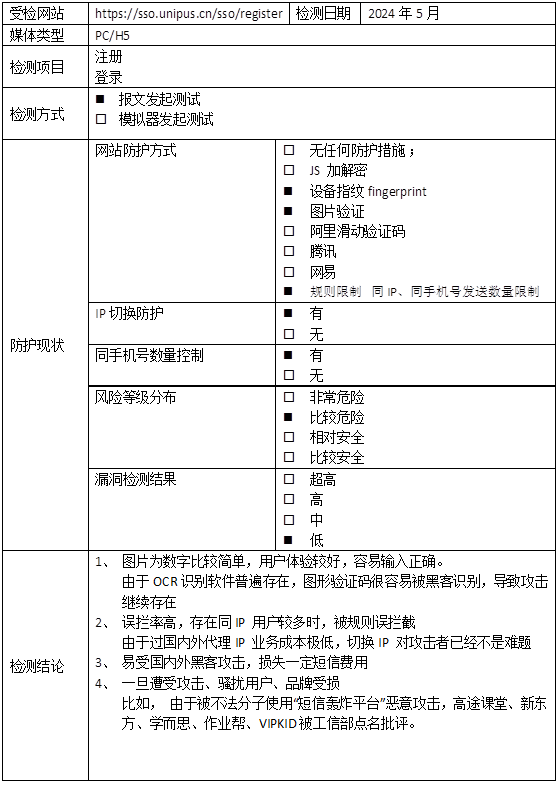
【外研在线-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...
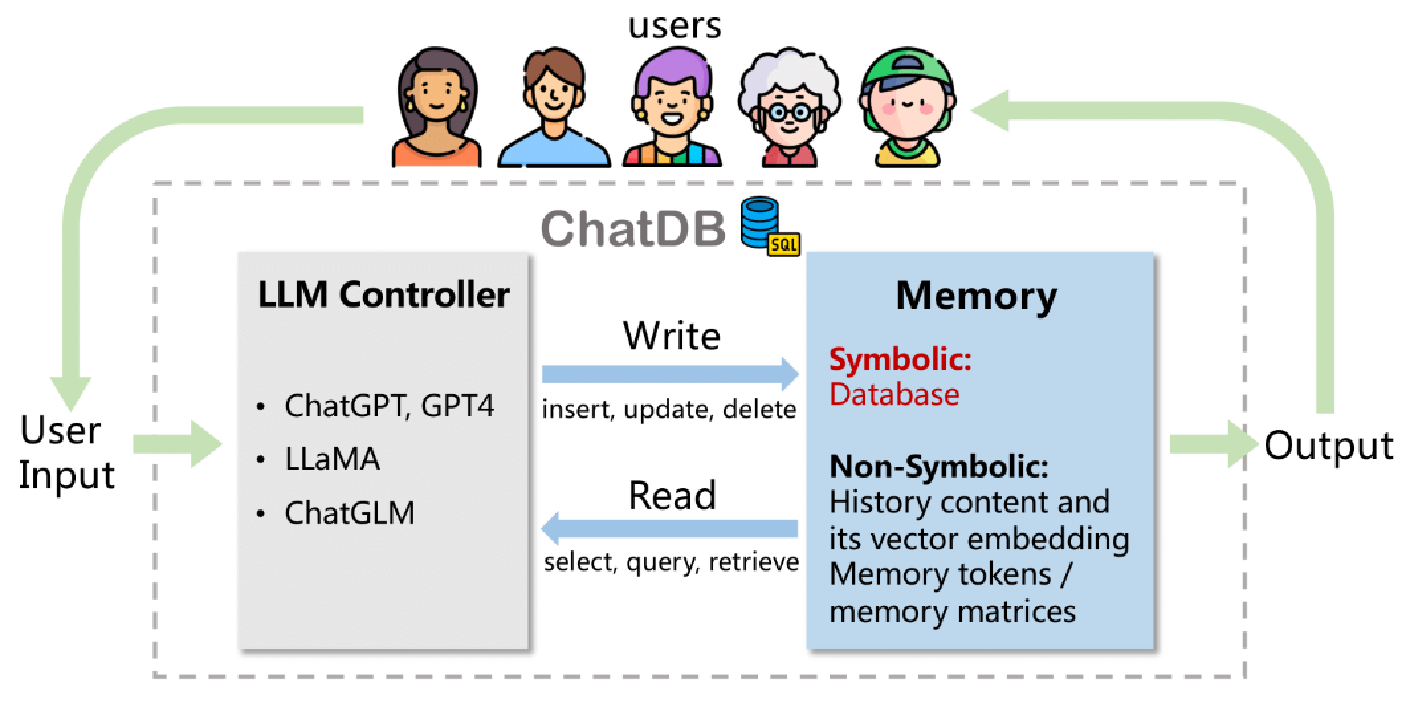
【NLP 63、大模型应用 —— Agent】
人与人最大的差距就是勇气和执行力,也是唯一的差距 —— 25.4.16 一、Agent 相关工作 二、Agent 特点 核心特征: 1.专有场景(针对某个垂直领域) 2.保留记忆(以一个特定顺序做一些特定任务,记忆当前任务的前…...

React 打包
路由懒加载 原本的加载方式 #使用lazy()函数声明的路由页面 使用Suspense组件进行加载 使用CDN优化...
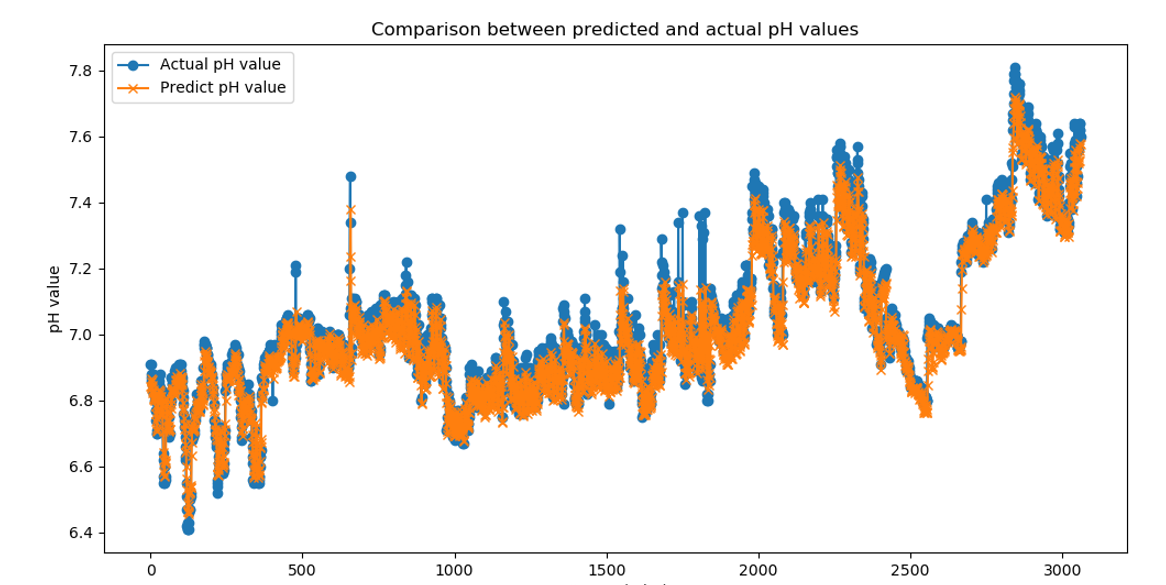
2025.4.14-2025.4.20学习周报
目录 摘要Abstract1. 文献阅读1.1 模型架构1.2 实验分析1.3 代码实践 总结 摘要 在本周阅读的论文中,作者提出了一种名为MGSFformer的空气质量预测模型。模型通过残差去冗余模块可以有效解耦多粒度数据间的信息重叠;时空注意力模块采用并行建模策略&…...

Spring 微服务解决了单体架构的哪些痛点?
1. 部署困难 (Deployment Difficulty & Risk) 单体痛点: 整体部署: 对单体应用的任何微小修改(哪怕只是一行代码),都需要重新构建、测试和部署整个庞大的应用程序。部署频率低: 由于部署过程复杂且风险高,发布周期通常很长&a…...
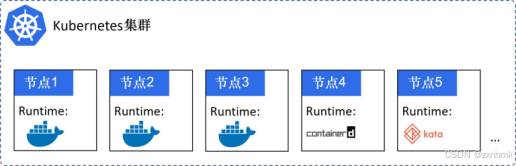
【1】云原生,kubernetes 与 Docker 的关系
Kubernetes?K8s? Kubernetes经常被写作K8s。其中的数字8替代了K和s中的8个字母——这一点倒是方便了发推,也方便了像我这样懒惰的人。 什么是云原生? 云原生: 它是一种构建和运行应用程序的方法,它包含&am…...
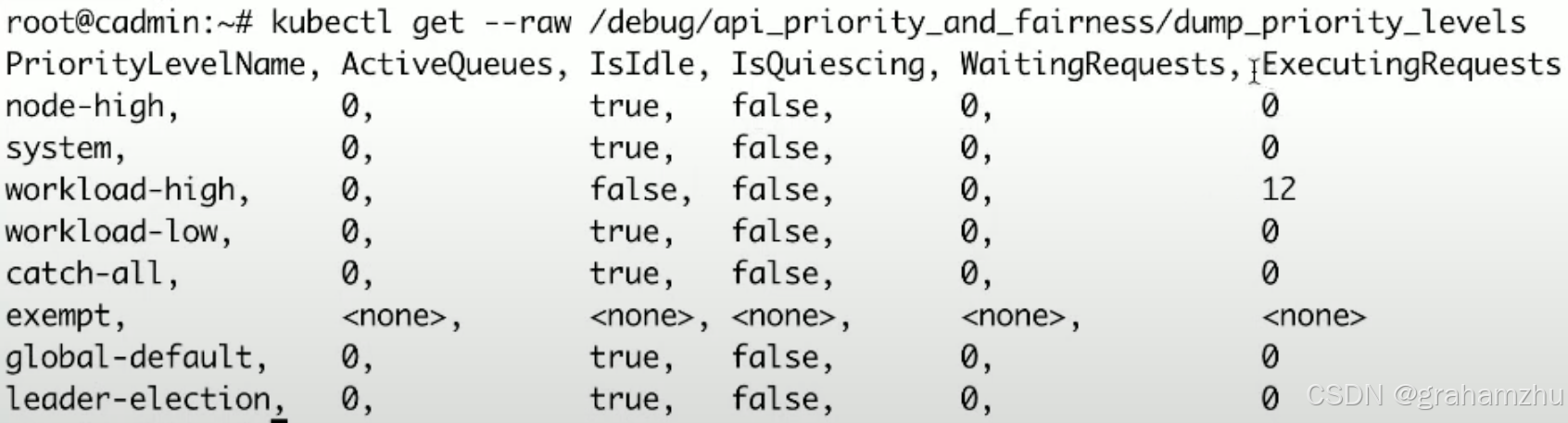
Kubernetes控制平面组件:APIServer 限流机制详解
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

springboot全局异常捕获处理
一、需求 实际项目中,经常抛出各种异常,不能直接抛出异常给前端,这样用户体验相当不好,用户看不懂你的Exception,对于一些sql异常,直接抛到页面上也不安全。所以有没有好的办法解决这些问题呢,当然有了&am…...
: 在windows系统上部署项目1)
Flask(1): 在windows系统上部署项目1
1 前言 学习python也有段时间了,最近一个小项目要部署,正好把过程写下来。 在程序的结构上我选择了w/s模式,相比于c/s模式,无需考虑客户端的升级;框架我选择了flask,就是冲着轻量级去的,就是插件…...
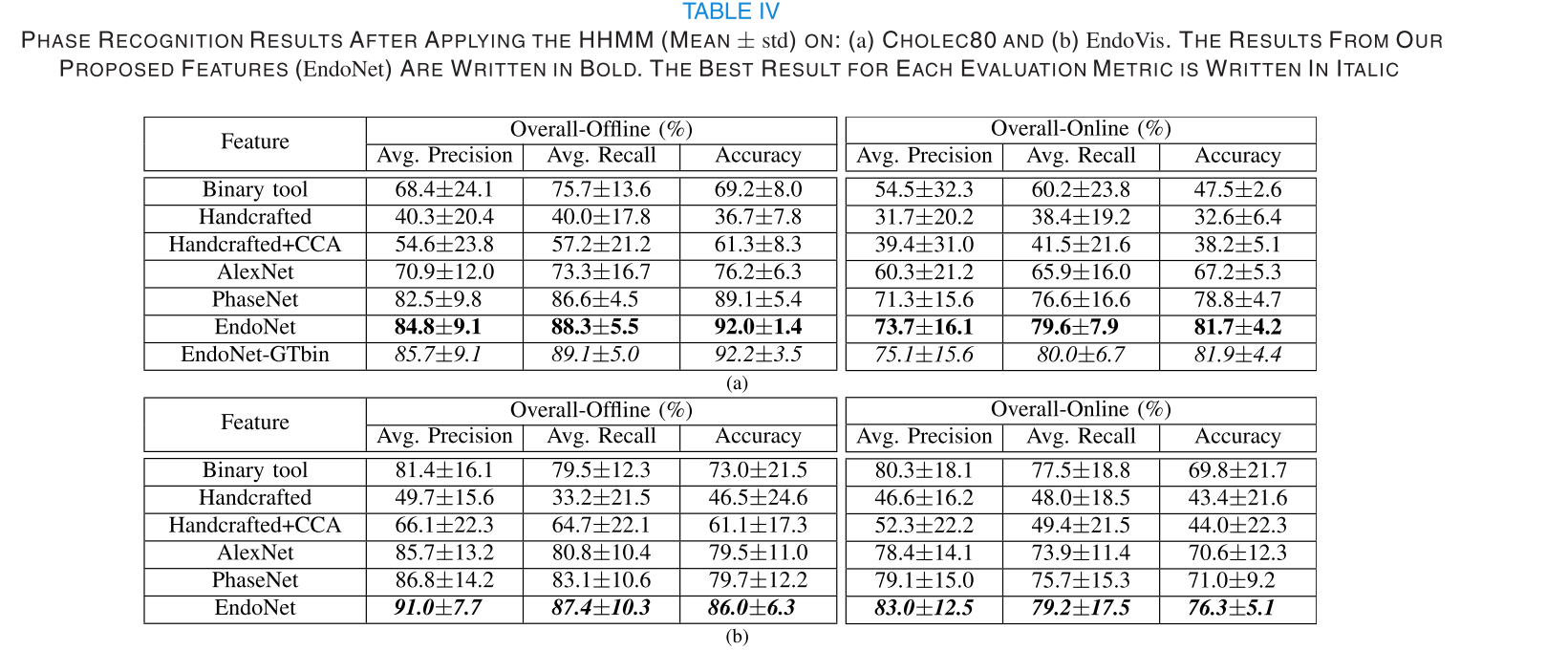
【文献阅读】EndoNet A Deep Architecture for Recognition Tasks on Laparoscopic Videos
关于数据集的整理 Cholec80 胆囊切除手术视频数据集介绍 https://zhuanlan.zhihu.com/p/700024359 数据集信息 Cholec80 数据集 是一个针对内窥镜引导 下的胆囊切除手术视频流程识别数据集。数据集提供了每段视频中总共7种手术动作及总共7种手术工具的标注,标…...
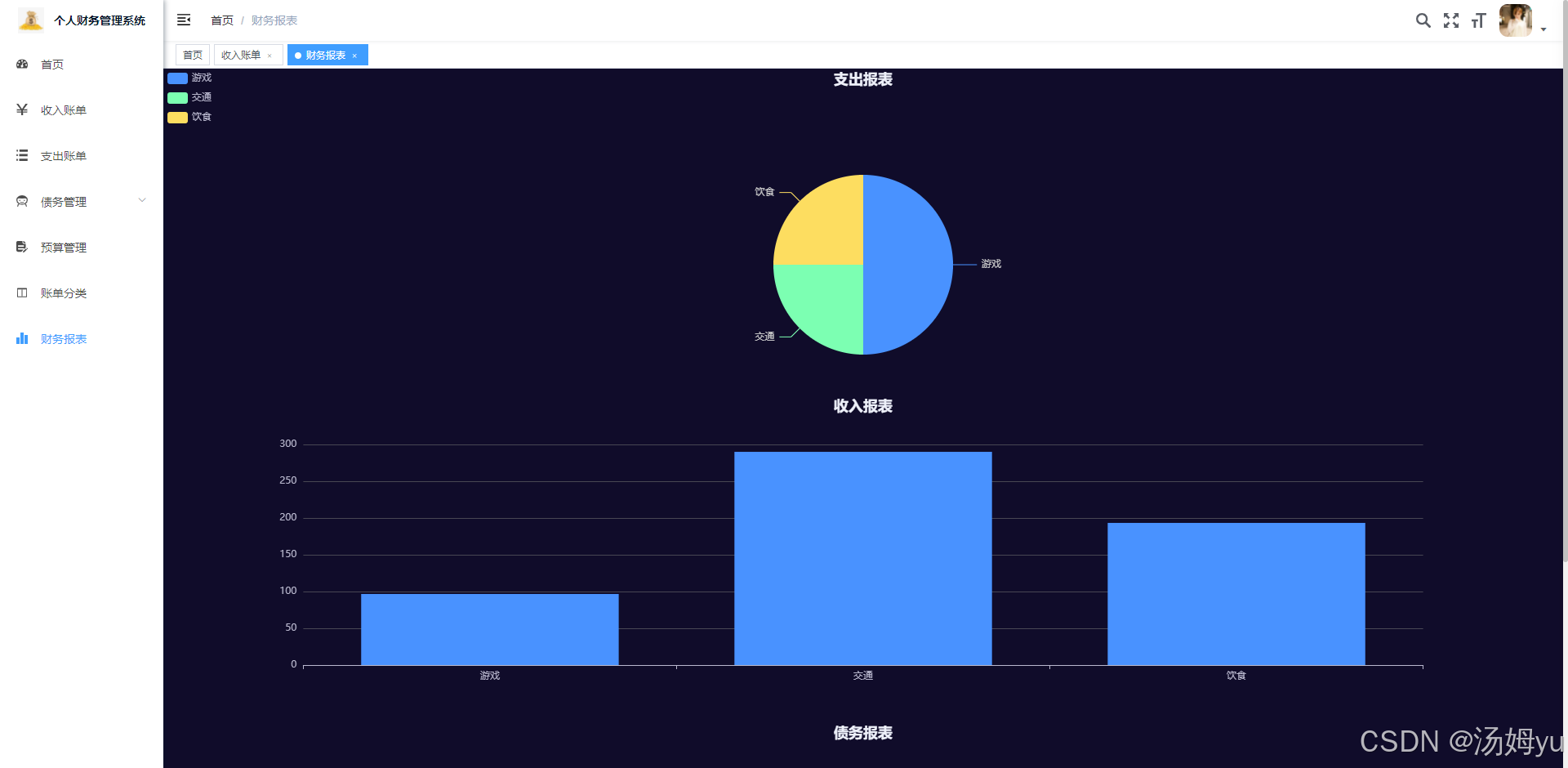
基于springboot的个人财务管理系统的设计与实现
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...
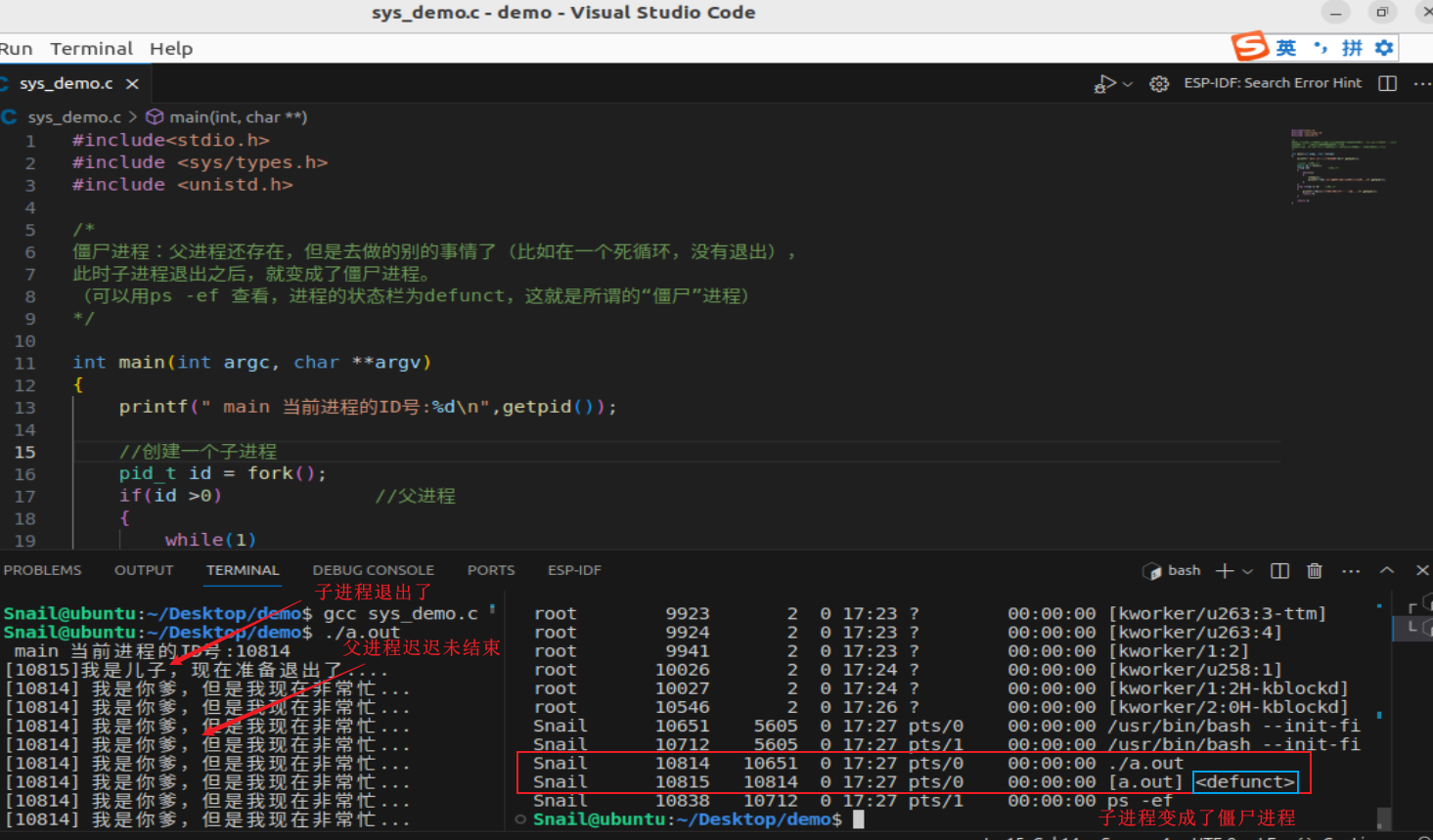
Linux系统编程---孤儿进程与僵尸进程
1、前言 在上一篇博客文章已经对Linux系统编程内容进行了较为详细的梳理,本文将在上一篇的基础上,继续梳理Linux系统编程中关于孤儿进程和僵尸进程的知识脉络。如有疑问的博客朋友可以通过下面的博文链接进行参考学习。 Linux系统编程---多进程-CSDN博客…...
简单使用MCP
简单使用MCP 1 简介 模型上下文协议(Model Context Protocol,MCP)是由Anthropic(产品是Claude)推出的开放协议,它规范了应用程序如何向LLM提供上下文。MCP可帮助你在LLM之上构建代理和复杂的工作流。 从…...

Semaphore的核心机制
在 Java 中,Semaphore 通过 许可计数器 和 同步队列 的机制实现并发线程数的限制。以下是其核心实现原理和步骤的详细分析: 一、核心机制 许可计数器(Permits) • 初始化时指定的许可数(如 new Semaphore(3)࿰…...