【AI论文】CLIMB:基于聚类的迭代数据混合自举语言模型预训练
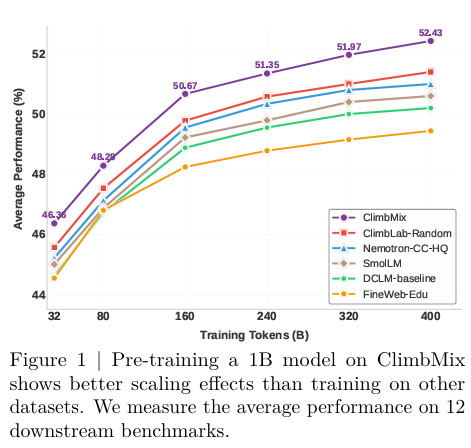
摘要:预训练数据集通常是从网络内容中收集的,缺乏固有的领域划分。 例如,像 Common Crawl 这样广泛使用的数据集并不包含明确的领域标签,而手动整理标记数据集(如 The Pile)则是一项劳动密集型工作。 因此,尽管预训练数据混合对预训练性能有显著的好处,但确定最佳的预训练数据混合仍然是一个具有挑战性的问题。 为了应对这些挑战,我们提出了基于聚类的迭代数据混合引导(CLIMB),这是一个自动化的框架,可以在预训练设置中发现、评估和优化数据混合。 具体而言,CLIMB将大规模数据集嵌入并聚类到语义空间中,然后使用较小的代理模型和预测器迭代搜索最优混合。 当使用这种混合物对400B令牌进行连续训练时,我们的1B模型超过了最先进的Llama-3.2-1B的2.0%。 此外,我们观察到,针对特定领域(如社会科学)进行优化,比随机抽样提高了5%。 最后,我们介绍了ClimbLab,这是一个经过筛选的1.2万亿令牌语料库,包含20个集群,作为一个研究游乐场,以及ClimbMix,这是一个紧凑但功能强大的4000亿令牌数据集,专为高效的预训练而设计,在相同的令牌预算下提供卓越的性能。 我们分析了最终的数据混合,阐明了最佳数据混合的特征。 我们的数据可在以下网址获取:CLIMB,Huggingface链接:Paper page,论文链接:2504.13161
研究背景和目的
随着大型语言模型(LLMs)的快速发展,预训练数据集在其性能提升中扮演了至关重要的角色。然而,预训练数据集通常是从网络内容中收集的,缺乏固有的领域划分。例如,广泛使用的Common Crawl数据集并不包含明确的领域标签,而手动整理标记数据集如The Pile则是一项劳动密集型工作。因此,尽管预训练数据混合对预训练性能有显著的好处,但确定最佳的预训练数据混合仍然是一个具有挑战性的问题。
本研究的目的是提出一种自动化的框架,即基于聚类的迭代数据混合引导(CLIMB),以在预训练设置中发现、评估和优化数据混合。CLIMB旨在通过大规模数据集在语义空间中的嵌入和聚类,以及使用较小的代理模型和预测器迭代搜索最优混合,从而在不依赖手动定义领域标签的情况下,提高预训练模型的性能。
研究方法
1. 数据预处理
- 文本嵌入:使用嵌入模型将文档映射到嵌入空间中,以便在相同集群内的文档之间实现更深的语义对齐。
- 嵌入聚类:采用k-means等聚类算法将嵌入后的文档分组为初始集群。为了后续处理的精细度,初始集群数量K_init设置为相对较大的值(如1000)。
- 集群合并:通过模型基分类器进行集群级别的修剪,去除低质量集群,并基于质心距离将剩余的高质量集群合并为增强集群(K_enhanced < K_pruned < K_init)。
2. 迭代引导:混合权重搜索
- 混合权重搜索作为双层优化问题:给定一组数据集群D={D1, D2,..., Dk}和目标函数ℓ(α,ω)(其中α为混合权重,ω为模型权重),目标是找到最优混合权重α*∈A,以最大化任务性能ℓ(α,ω)。
- 使用预测器近似目标函数:为了降低计算成本,使用预测器fθ(α)来近似目标函数ℓ(α,ω),基于一组(混合权重,性能)对进行训练。
- 迭代引导解决双层优化问题:通过坐标下降方法交替优化配置采样和预测器拟合子程序。在每次迭代中,根据预测性能对配置进行排序,并从顶部配置中随机采样新配置,以平衡利用和探索。然后,使用新采样的配置训练预测器,并用于评估配置和生成预测性能。
3. 实验设置
- 数据集:使用Nemotron-CC和smollm-corpus作为源数据集,通过CLIMB聚类得到21个超级集群,包含约8000亿令牌。评估在PIQA、ARC_C、ARC_E、HellaSwag、WinoGrande和SIQA等推理基准上进行。
- 模型:首先进行第一阶段预训练以建立坚实基础,然后训练62M、350M和1B三种规模的Transformer解码器模型。对于代理模型,使用62M和350M以提高效率。对于目标模型,评估所有三种规模以评估方法在不同尺度上的表现。
- 基线:与随机选择、DoReMi和RegMix等先进的数据混合方法进行比较。
研究结果
1. 与数据混合基线的比较
在350M和1B目标模型上,CLIMB在平均准确率上均优于所有基线数据混合方法。例如,在350M目标模型上,CLIMB的平均准确率为54.83%,高于随机选择的52.17%和最佳基线RegMix的53.78%。在1B目标模型上,CLIMB的平均准确率为60.41%,高于所有基线。
2. 与最先进的语言模型的比较
使用CLIMB找到的最优数据混合对400B令牌进行连续训练后,我们的1B模型在多数通用推理基准上均优于Llama-3.2-1B等先进基线,整体平均准确率提高了2.0%。
3. 针对特定领域的优化
除了优化通用推理任务外,CLIMB还能针对特定领域(如社会科学)进行优化。实验结果表明,针对社会科学领域的优化比随机抽样提高了5%的准确率。
4. 消融研究
- 搜索计算预算的影响:增加搜索的总计算量(如从100%增加到150%或200%)可以进一步提高下游准确性。
- 计算分配的影响:在迭代次数和每次迭代的搜索次数之间找到平衡(如4:2:1的分配比例)对于稳健地找到好的混合至关重要。
- 代理模型的影响:使用较大的代理模型(如350M)可以更准确地估计最终(较大)目标模型的性能。
- 集群数量的影响:CLIMB对集群数量不太敏感,表现出鲁棒性。
- 初始化方案的影响:Dirichlet初始化略优于随机初始化,但性能相当,表明数据混合方法对初始化选择不敏感。
研究局限
尽管CLIMB在预训练数据混合方面取得了显著成效,但仍存在一些局限性:
- 计算成本:尽管CLIMB通过迭代引导和使用较小的代理模型降低了计算成本,但在大规模数据集上进行嵌入、聚类和迭代搜索仍然需要相当的计算资源。
- 数据集依赖性:CLIMB的性能可能依赖于所使用的源数据集的质量和多样性。如果源数据集存在偏差或不足,可能会影响最终数据混合的效果。
- 预测器的局限性:预测器用于近似目标函数,但其准确性可能受到训练数据的质量和数量的限制。预测器的偏差可能会影响数据混合的搜索方向。
未来研究方向
- 降低计算成本:探索更高效的嵌入和聚类算法,以及更轻量级的代理模型,以进一步降低CLIMB的计算成本。
- 增强数据集的多样性和质量:研究如何整合更多样化的数据源,并改进数据清洗和过滤技术,以提高源数据集的质量和多样性。
- 改进预测器:研究更先进的预测器模型,以提高其对目标函数的近似准确性,从而更精确地指导数据混合的搜索过程。
- 扩展到更多领域和任务:将CLIMB扩展到更多领域和任务上,以验证其在不同场景下的有效性和通用性。
- 结合其他优化技术:探索将CLIMB与其他数据优化技术(如数据增强、数据选择等)相结合的可能性,以进一步提升预训练模型的性能。
总之,CLIMB为预训练数据混合提供了一种自动化的解决方案,通过迭代引导和预测器实现了对数据混合的有效搜索和优化。未来的研究可以进一步改进CLIMB的性能和效率,并探索其在更多领域和任务上的应用。
相关文章:
【AI论文】CLIMB:基于聚类的迭代数据混合自举语言模型预训练
摘要:预训练数据集通常是从网络内容中收集的,缺乏固有的领域划分。 例如,像 Common Crawl 这样广泛使用的数据集并不包含明确的领域标签,而手动整理标记数据集(如 The Pile)则是一项劳动密集型工作。 因此&…...

Linux操作系统--环境变量
目录 基本概念: 常见环境变量: 查看环境变量的方法: 测试PATH 测试HOME 和环境变量相关的命令 环境变量的组织方式:编辑 通过代码如何获取环境变量 通过系统调用获取或设置环境变量 环境变量通常具有全局属性 基本概念…...
Jenkins 多分支管道
如果您正在寻找一个基于拉取请求或分支的自动化 Jenkins 持续集成和交付 (CI/CD) 流水线,本指南将帮助您全面了解如何使用 Jenkins 多分支流水线实现它。 Jenkins 的多分支流水线是设计 CI/CD 工作流的最佳方式之一,因为它完全基于 git(源代…...
:如何筛选创业路上的关键数据指标)
精益数据分析(9/126):如何筛选创业路上的关键数据指标
精益数据分析(9/126):如何筛选创业路上的关键数据指标 大家好!在创业的漫漫长路中,数据就像一盏明灯,指引着我们前行的方向。但要让这盏灯发挥作用,关键在于找到那些真正有价值的数据指标。今天…...

C语言之图像文件的属性
🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 图像文件属性提取系统设计与实现 目录 设计题目设计内容系统分析总体设计详细设计程序实现…...
LeetCode hot 100—分割等和子集
题目 给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。 示例 示例 1: 输入:nums [1,5,11,5] 输出:true 解释:数组可以分割成 [1, 5, 5] 和 [11] 。…...

高等数学同步测试卷 同济7版 试卷部分 上 做题记录 上册期中同步测试卷 B卷
上册期中同步测试卷 B卷 一、单项选择题(本大题共5小题,每小题3分,总计15分) 1. 2. 3. 4. 5. 由f(2/n), n→∞可知 2/n→0, 即x→0. 二、填空题(本大题共5小题,每小题3分,总计15分) 6. 7. 8. 9. 10. 三、求解下列各题(本大题共5小…...
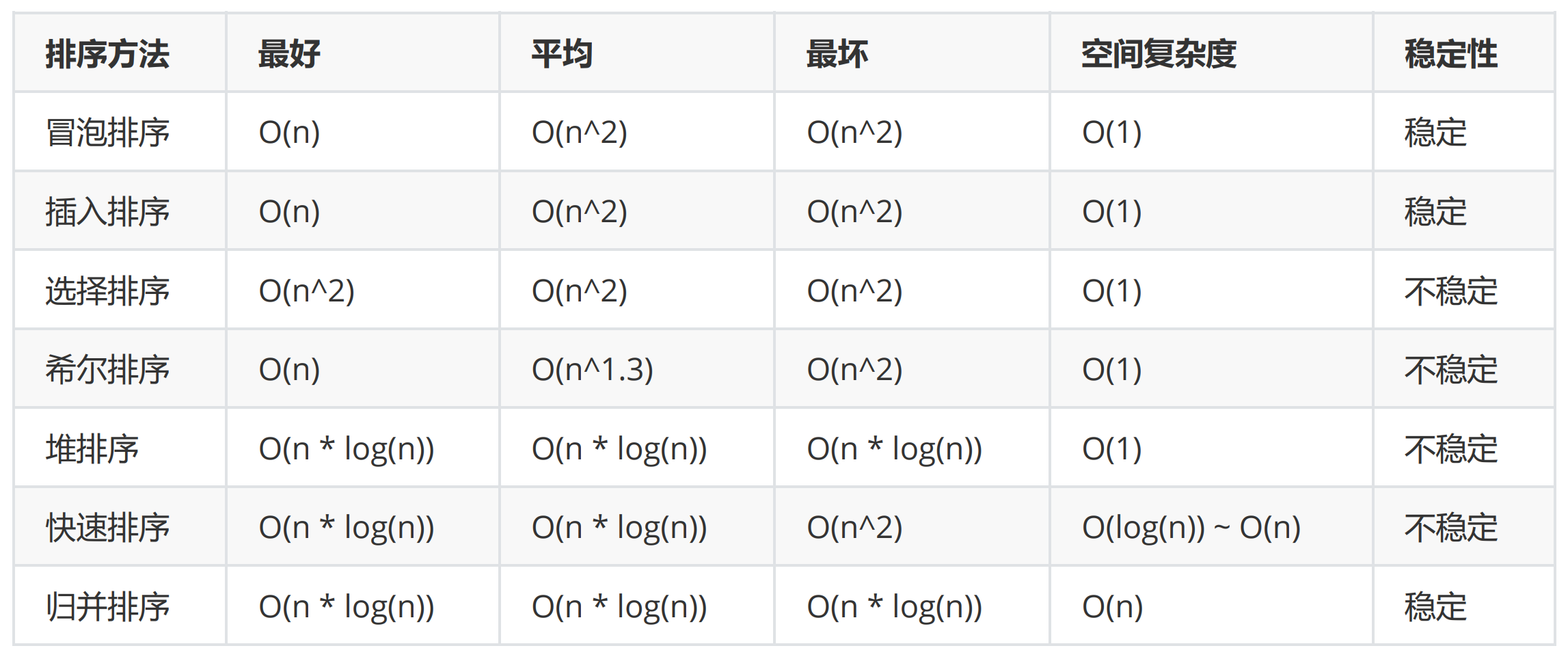
【算法】快速排序、归并排序(非递归版)
目录 一、快速排序(非递归) 1.原理 2.实现 2.1 stack 2.2 partition(array,left,right) 2.3 pivot - 1 > left 二、归并排序(非递归) 1.原理 2.实现 2.1 gap 2.1.1 i 2*gap 2.1.2 gap * 2 2.1.3 gap < array.…...

python-将文本生成音频
将文本生成音频通常需要结合 文本转语音(TTS,Text-to-Speech) 工具或库来实现,比如 Google TTS (gtts)、Amazon Polly、Microsoft Azure TTS 等。 一、使用 Google TTS (gtts) 将文本生成音频 gtts 是一个简单易用的 Python 库&a…...

[王阳明代数讲义]语言模型核心代码调研
语言模型核心代码调研 基于Consciciteation的才气张量持续思考综述将文本生成建模为才气张量网络扩散过程,实现非自回归推理通过才气张量的群-拓扑流形交叉注意力实现多模态推理,将输入压缩到低维空间持续迭代提出「条件计算提前终止」机制,…...
算了和周日一块写了 4月20日日记)
4月19日记(补)算了和周日一块写了 4月20日日记
周六啊 昨天晚上又玩的太嗨了。睡觉的时候有点晚了,眼睛疼就没写日记。现在补上 实际上现在是20号晚上八点半了。理论上来说应该写今天的日记。 周六上午打比赛啦,和研究生,输了,我是替补没上场。没关系再练一练明天就可以变强…...

trivy开源安全漏洞扫描器——筑梦之路
开源地址:https://github.com/aquasecurity/trivy.git 可扫描的对象 容器镜像文件系统Git存储库(远程)虚拟机镜像Kubernetes 在容器镜像安全方面使用广泛,其他使用相对较少。 能够发现的问题 正在使用的操作系统包和软件依赖项…...
【实战中提升自己】内网安全部署之dot1x部署 本地与集成AD域的主流方式(附带MAC认证)
1 dot1x部署【用户名密码认证,也可以解决私接无线AP等功能】 说明:如果一个网络需要通过用户名认证才能访问内网,而认证失败只能访问外网与服务器,可以部署dot1x功能。它能实现的效果是,当内部用户输入正常的…...
[matlab]南海地形眩晕图代码
[matlab]南海地形眩晕图代码 请ChatGPT帮写个南海地形眩晕图代码 图片 图片 代码 .rtcContent { padding: 30px; } .lineNode {font-size: 12pt; font-family: "Times New Roman", Menlo, Monaco, Consolas, "Courier New", monospace; font-style: n…...
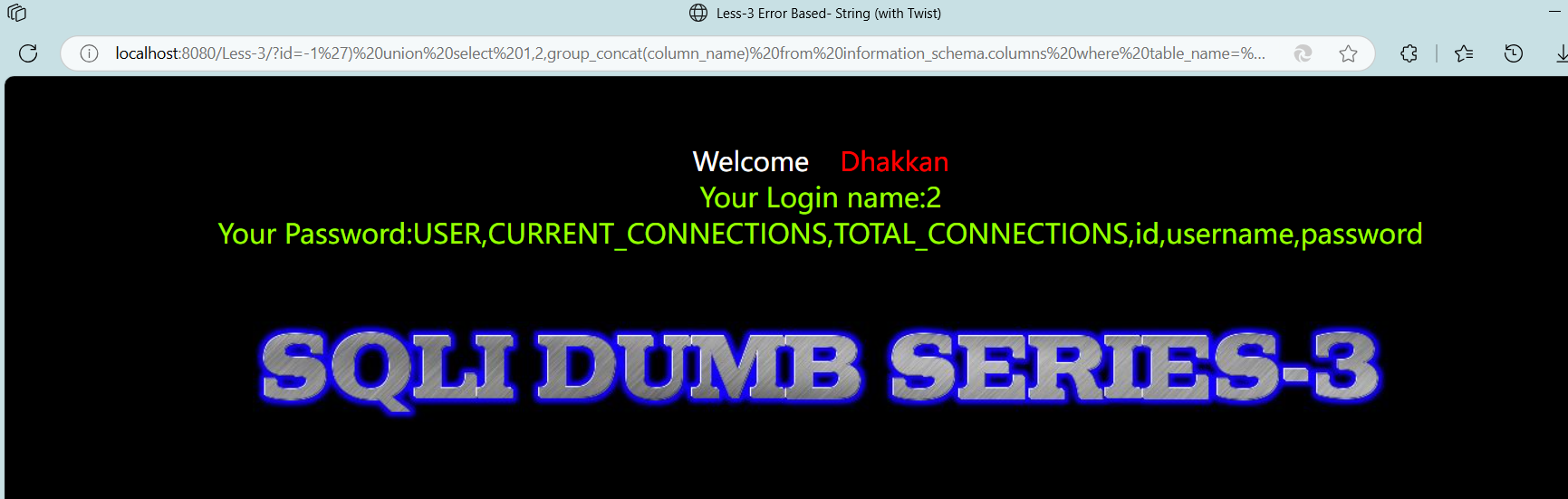
Web安全和渗透测试--day6--sql注入--part 1
场景: win11家庭版,edge浏览器 , sqlin靶场 定义: SQL 注入(SQL Injection)是一种常见的网络安全攻击方式,攻击者通过在 Web 应用程序中输入恶意的 SQL 代码,绕过应用程序的安全机…...
预测及治疗方案制定中的应用研究)
大模型在胆管结石(无胆管炎或胆囊炎)预测及治疗方案制定中的应用研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的 1.3 国内外研究现状 二、胆管结石相关理论基础 2.1 胆管结石概述 2.2 临床表现与诊断方法 2.3 传统治疗方法 三、大模型技术原理与应用优势 3.1 大模型基本原理 3.2 在医疗领域的应用潜力 3.3 用于胆管结石预测的可…...

MIT6.S081-lab4
MIT6.S081-lab4 注:本篇lab的前置知识在《MIT6.S081-lab3前置》 1. RISC-V assembly 第一个问题 Which registers contain arguments to functions? For example, which register holds 13 in main’s call to printf? 我们先来看看main干了什么: …...

精通 Spring Cache + Redis:避坑指南与最佳实践
Spring Cache 以其优雅的注解方式,极大地简化了 Java 应用中缓存逻辑的实现。结合高性能的内存数据库 Redis,我们可以轻松构建出响应迅速、扩展性强的应用程序。然而,在享受便捷的同时,一些常见的“坑”和被忽视的最佳实践可能会悄…...
[SpringBoot]快速入门搭建springboot
默认有spring基础,不会一行代码一行代码那么细致地讲。 SpringBoot的作用 Spring Boot是为了简化Spring应用的创建、运行、调试、部署等而出现的。就像我们整个SSM框架时,就常常会碰到版本导致包名对不上、Bean非法参数类型的一系列问题(原出…...
理解.NET Core中的配置Configuration
什么是配置 .NET中的配置,本质上就是key-value键值对,并且key和value都是字符串类型。 在.NET中提供了多种配置提供程序来对不同的配置进行读取、写入、重载等操作,这里我们以为.NET 的源码项目为例,来看下.NET中的配置主要是有…...

C++面试八股文:智能指针
一、了解哪些智能指针? 回答:智能指针是用于管理动态分配的内存,行为类似于指针,但又具有自动管理内存的能力,所以称为智能指针。 首先说一下 auto_ptr和unique_ptr,它们都是独占式指针,同一时…...

nohup命令使用说明
文章目录 如何在后台运行程序呢?如何正常运行代码重定向呢?nohup: ignoring input 如何在后台运行程序呢? 使用nohup命令即可, nohup python dataset/ReferESpatialDataset.py >>dataset_20250417.log 2>&1 &n…...
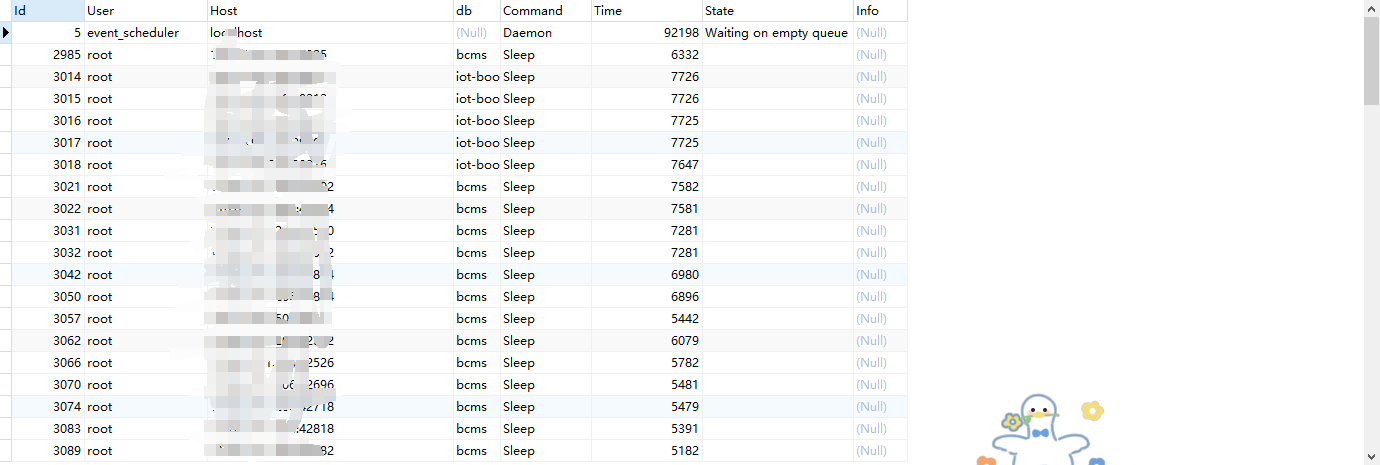
MYSQL “Too Many Connections“ 错误解决
1.查询当前连接数 show status like "Threads_connected"; 2.查询数据库最大连接数 show variables like "max_connections" 3.查询所有活动连接 show processlist; 4.根据查询结果观察是否有长时间未被释放的连接 参数解释 : 字段说明id连接的唯一…...

Linux `init 6` 相关命令的完整使用指南
Linux init 6 相关命令的完整使用指南—目录 一、init 系统简介二、init 6 的含义与作用三、不同 Init 系统下的 init 6 行为1. SysVinit(如 CentOS 6、Debian 7)2. systemd(如 CentOS 7、Ubuntu 16.04)3. Upstart(如 …...
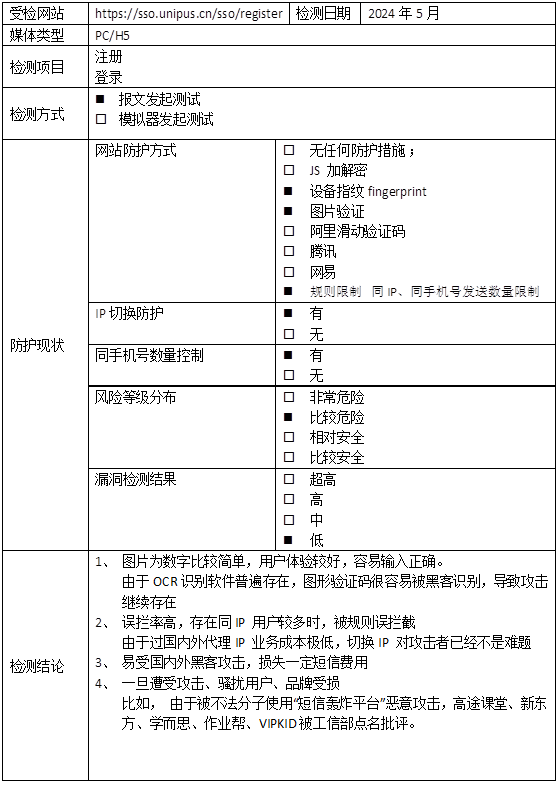
【外研在线-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...
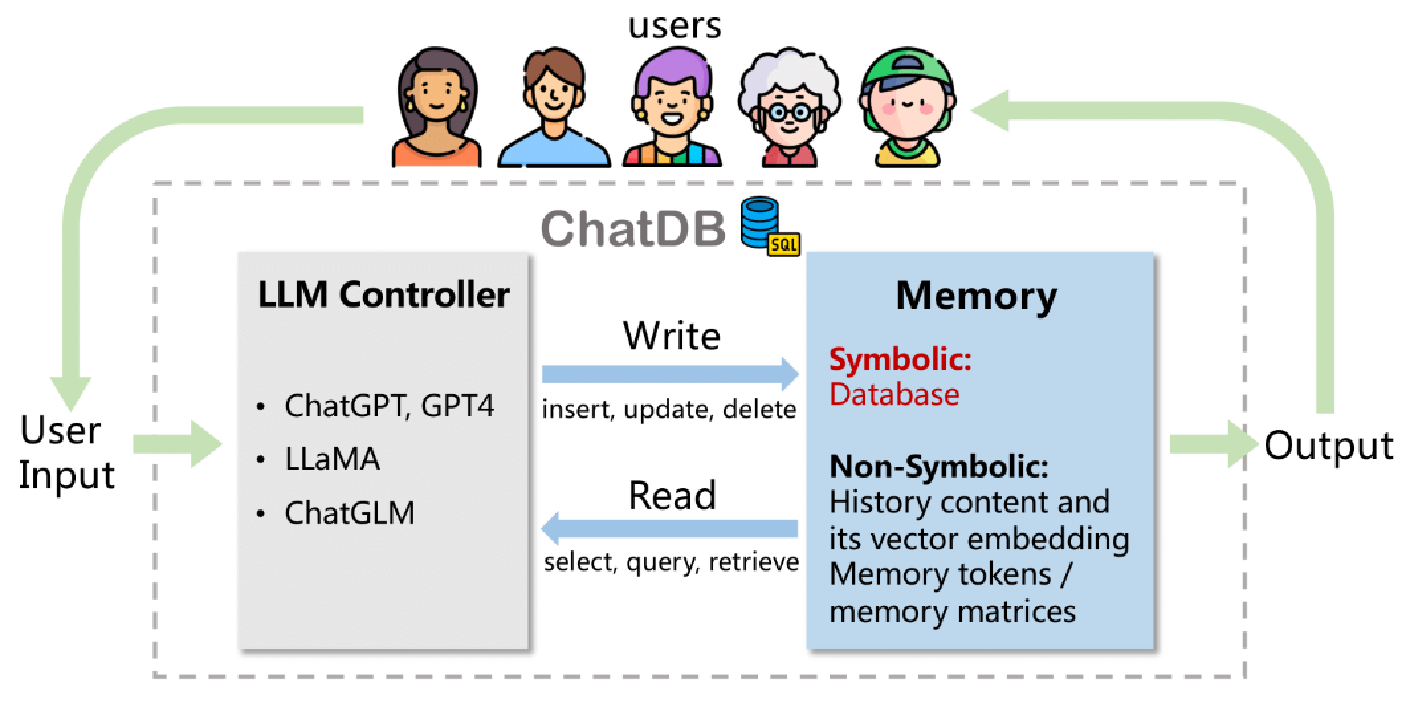
【NLP 63、大模型应用 —— Agent】
人与人最大的差距就是勇气和执行力,也是唯一的差距 —— 25.4.16 一、Agent 相关工作 二、Agent 特点 核心特征: 1.专有场景(针对某个垂直领域) 2.保留记忆(以一个特定顺序做一些特定任务,记忆当前任务的前…...

React 打包
路由懒加载 原本的加载方式 #使用lazy()函数声明的路由页面 使用Suspense组件进行加载 使用CDN优化...
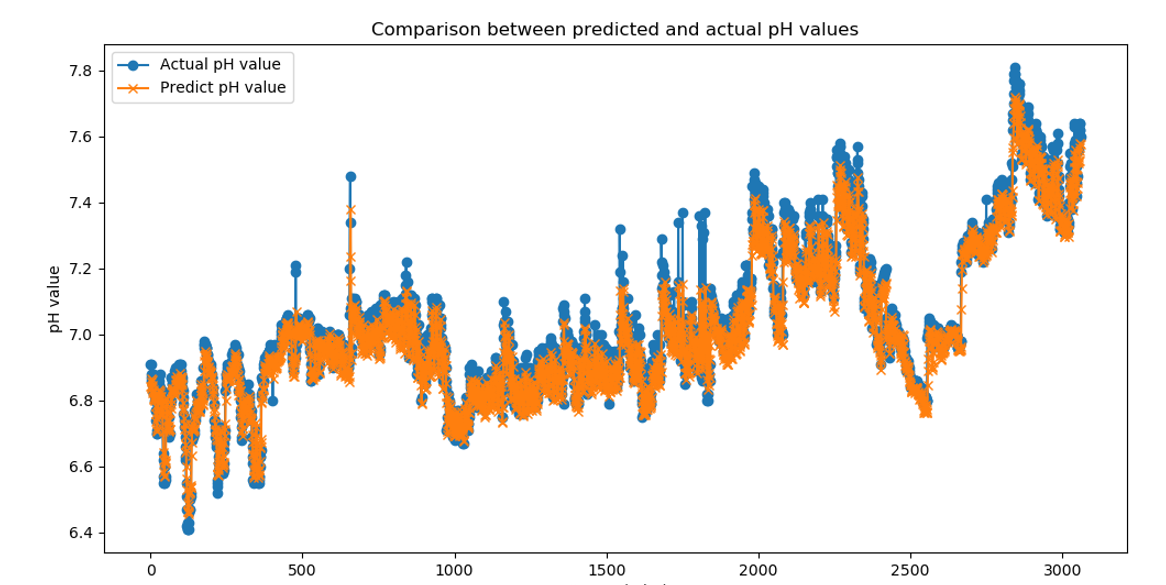
2025.4.14-2025.4.20学习周报
目录 摘要Abstract1. 文献阅读1.1 模型架构1.2 实验分析1.3 代码实践 总结 摘要 在本周阅读的论文中,作者提出了一种名为MGSFformer的空气质量预测模型。模型通过残差去冗余模块可以有效解耦多粒度数据间的信息重叠;时空注意力模块采用并行建模策略&…...

Spring 微服务解决了单体架构的哪些痛点?
1. 部署困难 (Deployment Difficulty & Risk) 单体痛点: 整体部署: 对单体应用的任何微小修改(哪怕只是一行代码),都需要重新构建、测试和部署整个庞大的应用程序。部署频率低: 由于部署过程复杂且风险高,发布周期通常很长&a…...
【1】云原生,kubernetes 与 Docker 的关系
Kubernetes?K8s? Kubernetes经常被写作K8s。其中的数字8替代了K和s中的8个字母——这一点倒是方便了发推,也方便了像我这样懒惰的人。 什么是云原生? 云原生: 它是一种构建和运行应用程序的方法,它包含&am…...