【教程】PyTorch多机多卡分布式训练的参数说明 | 附通用启动脚本
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
目录
torchrun
一、什么是 torchrun
二、torchrun 的核心参数讲解
三、torchrun 会自动设置的环境变量
四、torchrun 启动过程举例
机器 A(node_rank=0)上运行
机器 B(node_rank=1)上运行
五、小结表格
PyTorch
一、背景回顾
二、init_process_group
三、脚本中通常的典型写法
通用启动脚本
torchrun 与 torch.multiprocessing.spawn 的对比可以看这篇:
【知识】torchrun 与 torch.multiprocessing.spawn 的对比
torchrun
一、什么是 torchrun
torchrun 是 PyTorch 官方推荐的分布式训练启动器,它的作用是:
-
启动 多进程分布式训练(支持多 GPU,多节点)
-
自动设置每个进程的环境变量
-
协调节点之间建立通信
二、torchrun 的核心参数讲解
torchrun \--nnodes=2 \--nproc_per_node=2 \--node_rank=0 \--master_addr=192.168.5.228 \--master_port=29400 \xxx.py
🔹 1. --nnodes(Number of Nodes)
-
表示参与训练的总机器数。
-
你有几台服务器,就写几。
-
在分布式训练中,一个 node 就是一台物理或虚拟的主机。
-
node的编号从0开始。
✅ 例子:你用 2 台机器 → --nnodes=2
🔹 2. --nproc_per_node(Processes Per Node)
-
表示每台机器上要启动几个训练进程。
-
一个进程对应一个 GPU,因通常设置为你机器上要用到的GPU数。
-
因此,整个分布式环境下,总训练进程数 =
nnodes * nproc_per_node
✅ 例子:每台机器用了 2 张 GPU → --nproc_per_node=2
🔹 3. --node_rank
-
表示当前机器是第几台机器。
-
从 0 开始编号,必须每台机器都不同!
✅ 例子:
| 机器 IP | node_rank |
|---|---|
| 192.168.5.228 | 0 |
| 192.168.5.229 | 1 |
🔹 4. --master_addr 和 --master_port
-
指定主节点的 IP 和端口,用于 rendezvous(进程对齐)和通信初始化。
-
所有机器必须填写相同的值!
✅ 建议:
-
master_addr就是你指定为主节点的那台机器的 IP -
master_port选一个未被占用的端口,比如 29400
三、torchrun 会自动设置的环境变量
当用 torchrun 启动后,它会自动给每个进程设置这些环境变量:
| 环境变量 | 含义 |
|---|---|
RANK | 当前进程在全局中的编号(0 ~ world_size - 1) |
LOCAL_RANK | 当前进程在本机中的编号(0 ~ nproc_per_node - 1) |
WORLD_SIZE | 总进程数 = nnodes * nproc_per_node |
你可以在训练脚本里用 os.environ["RANK"] 来读取这些信息:
import os
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
world_size = int(os.environ["WORLD_SIZE"])
示例分配图:
四、torchrun 启动过程举例
假设:
-
有 2 台机器
-
每台机器有 2 个 GPU
-
总共会启动 4 个进程
机器 A(node_rank=0)上运行
torchrun \--nnodes=2 \--nproc_per_node=2 \--node_rank=0 \--master_addr=192.168.5.228 \--master_port=29400 \xxx.py
机器 B(node_rank=1)上运行
torchrun \--nnodes=2 \--nproc_per_node=2 \--node_rank=1 \--master_addr=192.168.5.228 \--master_port=29400 \xxx.py
torchrun 给每个进程编号的顺序(分配 RANK / LOCAL_RANK)
torchrun 按照每台机器上 node_rank 的顺序,并在每台机器上依次启动 LOCAL_RANK=0, 1, ..., n-1,最后合成 RANK。
RANK = node_rank × nproc_per_node + local_rankStep 1:按 node_rank 升序处理(node 0 → node 1)
Step 2:每个 node 内部从
local_rank=0开始递增
本质上:
torchrun是主从结构调度的
所有 node 启动后,都会和
master_addr通信。master 会统一收集所有 node 的状态。
每个 node 根据你给的
node_rank自行派生local_rank=0~n-1所有节点通过
RANK = node_rank * nproc_per_node + local_rank得到自己的全局编号。这个机制是 可预测、可控、可复现 的。
📦 node_rank=0 (机器 1)
├── local_rank=0 → RANK=0
└── local_rank=1 → RANK=1📦 node_rank=1 (机器 2)
├── local_rank=0 → RANK=2
└── local_rank=1 → RANK=3
最终分配:
| Node Rank | Local Rank | Global Rank (RANK) | 使用 GPU |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 2 | 0 |
| 1 | 1 | 3 | 1 |
五、小结表格
| 参数 | 作用 | 设置方式 |
|---|---|---|
--nnodes | 总节点数 | 你写在命令里 |
--nproc_per_node | 每台节点的进程数(= GPU 数) | 你写在命令里 |
--node_rank | 当前机器编号(0开始) | 每台机器唯一 |
--master_addr | 主节点 IP(所有节点需一致) | 你设置 |
--master_port | 主节点端口(所有节点需一致) | 你设置 |
RANK | 当前进程在所有进程中的编号 | torchrun 自动设置 |
LOCAL_RANK | 当前进程在本节点上的编号 | torchrun 自动设置 |
WORLD_SIZE | 总进程数 = nnodes * nproc_per_node | 自动设置 |
PyTorch
PyTorch 的分布式通信是如何通过 init_process_group 与 torchrun 生成的环境变量配合起来工作的。
一、背景回顾
你已经用 torchrun 启动了多个训练进程,并且 torchrun 为每个进程自动设置了这些环境变量:
| 变量名 | 含义 |
|---|---|
RANK | 当前进程的全局编号(从 0 开始) |
LOCAL_RANK | 本机上的编号(一般等于 GPU ID) |
WORLD_SIZE | 总进程数 |
MASTER_ADDR | 主节点的 IP |
MASTER_PORT | 主节点用于通信的端口 |
那么 这些变量是如何参与进程通信初始化的? 这就涉及到 PyTorch 的核心函数:
二、init_process_group
torch.distributed.init_process_group 是 PyTorch 初始化分布式通信的入口:
torch.distributed.init_process_group(backend="nccl", # 或者 "gloo"、"mpi"init_method="env://", # 通过环境变量读取设置
)
关键点:
-
backend="nccl":推荐用于 GPU 分布式通信(高性能) -
init_method="env://":表示通过环境变量来初始化
你不需要自己设置 RANK / WORLD_SIZE / MASTER_ADDR,只要写:
import torch.distributed as distdist.init_process_group(backend="nccl", init_method="env://")
PyTorch 会自动去环境中读这些变量:
-
RANK→ 当前进程编号 -
WORLD_SIZE→ 总进程数 -
MASTER_ADDR、MASTER_PORT→ 主节点 IP 和端口
然后就能正确初始化所有通信进程。
三、脚本中通常的典型写法
import os
import torch# 初始化 PyTorch 分布式通信环境
torch.distributed.init_process_group(backend="nccl", init_method="env://")# 获取全局/本地 rank、world size
rank = int(os.environ.get("RANK", -1))
local_rank = int(os.environ.get("LOCAL_RANK", -1))
world_size = int(os.environ.get("WORLD_SIZE", -1))# 设置 GPU 显卡绑定
torch.cuda.set_device(local_rank)
device = torch.device("cuda")# 打印绑定信息
print(f"[RANK {rank} | LOCAL_RANK {local_rank}] Using CUDA device {torch.cuda.current_device()}: {torch.cuda.get_device_name(torch.cuda.current_device())} | World size: {world_size}")
这段代码在所有进程中都一样写,但每个进程启动时带的环境变量不同,所以最终 rank、local_rank、world_size 就自然不同了。
通用启动脚本
#!/bin/bash# 设置基本参数
MASTER_ADDR=192.168.5.228 # 主机IP
MASTER_PORT=29400 # 主机端口
NNODES=2 # 参与训练的总机器数
NPROC_PER_NODE=2 # 每台机器上的进程数# 所有网卡的IP地址,用于筛选
ALL_LOCAL_IPS=$(hostname -I)
# 根据本机 IP 配置通信接口
if [[ "$ALL_LOCAL_IPS" == *"192.168.5.228"* ]]; thenNODE_RANK=0 # 表示当前机器是第0台机器IFNAME=ens1f1np1 mytorchrun=~/anaconda3/envs/dglv2/bin/torchrun
elif [[ "$ALL_LOCAL_IPS" == *"192.168.5.229"* ]]; thenNODE_RANK=1 # 表示当前机器是第1台机器IFNAME=ens2f1np1mytorchrun=/opt/software/anaconda3/envs/dglv2/bin/torchrun
elseexit 1
fi# 设置 RDMA 接口
export NCCL_IB_DISABLE=0 # 是否禁用InfiniBand
export NCCL_IB_HCA=mlx5_1 # 使用哪个RDMA接口进行通信
export NCCL_SOCKET_IFNAME=$IFNAME # 使用哪个网卡进行通信
export NCCL_DEBUG=INFO # 可选:调试用
export GLOO_IB_DISABLE=0 # 是否禁用InfiniBand
export GLOO_SOCKET_IFNAME=$IFNAME # 使用哪个网卡进行通信
export PYTHONUNBUFFERED=1 # 实时输出日志# 启动分布式任务
$mytorchrun \--nnodes=$NNODES \--nproc_per_node=$NPROC_PER_NODE \--node_rank=$NODE_RANK \--master_addr=$MASTER_ADDR \--master_port=$MASTER_PORT \cluster.py## 如果想获取准确报错位置,可以加以下内容,这样可以同步所有 CUDA 操作,错误不会“延迟触发”,你会看到确切是哪一行代码出了问题:
## CUDA_LAUNCH_BLOCKING=1 torchrun ...相关文章:

【教程】PyTorch多机多卡分布式训练的参数说明 | 附通用启动脚本
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 torchrun 一、什么是 torchrun 二、torchrun 的核心参数讲解 三、torchrun 会自动设置的环境变量 四、torchrun 启动过程举例 机器 A&#…...
Neo4j初解
Neo4j 是目前应用非常广泛的一款高性能的 NoSQL 图数据库,其设计和实现专门用于存储、查询和遍历由节点(实体)、关系(边)以及属性(键值对)构成的图形数据模型。它的核心优势在于能够以一种自然且…...

学习笔记二十——Rust trait
🧩 Rust Trait 彻底搞懂版 👀 目标读者:对 Rust 完全陌生,但想真正明白 “Trait、Trait Bound、孤岛法则” 在做什么、怎么用、为什么这样设计。 🛠 方法: 先给“心里模型”——用生活类比把抽象概念掰开揉…...

音视频小白系统入门课-2
本系列笔记为博主学习李超老师课程的课堂笔记,仅供参阅 课程传送门:音视频小白系统入门课 音视频基础ffmpeg原理 往期课程笔记传送门: 音视频小白系统入门笔记-0音视频小白系统入门笔记-1 课程实践代码仓库:传送门 音视频编解…...
Linux:安装 CentOS 7(完整教程)
文章目录 一、简介二、安装 CentOS 72.1 虚拟机配置2.2 安装CentOS 7 三、结语 一、简介 CentOS(Community ENTerprise Operating System)是一个基于 Linux 的发行版之一,旨在提供一个免费的、企业级的计算平台,因其稳定性、安全…...
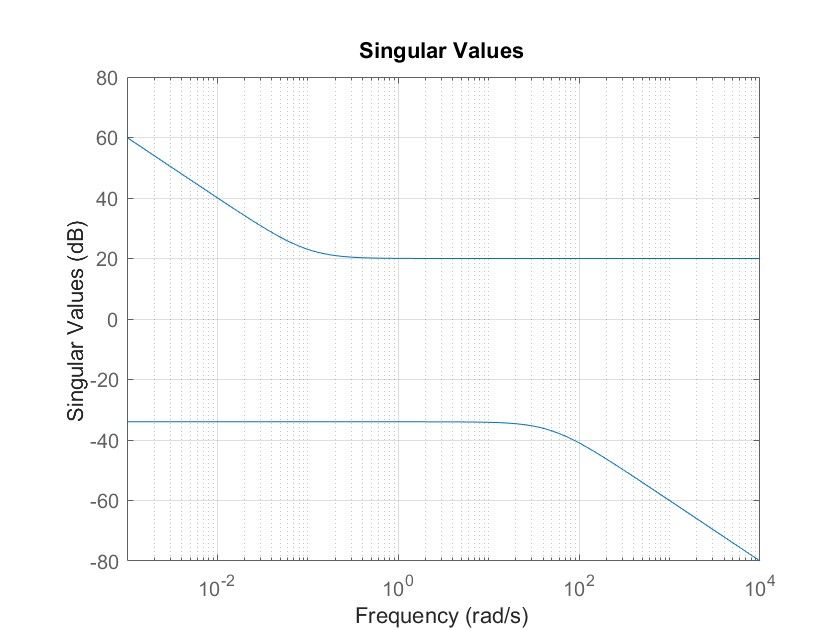
MATLAB 控制系统设计与仿真 - 34
多变量系统知识回顾 - MIMO system 这一章对深入理解多变量系统以及鲁棒分析至关重要 首先,对于如下系统: 当G(s)为单输入,单输出系统时: 如果: 则: 所以 因此,对于SISO,系统的增…...

【网络】通过Samba实现Window挂在Linux服务器路径
有时候我们去进行内网部署时,会遇到客户或者甲方爸爸说,需要将Linux中的某个路径共享出去到Window上,挂载出比如Z:\这种盘符。通过打开Z盘,来查看服务器的指定目录下的数据。 步骤1: 在Linux中安装samba yum install…...

DevOps 进阶指南:如何让工作流更丝滑?
DevOps 进阶指南:如何让工作流更丝滑? 引言 在 DevOps 世界里,我们追求的是高效、稳定、自动化。但现实总是充满挑战:代码部署失败、CI/CD 过程卡顿、环境不一致……这些痛点让开发和运维团队疲惫不堪。今天,我就来聊聊如何优化 DevOps 工作流,通过实战案例和代码示例,…...

架构思维:缓存层场景实战_读缓存(下)
文章目录 Pre业务场景缓存存储数据的时机与常见问题解决方案1. 缓存读取与存储逻辑2. 高并发下的缓存问题及解决方案3. 缓存预热(减少冷启动问题) 缓存更新策略(双写问题)1. 先更新缓存,再更新数据库(不推荐…...
uniapp微信小程序实现sse
微信小程序实现sse 注:因为微信小程序不支持sse请求,因为后台给的是分包的流,所以我们就使用接受流的方式,一直接受,然后把接受的数据拿取使用。这里还是使用uniapp的原生请求。 上代码 //注意:一定要下…...

C#语言的区块链
C#语言在区块链开发中的应用 引言 区块链技术自比特币问世以来,逐渐发展成为一种革命性的技术,其在金融、供应链、物联网等各个领域都产生了深远的影响。随着区块链应用的不断增加,开发者对区块链技术的需求也在不断上升。在众多编程语言中…...
 工具)
Ubuntu服务器日志满audit:backlog limit exceeded了会报错解决方案-Linux 审计系统 (auditd) 工具
auditd 是 Linux 系统中的审计守护进程,负责收集、记录和监控系统安全相关事件。以下是相关工具及其功能: 核心组件 auditd - 审计守护进程 系统的审计服务主程序 收集系统调用信息并写入日志文件 通常存储在 /var/log/audit/audit.log auditctl - 审计控…...
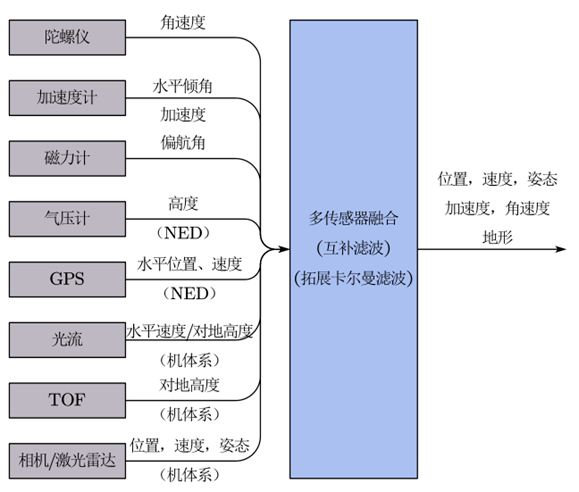
新能源汽车能量流测试的传感器融合技术应用指南
第一部分:核心原理模块化拆解 模块1:多源传感器物理层融合 关键技术: 高精度同步采集架构 采用PXIe-8840控制器同步定时模块(NI PXIe-6674T),实现CAN/LIN/模拟量信号的μs级同步光纤电压传感器࿰…...
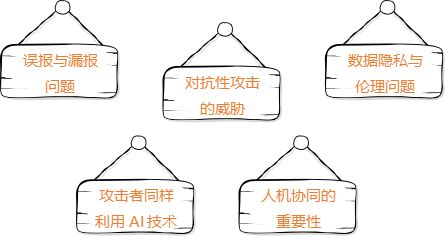
人工智能与网络安全:AI如何预防、检测和应对网络攻击?
引言:网络安全新战场,AI成关键角色 在数字化浪潮不断推进的今天,网络安全问题已经成为每一家企业、每一个组织无法回避的“隐形战场”。无论是电商平台、金融机构,还是政府机关、制造企业,都可能面临数据泄露、勒索病毒…...
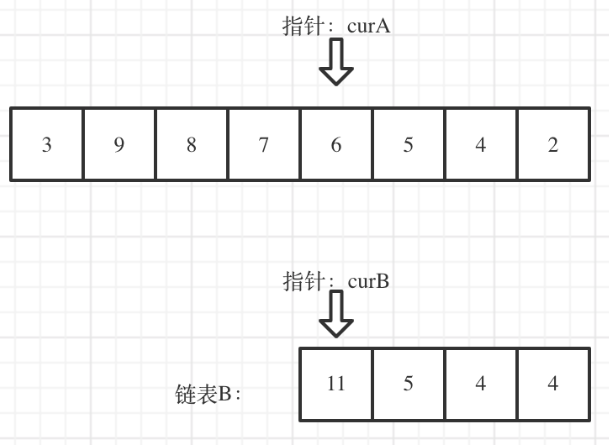
链表知识回顾
类型:单链表,双链表、循环链表 存储:在内存中不是连续存储 删除操作:即让c的指针指向e即可,无需释放d,因为java中又内存回收机制 添加节点: 链表的构造函数 public class ListNode {// 结点…...
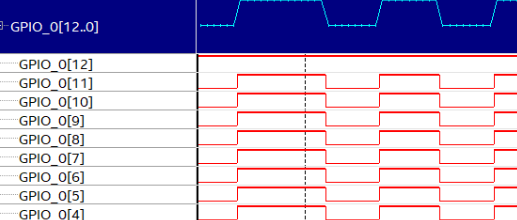
FPGA学习(五)——DDS信号发生器设计
FPGA学习(五)——DDS信号发生器设计 目录 FPGA学习(五)——DDS信号发生器设计一、FPGA开发中常用IP核——ROM/RAM/FIFO1、ROM简介2、ROM文件的设置(1)直接编辑法(2)用C语言等软件生成初始化文件 3、ROM IP核配置调用 二、DDS信号发…...

【数据结构入门训练DAY-18】信息学奥赛一本通T1331-后缀表达式的值
文章目录 前言一、题目二、解题思路总结 前言 本次训练内容: 栈的复习。栈模拟四则运算计算问题的练习。训练解题思维。 一、题目 从键盘读入一个后缀表达式(字符串),只含有0-9组成的运算数及加()、减…...

OpenCv高阶(六)——图像的透视变换
目录 一、透视变换的定义与作用 二、透视变换的过程 三、OpenCV 中的透视变换函数 1. cv2.getPerspectiveTransform(src, dst) 2. cv2.warpPerspective(src, H, dsize, dstNone, flagscv2.INTER_LINEAR, borderModecv2.BORDER_CONSTANT, borderValue0) 四、文档扫描校正&a…...
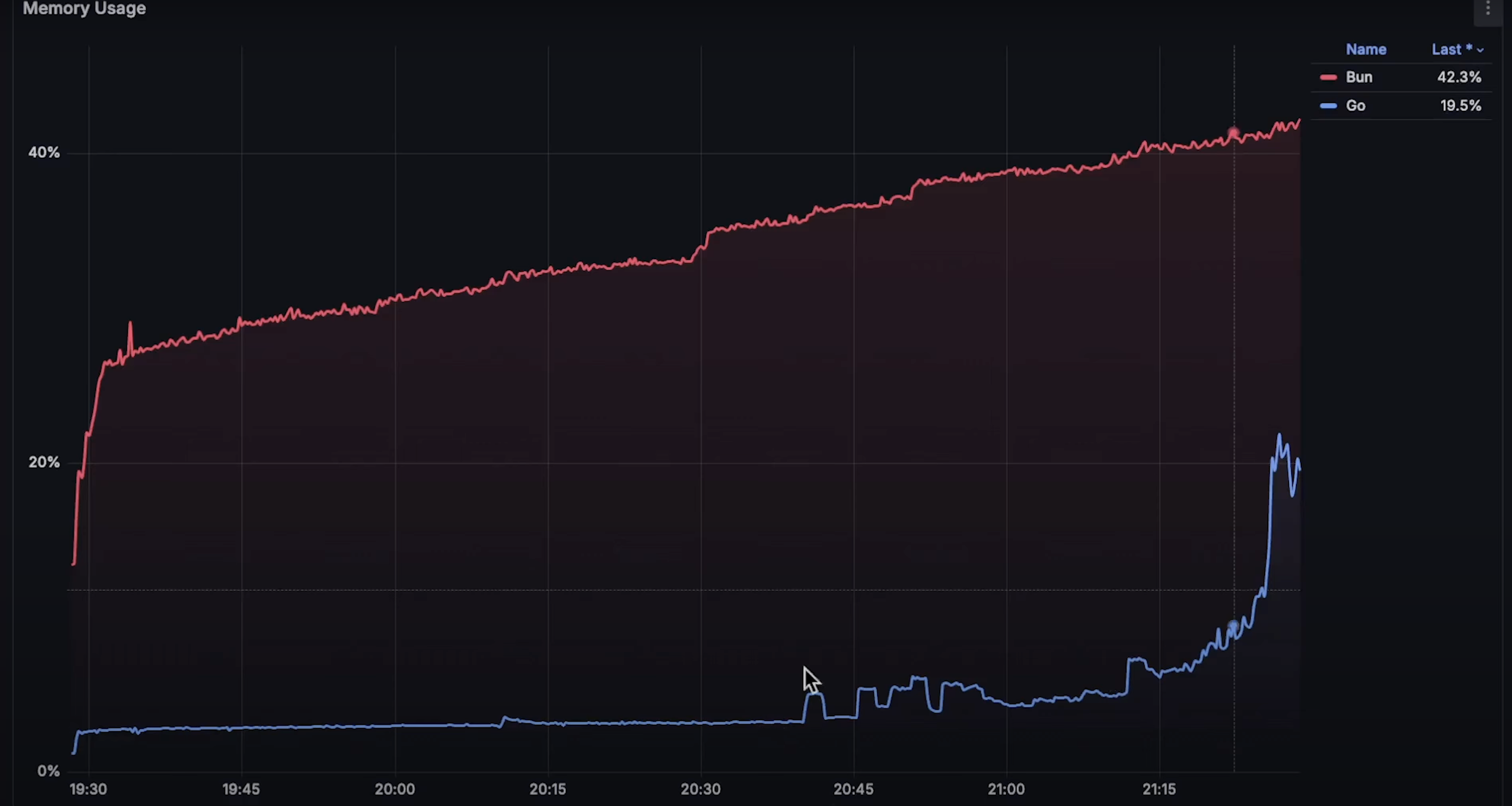
性能比拼: Go vs Bun
本内容是对知名性能评测博主 Anton Putra Go (Golang) vs. Bun: Performance (Latency - Throughput - Saturation - Availability) 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 我对 Bun 在之前的基准测试中的出色表现感到惊讶,因此我决定将它与 Go …...

定制化 Docsify 文档框架实战分享
🌟 定制化 Docsify 文档框架实战分享 在构建前端文档平台时,我们希望拥有更友好的用户界面、便捷的搜索、清晰的目录导航以及实用的代码复制功能。借助 Docsify,我实现了以下几个方面的定制优化,分享给大家 🙌。 &…...

Qt中读写结构体字节数据
在Qt中读写结构体字节数据通常涉及将结构体转换为字节数组(QByteArray)或直接从内存中读写。以下是几种常见方法: 方法1:使用QDataStream读写结构体 cpp #include <QFile> #include <QDataStream>// 定义结构体 #pragma pack(push, 1) //…...

鸿蒙ArkUI之布局实战,线性布局(Column,Row)、弹性布局(Flex)、层叠布局(Stack),详细用法
本文聚焦于ArkUI的布局实战,三种十分重要的布局,线性布局、弹性布局、层叠布局,在实际开发过程中这几种布局方法都十分常见,下面直接上手 线性布局 垂直布局(Column) 官方文档: Column-行列…...

测试基础笔记第七天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、cat命令二、ls -al命令三、>重定向符号四、>>追加重定向符号五、less/more命令六、grep命令七、|管道符八、clear命令九、head命令十、tail命令十一、…...
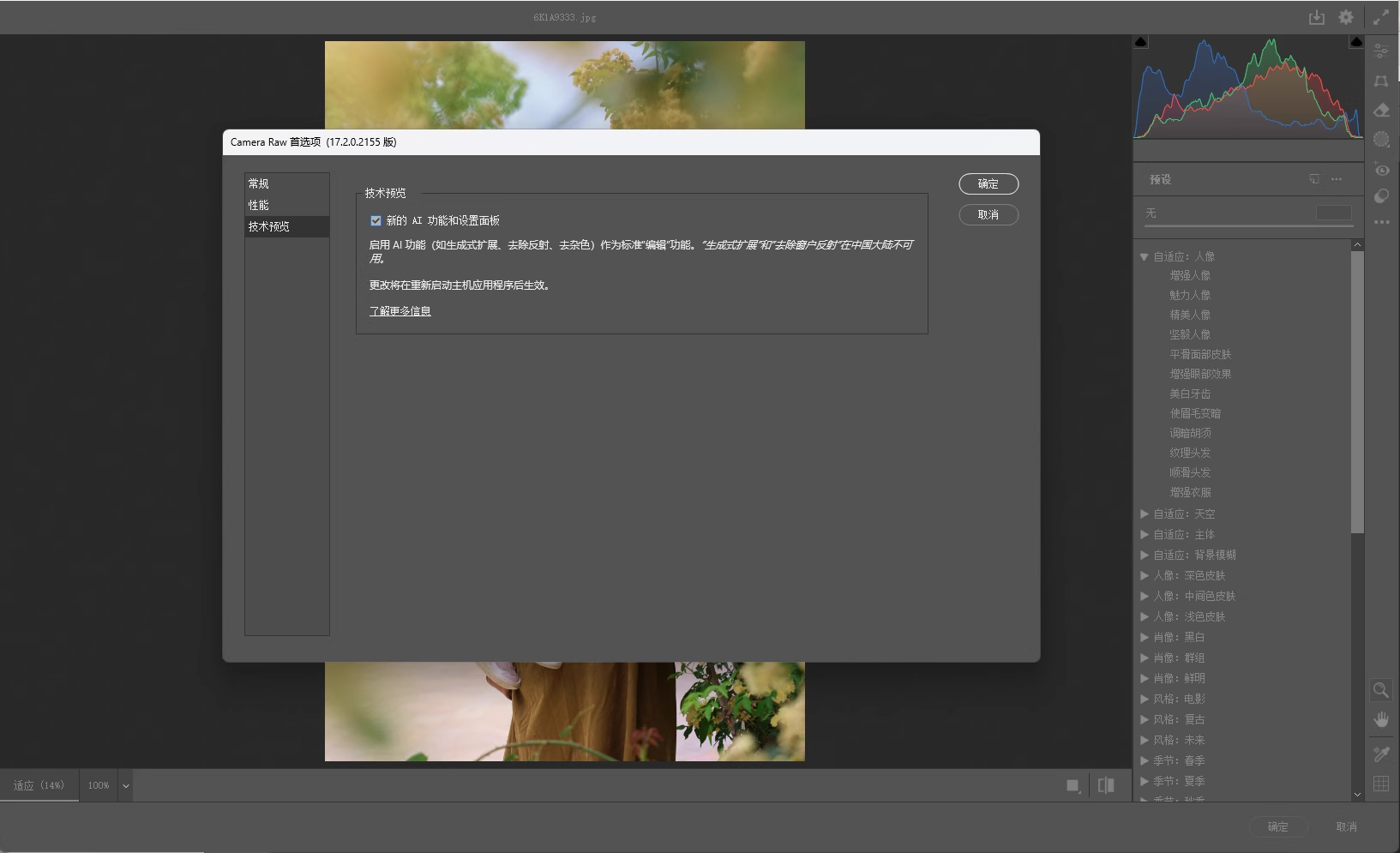
[Windows] Adobe Camera Raw 17.2 win/Mac版本
[Windows] Adobe Camera Raw 链接:https://pan.xunlei.com/s/VOOIAXoyaZcKAkf_NdP-qw_6A1?pwdpd5k# Adobe Camera Raw,支持Photoshop,lightroom等Adobe系列软件,对相片无损格式进行编辑调色。 支持PS LR 2022 2023 2024 2025版…...
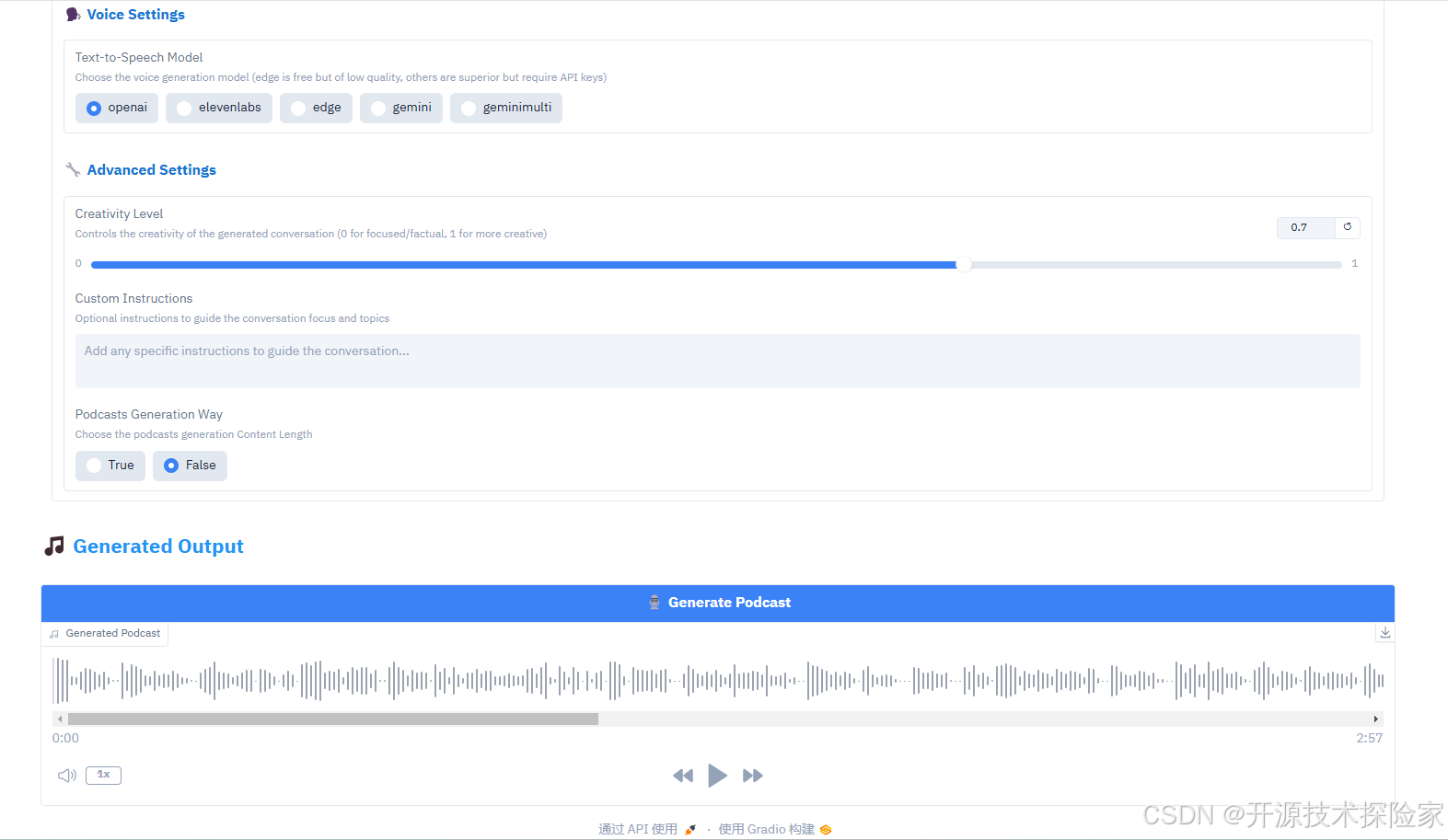
开源模型应用落地-Podcastfy-从文本到声音的智能跃迁-Gradio(一)
一、前言 在当今信息呈现方式越来越多样化的背景下,如何将文字、图片甚至视频高效转化为可听的音频体验,已经成为内容创作者、教育者和研究者们共同关注的重要话题。Podcastfy是一款基于Python的开源工具,它专注于将多种形式的内容智能转换成…...

深入剖析 Java Web 项目序列化:方案选型与最佳实践
在 Java Web 开发中,“序列化”是一个你无法绕过的概念。无论是缓存数据、共享 Session,还是进行远程过程调用(RPC)或消息传递,序列化都扮演着底层数据搬运工的角色。它负责将内存中的 Java 对象转换成可传输或可存储的…...

Python 深度学习实战 第11章 自然语言处理(NLP)实例
Python 深度学习实战 第11章 自然语言处理(NLP)实例 内容概要 第11章深入探讨了自然语言处理(NLP)的深度学习应用,涵盖了从文本预处理到序列到序列学习的多种技术。本章通过IMDB电影评论情感分类和英西翻译任务,详细介绍了如何使…...
:Matplotlib 高级图表定制 - 精雕细琢,让你的图表脱颖而出!)
零基础上手Python数据分析 (19):Matplotlib 高级图表定制 - 精雕细琢,让你的图表脱颖而出!
写在前面 —— 超越默认样式,掌握 Matplotlib 精细控制,打造专业级可视化图表 上一篇博客,我们学习了 Matplotlib 的基础绘图功能,掌握了如何绘制常见的折线图、柱状图、散点图和饼图,并进行了基本的图表元素定制,例如添加标题、标签、图例等。 这些基础技能已经能让我…...
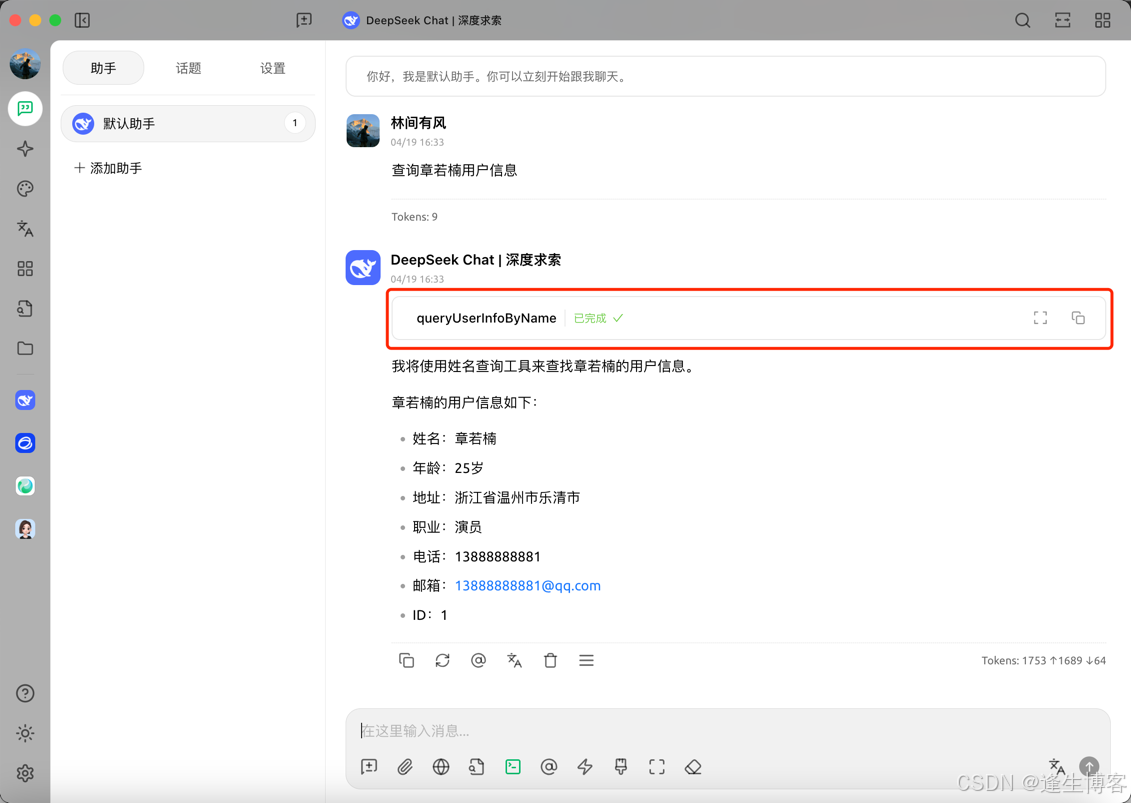
将 DeepSeek 集成到 Spring Boot 项目实现通过 AI 对话方式操作后台数据
文章目录 项目简介本项目分两大模块 GiteeMCP 简介环境要求项目代码核心实现代码MCP 服务端MCP 客户端 DeepSeek APIDockersse 连接ws 连接(推荐)http 连接 vue2-chat-windowCherry Studio配置模型配置 MCP调用 MCP 项目简介 在本项目中,我们…...
《前端面试题之 Vue 篇(第三集)》
目录 1、 nvm的常用命令①.Node.js 版本与 npm 版本的对应关系②Vue2 与 Vue3 项目的 Node.js 版本分界线③版本管理实践建议 2、Vue2 项目搭建(基于 vue-cli Webpack)① 环境准备② 安装 Vue CLI(脚手架)③.创建项目(…...