Python多任务编程:进程全面详解与实战指南
1. 进程基础概念
1.1 什么是进程?
进程(Process)是指正在执行的程序,是程序执行过程中的一次指令、数据集等的集合。简单来说,进程就是程序的一次执行过程,它是一个动态的概念。
想象你打开电脑上的音乐播放器听歌,同时又在用浏览器上网,这两个就是不同的进程。操作系统会为每个运行的程序创建一个进程,让它们看起来像是同时在运行。
1.2 进程的特征
-
动态性:进程有创建、执行、暂停、终止等生命周期
-
并发性:多个进程可以同时存在于内存中,在一段时间内交替执行
-
独立性:每个进程拥有独立的地址空间和系统资源
-
异步性:进程执行速度不可预知,可能随时被中断
1.3 进程与程序的区别
| 区别点 | 程序 | 进程 |
|---|---|---|
| 状态 | 静态的代码集合 | 动态的执行过程 |
| 生命周期 | 永久保存 | 暂时存在 |
| 资源占用 | 不占用系统资源 | 占用CPU、内存等资源 |
2. 进程调度算法
操作系统使用调度算法决定哪个进程可以使用CPU资源:
2.1 先来先服务(FCFS)
-
按照进程到达的顺序执行
-
简单但不利于短作业
-
示例:排队买票,先到先得
processes = ["P1", "P2", "P3"]
for p in processes:print(f"正在执行{p}")2.2 短作业优先(SJF)
-
优先执行预计运行时间短的进程
-
能减少平均等待时间
-
但难以准确预估作业长度
processes = [("P1",3), ("P2",1), ("P3",2)]
processes.sort(key=lambda x: x[1]) # 按执行时间排序2.3 时间片轮转(RR)
-
每个进程分配一个时间片(如100ms)
-
时间片用完就切换到下一个进程
-
公平但上下文切换开销大
from collections import deque
ready_queue = deque(["P1", "P2", "P3"])
time_slice = 1 # 单位时间while ready_queue:p = ready_queue.popleft()print(f"执行{p} {time_slice}单位时间")ready_queue.append(p) # 重新加入队列2.4 多级反馈队列
-
结合了多种算法的优点
-
设置多个优先级不同的队列
-
新进程进入高优先级队列
-
长时间运行的进程会被移到低优先级队列
3. 进程的并行与并发
3.1 基本概念
并行(Parallelism):
指多个任务真正同时执行,需要多核CPU支持。就像餐厅有多个厨师同时做不同的菜。
# 并行示例(假设4核CPU)
from multiprocessing import Pooldef task(n):return n * nif __name__ == '__main__':with Pool(4) as p: # 创建4个进程print(p.map(task, [1, 2, 3, 4])) # 4个任务真正同时执行并发(Concurrency):
指多个任务交替执行,在单核CPU上通过快速切换实现"看似同时"。就像一个厨师轮流做多道菜。
# 并发示例
from multiprocessing import Process
import timedef task(name):print(f"{name}开始")time.sleep(1)print(f"{name}结束")if __name__ == '__main__':processes = []for i in range(3): # 单核CPU上交替执行p = Process(target=task, args=(f"任务{i}",))p.start()processes.append(p)for p in processes:p.join()3.2 关键区别
| 特性 | 并行 | 并发 |
|---|---|---|
| 硬件要求 | 需要多核CPU | 单核即可 |
| 执行方式 | 真正同时执行 | 交替执行 |
| 效率 | 更高(理想情况) | 相对较低 |
| 适用场景 | CPU密集型任务 | I/O密集型任务 |
| 图示 | 🟢🟢🟢(同时进行) | 🟢→🟡→🔴(快速切换) |
3.3 Python中的实现特点
-
GIL限制:由于全局解释器锁(GIL),Python多线程无法实现真正的并行,多进程是Python实现并行的主要方式
-
进程开销:进程创建和上下文切换开销比线程大,适合CPU密集型任务
-
multiprocessing模块:绕过GIL限制,充分利用多核CPU
4. 同步/异步与阻塞/非阻塞
4.1 进程的三种基本状态

4.2 同步 vs 异步
同步(Synchronous):
-
像排队买奶茶,必须等前一个人完成才能轮到你
-
代码示例:
from multiprocessing import Process, Lockdef sync_task(lock, num):with lock: # 同步锁print(f"进程{num}开始工作")time.sleep(1)print(f"进程{num}结束")if __name__ == '__main__':lock = Lock()for i in range(3):Process(target=sync_task, args=(lock, i)).start()异步(Asynchronous):
-
像取号等餐,拿到号后可以去做其他事
-
代码示例:
from multiprocessing import Pooldef async_task(num):print(f"开始异步任务{num}")time.sleep(1)return num * 10if __name__ == '__main__':with Pool(3) as p:results = [p.apply_async(async_task, (i,)) for i in range(3)]for res in results:print(res.get()) # 需要时才获取结果4.3 阻塞 vs 非阻塞
阻塞(Blocking):
-
像打电话订餐,必须等客服回应才能做下一件事
-
典型表现:
join(),get()等方法会阻塞
p = Process(target=time.sleep, args=(5,))
p.start()
p.join() # 这里主程序会阻塞等待
print("子进程结束")非阻塞(Non-blocking):
-
像发短信订餐,发完就可以做其他事
-
典型表现:不调用
join()或使用Queue的nowait
processes = []
for i in range(3):p = Process(target=time.sleep, args=(i,))p.start()processes.append(p)# 主进程继续执行其他代码...
print("主进程继续运行")# 最后再统一等待
for p in processes:p.join()4.4 四种组合模式(重点理解)
-
同步阻塞:
-
最传统的方式
-
示例:直接函数调用,等待返回结果
result = time.sleep(3) # 同步调用,阻塞等待 -
-
同步非阻塞:
-
轮询检查状态
-
示例:检查进程是否完成
while True:if not p.is_alive():breaktime.sleep(0.1) -
-
异步阻塞:
-
较少使用
-
示例:使用回调但主线程等待
def callback(result):print("回调结果:", result)with Pool() as pool:res = pool.apply_async(func, args, callback=callback)res.wait() # 这里又变成了阻塞 -
-
异步非阻塞:
-
最高效的方式
-
示例:使用进程池+回调
def callback(result):print("Got result:", result)with Pool() as pool:for i in range(5):pool.apply_async(func=time.sleep,args=(1,),callback=callback)print("主进程继续执行...")pool.close()pool.join() -
4.5 实际应用场景建议
| 模式 | 适用场景 | Python实现方式 |
|---|---|---|
| 同步阻塞 | 简单线性任务 | 直接函数调用 |
| 同步非阻塞 | 需要轮询的任务 | 循环检查is_alive() |
| 异步阻塞 | 较少使用 | apply_async+wait() |
| 异步非阻塞 | 高并发I/O操作 | 进程池+回调函数 |
4.6 完整代码示例(综合应用)
"""
多进程模式下载器示例
演示并行、异步非阻塞模式
"""
from multiprocessing import Pool
import time
import randomdef download(url):print(f"开始下载 {url}")time.sleep(random.uniform(1, 3)) # 模拟下载时间print(f"完成下载 {url}")return f"{url}_内容"def save_content(result):print(f"保存结果: {result}")if __name__ == '__main__':urls = ["http://example.com/1","http://example.com/2","http://example.com/3","http://example.com/4"]with Pool(4) as pool: # 创建进程池# 异步非阻塞模式提交任务results = [pool.apply_async(download, (url,), callback=save_content) for url in urls]print("主进程可以继续处理其他任务...")# 最终等待所有任务完成pool.close()pool.join()print("所有下载任务完成!")这个示例展示了:
-
并行执行(4个下载任务同时进行)
-
异步非阻塞模式(提交任务后立即继续执行)
-
回调机制(下载完成后自动保存)
5. Python中的进程操作
Python通过multiprocessing模块实现多进程编程,下面介绍几种创建进程的方式。
5.1 方式一:使用Process类直接创建
from multiprocessing import Process
import osdef func(num):print(f"这是一个普通方法{num}")print(f"我是子进程,我的pid:{os.getpid()},我的父进程编号:{os.getppid()}")if __name__ == '__main__':# 创建进程对象p1 = Process(name="路飞", target=func, args=(1,))# 启动进程p1.start()# 输出父进程信息print(f"我是父进程,我的pid:{os.getpid()},我的父进程编号:{os.getppid()}")print(p1)代码解析:
-
导入
Process类和os模块 -
定义目标函数
func,它将在子进程中执行 -
创建
Process实例,指定目标函数和参数 -
调用
start()方法启动进程 -
os.getpid()获取当前进程ID,os.getppid()获取父进程ID
5.2 方式二:继承Process类创建
from multiprocessing import Process
import osclass MyProcess(Process):def __init__(self, *args):super(MyProcess, self).__init__()self.args = argsdef run(self):print(f"我是子进程{self.args[0]}")if __name__ == '__main__':p1 = MyProcess(1)p2 = MyProcess(2)p3 = MyProcess(3)p1.start()p2.start()p3.start()代码解析:
-
自定义类继承
Process类 -
重写
run()方法,定义进程执行逻辑 -
创建自定义类的实例并启动
-
这种方式更面向对象,适合复杂任务
5.3 进程常用方法
from multiprocessing import Process
import timedef fun():print("我是子进程")for i in range(3):time.sleep(5)print(f"我是子进程{i}")if __name__ == '__main__':p1 = Process(name='路飞', target=fun)p1.start()p1.join() # 父进程等待子进程结束for i in range(2):time.sleep(1)print(f"我是父进程{i}")关键方法:
-
p.start():启动进程,并调用该子进程中的p.run() - p.run (): 进程启动时运行的方法,正是它去调用target 指定的函数,我们自定义类的类中一定要实现该方法
-
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。
timeout 是可选的超时时间,需要强调的是, p.join 只能 join 住 start 开启的进程,而不能 join 住 run 开启的进程 -
p.is_alive():如果p仍然运行,返回True
-
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进 程。使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
5.4 进程常用属性
from multiprocessing import Process
import timedef fun():for i in range(10):time.sleep(1)print("我是子进程")if __name__ == '__main__':p = Process(target=fun)p.daemon = True # 设置为守护进程p.start()time.sleep(5)print("我是父进程")重要属性:
-
daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时, p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置守护进程:跟随着父进程的代码执行结束,守护进程就结束 -
name:进程名称 -
pid:进程ID -
exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
6. 进程同步与通信
6.1 进程间数据隔离
from multiprocessing import Processdef work():global nn = 0print('子进程内: ', n)if __name__ == '__main__':n = 100p = Process(target=work)p.start()print('主进程内: ', n)输出结果:
主进程内: 100
子进程内: 0解释:进程间内存空间独立,修改子进程中的变量不会影响父进程。
7. 实际应用建议
-
CPU密集型任务:适合使用多进程,可以充分利用多核CPU
-
I/O密集型任务:多线程可能更合适,避免进程创建开销
-
守护进程:用于执行后台任务,如日志记录、监控等
-
进程池:当需要创建大量进程时,考虑使用
Pool类
8. 注意事项
-
Windows平台必须使用
if __name__ == '__main__':保护主代码 -
进程创建和销毁开销较大,不宜创建过多进程
-
进程间通信需要使用队列(Queue)或管道(Pipe)等机制
-
避免僵尸进程(子进程结束但父进程未回收资源)
相关文章:
Python多任务编程:进程全面详解与实战指南
1. 进程基础概念 1.1 什么是进程? 进程(Process)是指正在执行的程序,是程序执行过程中的一次指令、数据集等的集合。简单来说,进程就是程序的一次执行过程,它是一个动态的概念。 想象你打开电脑上的音乐播放器听歌,…...
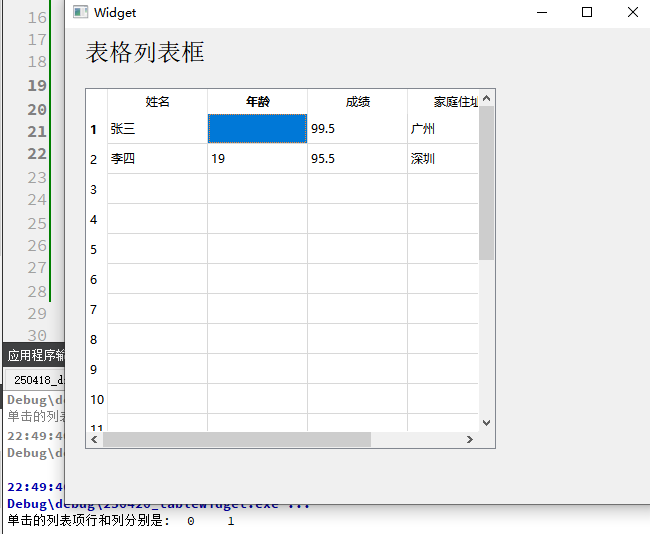
【QT】 QT中的列表框-横向列表框-树状列表框-表格列表框
QT中的列表框-横向列表框-树状列表框-表格列表框 1.横向列表框(1)主要方法(2)信号(3) 示例代码1:(4) 现象:(5) 示例代码2:加载目录项在横向列表框显示(6) 现象: 2.树状列表框 QTreeWidget(1)使用思路(2)信号(3)常用的接口函数(4) 示例代码&am…...

决策树:ID3,C4.5,CART树总结
树模型总结 决策树部分重点关注分叉的指标,多叉还是单叉,处理离散还是连续值,剪枝方法,以及回归还是分类 一、决策树 ID3(Iterative Dichotomiser 3) 、C4.5、CART决策树 ID3:确定分类规则判别指标、寻找能够最快速降低信息熵的方…...

easyexcel使用模板填充excel坑点总结
1.单层map设置值是{属性},那使用两层map进行设置值,是不是可以使用{属性.属性},以为取出map里字段只用{属性}就可以设置值,那再加个.就可以从里边map取出对应属性,没有两层map写法 填充得到的文件打开报错 was empty (…...

量子计算与经典计算融合:开启计算新时代
一、引言 随着科技的飞速发展,计算技术正迎来一场前所未有的变革。量子计算作为前沿技术,以其强大的并行计算能力和对复杂问题的高效处理能力,吸引了全球科技界的关注。然而,量子计算并非要完全取代经典计算,而是与经典…...

C# LINQ基础知识
简介 LINQ(Language Integrated Query),语言集成查询,是一系列直接将查询功能集成到 C# 语言的技术统称。使用LINQ表达式可以对数据集合进行过滤、排序、分组、聚合、串联等操作。 例子: public class Person {public int Id;public string…...
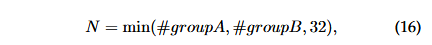
GCoNet+:更强大的团队协作 Co-Salient 目标检测器 2023 GCoNet+(翻译)
摘要 摘要:本文提出了一种新颖的端到端群体协作学习网络,名为GCoNet,它能够高效(每秒250帧)且有效地识别自然场景中的共同显著目标。所提出的GCoNet通过基于以下两个关键准则挖掘一致性表示,实现了共同显著…...

QT常见输入类控件及其属性
Line Edit QLineEdit用来表示单行输入框,可以输入一段文本,但是不能换行 核心属性: 核心信号 信号 说明 void cursorPositionChanged(int old,int new) 当鼠标移动时发出此型号,old为先前位置,new为新位置 void …...
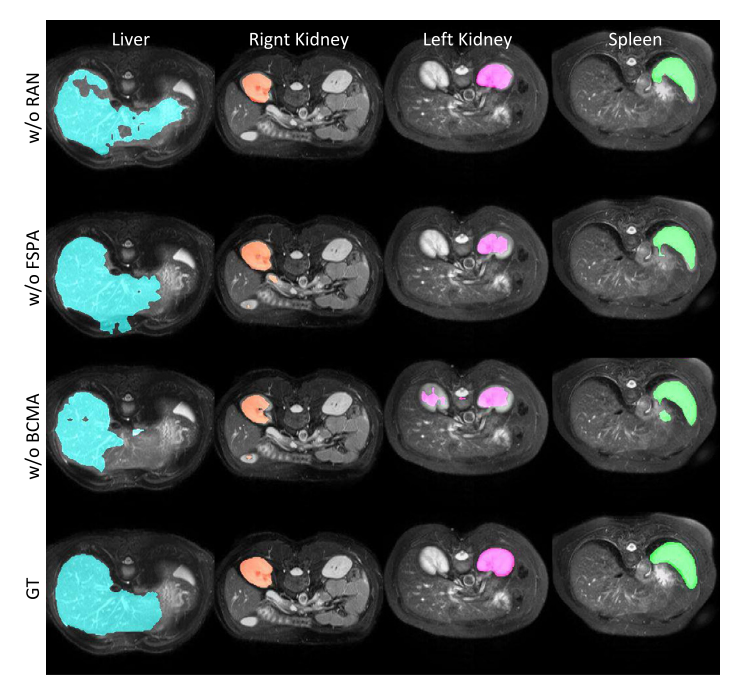
Few-shot medical image segmentation with high-fidelity prototypes 论文总结
题目:Few-shot medical image segmentation with high-fidelity prototypes(高精确原型) 论文:Few-shot medical image segmentation with high-fidelity prototypes - ScienceDirect 源码:https://github.com/tntek/D…...

DBA工作常见问题整理
MVCC机制: PostgreSQL的多版本并发控制(MVCC)是其核心特性之一,它允许数据库在高并发环境下保持高性能的同时提供事务隔离。 MVCC通过维护数据的多个版本实现: 读操作不阻塞写操作写操作不阻塞读操作避免使用锁实现并发控制 PostgreSQL的MVCC特点 写时…...

深入理解Java包装类:自动装箱拆箱与缓存池机制
深入理解Java包装类:自动装箱拆箱与缓存池机制 对象包装器 Java中的数据类型可以分为两类:基本类型和引用类型。作为一门面向对象编程语言, 一切皆对象是Java语言的设计理念之一。但基本类型不是对象,无法直接参与面向对象操作&…...
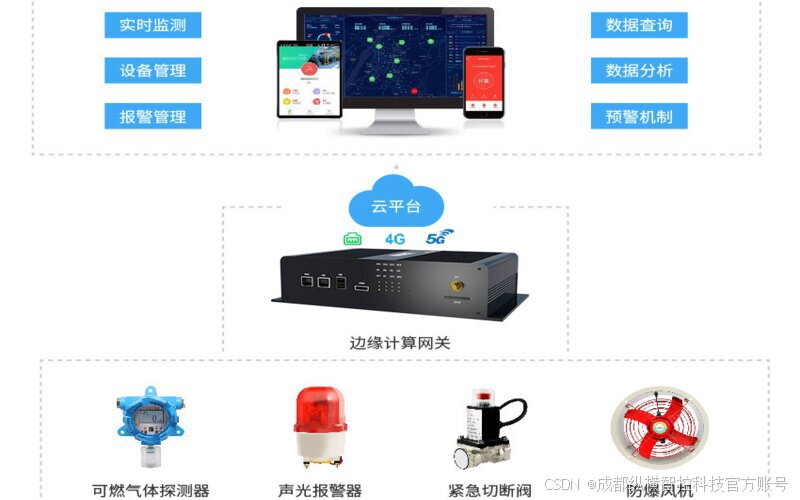
如何使用Node-RED采集西门子PLC数据通过MQTT协议实现数据交互并WEB组态显示
需求概述 本章节主要实现一个流程:使用纵横智控的EG网关通过Node-red(可视化编程)采集PLC数据,并通过MQTT协议和VISION(WEB组态)实现数据交互。 以采集西门子PLC为例,要采集的PLC的IP、端口和点…...
【cocos creator 3.x】速通3d模型导入, 模型创建,阴影,材质使用,模型贴图绑定
1、右键创建平面,立方体 2、点击场景根节点,shadows勾选enabled3、点击灯光,shadow enabled勾选 4、点击模型,勾选接收阴影,投射阴影(按照需要勾选) 5、材质创建 6、选中节点,找…...

批量创建OpenStack实例
在Linux终端实现批量创建OpenStack实例,支持支持统计、并发创建、安全确认、重试机制、日志。 #!/bin/bash # # 增强版OpenStack实例创建脚本(修复日志功能) # 功能:支持统计、并发创建、安全确认、重试机制 # 更新日期…...

常用的 SQL 语句分类整理
以下是常用的 SQL 语句分类整理,覆盖数据查询、操作、表管理和高级功能,适用于大多数关系型数据库(如 MySQL、PostgreSQL、SQL Server): 目录 一、数据查询(DQL) 1. 基础查…...
驱动开发硬核特训 · Day 15:电源管理核心知识与实战解析
在嵌入式系统中,电源管理(Power Management)并不是“可选项”,而是实际部署中影响系统稳定性、功耗、安全性的重要一环。今天我们将以 Linux 电源管理框架 为基础,从理论结构、内核架构,再到典型驱动实战&a…...

【零基础】基于DeepSeek-R1与Qwen2.5Max的行业洞察自动化平台
自动生成行业报告,通过调用两个不同的大模型(DeepSeek 和 Qwen),完成从行业趋势分析到结构化报告生成的全过程。 完整代码:https://mp.weixin.qq.com/s/6pHi_aIDBcJKw1U61n1uUg 🧠 1. 整体目的与功能 该脚本实现了一个名为 ReportGenerator 的类,用于: 调用 DeepSe…...
)
Web前端 (CSS篇)
什么是CSS? css(Cascading Style Sheets)是层叠样式表或级联样式表,是一组设置规则,用于控制web页面外观。 为什么使用CSS? CSS 用于定义网页的样式,包括针对不同设备和屏幕尺寸的设计和布局。 CSS 实例 body {background-col…...
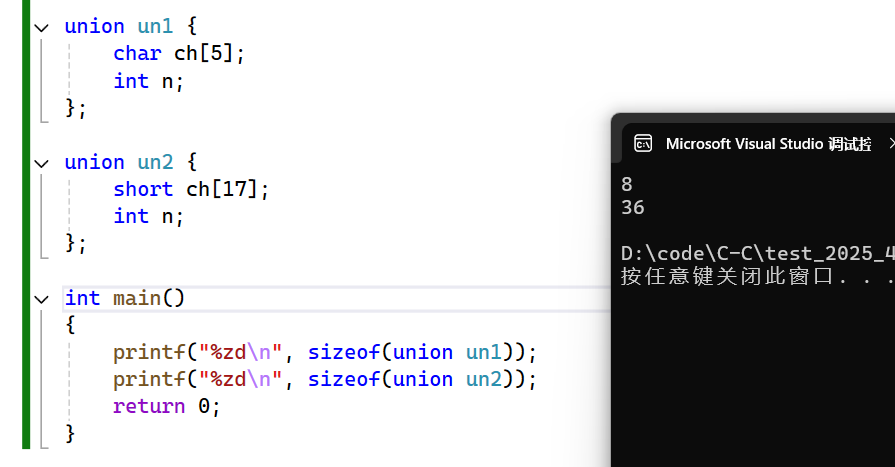
C 语言联合与枚举:自定义类型的核心解析
目录 1.联合体 1.1联合体的声明与创建 1.2联合体在内存中的存储 1.3相同成员的结构体与内存比较 1.4联合体内存空间大小的计算 1.5联合体的应用 2.枚举类型 2.1枚举变量的声明 2.2枚举变量的优点 2.3枚举的使用 上篇博客中,我们通过学习了解了C语言中一种自…...

基于Canal+Spring Boot+Kafka的MySQL数据变更实时监听实战指南
前期知识背景 binlog 什么是binlog 它记录了所有的DDL和DML(除 了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进制日志是事务安全型的。一般来说开启二进制日志大概会有1%的性能损耗。 binlog分类 MySQL Bi…...

MySQL运维三部曲初级篇:从零开始打造稳定高效的数据库环境
文章目录 一、服务器选型——给数据库一个舒适的家二、系统调优——打造高性能跑道三、MySQL配置——让数据库火力全开四、监控体系——数据库的体检中心五、备份恢复——数据安全的最后防线六、主从复制——数据同步的艺术七、安全加固——守护数据长城 引言:从小白…...

golang context源码
解析 context结构 Deadline:返回 context 的过期时间; Done:返回 context 中的 channel; Err:返回错误; Value:返回 context 中的对应 key 的值. type Context interface {Deadline() (deadl…...

【MySQL】MySQL的基础语法及其语句的介绍
1、基础语法 mysql -h【主机名】 -u【用户名】 -p //登录MySQL exit或quit; //退出MySQL show database; //查看MySQL下的所有数据库 use 【数据库名】; //进入数据库 show tables; //查看数据库下的所有表名 *MySQL的启动和关闭 &am…...

大模型应用开发自学笔记
理论学习地址: https://zh.d2l.ai/chapter_linear-networks/index.html autodl学术加速: source /etc/network_turboconda常见操作: 删除: conda remove --name myenv --all -y导出: conda env export > environment.yml…...

Spring能够有效地解决单例Bean之间的循环依赖问题
在Spring框架中,earlySingletonObjects和singletonObjects是两个与Bean实例化过程密切相关的概念,它们都存储在DefaultSingletonBeanRegistry类中。这两个概念主要用于Spring的依赖注入机制,特别是针对单例Bean的创建过程。 singletonObject…...

【计算机视觉】三维视觉项目 - Colmap二维图像重建三维场景
COLMAP 3D重建 项目概述项目功能项目运行方式1. 环境准备2. 编译 COLMAP3. 数据准备4. 运行 COLMAP 常见问题及解决方法1. **编译问题**2. **运行问题**3. **数据问题** 项目实战建议项目参考文献 项目概述 COLMAP 是一个开源的三维重建软件,专注于 Structure-from…...
)
Linux 离线部署 Docker 18.06.3 终极指南(附一键安装卸载脚本)
Linux 离线部署 Docker 18.06.3 终极指南(附一键安装/卸载脚本) 摘要:本文针对无外网环境的 Linux 服务器,提供基于二进制包的 Docker 18.06.3 离线安装全流程指南。包含自动化脚本设计、服务配置优化及安全卸载方案,…...
ALSA架构学习2(驱动MAX98357A)
1 前言和环境 之前其实写过两篇,一篇是讲ALSA,一篇是I2S。 ALSA架构学习1(框架)_alsa框架学习-CSDN博客 总线学习5--I2S_max98357接喇叭教程-CSDN博客 在ALSA那篇的结尾,也提了几个小练习。比如: ### 4…...
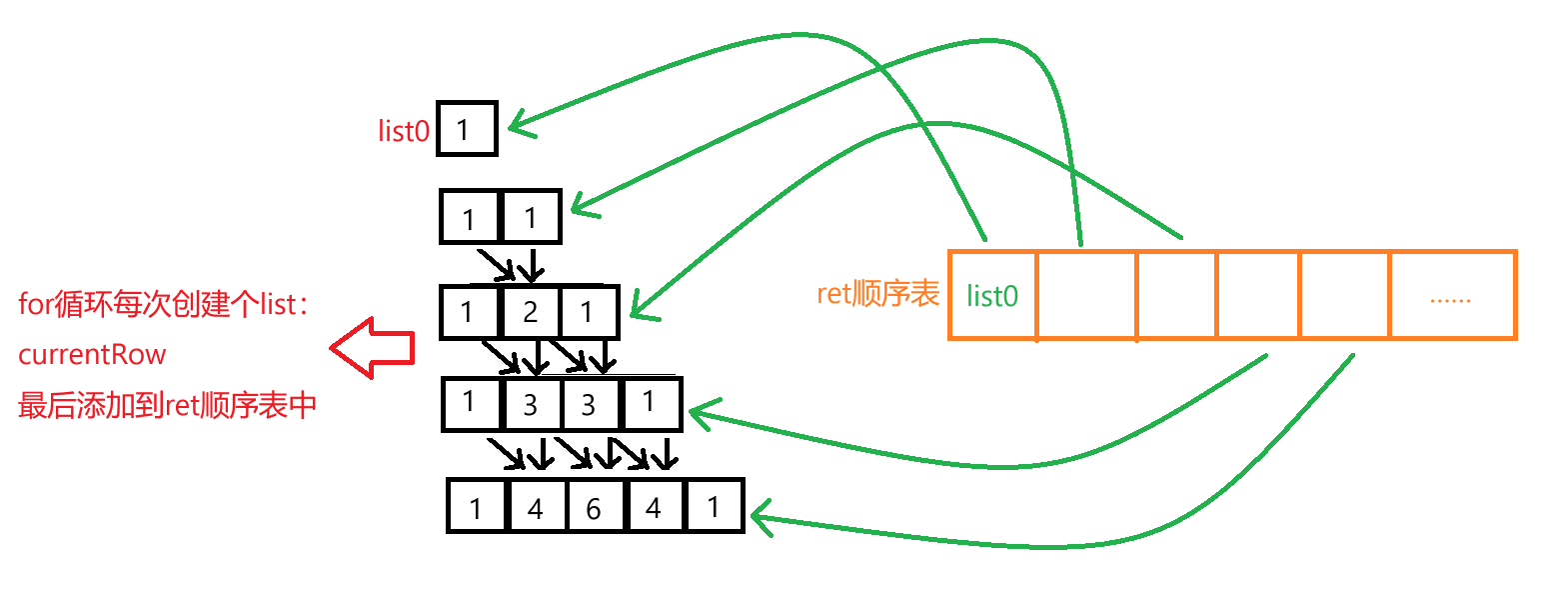
数据结构*集合框架顺序表-ArrayList
集合框架 常见的集合框架 什么是顺序表 顺序表是一种线性表数据结构,它借助一组连续的存储单元来依次存储线性表中的数据元素。一般情况下采用数组存储。 在数组上完成数据的增删查改。 自定义简易版的顺序表 代码展示: public interface IArray…...
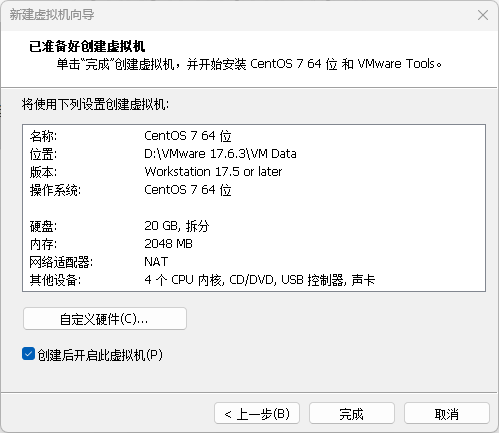
VMware Workstation 保姆级 Linux(CentOS) 创建教程(附 iso)
文章目录 一、下载二、创建 一、下载 CentOS-7.9-x86_64-DVD-2009.iso 二、创建 VMware Workstation 保姆级安装教程(附安装包) VMware Workstation 保姆级安装教程(附安装包) VMware Workstation 保姆级安装教程(附安装包)...