【技术追踪】Differential Transformer(ICLR-2025)
Differential Transformer:大语言模型新架构, 提出了 differential attention mechanism,Transformer 又多了一个小 trick~
论文:Differential Transformer
代码:https://github.com/microsoft/unilm/tree/master/Diff-Transformer
0、摘要
Transformer 倾向于过度分配注意力到无关的上下文。在这项工作中,本文引入了 DIFF Transformer,它放大了对相关上下文的注意力,同时消除了噪声。(大佬的表述总是那么简单朴素~)
具体来说,差分注意力机制(differential attention mechanism)将注意力分数计算为两个独立的 softmax 注意力图之间的差。减法可以消除噪声,促进稀疏注意力模式的出现。
语言建模的实验结果表明,DIFF Transformer 在模型规模和训练 tokens 的各种设置中都优于 Transformer。更有趣的是,它在实际应用中提供了显著的优势,如长上下文建模、关键信息检索、幻觉缓解、上下文学习和激活异常值的减少。
通过减少对无关上下文的干扰,DIFF Transformer 可以减轻问题回答和文本摘要中的幻觉。在上下文学习中,DIFF Transformer 不仅提高了准确率,还增强了对顺序排列的鲁棒性,这曾被认为是一个长期存在的稳定性问题。这些结果表明,DIFF Transformer 是一种非常有效且极具潜力的架构,能够推动大型语言模型的发展。(有种 ResNet 那种大道至简的感觉)
1、引言
1.1、当前挑战
(1)Transformer 的核心是注意力机制,它利用 Softmax 函数来衡量序列中各个 tokens 的重要性;
(2)最近的研究表明,大语言模型在准确检索上下文中的关键信息方面面临挑战;
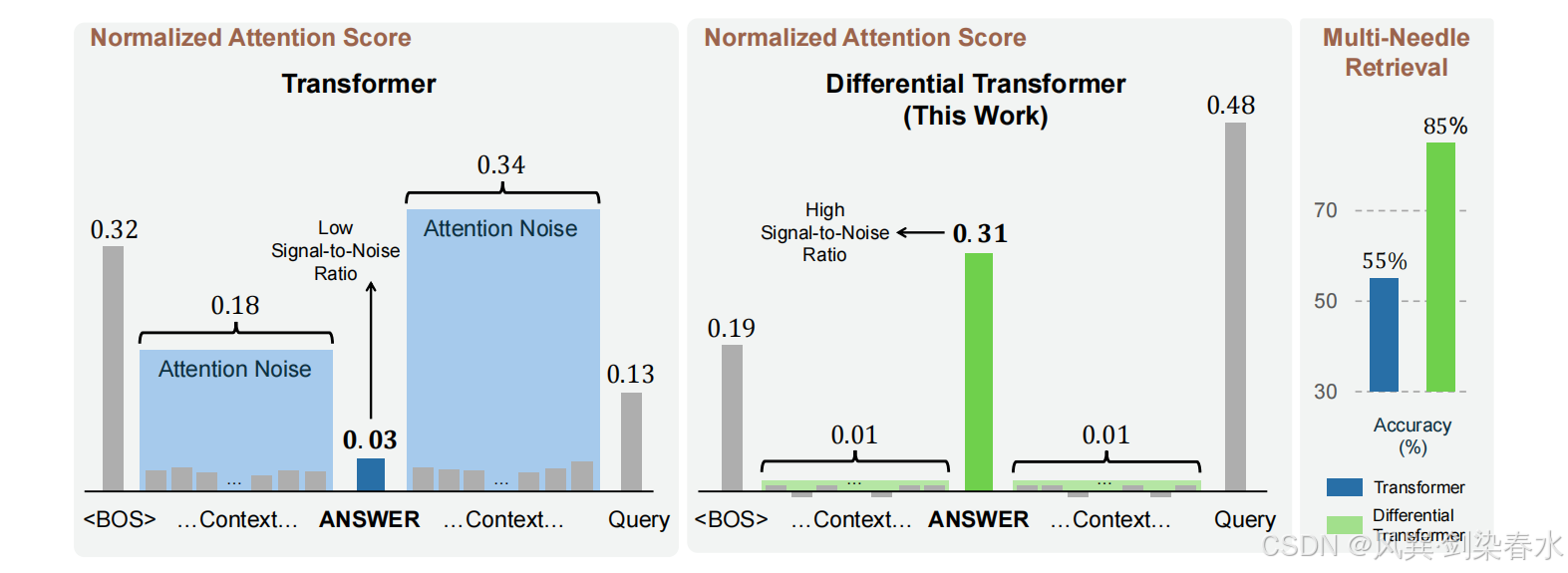
(3)Transformer 倾向于只将一小部分注意力分数分配给正确答案,而过度关注无关的上下文(如 图1 所示);
(4)分配在无关上下文上不可忽略的注意力分数,最终淹没了正确答案。本文将这些多余的分数称为注意力噪声。
Figure 1 | Transformer 经常过度关注无关的上下文:DIFF Transformer 强化了对答案片段的注意力,同时消除了噪声,从而提升了上下文建模的能力;
1.2、本文贡献
(1)介绍了差分 Transformer(DIFF Transformer),这是一种大型语言模型的基础架构。差分注意力机制被提出用于通过差分去噪,消除注意力噪声;
(2)与 Transformer 相比,DIFF Transformer 对正确答案的评分显著更高,而对无关上下文的评分则低得多, 图1右侧 显示,所提出的方法在检索能力方面取得了显著改进;
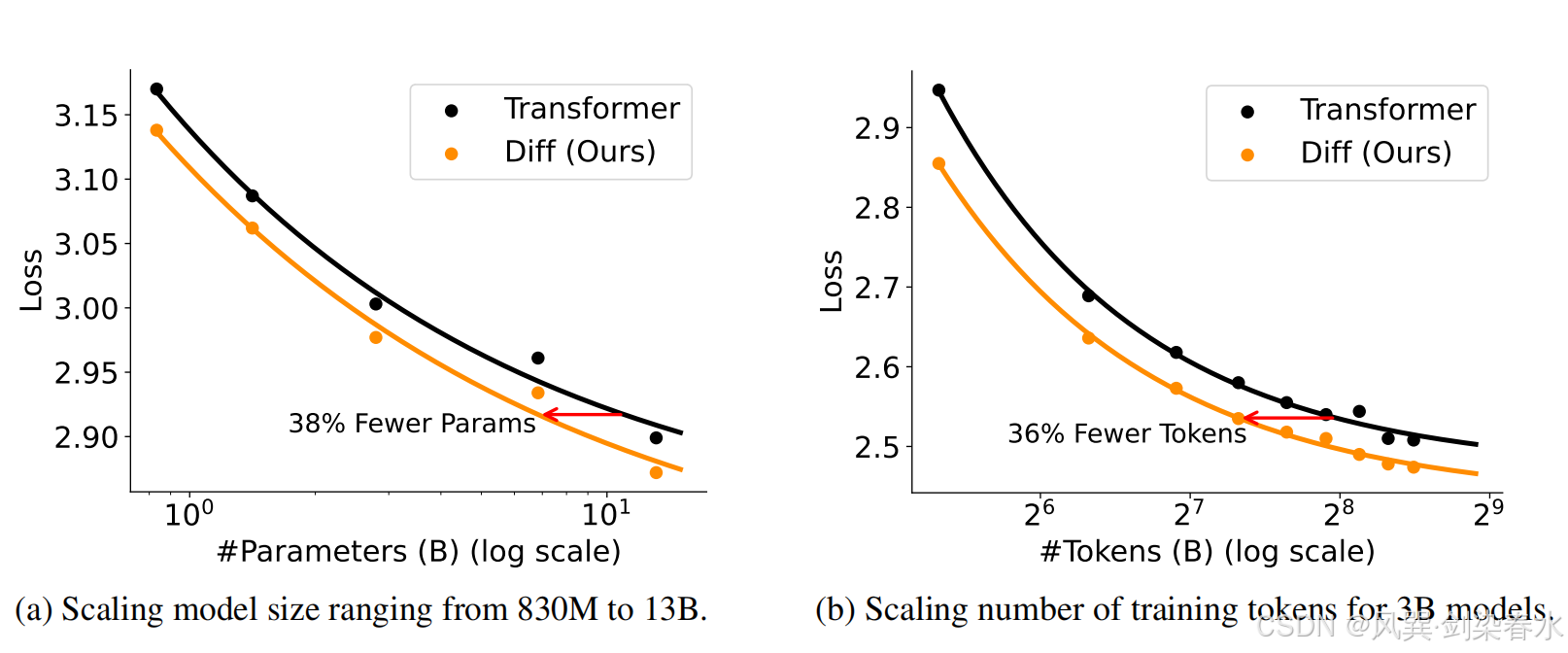
(3)规模扩展曲线表明,DIFF Transformer 只需要大约 65% 的模型大小或训练 tokens 数量,就能达到与 Transformer 相当的语言建模性能,此外,DIFF Transformer 在各种下游任务中的表现也优于 Transformer;
2、Differential Transformer
本文提出差分 Transformer(DIFF Transformer)作为序列建模的基础架构,例如大型语言模型(LLM)。本文以解码器模型为例来描述该架构,模型由 L L L 个 DIFF Transformer 层堆叠而成。
给定输入序列 x = x 1 . . . , x N x = x_1..., x_N x=x1...,xN,将输入嵌入打包到 X 0 = [ x 1 , ⋅ ⋅ ⋅ , x N ] ∈ R N × d m o d e l X^0 = [x1,···,xN ]∈\mathbb{R}^{N×d_{model}} X0=[x1,⋅⋅⋅,xN]∈RN×dmodel 中,其中 d m o d e l d_{model} dmodel 表示隐藏维度。进一步对输入进行上下文化处理,以获得输出 X L X^L XL,即 X l = D e c o d e r ( X l − 1 ) , l ∈ [ 1 , L ] X^l =Decoder(X^{l−1}),l∈[1, L] Xl=Decoder(Xl−1),l∈[1,L]。每一层由两个模块组成:一个差分注意力模块(differential attention module),随后是一个前馈网络模块(feed-forward network module)。
与 Transformer 相比,主要区别在于用差分注意力(differential attention)替换了传统的 softmax 注意力,而宏观布局保持不变。本文还采用了 pre-RMSNorm 和 SwiGLU,作为 LLaMA 之后的改进。
2.1、Differential Attention
差分注意力机制将查询向量、键向量和值向量映射到输出。利用查询向量和键向量来计算注意力分数,随后计算值向量的加权和。其关键设计在于,采用一对 Softmax 函数来消除注意力分数中的噪声。
具体来说,给定输入 X ∈ R N × d m o d e l X \in \mathbb{R}^{N×d_{model}} X∈RN×dmodel,首先将它们投影到查询、键和值, Q 1 , Q 2 , K 1 , K 2 ∈ R N × d , V ∈ R N × 2 d Q_1,Q_2,K_1,K_2 \in \mathbb{R}^{N×d},V \in \mathbb{R}^{N×2d} Q1,Q2,K1,K2∈RN×d,V∈RN×2d。然后,差分注意力算子 D i f f A t t n ( ⋅ ) DiffAttn(·) DiffAttn(⋅)通过以下方式计算输出:
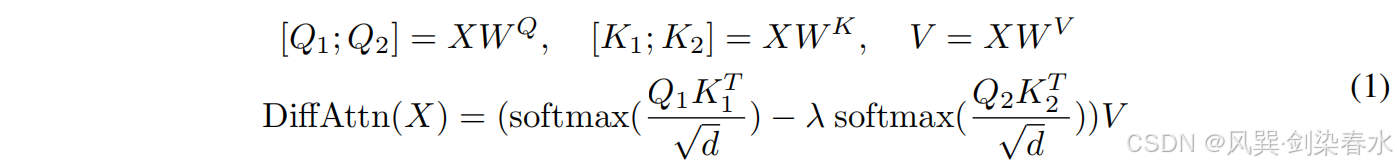
其中 W Q , W K , W V ∈ R d m o d e l × 2 d W^Q,W^K,W^V \in \mathbb{R}^{d_{model}×2d} WQ,WK,WV∈Rdmodel×2d 为参数, λ \lambda λ 为可学习标量。为了同步学习动态,将标量 λ \lambda λ 重新参数化为:
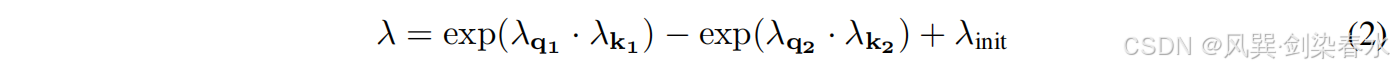
其中 λ q 1 , λ k 1 , λ q 2 , λ k 2 ∈ R d λ_{q1},λ_{k1},λ_{q2},λ_{k2} \in \mathbb{R}^d λq1,λk1,λq2,λk2∈Rd 是可学习向量, λ i n i t ∈ ( 0 , 1 ) λ_{init}∈(0,1) λinit∈(0,1) 是用于 λ \lambda λ 初始化的常数。本文通过实验发现 λ i n i t = 0.8 − 0.6 × e x p ( − 0.3 ⋅ ( l − 1 ) ) λ_{init} = 0.8−0.6×exp(−0.3·(l−1)) λinit=0.8−0.6×exp(−0.3⋅(l−1)) 在实际应用中效果良好,其中, l ∈ [ 1 , L ] l∈[1,L] l∈[1,L] 表示层索引。在实验中,它被用作默认策略。本文还探索了使用相同的 λ i n i t λ_{init} λinit(例如 0.8)对所有层进行初始化,作为另一种初始化策略。如消融研究(第 3.8 节)所示,不同的初始化策的性能相对稳健。
差分注意力机制通过计算两个 Softmax 注意力函数之间的差异来消除注意力噪声。这一思想类似于电气工程中提出的差分放大器,其中两个信号之间的差异被用作输出,从而可以抵消输入的共模噪声。Naderi 等人也证明了差分注意力机制可以使注意力矩阵的谱分布更加均衡,从而有效地解决了秩坍塌问题。此外,降噪耳机的设计也是基于类似的思想。正如附录 A 所描述的,可以直接使用 FlashAttention,这显著提高了模型的效率。
Figure 2 | 多头差分注意力:每个头使用两个 Softmax 图之间的差异来消除注意力噪声。 λ \lambda λ 是一个可学习的标量,初始化为 λ i n i t λ_{init} λinit。GroupNorm 对每个头独立应用归一化。在 GroupNorm 后使用一个固定的乘数 ( 1 − λ i n i t ) (1-λ_{init}) (1−λinit),以使梯度流动与 Transformer 对齐;
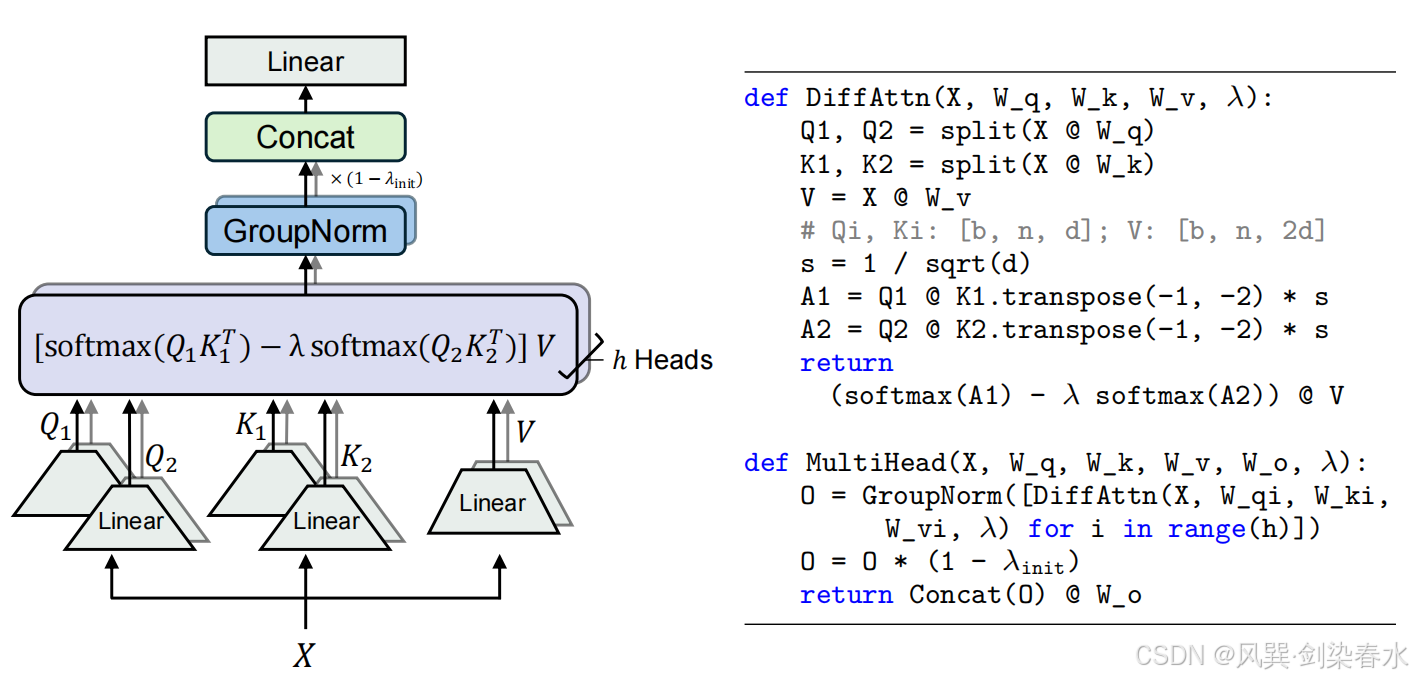
Multi-Head Differential Attention
在 Differential Transformer 中也使用了多头机制,设 h h h 表示注意力头的数量。使用不同的投影矩阵 W i Q , W i K , W i V , i ∈ [ 1 , h ] W_i^Q, W_i^K, W_i^V, i∈[1,h] WiQ,WiK,WiV,i∈[1,h] 用于不同 head。标量 λ \lambda λ 在同层的 head 之间共享。然后 head 输出被归一化并投影到最终结果,如下所示:
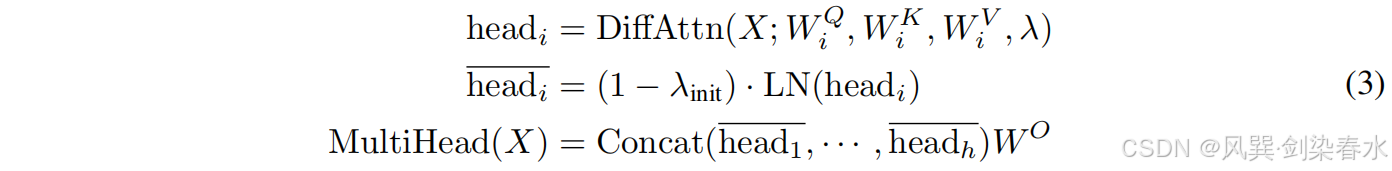
其中 λ i n i t λ_{init} λinit 是公式 (2) 中的常数标量, W O ∈ R d m o d e l × d m o d e l W^O∈R^{d_{model}×d_{model}} WO∈Rdmodel×dmodel 是一个可学习的投影矩阵, L N ( ⋅ ) LN(·) LN(⋅) 对每个头使用 RMSNorm, C o n c a t ( ⋅ ) Concat(·) Concat(⋅) 沿着通道维度将头连接在一起。
本文使用一个固定的乘数 ( 1 − λ i n i t ) (1-λ_{init}) (1−λinit) 作为 L N ( ⋅ ) LN(·) LN(⋅) 的尺度,使梯度与 Transformer 保持一致。附录 G 证明了整体梯度流与 Transformer 保持相似。这一优良特性使我们能够直接继承类似的超参数,并确保训练的稳定性。本文设头的数量为 h = d m o d e l / 2 d h = d_{model}/2d h=dmodel/2d,其中 d d d 等于 Transformer 的头维度,这样就可以对齐参数数量和计算复杂度。
Headwise Normalization
图 2 使用了 G r o u p N o r m ( ⋅ ) GroupNorm(·) GroupNorm(⋅) 来强调 L N ( ⋅ ) LN(·) LN(⋅) 是独立应用于每个头的。由于差分注意力倾向于产生更稀疏的模式,因此不同头之间的统计信息更加多样化。 L N ( ⋅ ) LN(·) LN(⋅) 操作符在拼接之前对每个头进行归一化,以改善梯度统计信息。
2.2、总体结构
整体架构由 L L L 层组成,每层包含一个多头差分注意力模块和一个前馈网络模块。本文将 Differential Transformer 层描述为:

其中 L N ( ⋅ ) LN(·) LN(⋅) 是 RMSNorm, S w i G L U ( X ) = ( s w i s h ( X W G ) ⊙ X W 1 ) W 2 SwiGLU(X) =(swish(XW^G)⊙XW_1)W_2 SwiGLU(X)=(swish(XWG)⊙XW1)W2 和 W G , W 1 ∈ R d m o d e l × 8 3 d m o d e l , W 2 ∈ R 8 3 d m o d e l × d m o d e l W^G, W_1∈\mathbb{R}^{d_{model}×\frac{8}{3} d_{model}}, W_2∈\mathbb{R}^{\frac{8}{3}d_{model}×d_{model}} WG,W1∈Rdmodel×38dmodel,W2∈R38dmodel×dmodel 是可学习矩阵。
3、实验与结果
本文从以下几方面对用于大型语言模型的 Differential Transformer 进行了评估。首先,在各种下游任务中将所提出的架构与 Transformer 进行比较(第3.1节),并研究扩大模型规模和训练标记数量的特性(第3.2节)。其次,将序列长度扩展至 64K,并评估其长序列建模能力(第3.3节)。第三,展示了关键信息检索、上下文幻觉评估以及上下文学习的结果(第3.4至3.6节)。第四,我们表明本文认为,与 Transformer 相比,Differential Transformer 能够减少模型激活中的异常值(第3.7节)。最后,本文针对各种设计选择进行了广泛的消融研究(第3.8节)。
3.1、语言模型评估
Table 1 | :使用 Eval Harness 来比较经过良好训练的 Transformer 语言模型的准确率。我们将 3B 模型的训练标记数量扩展到 1 万亿。StableLM-3B-4E1T 的 1T 结果取自其技术报告;

3.2、与 Transformer 相比的可扩展性
Figure 3 | 扩大参数数量和训练标记数量时的语言建模损失:DIFF Transformer 只需大约 65% 的模型规模或训练标记数量,就能达到与 Transformer 相当的性能;
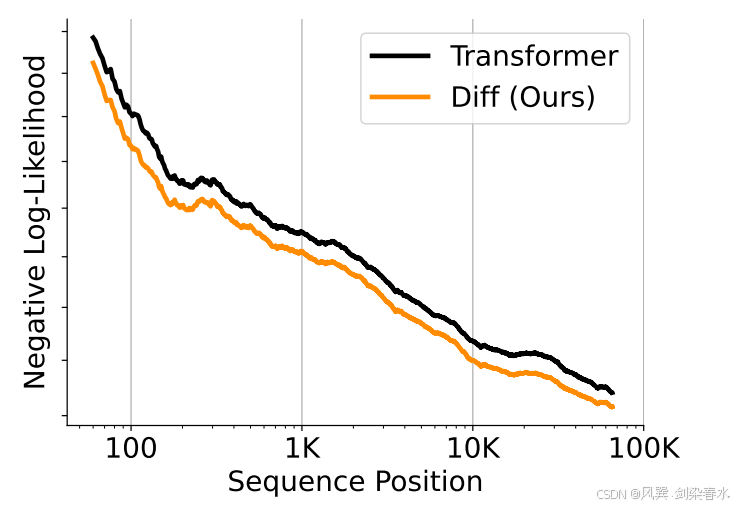
3.3、长语境评估
Figure 4 | 在图书数据上的累积平均负对数似然(越低越好):DIFF Transformer 更有效地利用了长文本上下文;
3.4、关键信息检索
Table 2 | 在 4K 长度下的多针检索准确率,结果对答案针的位置进行了平均: N N N 表示针的数量,而 R R R 表示查询城市的数量;
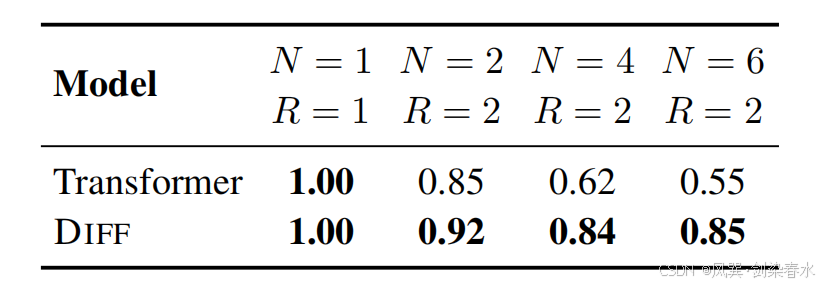
Figure 5 | 在 64K 长度下的多针检索结果:
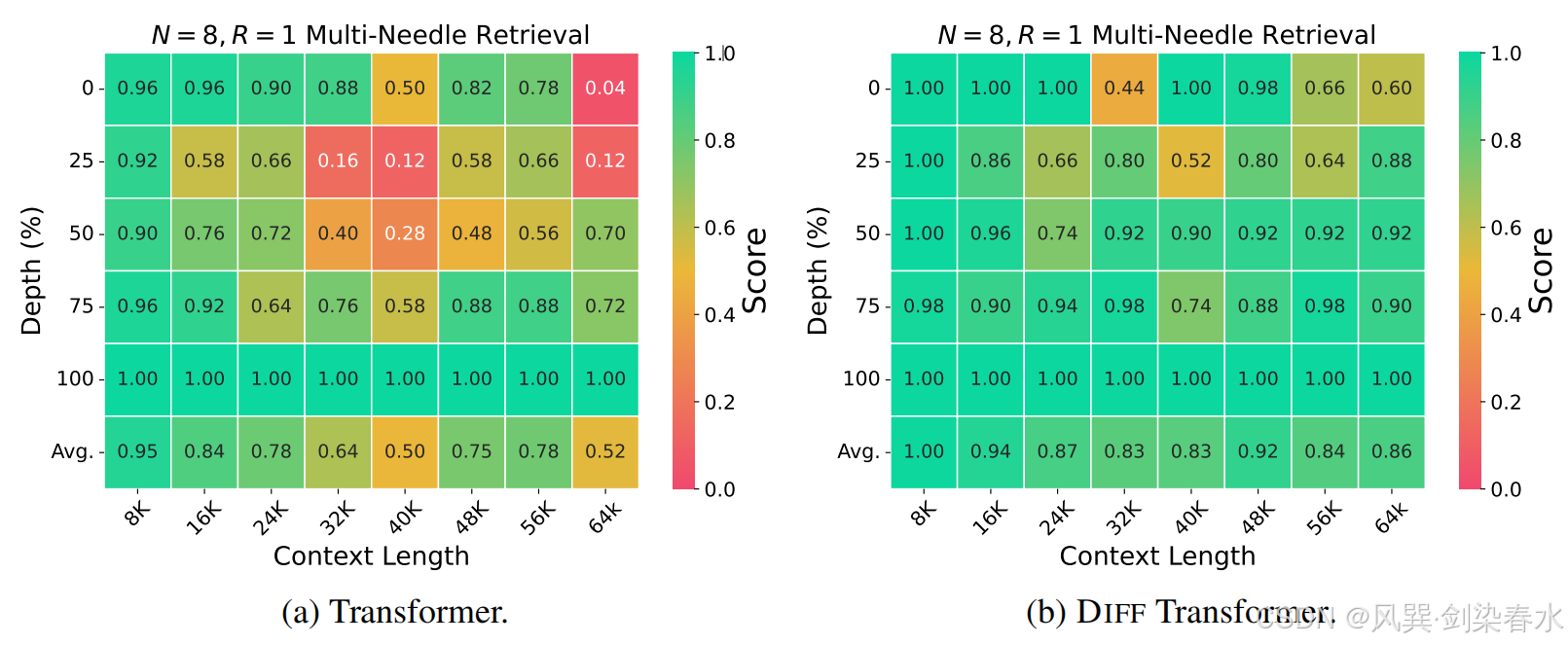
Table 3 | 在关键信息检索任务中,分配给答案片段和噪声上下文的注意力分数:目标答案被插入到上下文的不同位置(即深度),DIFF Transformer 更多地将注意力分数分配给有用的信息,并有效地消除了注意力噪声;

3.5、情境学习
从两个角度对情境学习进行评估,包括多镜头分类(many-shot classification)和情境学习(in-context learning)的鲁棒性。情境学习是语言模型的基本能力,表明模型利用输入情境的能力。
Figure 6 | 在四个数据集上的 Many-shot in-context learning 准确率:演示示例从单镜头(1-shot)开始,逐渐增加,直到总长度达到 64K 个标记,虚线表示在性能稳定后达到的平均准确率;
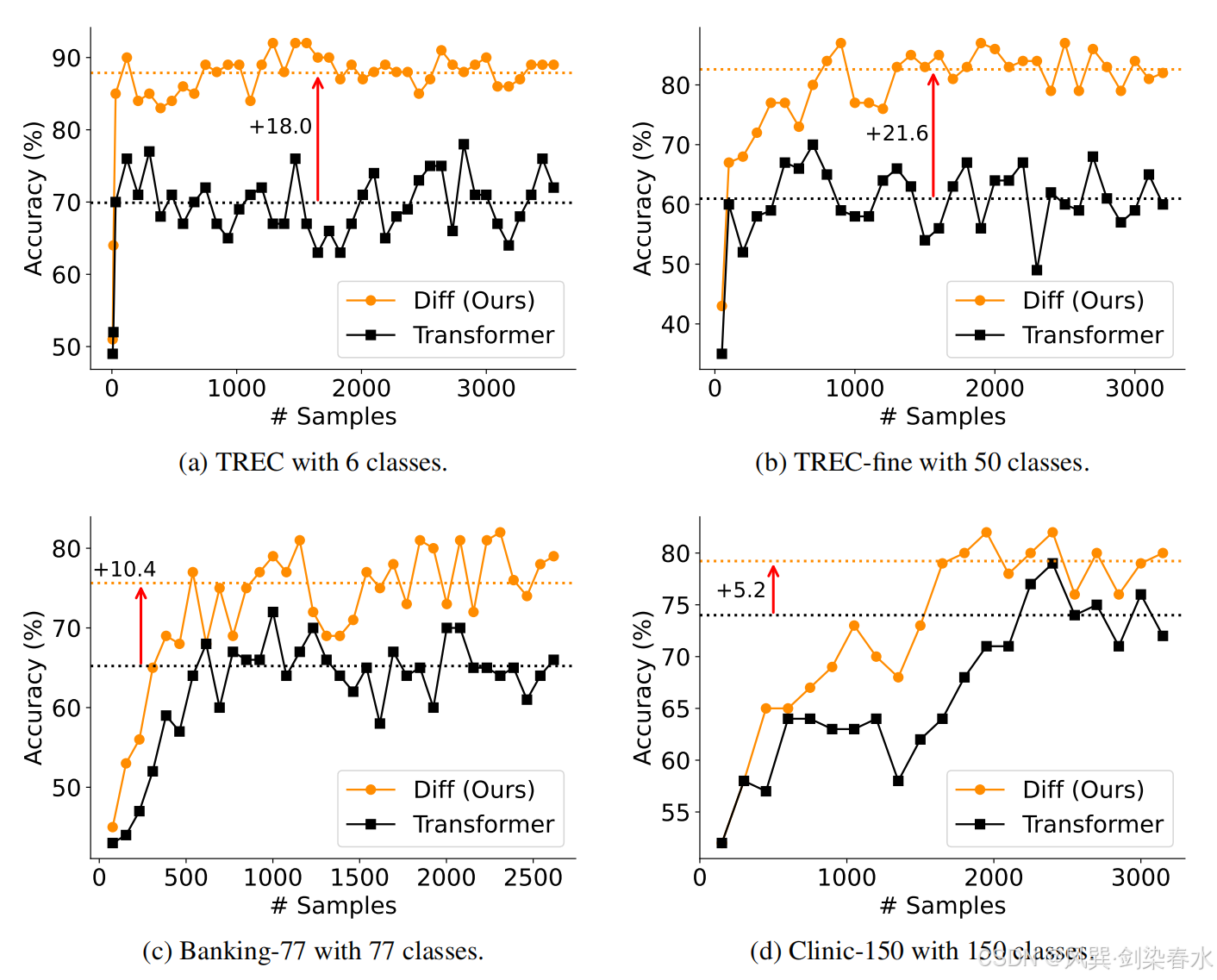
Figure 7 | 在 TREC 数据集上对上下文学习的鲁棒性进行评估:通过改变演示示例的顺序(使用不同的随机种子)来评估准确率,虚线表示最佳结果与最差结果之间的差距,较小的差距表明更强的鲁棒性,评估了两种提示格式;

3.6、上下文幻觉评估
Table 4 | 在文本摘要和问答任务中对上下文幻觉现象的评估:准确率越高,表明幻觉现象越少,本文遵循 Chuang 等人的方法,使用 GPT-4o 进行二元判断,这种方法与人工标注的结果有较高的契合度;

3.7、异常值分析
Table 5 | 注意力分数和隐藏状态的最大激活值:Top 激活值被视为激活异常值,因为它们的数值显著高于中位数,与 Transformer 相比,DIFF Transformer 减少了异常值;
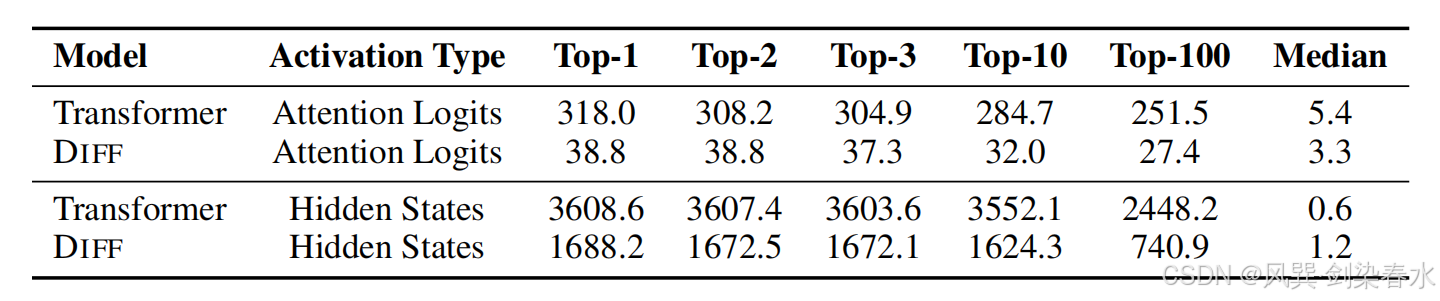
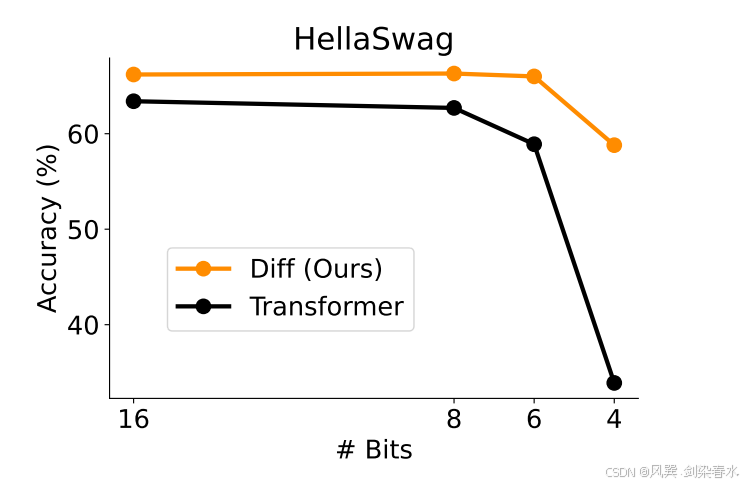
Figure 7 | HellaSwag 数据集上的 Zero-shot 准确率:本文将注意力 logit 从 16 位(即未量化)量化为 8 位、6 位和 4 位;
3.8、消融实验
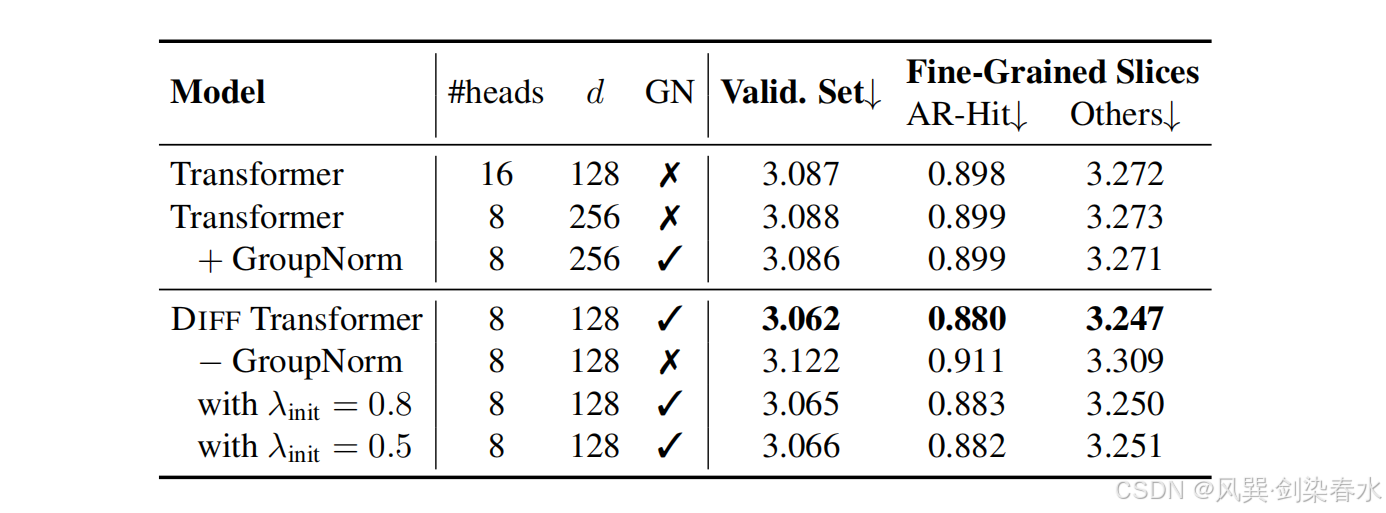
Figure 8 | 1.4B-size 模型的消融研究:在验证集上报告语言建模的损失,还遵循 Arora 等的方法,报告细粒度指标,其中 “AR-Hit” 用于评估在上下文中之前见过的 n-grams,“#Heads” 表示头的数量。“d” 是头的维度。“GN” 表示是否使用了组归一化;
试试? ٩(๑•̀ω•́๑)۶
相关文章:
【技术追踪】Differential Transformer(ICLR-2025)
Differential Transformer:大语言模型新架构, 提出了 differential attention mechanism,Transformer 又多了一个小 trick~ 论文:Differential Transformer 代码:https://github.com/microsoft/unilm/tree/master/Diff…...

overlay 模块加载失败问题分析
问题背景 CentOS 7系统上,内核版本是3.10.0-693.21.1.el7.x86_64,加载overlay模块的时候失败了。错误提示说找不到支持的overlay文件系统,让我确认内核足够新并且已经加载了overlay支持。但是检查发现/lib/modules/3.10.0-693.el7.x86_64/ke…...
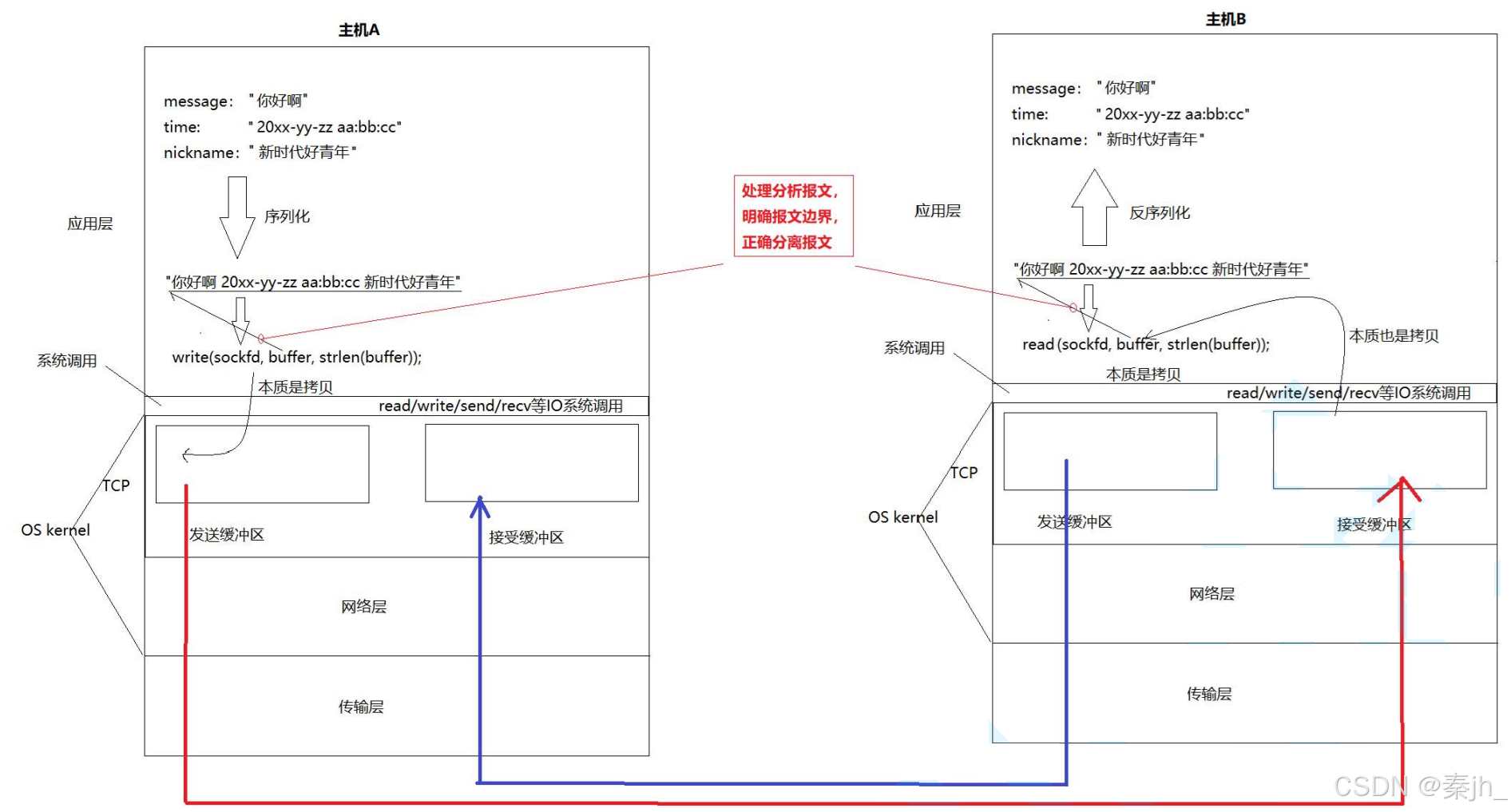
【Linux网络】应用层自定义协议与序列化
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12891150.html 目录 应用层 再谈 "协议" 网络版计算器 序列化 和 反序列化 重新理解…...
Vue接口平台学习十——接口用例页面2
效果图及简单说明 左边选择用例,右侧就显示该用例的详细信息。 使用el-collapse折叠组件,将请求到的用例详情数据展示到页面中。 所有数据内容,绑定到caseData中 // 页面绑定的用例编辑数据 const caseData reactive({title: "",…...
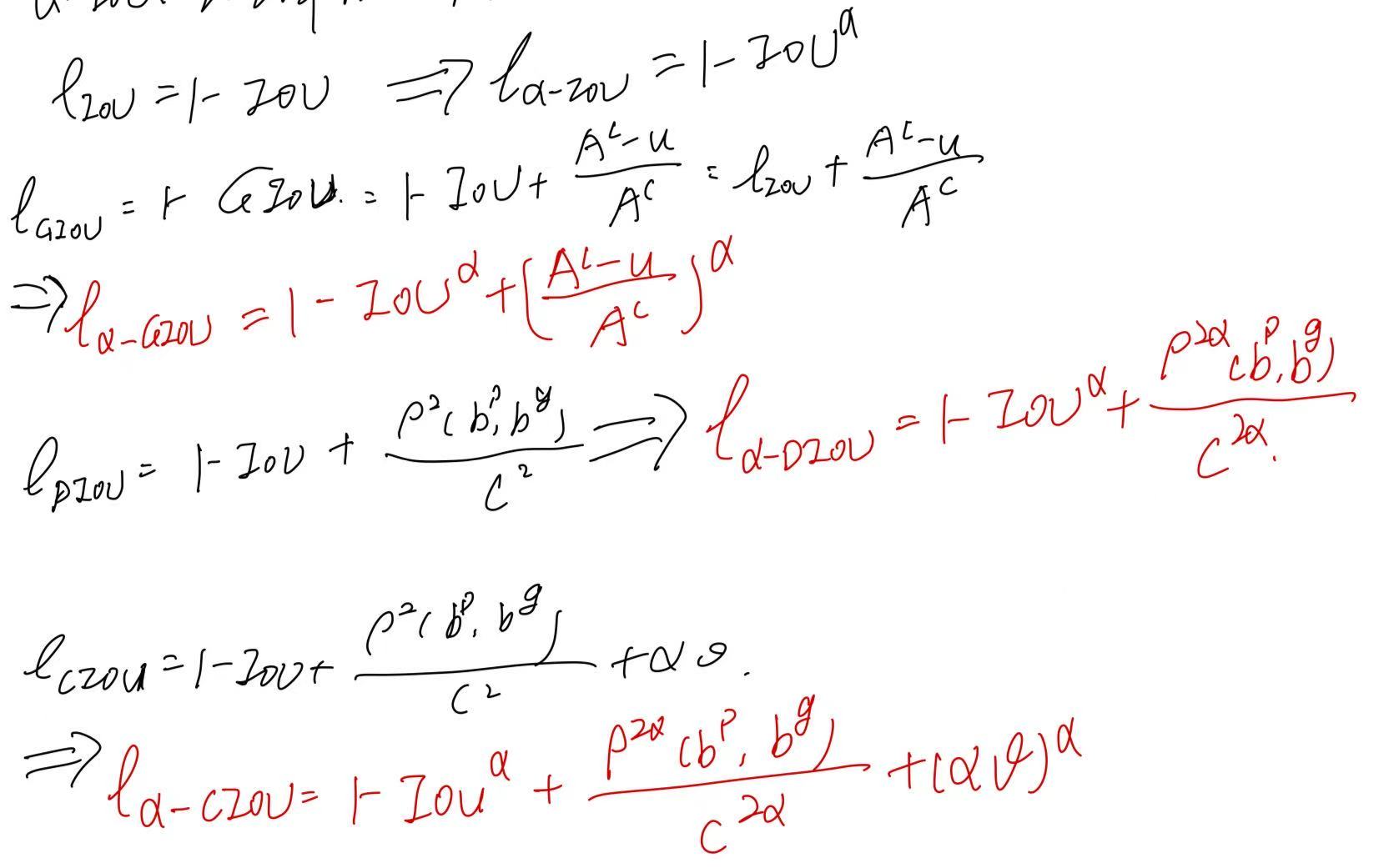
目标检测中的损失函数(二) | BIoU RIoU α-IoU
BIoU来自发表在2018年CVPR上的文章:《Improving Object Localization With Fitness NMS and Bounded IoU Loss》 论文针对现有目标检测方法只关注“足够好”的定位,而非“最优”的框,提出了一种考虑定位质量的NMS策略和BIoU loss。 这里不赘…...
 - 什么是MCP)
SpringAI系列 - MCP篇(一) - 什么是MCP
目录 一、引言二、MCP核心架构三、MCP传输层(stdio / sse)四、MCP能力协商机制(Capability Negotiation)五、MCP Client相关能力(Roots / Sampling)六、MCP Server相关能力(Prompts / Resources / Tools)一、引言 之前我们在接入大模型时,不同的大模型通常都有自己的…...
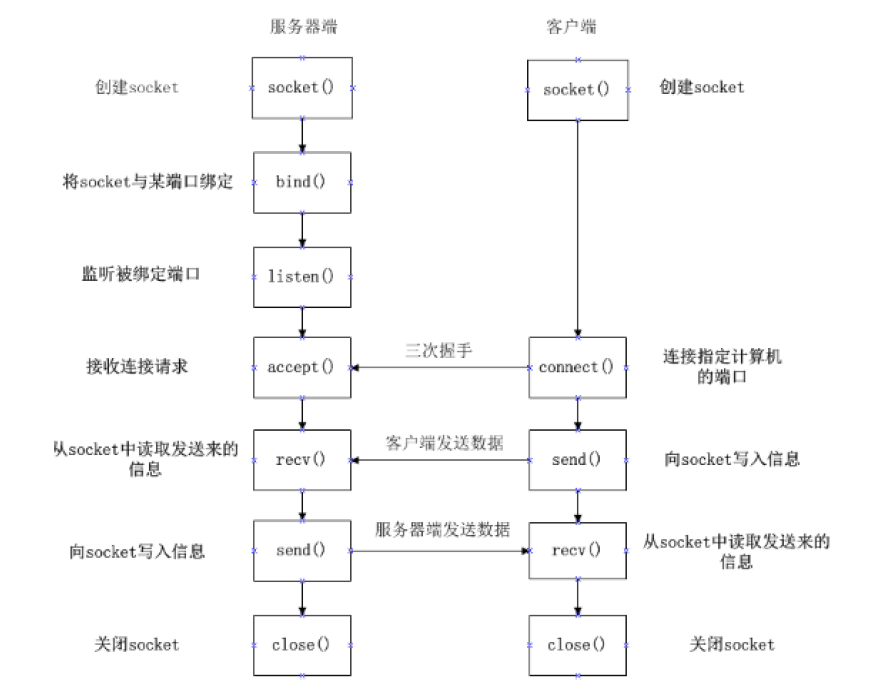
Linux 入门十一:Linux 网络编程
一、概述 1. 网络编程基础 网络编程是通过网络应用编程接口(API)编写程序,实现不同主机上进程间的信息交互。它解决的核心问题是:如何让不同主机上的程序进行通信。 2. 网络模型:从 OSI 到 TCP/IP OSI 七层模型&…...

沐渥氮气柜控制板温湿度氧含量氮气流量四显智控系统
氮气柜控制板通常用于实时监控和调节柜内环境参数,确保存储物品如电子元件、精密仪器、化学品等,处于低氧、干燥的稳定状态。以下是沐渥氮气柜控制板核心参数的详细介绍及控制逻辑: 一、控制板核心参数显示模块 1)温度显示&am…...

vue3 主题模式 结合 element-plus的主题
vue3 主题模式 结合 element-plus的主题 npm i element-plus --save-dev在 Vue 3 中,实现主题模式主要有以下几种方式 1.使用 CSS 变量(自定义属性) CSS 变量是一种在 CSS 中定义可重用值的方式。在主题模式中,可以将颜色、字体…...
)
Redis 有序集合(Sorted Set)
Redis 有序集合(Sorted Set) 以下从基础命令、内部编码和使用场景三个维度对 Redis 有序集合进行详细解析: 一、基础命令 命令时间复杂度命令含义zadd key score member [score member …] O ( k l o g ( n ) ) O(klog(n)) O(klog(n))&…...

[c语言日寄]免费文档生成器——Doxygen在c语言程序中的使用
【作者主页】siy2333 【专栏介绍】⌈c语言日寄⌋:这是一个专注于C语言刷题的专栏,精选题目,搭配详细题解、拓展算法。从基础语法到复杂算法,题目涉及的知识点全面覆盖,助力你系统提升。无论你是初学者,还是…...
QtCreator的设计器、预览功能能看到程序图标,编译运行后图标消失
重新更换虚拟机(Vmware Kylin),重新编译和配置了很多第三方库后,将代码跑到新的这个虚拟机环境中,但是出现程序图标不可见,占位也消失,后来继续检查ui文件,ui文件图标也异常&#x…...

QT文件和文件夹拷贝操作
1.拷贝文件夹 //(源文件目录路劲,目的文件目录,文件存在是否覆盖) bool copyDirectory(const QString& srcPath, const QString& dstPath, bool coverFileIfExist) { QDir srcDir(srcPath); QDir dstDir(dstPath); if (!dstDir.exi…...
面试常用基础算法
目录 快速排序归并排序堆排序 n n n皇后问题最大和子数组爬楼梯中心扩展法求最长回文子序列分割回文串动态规划求最长回文子序列最长回文子串单调栈双指针算法修改 分割回文串滑动窗口栈 快速排序 #include <iostream> #include <algorithm>using namespace std;…...

Python-24:小R的随机播放顺序
问题描述 小R有一个特殊的随机播放规则。他首先播放歌单中的第一首歌,播放后将其从歌单中移除。如果歌单中还有歌曲,则会将当前第一首歌移到最后一首。这个过程会一直重复,直到歌单中没有任何歌曲。 例如,给定歌单 [5, 3, 2, 1,…...
悬空引用和之道、之禅-《分析模式》漫谈57
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 “Analysis Patterns”的第5章“对象引用”原文: Unless you can catch all such references, there is the risk of a dangling reference, which often has painful con…...

Python accumulate 函数详解
https://docs.python.org/zh-cn/3/library/itertools.html#itertools.accumulate 在 Python 中,accumulate 是一个生成器(generator), 是来自 itertools 模块的一个函数。 它的作用是返回一个迭代器,该迭代器生成输入数据的累积结…...

Cursor可视化大屏搭建__0420
主题:用Cursor怎么进行数据洞察,做AI预测化内容。 Python基础语法与AI python生态强大,代码简洁,相对其他语言Python更好上手,浙江高考将Python列为可选科目 科学计算:Sklearn,Numpy,Pandas 人工智能:Tensorflow,Pytorch 网络爬虫:Scrapy…...
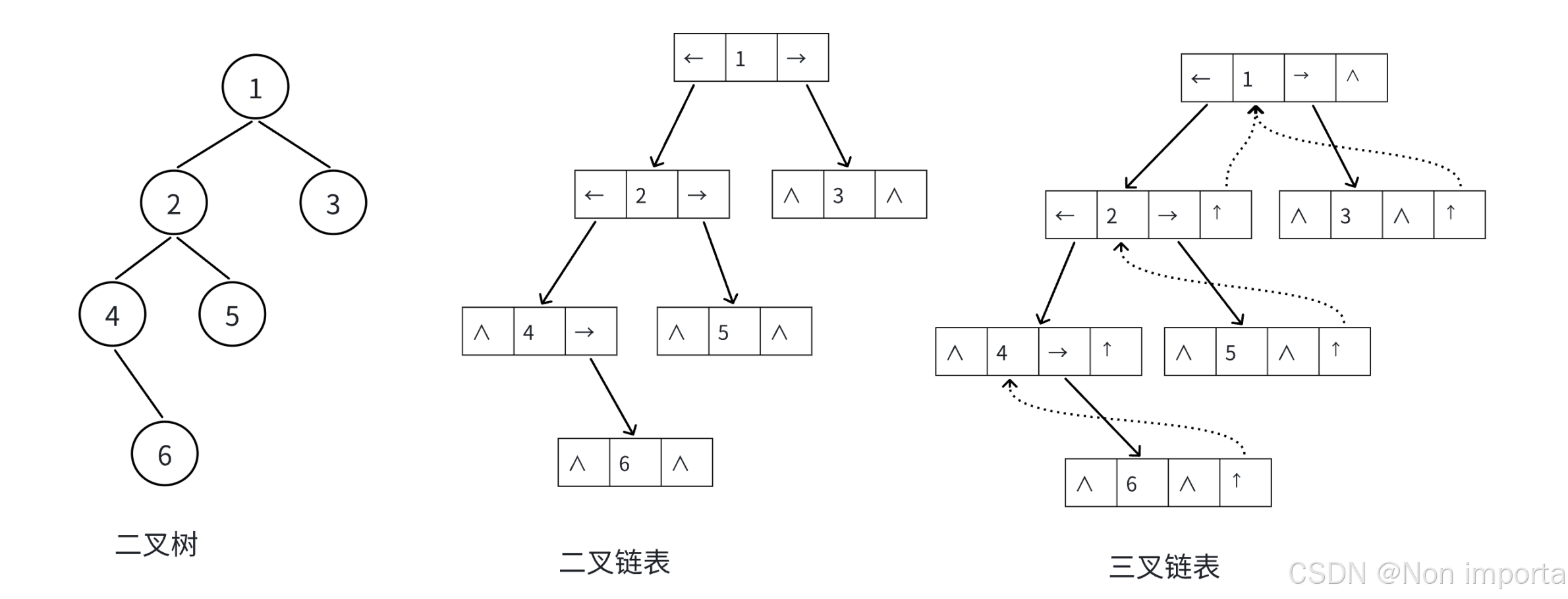
【初阶数据结构】树——二叉树(上)
文章目录 目录 前言 一、树 1.树的概念与结构 2.树相关术语 3.树的表示 二、二叉树 1.概念与结构 2.特殊的二叉树 3.二叉树存储结构 总结 前言 本篇带大家学习一种非线性数据结构——树,简单认识树和二叉数以及了解二叉树的存储结构。 一、树 1.树的概念与结构 树…...
ECharts散点图-散点图14,附视频讲解与代码下载
引言: ECharts散点图是一种常见的数据可视化图表类型,它通过在二维坐标系或其它坐标系中绘制散乱的点来展示数据之间的关系。本文将详细介绍如何使用ECharts库实现一个散点图,包括图表效果预览、视频讲解及代码下载,让你轻松掌握…...

C++中的算术转换、其他隐式类型转换和显示转换详解
C中的类型转换(Type Conversion)是指将一个数据类型的值转换为另一个数据类型的过程,主要包括: 一、算术类型转换(Arithmetic Conversions) 算术类型转换通常发生在算术运算或比较中,称为**“标…...

GAIA-2:用于自动驾驶的可控多视图生成世界模型
25年3月来自英国创业公司 Wayze 的论文“GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving”。(注:23年9月其发布GAIA-1) 生成模型为模拟复杂环境提供一种可扩展且灵活的范例,但目前的方法不足…...
CMake / MsBuild Ninja Make/ MSVC g++ clang++ 等c++编译概念解释)
(一)CMake / MsBuild Ninja Make/ MSVC g++ clang++ 等c++编译概念解释
c 几个编译概念 一 概念二 层级关系总结2.1层级表格2.2 关键点说明2.3 示例流程(以 Ninja 为例)2.4 示例流程(Windows 平台) 三 总结 一 概念 CMake 通过 CMakeLists.txt 生成不同平台的构建文件(如 .sln、build.n…...

创建 Node.js Playwright 项目:从零开始搭建自动化测试环境
一、环境准备 在开始创建 Playwright 项目之前,确保你的电脑上已经安装了以下工具: Node.js:Playwright 依赖于 Node.js 环境,确保你已经安装了最新版本的 Node.js。可以通过以下命令检查是否安装成功: node -v npm -…...
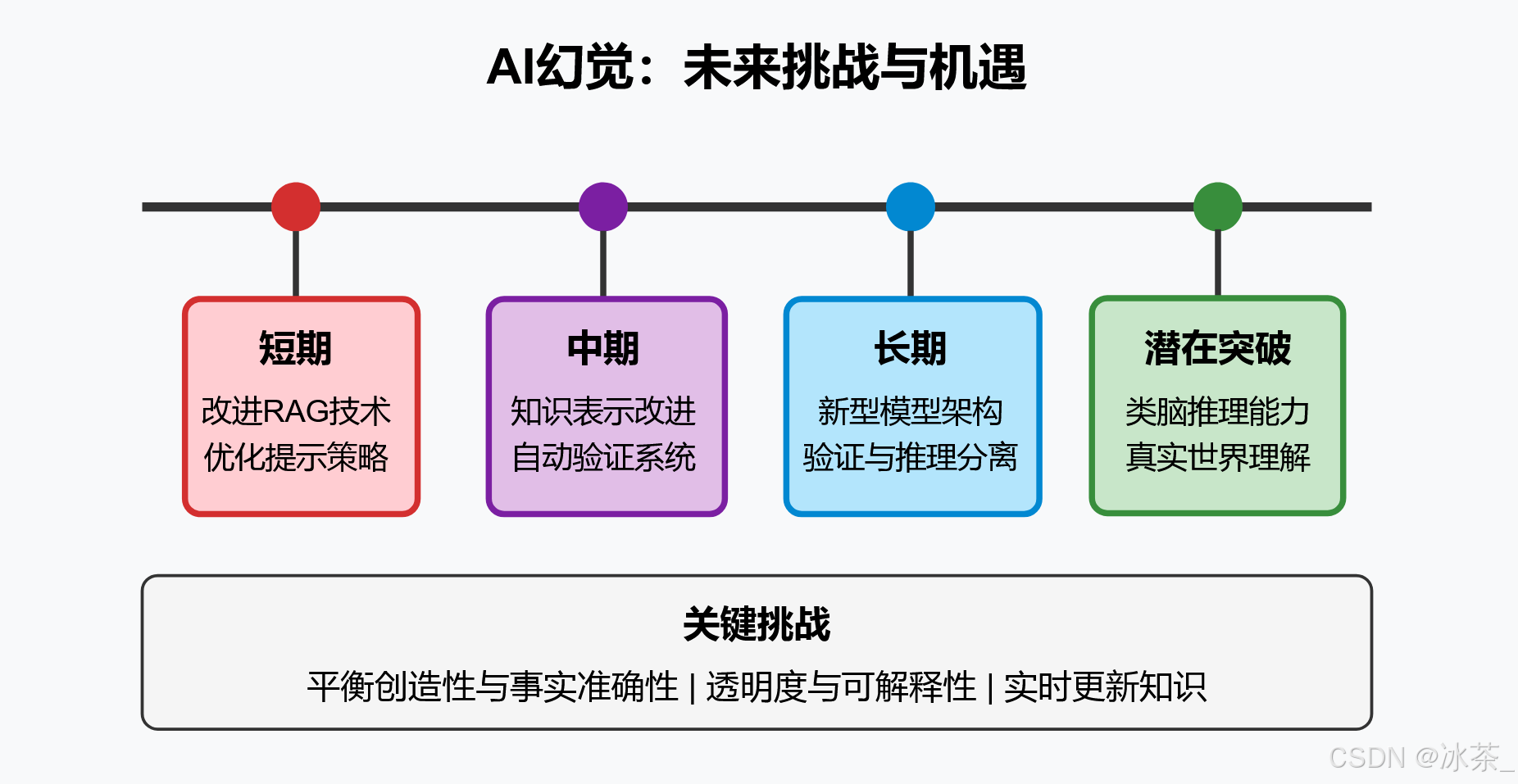
浅谈AI致幻
文章目录 当前形势下存在的AI幻觉(AI致幻)什么是AI幻觉AI幻觉的类型为什么AI会产生幻觉AI幻觉的危害与影响当前应对AI幻觉的技术与方法行业与学术界的最新进展未来挑战与展望结论 当前形势下存在的AI幻觉(AI致幻) 什么是AI幻觉 …...

postman乘法计算,变量赋值
postman脚本怎么计算乘法 在Postman中,你可以通过多种方式计算乘法,这取决于你的具体需求。例如,如果你想在发送请求前计算乘法结果,或者在测试标签中计算响应数据的乘法,下面是一些常见的方法。 1. 使用JavaScript代…...

自定义错误码的必要性
为什么要使用错误码,直接返回一个错误信息不好么? 下面介绍一下,在程序开发中使用错误码的必要性~ 便于排查问题 想象你开了一家奶茶店,顾客下单后可能出现各种问题: 没珍珠了(错误码:50…...

车载软件架构 --- 二级boot设计说明需求规范
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

管理杂谈——采石矶大捷的传奇与启示
南宋抗金史上,岳飞与岳家军的铁血传奇家喻户晓,但另一位力挽狂澜的“文官战神”却常被忽视——他从未掌兵,却在南宋存亡之际整合溃军,以少胜多,缔造采石矶大捷。此人正是虞允文。一介书生何以扭转乾坤?他的…...
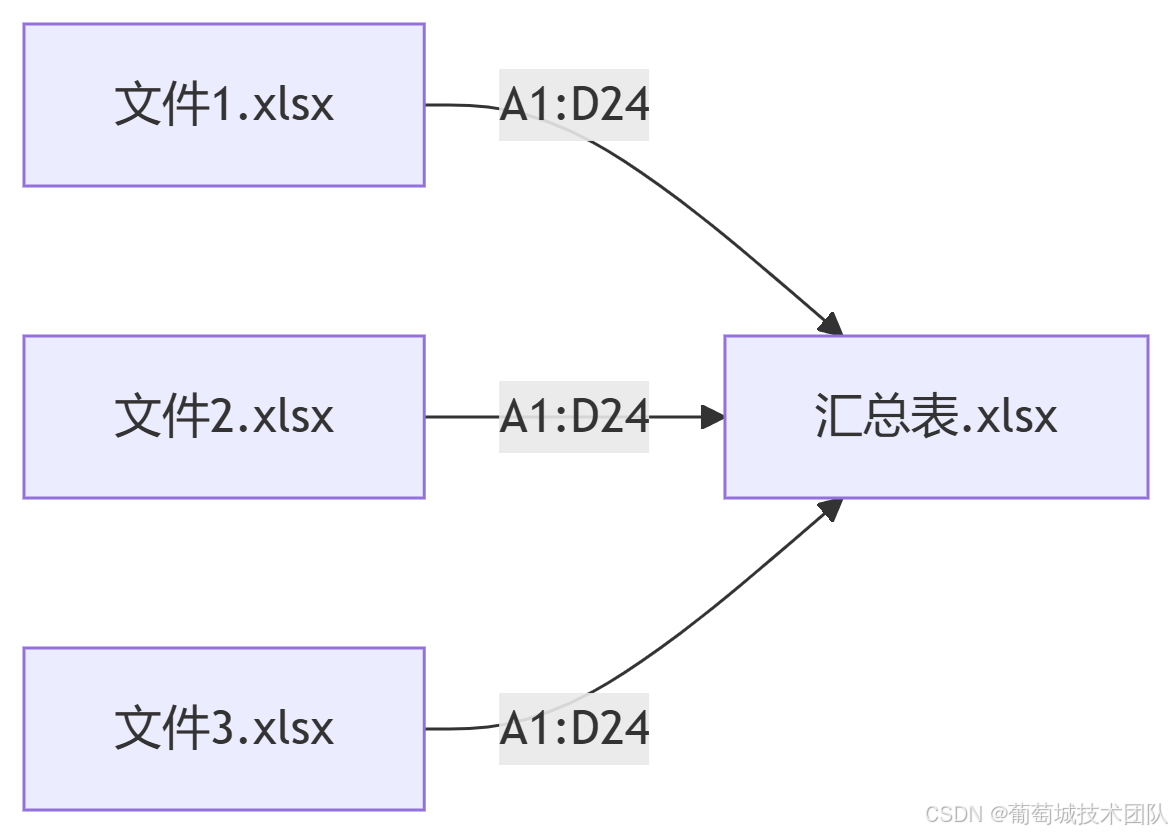
Java高效合并Excel报表实战:GcExcel让数据处理更简单
前言:为什么需要自动化合并Excel? 在日常办公场景中,Excel报表合并是数据分析的基础操作。根据2023年企业办公效率报告显示: 财务人员平均每周花费6.2小时在Excel合并操作上人工合并的错误率高达15%90%的中大型企业已采用自动化…...