深度学习训练中的显存溢出问题分析与优化:以UNet图像去噪为例
最近在训练一个基于 Tiny-UNet 的图像去噪模型时,我遇到了经典但棘手的错误:
RuntimeError: CUDA out of memory。本文记录了我如何从复现、分析,到逐步优化并成功解决该问题的全过程,希望对深度学习开发者有所借鉴。
-
训练数据:SIDD 小型图像去噪数据集
-
-
模型结构:简化版 U-Net(Tiny-UNet)
-
class UNetDenoiser(nn.Module):def __init__(self):super(UNetDenoiser, self).__init__()# Encoderself.enc1 = self.conv_block(3, 64)self.enc2 = self.conv_block(64, 128)self.enc3 = self.conv_block(128, 256)self.pool = nn.MaxPool2d(2)# Bottleneckself.bottleneck = self.conv_block(256, 512)# Decoderself.up3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)self.dec3 = self.conv_block(512, 256)self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)self.dec2 = self.conv_block(256, 128)self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.dec1 = self.conv_block(128, 64)# Outputself.final = nn.Conv2d(64, 3, kernel_size=1)def conv_block(self, in_channels, out_channels):return nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True))def forward(self, x):# Encodere1 = self.enc1(x) # [B, 64, H, W]e2 = self.enc2(self.pool(e1)) # [B, 128, H/2, W/2]e3 = self.enc3(self.pool(e2)) # [B, 256, H/4, W/4]# Bottleneckb = self.bottleneck(self.pool(e3)) # [B, 512, H/8, W/8]# Decoderd3 = self.up3(b) # [B, 256, H/4, W/4]d3 = self.dec3(torch.cat([d3, e3], dim=1))d2 = self.up2(d3) # [B, 128, H/2, W/2]d2 = self.dec2(torch.cat([d2, e2], dim=1))d1 = self.up1(d2) # [B, 64, H, W]d1 = self.dec1(torch.cat([d1, e1], dim=1))return self.final(d1)源代码:
# train_denoiser.py import os import math import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import Dataset, DataLoader from torchvision import transforms from torchvision.utils import save_image from PIL import Image# --- 数据集定义 --- class DenoisingDataset(Dataset):def __init__(self, noisy_dir, clean_dir, transform=None):self.noisy_paths = sorted([os.path.join(noisy_dir, f) for f in os.listdir(noisy_dir)])self.clean_paths = sorted([os.path.join(clean_dir, f) for f in os.listdir(clean_dir)])self.transform = transform if transform else transforms.ToTensor()def __len__(self):return len(self.noisy_paths)def __getitem__(self, idx):noisy_img = Image.open(self.noisy_paths[idx]).convert("RGB")clean_img = Image.open(self.clean_paths[idx]).convert("RGB")return self.transform(noisy_img), self.transform(clean_img)# --- 简单 CNN 去噪模型 --- # class SimpleDenoiser(nn.Module): # def __init__(self): # super(SimpleDenoiser, self).__init__() # self.encoder = nn.Sequential( # nn.Conv2d(3, 64, 3, padding=1), nn.ReLU(), # nn.Conv2d(64, 64, 3, padding=1), nn.ReLU() # ) # self.decoder = nn.Sequential( # nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), # nn.Conv2d(64, 3, 3, padding=1) # ) # # def forward(self, x): # x = self.encoder(x) # x = self.decoder(x) # return x class UNetDenoiser(nn.Module):def __init__(self):super(UNetDenoiser, self).__init__()# Encoderself.enc1 = self.conv_block(3, 64)self.enc2 = self.conv_block(64, 128)self.enc3 = self.conv_block(128, 256)self.pool = nn.MaxPool2d(2)# Bottleneckself.bottleneck = self.conv_block(256, 512)# Decoderself.up3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)self.dec3 = self.conv_block(512, 256)self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)self.dec2 = self.conv_block(256, 128)self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.dec1 = self.conv_block(128, 64)# Outputself.final = nn.Conv2d(64, 3, kernel_size=1)def conv_block(self, in_channels, out_channels):return nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True))def forward(self, x):# Encodere1 = self.enc1(x) # [B, 64, H, W]e2 = self.enc2(self.pool(e1)) # [B, 128, H/2, W/2]e3 = self.enc3(self.pool(e2)) # [B, 256, H/4, W/4]# Bottleneckb = self.bottleneck(self.pool(e3)) # [B, 512, H/8, W/8]# Decoderd3 = self.up3(b) # [B, 256, H/4, W/4]d3 = self.dec3(torch.cat([d3, e3], dim=1))d2 = self.up2(d3) # [B, 128, H/2, W/2]d2 = self.dec2(torch.cat([d2, e2], dim=1))d1 = self.up1(d2) # [B, 64, H, W]d1 = self.dec1(torch.cat([d1, e1], dim=1))return self.final(d1)# --- PSNR 计算函数 --- def calculate_psnr(img1, img2):mse = torch.mean((img1 - img2) ** 2)if mse == 0:return float("inf")return 20 * torch.log10(1.0 / torch.sqrt(mse))# --- 主训练过程 --- def train_denoiser():noisy_dir = r"F:\SIDD数据集\archive\SIDD_Small_sRGB_Only\noisy"clean_dir = r"F:\SIDD数据集\archive\SIDD_Small_sRGB_Only\clean"batch_size = 1num_epochs = 50lr = 0.0005device = torch.device("cuda" if torch.cuda.is_available() else "cpu")dataset = DenoisingDataset(noisy_dir, clean_dir, transform=transforms.ToTensor())dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# model = SimpleDenoiser().to(device)# 替换为 UNetmodel = UNetDenoiser().to(device)criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=lr)for epoch in range(num_epochs):model.train()total_loss = 0.0total_psnr = 0.0for noisy, clean in dataloader:noisy, clean = noisy.to(device), clean.to(device)denoised = model(noisy)loss = criterion(denoised, clean)optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()total_psnr += calculate_psnr(denoised, clean).item()avg_loss = total_loss / len(dataloader)avg_psnr = total_psnr / len(dataloader)print(f"Epoch [{epoch+1}/{num_epochs}] - Loss: {avg_loss:.4f}, PSNR: {avg_psnr:.2f} dB")# 保存模型os.makedirs("weights", exist_ok=True)torch.save(model.state_dict(), "weights/denoiser.pth")print("模型已保存为 weights/denoiser.pth")if __name__ == "__main__":train_denoiser() -
显卡:8GB 显存的 RTX GPU
-
问题定位
我们从报错堆栈中看到:
e3 = self.enc3(self.pool(e2))
RuntimeError: CUDA out of memory. Tried to allocate 746.00 MiB
说明问题发生在模型第三层 encoder(enc3)前的 pooling 后,这说明:
-
当前的输入尺寸、batch size 占用了太多显存;
-
或者模型本身结构太重;
-
又或者显存未被合理管理(例如碎片化)。
分析与优化过程
第一步:降低 batch size
原始 batch size 设置为 16,直接触发爆显存。
我们尝试逐步调小 batch size:
batch_size = 6 # 从16降低到6
观察显存变化,发现仍有波动。为更稳定,设置为 4 或动态适配:
batch_size = min(8, torch.cuda.get_device_properties(0).total_memory // estimated_sample_size)
发现同样的错误,显存不知。分析可能是网络参数太大了,或者训练过程没有启动内存优化。导致的内存不足,这些可以通过策略进行改进,达到训练的目的。
第二步:开启 cuDNN 自动优化
torch.backends.cudnn.benchmark = True
cuDNN 会根据不同卷积输入尺寸自动寻找最优算法,可能减少显存使用。
第三步:开启混合精度训练 AMP(Automatic Mixed Precision)
from torch.cuda.amp import autocast, GradScalerscaler = GradScaler()with autocast():output = model(input)loss = criterion(output, target)scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
-
autocast()自动在部分层使用 float16,提高速度并减小显存压力; -
GradScaler确保在 float16 条件下梯度依然稳定。
实测显存使用降低近 30%,OOM 问题明显缓解!
但以上训练的预加载时间太慢,显卡占有率过低,有点显卡当前没有任务----“偷懒”的意思。可能是数据的加载或者显存抖动造成的。
第四步:优化 DataLoader 性能(间接缓解显存抖动)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True,num_workers=num_workers, pin_memory=True)-
num_workers启用多进程加载数据; -
pin_memory=True启用固定内存,更快传输到 GPU。
虽然不直接节省显存,但显著减少显存峰值抖动(尤其在小 batch 训练时)。
第五步:检查图像输入尺寸是否太大
原始图像尺寸为 512×512:
transform = transforms.Compose([transforms.Resize((256, 256)), # 降低分辨率transforms.ToTensor()
])
最终训练代码结构
我们将上述策略集成到了 train.py 脚本中(如下),包括:
-
Dataset & Dataloader 加速
-
混合精度训练
-
cuDNN 优化
-
实时 PSNR 显示
-
自动保存模型权重
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
from torch.cuda.amp import autocast, GradScaler
from tqdm import tqdm# --- 启用 cuDNN 自动优化 ---
torch.backends.cudnn.benchmark = True# --- 数据集定义 ---
class DenoisingDataset(Dataset):def __init__(self, noisy_dir, clean_dir, transform=None):self.noisy_paths = sorted([os.path.join(noisy_dir, f) for f in os.listdir(noisy_dir)])self.clean_paths = sorted([os.path.join(clean_dir, f) for f in os.listdir(clean_dir)])self.transform = transform if transform else transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor()])def __len__(self):return len(self.noisy_paths)def __getitem__(self, idx):noisy_img = Image.open(self.noisy_paths[idx]).convert("RGB")clean_img = Image.open(self.clean_paths[idx]).convert("RGB")return self.transform(noisy_img), self.transform(clean_img)# --- Tiny UNet 模型 ---
class TinyUNet(nn.Module):def __init__(self):super(TinyUNet, self).__init__()self.enc1 = self.conv_block(3, 16)self.enc2 = self.conv_block(16, 32)self.enc3 = self.conv_block(32, 64)self.pool = nn.MaxPool2d(2)self.bottleneck = self.conv_block(64, 128)self.up3 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.dec3 = self.conv_block(128, 64)self.up2 = nn.ConvTranspose2d(64, 32, kernel_size=2, stride=2)self.dec2 = self.conv_block(64, 32)self.up1 = nn.ConvTranspose2d(32, 16, kernel_size=2, stride=2)self.dec1 = self.conv_block(32, 16)self.final = nn.Conv2d(16, 3, kernel_size=1)def conv_block(self, in_channels, out_channels):return nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, 3, padding=1), nn.ReLU(inplace=True))def forward(self, x):e1 = self.enc1(x)e2 = self.enc2(self.pool(e1))e3 = self.enc3(self.pool(e2))b = self.bottleneck(self.pool(e3))d3 = self.up3(b)d3 = self.dec3(torch.cat([d3, e3], dim=1))d2 = self.up2(d3)d2 = self.dec2(torch.cat([d2, e2], dim=1))d1 = self.up1(d2)d1 = self.dec1(torch.cat([d1, e1], dim=1))return self.final(d1)# --- PSNR 计算 ---
def calculate_psnr(img1, img2):mse = torch.mean((img1 - img2) ** 2)if mse == 0:return float("inf")return 20 * torch.log10(1.0 / torch.sqrt(mse))# --- 训练函数 ---
def train_denoiser():noisy_dir = r"F:\SIDD数据集\archive\SIDD_Small_sRGB_Only\noisy"clean_dir = r"F:\SIDD数据集\archive\SIDD_Small_sRGB_Only\clean"batch_size = 6num_epochs = 50lr = 0.0005num_workers = 4device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"Using device: {device}")transform = transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor()])dataset = DenoisingDataset(noisy_dir, clean_dir, transform=transform)dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True,num_workers=num_workers, pin_memory=True)model = TinyUNet().to(device)criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=lr)scaler = GradScaler() # AMP 梯度缩放器os.makedirs("weights", exist_ok=True)for epoch in range(num_epochs):model.train()total_loss = 0.0total_psnr = 0.0for noisy, clean in tqdm(dataloader, desc=f"Epoch {epoch+1}/{num_epochs}"):noisy = noisy.to(device, non_blocking=True)clean = clean.to(device, non_blocking=True)optimizer.zero_grad()with autocast(): # 混合精度推理denoised = model(noisy)loss = criterion(denoised, clean)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()total_loss += loss.item()total_psnr += calculate_psnr(denoised.detach(), clean).item()avg_loss = total_loss / len(dataloader)avg_psnr = total_psnr / len(dataloader)print(f"✅ Epoch [{epoch+1}/{num_epochs}] - Loss: {avg_loss:.4f}, PSNR: {avg_psnr:.2f} dB")torch.save(model.state_dict(), f"weights/tiny_unet_epoch{epoch+1}.pth")print("🎉 模型训练完成,所有权重已保存至 weights/ 目录")if __name__ == "__main__":train_denoiser()
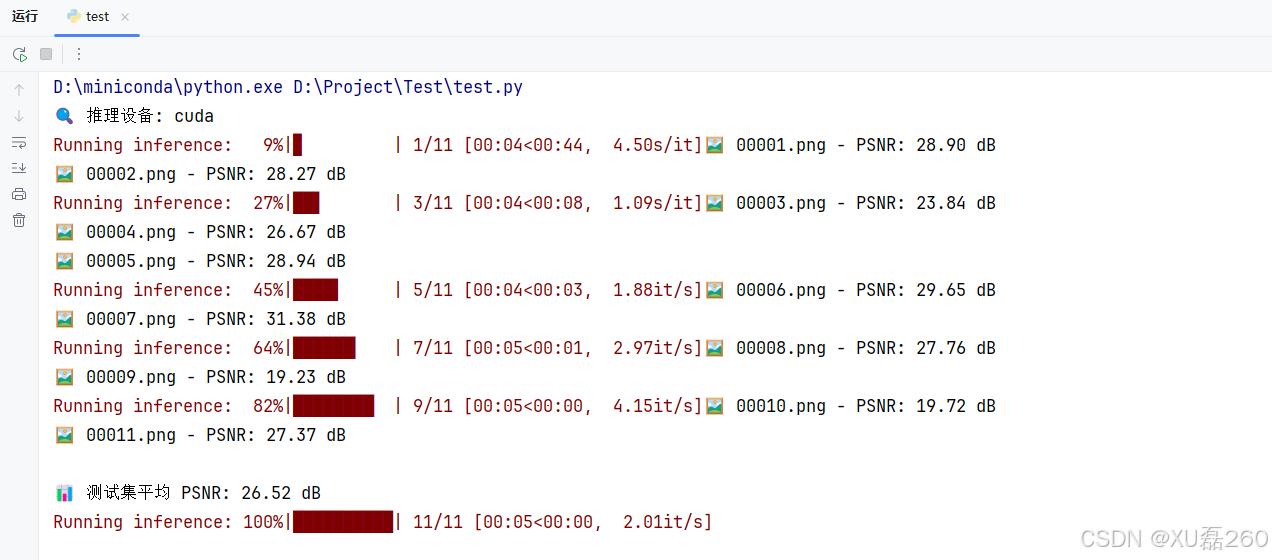
最后得到的训练文件,这里我设置的50次训练迭代:
测试模型的推理效果
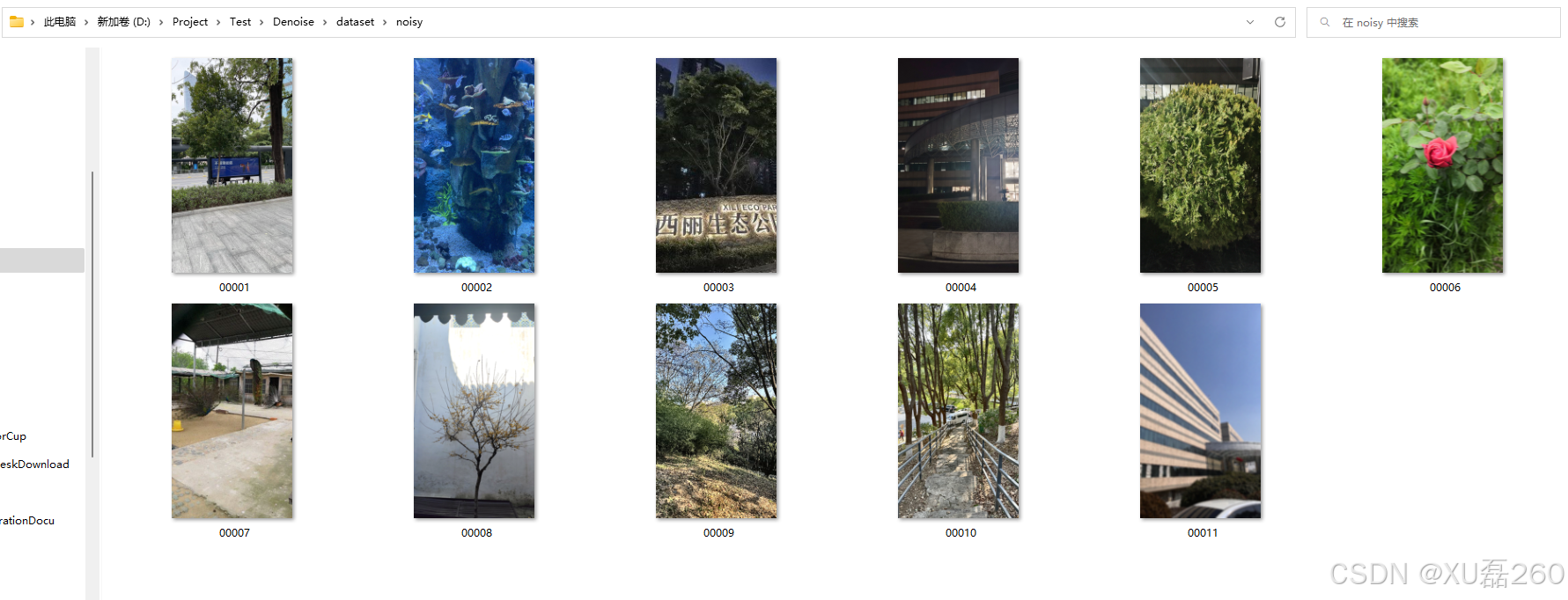
原去带噪声图片:
去噪后(可以看到这里仍然有bug,肉眼看效果并不是很好,需要进一步优化,考虑到模型的泛化性):

总结:处理 CUDA OOM 的思路模板
-
先查 batch size,这是最常见爆显存原因;
-
确认输入尺寸是否太大或未 resize;
-
启用 AMP,简单又高效;
-
合理设计模型结构(Tiny UNet > ResUNet);
-
使用 Dataloader 加速,避免数据传输抖动;
-
手动清理缓存防止 PyTorch 持有多余内存;
-
查看 PyTorch 显存使用报告,加上:
print(torch.cuda.memory_summary())
相关文章:
深度学习训练中的显存溢出问题分析与优化:以UNet图像去噪为例
最近在训练一个基于 Tiny-UNet 的图像去噪模型时,我遇到了经典但棘手的错误: RuntimeError: CUDA out of memory。本文记录了我如何从复现、分析,到逐步优化并成功解决该问题的全过程,希望对深度学习开发者有所借鉴。 训练数据&am…...

Python爬虫实战:获取优志愿专业数据
一、引言 在信息爆炸的当下,数据成为推动各领域发展的关键因素。优志愿网站汇聚了丰富的专业数据,对于教育研究、职业规划等领域具有重要价值。然而,为保护自身数据和资源,许多网站设置了各类反爬机制。因此,如何高效、稳定地从优志愿网站获取计算机专业数据成为一个具有…...

2025.4.22学习日记 JavaScript的常用事件
在 JavaScript 里,事件是在文档或者浏览器窗口中发生的特定交互瞬间,例如点击按钮、页面加载完成等等。下面是一些常用的事件以及案例: 1. click 事件 当用户点击元素时触发 const button document.createElement(button); button.textCo…...
如何修复WordPress中“您所关注的链接已过期”的错误
几乎每个管理WordPress网站的人都可能遇到过“您关注的链接已过期”的错误,尤其是在上传插件或者主题的时候。本文将详细解释该错误出现的原因以及如何修复,帮助您更好地管理WordPress网站。 为什么会出现“您关注的链接已过期”的错误 为了防止资源被滥…...

从零开始搭建Django博客①--正式开始前的准备工作
本文主要在Ubuntu环境上搭建,为便于研究理解,采用SSH连接在虚拟机里的ubuntu-24.04.2-desktop系统搭建的可视化桌面,涉及一些文件操作部分便于通过桌面化进行理解,最后的目标是在本地搭建好系统后,迁移至云服务器并通过…...
健身房管理系统(springboot+ssm+vue+mysql)含运行文档
健身房管理系统(springbootssmvuemysql)含运行文档 健身房管理系统是一个全面的解决方案,旨在帮助健身房高效管理其运营。系统提供多种功能模块,包括会员管理、员工管理、会员卡管理、教练信息管理、解聘管理、健身项目管理、指导项目管理、健身器材管理…...

Java从入门到“放弃”(精通)之旅——继承与多态⑧
Java从入门到“放弃”(精通)之旅🚀——继承与多态⑧ 一、继承:代码复用的利器 1.1 为什么需要继承? 想象一下我们要描述狗和猫这两种动物。如果不使用继承,代码可能会是这样: // Dog.java pu…...
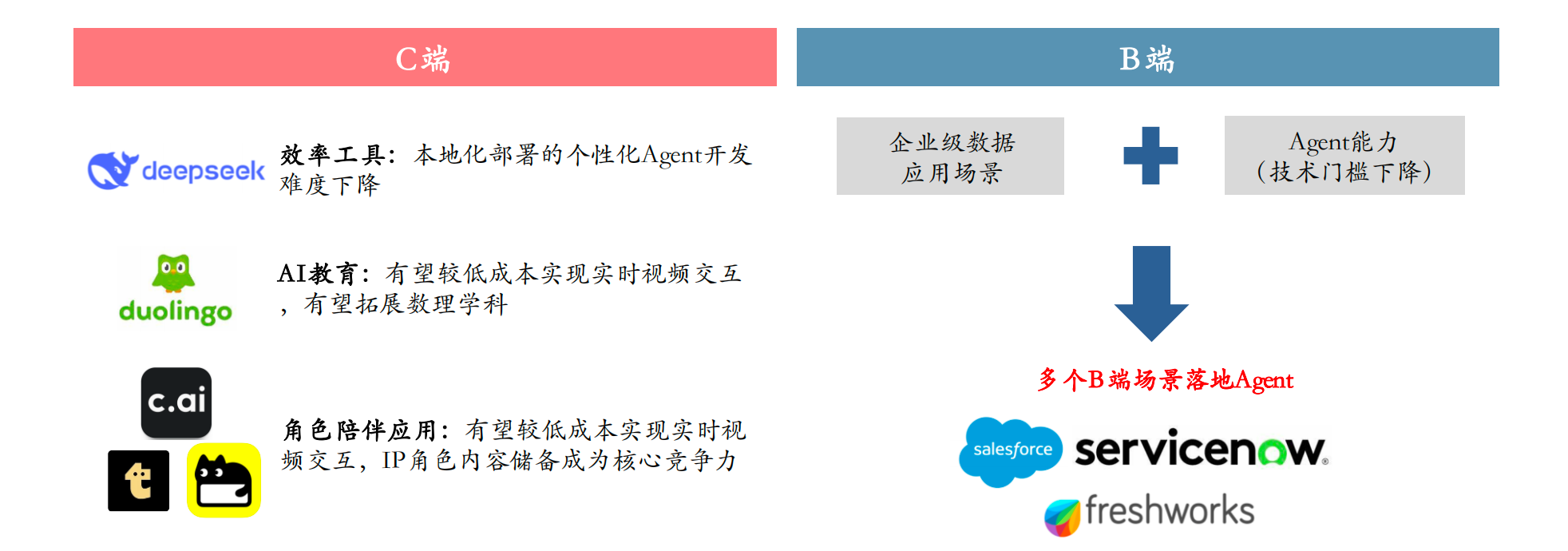
DeepSeek开源引爆AI Agent革命:应用生态迎来“安卓时刻”
开源低成本:AI应用开发进入“全民时代” 2025年初,中国AI领域迎来里程碑事件——DeepSeek开源模型的横空出世,迅速在全球开发者社区掀起热潮。其R1和V3模型以超低API成本(仅为GPT-4o的2%-10%)和本地化部署能力&#x…...

使用 LangChain + Higress + Elasticsearch 构建 RAG 应用
RAG(Retrieval Augmented Generation,检索增强生成) 是一种结合了信息检索与生成式大语言模型(LLM)的技术。它的核心思想是:在生成模型输出内容之前,先从外部知识库或数据源中检索相关信息&…...

深入解析C++ STL List:双向链表的特性与高级操作
一、引言 在C STL容器家族中,list作为双向链表容器,具有独特的性能特征。本文将通过完整代码示例,深入剖析链表的核心操作,揭示其底层实现机制,并对比其他容器的适用场景。文章包含4000余字详细解析,适合需…...

Uniapp:pages.json页面路由
目录 一、pages二、style 一、pages uni-app 通过 pages 节点配置应用由哪些页面组成,pages 节点接收一个数组,数组每个项都是一个对象,其属性值如下: 属性类型默认值描述pathString配置页面路径styleObject配置页面窗口表现nee…...

Self-Ask:LLM Agent架构的思考模式 | 智能体推理框架与工具调用实践
作为程序员,我们习惯将复杂问题分解为可管理的子任务,这正是递归和分治算法的核心思想。那么,如何让AI模型也具备这种结构化思考能力?本文深入剖析Self-Ask推理模式的工作原理、实现方法与最佳实践,帮助你构建具有清晰…...

【前端】【业务场景】【面试】在网页开发中,如何优化图片以提高页面加载速度?解决不同设备屏幕适配问题
📌 问题 1:在网页开发中,如何优化图片以提高页面加载速度? 🔍 一、关键词总结 关键词说明图片压缩借助 TinyPNG、ImageOptim 等工具,无损减小图片文件大小格式选择JPEG(照片类)、P…...

Git Flow分支模型
经典分支模型(Git Flow) 由 Vincent Driessen 提出的 Git Flow 模型,是管理 main(或 master)和 dev 分支的经典方案: main 用于生产发布,保持稳定; dev 用于日常开发,合并功能分支(feature/*); 功能开发在 feature 分支进行,完成后合并回 dev; 预发布分支(rele…...

安装 vmtools
第2章 安装 vmtools 1.安装 vmtools 的准备工作 1)现在查看是否安装了 gcc 查看是否安装gcc 打开终端 输入 gcc - v 安装 gcc 链接:https://blog.csdn.net/qq_45316173/article/details/122018354?ops_request_misc&request_id&biz_id10…...
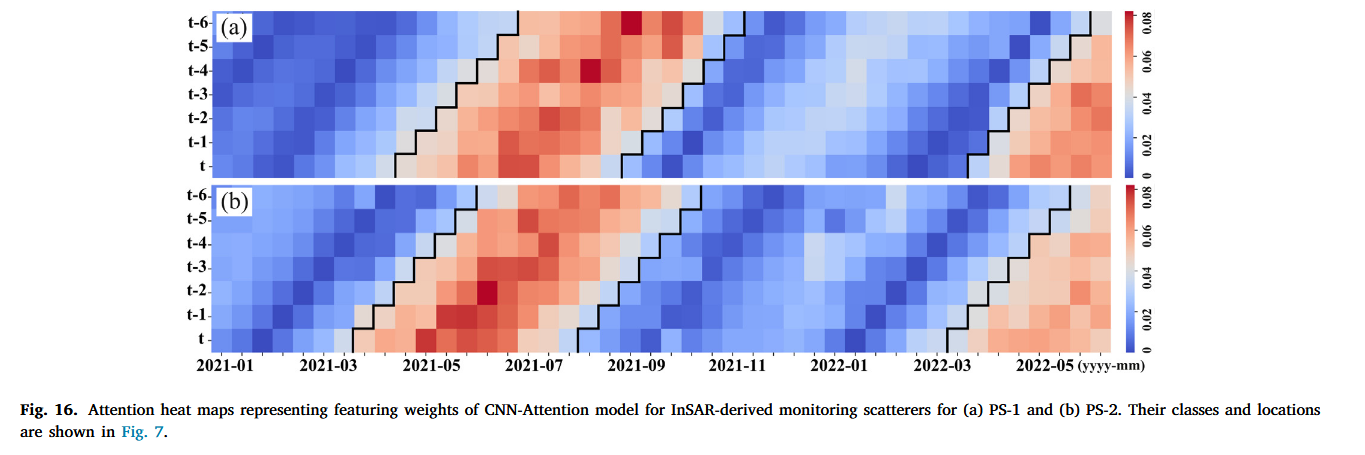
【论文阅读20】-CNN-Attention-BiGRU-滑坡预测(2025-03)
这篇论文主要探讨了基于深度学习的滑坡位移预测模型,结合了MT-InSAR(多时相合成孔径雷达干涉测量)观测数据,提出了一种具有可解释性的滑坡位移预测方法。 [1] Zhou C, Ye M, Xia Z, et al. An interpretable attention-based deep…...

滑动窗口学习
2090. 半径为 k 的子数组平均值 题目 问题分析 给定一个数组 nums 和一个整数 k,需要构建一个新的数组 avgs,其中 avgs[i] 表示以 nums[i] 为中心且半径为 k 的子数组的平均值。如果在 i 前或后不足 k 个元素,则 avgs[i] 的值为 -1。 思路…...

用户需求报告、系统需求规格说明书、软件需求规格说明的对比分析
用户需求报告、系统需求规格说明书(SyRS)和软件需求规格说明书(SRS)是需求工程中的关键文档,分别对应不同层次和视角的需求描述。以下是它们的核心区别对比: 1. 用户需求报告(User Requirem…...

# 基于PyTorch的食品图像分类系统:从训练到部署全流程指南
基于PyTorch的食品图像分类系统:从训练到部署全流程指南 本文将详细介绍如何使用PyTorch框架构建一个完整的食品图像分类系统,涵盖数据预处理、模型构建、训练优化以及模型保存与加载的全过程。 1. 系统概述 本系统实现了一个基于卷积神经网络(CNN)的…...
v-html 显示富文本内容
返回数据格式: 只有图片名称 显示不出完整路径 解决方法:在接收数据后手动给img格式的拼接vite.config中的服务器地址 页面: <el-button click"">获取信息<el-button><!-- 弹出层 --> <el-dialog v-model&…...

【数学建模】孤立森林算法:异常检测的高效利器
孤立森林算法:异常检测的高效利器 文章目录 孤立森林算法:异常检测的高效利器1 引言2 孤立森林算法原理2.1 核心思想2.2 算法流程步骤一:构建孤立树(iTree)步骤二:构建孤立森林(iForest)步骤三:计算异常分数 3 代码实现…...

<项目代码>YOLO小船识别<目标检测>
项目代码下载链接 YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN)࿰…...

Crawl4AI:打破数据孤岛,开启大语言模型的实时智能新时代
当大语言模型遇见数据饥渴症 在人工智能的竞技场上,大语言模型(LLMs)正以惊人的速度进化,但其认知能力的跃升始终面临一个根本性挑战——如何持续获取新鲜、结构化、高相关性的数据。传统数据供给方式如同输血式营养支持ÿ…...

AI 技术发展:从起源到未来的深度剖析
一、AI 的起源与早期发展 人工智能(AI)作为计算机科学的重要分支,其诞生可以追溯到 20 世纪中叶。1943 年,艾伦・图灵提出图灵机的概念,为计算机科学和 AI 理论奠定了基础。1950 年,图灵又提出著名的图灵…...

jsconfig.json文件的作用
jsconfig.json文件的作用 为什么今天会谈到这个呢?有这么一个场景:我们每次开发项目时都会给路径配置别名,配完别名之后可以简化我们的开发,但是随之而来的就有一个问题,一般来说,当我们使用相对路径时…...

nodejs的包管理工具介绍,npm的介绍和安装,npm的初始化包 ,搜索包,下载安装包
nodejs的包管理工具介绍,npm的介绍和安装,npm的初始化包 ,搜索包,下载安装包 🧰 一、Node.js 的包管理工具有哪些? 工具简介是否默认特点npmNode.js 官方的包管理工具(Node Package Manager&am…...

常见的raid有哪些,使用场景是什么?
RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)是一种将多个物理硬盘组合成一个逻辑硬盘的技术,目的是通过数据冗余和/或并行访问提高性能、容错能力和存储容量。不同的 RAID 级别有不同的实现方式和应用场景。以下…...

【Spring Boot】MyBatis多表查询的操作:注解和XML实现SQL语句
1.准备工作 1.1创建数据库 (1)创建数据库: CREATE DATABASE mybatis_test DEFAULT CHARACTER SET utf8mb4;(2)使用数据库 -- 使⽤数据数据 USE mybatis_test;1.2 创建用户表和实体类 创建用户表 -- 创建表[⽤⼾表…...
个人学习笔记(12):网络爬虫)
金融数据分析(Python)个人学习笔记(12):网络爬虫
一、导入模块和函数 from bs4 import BeautifulSoup from urllib.request import urlopen import re from urllib.error import HTTPError from time import timebs4:用于解析HTML和XML文档的Python库。 BeautifulSoup:方便地从网页内容中提取和处理数据…...
[Android]豆包爱学v4.5.0小学到研究生 题目Ai解析
拍照解析答案 【应用名称】豆包爱学 【应用版本】4.5.0 【软件大小】95mb 【适用平台】安卓 【应用简介】豆包爱学,一般又称河马爱学教育平台app,河马爱学。 关于学习,你可能也需要一个“豆包爱学”这样的AI伙伴,它将为你提供全方位的学习帮助…...