深度学习3.5 图像分类数据集
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
代码执行流程图
3.5.1 读取数据集
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)
下载并加载FashionMNIST数据集
关键参数:
transform=trans:将图像转换为张量(形状 [1, 28, 28],值域 [0,1])。
download=True:若本地无数据则自动下载。
数据集结构:
训练集:60,000 张 28x28 灰度图像。
测试集:10,000 张 28x28 灰度图像。
def get_fashion_mnist_labels(labels):text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]
标签映射
将数字标签(0-9)转换为可读的文本标签(如 0 → ‘t-shirt’)。
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):figsize = (num_cols * scale, num_rows * scale)_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):ax.imshow(img.numpy())else:ax.imshow(img)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])return axes
输入 imgs 可以是张量或PIL图像。
squeeze():移除单通道维度(1x28x28 → 28x28),否则 imshow 可能报错。
cmap=‘gray’:确保灰度图正确显示(默认可能为彩色)。
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y));
输出:显示 2行x9列 的图像网格,标题为对应的文本标签。
X.reshape(18, 28, 28):调整形状以匹配 imshow 的输入要求(原始形状为 18x1x28x28)。

3.5.2 读取小批量
batch_size = 256def get_dataloader_workers():return 4 # 根据CPU核心数调整(通常设为4-8)train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers())
shuffle=True:打乱训练数据顺序,避免模型记忆批次。
num_workers=4:启用4个进程并行加载数据,加速数据读取。
timer = d2l.Timer()
for X, y in train_iter:continue
print(f'加载时间:{timer.stop():.2f} sec')‘2.30 sec’
3.5.3 整合所有组件
def load_data_fashion_mnist(batch_size, resize=None):trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize)) # Resize必须在ToTensor前trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))
功能扩展:支持调整图像尺寸(如 resize=64 将图像缩放为 64x64)。
预处理顺序:
Resize(若指定)
ToTensor(转为张量并归一化)
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:print(f'X形状: {X.shape}, 数据类型: {X.dtype}') # 输出如 torch.Size([32,1,64,64])print(f'y形状: {y.shape}, 数据类型: {y.dtype}') # 输出如 torch.int64break
X形状: torch.Size([32, 1, 64, 64]), 数据类型: torch.float32
y形状: torch.Size([32]), 数据类型: torch.int64
X.shape = [batch_size, channels, height, width]
y 为标签张量,形状 [batch_size]
相关文章:
深度学习3.5 图像分类数据集
%matplotlib inline import torch import torchvision from torch.utils import data from torchvision import transforms from d2l import torch as d2l代码执行流程图 #mermaid-svg-WWhBmQvijswiICpI {font-family:"trebuchet ms",verdana,arial,sans-serif;font-…...

js原型链prototype解释
function Person(){} var personnew Person() console.log(啊啊,Person instanceof Function);//true console.log(,Person.__proto__Function.prototype);//true console.log(,Person.prototype.__proto__ Object.prototype);//true console.log(,Function.prototype.__prot…...

从M个元素中查找最小的N个元素时,使用大顶堆的效率比使用小顶堆更高,为什么?
我们有一个长度为 M 的数组,现在我们想从中找出 最小的 N 个元素。例如: int a[10] {12, 3, 5, 7, 19, 0, 8, 2, 4, 10};从中找出 最小的 4 个元素。 正确方法:使用大小为 N 的「大顶堆」 原因分析: 我们想保留最小的 4 个元素…...
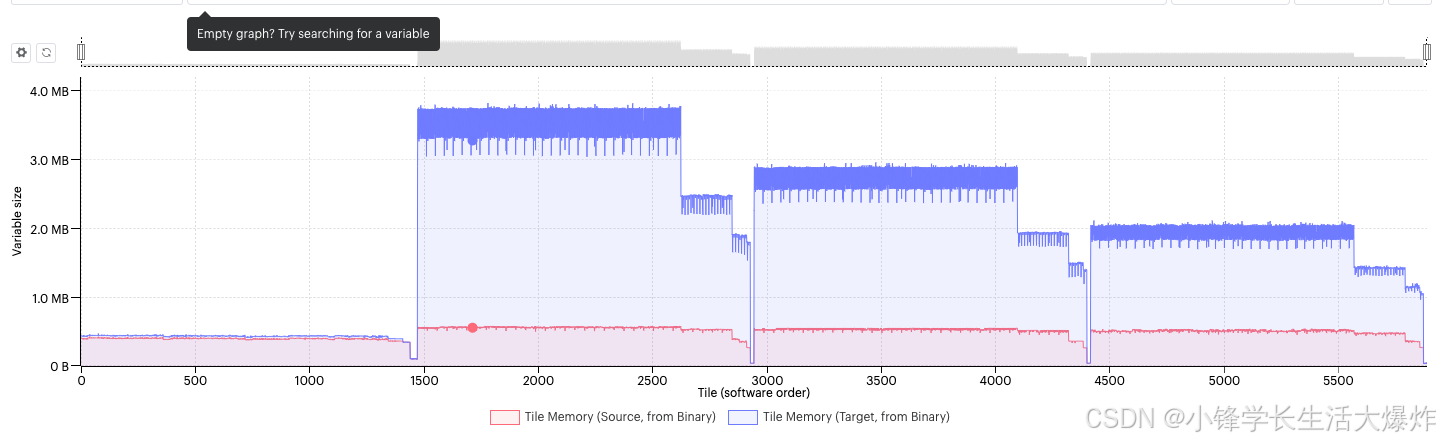
【知识】性能优化和内存优化的主要方向
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 前言 现在有很多论文,乍一看很高级,实际上一搜全是现有技术的堆砌,但是这种裁缝式的论文依然能发表在很好的会议和期…...
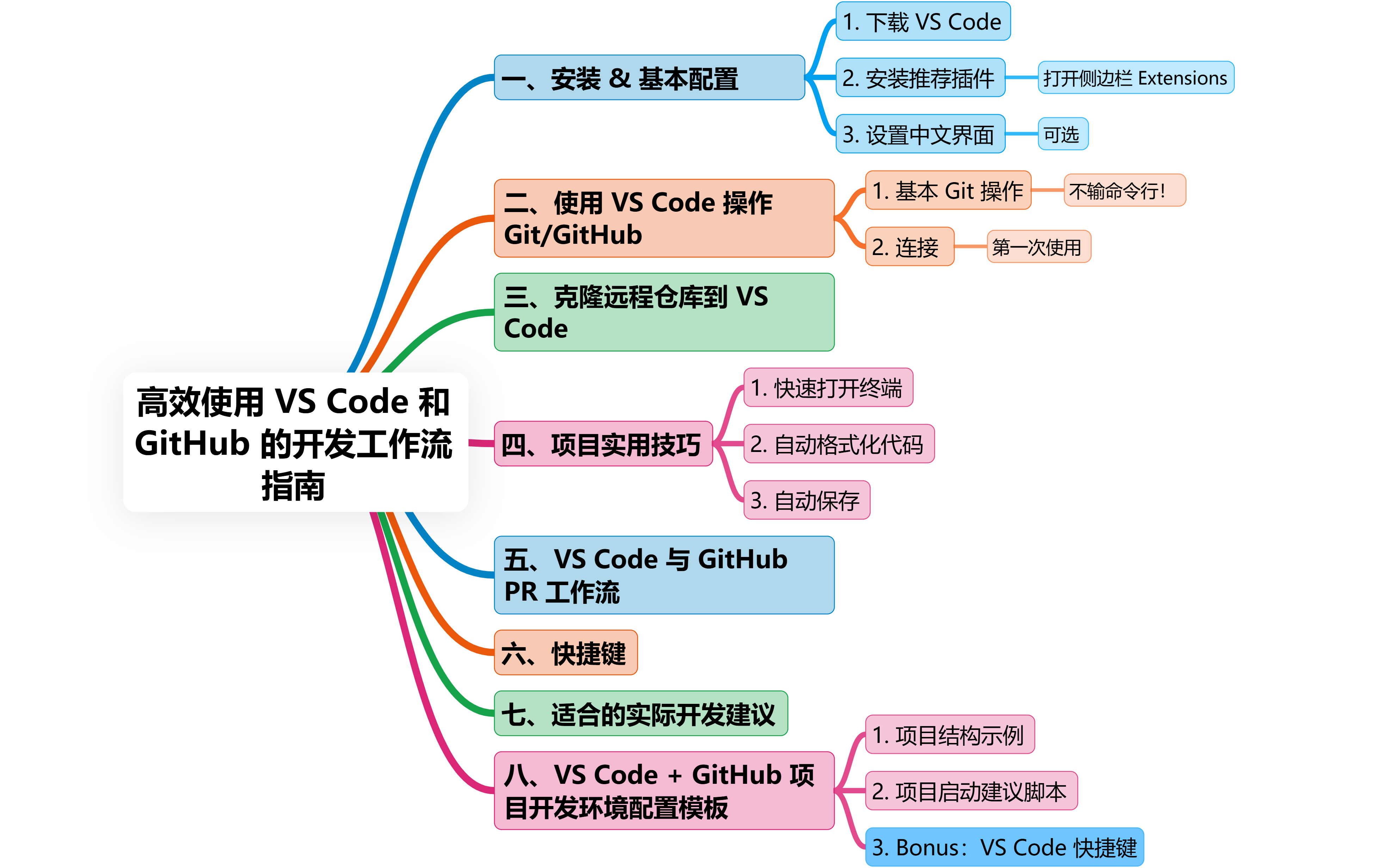
VS Code + GitHub:高效开发工作流指南
目录 一、安装 & 基本配置 1.下载 VS Code 2.安装推荐插件(打开侧边栏 Extensions) 3.设置中文界面(可选) 二、使用 VS Code 操作 Git/GitHub 1.基本 Git 操作(不输命令行!) 2.连接 GitHub(第一次使用) 三、克隆远程仓库到 VS Code 方法一(推荐): 方…...

软件测试之接口测试常见面试
一、什么是(软件)接口测试? 接口测试:是测试系统组件间接口的一种测试方法 接口测试的重点:检查数据的交换,数据传递的正确性,以及接口间的逻辑依赖关系 接口测试的意义:在较早期开展,在软件开发的同时…...

发送百度地图的定位
在vuephp写的聊天软件项目中,增加一个发送百度地图的定位功能 在 Vue PHP 的聊天软件中增加发送百度地图定位功能,需要从前端定位获取、地图API集成、后端存储到消息展示全流程实现。以下是详细步骤: 一、前端实现(Vue/Uni-app…...
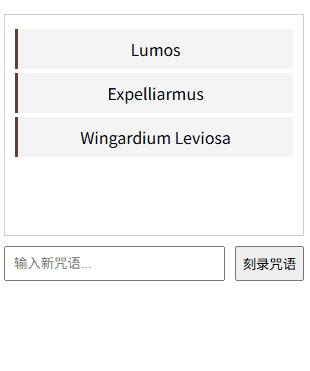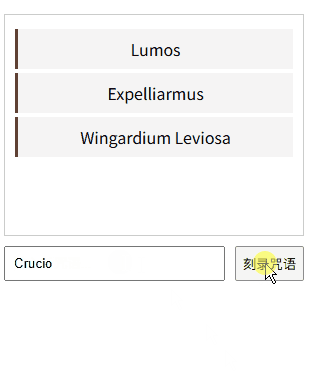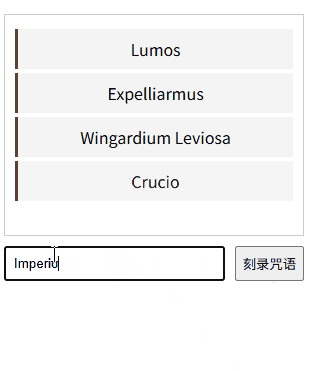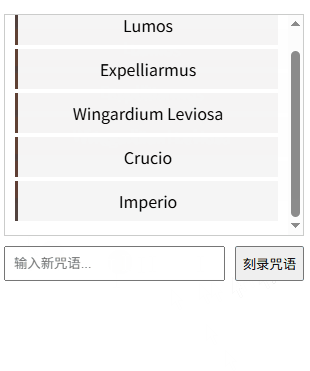
11、Refs:直接操控元素——React 19 DOM操作秘籍
一、元素操控的魔法本质 "Refs是巫师与麻瓜世界的连接通道,让开发者能像操控魔杖般精准控制DOM元素!"魔杖工坊的奥利凡德先生轻抚着魔杖,React/Vue的refs能量在杖尖跃动。 ——以神秘事务司的量子纠缠理论为基,揭示DOM…...
uniapp-商城-33-shop 布局搜索页面以及u-search
shop页面上有一个搜索,可以进行商品搜索,这里我们先做一个页面布局,后面再来进行数据i联动。 1、shop页面的搜索 2、搜索的页面代码 <navigator class"searchView" url"/pagesub/pageshop/search/search"> …...

npm的基本使用安装所有包,安装删除指定版本的包,配置命名别名
npm的基本使用安装所有包,安装删除指定版本的包,配置命名别名 安装所有依赖指定版本安装/删除包给 npm 脚本配置“命令别名(自定义命令)” ✅ 一、安装所有包(恢复依赖) 如果项目中已经存在 package.json…...
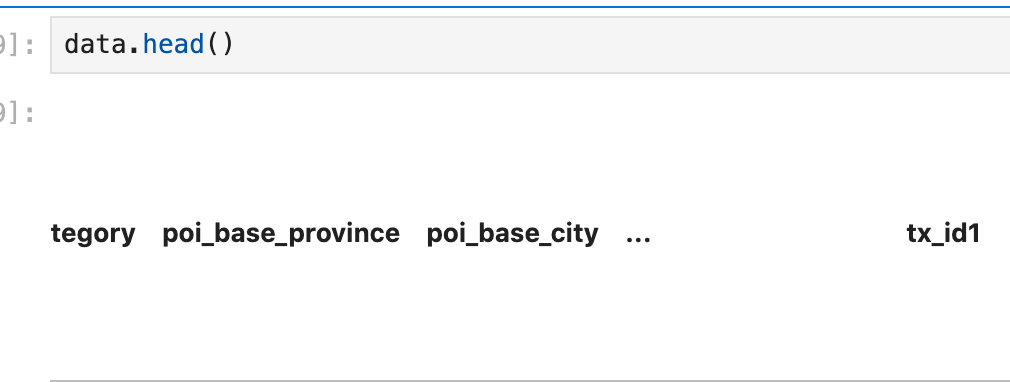
【dataframe显示不全问题】打开一个行列超多的excel转成df之后行列显示不全
出现问题如下图: 解决方案~ display.width解决列显示不全 pd.set_option(display.max_columns,1000) pd.set_option(display.width, 1000) pd.set_option(display.max_colwidth,1000) pd.set_option(display.max_rows,1000)...
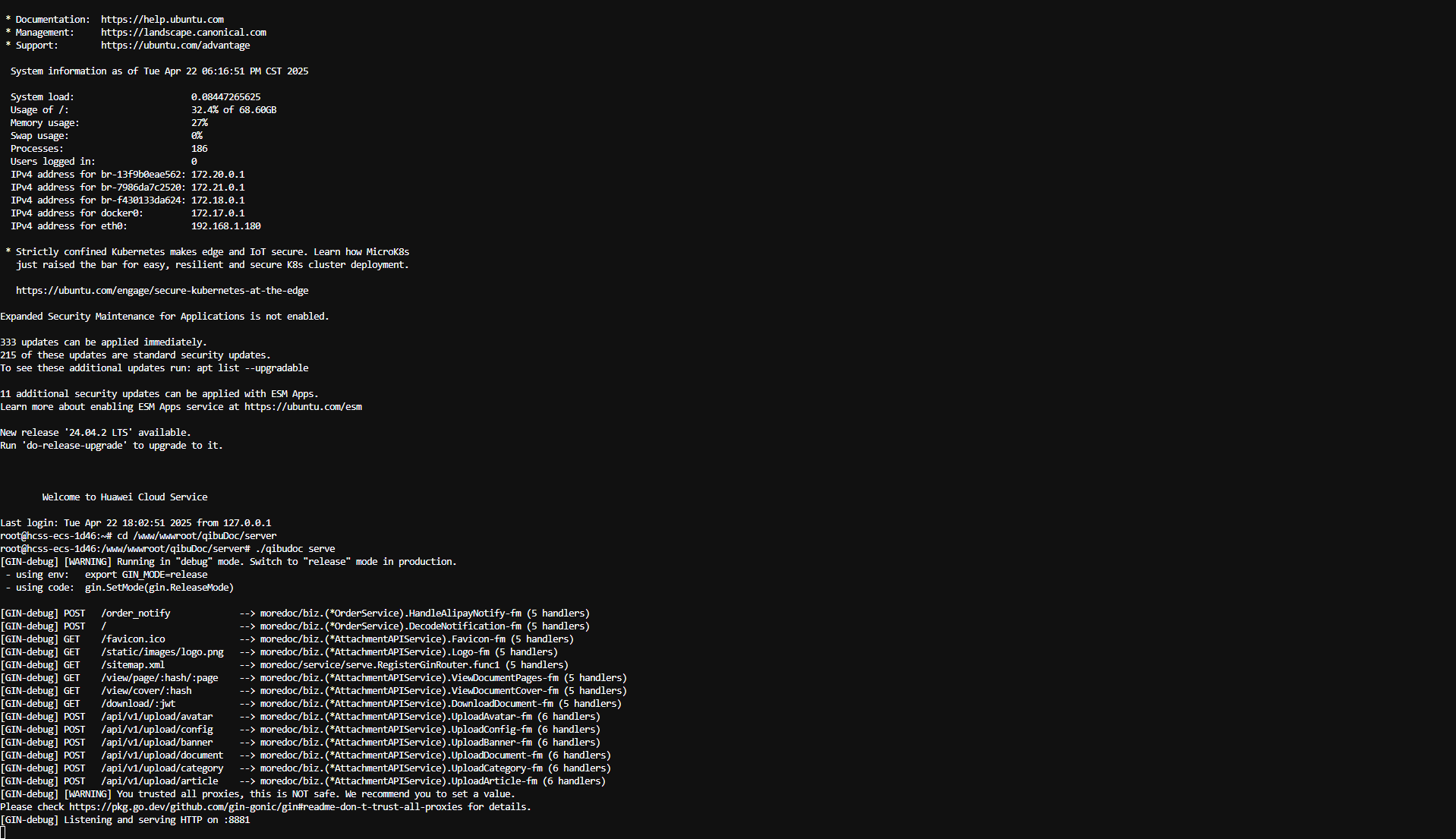
Windows下Golang与Nuxt项目宝塔部署指南
在Windows下将Golang后端和Nuxt前端项目打包,并使用宝塔面板部署的步骤如下 一、Golang后端打包 交叉编译为Linux可执行文件 在Windows PowerShell中执行: powershell复制下载 $env:GOOS "linux" $env:GOARCH "amd64" go build…...
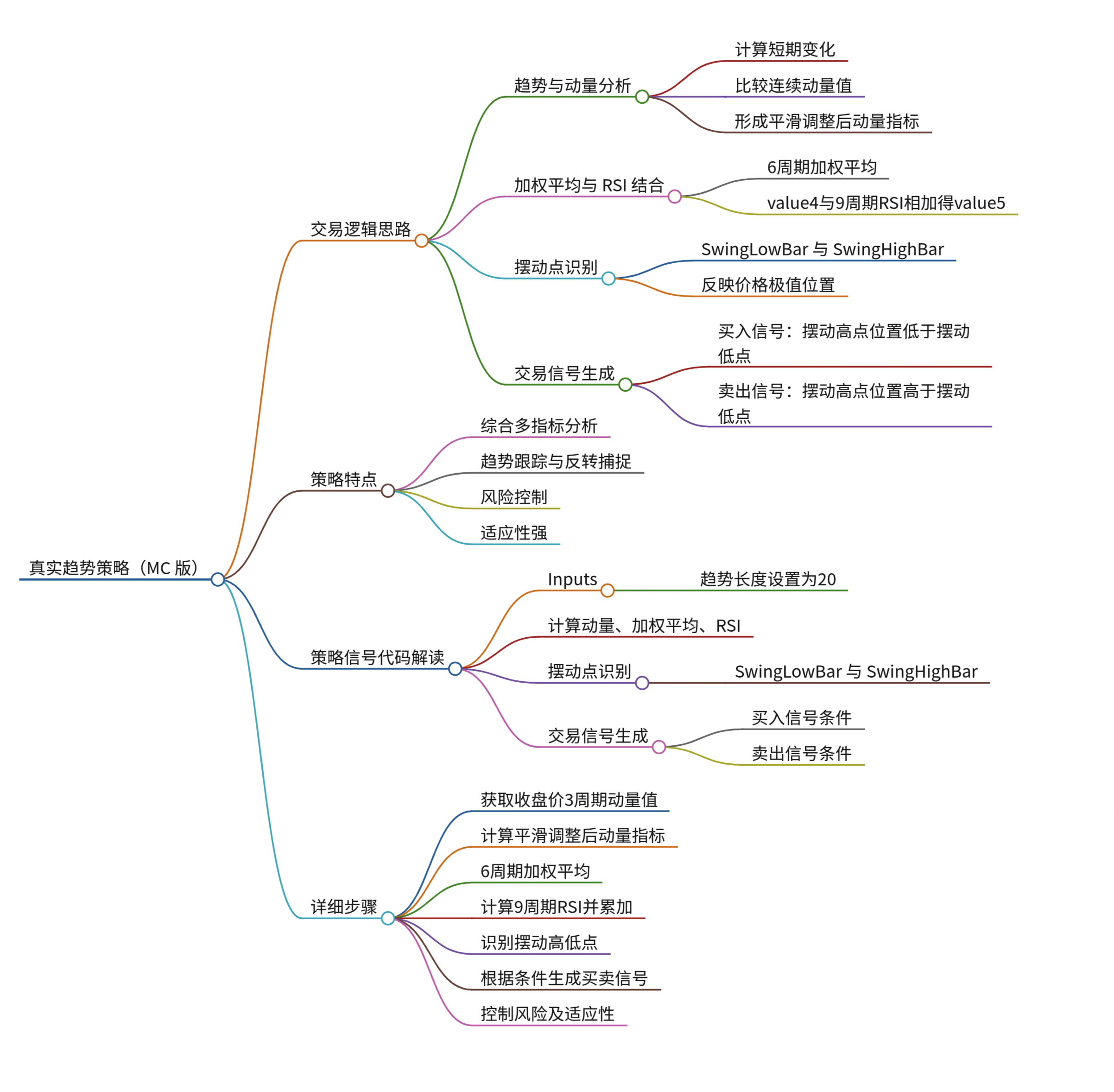
真实趋势策略思路
该交易策略通过一系列技术指标的计算与逻辑判断,旨在捕捉市场趋势的反转与延续点,以实现盈利。其主要交易逻辑思路可以概括如下: 1. 趋势与动量分析 策略首先利用动量函数计算收盘价的短期(3周期)变化,通过…...

江奇霖惊喜亮相泡泡岛音乐节,新歌首唱+合作舞台燃动现场
2025年4月20日,江奇霖受邀参加2025泡泡岛音乐与艺术节东南站。现场献唱三首歌曲,超5万名观众现场一同感受音乐的魅力。 在泡泡岛SPECIAL SET特别企划舞台中,江奇霖带来新歌的首唱,温暖的旋律如低语倾诉,观众们也纷纷喊…...
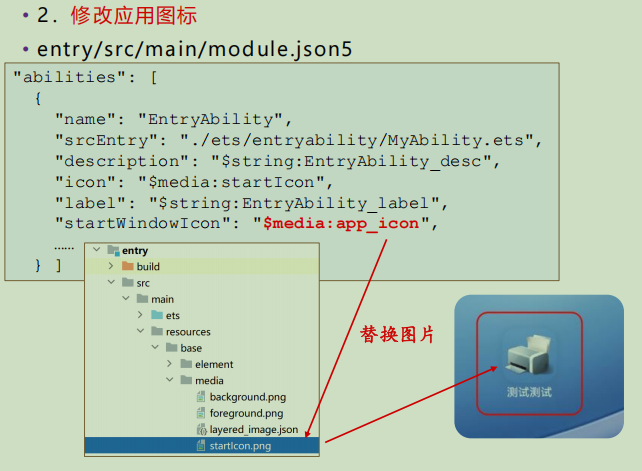
【HarmonyOS】ArKUI框架
目录 概述 声明式开发范式 基于ArKUI的项目 • 1.创建资源文件 • 2.引用资源 • 3.引用系统资源: • 系统资源有哪些 • 4. 在配置和资源中引用资源 声明式语法 UI描述规范 UI组件概述 组件化 组件渲染控制语法 修改…...

使用 Nacos 的注意事项与最佳实践
📹 背景 Nacos 凭借其强大💪的服务发现、配置管理和服务管理能力,成为构建分布式系统的得力助手。然而,要充分发挥 Nacos 的优势,实现系统的高性能、高可用,掌握其使用过程中的注意事项和最佳实践至关…...

Megatron - LM 重要文件解析 - /tools/preprocess_data.py
preprocess_data.py 的主要功能。这是 Megatron-LM 的数据预处理脚本,主要用于将原始文本数据转换为模型训练所需的格式。 核心功能: 1. 数据预处理流程: 输入:原始文本文件(JSON格式) 处理:…...
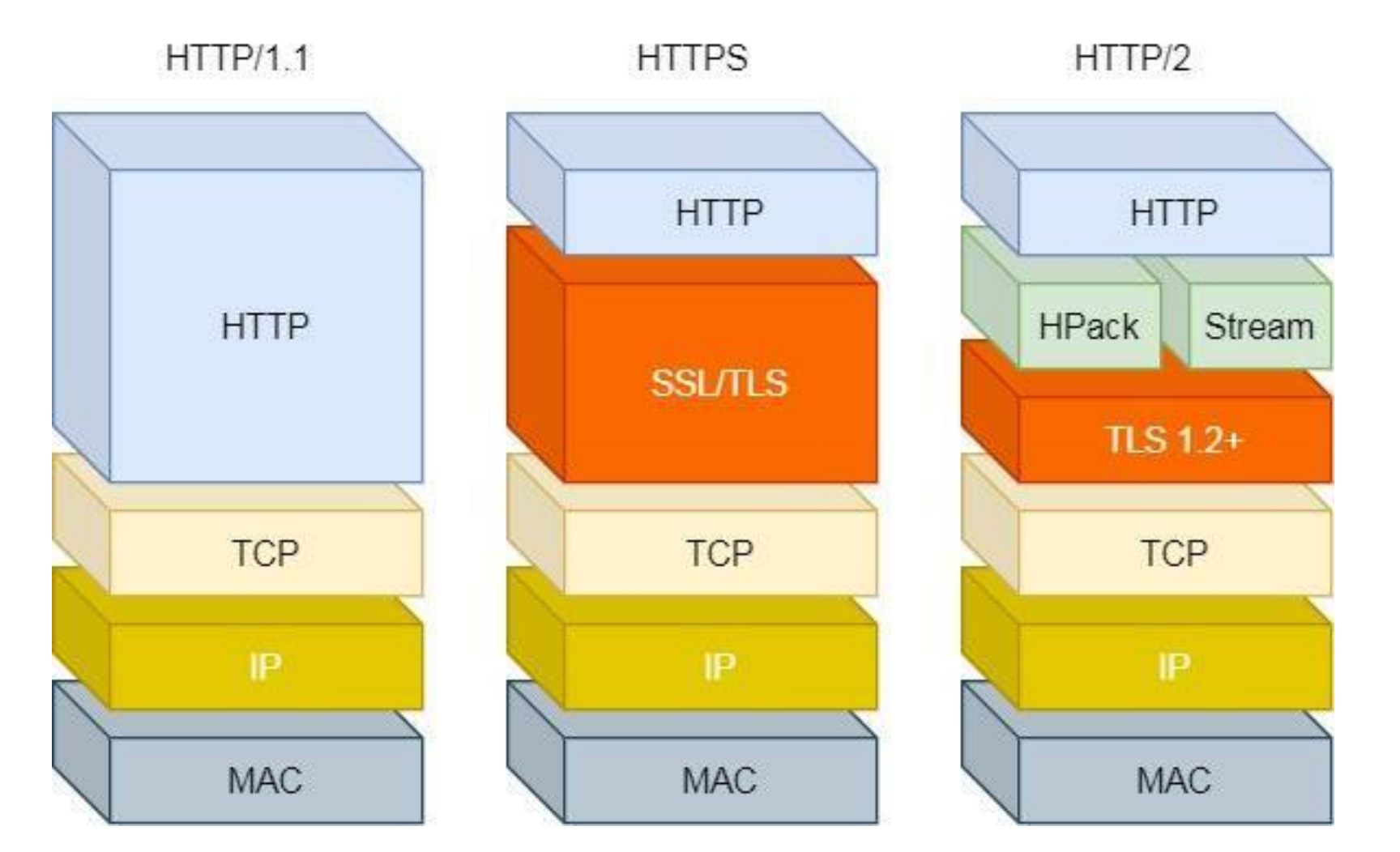
计算机网络八股——HTTP协议与HTTPS协议
目录 HTTP1.1简述与特性 1. 报文清晰易读 2. 灵活和易于扩展 3. ⽆状态 Cookie和Session 4. 明⽂传输、不安全 HTTP协议发展过程 HTTP/1.1的不足 HTTP/2.0 HTTP/3.0 HTTPS协议 HTTP协议和HTTPS协议的区别 HTTPS中的加密方式 HTTPS中建立连接的方式 前言ÿ…...

Unitest和pytest使用方法
unittest 是 Python 自带的单元测试框架,用于编写和运行可重复的测试用例。它的核心思想是通过断言(assertions)验证代码的行为是否符合预期。以下是 unittest 的基本使用方法: 1. 基本结构 1.1 创建测试类 继承 unittest.TestC…...

常用python爬虫框架介绍
文章目录 前言1. Scrapy2. BeautifulSoup 与 Requests 组合3. Selenium4. PySpider 前言 Python 有许多优秀的爬虫框架,每个框架都有其独特的特点和适用场景。以下为你详细介绍几个常用的 Python 爬虫框架: Python 3.13.2 安装教程(附安装包…...
2.3 预训练自己的模型)
AI大模型:(二)2.3 预训练自己的模型
目录 1.预训练原理 2.预训练范式 1.未标注数据 2.标注数据 3.有正确答案、也有错误答案 3.手撕transform模型 3.1.transform模型代码 3.2.训练数据集 3.3.预训练 3.4.推理 4.如何选择模型 5.如何确定模型需要哪种训练 大模型预训练(Large-scale Pre-training…...
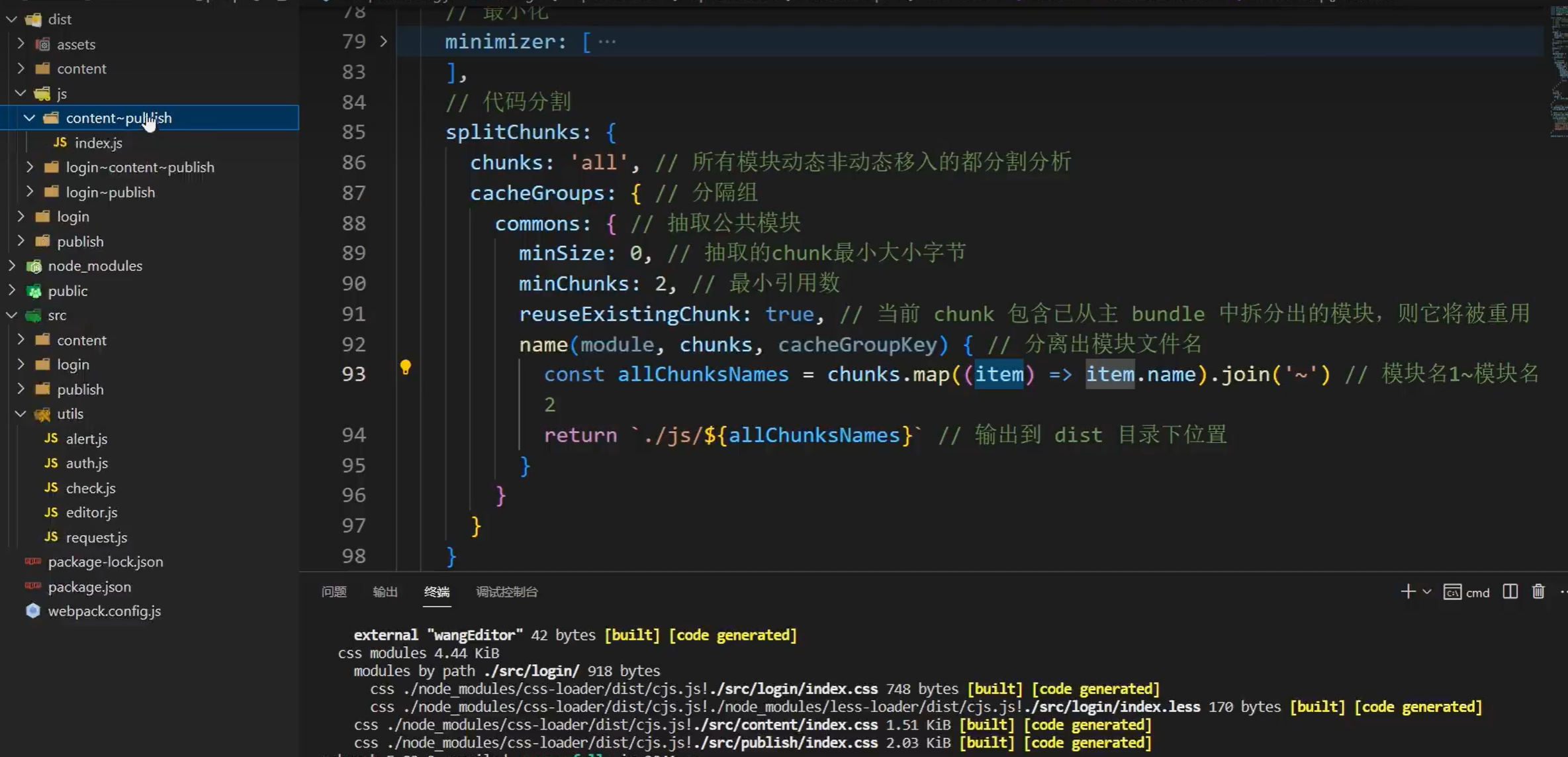
webpack基础使用了解(入口、出口、插件、加载器、优化、别名、打包模式、环境变量、代码分割等)
目录 1、webpack简介2、简单示例3、入口(entry)和输出(output)4、自动生成html文件5、打包css代码6、优化(单独提取css代码)7、优化(压缩过程)8、打包less代码9、打包图片10、搭建开发环境(webpack-dev-server…...
:时钟树综合——让芯片的「心跳」同步到每个角落)
数字后端设计 (四):时钟树综合——让芯片的「心跳」同步到每个角落
—— 试想全城的人要在同一秒按下开关——如果有的表快、有的表慢,结果会乱套!时钟树综合就是给芯片内部装一套精准的“广播对时系统”,让所有电路踩着同一个节拍工作。 1. 为什么时钟如此重要? 芯片的「心跳」:时钟信…...
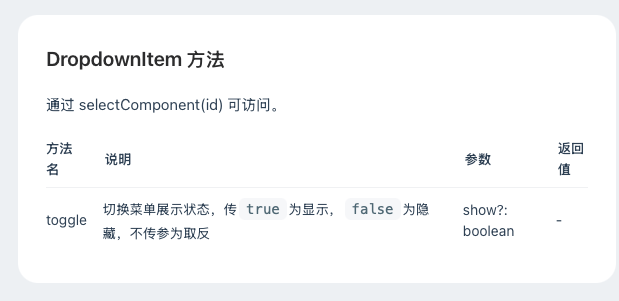
微信小程序 van-dropdown-menu
点击其他按钮,关闭van-dropdown-menu下拉框 DropdownMenu 引入页面使用index.wxmlindex.scssindex.ts(重点)index.ts(全部) DropdownMenu 引入 在app.json或index.json中引入组件 "usingComponents": {"van-dropdown-menu": "vant/weapp…...

智驱未来:AI大模型重构数据治理新范式
第一章 数据治理的进化之路 1.1 传统数据治理的困境 在制造业巨头西门子的案例中,其全球200个工厂每天产生1.2PB工业数据,传统人工清洗需要300名工程师耗时72小时完成,错误率高达15%。数据孤岛问题导致供应链决策延迟平均达48小时。 1.2 A…...

2025-04-22| Docker: --privileged参数详解
在 Docker 中,--privileged 是一个运行容器时的标志,它赋予容器特权模式,大幅提升容器对宿主机资源的访问权限。以下是 --privileged 的作用和相关细节: 作用 完全访问宿主机的设备: 容器可以访问宿主机的所有设备&am…...

[创业之路-380]:企业法务 - 企业经营中,企业为什么会虚开増值税发票?哪些是虚开増值税发票的行为?示例?风险?
一、动机与风险 1、企业虚开增值税发票的动机 利益驱动 骗抵税款:通过虚开发票虚增进项税额,减少应纳税额,降低税负。公司套取国家的利益。非法套现:虚构交易开具发票,将资金从公司账户转移至个人账户,用…...
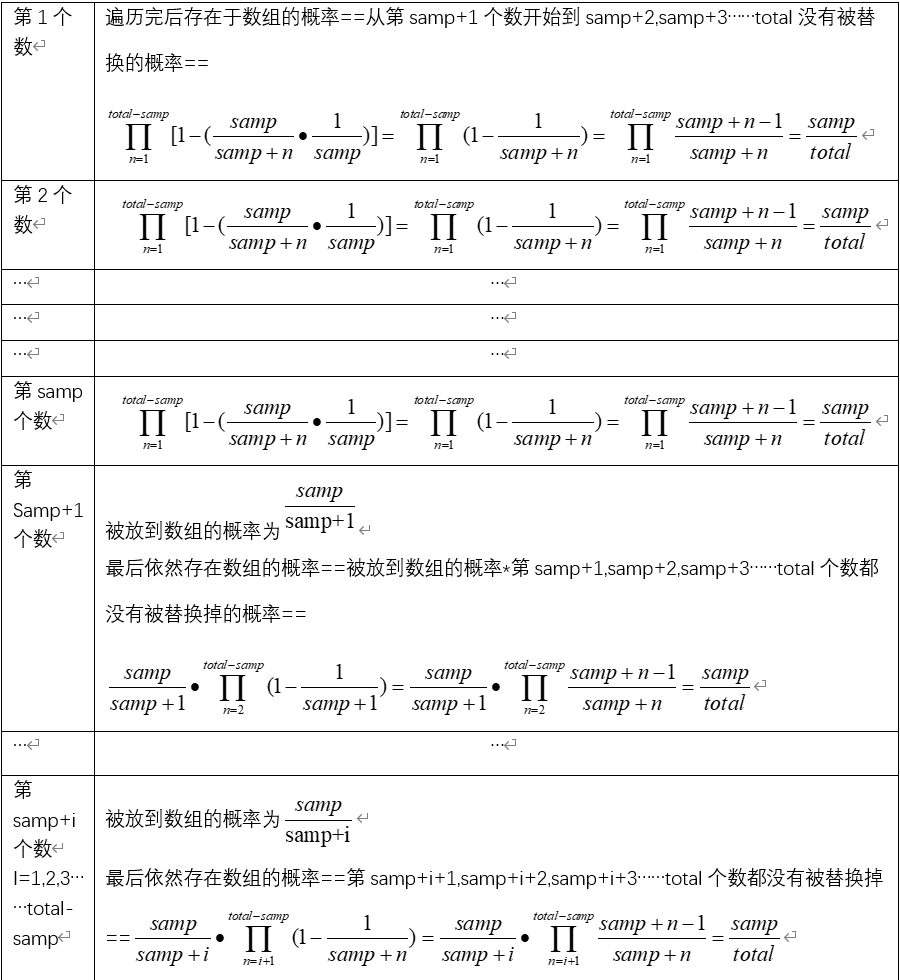
C++ 蓄水池抽样算法
(1)概念 蓄水池抽样算法(Reservoir Sampling)是一种用于从 大规模数据集(尤其是 流式数据 或 无法预先知晓数据总量 的场景)中 等概率随机抽取固定数量样本 的算法。 (2)实现 我们…...

uniapp-x 二维码生成
支持X,二维码生成,支持微信小程序,android,ios,网页 - DCloud 插件市场 免费的单纯用爱发电的...

蓝桥杯算法实战分享:C/C++ 题型解析与实战技巧
蓝桥杯全国软件和信息技术专业人才大赛,作为国内知名的算法竞赛之一,吸引了众多编程爱好者参与。在蓝桥杯的赛场上,C/C 因其高效性和灵活性,成为了众多选手的首选语言。本文将结合蓝桥杯的赛制特点、常见题型以及实战案例…...