蓝桥杯算法实战分享:C/C++ 题型解析与实战技巧
蓝桥杯全国软件和信息技术专业人才大赛,作为国内知名的算法竞赛之一,吸引了众多编程爱好者参与。在蓝桥杯的赛场上,C/C++ 因其高效性和灵活性,成为了众多选手的首选语言。本文将结合蓝桥杯的赛制特点、常见题型以及实战案例,分享一些 C/C++ 解题技巧与策略,帮助大家在比赛中取得更好的成绩。
一、蓝桥杯算法竞赛概述
蓝桥杯算法竞赛注重考察选手的算法设计能力、编程实现能力以及问题解决能力。比赛题目涵盖了数据结构、算法设计、动态规划、图论、数论等多个领域,要求选手在有限的时间内,快速分析问题、设计算法并编程实现。
二、C/C++ 解题基础
1. 语言特性
- 高效性:C/C++ 语言执行效率高,适合处理大规模数据和复杂算法。
- 灵活性:支持指针操作、内存管理,便于实现高级数据结构。
- 标准库:STL(Standard Template Library)提供了丰富的数据结构(如 vector、map、set)和算法(如 sort、lower_bound),可大大提高编程效率。
2. 编程规范
- 代码风格:保持代码整洁、易读,使用有意义的变量名和函数名。
- 注释习惯:在关键算法和复杂逻辑处添加注释,便于自己和他人理解。
- 错误处理:合理使用异常处理机制,确保程序的健壮性。
三、常见题型与解题技巧
1. 数据结构题
- 数组与字符串:掌握数组的遍历、排序、查找等基本操作;熟悉字符串的匹配、替换、分割等算法。
- 链表与树:理解链表和树的基本结构,掌握链表的插入、删除、反转等操作;熟悉二叉树的遍历、搜索、平衡等算法。
- 图论:掌握图的表示方法(邻接矩阵、邻接表);熟悉图的遍历(DFS、BFS)、最短路径(Dijkstra、Floyd)、最小生成树(Prim、Kruskal)等算法。
示例:Dijkstra 算法
给定一个有向加权图(以邻接表形式表示),以及一个起点,请计算并输出从起点到其它所有节点的最短距离。如果某个节点不可达,则输出 INF 表示无穷大。
#include <iostream>
#include <vector>
#include <queue>
#include <climits>using namespace std;// 定义无穷大的值
const int INF = INT_MAX;/*** 使用 Dijkstra 算法计算单源最短路径。* * @param n 节点的数量(从 0 到 n-1 编号)。* @param adj 邻接表表示的图,adj[u] 是一个 vector,存储从节点 u 出发的所有边,* 每条边用一个 pair 表示,pair 的 first 是目标节点 v,second 是边权重 w。* @param start 起始节点编号。* @return 一个 vector,存储从起始节点到每个节点的最短距离。如果某个节点不可达,则距离为 INF。*/
vector<int> dijkstra(int n, vector<vector<pair<int, int>>> &adj, int start) {// 初始化距离数组 dist,所有节点的距离设置为 INF,表示尚未访问vector<int> dist(n, INF);dist[start] = 0; // 起始节点到自身的距离为 0// 定义优先队列 pq,使用小顶堆存储 (当前距离, 当前节点),以实现每次取出最小距离的节点priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> pq;pq.push({0, start}); // 将起始节点加入优先队列,距离为 0// 当优先队列不为空时,继续处理while (!pq.empty()) {// 取出当前距离最小的节点 uint u = pq.top().second;pq.pop();// 遍历节点 u 的所有邻接边for (auto &edge : adj[u]) {int v = edge.first; // 边的目标节点int w = edge.second; // 边的权重// 如果通过节点 u 到节点 v 的路径更短,则更新 dist[v]if (dist[u] + w < dist[v]) {dist[v] = dist[u] + w; // 更新最短距离pq.push({dist[v], v}); // 将更新后的节点 v 加入优先队列}}}return dist;
}int main() {// 示例图结构(邻接表表示)// 图中有 5 个节点,编号从 0 到 4int n = 5;vector<vector<pair<int, int>>> adj(n);// 添加边及其权重adj[0].push_back({1, 10});adj[0].push_back({3, 5});adj[1].push_back({2, 1});adj[1].push_back({3, 2});adj[2].push_back({4, 4});adj[3].push_back({1, 3});adj[3].push_back({2, 9});adj[3].push_back({4, 2});adj[4].push_back({0, 7});adj[4].push_back({2, 6});// 起点int start = 0;// 计算最短路径vector<int> dist = dijkstra(n, adj, start);// 输出结果cout << "从节点 " << start << " 出发到各个节点的最短距离:" << endl;for (int i = 0; i < n; ++i) {cout << "到节点 " << i << " 的最短距离是 ";if(dist[i] == INF) cout << "INF"; // 如果距离为 INF,表示不可达else cout << dist[i];cout << endl;}return 0;
}示例:反转链表
给定一个单链表的头节点 head,请将其反转并返回反转后的链表头节点。例如:
- 输入:1 -> 2 -> 3 -> 4 -> 5
- 输出:5 -> 4 -> 3 -> 2 -> 1
#include <iostream>using namespace std;// 定义链表节点结构
struct ListNode {int val; // 节点值ListNode* next; // 指向下一个节点的指针ListNode(int x) : val(x), next(nullptr) {} // 构造函数
};/*** 反转链表的函数。* * @param head 单链表的头节点。* @return 反转后的链表头节点。*/
ListNode* reverseList(ListNode* head) {// 定义三个指针:prev、curr 和 nextListNode* prev = nullptr; // 初始时,前一个节点为空ListNode* curr = head; // 当前节点从头节点开始// 遍历链表,直到当前节点为空while (curr != nullptr) {ListNode* next = curr->next; // 保存当前节点的下一个节点curr->next = prev; // 将当前节点的 next 指向前一个节点,实现反转prev = curr; // 移动 prev 到当前节点curr = next; // 移动 curr 到下一个节点}// 循环结束后,prev 指向新的头节点(原链表的尾节点)return prev;
}// 辅助函数:打印链表
void printList(ListNode* head) {ListNode* curr = head;while (curr != nullptr) {cout << curr->val << " ";curr = curr->next;}cout << endl;
}int main() {// 创建一个示例链表:1 -> 2 -> 3 -> 4 -> 5ListNode* head = new ListNode(1);head->next = new ListNode(2);head->next->next = new ListNode(3);head->next->next->next = new ListNode(4);head->next->next->next->next = new ListNode(5);cout << "原链表:" << endl;printList(head);// 反转链表ListNode* reversedHead = reverseList(head);cout << "反转后的链表:" << endl;printList(reversedHead);return 0;
}示例:Kruskal 算法求最小生成树
给定一个无向加权图,请使用 Kruskal 算法找到其最小生成树(MST)。如果图不连通,则返回森林的最小生成树。例如:
- 输入:图的边列表 edges = [[0, 1, 10], [0, 2, 6], [0, 3, 5], [1, 3, 15], [2, 3, 4]],节点数 n = 4
- 输出:最小生成树的边集合及其总权重。
#include <iostream>
#include <vector>
#include <algorithm>using namespace std;// 定义边的结构体
struct Edge {int u; // 边的一个端点int v; // 边的另一个端点int weight; // 边的权重
};// 并查集(Union-Find)数据结构,用于检测环
class UnionFind {
private:vector<int> parent; // 每个节点的父节点vector<int> rank; // 树的高度(秩)public:// 构造函数,初始化并查集UnionFind(int n) {parent.resize(n);rank.resize(n, 0);for (int i = 0; i < n; ++i) {parent[i] = i; // 初始时每个节点的父节点是自身}}// 查找操作,带路径压缩int find(int x) {if (parent[x] != x) {parent[x] = find(parent[x]); // 路径压缩}return parent[x];}// 合并操作,按秩合并void unite(int x, int y) {int rootX = find(x);int rootY = find(y);if (rootX != rootY) {if (rank[rootX] > rank[rootY]) {parent[rootY] = rootX;} else if (rank[rootX] < rank[rootY]) {parent[rootX] = rootY;} else {parent[rootY] = rootX;rank[rootX]++;}}}
};/*** 使用 Kruskal 算法求最小生成树。* * @param n 节点的数量(从 0 到 n-1 编号)。* @param edges 图的边列表,每条边表示为 (u, v, weight)。* @return 最小生成树的边集合及其总权重。*/
pair<vector<Edge>, int> kruskal(int n, vector<Edge> &edges) {// 将边按权重从小到大排序sort(edges.begin(), edges.end(), [](const Edge &a, const Edge &b) {return a.weight < b.weight;});UnionFind uf(n); // 初始化并查集vector<Edge> mst; // 存储最小生成树的边int totalWeight = 0; // 最小生成树的总权重// 遍历所有边for (const auto &edge : edges) {int u = edge.u;int v = edge.v;int weight = edge.weight;// 如果 u 和 v 不在同一个集合中,则添加这条边到 MST 中if (uf.find(u) != uf.find(v)) {uf.unite(u, v); // 合并两个集合mst.push_back(edge); // 将边加入最小生成树totalWeight += weight; // 累加权重}}return {mst, totalWeight};
}int main() {// 图的节点数和边列表int n = 4;vector<Edge> edges = {{0, 1, 10}, {0, 2, 6}, {0, 3, 5},{1, 3, 15}, {2, 3, 4}};// 使用 Kruskal 算法求最小生成树pair<vector<Edge>, int> result = kruskal(n, edges);vector<Edge> mst = result.first;int totalWeight = result.second;// 输出结果cout << "最小生成树的边:" << endl;for (const auto &edge : mst) {cout << edge.u << " - " << edge.v << " (权重: " << edge.weight << ")" << endl;}cout << "最小生成树的总权重: " << totalWeight << endl;return 0;
}2. 算法设计题
- 动态规划:理解动态规划的基本思想,掌握状态定义、状态转移方程的设计方法。
- 贪心算法:学会分析问题的贪心性质,设计贪心策略。
- 回溯与搜索:掌握回溯算法的基本框架,学会剪枝优化。
示例:背包问题
给定一个容量为 W 的背包和 n 个物品,每个物品有一个重量 w[i] 和一个价值 v[i]。要求从这些物品中选择一些装入背包,在不超过背包容量的前提下,使得背包中的物品总价值最大。
此外,增加以下限制条件:
- 如果可以选择的物品数量超过 k 件,则必须使用回溯算法枚举所有可能的选择。
- 如果物品数量较少(小于等于 k),则使用动态规划解决。
- 使用贪心算法给出一种近似解,并与动态规划或回溯的结果进行比较。
算法设计:
- 动态规划(物品数 ≤ k):
- 状态定义:
dp[i][j]表示前i个物品在容量为j的情况下能获得的最大价值。 - 状态转移方程:
- 不选第
i个物品:dp[i][j] = dp[i-1][j] - 选第
i个物品:dp[i][j] = dp[i-1][j-w[i]] + v[i](前提是j >= w[i]) - 最终状态:
dp[i][j] = max(dp[i-1][j], dp[i-1][j-w[i]] + v[i])
- 不选第
- 状态定义:
-
贪心算法:
- 按照单位价值(
v[i]/w[i])对物品排序,优先选择单位价值高的物品,直到背包装满。
- 按照单位价值(
-
回溯与搜索(物品数 > k):
- 使用回溯算法枚举所有可能的选择。
- 剪枝优化:如果当前选择的物品总重量已经超过背包容量,则直接返回。
#include <iostream>
#include <vector>
#include <algorithm>using namespace std;// 物品结构体
struct Item {int weight; // 物品重量int value; // 物品价值
};// 动态规划求解
int knapsackDP(int W, const vector<Item> &items) {int n = items.size();vector<vector<int>> dp(n + 1, vector<int>(W + 1, 0));for (int i = 1; i <= n; ++i) {for (int j = 0; j <= W; ++j) {dp[i][j] = dp[i - 1][j]; // 不选第 i 个物品if (j >= items[i - 1].weight) { // 选第 i 个物品dp[i][j] = max(dp[i][j], dp[i - 1][j - items[i - 1].weight] + items[i - 1].value);}}}return dp[n][W];
}// 贪心算法求解
int knapsackGreedy(int W, const vector<Item> &items) {vector<pair<double, int>> unitValue(items.size()); // 单位价值和索引for (int i = 0; i < items.size(); ++i) {unitValue[i] = {static_cast<double>(items[i].value) / items[i].weight, i};}sort(unitValue.rbegin(), unitValue.rend()); // 按单位价值降序排序int totalValue = 0;int remainingWeight = W;for (const auto &[_, idx] : unitValue) {if (remainingWeight >= items[idx].weight) {totalValue += items[idx].value;remainingWeight -= items[idx].weight;}}return totalValue;
}// 回溯算法求解
void backtrack(int idx, int currentWeight, int currentValue, int W, const vector<Item> &items, int &maxValue) {if (currentWeight > W) return; // 剪枝:超出背包容量if (idx == items.size()) {maxValue = max(maxValue, currentValue); // 更新最大值return;}// 不选当前物品backtrack(idx + 1, currentWeight, currentValue, W, items, maxValue);// 选当前物品if (currentWeight + items[idx].weight <= W) {backtrack(idx + 1, currentWeight + items[idx].weight, currentValue + items[idx].value, W, items, maxValue);}
}int knapsackBacktrack(int W, const vector<Item> &items) {int maxValue = 0;backtrack(0, 0, 0, W, items, maxValue);return maxValue;
}int main() {// 输入数据int W = 50; // 背包容量vector<Item> items = {{10, 60}, {20, 100}, {30, 120}}; // 物品列表int k = 2; // 动态规划与回溯的分界点// 动态规划求解if (items.size() <= k) {cout << "动态规划结果: " << knapsackDP(W, items) << endl;} else {// 回溯算法求解cout << "回溯算法结果: " << knapsackBacktrack(W, items) << endl;}// 贪心算法求解cout << "贪心算法结果: " << knapsackGreedy(W, items) << endl;return 0;
}3. 数学题
- 数论:掌握素数判断、最大公约数、最小公倍数等算法。
- 组合数学:熟悉排列组合、二项式定理等知识点。
- 概率统计:理解基本概率模型,掌握期望、方差等统计量的计算。
示例:质因数分解与组合计数
给定一个正整数 n,请完成以下任务:
- 将
n进行质因数分解,并输出其所有质因数及其对应的指数。 - 计算从
1到n中所有数的排列数(即 n!n!)并输出结果。 - 如果 n!n! 的值过大,计算 n!mod 109+7n!mod109+7。
例如:
- 输入:
n = 6 - 输出:
- 质因数分解:
6 = 2^1 * 3^1 - 排列数:
6! = 720 - 模运算结果:
720 % (10^9+7) = 720
- 质因数分解:
#include <iostream>
#include <vector>
using namespace std;// 定义模数
const int MOD = 1e9 + 7;// 质因数分解函数
vector<pair<int, int>> primeFactorization(int n) {vector<pair<int, int>> factors; // 存储质因数及其指数for (int i = 2; i * i <= n; ++i) {if (n % i == 0) { // i 是 n 的因子int count = 0;while (n % i == 0) {n /= i;count++;}factors.emplace_back(i, count); // 添加质因数及其指数}}if (n > 1) { // 剩下的 n 是一个质数factors.emplace_back(n, 1);}return factors;
}// 阶乘计算函数(带模运算)
long long factorialMod(int n, int mod) {long long result = 1;for (int i = 1; i <= n; ++i) {result = (result * i) % mod; // 每一步取模}return result;
}int main() {// 输入数据int n;cout << "请输入一个正整数 n: ";cin >> n;// 1. 质因数分解vector<pair<int, int>> factors = primeFactorization(n);cout << "质因数分解结果: " << n << " = ";for (size_t i = 0; i < factors.size(); ++i) {cout << factors[i].first << "^" << factors[i].second;if (i != factors.size() - 1) cout << " * ";}cout << endl;// 2. 计算阶乘 n!long long factorial = 1;for (int i = 1; i <= n; ++i) {factorial *= i;}cout << "n! 的值: " << factorial << endl;// 3. 计算 n! % (10^9+7)long long factorialModResult = factorialMod(n, MOD);cout << "n! % (10^9+7): " << factorialModResult << endl;return 0;
}四、实战策略与技巧
1. 时间管理
- 合理安排时间,优先解决易得分的题目。
- 对于难题,先尝试部分分,再逐步攻克。
2. 代码调试
- 使用调试工具(如 gdb)进行逐步调试。
- 编写测试用例,验证代码的正确性。
3. 代码优化
- 减少不必要的计算,提高算法效率。
- 使用合适的数据结构,降低时间复杂度。
相关文章:

蓝桥杯算法实战分享:C/C++ 题型解析与实战技巧
蓝桥杯全国软件和信息技术专业人才大赛,作为国内知名的算法竞赛之一,吸引了众多编程爱好者参与。在蓝桥杯的赛场上,C/C 因其高效性和灵活性,成为了众多选手的首选语言。本文将结合蓝桥杯的赛制特点、常见题型以及实战案例…...

分布式光纤测温技术让森林火灾预警快人一步
2025年春季,多地接连发生森林火灾,累计过火面积超 3万公顷。春季历来是森林草原火灾易发、多发期,加之清明节已到来,生产生活用火活跃,民俗祭祀用火集中,森林火灾风险进一步加大。森林防火,人人…...

Vue2 el-checkbox 虚拟滚动解决多选框全选卡顿问题 - 高性能处理大数据量选项列表
一、背景 在我们开发项目中,经常会遇到需要展示大量选项的多选框场景,比如权限配置、数据筛选等。当选项数量达到几百甚至上千条时,传统的渲染方式全选时会非常卡顿,导致性能问题。本篇文章,记录我使用通过虚拟滚动实现…...
KUKA机器人KR 3 D1200 HM介绍
KUKA KR 3 D1200 HM是一款小型机器人,型号中HM代表“Hygienic Machine(卫生机械)用于主副食品行业”,也是一款并联机器人。用于执行高速、高精度的抓取任务。这款机器人采用食品级不锈钢设计,额定负载为3公斤ÿ…...

linux驱动---视频播放采集架构介绍
lcd驱动框架(图像显示) 图像显示基础 1. 核心组件架构 用户空间 ------------------------------------------ | X11/Wayland | FBDEV应用 | DRM/KMS应用 | ------------------------------------------ 内核空间 --------------------------------…...
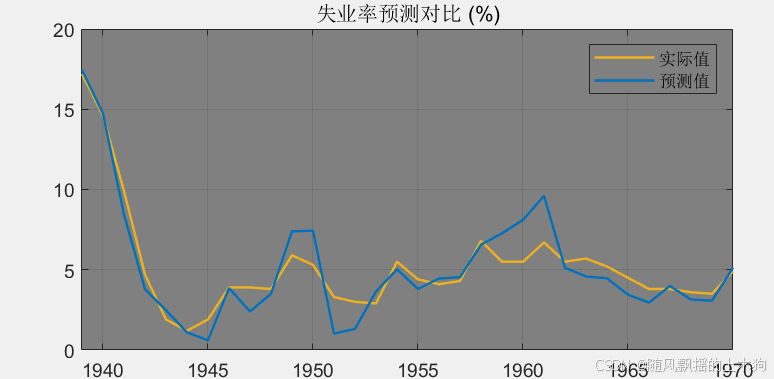
【MATLAB第117期】#源码分享 | 基于MATLAB的SSM状态空间模型多元时间序列预测方法(多输入单输出)
【MATLAB第117期】#源码分享 | 基于MATLAB的SSM状态空间模型多元时间序列预测方法(多输入单输出) 引言 本文使用状态空间模型实现失业率递归预测,状态空间模型(State Space Model, SSM)是一种用于描述动态系统行为的…...

状态管理最佳实践:Riverpod响应式编程
状态管理最佳实践:Riverpod响应式编程 引言 Riverpod是Flutter生态系统中一个强大的状态管理解决方案,它通过响应式编程的方式提供了更加灵活和可维护的状态管理机制。本文将深入探讨Riverpod的核心概念、实践应用以及性能优化技巧。 核心概念 Provi…...
【Linux】线程ID、线程管理、与线程互斥
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🌐 C 语言 上篇文章: 【Linux】线程:从原理到实战,全面掌握多线程编程!-CSDN博客 下…...

python包管理器,conda和uv 的区别
python包管理器,conda和uv 的区别 以下是 conda 和 uv 在 Python 包管理中的深度对比,结合知识库内容进行分析: 1. 核心设计理念 conda 以“环境为中心”,强调跨语言支持(如 Python、R、Julia)和严格的依赖…...

逻辑回归:损失和正则化技术的深入研究
逻辑回归:损失和正则化技术的深入研究 引言 逻辑回归是一种广泛应用于分类问题的统计模型,尤其在机器学习领域中占据着重要的地位。尽管其名称中包含"回归",但逻辑回归本质上是一种分类算法。它的核心思想是在线性回归的基础上添…...
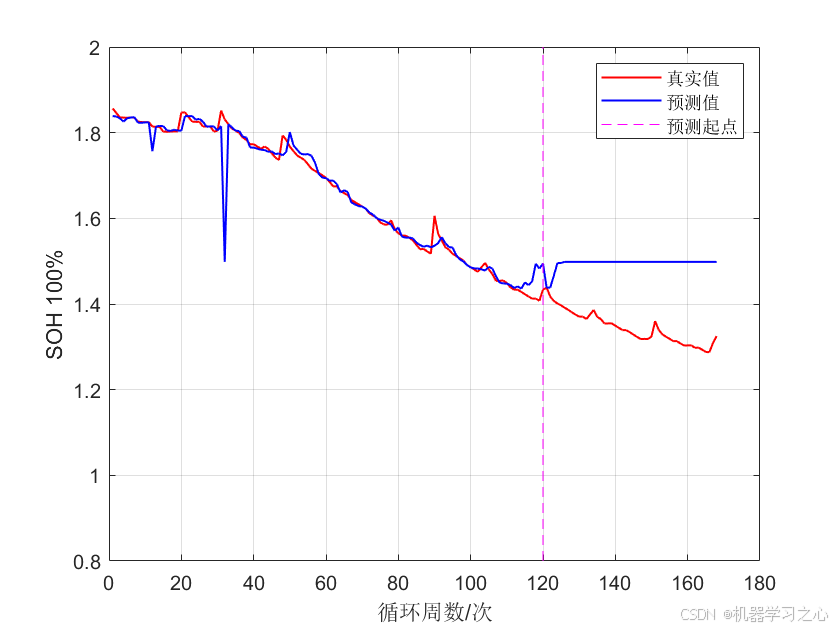
【锂电池SOH估计】RF随机森林锂电池健康状态估计,锂电池SOH估计(Matlab完整源码和数据)
目录 效果一览程序获取程序内容代码分享研究内容基于随机森林(RF)的锂电池健康状态(SOH)估计算法研究摘要1. 引言2. 锂电池SOH评估框架3. 实验与结果分析4. 未来研究方向6. 结论效果一览 程序获取 获取方式一:文章顶部资源处直接下载:【锂电池SOH估计】RF随机森林锂电池…...
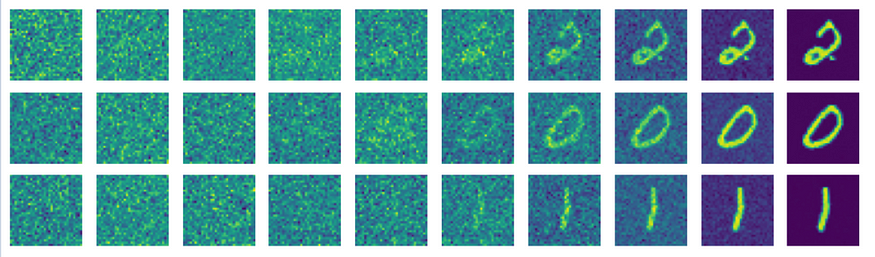
【Pytorch 中的扩散模型】去噪扩散概率模型(DDPM)的实现
介绍 广义上讲,扩散模型是一种生成式深度学习模型,它通过学习到的去噪过程来创建数据。扩散模型有很多变体,其中最流行的通常是文本条件模型,它可以根据提示生成特定的图像。一些扩散模型(例如 Control-Net࿰…...
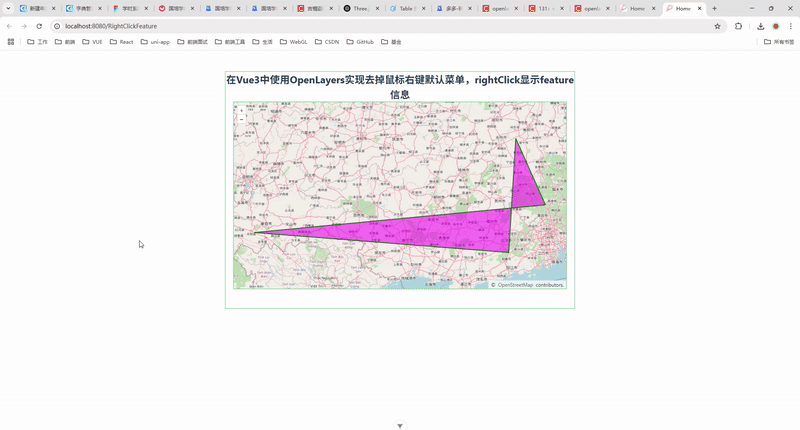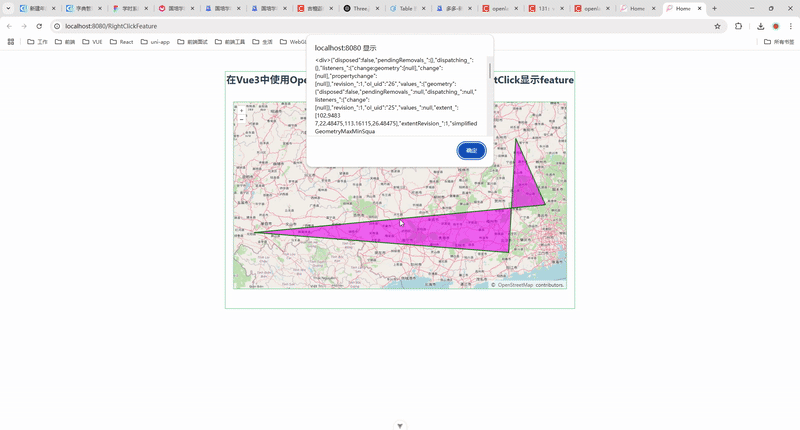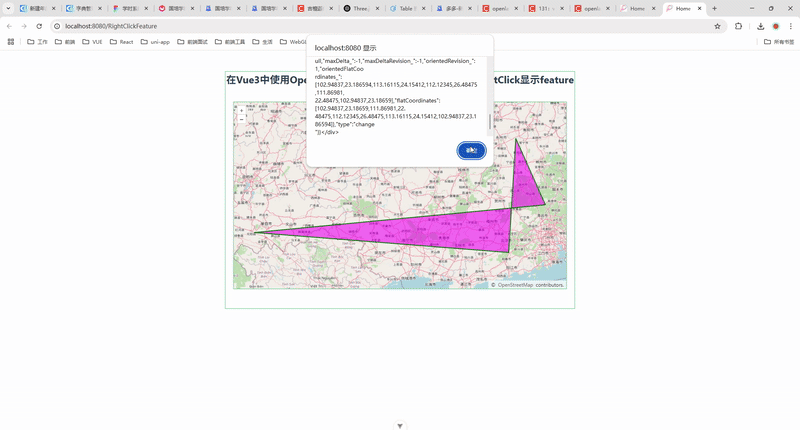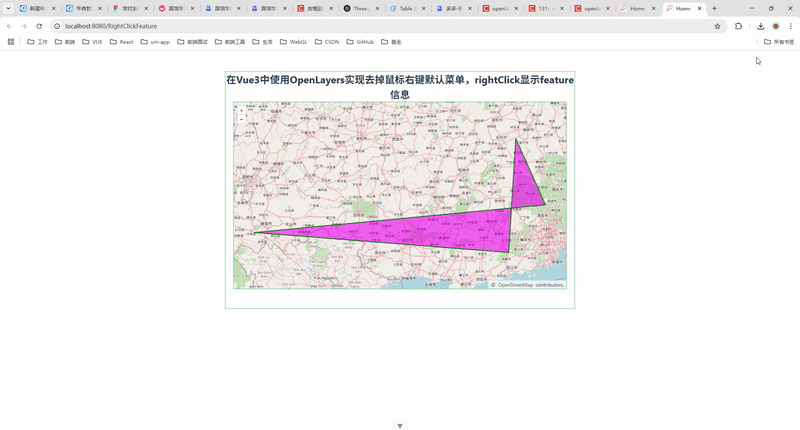
121.在 Vue3 中使用 OpenLayers 实现去掉鼠标右键默认菜单并显示 Feature 信息
🎯 实现效果 👇 本文最终实现的效果如下: ✅ 地图初始化时绘制一个多边形; ✅ 鼠标 右键点击地图任意位置; ✅ 若命中 Feature,则弹出该图形的详细信息; ✅ 移除浏览器默认的右键菜单,保留地图交互的完整控制。 💡 整个功能基于 Vue3 + OpenLayers 完成,采用 Com…...

仓颉造字,亦可造AI代理
CangjieMagic入门教程 本文将为您提供一份关于CangjieMagic代码库的详细入门教程,CangjieMagic托管于GitCode - 全球开发者的开源社区,开源代码托管平台。这是一个基于仓颉编程语言的LLM(大语言模型)Agent开发平台,具有独特的Age…...

进阶篇 第 6 篇:时间序列遇见机器学习与深度学习
进阶篇 第 6 篇:时间序列遇见机器学习与深度学习 (图片来源: Tara Winstead on Pexels) 在上一篇中,我们探讨了如何通过精心的特征工程,将时间序列预测问题转化为机器学习可以处理的监督学习任务。我们学习了如何创建滞后特征、滚动统计特征…...

【音视频】音频解码实战
音频解码过程 ⾳频解码过程如下图所示: FFmpeg流程 关键函数 关键函数说明: avcodec_find_decoder:根据指定的AVCodecID查找注册的解码器。av_parser_init:初始化AVCodecParserContext。avcodec_alloc_context3:为…...
DOCA介绍
本文分为两个部分: DOCA及BlueField介绍如何运行DOCA应用,这里以DNS_Filter为例子做大致介绍。 DOCA及BlueField介绍: 现代企业数据中心是软件定义的、完全可编程的基础设施,旨在服务于跨云、核心和边缘环境的高度分布式应用工作…...
# 利用迁移学习优化食物分类模型:基于ResNet18的实践
利用迁移学习优化食物分类模型:基于ResNet18的实践 在深度学习的众多应用中,图像分类一直是一个热门且具有挑战性的领域。随着研究的深入,我们发现利用预训练模型进行迁移学习是一种非常有效的策略,可以显著提高模型的性能&#…...
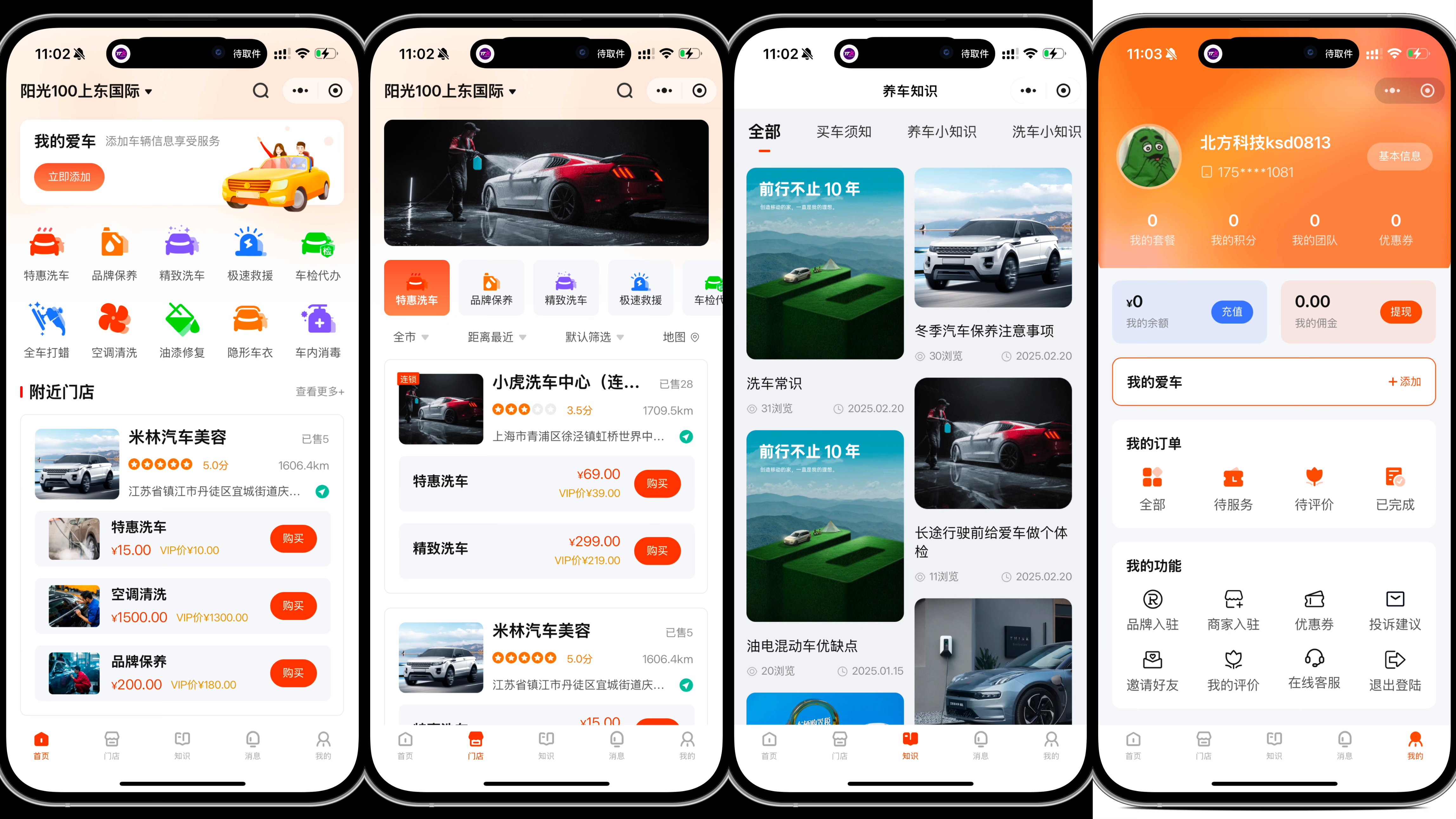
洗车小程序系统前端uniapp 后台thinkphp
洗车小程序系统 前端uniapp 后台thinkphp 支持多门店 分销 在线预约 套餐卡等...
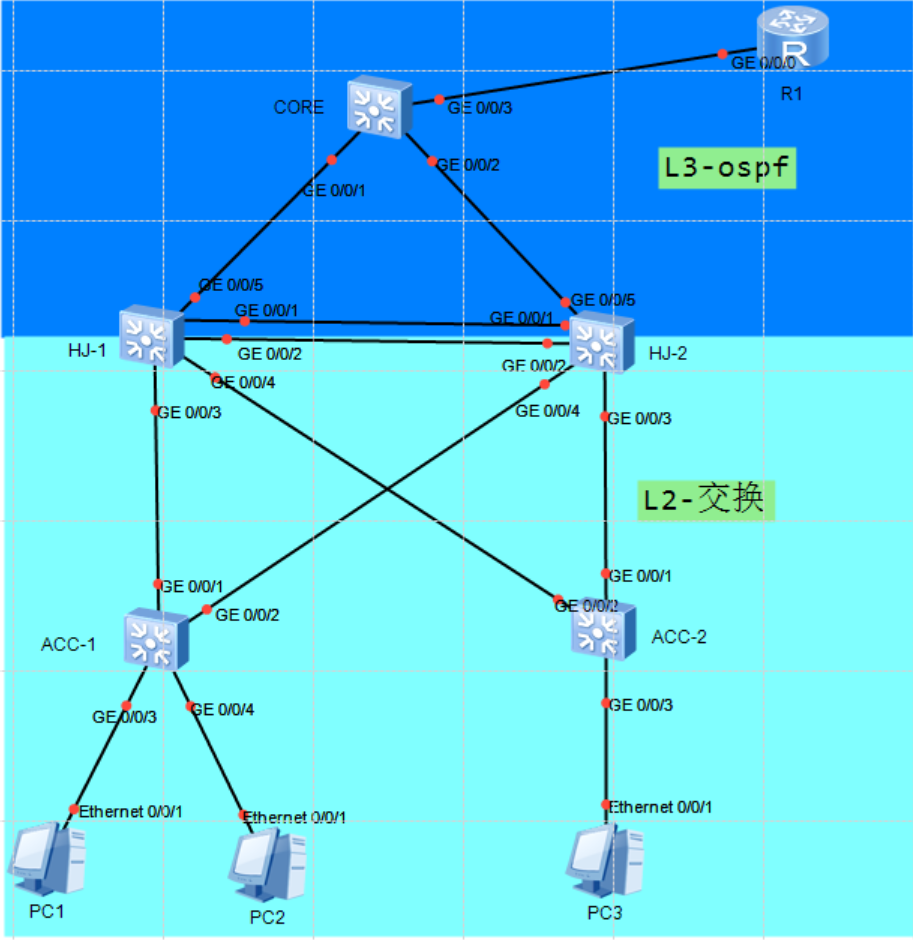
HCIP(综合实验2)
1.实验拓补图 2.实验要求 1.根据提供材料划分VLAN以及IP地址,PC1/PC2属于生产一部员工划分VLAN10,PC3属于生产二部划分VLAN20 2.HJ-1HJ-2交换机需要配置链路聚合以保证业务数据访问的高带宽需求 3.VLAN的放通遵循最小VLAN透传原则 4.配置MSTP生成树解决二层环路问题…...
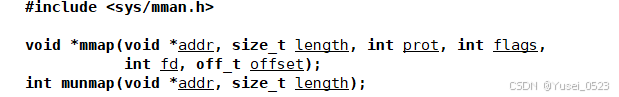
Linux mmp文件映射补充(自用)
addr一般为NULL由OS指明,length所需长度(4kb对齐),prot(权限,一般O_RDWR以读写), flag(MAP_SHARED(不刷新到磁盘上,此进程独有)和MAP_PRIVATE(刷新…...
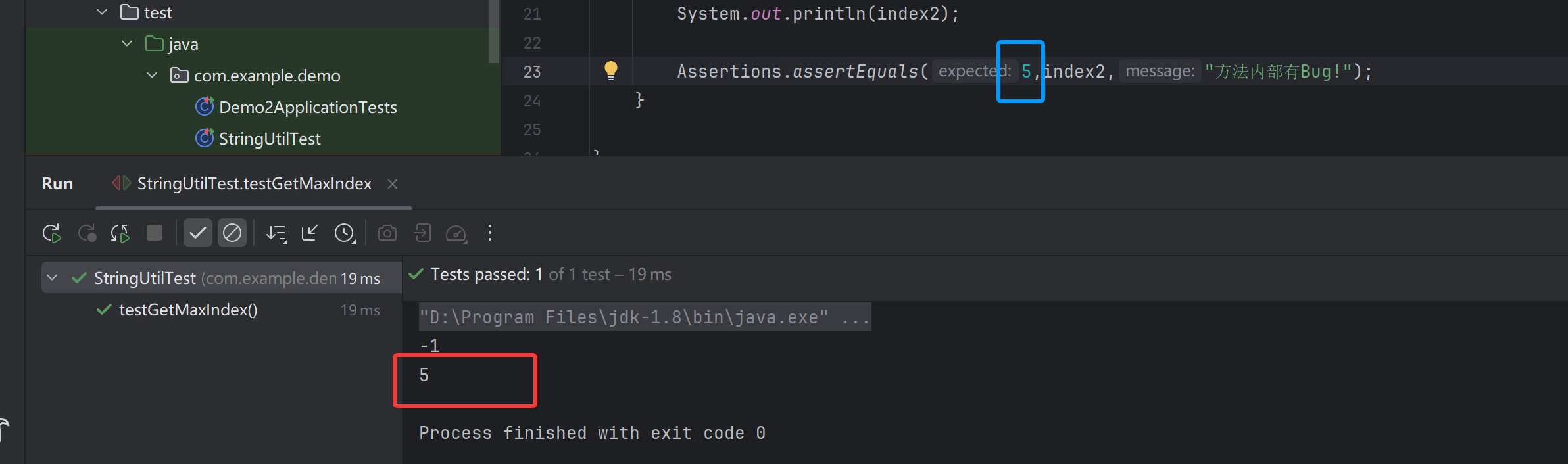
单元测试学习笔记(一)
自动化测试 通过测试工具/编程模拟手动测试步骤,全自动半自动执行测试用例,对比预期输出和实际输出,记录并统计测试结果,减少重复的工作量。 单元测试 针对最小的单元测试,Java中就是一个一个的方法就是一个一个的单…...

【深度学习新浪潮】新视角生成的研究进展调研报告(2025年4月)
新视角生成(Novel View Synthesis)是计算机视觉与图形学领域的核心技术,旨在从单张或稀疏图像中生成任意视角的高保真图像,突破传统多视角数据的限制,实现对三维场景的自由探索。作为计算机视觉与图形学的交叉领域,近新视角生成年来在算法创新、应用落地和工具生态上均取…...
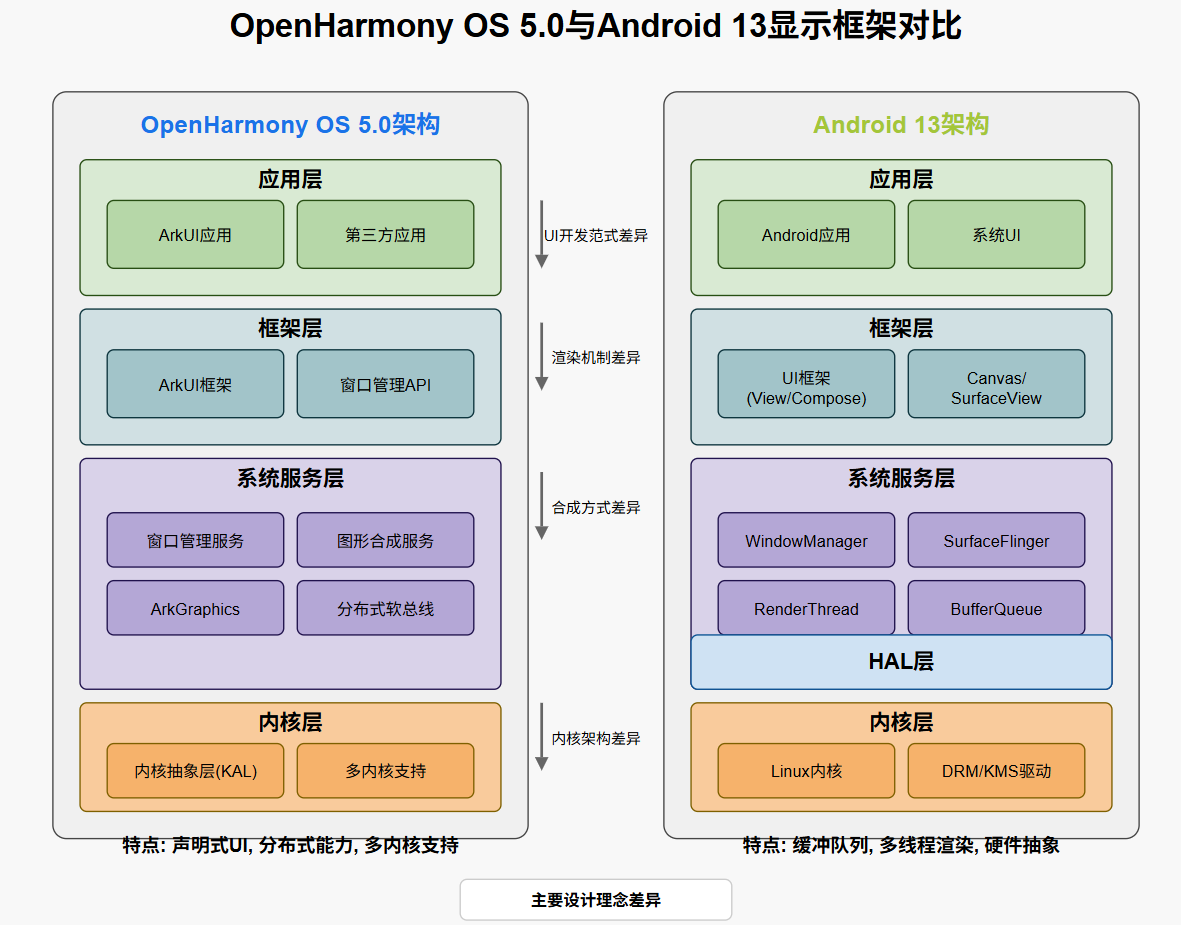
OpenHarmony OS 5.0与Android 13显示框架对比
1. 架构概述 1.1 OpenHarmony OS 5.0架构 OpenHarmony OS 5.0采用分层架构设计,图形显示系统从底层到顶层包括: 应用层:ArkUI应用和第三方应用框架层:ArkUI框架、窗口管理API系统服务层:图形合成服务、窗口管理服务…...

[Java] 泛型
目录 1、初识泛型 1.1、泛型类的使用 1.2、泛型如何编译的 2、泛型的上界 3、通配符 4、通配符上界 5、通配符下界 1、初识泛型 泛型:就是将类型进行了传递。从代码上讲,就是对类型实现了参数化。 泛型的主要目的:就是指定当前的容器…...
...)
Vue3 项目中零成本接入 AI 能力(以图搜图、知识问答、文本匹配)...
以下是在 Vue3 项目中零成本接入 AI 能力(以图搜图、知识问答、文本匹配)的完整解决方案,结合免费 API 和开源工具实现,无需服务器或付费服务: 一、以图搜图(基于 Hugging Face CLIP 模型) 核心思路 通过 Hugging Face Inference API 调用 CLIP 模型,将图片转换为向…...
Spark–steaming
实验项目: 找出所有有效数据,要求电话号码为11位,但只要列中没有空值就算有效数据。 按地址分类,输出条数最多的前20个地址及其数据。 代码讲解: 导包和声明对象,设置Spark配置对象和SparkContext对象。 使用Spark S…...

【目标检测】对YOLO系列发展的简单理解
目录 1.YOLOv12.YOLOv23.YOLOv34.YOLOv45.YOLOv66.YOLOv77.YOLOv9 YOLO系列文章汇总: 【论文#目标检测】You Only Look Once: Unified, Real-Time Object Detection 【论文#目标检测】YOLO9000: Better, Faster, Stronger 【论文#目标检测】YOLOv3: An Incremental …...

前端框架的“快闪“时代:我们该如何应对技术迭代的洪流?
引言:前端开发者的"框架疲劳" “上周刚学完Vue 3的组合式API,这周SolidJS又火了?”——这恐怕是许多前端开发者2023年的真实心声。前端框架的迭代速度已经达到了令人目眩的程度,GitHub每日都有新框架诞生,n…...

深度学习训练中的显存溢出问题分析与优化:以UNet图像去噪为例
最近在训练一个基于 Tiny-UNet 的图像去噪模型时,我遇到了经典但棘手的错误: RuntimeError: CUDA out of memory。本文记录了我如何从复现、分析,到逐步优化并成功解决该问题的全过程,希望对深度学习开发者有所借鉴。 训练数据&am…...