【音视频】音频解码实战
音频解码过程
⾳频解码过程如下图所示:

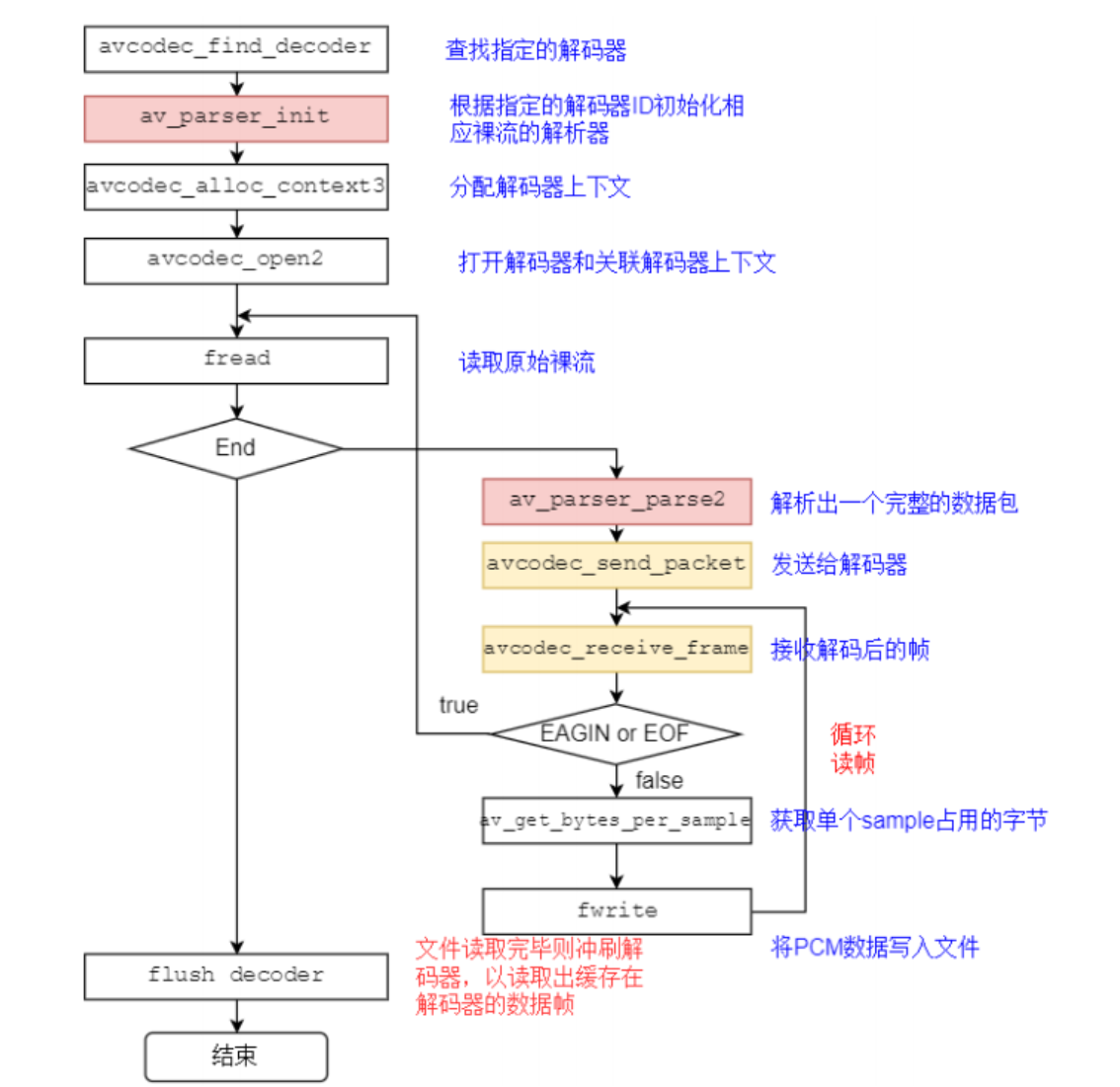
FFmpeg流程
关键函数
关键函数说明:
- avcodec_find_decoder:根据指定的AVCodecID查找注册的解码器。
- av_parser_init:初始化AVCodecParserContext。
- avcodec_alloc_context3:为AVCodecContext分配内存。
- avcodec_open2:打开解码器。
- av_parser_parse2:解析获得⼀个Packet。
- avcodec_send_packet:将AVPacket压缩数据给解码器。
- avcodec_receive_frame:获取到解码后的AVFrame数据。
- av_get_bytes_per_sample: 获取每个sample中的字节数。
关键数据结构
AVCodecParser:⽤于解析输⼊的数据流并把它分成⼀帧⼀帧的压缩编码数据。⽐较形象的说法就是把⻓⻓的⼀段连续的数据“切割”成⼀段段的数据。⽐如AAC aac_parser
ffmpeg-4.2.1\libavcodec\aac_parser.c
AVCodecParser ff_aac_parser = {codec_ids = { AV_CODEC_ID_AAC },priv_data_size = sizeof(AACAC3ParseContext),parser_init = aac_parse_init,parser_parse = ff_aac_ac3_parse,parser_close = ff_parse_close,
};
从AVCodecParser结构的实例化我们可以看出来,不同编码类型的parser是和CODE_ID进⾏绑定的。所以也就可以解释
parser = av_parser_init(codec->id);
可以通过CODE_ID查找到对应的码流 parser。
avcodec编解码API介绍
- avcodec_send_packet、avcodec_receive_frame的API是FFmpeg3版本加⼊的。
- 为了正确的使⽤它们,有必要阅读FFmpeg的⽂档说明:FFmpeg: send/receive encoding and decoding API overview
以下内容摘译⾃⽂档说明
FFmpeg提供了两组函数,分别⽤于编码和解码:
- 解码:avcodec_send_packet()、avcodec_receive_frame()。
- 解码:avcodec_send_frame()、avcodec_receive_packet()。
API的设计与编解码的流程⾮常贴切。
建议的使⽤流程如下:
- 像以前⼀样设置并打开AVCodecContext。
- 输⼊有效的数据:
- 解码:调⽤avcodec_send_packet()给解码器传⼊包含原始的压缩数据的AVPacket对象。
- 编码:调⽤ avcodec_send_frame()给编码器传⼊包含解压数据的AVFrame对象。
两种情况下推荐AVPacket和AVFrame都使⽤refcounted(引⽤计数)的模式,否则libavcodec可能不得不对输⼊的数据进⾏拷⻉。
- 在⼀个循环体内去接收codec的输出,即周期性地调⽤avcodec_receive_*()来接收codec输出的数据:
- 解码:调⽤avcodec_receive_frame(),如果成功会返回⼀个包含未压缩数据的AVFrame。
- 编码:调⽤avcodec_receive_packet(),如果成功会返回⼀个包含压缩数据的AVPacket。
反复地调⽤avcodec_receive_packet()直到返回 AVERROR(EAGAIN)或其他错误。返回AVERROR(EAGAIN)错误表示codec需要新的输⼊来输出更多的数据。对于每个输⼊的packet或frame,codec⼀般会输出⼀个frame或packet,但是也有可能输出0个或者多于1个。
- 流处理结束的时候需要flush(冲刷) codec。因为codec可能在内部缓冲多个frame或packet,出于性能或其他必要的情况(如考虑B帧的情况)。
处理流程如下:
- 调⽤avcodec_send_*()传⼊的AVFrame或AVPacket指针设置为NULL。 这将进⼊draining mode(排⽔模式)。
- 反复地调⽤avcodec_receive_*()直到返回AVERROR_EOF,该⽅法在draining mode时不会返回AVERROR(EAGAIN)的错误,除⾮你没有进⼊draining mode。
- 当重新开启codec时,需要先调⽤ avcodec_flush_buffers()来重置codec。
说明:
- 编码或者解码刚开始的时候,codec可能接收了多个输⼊的frame或packet后还没有输出数据,直到内部的buffer被填充满。上⾯的使⽤流程可以处理这种情况。
- 理论上,只有在输出数据没有被完全接收的情况调⽤avcodec_send_*()的时候才可能会发⽣AVERROR(EAGAIN)的错误。你可以依赖这个机制来实现区别于上⾯建议流程的处理⽅式,⽐如每次循环都调⽤avcodec_send_*(),在出现AVERROR(EAGAIN)错误的时候再去调⽤avcodec_receive_*()。
- 并不是所有的codec都遵循⼀个严格、可预测的数据处理流程,唯⼀可以保证的是 “调⽤avcodec_send_*()/avcodec_receive_*()返回AVERROR(EAGAIN)的时候去avcodec_receive_*()/avcodec_send_*()会成功,否则不应该返回AVERROR(EAGAIN)的错误。”⼀般来说,任何codec都不允许⽆限制地缓存输⼊或者输出。
- 在同⼀个AVCodecContext上混合使⽤新旧API是不允许的,这将导致未定义的⾏为。
avcodec_send_packet
函数:
int avcodec_send_packet(AVCodecContext *avctx, const AVPacket *avpkt);
作用:
- ⽀持将裸流数据包送给解码器
警告:
- 输⼊的avpkt-data缓冲区必须⼤于AV_INPUT_PADDING_SIZE,因为优化的字节流读取器必须⼀次读取32或者64⽐特的数据
- 不能跟之前的API(例如avcodec_decode_video2)混⽤,否则会返回不可预知的错误
备注:
- 在将包发送给解码器的时候,AVCodecContext必须已经通过avcodec_open2打开
参数:
- avctx:解码上下⽂
- avpkt:输⼊AVPakcet.通常情况下,输⼊数据是⼀个单⼀的视频帧或者⼏个完整的⾳频帧。调⽤者保留包的原有属性,解码器不会修改包的内容。解码器可能创建对包的引⽤。如果包没有引⽤计数将拷⻉⼀份。跟以往的API不⼀样,输⼊的包的数据将被完全地消耗,如果包含有多个帧,要求多次调⽤avcodec_recvive_frame,直到avcodec_recvive_frame返回VERROR(EAGAIN)或AVERROR_EOF。输⼊参数可以为NULL,或者AVPacket的data域设置为NULL或者size域设置为0,表示将刷新所有的包,意味着数据流已经结束了。第⼀次发送刷新会总会成功,第⼆次发送刷新包是没有必要的,并且返回AVERROR_EOF,如果×××缓存了⼀些帧,返回⼀个刷新包,将会返回所有的解码包
返回值:
- 0: 表示成功
- AVERROR(EAGAIN):当前状态不接受输⼊,⽤户必须先使⽤avcodec_receive_frame() 读取数据帧;
- AVERROR_EOF:解码器已刷新,不能再向其发送新包;
- AVERROR(EINVAL):没有打开解码器,或者这是⼀个编码器,或者要求刷新;
- AVERRO(ENOMEN):⽆法将数据包添加到内部队列。
avcodec_receive_frame
函数:
int avcodec_receive_frame ( AVCodecContext * avctx, AVFrame * frame )
作⽤:
- 从解码器返回已解码的输出数据。
参数:
- avctx: 编解码器上下⽂
- frame: 获取使⽤reference-counted机制的audio或者video帧(取决于解码器类型)。请注意,在执⾏其他操作之前,函数内部将始终先调⽤av_frame_unref(frame)。
返回值:
- 0: 成功,返回⼀个帧
- AVERROR(EAGAIN): 该状态下没有帧输出,需要使⽤avcodec_send_packet发送新的packet到解码器
- AVERROR_EOF: 解码器已经被完全刷新,不再有输出帧
- AVERROR(EINVAL): 编解码器没打开
- 其他<0的值: 具体查看对应的错误码
实现流程
准备文件
将aac和mp3文件放在build目录下
添加main函数参数,表示输入文件和输出文件

读取文件
使用二进制读取文件
// 打开输入文件
infile = fopen(filename, "rb");
if (!infile) {fprintf(stderr, "Could not open %s\n", filename);exit(1);
}
查找解码器
- 根据不同的格式使用不同的解码器
ID
enum AVCodecID audio_codec_id = AV_CODEC_ID_AAC;
if(strstr(filename, "aac") != NULL)
{audio_codec_id = AV_CODEC_ID_AAC;
}
else if(strstr(filename, "mp3") != NULL)
{audio_codec_id = AV_CODEC_ID_MP3;
}
- 根据解码器
ID查找解码器,填充解码器信息
const AVCodec *codec;
codec = avcodec_find_decoder(audio_codec_id);
- 分配解码器上下文,将解码器信息拷贝到解码器上下文
codec_ctx = avcodec_alloc_context3(codec);
- 打开解码器上下文,将解码器和解码器上下文关联
avcodec_open2(codec_ctx, codec, NULL)
初始化裸流解析器
- 需要解析为
pcm,因此需要使用到裸流解析器 - 根据不同的解码器
ID分配不同裸流解析器,填充解析器信息
AVCodecParserContext *parser = NULL;
parser = av_parser_init(codec->id);
打开输出文件
// 打开输出文件
FILE *outfile = NULL;
outfile = fopen(outfilename, "wb");
if (!outfile) {av_free(codec_ctx);exit(1);
}
- 开始读取文件内容、
AUDIO_INBUF_SIZE定义了单次最多读取的数量AV_INPUT_BUFFER_PADDING_SIZE宏为64,主要是防止一些编解码器适配问题而添加了尾部长度
#define AUDIO_INBUF_SIZE 20480
uint8_t inbuf[AUDIO_INBUF_SIZE + AV_INPUT_BUFFER_PADDING_SIZE];
uint8_t *data = NULL;data = inbuf;
data_size = fread(inbuf, 1, AUDIO_INBUF_SIZE, infile);循环读取文件内容
- 分配帧内存,如果分配失败,则进行相关错误操作
AVFrame *decoded_frame = NULL;
if (!decoded_frame){if (!(decoded_frame = av_frame_alloc())){fprintf(stderr, "Could not allocate audio frame\n");exit(1);}}
- 解码出的数据是一段连续的数据裸流,因此需要使用裸流解析器进行分开
av_parser_parse2函数用于将裸流数据解析成一帧一帧的数据包存入在packet中,AV_NOPTS_VALUE表示没有时间戳dts和pts,因为需要解析出的是pcm流,不存在时间戳ret返回的是已经解析了的数据大小,也就是说传进去的数据不一定全部被解析完,存在碎片信息
AVPacket *pkt = NULL;
pkt = av_packet_alloc();
ret = av_parser_parse2(parser, codec_ctx, &pkt->data, &pkt->size,data, data_size,AV_NOPTS_VALUE, AV_NOPTS_VALUE, 0)
- 根据返回的碎片大小,调整文件数据指针
data += ret; // 跳过已经解析的数据
data_size -= ret; // 对应的缓存大小也做相应减小
- 对
packet包的数据进行解码
if (pkt->size)decode(codec_ctx, pkt, decoded_frame, outfile);
decode函数
- 主要是使用
avcodec_send_packet发送数据包,以及avcodec_receive_frame接收数据包 - 需要判断一下返回值,根据不同返回值进行错误处理或者进行下一步解码
avcodec_send_packet
ret = avcodec_send_packet(dec_ctx, pkt);if(ret == AVERROR(EAGAIN)){fprintf(stderr, "Receive_frame and send_packet both returned EAGAIN, which is an API violation.\n");}else if (ret < 0){fprintf(stderr, "Error submitting the packet to the decoder, err:%s, pkt_size:%d\n",av_get_err(ret), pkt->size);
// exit(1);return;}
avcodec_receive_frame
ret = avcodec_receive_frame(dec_ctx, frame);if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF)return;else if (ret < 0){fprintf(stderr, "Error during decoding\n");exit(1);}
- 写入文件
- 根据不同的音频格式获取一个样本所占的字节数
int data_size;
data_size = av_get_bytes_per_sample(dec_ctx->sample_fmt);
- 根据不同的声道数,循环写入数据
- 这样写入的类型是
float类型
for (i = 0; i < frame->nb_samples; i++){for (ch = 0; ch < dec_ctx->channels; ch++) // 交错的方式写入, 大部分float的格式输出fwrite(frame->data[ch] + data_size*i, 1, data_size, outfile);}
- 循环读入文件,直到缓冲区
buf的内存少于我们设置的阈值后,重新读取文件信息 - 首先将没读取完的数据放到缓冲区头部,然后再读取剩下的大小
memove函数的作用是将data开始的data_size长度字节的数据拷贝到inbuf头部
#define AUDIO_REFILL_THRESH 4096
if (data_size < AUDIO_REFILL_THRESH) // 如果数据少了则再次读取{memmove(inbuf, data, data_size); // 把之前剩的数据拷贝到buffer的起始位置data = inbuf;// 读取数据 长度: AUDIO_INBUF_SIZE - data_sizelen = fread(data + data_size, 1, AUDIO_INBUF_SIZE - data_size, infile);if (len > 0)data_size += len;}
冲刷解码器
- 如果读取结束了,就退出循环
while (data_size > 0)
- 退出读取后需要冲刷解码器,让它进入
drain mode
drain mode是什么? - 在使用 FFmpeg 进行音视频解码时,当你已经将所有的编码数据包(
AVPacket)都发送给解码器后,解码器内部可能仍然存在一些已经接收但还未完全解码的数据。这可能是由于编解码器的特性,例如存在延迟解码的情况(像一些视频编码格式中,为了提高压缩效率,会使用 B 帧(双向预测帧),这就可能导致解码过程存在延迟)。“drain mode” 就是用于处理这种情况,确保解码器将内部所有剩余的数据都解码输出。
pkt->data = NULL; // 让其进入drain mode
pkt->size = 0;
decode(codec_ctx, pkt, decoded_frame, outfile);
释放内存
- 读取结束后需要释放相关上下文内存
avcodec_free_context(&codec_ctx);
av_parser_close(parser);
av_frame_free(&decoded_frame);
av_packet_free(&pkt);
- 关闭打开的文件
fclose(outfile);
fclose(infile);
完整代码
main.c
/**
* @projectName 07-05-decode_audio
* @brief 解码音频,主要的测试格式aac和mp3
* @author Liao Qingfu
* @date 2020-01-16
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#include <libavutil/frame.h>
#include <libavutil/mem.h>#include <libavcodec/avcodec.h>#define AUDIO_INBUF_SIZE 20480
#define AUDIO_REFILL_THRESH 4096static char err_buf[128] = {0};
static char* av_get_err(int errnum)
{av_strerror(errnum, err_buf, 128);return err_buf;
}static void print_sample_format(const AVFrame *frame)
{printf("ar-samplerate: %uHz\n", frame->sample_rate);printf("ac-channel: %u\n", frame->channels);printf("f-format: %u\n", frame->format);// 格式需要注意,实际存储到本地文件时已经改成交错模式
}static void decode(AVCodecContext *dec_ctx, AVPacket *pkt, AVFrame *frame,FILE *outfile)
{int i, ch;int ret, data_size;/* send the packet with the compressed data to the decoder */ret = avcodec_send_packet(dec_ctx, pkt);if(ret == AVERROR(EAGAIN)){fprintf(stderr, "Receive_frame and send_packet both returned EAGAIN, which is an API violation.\n");}else if (ret < 0){fprintf(stderr, "Error submitting the packet to the decoder, err:%s, pkt_size:%d\n",av_get_err(ret), pkt->size);
// exit(1);return;}/* read all the output frames (infile general there may be any number of them */while (ret >= 0){// 对于frame, avcodec_receive_frame内部每次都先调用ret = avcodec_receive_frame(dec_ctx, frame);if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF)return;else if (ret < 0){fprintf(stderr, "Error during decoding\n");exit(1);}data_size = av_get_bytes_per_sample(dec_ctx->sample_fmt);if (data_size < 0){/* This should not occur, checking just for paranoia */fprintf(stderr, "Failed to calculate data size\n");exit(1);}static int s_print_format = 0;if(s_print_format == 0){s_print_format = 1;print_sample_format(frame);}/**P表示Planar(平面),其数据格式排列方式为 :LLLLLLRRRRRRLLLLLLRRRRRRLLLLLLRRRRRRL...(每个LLLLLLRRRRRR为一个音频帧)而不带P的数据格式(即交错排列)排列方式为:LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLRL...(每个LR为一个音频样本)播放范例: ffplay -ar 48000 -ac 2 -f f32le believe.pcm*/for (i = 0; i < frame->nb_samples; i++){for (ch = 0; ch < dec_ctx->channels; ch++) // 交错的方式写入, 大部分float的格式输出fwrite(frame->data[ch] + data_size*i, 1, data_size, outfile);}}
}
// 播放范例: ffplay -ar 48000 -ac 2 -f f32le believe.pcm
int main(int argc, char **argv)
{const char *outfilename;const char *filename;const AVCodec *codec;AVCodecContext *codec_ctx= NULL;AVCodecParserContext *parser = NULL;int len = 0;int ret = 0;FILE *infile = NULL;FILE *outfile = NULL;uint8_t inbuf[AUDIO_INBUF_SIZE + AV_INPUT_BUFFER_PADDING_SIZE];uint8_t *data = NULL;size_t data_size = 0;AVPacket *pkt = NULL;AVFrame *decoded_frame = NULL;if (argc <= 2){fprintf(stderr, "Usage: %s <input file> <output file>\n", argv[0]);exit(0);}filename = argv[1];outfilename = argv[2];pkt = av_packet_alloc();enum AVCodecID audio_codec_id = AV_CODEC_ID_AAC;if(strstr(filename, "aac") != NULL){audio_codec_id = AV_CODEC_ID_AAC;}else if(strstr(filename, "mp3") != NULL){audio_codec_id = AV_CODEC_ID_MP3;}else{printf("error reading file!\n");printf("default codec id:%d\n", audio_codec_id);}// 查找解码器codec = avcodec_find_decoder(audio_codec_id); // AV_CODEC_ID_AACif (!codec) {fprintf(stderr, "Codec not found\n");exit(1);}// 获取裸流的解析器 AVCodecParserContext(数据) + AVCodecParser(方法)parser = av_parser_init(codec->id);if (!parser) {fprintf(stderr, "Parser not found\n");exit(1);}// 分配codec上下文codec_ctx = avcodec_alloc_context3(codec);if (!codec_ctx) {fprintf(stderr, "Could not allocate audio codec context\n");exit(1);}// 将解码器和解码器上下文进行关联if (avcodec_open2(codec_ctx, codec, NULL) < 0) {fprintf(stderr, "Could not open codec\n");exit(1);}// 打开输入文件infile = fopen(filename, "rb");if (!infile) {fprintf(stderr, "Could not open %s\n", filename);exit(1);}// 打开输出文件outfile = fopen(outfilename, "wb");if (!outfile) {av_free(codec_ctx);exit(1);}// 读取文件进行解码data = inbuf;data_size = fread(inbuf, 1, AUDIO_INBUF_SIZE, infile);while (data_size > 0){if (!decoded_frame){if (!(decoded_frame = av_frame_alloc())){fprintf(stderr, "Could not allocate audio frame\n");exit(1);}}ret = av_parser_parse2(parser, codec_ctx, &pkt->data, &pkt->size,data, data_size,AV_NOPTS_VALUE, AV_NOPTS_VALUE, 0);if (ret < 0){fprintf(stderr, "Error while parsing\n");exit(1);}data += ret; // 跳过已经解析的数据data_size -= ret; // 对应的缓存大小也做相应减小if (pkt->size)decode(codec_ctx, pkt, decoded_frame, outfile);if (data_size < AUDIO_REFILL_THRESH) // 如果数据少了则再次读取{memmove(inbuf, data, data_size); // 把之前剩的数据拷贝到buffer的起始位置data = inbuf;// 读取数据 长度: AUDIO_INBUF_SIZE - data_sizelen = fread(data + data_size, 1, AUDIO_INBUF_SIZE - data_size, infile);if (len > 0)data_size += len;}}/* 冲刷解码器 */pkt->data = NULL; // 让其进入drain modepkt->size = 0;decode(codec_ctx, pkt, decoded_frame, outfile);fclose(outfile);fclose(infile);avcodec_free_context(&codec_ctx);av_parser_close(parser);av_frame_free(&decoded_frame);av_packet_free(&pkt);printf("main finish, please enter Enter and exit\n");return 0;
}更多资料:https://github.com/0voice
相关文章:
【音视频】音频解码实战
音频解码过程 ⾳频解码过程如下图所示: FFmpeg流程 关键函数 关键函数说明: avcodec_find_decoder:根据指定的AVCodecID查找注册的解码器。av_parser_init:初始化AVCodecParserContext。avcodec_alloc_context3:为…...
DOCA介绍
本文分为两个部分: DOCA及BlueField介绍如何运行DOCA应用,这里以DNS_Filter为例子做大致介绍。 DOCA及BlueField介绍: 现代企业数据中心是软件定义的、完全可编程的基础设施,旨在服务于跨云、核心和边缘环境的高度分布式应用工作…...
# 利用迁移学习优化食物分类模型:基于ResNet18的实践
利用迁移学习优化食物分类模型:基于ResNet18的实践 在深度学习的众多应用中,图像分类一直是一个热门且具有挑战性的领域。随着研究的深入,我们发现利用预训练模型进行迁移学习是一种非常有效的策略,可以显著提高模型的性能&#…...
洗车小程序系统前端uniapp 后台thinkphp
洗车小程序系统 前端uniapp 后台thinkphp 支持多门店 分销 在线预约 套餐卡等...
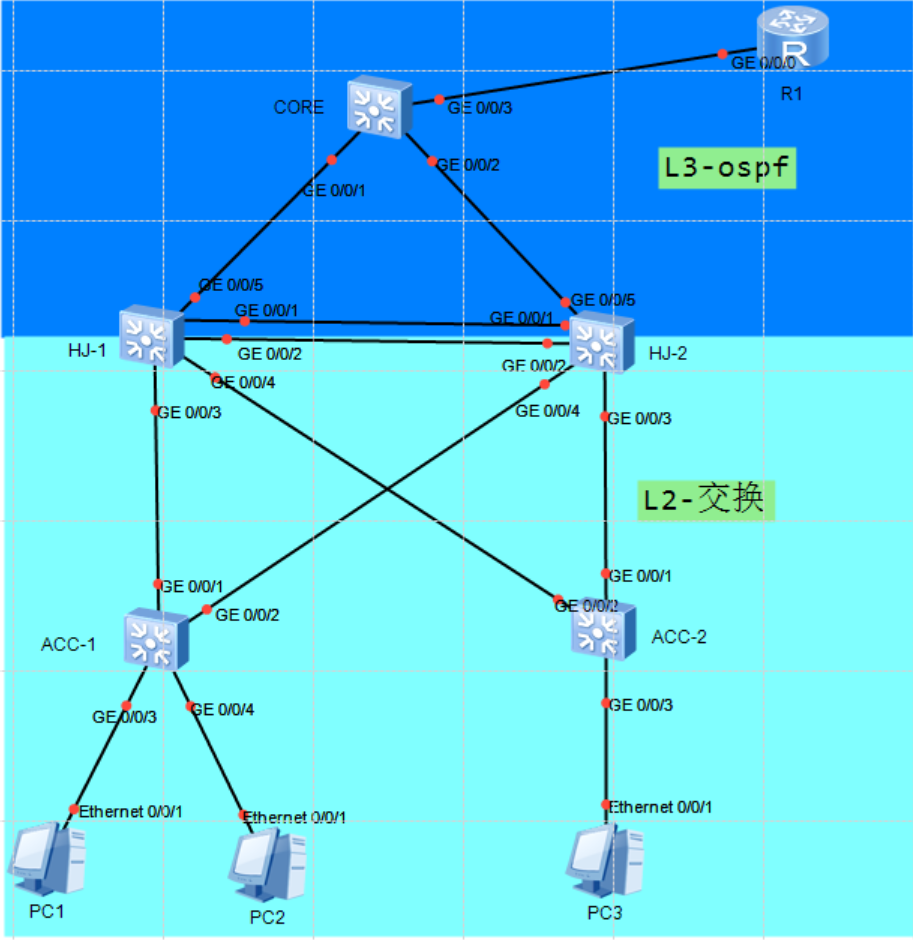
HCIP(综合实验2)
1.实验拓补图 2.实验要求 1.根据提供材料划分VLAN以及IP地址,PC1/PC2属于生产一部员工划分VLAN10,PC3属于生产二部划分VLAN20 2.HJ-1HJ-2交换机需要配置链路聚合以保证业务数据访问的高带宽需求 3.VLAN的放通遵循最小VLAN透传原则 4.配置MSTP生成树解决二层环路问题…...
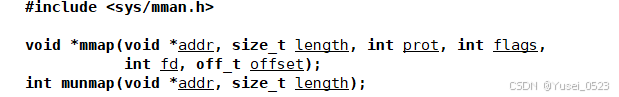
Linux mmp文件映射补充(自用)
addr一般为NULL由OS指明,length所需长度(4kb对齐),prot(权限,一般O_RDWR以读写), flag(MAP_SHARED(不刷新到磁盘上,此进程独有)和MAP_PRIVATE(刷新…...
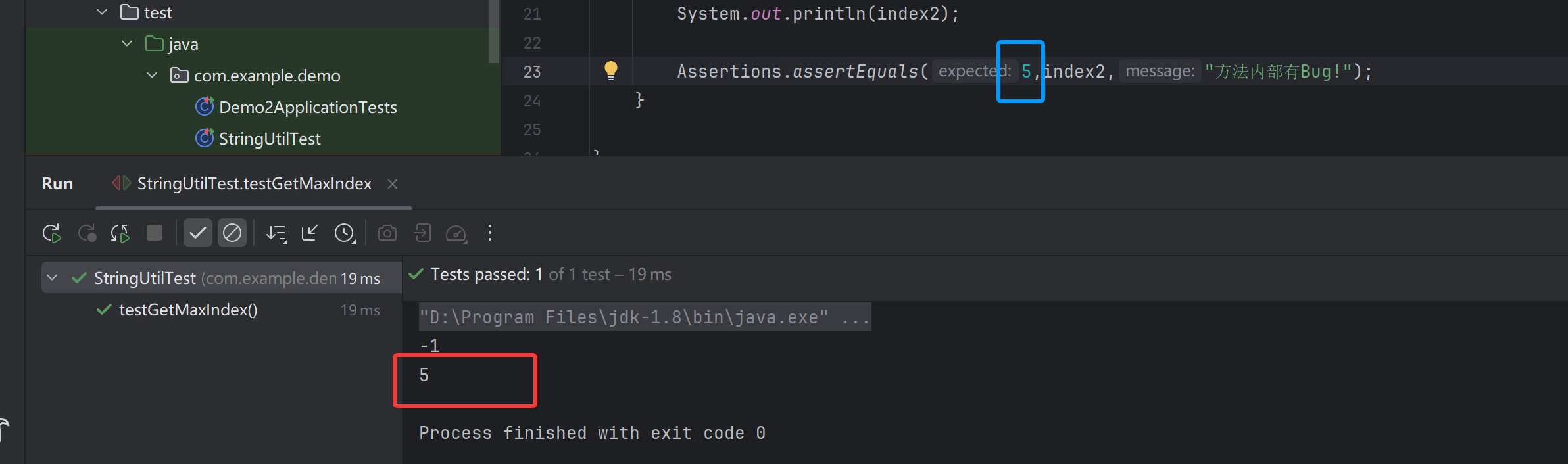
单元测试学习笔记(一)
自动化测试 通过测试工具/编程模拟手动测试步骤,全自动半自动执行测试用例,对比预期输出和实际输出,记录并统计测试结果,减少重复的工作量。 单元测试 针对最小的单元测试,Java中就是一个一个的方法就是一个一个的单…...

【深度学习新浪潮】新视角生成的研究进展调研报告(2025年4月)
新视角生成(Novel View Synthesis)是计算机视觉与图形学领域的核心技术,旨在从单张或稀疏图像中生成任意视角的高保真图像,突破传统多视角数据的限制,实现对三维场景的自由探索。作为计算机视觉与图形学的交叉领域,近新视角生成年来在算法创新、应用落地和工具生态上均取…...
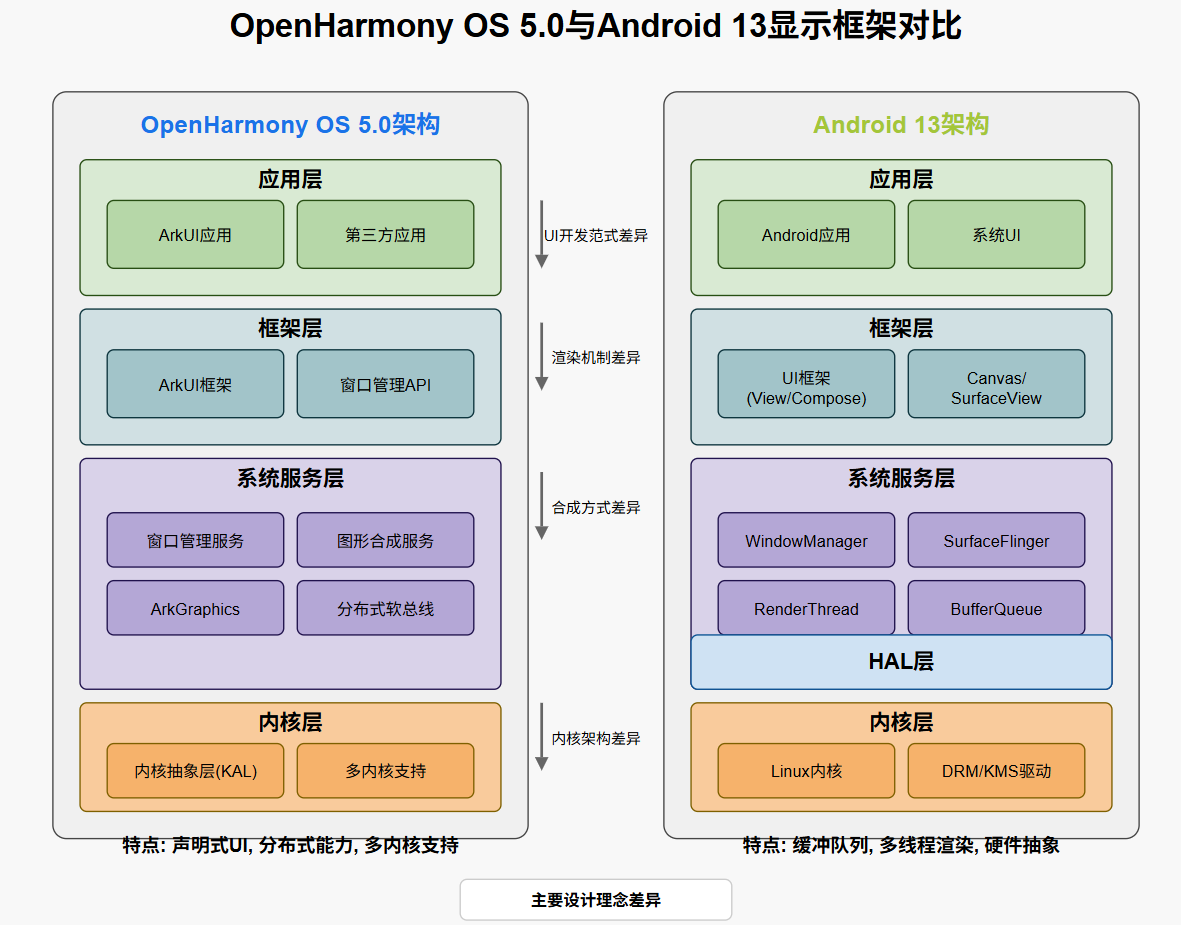
OpenHarmony OS 5.0与Android 13显示框架对比
1. 架构概述 1.1 OpenHarmony OS 5.0架构 OpenHarmony OS 5.0采用分层架构设计,图形显示系统从底层到顶层包括: 应用层:ArkUI应用和第三方应用框架层:ArkUI框架、窗口管理API系统服务层:图形合成服务、窗口管理服务…...

[Java] 泛型
目录 1、初识泛型 1.1、泛型类的使用 1.2、泛型如何编译的 2、泛型的上界 3、通配符 4、通配符上界 5、通配符下界 1、初识泛型 泛型:就是将类型进行了传递。从代码上讲,就是对类型实现了参数化。 泛型的主要目的:就是指定当前的容器…...
...)
Vue3 项目中零成本接入 AI 能力(以图搜图、知识问答、文本匹配)...
以下是在 Vue3 项目中零成本接入 AI 能力(以图搜图、知识问答、文本匹配)的完整解决方案,结合免费 API 和开源工具实现,无需服务器或付费服务: 一、以图搜图(基于 Hugging Face CLIP 模型) 核心思路 通过 Hugging Face Inference API 调用 CLIP 模型,将图片转换为向…...
Spark–steaming
实验项目: 找出所有有效数据,要求电话号码为11位,但只要列中没有空值就算有效数据。 按地址分类,输出条数最多的前20个地址及其数据。 代码讲解: 导包和声明对象,设置Spark配置对象和SparkContext对象。 使用Spark S…...

【目标检测】对YOLO系列发展的简单理解
目录 1.YOLOv12.YOLOv23.YOLOv34.YOLOv45.YOLOv66.YOLOv77.YOLOv9 YOLO系列文章汇总: 【论文#目标检测】You Only Look Once: Unified, Real-Time Object Detection 【论文#目标检测】YOLO9000: Better, Faster, Stronger 【论文#目标检测】YOLOv3: An Incremental …...

前端框架的“快闪“时代:我们该如何应对技术迭代的洪流?
引言:前端开发者的"框架疲劳" “上周刚学完Vue 3的组合式API,这周SolidJS又火了?”——这恐怕是许多前端开发者2023年的真实心声。前端框架的迭代速度已经达到了令人目眩的程度,GitHub每日都有新框架诞生,n…...

深度学习训练中的显存溢出问题分析与优化:以UNet图像去噪为例
最近在训练一个基于 Tiny-UNet 的图像去噪模型时,我遇到了经典但棘手的错误: RuntimeError: CUDA out of memory。本文记录了我如何从复现、分析,到逐步优化并成功解决该问题的全过程,希望对深度学习开发者有所借鉴。 训练数据&am…...

Python爬虫实战:获取优志愿专业数据
一、引言 在信息爆炸的当下,数据成为推动各领域发展的关键因素。优志愿网站汇聚了丰富的专业数据,对于教育研究、职业规划等领域具有重要价值。然而,为保护自身数据和资源,许多网站设置了各类反爬机制。因此,如何高效、稳定地从优志愿网站获取计算机专业数据成为一个具有…...

2025.4.22学习日记 JavaScript的常用事件
在 JavaScript 里,事件是在文档或者浏览器窗口中发生的特定交互瞬间,例如点击按钮、页面加载完成等等。下面是一些常用的事件以及案例: 1. click 事件 当用户点击元素时触发 const button document.createElement(button); button.textCo…...
如何修复WordPress中“您所关注的链接已过期”的错误
几乎每个管理WordPress网站的人都可能遇到过“您关注的链接已过期”的错误,尤其是在上传插件或者主题的时候。本文将详细解释该错误出现的原因以及如何修复,帮助您更好地管理WordPress网站。 为什么会出现“您关注的链接已过期”的错误 为了防止资源被滥…...

从零开始搭建Django博客①--正式开始前的准备工作
本文主要在Ubuntu环境上搭建,为便于研究理解,采用SSH连接在虚拟机里的ubuntu-24.04.2-desktop系统搭建的可视化桌面,涉及一些文件操作部分便于通过桌面化进行理解,最后的目标是在本地搭建好系统后,迁移至云服务器并通过…...
健身房管理系统(springboot+ssm+vue+mysql)含运行文档
健身房管理系统(springbootssmvuemysql)含运行文档 健身房管理系统是一个全面的解决方案,旨在帮助健身房高效管理其运营。系统提供多种功能模块,包括会员管理、员工管理、会员卡管理、教练信息管理、解聘管理、健身项目管理、指导项目管理、健身器材管理…...

Java从入门到“放弃”(精通)之旅——继承与多态⑧
Java从入门到“放弃”(精通)之旅🚀——继承与多态⑧ 一、继承:代码复用的利器 1.1 为什么需要继承? 想象一下我们要描述狗和猫这两种动物。如果不使用继承,代码可能会是这样: // Dog.java pu…...
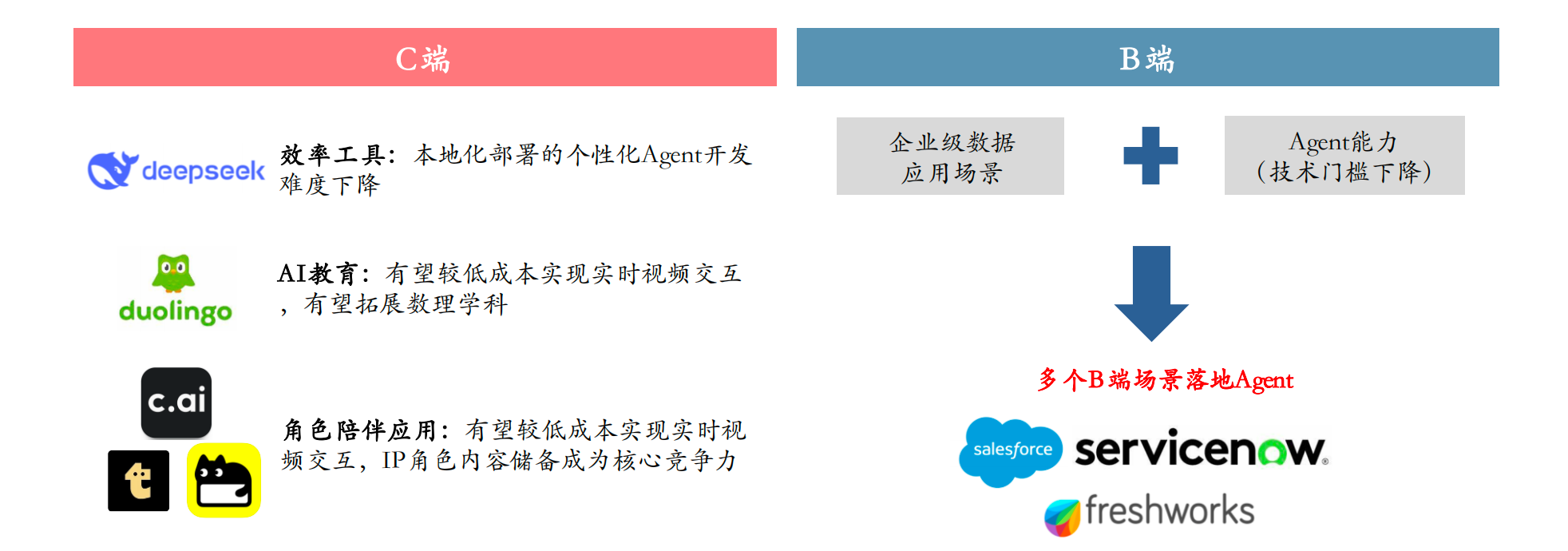
DeepSeek开源引爆AI Agent革命:应用生态迎来“安卓时刻”
开源低成本:AI应用开发进入“全民时代” 2025年初,中国AI领域迎来里程碑事件——DeepSeek开源模型的横空出世,迅速在全球开发者社区掀起热潮。其R1和V3模型以超低API成本(仅为GPT-4o的2%-10%)和本地化部署能力&#x…...

使用 LangChain + Higress + Elasticsearch 构建 RAG 应用
RAG(Retrieval Augmented Generation,检索增强生成) 是一种结合了信息检索与生成式大语言模型(LLM)的技术。它的核心思想是:在生成模型输出内容之前,先从外部知识库或数据源中检索相关信息&…...

深入解析C++ STL List:双向链表的特性与高级操作
一、引言 在C STL容器家族中,list作为双向链表容器,具有独特的性能特征。本文将通过完整代码示例,深入剖析链表的核心操作,揭示其底层实现机制,并对比其他容器的适用场景。文章包含4000余字详细解析,适合需…...

Uniapp:pages.json页面路由
目录 一、pages二、style 一、pages uni-app 通过 pages 节点配置应用由哪些页面组成,pages 节点接收一个数组,数组每个项都是一个对象,其属性值如下: 属性类型默认值描述pathString配置页面路径styleObject配置页面窗口表现nee…...

Self-Ask:LLM Agent架构的思考模式 | 智能体推理框架与工具调用实践
作为程序员,我们习惯将复杂问题分解为可管理的子任务,这正是递归和分治算法的核心思想。那么,如何让AI模型也具备这种结构化思考能力?本文深入剖析Self-Ask推理模式的工作原理、实现方法与最佳实践,帮助你构建具有清晰…...

【前端】【业务场景】【面试】在网页开发中,如何优化图片以提高页面加载速度?解决不同设备屏幕适配问题
📌 问题 1:在网页开发中,如何优化图片以提高页面加载速度? 🔍 一、关键词总结 关键词说明图片压缩借助 TinyPNG、ImageOptim 等工具,无损减小图片文件大小格式选择JPEG(照片类)、P…...

Git Flow分支模型
经典分支模型(Git Flow) 由 Vincent Driessen 提出的 Git Flow 模型,是管理 main(或 master)和 dev 分支的经典方案: main 用于生产发布,保持稳定; dev 用于日常开发,合并功能分支(feature/*); 功能开发在 feature 分支进行,完成后合并回 dev; 预发布分支(rele…...

安装 vmtools
第2章 安装 vmtools 1.安装 vmtools 的准备工作 1)现在查看是否安装了 gcc 查看是否安装gcc 打开终端 输入 gcc - v 安装 gcc 链接:https://blog.csdn.net/qq_45316173/article/details/122018354?ops_request_misc&request_id&biz_id10…...
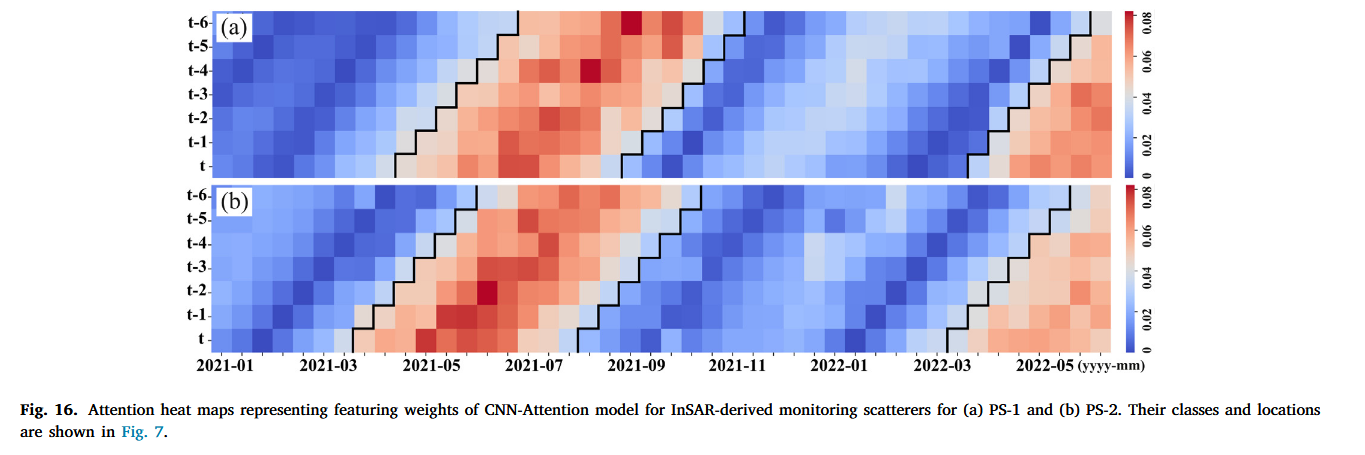
【论文阅读20】-CNN-Attention-BiGRU-滑坡预测(2025-03)
这篇论文主要探讨了基于深度学习的滑坡位移预测模型,结合了MT-InSAR(多时相合成孔径雷达干涉测量)观测数据,提出了一种具有可解释性的滑坡位移预测方法。 [1] Zhou C, Ye M, Xia Z, et al. An interpretable attention-based deep…...