Spark–steaming
实验项目:
找出所有有效数据,要求电话号码为11位,但只要列中没有空值就算有效数据。 按地址分类,输出条数最多的前20个地址及其数据。
代码讲解: 导包和声明对象,设置Spark配置对象和SparkContext对象。 使用Spark SQL语言进行数据处理,包括创建数据库、数据表,导入数据文件,进行数据转换。 筛选有效数据并存储到新表中。 按地址分组并统计出现次数,排序并输出前20个地址。 代码如下 import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession object Demo { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Demo") val spark = SparkSession.builder().enableHiveSupport() .config("spark.sql.warehouse.dir", "hdfs://node01:9000/user/hive/warehouse").config(sparkConf).getOrCreate() spark.sql(sqlText = "create database spark_sql_2") spark.sql(sqlText = "use spark_sql_2") //创建存放原始数据的表 spark.sql( """ |create table user_login_info(data string |row format delimited |""".stripMargin) spark.sql(sqlText = "load data local inpath 'Spark-SQL/input/user_login_info.json' into table user_login_info") //利用get_json_object将数据做转换 spark.sql( """ |create table user_login_info_1 |as |select get_json_object(data,'$.uid') as uid, |get_json_object(data,'$.phone') as phone, |get_json_object(data,'$.addr') as addr from user_login_info |""".stripMargin) spark.sql(sqlText = "select count(*) count from user_login_info_1").show() //获取有效数据 spark.sql( """ |create table user_login_info_2 |as |select * from user_login_info_1 |where uid != ' ' and phone != ' ' and addr != ' ' |""".stripMargin) spark.sql(sqlText = "select count(*) count from user_login_info_2").show() //获取前20个地址 spark.sql( """ |create table hot_addr |as |select addr,count(addr) count from user_login_info_2 |group by addr order by count desc limit 20 |""".stripMargin) spark.sql(sqlText = "select * from hot_addr").show() spark.stop() } }
Spark Streaming介绍 Spark Streaming概述: 用于流式计算,处理实时数据流。 支持多种数据输入源(如Kafka、Flume、Twitter、TCP套接字等)和输出存储位置(如HDFS、数据库等)。
Spark Streaming特点: 易用性:支持Java、Python、Scala等编程语言,编写实时计算程序如同编写批处理程序。 容错性:无需额外代码和配置即可恢复丢失的数据,确保实时计算的可靠性。 整合性:可以在Spark上运行,允许重复使用相关代码进行批处理,实现交互式查询操作。
Spark Streaming架构: 驱动程序(StreamingContext)处理数据并传给SparkContext。 工作节点接收和处理数据,执行任务并备份数据到其他节点。 背压机制协调数据接收能力和资源处理能力,避免数据堆积和资源浪费。 Spark Streaming实操 词频统计案例: 使用ipad工具向999端口发送数据,Spark Streaming读取端口数据并统计单词出现次数。 代码配置包括设置关键对象、接收TCP套接字数据、扁平化处理、累加相同键值对、分组统计词频。 启动和运行: 启动netpad发送数据,Spark Streaming每隔三秒收集和处理数据。 代码中没有显式关闭状态,流式计算默认持续运行,确保数据处理不间断。 DStream创建 DStream创建方式: RDD队列:通过SSC创建RDD队列,将RDD推送到队列中作为DStream处理。 自定义数据源:下节课详细讲解。
RDD队列案例: 循环创建多个RDD并推送到队列中,使用Spark Streaming处理RDD队列进行词频统计。 代码包括配置对象、创建可变队列、转换RDD为DStream、累加和分组统计词频。 代码如下 import org.apache.spark.SparkConf object WordCount { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("streaming") val ssc = new StreamingContext(sparkConf,Seconds(3)) val lineStreams = ssc.socketTextStream("node01",9999) val wordStreams = lineStreams.flatMap(_.split(" ")) val wordAndOneStreams = wordStreams.map((_,1)) val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_) wordAndCountStreams.print() ssc.start() ssc.awaitTermination() } }
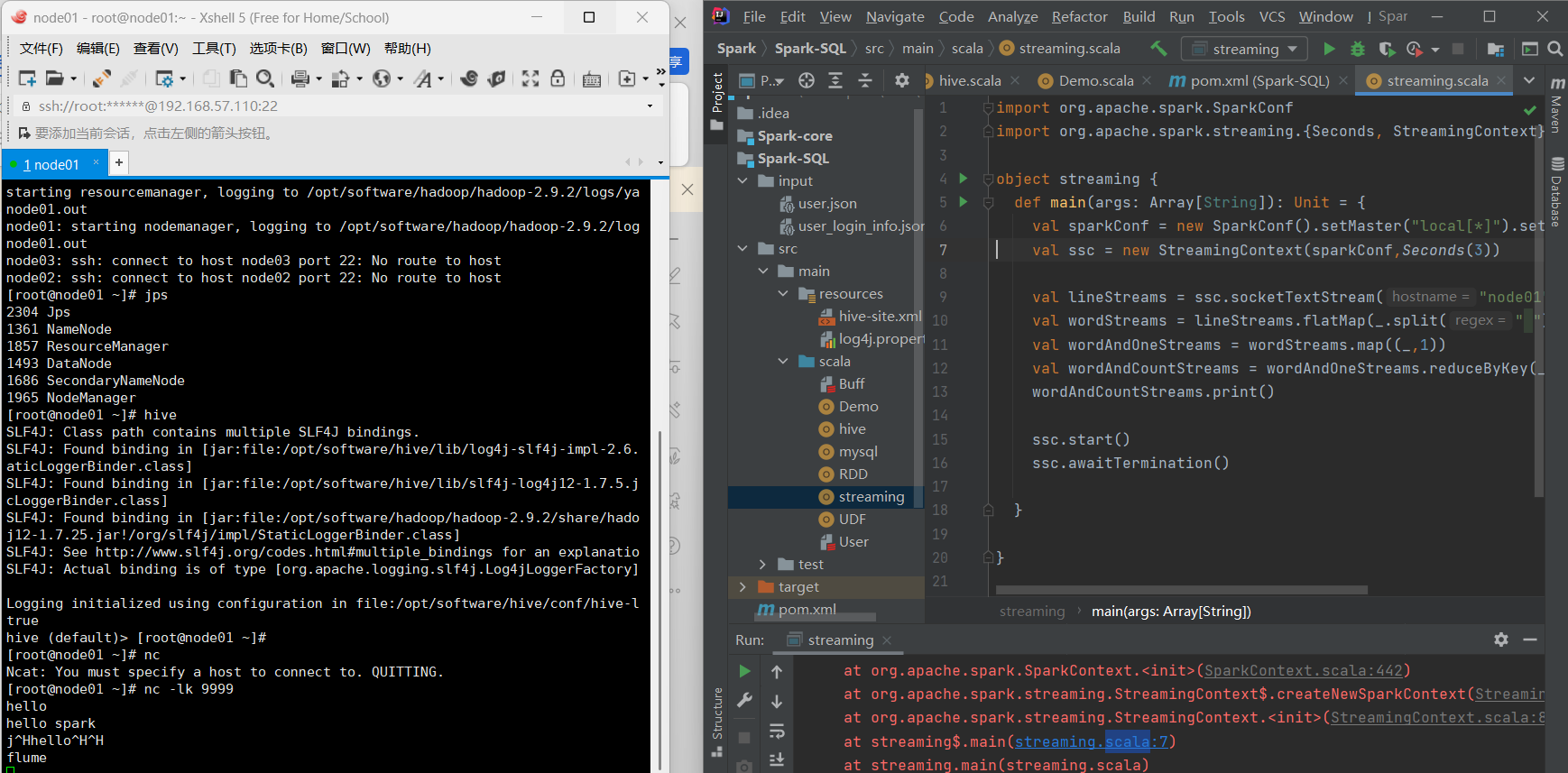
结果展示: 展示了词频统计的结果,验证了Spark Streaming的正确性和有效性。 自定义数据源的实现 需要导入新的函数并继承现有的函数。 创建数据源时需选择class而不是object。 在class中定义on start和on stop方法,并在这些方法中实现具体的功能。 类的定义和初始化 类的定义包括数据类型的设定,如端口号和TCP名称。 使用extends关键字继承父类的方法。 数据存储类型设定为内存中保存。 数据接收和处理 在on start方法中创建新线程并调用接收数据的方法。 连接到指定的主机和端口号,创建输入流并转换为字符流。 逐行读取数据并写入到spark stream中,进行词频统计。 数据扁平化和词频统计 使用block map进行数据扁平化处理。 将原始数据转换为键值对形式,并根据相同键进行分组和累加。 输出词频统计结果。 程序终止条件 设定手动终止和程序异常时的终止条件。 在满足终止条件时输出结果并终止程序。
相关文章:
Spark–steaming
实验项目: 找出所有有效数据,要求电话号码为11位,但只要列中没有空值就算有效数据。 按地址分类,输出条数最多的前20个地址及其数据。 代码讲解: 导包和声明对象,设置Spark配置对象和SparkContext对象。 使用Spark S…...

【目标检测】对YOLO系列发展的简单理解
目录 1.YOLOv12.YOLOv23.YOLOv34.YOLOv45.YOLOv66.YOLOv77.YOLOv9 YOLO系列文章汇总: 【论文#目标检测】You Only Look Once: Unified, Real-Time Object Detection 【论文#目标检测】YOLO9000: Better, Faster, Stronger 【论文#目标检测】YOLOv3: An Incremental …...

前端框架的“快闪“时代:我们该如何应对技术迭代的洪流?
引言:前端开发者的"框架疲劳" “上周刚学完Vue 3的组合式API,这周SolidJS又火了?”——这恐怕是许多前端开发者2023年的真实心声。前端框架的迭代速度已经达到了令人目眩的程度,GitHub每日都有新框架诞生,n…...

深度学习训练中的显存溢出问题分析与优化:以UNet图像去噪为例
最近在训练一个基于 Tiny-UNet 的图像去噪模型时,我遇到了经典但棘手的错误: RuntimeError: CUDA out of memory。本文记录了我如何从复现、分析,到逐步优化并成功解决该问题的全过程,希望对深度学习开发者有所借鉴。 训练数据&am…...

Python爬虫实战:获取优志愿专业数据
一、引言 在信息爆炸的当下,数据成为推动各领域发展的关键因素。优志愿网站汇聚了丰富的专业数据,对于教育研究、职业规划等领域具有重要价值。然而,为保护自身数据和资源,许多网站设置了各类反爬机制。因此,如何高效、稳定地从优志愿网站获取计算机专业数据成为一个具有…...

2025.4.22学习日记 JavaScript的常用事件
在 JavaScript 里,事件是在文档或者浏览器窗口中发生的特定交互瞬间,例如点击按钮、页面加载完成等等。下面是一些常用的事件以及案例: 1. click 事件 当用户点击元素时触发 const button document.createElement(button); button.textCo…...
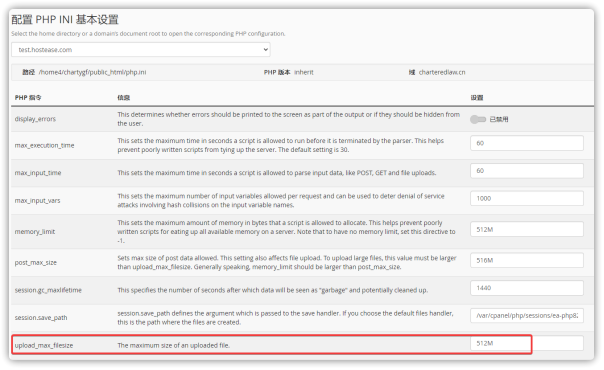
如何修复WordPress中“您所关注的链接已过期”的错误
几乎每个管理WordPress网站的人都可能遇到过“您关注的链接已过期”的错误,尤其是在上传插件或者主题的时候。本文将详细解释该错误出现的原因以及如何修复,帮助您更好地管理WordPress网站。 为什么会出现“您关注的链接已过期”的错误 为了防止资源被滥…...

从零开始搭建Django博客①--正式开始前的准备工作
本文主要在Ubuntu环境上搭建,为便于研究理解,采用SSH连接在虚拟机里的ubuntu-24.04.2-desktop系统搭建的可视化桌面,涉及一些文件操作部分便于通过桌面化进行理解,最后的目标是在本地搭建好系统后,迁移至云服务器并通过…...
健身房管理系统(springboot+ssm+vue+mysql)含运行文档
健身房管理系统(springbootssmvuemysql)含运行文档 健身房管理系统是一个全面的解决方案,旨在帮助健身房高效管理其运营。系统提供多种功能模块,包括会员管理、员工管理、会员卡管理、教练信息管理、解聘管理、健身项目管理、指导项目管理、健身器材管理…...

Java从入门到“放弃”(精通)之旅——继承与多态⑧
Java从入门到“放弃”(精通)之旅🚀——继承与多态⑧ 一、继承:代码复用的利器 1.1 为什么需要继承? 想象一下我们要描述狗和猫这两种动物。如果不使用继承,代码可能会是这样: // Dog.java pu…...
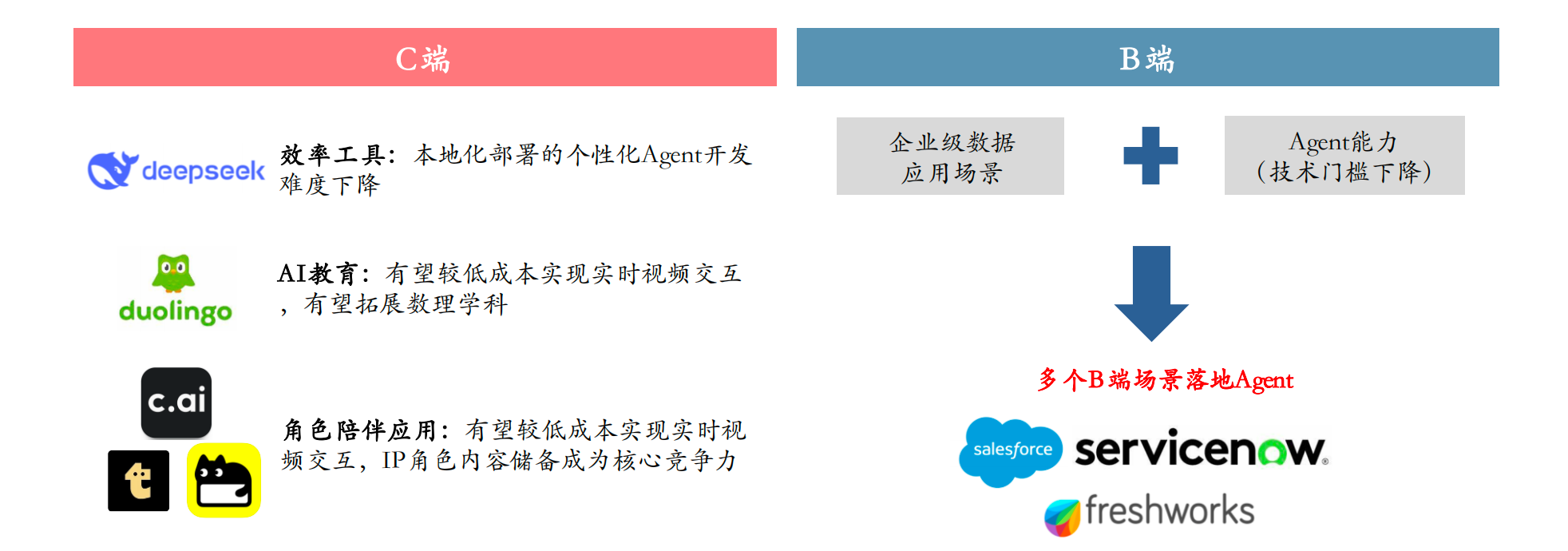
DeepSeek开源引爆AI Agent革命:应用生态迎来“安卓时刻”
开源低成本:AI应用开发进入“全民时代” 2025年初,中国AI领域迎来里程碑事件——DeepSeek开源模型的横空出世,迅速在全球开发者社区掀起热潮。其R1和V3模型以超低API成本(仅为GPT-4o的2%-10%)和本地化部署能力&#x…...

使用 LangChain + Higress + Elasticsearch 构建 RAG 应用
RAG(Retrieval Augmented Generation,检索增强生成) 是一种结合了信息检索与生成式大语言模型(LLM)的技术。它的核心思想是:在生成模型输出内容之前,先从外部知识库或数据源中检索相关信息&…...

深入解析C++ STL List:双向链表的特性与高级操作
一、引言 在C STL容器家族中,list作为双向链表容器,具有独特的性能特征。本文将通过完整代码示例,深入剖析链表的核心操作,揭示其底层实现机制,并对比其他容器的适用场景。文章包含4000余字详细解析,适合需…...

Uniapp:pages.json页面路由
目录 一、pages二、style 一、pages uni-app 通过 pages 节点配置应用由哪些页面组成,pages 节点接收一个数组,数组每个项都是一个对象,其属性值如下: 属性类型默认值描述pathString配置页面路径styleObject配置页面窗口表现nee…...

Self-Ask:LLM Agent架构的思考模式 | 智能体推理框架与工具调用实践
作为程序员,我们习惯将复杂问题分解为可管理的子任务,这正是递归和分治算法的核心思想。那么,如何让AI模型也具备这种结构化思考能力?本文深入剖析Self-Ask推理模式的工作原理、实现方法与最佳实践,帮助你构建具有清晰…...

【前端】【业务场景】【面试】在网页开发中,如何优化图片以提高页面加载速度?解决不同设备屏幕适配问题
📌 问题 1:在网页开发中,如何优化图片以提高页面加载速度? 🔍 一、关键词总结 关键词说明图片压缩借助 TinyPNG、ImageOptim 等工具,无损减小图片文件大小格式选择JPEG(照片类)、P…...

Git Flow分支模型
经典分支模型(Git Flow) 由 Vincent Driessen 提出的 Git Flow 模型,是管理 main(或 master)和 dev 分支的经典方案: main 用于生产发布,保持稳定; dev 用于日常开发,合并功能分支(feature/*); 功能开发在 feature 分支进行,完成后合并回 dev; 预发布分支(rele…...

安装 vmtools
第2章 安装 vmtools 1.安装 vmtools 的准备工作 1)现在查看是否安装了 gcc 查看是否安装gcc 打开终端 输入 gcc - v 安装 gcc 链接:https://blog.csdn.net/qq_45316173/article/details/122018354?ops_request_misc&request_id&biz_id10…...
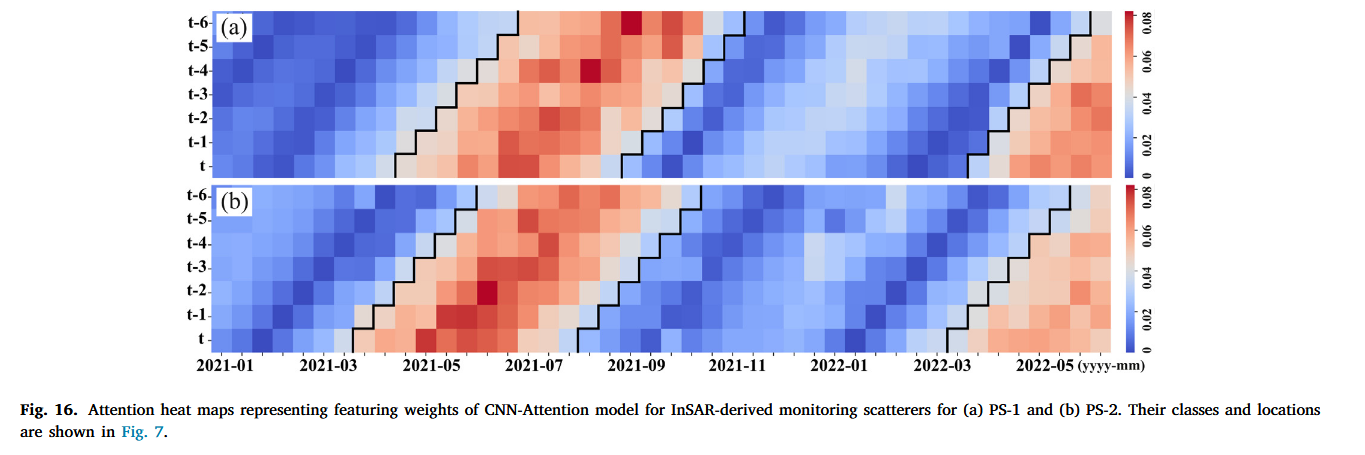
【论文阅读20】-CNN-Attention-BiGRU-滑坡预测(2025-03)
这篇论文主要探讨了基于深度学习的滑坡位移预测模型,结合了MT-InSAR(多时相合成孔径雷达干涉测量)观测数据,提出了一种具有可解释性的滑坡位移预测方法。 [1] Zhou C, Ye M, Xia Z, et al. An interpretable attention-based deep…...

滑动窗口学习
2090. 半径为 k 的子数组平均值 题目 问题分析 给定一个数组 nums 和一个整数 k,需要构建一个新的数组 avgs,其中 avgs[i] 表示以 nums[i] 为中心且半径为 k 的子数组的平均值。如果在 i 前或后不足 k 个元素,则 avgs[i] 的值为 -1。 思路…...

用户需求报告、系统需求规格说明书、软件需求规格说明的对比分析
用户需求报告、系统需求规格说明书(SyRS)和软件需求规格说明书(SRS)是需求工程中的关键文档,分别对应不同层次和视角的需求描述。以下是它们的核心区别对比: 1. 用户需求报告(User Requirem…...

# 基于PyTorch的食品图像分类系统:从训练到部署全流程指南
基于PyTorch的食品图像分类系统:从训练到部署全流程指南 本文将详细介绍如何使用PyTorch框架构建一个完整的食品图像分类系统,涵盖数据预处理、模型构建、训练优化以及模型保存与加载的全过程。 1. 系统概述 本系统实现了一个基于卷积神经网络(CNN)的…...
v-html 显示富文本内容
返回数据格式: 只有图片名称 显示不出完整路径 解决方法:在接收数据后手动给img格式的拼接vite.config中的服务器地址 页面: <el-button click"">获取信息<el-button><!-- 弹出层 --> <el-dialog v-model&…...

【数学建模】孤立森林算法:异常检测的高效利器
孤立森林算法:异常检测的高效利器 文章目录 孤立森林算法:异常检测的高效利器1 引言2 孤立森林算法原理2.1 核心思想2.2 算法流程步骤一:构建孤立树(iTree)步骤二:构建孤立森林(iForest)步骤三:计算异常分数 3 代码实现…...

<项目代码>YOLO小船识别<目标检测>
项目代码下载链接 YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN)࿰…...

Crawl4AI:打破数据孤岛,开启大语言模型的实时智能新时代
当大语言模型遇见数据饥渴症 在人工智能的竞技场上,大语言模型(LLMs)正以惊人的速度进化,但其认知能力的跃升始终面临一个根本性挑战——如何持续获取新鲜、结构化、高相关性的数据。传统数据供给方式如同输血式营养支持ÿ…...

AI 技术发展:从起源到未来的深度剖析
一、AI 的起源与早期发展 人工智能(AI)作为计算机科学的重要分支,其诞生可以追溯到 20 世纪中叶。1943 年,艾伦・图灵提出图灵机的概念,为计算机科学和 AI 理论奠定了基础。1950 年,图灵又提出著名的图灵…...

jsconfig.json文件的作用
jsconfig.json文件的作用 为什么今天会谈到这个呢?有这么一个场景:我们每次开发项目时都会给路径配置别名,配完别名之后可以简化我们的开发,但是随之而来的就有一个问题,一般来说,当我们使用相对路径时…...

nodejs的包管理工具介绍,npm的介绍和安装,npm的初始化包 ,搜索包,下载安装包
nodejs的包管理工具介绍,npm的介绍和安装,npm的初始化包 ,搜索包,下载安装包 🧰 一、Node.js 的包管理工具有哪些? 工具简介是否默认特点npmNode.js 官方的包管理工具(Node Package Manager&am…...

常见的raid有哪些,使用场景是什么?
RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)是一种将多个物理硬盘组合成一个逻辑硬盘的技术,目的是通过数据冗余和/或并行访问提高性能、容错能力和存储容量。不同的 RAID 级别有不同的实现方式和应用场景。以下…...