常用python爬虫框架介绍
文章目录
- 前言
- 1. Scrapy
- 2. BeautifulSoup 与 Requests 组合
- 3. Selenium
- 4. PySpider
前言
Python 有许多优秀的爬虫框架,每个框架都有其独特的特点和适用场景。以下为你详细介绍几个常用的 Python 爬虫框架:
Python 3.13.2 安装教程(附安装包):https://blog.csdn.net/2501_91193507/article/details/146770362
Python 3.13.2下载链接:https://pan.quark.cn/s/1bddf43c0c2f
1. Scrapy
- 简介:Scrapy 是一个为了爬取网站数据、提取结构性数据而编写的应用框架。它可以应用在数据挖掘、信息处理或存储历史数据等一系列的程序中。其功能强大,提供了数据抓取、数据处理、数据存储等一系列完整的解决方案。
- 特点
高效性:基于异步网络库 Twisted 实现,能够高效地处理大量的并发请求,大大提高了爬取效率。
组件化设计:具有高度模块化的架构,各个组件(如调度器、下载器、爬虫、管道等)之间相互独立又协同工作,方便用户根据需求进行定制和扩展。
数据处理方便:提供了强大的选择器(如 XPath、CSS 选择器)用于提取网页中的数据,还支持多种数据格式(如 JSON、CSV、XML 等)的存储。
中间件支持:支持多种中间件,如下载中间件和爬虫中间件,可以方便地对请求和响应进行处理,例如设置代理、处理请求头、处理异常等。
适用场景:适用于大规模、高效率的爬虫项目,如搜索引擎数据采集、电商网站商品信息抓取等。
示例代码
import scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"start_urls = ['https://quotes.toscrape.com',]def parse(self, response):for quote in response.css('div.quote'):yield {'text': quote.css('span.text::text').get(),'author': quote.css('small.author::text').get(),'tags': quote.css('div.tags a.tag::text').getall(),}next_page = response.css('li.next a::attr(href)').get()if next_page is not None:yield response.follow(next_page, self.parse)
你可以使用以下命令运行这个爬虫:
bash
scrapy runspider quotes_spider.py -o quotes.json
2. BeautifulSoup 与 Requests 组合
- 简介:严格来说,BeautifulSoup 是一个用于解析 HTML 和 XML 文档的库,而 Requests 是一个用于发送 HTTP 请求的库。它们通常一起使用,作为一个轻量级的爬虫解决方案。
- 特点
简单易用:API 设计简洁明了,容易上手,对于初学者来说非常友好。
灵活性高:可以根据具体需求自由组合和定制爬取逻辑,不受框架的限制。
广泛的解析支持:BeautifulSoup 支持多种解析器(如 Python 内置的 html.parser、lxml 等),可以根据不同的需求选择合适的解析器。
适用场景:适用于小规模、简单的爬虫任务,如抓取单个网页的数据、简单的数据采集等。
示例代码
import requests
from bs4 import BeautifulSoupurl = 'https://quotes.toscrape.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')quotes = soup.find_all('div', class_='quote')
for quote in quotes:text = quote.find('span', class_='text').textauthor = quote.find('small', class_='author').textprint(f'Quote: {text}, Author: {author}')
3. Selenium
- 简介:Selenium 是一个用于自动化浏览器操作的工具,它可以模拟用户在浏览器中的各种行为,如点击、输入、滚动等。在爬虫领域,Selenium 常用于处理动态网页,即需要通过 JavaScript 动态加载内容的网页。
- 特点
处理动态内容:能够模拟浏览器的渲染过程,获取动态加载的网页内容,解决了许多传统爬虫无法处理的问题。
跨浏览器支持:支持多种主流浏览器(如 Chrome、Firefox、Safari 等),可以根据需求选择合适的浏览器进行自动化操作。
丰富的操作方法:提供了丰富的 API 用于模拟用户的各种操作,如点击按钮、填写表单、切换页面等。
适用场景:适用于需要处理动态网页的爬虫任务,如爬取电商网站的商品详情页(需要点击 “查看更多” 按钮才能显示完整信息)、社交媒体网站的动态内容等。
示例代码
from selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get('https://quotes.toscrape.com')quotes = driver.find_elements(By.CSS_SELECTOR, 'div.quote')
for quote in quotes:text = quote.find_element(By.CSS_SELECTOR, 'span.text').textauthor = quote.find_element(By.CSS_SELECTOR, 'small.author').textprint(f'Quote: {text}, Author: {author}')driver.quit()
4. PySpider
- 简介:PySpider 是一个国产的、轻量级的爬虫框架,它提供了一个可视化的界面,方便用户进行爬虫的创建、调试和管理。
- 特点
可视化界面:具有直观的 Web 界面,用户可以通过浏览器访问和操作,无需编写复杂的命令行脚本。
分布式支持:支持分布式爬取,可以利用多台机器的资源提高爬取效率。
自动重试和断点续爬:具备自动重试机制,当请求失败时会自动重试;同时支持断点续爬,在爬取过程中中断后可以继续从上次中断的位置开始爬取。
适用场景:适用于需要快速开发和部署爬虫的场景,尤其是对于非专业的开发者来说,其可视化界面降低了开发门槛。
示例代码(通过 Web 界面创建爬虫)
启动 PySpider 服务:在命令行中运行 pyspider all。
打开浏览器,访问 http://localhost:5000,进入 PySpider 的 Web 界面。
在 Web 界面中创建一个新的爬虫,编写爬取逻辑:
from pyspider.libs.base_handler import *class Handler(BaseHandler):crawl_config = {}@every(minutes=24 * 60)def on_start(self):self.crawl('https://quotes.toscrape.com', callback=self.index_page)@config(age=10 * 24 * 60 * 60)def index_page(self, response):for each in response.doc('div.quote').items():self.crawl(each.attr.href, callback=self.detail_page)@config(priority=2)def detail_page(self, response):return {"url": response.url,"title": response.doc('title').text(),}
相关文章:

常用python爬虫框架介绍
文章目录 前言1. Scrapy2. BeautifulSoup 与 Requests 组合3. Selenium4. PySpider 前言 Python 有许多优秀的爬虫框架,每个框架都有其独特的特点和适用场景。以下为你详细介绍几个常用的 Python 爬虫框架: Python 3.13.2 安装教程(附安装包…...
2.3 预训练自己的模型)
AI大模型:(二)2.3 预训练自己的模型
目录 1.预训练原理 2.预训练范式 1.未标注数据 2.标注数据 3.有正确答案、也有错误答案 3.手撕transform模型 3.1.transform模型代码 3.2.训练数据集 3.3.预训练 3.4.推理 4.如何选择模型 5.如何确定模型需要哪种训练 大模型预训练(Large-scale Pre-training…...
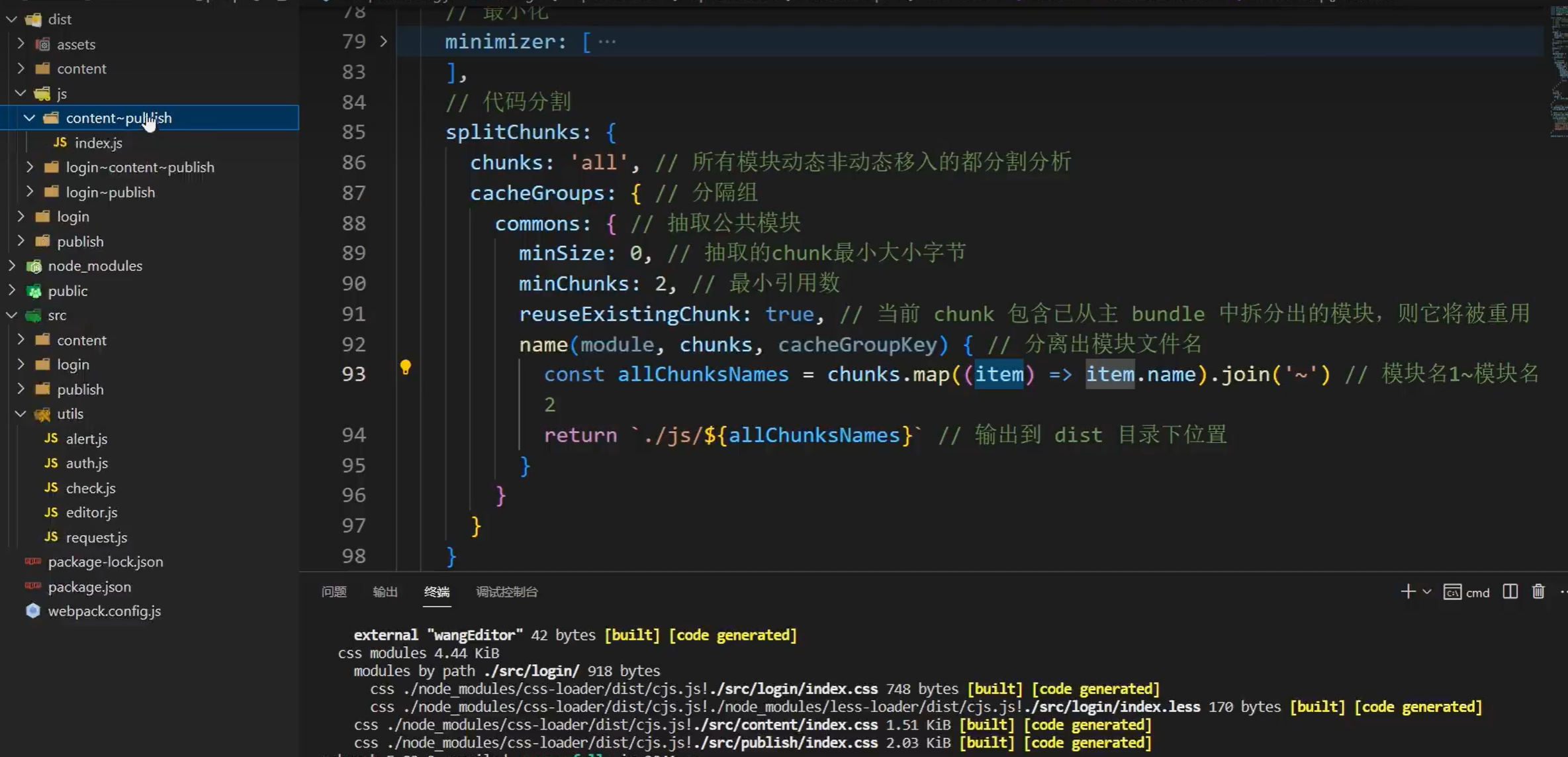
webpack基础使用了解(入口、出口、插件、加载器、优化、别名、打包模式、环境变量、代码分割等)
目录 1、webpack简介2、简单示例3、入口(entry)和输出(output)4、自动生成html文件5、打包css代码6、优化(单独提取css代码)7、优化(压缩过程)8、打包less代码9、打包图片10、搭建开发环境(webpack-dev-server…...
:时钟树综合——让芯片的「心跳」同步到每个角落)
数字后端设计 (四):时钟树综合——让芯片的「心跳」同步到每个角落
—— 试想全城的人要在同一秒按下开关——如果有的表快、有的表慢,结果会乱套!时钟树综合就是给芯片内部装一套精准的“广播对时系统”,让所有电路踩着同一个节拍工作。 1. 为什么时钟如此重要? 芯片的「心跳」:时钟信…...
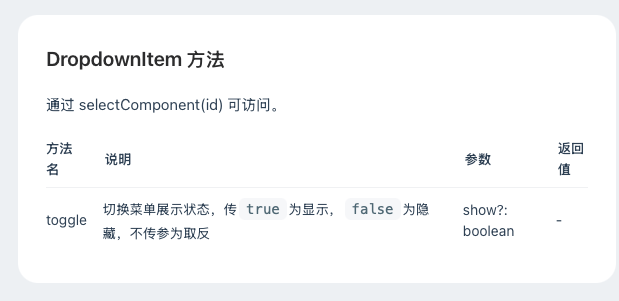
微信小程序 van-dropdown-menu
点击其他按钮,关闭van-dropdown-menu下拉框 DropdownMenu 引入页面使用index.wxmlindex.scssindex.ts(重点)index.ts(全部) DropdownMenu 引入 在app.json或index.json中引入组件 "usingComponents": {"van-dropdown-menu": "vant/weapp…...

智驱未来:AI大模型重构数据治理新范式
第一章 数据治理的进化之路 1.1 传统数据治理的困境 在制造业巨头西门子的案例中,其全球200个工厂每天产生1.2PB工业数据,传统人工清洗需要300名工程师耗时72小时完成,错误率高达15%。数据孤岛问题导致供应链决策延迟平均达48小时。 1.2 A…...

2025-04-22| Docker: --privileged参数详解
在 Docker 中,--privileged 是一个运行容器时的标志,它赋予容器特权模式,大幅提升容器对宿主机资源的访问权限。以下是 --privileged 的作用和相关细节: 作用 完全访问宿主机的设备: 容器可以访问宿主机的所有设备&am…...

[创业之路-380]:企业法务 - 企业经营中,企业为什么会虚开増值税发票?哪些是虚开増值税发票的行为?示例?风险?
一、动机与风险 1、企业虚开增值税发票的动机 利益驱动 骗抵税款:通过虚开发票虚增进项税额,减少应纳税额,降低税负。公司套取国家的利益。非法套现:虚构交易开具发票,将资金从公司账户转移至个人账户,用…...
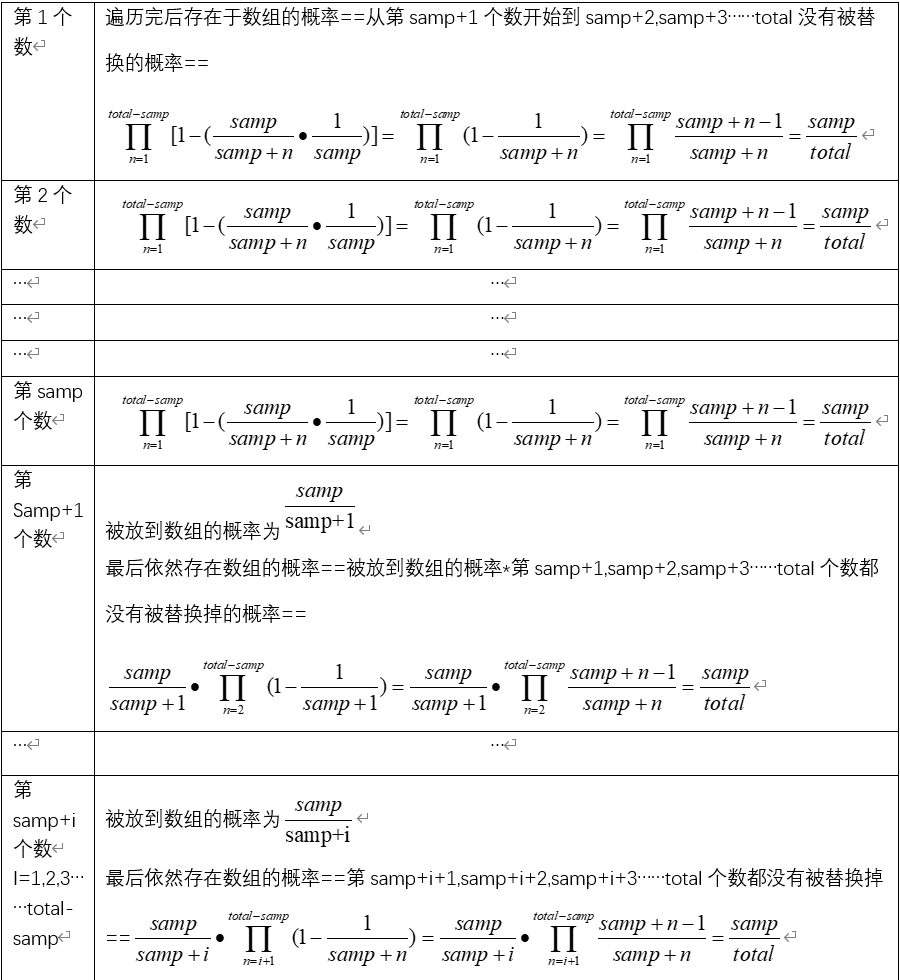
C++ 蓄水池抽样算法
(1)概念 蓄水池抽样算法(Reservoir Sampling)是一种用于从 大规模数据集(尤其是 流式数据 或 无法预先知晓数据总量 的场景)中 等概率随机抽取固定数量样本 的算法。 (2)实现 我们…...

uniapp-x 二维码生成
支持X,二维码生成,支持微信小程序,android,ios,网页 - DCloud 插件市场 免费的单纯用爱发电的...

蓝桥杯算法实战分享:C/C++ 题型解析与实战技巧
蓝桥杯全国软件和信息技术专业人才大赛,作为国内知名的算法竞赛之一,吸引了众多编程爱好者参与。在蓝桥杯的赛场上,C/C 因其高效性和灵活性,成为了众多选手的首选语言。本文将结合蓝桥杯的赛制特点、常见题型以及实战案例…...

分布式光纤测温技术让森林火灾预警快人一步
2025年春季,多地接连发生森林火灾,累计过火面积超 3万公顷。春季历来是森林草原火灾易发、多发期,加之清明节已到来,生产生活用火活跃,民俗祭祀用火集中,森林火灾风险进一步加大。森林防火,人人…...

Vue2 el-checkbox 虚拟滚动解决多选框全选卡顿问题 - 高性能处理大数据量选项列表
一、背景 在我们开发项目中,经常会遇到需要展示大量选项的多选框场景,比如权限配置、数据筛选等。当选项数量达到几百甚至上千条时,传统的渲染方式全选时会非常卡顿,导致性能问题。本篇文章,记录我使用通过虚拟滚动实现…...
KUKA机器人KR 3 D1200 HM介绍
KUKA KR 3 D1200 HM是一款小型机器人,型号中HM代表“Hygienic Machine(卫生机械)用于主副食品行业”,也是一款并联机器人。用于执行高速、高精度的抓取任务。这款机器人采用食品级不锈钢设计,额定负载为3公斤ÿ…...

linux驱动---视频播放采集架构介绍
lcd驱动框架(图像显示) 图像显示基础 1. 核心组件架构 用户空间 ------------------------------------------ | X11/Wayland | FBDEV应用 | DRM/KMS应用 | ------------------------------------------ 内核空间 --------------------------------…...
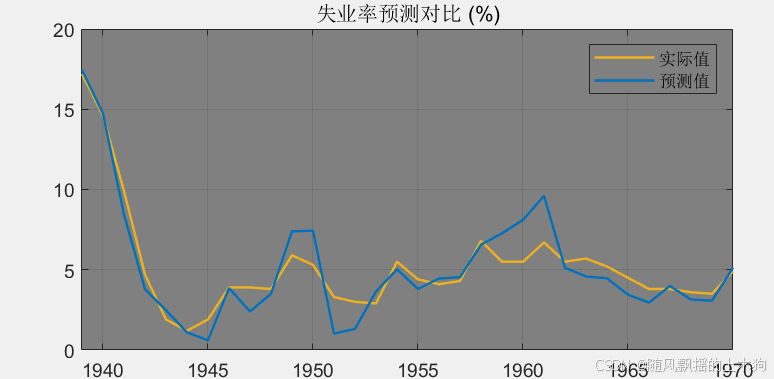
【MATLAB第117期】#源码分享 | 基于MATLAB的SSM状态空间模型多元时间序列预测方法(多输入单输出)
【MATLAB第117期】#源码分享 | 基于MATLAB的SSM状态空间模型多元时间序列预测方法(多输入单输出) 引言 本文使用状态空间模型实现失业率递归预测,状态空间模型(State Space Model, SSM)是一种用于描述动态系统行为的…...

状态管理最佳实践:Riverpod响应式编程
状态管理最佳实践:Riverpod响应式编程 引言 Riverpod是Flutter生态系统中一个强大的状态管理解决方案,它通过响应式编程的方式提供了更加灵活和可维护的状态管理机制。本文将深入探讨Riverpod的核心概念、实践应用以及性能优化技巧。 核心概念 Provi…...
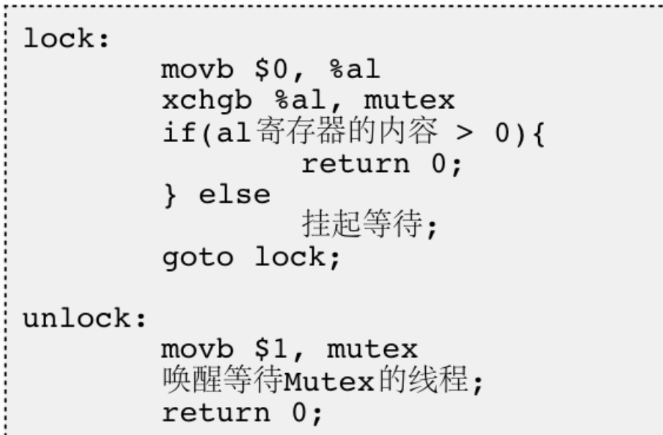
【Linux】线程ID、线程管理、与线程互斥
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🌐 C 语言 上篇文章: 【Linux】线程:从原理到实战,全面掌握多线程编程!-CSDN博客 下…...

python包管理器,conda和uv 的区别
python包管理器,conda和uv 的区别 以下是 conda 和 uv 在 Python 包管理中的深度对比,结合知识库内容进行分析: 1. 核心设计理念 conda 以“环境为中心”,强调跨语言支持(如 Python、R、Julia)和严格的依赖…...

逻辑回归:损失和正则化技术的深入研究
逻辑回归:损失和正则化技术的深入研究 引言 逻辑回归是一种广泛应用于分类问题的统计模型,尤其在机器学习领域中占据着重要的地位。尽管其名称中包含"回归",但逻辑回归本质上是一种分类算法。它的核心思想是在线性回归的基础上添…...
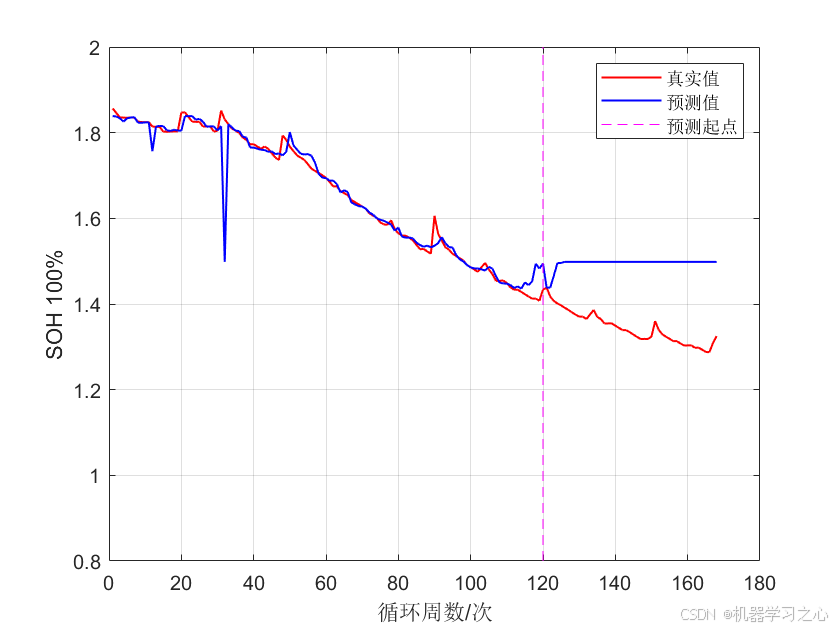
【锂电池SOH估计】RF随机森林锂电池健康状态估计,锂电池SOH估计(Matlab完整源码和数据)
目录 效果一览程序获取程序内容代码分享研究内容基于随机森林(RF)的锂电池健康状态(SOH)估计算法研究摘要1. 引言2. 锂电池SOH评估框架3. 实验与结果分析4. 未来研究方向6. 结论效果一览 程序获取 获取方式一:文章顶部资源处直接下载:【锂电池SOH估计】RF随机森林锂电池…...
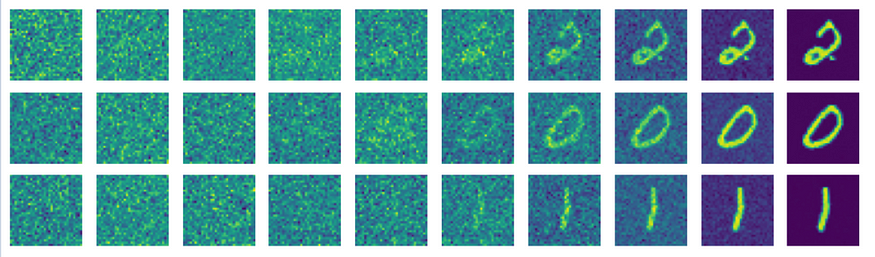
【Pytorch 中的扩散模型】去噪扩散概率模型(DDPM)的实现
介绍 广义上讲,扩散模型是一种生成式深度学习模型,它通过学习到的去噪过程来创建数据。扩散模型有很多变体,其中最流行的通常是文本条件模型,它可以根据提示生成特定的图像。一些扩散模型(例如 Control-Net࿰…...
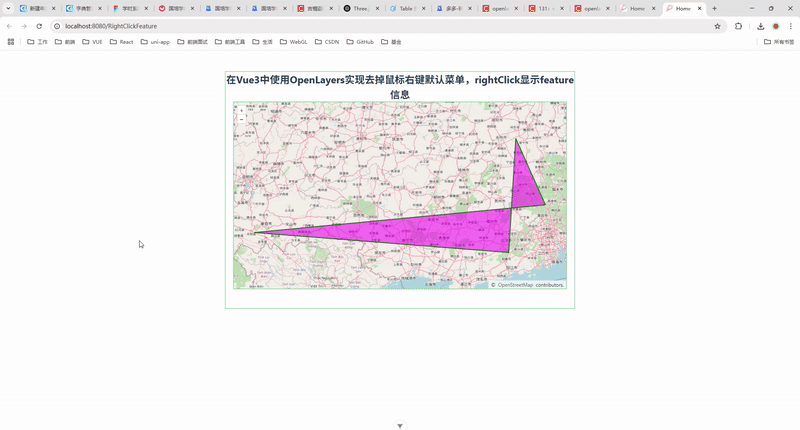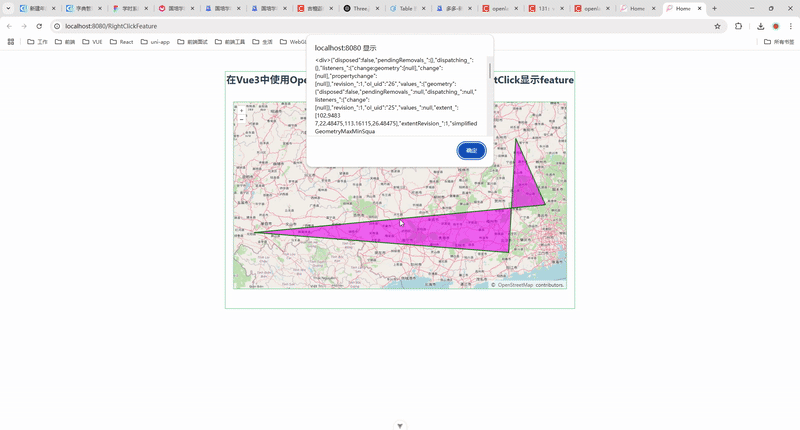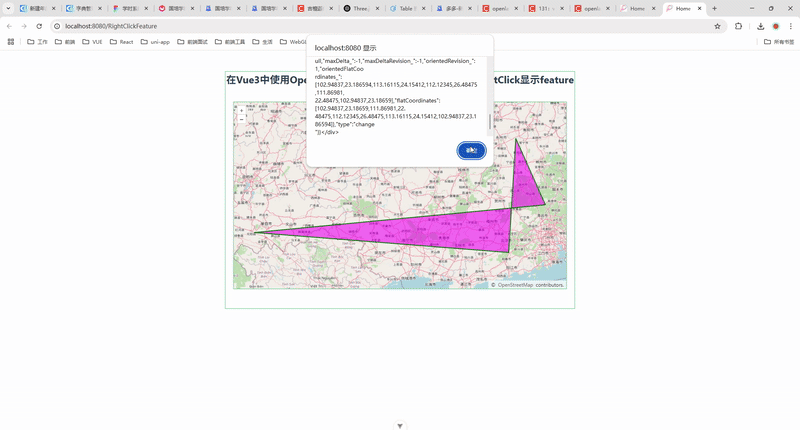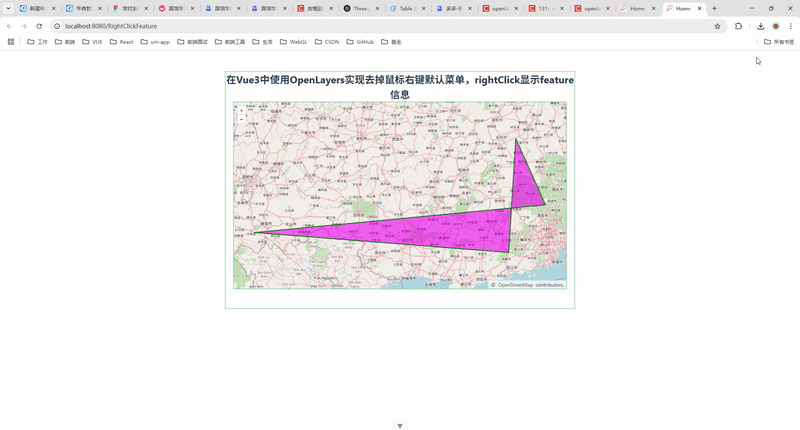
121.在 Vue3 中使用 OpenLayers 实现去掉鼠标右键默认菜单并显示 Feature 信息
🎯 实现效果 👇 本文最终实现的效果如下: ✅ 地图初始化时绘制一个多边形; ✅ 鼠标 右键点击地图任意位置; ✅ 若命中 Feature,则弹出该图形的详细信息; ✅ 移除浏览器默认的右键菜单,保留地图交互的完整控制。 💡 整个功能基于 Vue3 + OpenLayers 完成,采用 Com…...

仓颉造字,亦可造AI代理
CangjieMagic入门教程 本文将为您提供一份关于CangjieMagic代码库的详细入门教程,CangjieMagic托管于GitCode - 全球开发者的开源社区,开源代码托管平台。这是一个基于仓颉编程语言的LLM(大语言模型)Agent开发平台,具有独特的Age…...

进阶篇 第 6 篇:时间序列遇见机器学习与深度学习
进阶篇 第 6 篇:时间序列遇见机器学习与深度学习 (图片来源: Tara Winstead on Pexels) 在上一篇中,我们探讨了如何通过精心的特征工程,将时间序列预测问题转化为机器学习可以处理的监督学习任务。我们学习了如何创建滞后特征、滚动统计特征…...

【音视频】音频解码实战
音频解码过程 ⾳频解码过程如下图所示: FFmpeg流程 关键函数 关键函数说明: avcodec_find_decoder:根据指定的AVCodecID查找注册的解码器。av_parser_init:初始化AVCodecParserContext。avcodec_alloc_context3:为…...
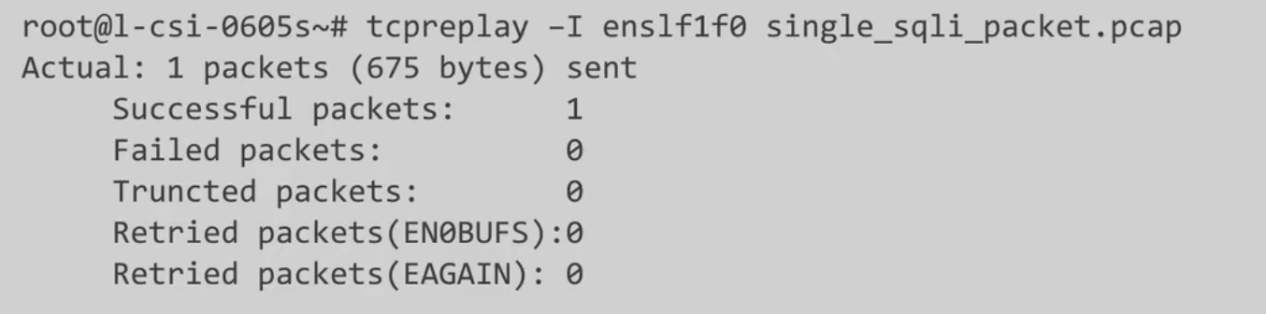
DOCA介绍
本文分为两个部分: DOCA及BlueField介绍如何运行DOCA应用,这里以DNS_Filter为例子做大致介绍。 DOCA及BlueField介绍: 现代企业数据中心是软件定义的、完全可编程的基础设施,旨在服务于跨云、核心和边缘环境的高度分布式应用工作…...
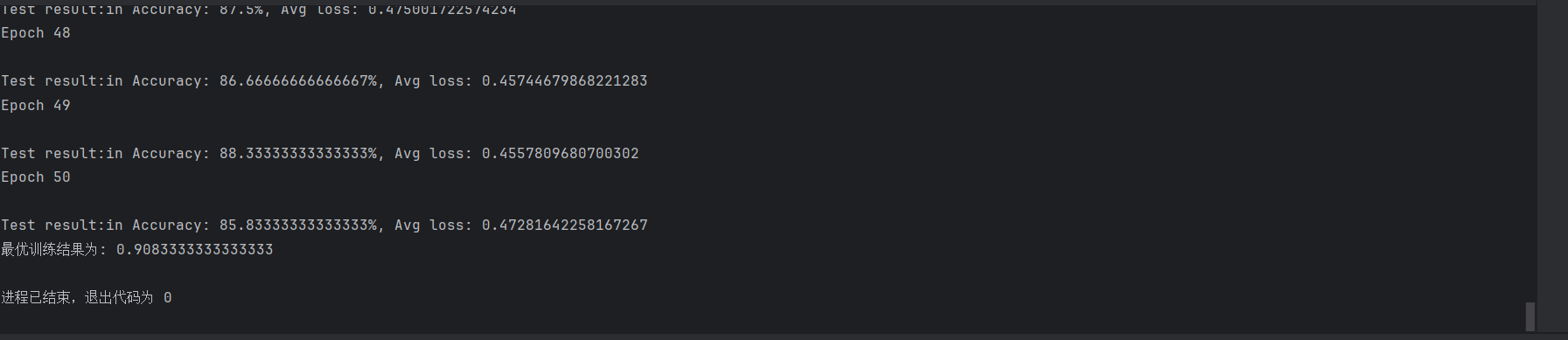
# 利用迁移学习优化食物分类模型:基于ResNet18的实践
利用迁移学习优化食物分类模型:基于ResNet18的实践 在深度学习的众多应用中,图像分类一直是一个热门且具有挑战性的领域。随着研究的深入,我们发现利用预训练模型进行迁移学习是一种非常有效的策略,可以显著提高模型的性能&#…...
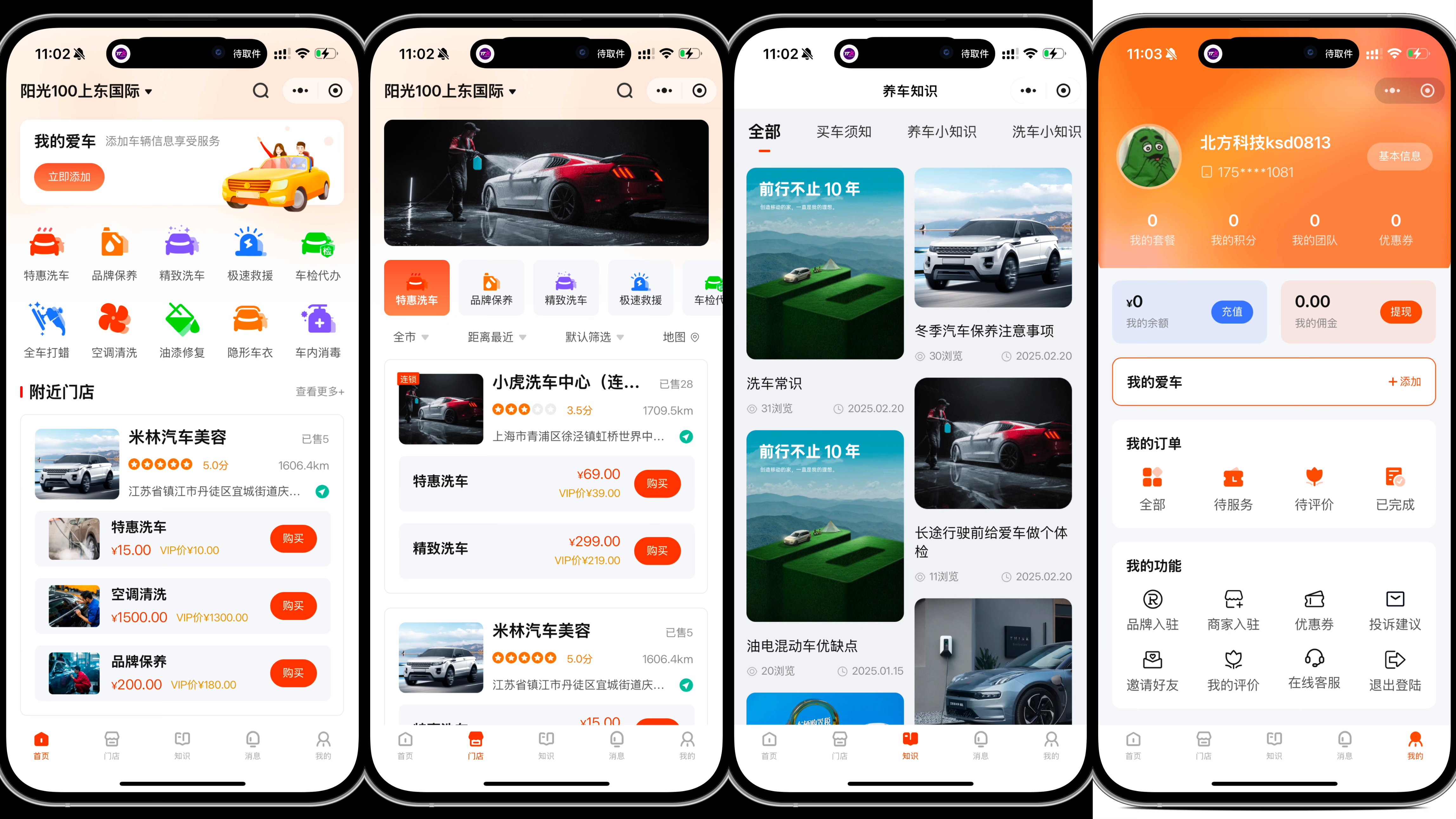
洗车小程序系统前端uniapp 后台thinkphp
洗车小程序系统 前端uniapp 后台thinkphp 支持多门店 分销 在线预约 套餐卡等...
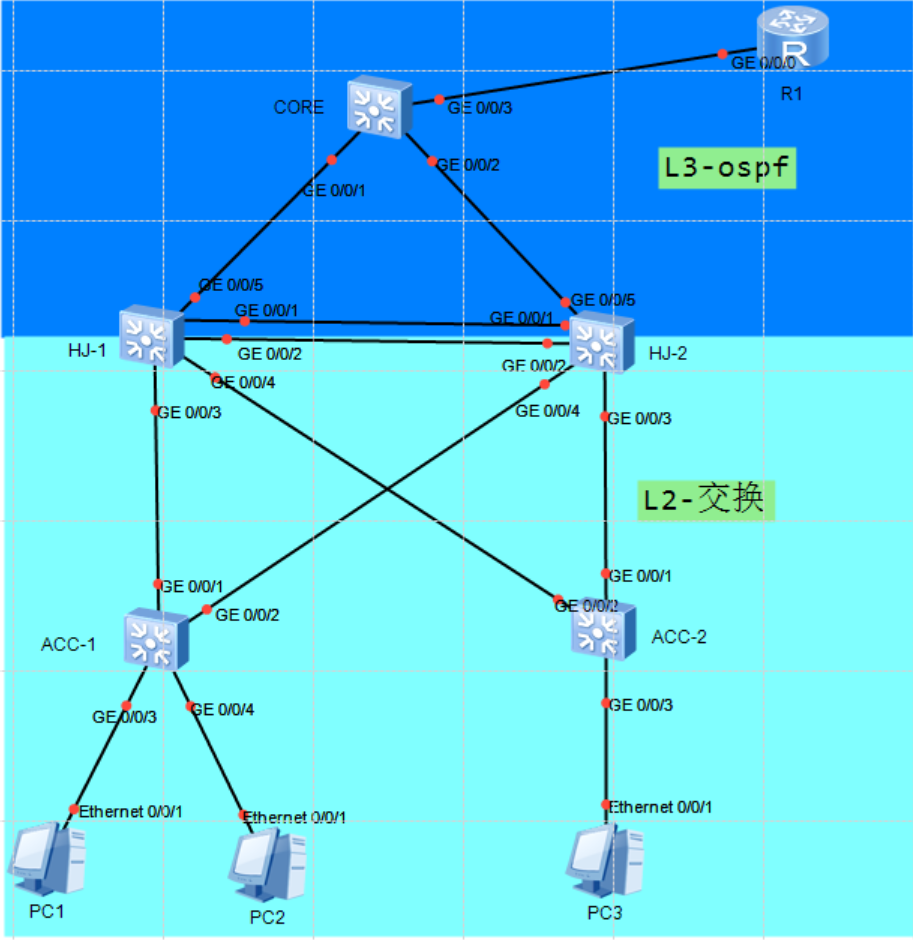
HCIP(综合实验2)
1.实验拓补图 2.实验要求 1.根据提供材料划分VLAN以及IP地址,PC1/PC2属于生产一部员工划分VLAN10,PC3属于生产二部划分VLAN20 2.HJ-1HJ-2交换机需要配置链路聚合以保证业务数据访问的高带宽需求 3.VLAN的放通遵循最小VLAN透传原则 4.配置MSTP生成树解决二层环路问题…...