力扣第446场周赛
有事没赶上, 赛后模拟了一下, 分享一下我的解题思路和做题感受
1.执行指令后的得分
题目链接如下:力扣
给你两个数组:
instructions和values,数组的长度均为n。你需要根据以下规则模拟一个过程:
- 从下标
i = 0的第一个指令开始,初始得分为 0。- 如果
instructions[i]是"add":
- 将
values[i]加到你的得分中。- 移动到下一个指令
(i + 1)。- 如果
instructions[i]是"jump":
- 移动到下标为
(i + values[i])的指令,但不修改你的得分。当以下任一情况发生时,过程会终止:
- 越界(即
i < 0或i >= n),或- 尝试再次执行已经执行过的指令。被重复访问的指令不会再次执行。
返回过程结束时的得分。
示例 1:
输入: instructions = ["jump","add","add","jump","add","jump"], values = [2,1,3,1,-2,-3]
输出: 1
解释:
从下标 0 开始模拟过程:
- 下标 0:指令是
"jump",移动到下标0 + 2 = 2。- 下标 2:指令是
"add",将values[2] = 3加到得分中,移动到下标 3。得分变为 3。- 下标 3:指令是
"jump",移动到下标3 + 1 = 4。- 下标 4:指令是
"add",将values[4] = -2加到得分中,移动到下标 5。得分变为 1。- 下标 5:指令是
"jump",移动到下标5 + (-3) = 2。- 下标 2:已经访问过。过程结束。
示例 2:
输入: instructions = ["jump","add","add"], values = [3,1,1]
输出: 0
解释:
从下标 0 开始模拟过程:
- 下标 0:指令是
"jump",移动到下标0 + 3 = 3。- 下标 3:越界。过程结束。
示例 3:
输入: instructions = ["jump"], values = [0]
输出: 0
解释:
从下标 0 开始模拟过程:
- 下标 0:指令是
"jump",移动到下标0 + 0 = 0。- 下标 0:已经访问过。过程结束。
提示:
n == instructions.length == values.length1 <= n <= 10^5instructions[i]只能是"add"或"jump"。-105 <= values[i] <= 10^5
解题思路:模拟的时候wa了好几次,注意不要越界
class Solution {
public:long long calculateScore(vector<string>& a, vector<int>& b) {unordered_map<int,int> mp;int i=0; long long score=0;while(i<a.size()){if(a[i]=="jump"){if(mp[i]) break;mp[i]=1;i=i+b[i];if (i >= a.size() || i < 0) { break;}}if(a[i]=="add"){if(mp[i]) break;mp[i]=1;score+=b[i];// cout<<score<<endl;i++;}}return score;}
};2.非递减数组的最大长度
题目链接如下:力扣
给你一个整数数组 nums。在一次操作中,你可以选择一个子数组,并将其替换为一个等于该子数组 最大值 的单个元素。
返回经过零次或多次操作后,数组仍为 非递减 的情况下,数组 可能的最大长度。
子数组 是数组中一个连续、非空 的元素序列。
示例 1:
输入: nums = [4,2,5,3,5]
输出: 3
解释:
实现最大长度的一种方法是:
将子数组 nums[1..2] = [2, 5] 替换为 5 → [4, 5, 3, 5]。
将子数组 nums[2..3] = [3, 5] 替换为 5 → [4, 5, 5]。
最终数组 [4, 5, 5] 是非递减的,长度为 3。示例 2:
输入: nums = [1,2,3]
输出: 3
解释:
无需任何操作,因为数组 [1,2,3] 已经是非递减的。
提示:
1 <= nums.length <= 2 * 10^5
1 <= nums[i] <= 2 * 10^5
解题思路: 题意是, 找到递减的子数组, 然后将该子数组用子数组中的最大值进行替换,保证剩余数组的长度尽可能长
class Solution {
public:int maximumPossibleSize(vector<int>& nums) {int n = nums.size();int count = 0;int preMax = 0;int i = 0;while (i < n) {if (nums[i] >= preMax) {preMax = nums[i];count++;i++;}else {int curNum = nums[i];int j = i + 1;while (j < n && curNum < preMax) {curNum = max(curNum, nums[j]);j++;}if (curNum < preMax) {break;}preMax = curNum;count++;i = j;}}return count;}
};
3. 求出数组的 X 值 I
题目链接如下:力扣
给你一个由 正 整数组成的数组
nums,以及一个 正 整数k。你可以对
nums执行 一次 操作,该操作中可以移除任意 不重叠 的前缀和后缀,使得nums仍然 非空 。你需要找出
nums的 x 值,即在执行操作后,剩余元素的 乘积 除以k后的 余数 为x的操作数量。返回一个大小为
k的数组result,其中result[x]表示对于0 <= x <= k - 1,nums的 x 值。数组的 前缀 指从数组起始位置开始到数组中任意位置的一段连续子数组。
数组的 后缀 是指从数组中任意位置开始到数组末尾的一段连续子数组。
子数组 是数组中一段连续的元素序列。
注意,在操作中选择的前缀和后缀可以是 空的 。
示例 1:
输入: nums = [1,2,3,4,5], k = 3
输出: [9,2,4]
解释:
- 对于
x = 0,可行的操作包括所有不会移除nums[2] == 3的前后缀移除方式。- 对于
x = 1,可行操作包括:
- 移除空前缀和后缀
[2, 3, 4, 5],nums变为[1]。- 移除前缀
[1, 2, 3]和后缀[5],nums变为[4]。- 对于
x = 2,可行操作包括:
- 移除空前缀和后缀
[3, 4, 5],nums变为[1, 2]。- 移除前缀
[1]和后缀[3, 4, 5],nums变为[2]。- 移除前缀
[1, 2, 3]和空后缀,nums变为[4, 5]。- 移除前缀
[1, 2, 3, 4]和空后缀,nums变为[5]。示例 2:
输入: nums = [1,2,4,8,16,32], k = 4
输出: [18,1,2,0]
解释:
- 对于
x = 0,唯一 不 得到x = 0的操作有:
- 移除空前缀和后缀
[4, 8, 16, 32],nums变为[1, 2]。- 移除空前缀和后缀
[2, 4, 8, 16, 32],nums变为[1]。- 移除前缀
[1]和后缀[4, 8, 16, 32],nums变为[2]。- 对于
x = 1,唯一的操作是:
- 移除空前缀和后缀
[2, 4, 8, 16, 32],nums变为[1]。- 对于
x = 2,可行操作包括:
- 移除空前缀和后缀
[4, 8, 16, 32],nums变为[1, 2]。- 移除前缀
[1]和后缀[4, 8, 16, 32],nums变为[2]。- 对于
x = 3,没有可行的操作。示例 3:
输入: nums = [1,1,2,1,1], k = 2
输出: [9,6]
提示:
1 <= nums[i] <= 10^91 <= nums.length <= 10^51 <= k <= 5
解题思路:看不懂题的可以直接看我下面提供的图片
1. 简单来说就是删除一个前缀/后缀后的子数组中元素的乘积除以
k的余数x,并返回一个数组 result,其中result[x]表示余数为x的子数组数量2. 因为可以删除0个元素, 1个元素, 2个元素, .... , 多个前缀/后缀, 统计删除后的子数组,其实就是在统计所有的子数组。
3. 将数组分两类,一种是不包含nums[i]%k==0, 另一种是包含nums[i]%k==0, 因为是求子数组的乘积%k, 所以只要包含nums[i]%k==0, 它的余数肯定是0, 其他不包含 nums[i]%k==0的子数组的乘积的余数就可能是1,2,3,...,k-1。所以我们就以nums[i]%k==0为分割点分开进行统计(详细在下面代码中), 在每个不包含 nums[i]%k==0的子数组中, 采用动态规划进行统计, 其中pre[x]表示以
nums[i-1]结尾的子数组,乘积余数为 x 的数量, cur[x]:表示以nums[i]结尾的子数组,乘积余数为x的数量。dp_counts[x]:最终统计所有子数组的乘积余数 x 的总数4. 补充解释一下, int a=nums[i]%k; int b=(i*a)%k; 当前元素为nums[i], %k的余数为 a, 其实我们只需要将 a和pre数组中的余数进行想乘即可,也就是 b= (i%a)%k, 看新子数组是否能产生新的余数, eg: 5%3=2, 再加nums[i]=2, 原本需要计算 5*2%3=1, 其实现在只需计算 2*2%3=1即可
5. 数学:计算某一数组中子数组的个数 n*(n+1)/2;
eg: nums=[1,2,3] 子数组:[1], [2], [3], [1,2], [1,2,3] ,[2,3], total_sub=3*4/2=6

class Solution {
public:vector<long long> resultArray(vector<int>& nums, int k) {int n=nums.size(); long long Total_Sub=(long long)n*(n+1)/2;//1. 找到以nums[i]%k==0为分界点的子区间vector<pair<int,int>> sub_interval;int start=0;for(int i=0;i<=n;i++){if(i==n||nums[i]%k==0){if(start<i){sub_interval.emplace_back(start,i-1);}start=i+1;}}//2. 统计各个子数组中余数的相关信息long long total_none_sub=0;vector<long long> dp_counts(k,0);for(auto& x:sub_interval){int l=x.first,r=x.second;int len=r-l+1;total_none_sub+=(long long)len*(len+1)/2;vector<long long> pre(k,0);for(int i=l;i<=r;i++){int a=nums[i]%k;vector<long long> cur(k,0);for(int i=0;i<k;i++){if(pre[i]==0) continue;int b=(i*a)%k;cur[b]+=pre[i];}cur[a]+=1;for(int i=0;i<k;i++){dp_counts[i]+=cur[i];}pre.swap(cur);}}// 3. 至少包含一个nums[i]%k=0 的子数组的数量long long zero_sub=Total_Sub-total_none_sub;// 4. 统计结果vector<long long> result(k,0);result[0]=dp_counts[0]+zero_sub;for(int i=1;i<k;i++){result[i]=dp_counts[i];}return result;}
};4. 求出数组的 X 值 II
题目链接如下:3525. 求出数组的 X 值 II - 力扣(LeetCode)
给你一个由 正整数 组成的数组
nums和一个 正整数k。同时给你一个二维数组queries,其中queries[i] = [indexi, valuei, starti, xi]。你可以对
nums执行 一次 操作,移除nums的任意 后缀 ,使得nums仍然非空。给定一个
x,nums的 x值 定义为执行以上操作后剩余元素的 乘积 除以k的 余数 为x的方案数。对于
queries中的每个查询,你需要执行以下操作,然后确定xi对应的nums的 x值:
- 将
nums[indexi]更新为valuei。仅这个更改在接下来的所有查询中保留。- 移除 前缀
nums[0..(starti - 1)](nums[0..(-1)]表示 空前缀 )。返回一个长度为
queries.length的数组result,其中result[i]是第i个查询的答案。数组的一个 前缀 是从数组开始位置到任意位置的子数组。
数组的一个 后缀 是从数组中任意位置开始直到结束的子数组。
子数组 是数组中一段连续的元素序列。
注意:操作中所选的前缀或后缀可以是 空的 。
注意:x值在本题中与问题 I 有不同的定义。
示例 1:
输入: nums = [1,2,3,4,5], k = 3, queries = [[2,2,0,2],[3,3,3,0],[0,1,0,1]]
输出: [2,2,2]
解释:
- 对于查询 0,
nums变为[1, 2, 2, 4, 5]。移除空前缀后,可选操作包括:
- 移除后缀
[2, 4, 5],nums变为[1, 2]。- 不移除任何后缀。
nums保持为[1, 2, 2, 4, 5],乘积为 80,对 3 取余为 2。- 对于查询 1,
nums变为[1, 2, 2, 3, 5]。移除前缀[1, 2, 2]后,可选操作包括:
- 不移除任何后缀,
nums为[3, 5]。- 移除后缀
[5],nums为[3]。- 对于查询 2,
nums保持为[1, 2, 2, 3, 5]。移除空前缀后。可选操作包括:
- 移除后缀
[2, 2, 3, 5]。nums为[1]。- 移除后缀
[3, 5]。nums为[1, 2, 2]。示例 2:
输入: nums = [1,2,4,8,16,32], k = 4, queries = [[0,2,0,2],[0,2,0,1]]
输出: [1,0]
解释:
- 对于查询 0,
nums变为[2, 2, 4, 8, 16, 32]。唯一可行的操作是:
- 移除后缀
[2, 4, 8, 16, 32]。- 对于查询 1,
nums仍为[2, 2, 4, 8, 16, 32]。没有任何操作能使余数为 1。示例 3:
输入: nums = [1,1,2,1,1], k = 2, queries = [[2,1,0,1]]
输出: [5]
提示:
1 <= nums[i] <= 10^91 <= nums.length <= 10^51 <= k <= 51 <= queries.length <= 2 * 10^4queries[i] == [indexi, valuei, starti, xi]0 <= indexi <= nums.length - 11 <= valuei <= 10^90 <= starti <= nums.length - 10 <= xi <= k - 1
解题思路:这道题,群里有人调了一个多小时,才写出来
1. 题意就是, 计算左端点为start, 右端点为start, start+1,....,n-1, 这一共有n-start个子数组, 元素乘积模k为x的子数组的个数
2. 分治计算 [l,r], 也就是左端点为l, 右端点为l, l+1, ... , r 的子数组的个数, 满足元素乘积取模k为x
3. 题目中既有查询, 合并又有修改,类似于前面那道题, M=(l+r)/2, 将右侧的对应的余数的个数合并到左侧
4. 下面代码中的线段树板子是抄的大佬的, 具体修改的部分已经在代码中指出。
class SegmentTree {int n; int k; using T = pair<int, array<int, 5>>;vector<T> tree;//1. 修改T merge_val(T a, T b) const {auto [x,cnt]=a;for(int i=0;i<k;i++){cnt[x*i%k]+=b.second[i];}return {x*b.first%k,cnt};}//2. 修改T new_val(int val) const {int x = val % k;array<int, 5> cnt{};cnt[x]=1;return {x, cnt};}void maintain(int node) {tree[node] = merge_val(tree[node * 2], tree[node * 2 + 1]);}void build(const vector<int>& a, int node, int l, int r) {if (l == r) { tree[node] = new_val(a[l]);return;}int m = (l + r) / 2;build(a, node * 2, l, m); build(a, node * 2 + 1, m + 1, r); maintain(node);}void update(int node, int l, int r, int i, int val) {if (l == r) { tree[node] = new_val(val);return;}int m = (l + r) / 2;if (i <= m) {update(node * 2, l, m, i, val);} else { update(node * 2 + 1, m + 1, r, i, val);}maintain(node);}T query(int node, int l, int r, int ql, int qr) const {if (ql <= l && r <= qr) { return tree[node];}int m = (l + r) / 2;if (qr <= m) { return query(node * 2, l, m, ql, qr);}if (ql > m) { return query(node * 2 + 1, m + 1, r, ql, qr);}T l_res = query(node * 2, l, m, ql, qr);T r_res = query(node * 2 + 1, m + 1, r, ql, qr);return merge_val(l_res, r_res);}
public:// SegmentTree(int n, T init_val) : SegmentTree(vector<T>(n, init_val)) {}SegmentTree(const vector<int>& a, int k) : k(k), n(a.size()), tree(2 << bit_width(a.size() - 1)) {build(a, 1, 0, n - 1);}void update(int i, int val) {update(1, 0, n - 1, i, val);}T query(int ql, int qr) const {return query(1, 0, n - 1, ql, qr);}T get(int i) const {return query(1, 0, n - 1, i, i);}
};
class Solution {
public:vector<int> resultArray(vector<int>& nums, int k, vector<vector<int>>& queries) {SegmentTree t(nums,k);int n=nums.size();vector<int> ans;for(auto& it:queries){//1. 按题意先修改t.update(it[0],it[1]);//2. 删除前缀和后auto [x,cnt]=t.query(it[2],n-1);ans.push_back(cnt[it[3]]);}return ans;}
};
// queries[i] = [indexi, valuei, starti, xi]
有不懂的地方可以发布到评论区!
最后,感谢大家的点赞和关注,你们的支持是我创作的动力!
相关文章:
力扣第446场周赛
有事没赶上, 赛后模拟了一下, 分享一下我的解题思路和做题感受 1.执行指令后的得分 题目链接如下:力扣 给你两个数组:instructions 和 values,数组的长度均为 n。 你需要根据以下规则模拟一个过程: 从下标 i 0 的第一个指令开…...

OpenCV中的透视变换方法详解
文章目录 引言1. 什么是透视变换2. 透视变换的数学原理3. OpenCV中的透视变换代码实现3.1 首先定义四个函数 3.1.1 cv_show() 函数 3.1.2 def resize() 函数 3.1.3 order_points() 函数 3.1.4 four_point_transform() 函数 3.2 读取图片并做预处理3.3 轮廓检测3.4 获取最大…...

并发设计模式实战系列(3):工作队列
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第三章工作队列(Work Queue),废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 生产者-消费者架构 …...
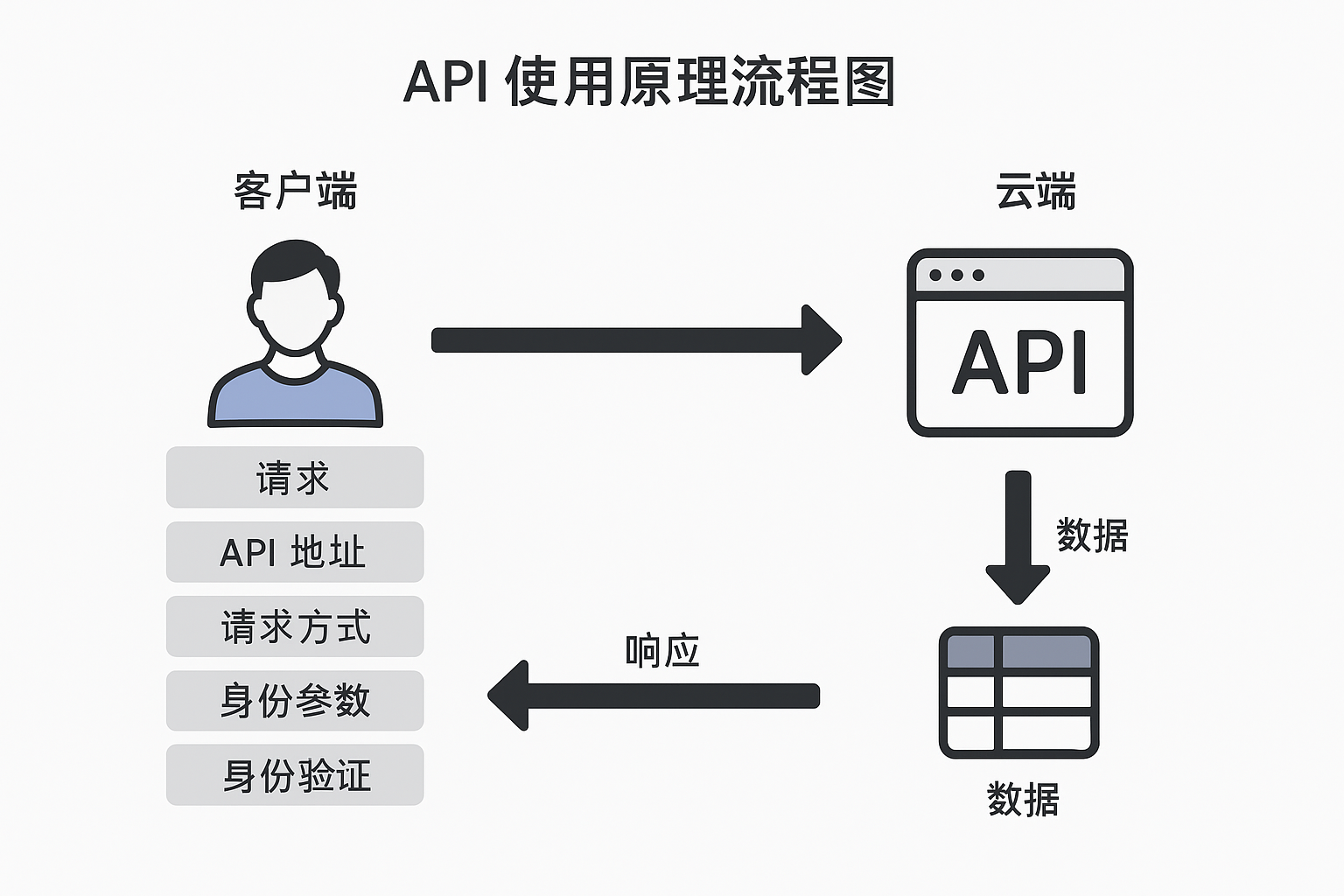
如何理解抽象且不易理解的华为云 API?
API的概念在华为云的使用中非常抽象,且不容易理解,用通俗的语言 形象的比喻来讲清楚——什么是华为云 API,怎么用,背后原理,以及主要元素有哪些,尽量让新手也能明白。 🧠 一句话先理解…...

10分钟二叉树的非递归排序完成
import java.util.Stack;public class test_04_23 {//二叉树的三种遍历static class TreeNode{int data;TreeNode left;TreeNode right;public TreeNode(int data){this.data data;}}//先序遍历public static void test1(TreeNode root){Stack<TreeNode> stack new Sta…...

[特殊字符]fsutil命令用法详解
🔧fsutil命令用法详解 以下是 fsutil 命令的常见用法及功能详解: 1. 基础语法 fsutil [子命令] [参数]2. 核心功能与用法 (1)管理硬链接 fsutil hardlink create <新硬链接路径> <原文件路径>作用:为文…...
详细介绍)
GPIO(通用输入输出端口)详细介绍
一、基本概念 GPIO(General - Purpose Input/Output)即通用输入输出端口,是微控制器(如 STM32 系列)中非常重要的一个外设。它是一种软件可编程的引脚,用户能够通过编程来控制这些引脚的输入或输出状态。在…...
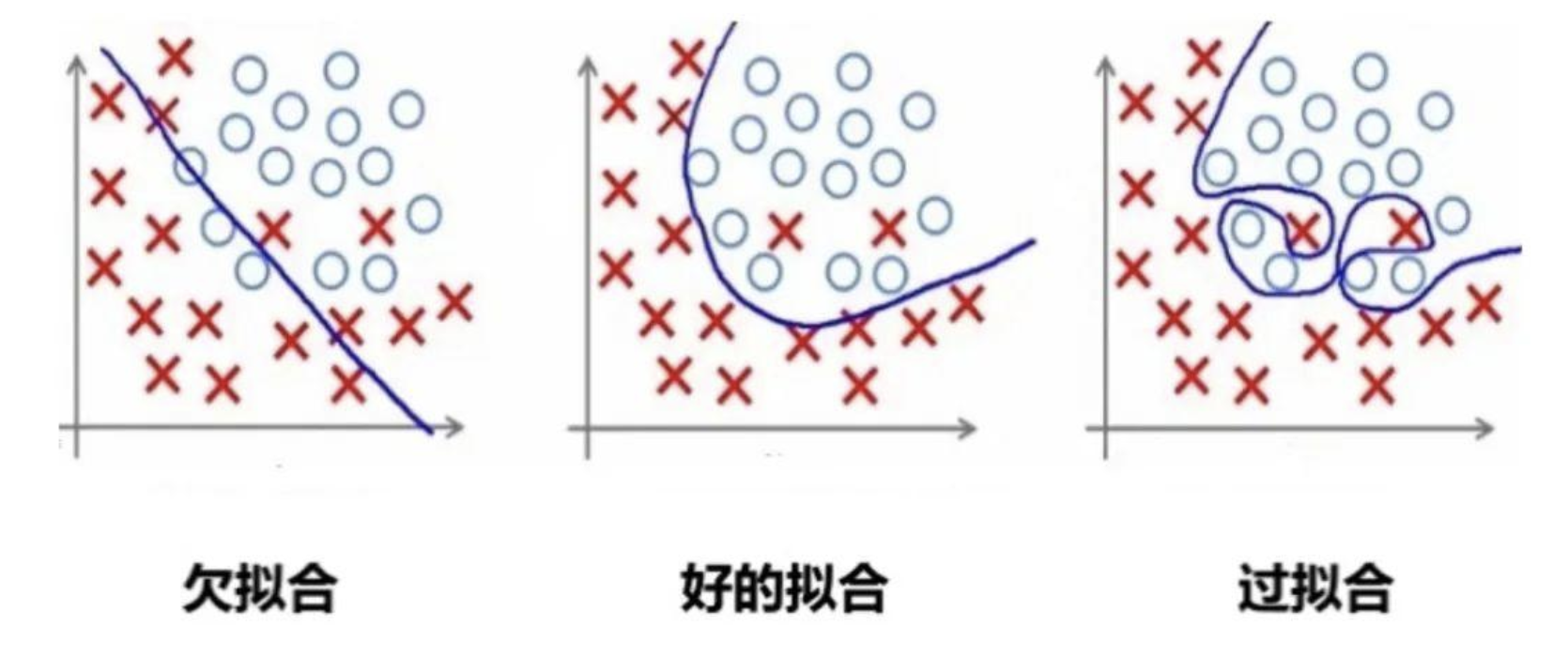
深度学习-全连接神经网络(过拟合,欠拟合。批量标准化)
七、过拟合与欠拟合 在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。 1. 概念认知 …...

Java面向对象的三大特性
## 1. 封装(Encapsulation) 封装是将数据和操作数据的方法绑定在一起,对外部隐藏对象的具体实现细节。通过访问修饰符来实现封装。 示例代码: java public class Student { // 私有属性 private String name; private int age; …...

多路转接select服务器
目录 select函数原型 select服务器 select的缺点 前面介绍过多路转接就是能同时等待多个文件描述符,这篇文章介绍一下多路转接方案中的select的使用 select函数原型 #include <sys/select.h> int select(int nfds, fd_set *readfds, fd_set *writefds, f…...
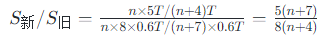
系统架构设计师:流水线技术相关知识点、记忆卡片、多同类型练习题、答案与解析
流水线记忆要点 公式 总时间 (n k - 1)Δt 吞吐率 TP n / 总时间 → 1/Δt(max) 加速比 S nk / (n k - 1) | 效率 E n / (n k - 1) 关键概念 周期:最长段Δt 冲突: 数据冲突(RAW) → 旁路/…...
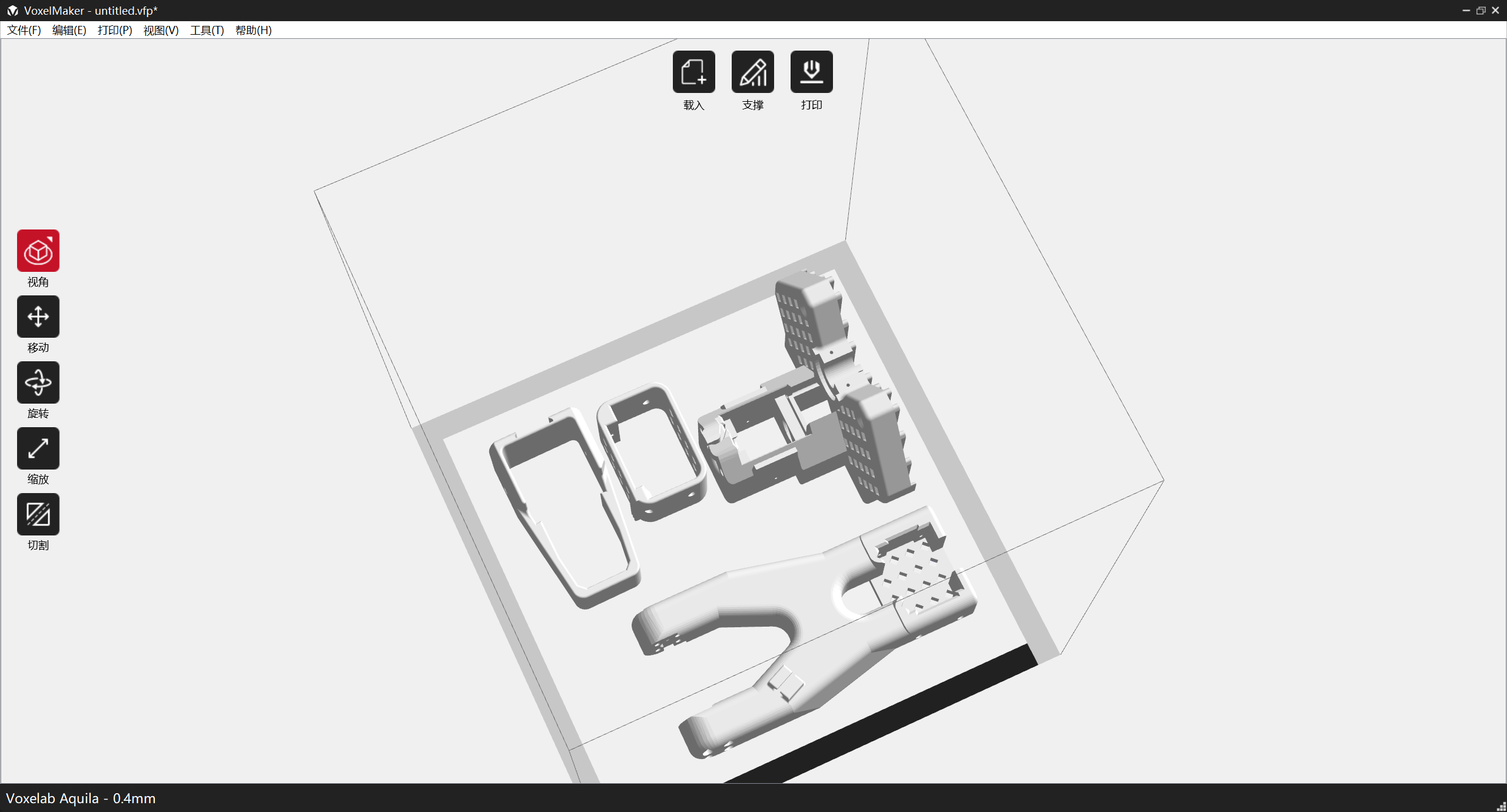
复刻低成本机械臂 SO-ARM100 3D 打印篇
视频讲解: 复刻低成本机械臂 SO-ARM100 3D 打印篇 清理了下许久不用的3D打印机,挤出机也裂了,更换了喷嘴和挤出机夹具,终于恢复了正常工作的状态,接下来还是要用起来,不然吃灰生锈了,于是乎想起…...

AudioRecord 简单分析
基于AudioRecord简单分析,以下是HeadsetMIC tinymix "TX_CDC_DMA_TX_4 Channels" "One" tinymix "TX_AIF2_CAP Mixer DEC0" "1" tinymix "TX DEC0 MUX" "SWR_MIC" tinymix "TX SMIC MUX0" "SWR_…...
Flutter IOS 真机 Widget 错误。Widget 安装后系统中没有
错误信息: SendProcessControlEvent:toPid: encountered an error: Error Domaincom.apple.dt.deviceprocesscontrolservice Code8 "Failed to show Widget com.xxx.xxx.ServerStatus error: Error DomainFBSOpenApplicationServiceErrorDomain Code1 "T…...
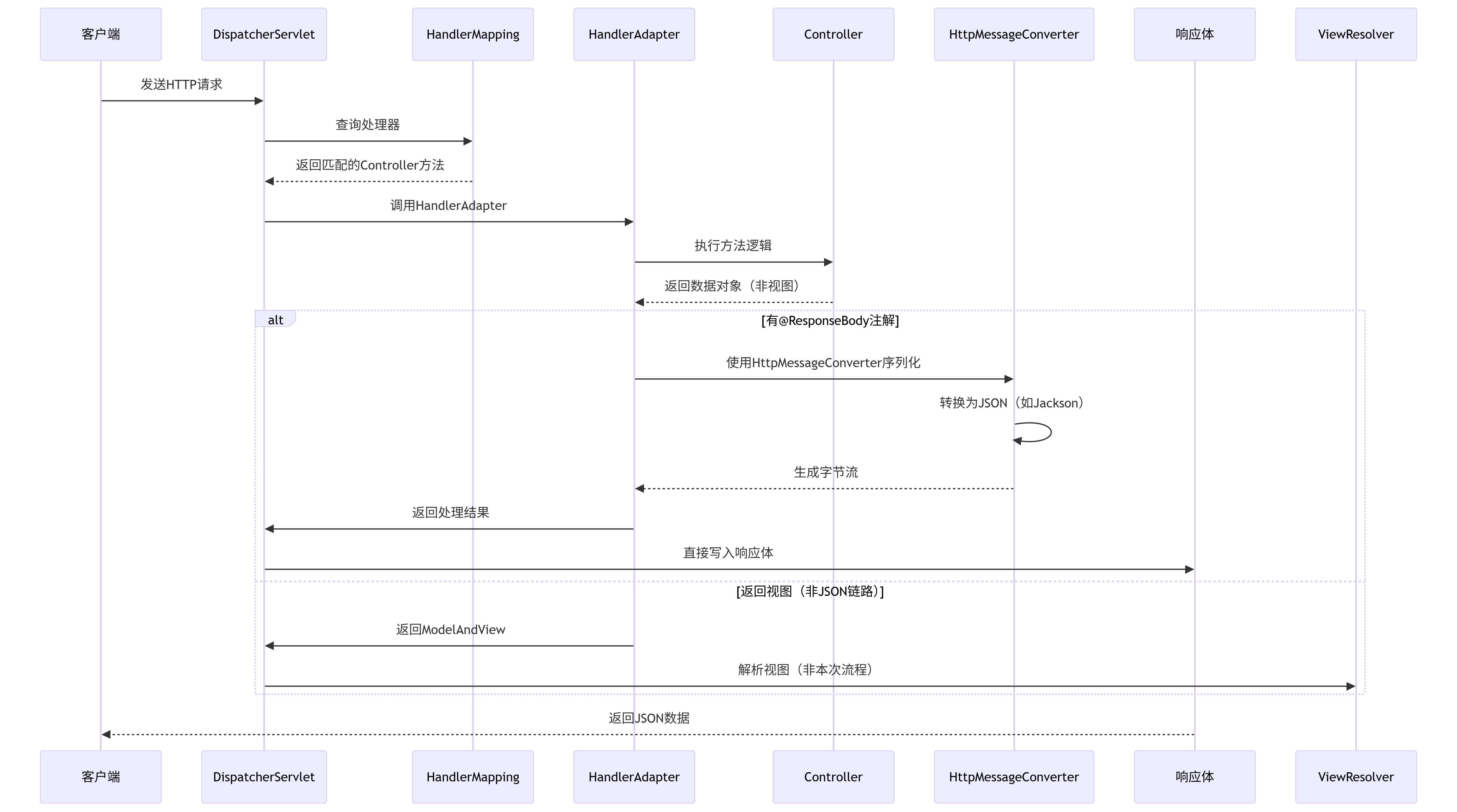
Spring之我见 - Spring MVC重要组件和基本流程
核心组件详解 前端控制器 - DispatcherServlet 作用:所有请求的入口,负责请求分发和协调组件。 public class DispatcherServlet extends HttpServlet {// 核心服务方法protected void doService(HttpServletRequest request, HttpServletResponse re…...

使用 Axios 进行 API 请求与接口封装:打造高效稳定的前端数据交互
引言 在现代前端开发中,与后端 API 进行数据交互是一项核心任务。Axios 作为一个基于 Promise 的 HTTP 客户端,以其简洁易用、功能强大的特点,成为了前端开发者处理 API 请求的首选工具。本文将深入探讨如何使用 Axios 进行 API 请求&#x…...
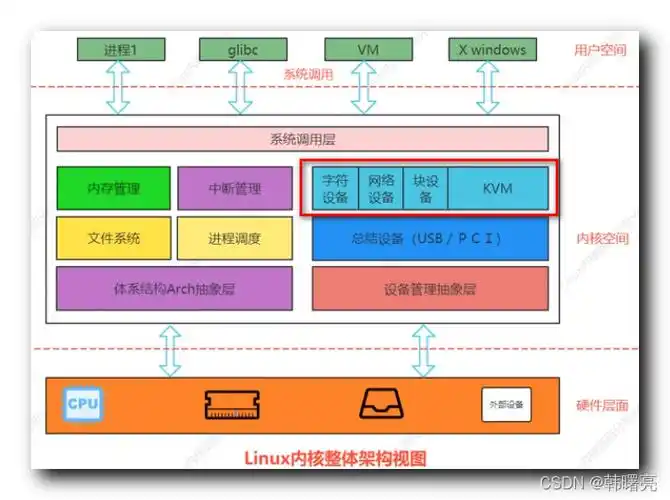
理解字符设备、设备模型与子系统:以 i.MX8MP 平台为例
视频教程请关注 B 站:“嵌入式 Jerry” Linux 内核驱动开发中,很多人在接触字符设备(char device)、设备模型(device model)和各种子系统(subsystem)时,往往会感到概念混…...
鸿蒙Flutter仓库停止更新?
停止更新 熟悉 Flutter 鸿蒙开发的小伙伴应该知道,Flutter 3.7.12 鸿蒙化 SDK 已经在开源鸿蒙社区发布快一年了, Flutter 3.22.x 的鸿蒙化适配一直由鸿蒙突击队仓库提供,最近有小伙伴反馈已经 2 个多月没有停止更新了,不少人以为停…...

vscode使用笔记
文章目录 安装快捷键 vscode是前端开发的一款利器。 安装 快捷键 ctrlp # 查找文件(和idea的双击shift不一样) ctrlshiftf # 搜索内容...

《 C++ 点滴漫谈: 三十四 》从重复到泛型,C++ 函数模板的诞生之路
一、引言 在 C 编程的世界里,类型是一切的基础。我们为 int 写一个求最大值的函数,为 double 写一个相似的函数,为 std::string 又写一个……看似合理的行为,逐渐堆积成了难以维护的 “函数墙”。这些函数逻辑几乎一致࿰…...
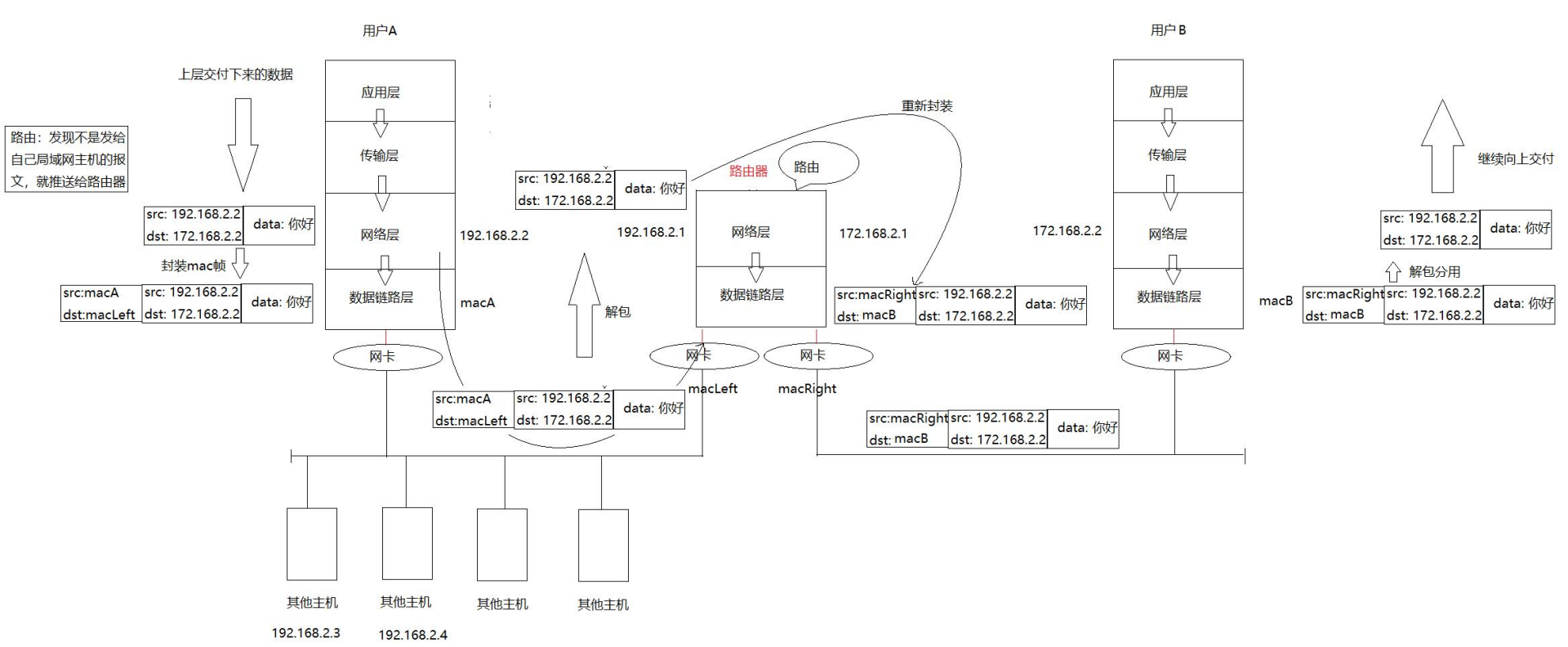
网络基础概念(下)
网络基础概念(上)https://blog.csdn.net/Small_entreprene/article/details/147261091?sharetypeblogdetail&sharerId147261091&sharereferPC&sharesourceSmall_entreprene&sharefrommp_from_link 网络传输的基本流程 局域网网络传输流…...
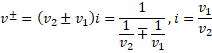
一个关于相对速度的假想的故事-4
回到公式, 正写速度叠加和倒写速度叠加的倒写相等,这就是这个表达式所要表达的意思。但倒写叠加用的是减法,而正写叠加用的是加法。当然是这样,因为正写叠加要的是单位时间上完成更远的距离,而倒写叠加说的是单位距离需…...
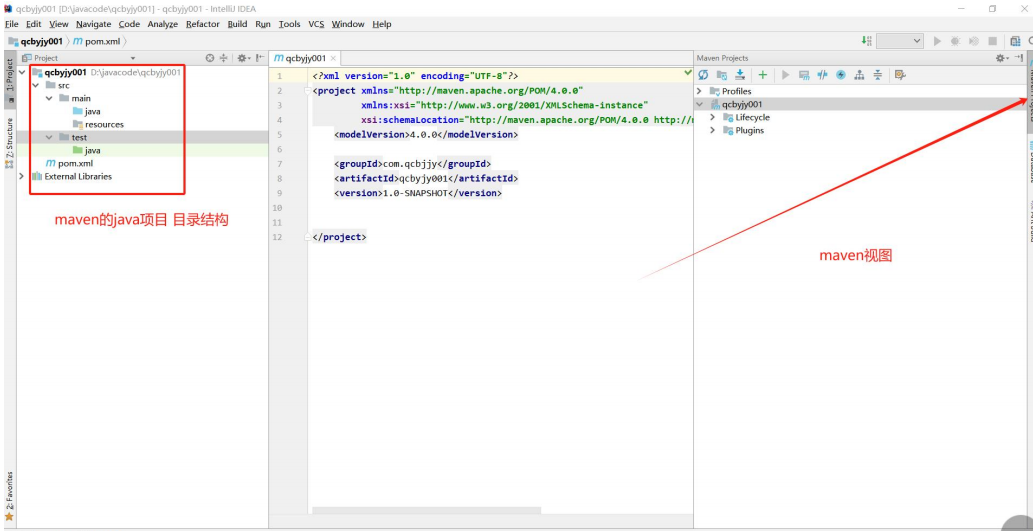
Idea创建项目的搭建方式
目录 一、普通Java项目 二、普通JavaWeb项目 三、maven的JavaWeb项目 四、maven的Java项目 一、普通Java项目 1. 点击 Create New Project 2. 选择Java项目,选择JDK,点击Next 3. 输入项目名称(驼峰式命名法),可选…...

My SQL 索引
核心目标: 理解 mysql 索引的工作原理、类型、优缺点,并掌握创建、管理和优化索引的方法,以显著提升数据库查询性能。 什么是索引? 索引是一种特殊的数据库结构,它包含表中一列或多列的值以及指向这些值所在物理行的指…...

人工智能02-深度学习中的不确定性测量
🔬 深度学习中的不确定性测量详解 Uncertainty Measurement in Deep Learning 🧠 一、什么是不确定性(Uncertainty)? 在深度学习中,不确定性是指模型对其预测结果的“信心程度”。一个模型不仅要输出预测…...
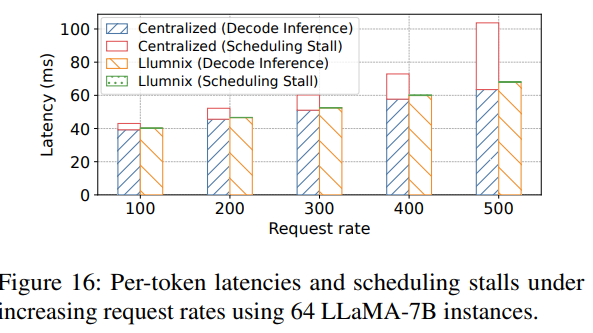
【DeepSeek 学习推理】Llumnix: Dynamic Scheduling for Large Language Model Serving实验部分
6.1 实验设置 测试平台。我们使用阿里云上的16-GPU集群(包含4个GPU虚拟机,类型为ecs.gn7i-c32g1.32xlarge)。每台虚拟机配备4个NVIDIA A10(24 GB)GPU(通过PCI-e 4.0连接)、128个vCPU、752 GB内…...

Kubernetes相关的名词解释kubeadm(19)
kubeadm是什么? kubeadm 是 Kubernetes 官方提供的一个用于快速部署和管理 Kubernetes 集群的命令行工具。它简化了集群的初始化、节点加入和升级过程,特别适合在生产环境或学习环境中快速搭建符合最佳实践的 Kubernetes 集群。 kubeadm 的定位 不是完整…...

什么是负载均衡?NGINX是如何实现负载均衡的?
大家好,我是锋哥。今天分享关于【什么是负载均衡?NGINX是如何实现负载均衡的?】面试题。希望对大家有帮助; 什么是负载均衡?NGINX是如何实现负载均衡的? 1000道 互联网大厂Java工程师 精选面试题-Java资源…...

docker容器,mysql的日志文件怎么清理
访问问题 你的问题是因为在当前路径 /home/ictrek/data/ragflow-mysql 下没有名为 data 的子目录。以下是详细分析和解决方法: 错误原因 路径不存在 当前目录 /home/ictrek/data/ragflow-mysql 下没有名为 data 的子目录,执行 cd data/ 时会报错 No suc…...
基于Python(Django)+SQLite实现(Web)校园助手
校园助手 本校园助手采用 B/S 架构。并已将其部署到服务器上。在网址上输入 db.uplei.com 即可访问。 使用说明 可使用如下账号体验: 学生界面: 账号1:123 密码1:123 账户2:201805301348 密码2:1 # --------------…...