Redis 处理读请求
在前文“Redis 接收连接”中,Redis 将接收的客户端连接加入了 epoll 中监听,同时还设置了读事件处理器 connSocketEventHandler。
假设现在客户端向 Redis 发来一条 set key value 命令。
事件循环 aeProcessEvents
在事件循环 aeProcessEvents 中会调用 connSocketEventHandler。
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{.....// aeApiPoll返回所有就绪的读事件numevents = aeApiPoll(eventLoop, tvp); // epoll_wait.....for (j = 0; j < numevents; j++) {.....if (!invert && fe->mask & mask & AE_READABLE) {// 调用读事件处理器connSocketEventHandler// fe->clientData指向fd地连接对象fe->rfileProc(eventLoop,fd,fe->clientData,mask);fired++;fe = &eventLoop->events[fd]; /* Refresh in case of resize. */}......}.....
}
connSocketEventHandler
// el:事件循环对象
// fd:就绪的fd
// clientData:连接对象(不是客户端对象)
// mask:就绪的事件(读写事件)
static void connSocketEventHandler(struct aeEventLoop *el, int fd, void *clientData, int mask)
{UNUSED(el);UNUSED(fd);connection *conn = clientData;// ------------------------ 第1部分 --------------------------// 当Redis作为客户端主动发起TCP连接时(如主从复制中的从节点连接主节点),// 会使用非阻塞scoekt调用connect()系统调用请求建立连接。由于socekt非阻塞,所有connect()会立即返回,// 如果返回的错误是EINPROGRESS,说明连接正在建立,忽略。// 接下来,Redis会将这个socket添加到epoll中监听其写事件,并将写处理器设置为本函数。// 当epoll触发其写事件后,会回调本函数,并在这里判断连接是否建立成功。// 调用getsockopt(cfd, SOL_SOCKET, SO_ERROR, (void*)(&errno) 检查错误码,// 如果errno=0,才是连接建立成功了,否则,就是建立失败了。if (conn->state == CONN_STATE_CONNECTING &&(mask & AE_WRITABLE) && conn->conn_handler) {// 调用getsockopt(cfd, SOL_SOCKET, SO_ERROR, (void*)(&conn_error) 检查错误码int conn_error = connGetSocketError(conn);// conn_error != 0,发生错误if (conn_error) {conn->last_errno = conn_error; // 记录错误号conn->state = CONN_STATE_ERROR; // 设置错误连接状态} else {// conn_error = 0,连接成功conn->state = CONN_STATE_CONNECTED; // 更新连接状态为已连接}// 如果连接写处理器为NULL,删除对写文件事件的监听// 调用connect()发起连接时,我们监听的就是写事件,并且回调函数设置为本函数,// 同时设置了连接处理器conn_handler(如syncWithMaster),但是没有设置连接的写处理器write_handler// 因为本次写事件监听仅仅只是想知道连接是否建立成功,不是想发数据,因此没必要设置连接的写处理器。if (!conn->write_handler) aeDeleteFileEvent(server.el,conn->fd,AE_WRITABLE);// 发起的连接建立成功,调用连接处理器conn_handler执行后续的操作。if (!callHandler(conn, conn->conn_handler)) return;conn->conn_handler = NULL;}// ------------------- 第2部分 --------------------// 通常情况下,我们先执行可读事件,然后再执行可写事件。这是很有用的,因为有时我们在处理完查询后,// 或许能够立即回复该查询的结果。// 然而,如果在掩码中设置了 WRITE_BARRIER(写屏障),我们的应用程序就会要求我们采取相反的做法:// 绝不在可读事件之后触发可写事件。在这种情况下,我们会颠倒这些事件的调用顺序。// 例如,当我们想要在 beforeSleep() 钩子函数中执行一些操作(比如在回复客户端之前,// 将文件同步到磁盘的 fsync 操作)时,这种处理方式就很有用。int invert = conn->flags & CONN_FLAG_WRITE_BARRIER;// 如果发生了写事件且设置了写事件处理器int call_write = (mask & AE_WRITABLE) && conn->write_handler;// 如果发生了读事件且设置了读事件处理器int call_read = (mask & AE_READABLE) && conn->read_handler;/* 处理正常的I/O工作流,即先处理读事件在再处理写事件 */if (!invert && call_read) {// 执行连接读事件处理器,即 if (!callHandler(conn, conn->read_handler)) return;}/* 处理写事件 */if (call_write) {// 执行连接写事件处理器,即 sendReplyToClientif (!callHandler(conn, conn->write_handler)) return;}/* 如果我们必须反转调用,在可写事件之后立即触发可读事件。 */if (invert && call_read) {if (!callHandler(conn, conn->read_handler)) return;}
}
Redis 6 之前,读文件事件的处理器是
readQueryFromClient;写文件事件的处理器是sendReplyToClient。从 Redis 6 开始,在事件层之上又引入了连接(层)的概念。事件层的读写文件事件处理器统一为
connSocketEventHandler。而readQueryFromClient和sendReplyToClient被移到了连接层,作为连接的读和写处理器。在connSocketEventHandler中根据读写事件分发给连接层,对于读事件调用连接读处理器readQueryFromClient,写事件调用连接写处理器sendReplyToClient。这样实现了连接和事件的分层,分层减少了耦合性,提高了代码的清晰度和可维护性。这也解释了为什么会在事件循环
aeProcessEvents中实现了一遍分发逻辑,又在connSocketEventHandler中实现了一遍分发逻辑。事件循环
aeProcessEvents中的分发逻辑貌似已经没什么用了(maybe),不知道会不会在未来移除。
第 1 部分
当 Redis 作为客户端主动发起 TCP 连接时(如主从复制中的从节点连接主节点),会使用非阻塞 scoekt 调用 connect() 系统调用请求建立连接。由于 socekt 非阻塞,所有 connect() 会立即返回,对于 EINPROGRESS 错误(连接正在建立),我们可以忽略。然后 Redis 会将这个 socket 添加到 epoll 中监听其写事件,并将写处理器设置为 connSocketEventHandler。当 epoll 触发其写事件后,回调 connSocketEventHandler 判断连接是否建立成功。调用 getsockopt(cfd, SOL_SOCKET, SO_ERROR, (void*)(&errno) 检查错误码,如果 errno=0,才是连接建立成功了,否则,就是建立失败了。
示例:
我们来看下从节点调用 connectWithMaster() 请求与主节点建立连接,位于 replication.c 中。
// 发起与主节点的连接
int connectWithMaster(void) {// 根据配置决定是与主节点建立TLS建立还是TCP连接,// 我们只关注TCP连接,connCreateSocket()创建了一个连接对象server.repl_transfer_s = server.tls_replication ? connCreateTLS() : connCreateSocket();// 发起连接if (connConnect(server.repl_transfer_s, server.masterhost, server.masterport,NET_FIRST_BIND_ADDR, syncWithMaster) == C_ERR) {serverLog(LL_WARNING,"Unable to connect to MASTER: %s",connGetLastError(server.repl_transfer_s));connClose(server.repl_transfer_s);server.repl_transfer_s = NULL;return C_ERR;}.....
}/* 获取第一个绑定地址,如果没有则返回 NULL,即获取 slave 节点的地址 */
#define NET_FIRST_BIND_ADDR (server.bindaddr_count ? server.bindaddr[0] : NULL)
将创建的连接对象作为第一个参数调用 connConnect(注意:连接回调是 syncWithMaster),位于 connection.h
static inline int connConnect(connection *conn, const char *addr, int port, const char *src_addr,ConnectionCallbackFunc connect_handler) {return conn->type->connect(conn, addr, port, src_addr, connect_handler);
}
conn->type->connect 实际调用 CT_Socket 的 connSocketConnect 接口实现。connSocketConnect 位于 connection.c
static int connSocketConnect(connection *conn, const char *addr, int port, const char *src_addr,ConnectionCallbackFunc connect_handler) {// 调用socket()、bind()(可选) 和 connect()int fd = anetTcpNonBlockBestEffortBindConnect(NULL,addr,port,src_addr);if (fd == -1) { // 失败conn->state = CONN_STATE_ERROR; // 设置错误连接状态conn->last_errno = errno; // 记录错误号return C_ERR;}// 到这里,连接不一定就建立成功了,可能正在建立连接,也可能出错了conn->fd = fd;conn->state = CONN_STATE_CONNECTING; // 设置连接类型conn->conn_handler = connect_handler;// 不论当前是建立成功还是失败亦或是正在建立连接,都监听其写事件// 连接建立成功或失败都会触发epoll的可写事件// 添加到epoll,监听可写事件,事件回调函数connSocketEventHandler// 我们在connSocketEventHandler处理连接的成功或失败情况aeCreateFileEvent(server.el, conn->fd, AE_WRITABLE,conn->type->ae_handler, conn);return C_OK;
}
我们来看下 anetTcpNonBlockBestEffortBindConnect 的实现,位于 anet.c。
int anetTcpNonBlockBestEffortBindConnect(char *err, const char *addr, int port,const char *source_addr)
{return anetTcpGenericConnect(err,addr,port,source_addr,ANET_CONNECT_NONBLOCK|ANET_CONNECT_BE_BINDING);
}
注意:flags 包含ANET_CONNECT_NONBLOCK,以非阻塞 socket 发起连接请求。
ANET_CONNECT_BE_BINDING是做什么的?主动发起连接的一方都可以称之为客户端(即,这里的 slave 节点)。
客户端发起连接时,只需要
socket()+connect()即可,无需调用 bind() 函数。这时内核会根据路由表选择合适的外发网络接口(如多网卡环境),同时分配一个临时端口(范围通常为32768-60999),发起连接。但如果系统需要客户端使用特定端口(如防火墙策略限制),或需要客户端通过指定网卡通信(如绑定192.168.1.100而非自动选择),当然这些都是假设,或许你的应用就是任性,喜欢用特定的地址和/或端口发起来连接,也没毛病。这时你就需要
bind()函数手动指定你要绑定的地址和/或端口了。
ANET_CONNECT_BE_BINDING的作用就是如果socket()+bind()+connect()序列失败,就执行socket()+connect()序列发起连接。
#define ANET_CONNECT_NONE 0
#define ANET_CONNECT_NONBLOCK 1
#define ANET_CONNECT_BE_BINDING 2 /* Best effort binding. */
static int anetTcpGenericConnect(char *err, const char *addr, int port,const char *source_addr, int flags)
{int s = ANET_ERR, rv;char portstr[6]; /* strlen("65535") + 1; */struct addrinfo hints, *servinfo, *bservinfo, *p, *b;snprintf(portstr,sizeof(portstr),"%d",port);memset(&hints,0,sizeof(hints));hints.ai_family = AF_UNSPEC; // 支持 IPv4/IPv6hints.ai_socktype = SOCK_STREAM; // TCP 协议// IPv4中使用 gethostbyname() 函数完成主机名到地址解析,这个函数仅仅支持 IPv4,// 且不允许调用者指定所需地址类型的任何信息,返回的结构只包含了用于存储IPv4地址的空间。// IPv6中引入了 getaddrinfo() 的新API,它是协议无关的,既可用于 IPv4 也可用于 IPv6。// getaddrinfo函数能够处理名字到地址以及服务到端口这两种转换,返回的是一个addrinfo的结构(列表)指针而不是一个地址清单。// 这些addrinfo结构随后可由套接口函数直接使用。如此以来,getaddrinfo函数把协议相关性安全隐藏在这个库函数内部。// 应用程序只要处理由getaddrinfo函数填写的套接口地址结构。该函数在POSIX规范中定义了。if ((rv = getaddrinfo(addr,portstr,&hints,&servinfo)) != 0) {anetSetError(err, "%s", gai_strerror(rv));return ANET_ERR;}// 遍历 addrinfo 链表,尝试所有可能的地址族(如 IPv6 失败时回退 IPv4)for (p = servinfo; p != NULL; p = p->ai_next) {// 尝试创建套接字并建立连接。// 如果在调用socket()函数或者connect()函数时失败,我们会使用servinfo中的下一项重新尝试。if ((s = socket(p->ai_family,p->ai_socktype,p->ai_protocol)) == -1)continue;// 设置 SO_REUSEADDR 选项(避免 TIME_WAIT 状态端口占用)if (anetSetReuseAddr(err,s) == ANET_ERR) goto error;// 我们传了ANET_CONNECT_NONBLOCK,因此设置为非阻塞模式if (flags & ANET_CONNECT_NONBLOCK && anetNonBlock(err,s) != ANET_OK)goto error;// 源地址,即slave从节点的地址if (source_addr) {int bound = 0;/* 使用getaddrinfo让我们无需自行判断是IPv4还是IPv6 */if ((rv = getaddrinfo(source_addr, NULL, &hints, &bservinfo)) != 0){anetSetError(err, "%s", gai_strerror(rv));goto error;}for (b = bservinfo; b != NULL; b = b->ai_next) {// 绑定源IPif (bind(s,b->ai_addr,b->ai_addrlen) != -1) {bound = 1; //bind 成功置1break;}}// 释放getaddrinfo分配的内存bservinfofreeaddrinfo(bservinfo);// bound=0说明bind()失败,直接返回if (!bound) {anetSetError(err, "bind: %s", strerror(errno));goto error;}}// 发起连接if (connect(s,p->ai_addr,p->ai_addrlen) == -1) {/* 如果套接字是非阻塞的,那么在这里connect() 返回一个EINPROGRESS错误是可以的。 */if (errno == EINPROGRESS && flags & ANET_CONNECT_NONBLOCK)goto end;// 其他错误(非EINPROGRESS错误)close(s); // 关闭sockets = ANET_ERR;continue;}// 到这里,说明没有错误地结束了一次for循环的迭代,我们就拥有了一个已连接的套接字。让我们返回给调用者。goto end;}// 到这里,说明遍历完addrinfo链表,调用socket()都出错if (p == NULL)anetSetError(err, "creating socket: %s", strerror(errno));error:if (s != ANET_ERR) {close(s); // 关闭sockets = ANET_ERR;}end:freeaddrinfo(servinfo); // 释放getaddrinfo分配的内存bservinfo// 尽力处理绑定操作:若已指定了绑定地址,但无法创建套接字,那么尝试不使用绑定地址再次进行创建if (s == ANET_ERR && source_addr && (flags & ANET_CONNECT_BE_BINDING)) {// 源地址source_addr传NULL,不执行bind操作return anetTcpGenericConnect(err,addr,port,NULL,flags);} else {return s;}
}
第 2 部分
注释很清楚了,没啥好说的,先执行连接的读处理器,再执行连接的写处理器,或者反转读写处理器的调用。
readQueryFromClient
经过事件层 connSocketEventHandler 的分发,进入到了连接层,调用连接层读处理器 readQueryFromClient。
readQueryFromClient 函数位于 networking.c。
void readQueryFromClient(connection *conn) {client *c = connGetPrivateData(conn); // 获取客户端对象int nread, readlen;size_t qblen;/* 是否需要延迟从客户端读取数据。如果启用了多线程I/O,则会出现这种情况 */if (postponeClientRead(c)) return;/* 统计读次数 */atomicIncr(server.stat_total_reads_processed, 1);readlen = PROTO_IOBUF_LEN;// 如果这是一个多批量请求,并且我们正在处理一个足够大的批量复制操作,// 那么要尽量提高查询缓冲区中恰好包含表示该对象的SDS(简单动态字符串)字符串的概率,// 即便这样做可能会有需要更多次调用 read(2) 函数的风险。// 通过这种方式,processMultiBulkBuffer() 函数就可以避免复制缓冲区来创建表示参数的Redis对象。if (c->reqtype == PROTO_REQ_MULTIBULK && c->multibulklen && c->bulklen != -1&& c->bulklen >= PROTO_MBULK_BIG_ARG){ssize_t remaining = (size_t)(c->bulklen+2)-sdslen(c->querybuf);/* Note that the 'remaining' variable may be zero in some edge case,* for example once we resume a blocked client after CLIENT PAUSE. */if (remaining > 0 && remaining < readlen) readlen = remaining;}// 输入缓冲区长度(不是总容量)qblen = sdslen(c->querybuf);// 更新缓冲区的峰值if (c->querybuf_peak < qblen) c->querybuf_peak = qblen;// 扩展readlen大小的缓冲区c->querybuf = sdsMakeRoomFor(c->querybuf, readlen);// read系统调用读取内核socket缓冲区的数据到querybuf+qblen(追加模式),读取长度为readlennread = connRead(c->conn, c->querybuf+qblen, readlen);// 注意,都是非阻塞socket读// 读操作出错if (nread == -1) {// 判断连接是否正常if (connGetState(conn) == CONN_STATE_CONNECTED) {return;} else {serverLog(LL_VERBOSE, "Reading from client: %s",connGetLastError(c->conn));freeClientAsync(c); //异步释放客户端return;}} else if (nread == 0) {serverLog(LL_VERBOSE, "Client closed connection");freeClientAsync(c); // 异步释放客户端return;} else if (c->flags & CLIENT_MASTER) {// 作为从节点,读取master发来的数据// 将数据追加到pending_querybuf中c->pending_querybuf = sdscatlen(c->pending_querybuf,c->querybuf+qblen,nread);}sdsIncrLen(c->querybuf,nread); // 增加querybuf已使用大小c->lastinteraction = server.unixtime; // 更新最后一次交互事件// master发来的数据,更新master的复制偏移量if (c->flags & CLIENT_MASTER) c->read_reploff += nread;// 统计从网络读取的字节数atomicIncr(server.stat_net_input_bytes, nread);// 检查输入缓冲区长度是否超过服务器设置的最大缓冲区长度// 防止缓冲区溢出攻击if (sdslen(c->querybuf) > server.client_max_querybuf_len) {sds ci = catClientInfoString(sdsempty(),c), bytes = sdsempty();bytes = sdscatrepr(bytes,c->querybuf,64);serverLog(LL_WARNING,"Closing client that reached max query buffer length: %s (qbuf initial bytes: %s)", ci, bytes);sdsfree(ci);sdsfree(bytes);freeClientAsync(c); // 异步释放客户端return;}// 客户端输入缓冲区中有更多数据,继续解析它,以防万一有完整的命令可供执行processInputBuffer(c);
}
延迟读
postponeClientRead 判断是否将客户端的读操作延迟到 I/O 线程处理。
/* 是否需要延迟从客户端读取数据。如果启用了多线程I/O,则会出现这种情况 */
if (postponeClientRead(c)) return;
当客户端可读事件触发时,通过以下四个条件决定是否推迟读操作:
server.io_threads_active:多线程 I/O 已激活(通过配置指令io-threads启用)。server.io_threads_do_reads:明确允许使用多线程处理读操作(需手动开启配置io-threads-do-reads yes,默认关闭)。!ProcessingEventsWhileBlocked:当前未处于阻塞事件处理状态(例如未在加载 RDB/AOF 文件)。- 排除以下客户端类型:
CLIENT_MASTER/CLIENT_SLAVE:主从复制专用连接CLIENT_PENDING_READ:已标记为延迟读的客户端CLIENT_BLOCKED:处于阻塞状态的客户端(如执行BLPOP)
当上面 4 个条件都满足,会使用I/O线程延迟读。
// 如果希望稍后使用线程I/O处理客户端读取操作,则返回 1。
// 此函数由事件循环的读处理器调用。
// 调用此函数的一个副作用是:
// 将客户端放入待处理读取客户端链表 server.clients_pending_read,并将其标记为 CLIENT_PENDING_READ 状态。
int postponeClientRead(client *c) {if (server.io_threads_active &&server.io_threads_do_reads &&!ProcessingEventsWhileBlocked &&!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ|CLIENT_BLOCKED))) {c->flags |= CLIENT_PENDING_READ;listAddNodeHead(server.clients_pending_read,c);return 1;} else {return 0;}
}
优化多批量请求(Multi-Bulk Request)
readlen = PROTO_IOBUF_LEN;// 如果这是一个多批量请求,并且我们正在处理一个足够大的批量复制操作,// 那么要尽量提高查询缓冲区中恰好包含表示该对象的SDS(简单动态字符串)字符串的概率,// 即便这样做可能会有需要更多次调用 read(2) 函数的风险。// 通过这种方式,processMultiBulkBuffer() 函数就可以避免复制缓冲区来创建表示参数的Redis对象。if (c->reqtype == PROTO_REQ_MULTIBULK && c->multibulklen && c->bulklen != -1&& c->bulklen >= PROTO_MBULK_BIG_ARG){ssize_t remaining = (size_t)(c->bulklen+2)-sdslen(c->querybuf);/* Note that the 'remaining' variable may be zero in some edge case,* for example once we resume a blocked client after CLIENT PAUSE. */if (remaining > 0 && remaining < readlen) readlen = remaining;}
读数据到 querybuf
调用 connRead 把 Socket 读缓冲区中的数据拷贝到 redis 的 querybuf 中。
// 从连接中读取数据,其行为与read(2)系统调用相同。
// 与 read(2)一样,有可能出现短读(即未读取到请求的全部字节数)的情况。返回值0表示连接已关闭,返回值-1表示出现了错误。
// 调用者不应依赖于errno(错误号)。要测试类似 EAGAIN(表示资源暂时不可用)的情况,
// 应使用connGetState()函数来查看连接状态是否仍为CONN_STATE_CONNECTED(连接已建立状态)。
static inline int connRead(connection *conn, void *buf, size_t buf_len) {return conn->type->read(conn, buf, buf_len);
}
CT_Socket 对 read 的实现是 connSocketRead,位于 connection.c。
static int connSocketRead(connection *conn, void *buf, size_t buf_len) {// 系统调用read读取内核缓冲区数据// 注意:这里的socket都是非阻塞的int ret = read(conn->fd, buf, buf_len);// read返回0,说明tcp连接断开了if (!ret) {conn->state = CONN_STATE_CLOSED; // 设置连接标志} else if (ret < 0 && errno != EAGAIN) {// 如果返回EAGAIN错误,只是因为缓冲区中没有更多数据可读了,这不算错误,可以忽略// 其他错误,需要处理conn->last_errno = errno; // 记录错误号// 不要覆盖尚未连接的连接的状态,以免干扰处理程序回调if (conn->state == CONN_STATE_CONNECTED)conn->state = CONN_STATE_ERROR; // 设置连接错误状态}return ret;
}
校验缓冲区大小
if (sdslen(c->querybuf) > server.client_max_querybuf_len){// .... 记录日志freeClientAsync(c); // 异步关闭客户端
}
可在 redis.conf 中使用配置指令 client-query-buffer-limit 修改,默认 1GB。防止恶意客户端通过超大请求耗尽内存。
协议解析入口
processInputBuffer(c)
processInputBuffer 支持解析两种请求格式 PROTO_REQ_MULTIBULK 和 PROTO_REQ_INLINE,它们会分别调用 processInlineBuffer 和 processMultibulkBuffer 进行处理。
如果是主线程调用 processInputBuffer,则它会解析一条命令执行一条命令,直到处理完 querybuf 中所有的完整命令。
如果是 I/O 线程调用 processInputBuffer,则只会在解析完一条完整命令后,便不再解析,并设置相关标志,让主线程去执行命令。
/* 每当客户端结构体 'c' 中有更多查询缓冲区数据需要处理时,就会调用此函数。* 这可能是因为我们从套接字读取了更多数据,* 或者客户端之前被阻塞,之后又被重新激活,* 所以可能存在已构成完整命令、待处理的查询缓冲区数据。 */
void processInputBuffer(client *c) {/* 只要输入缓冲区中有数据,就持续处理 */while(c->qb_pos < sdslen(c->querybuf)) {/* 如果客户端正在处理其他事情,立即终止处理 */if (c->flags & CLIENT_BLOCKED) break;/* 对于 c->argv 中已有待执行命令的客户端,不再处理更多缓冲区数据 */if (c->flags & CLIENT_PENDING_COMMAND) break;/* 当从节点上有繁忙脚本执行时,不处理主节点的输入。* 只是积累 replication stream(而不是像对待其他客户端那样回复 -BUSY),* 之后再恢复处理。 */if (server.lua_timedout && c->flags & CLIENT_MASTER) break;/* CLIENT_CLOSE_AFTER_REPLY 标志会在回复写入客户端后关闭连接。* 确保设置该标志后不再增加回复内容(即不再处理更多命令)。* 对于需要尽快终止的客户端同理。 */if (c->flags & (CLIENT_CLOSE_AFTER_REPLY|CLIENT_CLOSE_ASAP)) break;/* 当请求类型未知时,确定请求类型 */if (!c->reqtype) {// '*' 开头的表示MULTIBULK请求// MULTIBULK请求以 *<n>\r\n 开头,后跟多个 $<len>\r\n<data>\r\n 块。if (c->querybuf[c->qb_pos] == '*') { c->reqtype = PROTO_REQ_MULTIBULK;} else {// INLINE请求将命令及其参数用空格分隔,在一行内输入。整体请求格式以换行符(\r\n)结尾。// 例如,set key value\r\nc->reqtype = PROTO_REQ_INLINE;}}if (c->reqtype == PROTO_REQ_INLINE) {// 处理INLINE请求if (processInlineBuffer(c) != C_OK) break;// gopher请求,暂不关注if (server.gopher_enabled && !server.io_threads_do_reads &&((c->argc == 1 && ((char*)(c->argv[0]->ptr))[0] == '/') ||c->argc == 0)){processGopherRequest(c);resetClient(c);c->flags |= CLIENT_CLOSE_AFTER_REPLY;break;}} else if (c->reqtype == PROTO_REQ_MULTIBULK) {// 处理 MULTIBULK 请求// *3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$7\r\nmyvalue\r\n 解析为 // c->argv=["SET", "mykey", "myvalue"]if (processMultibulkBuffer(c) != C_OK) break;} else {serverPanic("Unknown request type");}/* MULTIBULK处理可能会遇到长度等于 0 的情况 */if (c->argc == 0) {resetClient(c);} else {// 在postponeClientRead中如果判断可以在I/O 线程中进行读取操作,// 就会设置 CLIENT_PENDING_READ 标志。// 但是 I/O 线程不负责执行命令,命令在解析完成后交给主线程执行。// 因此,如果当前是I/O线程执行该函数,在解析完命令后,只需设置CLIENT_PENDING_COMMAND标志即可if (c->flags & CLIENT_PENDING_READ) {c->flags |= CLIENT_PENDING_COMMAND;break;}// 走到这里说明当前是主线程在解析命令,// 接下来就需要执行命令了。if (processCommandAndResetClient(c) == C_ERR) {/* 如果客户端不再有效,避免退出此循环并稍后修剪客户端缓冲区。* 因此在这种情况下尽快返回。 */return;}}}// querybuf中还有未处理的数据if (c->qb_pos) {// 截断 querybuf,保留未处理字节sdsrange(c->querybuf,c->qb_pos,-1);c->qb_pos = 0; // qb_pos重置为0}
}
处理 MULTIBULK 请求
processMultibulkBuffer 用于解析 RESP 协议中的 MULTIBULK 请求(以 * 开头的数组格式,每一个数组元素就一个 bulk),将客户端发送的原始字节流转换为 client->argv 参数列表,为后续命令执行做准备。
例如:*3\r\n$3\r\nset\r\n$3\r\nkey\r\n$5\r\nvalue\r\n --> c->argv = [“set”,“key”,“value”],*3 表示数组长度为 3,$3 表示数组元素 bulk 占 3 个字节。
// 处理客户端 “c” 的查询缓冲区 querybuf,并设置客户端 c->argv,为命令执行做准备。
// 如果在运行该函数后,客户端拥有一个格式正确且可立即处理的命令,则返回 C_OK;
// 否则,如果仍需从缓冲区读取更多内容才能获取完整的命令,则返回 C_ERR。
// 当出现协议错误时,该函数同样返回 C_ERR:在这种情况下,会设置客户端c以回复错误信息并关闭连接。
// 如果 processInputBuffer () 检测到下一条命令是 RESP 格式(即命令的第一个字节为 '*'),就会调用此函数。
// 否则,对于内联命令,会调用 processInlineBuffer () 函数。
int processMultibulkBuffer(client *c) {char *newline = NULL;int ok;long long ll;// 如果上一个multibulk请求没有处理完,则 multibulklen != 0,// 否则,说明开始解析一条新的multibulk请求if (c->multibulklen == 0) {/* The client should have been reset */serverAssertWithInfo(c,NULL,c->argc == 0);/* Multi bulk length cannot be read without a \r\n */newline = strchr(c->querybuf+c->qb_pos,'\r');if (newline == NULL) {if (sdslen(c->querybuf)-c->qb_pos > PROTO_INLINE_MAX_SIZE) {addReplyError(c,"Protocol error: too big mbulk count string");setProtocolError("too big mbulk count string",c); // 客户端对象记录错误}return C_ERR;}/* Buffer should also contain \n */if (newline-(c->querybuf+c->qb_pos) > (ssize_t)(sdslen(c->querybuf)-c->qb_pos-2))return C_ERR;/* We know for sure there is a whole line since newline != NULL,* so go ahead and find out the multi bulk length. */serverAssertWithInfo(c,NULL,c->querybuf[c->qb_pos] == '*');// +1 跳过第一个 '*',\r\n前面的数字就是数组长度,例如:*3\r\n....ok = string2ll(c->querybuf+1+c->qb_pos,newline-(c->querybuf+1+c->qb_pos),&ll);if (!ok || ll > 1024*1024) {addReplyError(c,"Protocol error: invalid multibulk length");setProtocolError("invalid mbulk count",c); // 客户端对象记录错误return C_ERR;} else if (ll > 10 && authRequired(c)) {addReplyError(c, "Protocol error: unauthenticated multibulk length");setProtocolError("unauth mbulk count", c); // 客户端对象记录错误return C_ERR;}// 移动缓冲区指针,+2 跳过\r\nc->qb_pos = (newline-c->querybuf)+2;if (ll <= 0) return C_OK;c->multibulklen = ll; // 设置multibulk数组长度/* Setup argv array on client structure */if (c->argv) zfree(c->argv);// 分配multibulk数组,用以保存bulk数组元素c->argv = zmalloc(sizeof(robj*)*c->multibulklen);c->argv_len_sum = 0;}serverAssertWithInfo(c,NULL,c->multibulklen > 0);while(c->multibulklen) {/* Read bulk length if unknown */if (c->bulklen == -1) {newline = strchr(c->querybuf+c->qb_pos,'\r');if (newline == NULL) {if (sdslen(c->querybuf)-c->qb_pos > PROTO_INLINE_MAX_SIZE) {addReplyError(c,"Protocol error: too big bulk count string");setProtocolError("too big bulk count string",c); // 客户端对象记录错误return C_ERR;}break;}/* Buffer should also contain \n */if (newline-(c->querybuf+c->qb_pos) > (ssize_t)(sdslen(c->querybuf)-c->qb_pos-2))break;if (c->querybuf[c->qb_pos] != '$') {addReplyErrorFormat(c,"Protocol error: expected '$', got '%c'",c->querybuf[c->qb_pos]);setProtocolError("expected $ but got something else",c); // 客户端对象记录错误return C_ERR;}// ...\r\n$3\r\n,字符串3转为数字3ok = string2ll(c->querybuf+c->qb_pos+1,newline-(c->querybuf+c->qb_pos+1),&ll);if (!ok || ll < 0 ||(!(c->flags & CLIENT_MASTER) && ll > server.proto_max_bulk_len)) {addReplyError(c,"Protocol error: invalid bulk length");setProtocolError("invalid bulk length",c); // 客户端对象记录错误return C_ERR;} else if (ll > 16384 && authRequired(c)) {addReplyError(c, "Protocol error: unauthenticated bulk length");setProtocolError("unauth bulk length", c); // 客户端对象记录错误return C_ERR;}// 移动缓冲区位置qb_posc->qb_pos = newline-c->querybuf+2;if (ll >= PROTO_MBULK_BIG_ARG) {/* If we are going to read a large object from network* try to make it likely that it will start at c->querybuf* boundary so that we can optimize object creation* avoiding a large copy of data.** But only when the data we have not parsed is less than* or equal to ll+2. If the data length is greater than* ll+2, trimming querybuf is just a waste of time, because* at this time the querybuf contains not only our bulk. */if (sdslen(c->querybuf)-c->qb_pos <= (size_t)ll+2) {sdsrange(c->querybuf,c->qb_pos,-1);c->qb_pos = 0;/* Hint the sds library about the amount of bytes this string is* going to contain. */c->querybuf = sdsMakeRoomFor(c->querybuf,ll+2-sdslen(c->querybuf));}}c->bulklen = ll; // 设置bulk数组元素长度}/* Read bulk argument */// 例如,...\r\n$3\r\nset\r\n,+2 表示 set 数组元素后面的 \r\n// 如果数据不完全,不是错误,等待客户端继续发送数据,直到凑成完整的命令if (sdslen(c->querybuf)-c->qb_pos < (size_t)(c->bulklen+2)) {/* Not enough data (+2 == trailing \r\n) */break; } else {// 优化措施:如果缓冲区中仅包含我们的批量元素,并且bulk足够大(大于PROTO_MBULK_BIG_ARG,32KB)// 那么我们不会通过复制querybuf中的数据来创建一个新对象,// 而是直接使用当前的SDS字符串(querybufV就是个SDS)。if (c->qb_pos == 0 &&c->bulklen >= PROTO_MBULK_BIG_ARG &&sdslen(c->querybuf) == (size_t)(c->bulklen+2)){c->argv[c->argc++] = createObject(OBJ_STRING,c->querybuf);c->argv_len_sum += c->bulklen;sdsIncrLen(c->querybuf,-2); /* remove CRLF *//* Assume that if we saw a fat argument we'll see another one* likely... */// querybuf已经给bulk用了,// 重新分配一个sds给querybufc->querybuf = sdsnewlen(SDS_NOINIT,c->bulklen+2);sdsclear(c->querybuf);} else {// 根据querybuf中的bulk,为它分配一个sds,将数据拷贝过去c->argv[c->argc++] =createStringObject(c->querybuf+c->qb_pos,c->bulklen);c->argv_len_sum += c->bulklen; // 累计bulk长度c->qb_pos += c->bulklen+2; // 更新缓冲区指针qb_pos}c->bulklen = -1; // 一个bulk处理完,bulklen 置为 -1,继续下一个bulkc->multibulklen--;}}/* We're done when c->multibulk == 0 */// 完整的multibulk请求处理完成,返回okif (c->multibulklen == 0) return C_OK;/* Still not ready to process the command */// 否则返回错误,继续累计网络数据,再处理return C_ERR;
}
当协议解析错误,向客户端回复错误消息,然后调用 setProtocolError。我们看看这个函数做了什么
#define PROTO_DUMP_LEN 128
static void setProtocolError(const char *errstr, client *c) {if (server.verbosity <= LL_VERBOSE || c->flags & CLIENT_MASTER) {// ..... 记录日志}c->flags |= (CLIENT_CLOSE_AFTER_REPLY|CLIENT_PROTOCOL_ERROR); // 设置错误标志,后面处理
}
也是记录日志,设置客户端标志,后面销毁客户端,断开连接。
处理 INLINE 请求
INLINE 请求格式通过空格分隔参数,并在最后添加 \r\n。例如:get key\r\n。适用于 Telnet 等简单交互场景。
// 与processMultibulkBuffer()函数类似,但此函数处理的是内联协议(而不是RESP协议),
// 它会使用客户端的查询缓冲区,并在客户端结构体中创建一个准备好执行的命令。
// 如果命令已准备好执行,则返回C_OK;如果仍需要读取更多协议内容才能形成一个格式正确的命令,则返回C_ERR。
// 当存在协议错误时,该函数也会返回C_ERR:在这种情况下,会设置客户端结构体以回复错误信息并关闭连接。
int processInlineBuffer(client *c) {char *newline;int argc, j, linefeed_chars = 1;sds *argv, aux;size_t querylen;/* Search for end of line */newline = strchr(c->querybuf+c->qb_pos,'\n');/* Nothing to do without a \r\n */if (newline == NULL) {if (sdslen(c->querybuf)-c->qb_pos > PROTO_INLINE_MAX_SIZE) {addReplyError(c,"Protocol error: too big inline request");setProtocolError("too big inline request",c); // 客户端对象记录错误}return C_ERR;}/* Handle the \r\n case. */if (newline != c->querybuf+c->qb_pos && *(newline-1) == '\r')newline--, linefeed_chars++;/* Split the input buffer up to the \r\n */querylen = newline-(c->querybuf+c->qb_pos);// 去除最后的\r\n,创建一个新的sds,拷贝过去aux = sdsnewlen(c->querybuf+c->qb_pos,querylen);argv = sdssplitargs(aux,&argc); // 分割命令和参数sdsfree(aux);if (argv == NULL) {addReplyError(c,"Protocol error: unbalanced quotes in request");setProtocolError("unbalanced quotes in inline request",c); // 客户端对象记录错误return C_ERR;}// 全量复制期间,从节点需完成 RDB 文件接收、数据加载等操作,可能耗时数分钟(尤其在数据量大的场景)。// 若主节点在此期间未收到从节点心跳,可能触发超时机制,强制终止复制(replication)连接。// 此时,从节点通过发送空行(querylen == 0)向主节点(Master)表明存活状态,防止主节点误判。if (querylen == 0 && getClientType(c) == CLIENT_TYPE_SLAVE)c->repl_ack_time = server.unixtime;// 主节点永远都不应该向我们发送内联协议来执行实际命令。若出现这种情况,// 很可能是 Redis 存在漏洞,致使协议出现了某种不同步,比如 PSYNC 操作失败。//// 不过存在一个例外:主节点可能仅发送一个换行符,以此来维持连接的活跃状态。if (querylen != 0 && c->flags & CLIENT_MASTER) {sdsfreesplitres(argv,argc);serverLog(LL_WARNING,"WARNING: Receiving inline protocol from master, master stream corruption? Closing the master connection and discarding the cached master.");setProtocolError("Master using the inline protocol. Desync?",c); // 客户端对象记录错误return C_ERR;}/* Move querybuffer position to the next query in the buffer. */c->qb_pos += querylen+linefeed_chars;/* Setup argv array on client structure */if (argc) {if (c->argv) zfree(c->argv);c->argv = zmalloc(sizeof(robj*)*argc);c->argv_len_sum = 0;}/* Create redis objects for all arguments. */for (c->argc = 0, j = 0; j < argc; j++) {c->argv[c->argc] = createObject(OBJ_STRING,argv[j]);c->argc++;c->argv_len_sum += sdslen(argv[j]);}zfree(argv);return C_OK;
}
相关文章:

Redis 处理读请求
在前文“Redis 接收连接”中,Redis 将接收的客户端连接加入了 epoll 中监听,同时还设置了读事件处理器 connSocketEventHandler。 假设现在客户端向 Redis 发来一条 set key value 命令。 事件循环 aeProcessEvents 在事件循环 aeProcessEvents 中会调…...
Sentinel源码—8.限流算法和设计模式总结二
大纲 1.关于限流的概述 2.高并发下的四大限流算法原理及实现 3.Sentinel使用的设计模式总结 3.Sentinel使用的设计模式总结 (1)责任链模式 (2)监听器模式 (3)适配器模式 (4)模版方法模式 (5)策略模式 (6)观察者模式 (1)责任链模式 一.责任链接口ProcessorSlot 二.责…...
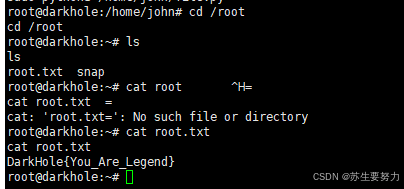
VulnHub-DarkHole_1靶机渗透教程
VulnHub-DarkHole_1靶机渗透教程 1.靶机部署 [Onepanda] Mik1ysomething 靶机下载:https://download.vulnhub.com/darkhole/DarkHole.zip 直接使用VMware打开就行 导入成功,打开虚拟机,到此虚拟机部署完成! 注意:…...

Keil MDK‑5 中使用 GNU ARM GCC 的 -Wno-* 选项屏蔽编译警告
在项目编译过程中,我们常常会遇到许多警告提示;而在有些情况下,当我们已经了解这些警告的原因时,可以选择忽略它们,从而减少干扰,集中精力修复其他更重要的问题。 一、添加屏蔽警告的编译选项 (…...

边缘计算全透视:架构、应用与未来图景
边缘计算全透视:架构、应用与未来图景 一、产生背景二、本质三、特点(一)位置靠近数据源(二)分布式架构(三)实时性要求高 四、关键技术(一)硬件技术(二&#…...

爬虫学习——下载文件和图片、模拟登录方式进行信息获取
一、下载文件和图片 Scrapy中有两个类用于专门下载文件和图片,FilesPipeline和ImagesPipeline,其本质就是一个专门的下载器,其使用的方式就是将文件或图片的url传给它(eg:item[“file_urls”])。使用之前需要在settings.py文件中对其进行声明…...

路由器转发规则设置方法步骤,内网服务器端口怎么让异地连接访问的实现
在路由器上设置端口转发(Port Forwarding)可以将外部网络流量引导到特定的局域网设备,这对于需要远程访问服务器、摄像头、游戏主机等设备非常有用。 登录路由器管理界面,添加端口转发规则让外网访问内网的实现教程分享。以下是设…...
MQ底层原理
RabbitMQ 概述 RabbitMQ 是⼀个开源的⾼性能、可扩展、消息中间件(Message Broker),实现了 Advanced Message Queuing Protocol(AMQP)协议,可以帮助不同应⽤程序之间进⾏通信和数据交换。RabbitMQ 是由 E…...
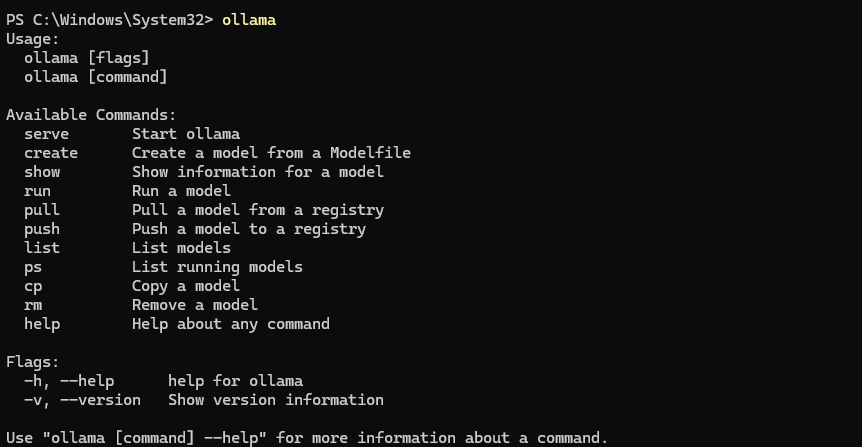
本地部署DeepSeek-R1模型接入PyCharm
以下是DeepSeek-R1本地部署及接入PyCharm的详细步骤指南,整合了视频内容及官方文档核心要点: 一、本地部署DeepSeek-R1模型 1. 安装Ollama框架 下载安装包 访问Ollama官网(https://ollama.com/download)Windows用户选择.exe文件,macOS用户选择.dmg包。 安装验证 双击…...

jvm-描述符与特征签名的区别
在Java虚拟机(JVM)中,存储的是方法签名,而不是仅仅方法描述符。方法签名包含了方法的参数类型和返回值类型的信息,而方法描述符通常指的是仅包含参数类型的那部分信息。为了更清晰地理解这两者的区别以及它们如何在JVM…...

Java基于SpringBoot的企业车辆管理系统,附源码+文档说明
博主介绍:✌Java老徐、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&…...

QT调用ffmpeg库实现视频录制
可以通过QProcess调用ffmpeg命令行,也可以直接调用ffmpeg库,方便。 调用库 安装ffmpeg ffmpeg -version 没装就装 sudo apt-get update sudo apt-get install ffmpeg sudo apt-get install ffmpeg libavdevice-dev .pro引入库路径,引入库 LIBS += -L/usr/lib/aarch64-l…...

百度 Al 智能体心响 App 上线
百度 AI 智能体心响 App 于 2025 年 4 月 17 日低调上线安卓应用市场,4 月 22 日正式登陆各大安卓应用市场。以下是对这款应用的详细介绍: 产品定位:这是一款以 “AI 任务完成引擎” 为核心的手机端超级智能体产品,定位为 “复杂任…...

进阶篇 第 2 篇:自相关性深度解析 - ACF 与 PACF 图完全指南
进阶篇 第 2 篇:自相关性深度解析 - ACF 与 PACF 图完全指南 (图片来源: Negative Space on Pexels) 欢迎来到进阶系列的第二篇!在上一篇,我们探讨了更高级的时间序列分解技术和强大的指数平滑 (ETS) 预测模型。ETS 模型通过巧妙的加权平均捕…...

【Java面试笔记:基础】7.int和Integer有什么区别?
在Java中,int和Integer虽然都用于表示整数值,但它们在本质、用法和特性上有显著差异。 1. int 和 Integer 的区别 int: 原始数据类型:int 是 Java 的 8 个原始数据类型之一,用于表示整数。性能优势:直接存…...
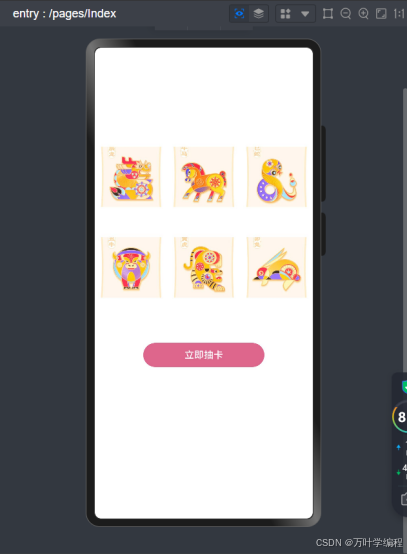
鸿蒙移动应用开发--渲染控制实验
任务:使用“对象数组”、“ForEach渲染”、“Badge角标组件”、“Grid布局”等相关知识,实现生效抽奖卡案例。如图1所示: 图1 生肖抽奖卡实例图 图1(a)中有6张生肖卡可以抽奖,每抽中一张,会通过弹层显示出来…...

AI代表企业签订的合同是否具有法律效力?
AI代表企业签订的合同是否具有法律效力? 首席数据官高鹏律师团队编著 在数字经济高速发展的今天,人工智能(AI)技术已广泛应用于商业活动,包括合同起草、审查甚至签署环节。然而,AI代表企业签订的合同是否具…...

安宝特分享|AR智能装备赋能企业效率跃升
AR装备开启智能培训新时代 在智能制造与数字化转型浪潮下,传统培训体系正面临深度重构。安宝特基于工业级AR智能终端打造的培训系统,可助力企业构建智慧培训新生态。 AR技术在不同领域的助力 01远程指导方面 相较于传统视频教学的单向输出模式&#x…...
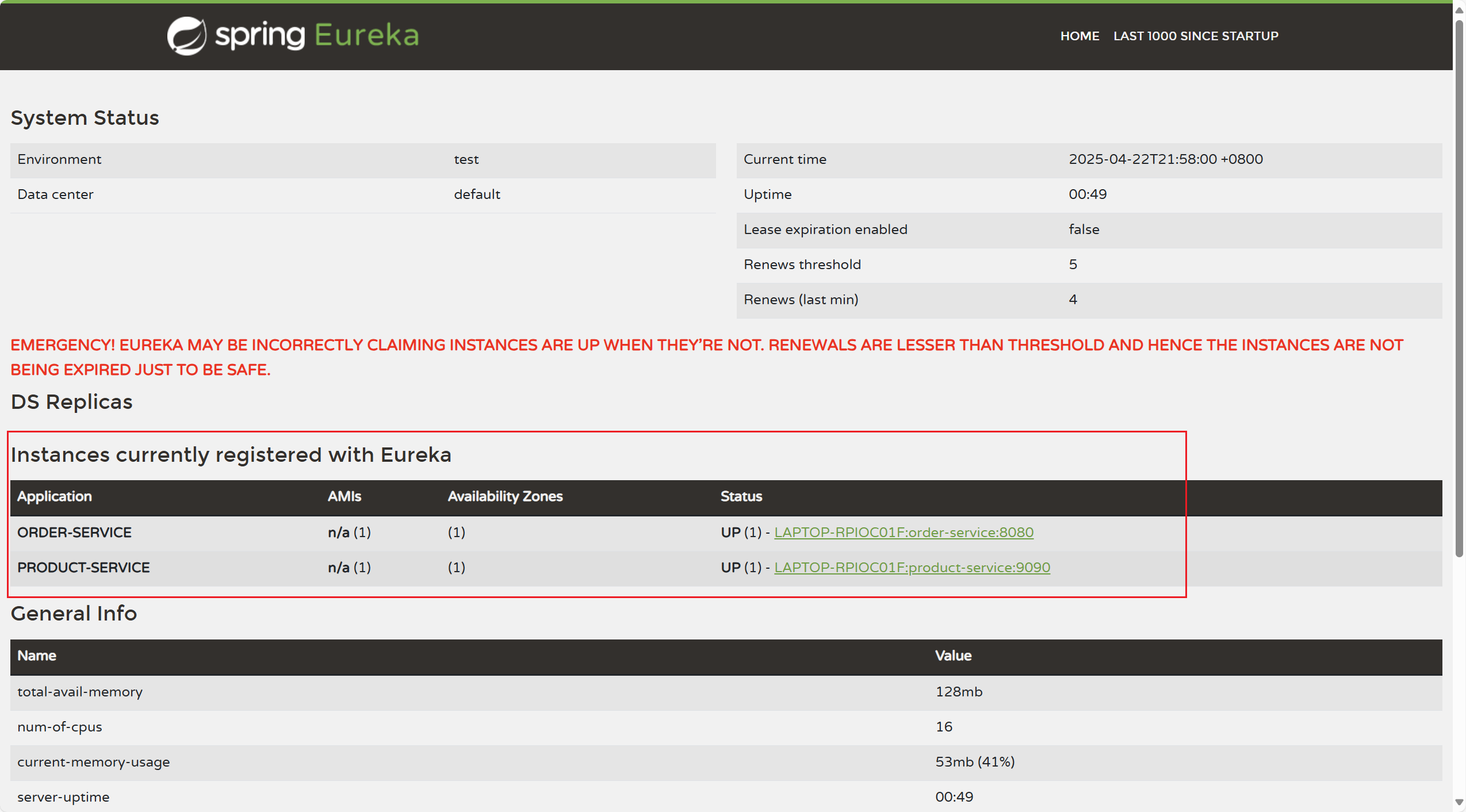
SpringCloud组件—Eureka
一.背景 1.问题提出 我们在一个父项目下写了两个子项目,需要两个子项目之间相互调用。我们可以发送HTTP请求来获取我们想要的资源,具体实现的方法有很多,可以用HttpURLConnection、HttpClient、Okhttp、 RestTemplate等。 举个例子&#x…...

模型 螃蟹效应
系列文章分享模型,了解更多👉 模型_思维模型目录。个体互钳,团队难行。 1 螃蟹效应的应用 1.1 教育行业—优秀教师遭集体举报 行业背景:某市重点中学推行绩效改革,将班级升学率与教师奖金直接挂钩,打破原…...

符号速率估计——小波变换法
[TOC]符号速率估计——小波变换法 一、原理 1.Haar小波变换 小波变换在信号处理领域被成为数学显微镜,不同于傅里叶变换,小波变换可以观测信号随时间变换的频谱特征,因此,常用于时频分析。 当小波变换前后位置处于同一个码元…...

【架构】ANSI/IEEE 1471-2000标准深度解析:软件密集型系统架构描述推荐实践
引言 在软件工程领域,架构设计是确保系统成功的关键因素之一。随着软件系统日益复杂化,如何有效描述和沟通系统架构成为了一个亟待解决的问题。ANSI/IEEE 1471-2000(正式名称为"推荐软件密集型系统架构描述实践")应运而…...

python兴趣匹配算法
python兴趣匹配算法,用于推荐好友,短视频推荐等等领域 功能列表: 1.用户类的定义,存储用户的基本信息和兴趣。 2.计算两个用户之间兴趣的匹配分数,比较每一位是否相同。 3.根据匹配分数对候选人进行排序。 4.提供交互…...

每日算法-250422
每日算法 - 250422 1561. 你可以获得的最大硬币数目 题目 思路 贪心 解题过程 根据题意,我们想要获得最大的硬币数目。每次选择时,有三堆硬币:最大的一堆会被 Alice 拿走,最小的一堆会被 Bob 拿走,剩下的一堆…...
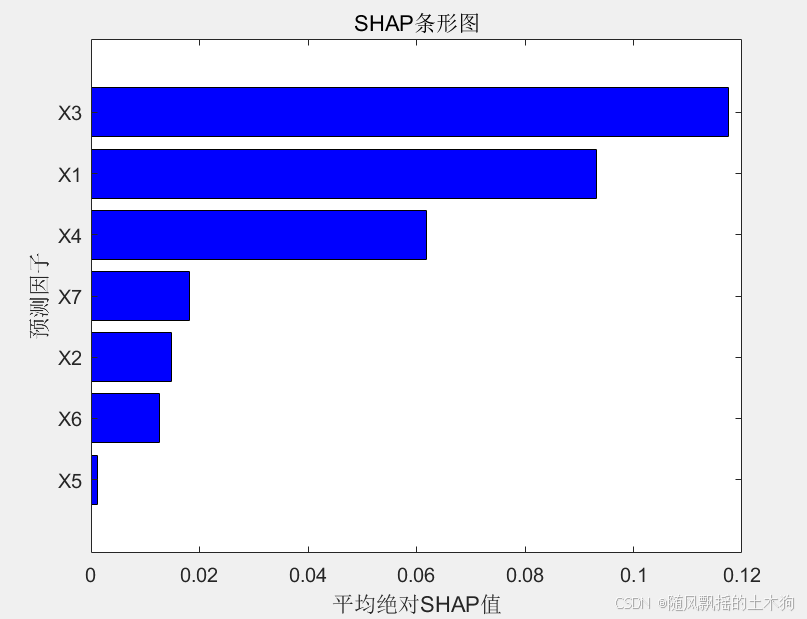
【MATLAB第116期】基于MATLAB的NBRO-XGBoost的SHAP可解释回归模型(敏感性分析方法)
【MATLAB第116期】基于MATLAB的NBRO-XGBoost的SHAP可解释回归模型(敏感性分析方法) 引言 该文章实现了一个可解释的回归模型,使用NBRO-XGBoost(方法可以替换,但是需要有一定的编程基础)来预测特征输出。该…...
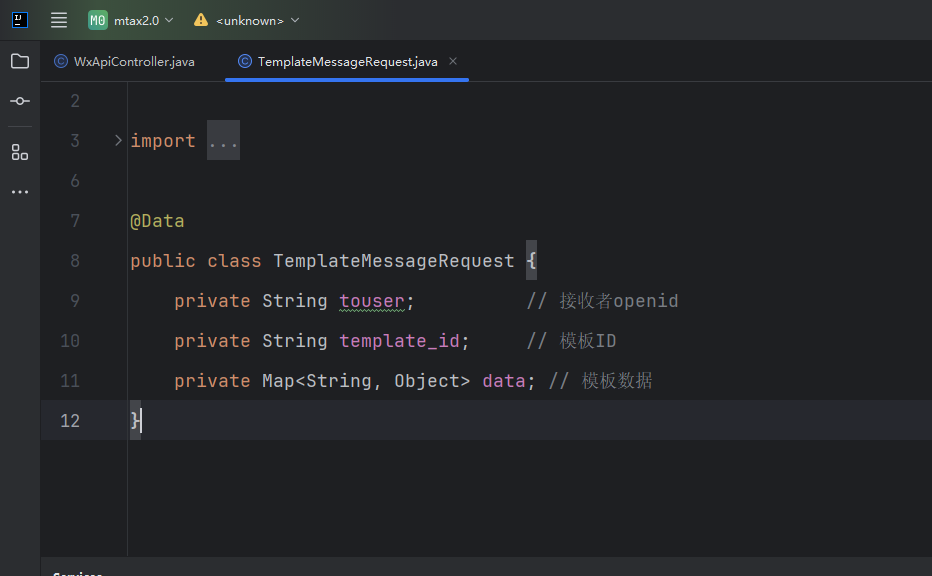
微信公众号消息模板推送没有“详情“按钮?无法点击跳转
踩坑!!!!踩坑!!!!踩坑!!!! 如下 简单说下我的情况,按官方文档传参url了 、但就是看不到查看详情按钮 。如下 真凶&#x…...

WHAT - 静态资源缓存穿透
文章目录 1. 动态哈希命名的基本思路2. 具体实现2.1 Vite/Webpack 配置动态哈希2.2 HTML 文件中动态引用手动引用使用 index.html 模板动态插入 2.3 结合 Cache-Control 避免缓存穿透2.4 适用于多环境的动态策略 总结 在多环境部署中,静态资源缓存穿透是一个常见问题…...

电动单座V型调节阀的“隐形守护者”——阀杆节流套如何解决高流速冲刷难题
电动单座V型调节阀的“隐形守护者”——阀杆节流套如何解决高流速冲刷难题? 在工业自动化控制中,电动单座V型调节阀因其精准的流量调节能力,成为石油、化工等领域的核心设备。然而,长期高流速工况下,阀芯与阀座的冲刷腐…...

Redis高级篇之I/O多路复用的引入解析
文章目录 一、问题背景1. 高并发连接的管理2. 避免阻塞和延迟3. 减少上下文切换开销4. 高效的事件通知机制5. 简化编程模型6. 低延迟响应本章小节 二、I/O多路复用高性能的本质1. 避免无意义的轮询:O(1) 事件检测2. 非阻塞 I/O 零拷贝:最大化 CPU 利用率…...
(ArkTs))
鸿蒙NEXT开发权限工具类(申请授权相关)(ArkTs)
import abilityAccessCtrl, { Permissions } from ohos.abilityAccessCtrl; import { bundleManager, common, PermissionRequestResult } from kit.AbilityKit; import { BusinessError } from ohos.base; import { ToastUtil } from ./ToastUtil;/*** 权限工具类(…...