C++项目 —— 基于多设计模式下的同步异步日志系统(3)(日志器类)
C++项目 —— 基于多设计模式下的同步&异步日志系统(3)(日志器类)
- 整体思想设计
- 日志消息的构造
- C语言式的不定参
- 函数的作用
- 函数的具体实现逻辑
- 1. 日志等级检查
- 2. 初始化可变参数列表
- 3. 格式化日志消息
- 4. 释放参数列表
- 5. 序列化和输出日志
- 函数的关键点总结
- vasprintf
- `vasprintf` 函数详解
- 函数原型
- 参数说明
- 返回值
- 关键特性
- 使用示例
- 内存管理注意事项
- 平台兼容性
- 与相关函数的对比
- C++ 中的替代方案
- 总结
- 同步日志器
- 扩充
- using的用法
- 1. 类型别名(Type Aliases)
- 2. 命名空间引入(Namespace Directives)
- 3. 继承中的用法
- 4. 类型转换(Type Traits)
- 5. 模板编程中的依赖类型
- 对比 `typedef` 与 `using`
- 最佳实践建议
我们之前的两次博客,已经把日志器模块的一些基本组成要素已经搭建完成了,包括基本工具类的创建,格式化消息类,日志落地方向类的编写也已经完成了。如果还有小伙伴不熟悉这些,可以先看看我的前两次博客:
https://blog.csdn.net/qq_67693066/article/details/147190387?spm=1011.2415.3001.5331
https://blog.csdn.net/qq_67693066/article/details/147162921?spm=1011.2415.3001.5331
我们今天的任务主要是将前面的我们所编写的类组合起来,组合成一个实实在在的日志器,同时日志器也分两个方向,分为同步日志器和异步日志器。
整体思想设计
跟我们之前设计日志落地方向的时候一样,我们也是设计一个基类日志器,然后继承分化成两类不同的日志器,一个是同步日志器,另一个是异步日志器:
#ifndef __M_LOGGER_H__
#define __M_LOGGER_H__
#include "utils.hpp"
#include "message.hpp"
#include "utils.hpp"
#include "level.hpp"
#include "sink.hpp"
#include <atomic>
#include <mutex>
#include <iostream>
#include <memory>
#include <ctime>
#include <vector>
#include <cassert>
#include <sstream>namespace logs
{class BaseLogger{public:BaseLogger(const std::string& logger_name,Loglevel::value level,Formetter::ptr &formetter,std::vector<BaseSink::ptr> &sinks) :_logger_name(logger_name),_level(level),_formetter(formetter),_sinks(sinks.begin(), sinks.end()){}protected:std::mutex _mutex; //锁std::string logger_name; //日志器名称std::atomic<logs::Loglevel> _level; //日志等级Formetter::ptr _formetter; //格式化消息指针std::vector<BaseSink::ptr> _sink; //落地方向 };class SyncLogger : protected BaseLogger{};class AsyncLogger : protected BaseLogger{};
}#endif
这样我们就把大概的架子搭好了,我们这时候先把转化日志消息的这个功能做好:
void serialize(Loglevel::value level,const std::string& file_name,size_t line,const std::string& logger_name,char* str){//1.构造msg对象logs::logMsg msg(level,file_name,line,logger_name,str);//2.利用Formetter进行消息格式化std::stringstream ss;_formetter->format(ss,str);//3.落地方向的输出log(ss.str().c_str(), ss.str().size());}
日志消息的构造
我们日志器最重要的一个部分就是对不同日志等级消息进行输出,所以我们要对不同的日志等级设计接口,使他们能够输出对应自身的日志消息:
我们拿debug来举例,我们要设计对应的接口,使得对应消息进入debug接口能够被格式化组织出来,按照我们想要的方向进行输出:
/*完成构造日志消息对象过程并进行格式化,得到格式化后的日志消息字符串---然后进行输出*/void debug(){}
这里我们要考虑一个问题,就是我们传入的消息可能不是固定的,参数可能不是固定的,所以我们的接口参数个数就不能写死。这里我们我们要介绍一下C语言风格的不定参:
C语言式的不定参
在C语言中,函数可以接受不定数量的参数,这称为可变参数函数(variadic functions)。标准库中的printf()和scanf()就是典型的例子。我们可以举一个简单的例子:
double average(int count, ...)
{va_list ap; 声明参数列表变量int j = 0;double sum = 0;va_start(ap,count); //count是最后一个参数for (j = 0; j < count; j++){sum += va_arg(ap, int); //依次获得int类型的参数}va_end(ap);return sum / count;
}
这个average函数可以接受若干参数,像这里,我就声明接受5个参数。
我们可以把这样的思想用到我们日志器不同等级日志打印上:
void debug(const std::string& file,size_t line,const std::string fmt,...){//如果限制输出的日志等级比debug高,则直接返回if(Loglevel::value::DEBUG < _limt_level){return;}//声明参数列表变量va_list ap;va_start(ap,fmt); // 初始化fmt是最后一个固定的参数char* res; //声明缓冲区int ret = vasprintf(&res,fmt.c_str(),ap);if(ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap); //释放参数列表变量serialize(Loglevel::value::DEBUG, file, line, res);free(res);}
这个函数是一个日志输出工具的一部分,用于生成和输出格式化的调试日志消息。以下是对其作用的详细解释:
函数的作用
这个 debug 函数的主要目的是:
- 判断是否需要输出日志:根据当前的日志等级限制
_limt_level,决定是否需要输出DEBUG级别的日志消息。 - 构造日志消息:通过接收一个格式化字符串(类似于
printf的方式)和可变参数列表,生成最终的日志消息内容。 - 格式化日志消息:将传入的格式化字符串和参数组合成一个完整的日志消息字符串。
- 序列化和输出日志:将日志消息传递给另一个函数(如
serialize),进行进一步处理或输出。
函数的具体实现逻辑
1. 日志等级检查
if(Loglevel::value::DEBUG < _limt_level)
{return;
}
- 这部分代码首先检查当前的日志等级限制
_limt_level是否允许输出DEBUG级别的日志。 - 如果
_limt_level的值比DEBUG级别更高(例如设置为INFO或ERROR),则直接返回,不执行后续的日志记录操作。这样可以避免不必要的日志生成和输出。
2. 初始化可变参数列表
va_list ap;
va_start(ap, fmt);
- 使用
va_list类型变量ap来存储可变参数列表。 va_start初始化ap,并指定fmt是最后一个固定的参数(即可变参数列表从fmt后面开始)。
3. 格式化日志消息
char* res;
int ret = vasprintf(&res, fmt.c_str(), ap);
- 使用
vasprintf函数将格式化字符串fmt和可变参数列表ap转换为一个动态分配的字符串res。 vasprintf是 C 标准库中的一个扩展函数,它会根据格式化字符串和参数生成结果字符串,并自动分配足够的内存。- 如果
vasprintf返回-1,表示格式化失败,程序会输出错误信息并直接返回。
4. 释放参数列表
va_end(ap);
- 在完成对可变参数列表的操作后,调用
va_end释放ap,以确保资源被正确清理。
5. 序列化和输出日志
serialize(Loglevel::value::DEBUG, file, line, res);
free(res);
- 调用
serialize函数,将日志等级(DEBUG)、文件名(file)、行号(line)以及格式化后的日志消息(res)传递给它。 serialize函数可能会将这些信息进一步处理(例如添加时间戳、线程 ID 等),然后输出到文件、控制台或其他目标。- 最后,使用
free(res)释放由vasprintf分配的内存,避免内存泄漏。
函数的关键点总结
-
日志等级过滤:
- 通过
_limt_level控制日志输出的行为,避免输出不必要的日志消息,提高性能。
- 通过
-
格式化日志消息:
- 使用
vasprintf动态生成格式化的日志消息,支持类似printf的占位符语法(如%s,%d等)。
- 使用
-
资源管理:
- 使用
va_start和va_end管理可变参数列表。 - 使用
free释放动态分配的内存,防止内存泄漏。
- 使用
-
日志输出:
- 将日志消息传递给
serialize函数进行进一步处理和输出。
- 将日志消息传递给
vasprintf
vasprintf 函数详解
vasprintf 是一个非常有用的 C 库函数(GNU 扩展),用于安全地格式化字符串并自动分配内存。下面我将全面介绍这个函数。
函数原型
int vasprintf(char **strp, const char *format, va_list ap);
参数说明
strp:指向字符指针的指针,函数会将分配的缓冲区地址存储在这里format:格式化字符串(与printf风格相同)ap:可变参数列表(通过va_start初始化)
返回值
- 成功时:返回写入的字符数(不包括结尾的 null 字符)
- 失败时:返回 -1,并且不修改
*strp
关键特性
-
自动内存分配
- 函数会根据需要自动分配足够大的内存
- 调用者负责后续释放这块内存
-
安全性
- 避免了缓冲区溢出风险
- 不需要预先猜测缓冲区大小
-
与
vsprintf的关系- 类似于
vsprintf,但自动处理内存分配 - 类似于
asprintf的可变参数版本
- 类似于
使用示例
#include <stdio.h>
#include <stdarg.h>
#include <stdlib.h>void log_message(const char *format, ...) {va_list args;va_start(args, format);char *buffer = NULL;int len = vasprintf(&buffer, format, args);va_end(args);if (len != -1) {printf("Formatted message: %s\n", buffer);free(buffer); // 必须释放分配的内存} else {printf("Formatting failed\n");}
}int main() {log_message("Current value: %d, name: %s", 42, "example");return 0;
}
内存管理注意事项
-
必须释放内存
char *str = NULL; vasprintf(&str, ...); // 使用str... free(str); // 必须调用free释放 -
错误处理
- 总是检查返回值是否为-1
- 失败时不要尝试使用或释放缓冲区
平台兼容性
-
支持平台
- GNU/Linux 系统
- 大多数 Unix-like 系统
-
Windows 替代方案
_vasprintf(微软实现)- 或使用
_vscprintf+malloc+vsprintf组合
与相关函数的对比
| 函数 | 自动分配内存 | 安全性 | 需要缓冲区大小参数 |
|---|---|---|---|
vsprintf | 否 | 不安全 (可能溢出) | 否 |
vsnprintf | 否 | 安全 | 是 |
vasprintf | 是 | 安全 | 否 |
C++ 中的替代方案
现代 C++ 可以使用以下替代方案:
-
C++20
std::format#include <format> std::string msg = std::format("Value: {}", 42); -
fmt库#include <fmt/core.h> std::string msg = fmt::format("Value: {}", 42); -
字符串流
#include <sstream> std::ostringstream oss; oss << "Value: " << 42; std::string msg = oss.str();
总结
vasprintf 是一个方便且安全的字符串格式化函数,特别适合需要动态构建字符串的场景。它的主要优点是自动内存管理和避免缓冲区溢出,但需要注意正确释放分配的内存和考虑跨平台兼容性。
以上的阐述足够让大家具体了解这个debug函数的具体用法和语法细节,其他等级的日志输出函数我们如法炮制就行了:
给大家贴上完整代码:
#ifndef __M_LOGGER_H__
#define __M_LOGGER_H__
#include "utils.hpp"
#include "message.hpp"
#include "utils.hpp"
#include "level.hpp"
#include "sink.hpp"
#include <atomic>
#include <mutex>
#include <iostream>
#include <memory>
#include <ctime>
#include <vector>
#include <cassert>
#include <sstream>
#include<stdarg.h>namespace logs
{class BaseLogger{public:using ptr = std::shared_ptr<BaseLogger>;BaseLogger(const std::string& logger_name,Loglevel::value limt_level,Formetter::ptr &formetter,std::vector<BaseSink::ptr> &sinks) :_logger_name(logger_name),_limt_level(limt_level),_formetter(formetter),_sinks(sinks.begin(), sinks.end()){}const std::string& get_logger_name(){return _logger_name;}/*完成构造日志消息对象过程并进行格式化,得到格式化后的日志消息字符串---然后进行输出*/void debug(const std::string& file,size_t line,const std::string fmt,...){//如果限制输出的日志等级比debug高,则直接返回if(Loglevel::value::DEBUG < _limt_level){return;}//声明参数列表变量va_list ap;va_start(ap,fmt); // 初始化fmt是最后一个固定的参数char* res; //声明缓冲区int ret = vasprintf(&res,fmt.c_str(),ap);if(ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap); //释放参数列表变量serialize(Loglevel::value::DEBUG, file, line, res);free(res);}void info(const std::string& file,size_t line,const std::string fmt,...){//如果限制输出的日志等级比debug高,则直接返回if(Loglevel::value::INFO < _limt_level){return;}//声明参数列表变量va_list ap;va_start(ap,fmt); // 初始化fmt是最后一个固定的参数char* res; //声明缓冲区int ret = vasprintf(&res,fmt.c_str(),ap);if(ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap); //释放参数列表变量serialize(Loglevel::value::INFO, file, line, res);free(res);}void warn(const std::string& file,size_t line,const std::string fmt,...){//如果限制输出的日志等级比debug高,则直接返回if(Loglevel::value::WARN < _limt_level){return;}//声明参数列表变量va_list ap;va_start(ap,fmt); // 初始化fmt是最后一个固定的参数char* res; //声明缓冲区int ret = vasprintf(&res,fmt.c_str(),ap);if(ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap); //释放参数列表变量serialize(Loglevel::value::WARN, file, line, res);free(res);}void error(const std::string &file, size_t line, const std::string &fmt, ...){// 1.通过传入的参数构造一个日志对象,进行日志的格式化,最终落地if (Loglevel::value::ERROR < _limt_level){return;}// 2.对fmt格式化字符串和不定参进行字符串组织,得到日志消息字符串va_list ap;va_start(ap, fmt);char *res;int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap);serialize(Loglevel::value::ERROR, file, line, res);free(res);}void fatal(const std::string &file, size_t line, const std::string &fmt, ...){// 1.通过传入的参数构造一个日志对象,进行日志的格式化,最终落地if (Loglevel::value::FATAL < _limt_level){return;}// 2.对fmt格式化字符串和不定参进行字符串组织,得到日志消息字符串va_list ap;va_start(ap, fmt);char *res;int ret = vasprintf(&res, fmt.c_str(), ap);if (ret == -1){std::cout << "vasprintf failed!\n";return;}va_end(ap);serialize(Loglevel::value::FATAL, file, line, res);free(res);}protected:void serialize(Loglevel::value level,const std::string& file_name,size_t line,char* str){//1.构造msg对象logs::logMsg msg(level,file_name,line,_logger_name,str);//2.利用Formetter进行消息格式化std::stringstream ss;_formetter->format(ss,msg);//3.落地方向的输出log(ss.str().c_str(), ss.str().size());}/*抽象接口完成实际的落地输出---不同的日志器会有不同的落地方式*/virtual void log(const char *data, size_t len) = 0;protected:std::mutex _mutex; //锁std::string _logger_name; //日志器名称std::atomic<Loglevel::value> _limt_level; //日志等级Formetter::ptr _formetter; //格式化消息指针std::vector<BaseSink::ptr> _sinks; //落地方向 };class SyncLogger : public BaseLogger{};class AsyncLogger : public BaseLogger{};
}#endif
同步日志器
同步日志器比较简单,我们继承基础的日志器然后把接口log实现一下就可以了:
class SyncLogger : public BaseLogger{public:SyncLogger(const std::string& logger_name,Loglevel::value limt_level,Formetter::ptr &formetter,std::vector<BaseSink::ptr> &sinks):BaseLogger(logger_name, limt_level, formetter, sinks) {}protected:void log(const char *data, size_t len){//1.上锁std::unique_lock<std::mutex> _lock(std::mutex);if (_sinks.empty())return;for (auto &sink : _sinks){sink->log(data, len);}}};
我们可以来测试一下:
#include "utils.hpp"
#include "level.hpp"
#include "message.hpp"
#include "fometter.hpp"
#include "sink.hpp"
#include "logger.hpp"int main()
{// 1. 创建 Formatter 对象(假设构造函数接受格式字符串)logs::Formetter formatter("abc[%d{%H:%M:%S}][%c]%T%m%n");// 2. 创建智能指针logs::Formetter::ptr fmt_ptr = std::make_shared<logs::Formetter>(formatter);auto st1 = logs::SinkFactory::create<logs::StdoutSink>();std::vector<logs::BaseSink::ptr> sinks = {st1};std::string logger_name = "synclogger";logs::BaseLogger::ptr logger(new logs::SyncLogger(logger_name, logs::Loglevel::value::DEBUG, fmt_ptr, sinks));logger->debug("main.cc", 53, "%s","格式化功能测试....");
}

扩充
using的用法
在 C++ 中,using 是一个多功能关键字,主要有以下几种用法:
1. 类型别名(Type Aliases)
- 替代
typedef,更直观地定义类型别名
using IntPtr = int*; // 等价于 typedef int* IntPtr;
using StringVector = std::vector<std::string>;
模板别名(typedef 无法实现):
template<typename T>
using Vec = std::vector<T>; // Vec<int> 等价于 std::vector<int>
2. 命名空间引入(Namespace Directives)
- 引入整个命名空间(谨慎使用):
using namespace std; // 引入 std 命名空间
- 引入特定成员:
using std::cout; // 只引入 cout
3. 继承中的用法
- 引入基类成员(解决名称隐藏问题):
class Base {
public:void func() {}
};class Derived : private Base {
public:using Base::func; // 将基类的 func 引入到 public 区域
};
- 继承构造函数(C++11 起):
class Derived : public Base {
public:using Base::Base; // 继承基类的所有构造函数
};
4. 类型转换(Type Traits)
与 decltype 配合定义复杂类型:
using ResultType = decltype(a + b); // 根据表达式推断类型
5. 模板编程中的依赖类型
指定模板依赖的类型名:
template<typename T>
class Widget {using ValueType = typename T::value_type; // 明确 value_type 是类型
};
对比 typedef 与 using
| 特性 | typedef | using |
|---|---|---|
| 语法直观性 | 较晦涩 | 更清晰(类似赋值) |
| 支持模板别名 | ❌ 不支持 | ✅ 支持 |
| 可读性 | 类型名在末尾 | 类型名在左侧 |
| 函数指针别名 | 可支持但语法复杂 | 更简洁 |
函数指针别名示例:
// typedef 写法
typedef void (*FuncPtr)(int, int);// using 写法
using FuncPtr = void (*)(int, int);
最佳实践建议
- 优先使用
using(现代 C++ 推荐) - 避免全局
using namespace(易引发命名冲突) - 模板编程中必须用
using(typedef无法替代) - 合理使用继承中的
using(解决重载或访问控制问题)
通过灵活运用 using,可以显著提升代码的可读性和可维护性。
相关文章:
C++项目 —— 基于多设计模式下的同步异步日志系统(3)(日志器类)
C项目 —— 基于多设计模式下的同步&异步日志系统(3)(日志器类) 整体思想设计日志消息的构造C语言式的不定参函数的作用函数的具体实现逻辑1. 日志等级检查2. 初始化可变参数列表3. 格式化日志消息4. 释放参数列表5. 序列化和…...

【数学建模】随机森林算法详解:原理、优缺点及应用
随机森林算法详解:原理、优缺点及应用 文章目录 随机森林算法详解:原理、优缺点及应用引言随机森林的基本原理随机森林算法步骤随机森林的优点随机森林的缺点随机森林的应用场景Python实现示例超参数调优结论参考文献 引言 随机森林是机器学习领域中一种…...
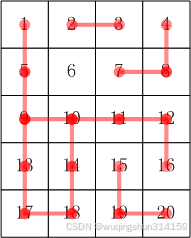
蓝桥杯 19.合根植物
合根植物 原题目链接 题目描述 W 星球的一个种植园被分成 m n 个小格子(东西方向 m 行,南北方向 n 列)。每个格子里种了一株合根植物。 这种植物有个特点,它的根可能会沿着南北或东西方向伸展,从而与另一个格子的…...

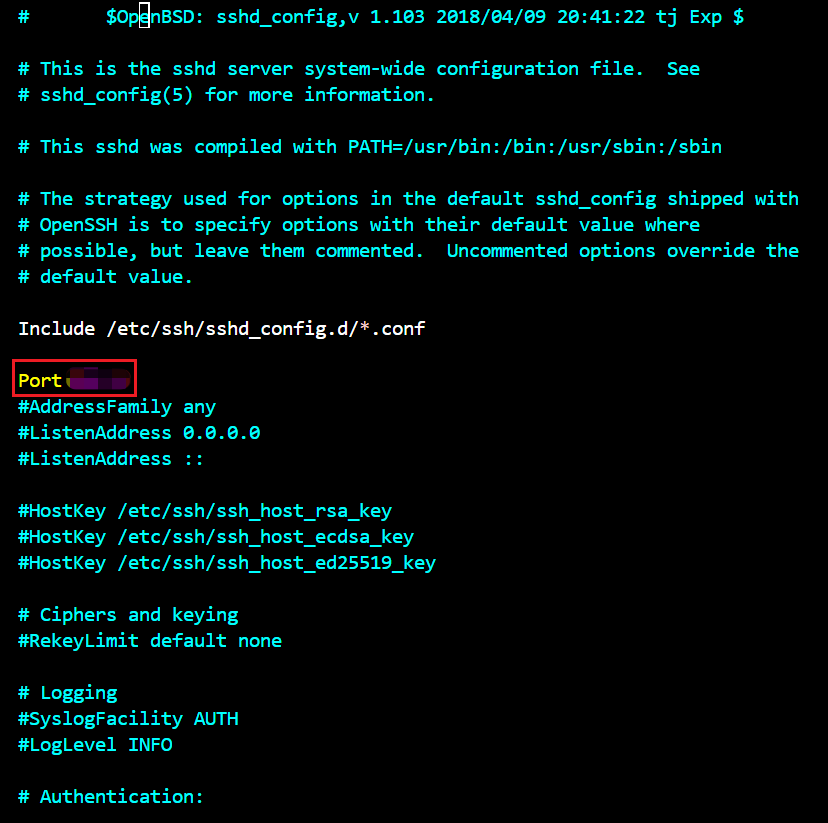
Linux环境MySQL出现无法启动的问题解决 [InnoDB] InnoDB initialization has started.
目录 起因 强制启用恢复模式 备份数据 起因 服务器重启了,然后服务器启动完成之后我发现MySQL程序没有启动,错误信息如下: 2025-04-19T12:46:47.648559Z 1 [System] [MY-013576] [InnoDB] InnoDB initialization has started. 2025-04-1…...
高性能服务器配置经验指南1——刚配置好服务器应该做哪些事
文章目录 安装ubuntu安装必要软件设置用户远程连接安全问题ClamAV安装教程步骤 1:更新系统软件源步骤 2:升级系统(可选但推荐)步骤 3:安装 ClamAV步骤 4:更新病毒库步骤 5:验证安装ClamAV 常用命…...

DePIN驱动的分布式AI资源网络
GAEA通过通证经济模型激励全球用户共享闲置带宽、算力、存储资源,构建覆盖150多个国家/地区的分布式AI基础设施网络。相比传统云服务,GAEA具有显著优势: 成本降低70%:通过利用边缘设备资源,避免了集中式数据中心所需…...

徐州服务器租用:虚拟主机的应用场景
虚拟主机也可以被称为网站空间或者是共享主机,主要是通过软硬件技术将一台物理服务器分割成多个逻辑单元的技术,让每一个单元都拥有着独立的IP地址和完整的网络服务功能,那么虚拟主机的应用场景都有哪些呢? 许多中小型企业会选择租…...
Centos7安装Jenkins(图文教程)
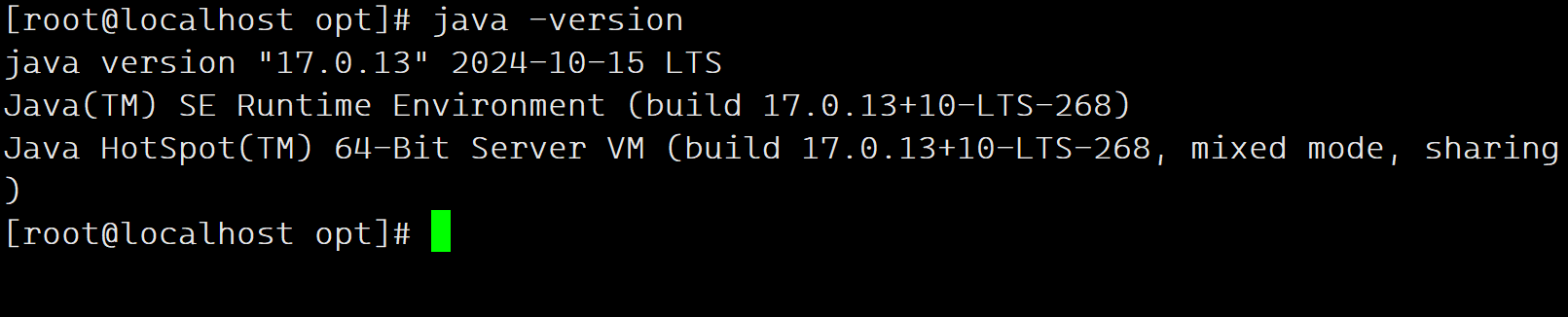
本章教程,主要记录在centos7安装部署Jenkins 的详细过程。 [root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core) 一、基础环境安装 内存大小要求:256 MB 内存以上 硬盘大小要求:10 GB 及以上 安装基础java环境:Java 17 ( JRE 或者 JDK 都可…...

【JAVA】十三、基础知识“接口”精细讲解!(二)(新手友好版~)
哈喽大家好呀qvq,这里是乎里陈,接口这一知识点博主分为三篇博客为大家进行讲解,今天为大家讲解第二篇java中实现多个接口,接口间的继承,抽象类和接口的区别知识点,更适合新手宝宝们阅读~更多内容持续更新中…...

边缘计算盒子是什么?
边缘计算盒子是一种小型的硬件设备,通常集成了处理器、存储器和网络接口等关键组件,具备一定的计算能力和存储资源,并能够连接到网络。它与传统的云计算不同,数据处理和分析直接在设备本地完成,而不是上传到云端&#…...

量子计算在密码学中的应用与挑战:重塑信息安全的未来
在当今数字化时代,信息安全已成为全球关注的焦点。随着量子计算技术的飞速发展,密码学领域正面临着前所未有的机遇与挑战。量子计算的强大计算能力为密码学带来了新的应用场景,同时也对传统密码体系构成了潜在威胁。本文将深入探讨量子计算在…...
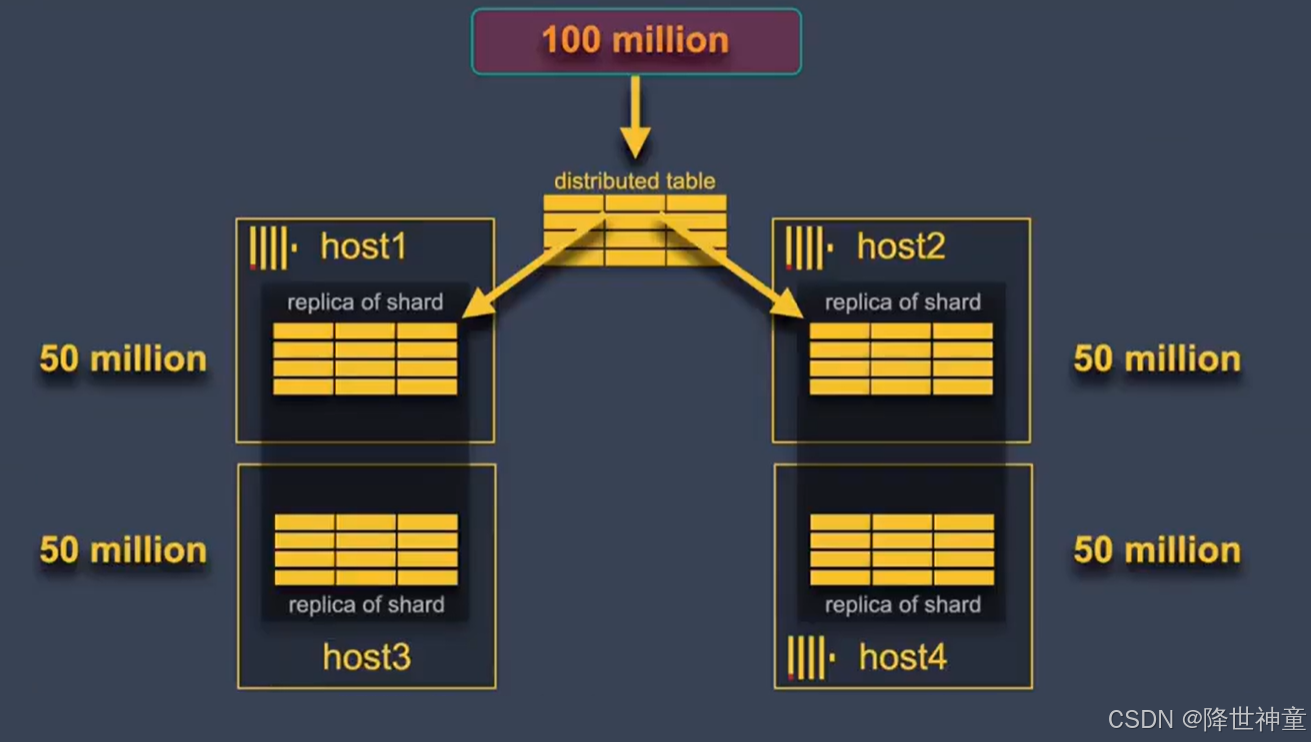
大数据系列 | 详解基于Zookeeper或ClickHouse Keeper的ClickHouse集群部署--完结
大数据系列 | 详解基于Zookeeper或ClickHouse Keeper的ClickHouse集群部署 1. ClickHouse与MySQL的区别2. 在群集的所有机器上安装ClickHouse服务端2.1. 在线安装clickhouse2.2. 离线安装clickhouse 3. ClickHouse Keeper/Zookeeper集群安装4. 在配置文件中设置集群配置5. 在每…...
——辐射度量学)
【C++游戏引擎开发】第20篇:基于物理渲染(PBR)——辐射度量学
引言 在基于物理渲染(PBR)中,辐射度量学是描述光与物质交互的核心数学框架。本文将深入解析辐射度量学的四大基础量,双向反射分布函数(BRDF)的物理本质,以及如何通过积分形式推导出渲染方程。最后,通过OpenGL实践,直观展示辐射率(Radiance)在三维场景中的分布规律。…...
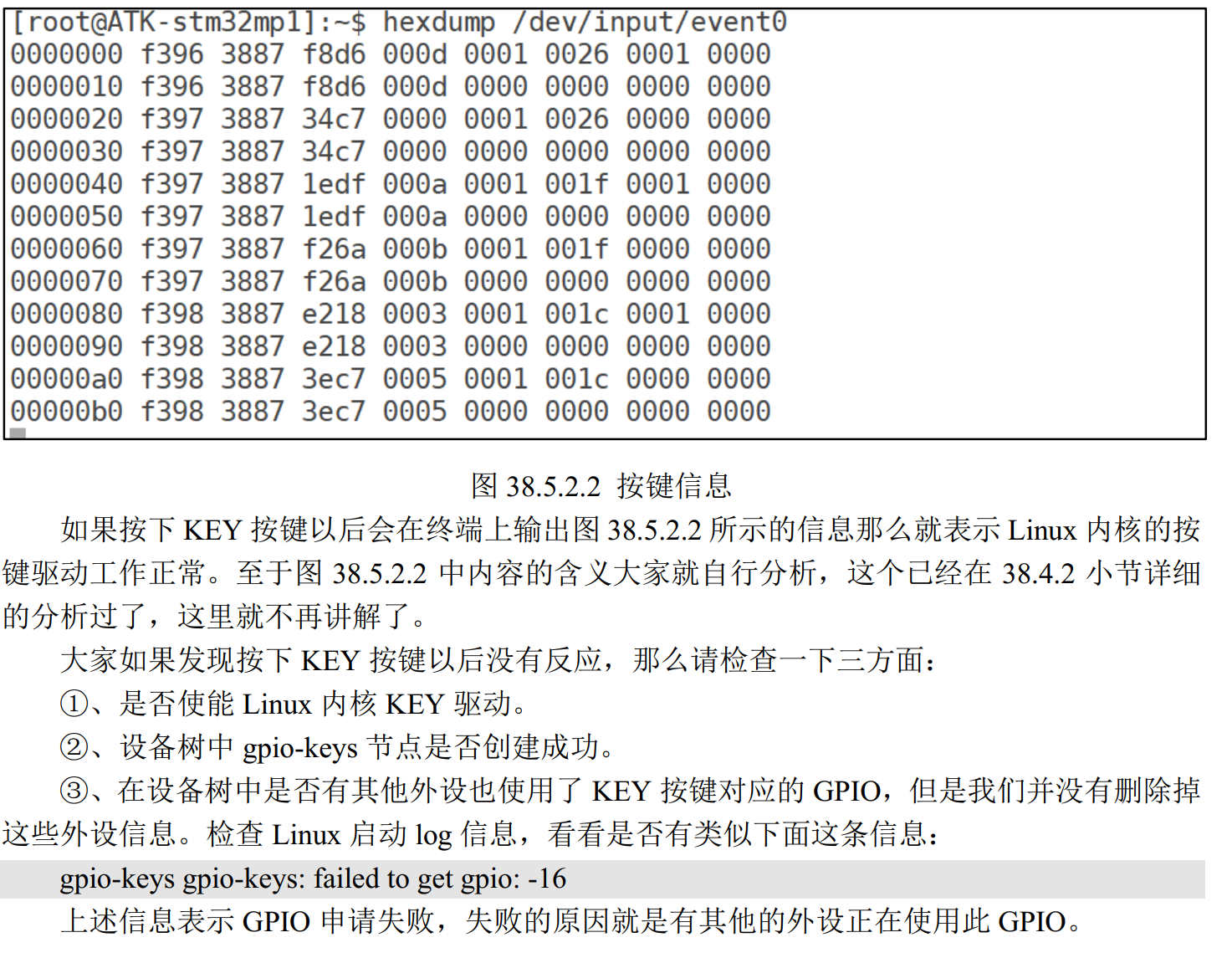
19Linux自带按键驱动程序的使用_csdn
1、自带按键驱动程序源码简析 2、自带按键驱动程序的使用 设备节点信息: gpio-keys {compatible "gpio-keys";pinctrl-names "default";pinctrl-0 <&key_pins_a>;autorepeat;key0 {label "GPIO Key L";linux,code &l…...
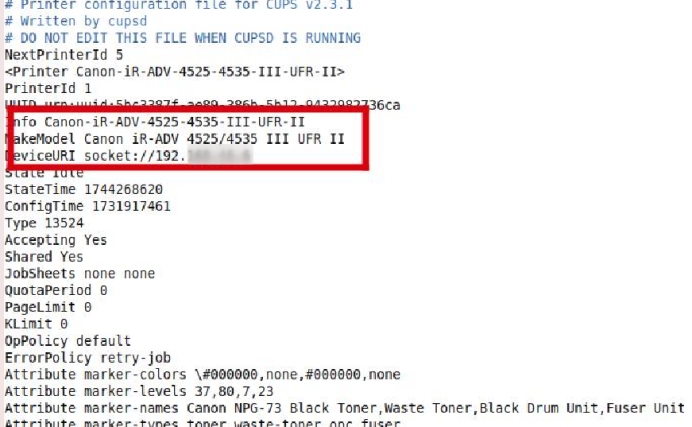
用银河麒麟 LiveCD 快速查看原系统 IP 和打印机配置
原文链接:用银河麒麟 LiveCD 快速查看原系统 IP 和打印机配置 Hello,大家好啊!今天给大家带来一篇在银河麒麟操作系统的 LiveCD 或系统试用镜像环境下,如何查看原系统中电脑的 IP 地址与网络打印机 IP 地址的实用教程。在系统损坏…...
.net core 项目快速接入Coze智能体-开箱即用-第2节
目录 一、Coze智能体的核心价值 二、开箱即用-效果如下 三 流程与交互设计 本节内容调用自有或第三方的服务 实现语音转文字 四:代码实现----自行实现 STT 【语音转文字】 五:代码实现--调用字节API实现语音转文字 .net core 项目快速接入Coze智能…...
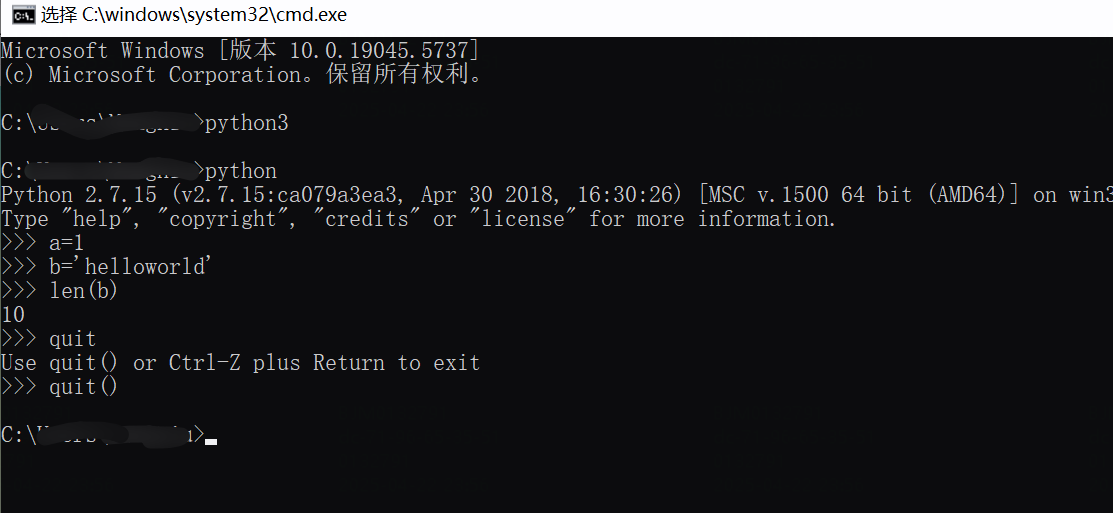
win10中打开python的交互模式
不是输入python3,输入python,不知道和安装python版本有没有关系。做个简单记录,不想记笔记了...
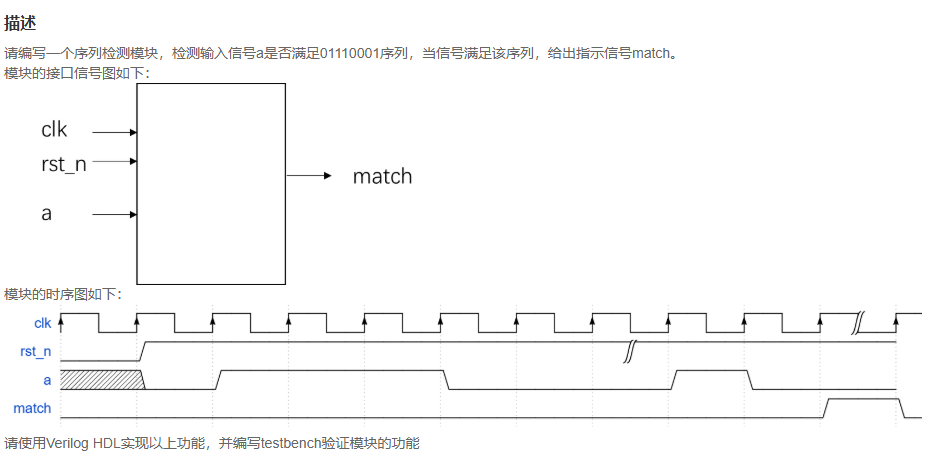
时序逻辑电路——序列检测器
文章目录 一、序列检测二、牛客真题1. 输入序列连续的序列检测(输入连续、重叠、不含无关项、串行输入)写法一:移位寄存器写法二:Moore状态机写法三:Mealy状态机 一、序列检测 序列检测器指的就是将一个指定的序列&…...

SVT-AV1编码器中的模块
一 模块列表 1 svt_input_cmd_creator 2 svt_input_buffer_header_creator 3 svt_input_y8b_creator 4 svt_output_buffer_header_creator 5 svt_output_recon_buffer_header_creator 6 svt_aom_resource_coordination_result_creator 7 svt_aom_picture_analysis_result_creat…...

TikTok X-Gnarly纯算分享
TK核心签名校验:X-Bougs 比较简单 X-Gnarly已经替代了_signature参数(不好校验数据) 主要围绕query body ua进行加密验证 伴随着时间戳 浏览器指纹 随机值 特征值 秘钥转换 自写算法 魔改base64编码 与X-bougs 长a-Bougs流程一致。 视频…...

LPDDR5协议新增特性
文章目录 一、BL/n_min参数含义二、RDQS_t/RDQS_c引脚的功能三、DMI引脚的功能3.1、Write操作时的Data Mask数据掩码操作3.2、Write/Read操作时的Data Bus Inversion操作四、CAS命令针对WR/RD/Mask WR命令的低功耗组合配置4.1、Write/Read操作前的WCK2CK同步操作4.2、Write/Rea…...
:Python Pandas索引技术详解)
python数据分析(二):Python Pandas索引技术详解
Python Pandas索引技术详解:从基础到多层索引 1. 引言 Pandas是Python数据分析的核心库,而索引技术是Pandas高效数据操作的关键。良好的索引使用可以显著提高数据查询和操作的效率。本文将系统介绍Pandas中的各种索引技术,包括基础索引、位…...
【深度学习】#8 循环神经网络
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 为了进一步提高长线学习的效率,该系列从本章开始将舍弃原始教材的代码部分,专注于理论和思维的提炼,系列名也改为“深度学习…...

开源状态机引擎,在实战中可以放心使用
### Squirrel-Foundation 状态机开源项目介绍 **Squirrel-Foundation** 是一个轻量级、灵活、可扩展、易于使用且类型安全的 Java 状态机实现,适用于企业级应用。它提供了多种方式来定义状态机,包括注解声明和 Fluent API,并且支持状态转换、…...

机器学习超参数优化全解析
机器学习超参数优化全解析 摘要 本文全面深入地剖析了机器学习模型中的超参数优化策略,涵盖了从参数与超参数的本质区别,到核心超参数(如学习率、批量大小、训练周期)的动态调整方法;从自动化超参数优化技术…...

AI 模型在前端应用中的典型使用场景和限制
典型使用场景 1. 智能表单处理 // 使用TensorFlow.js实现表单自动填充 import * as tf from tensorflow/tfjs; import { loadGraphModel } from tensorflow/tfjs-converter;async function initFormPredictor() {// 加载预训练的表单理解模型const model await loadGraphMod…...
Linux学习——UDP
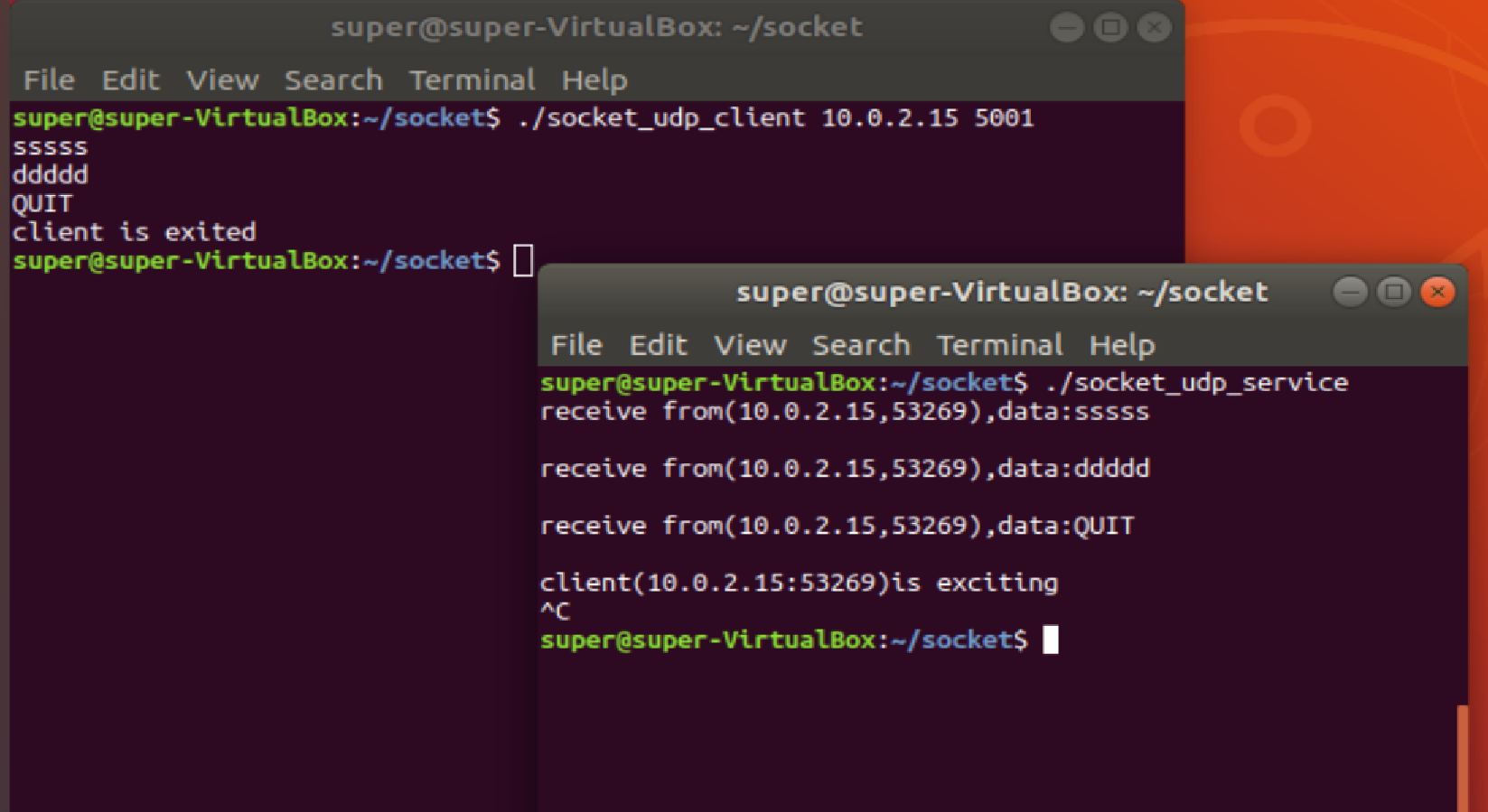
编程的整体框架 bind:绑定服务器:TCP地址和端口号 receivefrom():阻塞等待客户端数据 sendto():指定服务器的IP地址和端口号,要发送的数据 无连接尽力传输,UDP:是不可靠传输 实时的音视频传输&#x…...

leetcode205.同构字符串
两个哈希表存储字符的映射关系,如果前面字符的映射关系和后面的不一样则返回false class Solution {public boolean isIsomorphic(String s, String t) {if (s.length() ! t.length()) {return false;}int length s.length();Map<Character, Character> s2…...

软考软件设计师考试情况与大纲概述
文章目录 **一、考试科目与形式****二、考试大纲与核心知识点****科目1:计算机与软件工程知识****科目2:软件设计** **三、备考建议****四、参考资料** 这是一个系列文章的开篇 本文对2025年软考软件设计师考试的大纲及核心内容进行了整理,并…...

24. git revert
基本概述 git revert 的作用是:撤销某次的提交。与 git reset 不同的是,git revert 不会修改提交历史,而是创建一个新的提交来反转之前的提交。 基本用法 1.基本语法 git revert <commit-hash>该命令会生成一个新的提交,…...