【项目】基于MCP+Tabelstore架构实现知识库答疑系统
基于MCP+Tabelstore架构实现知识库答疑系统
- 整体流程设计
- (一)Agent 架构
- (二)知识库存储
- (1)向量数据库Tablestore
- (2)MCP Server
- (三)知识库构建
- (1)对文本进行切段并提取 FAQ
- (2)写入知识库和 FAQ 库
- (四)知识库检索
- (五)知识库问答
- 项目实践一
- (1)创建知识库存储实例
- (2)启动MCP Server
- (3)导入知识库
- (4)检索知识库
- (5)基于知识库进行问答
- 项目实践二:利用CherryStudio实现MCP
- (1)效果
- 1.1 写入到Tablestore
- 1.2 搜索文档
- (2)流程
- (3)本地运行
- 3.1 下载源码
- 3.2 准备环境
- 3.3 配置环境变量
- 3.4 Embedding
- 3.5 运行 MCP 服务
- (4)集成三方工具
- 4.1 Cherry Studio
- (5)拓展应用场景
整体流程设计

主要分为两部分:知识库构建和检索。
1.知识库构建
- 文本切段:对文本进行切段,切段后的内容需要保证文本完整性以及语义完整性。
- 提取 FAQ:根据文本内容提取 FAQ,作为知识库检索的一个补充,以提升检索效果。
- 导入知识库:将文本和 FAQ 导入知识库,并进行 Embedding 后导入向量。
2.知识检索(RAG)
- 问题拆解:对输入问题进行拆解和重写,拆解为更原子的子问题。
- 检索:针对每个子问题分别检索相关文本和 FAQ,针对文本采取向量检索,针对 FAQ 采取全文和向量混合检索。
- 知识库内容筛选:针对检索出来的内容进行筛选,保留与问题最相关的内容进行参考回答。
相比传统的 Naive RAG,在知识库构建和检索分别做了一些常见的优化,包括 Chunk 切分优化、提取 FAQ、Query Rewrite、混合检索等。
(一)Agent 架构

整体架构分为三个部分:
- 知识库:内部包含 Knowledge Store 和 FAQ Store,分别存储文本内容和 FAQ 内容,支持向量和全文的混合检索。
- MCP Server:提供对 Knowledge Store 和 FAQ Store 的读写操作,总共提供 4 个 Tools。
- 功能实现部分:完全通过 Prompt + LLM 来实现对知识库的导入、检索和问答这几个功能。
具体实现
所有代码开源在这里,分为两部分:
- Python 实现的 Client 端:实现了与大模型进行交互,通过 MCP Client 获取 Tools,根据大模型的反馈调用 Tools 等基本能力。通过 Prompt 实现了知识库构建、检索和问答三个主要功能。
- Java 实现的 Server 端:基于 Spring AI 框架实现 MCP Server,由于底层存储用的是 Tablestore,所以主体框架是基于这篇文章的代码进行改造。
(二)知识库存储
(1)向量数据库Tablestore
知识库存储选择 Tablestore(向量检索功能介绍),主要原因为:
- 简单易用:仅一个创建实例步骤后即可开始使用,Serverless 模式无需管理容量和后续运维。
- 低成本:完全按量计费,自动根据存储规模水平扩展,最大可扩展至 PB 级。当然如果采用本地知识库肯定是零成本,但这里实现的是一个企业级、可通过云共享的知识库。
- 功能完备:支持全文、向量和标量等检索功能,支持混合检索。
(2)MCP Server
实现了 4 个 Tools(具体注册代码可参考 TablestoreMcp),相关描述如下:
| Tools | 功能 | 给 LLM 的描述 | 输入参数 | 输出结果 |
|---|---|---|---|---|
| storeKnowledge | 写入知识库内容,同时进行 Embedding 后写入向量。 | Store document into knowledge store for later retrieval. | { “content”:“知识库内容”, “meta_data”: { “source”: “文档” } } | { “content”: [ { “type”: “text”, “text”: “null” } ], “isError”: false } |
| searchKnowledge | 对知识库进行向量检索提取内容 | Search for similar documents on natural language descriptions from knowledge store. | { “query”: “知识库内容”, “size”: 100 } | { “content”: [ { “type”: “text”, “text”: “[{“content”:“知识库内容”,“meta_data”:{“source”:“文档”}}]}” } ], “isError”: false } |
| storeFAQ | 写入 FAQ 内容,问题和答案分别写入 Question 和 Answer 两个字段,Question 字段额外进行 Embedding 后写入向量。 | Store document into FAQ store for later retrieval. | { “question”: “问题”, “answer”: “答案” } | { “content”: [ { “type”: “text”, “text”: “null” } ], “isError”: false } |
| searchFAQ | 通过对 Question 的全文和向量的混合检索来提取内容。 | Search for similar documents on natural language descriptions from FAQ store. | { “query”: “问题”, “size”: 100 } | { “content”: [{ “type”: “text”, “text”: “[{“question”:“问题”,“answer”:“答案”}]” } ], “isError”: false } |
(三)知识库构建
(1)对文本进行切段并提取 FAQ
完全通过提示词来完成,可根据自己的要求进行调优。
| 提示词 | 输入 | 输出 |
|---|---|---|
| 需要将以下文本切段,并根据文本内容整理 FAQ。文本切段的要求: <1>保证语义的完整性:不要将一个完整的句子切断,不要把表达同一个语义的不同句子分割开 <2>保留足够多的上下文信息:如果切割后的文本段必须依赖上下文信息才能表达正确的语义,那就不能切割开 <3>过滤无效信息:过滤格式化内容如大量填充的空格,过滤不完整的段落以及过滤 <4>移除 markdown 内容的标记,层次关系按 1, 2, 3 以及 1.1, 2.1 来标记 <5>只保留文本内容,移除链接等信息 <6>不要对标题单独切段:仅对正文进行切段,标题可以与正文合并一起,或者是作为上下文信息扩充进正文分段内 <7>切段后的文本如果不是一个完整的句子,请修改为一个完整表述的句子 | 表格存储向量检索在原有的 DiskANN 算法之上进行优化,提供大规模和高性能的向量检索服务。前期,我们也先对用户提供了基于 HNSW 的图算法,但是发现明显的性能问题,HNSW 对内存要求很高,很难支撑大规模数据,当内存不足时,HNSW 访问磁盘的性能较差。表格存储上的用户大多数数量相对较大,HNSW 的规模和成本问题不符合我们产品的定位,我们希望可以让更多的数据可以低成本的使用上向量能力,因此我们后续废弃掉了 HNSW 算法,使用 DiskAnn 重新实现了向量检索能力。 | { “Chunks”: [ “表格存储向量检索在原有的 DiskANN 算法之上进行优化,提供大规模和高性能的向量检索服务。前期,我们也先对用户提供了基于 HNSW 的图算法,但是发现明显的性能问题。”, “HNSW 对内存要求很高,很难支撑大规模数据,当内存不足时,HNSW 访问磁盘的性能较差。表格存储上的用户大多数数量相对较大,HNSW 的规模和成本问题不符合我们产品的定位。”, “我们希望可以让更多的数据可以低成本使用上向量能力,因此我们后续废弃掉了 HNSW 算法,使用 DiskAnn 重新实现了向量检索能力。” ] } { “FAQ”: [ {“Question”: “表格存储向量检索使用了什么算法?”, “Answer”: “表格存储向量检索在原有的 DiskANN 算法之上进行了优化,提供大规模和高性能的向量检索服务。” }, {“Question”: “为什么最初选择了 HNSW 图算法?”, “Answer”: “前期对用户提供了基于 HNSW 的图算法,但发现其存在明显的性能问题。” }, {“Question”: “HNSW 算法的主要缺点是什么?”, “Answer”: “HNSW 对内存要求很高,难以支撑大规模数据,且在内存不足时访问磁盘的性能较差。”}, { “Question”: “为什么废弃了 HNSW 算法?”, “Answer”: “HNSW 的规模和成本问题不符合表格存储产品的定位,无法满足大规模数据低成本使用向量能力的需求。” }, {“Question”: “表格存储最终采用什么算法替代 HNSW?”, “Answer”: “后续废弃了 HNSW 算法,使用 DiskANN 重新实现了向量检索能力。” } ] } |
以上是一个示例,可以看到通过大模型能比较准确的对文本进行切段并提取 FAQ。这种方式的优势是切段的文本能保证完整性以及语义一致性,能够比较灵活的对格式做一些处理。提取的 FAQ 很全面,对于简单问题的问答通过直接搜索 FAQ 是最准确直接的。最大的缺点就是执行比较慢并且成本较高,一次会消耗大量的 Token,不过好在是一次性的投入。
(2)写入知识库和 FAQ 库
这一步也是通过提示词来完成,基于 MCP 架构可以非常简单的实现,样例如下:
| 操作类型 | 提示词模板 |
|---|---|
| 写入知识库 | 将以下内容存储入 Knowledge 知识库内:%s |
| 写入 FAQ | 将以下内容存储入 FAQ 库内: Question:%s Answer:%s |
(四)知识库检索
同样这一步也是通过提示词加 MCP 来实现,非常的简单,样例如下:
| 提示词模板 | 检索条件 | 检索结果 |
|---|---|---|
| 你是产品答疑助手,在回答问题之前请先检索 Knowledge 库和 FAQ 库: 1. 先理解问题并对问题进行拆解,拆解成多个子问题。 2. 每个子问题同时检索 Knowledge 库和 FAQ 库,每次检索结果不超过 20 条 3. 对检索的内容进行筛选,保留与问题最相关的内容,Knowledge 和 FAQ 分别不超过 10 条。 最后合并检索内容,返回与检索内容最相关的 20 条,直接返回检索的结果,样例如下: 1. 如果是 Knowledge,格式为:Knowledge:<结果一> 2. 如果是 FAQ,格式为:FAQ:<结果二> 检索内容:%s | Tablestore 底层向量索引算法选择了哪种实现? | Knowledge:表格存储向量检索在原有的 DiskANN 算法之上进行优化。 Knowledge:表格存储上的用户大多数数据量相对较大。 FAQ:为什么最初选择了 HNSW 图算法? FAQ:为了给用户提供一种向量检索的服务选项。 FAQ:表格存储向量检索是基于什么算法实现的? FAQ:表格存储向量检索是在原有的 DiskANN 算法基础上进行了优化。 |
通过提示词描述实现了一个稍微复杂点的检索:
-
1.先对问题进行拆解,拆解为更原子的子问题。
-
2.每个子问题分别检索知识库和 FAQ,检索结果汇总后筛选留下与问题最相关的内容。
-
3.按照格式返回结果。
(五)知识库问答
直接看下提示词和效果
| 提示词模板 | 问题 | 答案 |
|---|---|---|
| 你是产品答疑助手,在回答问题之前请先检索 Knowledge 库和 FAQ 库: 1. 先理解问题并对问题进行拆解,拆解成多个子问题,子问题尽量是比较小比较原子的问题。 2. 每个子问题同时检索 Knowledge 库和 FAQ 库,每次检索结果不超过 10 条,最后合并所有子问题的检索结果。 对检索的内容进行筛选,保留与问题最相关的检索结果,利用检索到的内容进行回答,不要乱给答案。 我的问题是:%s | Tablestore 底层向量索引算法选择了哪种实现? | Tablestore 底层向量索引算法选择了 DiskANN 算法实现。 最初,Tablestore 曾尝试使用 HNSW (Hierarchical Navigable Small World) 图算法来提供向量检索服务。 然而,HNSW 对内存要求很高,难以支撑大规模数据。当内存不足时,HNSW 访问磁盘的性能极差。考虑到大多数用户的大量数据需求以及希望让更多的数据能够以较低成本使用上向量能力的愿望, 最终决定不再使用 HNSW 算法,而是基于 DiskANN 算法进行了优化,提供了大规模和高性能的向量检索服务。 |
从 MCP Server 的 Log 内可以看到自动调用了知识库和 FAQ 的检索工具,并能根据之前导入的内容进行回答。
项目实践一
开源地址:aliyun/alibabacloud-tablestore-mcp-server
(1)创建知识库存储实例
可通过命令行工具(下载地址)来创建 Tablestore 实例,参考这个文档先进行配置。
配置成功后执行以下命令进行实例创建,实例名自行选择,需要保证 Region 内唯一。
tablestore> create_instance -r cn-hangzhou -d 'Knowledge store for AI Agent.' -n 'my-store' done
(2)启动MCP Server
启动前需要在环境变量内配置如下几个参数:
| 变量名 | 必填 | 含义 | 默认值 |
|---|---|---|---|
| TABLESTORE_INSTANCE_NAME | 是(yes) | 实例名 | - |
| TABLESTORE_ENDPOINT | 是(yes) | 实例访问地址 | - |
| TABLESTORE_ACCESS_KEY_ID | 是(yes) | 秘钥 ID | - |
| TABLESTORE_ACCESS_KEY_SECRET | 是(yes) | 秘钥 SECRET | - |
可参考代码库 README 内的步骤进行启动,也可将项目导入 IDE 后直接运行 App 这个类,启动后会自动初始化表和索引。
(3)导入知识库
这一步需要执行代码库内的 knowledge_manager.py 工具,执行前需要先配置访问大模型的 API-KEY,默认采用 qwen-max。
export LLM_API_KEY=sk-xxxxxx
请自行准备知识库文档,使用 markdown 格式,执行如下:

(4)检索知识库
执行如下:

(5)基于知识库进行问答

项目实践二:利用CherryStudio实现MCP
(1)效果
这里展示 2 个 tool 的能力,一个是存储工具,一个是搜索工具。 我们使用的软件是热门的开源软件 cherry-studio, 使用的大模型是通义千问的 qwen-max 模型
1.1 写入到Tablestore
cherry-studio 使用示例如下图:

python Server 端代码的写入日志如下图:

Tablestore(表格存储) 控制台数据存储结果如下图:

1.2 搜索文档
Tablestore(表格存储) 的多元索引支持向量、标量、全文检索等各种类型的组合查询,该示例代码中使用了混合检索,如需更复杂的查询,可以参考文章最后的“贡献代码和二次开发”章节了解如何自定义开发。
cherry-studio 搜索查询示例如下图:

python Server 端的查询日志如下图:

Tablestore(表格存储) 控制台数据也可以进行查询,这里以全文检索示例:

(2)流程

MCP server 提供的 2 个工具十分简单:
- 写入: 文档经过 MCP server 内置的 Embedding ( 默认为 BAAI/bge-base-zh-v1.5 ) 模型,写入到Tablestore(表格存储)即可。
- 查询: 用户的查询文本经过 MCP server 内置的 Embedding 模型转成向量,然后调用表格存储的 多元索引即可,其内部使用了 向量检索 和 全文检索 进行混合查询,最终召回用户期望的结果。
(3)本地运行
3.1 下载源码
- 使用
git clone将代码下载到本地。 - 进入 python 源码的根目录:
cd tablestore-mcp-server/tablestore-python-mcp-server
3.2 准备环境
代码需要 python3.10 版本以上进行构建,使用了 uv 进行包和环境管理。
安装 uv:
# 方式1:使用现有 python3 安装 uv
pip3 install uv
# 方式2:源码安装 uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
准备 Python 环境:
如果本地有
python3.10版本以上环境,无需执行这一小步。
因为我们项目至少需要 python3.10 版本,这里使用 python3.12 进行示例。
# 查看当前有哪些 python 环境
uv python list
# 如果没有python 3.12.x 相关版本,请安装 python3.12 版本. 内部会从 github 下载 uv 官方维护的 python 包。
uv python install 3.12
创建虚拟环境:
# 使用 python 3.12 版本当做虚拟环境
uv venv --python 3.12
3.3 配置环境变量
代码里所有的配置是通过环境变量来实现的,出完整的变量见下方表格。 主要依赖的数据库 Tablestore(表格存储) 支持按量付费,使用该工具,表和索引都会自动创建,仅需要在控制台上申请一个实例即可。
| 变量名 | 必填 | 含义 | 默认值 |
|---|---|---|---|
| SERVER_HOST | 否 | MCP server 的 host | 0.0.0.0 |
| SERVER_PORT | 否 | MCP server 的 port | 8001 |
| TABLESTORE_INSTANCE_NAME | 是(yes) | 实例名 | - |
| TABLESTORE_ENDPOINT | 是(yes) | 实例访问地址 | - |
| TABLESTORE_ACCESS_KEY_ID | 是(yes) | 秘钥 ID | - |
| TABLESTORE_ACCESS_KEY_SECRET | 是(yes) | 秘钥 SECRET | - |
| TABLESTORE_TABLE_NAME | 否 | 表名 | ts_mcp_server_py_v1 |
| TABLESTORE_INDEX_NAME | 否 | 索引名 | ts_mcp_server_py_index_v1 |
| TABLESTORE_VECTOR_DIMENSION | 否 | 向量维度 | 768 |
| TABLESTORE_TEXT_FIELD | 否 | 文本字段名 | _content |
| TABLESTORE_VECTOR_FIELD | 否 | 向量字段名 | _embedding |
| EMBEDDING_PROVIDER_TYPE | 否 | Embedding 模型提供者 | hugging_face(当前仅支持 hugging_face) |
| EMBEDDING_MODEL_NAME | 否 | Embedding 模型名字 | BAAI/bge-base-zh-v1.5(维度是768,和 TABLESTORE_VECTOR_DIMENSION 呼应) |
| TOOL_STORE_DESCRIPTION | 否 | 写入的 MCP tool 的描述文字 | 参考 settings.py |
| TOOL_SEARCH_DESCRIPTION | 否 | 查询的 MCP tool 的描述文字 | 参考 settings.py |
3.4 Embedding
为了方便,这里不使用云服务的Embedding能力,而使用了内置的本地Embedding模型,示例代码仅支持了 HuggingFace 的本地Embedding模型,使用十分简单,如果网络不好,可以配置 HuggingFace 的镜像。
export HF_ENDPOINT=http://hf-mirror.com
3.5 运行 MCP 服务
# 加速下载 Hugging 的 Embedding Model
export HF_ENDPOINT=http://hf-mirror.comexport TABLESTORE_ACCESS_KEY_ID=xx
export TABLESTORE_ACCESS_KEY_SECRET=xx
export TABLESTORE_ENDPOINT=xxx
export TABLESTORE_INSTANCE_NAME=xxx
# 默认以 sse 模式运行,如果希望以 stdio 模式运行可以添加: `--transport stdio`
uv run tablestore-mcp-server
(4)集成三方工具
4.1 Cherry Studio
Cherry-Studio,是一个热门的开源的 AI Client 软件, 免费使用,其支持 MCP 服务。
安装 :Github链接 下载最新版本的适合自己机器运行环境的安装包. 比如我的电脑是m1芯片的mac,因此下载 Cherry-Studio-1.1.4-arm64.dmg 进行安装。安装好后,需要配置大模型的 api-key 相关信息,这里不再一一描述。
按照如下所示创建MCP服务:

在聊天里使用MCP服务(可以把一些模版填充到 Cherry Studio 的模版里,生成一个自己的特殊助手,后续可以直接使用):

(5)拓展应用场景
MCP 的 Tool 的能力和场景是 Tool 的描述来提供的,因此我们可以定义一些特殊的能力,可以发挥你的想象力。另外,当前我们没有接入一些复杂的多字段自由 Filter 能力、稀疏向量(Sparse Vector)能力,后续有时间会继续进行集成。
仅需要修改如下配置即可, 如何写可以参考 settings.py
export TOOL_STORE_DESCRIPTION="你的自定义的描述"export TOOL_SEARCH_DESCRIPTION="你的自定义的描述"
修改后从 MCP Client 中可以看到工具 (Tool) 的描述已经变成了自定义的描述,那么大模型(LLM)就会根据你的描述去使用工具(Tool)。

相关文章:
【项目】基于MCP+Tabelstore架构实现知识库答疑系统
基于MCPTabelstore架构实现知识库答疑系统 整体流程设计(一)Agent 架构(二)知识库存储(1)向量数据库Tablestore(2)MCP Server (三)知识库构建(1&a…...

当OCR遇上“幻觉”:如何让AI更靠谱地“看懂”文字?
在数字化的世界里,OCR(光学字符识别)技术就像给机器装上了“电子眼”。但当这项技术遇上大语言模型,一个意想不到的问题出现了——AI竟然会像人类一样产生“幻觉”。想象一下,当你拿着模糊的财务报表扫描件时ÿ…...
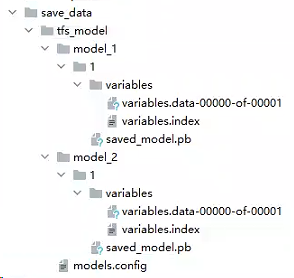
Docker用model.config部署及更新多个模型
步骤: 1、本地打包模型 2、编写model.config文件 3、使用 Docker 启动一个 TensorFlow Serving 容器 4、本地打包后的模型修改后,修改本地model.config,再同步更新容器的model.config 1、本地打包模型(本地路径) 2、…...
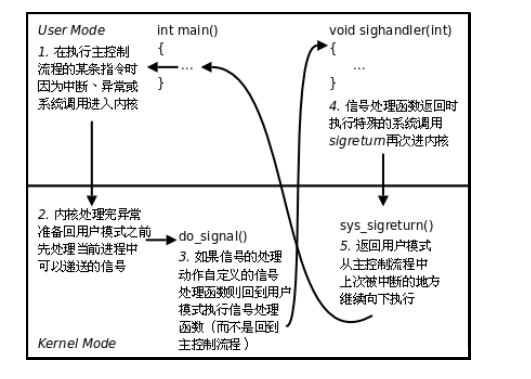
Linux kernel signal原理(下)- aarch64架构sigreturn流程
一、前言 在上篇中写到了linux中signal的处理流程,在do_signal信号处理的流程最后,会通过sigreturn再次回到线程现场,上篇文章中介绍了在X86_64架构下的实现,本篇中介绍下在aarch64架构下的实现原理。 二、sigaction系统调用 #i…...
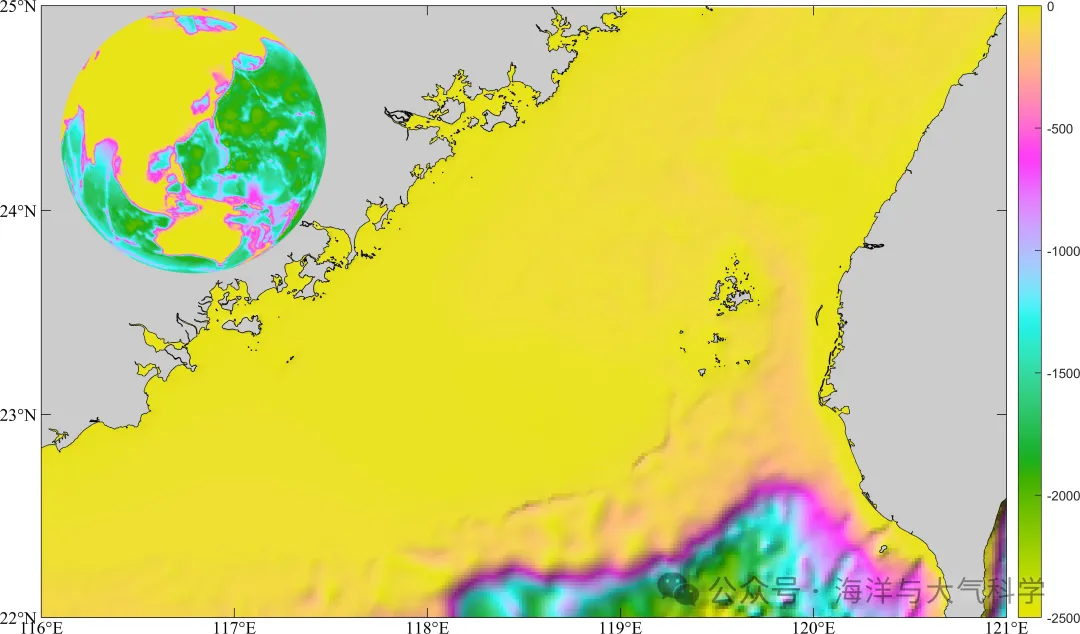
matlab论文图一的地形区域图的球形展示Version_1
matlab论文图一的地形区域图的球形展示Version_1 图片 此图来源于: 
发布一个npm包,更新包,删除包
发布一个npm包,更新包,删除包 如何将自己的项目 发布为一个 npm 包,并掌握 更新 和 删除 的操作流程。 🚀 一、发布一个 npm 包的完整流程 ✅ 1. 注册并登录 npm 账号 如果还没有账号,先注册: 官网注册&…...

Redis专题
前言 Redis的各种思想跟机组Cache和操作系统对进程的管理非常类似! 一:看到你的简历上写了你的项目里面用到了redis,为啥用redis? 因为传统的关系型数据库如Mysql,已经不能适用所有的场景,比如秒杀的库存扣减ÿ…...

LeetCode[232]用栈实现队列
思路: 一道很简单的题,就是栈是先进后出,队列是先进先出,用两个栈底相互对着,这样一个队列就产生了,右栈为空的情况,左栈栈底就是队首元素,所以我们需要将左栈全部压入右栈ÿ…...
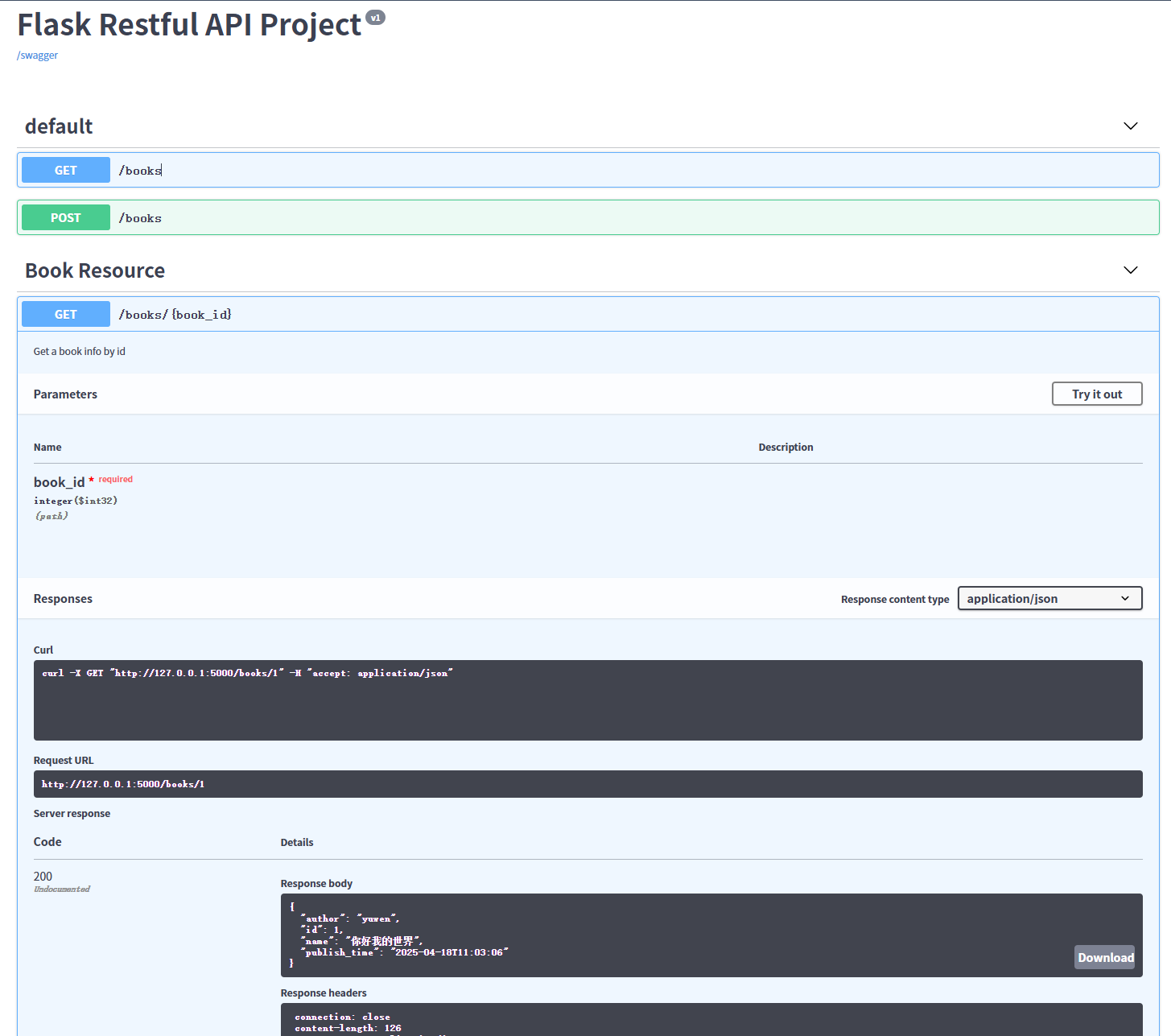
Flask API 项目 Swagger 版本打架不兼容
Flask API 项目 Swagger 版本打架不兼容 1. 问题背景 在使用 Flask 3.0.0 时遇到以下问题: 安装 flask_restful_swagger 时,它强制将 Flask 降级到 1.1.4,并导致其他依赖(如 flask-sqlalchemy、flask-apispec)出现版…...
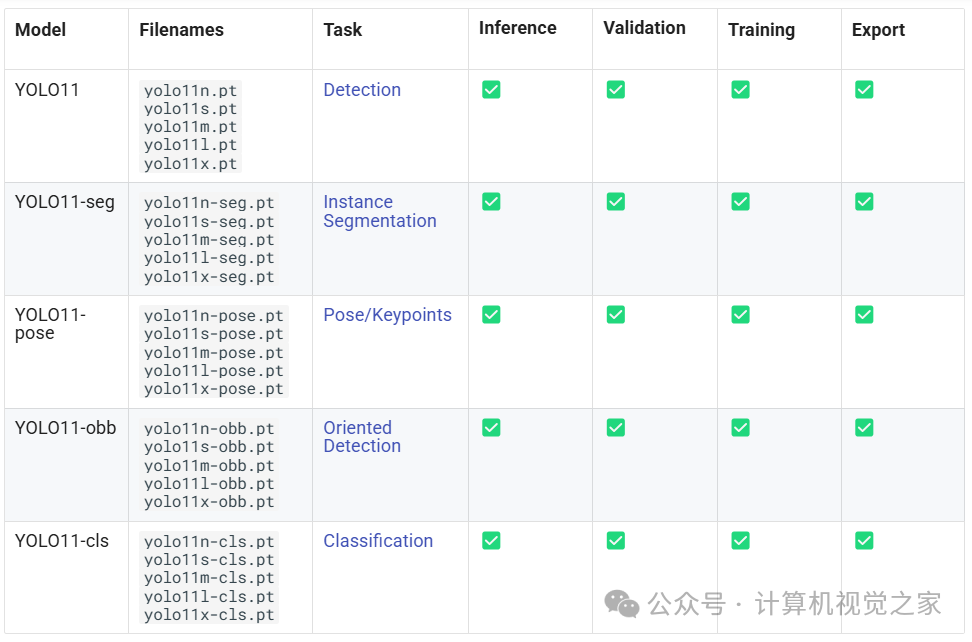
基于YOLOv11 和 ByteTrack 实现目标跟踪
介 绍 之前我们介绍了使用YOLOv9与 ByteTrack 结合进行对象跟踪的概念,展示了这两种强大的技术如何有效地协同工作。现在,让我们通过探索与 ByteTrack 结合的 YOLOv11 来进一步了解这一概念。 实战 | 基于YOLOv9和OpenCV实现车辆跟踪计数(步骤…...
Qt Creator 创建 Qt Quick Application一些问题
一、Qt Creator 创建 Qt Quick Application 时无法选择 MSVC 编译器(即使已安装 Qt 5.15.2 和 MSVC2019) 1、打开 Qt Creator 的编译器设置 工具 (Tools) → 选项 (Options) → Kits → 编译器 (Compilers) 检查是否存在 Microsoft Visual C++ Compiler (x86_amd64) 或类似条…...

编码转换器
大批量转换编码 可以将整个工程文件夹从GB18030转为UTF-8 使用Qt C制作 项目背景 比较老的工程,尤其是keil嵌入式的工程,其文本文件(.c、.cpp、.h、.txt、……)编码为gb2312,这为移植维护等带来了不便。现在uit-8用…...

Django 中集成 Apache Kafka 可以实现异步消息处理、数据流式传输
在 Django 中集成 Apache Kafka 可以实现异步消息处理、数据流式传输等功能,以下是详细的集成步骤和示例代码: 1. 安装必要的库 首先,你需要安装 kafka-python 库,它是 Python 中操作 Kafka 的常用库。可以使用以下命令进行安装: pip install kafka-python2. 配置 Kafk…...

Scala 入门指南
Scala 入门指南 目录 简介环境搭建基础语法面向对象编程函数式编程集合模式匹配特质隐式转换并发编程与 Java 互操作最佳实践常见问题 简介 Scala 是一种多范式编程语言,结合了面向对象编程和函数式编程的特性。它运行在 JVM 上,与 Java 完全兼容&am…...

[密码学实战]密评考试训练系统v1.0程序及密评参考题库(获取路径在文末)
[密码学实战]密评考试训练系统v1.0程序及密评参考题库 引言:密评考试的重要性与挑战 商用密码应用安全性评估(简称"密评") 作为我国密码领域的重要认证体系,已成为信息安全从业者的必备技能。根据国家密码管理局最新数据,截至2024年6月,全国仅有3000余人持有…...

【Rust 精进之路之第6篇-流程之舞】控制流:`if/else`, `loop`, `while`, `for` 与模式匹配初窥
系列: Rust 精进之路:构建可靠、高效软件的底层逻辑 作者: 码觉客 发布日期: 2025-04-20 引言:让代码“活”起来——指令的流动 在前面的文章中,我们已经掌握了 Rust 的基础数据类型(标量和复合类型)以及如何通过变量绑定来存储和命名它们。这相当于我们准备好了程序…...

Git ——提交至github,Vercel拉取,更新不了项目的问题解决
首先因为github上有个错误 1 failing check Vercel - No GitHub account was found matching the commit author email address 发现好像是vercel拉取不了项目,vercel登录的邮箱与我此次提交更改的邮箱不匹配,查看Git的user确实如此(之前的…...
)
原型模式详解及在自动驾驶场景代码示例(c++代码实现)
模式定义 原型模式(Prototype Pattern)是一种创建型设计模式,通过克隆已有对象来创建新对象,避免重复执行昂贵的初始化操作。该模式特别适用于需要高效创建相似对象的场景,是自动驾驶感知系统中处理大量重复数据结构的…...

蓝桥杯常考的找规律题
目录 灵感来源: B站视频链接: 找规律题具有什么样的特点: 报数游戏(Java组): 题目描述: 题目链接: 思路详解: 代码详解: 阶乘求和(Java组…...
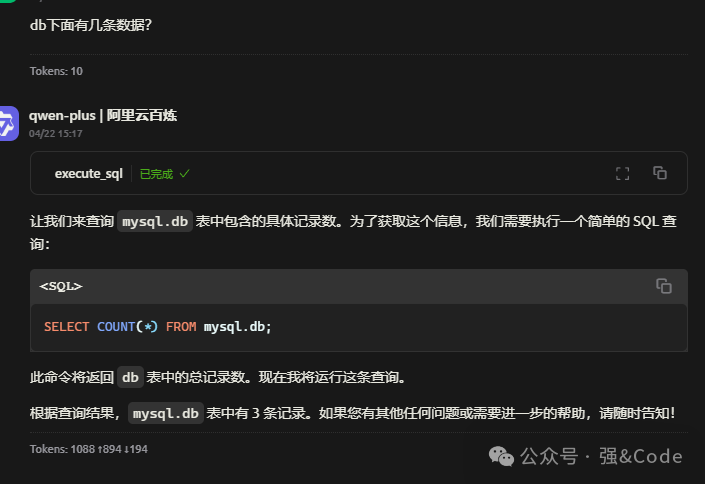
MySQL_MCP_Server_pro接入cherry_studio实现大模型操作数据库
大模型直接与数据库交互,实现基本增删改查操作。首先贴下代码地址: https://github.com/wenb1n-dev/mysql_mcp_server_pro 安装环境:win10 1、下载代码 git clone https://github.com/wenb1n-dev/mysql_mcp_server_pro 2、使用conda创建…...

Element UI、Element Plus 里的表单验证的required必填的属性不能动态响应?
一 问题背景 想要实现: 新增/修改对话框中(同一个),修改时“备注”字段非必填,新增时"备注"字段必填 结果发现直接写不生效-初始化一次性 edit: [{ required: true, message: "请输入备注", trigger: "blur" }…...
Spark-Streaming
WordCount案例 添加依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation"…...
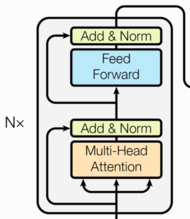
transformer 子层连接结构
子层连接结构 目标 了解什么是子层连接结构掌握子层连接结构的实现过程 什么是子层连接结构? 输入到每个子层以及规范化层的过程中, 使用了残差连接(跳跃连接, 从Add&Norm -> Add&Norm), 因此我们把这一部分结构整体叫做子层连接(代表子层及其链接结构), 在每个…...
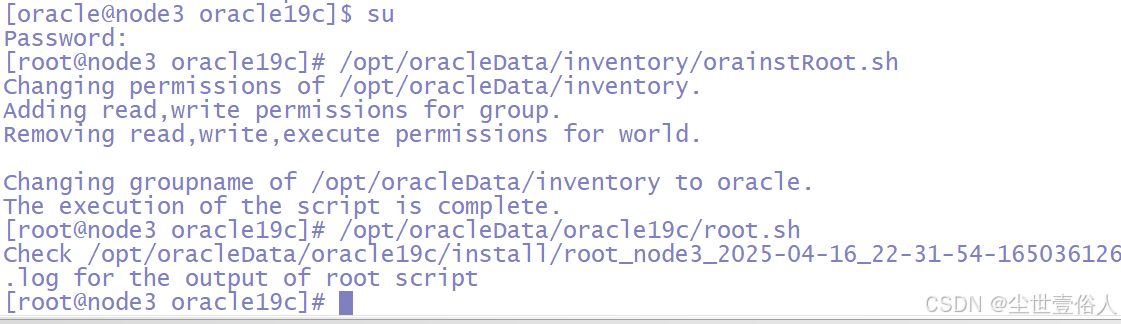
linux oracle 19c 静默安装
oracle数据库有个比较很抓瞎的事情,不同的版本搭建的大致流程是一样的,但是在实操细节上会有不同,比如操作的脚本位置和配置项等等,这些会变,所以需要时常积累不同版本的文档 这里有一点要说明,之所以使用…...
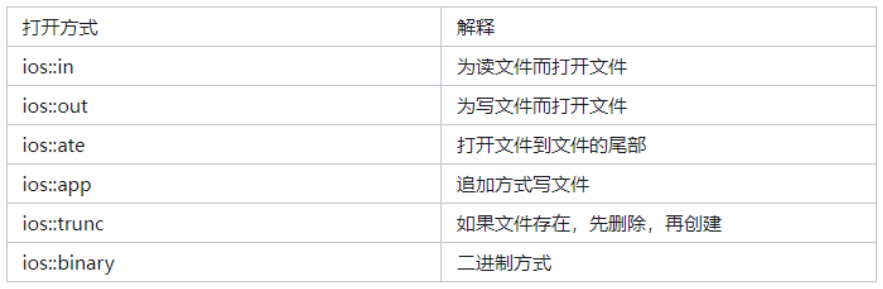
C++ 的 输入输出流(I/O Streams)
什么是输入输出流 C 的输入输出操作是通过 流(stream) 机制实现的。 流——就是数据的流动通道,比如: 输入流:从设备(如键盘、文件)读取数据 → 程序 输出流:程序将数据写入设备&…...

mybatis-plus开发orm
1、mybatis 使用mybatis-generator自动生成代码 这个也是有系统在使用 2、mybatis-plus开发orm--有的系统在使用 MybatisPlus超详细讲解_mybatis-plus-CSDN博客...

使用Python+OpenCV将多级嵌套文件夹下的视频文件抽帧为JPG图片
使用PythonOpenCV将多级嵌套文件夹下的视频文件抽帧为JPG图片 import os import cv2 import time# 存放视频文件的多层嵌套文件夹路径 videoPath D:\\videos\\ # 保存抽帧的图片的文件夹路径 savePath D:\\images\\if not os.path.exists(savePath):os.mkdir(savePath) vide…...
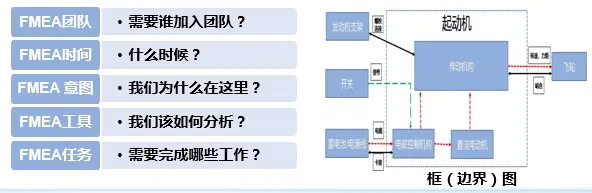
电子电器架构 --- DFMEA设计失效模式和后果分析
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

C#抽象类和虚方法的作用是什么?
抽象类 (abstract class): 不能直接实例化,只能被继承。 用来定义一套基础框架和规范,强制子类必须实现某些方法(抽象方法)。 可用来封装一些共通的逻辑,减少代码重复。 虚方法 (virtual): …...

C#获取当前方法的命名空间、类名称、方法名称以及方法的参数信息
C#获取当前方法的命名空间、类名称、方法名称以及方法的参数信息 输出示例模块示例 输出示例 获取信息:WindowsFormsApp1.Form1.button1_Click(System.Object sender,System.EventArgs e) 引发的异常:“System.IndexOutOfRangeException”(位于 WindowsFormsApp1.ex…...