在离线 Ubuntu 环境下部署双 Neo4j 实例(Prod Dev)
在许多开发和生产场景中,我们可能需要在同一台服务器上运行多个独立的 Neo4j 数据库实例,例如一个用于生产环境 (Prod),一个用于开发测试环境 (Dev)。本文将详细介绍如何在 离线 的 Ubuntu 服务器上,使用 tar.gz 包部署两个 Neo4j 4.4 实例,并配置不同的端口以供外部访问,同时涵盖了部署过程中可能遇到的常见问题及其解决方案。
1. 需求:
ubuntu系统下,离线环境,我想要部署两套neo4j的数据库(一套prod(服务端口17687,浏览器端口17474),一套dev(服务端口17688,浏览器端口17475),都需要别的主机能访问到)(下载的neo4j版本为neo4j-community-4.4.42-unix.tar.gz)
**前提条件:**Java 11 运行环境
2. 场景目标
- 环境: 离线 Ubuntu 服务器。
- 软件: Neo4j Community Edition 4.4.42 (以 neo4j-community-4.4.42-unix.tar.gz 形式提供)。
- 目标:
- 部署一个生产实例 (Prod),服务端口 17687 ,浏览器端口 17474 。
- 部署一个开发实例 (Dev),服务端口 17688 ,浏览器端口 17475 。
- 两个实例均需配置为可从其他主机访问。
- 解决部署过程中可能遇到的常见问题。
3. 准备工作
在开始部署之前,请确保满足以下前提条件:
- 操作系统: Ubuntu Server (本文以 Ubuntu 为例,其他 Linux 发行版类似)。
- Neo4j 安装包: 已将 neo4j-community-4.4.42-unix.tar.gz 文件传输到目标服务器。
- Java 运行环境 (JRE/JDK): 至关重要的一点 ,Neo4j 4.4.x 版本明确要求 Java 11 。由于是离线环境,你需要预先将 Java 11 的安装包(例如 OpenJDK 11 JRE/JDK 的 .deb 包或压缩包)传输到服务器并完成安装。可以通过 java -version 命令检查当前 Java 版本。版本不匹配是导致启动失败或功能异常的常见原因。
4. 部署步骤
4.1 必须的配置
**4.1.1 创建安装目录: **为 prod 和 dev 环境分别创建独立的目录。建议放在 /opt 目录下。
sudo mkdir -p /opt/neo4j-prod
sudo mkdir -p /opt/neo4j-dev
**4.1.2 解压 Neo4j: **将 neo4j-community-4.4.42-unix.tar.gz 分别解压到对应的目录。假设你的压缩包位于当前用户的 home 目录下 ( ~ )。
tar -xzf neo4j-community-4.4.42-unix.tar.gz -C /opt/neo4j-prod --strip-components=1
tar -xzf neo4j-community-4.4.42-unix.tar.gz -C /opt/neo4j-dev --strip-components=1
- –strip-components=1 用于去除压缩包内顶层的目录结构。
4.1.3 创建数据和日志目录: 为两个实例分别创建数据和日志存储目录,并确保 Neo4j 进程有权限访问(如果使用特定用户运行 Neo4j,需要调整权限)。
sudo mkdir -p /var/lib/neo4j-prod/data
sudo mkdir -p /var/log/neo4j-prod
sudo mkdir -p /var/lib/neo4j-dev/data
sudo mkdir -p /var/log/neo4j-dev
**4.1.4 配置 Prod 实例: **编辑 prod 实例的配置文件 /opt/neo4j-prod/conf/neo4j.conf 。你可以使用 nano 或 vim 编辑器。
sudo nano /opt/neo4j-prod/conf/neo4j.conf
找到并修改或取消注释以下行:
# ... 其他配置 ...# Bolt connector
# Bolt 监听地址和端口,0.0.0.0 表示监听所有网络接口
dbms.connector.bolt.listen_address=0.0.0.0:17687# HTTP connector
# HTTP 浏览器监听地址和端口
dbms.connector.http.listen_address=0.0.0.0:17474# HTTPS connector
# HTTPS 浏览器监听地址和端口 (如果启用HTTPS)
# dbms.connector.https.listen_address=0.0.0.0:17473 # 可以保持注释或配置一个不同于dev的端口# 数据目录
dbms.directories.data=/var/lib/neo4j-prod/data# 日志目录
dbms.directories.logs=/var/log/neo4j-prod# 导入目录 (如果需要)
# dbms.directories.import=/path/to/prod/import# 内存配置 (根据服务器资源调整)
# dbms.memory.heap.initial_size=1g
# dbms.memory.heap.max_size=1g
# dbms.memory.pagecache.size=2g# 允许远程访问浏览器 (4.x 版本通常默认允许,但明确设置更保险)
# dbms.security.allow_csv_import_from_urls=true # 如果需要从URL导入CSV
# dbms.security.procedures.unrestricted=my.extensions.example,my.procedures.* # 如果有自定义插件# ... 其他配置 ...
保存并关闭文件 (在 nano 中是 Ctrl+X , 然后 Y , 然后 Enter )。
4.1.5 配置 Dev 实例: 编辑 dev 实例的配置文件 /opt/neo4j-dev/conf/neo4j.conf 。
sudo nano /opt/neo4j-dev/conf/neo4j.conf
找到并修改或取消注释以下行:
# ... 其他配置 ...# Bolt connector
dbms.connector.bolt.listen_address=0.0.0.0:17688# HTTP connector
dbms.connector.http.listen_address=0.0.0.0:17475# HTTPS connector
# dbms.connector.https.listen_address=0.0.0.0:17476 # 可以保持注释或配置一个不同于prod的端口# 数据目录
dbms.directories.data=/var/lib/neo4j-dev/data# 日志目录
dbms.directories.logs=/var/log/neo4j-dev# 导入目录 (如果需要)
# dbms.directories.import=/path/to/dev/import# 内存配置 (通常 dev 环境可以配置得比 prod 低)
# dbms.memory.heap.initial_size=512m
# dbms.memory.heap.max_size=512m
# dbms.memory.pagecache.size=1g# ... 其他配置 ...
保存并关闭文件 (在 nano 中是 Ctrl+X , 然后 Y , 然后 Enter )。
4.1.6 配置防火墙: 如果你的 Ubuntu 服务器启用了防火墙 (如 ufw ),需要允许外部访问配置的端口。
# 允许 Prod 实例端口
sudo ufw allow 17687/tcp
sudo ufw allow 17474/tcp
# 如果启用了 HTTPS for Prod,也需要允许对应端口
# sudo ufw allow 17473/tcp
# 允许 Dev 实例端口
sudo ufw allow 17688/tcp
sudo ufw allow 17475/tcp
# 如果启用了 HTTPS for Dev,也需要允许对应端口
# sudo ufw allow 17476/tcp
# 重新加载防火墙规则使之生效
sudo ufw reload
# 查看防火墙状态和规则
sudo ufw status verbose
**4.1.7 启动 Neo4j 实例: **分别启动两个实例。
启动 Prod 实例:
sudo /opt/neo4j-prod/bin/neo4j start
启动 Dev 实例:
sudo /opt/neo4j-dev/bin/neo4j start
**4.1.8 检查状态: **检查两个实例的运行状态。
检查 Prod 实例:
sudo /opt/neo4j-prod/bin/neo4j status
检查 Dev 实例:
sudo /opt/neo4j-dev/bin/neo4j status
如果看到 “Neo4j is running” 或类似信息,表示启动成功。
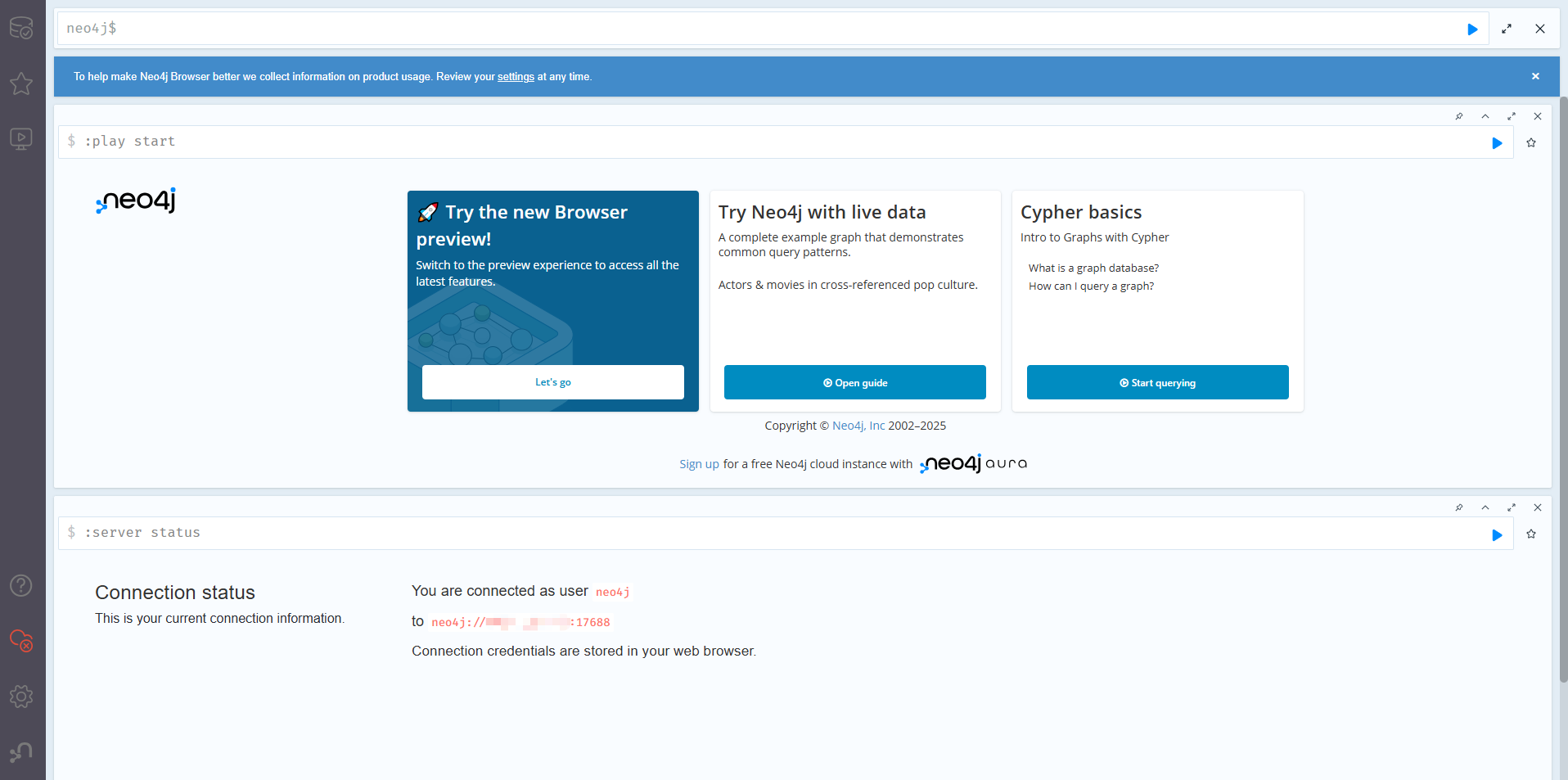
4.1.9 访问和初始设置:
至此,就算是部署完成了。
- **Prod 实例: **在其他机器的浏览器中访问 http://<你的服务器IP>:17474 。
- **Dev 实例: **在其他机器的浏览器中访问 http://<你的服务器IP>:17475 。
首次连接时,会要求使用默认用户名 neo4j 和默认密码 neo4j 登录。登录后,系统会强制你修改密码。请为每个实例设置不同的强密码。
4.1.10 停止实例 (如果需要):
停止 Prod 实例:
sudo /opt/neo4j-prod/bin/neo4j stop
停止 Dev 实例:
sudo /opt/neo4j-dev/bin/neo4j stop
4.2 可选的配置
可选:配置为 Systemd 服务 (推荐)
为了方便管理(开机自启、后台运行、重启等),建议将 Neo4j 实例配置为 systemd 服务。
4.2.1 创建 Prod 服务文件:
sudo nano /etc/systemd/system/neo4j-prod.service
粘贴以下内容 (如果使用特定用户运行,请修改 User 和 Group ):
[Unit]
Description=Neo4j Graph Database (Prod)
After=network.target[Service]
Type=forking
User=root # 或者你创建的专用用户,如 neo4j
Group=root # 或者你创建的专用用户组,如 neo4j
ExecStart=/opt/neo4j-prod/bin/neo4j start
ExecStop=/opt/neo4j-prod/bin/neo4j stop
ExecStatus=/opt/neo4j-prod/bin/neo4j status
PIDFile=/opt/neo4j-prod/run/neo4j.pid # 确认 PID 文件路径是否正确,可能在 /var/run/neo4j-prod 等
Restart=on-failure
LimitNOFILE=65536 # 增加文件描述符限制[Install]
WantedBy=multi-user.target
注意: PIDFile 的路径可能需要根据实际情况调整,检查 Neo4j 启动后 run 目录下的 neo4j.pid 文件位置。如果以非 root 用户运行,确保该用户对 /opt/neo4j-prod 及其子目录有读写执行权限,特别是 run , logs , data 目录。
4.2.2 创建 Dev 服务文件:
sudo nano /etc/systemd/system/neo4j-dev.service
粘贴以下内容 (同样注意 User 和 Group ):
[Unit]
Description=Neo4j Graph Database (Dev)
After=network.target[Service]
Type=forking
User=root # 或者你创建的专用用户
Group=root # 或者你创建的专用用户组
ExecStart=/opt/neo4j-dev/bin/neo4j start
ExecStop=/opt/neo4j-dev/bin/neo4j stop
ExecStatus=/opt/neo4j-dev/bin/neo4j status
PIDFile=/opt/neo4j-dev/run/neo4j.pid # 确认 PID 文件路径
Restart=on-failure
LimitNOFILE=65536[Install]
WantedBy=multi-user.target
4.2.3 启用和管理服务:
# 重新加载 systemd 配置
sudo systemctl daemon-reload
# 启动 Prod 服务
sudo systemctl start neo4j-prod
# 启动 Dev 服务
sudo systemctl start neo4j-dev
# 查看 Prod 服务状态
sudo systemctl status neo4j-prod
# 查看 Dev 服务状态
sudo systemctl status neo4j-dev
# 设置 Prod 服务开机自启
sudo systemctl enable neo4j-prod
# 设置 Dev 服务开机自启
sudo systemctl enable neo4j-dev
# 停止服务 (示例: 停止 prod)
# sudo systemctl stop neo4j-prod
# 重启服务 (示例: 重启 dev)
# sudo systemctl restart neo4j-dev
5. 总结
通过以上步骤,我们成功地在离线的 Ubuntu 服务器上部署了两个独立的 Neo4j 实例,并配置了不同的端口供外部访问。关键在于为每个实例提供独立的安装、数据和日志目录,并仔细配置 neo4j.conf 文件中的监听地址、端口和目录路径。同时,确保运行环境满足 Neo4j 的要求(特别是 Java 11),并掌握了通过检查日志、访问地址和端口监听状态来排查启动问题的基本方法。使用 systemd 服务管理 Neo4j 实例是推荐的最佳实践,可以大大简化运维工作。
6. 附录
Neo4j下载地址:
https://neo4j.com/deployment-center/
相关文章:
在离线 Ubuntu 环境下部署双 Neo4j 实例(Prod Dev)
在许多开发和生产场景中,我们可能需要在同一台服务器上运行多个独立的 Neo4j 数据库实例,例如一个用于生产环境 (Prod),一个用于开发测试环境 (Dev)。本文将详细介绍如何在 离线 的 Ubuntu 服务器上,使用 tar.gz 包部署两个 Neo4j…...
)
【Spring】单例模式的创建方式(Bean解析)
在Java中,单例模式(Singleton Pattern)确保一个类只有一个实例,并提供全局访问点。以下是实现单例的五种常见方式:懒汉式、饿汉式、双重检查锁、静态内部类和枚举,包括代码示例和优缺点分析。 1. 懒汉式&am…...

关于hadoop和yarn的问题
1.hadoop的三大结构及各自的作用? HDFS(Hadoop Distributed File System):分布式文件系统,负责海量数据的存储,具有高容错性和高吞吐量。 MapReduce:分布式计算框架,用于并行处理大…...

【飞渡科技数字孪生虚拟环境部署与集成教程 - CloudMaster实战指南】
飞渡科技数字孪生虚拟环境部署与集成教程 - CloudMaster实战指南 前言 本教程详细记录了飞渡科技的数字孪生平台CloudMaster的配置过程,以及如何将三维数字孪生场景集成到前端项目中。数字孪生技术能够在虚拟环境中精确复现物理实体的数据、特性和行为,…...

计算机软考中级 知识点记忆——排序算法 冒泡排序-插入排序- 归并排序等 各种排序算法知识点整理
一、📌 分类与比较 排序算法 最优时间复杂度 平均时间复杂度 最坏时间复杂度 空间复杂度 稳定性 应用场景与特点 算法策略 冒泡排序 O(n) O(n) O(n) O(1) 稳定 简单易实现,适用于小规模数据排序。 交换排序策略 插入排序 O(n) O(n) O…...

第十五届蓝桥杯 2024 C/C++组 下一次相遇
目录 题目: 题目描述: 题目链接: 思路: 自己的思路详解: 更好的思路详解: 代码: 自己的思路代码详解: 更好的思路代码详解: 题目: 题目描述…...
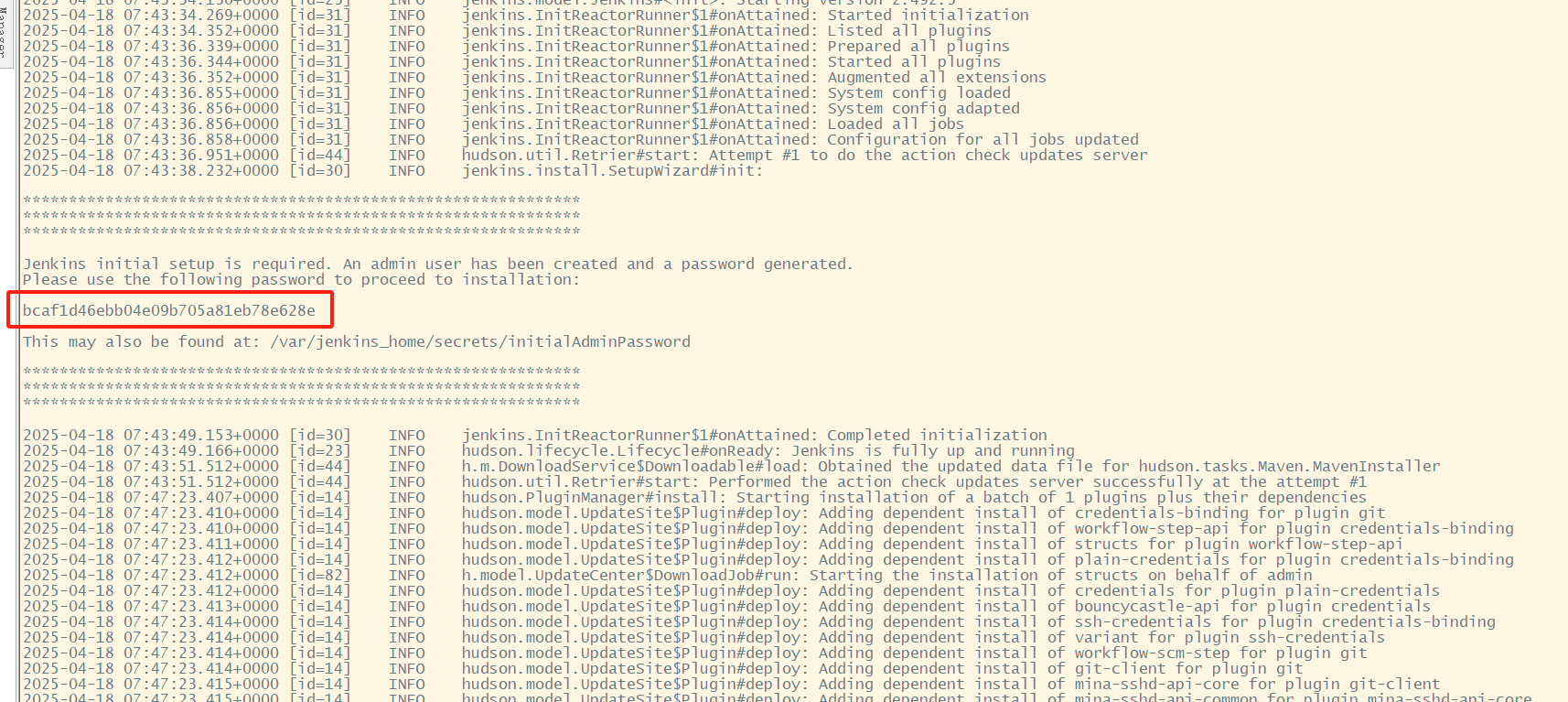
【2】CICD持续集成-k8s集群中安装Jenkins
一、背景: Jenkins是一款开源 CI&CD 系统,用于自动化各种任务,包括构建、测试和部署。 Jenkins官方提供了镜像:https://hub.docker.com/r/jenkins/jenkins 使用Deployment来部署这个镜像,会暴露两个端口ÿ…...

监控+日志=DevOps 运维的“千里眼”与“顺风耳”
监控+日志=DevOps 运维的“千里眼”与“顺风耳” 在 DevOps 体系中,监控和日志管理是不可或缺的运维基石。有人说,开发只管把代码写好,运维才是真正的“操盘手”,让系统稳定运行、不宕机、不崩溃。而要做到这一点,精准的监控与日志管理 是关键。 试想一下:如果没有监控…...

安卓的Launcher 在哪个环节进行启动
安卓Launcher在系统启动过程中的关键环节启动,具体如下: 内核启动:安卓设备开机后,首先由引导加载程序启动Linux内核。内核负责初始化硬件设备、建立内存管理机制、启动系统进程等基础工作,为整个系统的运行提供底层支…...
IDEA 创建Maven 工程(图文)
设置Maven 仓库 打开IDEA 开发工具,我的版本是2024.3.1(每个版本的位置不一样)。在【Customize】选项中,可以直接设置【语言】,在最下面选择【All setting】。 进入到熟悉的配置界面,选择配置的【setting…...
和地址(Address))
映射(Mapping)和地址(Address)
Addresses (地址) 以太坊区块链由 _ account _ (账户)组成,你可以把它想象成银行账户。一个帐户的余额是 以太 (在以太坊区块链上使用的币种),你可以和其他帐户之间支付和接受以太币,就像你的银…...

通过C# 将Excel表格转换为图片(JPG/ PNG)
Excel 表格可能会因为不同设备、不同软件版本或字体缺失等问题,导致格式错乱或数据显示异常。转换为图片后,能确保数据的排版、格式和外观始终保持一致,无论在何种设备或平台上查看,都能呈现出固定的样式,避免了因环境…...

国产紫光同创FPGA实现SDI视频编解码+图像缩放,基于HSSTHP高速接口,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目本博已有的 SDI 编解码方案本方案在Xilinx--Artix7系列FPGA上的应用本方案在Xilinx--Kintex系列FPGA上的应用本方案在Xilinx--Zynq系列FPGA上的应用本方案在Xilinx--U…...
)
day46—双指针-两数之和-输入有序数组(LeetCode-167)
题目描述 给你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数 target 的两个数。如果设这两个数分别是 numbers[index1] 和 numbers[index2] ,则 1 < index1 < index2 &l…...

自动驾驶安全模型研究
自动驾驶安全模型研究 自动驾驶安全模型研究 自动驾驶安全模型研究1.自动驾驶安全模型概述2. 自动驾驶安全模型应用3. 自动驾驶安全模型介绍3.1 Last Point to Steer3.2 Safety Zone3.3 RSS (Responsibility-Sensitive Safety)3.4 SFF (Safety Force Field)3.5 FSM (Fuzzy Safe…...

【项目】基于MCP+Tabelstore架构实现知识库答疑系统
基于MCPTabelstore架构实现知识库答疑系统 整体流程设计(一)Agent 架构(二)知识库存储(1)向量数据库Tablestore(2)MCP Server (三)知识库构建(1&a…...

当OCR遇上“幻觉”:如何让AI更靠谱地“看懂”文字?
在数字化的世界里,OCR(光学字符识别)技术就像给机器装上了“电子眼”。但当这项技术遇上大语言模型,一个意想不到的问题出现了——AI竟然会像人类一样产生“幻觉”。想象一下,当你拿着模糊的财务报表扫描件时ÿ…...
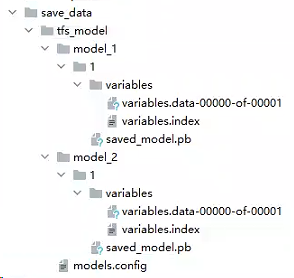
Docker用model.config部署及更新多个模型
步骤: 1、本地打包模型 2、编写model.config文件 3、使用 Docker 启动一个 TensorFlow Serving 容器 4、本地打包后的模型修改后,修改本地model.config,再同步更新容器的model.config 1、本地打包模型(本地路径) 2、…...
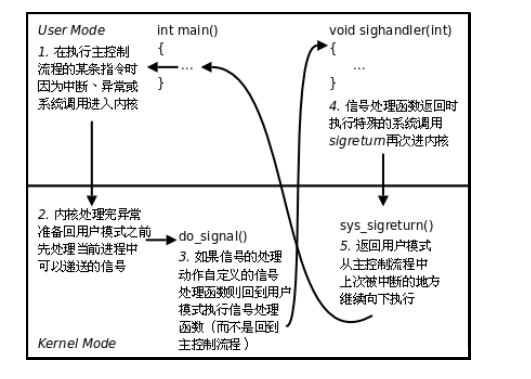
Linux kernel signal原理(下)- aarch64架构sigreturn流程
一、前言 在上篇中写到了linux中signal的处理流程,在do_signal信号处理的流程最后,会通过sigreturn再次回到线程现场,上篇文章中介绍了在X86_64架构下的实现,本篇中介绍下在aarch64架构下的实现原理。 二、sigaction系统调用 #i…...
matlab论文图一的地形区域图的球形展示Version_1
matlab论文图一的地形区域图的球形展示Version_1 图片 此图来源于: 
发布一个npm包,更新包,删除包
发布一个npm包,更新包,删除包 如何将自己的项目 发布为一个 npm 包,并掌握 更新 和 删除 的操作流程。 🚀 一、发布一个 npm 包的完整流程 ✅ 1. 注册并登录 npm 账号 如果还没有账号,先注册: 官网注册&…...

Redis专题
前言 Redis的各种思想跟机组Cache和操作系统对进程的管理非常类似! 一:看到你的简历上写了你的项目里面用到了redis,为啥用redis? 因为传统的关系型数据库如Mysql,已经不能适用所有的场景,比如秒杀的库存扣减ÿ…...

LeetCode[232]用栈实现队列
思路: 一道很简单的题,就是栈是先进后出,队列是先进先出,用两个栈底相互对着,这样一个队列就产生了,右栈为空的情况,左栈栈底就是队首元素,所以我们需要将左栈全部压入右栈ÿ…...
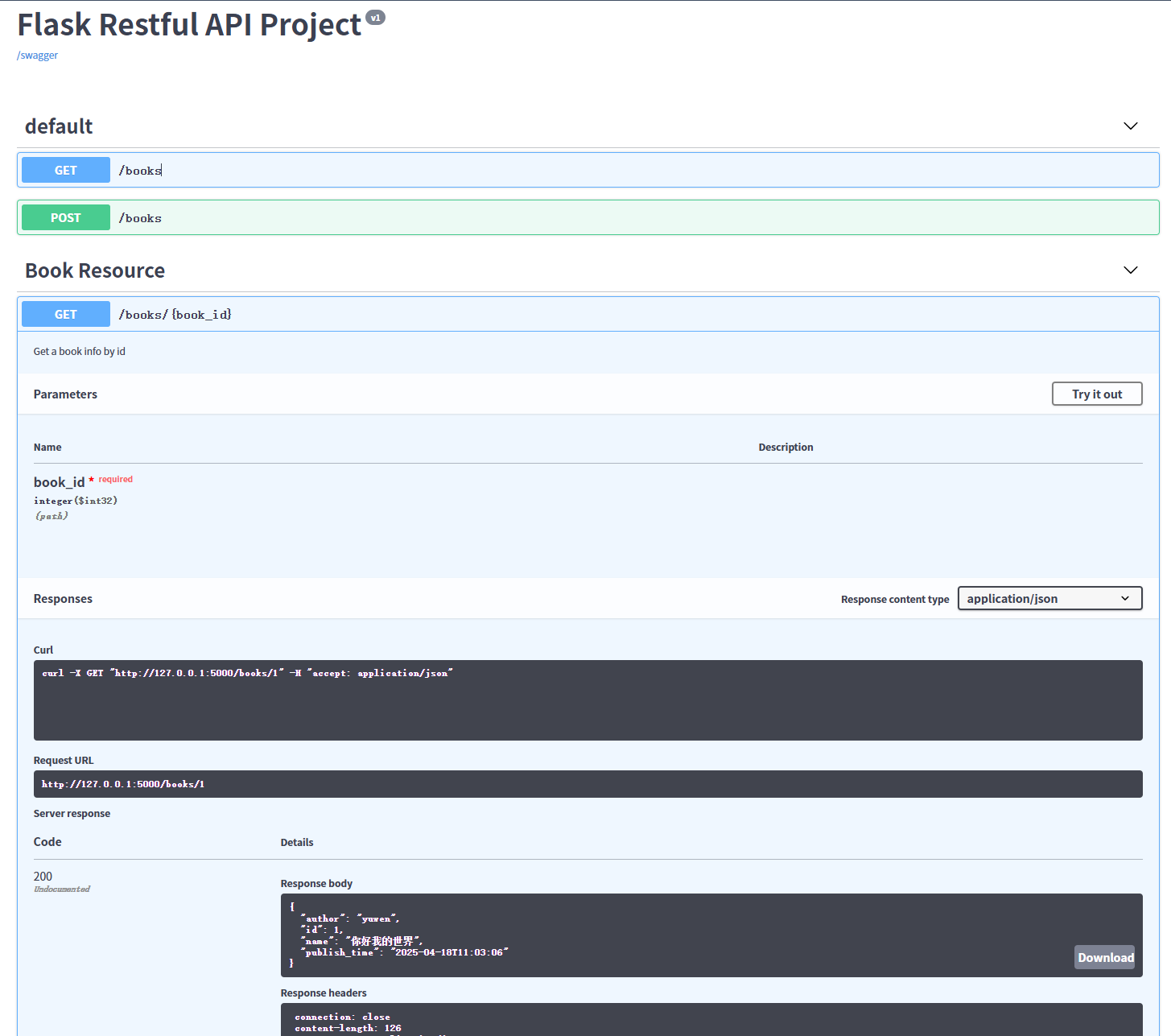
Flask API 项目 Swagger 版本打架不兼容
Flask API 项目 Swagger 版本打架不兼容 1. 问题背景 在使用 Flask 3.0.0 时遇到以下问题: 安装 flask_restful_swagger 时,它强制将 Flask 降级到 1.1.4,并导致其他依赖(如 flask-sqlalchemy、flask-apispec)出现版…...
基于YOLOv11 和 ByteTrack 实现目标跟踪
介 绍 之前我们介绍了使用YOLOv9与 ByteTrack 结合进行对象跟踪的概念,展示了这两种强大的技术如何有效地协同工作。现在,让我们通过探索与 ByteTrack 结合的 YOLOv11 来进一步了解这一概念。 实战 | 基于YOLOv9和OpenCV实现车辆跟踪计数(步骤…...
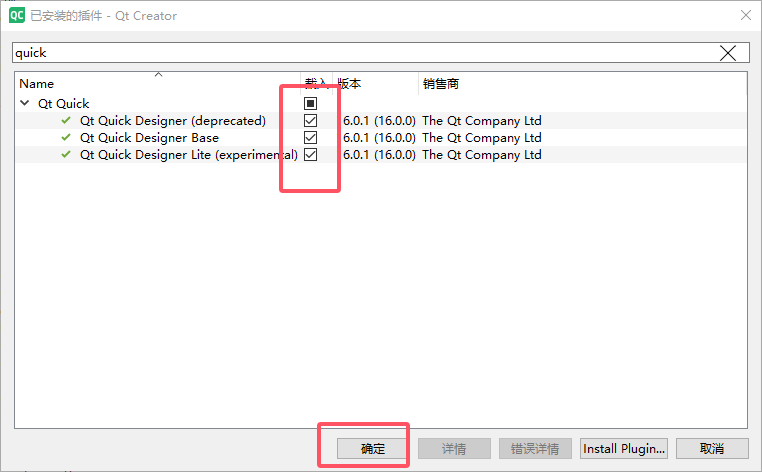
Qt Creator 创建 Qt Quick Application一些问题
一、Qt Creator 创建 Qt Quick Application 时无法选择 MSVC 编译器(即使已安装 Qt 5.15.2 和 MSVC2019) 1、打开 Qt Creator 的编译器设置 工具 (Tools) → 选项 (Options) → Kits → 编译器 (Compilers) 检查是否存在 Microsoft Visual C++ Compiler (x86_amd64) 或类似条…...

编码转换器
大批量转换编码 可以将整个工程文件夹从GB18030转为UTF-8 使用Qt C制作 项目背景 比较老的工程,尤其是keil嵌入式的工程,其文本文件(.c、.cpp、.h、.txt、……)编码为gb2312,这为移植维护等带来了不便。现在uit-8用…...

Django 中集成 Apache Kafka 可以实现异步消息处理、数据流式传输
在 Django 中集成 Apache Kafka 可以实现异步消息处理、数据流式传输等功能,以下是详细的集成步骤和示例代码: 1. 安装必要的库 首先,你需要安装 kafka-python 库,它是 Python 中操作 Kafka 的常用库。可以使用以下命令进行安装: pip install kafka-python2. 配置 Kafk…...

Scala 入门指南
Scala 入门指南 目录 简介环境搭建基础语法面向对象编程函数式编程集合模式匹配特质隐式转换并发编程与 Java 互操作最佳实践常见问题 简介 Scala 是一种多范式编程语言,结合了面向对象编程和函数式编程的特性。它运行在 JVM 上,与 Java 完全兼容&am…...

[密码学实战]密评考试训练系统v1.0程序及密评参考题库(获取路径在文末)
[密码学实战]密评考试训练系统v1.0程序及密评参考题库 引言:密评考试的重要性与挑战 商用密码应用安全性评估(简称"密评") 作为我国密码领域的重要认证体系,已成为信息安全从业者的必备技能。根据国家密码管理局最新数据,截至2024年6月,全国仅有3000余人持有…...