Oracle DBA 高效运维指南:高频实用 SQL 大全
大家好,这里是 DBA学习之路,专注于提升数据库运维效率。
目录
- 前言
- Top SQL
- 表空间使用率
- RMAN 备份
- DataGuard
- 等待事件
- 行级锁
- 在线日志切换
- 用户信息
- ASM 磁盘组
- DBLink
- 数据文件收缩
- AWR
- 写在最后
前言
作为一名 Oracle DBA,在日常数据库运维工作中,我们经常需要快速获取数据库关键信息、排查性能问题或执行维护操作。经过多年实战积累,我整理了一套高频使用的 SQL 查询集合,涵盖了表空间监控、备份恢复、DataGuard 管理、性能诊断等核心场景。
这些 SQL 经过生产环境验证,能显著提升 DBA 的工作效率。现在将这些实用脚本分享给大家,希望能帮助各位同行更高效地完成数据库运维工作。
Top SQL
表空间使用率
一键查询表空间使用率 SQL:
set linesize 2222 pagesize 1000 heading on wrap on
COLUMN tbsname HEADING 'Name'
COLUMN total_gb FORMAT 99,990.99 HEADING 'Total(GB)'
COLUMN used_gb FORMAT 99,990.99 HEADING 'Used(GB)'
COLUMN left_gb FORMAT 99,990.99 HEADING 'Left(GB)'
COLUMN used_percent FORMAT 990.99 HEADING 'Used(%)'
COLUMN count_file FORMAT 9999 HEADING 'File Count'-- 11G
SELECT d.tablespace_name tbsname,round(d.tablespace_size * (SELECT value FROM v$parameter WHERE name='db_block_size') / 1024 / 1024 / 1024,2) total_gb,round(d.used_space * (SELECT value FROM v$parameter WHERE name='db_block_size') / 1024 / 1024 / 1024,2) used_gb,round((d.tablespace_size - d.used_space) * (SELECT value FROM v$parameter WHERE name='db_block_size') / 1024 / 1024 / 1024,2) left_gb,round(d.used_percent,2) used_percent,(select COUNT(file_name) from dba_data_files where tablespace_name = d.tablespace_name) count_fileFROM dba_tablespace_usage_metrics dORDER BY 2 DESC;-- 12C 以上
SELECT d.tablespace_name tbsname,round(d.tablespace_size * (SELECT value FROM v$parameter WHERE name='db_block_size') / 1024 / 1024 / 1024,2) total_gb,round(d.used_space * (SELECT value FROM v$parameter WHERE name='db_block_size') / 1024 / 1024 / 1024,2) used_gb,round((d.tablespace_size - d.used_space) * (SELECT value FROM v$parameter WHERE name='db_block_size') / 1024 / 1024 / 1024,2) left_gb,round(d.used_percent,2) used_percent,(select COUNT(file_name) from cdb_data_files where con_id = d.con_id and tablespace_name = d.tablespace_name) count_fileFROM cdb_tablespace_usage_metrics d
WHERE d.con_id not in (1,2)ORDER BY d.con_id,2 DESC;
RMAN 备份
一键查询 RMAN 备份情况:
set linesize 2222 pagesize 1000 heading on wrap on
col status for a30
col input_type for a20
col start_time for a25
col end_time for a25
col input_bytes_display for a10
col output_bytes_display for a10
col time_taken_display for a10SELECT input_type, status,to_char(start_time, 'yyyy-mm-dd hh24:mi:ss') as start_time,to_char(end_time, 'yyyy-mm-dd hh24:mi:ss') as end_time,input_bytes_display, output_bytes_display, time_taken_display, compression_ratio
FROM v$rman_backup_job_details
ORDER BY start_time DESC;
DataGuard
DG 日常运维高频 SQL:
-- 主库查询 DataGuard 同步状态
set linesize 2222 heading on wrap on
column dest_name format a20
column status format a8
column database_mode format a15
column recovery_mode format a35
column protection_mode format a25
column destination format a15
column archived_seq# format 999999999
column applied_seq# format 999999999
column error format a10
column srl format a5
column db_unique_name format a15
column gap_status format a10SELECT inst_id, dest_name, status, database_mode, protection_mode,recovery_mode, gap_status, archived_seq#, applied_seq#, srl,db_unique_name, destination, error
FROM gv$archive_dest_status
WHERE status <> 'INACTIVE'
AND type = 'PHYSICAL';-- 主库查看当前归档日志
set line2222 pages1000
SELECT thread#,MAX(sequence#) "Last Primary Seq Generated"FROM v$archived_log val,v$database vdbWHERE val.resetlogs_change# = vdb.resetlogs_change#GROUP BY thread#ORDER BY 1;-- 备库查看当前归档日志
set line2222 pages1000
SELECT thread#,MAX(sequence#) "Last Standby Seq Received"FROM v$archived_log val,v$database vdbWHERE val.resetlogs_change# = vdb.resetlogs_change#GROUP BY thread#ORDER BY 1;set line2222 pages1000
SELECT thread#,MAX(sequence#) "Last Standby Seq Applied"FROM v$archived_log val,v$database vdbWHERE val.resetlogs_change# = vdb.resetlogs_change#AND val.applied IN ('YES','IN-MEMORY')GROUP BY thread#ORDER BY 1;-- 备库查询 DataGuard 进程同步状态
set line2222 pages1000
select inst_id,pid,process,thread#,sequence#,status,delay_mins from gv$managed_standby;-- 备库查询未应用的归档日志
select inst_id,count(*) from gv$archived_log where applied='NO' group by inst_id order by inst_id;-- 检查是否存在 GAP
select * from gv$archive_gap;-- 备库查看闪回情况
set linesize 2222 heading on wrap on
column check_date format a19
column flashback_to format a19
column interval_day format 99999.99
SELECT to_char(SYSDATE, 'yyyy-mm-dd hh24:mi:ss') AS check_date,to_char(oldest_flashback_time, 'yyyy-mm-dd hh24:mi:ss') AS flashback_to,round(SYSDATE - oldest_flashback_time, 2) AS interval_day,retention_target,round(flashback_size / 1024 / 1024, 2) AS flashback_mb,round(estimated_flashback_size / 1024 / 1024, 2) AS estimated_flashback_mb
FROM v$flashback_database_log;
等待事件
一键获取当前数据库 Top 等待事件:
-- 查看当前 top event 的源头
set line2222 pages1000
column serial# format 999999
column object_name format a30
column sql_text format a50
col session_detail format a30SELECT rpad('+',LEVEL,'-') || sid || ' ' || sess.module session_detail,sid,serial#,'alter system kill session ''' || sid || ',' || serial# || ',@' || sess.inst_id || ''' immediate;' AS kill_sql,blocker_sid,sess.inst_id,wait_event_text,object_name,rpad(' ',LEVEL) || sql_text sql_textFROM v$wait_chains cLEFT OUTER JOIN dba_objects oON (row_wait_obj# = object_id)JOIN gv$session sessUSING (sid)LEFT OUTER JOIN v$sql SQLON (sql.sql_id = sess.sql_id AND sql.child_number = sess.sql_child_number)
CONNECT BY PRIOR sid = blocker_sidAND PRIOR sess_serial# = blocker_sess_serial#AND PRIOR instance = blocker_instanceSTART WITH blocker_is_valid = 'FALSE';
行级锁
一键获取当前数据库行级锁 SQL:
-- 查看当前数据库节点是否存在锁
set line2222 pages1000
col OS_USER_NAME for a10
col owner for a20
col object_name for a40
col object_type for a30
select a.OS_USER_NAME, c.owner, c.object_name,c.object_type, b.sid, b.serial#, logon_time from v$locked_object a, v$session b, dba_objects c where a.session_id = b.sid and a.object_id = c.object_id order by b.logon_time;-- 查看锁的 sql
select sql_text from v$sql where hash_value in (select sql_hash_value from v$session where sid in (select session_id from v$locked_object));
select 'kill -9 '||spid from v$process where addr in (select paddr from v$session where sid in ( select session_id from v$locked_object));-- 系统层面 kill 会话
set line2222 pages10000
select 'kill -9 ' || a.spidfrom v$process a, v$session bwhere a.addr = b.paddrand a.background is nulland b.sid = 2721and b.serial# = 4317;## 关闭连接当前数据库的监听进程
ps -ef|grep -v grep|grep LOCAL=NO|awk '{print $2}'|xargs kill -9
在线日志切换
一键查询在线日志切换频率:
SELECTSUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5) DAY, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'00',1,0)) H00, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'01',1,0)) H01, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'02',1,0)) H02, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'03',1,0)) H03, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'04',1,0)) H04, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'05',1,0)) H05, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'06',1,0)) H06, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'07',1,0)) H07, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'08',1,0)) H08, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'09',1,0)) H09, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'10',1,0)) H10, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'11',1,0)) H11, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'12',1,0)) H12, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'13',1,0)) H13, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'14',1,0)) H14, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'15',1,0)) H15, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'16',1,0)) H16, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'17',1,0)) H17, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'18',1,0)) H18, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'19',1,0)) H19, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'20',1,0)) H20, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'21',1,0)) H21, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'22',1,0)) H22, SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'),10,2),'23',1,0)) H23, COUNT(*) TOTAL
FROMgv$log_history a where SYSDATE - first_time < 7
GROUP BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'),1,5) order by 1;
用户信息
一键查询非系统用户信息:
-- 11G
set lines222 pages1000
col username for a25
col account_status for a20
col default_tablespace for a20
col temporary_tablespace for a20
col profile for a20
SELECT username,account_status,default_tablespace,temporary_tablespace,created,profileFROM dba_usersWHERE account_status = 'OPEN'ORDER BY created;-- 12C 以上
set lines222 pages1000
col username for a25
col account_status for a20
col default_tablespace for a20
col temporary_tablespace for a20
col profile for a20
SELECT a.username,b.account_status,b.default_tablespace,b.temporary_tablespace,b.created,b.profileFROM all_users a,dba_users bWHERE a.user_id = b.user_idAND a.oracle_maintained = 'N'AND b.account_status = 'OPEN';
ASM 磁盘组
一键查询 ASM 磁盘组相关信息:
-- asm 磁盘组信息
set lines2222 pages10000
select name,round(usable_file_mb/1024,2) usable_file_gb,round((total_mb - free_mb)/total_mb * 100,2) usedfrom v$asm_diskgroup;-- asm 磁盘信息
set line2222 pages1000
col path for a60
col FAILGROUP for a12
col header_status for a16
select path,MOUNT_STATUS,HEADER_STATUS,MODE_STATUS,STATE,TOTAL_MB from v$asm_disk order by 2,3,4,5;-- asm 磁盘组明细信息
set lines2222 pages10000
col path for a40
col FAILGROUP for a12
col diskgroup_name for a30
col disk_name for a30
col HEADER_STATUS for a10
col state for a10
Col MOUNT_STATUS for a7
col MODE_STATUS for a10
select b.name diskgroup_name,a.path,a.FAILGROUP,a.name as disk_name,a.STATE,a.MODE_STATUS,a.HEADER_STATUS,a.MOUNT_STATUS,a.REPAIR_TIMER
from v$asm_disk a,v$asm_diskgroup b where a.GROUP_NUMBER = b.GROUP_NUMBER
order by a.FAILGROUp;-- 查看 ASM 磁盘重平衡
set line2222 pages10000
col error_code for a20
select * from gv$asm_operation;
DBLink
一键获取 DBLink 创建 SQL:
set line2222 pages1000
col text for a150
SELECT 'CREATE '||DECODE(U.NAME,'PUBLIC','public ')||'DATABASE LINK '|| DECODE(U.NAME,'PUBLIC',Null, 'SYS','',U.NAME||'.')|| L.NAME||'CONNECT TO ' || L.USERID || ' IDENTIFIED BY "'||L.PASSWORD||'" USING '''||L.HOST ||';' TEXT
FROM SYS.LINK$ L, SYS.USER$ U
WHERE L.OWNER# = U.USER#;
数据文件收缩
一键收缩数据文件 SQL:
set line222 pagesize1000
col tablespace_name for a30
col sql for a100
SELECT a.tablespace_name,
'alter database datafile ''' || file_name || ''' resize ' ||(ceil((nvl(hwm,1) * c.value) / 1024 / 1024) + 50) || 'M;' sqlFROM dba_data_files a,(SELECT file_id,MAX(block_id + blocks - 1) hwmFROM dba_extentsGROUP BY file_id) b,(SELECT VALUEFROM v$parameterWHERE NAME = 'db_block_size') cWHERE a.file_id = b.file_id(+)AND a.status != 'INVALID'AND a.online_status != 'OFFLINE'AND a.tablespace_name NOT IN ('UNDOTBS1','UNDOTBS2','SYSTEM','SYSAUX','USERS')ORDER BY 1 DESC;
AWR
一键生成 AWR 性能报告:
-- 生成单实例 AWR 报告:
@$ORACLE_HOME/rdbms/admin/awrrpt.sql--生成 Oracle RAC AWR 报告
@$ORACLE_HOME/rdbms/admin/awrgrpt.sql-- 生成 RAC 环境中特定数据库实例的 AWR 报告
@$ORACLE_HOME/rdbms/admin/awrrpti.sql-- 生成 Oracle RAC 环境中多个数据库实例的 AWR 报告的方法
@$ORACLE_HOME/rdbms/admin/awrgrpti.sql-- 生成 SQL 语句的 AWR 报告
@$ORACLE_HOME/rdbms/admin/awrsqrpt.sql-- 生成特定数据库实例上某个 SQL 语句的 AWR 报告
@$ORACLE_HOME/rdbms/admin/awrsqrpi.sql
写在最后
数据库运维是一门需要不断积累和实践的艺术。本文分享的 SQL 脚本只是 DBA 工具箱中的一部分基础工具,真正的专业能力在于理解这些查询背后的原理,并能够根据实际场景灵活运用。
建议各位 DBA 同行在日常工作中持续积累自己的 SQL 脚本库,并定期整理优化。如果您有更好的 SQL 脚本或使用技巧,欢迎在评论区分享交流。让我们共同提升 Oracle 数据库的运维效率,打造更稳定高效的数据库环境!
温馨提示:在生产环境执行任何管理操作前,请务必先在测试环境验证,并确保有完整的备份方案。
相关文章:

Oracle DBA 高效运维指南:高频实用 SQL 大全
大家好,这里是 DBA学习之路,专注于提升数据库运维效率。 目录 前言Top SQL表空间使用率RMAN 备份DataGuard等待事件行级锁在线日志切换用户信息ASM 磁盘组DBLink数据文件收缩AWR 写在最后 前言 作为一名 Oracle DBA,在日常数据库运维工作中&…...
)
【xlog日志文件】怎么删除里面包含某些字符串的行(使用excel)
将log日志,复制到单独一行 B列(可能一行很长,所以将整合后的放在A列) 使用公式可以筛选出 包含某些字符串的行 为true,将这些行直接删除 IF(COUNT(FIND("MediaMuxterThreadRussia",B2,1))>0,"包含",&quo…...
Spark-Streaming简介和核心编程
Spark-Streaming简介 概述:用于流式数据处理,支持Kafka、Flume等多种数据输入源,可使用Spark原语运算,结果能保存到HDFS、数据库等。它以DStream(离散化流)为抽象表示,是RDD在实时场景的封装&am…...
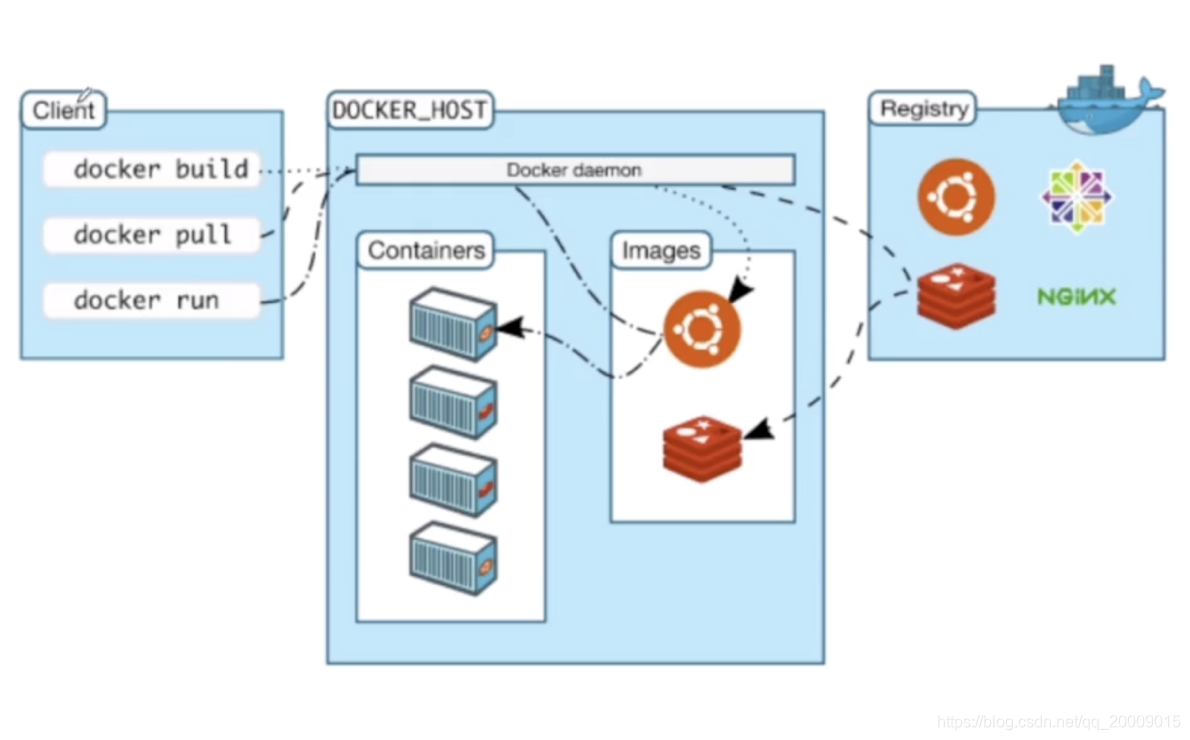
Docker 快速入门教程
1. Docker 基本概念 镜像(Image): 只读模板,包含创建容器的指令 容器(Container): 镜像的运行实例 Dockerfile: 用于构建镜像的文本文件 仓库(Repository): 存放镜像的地方(如Docker Hub) 2. 安装Docker 根据你的操作系统选择安装方式:…...
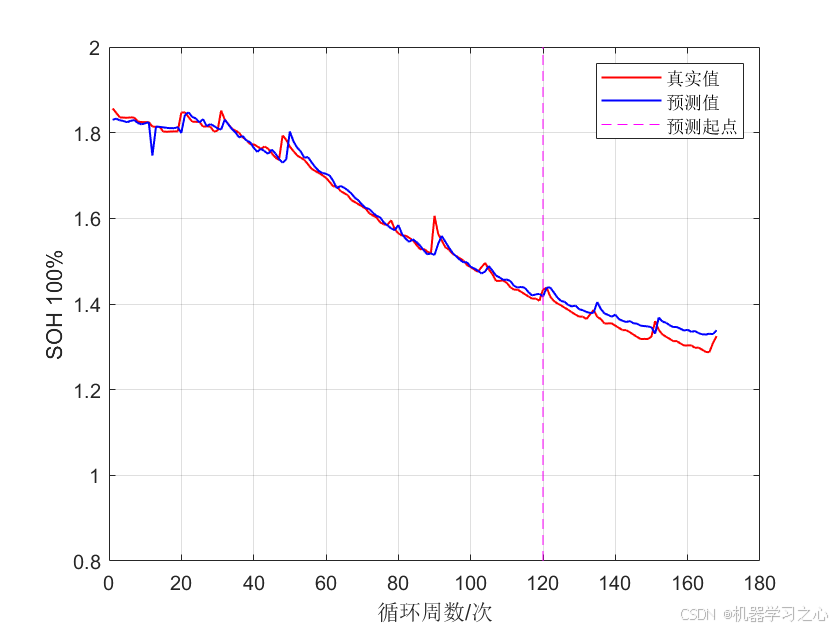
【锂电池SOH估计】BP神经网络锂电池健康状态估计,锂电池SOH估计(Matlab完整源码和数据)
目录 效果一览程序获取程序内容研究内容基于BP神经网络的锂电池健康状态估计研究摘要关键词1. 引言1.1 研究背景1.2 研究意义1.3 研究目标2. 文献综述2.1 锂电池SOH估计理论基础2.2 传统SOH估计方法2.3 基于BP神经网络的SOH估计研究进展2.4 研究空白与创新点3. BP神经网络原理3…...
Python常用的第三方模块之二【openpyxl库】读写Excel文件
openpyxl库模块是用于处理Microsoft Excel文件的第三方库,可以对Excel文件中的数据进行写入和读取。 weather.pyimport reimport requests#定义函数 def get_html():urlhttps://www.weather.com.cn/weather1d/101210101.shtml #爬虫打开浏览器上的网页resprequests.…...

成熟软件项目解决方案:360°全景影像显控软件系统
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/147425300 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、Open…...
前端开发核心知识详解:Vue2、JavaScript 与 CSS
一、Vue2 核心知识点 1. Vue2 的双向绑定原理 Vue2 实现双向绑定主要依赖数据劫持与发布 - 订阅者模式。 利用Object.defineProperty方法对数据对象的属性进行劫持,为每个属性定义getter和setter。getter用于收集依赖,当视图中使用到该属性时…...

JDK安装超详细步骤
🔥【JDK安装超详细步骤】 文章目录 🔥【JDK安装超详细步骤】1. 卸载系统自带的旧版JDK2. 安装JDK113. 验证安装是否成功4. 常见问题4.1 执行java -version提示命令未找到? 1. 卸载系统自带的旧版JDK 查询已安装的OpenJDK包。 rpm -qa | gre…...

PHP中的ReflectionClass讲解【详细版】
快餐: ReflectionClass精简版 在PHP中,ReflectionClass是一个功能强大的反射类,它就像是一个类的“X光透视镜”,能让我们在程序运行时深入了解类的内部结构和各种细节。 一、反射类的基本概念和重要性 反射是指在程序运行期间获…...

JAVA:Web安全防御
目录 一、Web安全基础与常见威胁 OWASP Top 10核心漏洞解析 • SQL注入(SQLi)、跨站脚本(XSS)、跨站请求伪造(CSRF) • 不安全的反序列化、敏感数据泄露 Java后端常见攻击场景 • 通过HttpServletRequest…...

39.剖析无处不在的数据结构
数据结构是计算机中组织和存储数据的特定方式,它的目的是方便且高效地对数据进行访问和修改。数据结构表述了数据之间的关系,以及操作数据的一系列方法。数据又是程序的基本单元,因此无论是哪种语言、哪种领域,都离不开数据结构&a…...
在离线 Ubuntu 环境下部署双 Neo4j 实例(Prod Dev)
在许多开发和生产场景中,我们可能需要在同一台服务器上运行多个独立的 Neo4j 数据库实例,例如一个用于生产环境 (Prod),一个用于开发测试环境 (Dev)。本文将详细介绍如何在 离线 的 Ubuntu 服务器上,使用 tar.gz 包部署两个 Neo4j…...
)
【Spring】单例模式的创建方式(Bean解析)
在Java中,单例模式(Singleton Pattern)确保一个类只有一个实例,并提供全局访问点。以下是实现单例的五种常见方式:懒汉式、饿汉式、双重检查锁、静态内部类和枚举,包括代码示例和优缺点分析。 1. 懒汉式&am…...

关于hadoop和yarn的问题
1.hadoop的三大结构及各自的作用? HDFS(Hadoop Distributed File System):分布式文件系统,负责海量数据的存储,具有高容错性和高吞吐量。 MapReduce:分布式计算框架,用于并行处理大…...

【飞渡科技数字孪生虚拟环境部署与集成教程 - CloudMaster实战指南】
飞渡科技数字孪生虚拟环境部署与集成教程 - CloudMaster实战指南 前言 本教程详细记录了飞渡科技的数字孪生平台CloudMaster的配置过程,以及如何将三维数字孪生场景集成到前端项目中。数字孪生技术能够在虚拟环境中精确复现物理实体的数据、特性和行为,…...

计算机软考中级 知识点记忆——排序算法 冒泡排序-插入排序- 归并排序等 各种排序算法知识点整理
一、📌 分类与比较 排序算法 最优时间复杂度 平均时间复杂度 最坏时间复杂度 空间复杂度 稳定性 应用场景与特点 算法策略 冒泡排序 O(n) O(n) O(n) O(1) 稳定 简单易实现,适用于小规模数据排序。 交换排序策略 插入排序 O(n) O(n) O…...

第十五届蓝桥杯 2024 C/C++组 下一次相遇
目录 题目: 题目描述: 题目链接: 思路: 自己的思路详解: 更好的思路详解: 代码: 自己的思路代码详解: 更好的思路代码详解: 题目: 题目描述…...
【2】CICD持续集成-k8s集群中安装Jenkins
一、背景: Jenkins是一款开源 CI&CD 系统,用于自动化各种任务,包括构建、测试和部署。 Jenkins官方提供了镜像:https://hub.docker.com/r/jenkins/jenkins 使用Deployment来部署这个镜像,会暴露两个端口ÿ…...

监控+日志=DevOps 运维的“千里眼”与“顺风耳”
监控+日志=DevOps 运维的“千里眼”与“顺风耳” 在 DevOps 体系中,监控和日志管理是不可或缺的运维基石。有人说,开发只管把代码写好,运维才是真正的“操盘手”,让系统稳定运行、不宕机、不崩溃。而要做到这一点,精准的监控与日志管理 是关键。 试想一下:如果没有监控…...

安卓的Launcher 在哪个环节进行启动
安卓Launcher在系统启动过程中的关键环节启动,具体如下: 内核启动:安卓设备开机后,首先由引导加载程序启动Linux内核。内核负责初始化硬件设备、建立内存管理机制、启动系统进程等基础工作,为整个系统的运行提供底层支…...
IDEA 创建Maven 工程(图文)
设置Maven 仓库 打开IDEA 开发工具,我的版本是2024.3.1(每个版本的位置不一样)。在【Customize】选项中,可以直接设置【语言】,在最下面选择【All setting】。 进入到熟悉的配置界面,选择配置的【setting…...
和地址(Address))
映射(Mapping)和地址(Address)
Addresses (地址) 以太坊区块链由 _ account _ (账户)组成,你可以把它想象成银行账户。一个帐户的余额是 以太 (在以太坊区块链上使用的币种),你可以和其他帐户之间支付和接受以太币,就像你的银…...

通过C# 将Excel表格转换为图片(JPG/ PNG)
Excel 表格可能会因为不同设备、不同软件版本或字体缺失等问题,导致格式错乱或数据显示异常。转换为图片后,能确保数据的排版、格式和外观始终保持一致,无论在何种设备或平台上查看,都能呈现出固定的样式,避免了因环境…...

国产紫光同创FPGA实现SDI视频编解码+图像缩放,基于HSSTHP高速接口,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目本博已有的 SDI 编解码方案本方案在Xilinx--Artix7系列FPGA上的应用本方案在Xilinx--Kintex系列FPGA上的应用本方案在Xilinx--Zynq系列FPGA上的应用本方案在Xilinx--U…...
)
day46—双指针-两数之和-输入有序数组(LeetCode-167)
题目描述 给你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数 target 的两个数。如果设这两个数分别是 numbers[index1] 和 numbers[index2] ,则 1 < index1 < index2 &l…...

自动驾驶安全模型研究
自动驾驶安全模型研究 自动驾驶安全模型研究 自动驾驶安全模型研究1.自动驾驶安全模型概述2. 自动驾驶安全模型应用3. 自动驾驶安全模型介绍3.1 Last Point to Steer3.2 Safety Zone3.3 RSS (Responsibility-Sensitive Safety)3.4 SFF (Safety Force Field)3.5 FSM (Fuzzy Safe…...

【项目】基于MCP+Tabelstore架构实现知识库答疑系统
基于MCPTabelstore架构实现知识库答疑系统 整体流程设计(一)Agent 架构(二)知识库存储(1)向量数据库Tablestore(2)MCP Server (三)知识库构建(1&a…...

当OCR遇上“幻觉”:如何让AI更靠谱地“看懂”文字?
在数字化的世界里,OCR(光学字符识别)技术就像给机器装上了“电子眼”。但当这项技术遇上大语言模型,一个意想不到的问题出现了——AI竟然会像人类一样产生“幻觉”。想象一下,当你拿着模糊的财务报表扫描件时ÿ…...
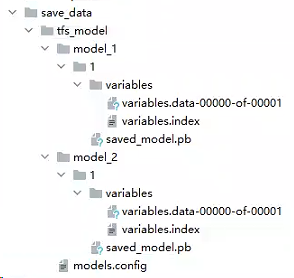
Docker用model.config部署及更新多个模型
步骤: 1、本地打包模型 2、编写model.config文件 3、使用 Docker 启动一个 TensorFlow Serving 容器 4、本地打包后的模型修改后,修改本地model.config,再同步更新容器的model.config 1、本地打包模型(本地路径) 2、…...