大语言模型的评估指标
目录
一、混淆矩阵
1. 混淆矩阵的结构(二分类为例)
2.从混淆矩阵衍生的核心指标
3.多分类任务的扩展
4. 混淆矩阵的实战应用
二、分类任务核心指标
1. Accuracy(准确率)
2. Precision(精确率)
3. Recall(召回率)
二、生成任务核心指标
1. BLEU(Bilingual Evaluation Understudy)
2. ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
3. PPL(Perplexity,困惑度)
三、指标对比与选型指南
四:总结
一、混淆矩阵
混淆矩阵是评估分类模型性能的核心工具,是计算准确率(Accuracy)、精确率(Precision)和召回率(Recall)的基础工具,三者直接由混淆矩阵中的四个核心元素(TP、FP、FN、TN)定义。以矩阵形式直观展示模型的预测结果与真实标签的对比情况,尤其适用于二分类问题(可扩展至多分类)。以下是其完整解析:
1. 混淆矩阵的结构(二分类为例)
| 真实为正类(Positive) | 真实为负类(Negative) | |
|---|---|---|
| 预测为正类(Positive) | True Positive (TP) | False Positive (FP) |
| 预测为负类(Negative) | False Negative (FN) | True Negative (TN) |
-
TP(真正例):模型正确预测为正类的样本数(例:真实为垃圾邮件,模型判定为垃圾邮件)。
-
FP(假正例):模型错误预测为正类的样本数(例:真实为正常邮件,模型误判为垃圾邮件)。
-
FN(假负例):模型错误预测为负类的样本数(例:真实为垃圾邮件,模型漏判为正常邮件)。
-
TN(真负例):模型正确预测为负类的样本数(例:真实为正常邮件,模型判定为正常邮件)。
2.从混淆矩阵衍生的核心指标
所有分类评估指标(Accuracy/Precision/Recall/F1)均可通过混淆矩阵计算:
| 指标 | 公式 | 物理意义 |
|---|---|---|
| 准确率(Accuracy) |  | 模型预测正确的总体比例,但对类别不均衡数据敏感(如99%负类时,全预测负类准确率99%)。 |
| 精确率(Precision) |  | 模型预测为正类的样本中,真实为正类的比例(减少误报)。 |
| 召回率(Recall) |  | 真实为正类的样本中,被模型正确预测的比例(减少漏报)。 |
| F1-Score | 精确率和召回率的调和平均数,平衡两者矛盾。 |
3.多分类任务的扩展
对于多分类问题(如猫、狗、鸟分类),混淆矩阵扩展为 3×3 或更大的矩阵:
| 预测:猫 | 预测:狗 | 预测:鸟 | |
|---|---|---|---|
| 真实:猫 | TP₁=50 | 5(猫→狗) | 3(猫→鸟) |
| 真实:狗 | 2(狗→猫) | TP₂=45 | 4(狗→鸟) |
| 真实:鸟 | 1(鸟→猫) | 2(鸟→狗) | TP₃=40 |
-
对角线(TP₁, TP₂, TP₃):各类别正确预测数。
-
非对角线:类别间的混淆情况(如“猫→狗”表示真实为猫但预测为狗的样本数)。
多分类指标计算方式:
-
宏平均(Macro):对每个类别的指标单独计算后取平均(平等看待所有类别)。
-
微平均(Micro):合并所有类别的TP/FP/FN后计算整体指标(受大类别影响更大)。
4. 混淆矩阵的实战应用
场景1:医疗诊断(二分类)
-
目标:癌症筛查需最小化漏诊(FN↓),允许一定误诊(FP↑)。
-
优化策略:提高召回率(Recall),通过降低分类阈值(如概率>0.2即判为患病)。
场景2:电商评论情感分析(三分类:正面/中性/负面)
-
问题:负面评论的识别对商家更重要。
-
优化策略:针对“负面”类别单独优化召回率,同时监控宏平均F1-Score。
场景3:推荐系统(点击预测)
-
需求:减少误推荐(FP↓),避免用户流失。
-
优化策略:提高精确率(Precision),仅对高置信度样本(如概率>0.8)进行推荐。
二、分类任务核心指标
1. Accuracy(准确率)
-
定义:模型预测正确的样本数量占总样本量的比重。
-
公式:
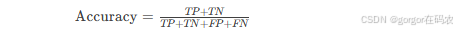
-
特点:
-
简单直观,但类别不均衡时失效
-
例:100个样本中95个正类,全预测正类时准确率95%,但模型无意义
-
-
适用场景:类别分布均衡的二分类或多分类任务
-
意义:
所有预测中正确的比例,反映模型的整体表现。 -
局限性:
在类别不均衡时(如99%负类),即使全预测为负类,准确率也可高达99%,但模型无实际意义
2. Precision(精确率)
-
定义:在被识别为正类别的样本中,为正类别的比例。
-
公式:

-
意义:衡量模型预测的精准度
-
例:癌症筛查中,减少误诊(FP)更重要,需高精确率
-
-
别名:查准率
-
应用场景:
需减少误报(FP)的任务,如垃圾邮件分类(避免将正常邮件误判为垃圾)。
3. Recall(召回率)
-
定义:在所有正类别样本中,被正确识别为正类别的比例。
-
公式:

-
意义:衡量模型对正类的覆盖能力
-
例:金融风控中,漏掉欺诈交易(FN)损失大,需高召回率
-
-
别名:查全率
-
应用场景:
需减少漏报(FN)的任务,如癌症筛查(宁可误诊,不可漏诊)。
二、生成任务核心指标
1. BLEU(Bilingual Evaluation Understudy)
-
定义:BLEU 分数是评估一种语言翻译成另一种语言的文本质量的指标. 它将“质量”的好坏定义为与人类翻译结果的一致性程度. 取值范围是[0, 1], 越接近1, 表明翻译质量越好.
-
用途:机器翻译、文本生成质量评估
-
原理:通过n-gram(连续n个词)匹配计算生成文本与参考文本的相似度
-
公式:
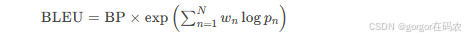
-
BP(Brevity Penalty):惩罚过短生成结果
-
pnpn:n-gram精度(匹配次数/生成文本n-gram总数)
-
-
特点:
-
值域0~1,越高越好
-
对长文本连贯性评估不足
-
侧重精确性(生成文本是否包含参考文本的关键词)。
-
- BLEU举例:
下面举例说计算过程(基本步骤):
1. 分别计算candidate句和reference句的N-grams模型,然后统计其匹配的个数,计算匹配度.
2. 公式:candidate和reference中匹配的 n−gram 的个数 /candidate中n−gram 的个数.
Ø 假设机器翻译的译文candidate和一个参考翻译reference如下:
candidate: It is a nice day todayreference: today is a nice day
candidate: {it, is, a, nice, day, today}reference: {today, is, a, nice, day}结果:其中{today, is, a, nice, day}匹配,所以 匹配度为5/6
candidate: {it is, is a, a nice, nice day, day today}reference: {today is, is a, a nice, nice day}结果:其中{is a, a nice, nice day}匹配,所以 匹配度为3/5
Ø 使用3-gram进行匹配:
candidate: {it is a, is a nice, a nice day, nice day today}reference: {today is a, is a nice, a nice day}结果:其中{is a nice, a nice day}匹配,所以 匹配度为2/4
candidate: {it is a nice, is a nice day, a nice day today}reference: {today is a nice, is a nice day}结果:其中{is a nice day}匹配,所以 匹配度为1/3
通过上面的例子分析可以发现,匹配的个数越多,BLEU值越大,则说明候选句子更好. 但是也会出现下面的极端情况:
candidate: the the the thereference: The cat is standing on the ground如果按照1-gram的方法进行匹配,则匹配度为1,显然是不合理的
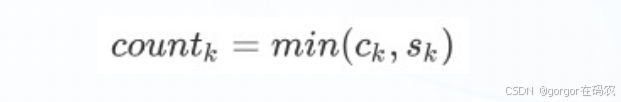
candidate: the the the thereference: The cat is standing on the ground如果按照1-gram的方法进行匹配,ck=4 sk=2 ,countk=min(4,2)=2则匹配度为2/4=1/2.
# 安装nltk的包-->pip install nltk
from nltk.translate.bleu_score import sentence_bleu
def cumulative_bleu(reference, candidate):bleu_1_gram = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0))bleu_2_gram = sentence_bleu(reference, candidate, weights=(0.5, 0.5, 0, 0))bleu_3_gram = sentence_bleu(reference, candidate, weights=(0.33, 0.33, 0.33, 0))bleu_4_gram = sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25))return bleu_1_gram, bleu_2_gram, bleu_3_gram, bleu_4_gram# 生成文本
condidate_text = ["This", "is", "some", "generated", "text"]
# 参考文本列表
reference_texts = [["This", "is", "a", "reference", "text"],
["This", "is", "another", "reference", "text"]]
# 计算 Bleu 指标
c_bleu = cumulative_bleu(reference_texts, condidate_text)
# 打印结果
print("The Bleu score is:", c_bleu)
# The Bleu score is: (0.6, 0.387, 1.5945e-102, 9.283e-155)2. ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
-
定义:ROUGE 指标是在机器翻译、自动摘要、问答生成等领域常见的评估指标. ROUGE 通过将模型生 成的摘要或者回答与参考答案(一般是人工生成的)进行比较计算,得到对应的得分。
-
用途:文本摘要、对话生成评估
-
常见变体:
-
ROUGE-N:基于n-gram的召回率

-
ROUGE-L:基于最长公共子序列(LCS)
-
评估生成文本与参考文本的语义覆盖度
-
-
-
特点:
-
ROUGE-N侧重词汇重叠,ROUGE-L关注语义连贯
-
值域0~1,越高越好
-
侧重内容覆盖度(生成文本是否包含参考文本的核心信息)。
-
侧重召回率
-
-
ROUGE举例:
下面举例说计算过程(这里只介绍ROUGE_N):
基本步骤:Rouge-N实际上是将模型生成的结果和标准结果按N-gram拆分后,计算召回率.
Ø 假设模型生成的文本candidate和一个参考文本reference如下:
candidate: It is a nice day todayreference: today is a nice day
candidate: {it, is, a, nice, day, today}
reference: {today, is, a, nice, day}
结果:其中{today, is, a, nice, day}匹配,所以匹配度为5/5=1,这说明生成的内容完全覆盖了参考文本中的所有单词,质量较高.代码
# 安装rouge-->pip install rouge
from rouge import Rouge# 生成文本
generated_text = "This is some generated text."
# 参考文本列表
reference_texts = ["This is a reference text.", "This is another generated reference text."]
# 计算 ROUGE 指标
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_texts[1])# 打印结果
print("ROUGE-1 precision:", scores[0]["rouge-1"]["p"])
print("ROUGE-1 recall:", scores[0]["rouge-1"]["r"])
print("ROUGE-1 F1 score:", scores[0]["rouge-1"]["f"])
# ROUGE-1 precision: 0.8
# ROUGE-1 recall: 0.6666666666666666
# ROUGE-1 F1 score: 0.72727272231404963. PPL(Perplexity,困惑度)
-
定义:PPL用来度量一个概率分布或概率模型预测样本的好坏程度. PPL越小,标明模型越好.
-
用途:语言模型(如GPT、BERT)的预训练评估
-
定义:模型对测试数据集的“困惑程度”,反映预测能力
-
公式:
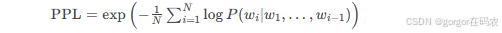
-
NN为测试集总词数,PP为模型预测概率
-
-
特点:
-
PPL越低,模型对语言分布拟合越好
-
与生成质量间接相关(低PPL的模型生成文本更流畅,但未必内容正确)。
-
例:GPT-3的PPL约20,远优于传统RNN模型(PPL>100)
-
代码
import math#定义语料库
sentences = [
['I', 'have', 'a', 'pen'],
['He', 'has', 'a', 'book'],
['She', 'has', 'a', 'cat']
]
#定义语言模型
unigram = {'I':1/12, 'have':1/12, 'a': 3/12, 'pen':1/12, 'He':1/12,'has':2/12,'book':1/12,'She':1/12, 'cat':1/12}# 计算困惑度
perplexity = 0
for sentence in sentences:sentence_prob = 1for word in sentence:sentence_prob *= unigram[word]temp = -math.log(sentence_prob, 2)/len(sentence)perplexity+=2**temp
perplexity = perplexity/len(sentences)
print('困惑度为:', perplexity)
# 困惑度为: 8.15三、指标对比与选型指南
| 任务类型 | 推荐指标 | 核心关注点 |
|---|---|---|
| 文本分类 | Accuracy, F1, AUC-ROC | 类别均衡性、精确率与召回率平衡 |
| 机器翻译 | BLEU, METEOR | n-gram匹配、语义相似度 |
| 文本摘要 | ROUGE-L, ROUGE-1/2 | 内容覆盖度、关键信息保留 |
| 语言模型预训练 | PPL | 语言建模能力(预测下一个词的能力) |
| 情感分类 | Accuracy(均衡数据),F1(不均衡数据) |
四:总结
Accuracy、Precision、Recall主要用于分类任务(如翻译、摘要),评估模型预测的准确性、精确性和覆盖性。而BLEU、ROUGE用于生成任务(如情感分析、意图识别),如机器翻译和文本摘要,评估生成文本的质量。PPL(困惑度)则用于评估语言模型本身的预测能力,不直接涉及具体任务的结果。以下是它们的关联与区别详解:
核心定位与任务类型
| 指标类型 | 适用任务 | 核心目标 |
|---|---|---|
| BLEU/ROUGE/PPL | 生成任务(文本生成、翻译、摘要) | 评估生成文本的质量(内容匹配、流畅性) |
| Accuracy/Precision/Recall | 分类任务(二分类、多分类) | 评估分类结果的准确性、覆盖度与精准度 |
相关文章:
大语言模型的评估指标
目录 一、混淆矩阵 1. 混淆矩阵的结构(二分类为例) 2.从混淆矩阵衍生的核心指标 3.多分类任务的扩展 4. 混淆矩阵的实战应用 二、分类任务核心指标 1. Accuracy(准确率) 2. Precision(精确率) 3. …...

Python 设计模式:模板模式
1. 什么是模板模式? 模板模式是一种行为设计模式,它定义了一个操作的算法的骨架,而将一些步骤延迟到子类中。模板模式允许子类在不改变算法结构的情况下,重新定义算法的某些特定步骤。 模板模式的核心思想是将算法的固定部分提取…...

HSTL详解
一、HSTL的基本定义 HSTL(High-Speed Transceiver Logic) 是一种针对高速数字电路设计的差分信号接口标准,主要用于高带宽、低功耗场景(如FPGA、ASIC、高速存储器接口)。其核心特性包括: 差分信号传输&…...
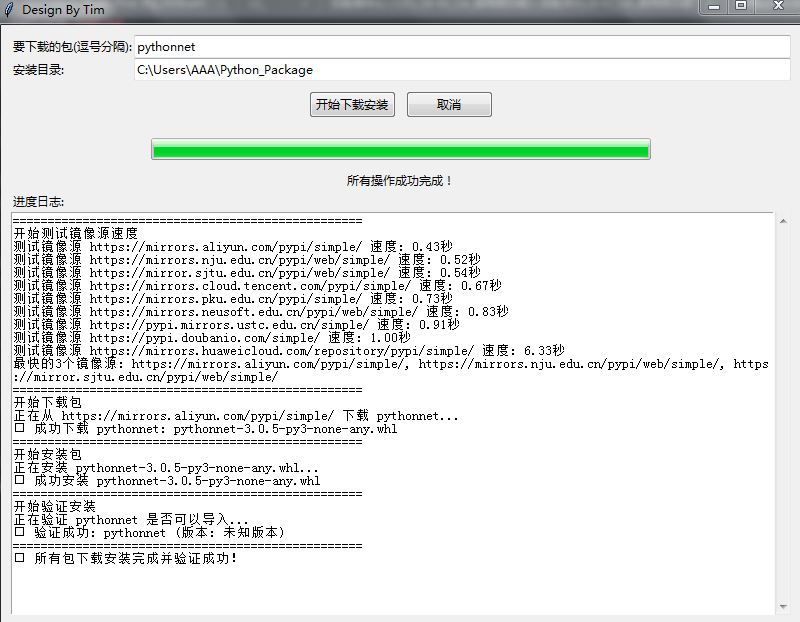
好用————python 库 下载 ,整合在一个小程序 UIUIUI
上图~ import os import time import threading import requests import subprocess import importlib import tkinter as tk from tkinter import ttk, messagebox, scrolledtext from concurrent.futures import ThreadPoolExecutor, as_completed from urllib.parse im…...

OpenVINO教程(五):实现YOLOv11+OpenVINO实时视频目标检测
目录 实现讲解效果展示完整代码 本文作为上篇博客的延续,在之前实现了图片推理的基础上,进一步介绍如何进行视频推理。 实现讲解 首先,我们需要对之前的 predict_and_show_image 函数进行拆分,将图像显示与推理器(pre…...
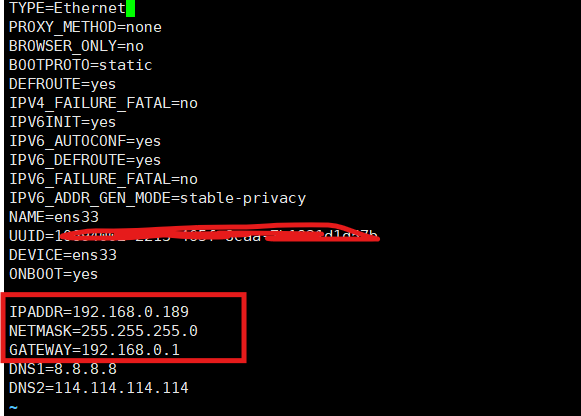
CentOS的安装以及网络配置
CentOS的下载 在学习docker之前,我们需要知道的就是docker是运行在Linux内核之上的,所以我们需要Linux环境的操作系统,当然了你也可以选择安装ubuntu等操作系统,如果你不想在本机安装的话还可以考虑买阿里或者华为的云服务器&…...
)
【初级】前端开发工程师面试100题(一)
本题库共计包含100题,考察html,css,js,以及react,vue,webpack等基础知识掌握情况。 HTML基础篇 说说你对HTML语义化的理解? 语义化就是用合适的标签表达合适的内容,比如<header&…...

eplan许可证与防火墙安全软件冲突
在使用EPLAN电气设计软件时,有时会遇到许可证与防火墙或安全软件之间的冲突。这种冲突可能导致许可证无法激活或软件无法正常运行,给用户带来诸多不便。本文将为您解析EPLAN许可证与防火墙/安全软件冲突的原因,并提供解决方案,帮助…...
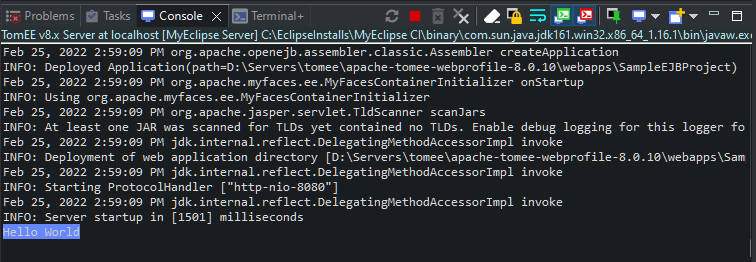
「Java EE开发指南」用MyEclipse开发EJB 3无状态会话Bean(二)
本教程介绍在MyEclipse中开发EJB 3无状态会话bean,由于JPA实体和EJB 3实体非常相似,因此本教程不涉及EJB 3实体Bean的开发。在本教程中,您将学习如何: 创建EJB 3项目创建无状态会话bean部署并测试bean 在上文中(点击…...

Stable Diffusion秋叶整合包V4独立版Python本地API连接指南
秋叶整合包V4独立版Python本地API连接指南 秋叶整合的Stable Diffusion V4独立版支持通过Python调用本地API实现自动化图像生成。以下是具体操作流程及注意事项: 一、启用API服务 启动器配置 • 在秋叶启动器的 高级选项 中添加以下参数: --api --liste…...

小程序 GET 接口两种传值方式
前言 一般 GET 接口只有两种URL 参数和路径参数 一:URL 参数(推荐方式) 你希望请求: https://serve.zimeinew.com/wx/products/info?id5124接口应该写成这样,用 req.query.id 取 ?id5124: app.get(&…...

深度学习在DOM解析中的应用:自动识别页面关键内容区块
摘要 本文介绍了如何在爬取东方财富吧(https://www.eastmoney.com)财经新闻时,利用深度学习模型对 DOM 树中的内容区块进行自动识别和过滤,并将新闻标题、时间、正文等关键信息分类存储。文章聚焦爬虫整体性能瓶颈,通…...
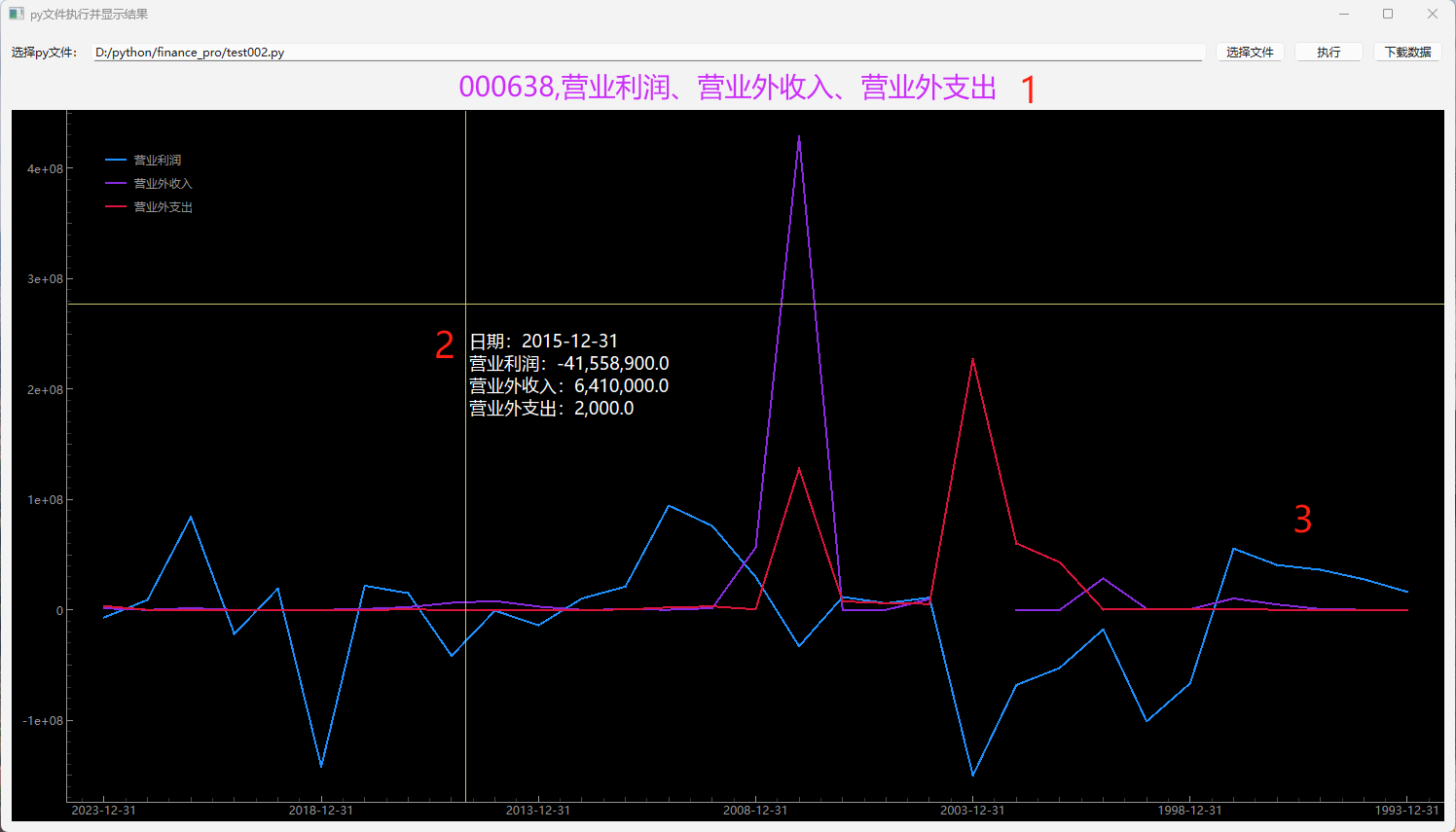
PyQt6实例_pyqtgraph多曲线显示工具_代码分享
目录 概述 效果 代码 返回结果对象 字符型横坐标 通用折线图工具 工具主界面 使用举例 概述 1 分析数据遇到需要一个股票多个指标对比或一个指标多个股票对比,涉及到同轴多条曲线的显示,所以开发了本工具。 2 多曲线显示部分可以当通用工具使…...
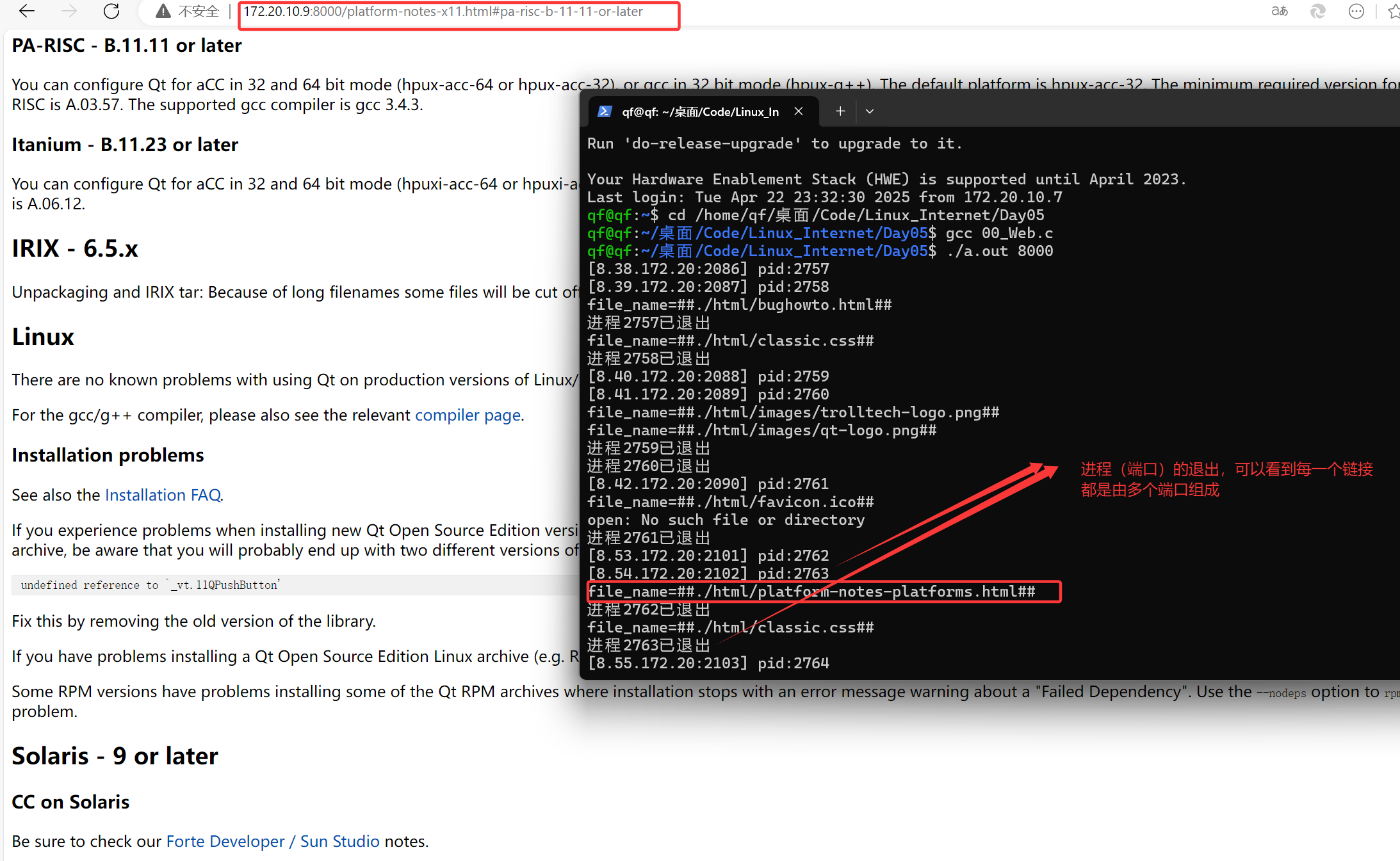
Linux网络编程 多线程Web服务器:HTTP协议与TCP并发实战
问题解答 TCP是如何防止SYN洪流攻击的? 方式有很多种,我仅举例部分: 1、调整内核参数 我们知道SYN洪流攻击的原理就是发送一系列无法完成三次握手的特殊信号,导致正常的能够完成三次握手的信号因为 连接队列空间不足ÿ…...
)
【Vulkan 入门系列】创建帧缓冲、命令池、命令缓存,和获取图片(六)
这一节主要介绍创建帧缓冲(Framebuffer),创建命令池,创建命令缓存,和从文件加载 PNG 图像数据,解码为 RGBA 格式,并将像素数据暂存到 Vulkan 的 暂存缓冲区中。 一、创建帧缓冲 createFramebu…...

【Git】fork 和 branch 的区别
在 Git 中,“fork” 和 “branch” 是两个不同的概念,它们用于不同的场景并且服务于不同的目的。理解这两者的区别对于有效地使用 Git 进行版本控制非常重要。 1. Fork(分叉) 定义 Fork 是指在 GitHub、GitLab 等代码托管平台上…...
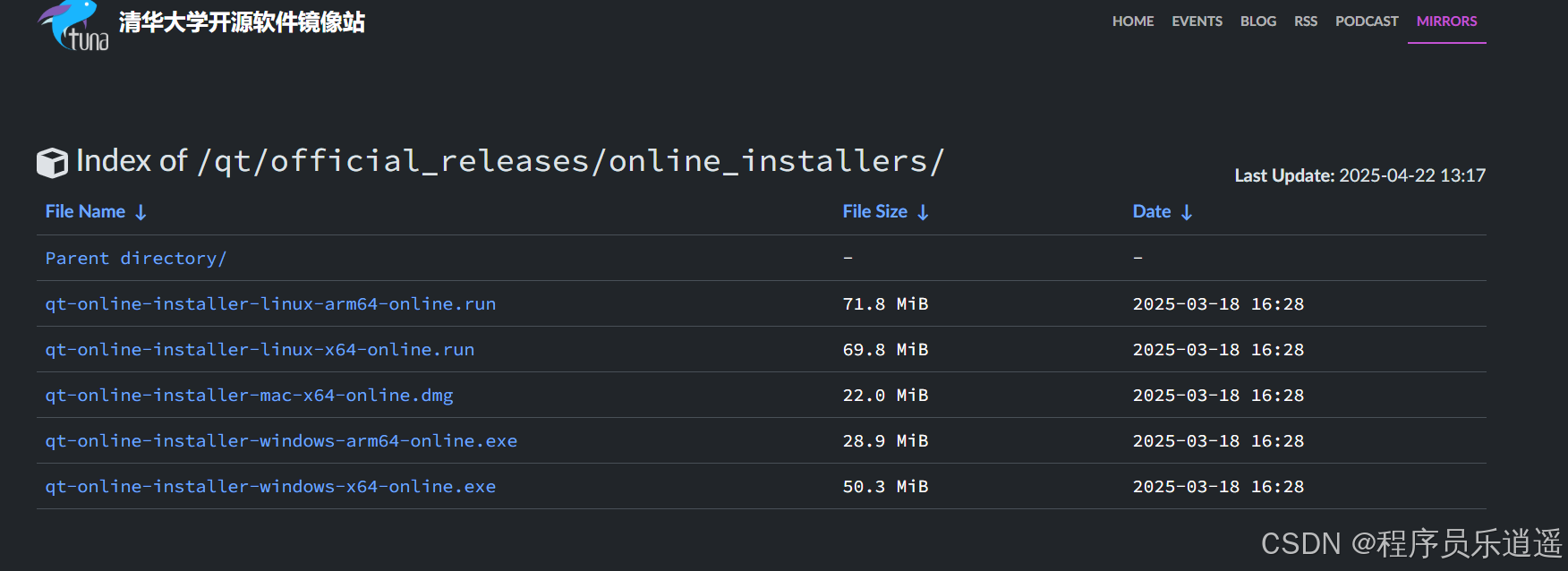
Qt 下载的地址集合
Qt 下载离线安装包 download.qt.io/archive/qt/5.14/5.14.2/ Qt 6 安装下载在线安装包 Index of /qt/official_releases/online_installers/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror...

java将pdf转换成word
1、jar包准备 在项目中新增lib目录,并将如下两个文件放入lib目录下 aspose-words-15.8.0-jdk16.jar aspose-pdf-22.9.jar 2、pom.xml配置 <dependency><groupId>com.aspose</groupId><artifactId>aspose-pdf</artifactId><versi…...
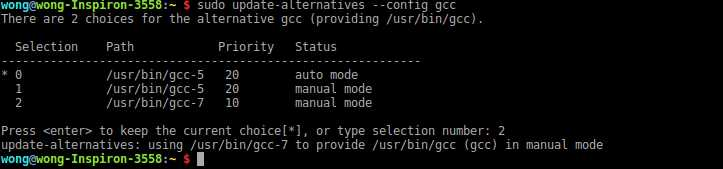
ubuntu下gcc/g++安装及不同版本切换
1. 查看当前gcc版本 $ gcc --version# 查看当前系统中已安装版本 $ ls /usr/bin/gcc*2. 安装新版本gcc $ sudo apt-get update# 这里以版本12为依据(也可以通过源码方式安装,请自行Google!) $ sudo apt-get install -y gcc-12 g…...

缓存与内存;缺页中断;缓存映射:组相联
文章目录 内存(RAM)与缓存(Cache)Memory Management Unit缺页中断 多级缓存缓存替换策略缓存的映射方式 内存(RAM)与缓存(Cache) 缓存: CPU 内部或非常靠近的高速存储&a…...

FPGA入门学习Day1——设计一个DDS信号发生器
目录 一、DDS简介 (一)基本原理 (二)主要优势 (三)与传统技术的对比 二、FPGA存储器 (一)ROM波形存储器 (二)RAM随机存取存储器 (三&…...

微信小程序拖拽排序有效果图
效果图 .wxml <view class"container" style"--w:{{w}}px;" wx:if"{{location.length}}"><view class"container-item" wx:for"{{list}}" wx:key"index" data-index"{{index}}"style"--…...

elasticsearch 查询检索
一、查询方式列举 1、多维度查询 关键词:bool must match {"query": {"bool": {"must": [{"match": {"server_name": "www.test.com"}},{"range": { //时间查询"createTime": …...
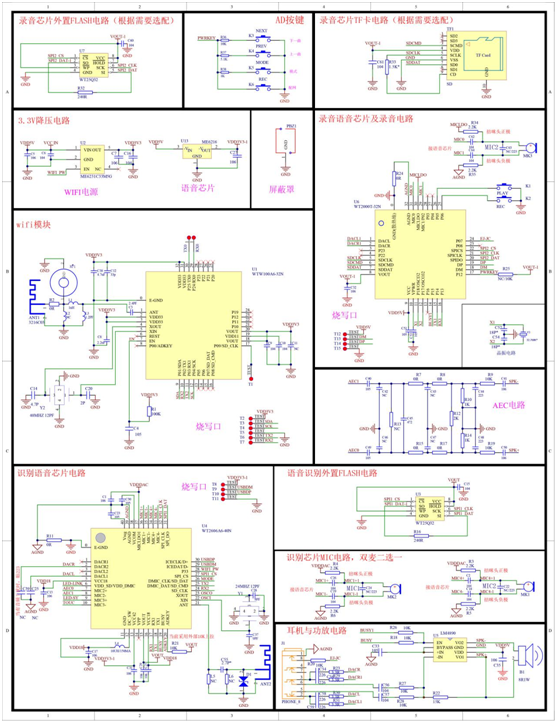
WT2000T专业录音芯片:破解普通录音设备信息留存、合规安全与远程协作三大难题
在快节奏的现代商业环境中,会议是企业决策、创意碰撞和战略部署的核心场景。然而,传统会议记录方式常面临效率低、信息遗漏、回溯困难等痛点。如何确保会议内容被精准记录并高效利用?会议室专用录音芯片应运而生,以智能化、高保真…...

【Python 学习笔记】 pip指令使用
系列文章目录 pip指令使用 文章目录 系列文章目录前言安装配置使用pip 管理Python包修改pip下载源 前言 提示:这里可以添加本文要记录的大概内容: 当前文章记录的是我在学习过程的一些笔记和思考,可能存在有误解的地方,仅供大家…...

与Ubuntu相关命令
windows将文件传输到Ubuntu 传输文件夹或文件 scp -r 本地文件夹或文件 ubuntu用户名IP地址:要传输到的文件夹路径 例如: scp -r .\04.py gao192.168.248.129:/home/gao 如果传输文件也可以去掉-r 安装软件 sudo apt-get update 更新软件包列表 sudo apt insta…...

C# 文件读取
文件读取是指使用 C# 程序从计算机文件系统中获取文件内容的过程。将存储在磁盘上的文件内容加载到内存中,供程序处理。主要类型有:文本文件读取(如 .txt, .csv, .json, .xml);二进制文件读取(如 .jpg, .pn…...

leetcode125.验证回文串
class Solution {public boolean isPalindrome(String s) {s s.replaceAll("[^a-zA-Z0-9]", "").toLowerCase();for(int i0,js.length()-1;i<j;i,j--){if(s.charAt(i)!s.charAt(j))return false;}return true;} }...
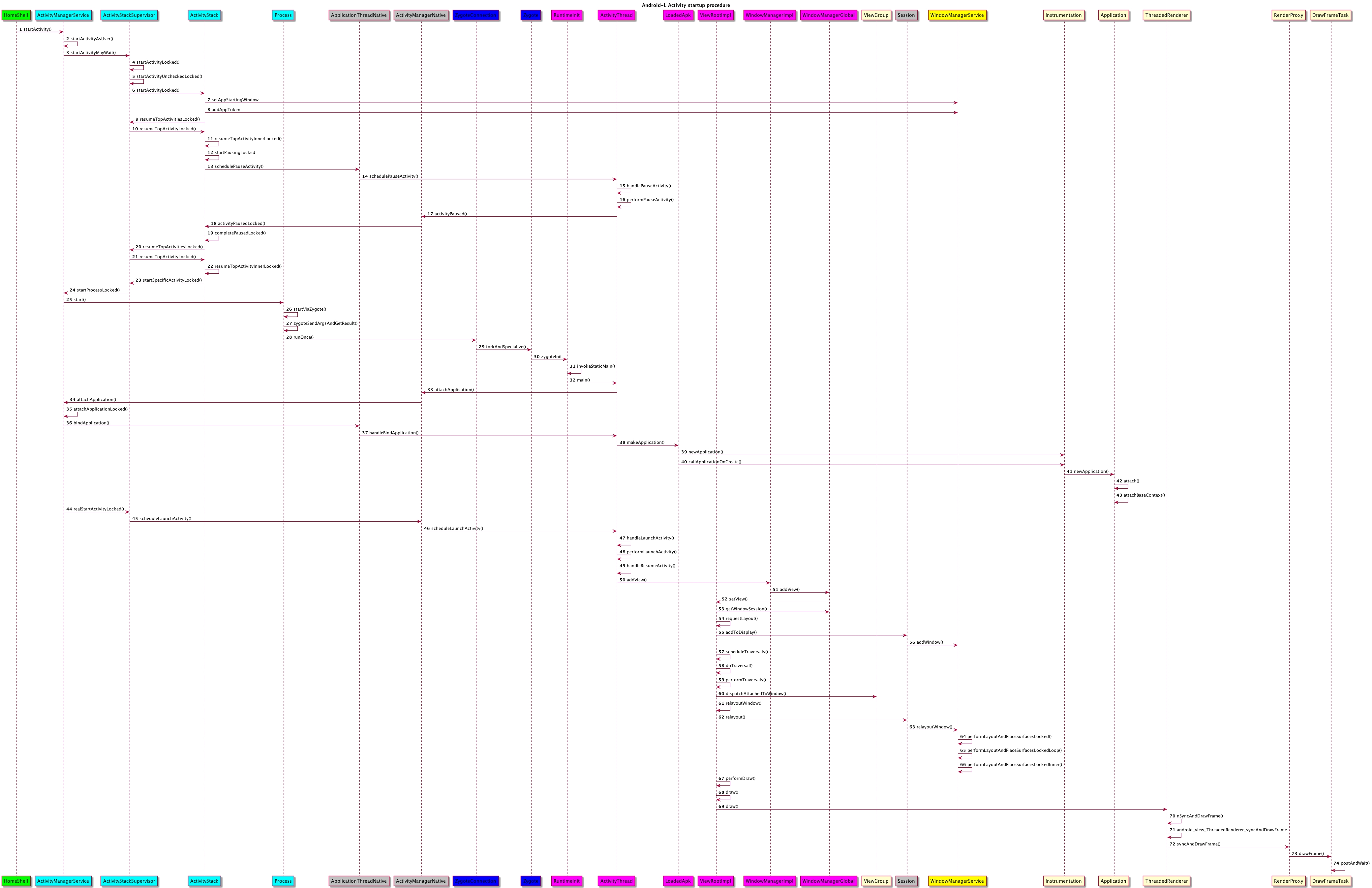
【Android面试八股文】Android系统架构【一】
Android系统架构图 1.1 安卓系统启动 1.设备加电后执行第一段代码:Bootloader 系统引导分三种模式:fastboot,recovery,normal: fastboot模式:用于工厂模式的刷机。在关机状态下,按返回开机 键进…...
——BERT 变体详解)
NLP高频面试题(五十二)——BERT 变体详解
在现代自然语言处理领域,BERT 系列模型不断演进,衍生出多种变体,它们通过改进预训练任务、模型结构和训练策略,在不同应用场景下取得了更优表现。本文首先概览主要 BERT 变体(如 ALBERT、RoBERTa、ELECTRA、SpanBERT、Transformer-XL 等),随后针对以下几个关键问题逐一展…...