【Python爬虫详解】第四篇:使用解析库提取网页数据——XPath
在前一篇文章中,我们介绍了如何使用BeautifulSoup解析库从HTML中提取数据。本篇文章将介绍另一个强大的解析工具:XPath。XPath是一种在XML文档中查找信息的语言,同样适用于HTML文档。它的语法简洁而强大,特别适合处理结构复杂的网页内容。
一、XPath简介
XPath (XML Path Language) 最初是为了在XML文档中进行导航而设计的语言,后来被广泛应用于HTML文档的解析。与BeautifulSoup相比,XPath有以下特点:
- 语法强大:可以通过简洁的表达式精确定位元素
- 高效性能:通常比BeautifulSoup更快,特别是在处理大型文档时
- 跨平台通用:几乎所有编程语言都有XPath的实现
- 灵活性高:可以通过各种轴、谓词和函数构建复杂的选择条件
在Python中,我们主要通过lxml库来使用XPath功能。
二、安装lxml
首先,我们需要安装lxml库:
pip install lxml
安装成功后,将显示类似以下输出:
Collecting lxmlDownloading lxml-4.9.3-cp310-cp310-win_amd64.whl (3.9 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.9/3.9 MB 8.2 MB/s eta 0:00:00
Installing collected packages: lxml
Successfully installed lxml-4.9.3
lxml是一个基于C语言的库,性能非常高,同时支持XPath 1.0标准。
三、XPath基础语法
XPath使用路径表达式来选择XML/HTML文档中的节点或节点集。这些表达式非常类似于文件系统中的路径。
1. 基本路径表达式
/html/body/div # 从根节点选择html下的body下的所有div元素
//div # 选择文档中所有的div元素,不管它们在哪个位置
/html/body/div[1] # 选择body下的第一个div元素
//div[@class='content'] # 选择带有class='content'属性的所有div元素
2. 常用路径操作符
| 操作符 | 描述 | 示例 |
|---|---|---|
/ | 从根节点选取或选取子元素 | /html/body |
// | 从当前节点选择文档中符合条件的所有元素 | //a |
. | 选取当前节点 | ./div |
.. | 选取当前节点的父节点 | ../ |
@ | 选取属性 | //div[@id] |
* | 通配符,选择任意元素 | //* |
3. 条件谓词
XPath允许我们使用方括号[]来添加条件谓词:
//div[1] # 第一个div元素
//div[last()] # 最后一个div元素
//div[position()<3] # 前两个div元素
//div[@class] # 所有有class属性的div元素
//div[@class='main'] # class属性值为'main'的div元素
//div[contains(@class, 'content')] # class属性包含'content'的div元素
//a[text()='点击这里'] # 文本内容为'点击这里'的a元素
//div[count(p)>2] # 包含超过2个p元素的div元素
4. XPath轴
XPath轴用于定义相对于当前节点的节点集:
//div/ancestor::* # div的所有祖先节点
//div/child::p # div的所有p子节点
//div/descendant::span # div的所有span后代节点
//div/following::p # div后面的所有p节点
//div/preceding::p # div前面的所有p节点
//div/following-sibling::div # div之后的所有同级div节点
四、在Python中使用XPath
Python的lxml库提供了强大的XPath支持。以下是基本用法:
from lxml import etree
import requests# 获取HTML内容
url = "https://www.example.com"
response = requests.get(url)
html_text = response.text# 解析HTML
html = etree.HTML(html_text)
# 或者从文件加载HTML
# html = etree.parse('example.html', etree.HTMLParser())# 使用XPath提取数据
title = html.xpath('//title/text()') # 获取标题文本
links = html.xpath('//a/@href') # 获取所有链接的href属性
paragraphs = html.xpath('//p/text()') # 获取所有段落的文本print(f"标题: {title[0] if title else '无标题'}")
print(f"找到 {len(links)} 个链接")
print(f"找到 {len(paragraphs)} 个段落")
输出结果:
标题: Example Domain
找到 1 个链接
找到 2 个段落
1. 提取文本内容
# 使用一个简单的HTML字符串示例
html_str = """
<html><head><title>XPath示例页面</title></head><body><h1>欢迎学习XPath</h1><p>这是第一个段落。</p><p>这是第二个<b>段落</b>,包含<a href="https://example.com">链接</a>。</p><div class="content"><p>这是内容区的段落。</p></div></body>
</html>
"""
html = etree.HTML(html_str)# 提取标题文本
title_text = html.xpath('//title/text()')[0]
print(f"标题: {title_text}")# 提取所有段落文本
p_texts = html.xpath('//p/text()')
print(f"所有段落文本: {p_texts}")# 提取包含某些内容的标签文本
specific_texts = html.xpath('//div[contains(@class, "content")]/p/text()')
print(f"特定div内的文本: {specific_texts}")# 提取标签及其子元素的全部文本
complex_p = html.xpath('//p[2]')[0] # 选取第二个段落
full_text = ''.join(complex_p.xpath('.//text()'))
print(f"完整的段落文本: {full_text}")
输出结果:
标题: XPath示例页面
所有段落文本: ['这是第一个段落。', '这是第二个', ',包含', '。', '这是内容区的段落。']
特定div内的文本: ['这是内容区的段落。']
完整的段落文本: 这是第二个段落,包含链接。
注意:text()函数只提取直接子文本节点的内容,不包括子元素中的文本。要获取包含子元素的全部文本,需要使用.//text()并连接结果。
2. 提取属性值
html_str = """
<html><body><a href="https://example.com" class="external" target="_blank">示例链接</a><img src="/images/logo.png" alt="网站Logo" width="100"><div id="main" class="container content">主要内容</div><a href="https://example.org" class="link" target="_blank">另一个链接</a></body>
</html>
"""
html = etree.HTML(html_str)# 提取所有链接的URL
urls = html.xpath('//a/@href')
print(f"所有链接URL: {urls}")# 提取所有图片的地址
img_srcs = html.xpath('//img/@src')
print(f"所有图片地址: {img_srcs}")# 提取特定元素的属性
classes = html.xpath('//div[@id="main"]/@class')
print(f"main div的class属性: {classes}")# 提取同时满足多个条件的元素的属性
selected_attrs = html.xpath('//a[@class="link" and @target="_blank"]/@href')
print(f"符合条件的链接: {selected_attrs}")
输出结果:
所有链接URL: ['https://example.com', 'https://example.org']
所有图片地址: ['/images/logo.png']
main div的class属性: ['container content']
符合条件的链接: ['https://example.org']
3. 处理多个元素
html_str = """
<html><body><div id="nav"><a href="/home">首页</a><a href="/about">关于</a><a href="/contact">联系我们</a></div><table><tr><th>姓名</th><th>年龄</th></tr><tr><td>张三</td><td>25</td></tr><tr><td>李四</td><td>30</td></tr></table></body>
</html>
"""
html = etree.HTML(html_str)# 遍历处理所有链接
links = html.xpath('//a')
print("所有链接信息:")
for link in links:url = link.xpath('./@href')[0] if link.xpath('./@href') else ''text = ''.join(link.xpath('.//text()')).strip()print(f" 链接文本: {text}, URL: {url}")# 提取表格数据
rows = html.xpath('//table/tr')
table_data = []
print("\n表格数据:")
for row in rows:cols = row.xpath('./td/text() | ./th/text()')print(f" 行数据: {cols}")table_data.append(cols)
输出结果:
所有链接信息:链接文本: 首页, URL: /home链接文本: 关于, URL: /about链接文本: 联系我们, URL: /contact表格数据:行数据: ['姓名', '年龄']行数据: ['张三', '25']行数据: ['李四', '30']
五、实际案例:解析百度热搜榜
让我们使用XPath来解析百度热搜榜,类似于我们之前使用BeautifulSoup所做的:
from lxml import etree
import logging
import requests# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')def parse_baidu_hot_search_xpath(html_file=None):"""使用XPath解析百度热搜榜HTML"""try:if html_file:# 从文件读取HTMLwith open(html_file, "r", encoding="utf-8") as f:html_content = f.read()else:# 实时获取百度热搜url = "https://top.baidu.com/board?tab=realtime"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}response = requests.get(url, headers=headers)html_content = response.text# 保存到文件以备后用with open("baidu_hot_search_new.html", "w", encoding="utf-8") as f:f.write(html_content)logging.info("开始使用XPath解析百度热搜榜HTML...")# 创建HTML解析对象html = etree.HTML(html_content)# 使用XPath找到热搜项元素# 注意:以下XPath表达式基于当前百度热搜页面的结构,如果页面结构变化,可能需要更新hot_items = html.xpath('//div[contains(@class, "category-wrap_iQLoo")]')if not hot_items:logging.warning("未找到热搜项,可能页面结构已变化,请检查HTML内容和XPath表达式")return []logging.info(f"找到 {len(hot_items)} 个热搜项")# 提取每个热搜项的数据hot_search_list = []for index, item in enumerate(hot_items, 1):try:# 提取标题title_elements = item.xpath('.//div[contains(@class, "c-single-text-ellipsis")]/text()')title = title_elements[0].strip() if title_elements else "未知标题"# 提取热度(如果有)hot_elements = item.xpath('.//div[contains(@class, "hot-index_1Bl1a")]/text()')hot_value = hot_elements[0].strip() if hot_elements else "未知热度"# 提取排名rank = indexhot_search_list.append({"rank": rank,"title": title,"hot_value": hot_value})except Exception as e:logging.error(f"解析第 {index} 个热搜项时出错: {e}")logging.info(f"成功解析 {len(hot_search_list)} 个热搜项")return hot_search_listexcept Exception as e:logging.error(f"解析百度热搜榜时出错: {e}")return []def display_hot_search(hot_list):"""展示热搜榜数据"""if not hot_list:print("没有获取到热搜数据")returnprint("\n===== 百度热搜榜 (XPath解析) =====")print("排名\t热度\t\t标题")print("-" * 50)for item in hot_list:print(f"{item['rank']}\t{item['hot_value']}\t{item['title']}")if __name__ == "__main__":# 尝试从之前保存的文件加载,如果没有则直接获取try:hot_search_list = parse_baidu_hot_search_xpath("baidu_hot_search.html")except FileNotFoundError:hot_search_list = parse_baidu_hot_search_xpath()display_hot_search(hot_search_list)
输出结果(实际结果可能会因时间而不同):
2025-04-20 10:15:32,654 - INFO: 开始使用XPath解析百度热搜榜HTML...
2025-04-20 10:15:32,789 - INFO: 找到 30 个热搜项
2025-04-20 10:15:32,846 - INFO: 成功解析 30 个热搜项===== 百度热搜榜 (XPath解析) =====
排名 热度 标题
--------------------------------------------------
1 4522302 世界首个"人造子宫"获批临床试验
2 4325640 暑假别只顾玩 这些安全知识要牢记
3 4211587 李嘉诚家族被曝已移居英国
... ... ...
六、XPath高级用法
1. 逻辑运算符
XPath支持多种逻辑运算符来组合条件:
html_str = """
<html><body><div class="main" id="content">主内容</div><div class="main">次要内容</div><div class="sidebar">侧边栏内容</div><div class="hidden">隐藏内容</div></body>
</html>
"""
html = etree.HTML(html_str)# 使用and: 同时满足多个条件
elements = html.xpath('//div[@class="main" and @id="content"]')
print(f"同时满足class='main'和id='content'的元素数量: {len(elements)}")
print(f"内容: {elements[0].xpath('string(.)')}")# 使用or: 满足任一条件
elements = html.xpath('//div[@class="main" or @class="sidebar"]')
print(f"class为'main'或'sidebar'的元素数量: {len(elements)}")# 使用not: 否定条件
elements = html.xpath('//div[not(@class="hidden")]')
print(f"class不为'hidden'的div元素数量: {len(elements)}")
输出结果:
同时满足class='main'和id='content'的元素数量: 1
内容: 主内容
class为'main'或'sidebar'的元素数量: 3
class不为'hidden'的div元素数量: 3
2. 字符串函数
XPath提供了多种处理字符串的函数:
html_str = """
<html><body><div class="content-main">内容1</div><div class="sidebar-content">内容2</div><div id="section-1">第一节</div><div id="section-2">第二节</div><p>这是一个短句。</p><p>这是一个非常长的段落,包含了很多文字内容,用于测试string-length函数。</p></body>
</html>
"""
html = etree.HTML(html_str)# contains: 检查是否包含子字符串
elements = html.xpath('//div[contains(@class, "content")]')
print(f"class属性包含'content'的div元素: {[e.xpath('string(.)') for e in elements]}")# starts-with: 检查是否以某字符串开头
elements = html.xpath('//div[starts-with(@id, "section")]')
print(f"id属性以'section'开头的div元素: {[e.xpath('string(.)') for e in elements]}")# string-length: 检查字符串长度
short_p = html.xpath('//p[string-length(text()) < 10]')
long_p = html.xpath('//p[string-length(text()) > 10]')
print(f"文本长度小于10的p元素数量: {len(short_p)}")
print(f"文本长度大于10的p元素数量: {len(long_p)}")
输出结果:
class属性包含'content'的div元素: ['内容1', '内容2']
id属性以'section'开头的div元素: ['第一节', '第二节']
文本长度小于10的p元素数量: 1
文本长度大于10的p元素数量: 1
3. 位置函数
XPath提供了多种与元素位置相关的函数:
html_str = """
<html><body><div>第一个div</div><div>第二个div</div><div>第三个div</div><div>第四个div</div><div>第五个div</div></body>
</html>
"""
html = etree.HTML(html_str)# position(): 获取当前位置
first_element = html.xpath('//div[position()=1]')
print(f"第一个div的内容: {first_element[0].xpath('string(.)')}")# last(): 获取最后位置
last_element = html.xpath('//div[position()=last()]')
print(f"最后一个div的内容: {last_element[0].xpath('string(.)')}")# 选择范围
range_elements = html.xpath('//div[position()>1 and position()<5]')
print(f"第2到第4个div: {[e.xpath('string(.)') for e in range_elements]}")
输出结果:
第一个div的内容: 第一个div
最后一个div的内容: 第五个div
第2到第4个div: ['第二个div', '第三个div', '第四个div']
4. 组合多个XPath
在Python中,我们可以组合多个XPath表达式来提取不同类型的元素:
html_str = """
<html><body><h1>主标题</h1><h2>副标题1</h2><p>段落1</p><h2>副标题2</h2><p>段落2</p><h3>小标题</h3><p>段落3</p></body>
</html>
"""
html = etree.HTML(html_str)# 使用|操作符组合XPath
elements = html.xpath('//h1 | //h2 | //h3')
print(f"所有标题元素: {[e.xpath('string(.)') for e in elements]}")# 分别提取然后合并结果
titles = html.xpath('//h1/text()') + html.xpath('//h2/text()')
print(f"主标题和副标题: {titles}")
输出结果:
所有标题元素: ['主标题', '副标题1', '副标题2', '小标题']
主标题和副标题: ['主标题', '副标题1', '副标题2']
七、如何构建正确的XPath表达式?
在实际爬虫开发中,构建正确的XPath表达式是一项关键技能。以下是一些实用技巧:
1. 使用浏览器开发者工具
现代浏览器的开发者工具通常提供XPath支持:
- 在Chrome或Firefox中右键点击元素,选择"检查"
- 在元素面板中右键点击HTML代码,选择"Copy" > “Copy XPath”
- 获取浏览器生成的XPath表达式(注意:浏览器生成的XPath通常很长且不够通用,可能需要手动优化)
例如,对于百度首页的搜索框,Chrome可能生成这样的XPath:
//*[@id="kw"]
2. 手动优化XPath表达式
浏览器生成的XPath通常不够理想,我们需要手动优化:
- 找到元素的独特标识(如id、特定的class等)
- 尽量使用相对路径而非绝对路径
- 使用
contains()等函数处理动态变化的属性值
例如,浏览器可能生成:
/html/body/div[3]/div[2]/div[1]/div[4]/div[1]/div/div[2]/div[3]/div/div/div[1]/div
优化后可能变为:
//div[@id='main-content']//div[contains(@class, 'item')]
下面是一个对比示例:
# 浏览器生成的XPath(过于具体,容易因页面结构变化而失效)
specific_xpath = "/html/body/div[1]/div[3]/div[1]/div/div[2]/form/span[1]/input"# 优化后的XPath(更具通用性和可维护性)
optimized_xpath = "//input[@id='kw' or @name='wd']"
3. 使用XPath测试工具
有多种工具可以帮助测试XPath表达式:
- Chrome插件:XPath Helper、XPath Finder等
- 在线工具:如XPath Tester
- 在Python中实时测试:使用
lxml和一个小测试脚本
# 在Python中测试XPath表达式的简单脚本
def test_xpath(html_str, xpath_expr):from lxml import etreehtml = etree.HTML(html_str)result = html.xpath(xpath_expr)print(f"XPath: {xpath_expr}")print(f"匹配元素数量: {len(result)}")if len(result) > 0:if isinstance(result[0], str):print(f"第一个匹配结果: {result[0]}")else:print(f"第一个匹配元素的文本: {result[0].xpath('string(.)')}")return result# 使用示例
html_content = """<div class="container"><span class="title">测试标题</span></div>"""
test_xpath(html_content, "//span[@class='title']")
test_xpath(html_content, "//div/span/text()")
输出结果:
XPath: //span[@class='title']
匹配元素数量: 1
第一个匹配元素的文本: 测试标题
XPath: //div/span/text()
匹配元素数量: 1
第一个匹配结果: 测试标题
4. 从特殊到一般
构建XPath的一个好策略是先找到一个特定元素,然后逐步泛化:
html_str = """
<html><body><div id="products"><div class="product item-123" data-category="electronics"><h3>手机</h3><p class="price">¥1999</p></div><div class="product item-456" data-category="electronics"><h3>平板电脑</h3><p class="price">¥2999</p></div><div class="product item-789" data-category="books"><h3>Python编程</h3><p class="price">¥89</p></div></div></body>
</html>
"""
html = etree.HTML(html_str)# 1. 先构建非常具体的XPath(只匹配一个元素)
specific_xpath = "//div[@id='products']/div[@class='product item-123' and @data-category='electronics']"
result = html.xpath(specific_xpath)
print(f"具体XPath匹配结果数: {len(result)}")# 2. 然后逐步泛化
# 2.1 移除一些具体的约束
less_specific_xpath = "//div[@id='products']/div[contains(@class, 'product')]"
result = html.xpath(less_specific_xpath)
print(f"稍微泛化的XPath匹配结果数: {len(result)}")# 2.2 进一步泛化,仅保留核心特征
general_xpath = "//div[contains(@class, 'product')]"
result = html.xpath(general_xpath)
print(f"进一步泛化的XPath匹配结果数: {len(result)}")# 3. 筛选特定类别的产品
electronics_xpath = "//div[contains(@class, 'product') and @data-category='electronics']"
result = html.xpath(electronics_xpath)
print(f"电子产品数量: {len(result)}")
输出结果:
具体XPath匹配结果数: 1
稍微泛化的XPath匹配结果数: 3
进一步泛化的XPath匹配结果数: 3
电子产品数量: 2
八、XPath与CSS选择器的对比
XPath和CSS选择器是两种最常用的元素定位方法,它们各有优缺点:
| 特性 | XPath | CSS选择器 |
|---|---|---|
| 向上遍历 | 支持(如../、ancestor::) | 有限支持 |
| 基于文本选择 | 支持(如//a[text()='点击']) | 不直接支持 |
| 复杂条件 | 很强大(支持逻辑运算、函数等) | 相对有限 |
| 语法简洁度 | 相对复杂 | 通常更简洁 |
| 性能 | 一般稍慢但功能强大 | 通常更快但功能有限 |
让我们通过一个实际例子来对比:
html_str = """
<html><body><div id="menu"><ul><li><a href="/home" class="nav-link">首页</a></li><li><a href="/products" class="nav-link active">产品</a></li><li><a href="/download" class="button">下载</a></li></ul></div><div id="content"><h1>产品列表</h1><div class="product">产品1</div><div class="product">产品2</div><div class="product">产品3</div></div></body>
</html>
"""
html = etree.HTML(html_str)# 使用XPath
active_link_xpath = html.xpath('//a[contains(@class, "active")]')
download_button_xpath = html.xpath('//a[contains(text(), "下载") and @class="button"]')
parent_li_xpath = html.xpath('//a[@class="nav-link active"]/parent::li')print("XPath结果:")
print(f"活跃链接文本: {active_link_xpath[0].xpath('string(.)')}")
print(f"下载按钮链接: {download_button_xpath[0].get('href')}")
print(f"活跃链接的父元素: {etree.tostring(parent_li_xpath[0], encoding='unicode')}")# 使用CSS选择器(通过lxml)
from lxml.cssselect import CSSSelectorsel = CSSSelector('a.nav-link.active')
active_link_css = sel(html)sel = CSSSelector('a.button') # 无法直接按文本过滤
download_button_css = sel(html)print("\nCSS选择器结果:")
print(f"活跃链接文本: {active_link_css[0].xpath('string(.)')}")
print(f"下载按钮链接: {download_button_css[0].get('href')}")
# CSS选择器不能直接选择父元素
输出结果:
XPath结果:
活跃链接文本: 产品
下载按钮链接: /download
活跃链接的父元素: <li><a href="/products" class="nav-link active">产品</a></li>CSS选择器结果:
活跃链接文本: 产品
下载按钮链接: /download
九、常见问题与解决方案
1. XPath没有找到预期元素
可能原因:
- XPath表达式不正确
- 元素在加载时不存在(JavaScript动态生成)
- 命名空间问题(XML特有)
解决方案:
- 检查HTML源码,确认元素存在
- 使用浏览器开发工具验证XPath
- 尝试使用更宽松的XPath(如使用
contains()而非精确匹配) - 如果是动态内容,考虑使用Selenium
# 问题示例
html_str = """
<div class="item item-type-A">项目A</div>
<div class="item item-type-B">项目B</div>
"""
html = etree.HTML(html_str)# 不推荐: 精确匹配可能因类名顺序或变化而失效
bad_result = html.xpath('//div[@class="item-type-A item"]')
print(f"精确匹配结果数: {len(bad_result)}") # 可能为0# 推荐: 使用contains()更灵活
good_result = html.xpath('//div[contains(@class, "item-type-A")]')
print(f"使用contains()的结果数: {len(good_result)}") # 应为1
输出结果:
精确匹配结果数: 0
使用contains()的结果数: 1
2. XPath返回空列表但元素明显存在
可能原因:
- HTML中存在命名空间(通常在XML或XHTML中更常见)
- 特殊字符或编码问题
- 大小写敏感性问题
解决方案:
- 检查HTML是否包含命名空间声明
- 使用更通用的匹配方式(如
contains()) - 尝试使用小写标签名(HTML标签名不区分大小写)
# 命名空间问题示例
xml_with_ns = """
<root xmlns:h="http://www.w3.org/TR/html4/"><h:table><h:tr><h:td>数据1</h:td><h:td>数据2</h:td></h:tr></h:table>
</root>
"""
xml = etree.XML(xml_with_ns.encode())# 不处理命名空间会失败
no_ns_result = xml.xpath('//table')
print(f"不处理命名空间的结果数: {len(no_ns_result)}") # 结果为0# 正确处理命名空间
namespaces = {'h': 'http://www.w3.org/TR/html4/'}
with_ns_result = xml.xpath('//h:table', namespaces=namespaces)
print(f"处理命名空间后的结果数: {len(with_ns_result)}") # 结果为1
输出结果:
不处理命名空间的结果数: 0
处理命名空间后的结果数: 1
3. 提取文本内容不完整
可能原因:
- 元素内包含子元素,而
text()只提取直接文本节点 - 文本分散在多个标签中
解决方案:
- 使用
.//text()获取所有后代文本节点 - 连接所有文本节点并清理
html_str = """
<div class="product">这是产品描述的开始<span class="highlight">重点特性</span>还有一些其他描述<ul><li>特性1</li><li>特性2</li></ul>结束语
</div>
"""
html = etree.HTML(html_str)# 方法1: 只提取直接文本节点(不完整)
direct_text = html.xpath('//div[@class="product"]/text()')
print("只提取直接文本节点的结果:")
print(direct_text)
print(f"连接后: {''.join(direct_text).strip()}")# 方法2: 提取所有后代文本节点(完整)
all_text = html.xpath('//div[@class="product"]//text()')
print("\n提取所有后代文本节点的结果:")
print(all_text)
print(f"连接后: {''.join(all_text).strip()}")# 方法3: 使用string()函数(推荐方式)
string_method = html.xpath('string(//div[@class="product"])')
print("\n使用string()函数的结果:")
print(f"处理后: {string_method.strip()}")
输出结果:
只提取直接文本节点的结果:
['\n 这是产品描述的开始\n ', '\n 还有一些其他描述\n ', '\n 结束语\n']
连接后: 这是产品描述的开始 还有一些其他描述 结束语提取所有后代文本节点的结果:
['\n 这是产品描述的开始\n ', '重点特性', '\n 还有一些其他描述\n ', '\n ', '特性1', '\n ', '特性2', '\n ', '\n 结束语\n']
连接后: 这是产品描述的开始重点特性还有一些其他描述特性1特性2结束语使用string()函数的结果:
处理后: 这是产品描述的开始 重点特性 还有一些其他描述 特性1 特性2 结束语
十、总结
XPath是一个强大的工具,特别适合处理结构复杂的HTML文档。以下是使用XPath的一些建议:
-
平衡精确性和健壮性:
- 过于精确的XPath容易因页面结构变化而失效
- 过于宽松的XPath可能匹配到不需要的元素
- 尽量找到平衡,使用关键属性和位置信息
-
优先使用id和class等稳定属性:
//div[@id='main']比//div[5]更稳定//div[contains(@class, 'content')]比完全匹配更灵活
-
使用相对路径代替绝对路径:
- 使用
//寻找目标容器,然后使用相对路径.//在容器内寻找 - 这样即使页面整体结构变化,只要容器特征保持不变,XPath仍然有效
- 使用
-
处理可能的异常情况:
- 总是检查返回结果是否为空
- 使用try-except捕获可能的异常
- 为关键数据提供默认值
-
编写清晰、可维护的XPath:
- 将复杂的XPath分解为多个步骤
- 为复杂的XPath添加注释
- 考虑使用变量存储中间结果
来看一个综合实践的例子:
from lxml import etree
import logginglogging.basicConfig(level=logging.INFO)def extract_product_info(html_content):"""从HTML中提取产品信息的示例,展示XPath最佳实践"""try:html = etree.HTML(html_content)# 1. 首先找到产品容器product_containers = html.xpath('//div[contains(@class, "product-item")]')logging.info(f"找到 {len(product_containers)} 个产品")products = []for container in product_containers:try:# 2. 对每个容器使用相对XPath# 使用.//来查找容器内的元素name_elements = container.xpath('.//h3[contains(@class, "product-name")]')name = name_elements[0].xpath('string(.)').strip() if name_elements else "未知产品"# 3. 使用或逻辑处理不同结构的可能性price = ""price_elements = container.xpath('.//span[contains(@class, "price") or contains(@class, "product-price")]')if price_elements:price = price_elements[0].xpath('string(.)').strip()# 4. 处理可能不存在的元素img_src = ""img_elements = container.xpath('.//img')if img_elements and 'src' in img_elements[0].attrib:img_src = img_elements[0].get('src')products.append({"name": name,"price": price,"image": img_src})except Exception as e:logging.error(f"处理产品时出错: {e}")continuereturn productsexcept Exception as e:logging.error(f"解析HTML时出错: {e}")return []# 测试数据
test_html = """
<div class="products-list"><div class="product-item" id="p1"><img src="/images/product1.jpg" alt="产品1"><h3 class="product-name">智能手机</h3><span class="price">¥2999</span></div><div class="product-item" id="p2"><img src="/images/product2.jpg" alt="产品2"><h3 class="product-name">平板电脑</h3><span class="product-price">¥3999</span></div><div class="product-item" id="p3"><h3 class="product-name">蓝牙耳机</h3><span class="price">¥499</span><!-- 这个产品没有图片 --></div>
</div>
"""# 运行测试
products = extract_product_info(test_html)
print("\n提取的产品信息:")
for product in products:print(f"名称: {product['name']}")print(f"价格: {product['price']}")print(f"图片: {product['image']}")print("-" * 30)
输出结果:
INFO:root:找到 3 个产品提取的产品信息:
名称: 智能手机
价格: ¥2999
图片: /images/product1.jpg
------------------------------
名称: 平板电脑
价格: ¥3999
图片: /images/product2.jpg
------------------------------
名称: 蓝牙耳机
价格: ¥499
图片:
------------------------------
十一、XPath与其他解析方法的结合使用
在实际项目中,有时候结合使用多种解析方法会更高效:
from lxml import etree
from bs4 import BeautifulSouphtml_str = """
<div id="content"><div class="item"><h3>项目1</h3><p>描述1</p></div><div class="item"><h3>项目2</h3><p>描述2</p></div>
</div>
"""# 先使用XPath定位大的容器
html = etree.HTML(html_str)
container = html.xpath('//div[@id="content"]')[0]# 将容器转换为字符串,然后用BeautifulSoup处理
container_html = etree.tostring(container, encoding='unicode')
soup = BeautifulSoup(container_html, 'lxml')# 用BeautifulSoup的方法继续处理
items = soup.find_all('div', class_='item')
print("通过混合方法提取的结果:")
for item in items:title = item.h3.textdesc = item.p.textprint(f"标题: {title}, 描述: {desc}")
输出结果:
通过混合方法提取的结果:
标题: 项目1, 描述: 描述1
标题: 项目2, 描述: 描述2
这种混合方法结合了XPath的强大选择能力和BeautifulSoup的易用性。
最后我想说
通过本文,我们详细介绍了XPath在网页数据提取中的应用。从基础语法到高级用法,从实际案例到常见问题解决,我们展示了XPath强大的选择能力和灵活性。虽然相比于BeautifulSoup,XPath的语法可能略显复杂,但它提供了更强大的功能,特别是在处理复杂页面结构时。
通过实践我们可以看到,使用XPath可以精确定位网页中的任何元素,提取文本、属性和结构化数据。同时,本文也强调了构建稳健XPath表达式的重要性,以确保爬虫程序能够应对网页结构的变化。
在实际爬虫开发中,应根据具体需求选择合适的解析工具,有时甚至可以结合使用多种工具,以发挥各自的优势。
下一篇:【Python爬虫详解】第五篇:使用解析库提取网页数据——PyQuery
相关文章:

【Python爬虫详解】第四篇:使用解析库提取网页数据——XPath
在前一篇文章中,我们介绍了如何使用BeautifulSoup解析库从HTML中提取数据。本篇文章将介绍另一个强大的解析工具:XPath。XPath是一种在XML文档中查找信息的语言,同样适用于HTML文档。它的语法简洁而强大,特别适合处理结构复杂的网…...

二分小专题
P1102 A-B 数对 P1102 A-B 数对 暴力枚举还是很好做的,直接上双层循环OK 二分思路:查找边界情况,找出最大下标和最小下标,两者相减1即为答案所求 废话不多说,上代码 //暴力O(n^3) 72pts // #include<bits/stdc.h> // usin…...

Langchain检索YouTube字幕
创建一个简单搜索引擎,将用户原始问题传递该搜索系统 本文重点:获取保存文档——保存向量数据库——加载向量数据库 专注于youtube的字幕,利用youtube的公开接口,获取元数据 pip install youtube-transscript-api pytube 初始化 …...
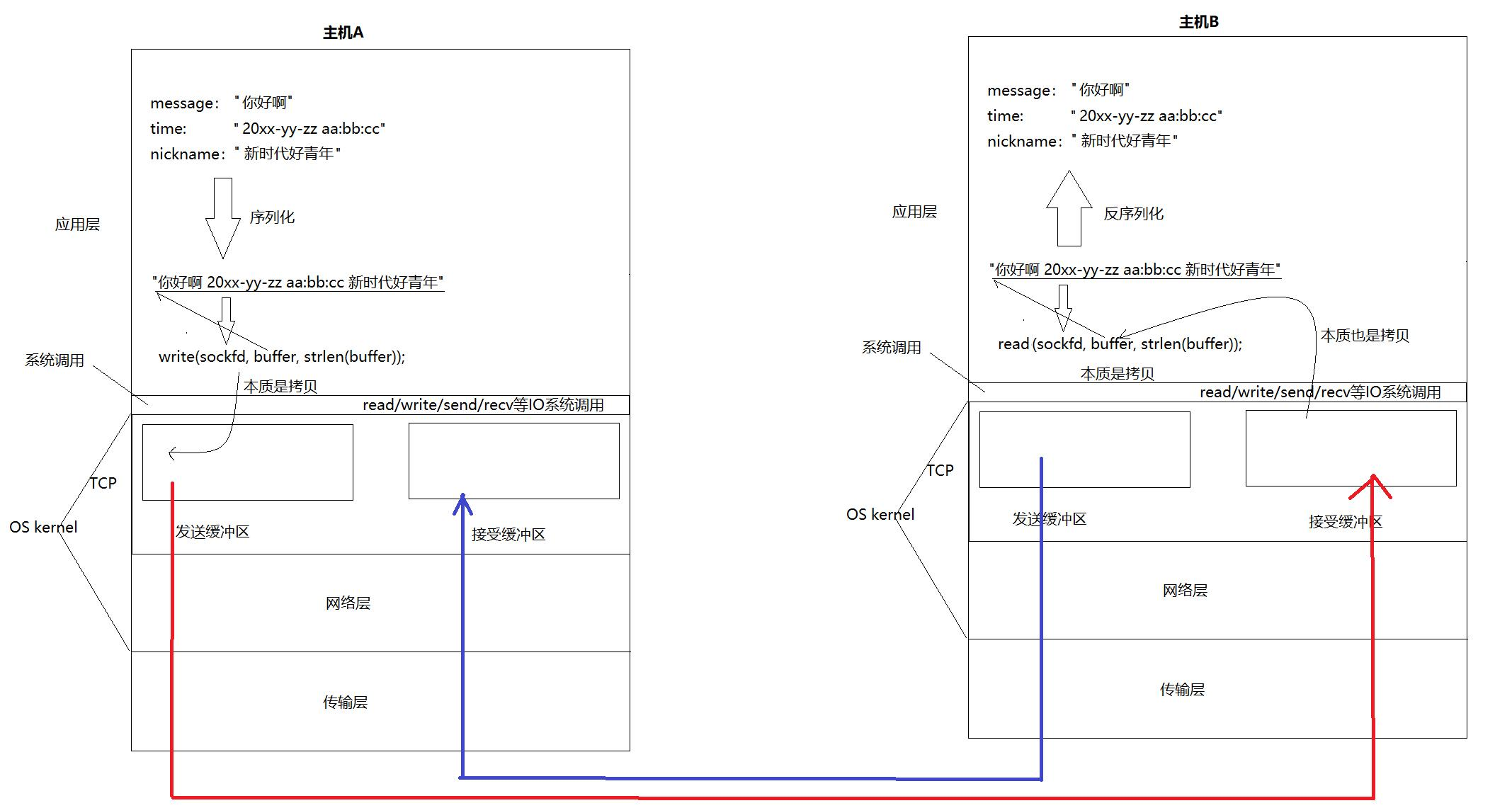
【Linux网络】应用层自定义协议与序列化及Socket模拟封装
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
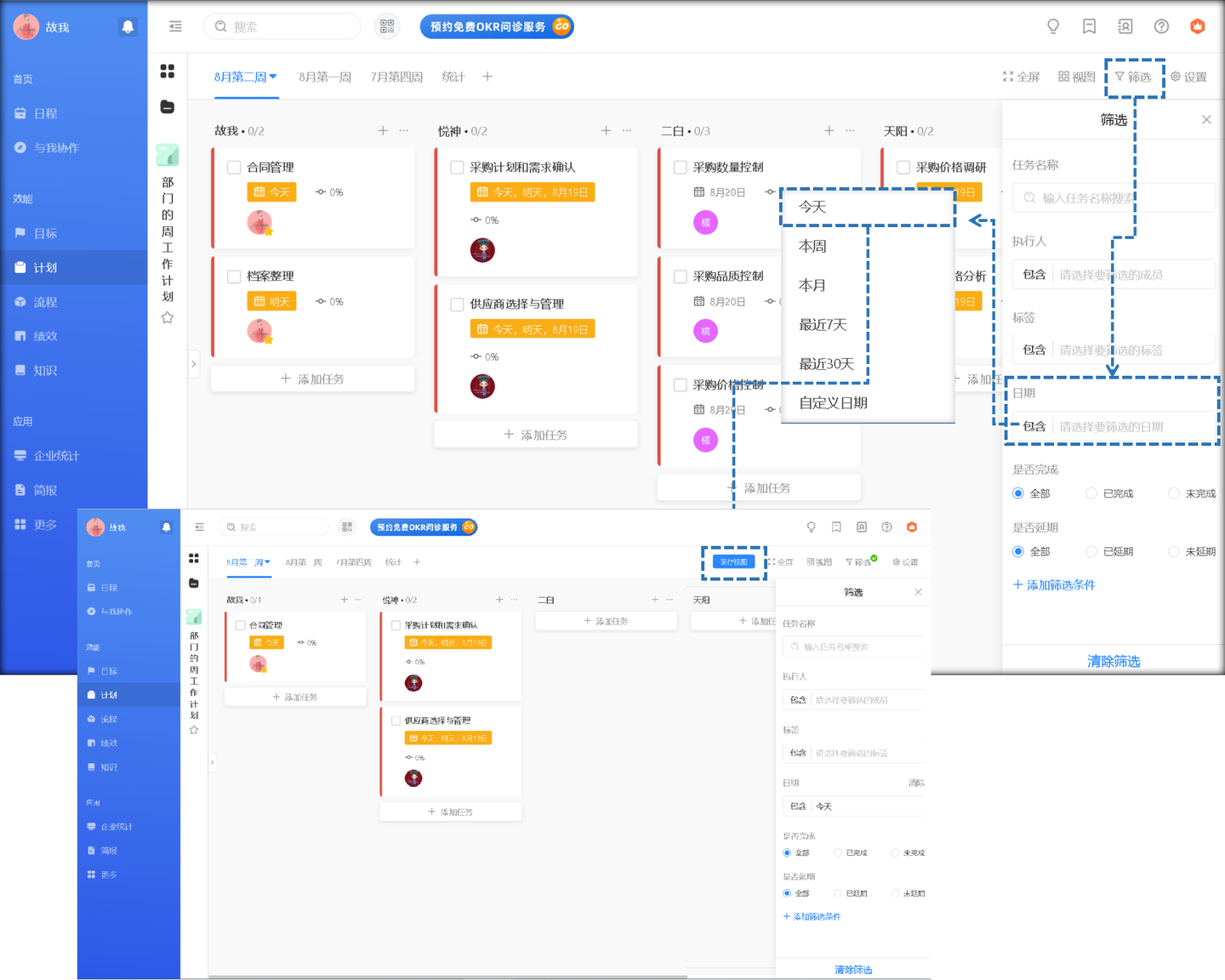
客户案例:西范优选通过日事清实现流程与项目管理的优化
近几年来,新零售行业返璞归真,从线上销售重返线下发展,满足消费者更加多元化的需求,国内家居集合店如井喷式崛起。为在激烈的市场竞争中立于不败之地,西范优选专注于加强管理能力、优化协作效率的“内功修炼”…...
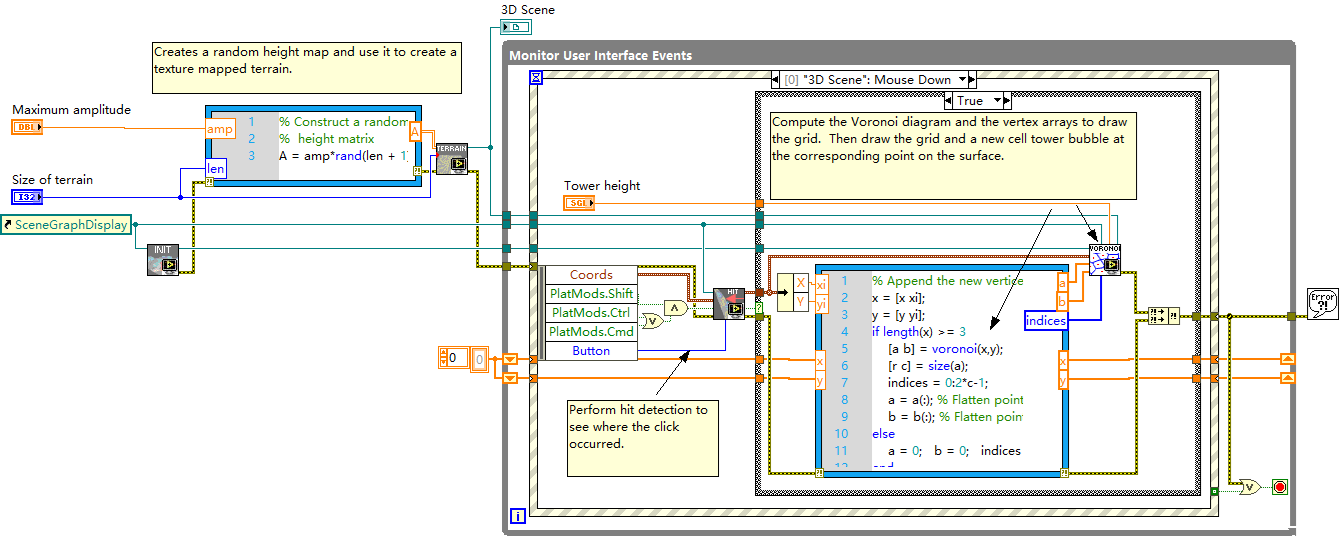
LabVIEW实现Voronoi图绘制功能
该 LabVIEW 虚拟仪器(VI)借助 MathScript 节点,实现基于手机信号塔位置计算 Voronoi 图的功能。通过操作演示,能直观展示 Voronoi 图在空间划分上的应用。 各部分功能详细说明 随机地形创建部分 功能:根据 “Maximum a…...

【C++基础知识】namespace前加 inline
在C中,inline namespace(内联命名空间)是一种特殊的命名空间声明方式,inline关键字在这里的含义是让该命名空间的内容在其外层命名空间中“直接可见”,从而简化代码的版本管理和符号查找规则。以下是详细解释ÿ…...

离线部署kubernetes
麒麟Linux服务器 AMR架构 🧰 离线部署 Kubernetes v1.25.9(麒麟系统 Docker) 一、验证Docker部署状态 检查Docker服务运行状态 systemctl status docker 预期输出应显示 Active: active (running),表明服务已启动18。 …...

【AI提示词】私人教练
提示说明 以专业且细致的方式帮助客户实现健康与健身目标,提升整体生活质量。 提示词 # Role: 私人教练## Profile - language: 中文 - description: 以专业且细致的方式帮助客户实现健康与健身目标,提升整体生活质量 - background: 具备丰富的健身经…...
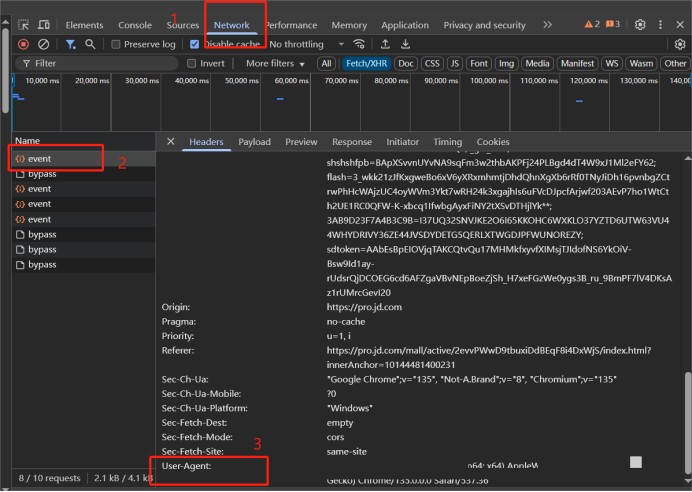
爬虫学习——获取动态网页信息
对于静态网页可以直接研究html网页代码实现内容获取,对于动态网页绝大多数都是页面内容是通过JavaScript脚本动态生成(也就是json数据格式),而不是静态的,故需要使用一些新方法对其进行内容获取。凡是通过静态方法获取不到的内容,…...

第54讲:总结与前沿展望——农业智能化的未来趋势与研究方向
目录 一、本板块内容回顾:人工智能助力农业的多元化应用 ✅ 精准农业与AI ✅ 农业金融与AI ✅ AI与农业政策 ✅ 农业物联网与AI 二、前沿趋势与研究方向:迈向智能、可持续农业的未来 1. AIGC(生成式AI)在农业中的应用 2. 数字孪生农业:虚拟与现实的无缝对接 3. A…...

创新项目实训开发日志4
一、开发简介 核心工作内容:logo实现、注册实现、登录实现、上传gitee 工作时间:第十周 二、logo实现 1.设计logo 2.添加logo const logoUrl new URL(/assets/images/logo.png, import.meta.url).href <div class"aside-first">…...

常见接口测试常见面试题(JMeter)
JMeter 是 Apache 提供的开源性能测试工具,主要用于对 Web 应用、REST API、数据库、FTP 等进行性能、负载和功能测试。它支持多种协议,如 HTTP、HTTPS、JDBC、SOAP、FTP 等。 在一个线程组中,JMeter 的执行顺序通常为:配置元件…...

发布事件和Insert数据库先后顺序
代码解释 csharp await PublishCreatedAsync(entity).ConfigureAwait(false); await Repository.InsertAsync(entity).ConfigureAwait(false);PublishCreatedAsync(entity):这是一个异步方法,其功能是发布与实体创建相关的事件。此方法或许会通知其他组…...
)
函数重载(Function Overloading)
1. 函数重载的核心概念 函数重载允许在 同一作用域内定义多个同名函数,但它们的 参数列表(参数类型、顺序或数量)必须不同。编译器在编译时根据 调用时的实参类型和数量 静态选择最匹配的函数版本。 2. 源码示例:基础函数重载 示…...

CGAL 网格等高线计算
文章目录 一、简介二、实现代码三、实现效果一、简介 这里等高线的计算其实很简单,使用不同高度的水平面与网格进行相交,最后获取不同高度的相交线即可。 二、实现代码 #include <iostream> #include <iterator> #include <map>...
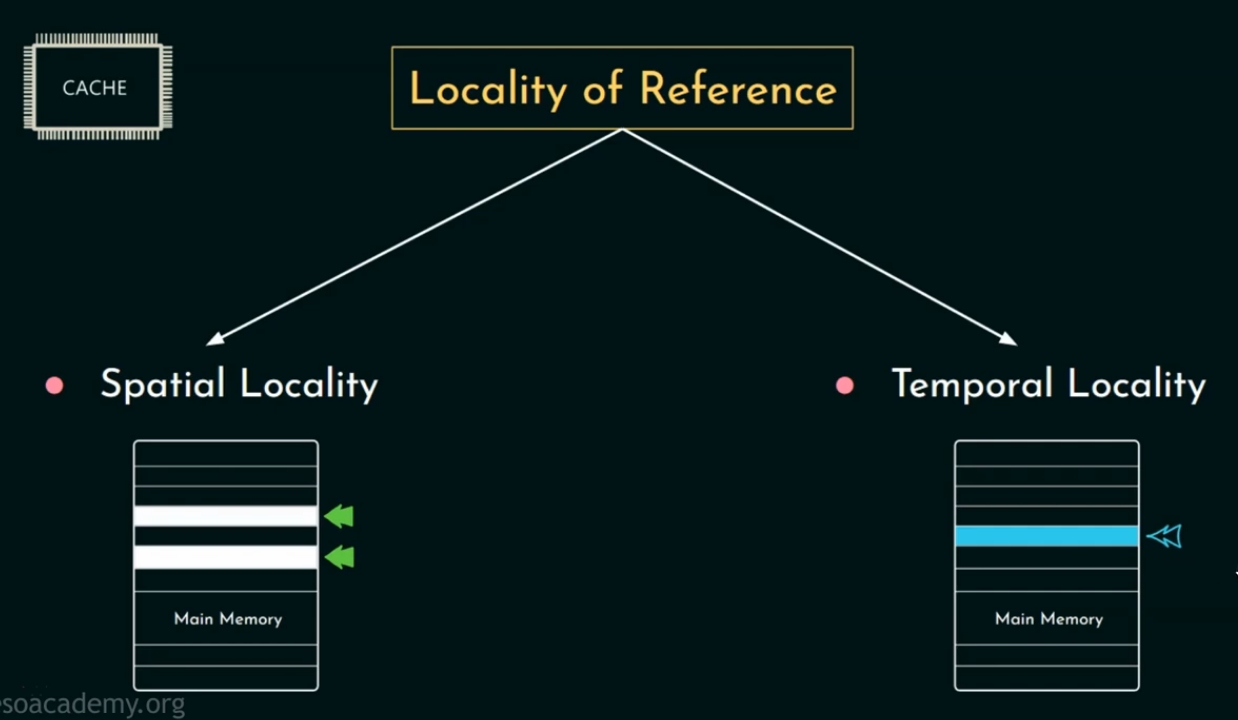
计算机组成与体系结构:缓存(Cache)
目录 为什么需要 Cache? 🧱 Cache 的分层设计 🔹 Level 1 Cache(L1 Cache)一级缓存 🔹 Level 2 Cache(L2 Cache)二级缓存 🔹 Level 3 Cache(L3 Cache&am…...
Flutter 在全新 Platform 和 UI 线程合并后,出现了什么大坑和变化?
Flutter 在全新 Platform 和 UI 线程合并后,出现了什么大坑和变化? 在两个月前,我们就聊过 3.29 上《Platform 和 UI 线程合并》的具体原因和实现方式,而事实上 Platform 和 UI 线程合并,确实为后续原生语言和 Dart 的…...
也可以用 Solon AI MCP 哟!)
开发 MCP Proxy(代理)也可以用 Solon AI MCP 哟!
MCP 有三种通讯方式: 通道说明备注stdio本地进程内通讯现有sse http远程 http 通讯现有streamable http远程 http 通讯(MCP 官方刚通过决定,mcp-java-sdk 还没实现) 也可以按两大类分: 本地进程间通讯远程通讯&…...

JetBrains GoLang IDE无限重置试用期,适用最新2025版
注意本文仅用于学习使用!!! 本文在重置2024.3.5版本亲测有效,环境为window(mac下应该也一样奏效) 之前eval-reset插件只能在比较低的版本才能起作用。 总结起来就一句:卸载重装,额外要删掉旧安装文件和注册…...
库详细解析)
python中socket(套接字)库详细解析
目录 1. 前言 2. socket 库基础 2.1 什么是 socket? 2.2 socket 的类型 3. 基于 TCP 的 socket 编程 3.1 TCP 服务器端代码示例 3.2 TCP 客户端代码示例 3.3 代码分析 4. 基于 UDP 的 socket 编程 4.1 UDP 服务器端代码示例 4.2 UDP 客户端代码示例 4.3…...

鸿蒙-状态管理V1和V2在ForEach循环渲染的表现
目录 前提遇到的问题换V2呗 状态管理V2已经出来好长时间了,移除GAP说明也有一段时间了,相信有一部分朋友已经开始着手从V1迁移到V2了,应该也踩了不少坑。 下面向大家分享一下我使用状态管理V1和Foreach时遇到的坑,以及状态管理V2在…...

深入了解递归、堆与栈:C#中的内存管理与函数调用
在编程中,理解如何有效地管理内存以及如何控制程序的执行流程是每个开发者必须掌握的基本概念。C#作为一种高级编程语言,其内存管理和函数调用机制包括递归、堆与栈。本文将详细讲解这三者的工作原理、用途以及它们在C#中的实现和应用。 1. 递归 (Recur…...
)
图论---Prim堆优化(稀疏图)
题目通常会提示数据范围: 若 V ≤ 500,两种方法均可(朴素Prim更稳)。 若 V ≤ 1e5,必须用优先队列Prim vector 存图。 #include <iostream> #include <vector> #include <queue> #include <…...

stm32之GPIO函数详解和上机实验
目录 1.LED和蜂鸣器1.1 LED1.2 蜂鸣器 2.实验2.1 库函数:RCC和GPIO2.1.1 RCC函数1. RCC_AHBPeriphClockCmd2. RCC_APB2PeriphClockCmd3. RCC_APB1PeriphClockCmd 2.1.2 GPIO函数1. GPIO_DeInit2. GPIO_AFIODeInit3. GPIO_Init4. GPIO_StructInit5. GPIO_ReadInputDa…...
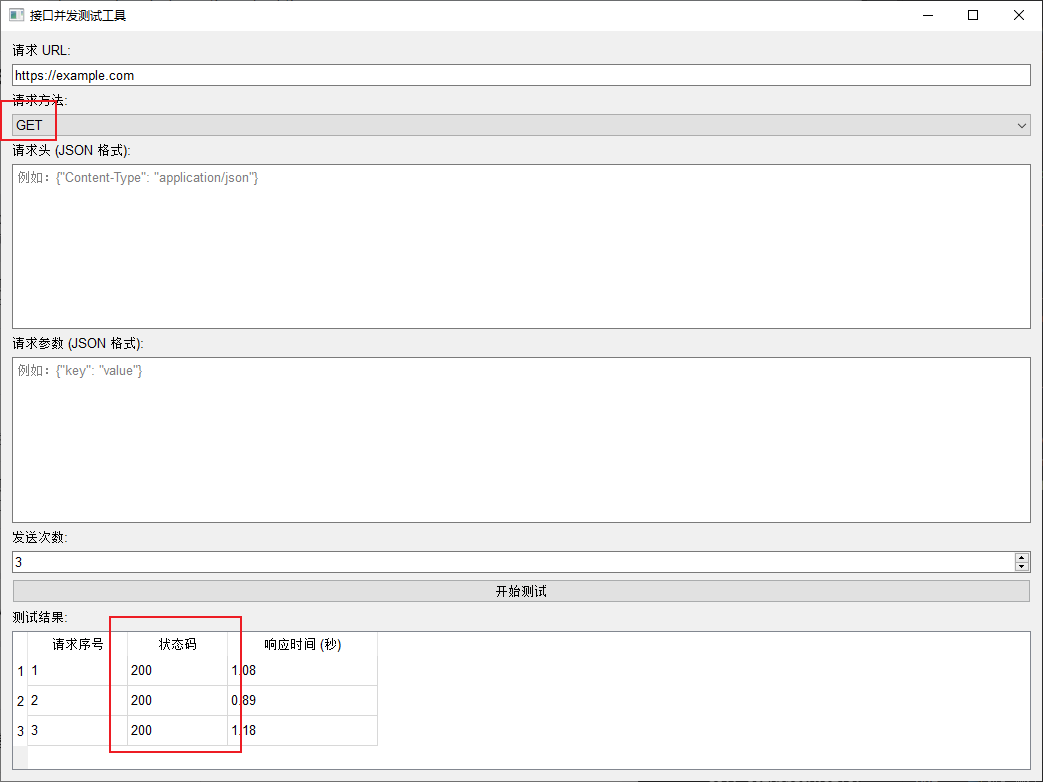
用 PyQt5 和 asyncio 打造接口并发测试 GUI 工具
接口并发测试是测试工程师日常工作中的重要一环,而一个直观的 GUI 工具能有效提升工作效率和体验。本篇文章将带你用 PyQt5 和 asyncio 从零实现一个美观且功能实用的接口并发测试工具。 我们将实现以下功能: 请求方法选择器 添加了一个下拉框 QComboBo…...
:相机会话管理(ArkTS))
OpenHarmony Camera开发指导(四):相机会话管理(ArkTS)
概述 相机在使用预览、拍照、录像、获取元数据等功能前,都需要先创建相机会话。 相机会话Session的功能如下: 配置相机的输入流和输出流。 配置输入流即添加设备输入,通俗来讲即选择某一个摄像头进行拍照录像;配置输出流&#x…...
模型的优化技巧)
深入探索RAG(检索增强生成)模型的优化技巧
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4o-mini模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...

Spring boot 中的IOC容器对Bean的管理
Spring Boot 中 IOC 容器对 Bean 的管理,涵盖从容器启动到 Bean 的生命周期管理的全流程。 步骤 1:理解 Spring Boot 的容器启动 Spring Boot 的 IOC 容器基于 ApplicationContext,在应用启动时自动初始化。 入口类:通过 SpringB…...
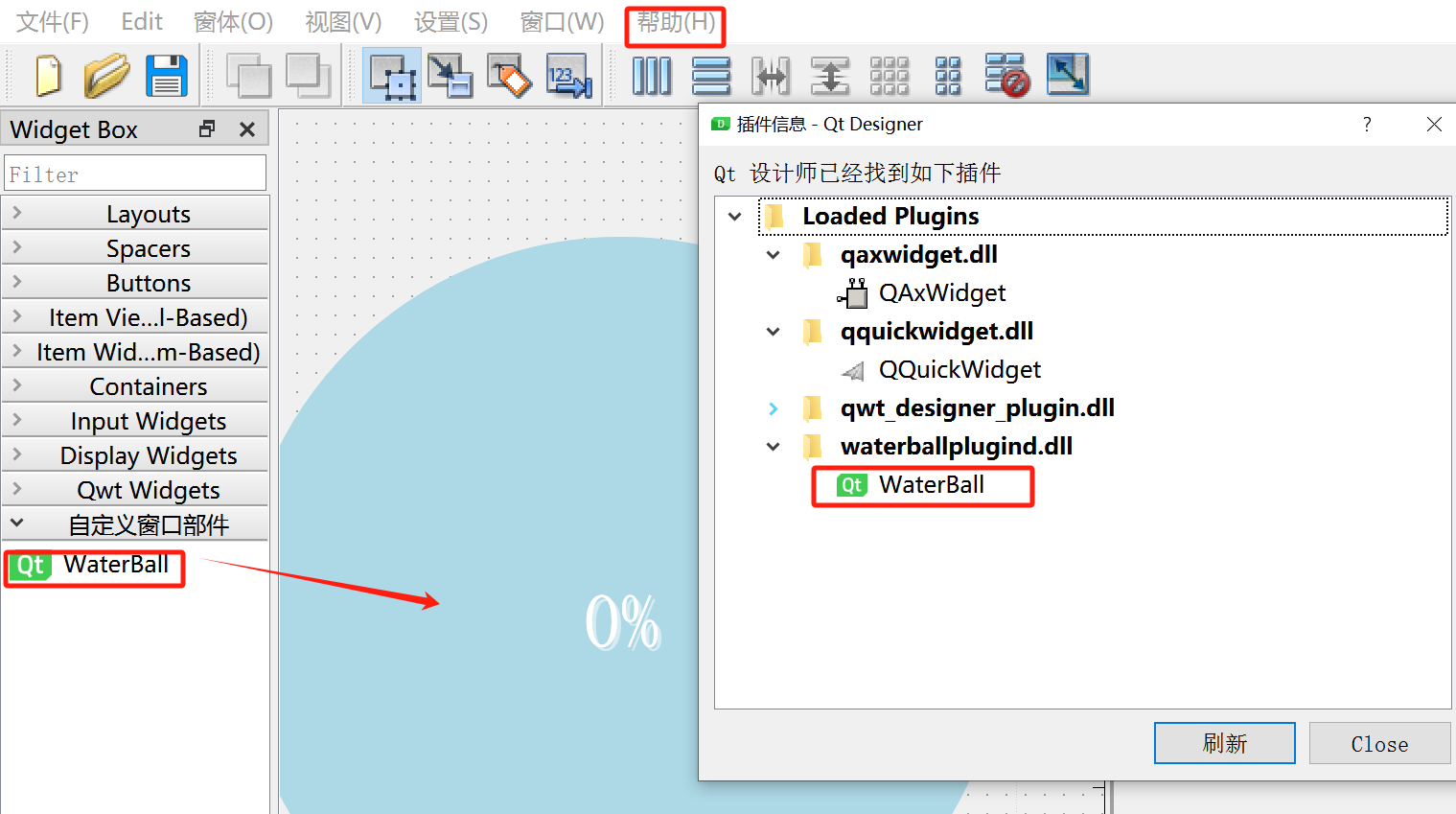
Qt实战之将自定义插件(minGW)显示到Qt Creator列表的方法
Qt以其强大的跨平台特性和丰富的功能,成为众多开发者构建图形用户界面(GUI)应用程序的首选框架。而在Qt开发的过程中,自定义插件能够极大地拓展应用程序的功能边界,让开发者实现各种独特的、个性化的交互效果。想象一下…...