【AI模型学习】双流网络——更强大的网络设计
文章目录
- 一 背景
- 1.1 背景
- 1.2 研究目标
- 二 模型
- 2.1 双流架构
- 2.2 光流
- 三 实验
- 四 思考
- 4.1 多流架构
- 4.2 fusion策略
- 4.3 fusion的early与late
先简单聊了双流网络最初在视频中的起源,之后把重点放在 “多流结构"和"fusion” 上。
一 背景
1.1 背景
Two-Stream Convolutional Networks for Action Recognition in Videos
作者:Karen Simonyan & Andrew Zisserman(牛津 VGG)
在图像分类(ImageNet)中,CNN 已经大获成功,但视频是图像的“时序扩展”,有两个新问题:
| 挑战 | 说明 |
|---|---|
| 时空建模难 | 视频不仅有空间信息(每一帧的画面),还有时间信息(帧之间的运动) |
| 计算复杂 | 直接对 3D 视频卷积计算代价极高(3D CNN 很重) |
| 表征不足 | 如果只用单帧静态图做分类,会忽略动作的动态过程 |
1.2 研究目标
论文的目标是:
在不使用 3D 卷积或循环网络的前提下,设计一个高效的 CNN 框架,能够同时提取视频的:
- 空间外观特征(谁在做)
- 时间运动特征(动作怎么做)
核心思想:双流架构
作者提出将视频信息分为两类独立学习:
| 模块 | 输入 | 目标 |
|---|---|---|
| Spatial Stream | RGB 静态图像 | 识别外观(场景、对象) |
| Temporal Stream | 光流序列 | 捕捉动作的运动信息 |
- 两个网络分别独立训练
- 最后在 softmax 输出层融合(late fusion)
二 模型
2.1 双流架构

一、Spatial Stream 输入
输入内容:
- 视频中单帧图像(RGB)
- 每个动作样本会从视频中抽取若干帧(random sampling)
Shape: (N, 3, 224, 224)
- N:batch size
二、Temporal Stream 输入
输入内容:
- 多帧之间的光流图(Optical Flow)
- 光流图反映的是像素在 x、y 方向上的位移量
- 对每帧计算 optical flow,作者用 堆叠光流帧 来表达时间信息
作者默认使用 10 帧的光流,x 与 y 两个方向:
10 帧 × 2 个方向(x, y)= 20 个通道
所以:
Shape: (N, 20, 224, 224)
2.2 光流
光流(Optical Flow)是什么?
定义:
光流是指:物体在运动时,图像上像素点的移动速度和方向,通常表现为连续两帧图像中每个像素点的位移。
- 假设一个人从左走到右;
- 我们拍了两张连续的视频帧(比如第 t 帧和第 t+1 帧);
- 那么在这两帧之间,人身上的每个像素点都“移动”了一个位置;
- 光流就是把这种位移提取出来,形成一张“光流图”;
- x方向的速度图(水平移动)
- y方向的速度图(垂直移动)
(x方向位移图, y方向位移图)
⇒ 通道数 = 2
每个像素的 (x, y) 分量告诉你它的运动方向与幅度。
光流的计算方法
- 论文中使用了 TV-L1 算法,这是经典的光流计算方法(速度和鲁棒性折中);
- 实际实现通常使用 OpenCV 的
cv2.calcOpticalFlowFarneback()或 DeepFlow、RAFT 等现代方法。
在 Two-Stream 网络中的光流处理流程
具体来看 Temporal Stream 的数据预处理流程:
输入阶段:从视频 → 光流堆叠张量
-
取连续 T 帧视频图像
假设 T = 10 -
对每一对相邻帧计算光流
会得到 T-1 张光流图,每张包含:- x方向:shape = (H, W)
- y方向:shape = (H, W)
-
将 x 和 y 的结果堆叠起来
得到 2 × (T-1) 通道的张量:Shape: (2 × (T-1), H, W) ≈ (20, 224, 224)
视频帧序列: F1 F2 F3 ... F10↓ ↓ ↓ ↓
光流图计算: Flow1 Flow2 ... Flow9↓ ↓ ↓
通道堆叠: [dx1, dy1, dx2, dy2, ..., dx9, dy9] → (20, H, W)
文章还讨论了两种获取光流的方法:
左边的是“刻舟求剑”法,右边的是“追踪”法。
不过在论文的模型中,最后“刻舟求剑”反而更好,作者也无法解释。

三 实验
| 实验类型 | 方法 / 配置 | 数据集 | Top-1 精度 (%) | 备注说明 |
|---|---|---|---|---|
| 主实验 | Spatial Stream (RGB 单帧) | UCF-101 | 73.0 | 使用 ImageNet 预训练 CNN |
| Temporal Stream (光流序列) | UCF-101 | 81.0 | 输入为 10 帧光流 (20 通道) | |
| Two-Stream Fusion | UCF-101 | 88.0 | 空间 + 时间流 softmax 输出平均融合 | |
| Spatial Stream | HMDB-51 | 40.5 | - | |
| Temporal Stream | HMDB-51 | 54.6 | - | |
| Two-Stream Fusion | HMDB-51 | 59.4 | - | |
| 主对比 | Improved Dense Trajectories (IDT) | UCF-101 | 85.9 | 手工特征方法 |
| Improved Dense Trajectories (IDT) | HMDB-51 | 57.2 | - | |
| 消融实验 | Temporal 流输入帧数 = 5 | UCF-101 | ~78.0 | 光流帧少,时序建模不足 |
| Temporal 流输入帧数 = 10 | UCF-101 | 81.0 | 默认使用配置 | |
| Temporal 流输入帧数 = 20 | UCF-101 | ~82.3 | 提升有限,开销更大 | |
| SVM Late Fusion | UCF-101 | ≈88.0 | 与 softmax 融合相当,复杂度高 | |
| Softmax Averaging Fusion | UCF-101 | 88.0 | 简洁有效,推荐使用 |
- 时间流 > 空间流:光流序列对于动作识别贡献更大;
- 融合优于单流:融合后显著提升识别性能;
- 堆叠帧数的 tradeoff:10 帧是精度与效率的较好平衡;
- 融合策略:softmax 平均足够好,不必上复杂 SVM;
- 对比 IDT:Two-Stream 模型在精度上成功超越传统特征。
四 思考
4.1 多流架构
“多流架构不是模型结构,而是一种视野和思维方式。”
它鼓励从任务本质中挖掘“不同视角”,然后用网络结构显式表达它们。
“多流架构(Multi-Stream Architecture)”的通用思想 不仅适用于视频动作识别,在很多任务中都可以迁移这种结构设计思想
核心理念:不同模态/视角/尺度的信息,各自建模,再融合
视频理解(动作识别 / 视频问答)
- Two-Stream → RGB + Optical Flow
- SlowFast → 快帧流 + 慢帧流(建模短期 vs 长期动态)
NLP 多源信息融合
- 多语言嵌入流(BERT + 翻译结果)
- Query/Document 双流(Dense Retrieval)
生物信息学
- 序列流(FASTA)+ 结构流(PDB)+ 图拓扑流(Graph)
- 蛋白质中可以分别建模残基特征 vs 二级结构 vs 相互作用图谱
图像识别 / 细粒度分类
- 原图流 + 注意力放大图流(如 Bilinear CNN)
- 多尺度输入(如 FPN)
为什么有效?
| 机制 | 好处 |
|---|---|
| 解耦学习 | 每种信息流都可以专注于某种特征维度 |
| 表征增强 | 比单一路径更强,互补增强鲁棒性 |
| 易于融合 | 可以在特征级或决策级灵活组合 |
| 并行训练 | 多流结构天然适配分布式/并行计算 |
4.2 fusion策略
聊聊 Fusion 模型设计 ——多流网络的灵魂部分
一 特征级融合(Feature-Level Fusion)
将不同流提取的特征表示向量在隐空间中合并,生成一个更具表达力的 joint representation。
-
直接拼接(Concatenation)
fused = torch.cat([f_seq, f_phys, f_struct], dim=-1)- 优点:操作简单,保留全部特征
- 缺点:维度急剧升高,可能冗余或造成过拟合
-
加权求和(Fixed or Learnable Weights)
fused = α*f_seq + β*f_phys + γ*f_struct- α, β, γ 可为超参数或可训练变量
- 更轻量,也利于后续网络收敛
-
注意力融合(Attention Fusion)
# 跨模态 attention 融合多个分支输出 w_i = softmax(W_q · tanh(W_k f_i)) # 生成每个分支的 attention 权重 fused = Σ w_i * f_i- 动态融合不同“模态”的重要性
- 可以引入 transformer-style 多头注意力
二 加权融合(Weighted Fusion)
每条信息流不仅提取自己的特征,还由模型学习一个权重 来衡量其“重要性”,用于加权组合。
-
Gating Network
gate = sigmoid(W · [f_seq, f_phys, f_struct]) fused = gate ⊙ f_seq + (1 - gate) ⊙ f_phys- 类似于 GRU 的门控机制
- 可以设计为 scalar 或 vector 权重(每个通道或维度)
-
Modal Attention
- 给不同“模态”分配注意力权重
- 通常以 transformer 为骨干:
query = f_seq # 当前主导模态 keys = [f_phys, f_struct] values = [f_phys, f_struct] attn = softmax(query · keyᵀ) fused = query + attn · values
三 决策级融合(Decision-Level Fusion)
每个子网络(分支)独立产生一个预测输出,然后在“输出阶段”融合多个决策。
-
平均法(Averaging)
pred = (pred_seq + pred_phys + pred_struct) / 3- 简单稳定,适合 soft target 情况(如 sigmoid 输出)
-
投票法(Voting)
- 用于 hard prediction(如 argmax 输出)
- 多数投票法:
vote = mode([argmax(p1), argmax(p2), argmax(p3)]) -
Meta-classifier(堆叠融合)
- 用一个新的 MLP 学习如何根据多个分支输出组合最终预测:
meta_input = [pred1, pred2, pred3] meta_out = MLP(meta_input)
如何选择?
| 对比维度 | 特征级融合(Feature Fusion) | 加权融合(Weighted Fusion) | 决策级融合(Decision Fusion) |
|---|---|---|---|
| 原理 | 拼接所有模态特征 | 学习每个模态的重要性再融合 | 每个模态独立输出结果,后期组合 |
| 输入要求 | 特征 shape 可以对齐 | 各流要能共享语义空间 | 各流可以完全异构 |
| 模型结构 | 单一模型结构接入多个特征 | 有 Attention / Gating 模块 | 每条流都是独立模型 |
| 表达能力 | 高 | 最高(信息选择+建模) | 中(主要靠“投票”或 stack 学习) |
| 实现复杂度 | 低 | 中高(需加权机制) | 高(多模型集成 + output 决策) |
| 性能表现 | 较好 | 较优 | 稳定,提升有限 |
| 适用场景 | 多个低维或结构相似的特征 | 多模态融合,特征异质性中等偏高 | 模态完全不同,或者训练时难以对齐 |
1. 特征级融合:最常用,适合“半模态差异”
使用条件:
- 每条流提取的是中间向量(embedding、特征向量)
- 模态不完全不同(如:序列和理化、结构向量)
应用:
- 肽链序列嵌入 + PseAAC + PSSM → 拼接送入 MLP/CNN
- 图结构向量 + CNN 特征拼接 → 送入 Transformer
2. 加权融合:信息噪声多、流重要性差异大时用!
使用条件:
- 某些模态“好坏不一”,例如预测 contact map 有噪声
- 想“让模型自己决定”谁重要应用:
- 序列流 vs 图结构流中自动识别信任度
- 多种生物特征拼接后加权(蛋白结构有时预测不准)
3. 决策级融合:结构完全不同 or 模型已训练好
使用条件:
- 流之间完全异构,不能 early 或 mid fusion
- 模型已经训练好,后面想“ensemble 提升”应用:
- CNN 模型 vs GNN 模型,投票融合
- 多个独立网络:序列预测 + 结构预测 + 文本(文献)预测,最终结果由“多数模型决定”
4.3 fusion的early与late
然后是early fusion 和 late fusion的对比和介绍:
定义与基本区别
| 类型 | 定义 |
|---|---|
| Early Fusion | 多个模态/特征在输入阶段或浅层特征即融合,模型整体作为一个网络处理 |
| Late Fusion | 各个模态/特征独立编码(不同网络或分支),在深层语义或输出阶段融合 |
对比:
| 对比点 | Early Fusion | Late Fusion |
|---|---|---|
| 融合位置 | 输入前 or 第1~2层 | 特征层、中间层或决策层 |
| 表达能力 | 低~中 | 高(每模态单独学习) |
| 实现难度 | 简单,维度统一即可 | 较复杂,需要设计多分支、统一维度 |
| 模态干扰风险 | 高(不同模态混合过早) | 低(先独立再融合) |
| 信息保留 | 容易丢失语义,需 careful tuning | 每个模态语义表达充分 |
| 计算开销 | 通常更低 | 多个网络并行,计算量大 |
| 适用场景 | 模态差异小,如多组蛋白理化特征 | 模态差异大,如序列+结构+图 |
什么时候选 Early Fusion?
适合的场景:
- 特征类型“同质”:如全是理化性质数值(1D向量)
- 特征维度相近 / 对齐:如 AC, AAC, CTD(拼成一条向量即可)
- 要求轻量部署 / 计算资源受限(模型更小)
- 对融合机制无特殊要求(拼接即可)
不适合:
- 异构模态(如:结构图 + 序列)
- 大模型(Transformer、GNN 等)应用中
什么时候选 Late Fusion?
适合的场景:
- 模态差异大(比如生物信息里面的 序列 + PSSM + 图结构)
- 每个模态都希望学习语义特征(独立网络)
- 需要灵活控制信息流通(可加 attention)
- 希望进行模态消融分析(每个分支可单独关闭)
进一步增强:
- 可以使用 cross-attention 让模态间互动(如 ESM-IF)
相关文章:
【AI模型学习】双流网络——更强大的网络设计
文章目录 一 背景1.1 背景1.2 研究目标 二 模型2.1 双流架构2.2 光流 三 实验四 思考4.1 多流架构4.2 fusion策略4.3 fusion的early与late 先简单聊了双流网络最初在视频中的起源,之后把重点放在 “多流结构"和"fusion” 上。 一 背景 1.1 背景 Two-Str…...
HarmonyOS:一多能力介绍:一次开发,多端部署
概述 如果一个应用需要在多个设备上提供同样的内容,则需要适配不同的屏幕尺寸和硬件,开发成本较高。HarmonyOS 系统面向多终端提供了“一次开发,多端部署”(后文中简称为“一多”)的能力,可以基于一种设计…...

“在中国,为中国” 英飞凌汽车业务正式发布中国本土化战略
3月28日,以“夯实电动化,推进智能化,实现高质量发展”为主题的2025中国电动汽车百人会论坛在北京举办。众多中外机构与行业上下游嘉宾就全球及中国汽车电动化的发展现状、面临的挑战与机遇,以及在技术创新、市场布局、供应链协同等…...

《Pinia 从入门到精通》Vue 3 官方状态管理 -- 基础入门篇
《Pinia 从入门到精通》Vue 3 官方状态管理 – 基础入门篇 《Pinia 从入门到精通》Vue 3 官方状态管理 – 进阶使用篇 《Pinia 从入门到精通》Vue 3 官方状态管理 – 插件扩展篇 📖 教程目录 为什么选择 Pinia?1.1 背景介绍1.2 Vuex 的痛点(对…...
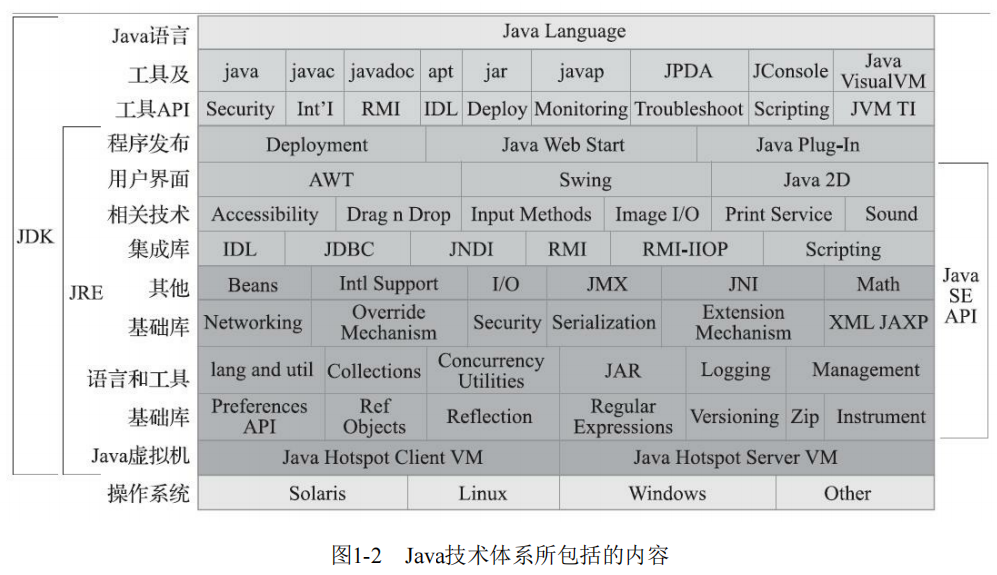
Java技术体系的主要产品线详解
Java技术体系的主要产品线详解 Java Card:支持Java小程序(Applets)运行在小内存设备(如智能卡)上的平台。 Java ME(Micro Edition):支持Java程序运行在移动终端(手机、P…...
机器学习快速入门--0算力起步实践篇
在学习人工智能的过程中,显卡是必不可少的工具,但它的成本较高且更新换代速度很快。那么,没有GPU的情况下如何学习人工智能呢?以下是针对普通电脑与有算力环境分离的学习规划方案,尤其适合前期无GPU/云计算资源的学习者…...

MySQL 详解之索引:提升查询效率的秘密武器
在数据库的世界里,数据量通常是巨大的。想象一下,一个拥有数百万甚至数十亿条记录的表格,如果你需要从中查找符合特定条件的几条甚至一条记录,数据库是如何快速找到它们的呢?如果没有高效的机制,数据库不得不一条条地遍历整个表格,这无疑会非常缓慢和耗费资源。这时,索…...

中通 Redis 集群从 VM 迁移至 PVE:技术差异、PVE 优劣势及应用场景深度解析
在数字化转型浪潮下,企业对服务器资源的高效利用与成本控制愈发重视。近期,中通快递将服务器上的 Redis 集群服务从 VM(VMware 虚拟化技术)迁移至 PVE(Proxmox VE),这一技术举措引发了行业广泛关…...
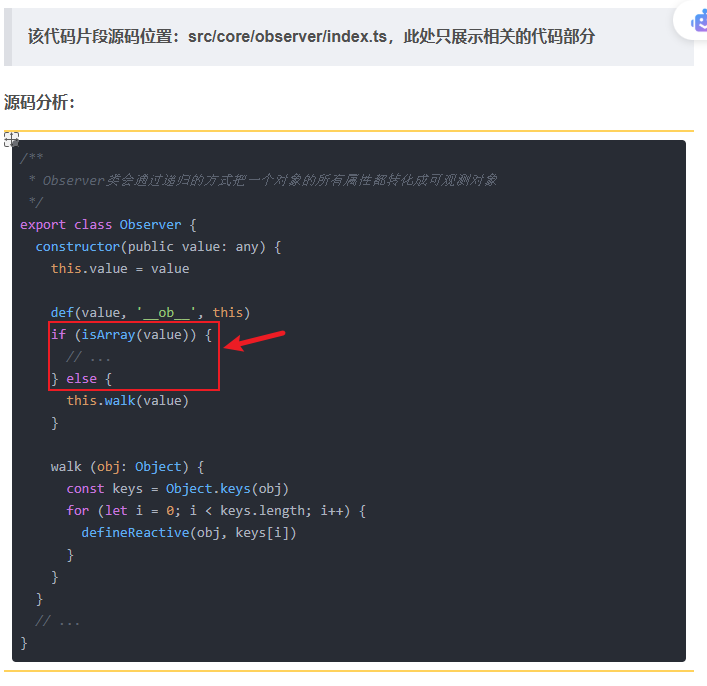
源码篇 剖析 Vue2 双向绑定原理
前置操作 源码代码仓地址:https://github.com/vuejs/vue/tree/main 1.查看源码当前版本 当前版本为 v2.7.16 2.Clone 代码 在【Code】位置点击,复制 URL 用于 Clone 代码 3.执行 npm install 4.执行 npm run dev 前言 在 Vue 中最经典的问题就是双…...

Restful接口学习
一、为什么RESTful接口是数据开发的核心枢纽? 在数据驱动的时代,RESTful接口如同数据高速公路上的收费站,承担着数据交换的核心职责。数据工程师每天需要面对: 异构系统间的数据交互(Hadoop集群 ↔ 业务系统…...
)
C++ round 函数笔记 (适用于算法竞赛)
在算法竞赛中,处理浮点数并将其转换为整数是常见的需求,round 函数是标准库提供的用于执行“四舍五入”到最近整数的工具。理解其工作方式和潜在问题对于避免错误至关重要。 1. 基本用法 头文件 要使用 round 函数,需要包含 <cmath>…...

1.5软考系统架构设计师:架构师的角色与能力要求 - 超简记忆要点、知识体系全解、考点深度解析、真题训练附答案及解析
超简记忆要点 角色职责 需求规划→架构设计→质量保障 能力要求 技术(架构模式/性能优化) 业务(模型抽象→技术方案) 管理(团队协作/风险控制) 知识体系 基础:CAP/设计模式/网络协议案例&am…...
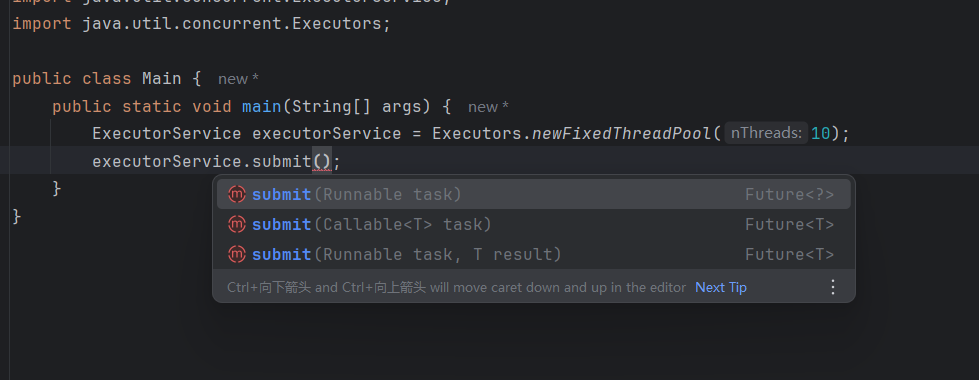
单例模式与消费者生产者模型,以及线程池的基本认识与模拟实现
前言 今天我们就来讲讲什么是单例模式与线程池的相关知识,这两个内容也是我们多线程中比较重要的内容。其次单例模式也是我们常见设计模式。 单例模式 那么什么是单例模式呢?上面说到的设计模式又是什么? 其实单例模式就是设计模式的一种。…...

JAVA程序获取SVN提交记录
1.获取文件提交记录 private String userName "userName "; //svn账号 private String password "password "; //svn密码 private String urlString "urlString "; //svnurl 换成自己对应的svn信息 package com.tengzhi.common.dao;import…...
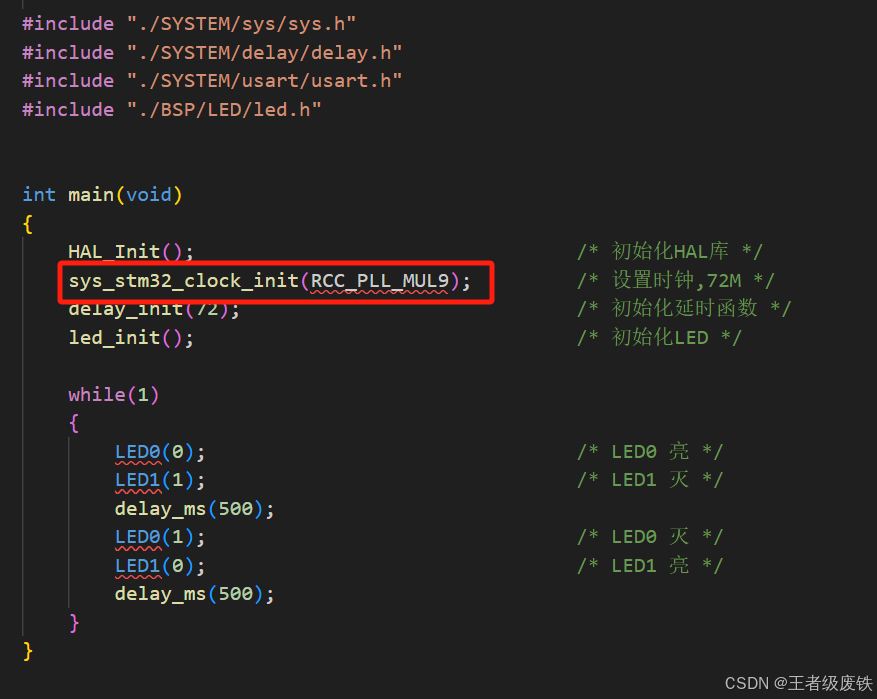
STM32配置系统时钟
1、STM32配置系统时钟的步骤 1、系统时钟配置步骤 先配置系统时钟,后面的总线才能使用时钟频率 2、外设时钟使能和失能 STM32为了低功耗,一开始是关闭了所有的外设的时钟,所以外设想要工作,首先就要打开时钟,所以后面…...

React 与 Vue:两大前端框架的深度对比
在前端开发领域,React 和 Vue 无疑是当下最受欢迎的两大框架。它们各自拥有独特的优势和特点,吸引了大量开发者。无论是初学者还是经验丰富的工程师,选择 React 还是 Vue 都是一个常见的问题。本文将从多个角度对 React 和 Vue 进行对比&…...

Node.js 学习入门指南
Node.js 学习入门指南 Node.js 是一种流行的开源、跨平台的 JavaScript 运行时环境,它使开发者能够在服务器端运行JavaScript代码。本篇文章旨在帮助初学者快速入门并掌握Node.js的基础知识和常用技巧。 一、什么是Node.js? 定义 Node.js 是一个基于…...

Java24新增特性
Java 24(Oracle JDK 24)作为Java生态的重要更新,聚焦AI开发支持、后量子安全、性能优化及开发者效率提升,带来20余项新特性和数千项改进。以下是核心特性的分类解析: 一、语言特性增强:简化代码与模式匹配 …...
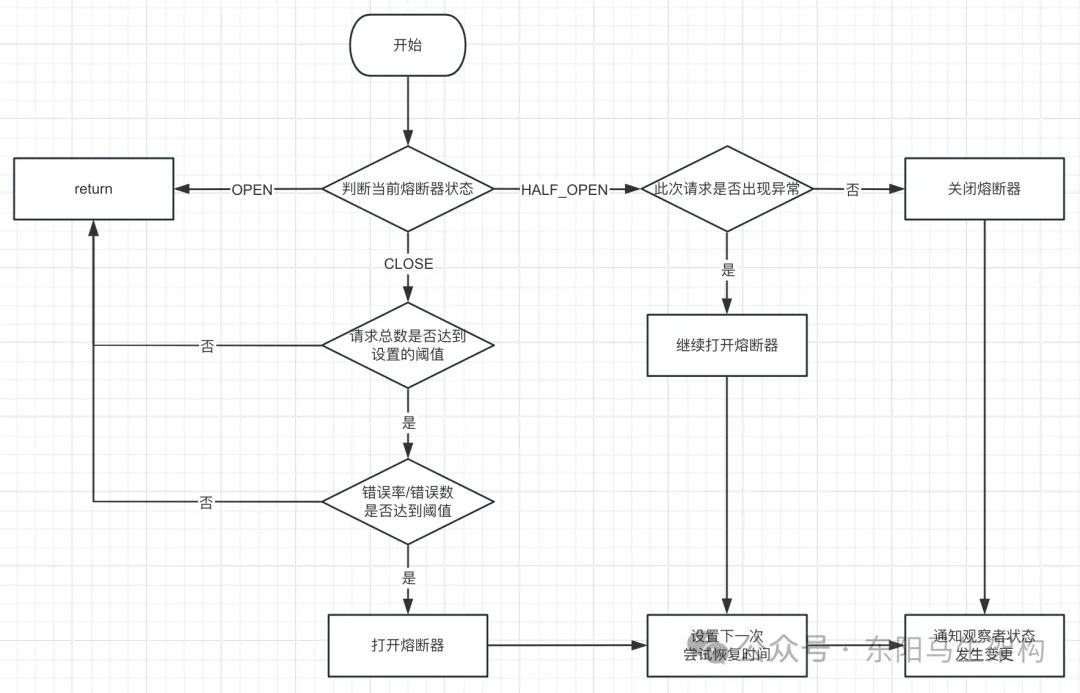
Sentinel源码—6.熔断降级和数据统计的实现一
大纲 1.DegradeSlot实现熔断降级的原理与源码 2.Sentinel数据指标统计的滑动窗口算法 1.DegradeSlot实现熔断降级的原理与源码 (1)熔断降级规则DegradeRule的配置Demo (2)注册熔断降级监听器和加载熔断降级规则 (3)DegradeSlot根据熔断降级规则对请求进行验证 (1)熔断降级…...
Volcano 实战快速入门 (一)
一、技术背景 随着大型语言模型(LLM)的蓬勃发展,其在 Kubernetes (K8s) 环境下的训练和推理对资源调度与管理提出了前所未有的挑战。这些挑战主要源于 LLM 对计算资源(尤其是 GPU)的巨大需求、分布式任务固有的复杂依…...
)
快速体验tftp文件传输(嵌入式设备)
一、参考资料 Linux tftp 命令 | 菜鸟教程 Ubuntu最新版本(Ubuntu22.04LTS)安装Tftp服务及其使用教程-CSDN博客 Windows下的Tftpd32(Tftpd64)软件下载和使用教程-集成了Tftp服务器、客户端-CSDN博客 tftpd32 tftpd64文件传输安装和使用教程【图文并茂】-CSDN博客 二、快速…...

用交换机连接两台电脑,电脑A读取/写电脑B的数据
1、第一步,打开控制面板中的网络和共享中心,如下图配置,电脑A和电脑B均要配置; 注意:要保证电脑A和电脑B在同一子网掩码下,不同的IP地址; 2、在电脑上同时按‘CommandR’,在弹出的输…...

问道数码兽 怀旧剧情回合手游源码搭建教程(反查重优化版)
本文将对"问道数码兽"这一经典卡通风格回合制手游的服务端部署与客户端调整流程进行详细拆解,适用于具备基础 Windows 运维和手游源码调试经验的开发者参考使用。教程以实战为导向,基于原始说明内容重构优化,具备较高的内容查重避重…...
WLAN共享给以太网后以太网IP为169.254.xx.xx以及uboot无法使用nfs下载命令的的解决方案
WLAN共享网络给以太网,实际上是把以太网口当作一个路由器,这个路由器的IP是由WLAN给他分配的,169.254.xx.xx是windows设定的ip,当网络接口无法从上一级网络接口获得ip时,该网络接口的ip被设置为169.254 ,所…...
:环境安装与基础使用)
Gazebo 仿真环境系列教程(一):环境安装与基础使用
文章目录 一、版本说明与技术背景1.1 Gazebo 版本分支1.2 版本选择建议 二、系统环境准备2.1 硬件要求2.2 软件依赖 三、Gazebo Garden 安装流程3.1 添加官方软件源3.2 执行安装命令3.3 环境验证 四、Gazebo Classic 安装方法4.1 添加软件仓库4.2 安装核心组件4.3 验证安装 五、…...

ROS 快速入门教程03
8.编写Subscriber订阅者节点 8.1 创建订阅者节点 cd catkin_ws/src/ catkin_create_pkg atr_pkg rospy roscpp std_msgs ros::Subscriber sub nh.subscribe(话题名, 缓存队列长度, 回调函数) 回调函数通常在你创建订阅者时定义。一个订阅者会监听一个话题,并在有…...
在 macOS 上合并 IntelliJ IDEA 的项目窗口
在使用 IntelliJ IDEA 开发时,可能会打开多个项目窗口,这可能会导致界面变得混乱。为了提高工作效率,可以通过合并项目窗口来简化界面。本文将介绍如何在 macOS 上合并 IntelliJ IDEA 的项目窗口。 操作步骤 打开 IntelliJ IDEA: 启动你的 I…...
相关知识点)
SEO(Search Engine Optimization,搜索引擎优化)相关知识点
SEO(Search Engine Optimization)是指搜索引擎优化,是计算机领域中通过技术手段和内容策略,提升网站在搜索引擎(如Google、Bing、百度)中自然(非付费)排名的系统性方法。是一种通过优…...
)
C#森林中的兔子(力扣题目)
C#森林中的兔子(力扣题目) 题目介绍 森林中有未知数量的兔子。提问其中若干只兔子 “还有多少只兔子与你(指被提问的兔子)颜色相同?” ,将答案收集到一个整数数组 answers 中,其中 answers[i] 是第 i 只兔子的回答。 给你数组…...
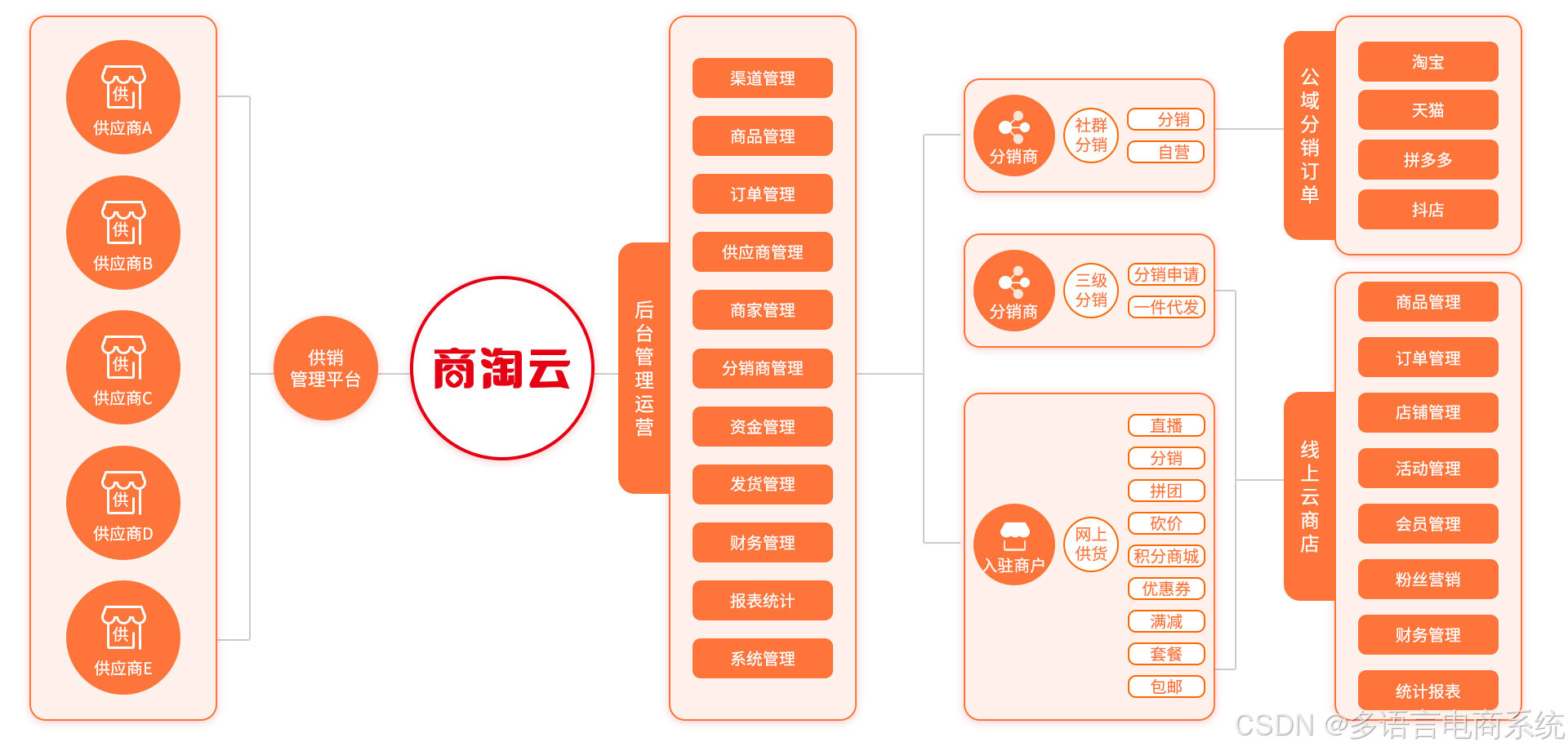
基于多用户商城系统的行业资源整合模式与商业价值探究
随着电子商务的蓬勃发展,传统的单一商家电商模式逐渐显现出一定的局限性。为了解决商家成本过高、市场竞争激烈等问题,多用户商城系统应运而生,成为一种新型的电商平台模式。通过整合行业资源,这种模式不仅极大地提升了平台和商家…...