AI书籍大模型微调-基于亮数据获取垂直数据集
大模型的开源,使得每位小伙伴都能获得AI的加持,包括你可以通过AIGC完成工作总结,图片生成等。这种加持是通用性的,并不会对个人的工作带来定制的影响,因此各个行业都出现了垂直领域大模型。
垂直大模型是如何训练出来的
简单来说,就是各个大模型公司通过大量的数据集,训练出一个base模型或SFT模型,就是下图的Pre-trained LLM预训练大模型,这个大模型就是通用大模型。
在基于垂直领域的数据集Custom knowledge进行微调Fine tuning,微调的过程也是一个训练的过程,最终获得一个微调后的垂直领域大模型Fine-tuned LLM。
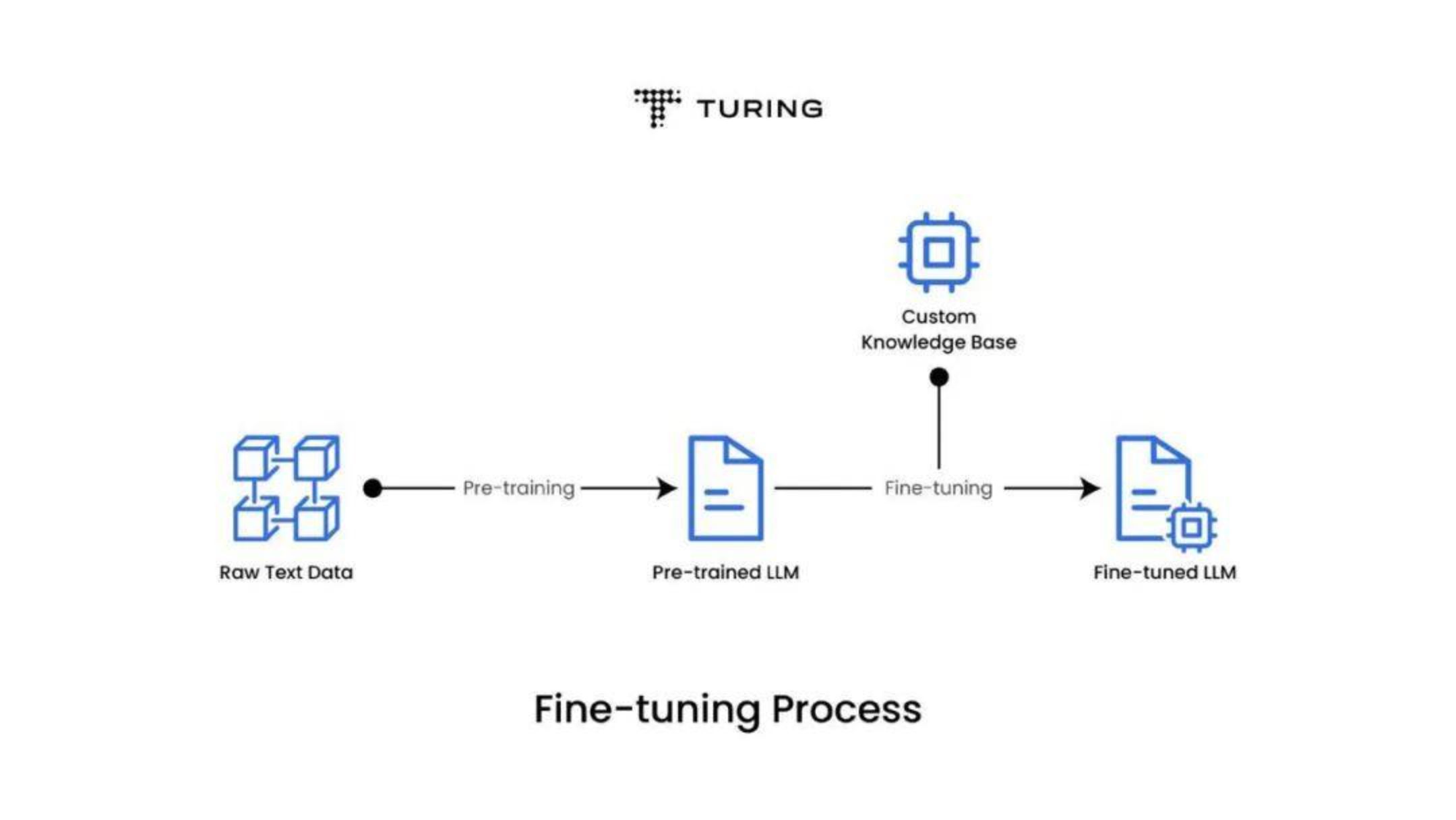
如果想制作一个与书籍相关的垂直领域大模型,就需要大量的书籍数据,这时就需要获得相关数据,以下通过亮数据(Bright Data) 完成书籍相关数据的获取工作。
如果获取AI书籍大模型的数据集
想构建一个AI书籍大模型,完成一个更懂人类书籍的大模型,为喜欢阅读书籍的朋友提供定制服务,比如可以更懂古代文献,更懂专业书籍的大模型。首先就需要获取书籍的相关数据,包括评论数据和书籍内容。
数据采集技术很多,基于Python的框架也是足够的丰富,如requests和selenium,这就要求读者会进行网页解析。
对于想快速获取数据集的同学来说,可以基于一个数据采集工具,🌰,本文基于亮数据(Bright Data)获取相关数据集,链接如下:
https://get.brightdata.com/
书籍领域的数据获取
数据获取平台-亮数据(Bright Data)介绍
亮数据(Bright Data) ,是一款低代码爬虫平台,既有现成的爬虫解锁框架,还提供IP代理服务。
亮数据首页
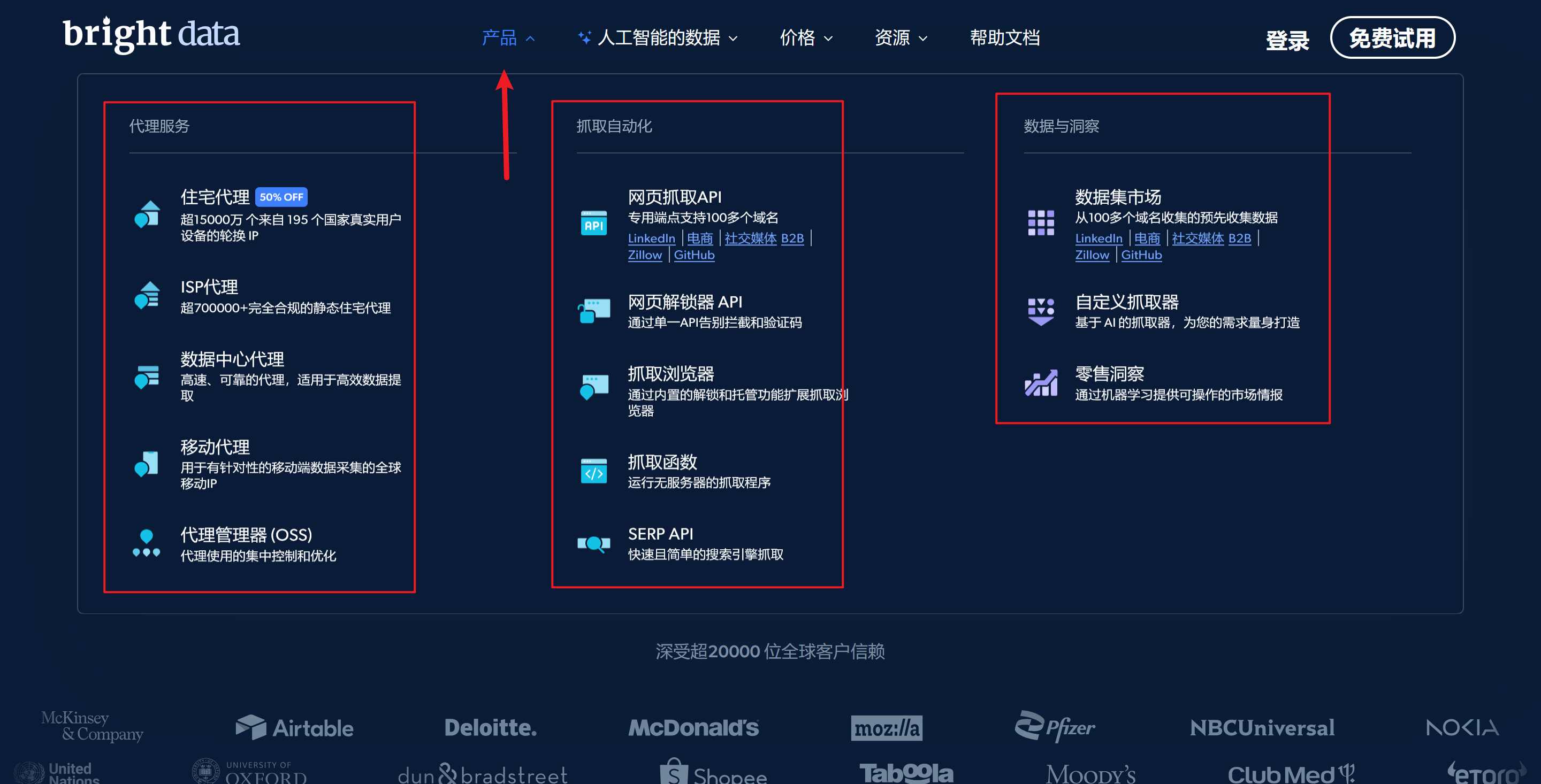
亮数据提供的产品主要包括代理服务,抓取自动化与数据洞察等
本文主要基于抓取自动化中的完成数据采集的测试与爬取
亮数据使用步骤
新用户有亮数据的免费赠送的$,可以率先体验下,比较友好。
1.注册亮数据
点击链接进入主页
亮数据(Bright Data)
单击登录
首次使用可以点击注册
输入必备的信息后,点击创建账户,创建完毕后,可进入控制台
2.创建爬虫任务
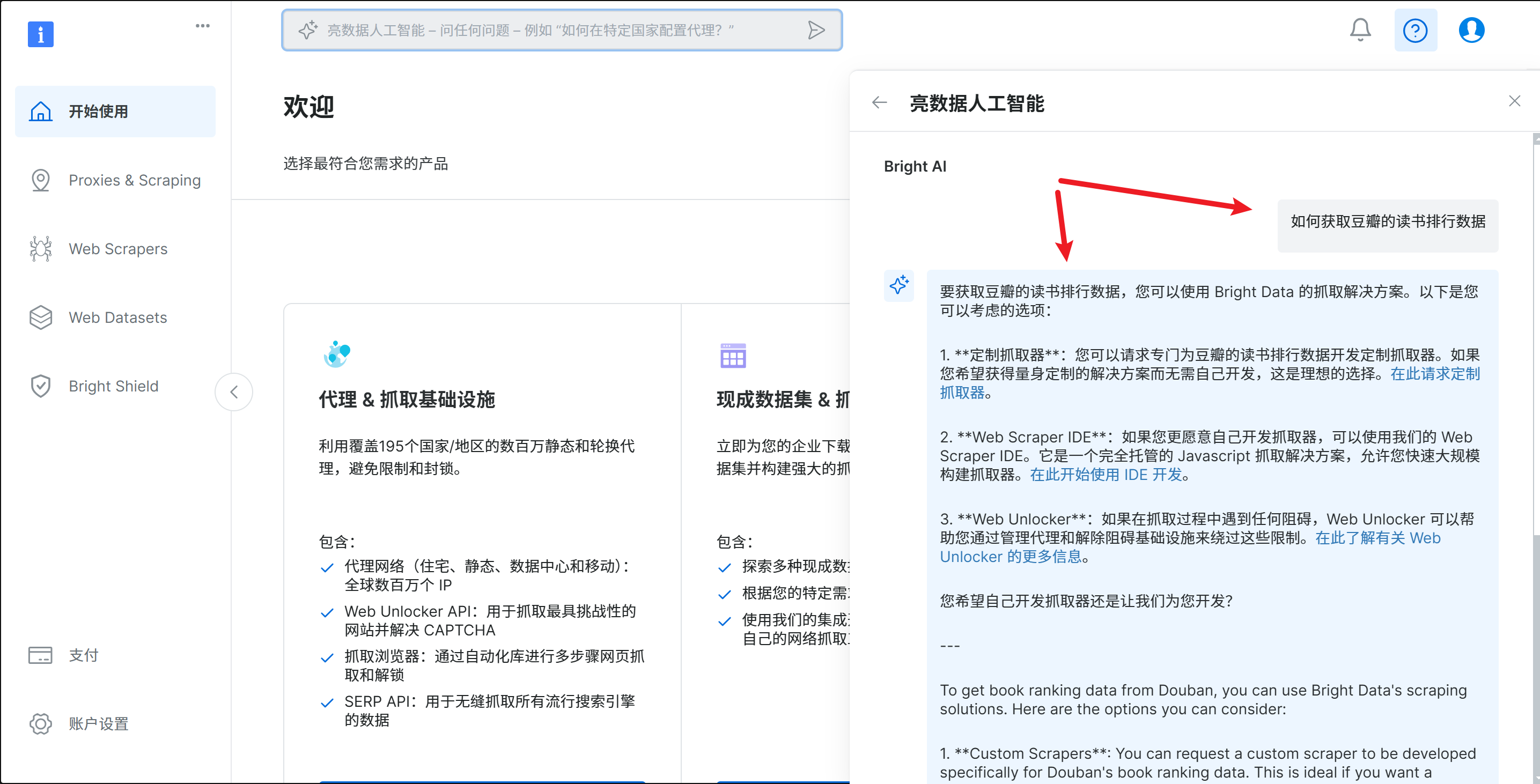
在控制台页面可以看到右上角提供了一个AI对话功能
询问以下如何获取相关数据集
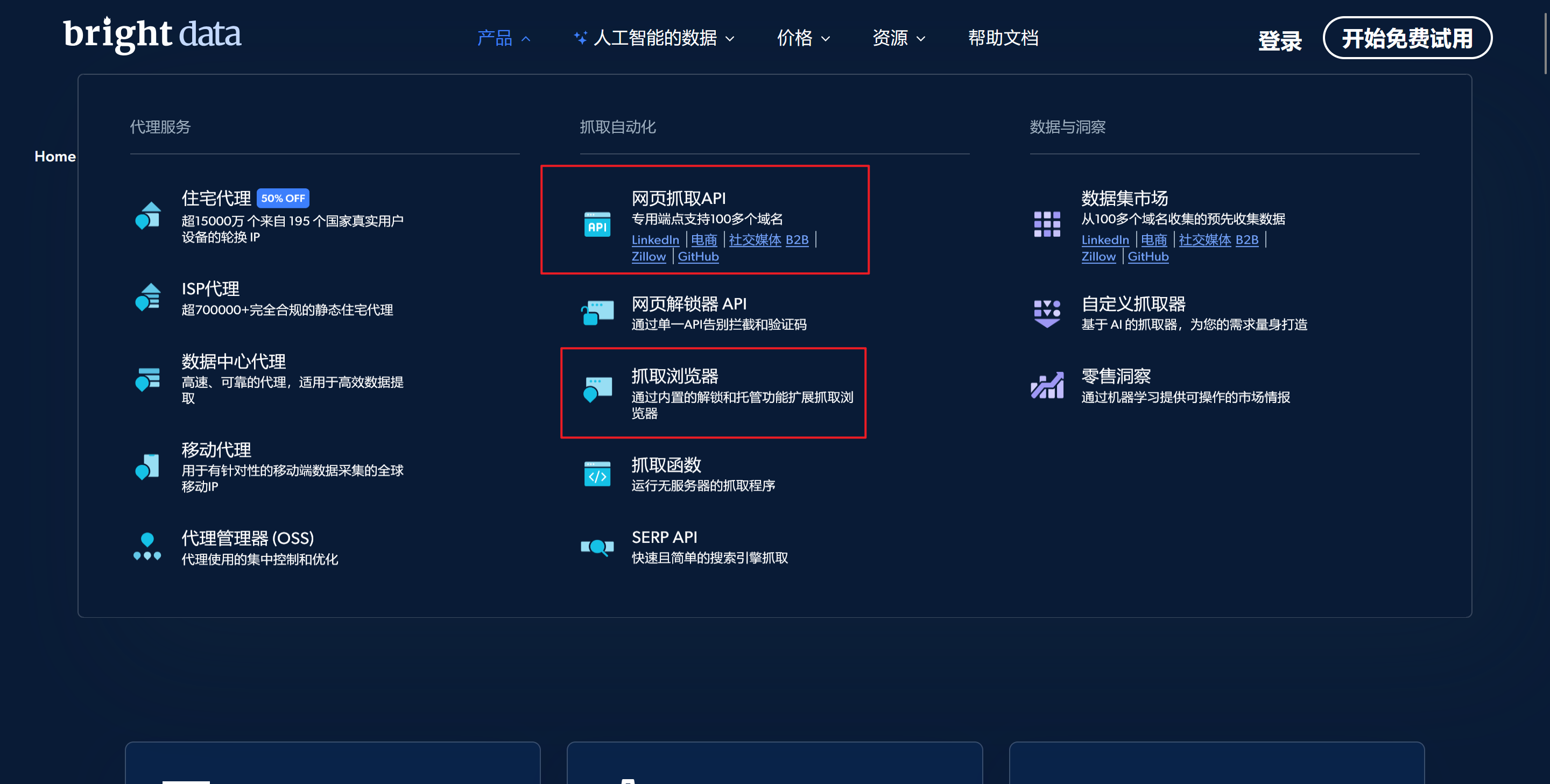
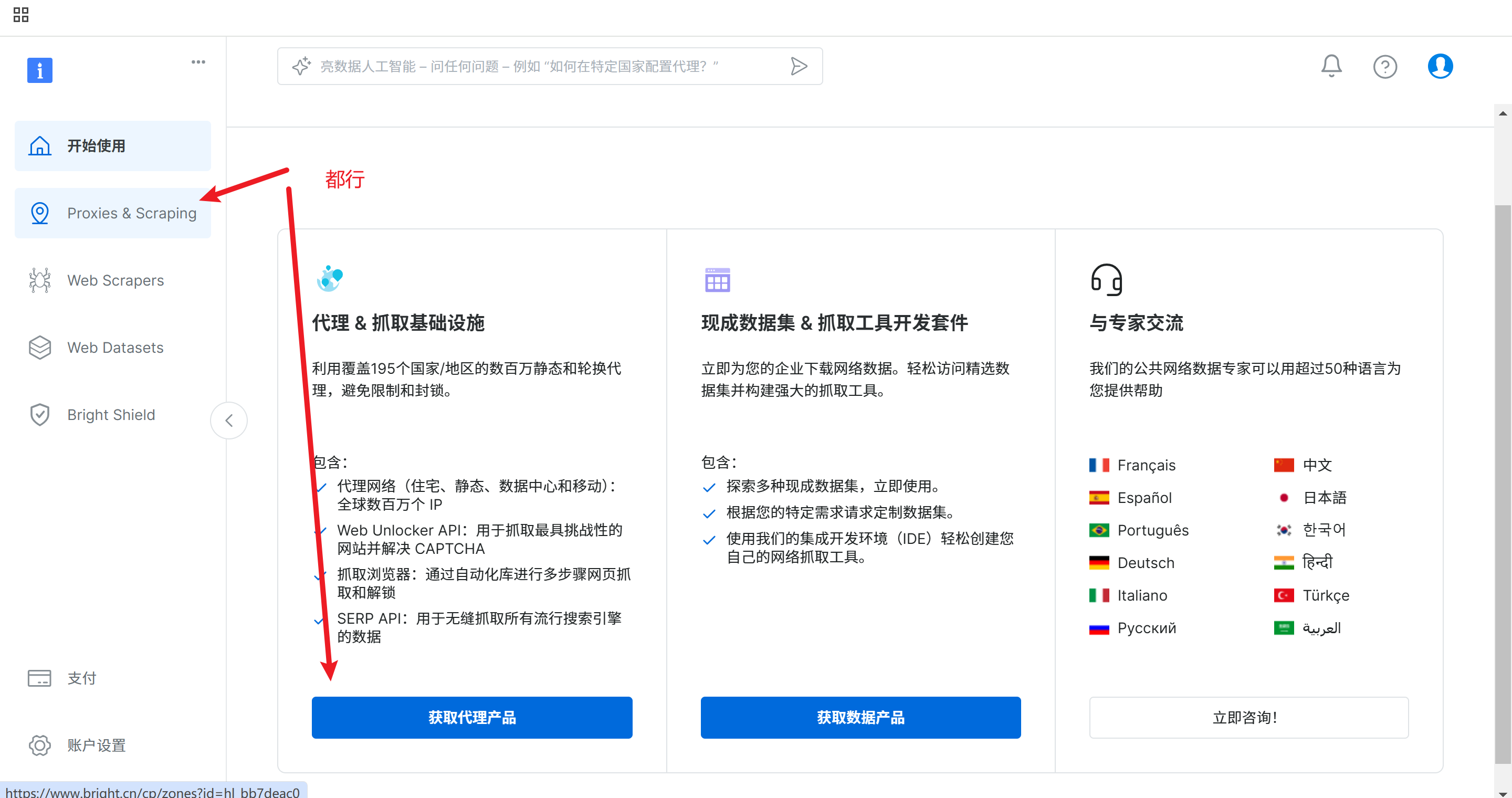
也可以直接单击代理&抓取集成设置下的代理产品
单击获取代理产品
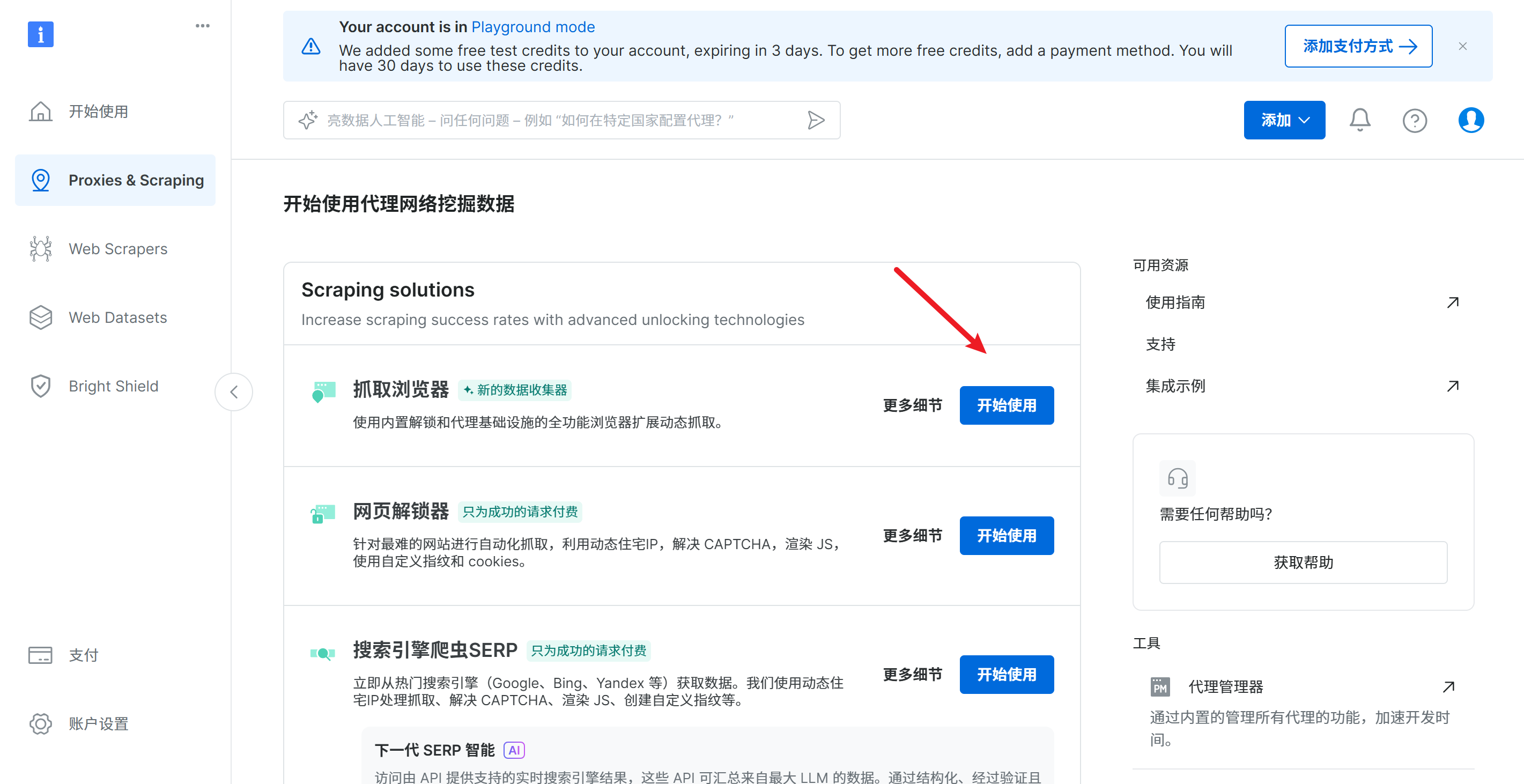
单击开始使用
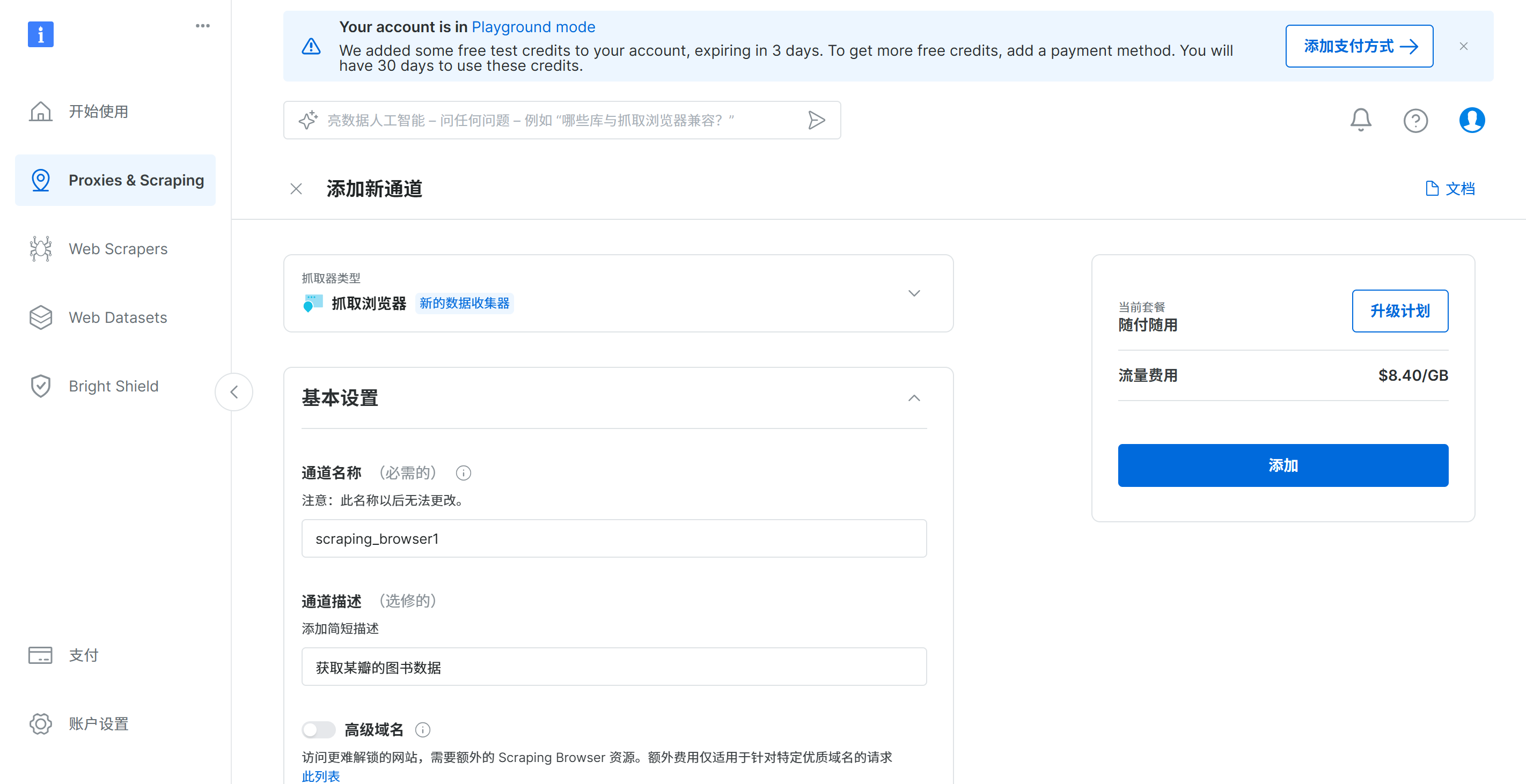
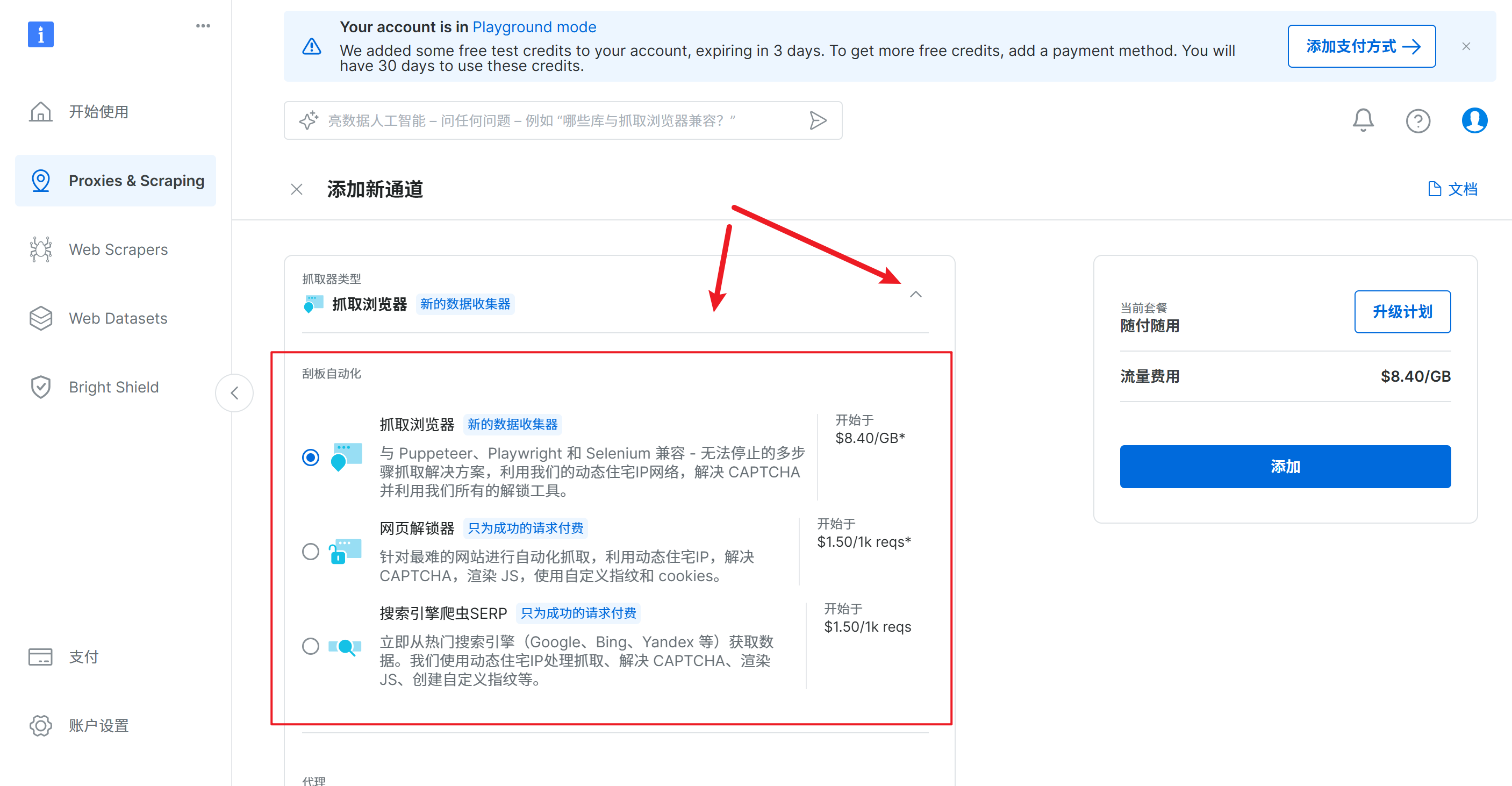
输入通道名称为:scraping_browser1_douban
通道描述为:获取某瓣的图书数据单击向下箭头,也可以切换抓取器类型,这里选择默认的抓取浏览器
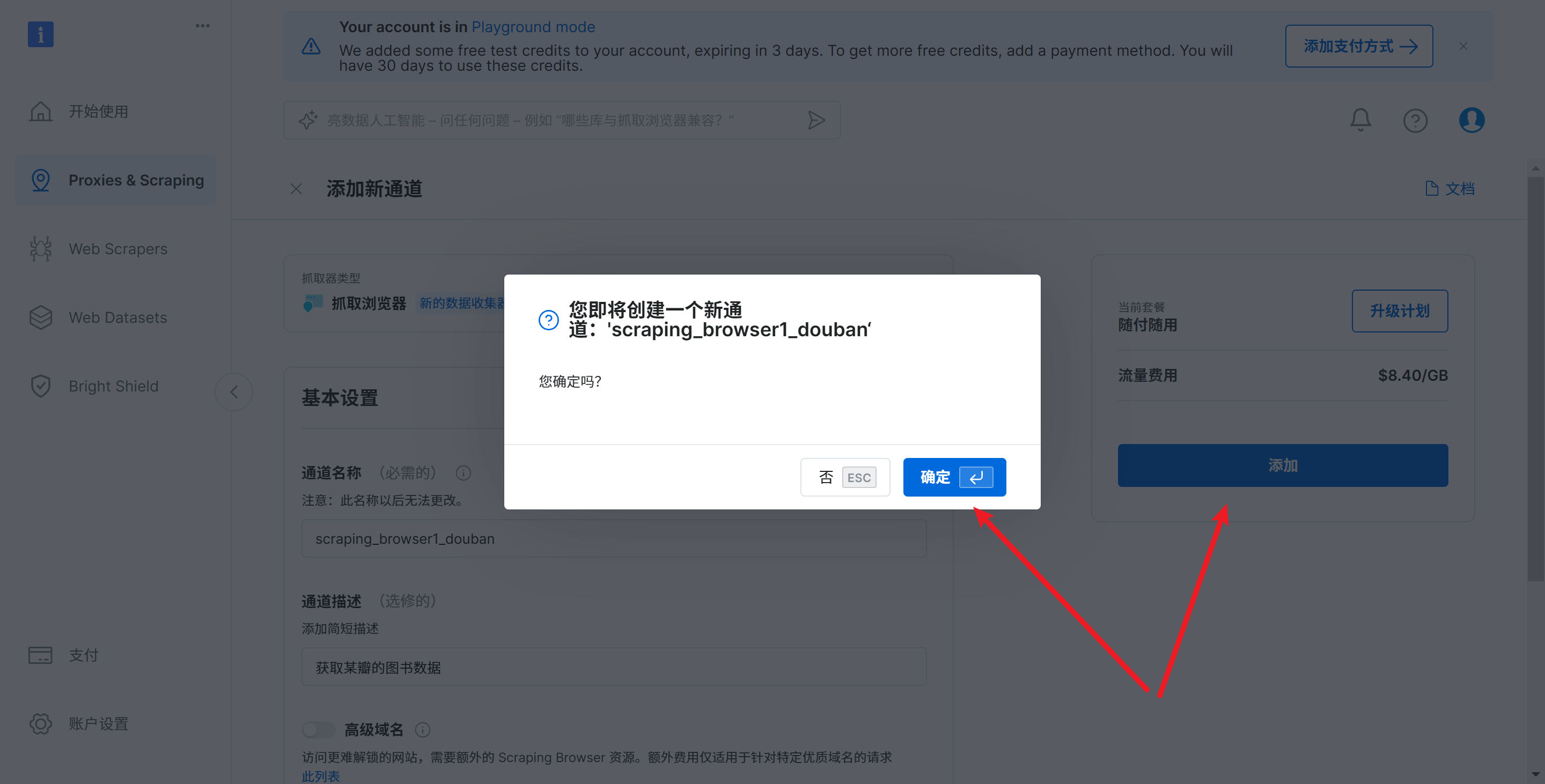
单击添加和确定,完成通道添加
会提示配置信息
单击 continue with Scraping browser playground,完成爬虫任务创建
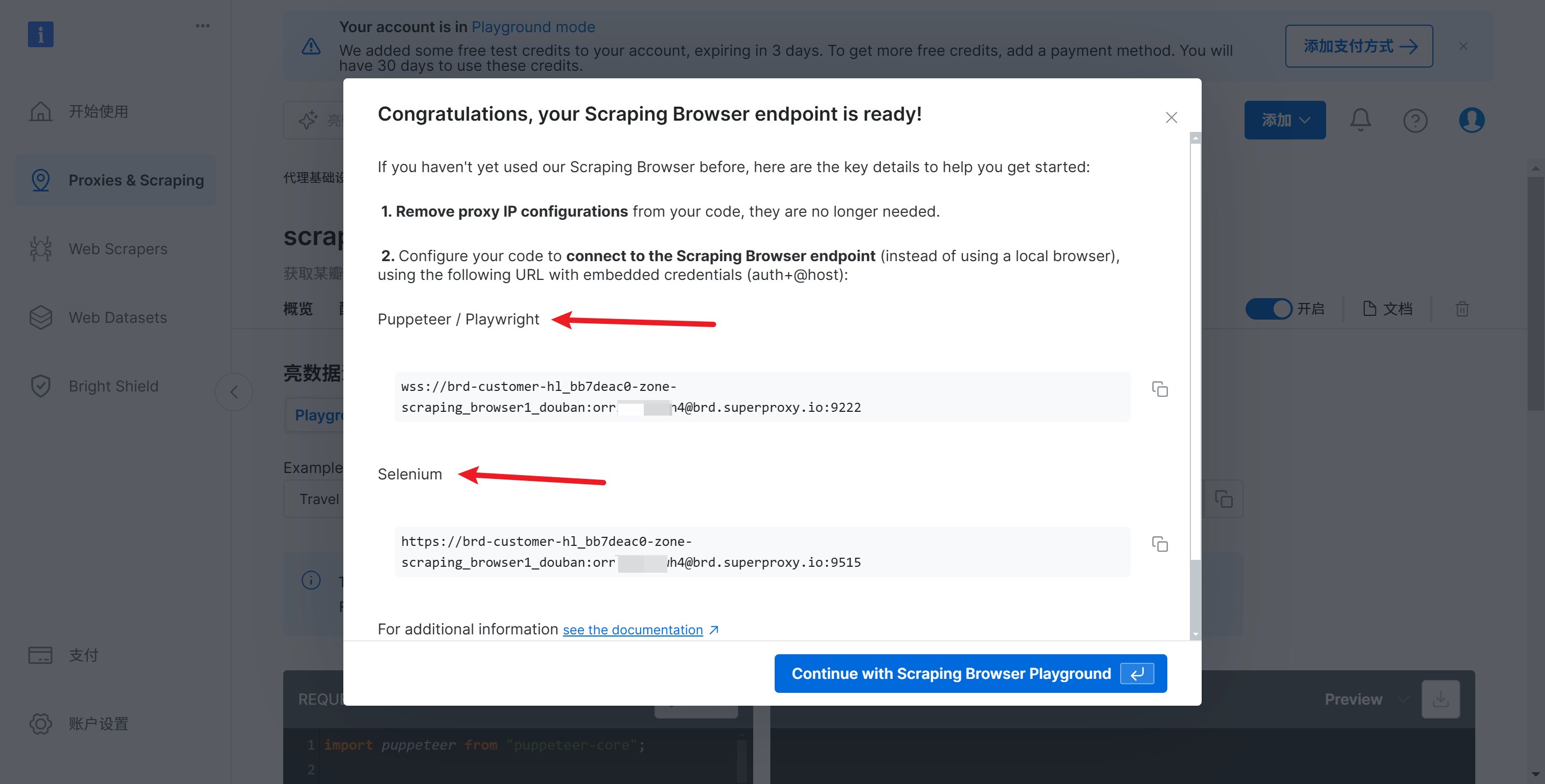
3.生成代码-测试亮数据的ip池
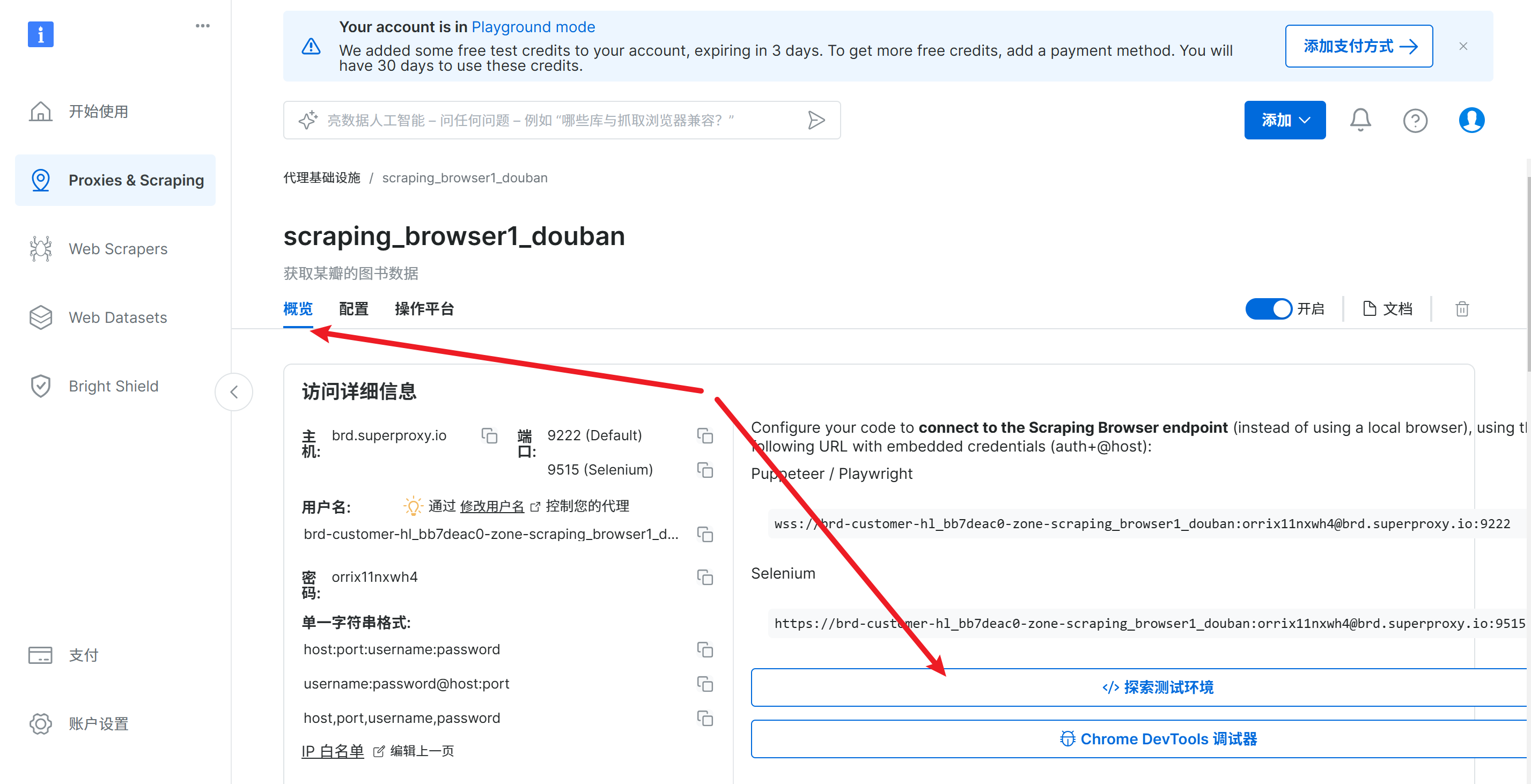
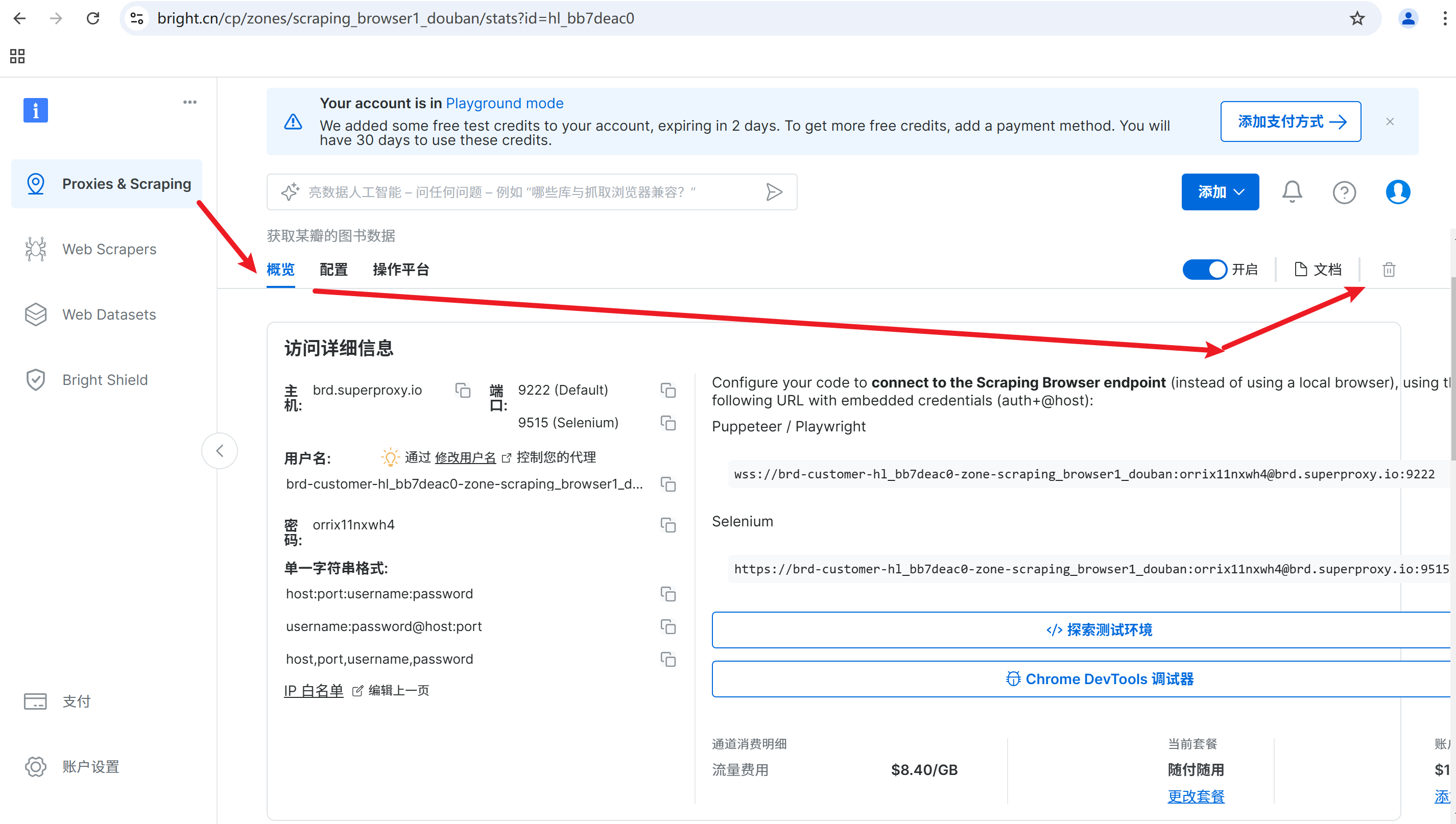
在弹出的页面配置中,选择概览,在选择探索测试环境
在操作平台中可以切换要生成的爬虫案例代码,这里选择python语言的selenium框架
按照提示安装selenium依赖
pip3 install selenium
提示如下:
Successfully installed cffi-1.17.1 outcome-1.3.0.post0 pycparser-2.22 pysocks-1.7.1 selenium-4.31.0 sortedcontainers-2.4.0 trio-0.29.0 trio-websocket-0.12.2 wsproto-1.2.0
在本地创建 scrapydemo.py,复制代码到本地
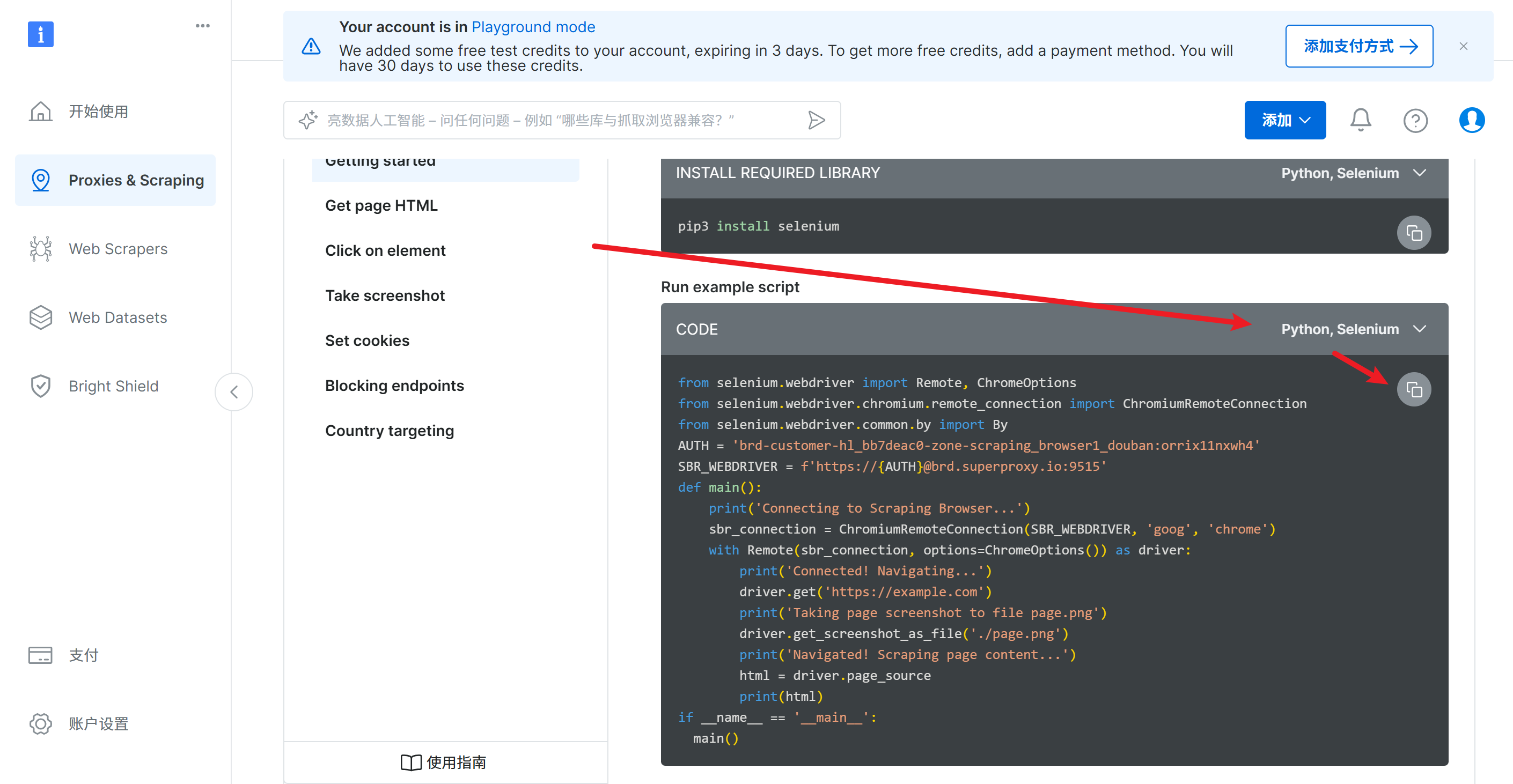
代码如下,这里的AUTH已经填充完毕,如果需要更改,可以在配置中复制用户名即可
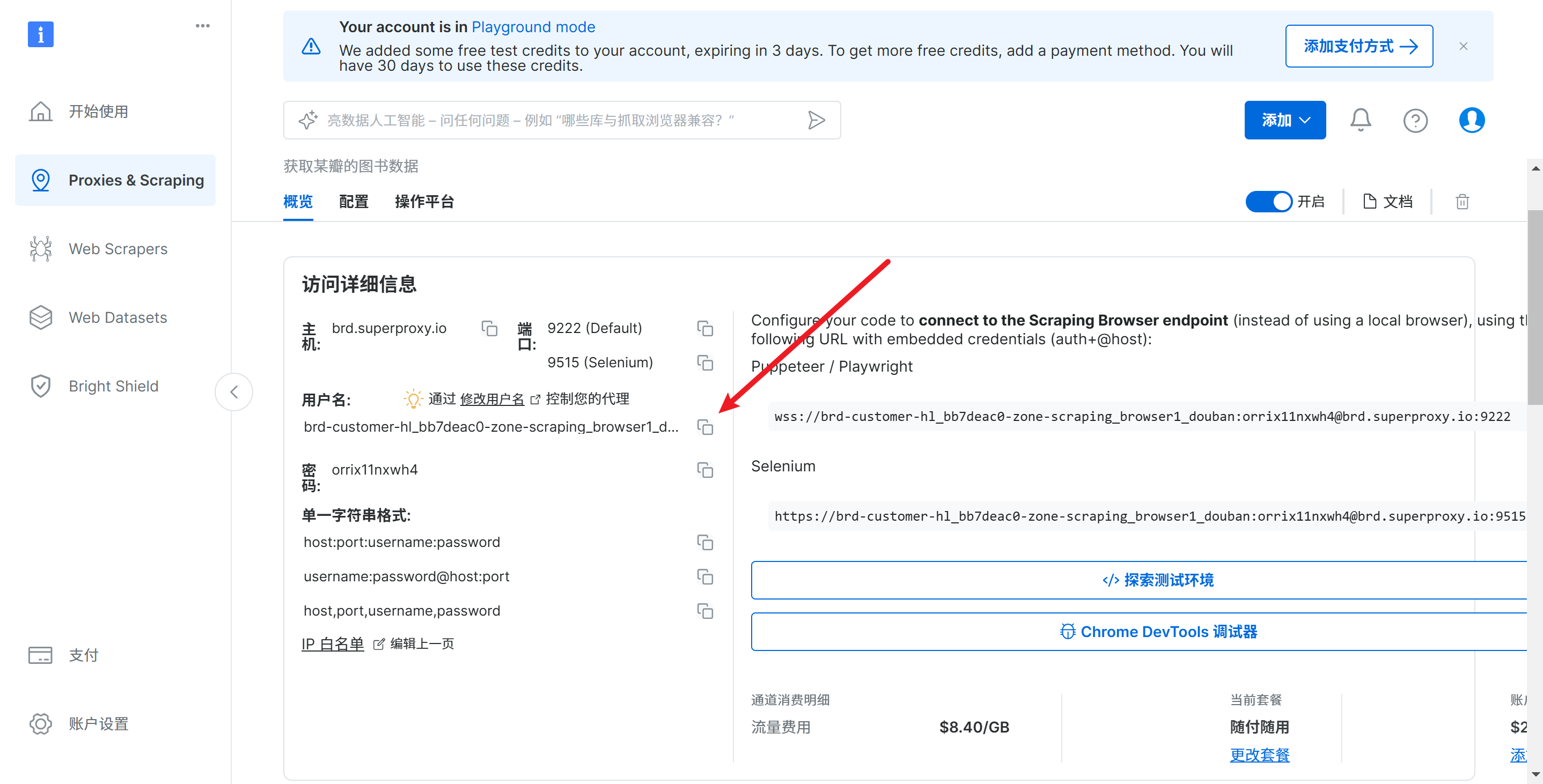
代码如下:
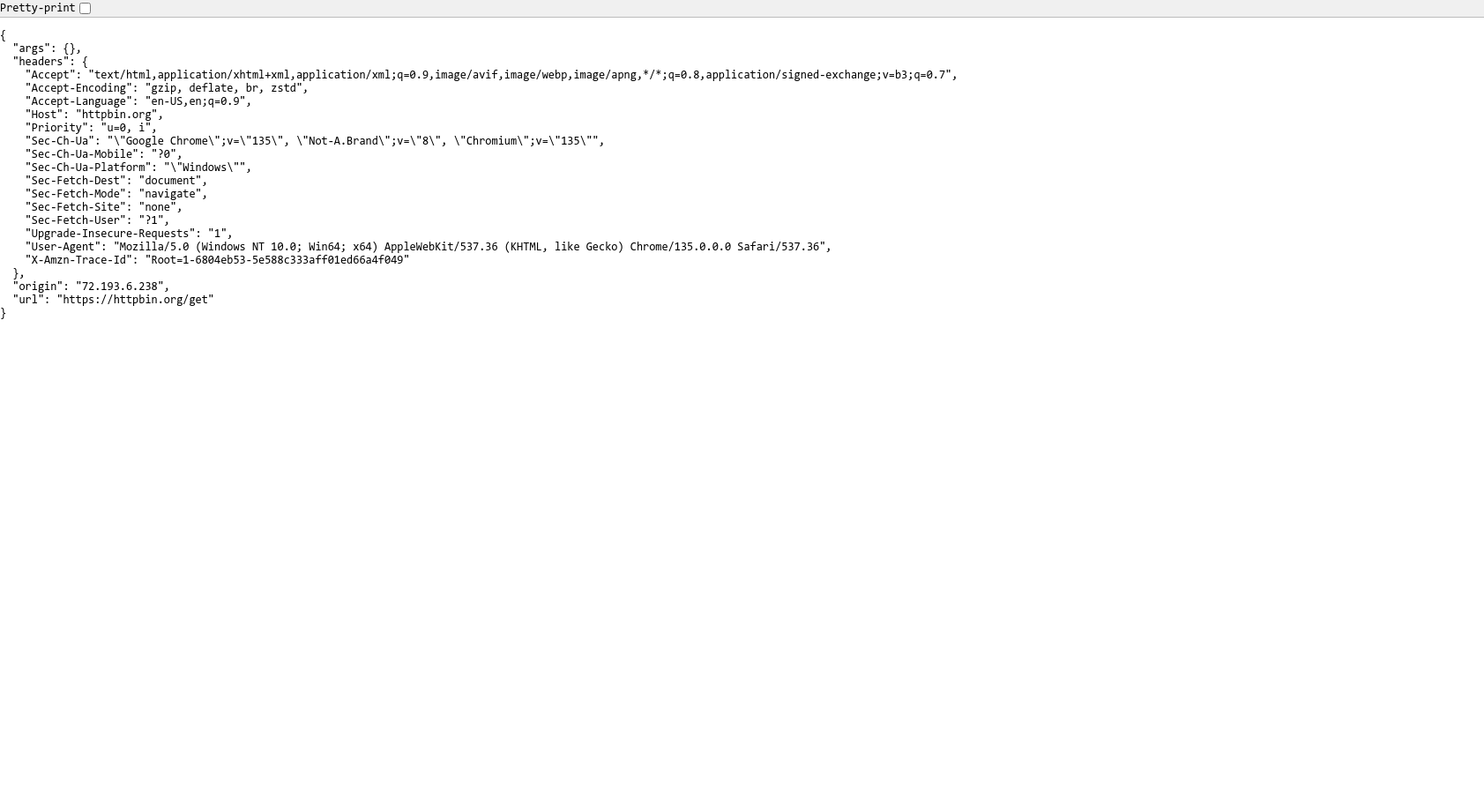
把测试的网址替换为: http://httpbin.org/get,该网站可以返回请求的信息
备注:这里的代理信息会在后文删除,在使用过程中,替换为自己的信息就好
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
AUTH = 'brd-customer-hl_bb7deac0-zone-scraping_browser1_douban:orrix11nxwh4'
SBR_WEBDRIVER = f'https://{AUTH}@brd.superproxy.io:9515'
def main():print('Connecting to Scraping Browser...')sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')with Remote(sbr_connection, options=ChromeOptions()) as driver:print('Connected! Navigating...')# 这里把测试网站替换位 http://httpbin.org/geturl = "http://httpbin.org/get"# url = "https://example.com"driver.get(url)print('Taking page screenshot to file page.png')driver.get_screenshot_as_file('./page.png')print('Navigated! Scraping page content...')html = driver.page_sourceprint(html)
if __name__ == '__main__':main()
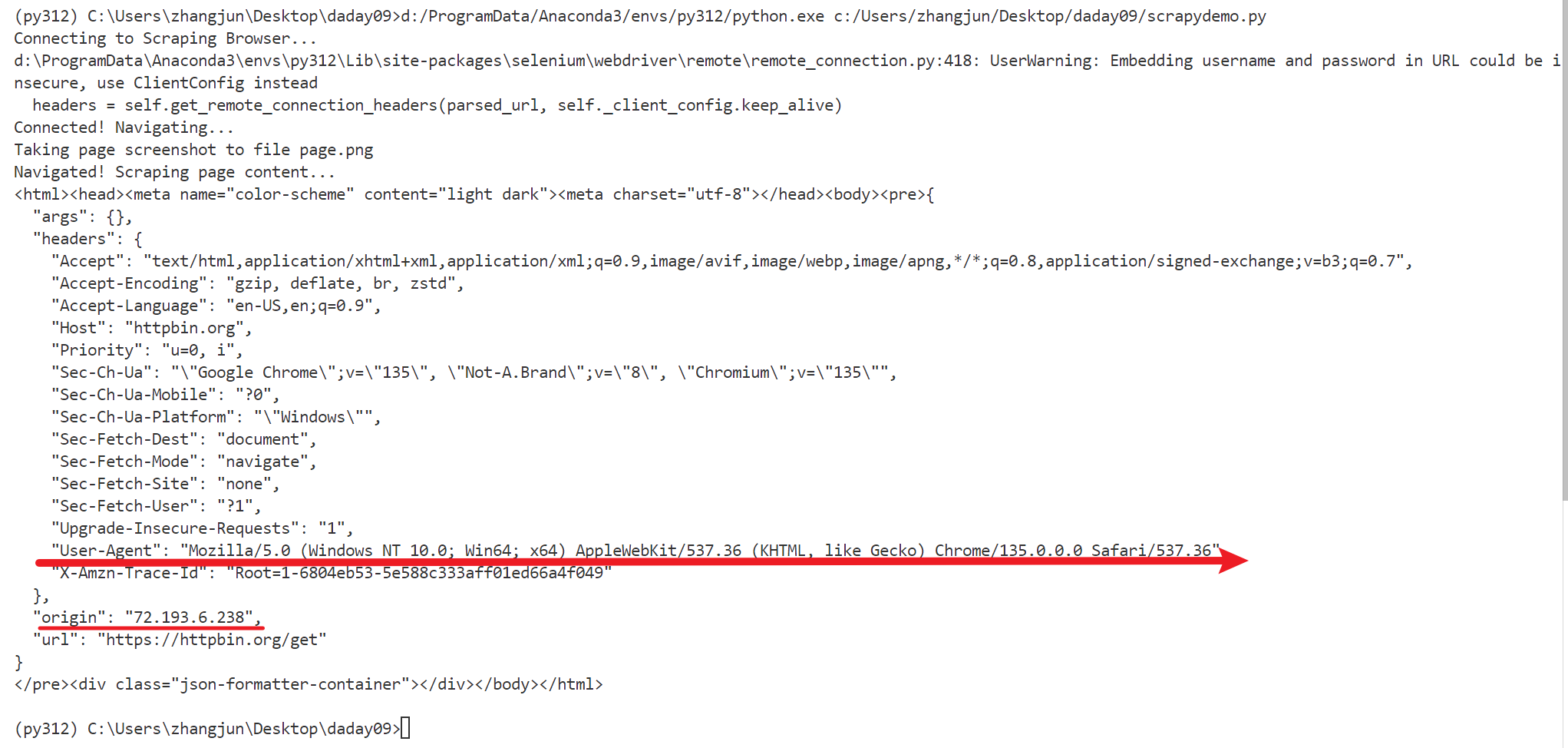
运行测试,输出如下:
控制台输出
保存的页面png如下
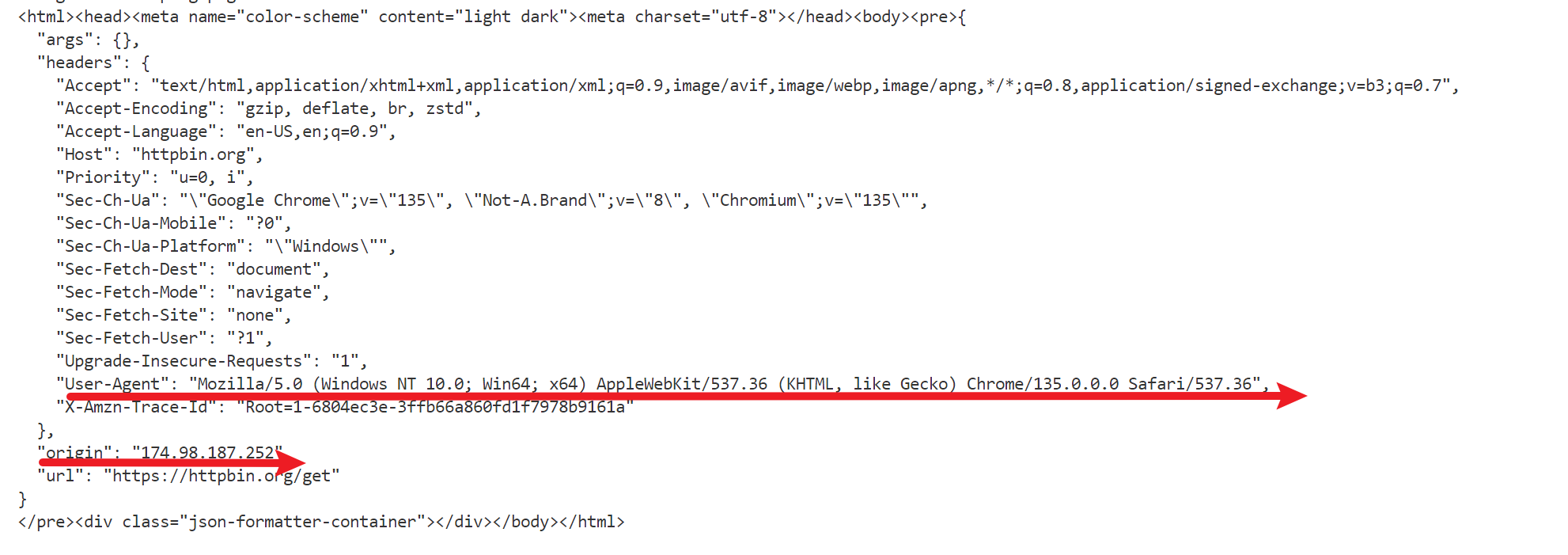
再次运行该代码,返回如下:
可以看到两次的地址发生了改变,可以减少被屏蔽ip的情况发生。
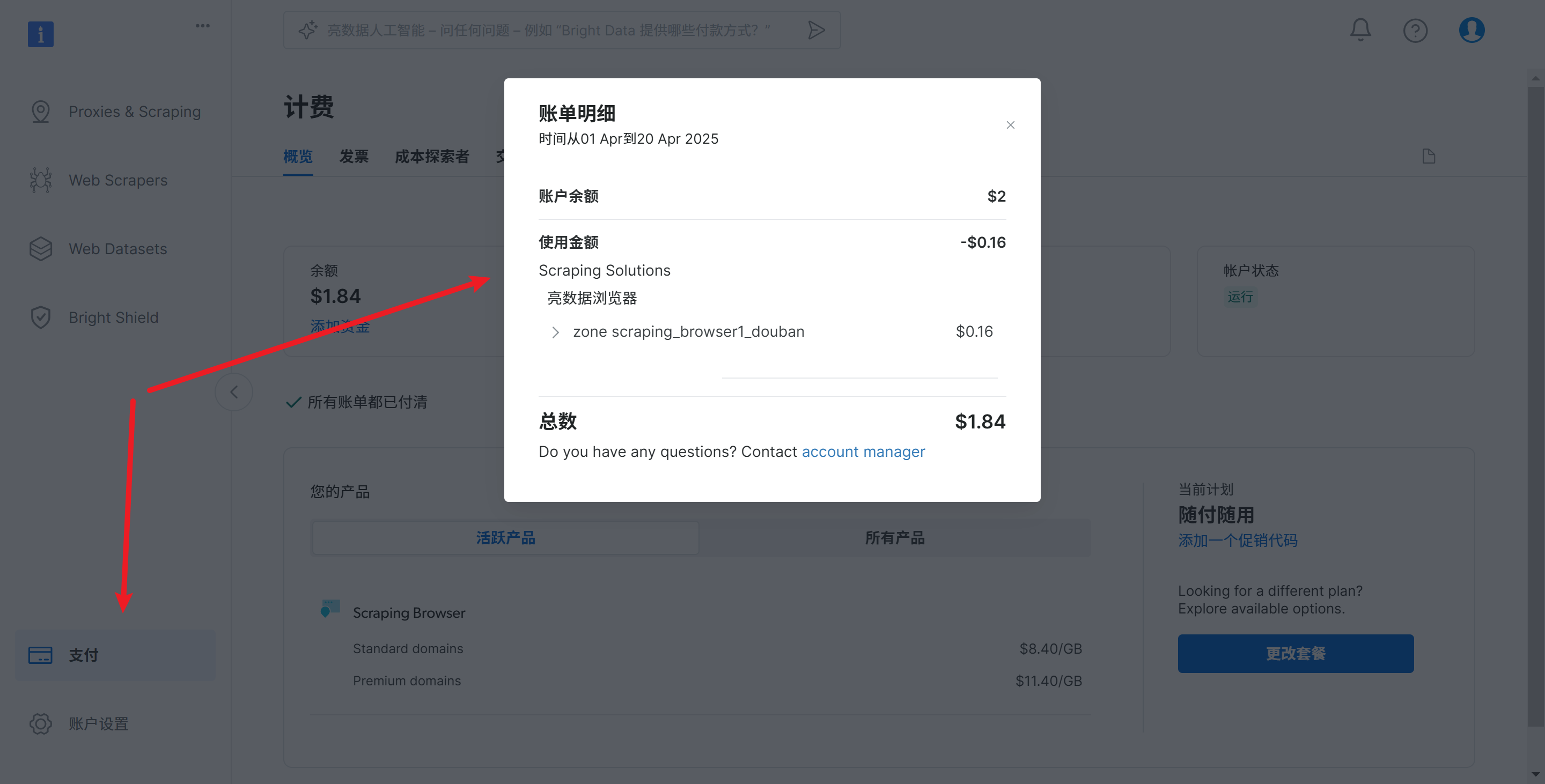
同时点击控制台中的左下角的支付,可以查看消费情况
4.修改代码获取豆瓣的书籍数据(可用代码)
import time
from lxml import etree
import csv
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
AUTH = 'brd-customer-hl_bb7deac0-zone-scraping_browser1_douban:orrix11nxwh4'
SBR_WEBDRIVER = f'https://{AUTH}@brd.superproxy.io:9515'
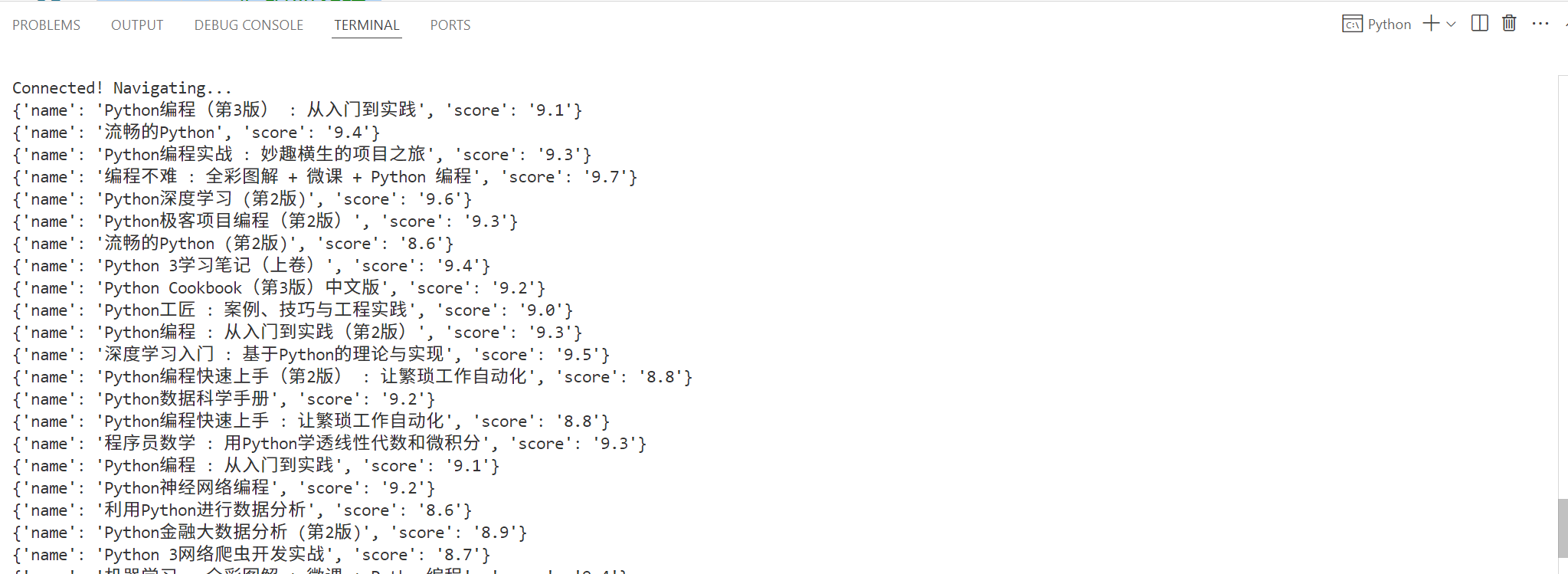
def main():print('Connecting to Scraping Browser...')sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')with Remote(sbr_connection, options=ChromeOptions()) as driver:print('Connected! Navigating...')# url = "http://httpbin.org/get"start_url = "https://book.douban.com/subject_search?search_text=python&cat=1001&start=%25s0"# url = "https://example.com"content = driver.get(start_url)num=0while True:num+=1# 停一下,等待加载完毕time.sleep(2)# 获取网页内容Elementscontent = driver.page_source# 提取数据data_list = etree.HTML(content).xpath('//div[@class="item-root"]')[1:]for data in data_list:item = {}item["name"] = data.xpath("./div/div[1]/a/text()")[0]item["score"] = data.xpath("./div/div[2]/span[2]/text()")[0]with open("./豆瓣图书.csv", "a", encoding="utf-8") as file:writer = csv.writer(file)writer.writerow(item.values())print(item)# 找到后页next = driver.find_element(By.XPATH,'//a[contains(text(),"后页")]')# 判断if next.get_attribute("href"):# 单击next.click()else:# 跳出循环breakif num>3:breakprint('Taking page screenshot to file page.png')driver.get_screenshot_as_file(f'./page{num}.png')print('Navigated! Scraping page content...',num)# html = driver.page_source# print(html)
if __name__ == '__main__':main()
输出如下:
保存的页面快照如下
5.删除亮数据的代理
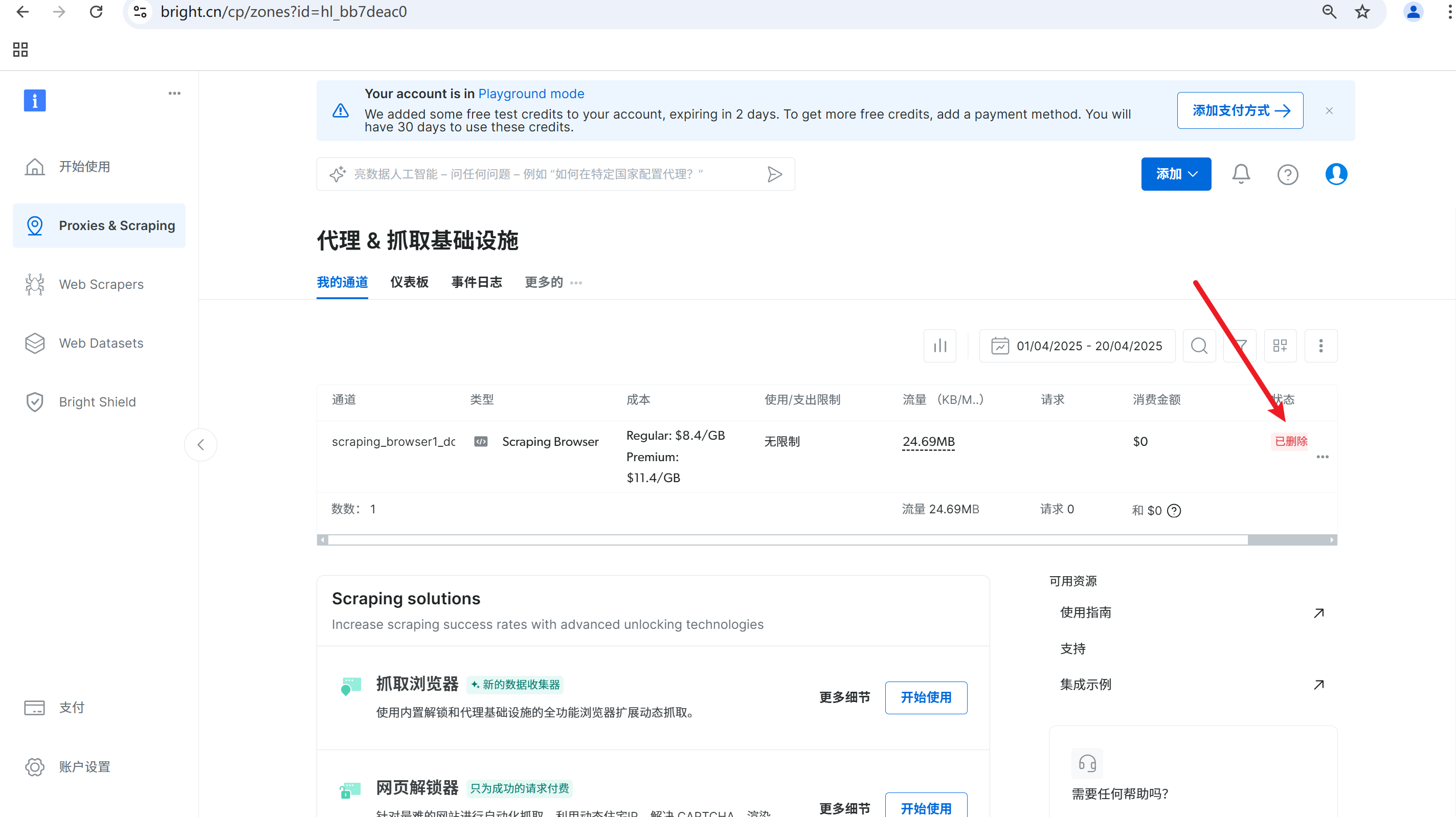
如果数据采集任务完成,我们可以选择删除代理,便于控制使用费用,这点是十分友好的,避免定时爬虫的反复消费。
删除后状态如下
通过亮数据的WEB Datasets下载
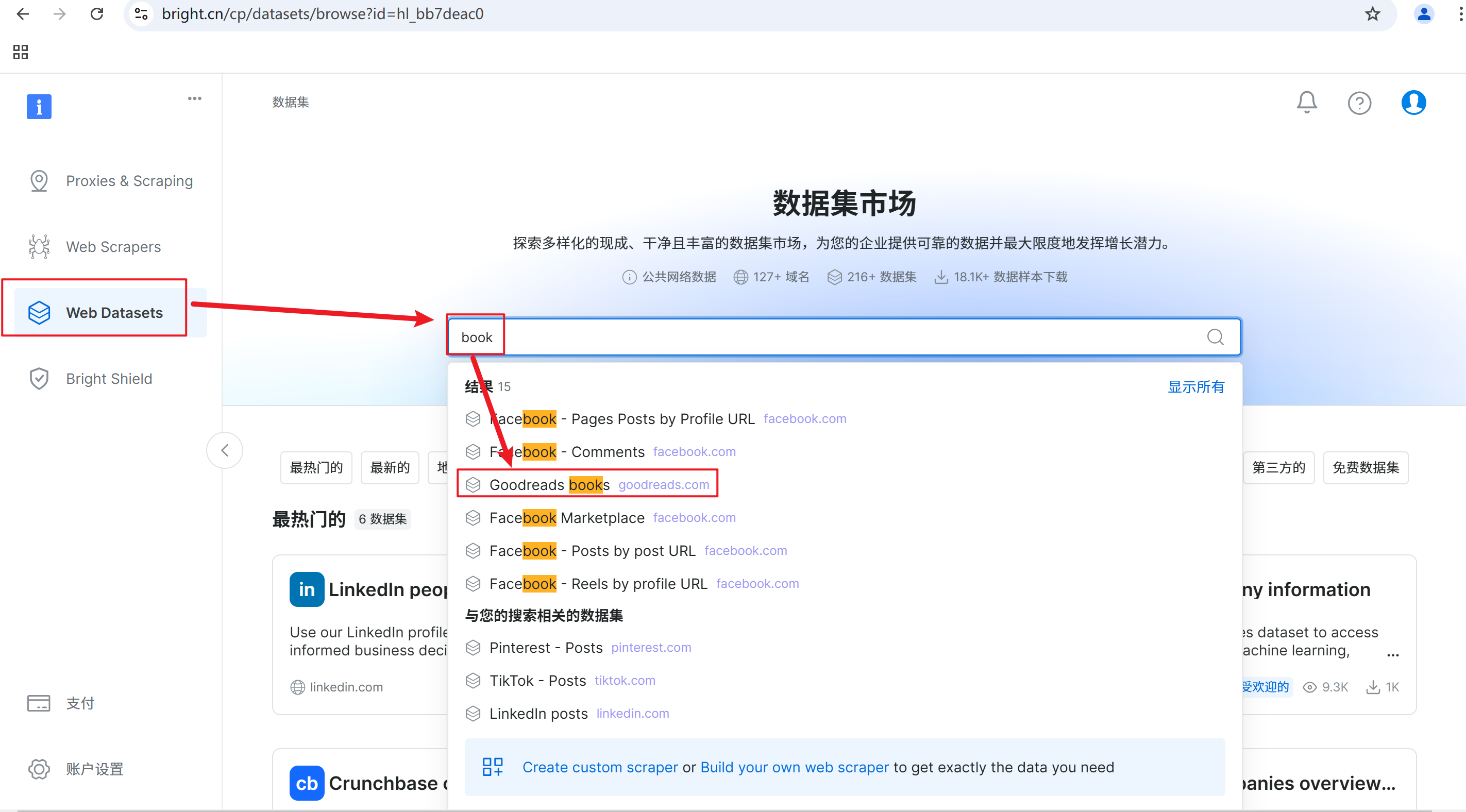
如果是对爬虫技术不了解的朋友,也可以在亮数据的WEB Datasets中下载数据,步骤如下:
单击Web Datasets -->输入book–>选择Goodreads books
Goodreads是“美国版豆瓣”。
它是全球最大的在线读者社区和图书推荐平台,拥有庞大的书籍数据库,涵盖各种类型的书籍。同时会员数量过亿,分布在全世界各地。Goodreads的用户们可以对读过的书籍撰写书评并打分,其他用户也可以进行点赞、评论,加入讨论、分享观点。
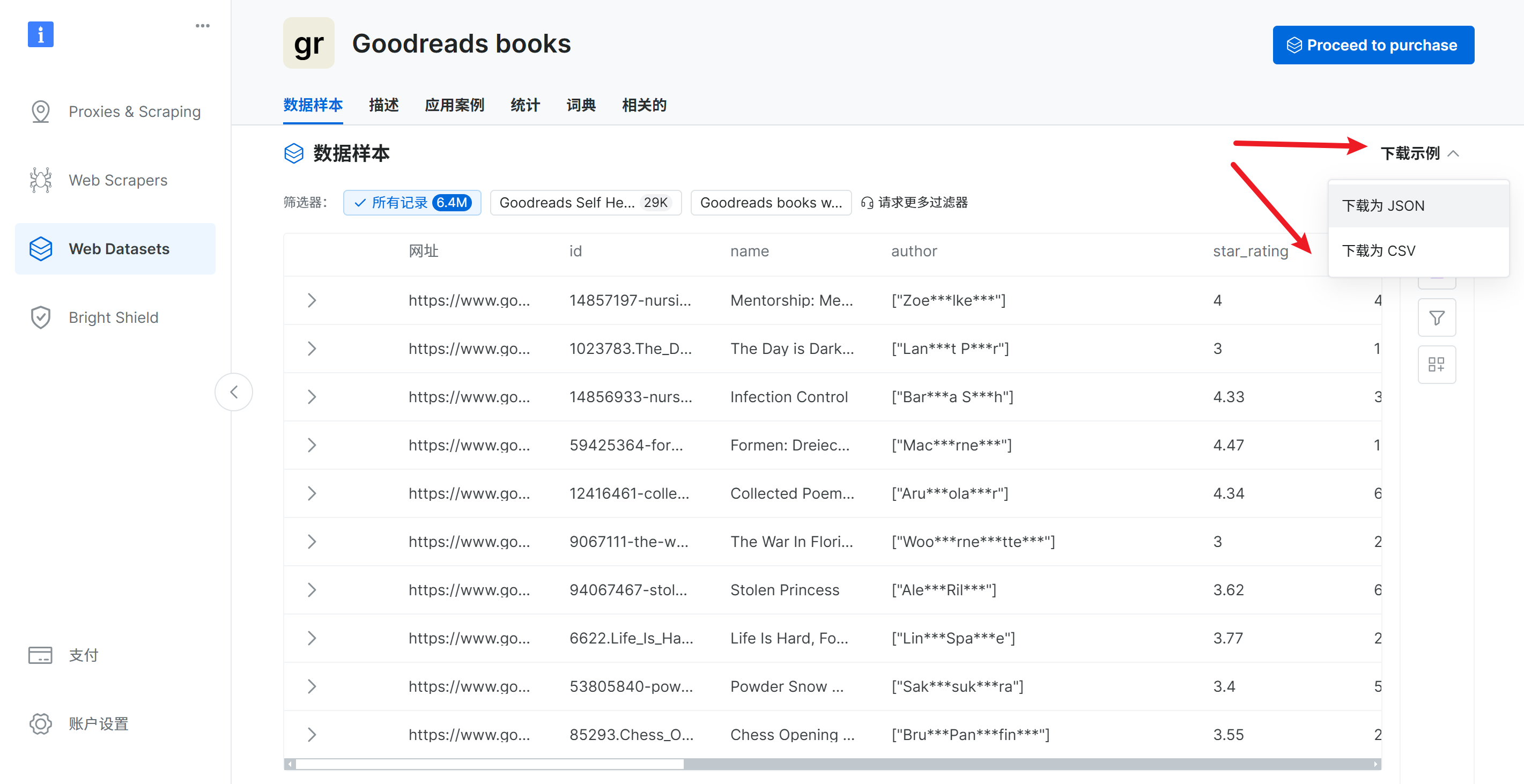
进入页面后,可以下载样例数据
下载后的样例如下:

数据获取总结
如果需要获取垂直领域的数据集,可以通过代理自行下载,也可以查找亮数据(Bright Data) 是否有现有的数据集,这两点可以满足不同的需求,比较友好💯。
垂直大模型举例
氢界专利大模型

医疗领域大模型
链接:https://baijiahao.baidu.com/s?id=1808887323039887765
相关文章:
AI书籍大模型微调-基于亮数据获取垂直数据集
大模型的开源,使得每位小伙伴都能获得AI的加持,包括你可以通过AIGC完成工作总结,图片生成等。这种加持是通用性的,并不会对个人的工作带来定制的影响,因此各个行业都出现了垂直领域大模型。 垂直大模型是如何训练出来…...

Vue3 + Vite + TS,使用 ExcelJS导出excel文档,生成水印,添加背景水印,dom转图片,插入图片,全部代码
Vue3 Vite TS,使用 ExcelJS导出excel文档,生成水印,添加背景水印,dom转图片,插入图片,全部代码 ExcelJS生成文档并导出导出表头其他函数 生成水印设置文档的背景水印dom 转图片插入图片全部代码 ExcelJS 读取&#…...
Kafka命令行的使用/Spark-Streaming核心编程(二)
Kafka命令行的使用 创建topic kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic test1 --partitions 3 --replication-factor 3 分区数量,副本数量,都是必须的。 数据的形式: 主题名称-分区编号。 在…...

2020-06-23 暑期学习日更计划(机器学习入门之路(资源汇总)+概率论)
机器学习入门 前言 说实话,机器学习想学好真心不易,很多时候都感觉自己学得云里雾里。以前一段时间自己为了完成毕业设计,在机器学习的理论部分并没有深究,仅仅通过TensorFlow框架力求快速实现模型。现在来看,很多时候…...
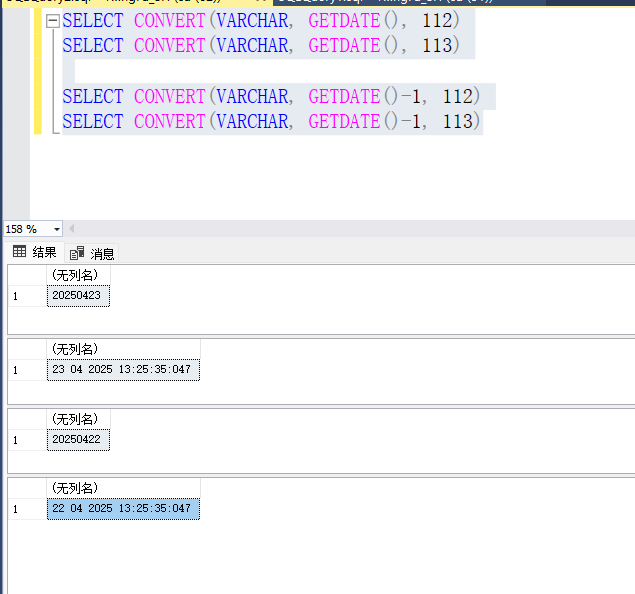
SQL 时间转换的CONVERT()函数应用说明
目录 1.常用查询使用的几个 2.其他总结 1.常用查询使用的几个 SELECT CONVERT(VARCHAR, GETDATE(), 112) SELECT CONVERT(VARCHAR, GETDATE(), 113)SELECT CONVERT(VARCHAR, GETDATE()-1, 112) SELECT CONVERT(VARCHAR, GETDATE()-1, 113) 2.其他总结 SELECT CONVERT(VARCHA…...

高企复审奖补!2025年合肥市高新技术企业重新认定奖励补贴政策及申报条件
一、合肥市高新技术企业重新认定奖励补贴政策 (一)高新区高新技术企业重新认定复审补贴奖励 重新认定为国家高新技术企业的给予5万元一次性奖励。 (二)经开区高新技术企业重新认定复审补贴奖励 对重新认定的企业,给…...

手机端本地服务与后端微服务的技术差异
以下是手机内部本地服务与后端微服务架构及通信协议的对比分析,结合两者的核心设计差异与技术实现特点展开: 一、架构设计对比 维度手机端本地服务后端微服务核心目标资源效率、离线优先、动态更新高并发处理、分布式事务、服务治理服务拆分粒度按功能…...

SystemWeaver详解:从入门到精通的深度实战指南
SystemWeaver详解:从入门到精通的深度实战指南 文章目录 SystemWeaver详解:从入门到精通的深度实战指南一、SystemWeaver环境搭建与基础配置1.1 多平台安装全流程 二、新手必学的十大核心操作2.1 项目创建全流程2.2 建模工具箱深度解析 三、需求工程与系…...

高光谱相机在工业检测中的应用:LED屏检、PCB板缺陷检测
随着工业检测精度要求的不断提升,传统机器视觉技术逐渐暴露出对非可见光物质特性识别不足、复杂缺陷检出率低等局限性。高光谱相机凭借其独特的光谱分析能力,为工业检测提供了革命性的解决方案。以下结合中达瑞和VIX系列推扫式高光谱相机的技术特点与实际…...
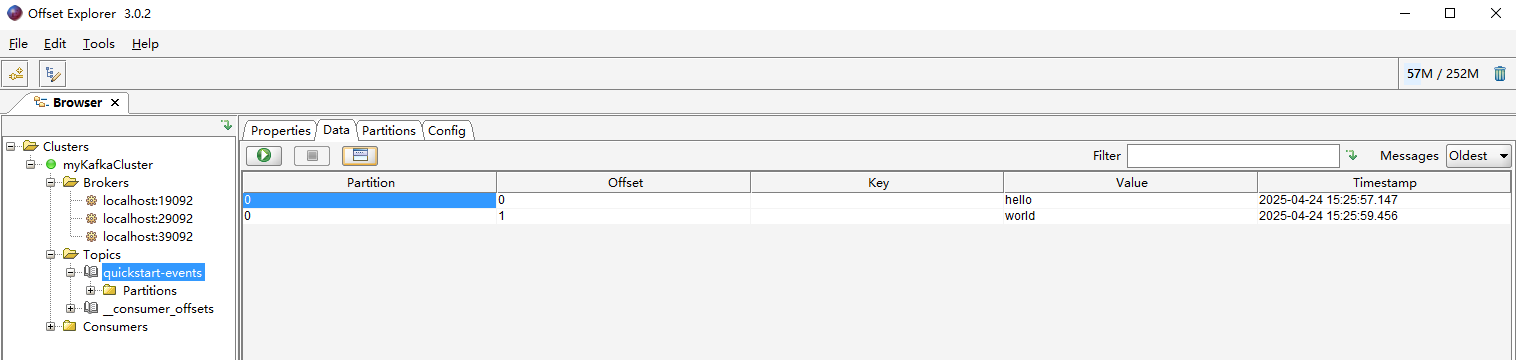
windows中kafka4.0集群搭建
参考文献 Apache Kafka windows启动kafka4.0(不再需要zookeeper)_kafka压缩包-CSDN博客 Kafka 4.0 KRaft集群部署_kafka4.0集群部署-CSDN博客 正文 注意jdk需要17版本以上的 修改D:\software\kafka_2.13-4.0.0\node1\config\server.properties配置文…...

Oracle Linux8 安装 MySQL 8.4.3,搭建一主一从
文章目录 安装依赖获取安装包解压准备相关目录设置配置文件启动数据库连接数据库socket 文件优化同样方法准备 3307 数据库实例设置配置文件启动 3307 实例数据库连接并查看 3307 数据库实例基于 bin log 搭建主从模式 安装依赖 yum install -y numactl libaio ncurses-compat…...

【JavaWeb后端开发04】java操作数据库(JDBC + Mybatis+ yml格式)详解
文章目录 1. 前言2. JDBC2.1 介绍2.2 入门程序2.2.1 DataGrip2.2.2 在IDEA执行sql语句 2.3 查询数据案例2.3.1 需求2.3.2 准备工作2.3.3 AI代码实现2.3.4 代码剖析2.3.4.1 ResultSet2.3.4.2 预编译SQL2.3.4.2.1 SQL注入2.3.4.2.2 SQL注入解决2.3.4.2.3 性能更高 2.4 增删改数据…...
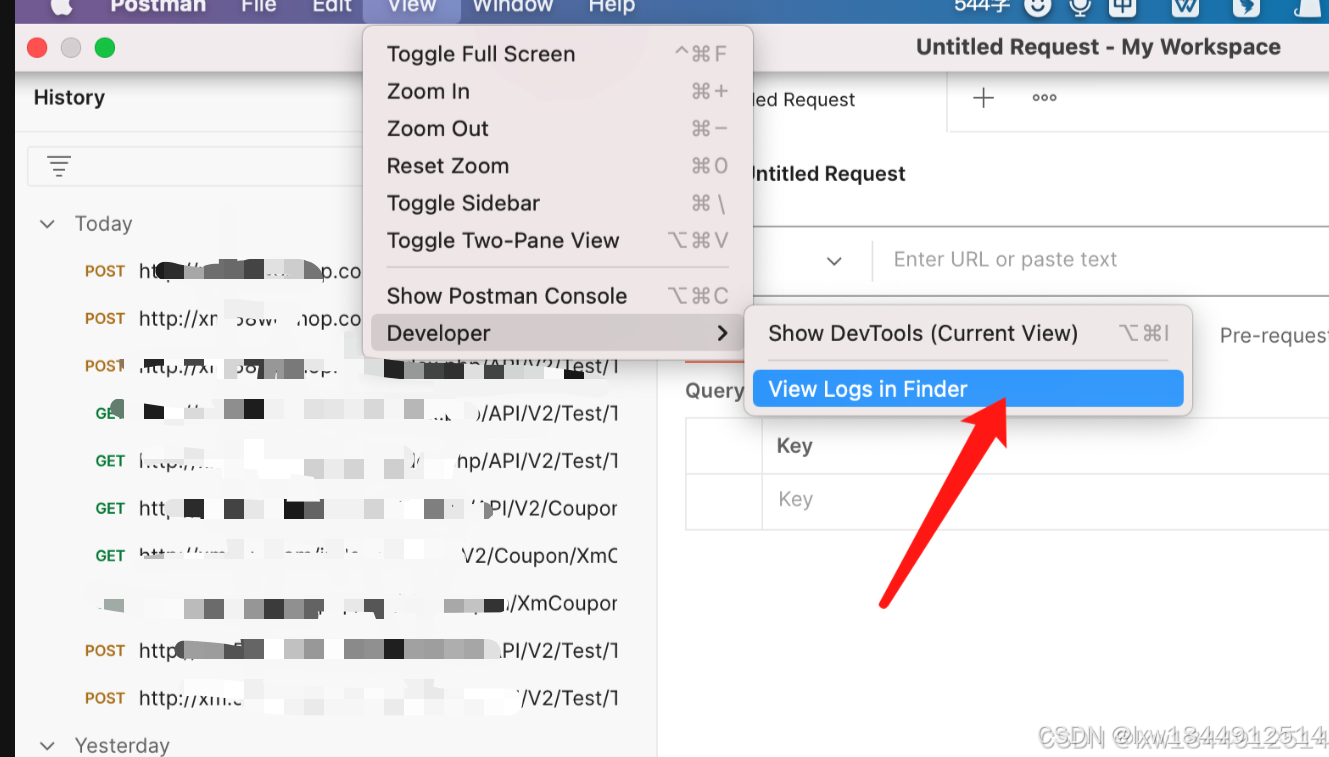
postman 删除注销账号
一、删除账号 1.右上角找到 头像,view profile https://123456-6586950.postman.co/settings/me/account 二、找回账号 1.查看日志所在位置 三、postman更新后只剩下history 在 Postman 中,如果你发现更新后只剩下 History(历史记录&…...
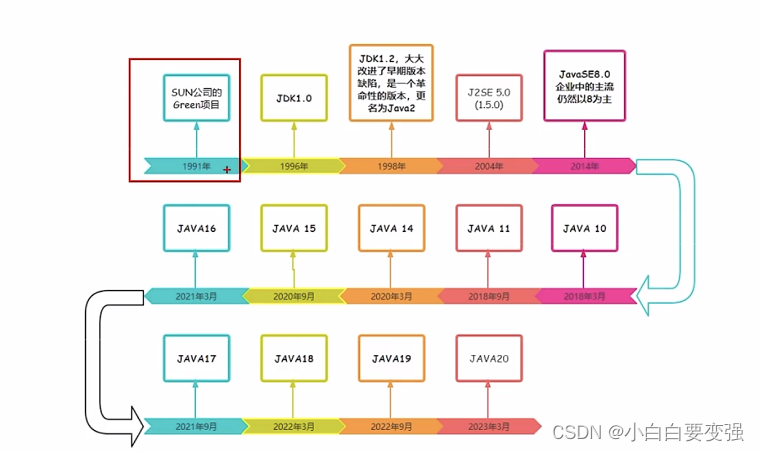
Java发展史及版本详细说明
Java发展史及版本详细说明 1. Java 1.0(1996年1月23日) 核心功能: 首个正式版本,支持面向对象编程、垃圾回收、网络编程。包含基础类库(java.lang、java.io、java.awt)。支持Applet(浏览器嵌入…...

React 5 种组件提取思路与实践
在开发时,经常遇到一些高度重复但略有差异的 UI 模式,此时我们当然会把组件提取出去,但是组件提取的方式有很多,怎么根据不同场景选取合适的方式呢?尤其时在复杂的业务场景中,组件提取的思路影响着着代码的可维护性、可读性以及扩展性。本文将以一个[详情]组件为例,探讨…...
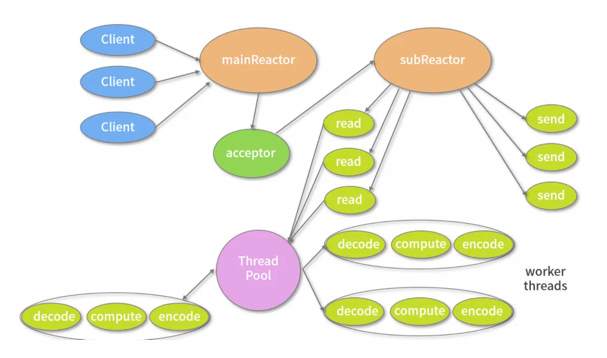
[java八股文][Java基础面试篇]I/O
Java怎么实现网络IO高并发编程? 可以用 Java NIO ,是一种同步非阻塞的I/O模型,也是I/O多路复用的基础。 传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据…...
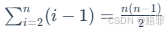
数据结构-冒泡排序(Python)
目录 冒泡排序算法思想 冒泡排序算法步骤 冒泡排序代码实现 冒泡排序算法分析 冒泡排序算法思想 冒泡排序(Bubble Sort)基本思想: 经过多次迭代,通过相邻元素之间的比较与交换,使值较小的元素逐步从后面移到前面…...

Java单例模式详解:实现线程安全的全局访问点
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、什么是单例模式? 单例模式(Singleton Pattern)是一种创建型设计模式,它保证一个类仅有一个实例ÿ…...

React-组件和props
1、类组件 import React from react; class ClassApp extends React.Component {constructor(props) {super(props);this.state{};}render() {return (<div><h1>这是一个类组件</h1><p>接收父组件传过来的值:{this.props.name}</p>&…...

Java面试:从Spring Boot到微服务的全面考核
Java面试:从Spring Boot到微服务的全面考核 场景设定: 在一家互联网大厂的面试室内,严肃的面试官正准备开始对前来面试的赵大宝进行技术考核。赵大宝是一位自称在Java开发方面经验丰富的求职者,不过却是个搞笑的水货程序员。 第…...

深入理解React高阶组件(HOC):原理、实现与应用实践
组件复用的艺术 在React应用开发中,随着项目规模的增长,组件逻辑的复用变得越来越重要。传统的组件复用方式如组件组合和props传递在某些复杂场景下显得力不从心。高阶组件(Higher-Order Component,简称HOC)作为React中…...
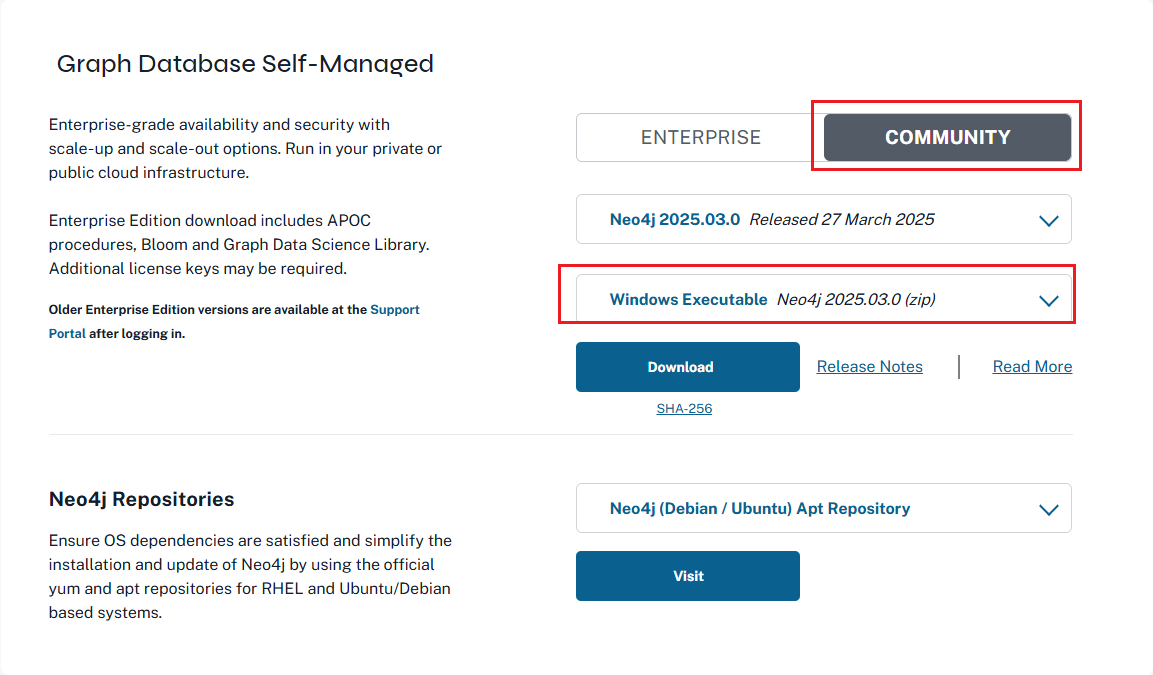
Neo4j社区版在win下安装教程(非docker环境)
要在 Windows 10 上安装 Neo4j 社区版数据库并且不使用 Docker Desktop,你可以按照以下步骤操作: 1. 安装 Java Development Kit (JDK) Neo4j 需要 Java 运行环境。推荐安装 JDK 17 或 JDK 11(请根据你下载的 Neo4j 版本查看具体的兼容性要…...
)
【AI 加持下的 Python 编程实战 2_10】DIY 拓展:从扫雷小游戏开发再探问题分解与 AI 代码调试能力(中)
文章目录 DIY 实战:从扫雷小游戏开发再探问题分解能力3 问题分解实战(自顶向下)3.2 页面渲染逻辑3.3 事件绑定逻辑 4 代码实现(自底向上)4.1 页面渲染部分4.2 事件绑定部分 写在前面 本篇将利用《Learn AI-assisted Py…...

使用PHP对接印度尼西亚股票市场
在本篇文章中,我们将介绍如何使用PHP语言与StockTV API接口对接,获取并处理印度尼西亚(Indonesia)的股票市场数据。我们将以查询IPO信息和查看涨跌排行榜为例,展示具体的操作流程。 准备工作 首先,确保您…...

如何在 Odoo 18 中配置自动化动作
如何在 Odoo 18 中配置自动化动作 Odoo是一款多功能的业务管理平台,旨在帮助各种规模的企业更高效地处理日常运营。凭借其涵盖销售、库存、客户关系管理(CRM)、会计和人力资源等领域的多样化模块,Odoo 简化了业务流程,…...
node.js 实战——(Http 知识点学习)
HTTP 又称为超文本传输协议 是一种基于TCP/IP的应用层通信协议;这个协议详细规定了 浏览器 和万维网 服务器 之间互相通信的规则。协议中主要规定了两个方面的内容: 客户端:用来向服务器发送数据,可以被称之为请求报文服务端&am…...

新市场环境下新能源汽车电流传感技术发展前瞻
新能源革命重构产业格局 在全球碳中和战略驱动下,新能源汽车产业正经历结构性变革。国际清洁交通委员会(ICCT)最新报告显示,2023年全球新能源汽车渗透率突破18%,中国市场以42%的市占率持续领跑。这种产业变革正沿着&q…...

系统重装——联想sharkbay主板电脑
上周给一台老电脑重装系统系统,型号是lenovo sharkbay主板的电脑,趁着最近固态便宜,入手了两块长城的固态,装上以后插上启动U盘,死活进不去boot系统。提示 bootmgr 缺失,上网查了许久,终于解决了…...

CentOS 7.9升级OpenSSH到9.9p2
初始版本 ssh -V OpenSSH_7.4p1, OpenSSL 1.0.2k-fips 26 Jan 2017 1.安装编译依赖 yum install -y gcc perl make zlib-devel pam-devel openssl-devel wget 2.升级OpenSSL到1.1.1版本 2.1 备份当前OpenSSL配置 sudo cp -r /usr/bin/openssl /usr/bin/openssl.bak sudo …...

fastjson使用parseObject转换成JSONObject出现将字符特殊字符解析解决
现象:将字符串的${TARGET_VALUE}转换成NULL字符串了问题代码: import com.alibaba.fastjson.JSON;JSONObject config JSON.parseObject(o.toString()); 解决方法: 1.更换fastjson版本 import com.alibaba.fastjson2.JSON;或者使用其他JS…...