PyTorch 实现食物图像分类实战:从数据处理到模型训练
一、简介
在计算机视觉领域,图像分类是一项基础且重要的任务,广泛应用于智能安防、医疗诊断、电商推荐等场景。本文将以食物图像分类为例,基于 PyTorch 框架,详细介绍从数据准备、模型构建到训练测试的全流程,帮助读者深入理解深度学习图像分类的实践过程。
二、原理
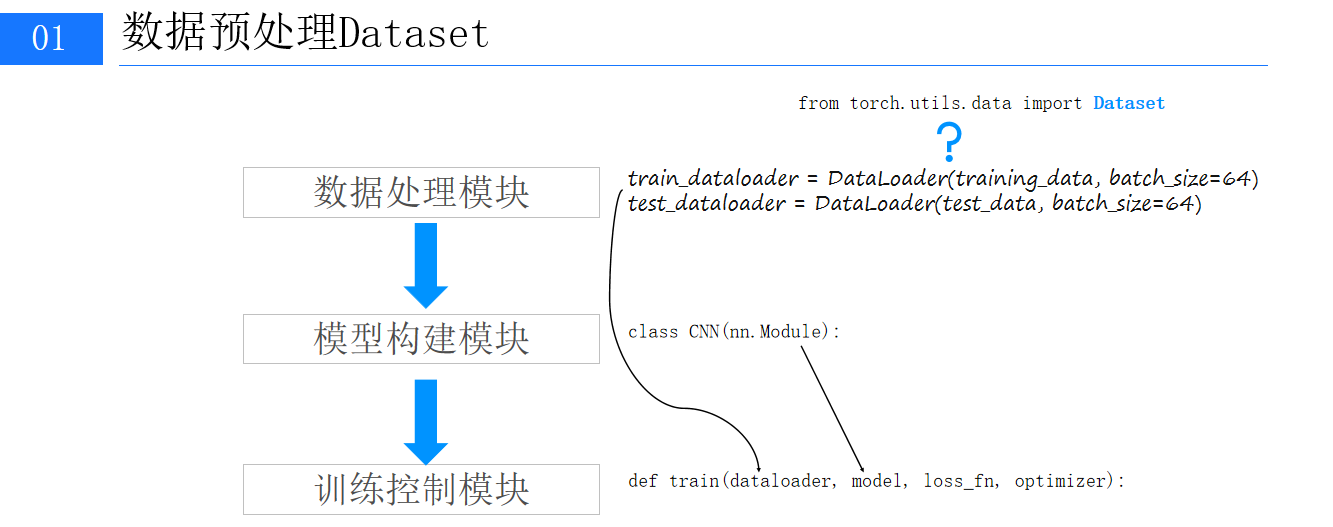
三、代码示例
1、数据文件路径准备
在实际项目中,原始图像数据通常按类别存储在不同文件夹下。代码中的train_test_file函数用于遍历数据文件夹,将图像文件路径及其对应的类别标签写入文本文件,方便后续数据加载:
import os
def train_test_file(root, dir):file_txt = open(dir+'.txt','w')path = os.path.join(root, dir)for roots, directories, files in os.walk(path):#os.walk(path)代表开始去遍历path路径下的文件if len(directories) != 0:dirs = directorieselse:now_dir = roots.split('\\')for file in files:path_1 = os.path.join(roots,file)print(path_1)file_txt.write(path_1+' '+str(dirs.index(now_dir[-1]))+'\n')file_txt.close()
root = r'.\食物分类\food_dataset2'
train_dir = 'train'
test_dir = 'test'
train_test_file(root,train_dir)
train_test_file(root,test_dir)
该函数通过os.walk递归遍历文件夹,将每个图像文件的绝对路径与对应的类别索引(通过文件夹名称顺序确定)写入.txt文件,格式为图像路径 标签。
2、自定义数据集类
import torch
import numpy as np
from PIL import Image
from torch.utils.data import Dataset,DataLoader #用于处理数据集
from torchvision import transforms
data_transforms = {#字典'train':transforms.Compose([#对图片做预处理的,组合transforms.Resize([256,256]),#数据进行改变大小transforms.ToTensor(),#数据转换为tensor,默认把通道维度放在前面]),'valid':transforms.Compose([transforms.Resize([256, 256]),transforms.ToTensor(),]),
}#数组增强class food_dataset(Dataset):def __init__(self, file_path, transform=None):self.file_path = file_path#为了将外部空间的路径传递给共享空间,以便于后期可以使用self.imgs = []self.labels = []self.transform = transformwith open(self.file_path) as f:samples = [x.strip().split(' ') for x in f.readlines()]for img_path, label in samples:self.imgs.append(img_path)#图像的路径self.labels.append(label)#标签,还不是tensordef __len__(self):return len(self.imgs)def __getitem__(self, idx):image = Image.open(self.imgs[idx])#读取到图片数据,还不是tensor,BGRif self.transform:#将pil图像数据转换为tensorimage = self.transform(image)label = self.labels[idx]#label还不是tensorlabel = torch.from_numpy(np.array(label, dtype = np.int64))#label也转换为tensorreturn image, labelfood_dataset类实现了__len__和__getitem__两个关键方法:
__len__返回数据集的样本总数;
__getitem__根据索引读取图像文件,应用数据变换(如调整大小、转换为张量),并将标签转换为torch.Tensor格式后返回。
3、数据加载器配置
#training_data包含了本次训练需要的全部数据集
training_data = food_dataset(file_path = './train.txt',transform = data_transforms['train'])
test_data = food_dataset(file_path = './test.txt',transform = data_transforms['valid'])
#training_data需要具备索引的功能,还要确保数据是tensor
train_dataloader = DataLoader(training_data, batch_size=64,shuffle = True)#64个图片为一个包,shuffle = True用于将数据进行打乱
test_dataloader = DataLoader(test_data, batch_size = 64,shuffle = True)DataLoader的batch_size参数指定每个批次包含的样本数量,shuffle=True表示在每个 epoch 训练前打乱数据顺序,有助于提高模型的泛化能力
4、搭建卷积神经网路模型
'''定义神经网络'''
from torch import nn #导入神经网络模块class CNN(nn.Module):def __init__(self): #python基础关于类,self类自已本身super(CNN,self).__init__() #继承的父类初始化self.conv1=nn.Sequential( #将多个层组合成一起。创建了一个容器,将多个网络合在一起nn.Conv2d( #2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据in_channels=3, #、图像通道个数,1表示灰度图(确定了卷积核 组中的个数)out_channels=16, # 要得到几多少个特征图,卷积核的个数kernel_size=5, # 卷积核大小,5*5stride=1, # 步长padding=2, #一般希望卷积核处理后的结果大小与处理前的数据大小相同,效果会比较好。那padding改如何), # 输出的特征图为(16,28,28)nn.ReLU(), # relu层,不会改变特征图的大小nn.MaxPool2d(kernel_size=2), #进行池化操作(2x2 区域),输出结果为:(16,128,128))self.conv2=nn.Sequential( #输入nn.Conv2d(16,32,5,1,2), # 输出(32 128 128)nn.ReLU(),nn.Conv2d(32,32,5,1,2), # 输出(32 128 128)nn.ReLU(),nn.MaxPool2d(2), #输出(32,64,64))self.conv3=nn.Sequential( #输入(32 64 64)nn.Conv2d(32,128,5,1,2), #(128 64 64)nn.ReLU(),)self.out=nn.Linear(128*64*64,20) #全连接层得到的结果def forward(self,x):x=self.conv1(x)x=self.conv2(x)x=self.conv3(x)x=x.view(x.size(0),-1)output=self.out(x)return outputmodel = CNN().to(device)
print(model)5、训练与测试函数实现
def train(dataloader,model,loss_fn,optimizer):model.train() #告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w。在训练过程中,w会被修改的
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train()和 model.eval()。
#一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval()batch_size_num=1for X,y in dataloader: #其中batch为每一个数据的编号,X是打包好的每一个数据包X,y=X.to(device),y.to(device) #把训练数据集和标签传入cpu或GPUpred=model.forward(X) #.forward可以被省略,父类中已经对次功能进行了设置。自动初始化w权值loss=loss_fn(pred,y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值woptimizer.step() #根据梯度更新网络w参数loss_value=loss.item() #从tensor数据中提取数据出来,tensor获取损失值if batch_size_num %1 ==0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num+=1def test(dataloader,model,loss_fn):size=len(dataloader.dataset)num_batches=len(dataloader) #打包的数量model.eval() #测试,w就不能再更新。test_loss,correct=0,0with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)test_loss+=loss_fn(pred,y).item() #test_loss是会自动累加每一个批次的损失值correct+=(pred.argmax(1)==y).type(torch.float).sum().item()a=(pred.argmax(1)==y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值b=(pred.argmax(1)==y).type(torch.float)test_loss /=num_batchescorrect /= sizeprint(f'Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}')6、模型训练与评估
loss_fn=nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为食物的类别是20
optimizer=torch.optim.Adam(model.parameters(),lr=0.001) #创建一个优化器,SGD为随机梯度下降算法
# #params:要训练的参数,一般我们传入的都是model.parameters()#
# lr:learning_rate学习率,也就是步长#loss表示模型训练后的输出结果与,样本标签的差距。如果差距越小,就表示模型训练越好,越逼近干真实的模型。# train(train_dataloader,model,loss_fn,optimizer)
# test(test_dataloader,model,loss_fn)epochs=1
for t in range(epochs):print(f"Epoch {t+1}\n---------------------------")train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
test(test_dataloader,model,loss_fn) 7、运行结果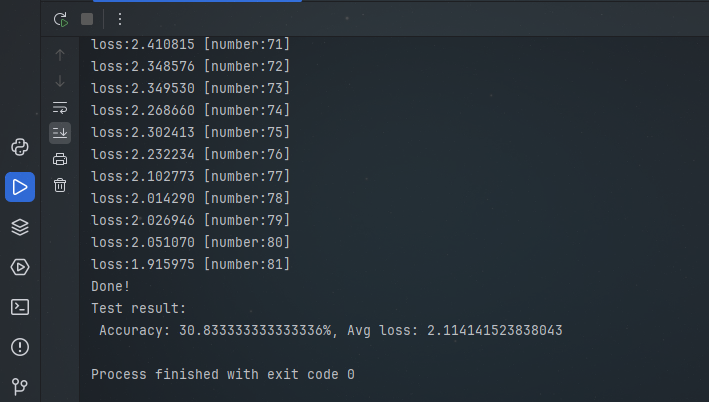
四、总结与优化方向
本文完整展示了基于PyTorch的食物图像分类项目流程,涵盖数据处理、模型构建和训练测试等核心环节。然而,当前模型仍有优化空间:
- 数据增强:增加更多数据增强策略(如随机裁剪、颜色抖动)以扩充数据集;
- 模型优化:尝试更复杂的预训练模型(如ResNet、VGG)或调整超参数(学习率、batch size);
- 正则化:添加Dropout或L2正则化防止过拟合。
通过不断改进和实践,图像分类模型的准确率和泛化能力将得到进一步提升。希望本文能为读者在深度学习图像分类领域的学习和实践提供有益参考。
相关文章:
PyTorch 实现食物图像分类实战:从数据处理到模型训练
一、简介 在计算机视觉领域,图像分类是一项基础且重要的任务,广泛应用于智能安防、医疗诊断、电商推荐等场景。本文将以食物图像分类为例,基于 PyTorch 框架,详细介绍从数据准备、模型构建到训练测试的全流程,帮助读者…...
Qt —— 在Linux下试用QWebEngingView出现的Js错误问题解决(附上四种解决办法)
错误提示:js: A parser-blocking, cross site (i.e. different eTLD+1) script, https:xxxx, is invoked via document.write. The network request for this script MAY be blocked by the browser in this or a future page load due to poor network connectivity. If bloc…...
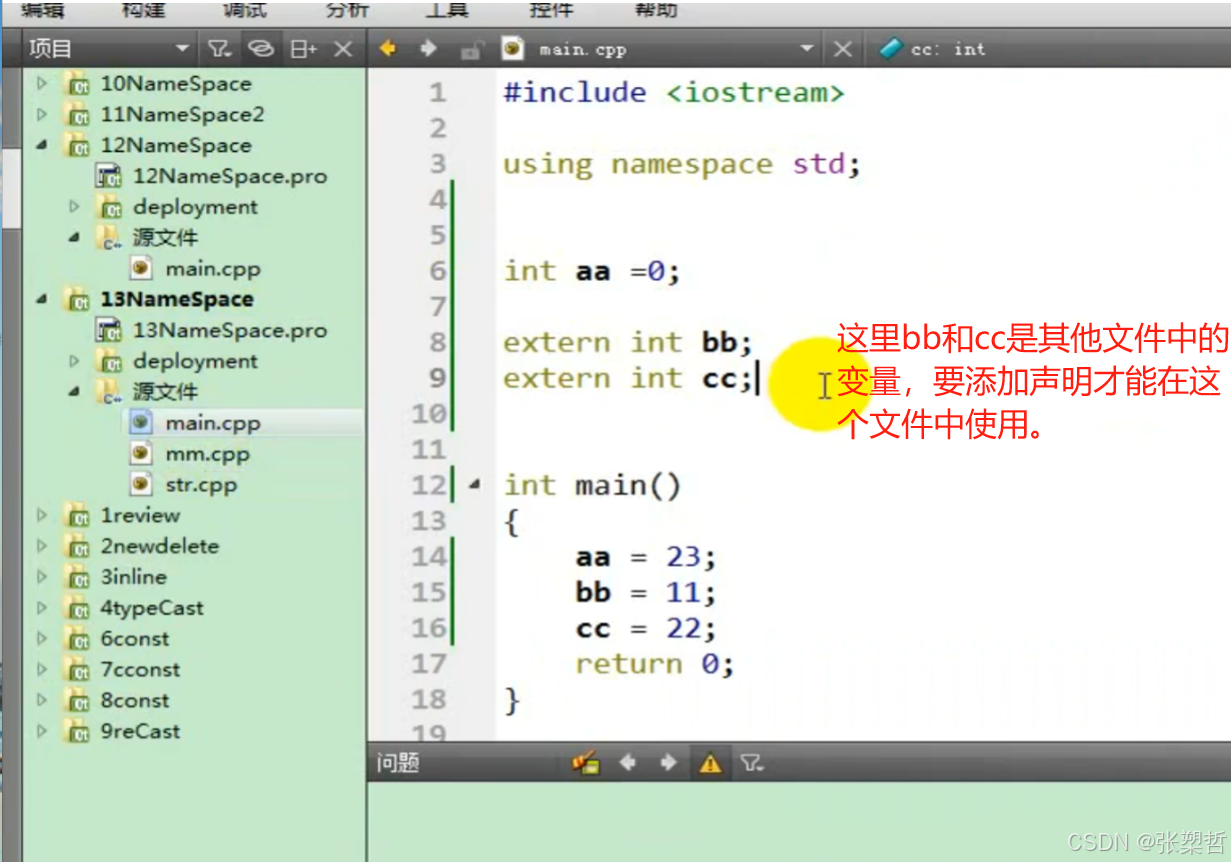
命名空间(C++)
命名空间主要用于大型项目中。 局部命名在该局部会覆盖全局命名。C语言中唯一一种在局部调用全局相同命名的全局变量的方式:指针在C中可以用作用域运算符来访问全局变量,作用域运算符的前面可以是作用域也可以是类。 命名空间实际上是对全局作用域的再次…...

使用Python脚本在Mac上彻底清除Chrome浏览历史:开发实战与隐私保护指南
题目: 《基于PyCharm与Mac系统的Chrome历史记录清理工具开发实战》 引言 在Mac系统下,Chrome浏览器的历史记录文件通常以SQLite数据库形式存储于用户目录中,仅通过浏览器内置功能清理可能残留索引文件。本文通过一个Python脚本(c…...
LabVIEW圆锥滚子视觉检测系统
基于LabVIEW平台的视觉检测系统提高圆锥滚子内组件的生产质量和效率。通过集成高分辨率摄像头和先进的图像处理算法,系统能够自动识别和分类产品缺陷,从而减少人工检查需求,提高检测的准确性和速度。 项目背景 随着制造业对产品质…...

OpenAI 推出「轻量级」Deep Research,免费用户同享
刚刚,OpenAI 正式上线了面向所有用户的「轻量级」Deep Research 版本,意味着即便没有付费订阅,也能体验这一强大工具的核心功能。 核心差异:o4-mini vs. o3 模型迭代 传统的深度研究功能基于更大规模的 o3 模型。轻量级版本则改以…...
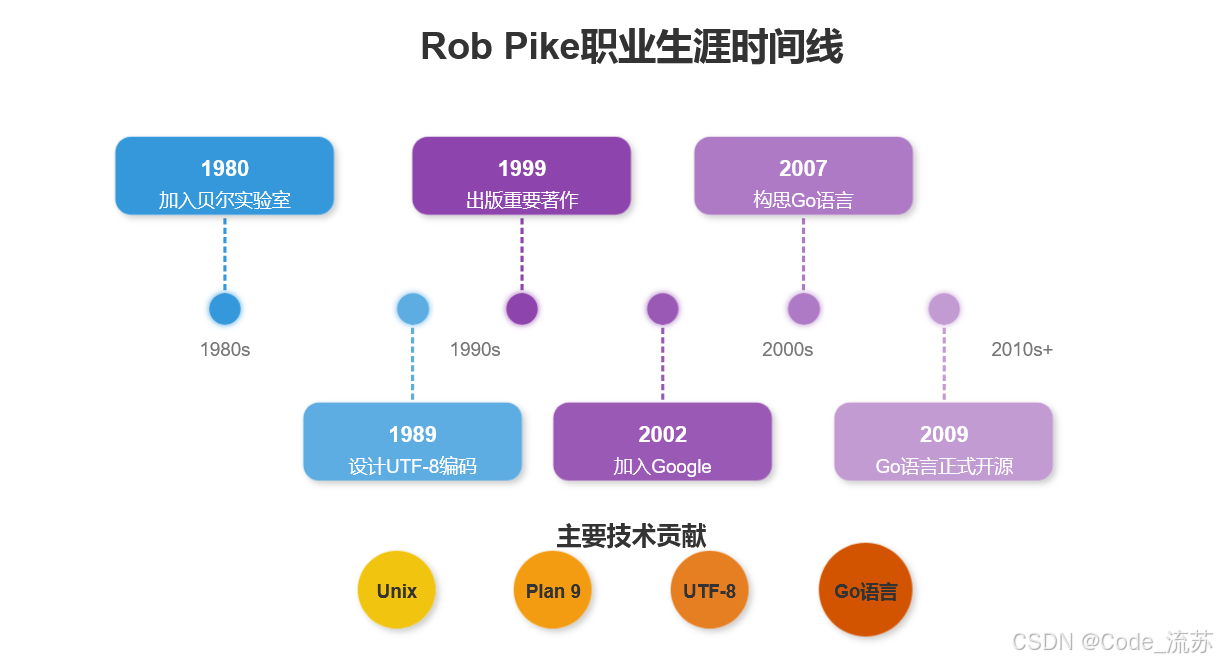
罗伯·派克:Go语言创始者的极客人生
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 罗伯派克:Go语言创始者的极客人生 一、传奇程序员的成长历程 1. 早年经历…...

面试题:Redis 一次性获取大量Key的风险及优化方案
Redis 一次性获取大量Key的风险及优化方案 在Redis中一次性获取大量Key(如使用KEYS命令或大量GET操作)会带来多种风险和性能问题,以下是详细分析和解决方案: 主要风险 1. 阻塞风险 KEYS命令阻塞:KEYS *会扫描整个数…...

中国头部云服务商分析
1. 阿里云 国内云服务的开创者与龙头,占据约三分之一的国内市场份额,其中IaaS占比72%,PaaS与SaaS占比相对较小 全球范围内500万客户,基础设施目前面向全球四大洲,开服运营15个国家、30个公共云地域、89个可用区&#x…...

关于使用git init --bare 裸仓库的使用
1、创建文件夹 对于需要作为仓库的文件夹使用git init --bare进行裸仓库初始化 2、将裸仓库添加为自己的远程仓库 使用的方法和添加远程仓库的方式相同,但是路径需要为绝对路径,同时需要加入file:///协议 git remote add origin file:///d:/Desktop/Lo…...

解释一下计算机中的内存对齐
1. 内存对齐的基本概念 内存对齐是计算机系统优化内存访问效率的一种机制,要求数据在内存中的起始地址必须为某个值的整数倍(通常为数据类型大小的整数倍)。例如: int (4字节) 应对齐到4的倍数地址(如0x00, 0x04, 0x…...
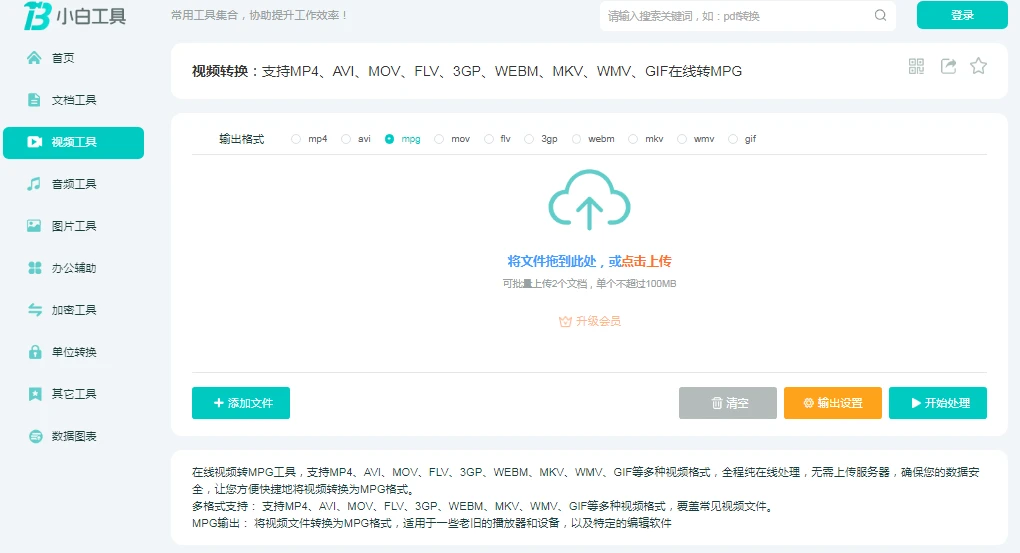
小白工具视频转MPG, 功能丰富齐全,无需下载软件,在线使用,超实用
在视频格式转换需求日益多样的今天,小白工具网的在线视频转 MPG 功能https://www.xiaobaitool.net/videos/convert-to-mpg/ )脱颖而出,凭借其出色特性,成为众多用户处理视频格式转换的优质选择。 从格式兼容性来看,它支…...

跟着deepseek学golang--认识golang
文章目录 一、Golang核心优势1. 极简部署方式生产案例:依赖管理:容器实践: 2. 静态类型系统类型安全示例:性能优势:代码重构: 3. 语言级并发支持GMP调度模型实例&…...

目前市面上知名的数据采集器
程序员爱自己动手打造一切,但这样离钱就会比较远。 市面上知名的数据采集工具 数据采集工具(也称为网络爬虫或数据抓取工具)在市场上有很多选择,以下是目前比较知名和广泛使用的工具分类介绍: 一、开源免费工具 Scra…...

问答页面支持拖拽和复制粘贴文件,MaxKB企业级AI助手v1.10.6 LTS版本发布
2025年4月24日,MaxKB开源企业级AI助手正式发布v1.10.6 LTS版本。这一版本主要进行了一些功能优化和问题修复。 功能优化 ■ 应用:文件上传支持上传其他自定义的文件类型,该类型文件需要自行写入函数解析; ■ 问答页面ÿ…...
day32 学习笔记
文章目录 前言一、霍夫变换二、标准霍夫变换三、统计概率霍夫变换四、霍夫圆变换 前言 通过今天的学习,我掌握了霍夫变换的基本原本原理及其在OpenCV中的应用方法 一、霍夫变换 霍夫变换是图像处理中的常用技术,主要用于检测图像中的直线,圆…...

二项分布详解:从基础到应用
二项分布详解:从基础到应用 目录 引言二项分布的定义概率质量函数及其证明期望与方差推导二项分布的重要性质常见应用场景与其他分布的关系知识梳理练习与思考 引言 概率论中,二项分布是最基础也是最常用的离散概率分布之一。它描述了在固定次数的独…...
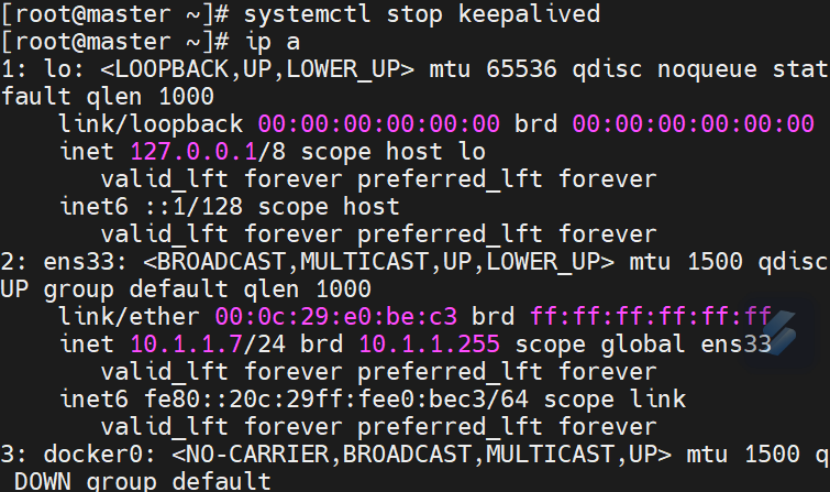
CentOS 7上Memcached的安装、配置及高可用架构搭建
Memcached是一款高性能的分布式内存缓存系统,常用于加速动态Web应用的响应。本文将在CentOS 7上详细介绍Memcached的安装、配置,以及如何实现Memcached的高可用架构。 (1)、搭建memcached 主主复制架构 Memcached 的复制功能支持…...

如何让 HTML 文件嵌入另一个 HTML 文件:详解与实践
目录 一、为什么需要在HTML中嵌入其他HTML文件? 二、常用的方法概览 三、利用 1. 基本原理 2. 使用场景 3. 优缺点 4. 实践示例 5. 适用建议 四、利用JavaScript动态加载内容 1. 原理简介 2. 实现步骤 示例代码 3. 优缺点分析 4. 应用场景 5. 实践建…...

mac brew 无法找到php7.2 如何安装php7.2
mac brew 无法找到php7.2 如何安装php7.2 原因是升级过高版本的brew后已经不支持7.2了,但可以通过第三方工具来安装 brew tap shivammathur/php brew install shivammathur/php/php7.2标题安装完成后会提示以下信息: The php.ini and php-fpm.ini fil…...
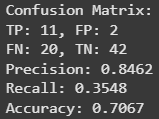
人工智能与机器学习:Python从零实现逻辑回归模型
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...
windows服务器及网络:搭建FTP服务器
前言:(各位大佬们,昨天太忙了,整得没有发布昨天那该写的那一篇,属实有点可惜的说QAQ,不过问题已经解决,我又回来啦) 今天我要介绍的是在Windows中关于搭建FTP服务器的流程与方法 注…...
-接口API)
Python学习之路(五)-接口API
在 Python 中结合数据库开发接口 API 通常使用 Web 框架(如 Flask 或 Django)和 ORM(对象关系映射)工具(如 SQLAlchemy 或 Django ORM)。以下是使用 Flask 和 SQLAlchemy 的详细步骤,展示如何结合数据库开发一个简单的 API。 使用 Flask 和 SQLAlchemy 开发 API 1. 安…...

欧拉计划 Project Euler56(幂的数字和)题解
欧拉计划 Project Euler 56 题解 题干思路code 题干 思路 直接暴力枚举即可,用c要模拟大数的乘法,否则会溢出 code // 972 #include <bits/stdc.h>using namespace std;using ll long long;string mul(const string &num1, int num2) {int…...

C++初窥门径
const关键字 一、const关键字 修饰成员变量 常成员变量:必须通过构造函数的初始化列表进行初始化,且初始化后不可修改。 示例: class Student { private: const int age; // 常成员变量 public: Student(string name, int age) : age(ag…...
AlarmClock4.8.4(官方版)桌面时钟工具软件下载安装教程
1.软件名称:AlarmClock 2.软件版本:4.8.4 3.软件大小:187 MB 4.安装环境:win7/win10/win11(64位) 5.下载地址: https://www.kdocs.cn/l/cdZMwizD2ZL1?RL1MvMTM%3D 提示:先转存后下载,防止资…...

白鲸开源WhaleStudio与崖山数据库管理系统YashanDB完成产品兼容互认证
近日,北京白鲸开源科技有限公司与深圳计算科学研究院联合宣布,双方已完成产品兼容互认证。此次认证涉及深圳计算科学研究院自主研发的崖山数据库管理系统YashanDB V23和北京白鲸开源科技有限公司的核心产品WhaleStudio V2.6。经过严格的测试与验证&#…...

【金仓数据库征文】- 金融HTAP实战:KingbaseES实时风控与毫秒级分析一体化架构
文章目录 引言:金融数字化转型的HTAP引擎革命一、HTAP架构设计与资源隔离策略1.1 混合负载物理隔离架构1.1.1 行列存储分区策略1.1.2 四级资源隔离机制 二、实时流处理与增量同步优化2.1 分钟级新鲜度保障2.1.1 WAL日志增量同步2.1.2 流计算优化 2.2 物化视图实时刷…...

云服务器centos 安装hadoop集群
百度 搜索 云服务器centos 安装hadoop 创建Hadoop用户 sudo useradd hadoop -m -s /bin/bash sudo passwd hadoop 123456 下载Hadoop wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz 解压并移动Hadoop到指定目录 tar …...
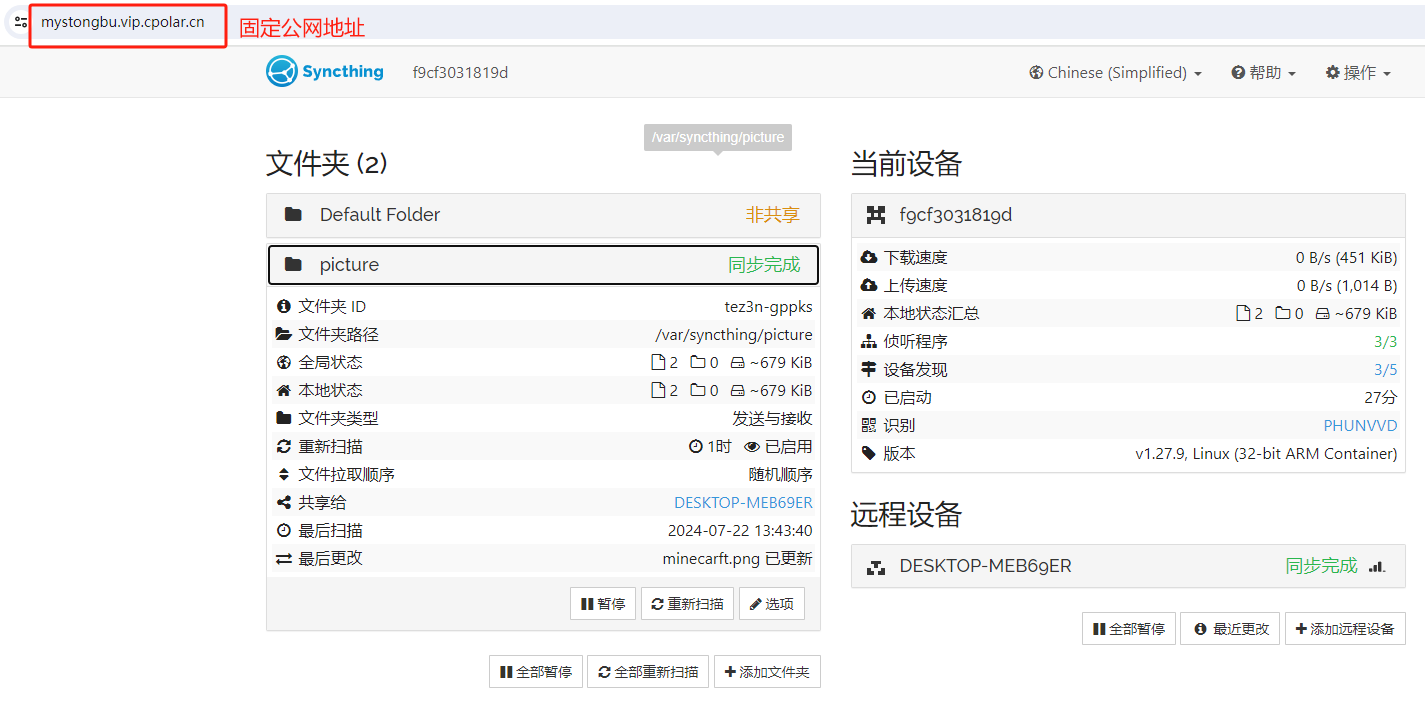
Windows与CasaOS跨平台文件同步:SyncThing本地部署与同步配置流程
文章目录 前言1. 添加镜像源2. 应用安装测试3. 安装syncthing3.1 更新应用中心3.2 SyncThing安装与配置3.3 Syncthing使用演示 4. 安装内网穿透工具5. 配置公网地址6. 配置固定公网地址 推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽…...