数据结构手撕--【二叉树】
目录
定义结构体:
初始化:
手动创建一个二叉树:
前序遍历:
中序遍历:
后序遍历
二叉树节点个数:
叶子节点个数:
二叉树第k层节点个数:
二叉树的高度:
查找值为x的节点:
二叉树的层序遍历:
判断二叉树是否为完全二叉树:
销毁二叉树:
二叉树增删查改没有具体意义。我们主要实现搜索二叉树
特殊的二叉树---完全二叉树(堆) 适合数组结构表示 (堆结构下节更新)
对于普通二叉树我们采用 链式结构
定义结构体:
一个结构体就是一个树节点
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>//链式二叉树//定义结构体 --- 一个结构体就是一个树节点
typedef char BTDataType;
typedef struct BinaryTreeNode
{BinaryTreeNode* left; //指向节点的指针 类型为节点类型BinaryTreeNode* right;BTDataType data;
}BTNode;初始化:
链式结构 开辟空间创建新节点
BTNode BuyNode(BTDataType x)
{BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));newnode->left = NULL;newnode->right = NULL;newnode->data = x;return newnode;
}手动创建一个二叉树:
BTNode* CreatBinaryTree()
{BTNode* nodeA = BuyNode('A');BTNode* nodeB = BuyNode('B');BTNode* nodeC = BuyNode('C');BTNode* nodeD = BuyNode('D');BTNode* nodeE = BuyNode('E');BTNode* nodeF = BuyNode('F');nodeA->left = nodeB;nodeA->right = nodeC;nodeB->left = nodeD;nodeC->left = nodeE;nodeC->right = nodeF;return nodeA;
}前序遍历:
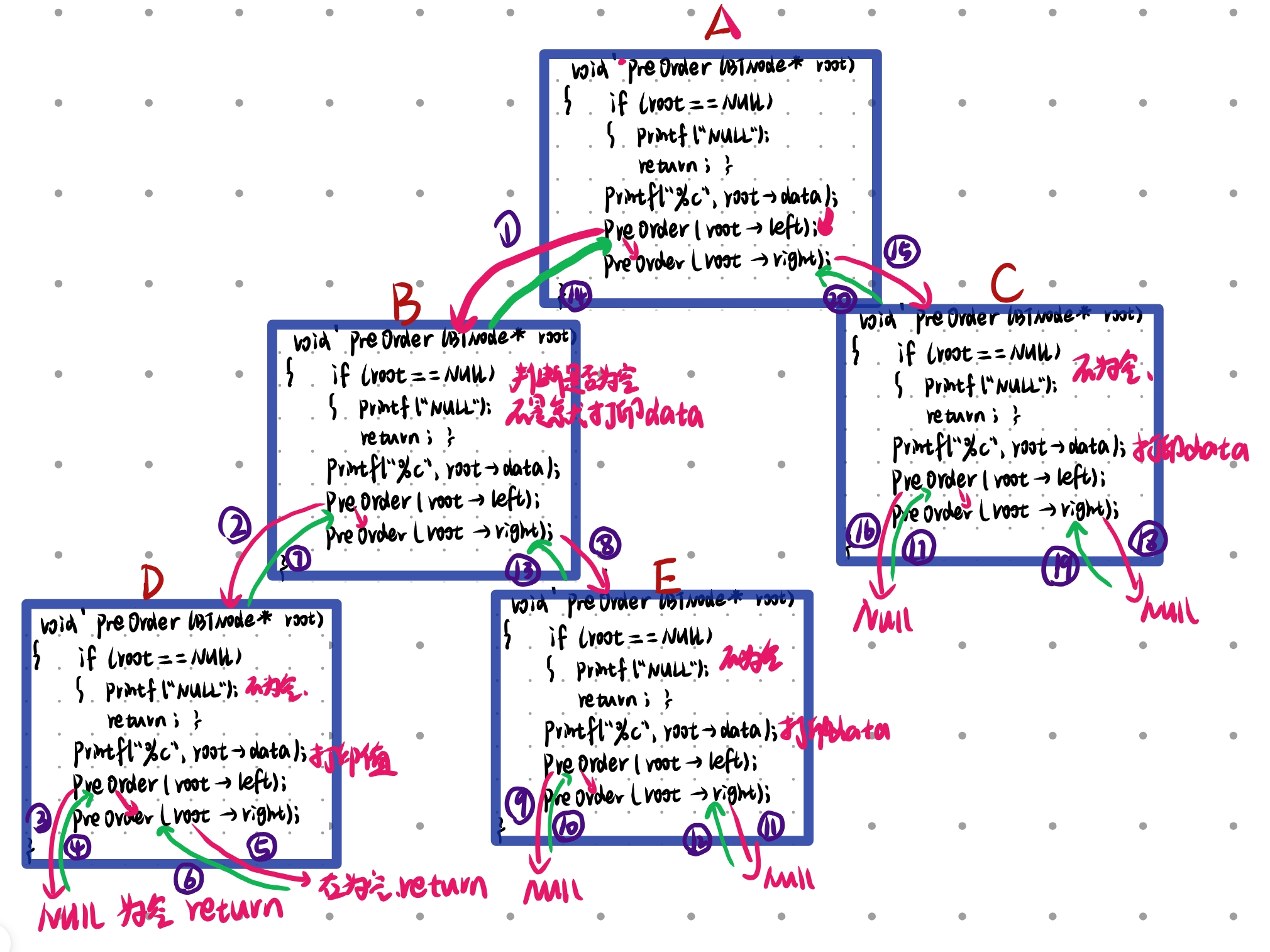
--- 根左右 打印放在最前面 再左、右递归
void PerOrder(BTNode* root)
{if (root == NULL){return NULL;}printf("%c", root->data);PerOrder(root->left);PerOrder(root->right);
}画图理解递归过程:
中序遍历:
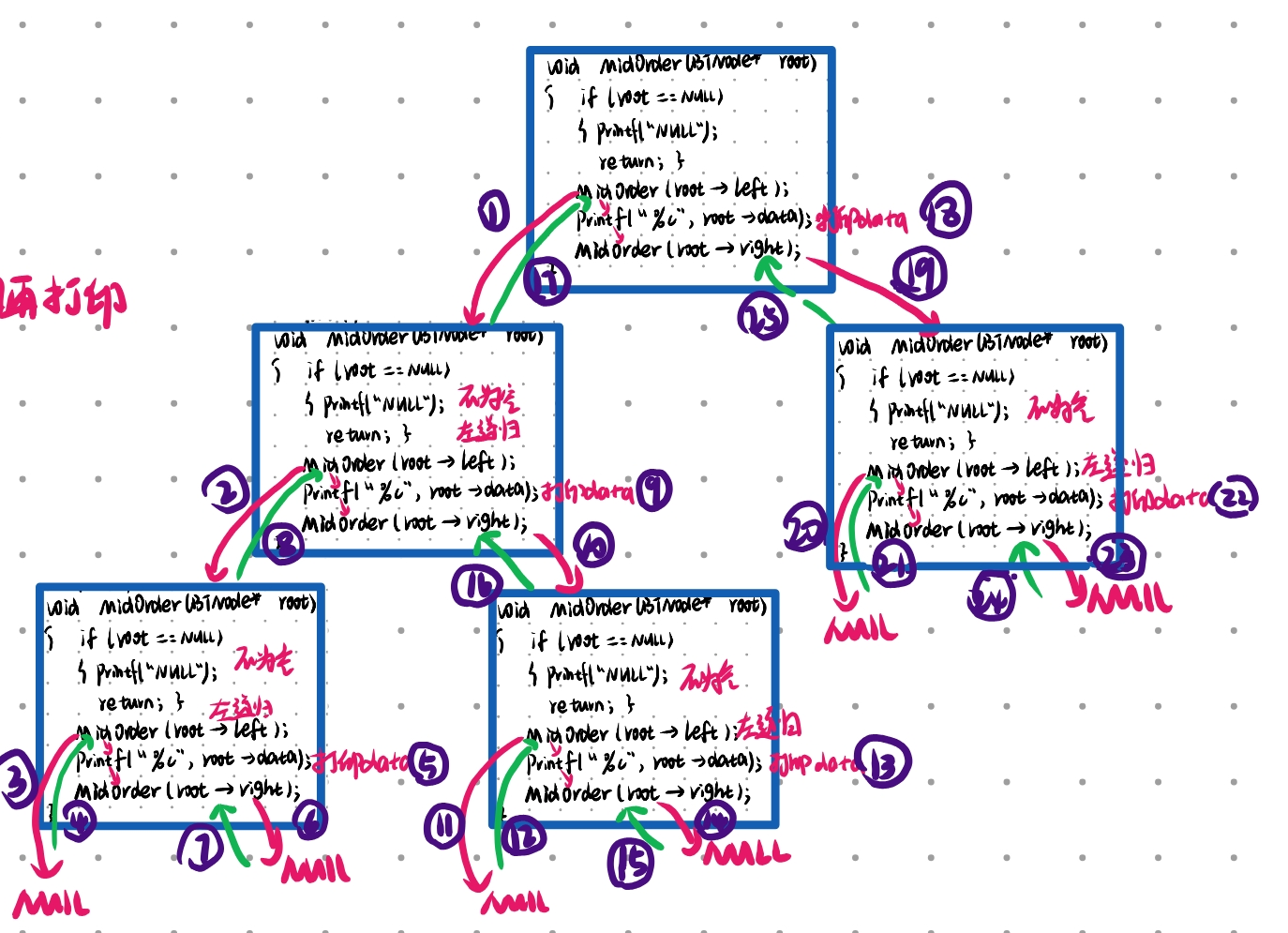
--- 左根右 打印放在中间 先左递归 打印 再右递归
void MidOrder(BTNode* root)
{if (root == NULL){return NULL;}MidOrder(root->left);printf("%c", root->data);MidOrder(root->right);
} 
后序遍历
-- 左右根
void PostOrder(BTNode* root)
{if (root == NULL){return NULL;}PostOrder(root->left);PostOrder(root->right);printf("%c", root->data);
}二叉树节点个数:
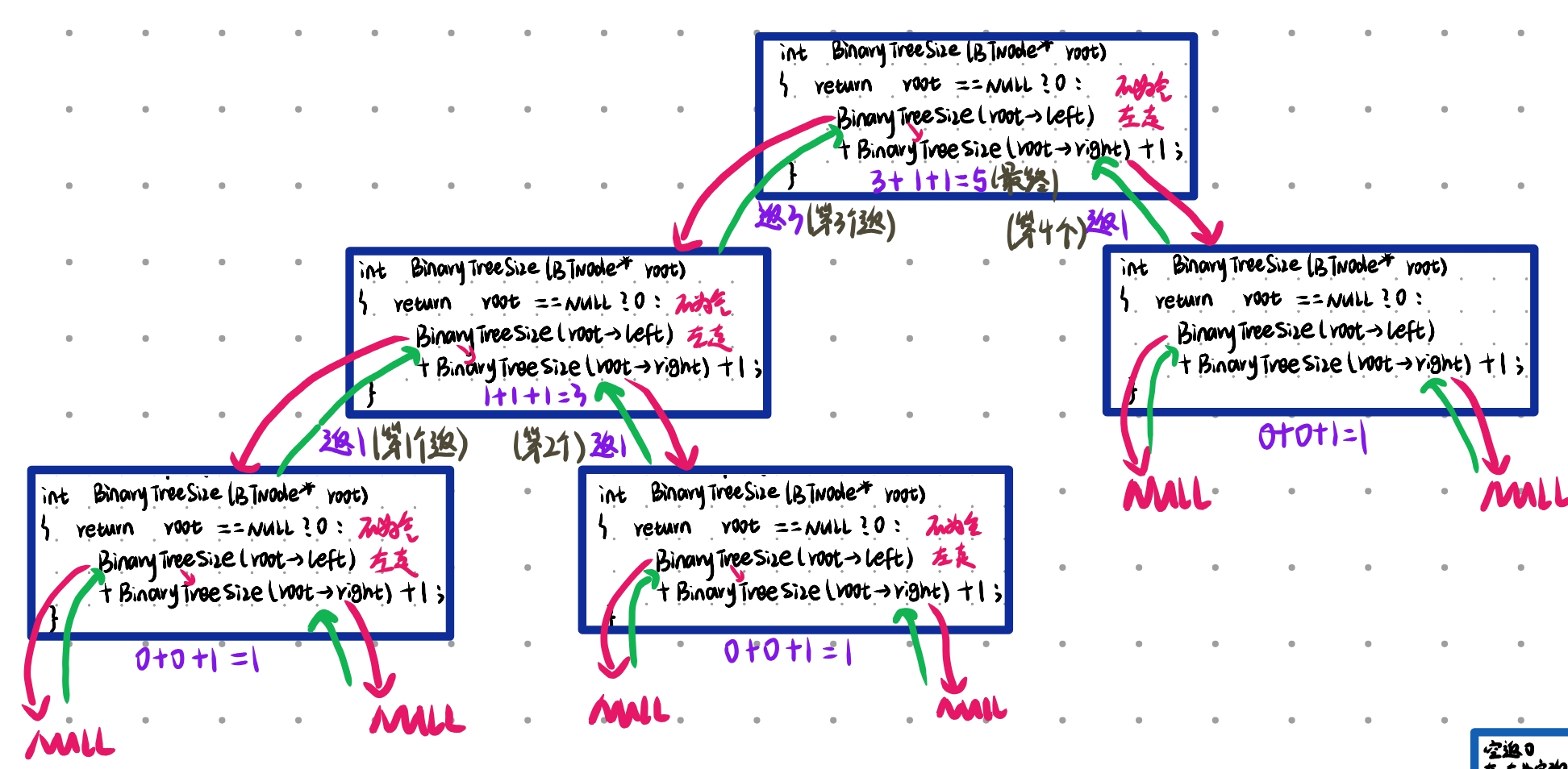
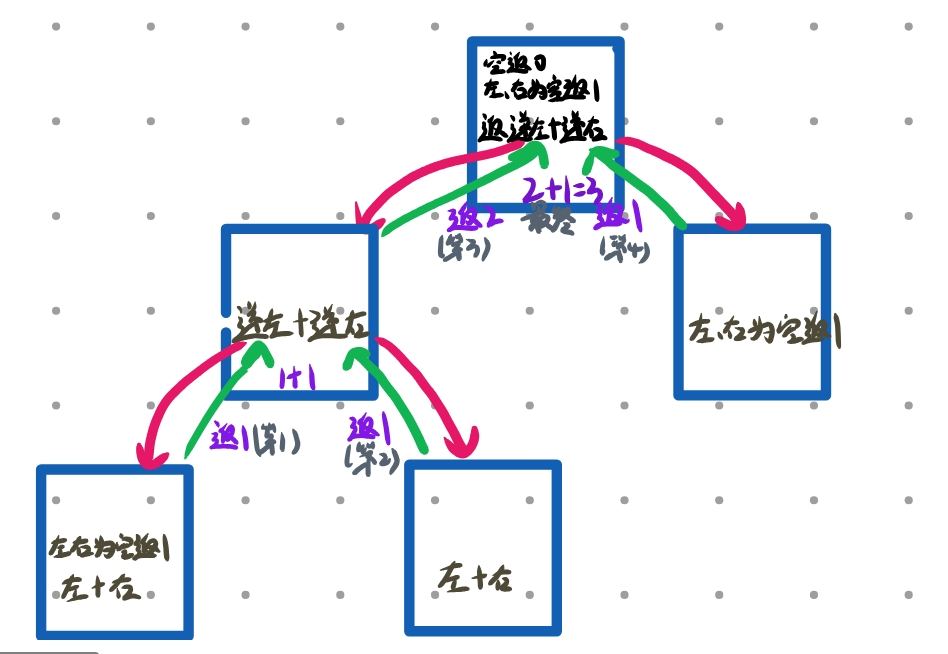
为空返回0,不为空去递归左右子树,+1是递归完左右返回之后+1的,即就会算此时的root节点的数量。(下图有具体的递归过程)左+右+根(1)
int BinaryTreeSize(BTNode* root)
{return root == NULLL ? 0 : BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1;
}
叶子节点个数:
走到叶子返回1(不再向下递归),返回 左+右 不算根的个数
int BinaryTreeLeafSize(BTNode* root)
{if (root == NULL){return 0;}if (root->left && root->right == NULL) //在递归的过程中 走到叶子就会返回1 最后左+右即可{return 1;}return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}
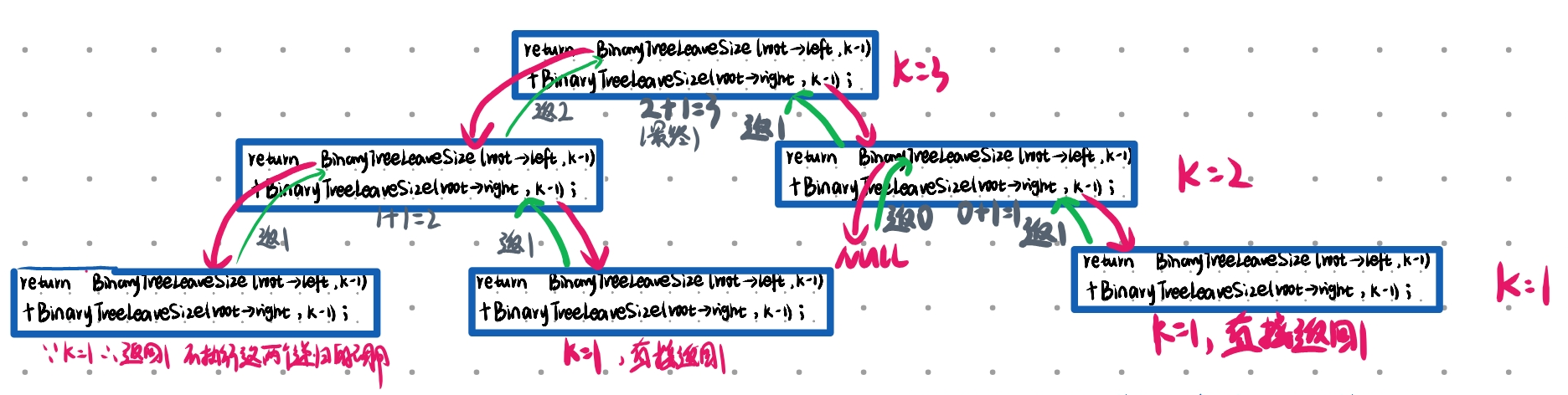
二叉树第k层节点个数:
往下走一层k都会减一,假如要求第五层,走到第五层k=1,把1返回即可
int BinaryTreeLeaveSize(BTNode* root, int k)
{if (root == NULL){return 0;}if (k == 1){return 1;}return BinaryTreeLeaveSize(root->left, k - 1) + BinaryTreeLeaveSize(root->right, k - 1);
} 
二叉树的高度:
当这棵树为空树时,二叉树的高度应该是0,所以当数为空我们返回0,然而当树不等于空时,我们可以以大事化小,小事化了的思想,将当前树的高度转换成左右子树两个中的最大高度再加上一,然后左右子树中最大高度的树的高度又可以转换成我们刚刚的思想,就这样不断递归下去直接我们遇见空节点.
nt BinaryTreeDepth(BTNode* root)
{//为空 返回0//递归左树 遇到左右都为空的节点 返回1 再递归右树 左右都为空 返回1,//左右比较 返回大的+1if (root == NULL){return NULL;}NTNode* left = BinaryTreeDepth(root->left);NTNode* right = BinaryTreeDepth(root->right);return left > right ? left + 1 : right + 1;
}查找值为x的节点:
只要找到了就不会返回空,只要返回的不是空就是找到了。左子树找到了就不会再去右子树找
BTNode* BinaryTreeFind(BTNode* root, BTNodeType x)
{if (root == NULL){return NULL;}if (root->data == x){return root;}BTNode* left = BinaryTreeFind(root->left);if (left != NULL){return left;}BTNode* right = BinaryTreeFind(root->right);if (left != NULL){return right;}return NULL;
}二叉树的层序遍历:
借助队列
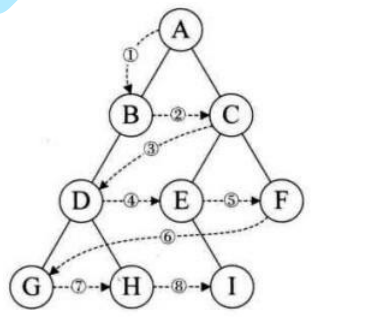
- 先将根入队列
- 当前节点出队列后,将次此节点的左右孩子入队列
- 一直这样循环往复直到队列为空,说明最后一层已经没有节点了,遍历结束
void BinaryTreeLevelOrder(BTNode* root)
{if (root == NULL){return NULL;}Queue q;QueueInit(&q);QueuePush(&q, root);while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);printf("%c", front->data);if (front->left != NULL){QueuePush(&q, front->left);}if (front->right != NULL){QueuePush(&q, front->right);}}printf("\n");QueueDestroy(&q);
}判断二叉树是否为完全二叉树:
完全二叉树和非完全二叉树的区别:前者一旦有空后面就都是空,而后者一旦有空后面还会出现非空。
第二个while循环是遇到空时候,看后面是否全为空,如果是就是完全二叉树
QueueEmpty(&q)判断队列是否为空,看的是front是否为空
bool BinaryTreeComplete(BTNode* root)
{Queue q;QueueInit(&q);QueuePush(&q, root);while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (front == NULL){break;}else{QueuePush(&q, front->left);QueuePush(&q, front->right);}}//遇到空了while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (front){QueueDestory(&q);return false;}}QueueDestory(&q);return true;
}销毁二叉树:
void BinaryTreeDestory(BTNode* root)
{if (root == NULL){return;}BinaryTreeDestory(root->left);BinaryTreeDestory(root->right);free(root);
}相关文章:
数据结构手撕--【二叉树】
目录 定义结构体: 初始化: 手动创建一个二叉树: 前序遍历: 中序遍历: 后序遍历 二叉树节点个数: 叶子节点个数: 二叉树第k层节点个数: 二叉树的高度: 查找值为x…...
)
【刷题Day26】Linux命令、分段分页和中断(浅)
说下你常用的 Linux 命令? 文件与目录操作: ls:列出当前目录的文件和子目录,常用参数如-l(详细信息)、-a(包括隐藏文件)cd:切换目录,用于在文件系统中导航m…...

星火燎原:大数据时代的Spark技术革命在数字化浪潮席卷全球的今天,海量数据如同奔涌不息的洪流,传统的数据处理方式已难以满足实时、高效的需求。
星火燎原:大数据时代的Spark技术革命 在数字化浪潮席卷全球的今天,海量数据如同奔涌不息的洪流,传统的数据处理方式已难以满足实时、高效的需求。Apache Spark作为大数据领域的璀璨明星,凭借其卓越的性能和强大的功能,…...
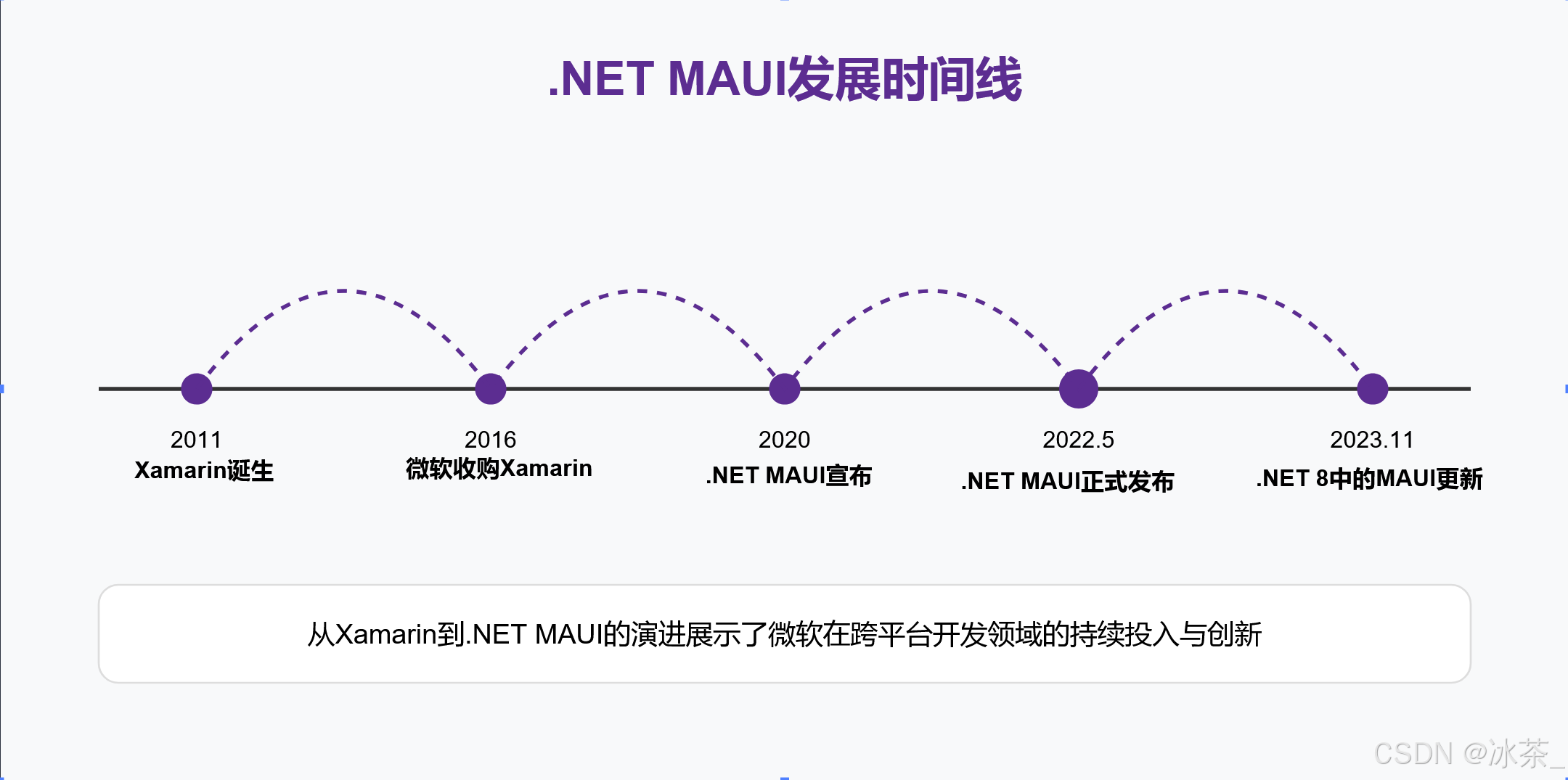
.NET MAUI 发展历程:从 Xamarin 到现代跨平台应用开发框架
文章目录 引言Xamarin 起源:MAUI 的前身Xamarin 的创立(2011年)Xamarin Studio 与 Visual Studio 集成(2013年)Xamarin.Forms 的诞生(2014年)微软收购Xamarin(2016年) .N…...

多模态大语言模型arxiv论文略读(四十)
The Wolf Within: Covert Injection of Malice into MLLM Societies via an MLLM Operative ➡️ 论文标题:The Wolf Within: Covert Injection of Malice into MLLM Societies via an MLLM Operative ➡️ 论文作者:Zhen Tan, Chengshuai Zhao, Raha M…...

【蓝桥杯选拔赛真题104】Scratch回文数 第十五届蓝桥杯scratch图形化编程 少儿编程创意编程选拔赛真题解析
目录 scratch回文数 一、题目要求 1、准备工作 2、功能实现 二、案例分析 1、角色分析 2、背景分析 3、前期准备 三、解题思路 四、程序编写 五、考点分析 六、推荐资料 1、scratch资料 2、python资料 3、C++资料 scratch回文数 第十五届青少年蓝桥杯scratch编…...
OpenWrt 与 Docker:打造轻量级容器化应用平台技术分享
文章目录 前言一、OpenWrt 与 Docker 的集成前提1.1 硬件与内核要求1.2 软件依赖 二、Docker 环境部署与验证2.1 基础服务配置2.2 存储驱动适配 三、容器化应用部署实践3.1 资源限制策略3.2 Docker Compose 适配 四、性能优化与监控4.1 容器资源监控4.2 镜像精简策略 五、典型问…...

tkinter的文件对话框:filedialog
诸神缄默不语-个人技术博文与视频目录 文章目录 一、前言二、tkinter.filedialog模块详解2.1 模块导入方式2.2 通用参数说明 三、五大核心函数实战3.1 选择单个文件 - askopenfilename()3.2 多文件选择 - askopenfilenames()3.3 保存文件对话框 - asksaveasfilename()3.4 选择目…...
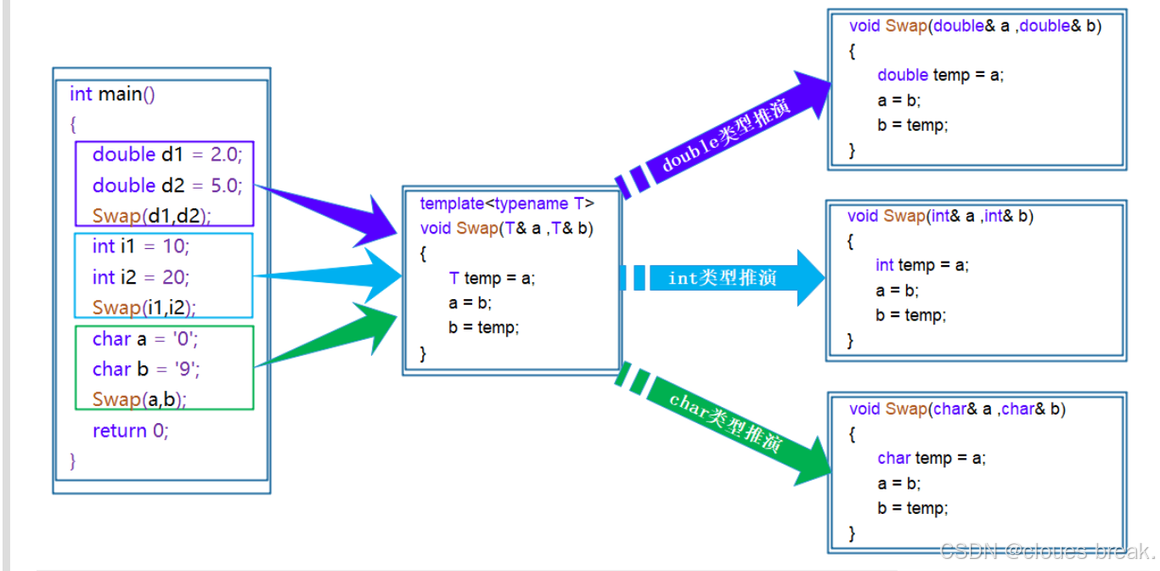
C++初阶----模板初阶
引言 什么是模板 模板是泛型编程的基础,泛型编程是以一种独立于任何特定类型的方式编写代码。 模板也是创建泛型类或者函数的蓝图。 如:库容器,迭代器和算法,都是泛型编程的例子 1. 泛型编程 首先,我们应该了解什么是…...

网络流量分析 | 流量分析基础
流量分析是网络安全领域的一个子领域,其主要重点是调查网络数据,以发现问题和异常情况。本文将涵盖网络安全和流量分析的基础知识。 网络安全与网络中的数据 网络安全的两个最关键概念就是:认证(Authentication)和授…...

幻读是什么项目中是怎么保证不会出现幻读
幻读(Phantom Read)是数据库并发控制中的一种现象,指的是在事务处理中,一个事务在读取某个数据范围时,另一个事务插入、删除或者修改了该数据范围,导致第一个事务再次读取数据时,看到的数据发生…...

C语言实现对哈希表的操作:创建哈希表与扩容哈希表
一. 简介 前面文章简单了解了哈希表 这种数据结构,文章如下: 什么是哈希表-CSDN博客 本文来学习一下哈希表,具体学习一下C语言实现对哈希表的简单实现。 二. C语言实现对哈希表的操作 1. 哈希表 哈希表(Hash Tableÿ…...

MYSQL 常用字符串函数 和 时间函数详解
一、字符串函数 1、CONCAT(str1, str2, …) 拼接多个字符串。 SELECT CONCAT(Hello, , World); -- 输出 Hello World2、SUBSTRING(str, start, length) 或 SUBSTR() 截取字符串。 SELECT SUBSTRING(MySQL, 3, 2); -- 输出 SQ3、LENGTH(str) 与 CHAR_LENGTH…...
)
通过API接口在自己的独立站系统上架商品信息。(实战案例)
以下是一个通过API接口在独立站系统上架商品信息的实战案例,以某跨境电商独立站集成亚马逊产品数据为例,详细说明技术实现流程和关键代码逻辑: 案例背景 某跨境电商独立站需要从亚马逊平台同步商品数据(标题、价格、库存、图片、…...
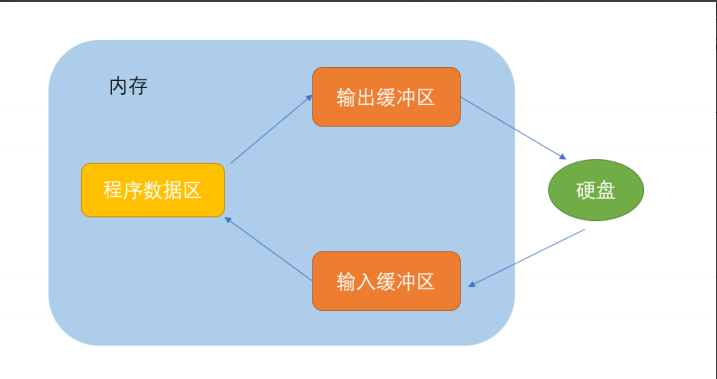
C语言文件操作完全手册:读写·定位·实战
1.什么是文件 1.1文件的概念 文件(File)是计算机中用于持久化存储数据的基本单位。它可以存储文本、图片、音频、程序代码等各种信息,并在程序运行结束后仍然保留数据。 1.2文件名 一个文件要有一个唯一的文件标识,以便用户识别…...

多模态大语言模型arxiv论文略读(三十七)
A Spectrum Evaluation Benchmark for Medical Multi-Modal Large Language Models ➡️ 论文标题:A Spectrum Evaluation Benchmark for Medical Multi-Modal Large Language Models ➡️ 论文作者:Jie Liu, Wenxuan Wang, Yihang Su, Jingyuan Huan, …...

IDEA创建Gradle项目然后删除报错解决方法
根据错误信息,你的项目目录中缺少Gradle构建必需的核心文件(如settings.gradle/build.gradle),且IDEA可能残留了Gradle的配置。以下是具体解决方案: 一、问题根源分析 残留Gradle配置 你通过IDEA先创建了Gradle子模块…...

SpringBoot 学习
什么是 SpringBoot SpringBoot 是基于 Spring 生态的开源框架,旨在简化 Spring 应用的初始化搭建和开发配置。它通过约定大于配置的理念,提供快速构建生产级应用的解决方案,显著降低开发者对 XML 配置和依赖管理的负担。 特点: …...

MoE架构解析:如何用“分治”思想打造高效大模型?
在人工智能领域,模型规模的扩大似乎永无止境。从GPT-3的1750亿参数到传闻中的GPT-4万亿级规模,每一次突破都伴随着惊人的算力消耗。但当我们为这些成就欢呼时,一个根本性问题愈发尖锐:如何在提升模型能力的同时控制计算成本&#…...

云服务器和独立服务器的区别在哪
在当今数字化的时代,服务器成为了支撑各种业务和应用的重要基石。而在服务器的领域中,云服务器和独立服务器是两个备受关注的选项。那么,它们到底有何区别呢? 首先,让我们来聊聊成本。云服务器通常采用按需付费的模式…...

使用 Pandas 进行多格式数据整合:从 Excel、JSON 到 HTML 的处理实战
前言 在数据处理与分析的实际场景中,我们经常需要整合不同格式的数据,例如 Excel 表格、JSON 配置文件、HTML 报表等。本文以一个具体任务(蓝桥杯模拟练习题)为例,详细讲解如何使用 Python 的 Pandas 库结合其他工具&…...

深入解析 Linux 中动静态库的加载机制:从原理到实践
引言 在 Linux 开发中,动静态库是代码复用的核心工具。静态库(.a)和动态库(.so)的加载方式差异显著,直接影响程序的性能、灵活性和维护性。本文将深入剖析两者的加载机制,结合实例演示和底层原…...

VuePress 使用教程:从入门到精通
VuePress 使用教程:从入门到精通 VuePress 是一个以 Vue 驱动的静态网站生成器,它为技术文档和技术博客的编写提供了优雅而高效的解决方案。无论你是个人开发者、团队负责人还是开源项目维护者,VuePress 都能帮助你轻松地创建和管理你的文档…...

Kafka与Spark-Streaming
大数据处理的得力助手:Kafka与Spark-Streaming 在大数据处理的领域中,Kafka和Spark-Streaming都是极为重要的工具。今天,咱们就来深入了解一下它们,看看这些技术是如何让数据处理变得高效又强大的。先来说说Kafka,它是…...

【设计】接口幂等性设计
1. 幂等性定义 接口幂等性: 无论调用次数多少,对系统状态的影响与单次调用相同。 比如用户支付接口因网络延迟重复提交了三次。 导致原因: 用户不可靠(手抖多点)网络不可靠(超时重传)系统不可…...

闲聊人工智能对媒体的影响
技术总是不断地改变信息的传播方式。互联网促进了社交媒体的蓬勃发展。 网络媒体成为主流。大语言模型为代表的人工智能的出现,又会对媒体传播带来怎样的改变呢?媒体的演变反映了社会和技术的演变。 人工智能(AI) 将继续对整个媒体行业产生变革性的影响。…...

卷积神经网络--手写数字识别
本文我们通过搭建卷积神经网络模型,实现手写数字识别。 pytorch中提供了手写数字的数据集 ,我们可以直接从pytorch中下载 MNIST中包含70000张手写数字图像:60000张用于训练,10000张用于测试 图像是灰度的,28x28像素 …...

Pandas 数据导出:如何将 DataFrame 追加到 Excel 的不同工作表
在数据分析和数据处理过程中,将数据导出到 Excel 文件是一个常见的需求。Pandas 提供了强大的功能来实现这一需求,尤其是将数据追加到同一个 Excel 文件的不同工作表(Sheet)中。本文将详细介绍如何使用 Pandas 实现这一功能&#…...
)
Unity中数据和资源加密(异或加密,AES加密,MD5加密)
在项目开发中,始终会涉及到的一个问题,就是信息安全,在调用接口,或者加载的资源,都会涉及安全问题,因此就出现了各种各样的加密方式。 常见的也是目前用的最广的加密方式,分别是:DE…...
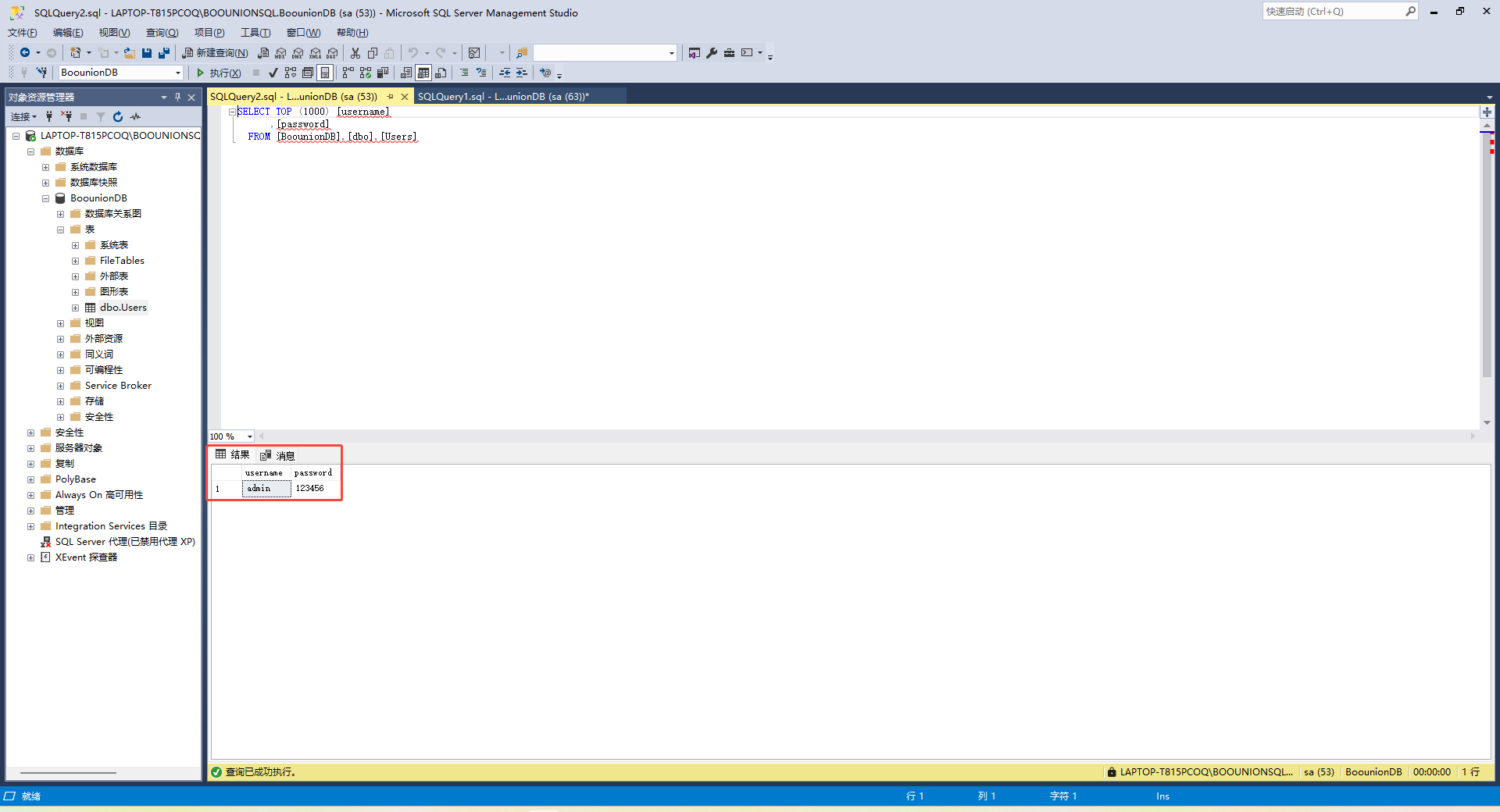
SQL Server 2019 安装与配置详细教程
一、写在最前的心里话 和 MySQL 对比,SQL Server 的安装和使用确实要处理很多细节: 需要选择配置项很多有“定义实例”的概念,同一机器可以运行多个数据库服务设置身份验证方式时,需要同时配置 Windows 和 SQL 登录要想 Spring …...