【实战】基于强化学习的 Agent 训练框架全流程拆解
一、引言
在人工智能蓬勃发展的今天,强化学习(Reinforcement Learning, RL)作为让智能体(Agent)在复杂环境中自主学习并做出最优决策的核心技术,正日益受到关注。从游戏领域中击败人类顶尖选手的 AlphaGo,到机器人控制、自动驾驶等实际应用场景,强化学习驱动的 Agent 展现出了强大的适应能力和决策智慧。本文将围绕基于强化学习的 Agent 训练框架,从核心概念、架构设计、关键技术到实战案例进行全流程拆解,帮助读者深入理解并掌握这一前沿技术。
二、强化学习核心概念与基础原理
(一)强化学习基本要素
强化学习是一种通过智能体与环境的交互来学习决策策略的技术,其核心要素包括:
- 智能体(Agent):在环境中执行动作并进行学习的主体,能够根据环境状态选择动作,并从环境中获得奖励。
- 环境(Environment):智能体所处的外部世界,它接收智能体的动作并返回新的状态和奖励。
- 状态(State):描述环境当前状况的信息集合,是智能体决策的依据。
- 动作(Action):智能体在当前状态下可以采取的行为。
- 奖励(Reward):环境对智能体动作的反馈信号,用于评估动作的好坏,引导智能体学习最优策略。
(二)强化学习目标与策略
强化学习的目标是使智能体在与环境的长期交互中,最大化累计奖励。智能体通过学习策略(Policy)来决定在不同状态下选择何种动作。策略可以分为确定性策略(给定状态输出确定的动作)和随机性策略(给定状态输出动作的概率分布)。
(三)强化学习算法分类
根据学习方式的不同,强化学习算法主要分为以下几类:
- 基于值的方法(Value - Based Methods):通过学习值函数(Value Function)来评估状态或状态 - 动作对的好坏,如 Q - Learning、Sarsa 等算法。值函数表示从某个状态或状态 - 动作对开始,遵循某种策略所能获得的累计奖励的期望。
- 基于策略的方法(Policy - Based Methods):直接学习策略函数,如策略梯度(Policy Gradient)算法。该类方法通过调整策略参数,使期望奖励最大化。
- Actor - Critic 方法:结合了基于值和基于策略的方法,通过 Actor(策略网络)生成动作,Critic(值网络)评估动作的价值,两者相互配合进行学习,如 A3C(Asynchronous Advantage Actor - Critic)、PPO(Proximal Policy Optimization)等算法。
三、强化学习 Agent 训练框架整体架构
一个完整的基于强化学习的 Agent 训练框架通常包括环境模块、智能体模块、训练模块和评估模块等部分,各模块相互协作,实现智能体的训练和优化。
(一)环境模块
环境是智能体学习的对象,环境模块的设计直接影响智能体的训练效果。环境可以分为真实环境和仿真环境。在实际应用中,由于真实环境的复杂性和安全性限制,通常会先在仿真环境中进行训练,待智能体具备一定能力后再迁移到真实环境中。
- 环境建模:需要明确环境的状态空间(State Space)、动作空间(Action Space)和奖励函数(Reward Function)。状态空间描述了环境中所有可能的状态,动作空间定义了智能体可以采取的所有动作,奖励函数则用于衡量智能体动作的优劣。
- 环境交互接口:提供智能体与环境交互的接口,使智能体能够向环境发送动作,并接收环境返回的新状态、奖励和是否结束等信息。
(二)智能体模块
智能体模块是训练框架的核心,它包含了智能体的策略网络、值网络(如果使用 Actor - Critic 方法)以及相关的参数和数据结构。
- 网络结构设计:根据问题的特点和复杂度,选择合适的神经网络结构,如深度神经网络(DNN)、卷积神经网络(CNN,适用于图像等空间数据)、循环神经网络(RNN,适用于序列数据)等。网络的输入通常是环境状态,输出根据算法类型有所不同,基于值的方法输出状态 - 动作对的 Q 值,基于策略的方法输出动作的概率分布,Actor - Critic 方法中 Actor 输出动作概率分布,Critic 输出状态或状态 - 动作对的值。
- 策略与值函数表示:策略函数和值函数通过神经网络参数化,训练过程就是调整这些参数,使智能体的行为逐渐接近最优策略。
(三)训练模块
训练模块负责协调智能体与环境的交互,收集训练数据,并根据算法对智能体进行更新。
- 训练流程:
- 初始化:初始化智能体的网络参数、经验回放缓冲区(如果使用)等。
- 数据收集:智能体在环境中执行动作,收集状态、动作、奖励、下一个状态和是否结束等数据,并将这些数据存储到经验回放缓冲区(用于提高数据利用率和训练稳定性)或直接用于训练。
- 策略更新:根据收集到的数据,使用强化学习算法对智能体的网络参数进行更新。不同算法的更新方式有所不同,如 Q - Learning 通过最大化 Q 值来更新值函数,策略梯度算法通过计算梯度来更新策略参数。
- 探索与利用平衡:在训练初期,智能体需要更多地探索环境,以发现新的状态和动作组合;随着训练的进行,逐渐转向利用已有的知识,选择当前认为最优的动作。常用的探索策略包括 ε - greedy 策略(以 ε 的概率随机选择动作,以 1 - ε 的概率选择当前最优动作)、玻尔兹曼探索(根据动作的概率分布选择动作,温度参数控制探索程度)等。
- 优化器选择:常用的优化器包括随机梯度下降(SGD)、Adam、RMSprop 等,不同的优化器具有不同的特点和适用场景,需要根据具体问题进行选择。
(四)评估模块
评估模块用于检验训练后的智能体性能,判断训练是否达到预期效果。
- 评估指标:根据任务的不同,评估指标可以是累计奖励、成功率、完成任务的时间等。例如,在游戏任务中,常用累计得分作为评估指标;在机器人控制任务中,可能更关注任务完成的精度和稳定性。
- 评估方法:在固定的环境场景下,让智能体执行一定次数的测试,记录评估指标并计算平均值、标准差等统计量,以全面评估智能体的性能。
四、训练框架关键技术详解
(一)数据预处理与特征工程
在强化学习中,环境状态可能是高维的、复杂的,如图像、传感器数据等。数据预处理和特征工程可以提高数据质量,减少噪声,降低维度,从而提高模型的训练效率和效果。
- 状态归一化 / 标准化:对连续的状态变量进行归一化或标准化处理,使不同维度的状态数据具有相同的尺度,避免数值较大的维度对训练产生过大影响。
- 特征提取:对于图像等复杂数据,使用卷积神经网络等进行特征提取,自动学习具有代表性的特征;对于时序数据,可使用循环神经网络或时间卷积网络提取时间序列特征。
(二)奖励工程
奖励函数的设计是强化学习中的关键环节,直接影响智能体的学习方向和效果。
- 稀疏奖励处理:在一些任务中,奖励信号可能非常稀疏,如只有在任务成功或失败时才给予奖励,这会导致智能体学习困难。常用的解决方法包括设置中间奖励(根据任务进展给予阶段性奖励)、使用模仿学习(结合专家演示数据)等。
- 奖励塑形(Reward Shaping):通过设计额外的奖励函数来引导智能体学习期望的行为,帮助智能体更快地收敛到最优策略。例如,在机器人导航任务中,可以给予智能体靠近目标的正向奖励,远离目标的负向奖励。
(三)经验回放(Experience Replay)
经验回放是强化学习中常用的技术,它将智能体与环境交互产生的数据存储在回放缓冲区中,然后随机抽取样本进行训练。这样可以打破数据之间的相关性,提高数据的利用率,稳定训练过程。
- 回放缓冲区设计:需要考虑缓冲区的大小(过大的缓冲区会占用更多内存,过小的缓冲区可能导致数据不足)、数据存储格式(通常存储状态、动作、奖励、下一个状态和是否结束等信息)以及数据采样策略(如均匀采样、优先经验回放,优先回放重要的样本,提高训练效率)。
(四)分布式训练技术
随着强化学习任务的复杂度不断提高,单节点训练往往难以满足需求,分布式训练技术应运而生。分布式训练可以利用多个计算节点并行处理,加快训练速度,提高模型的规模和性能。
- 分布式架构:主要包括数据并行(将训练数据分配到多个节点,每个节点运行相同的模型,同步更新模型参数)、模型并行(将模型的不同部分分配到多个节点,适用于大型模型)和混合并行(结合数据并行和模型并行)。
- 通信与同步:分布式训练中需要解决节点之间的数据通信和模型参数同步问题,常用的方法包括异步更新(节点之间无需等待,提高训练速度,但可能导致训练不稳定)和同步更新(节点之间同步参数,训练更稳定,但速度较慢)。
五、实战案例:基于 PPO 算法的 Atari 游戏 Agent 训练
(一)环境选择与搭建
选择经典的 Atari 游戏环境,如 Pong、Breakout 等。使用 OpenAI Gym 库中的 Atari 环境,该库提供了丰富的游戏环境接口,方便智能体与环境的交互。
(二)智能体设计
采用 Actor - Critic 架构,Actor 网络和 Critic 网络均使用卷积神经网络。Actor 网络输入为游戏画面(预处理为灰度图像并调整尺寸),输出各动作的概率分布;Critic 网络输入同样为游戏画面,输出当前状态的值。
(三)训练过程
- 初始化:设置训练参数,如学习率、折扣因子 γ、批量大小、训练轮数等;初始化 Actor 和 Critic 网络参数。
- 数据收集:智能体在 Atari 环境中根据当前策略执行动作,收集游戏画面、动作、奖励、下一个画面和是否结束等数据,存储到经验回放缓冲区。
- 策略更新:使用 PPO 算法对 Actor 和 Critic 网络进行更新。PPO 通过限制新旧策略之间的差异,保证训练的稳定性和收敛性。具体来说,计算优势函数(Advantage Function),然后优化目标函数,其中包含策略梯度项和值函数误差项。
- 探索策略:在训练初期使用 ε - greedy 策略进行探索,随着训练的进行,逐渐减小 ε 的值,降低探索比例。
(四)评估与优化
定期对训练中的智能体进行评估,记录在固定游戏场景下的得分。根据评估结果调整训练参数,如学习率、网络结构等,优化训练过程。经过一定轮数的训练后,智能体能够在 Atari 游戏中取得较高的得分,表现出良好的决策能力。
六、总结
本文详细拆解了基于强化学习的 Agent 训练框架全流程,从核心概念、架构设计到关键技术和实战案例进行了全面介绍。强化学习在 Agent 训练中展现出了强大的潜力,但也面临着许多挑战,如样本效率低、训练稳定性差、复杂环境下的泛化能力等。未来,随着技术的不断发展,强化学习与深度学习、迁移学习、多智能体系统等技术的结合将更加紧密,有望在更多领域取得突破性应用。
相关文章:
【实战】基于强化学习的 Agent 训练框架全流程拆解
一、引言 在人工智能蓬勃发展的今天,强化学习(Reinforcement Learning, RL)作为让智能体(Agent)在复杂环境中自主学习并做出最优决策的核心技术,正日益受到关注。从游戏领域中击败人类顶尖选手的 AlphaGo&a…...

【音视频】⾳频处理基本概念及⾳频重采样
一、重采样 1.1 什么是重采样 所谓的重采样,就是改变⾳频的采样率、sample format、声道数等参数,使之按照我们期望的参数输出。 1.2 为什么要重采样 为什么要重采样? 当然是原有的⾳频参数不满⾜我们的需求,⽐如在FFmpeg解码⾳频的时候…...

Prompt 结构化提示工程
Prompt 结构化提示工程 目前ai开发工具都大同小异,随着deepseek的流行,ai工具的能力都差不太多,功能基本都覆盖到了。而prompt能力反而是需要更加关注的(说白了就是能不能把需求清晰的输出成文档)。因此大家可能需要加…...

设计心得——数据结构的意义
一、数据结构 在老一些的程序员中,可能都听说过,程序其实就是数据结构算法这种说法。它是由尼克劳斯维特在其著作《算法数据结构程序》中提出的,然后在一段时期内这种说法非常流行。这里不谈论其是否正确,只是通过这种提法&#…...

【Pandas】pandas DataFrame rdiv
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

Pycharm 代理配置
Pycharm 代理配置 文章目录 Pycharm 代理配置1. 设置系统代理1.1 作用范围1.2 使用场景1.3 设置步骤 2. 设置 python 运行/调试代理2.1 作用范围2.2 使用场景2.3 设置步骤 Pycharm 工具作为一款强大的 IDE,其代理配置在实际开发中也是必不可少的,下面介绍…...
)
GPU 加速库(CUDA/cuDNN)
现代数字图像处理与深度学习任务对计算效率提出极高要求,GPU 加速库通过硬件并行计算能力大幅提升数据处理速度。 一、CUDA 并行计算架构深度解析 1. 架构设计与硬件协同 CPU-GPU 异构计算模型CPU 作为主机端,主要负责逻辑控制、任务调度以及数据预处…...

Spring Native:GraalVM原生镜像编译与性能优化
文章目录 引言一、Spring Native与GraalVM基础1.1 GraalVM原理与优势1.2 Spring Native架构设计 二、原生镜像编译实践2.1 构建配置与过程2.2 常见问题与解决方案 三、性能优化技巧3.1 内存占用优化3.2 启动时间优化3.3 实践案例分析 总结 引言 微服务架构的普及推动了轻量级、…...

JAVA JVM面试题
你的项目中遇到什么问题需要jvm调优,怎么调优的,堆的最小值和最大值设置为什么不设置成一样大? 在项目中,JVM调优通常源于以下典型问题及对应的调优思路,同时关于堆内存参数(-Xms/-Xmx)的设置逻…...
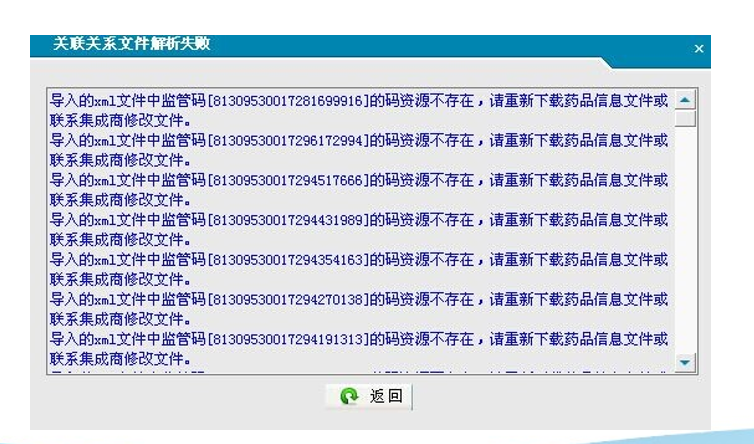
药监平台上传数据报资源码不存在
问题:电子监管码上传药监平台提示“导入的资源码不存在” 现象:从生产系统导出的关联关系数据包上传到药监平台时显示: 原因:上传数据包的通道的资源码与数据包的资源码不匹配。 解决方法:检查药监平台和生产系统的药…...
)
世界比较权威的新车安全评鉴协会(汽车安全性测试,自动驾驶功能测试)
NCAP是英文“New Car Assessment Program”的缩写,即新车评价规程,最能考验汽车安全性的测试,在自动驾驶发展迅速的现阶段,安全问题频发,自动驾驶相关功能显然也需要进行测试评价。 1. 欧洲新车安全评鉴协会ÿ…...
【Linux应用】交叉编译环境配置,以及最简单粗暴的环境移植(直接从目标板上复制)
【Linux应用】交叉编译环境配置,以及最简单粗暴的环境移植(直接从目标板上复制) 文章目录 交叉编译器含有三方库的交叉编译直接从目标板上复制编译环境glibc库不一致报错方法1方法2 附录:ZERO 3烧录ZERO 3串口shell外设挂载连接Wi…...

CentOS 7 磁盘阵列搭建与管理全攻略
CentOS 7 磁盘阵列搭建与管理全攻略 在数据存储需求日益增长的今天,磁盘阵列(RAID)凭借其卓越的性能、数据安全性和可靠性,成为企业级服务器和数据中心的核心存储解决方案。CentOS 7 作为一款稳定且功能强大的 Linux 操作系统&am…...
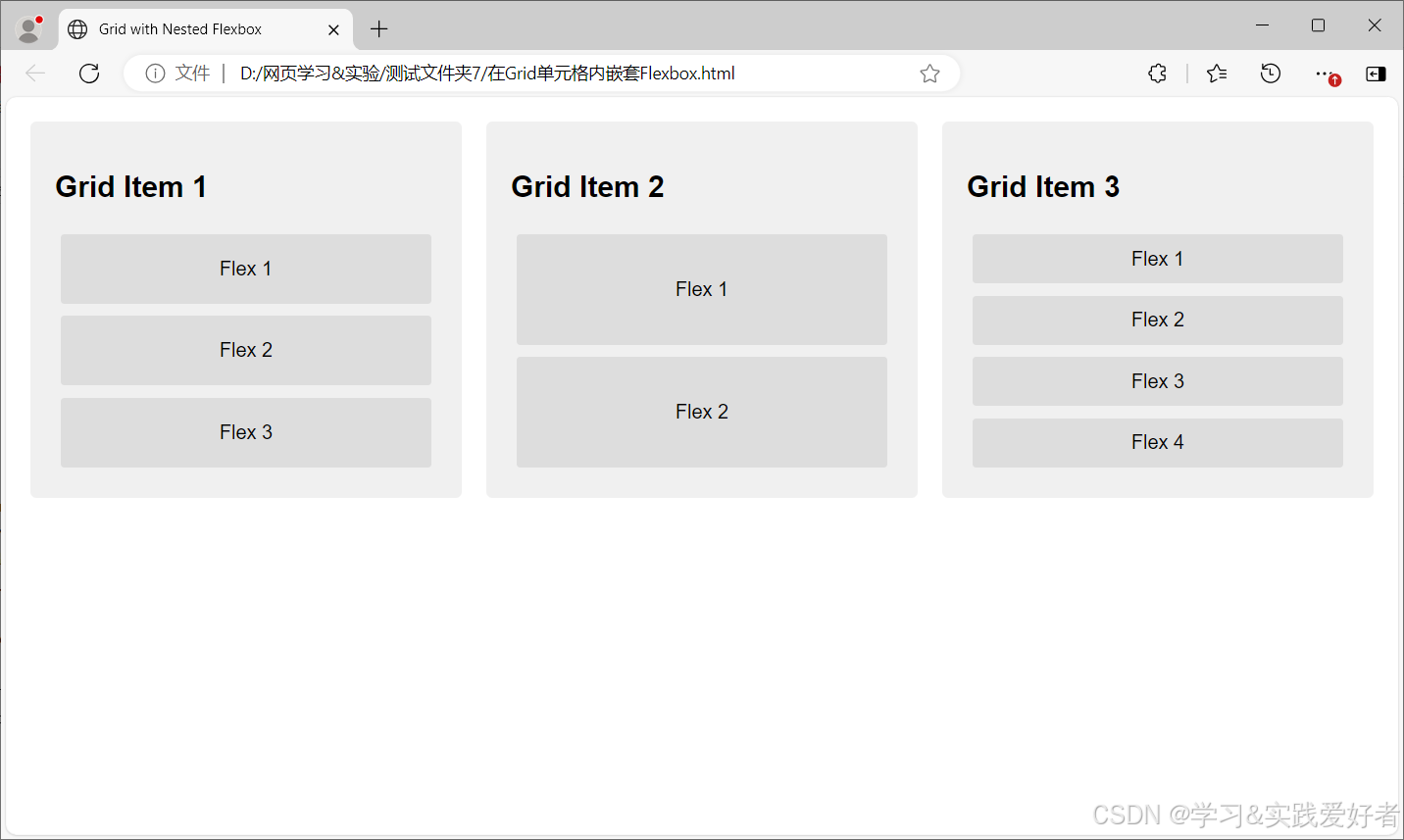
CSS3布局方式介绍
CSS3布局方式介绍 CSS3布局(Layout)系统是现代网页设计中用于构建页面结构和控制元素排列的一组强大工具。CSS3提供了多种布局方式,每种方式都有其适用场景,其中最常用的是Flexbox和CSS Grid。 先看传统上几种布局方式ÿ…...
FPGA设计 时空变换
1、时空变换基本概念 1.1、时空概念简介 时钟速度决定完成任务需要的时间,规模的大小决定完成任务所需要的空间(资源),因此速度和规模就是FPGA中时间和空间的体现。 如果要提高FPGA的时钟,每个clk内组合逻辑所能做的事…...

AI心理健康服务平台项目面试实战
AI心理健康服务平台项目面试实战 第一轮提问: 面试官: 请简要介绍一下AI心理健康服务平台的核心技术架构。在AI领域,心理健康服务的机遇主要体现在哪些方面?如何利用NLP技术提升用户与AI的心理健康对话体验? 马架构…...
)
Eigen稀疏矩阵类 (SparseMatrix)
1. SparseMatrix 核心属性与初始化 模板参数 cpp SparseMatrix<Scalar, Options, StorageIndex> Scalar:数据类型(如 double, float)。 Options:存储格式(默认 ColMajor,可选 RowMajor࿰…...

《AI大模型趣味实战》智能Agent和MCP协议的应用实例:搭建一个能阅读DOC文件并实时显示润色改写过程的Python Flask应用
智能Agent和MCP协议的应用实例:搭建一个能阅读DOC文件并实时显示润色改写过程的Python Flask应用 引言 随着人工智能技术的飞速发展,智能Agent与模型上下文协议(MCP)的应用场景越来越广泛。本报告将详细介绍如何基于Python Flask框架构建一个智能应用&…...
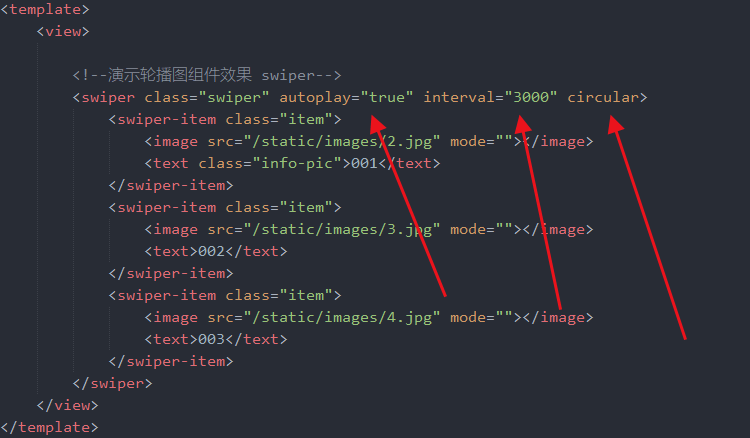
uniapp开发03-轮播图组件swiper的简单使用案例
uniapp开发03-轮播图组件swiper的简单使用案例!这个仅仅是官方提供的一个轮播图组件啊。实际上我们项目开发的时候,会应用到其他第三方公司的轮播图组件资源!效果更强大。兼容性更强。 废话不多说,我们直接上代码。分析代码。 &l…...

DAM-3B,英伟达推出的多模态大语言模型
DAM-3B是什么 DAM-3B(Describe Anything 3B)是英伟达推出的一款多模态大语言模型,专门用于为图像和视频中的特定区域生成详细描述。用户可以通过点、边界框、涂鸦或掩码等方式来标识目标区域,从而得到精准且符合上下文的文本描述…...

【虚幻C++笔记】碰撞检测
目录 碰撞检测参数详情示例用法 碰撞检测 显示名称中文名称CSphere Trace By Channel按通道进行球体追踪UKismetSystemLibrary::SphereTraceSingleSphere Trace By Profile按描述文件进行球体追踪UKismetSystemLibrary::SphereTraceSingleByProfileSphere Trace For Objects针…...

C++学习:六个月从基础到就业——STL:分配器与设计原理
C学习:六个月从基础到就业——STL:分配器与设计原理 本文是我C学习之旅系列的第三十篇技术文章,也是第二阶段"C进阶特性"的第九篇,主要介绍C STL中的分配器设计原理与实现。查看完整系列目录了解更多内容。 引言 在之前…...
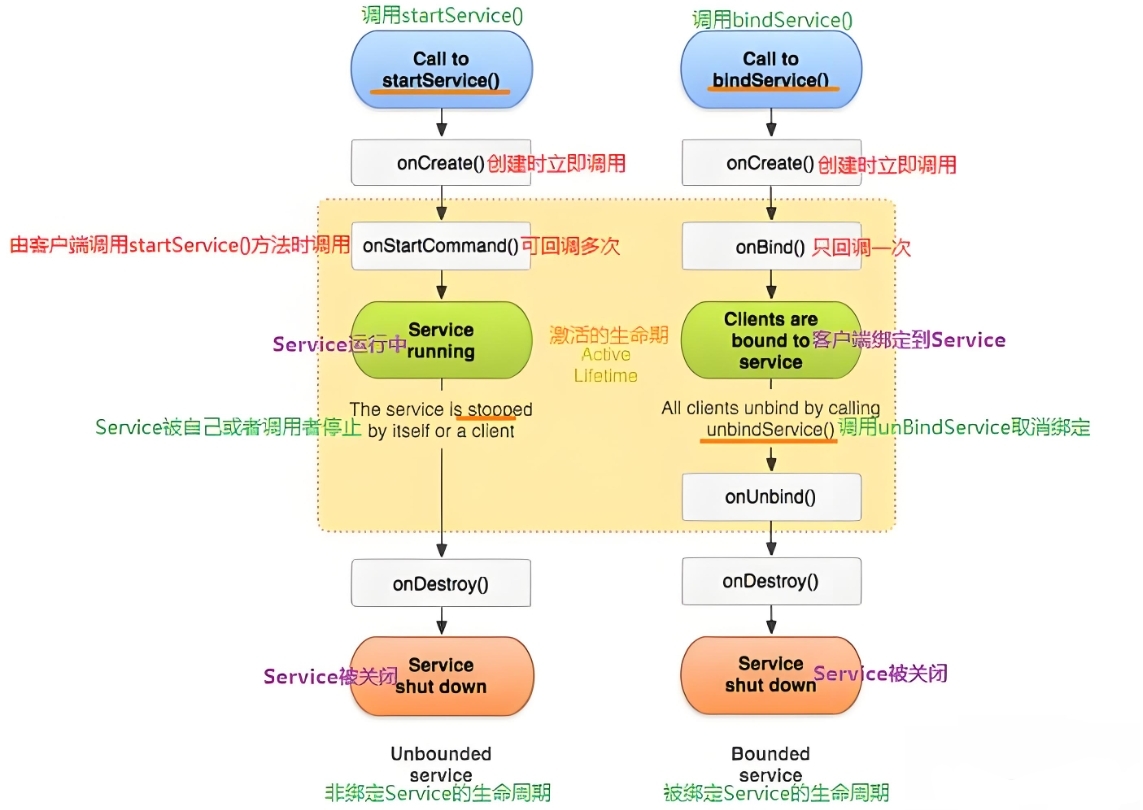
【Android】四大组件之Service
目录 一、什么是Service 二、启停 Service 三、绑定 Service 四、前台服务 五、远程服务扩展 六、服务保活 七、服务启动方法混用 你可以把Service想象成一个“后台默默打工的工人”。它没有UI界面,默默地在后台干活,比如播放音乐、下载文件、处理…...
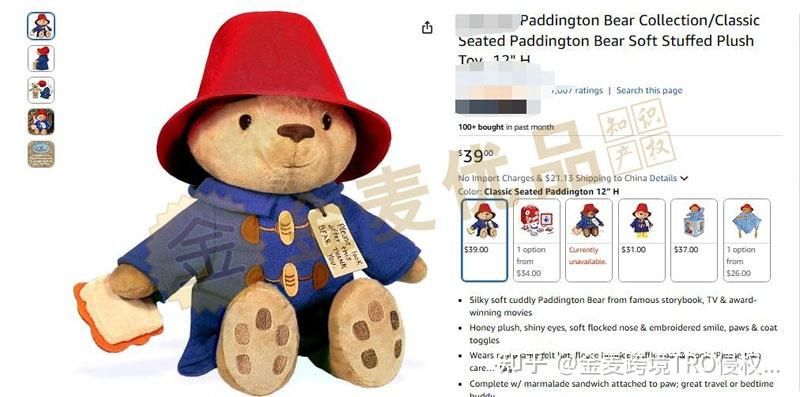
TRO再添新案 TME再拿下一热门IP,涉及Paddington多个商标
4月2日和4月8日,TME律所代理Paddington & Company Ltd.对热门IP Paddington Bear帕丁顿熊的多类商标发起维权,覆盖文具、家居用品、毛绒玩具、纺织用品、游戏、电影、咖啡、填充玩具等领域。跨境卖家需立即排查店铺内的相关产品! 案件基…...

spring-session-data-redis使用
spring-session-data-redis是spring session项目中的一个子模块,,他允许你使用Redis来存储http session,,从而支持多个应用实例之间共享session,,,即分布式session 原理: EnableRed…...
)
图论---LCA(倍增法)
预处理 O( n logn ),查询O( log n ) #include<bits/stdc.h> using namespace std; typedef pair<int,int> pii; const int N40010,M2*N;//是无向边,边需要见两边int n,m; vector<int> g[N]; //2的幂次范围 0~15 int depth[N],fa[N][1…...

WPF实现类似Microsoft Visual Studio2022界面效果及动态生成界面技术
WPF实现类似VS2022界面效果及动态生成界面技术 一、实现类似VS2022界面效果 1. 主窗口布局与主题 <!-- MainWindow.xaml --> <Window x:Class"VsStyleApp.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x…...

【安全扫描器原理】网络扫描算法
【安全扫描器原理】网络扫描算法 1.非顺序扫描2.高速扫描 & 分布式扫描3.服务扫描 & 指纹扫描 1.非顺序扫描 参考已有的扫描器,会发现几乎所有的扫描器都无一例外地使用增序扫描,即对所扫描的端口自小到大依次扫描,殊不知࿰…...
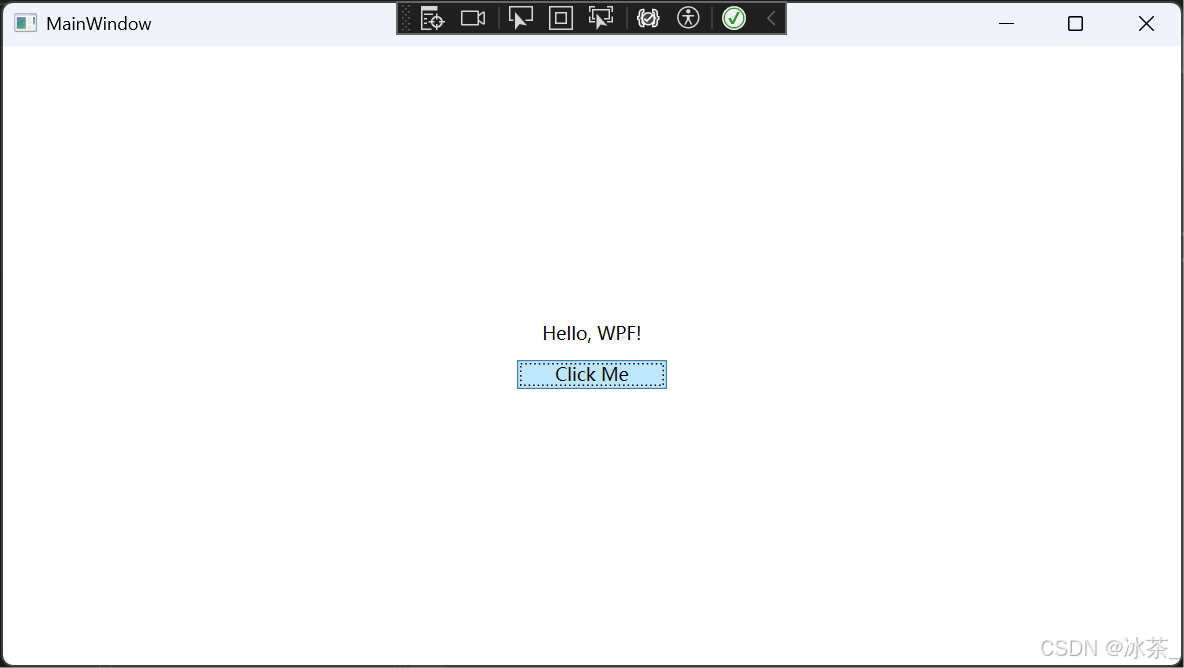
WPF之项目创建
文章目录 引言先决条件创建 WPF 项目步骤理解项目结构XAML 与 C# 代码隐藏第一个 "Hello, WPF!" 示例构建和运行应用程序总结相关学习资源 引言 Windows Presentation Foundation (WPF) 是 Microsoft 用于构建具有丰富用户界面的 Windows 桌面应用程序的现代框架。它…...

Unity中数据储存
在Unity项目开发中,会有很多数据,有需要保存到本地的数据,也有直接保存在缓存中的临时数据,一般为了方便整个项目框架中各个地方能调用需要的数据,因此都会实现一个数据工具或者叫数据管理类,用来管理项目中所有的数据。 首先保存在缓存中的数据,比如用户信息,我们只需…...