numpy pandas
视频链接
numpy
numpy是基于一个矩阵的运算
矩阵的属性
import numpy as np# 把一个列表转换成矩阵的方法
array = np.array([[1,2,3],[3,4,5]])# 打印矩阵
print(array)# 维度
print('number of dim:',array.ndim)# 行数和列数
print('shape:',array.shape)# 总共有多少个元素在里面
print('size:',array.size)
生成矩阵
import numpy as nparray = np.array([[1,2,3],[3,4,5]],dtype=np.int)# 矩阵里的元素的数据类型
print(a.dtype)# 生成一个0矩阵
a1 = np.zeros((3,4))
print(a)# 生成一个全是1的矩阵
a2 = np.ones((1,4),dtpye=np.int16)# 生成一个空矩阵
a3 = np.empty((3,4))# 生成一个有序的矩阵
a4 = np.arange(10,20,2)# 有序和矩阵形状结合
a5 = np.arange(12).reshape((3,4))# 一个线段
a6 = np.linspace(1,10,6).reshape(2,3)
numpy的基础运算
import numpy as npa1 = np.array([10,20,30,40])
b1 = np.arange(4)# 减法
c1 = a1 - b1
print(c1)# 加法
c2 = a1 - b1
print(c2)# 乘法
c3 = a1 * b1
print(c3)# 次方
c4 = a1**2
print(c4)# 三角运算
# 注:这里的sin 可以换成cos,tan
c5 = 10*np.sin(a1)
print(c5)# 列表中的大小关系
a2 = np.arange(1,5)
print(a2)
print(a2>3)# [1 2 3 4]
# [False False False True]# 乘法a3 = np.array([[1,1],[0,1]])
b3 = np.arange(4).reshape((2,2))c = a*b # 逐一相乘
c_dot = np.dot(a,b) # 矩阵乘法
c_dot_2 = a.dot(b) # 矩阵乘法的另外一种形式print(c)
print(c_dot)
print(c_dot_2)# [[0 1]
# [0 3]]
# [[2 4]
# [2 3]]# 随机生成一些值
a = np.random.random(2,3)print(a)
print(np.sum(a,axis=1))
print(np.min(a,axis=0))
print(np.max(a,axis=1))
# 注:axis=1 是在每一行中进行处理,最后返回是一个矩阵
# 注:axis=0 是在每一列中进行处理,最后返回是一个矩阵
# 注:axis 对矩阵的大多数指令都有用numpy的基础运算2
import numpy as npA = np.arange(2,14).reshape((3,4))# 整个矩阵的最大值和最小值print(np.argmin(A))
print(np.argmax(A))#平均值print(np.mean(A))
print(A.mean())print(np.average(A))# 求中位数print(np.median(A))# 求和print(A)
print(np.cumsum(A))
print(np.diff(A)) # 累差# [[ 2 3 4 5][ 6 7 8 9][10 11 12 13]]
#[ 2 5 9 14 20 27 35 44 54 65 77 90]# 排序
print(np,.sort(A)) # 逐行排序# 转置
print(A)
print(np.transpose(A))
print(A.T)# 让所有小于5的数字变成5,让所有大于9的数字,变成9
print(np.clip(A,5,9))
np的索引
矩阵合并
有些不是很懂,先这样
A = np.array([1,1,1])B = np.array([2,2,2])# vertical stack 向下的合并
C1 = np.vstack((A,B))
print(A.shape,C.shape)# horizontal 左右合并
C2 = np.hstack((A,B))
print(C2)# 这里将A,B转了一个方向
A = A[:,np.newaxis]
B = B[:,np.newaxis]# 多矩阵,可要求方向的合并C3 = np.concatenate((A,B,B,A),axis=0)分隔矩阵
import numpy as npA = np.arange(12),reshape((3,4))# 分隔
print(np.split(A,2,axis=1))# 不等分隔
print(np.array_split(A,3,axis=1))# 分隔
print(np.vsplit(A,3))
print(np.hsplit(A,2))
赋值和复制
import numpy as py
a = np.arrange(4)b = a
c = a
d = b
a[0] = 11print(b) # b 也会变,因为a和b,c,d都指向一个实体# deep copy
b1 = a.copy()Pandas
创建一个DataFrame
import pandas as pd
import numpy as np# 创建pandas的一个序列s = pd.Series([1,2,3,np.nan,44,1])
print(s)0 1.0
1 2.0
2 3.0
3 NaN
4 44.0
5 1.0
dtype: float64# 创建一个dataformdates = pd.date_range('20250507',periods=6)
print(dates)DatetimeIndex(['2025-05-07', '2025-05-08', '2025-05-09', '2025-05-10','2025-05-11', '2025-05-12'],
dtype='datetime64[ns]', freq='D')df1 = pd.DataFrame(np.random.randn(6,4),index=dates,columns=['a','b','c','d'])a b c d
2025-05-07 1.707762 1.067165 -0.030727 -0.501342
2025-05-08 -0.743115 -0.543604 0.591870 -1.422352
2025-05-09 0.418383 -1.863935 -1.131557 -0.529528
2025-05-10 1.242757 -0.054061 1.878575 1.810151
2025-05-11 -0.392040 -0.467716 -1.235588 0.007852
2025-05-12 -1.293517 0.573971 0.913581 -0.293789# 默认状态下的DataFrame的(第一)横竖栏
df2 = pf.DataFrame(np.arange(12).reshape((3,4)))0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11# 用字典生成DataFramedf3 = pd.DataFrame({'A':1,'B':pd.Timestamp('20252507'),'C':pd.Series(1,index=list(range(4)),dtype='float32')'D':np.array([3]*4,dtype='int32'),'E':pd.Categorical(["test","train","test","train"]),'F':'foo'
})A B C D E F
0 1 2025-05-07 1.0 3 test foo
1 1 2025-05-07 1.0 3 train foo
2 1 2025-05-07 1.0 3 test foo
3 1 2025-05-07 1.0 3 train foo
DataFrame的属性
# 输出每一列的属性
print(df3.dtypes)A int64
B datetime64[s]
C float32
D int32
E category
F object
dtype: object# 输出所有行的名字
print(df2.index)
RangeIndex(start=0, stop=3, step=1)# 输出所有的列的名字
print(df2.columns)
RangeIndex(start=0, stop=4, step=1)# 输出所有的values
print(df2.values)
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])# 处理表中的一些数学运算
print(df2.describe())0 1 2 3
count 3.0 3.0 3.0 3.0
mean 4.0 5.0 6.0 7.0
std 4.0 4.0 4.0 4.0
min 0.0 1.0 2.0 3.0
25% 2.0 3.0 4.0 5.0
50% 4.0 5.0 6.0 7.0
75% 6.0 7.0 8.0 9.0
max 8.0 9.0 10.0 11.0# 转置
print(df2.T)0 1 2
0 0 4 8
1 1 5 9
2 2 6 10
3 3 7 11# 排序
print(df2.sort_index(axis=1,ascending=False))>>> df2.sort_index(axis=1,ascending=False)3 2 1 0
0 3 2 1 0
1 7 6 5 4
2 11 10 9 8
>>> df20 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11>>> df2.sort_index(axis=0,ascending=False)0 1 2 3
2 8 9 10 11
1 4 5 6 7
0 0 1 2 3
>>> df20 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11# 排序value
print(df3.sort_values(by='E))A B C D E F
0 1 2025-05-07 1.0 3 test foo
2 1 2025-05-07 1.0 3 test foo
1 1 2025-05-07 1.0 3 train foo
3 1 2025-05-07 1.0 3 train foo
选择数据
import pandas as pd
import numpy as npdates = pd.date_range('20250507',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])# 直接索引(列)print(df["A"])
print(df.A)2025-05-07 0
2025-05-08 4
2025-05-09 8
2025-05-10 12
2025-05-11 16
2025-05-12 20
Freq: D, Name: A, dtype: int64# 切片 (行)
print(df[0:3])
print(df['20250507':'202505010']) # 左闭右闭A B C D
2025-05-07 0 1 2 3
2025-05-08 4 5 6 7
2025-05-09 8 9 10 11# select by loc
# , 前面挑选行,‘,’后面挑选列
print(df.loc['20250507']) #打印一行
print(df.loc[:,'A']) # 打印一列
print(df.loc['20250507','B'])# select by position:iloc
# 这里的用法和上面差不多,只不过将索引变成了数字
print(df.iloc[1,2])# mixed selection:ix
# 上面两种的混合使用# Boolean indexing
print(df)
print(df[df.A > 8])>>> dfA B C D
2025-05-07 0 1 2 3
2025-05-08 4 5 6 7
2025-05-09 8 9 10 11
2025-05-10 12 13 14 15
2025-05-11 16 17 18 19
2025-05-12 20 21 22 23
>>> df[df.A >8]A B C D
2025-05-10 12 13 14 15
2025-05-11 16 17 18 19
2025-05-12 20 21 22 23
>>>设置值
import pandas as pd
import numpy as npdates = pd.date_range('20250507',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])# 使用数据的选择来改变df.iloc[2,2] = 1111
df.loc['20250506','B'] = 22222# 这样是更改一行
df[df.A>0] = 0# 更改一个,A这一列符合条件的元素将会被更改
df.A[df.A>4] = 0# 定义一个空列
df['F'] = np.nan# 添加一个列
df['E'] = pd.Series([1,2,3,4,5,6],index=pd.date_range('20250507',periods=6))A B C D (1, 1) F E
2025-05-07 0 1 2 3 1111 NaN 1
2025-05-08 4 100 6 7 1111 NaN 2
2025-05-09 8 9 10 11 1111 NaN 3
2025-05-10 12 13 14 15 1111 NaN 4
2025-05-11 16 17 18 19 1111 NaN 5
2025-05-12 20 21 22 23 1111 NaN 6
处理丢失数据
import pandas as pd
import numpy as npdates = pd.date_range('20250507',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])>>> df.iloc[0,1] = np.nan
>>> df.iloc[1,2] = np.nan
>>> dfA B C D
2025-05-07 0 NaN 2.0 3
2025-05-08 4 5.0 NaN 7
2025-05-09 8 9.0 10.0 11
2025-05-10 12 13.0 14.0 15
2025-05-11 16 17.0 18.0 19
2025-05-12 20 21.0 22.0 23# dropna 的使用(丢掉)print(df.dropna(axis=1,how='any'))>>> df.dropna(axis=1,how='any')A D
2025-05-07 0 3
2025-05-08 4 7
2025-05-09 8 11
2025-05-10 12 15
2025-05-11 16 19
2025-05-12 20 23# axis=1 丢失含nan的列
# how={'any','all'}# 将没有数据的位置填上默认print(df.fillna(value=0))>>> df.fillna(value=0)A B C D
2025-05-07 0 0.0 2.0 3
2025-05-08 4 5.0 0.0 7
2025-05-09 8 9.0 10.0 11
2025-05-10 12 13.0 14.0 15
2025-05-11 16 17.0 18.0 19
2025-05-12 20 21.0 22.0 23# 检查有没有丢失数据print(df,.isnull())>>> df.isnull()A B C D
2025-05-07 False True False False
2025-05-08 False False True False
2025-05-09 False False False False
2025-05-10 False False False False
2025-05-11 False False False False
2025-05-12 False False False Falseprint(np.any(df.isnull()) == True)
pandas的导入导出
读取文件
- read_csv
- read_excel
- read_hdf
- read_sql
- read_json
- read_msgpack
- read_html
- read_gbq
- read_stata
- read_sas
- read_clipboard
- read_pickle
保存数据
- to_csv
- to_excel
- to_hdf
- to_sql
- to_json
- to_msgpack
- to_html
- to_gbq
- to_stata
- to_clipboard
- to_pickle
import pandas as pddata = pd.read_csv('文件名')data.to_csv('文件名')
合并
import pandas as pd
import numpy as np# concatenating 以及它的参数df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])# concat
>>> res = pd.concat([df1,df2,df3],axis=0,ignore_index=True)
>>> resa b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 2.0 2.0 2.0 2.0
7 2.0 2.0 2.0 2.0
8 2.0 2.0 2.0 2.0# join,[inner','outer']df4 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df5 = pd.DataFrame(np.ones((3,4))*1,columns=['b','c','d','e'],index=[2,3,4])# 如果直接合并,join默认是 outer
res1 = pd.conct([df1,df2])>>> res1 = pd.concat([df4,df5])
>>> res1a b c d e
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 0.0 0.0 0.0 0.0 NaN
2 NaN 1.0 1.0 1.0 1.0
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0>>> res2 = pd.concat([df4,df5],join='inner',ignore_index=True)
>>> res2b c d
0 0.0 0.0 0.0
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 1.0 1.0 1.0
4 1.0 1.0 1.0
5 1.0 1.0 1.0# _append
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'],index=[2,3,4])>>> res = df1._append(df2,ignore_index=True)
>>> resa b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
merge
>>> import pandas as pd
>> left = pd.DataFrame({'key':['K0','K1','K2','K3'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})
>> right = pd.DataFrame({'key':['K0','K1','K2','K3'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})# merging two df by key/keys
>>> res = pd.merge(left,right,on='key')
>>> reskey A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3# consider two keysleft1 = pd.DataFrame({'key1':['K0','K0','K1','K2'],'key2':['K0','K1','K0','K1'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})right1 = pd.DataFrame({'key1':['K0','K1','K1','K2'],'key2':['K0','K0','K0','K0'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})>>> res = pd.merge(left1,right1,on=['key1','key2'])
>>> reskey1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
>>> left1key1 key2 A B
0 K0 K0 A0 B0
1 K0 K1 A1 B1
2 K1 K0 A2 B2
3 K2 K1 A3 B3
>>> right1key1 key2 C D
0 K0 K0 C0 D0
1 K1 K0 C1 D1
2 K1 K0 C2 D2
3 K2 K0 C3 D3# how=['left','right','out','inner']
# left ---> 基于left 的key来填充# indicator -----> 显示怎么合并的# left_index and right_index>>> res1 = pd.merge(left,right,left_index=True,right_index=True,how='outer')
>>> res1key_x A B key_y C D
0 K0 A0 B0 K0 C0 D0
1 K1 A1 B1 K1 C1 D1
2 K2 A2 B2 K2 C2 D2
3 K3 A3 B3 K3 C3 D3
plot
>>> import pandas as pd
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> data = pd.Series(np.random.randn(1000),index=np.arange(1000))
>>> data = data.cumsum()
>>> data.plot()
>>> plt.show()
相关文章:

numpy pandas
视频链接 numpy numpy是基于一个矩阵的运算 矩阵的属性 import numpy as np# 把一个列表转换成矩阵的方法 array np.array([[1,2,3],[3,4,5]])# 打印矩阵 print(array)# 维度 print(number of dim:,array.ndim)# 行数和列数 print(shape:,array.shape)# 总共有多少个元素在…...

Amazon Redshift 使用场景解析与最佳实践
作为 AWS 云上数据仓库服务的核心成员,Amazon Redshift 凭借其高性能、可扩展性与经济性,正在成为越来越多企业实现数据驱动决策的首选方案。本文将解析 Redshift 的典型使用场景,并分享几项实用的落地最佳实践,帮助企业在数据仓库…...

STM32F446 RTC在VDD/VDDA关闭后失振问题的分析与解决
【原创】STM32F446 RTC在VDD/VDDA关闭后失振问题的分析与解决 作者: 思考的味道[你的ID] | weix_42368227 版权声明: 禁止未经授权转载 1. 问题描述 在某低功耗STM32F446项目中,采用以下供电方案: VDD:由DC-DC 3.3V提供(主电源…...
整合配置的详细步骤)
SSM框架(Spring + Spring MVC + MyBatis)整合配置的详细步骤
以下是 SSM框架(Spring Spring MVC MyBatis)整合配置的详细步骤,适用于 Maven 项目。 (一)、pom.xml中添加相关依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"ht…...
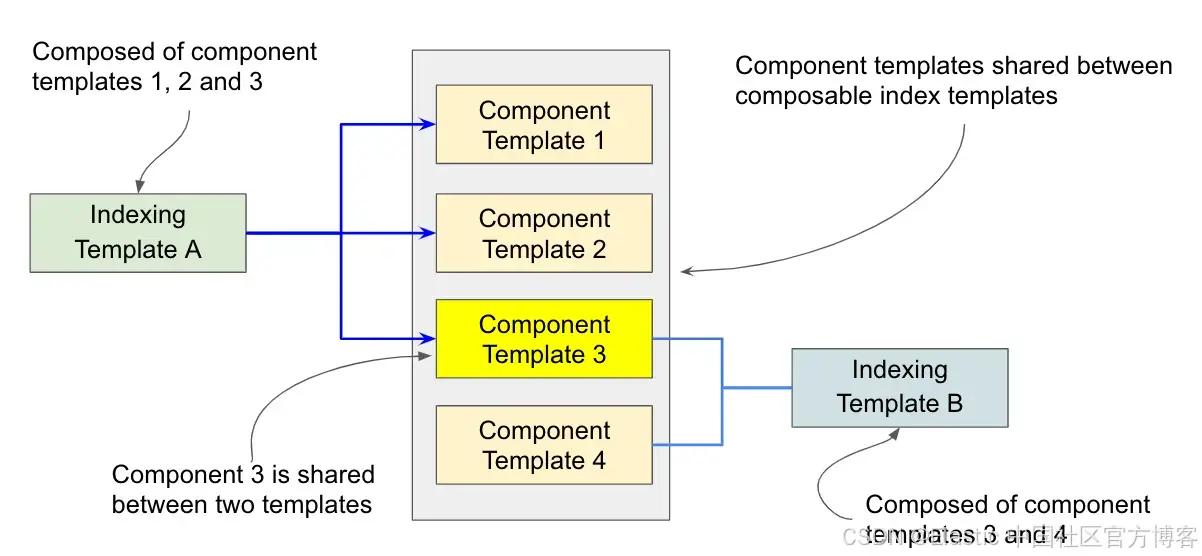
Elasticsearch 中的索引模板:如何使用可组合模板
作者:来自 Elastic Kofi Bartlett 探索可组合模板以及如何创建它们。 更多阅读: Elasticsearch:可组合的 Index templates - 7.8 版本之后 想获得 Elastic 认证吗?查看下一期 Elasticsearch Engineer 培训的时间! El…...
内存分配和释放原理)
内存泄漏系列专题分析之七:高通相机CamX--Android通用ION(dmabuf)内存分配和释放原理
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:内存泄漏系列专题分析之六:高通camx 内存泄漏测试的未回收问题分析 这一篇我们开始讲:内存泄漏系列专题分析之七:高通相机CamX--Android通用ION(dmabuf)内存分配和释放原理 目录 一、背景 二、…...

【LeetCode 42】接雨水(单调栈、DP、双指针)
题面: 思路: 能接雨水的点,必然是比两边都低(小)的点。有两种思路,一种是直接计算每个点的最大贡献(也就是每个点在纵向上最多能接多少水),另一种就是计算每个点在横向上…...
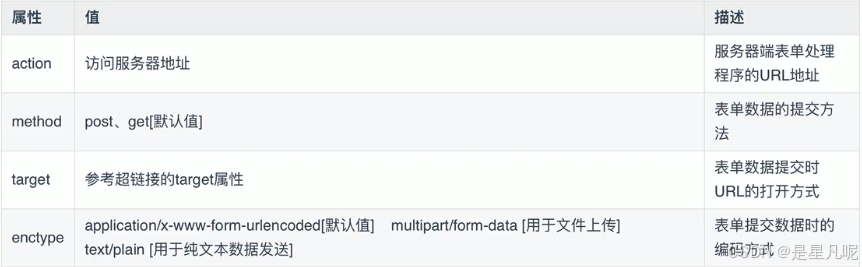
【JS逆向基础】前端基础-HTML与CSS
1,flask框架 以下是一个使用flask框架写成的serve程序 # noinspection PyUnresolvedReferences #Flash框架的基本内容from flask import Flask app Flask(__name__)app.route(/index) def index():return "hello index"app.route(/login) def login():re…...

什么是HTML、CSS 和 JavaScript?
HTML、CSS 和 JavaScript 是构建网页的三大核心技术,它们分工明确又紧密协作。接下来我将分别介绍三者的定义、功能,并阐述它们如何共同构成网页,最后推荐学习资源。 一、HTML:网页的骨架与内容基础 HTML(HyperText …...

手机网页提示ip被拉黑名单什么意思?怎么办
当您使用手机浏览网页时,突然看到“您的IP地址已被列入黑名单”的提示,是否感到困惑和不安?这种情况在现代网络生活中并不罕见,但确实会给用户带来诸多不便。本文将详细解释IP被拉黑的含义、常见原因,并提供一系列实…...

CCF编程能力等级认证 一级 第一次课
介绍 CCF 编程能力等级认证(GESP)为青少年计算机和编程学习者提供学业能力验证的规则和平台,由中国计算机学会发起并主办。 每年考试分四次,时间是每年的3月、6月、9月、12月,以当年每期公布的时间为准。 GESP适用年…...

SpringBoot 讯飞星火AI WebFlux流式接口返回 异步返回 对接AI大模型 人工智能接口返回
介绍 用于构建基于 WebFlux 的响应式 Web 应用程序。集成了 Spring WebFlux 模块,支持响应式编程模型,构建非阻塞、异步的 Web 应用。WebFlux 使用了非阻塞的异步模型,能够更好地处理高并发请求。适合需要实时数据推送的应用场景。 WebClie…...

Python爬虫中time.sleep()与动态加载的配合使用
一、动态加载网页的挑战 动态加载网页是指网页的内容并非一次性加载完成,而是通过JavaScript等技术在用户交互或页面加载过程中逐步加载。这种设计虽然提升了用户体验,但对于爬虫来说,却增加了抓取的难度。传统的爬虫方法,如简单…...

学习Cesium Entities
🌐 Cesium中的Entities系统趣味学习 📊 Entities系统架构流程图 #mermaid-svg-Lkue5O3gYOkEVSbD {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Lkue5O3gYOkEVSbD .error-icon{fill:#552222;}#mermaid-svg-Lku…...

如何减少锁竞争并细化锁粒度以提高 Rust 多线程程序的性能?
在并发编程中,锁(Lock)是一种常用的同步机制,用于保护共享数据免受多个线程同时访问造成的竞态条件(Race Condition)。然而,不合理的锁使用会导致严重的性能瓶颈,特别是在高并发场景…...

Logback官方文档翻译章节目录
Logback官方文档翻译章节目录 第一章 Logback简介 第二章 Logback的架构(一) Logback的架构(二) Logback的架构(三) 持续更新中…...

AtCoder Beginner Contest 404 A-E 题解
还是ABC好打~比ARC好打多了( 题解部分 A - Not Found 给定你一个长度最大25的字符串,任意输出一个未出现过的小写字母 签到题,map或者数组下标查询一下就好 #include<bits/stdc.h>using namespace std;#define int long long #def…...
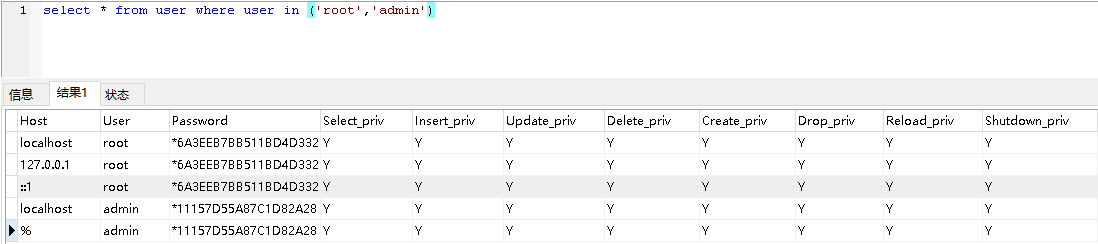
【mysql】常用命令
一 系统mysql用户密码查询 1、在工程目录如/usr/local/httpd/下的*.php中查找类似有db.inf的文件 以php为例。 2、在代码文件中确认有数据库连接的的功能实现 例如: $dbconf parse_ini_file(/usr/local/httpd/conf/db.inf); $link mysql_connect($dbconf[d…...
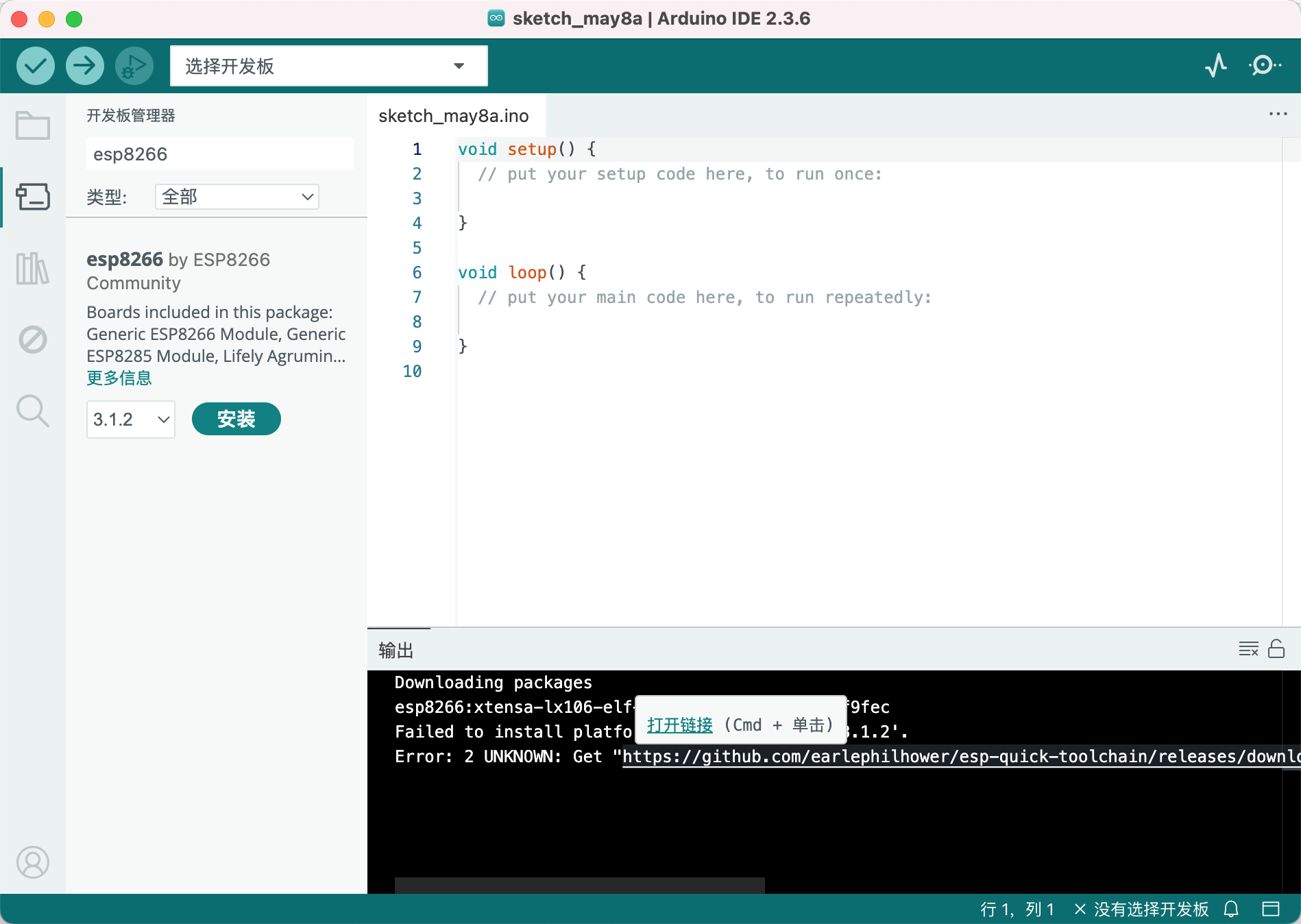
macOS Arduino IDE离线安装ESP8266支持包
其实吧,本来用platformio也是可以的,不过有时候用Arduino IDE可能更快一些,因为以前一直是Arduino.app和Arduino IDE.app共存了一段时间,后来下决心删掉Arduino.app并升级到最新的Arduino IDE.app。删除了旧的支持板级支持包之后就…...
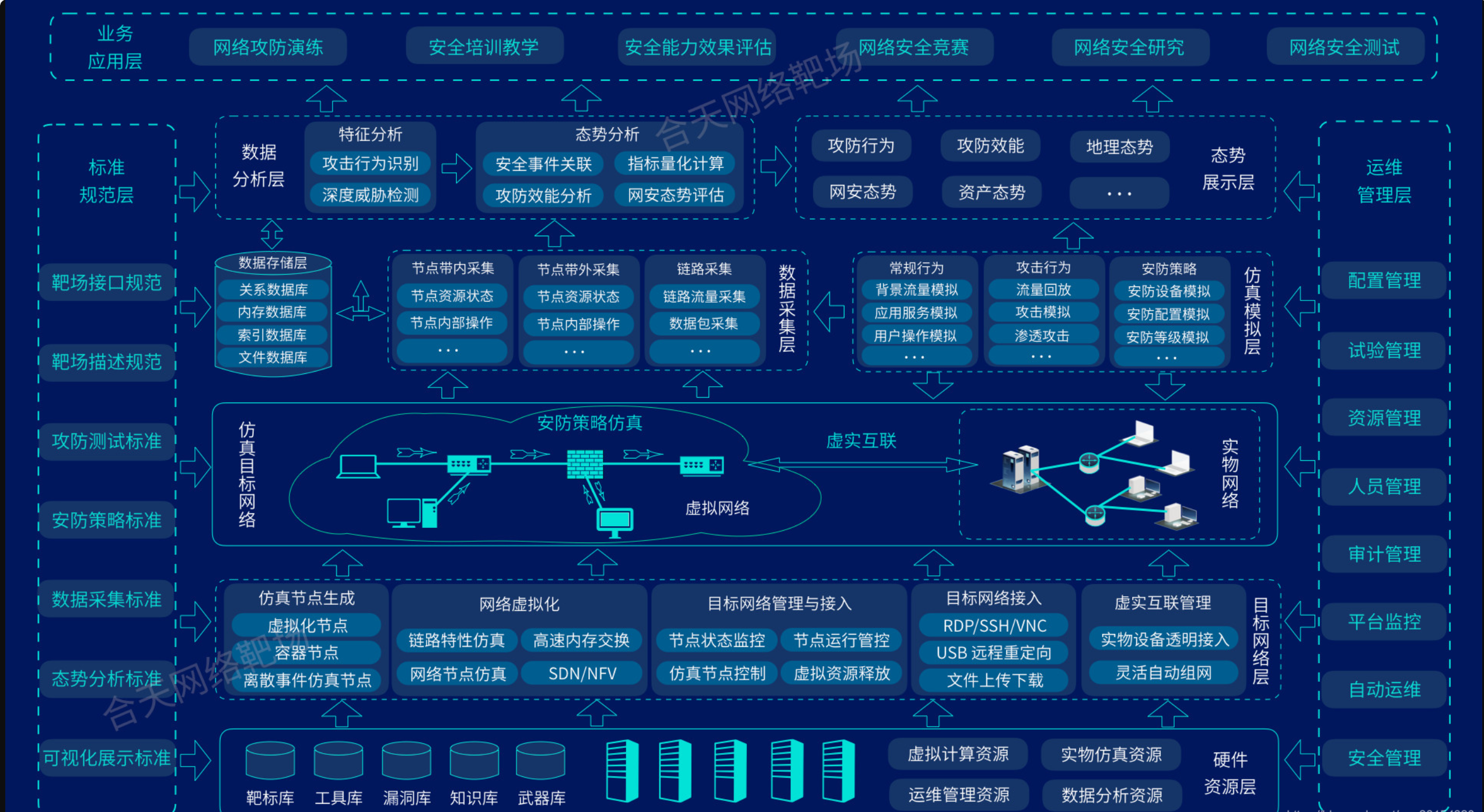
网络靶场基础知识
一、网络靶场的核心概念 网络靶场(Cyber Range)是一种基于虚拟化和仿真技术的网络安全训练与测试平台,通过模拟真实网络环境和业务场景,为攻防演练、漏洞验证、安全测试和人才培养提供安全可控的实验空间。其核心目标是通过“虚实…...

基于Partial Cross Entropy的弱监督语义分割实战指南
一、问题背景:弱监督学习的挑战 在计算机视觉领域,语义分割任务面临最大的挑战之一是**标注成本**。以Cityscapes数据集为例,单张图像的像素级标注需要约90分钟人工操作。这催生了弱监督学习(Weakly Supervised Learning)的研究方向,其中partial cross entropy loss(部…...

【算法基础】选择排序算法 - JAVA
一、算法基础 1.1 什么是选择排序 选择排序是一种简单直观的排序算法,它的工作原理是:首先在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后再从剩余未排序元素中继续寻找最小…...

电商平台的流量秘密:代理IP在用户行为分析中的角色
在电商江湖中,流量是氧气,用户行为数据是DNA。当你在电商平台点击商品、加入购物车时,背后有一套精密的系统正在分析你的每个动作。而在这套系统的运作中,代理IP正扮演着"隐形推手"的角色——它既是数据采集的"隐身…...

批量清洗与修改 YOLO 标签:删除与替换指定类别
在使用 YOLO 格式的数据进行训练或部署前,常常需要对标签文件进行清洗或修改。本文整理了两种常见场景的 Python 脚本:删除指定类别 和 修改某类为其他类,并支持自动打印检测到该类别的文件名,帮助你快速定位问题数据。 …...
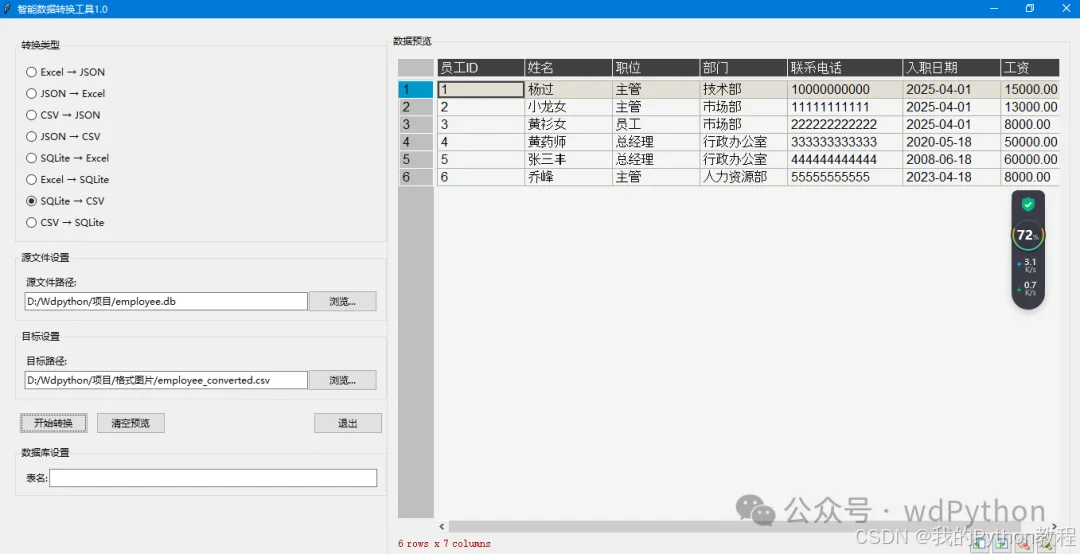
Python项目源码57:数据格式转换工具1.0(csv+json+excel+sqlite3)
1.智能路径处理:自动识别并修正文件扩展名,根据转换类型自动建议目标路径,实时路径格式验证,自动补全缺失的文件扩展名。 2.增强型预览功能:使用pandastable库实现表格预览,第三方模块自己安装一下&#x…...

TypeScript 中,属性修饰符
在 TypeScript 中,属性修饰符(Property Modifiers)是用于修饰类的属性或方法的关键字,它们可以改变属性或方法的行为和访问权限。TypeScript 提供了三种主要的属性修饰符:public、private 和 protected。此外ÿ…...
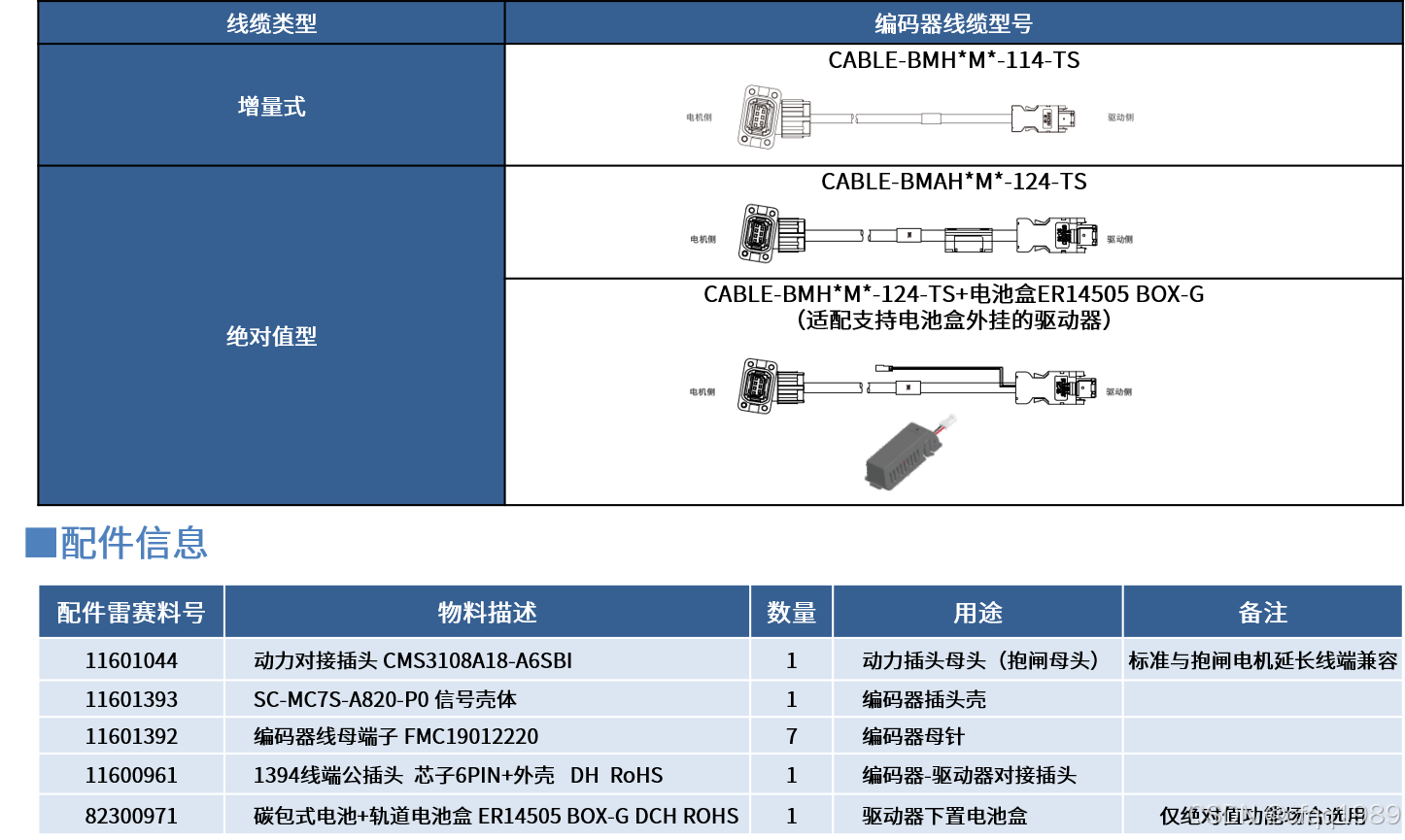
雷赛伺服电机
ACM0经济 编码器17位: ACM1基本 编码器23位磁编, ACM2通用 编码器24位光电, 插头定义:...

基础编程题目集 6-8 简单阶乘计算
本题要求实现一个计算非负整数阶乘的简单函数。 函数接口定义: int Factorial( const int N ); 其中N是用户传入的参数,其值不超过12。如果N是非负整数,则该函数必须返回N的阶乘,否则返回0。 裁判测试程序样例: #in…...

【deepseek教学应用】001:deepseek如何撰写教案并自动实现word排版
本文讲述利用deepseek如何撰写教案并自动实现word高效完美排版。 文章目录 一、访问deepseek官网二、输入教案关键词三、格式转换四、word进一步排版 一、访问deepseek官网 官网:https://www.deepseek.com/ 进入主页后,点击【开始对话】,如…...
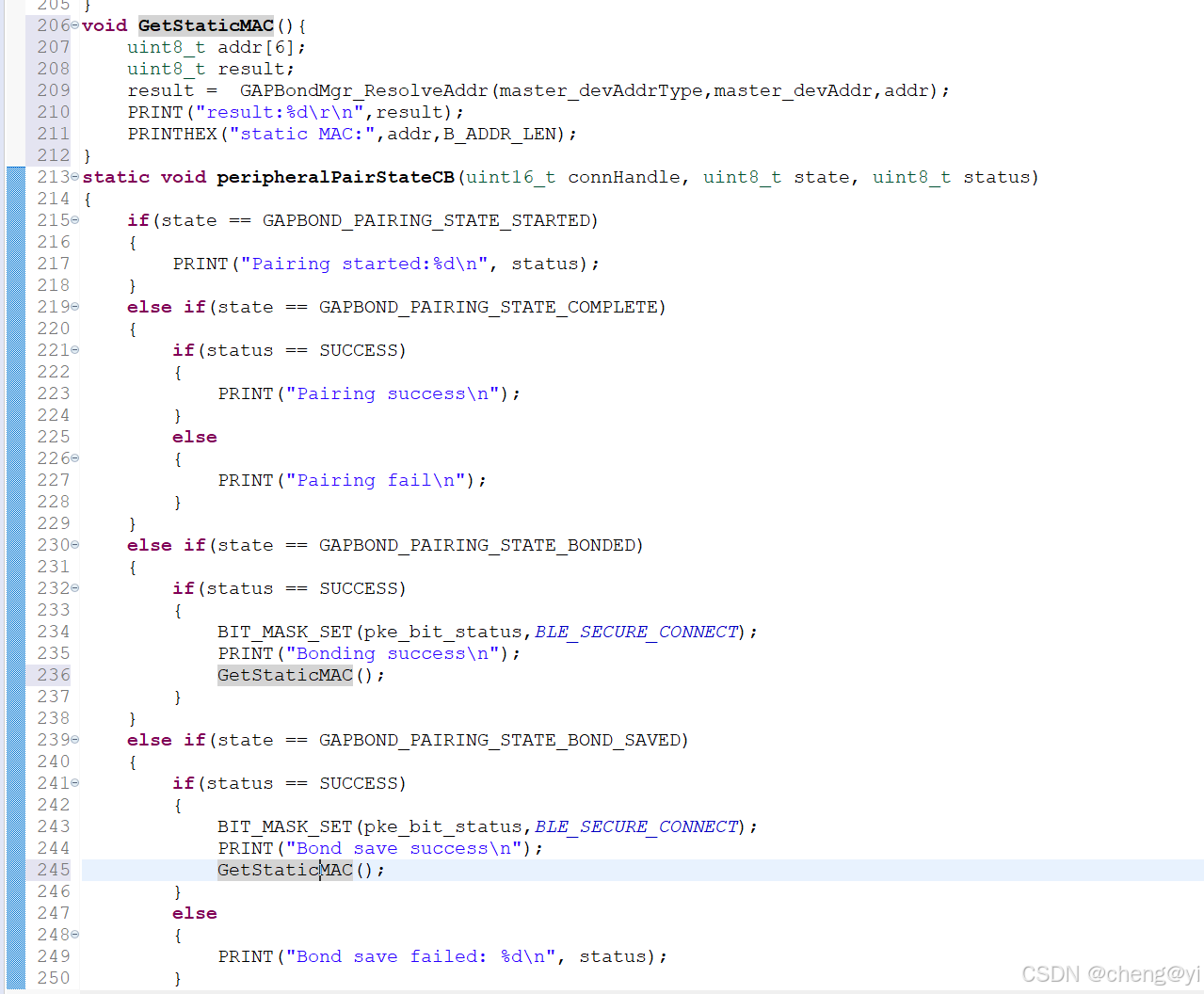
CH32V208GBU6沁恒绑定配对获取静态地址
从事嵌入式单片机的工作算是符合我个人兴趣爱好的,当面对一个新的芯片我即想把芯片尽快搞懂完成项目赚钱,也想着能够把自己遇到的坑和注意事项记录下来,即方便自己后面查阅也可以分享给大家,这是一种冲动,但是这个或许并不是原厂希望的,尽管这样有可能会牺牲一些时间也有哪天原…...