python基础:序列和索引-->Python的特殊属性
一.序列和索引
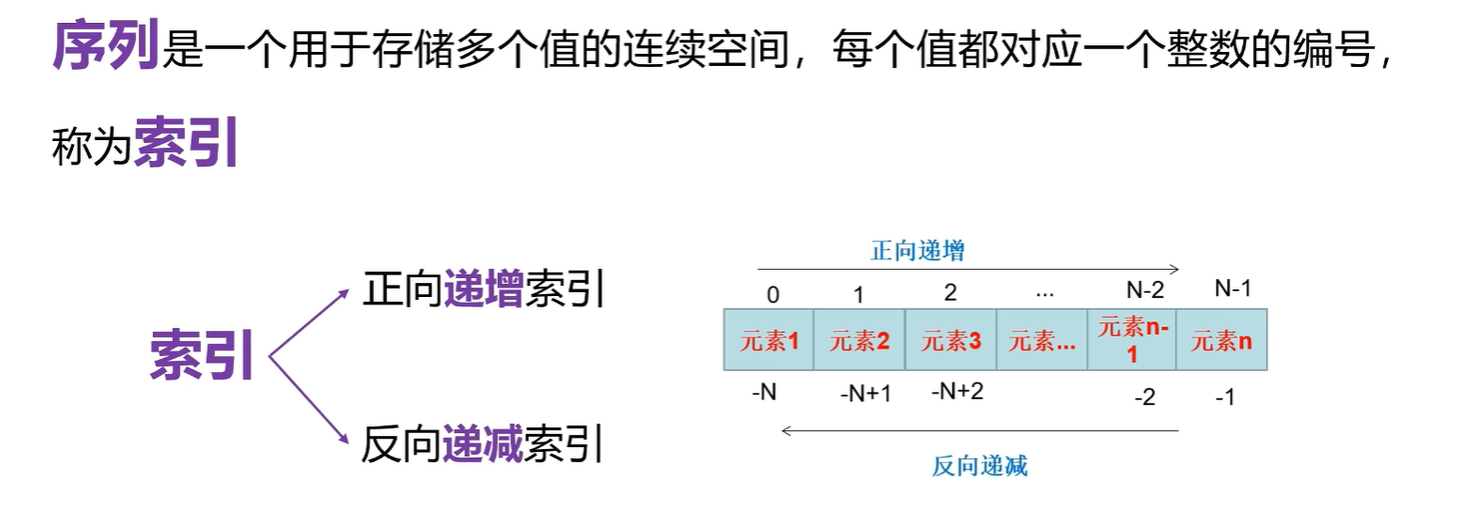
1.1 用索引检索字符串中的元素
# 正向递增
s='helloworld'
for i in range (0,len(s)):# i是索引print(i,s[i],end='\t\t')
print('\n--------------------------')
# 反向递减
for i in range (-10,0):print(i,s[i],end='\t\t')print('\n--------------------------')
print('\n',s[9],s[-1])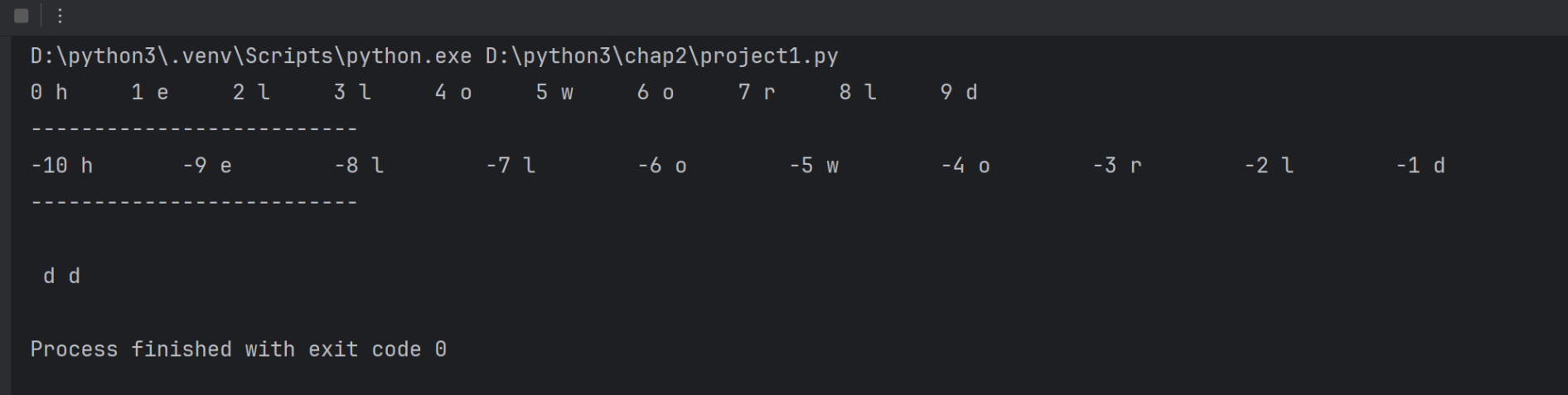
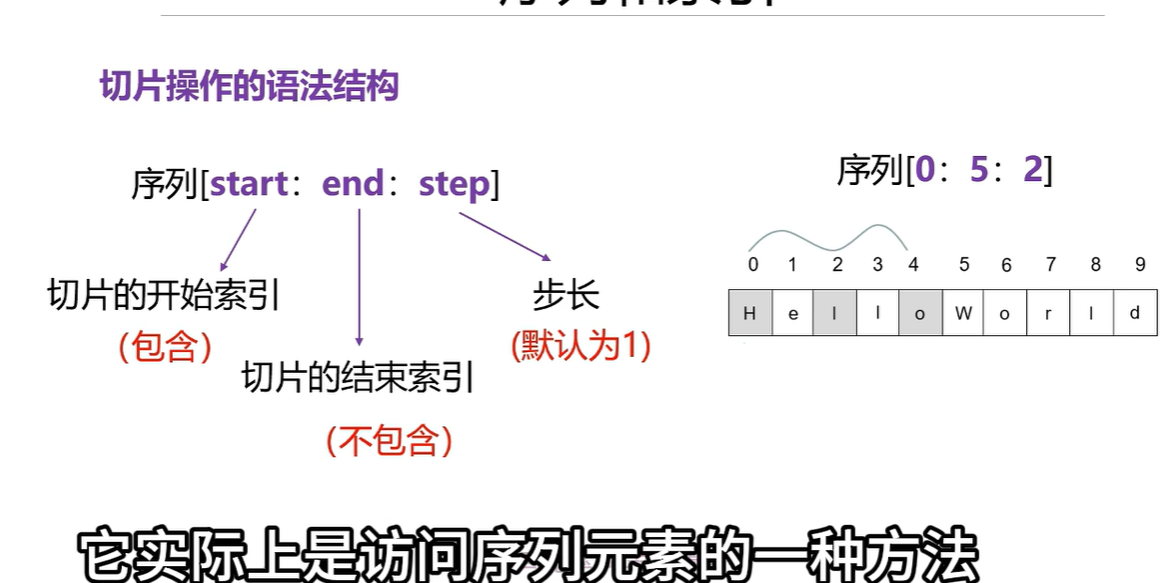
1.2通过切片操作可以获取一个新的序列(从0开始切到五不包含5,步长为2)
s='hello'
s2='world'
print(s+s2)#产生一个新的字符串序列
# 序列的相乘操作
print(s*5)
print('-'*40)
1.3序列的箱操作和函数的使用
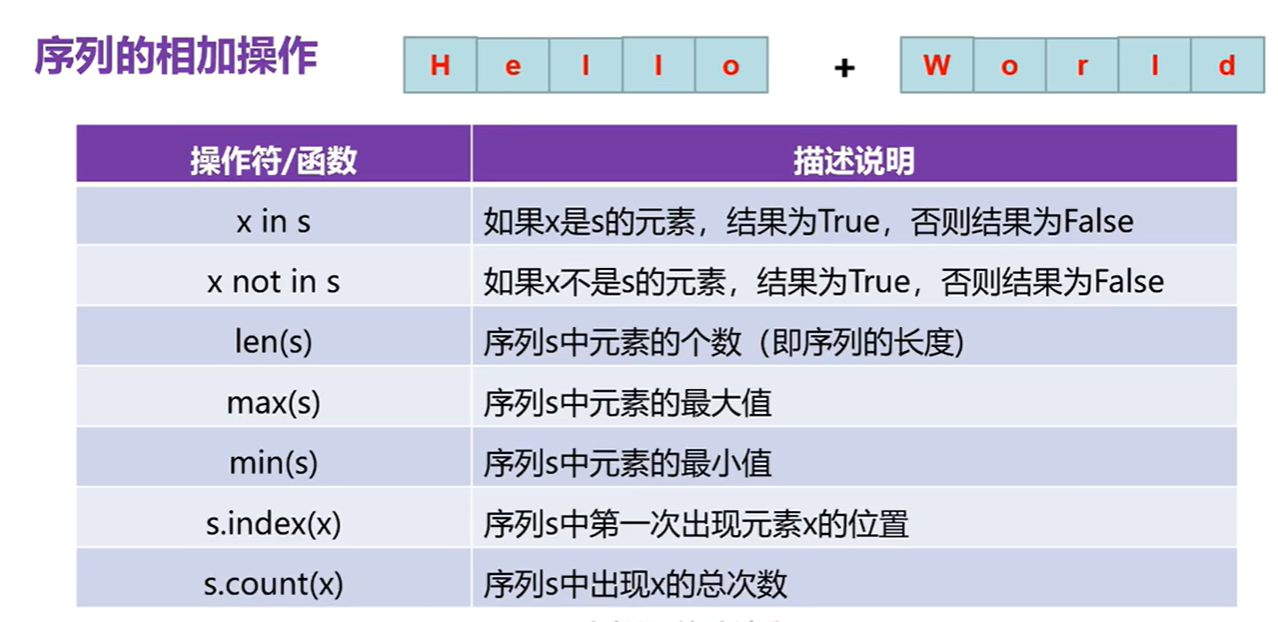
s='helloworld'
print('e在helloworld中存在吗',('e'in s))
print('e在helloworld中存在吗',('v'in s))#not in的使用
print('e在helloworld中存在吗',('e'not in s))# not in的使用
print('e在helloworld中存在吗',('v'not in s))#内置函数的使用
print('len()',len(s))
print('min(s)',min(s))
print('max(s)',max(s))# 序列对象的方法,使用序列的方法,打点调用
print('s.index():',s.index('o'))#o在s中第一次出现的索引位置4
print('s.count():',s.count('o'))#统计o在字符串之间的位置
二.列表的基本操作

列表名是自己取的变量名,列表与字符串一样,都是序列中的一种

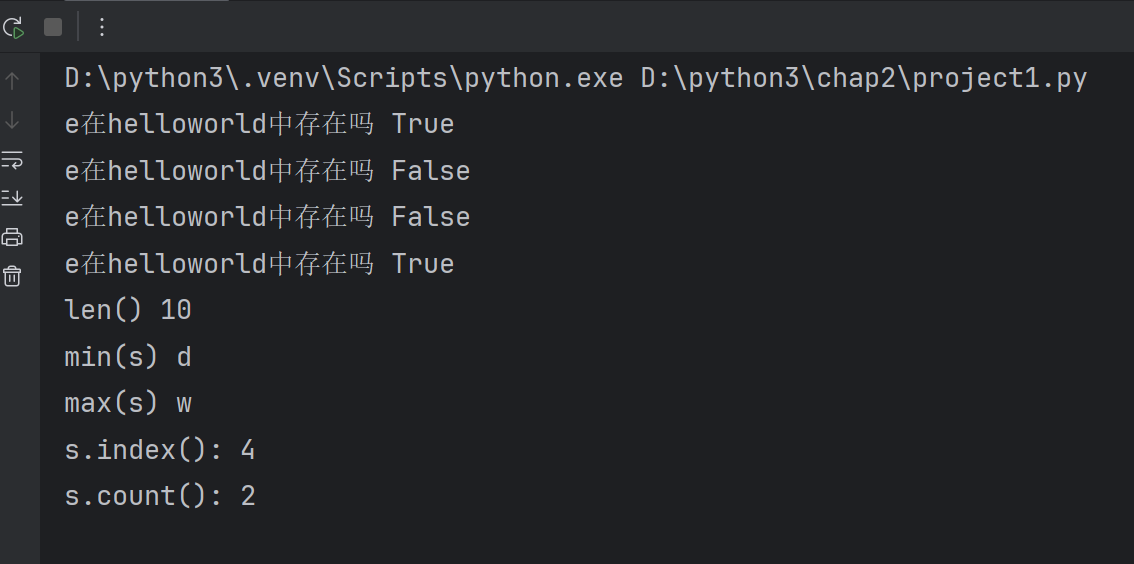
lst=['hello','world',98,100.5]
print(lst)
# 可以使用内置的函数list()创建列表
lst2=list('helloworld')
lst3=list(range(1,10,2))#从1开始到10结束,步长为2,不包含10,1、3、5、7、9
print(lst2)
print(lst3)#列表是序列中的一种,对列表的操作符,运算符,函数均可操作
print(lst+lst2+lst3)# 序列中的相加操作
print(lst*3)#序列的相乘操作
print(len(lst))
print(max(lst3))
print(min(lst3))print(lst2.count('o'))#统计o的个数
print(lst2.index('o'))# o在列表lst2中第一次的位置# 列表的删除操作
lst4=[10,20,30,40,50]
print(lst4)
# 删除列表
del lst4
#print(lst4)

列表的遍历操作
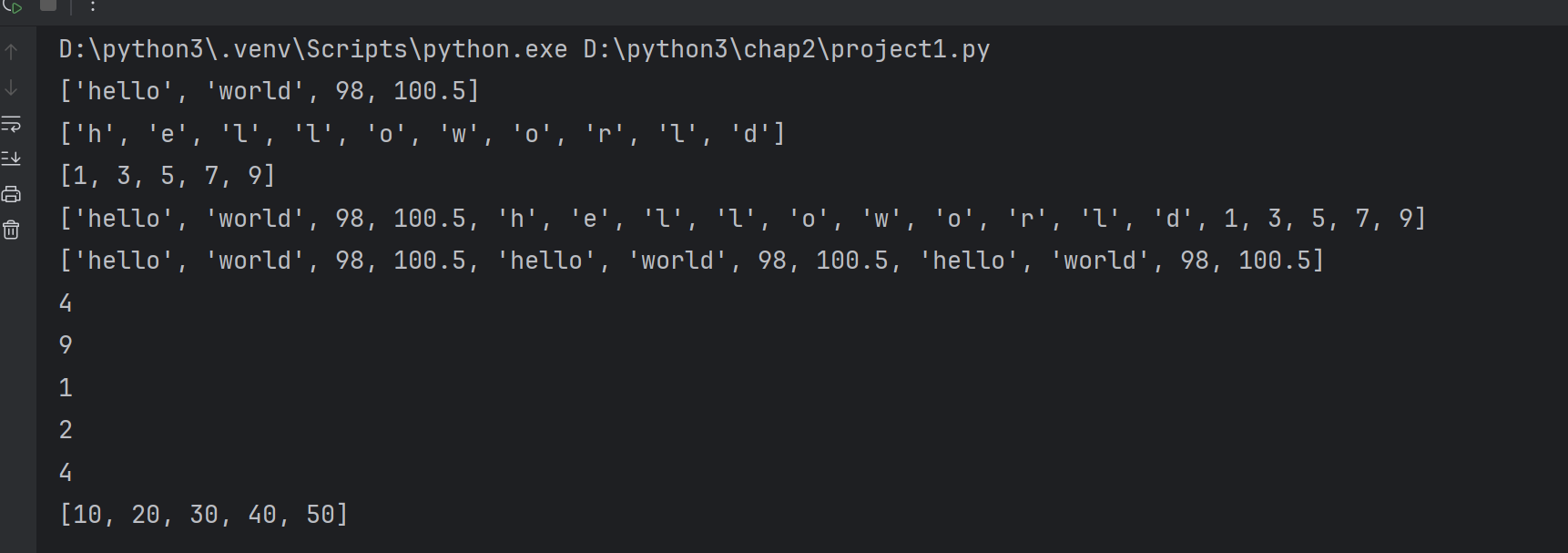
lst=['hello','world','python','php']
# for循环遍历元素
for item in lst:print(item)# 使用for循环,range()函数,len()函数,根据索引进行遍历
for i in range(0,len(lst)):print(i,'--->',lst[i])# 第三种遍历方式 enumerate()函数
for index,item in enumerate(lst):print(index,item)# index是序号,不是索引 元素
#手动修改序号的起始值
for index,item in enumerate(lst,start=1):#直接写1,start不写也可以print(index,item)
2.1列表特有操作

列表的相关操作
lst=['hello','world','python']
print('原列表',lst,id(lst))
#增加元素的操作
lst.append('sql')
print('增加元素之后',lst,id(lst))#使用insert(index,x)在指定的index位置上插入元素x
lst.insert(1,100)
print(lst)#列表元素的删除操作
lst.remove('python')
print('删除元素之后的列表',lst,id(lst))#使用pop(index)根据索引将元素取出,然后再删除
print(lst.pop(1))
print(lst)#清除列表中所有的元素clear()
# lst.clear()
# print(lst,id(lst))#列表的反向
lst.reverse()#不会产生新的列表,在原列表的基础上进行的
print(lst)# 列表的拷贝,将产生的一个新的列表对象
new_lst=lst.copy()
print(lst,id(lst))
print(new_lst,id(new_lst))#列表元素的修改操作
#根据索引进行修改元素
lst[1]='mysql'
print(lst)
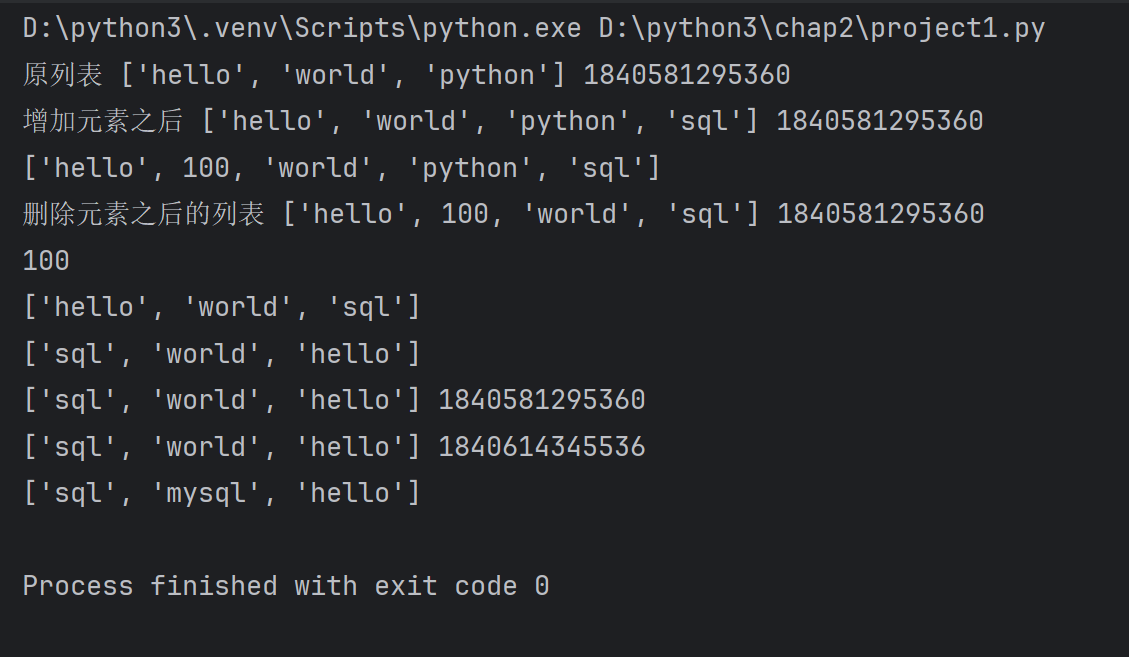
ctrl+?:注释
列表的排序操作
lst=[4,56,3,78,40,56,89]
print('原列表',lst)#排序,默认是升序
lst.sort()#排序是在原列表的基础上进行的,不会产生新的列表
print(lst)
print('升序',lst)#排序,降序
lst.sort(reverse=True)#大的在前小的在后
print('降序',lst)print('------------------------------')
lst2=['banana','apple','Cat','Orange']
print('原列表',lst2)
#升序排序,先排大写,再排小写 大写A 65,小写a 97
lst2.sort()#默认升序
print('升序',lst2)#降序,先排小写,后排大写
lst2.sort(reverse=True)
print('降序:',lst2)# 忽略大小写进行比较
lst2.sort(key=str.lower)# 参数不加括号,调用加括号
print(lst2)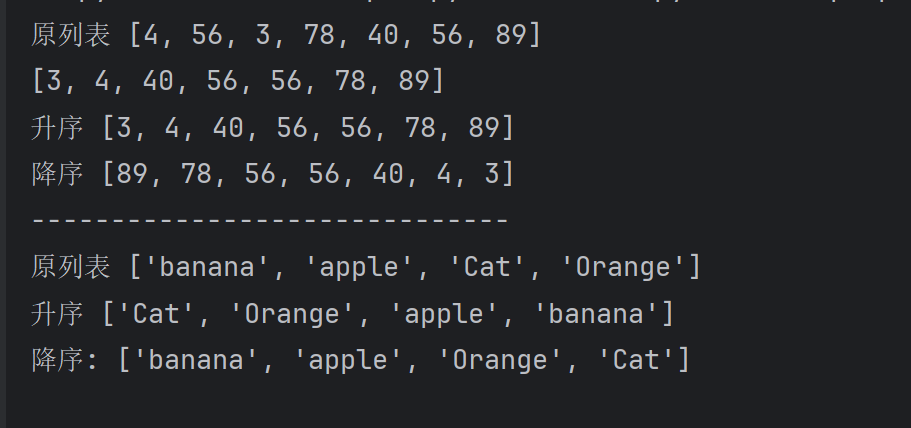
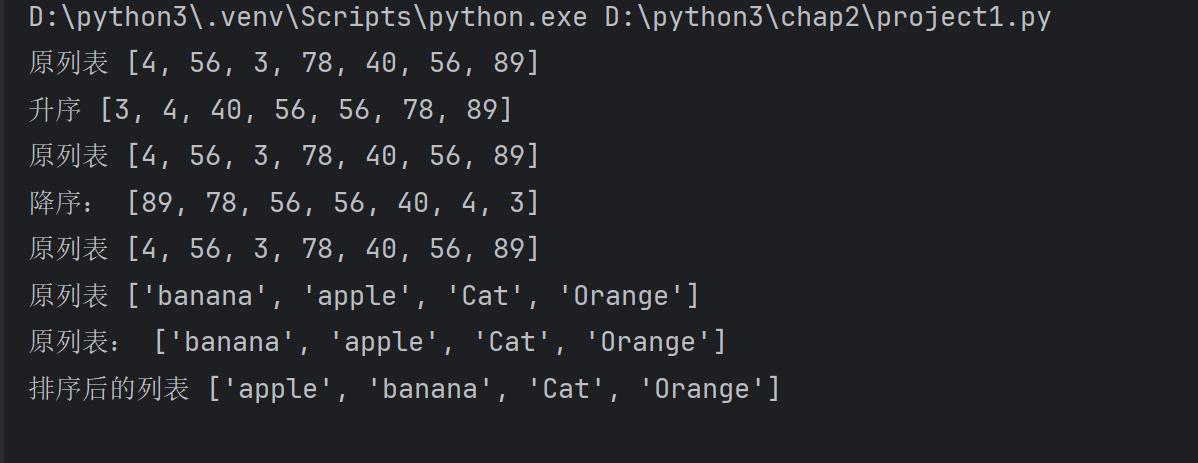
列表的排序sorted
lst=[4,56,3,78,40,56,89]
print('原列表',lst)#排序
asc_lst=sorted(lst)
print('升序',asc_lst)
print('原列表',lst)#降序
desc_lst=sorted(lst,reverse=True)
print('降序:',desc_lst)
print('原列表',lst)lst2=['banana','apple','Cat','Orange']
print('原列表',lst2)#忽略大小写进行排序
new_lst2=sorted(lst2,key=str.lower)
print('原列表:',lst2)
print('排序后的列表',new_lst2)#默认升序
2.2 列表的生成式及二维列表
2.2.1一维列表

列表生成式的使用
import random
lst=[item for item in range(1,11)]
print(lst)lst=[item*item for item in range(1,11)]
print(lst)lst=[random.randint(1,100) for _ in range(1,11)]
print(lst)# 从列表中选择符合条件的元素组成新的列表
lst=[i for i in range(10) if i%2==0 ]
print(lst)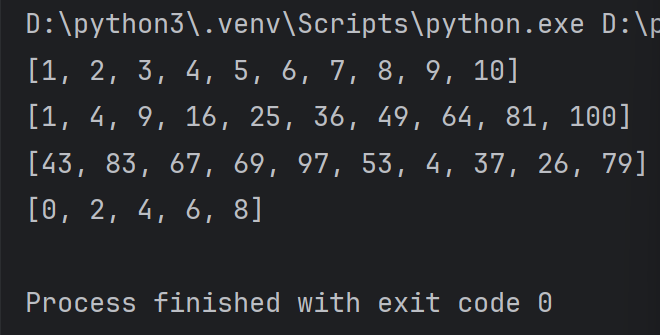
2.2.2 二维列表
二维列表的遍历及列表生成式
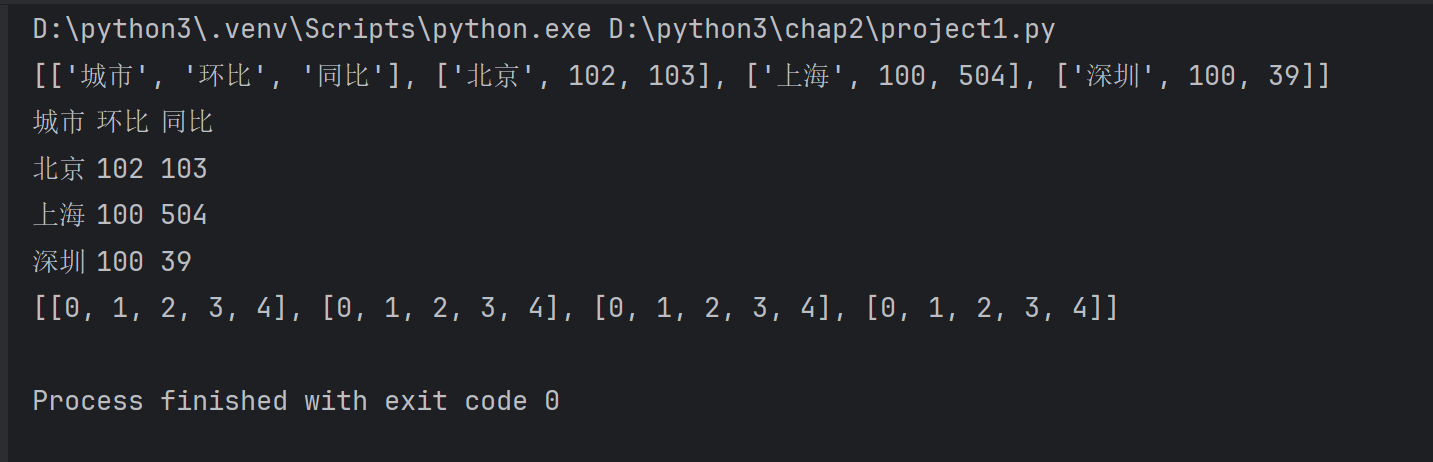
# 创建二维列表
lst=[['城市','环比','同比'],['北京',102,103],['上海',100,504],['深圳',100,39]
]
print(lst)#遍历二维列表使用双层for循环
for row in lst:#行for item in row:#列print(item,end='\t')print()#换行#列行生成式生成一个4行5列的二维列表
lst2=[[j for j in range(5)]for i in range(4)]
print(lst2)
2.3元组的创建与删除

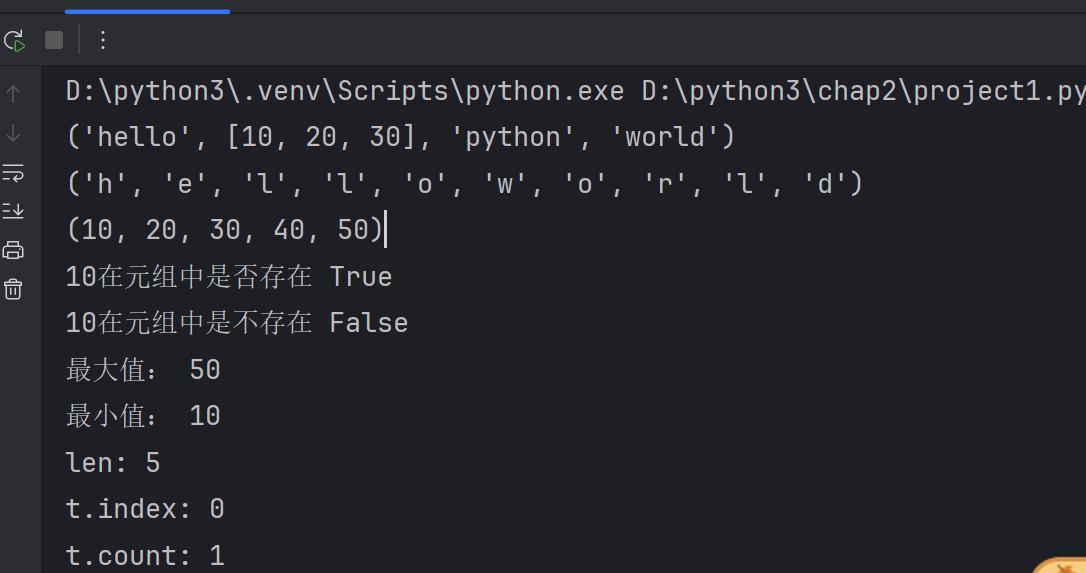
# 使用小括号创建元组
t=('hello',[10,20,30],'python','world')
print(t)# 使用内置函数tuple()创建元组
t=tuple('helloworld')
print(t)t=tuple([10,20,30,40,50])
print(t)print('10在元组中是否存在',(10 in t))
print('10在元组中是不存在',(10 not in t))
print('最大值:',max(t))
print('最小值:',min(t))
print('len:',len(t))
print('t.index:',t.index(10))
print('t.count:',t.count(10))#如果元组中只有一个元素
t=(10)
print(t,type(t))#如果元组只有一个元素,逗号不能省略
y=(10,)
print(y,type(y))#元组的删除
del t
#print(t)
2.4 元组元素的遍历和访问
t=('python','hello','world')
# 根据索引访问元组
print(t[0])
t2=t[0:3:2]#元组支持切片操作
print(t2)#元组的遍历
for item in t:print(item)# for+range()+len()
for i in range(len(t)):print(i,t[i])# 索引 根据索引获取到的元素# 使用enumerate
for index,item in enumerate(t):print(index,'----->',item)for index,item in enumerate(t,start=11): #序号从11开始print(index,'----->',item)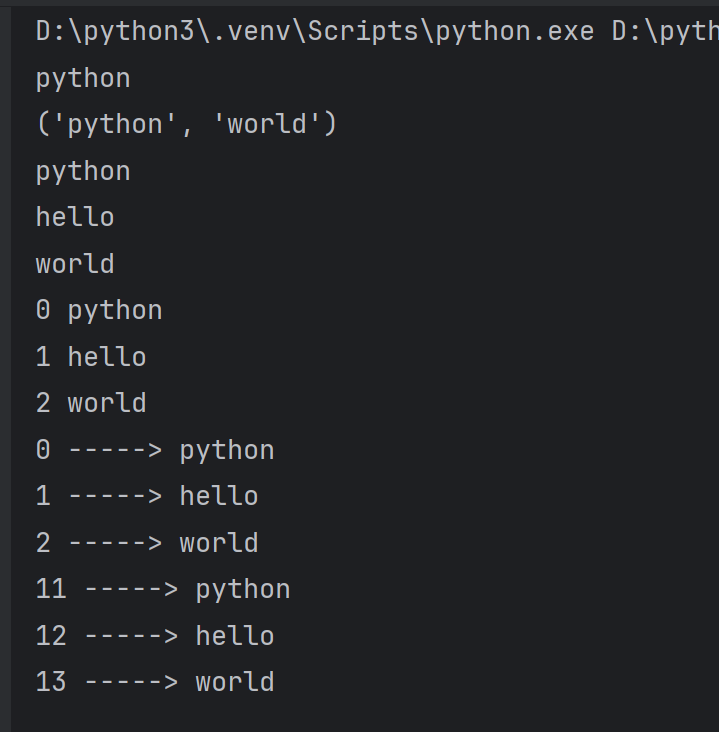
2.5 元组生成式
t=(i for i in range(1,4))
print(t)#t是生成器对象
# t=tuple(t)
# print(t)
#遍历
#for item in t:
# print(item)
print(t.__next__())
print(t.__next__())
print(t.__next__())t=tuple(t)
print(t)# 使用__next__()方法已经把生成器中的元素取出来了,里面没有元素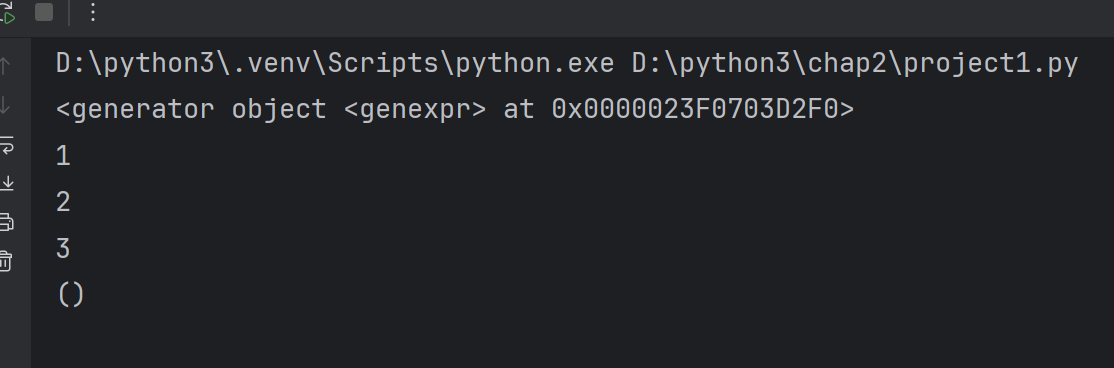
2.6 字典类型


2.6.1 字典的创建与删除
# 1.创建字典
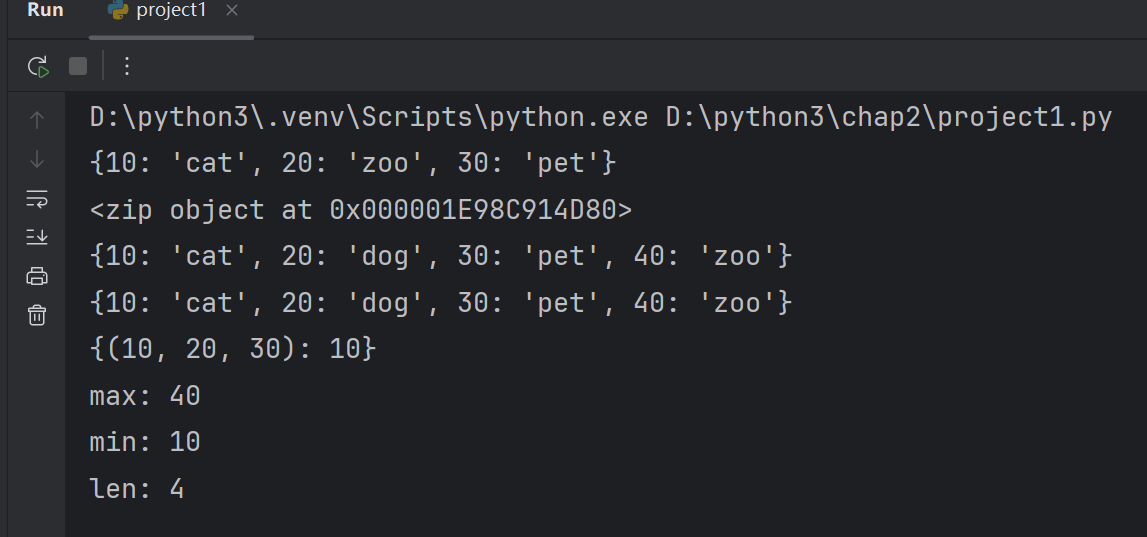
d={10:'cat',20:'dog',30:'pet',20:'zoo'}
print(d)# key相同时,value值进行覆盖# 2.zip函数
lst1=[10,20,30,40]
lst2=['cat','dog','pet','zoo','car']
zipobj=zip(lst1,lst2)
print(zipobj)#<zip object at 0x0000020A30625500>(zip映射对象,看不到里面内容)
#print(list(zipobj))zipobj映射对象里面的内容已经转成列表类型,不能再转成字典了
d=dict(zipobj)
print(d)#使用参数创建字典
d=dict(zip(lst1,lst2))# 左侧cat是key,右侧是value
print(d)t=(10,20,30)
print({t:10})# t是key,10是value,元组是可以作为字典中的key# lst=[10,20,30]#列表和元组目前的区别只是创建符号,元组使用小括号,列表使用方括号
# print(lst:10) SyntaxError: invalid syntax
#列表不可以去作为字典当中的键,列表是可变数据类型#字典属于序列
print('max:',max(d))
print('min:',min(d))
print('len:',len(d))#长度计算式字典当中元素的个数#字典的删除
del d
#print(d)删除之后就不能再使用了
字典中的key是无序的,解释器是帮忙处理了,所以有序
2.6.2 字典元素的访问和遍历

d={'hello':10,'world':20,'python':30}
# 访问字典中的元素
# 1.使用d[key]
print(d['hello'])
# 2. d.get(key)
print(d.get('hello'))# 二者之间是有区别的,如果key不存在,d[key]报错。get(key)
#print(d.['java']) SyntaxError: invalid syntax
print(d.get('java'))#None
print(d.get('java','不存在'))#字典的遍历
for item in d.items():print(item) # key=value组成的一个元组类型# 在使用for循环遍历时,分别获取key,value
for key,value in d.items():print(key,'----->',value)
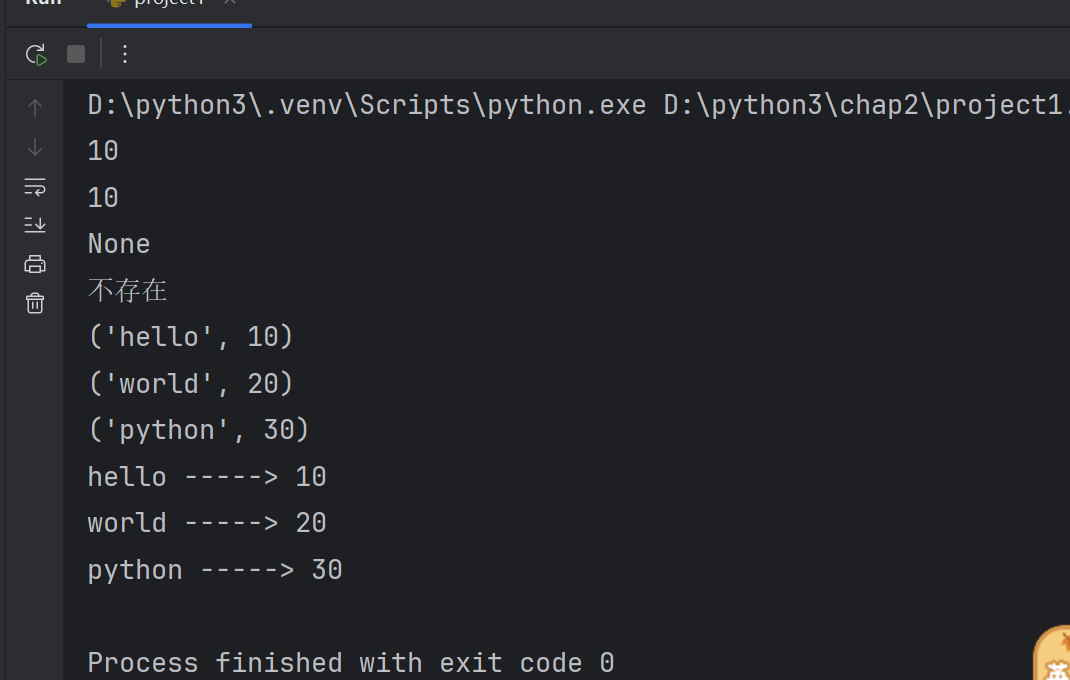
2.6.3字典操作及相关方法
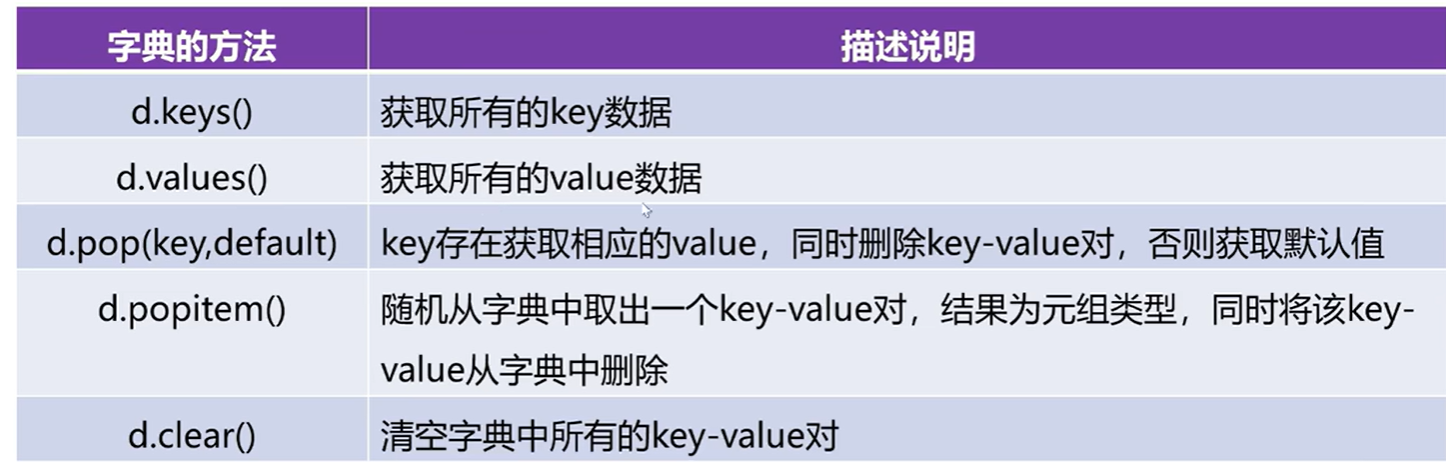
d={1001:'李梅',1002:'王华',1003:'张峰'}
print(d)# 向字典中添加元素
d[1004]='张丽丽'#直接使用赋值运算符向字典中添加元素
print(d)#获取字典中所有的key
keys=d.keys()
print(keys)#dict_keys([1001, 1002, 1003, 1004])
print(list(keys))#转成列表类型查看元素 方括号
print(tuple(keys))# 转成元组类型查看元素 小括号#获取字典中所有的value
values=d.values()
print(values)#dict_values(['李梅', '王华', '张峰', '张丽丽'])
print(list(values))#转成列表类型
print(tuple(values))#转成元组类型# 如果将字典中的数据转成key-value的形式,以元组的方式进行展现
lst=list(d.items())
print(lst)#映射的结果d=dict(list)#转成字典类型
print(d)#使用pop函数
print(d.pop(1001))
print(d)print(d.pop(1008,'不存在'))# 随机删除
print(d.popitem())
print(d)# 清空字典中所有的元素
d.clear()
print(d)
# python中一切皆对象,每个对象都有一个布尔值
print(bool(d))#空字典的布尔值为False
2.6.4 字典生成式

import random
d={ item:random.randint(1,100) for item in range(1,4) }#item(0 1 2 3)做键
#item:random.randint(1,100) 1-100之间随机数做值
print(d)#创建两个列表
lst=[1001,1002,1003]
lst2=['张三','王五','李四']#第一个列表元素做键,第二个元素列表做值
d={key:value for key,value in zip(lst,lst2)}
print(d)
2.7.1集合的创建与删除

#{}直接创建集合
s={10,20,30,40}
print(s)#集合只能存储不可变数据类型
#s={[10,20],[30,40]} 列表不能进行hash的类型
print(s)#使用set()创建集合
s=set()#创建一个空集合,空集合的布尔值是false
print(s)
s={} #创建的是集合还是字典呢?字典
print(s,type(s))#dicts=set('helloworld')
print(s)s2=set([10,20,30])
print(s2)s3=set(range(1,10))
print(s3)#集合属于序列的一种
print('max',max(s3))
print('min',min(s3))
print('len',len(s3))print('9在集合中存在吗',(9 in s3))
print('9在集合中不存在吗',(9 not in s3))# 集合的删除操作
del s3
#print(s3)#未定义
2.7.2集合类型

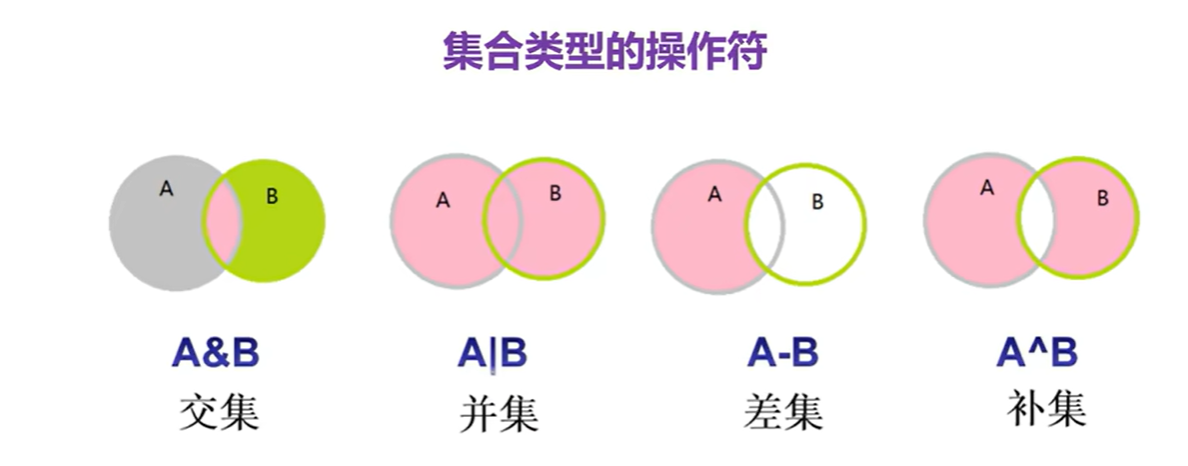
集合的操作符
A={10,20,30,40,50}
B={30,50,88,76,20}
# 交集操作
print(A&B)#两个集合中共有的部分
#并集
print(A|B)
#差集
print(A-B)#补集操作:得到不相交的部分
print(A^B)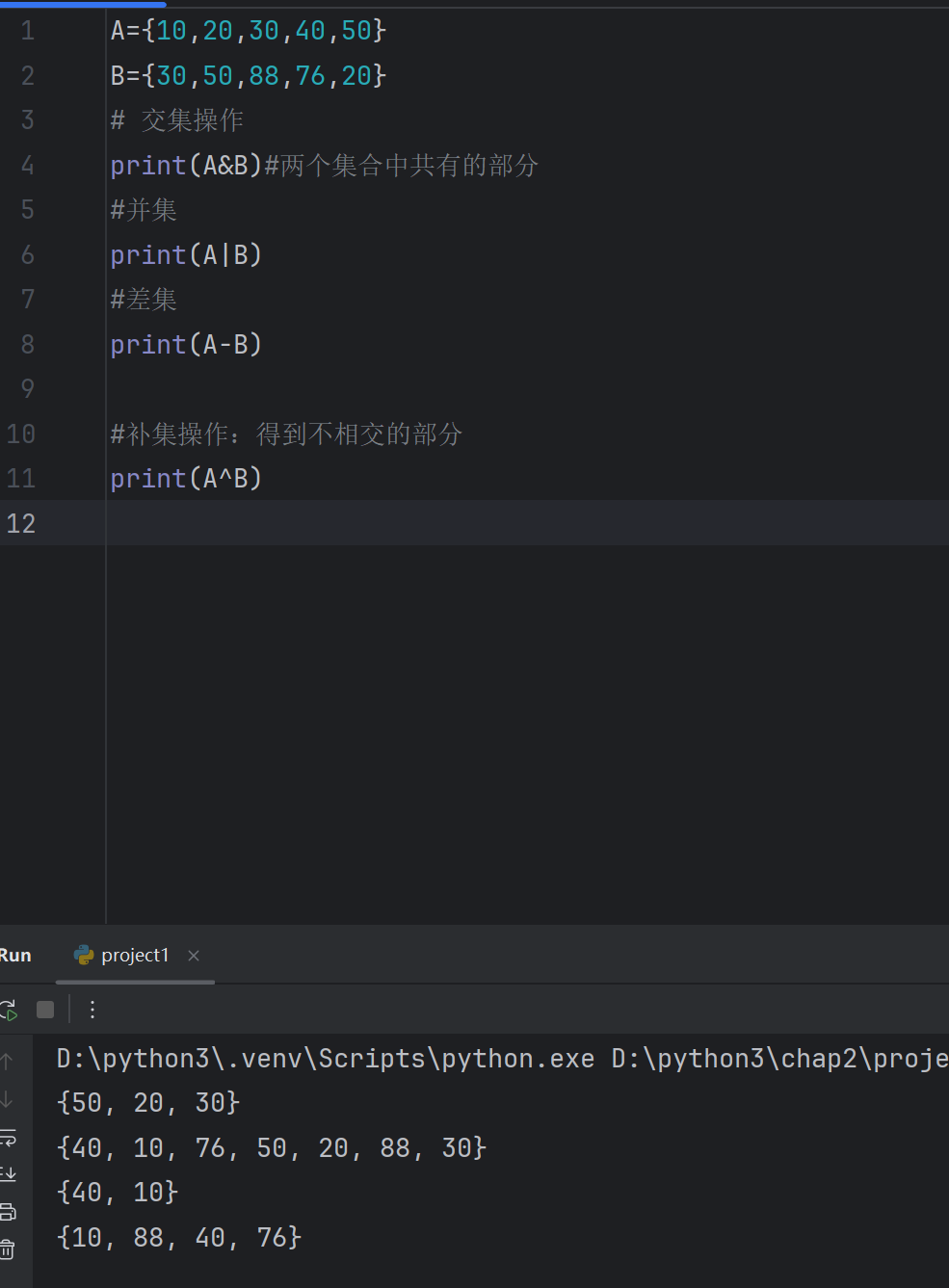
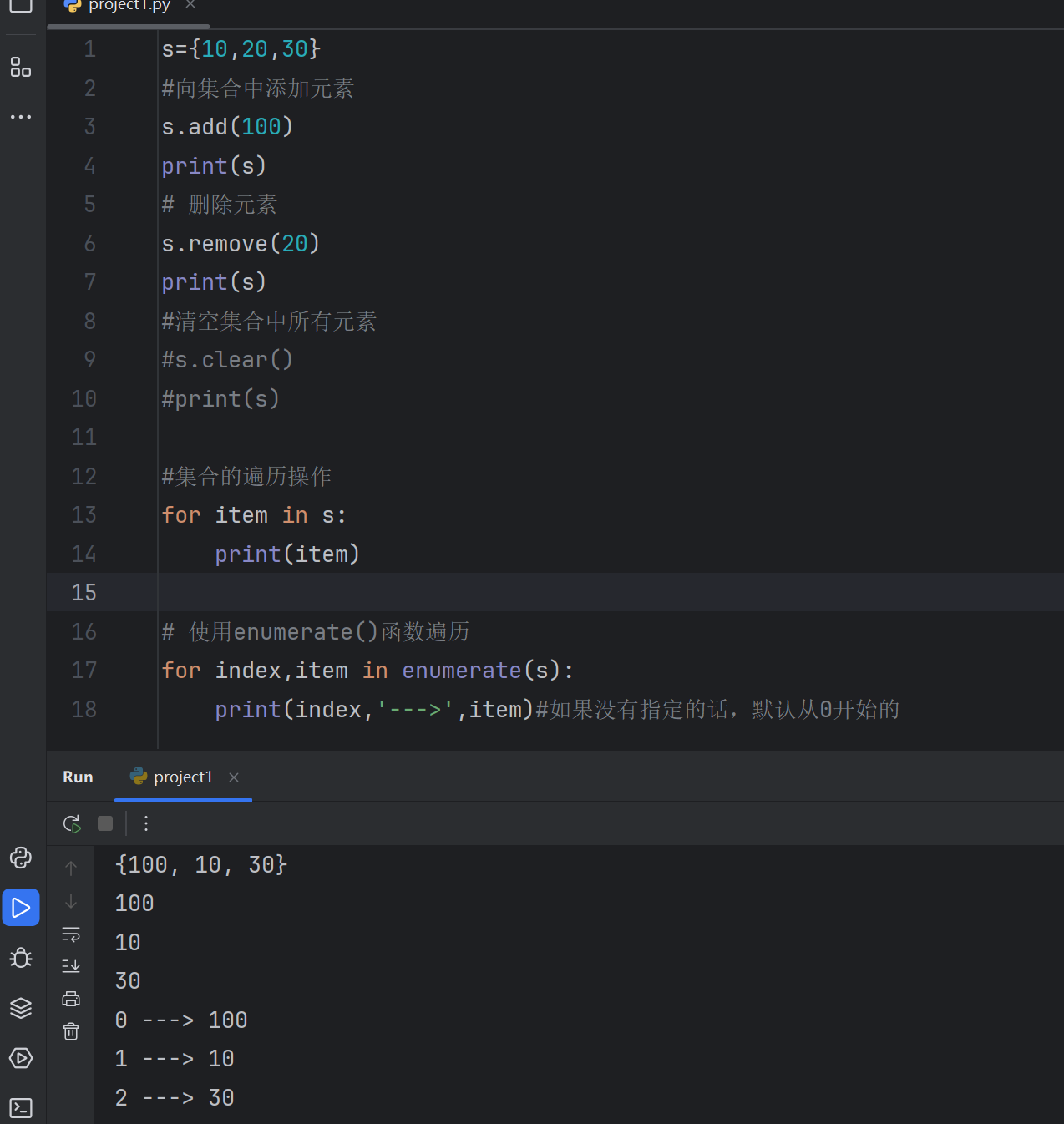
2.7.3 集合的操作方法及集合的遍历:集合的遍历可以使用for与enumerate函数来进行

s={10,20,30}
#向集合中添加元素
s.add(100)
print(s)
# 删除元素
s.remove(20)
print(s)
#清空集合中所有元素
#s.clear()
#print(s)#集合的遍历操作
for item in s:print(item)# 使用enumerate()函数遍历
for index,item in enumerate(s):print(index,'--->',item)#如果没有指定的话,默认从0开始的#集合的生成式
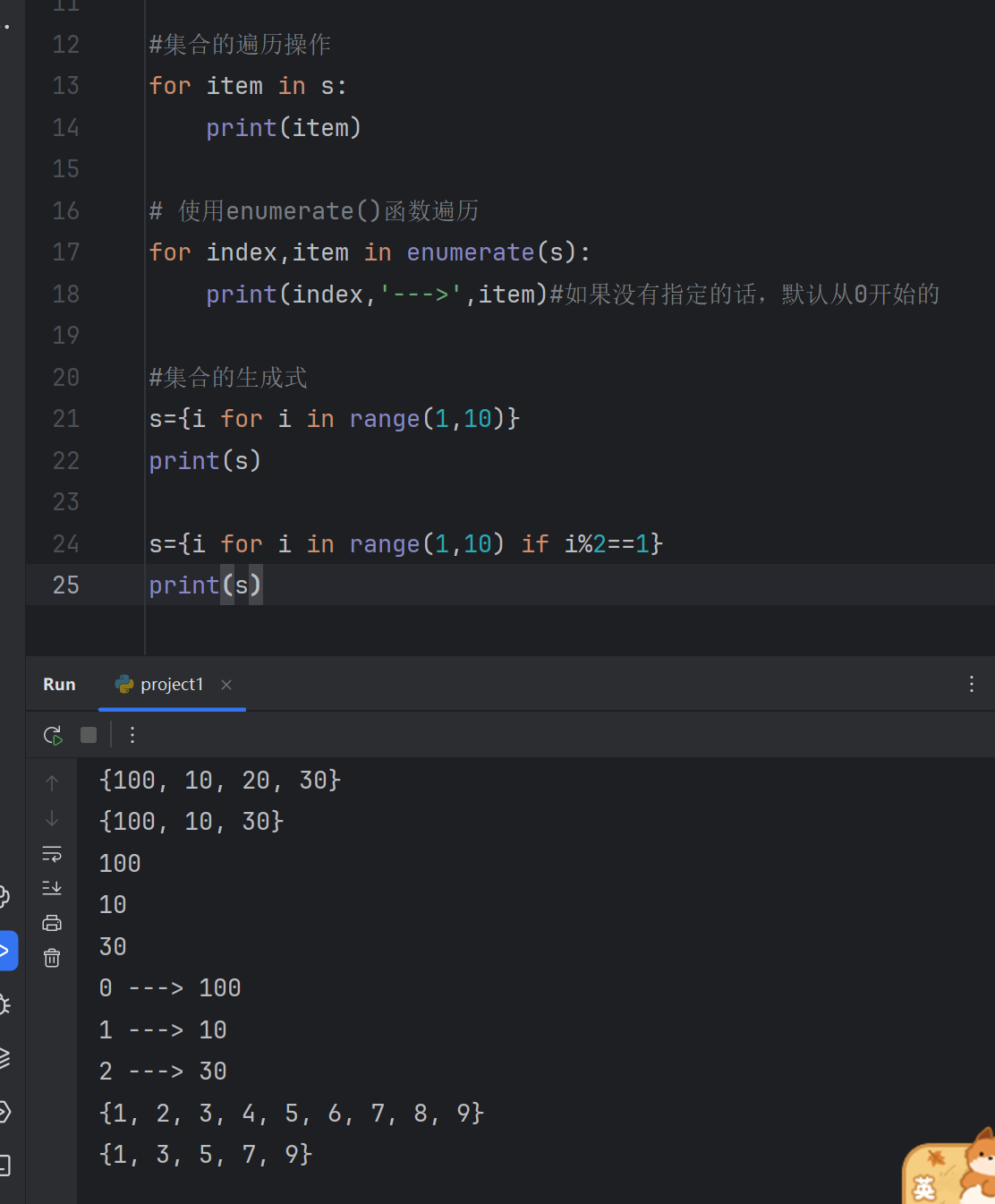
s={i for i in range(1,10)}
print(s)s={i for i in range(1,10) if i%2==1}
print(s)
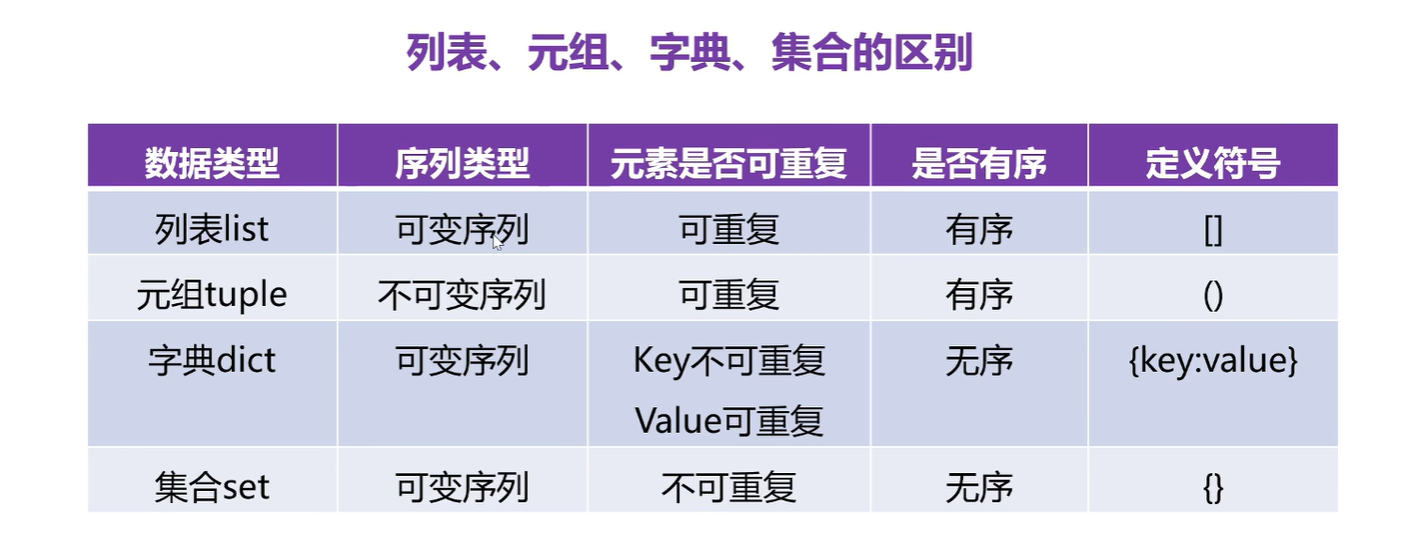
列表是插入顺序。元组是唯一不可变数据类型,使用()定义。字典是无序的,因为底层用到了hash表,定义符号用{}。
2.8 python3.11新特性

2.8.1 结构的模式匹配
data=eval(input('请输入要匹配的数据'))
match data:case {'name':'yy','age':22}:print('字典')case [10,20,30]:print('列表')case (10,20,40):print('元组')case _:print('相当于多重if中的else')
#如果是输入helloworld,helloworld未定义,“helloworld”当去掉一对引号,还带有一对引号
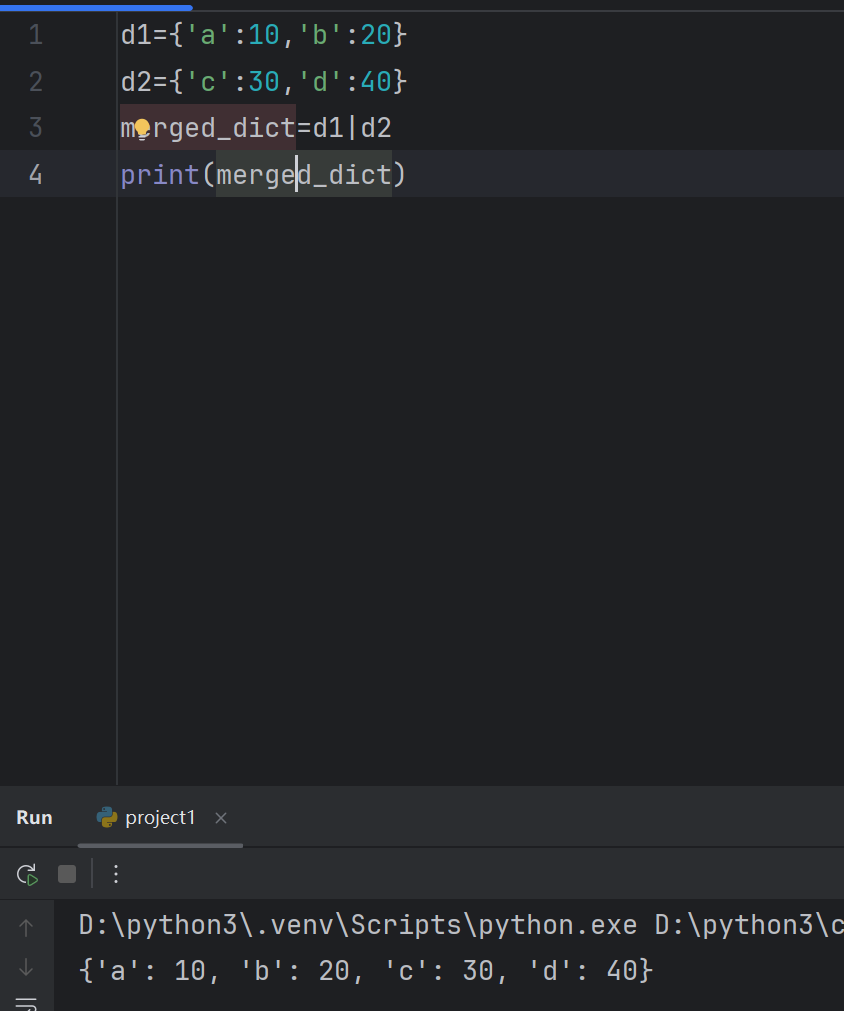
2.8.2 合并字典运算符
d1={'a':10,'b':20}
d2={'c':30,'d':40}
merged_dict=d1|d2
print(merged_dict)
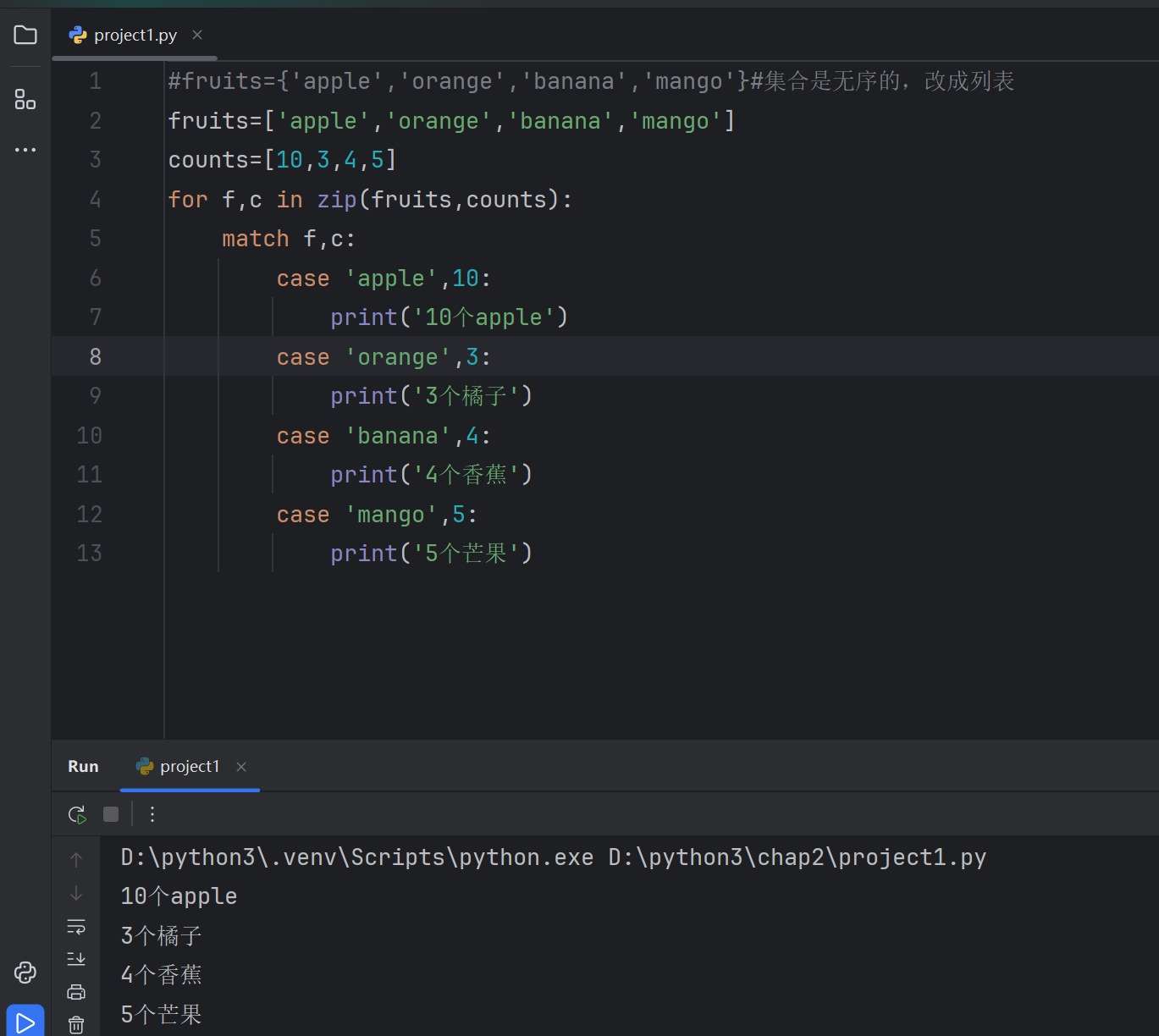
2.8.3同步迭代
#fruits={'apple','orange','banana','mango'}#集合是无序的,改成列表
fruits=['apple','orange','banana','mango']
counts=[10,3,4,5]
for f,c in zip(fruits,counts):match f,c:case 'apple',10:print('10个apple')case 'orange',3:print('3个橘子')case 'banana',4:print('4个香蕉')case 'mango',5:print('5个芒果')
本章总结
列表是无序序列。

在元组中只有一个函数的时候,逗号不能省略。创建字典的方式使用{}直接创建,使用内置函数创建,第一种得到zip对象,需要进行类型转换。第二种左边是键,右边是值。字典是可变数据类型,具有查询的方法
get()获取单个值,keys()获取所有键,values获取所有的值,items获取所有的键值对


列表中有四个元素,向列表中添加一个元组‘hello,world’,将元组作为一个元素添加到列表当中

d是一个字典,d2和d指向同一个内存空间,把b的值修改为100,d2也是100

在字典中的键是不可变数据类型,1是整数,不可变数据类型。元组是不可变数据类型做键可以,字符串是不可变数据类型做键可以,列表是可变数据类型,不能做字典中的键

第四个元素是列表,是整体作为一个元素添加进来
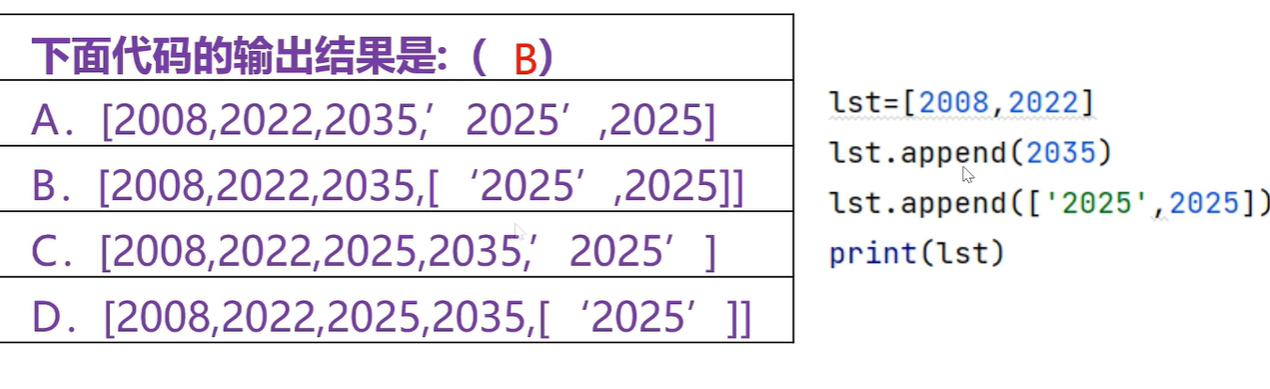

在索引为2的位置添加20

reverse没有返回值



章节习题

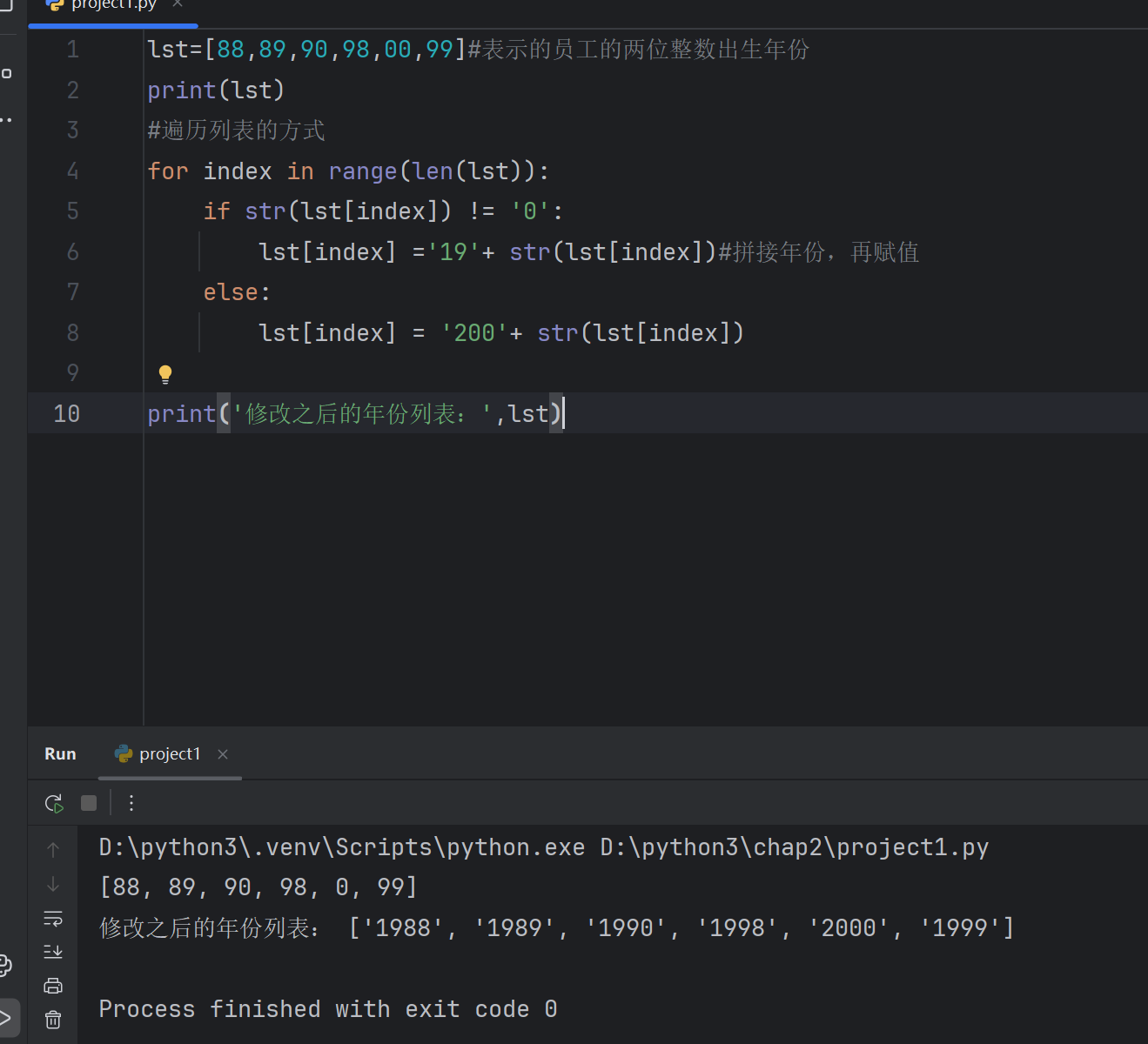
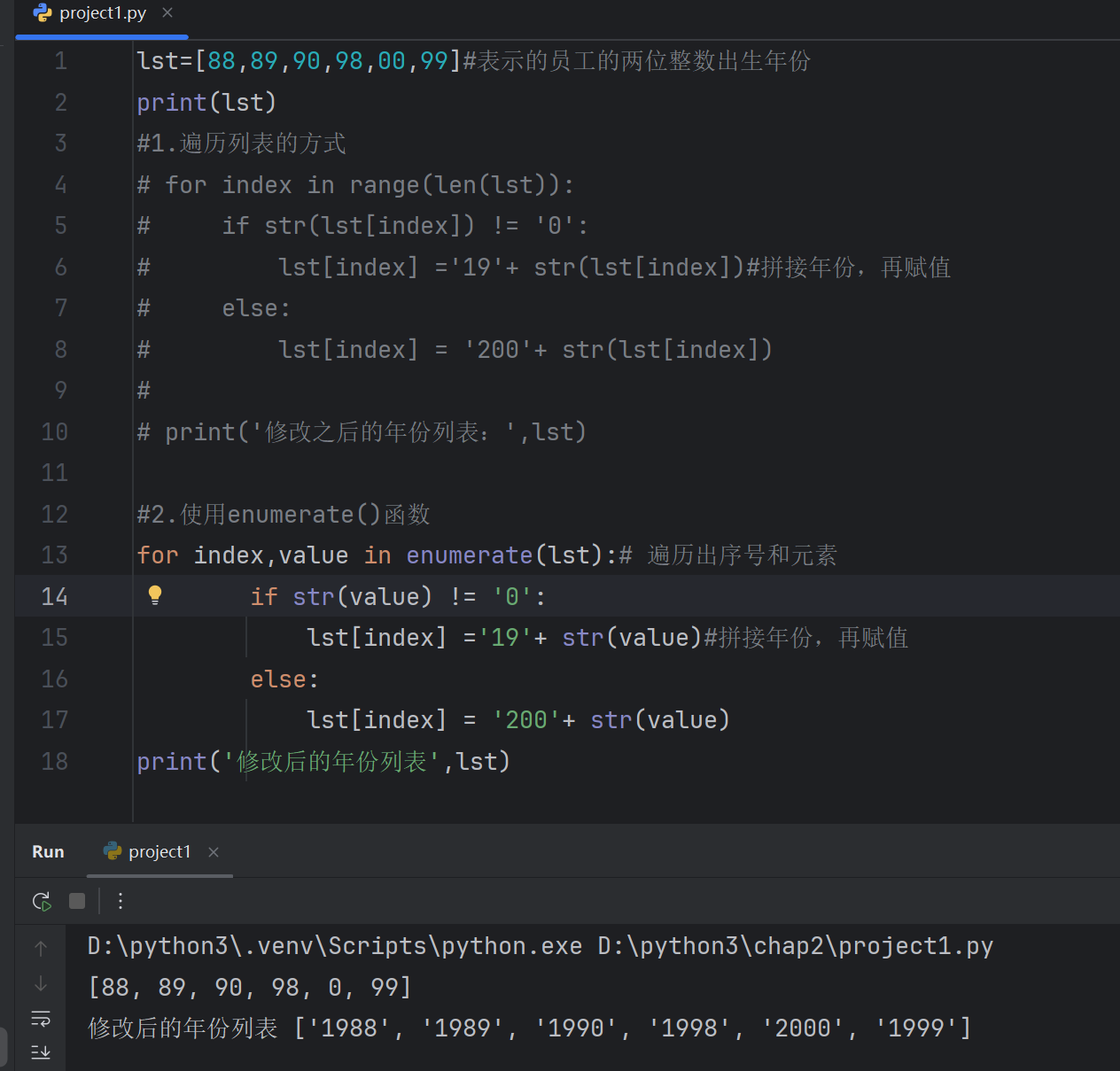
lst=[88,89,90,98,00,99]#表示的员工的两位整数出生年份
print(lst)
#遍历列表的方式
for index in range(len(lst)):if str(lst[index]) != '0':lst[index] ='19'+ str(lst[index])#拼接年份,再赋值else:lst[index] = '200'+ str(lst[index])print('修改之后的年份列表:',lst)
lst=[88,89,90,98,00,99]#表示的员工的两位整数出生年份
print(lst)
#1.遍历列表的方式
# for index in range(len(lst)):
# if str(lst[index]) != '0':
# lst[index] ='19'+ str(lst[index])#拼接年份,再赋值
# else:
# lst[index] = '200'+ str(lst[index])
#
# print('修改之后的年份列表:',lst)#2.使用enumerate()函数
for index,value in enumerate(lst):# 遍历出序号和元素if str(value) != '0':lst[index] ='19'+ str(value)#拼接年份,再赋值else:lst[index] = '200'+ str(value)
print('修改后的年份列表',lst)
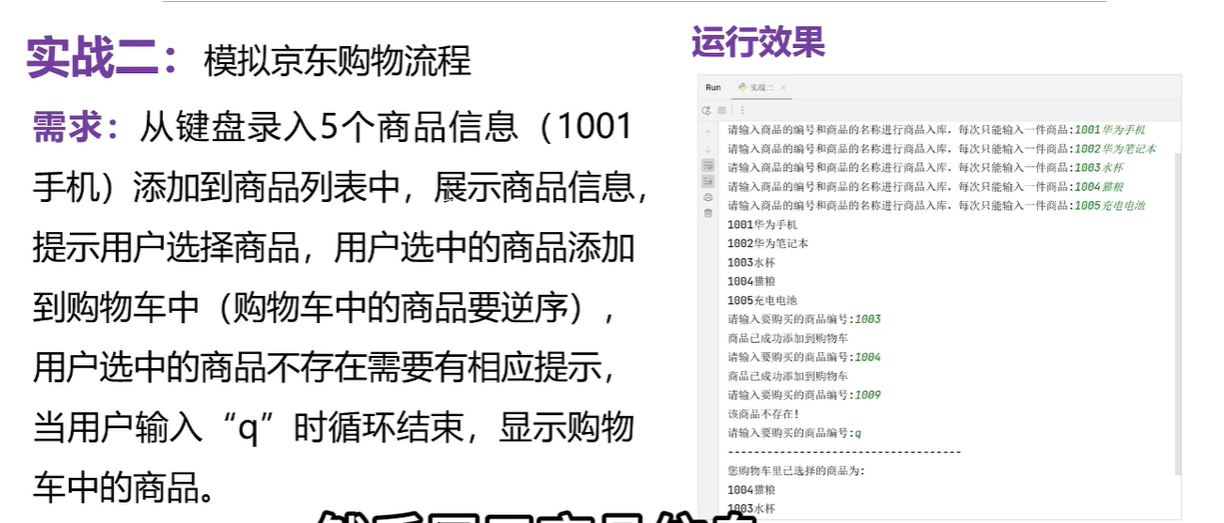
# 创建一个空列表:用于存储入库的商品信息
lst=[]
for i in range(5):#5次赋值goods=input('请输入商品的编号和商品的名称进行商品入库,每次只能输入一次商品')lst.append(goods)
#输入所有的商品信息
for item in lst:print(item)#创建一个空列表,用于存储购物车中的商品
cart=[]
while True:flag=False#代表没有商品的情况num=input('请输入要购买的商品编号:')# 遍历商品列表,查询一下购买的商品是否存在for item in lst:if num==item[0:4]:#前四位是商品编号(切片操作,切到3不包含四)flag=True#代表商品已找到cart.append(item)# 添加到商品当中print('商品已成功添加到购物车')break#退出的是for循环if not flag and num!='q':# not flag 等价于flag==Falseprint('商品不存在')if num=='q':break#退出的是while循环
print('-'*50)
print('您的购物车里已选择的商品为:')
cart.reverse()
for item in cart:print(item)

模拟12306车票订票流程
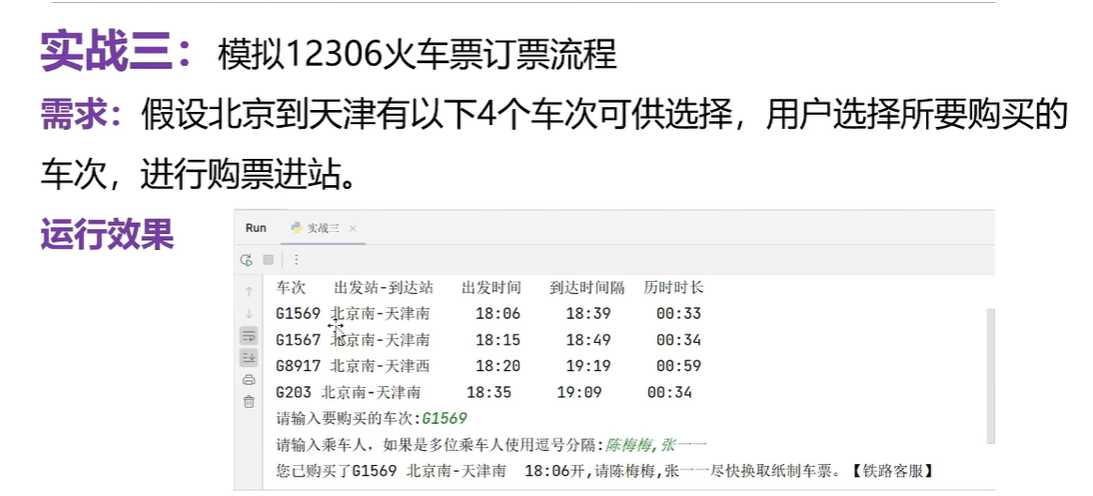
# 创建字典用于存储车票信息,使用车次做key,使用其他信息做value
dict_ticket={'G1569':['北京南-天津南','18:06','18:39','00:33'],'G1567':['北京南-天津南','18:15','18:49','00:34'],'G8917':['北京南-天津南','18:20','18:19','00:59'],'G203':['北京南-天津南','18:35','19:09','00:34'],
}
print('车次 出发站 出发时间 到达时间 历时时长')
#遍历字典中的元素
for key in dict_ticket.keys():print(key,end=' ')#为什么不换行,因为车次和车次的详细信息在一行显示# 根据key获取出来的值是一个列表for item in dict_ticket.get(key):#根据键获取值print(item,end='\t\t ')# 换行print()# 输入用户的购票车次
train_no=input('请输入要购买的车次')
# 根据key获取值
info=dict_ticket.get(train_no,'车次不存在') # info是一个列表类型
#判断车次不存在
if info!='车次不存在':person=input('请输入乘车人,如果多位乘车人使用逗号分隔:')# 获取车次的出发站--到达站,还有出发时间s=info[0]+' '+info[1]+'开'print('您已购买了'+train_no+' '+s+person+'尽快换取纸制车式')
else:print('对不起,选择的车次可能不存在')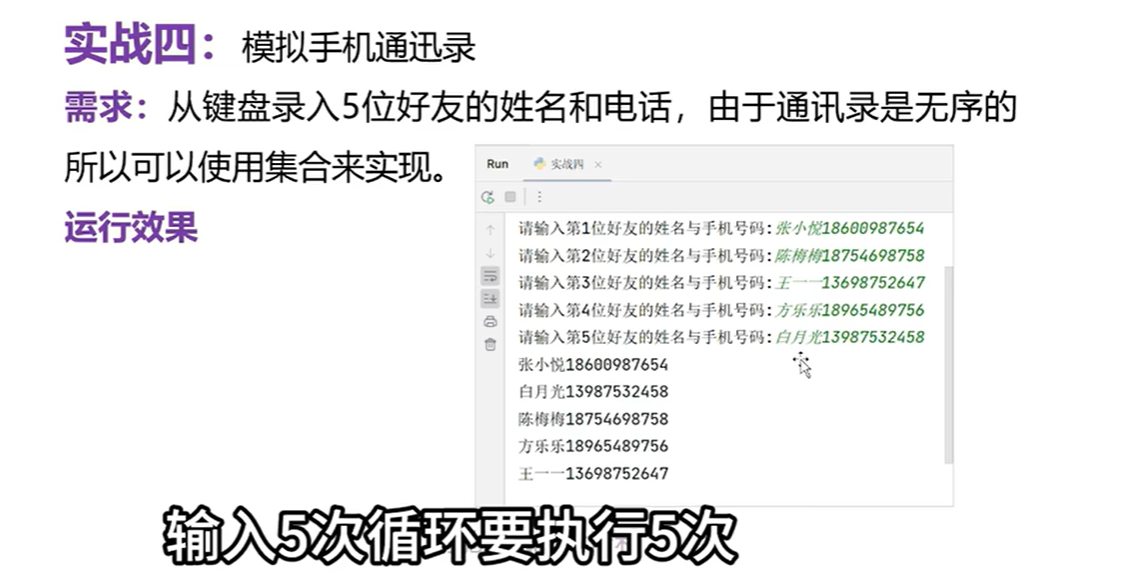
# 创建一个空集合
s=set()
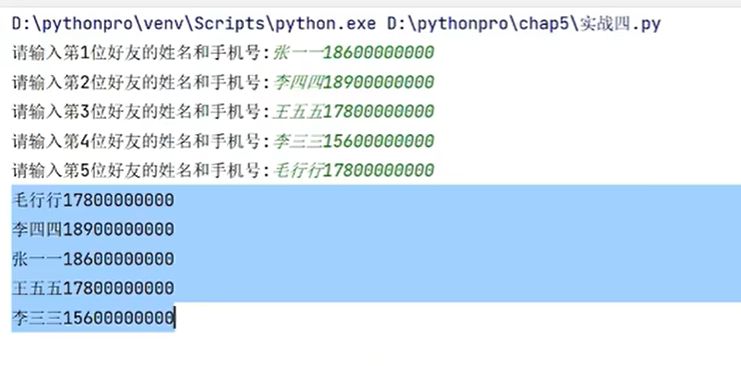
# 录入5位好友的姓名和手机号
for i in range(1,6):info=input(f'请输入第{i}位好友的姓名和手机号:')#添加到集合当中s.add(info)
# 遍历集合
for item in s:print(item)
三、字符串及正则表达式

3.1 字符串的常用方法1
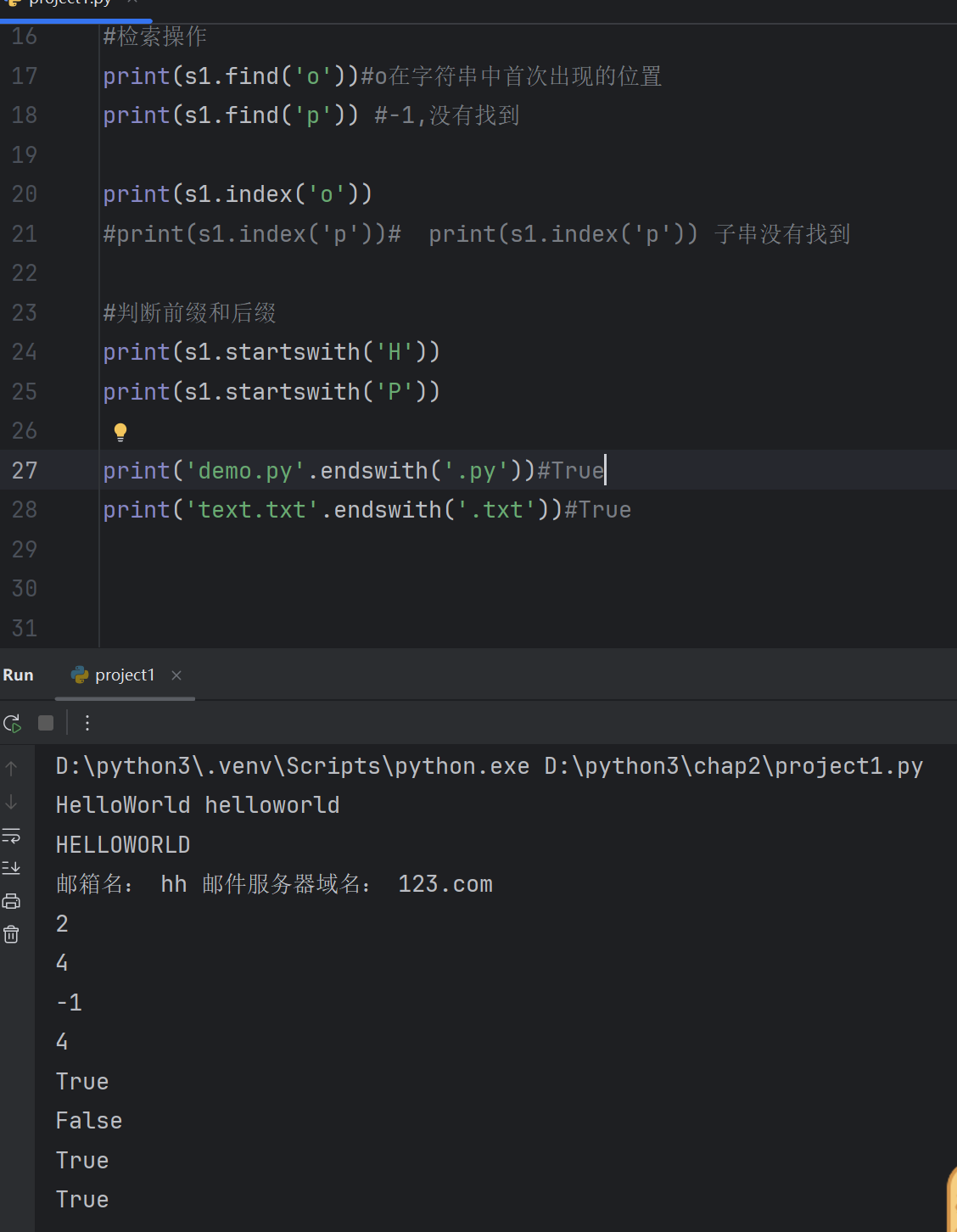
# 大小写转换
s1='HelloWorld'
new_s2=s1.lower()
print(s1,new_s2)new_s3=s1.upper()
print(new_s3)#字符串的分隔
e_mail='hh@123.com'
lst=e_mail.split('@')
print('邮箱名:',lst[0],'邮件服务器域名:',lst[1])print(s1.count('o'))#o在字符串s1中出现了两次#检索操作
print(s1.find('o'))#o在字符串中首次出现的位置
print(s1.find('p')) #-1,没有找到print(s1.index('o'))
#print(s1.index('p'))# print(s1.index('p')) 子串没有找到#判断前缀和后缀
print(s1.startswith('H'))
print(s1.startswith('P'))print('demo.py'.endswith('.py'))#True
print('text.txt'.endswith('.txt'))#True

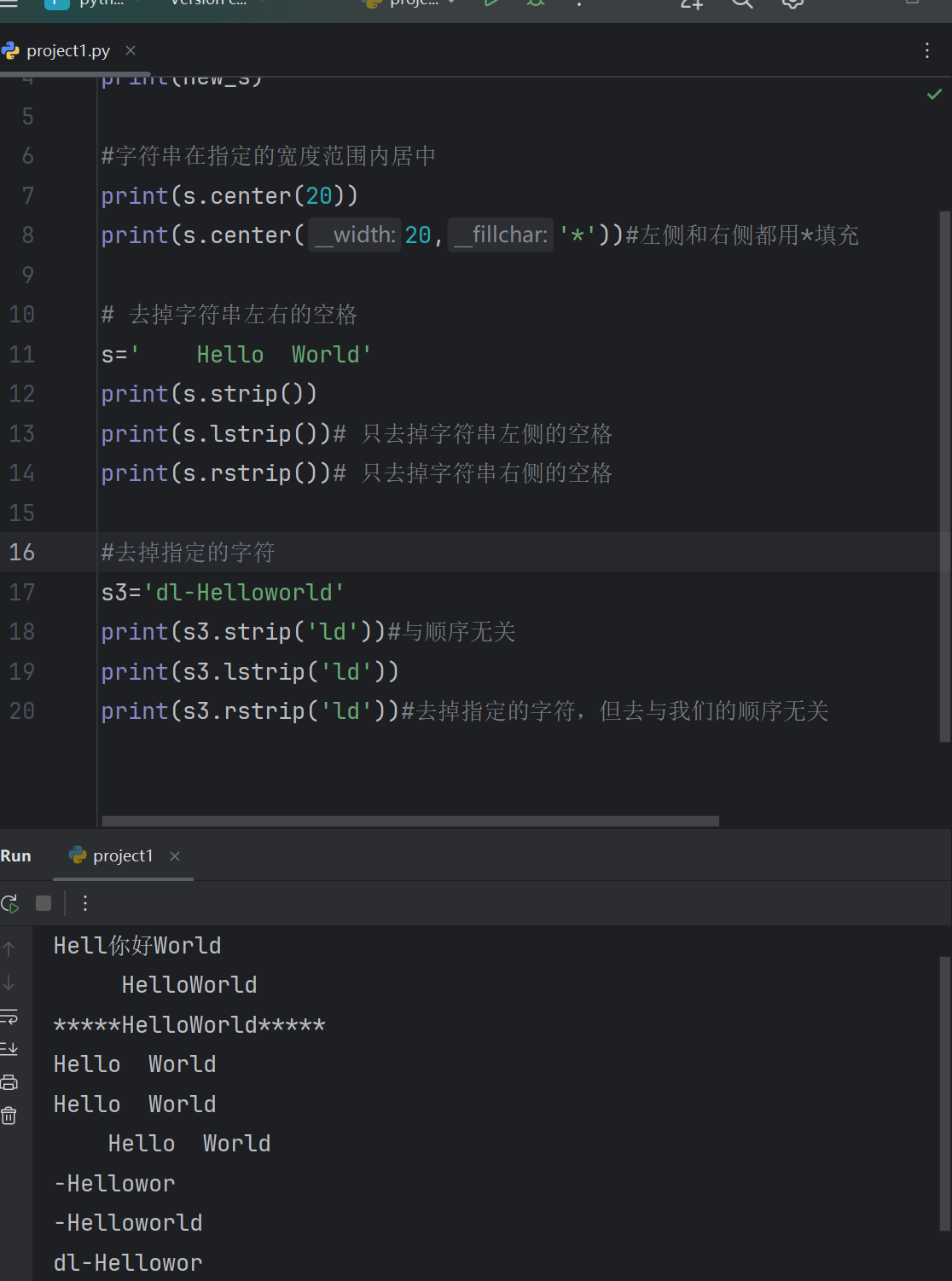
3.2 字符串的常用方法2
s='HelloWorld'
# 字符串的替换
new_s=s.replace('o','你好',1)#最后一个参数是替换次数,默认全部替换
print(new_s)#字符串在指定的宽度范围内居中
print(s.center(20))
print(s.center(20,'*'))#左侧和右侧都用*填充# 去掉字符串左右的空格
s=' Hello World'
print(s.strip())
print(s.lstrip())# 只去掉字符串左侧的空格
print(s.rstrip())# 只去掉字符串右侧的空格#去掉指定的字符
s3='dl-Helloworld'
print(s3.strip('ld'))#与顺序无关
print(s3.lstrip('ld'))
print(s3.rstrip('ld'))#去掉指定的字符,但去与我们的顺序无关
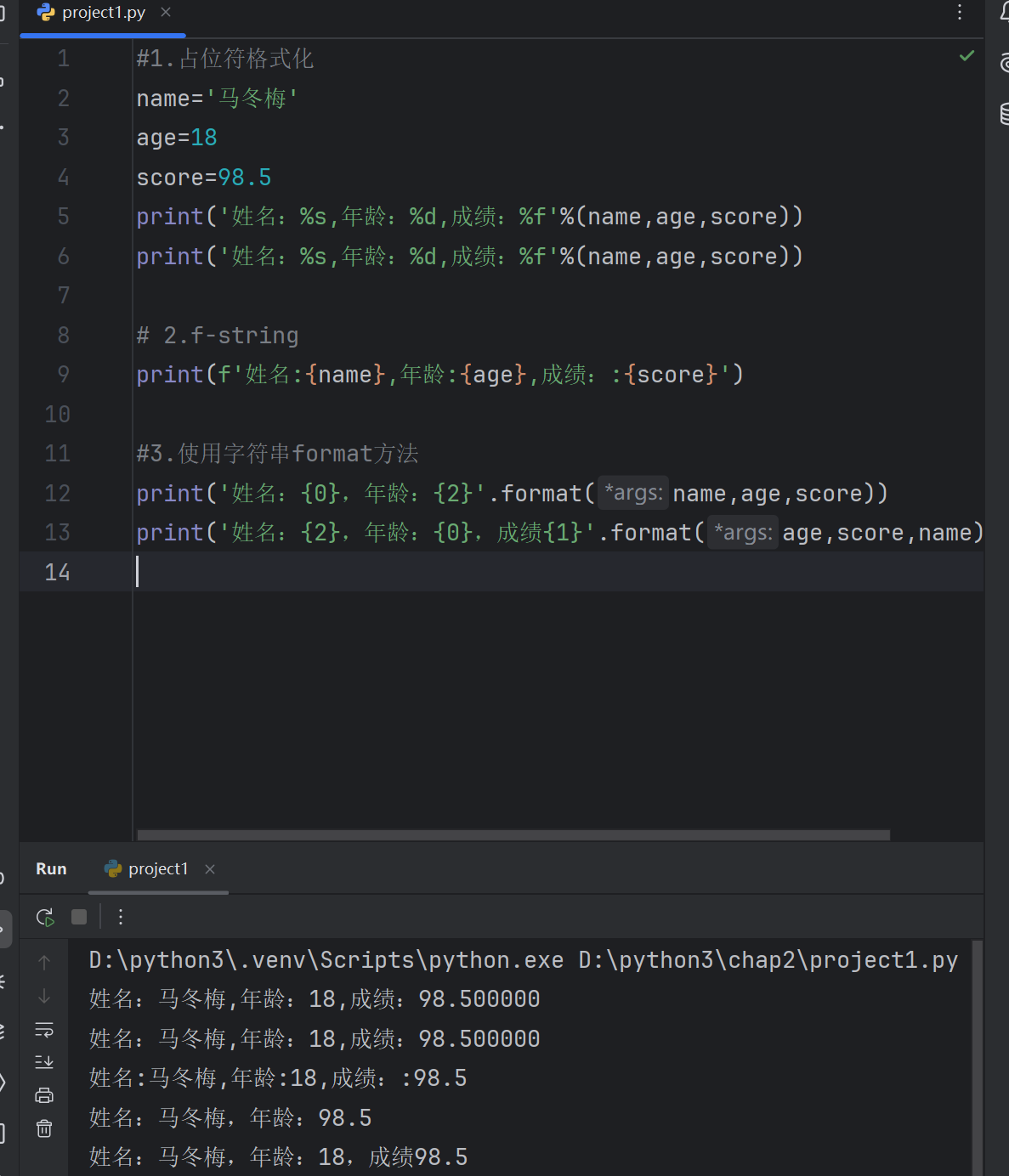
3.3格式化字符串的方式

#1.占位符格式化
name='马冬梅'
age=18
score=98.5
print('姓名:%s,年龄:%d,成绩:%f'%(name,age,score))
print('姓名:%s,年龄:%d,成绩:%f'%(name,age,score))# 2.f-string
print(f'姓名:{name},年龄:{age},成绩::{score}')#3.使用字符串format方法
print('姓名:{0},年龄:{2}'.format(name,age,score))
print('姓名:{2},年龄:{0},成绩{1}'.format(age,score,name))

3.4 mat的格式控制
s='helloworld'
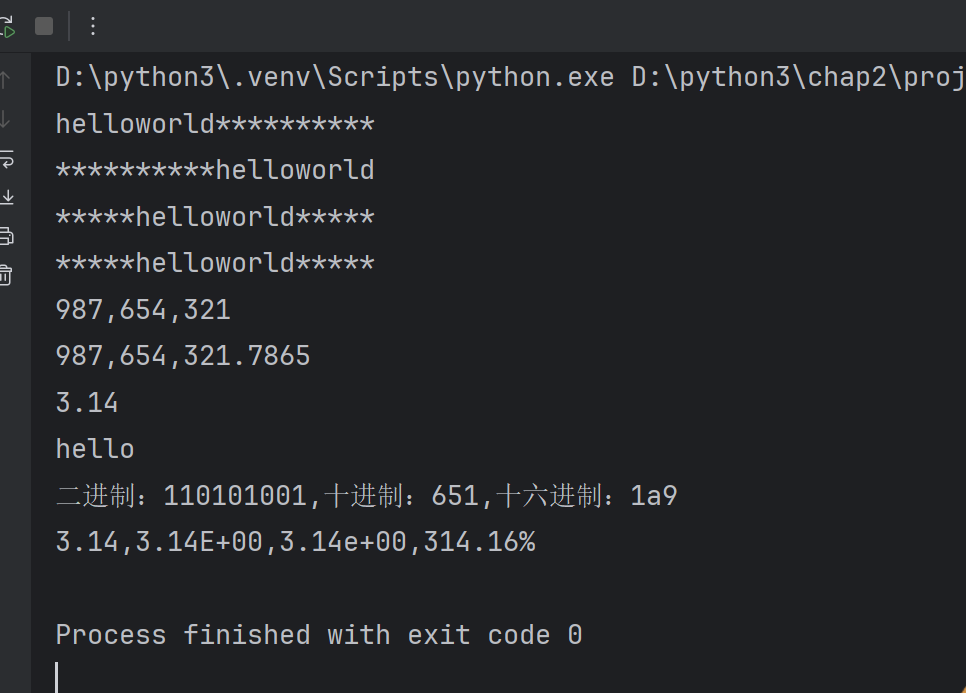
print('{0:*<20}'.format(s))#字符串的显示宽度为20,左对齐,空白部分使用*号填充
print('{0:*>20}'.format(s))
print('{0:*^20}'.format(s))#居中对齐
print(s.center(20,'*'))# 千位分隔符(只适用于整数和浮点数)
print('{0:,}'.format(987654321))
print('{0:,}'.format(987654321.7865))#浮点数小数部分的精度
print('{0:.2f}'.format(3.1415))# 字符串类型,显示的是最大的显示长度
print('{0:.5}'.format('helloworld')) # hello#整数类型
a=425
print('二进制:{0:b},十进制:{0:o},十六进制:{0:x}'.format(a))# 浮点数类型
b=3.1415926
print('{0:.2f},{0:.2E},{0:.2e},{0:.2%}'.format(b))
3.5 字符串的编码和解码

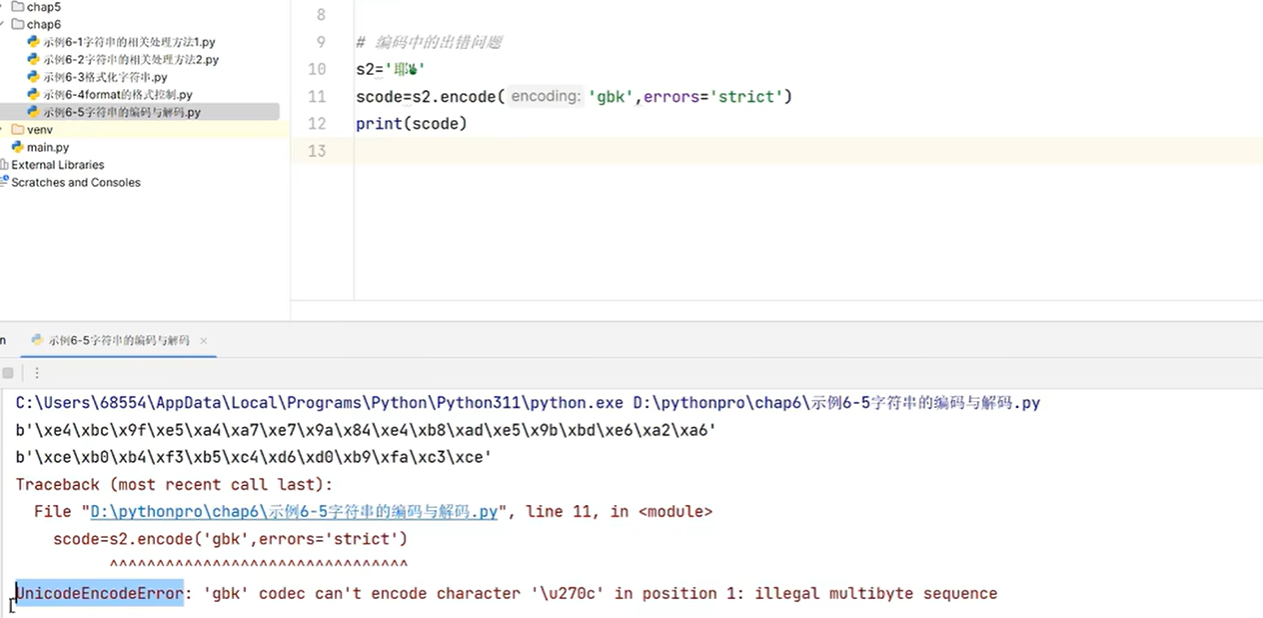
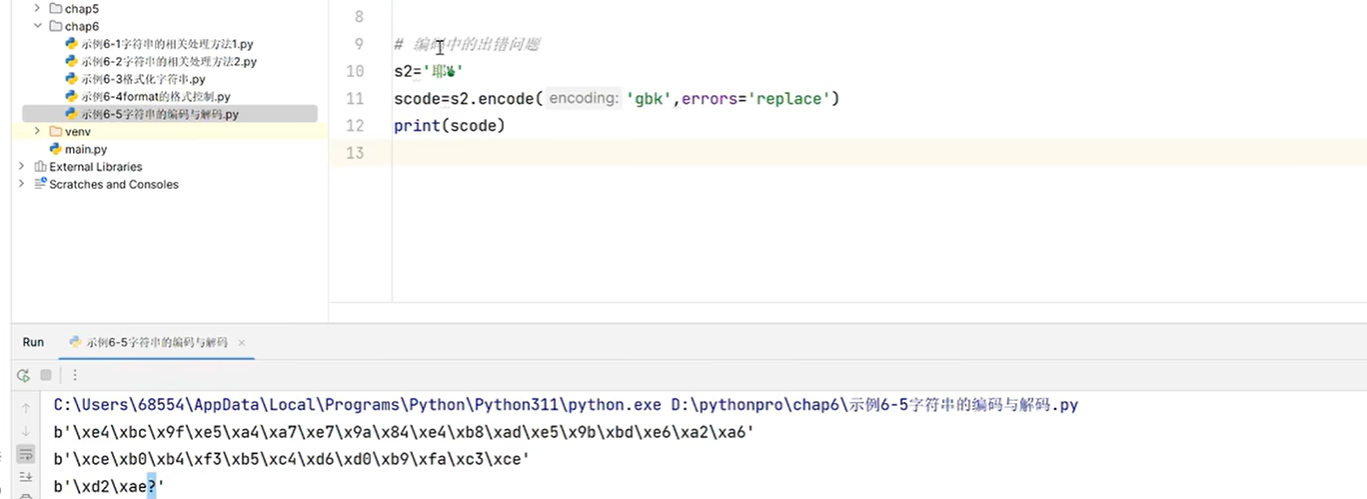
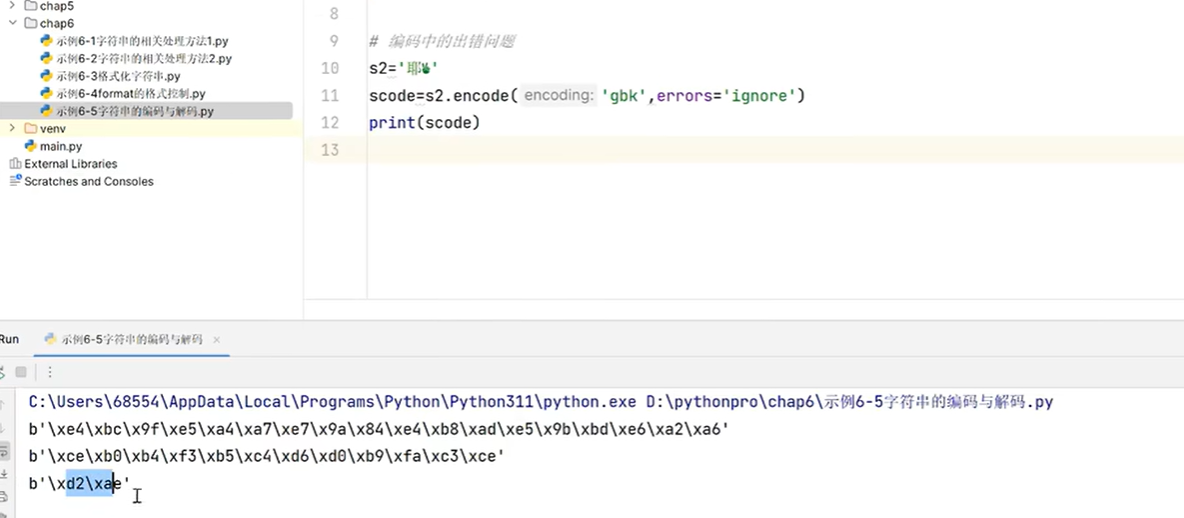
s='伟大的中国梦'
# 编码 str->bytes
scode=s.encode(errors='replace')# 默认utf-8,因为utf-8中文占3个字符
print(scode)scode_gbk=s.encode('gbk',errors='replace')#gbk中文占2个字符
print(scode_gbk)# 解码过程bytes->str
print(bytes.decode(scode_gbk,'gbk'))
print(bytes.decode(scode,'utf-8'))
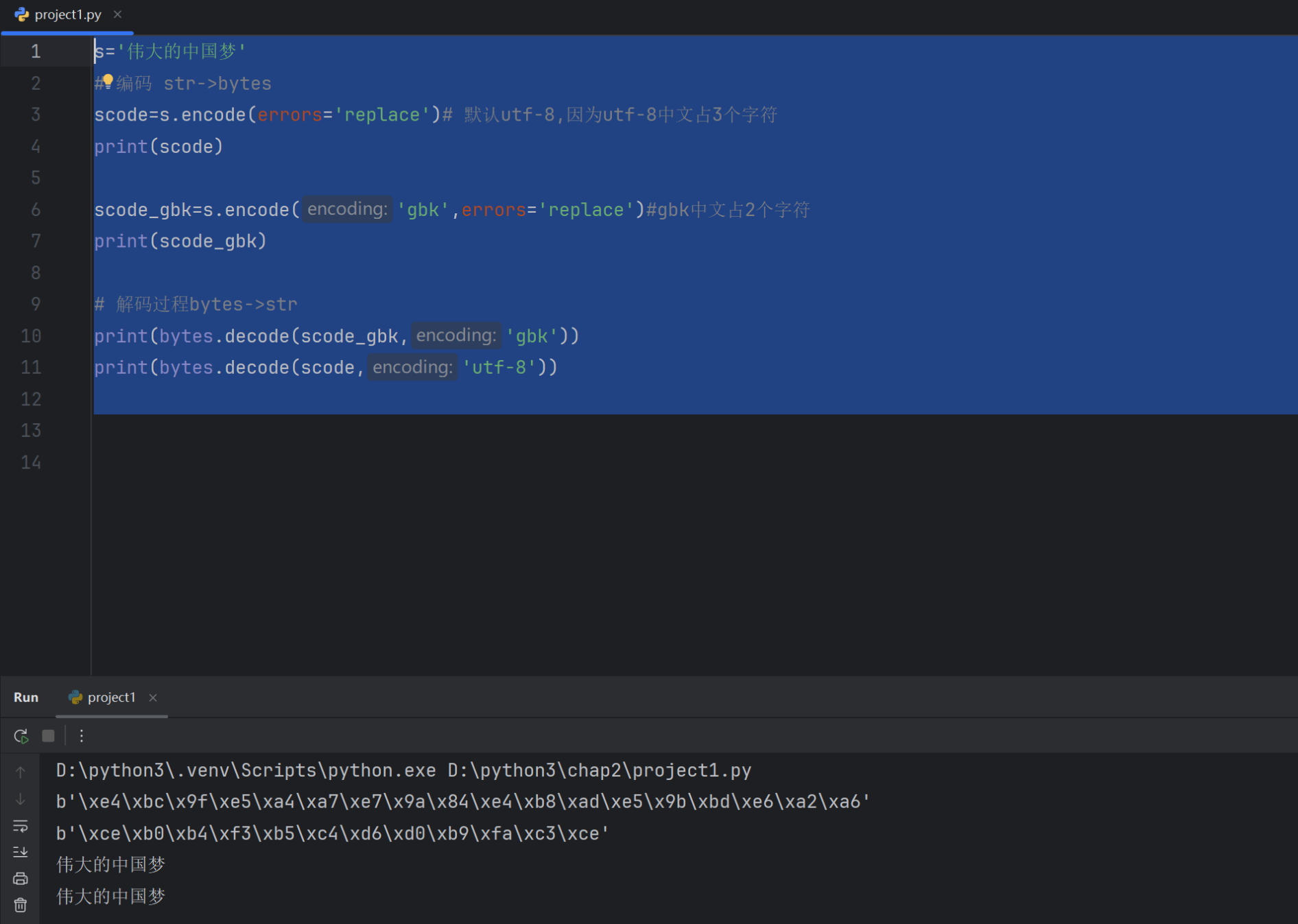
3.6 数据验证的方法
from curses.ascii import isdigit
#isdigit()十进制的阿拉伯数字
print('123',isdigit())#True
print('一二三',isdigit()) #False
print('0b1010',isdigit()) #False
print('IIIIII',isdigit()) #False
print('-'*50)# 所有字符都是数字
print('123'.isnumeric()) #True
print('一二三'.isnumeric()) #True
print('0b1010'.isnumeric()) #False
print('IIIIII'.isnumeric()) #True
print('壹贰叁'.isnumeric()) #True
print('-'*50)#所有的字符都是字母(包含中文字符)
print('hello你好'.isalpha()) #True
print('hello你好123'.isalpha()) #False
print('hello你好一二三'.isalpha()) #True
print('hello你好IIIIII'.isalpha()) #False
print('-'*50)# 所有字符都是数字或字母
print('hello你好'.isalnum()) #True
print('hello你好123'.isalnum()) #True
print('hello你好一二三'.isalnum()) #True
print('hello你好IIIIII'.isalnum()) #True
print('hello你好壹贰叁'.isalnum()) #True
print('-'*50)
#判断字符的大小写
print('HelloWorld'.islower())#False
print('helloworld'.islower())#True
print('hello你好'.islower())#True
# 所有字符都是首字母大写
print('Hello'.istitle())#True
print('HelloWorld'.istitle())#False
print('Helloworld'.istitle())#True
print('Hello World'.istitle())#True
print('Hello world'.istitle())#False# 判断是否都是空白字符
print('-'*50)
print('\t'.isspace())#True
print(' '.isspace())#True
print('\n'.isspace())#True
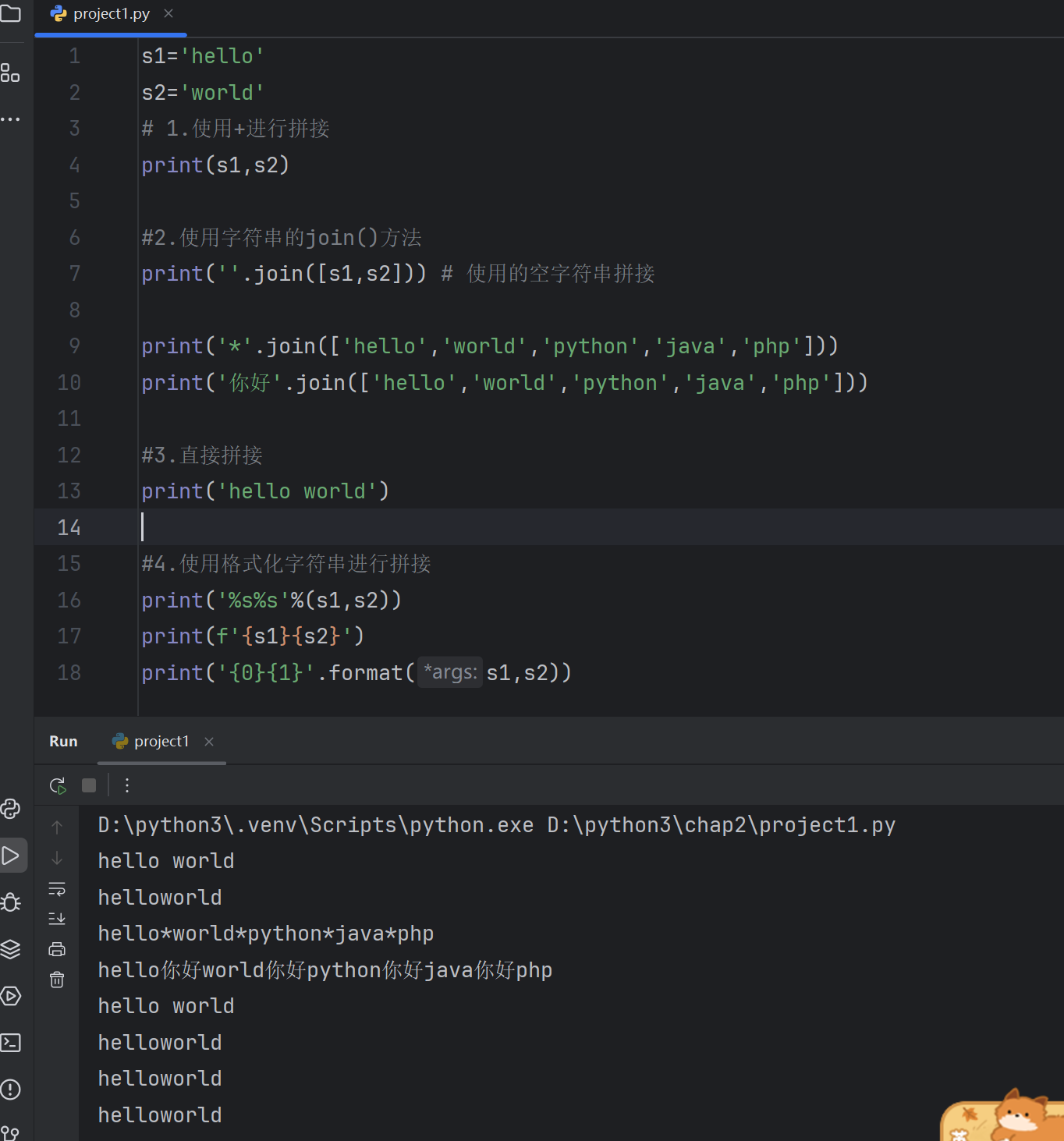
3.7 字符串的拼接处理

s1='hello'
s2='world'
# 1.使用+进行拼接
print(s1,s2)#2.使用字符串的join()方法
print(''.join([s1,s2])) # 使用的空字符串拼接print('*'.join(['hello','world','python','java','php']))
print('你好'.join(['hello','world','python','java','php']))#3.直接拼接
print('hello world')#4.使用格式化字符串进行拼接
print('%s%s'%(s1,s2))
print(f'{s1}{s2}')
print('{0}{1}'.format(s1,s2))
字符串的去重操作
s='helloworldhelloworldacddfc'
# 1.字符串的拼接及not in
new_s=''
for item in s:#遍历if item not in new_s: #不存在new_s+=item #拼接
print(new_s)# 2.使用索引+not in
new_s2=''
for i in range(len(s)):if s[i] not in new_s2:new_s2+=s[i]#根据索引取值
print(new_s2)#3.通过集合去重+列表排序
new_s3=set(s)#集合去重打乱了顺序
lst=list(new_s3)
lst.sort(key=s.index)
print(''.join(lst))
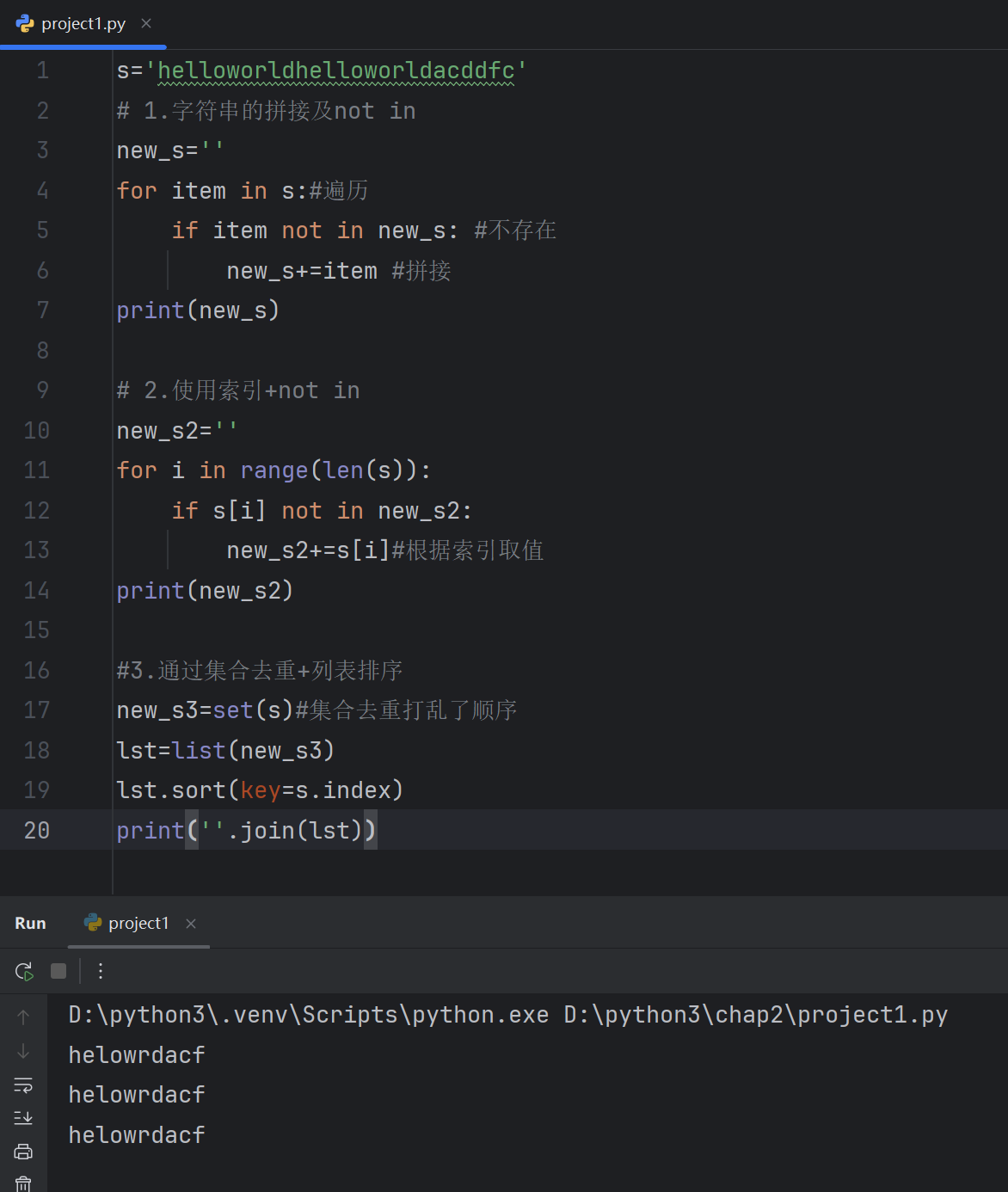
3.8 正则表达式
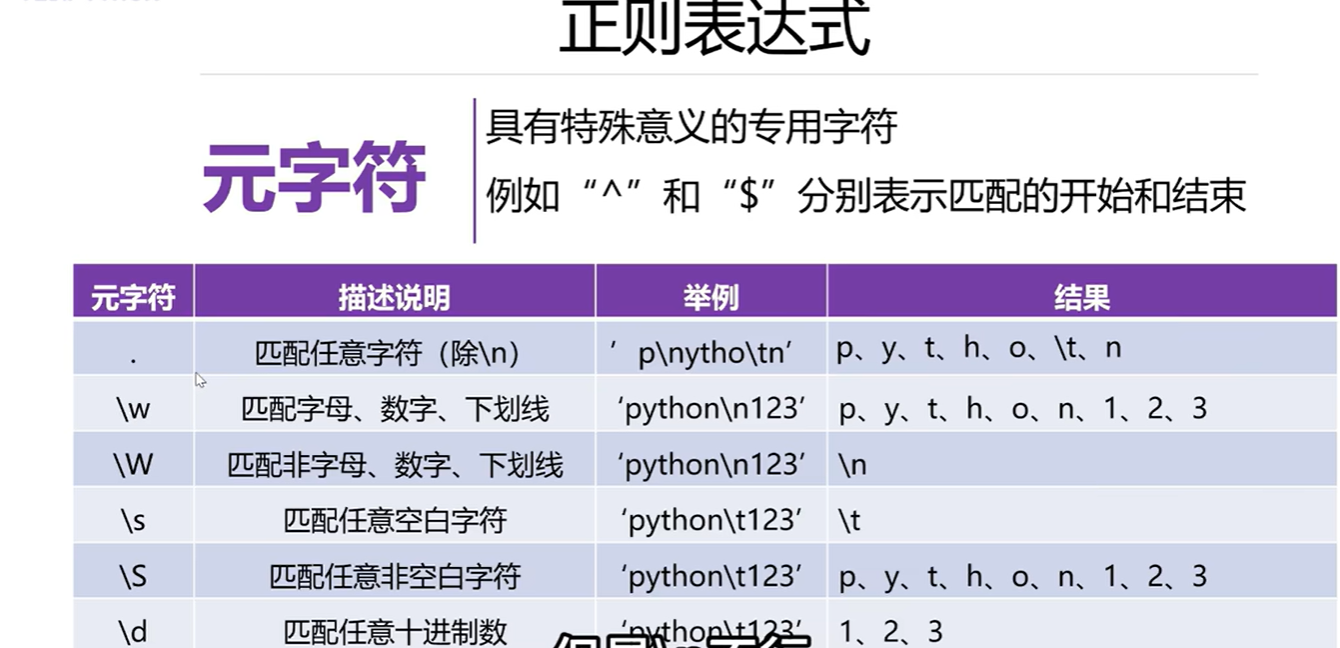
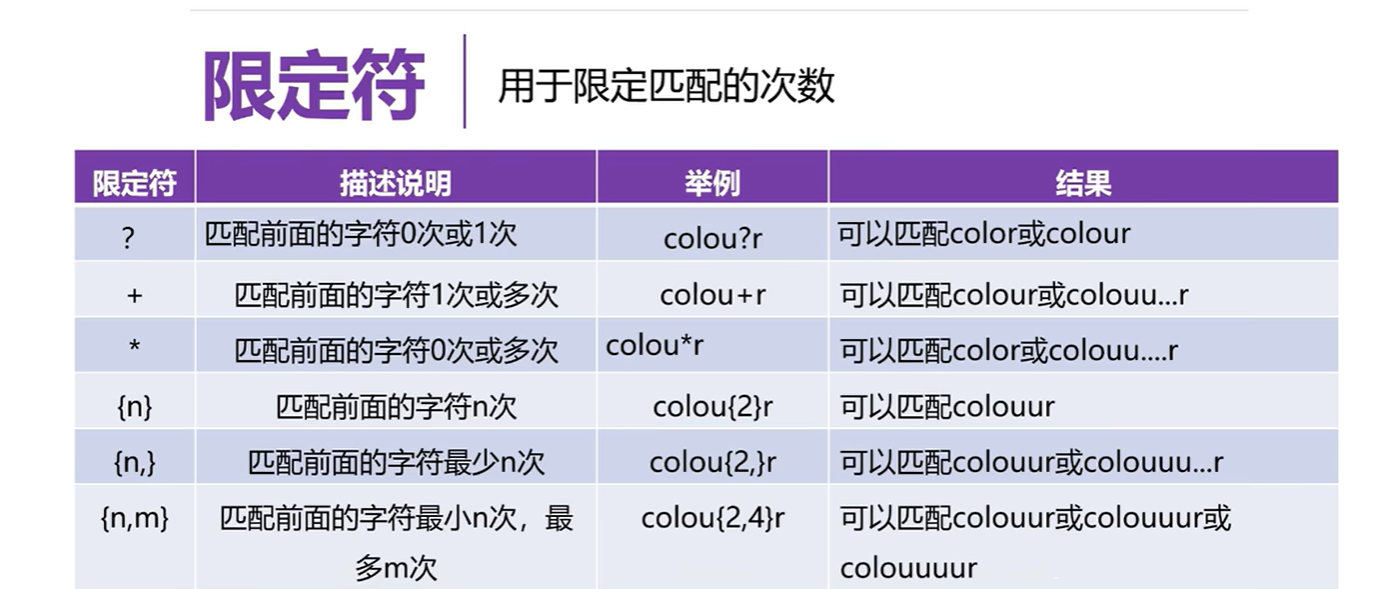
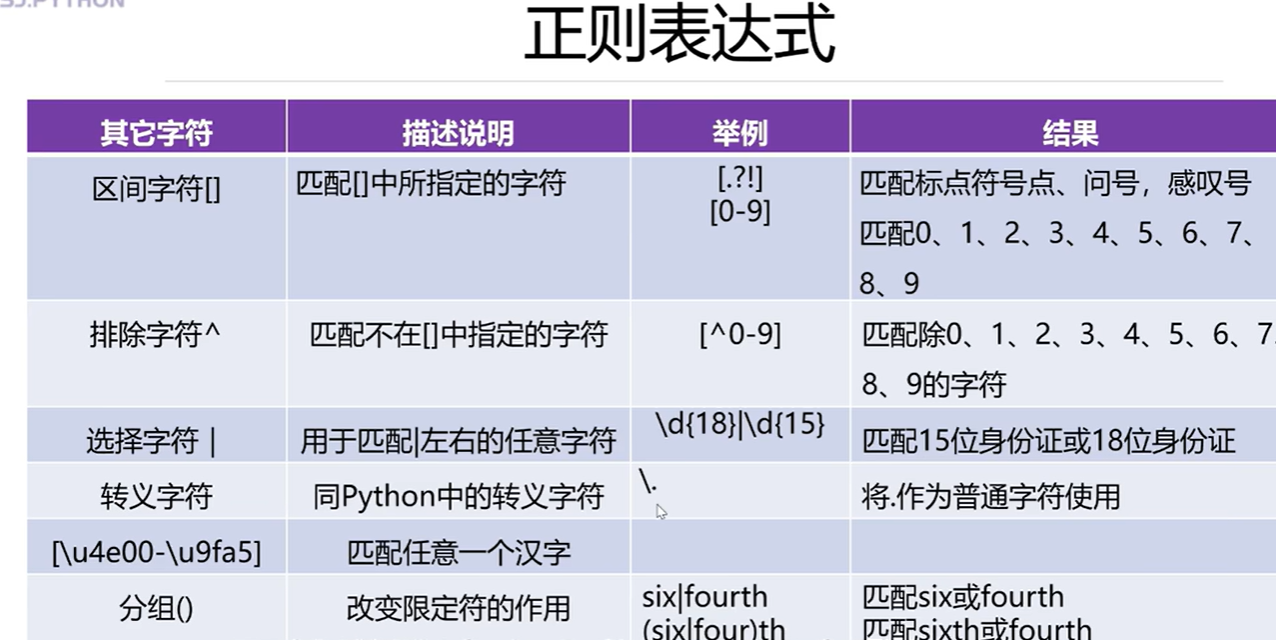
3.9 re模块中的match函数的使用
import re # 导入
pattern='\d\.\d+'# +限定符, 0-9出现1次或多次
s='I study Python 3.11 every day'match=re.match(pattern,s,re.I)#忽略大小写
print(match)#从头开始匹配,所以是None
s2='3.11Python I study Python 3.11 every day'
match2=re.match(pattern,s2,re.I)
print(match2)#\d是一个数字,没有写次数,就是1次,.作为普通字符,.后面还要0-9的数字,就是1-多次,找的是2次print('匹配的起始位置:',match2.start())
print('匹配值的结束位置',match2.end())
print('匹配区间的位置元素',match2.span())# 元组
print('待匹配的字符串',match2.string)
print('匹配的数据',match2.group())
3.9re模块中的search函数和findall函数的使用
import re # 导入
pattern='\d\.\d+'# +限定符, 0-9出现1次或多次
s='I study Python 3.11 every day Python 2.7 I love you'
match=re.search(pattern,s)#用pattern这个规则在s中查找
print(match)s2='4.10 Python I study every day'
s3='I study every day'
match2=re.search(pattern,s2)
match3=re.search(pattern,s3)
print(match2)
print(match3)
#输出内容用match.group
print(match.group())
print(match2.group())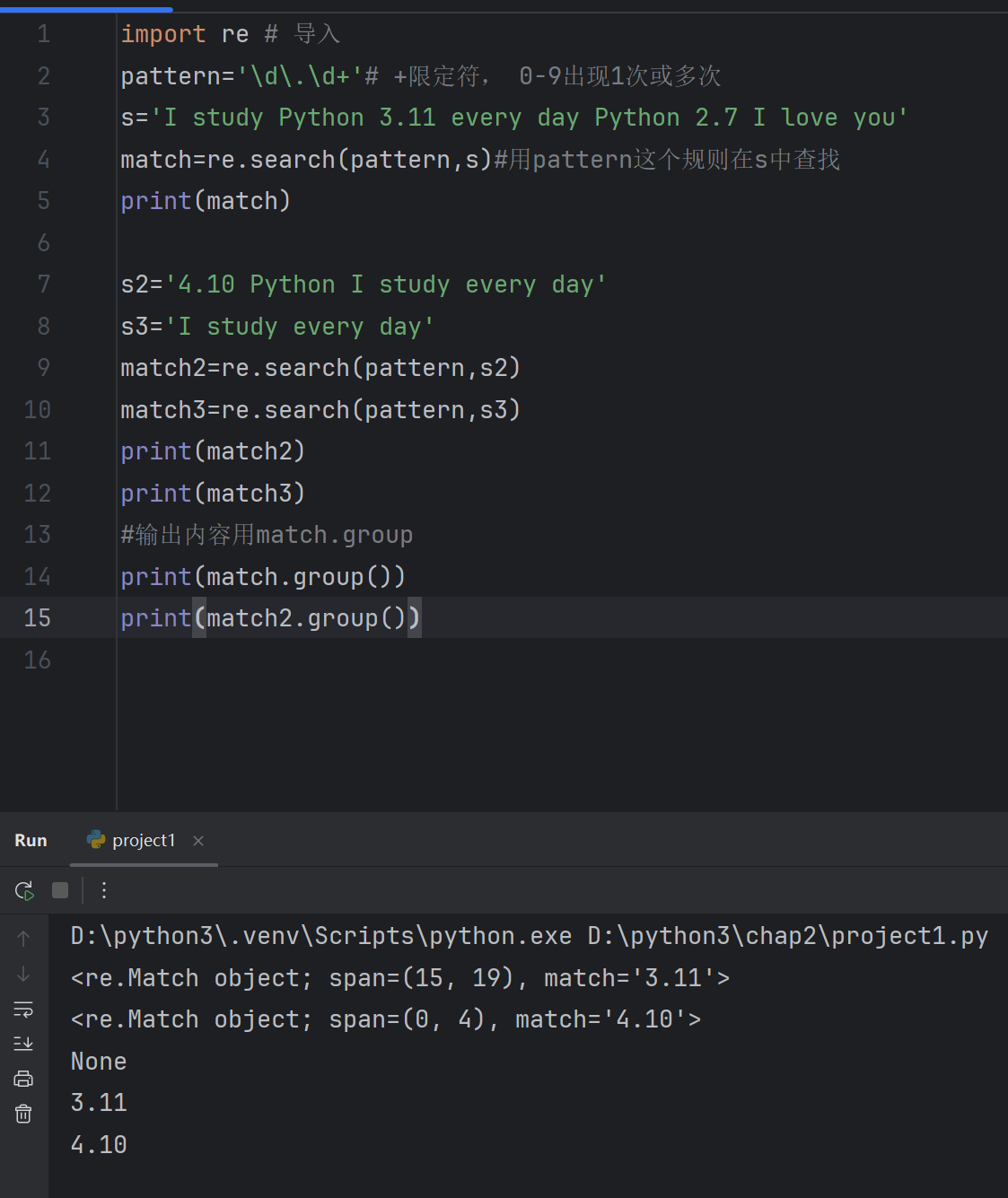
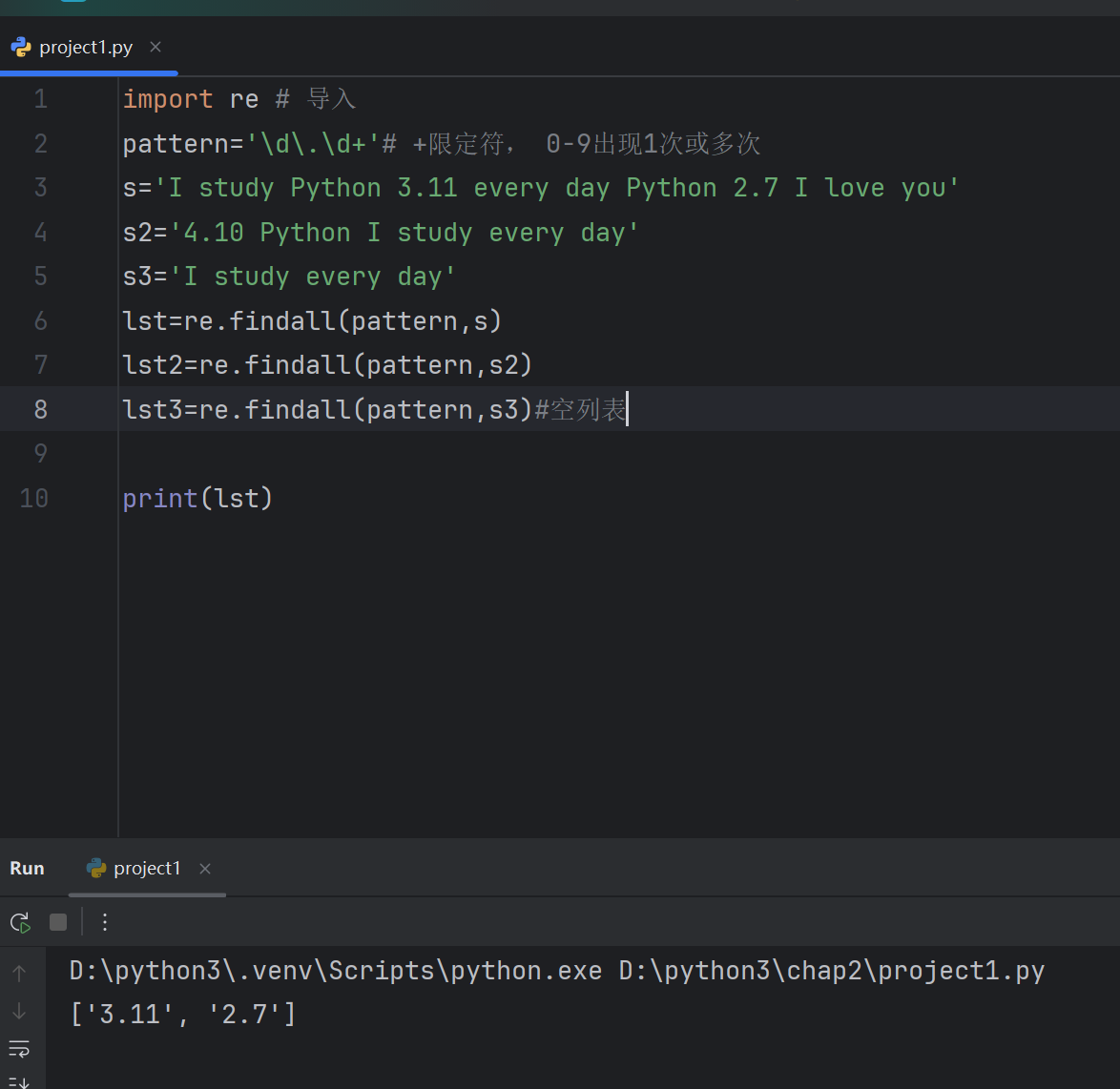
import re # 导入
pattern='\d\.\d+'# +限定符, 0-9出现1次或多次
s='I study Python 3.11 every day Python 2.7 I love you'
s2='4.10 Python I study every day'
s3='I study every day'
lst=re.findall(pattern,s)
lst2=re.findall(pattern,s2)
lst3=re.findall(pattern,s3)#空列表print(lst)
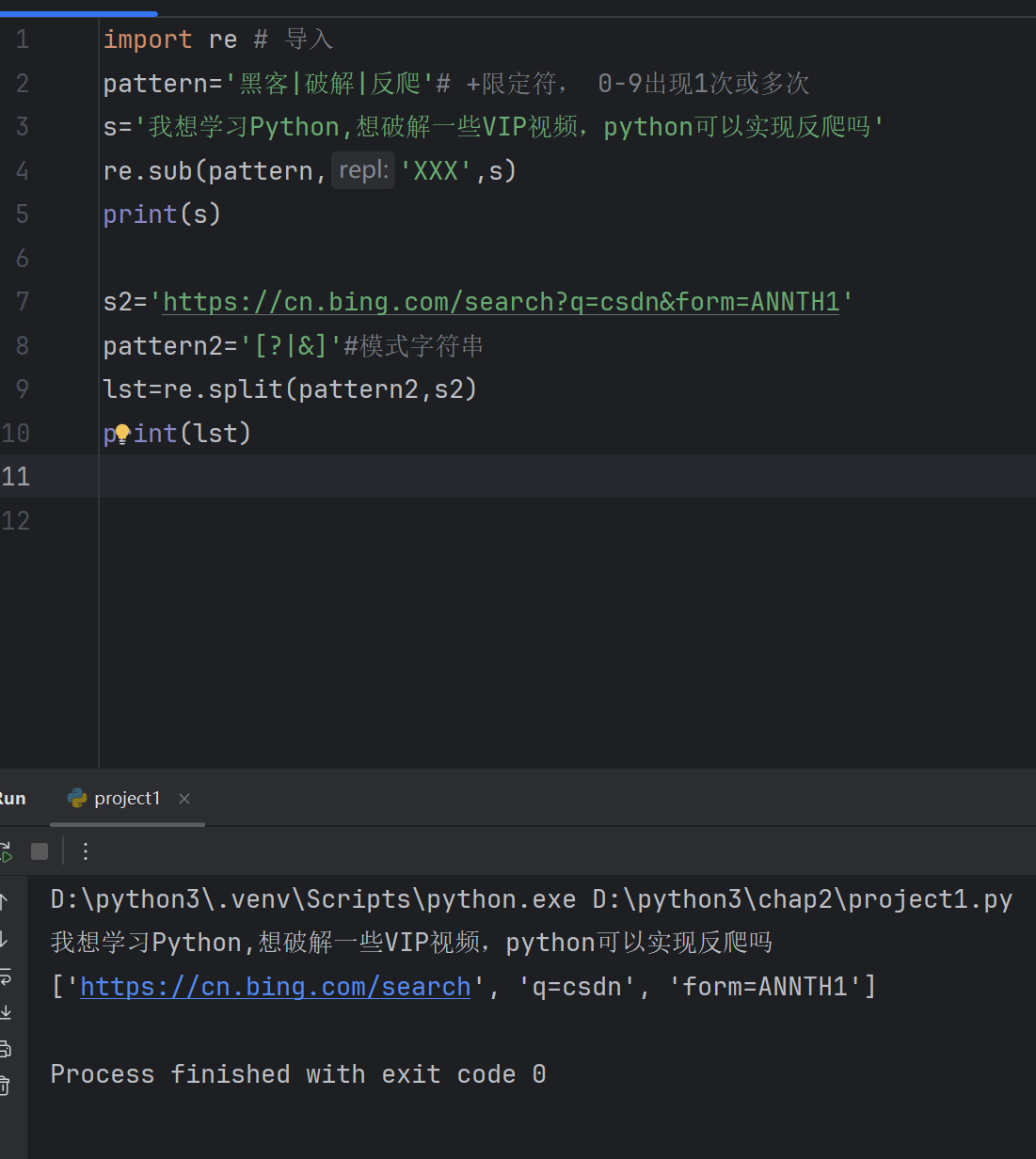
3.10 re模块的sub函数和spilt函数的使用
import re # 导入
pattern='黑客|破解|反爬'# +限定符, 0-9出现1次或多次
s='我想学习Python,想破解一些VIP视频,python可以实现反爬吗'
re.sub(pattern,'XXX',s)
print(s)s2='https://cn.bing.com/search?q=csdn&form=ANNTH1'
pattern2='[?|&]'#模式字符串
lst=re.split(pattern2,s2)
print(lst)
本章总结:
lower和upper结果是一个新的字符串对象
spilt结果是一个列表类型
字符串判断的方法结果是一个bool类型
replace可以指定替换的次数,如果不指定默认会替换全部

match是从字符串的开头,search是查找到第一个,findall查找所有,subn替换,spilt分隔

章节习题
英文占一个字节,中文在utf-8占3个字节

如果不写编码格式就按utf-8编写
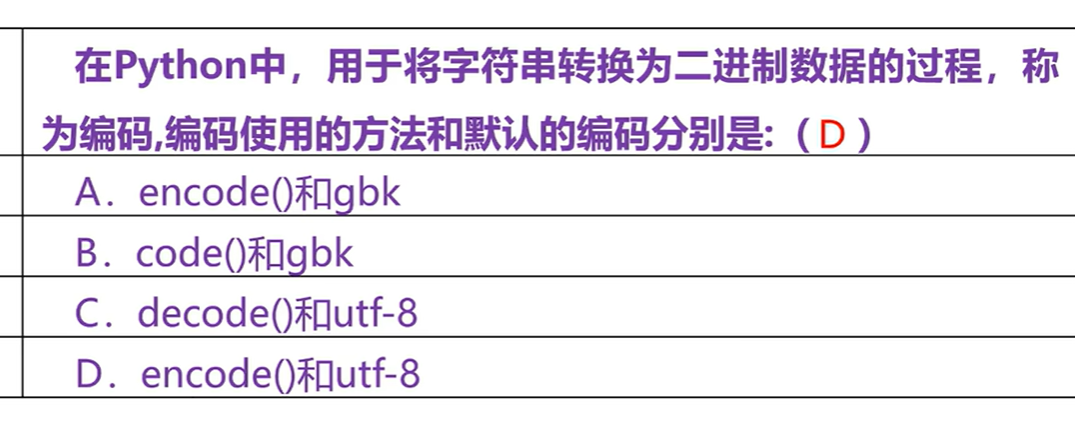
字符串第一个转成小写再连接剩余部分

spilt结果是列表,将ab去掉

index是起始索引,不是全部索引,find查不到是-1,index会报错

lower转小写,upper转大写,strip去掉左右空格或者特殊字符,spilt()分隔不符合要求的

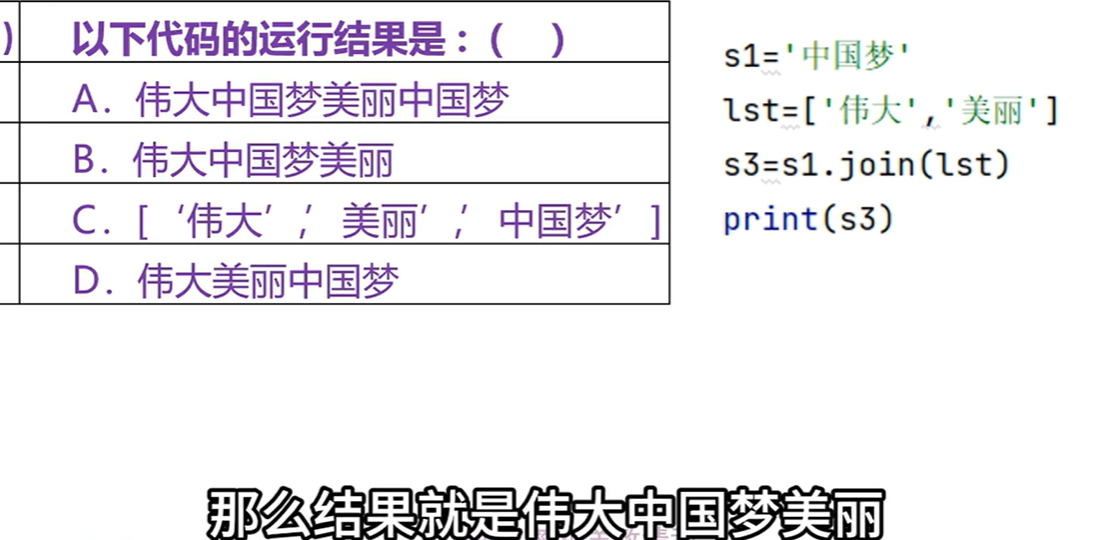
\d 0-9的数字出现8次

小写w是字母、数字、下划线,+是出现的一个次数一到多次,s是待匹配的字符串,re.search使用这个模式字符串到s中查找,只查找到符合条件的第一个

spilt结果是列表类型

章节习题
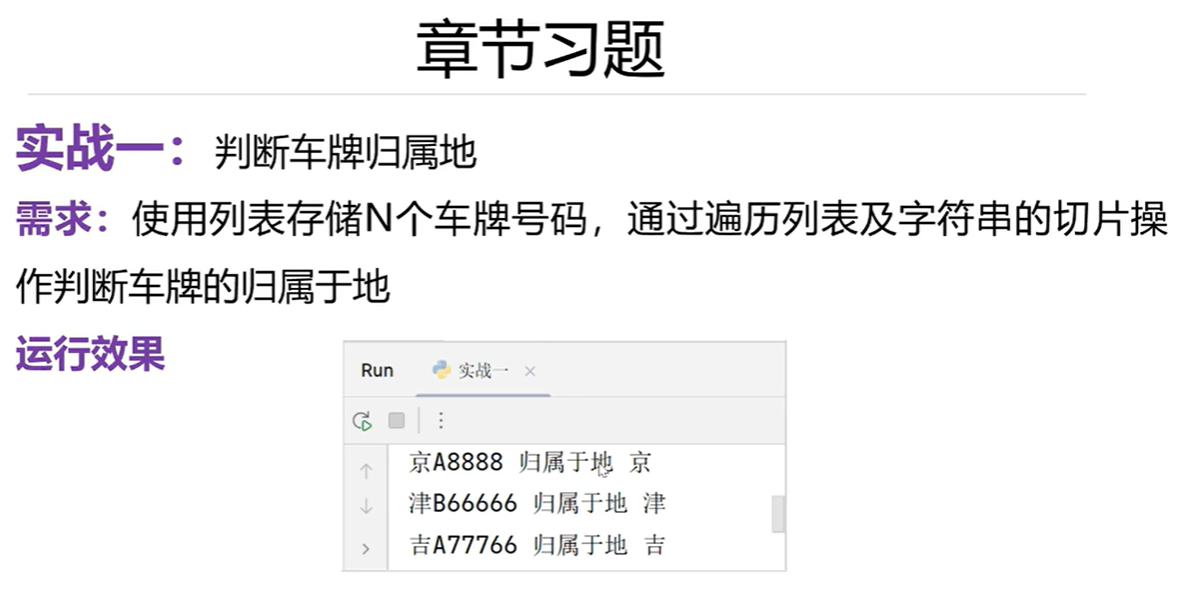
lst=['京A8888','津B6666','吉A777666']
for item in lst:item[0:1]#归属地是车牌第一个字,使用切片操作0:切一个,0-1不包含索引为1area=item[0:1]print(item,'归属地:',area)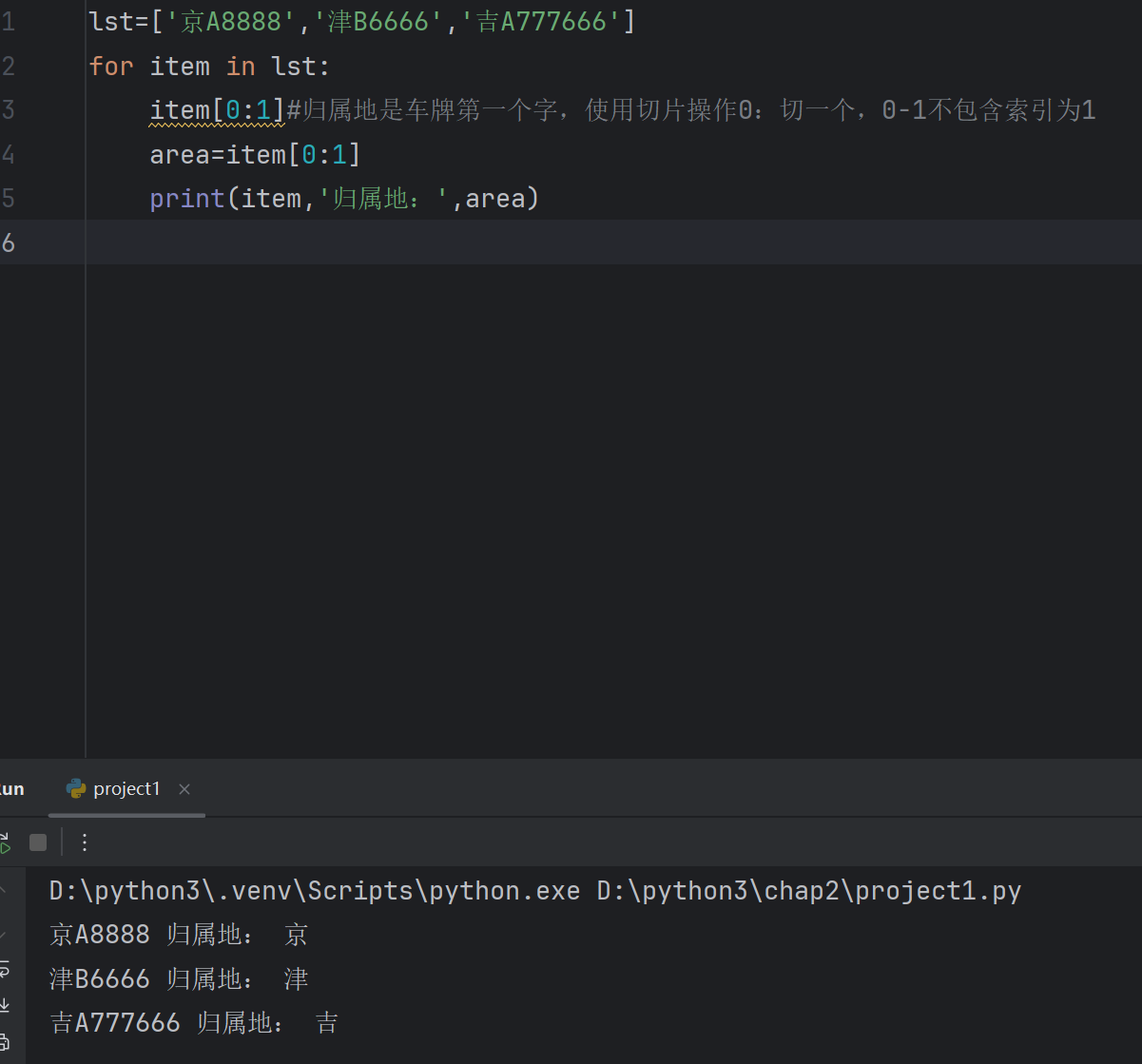
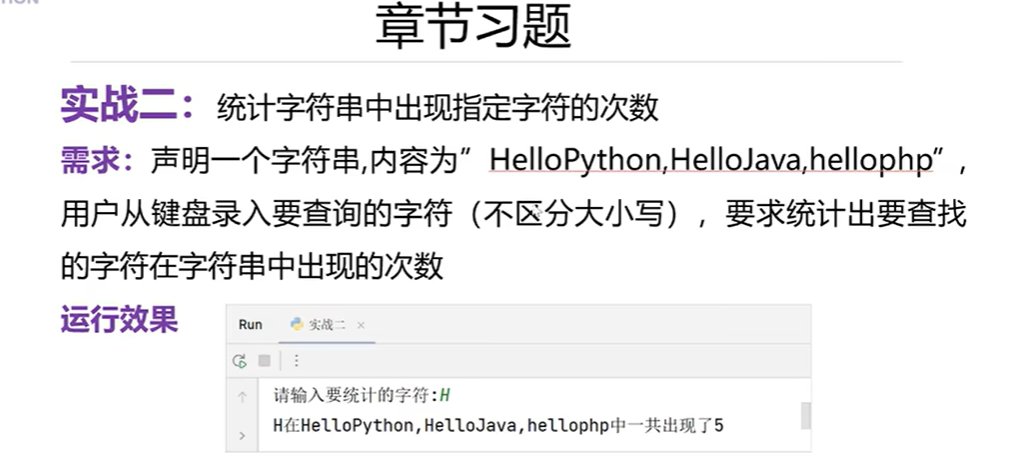
s='HelloPython,HelloJava,hellophp'
word=input('请输入要统计的字符')
print('{0}在{1}一共出现了{2}'.format(word,s,s.upper().count(word)))#字符串的格式化
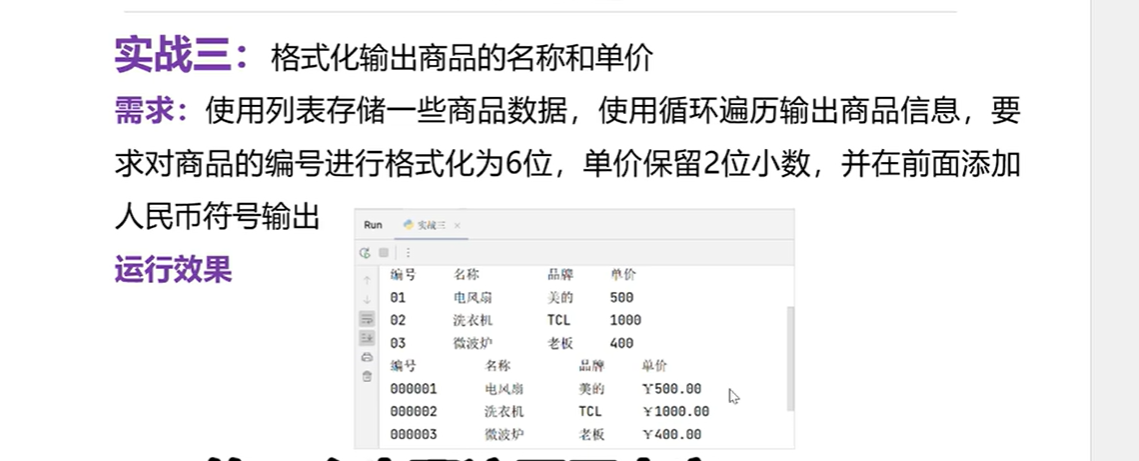
lst=[['01','电风扇','美的',500],['02','洗衣机','TCL',1000],['03','微波炉','老板',500]
]
print('编号\t\t名称\t\t\t品牌\t\t单价')
for item in lst:#item是元素,继续遍历for i in item:print(i,end='\t\t')print()#换行
#格式化
for item in lst:item[0]='0000'+item[0]item[3]='Y{0:.2f}'.format(item[3])#0是索引位置,:是引导符,.2f保留两位小数
print()
print('编号\t\t\t名称\t\t\t品牌\t\t单价')
for item in lst:#item是元素,继续遍历for i in item:print(i,end='\t\t')print()#换行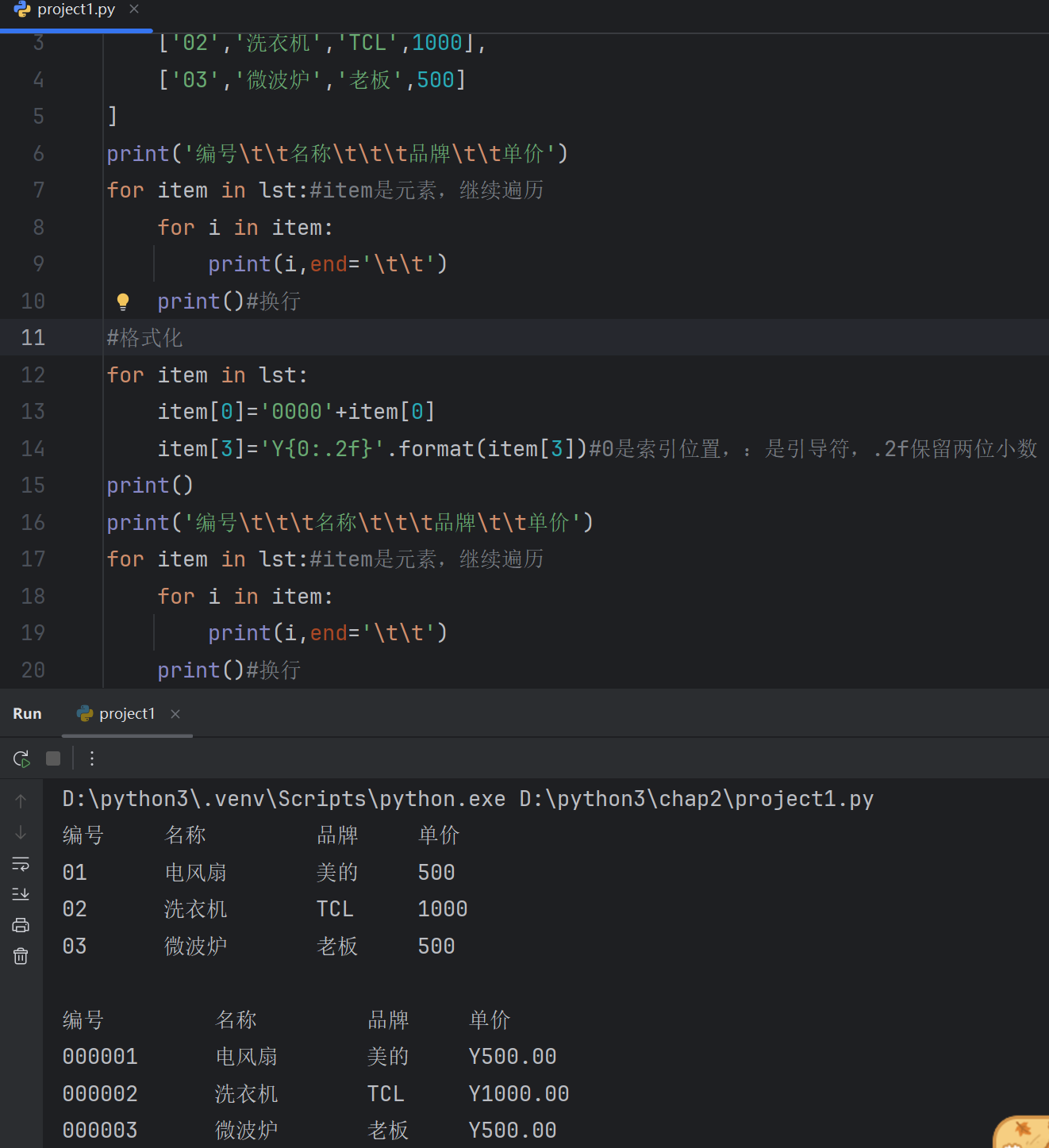
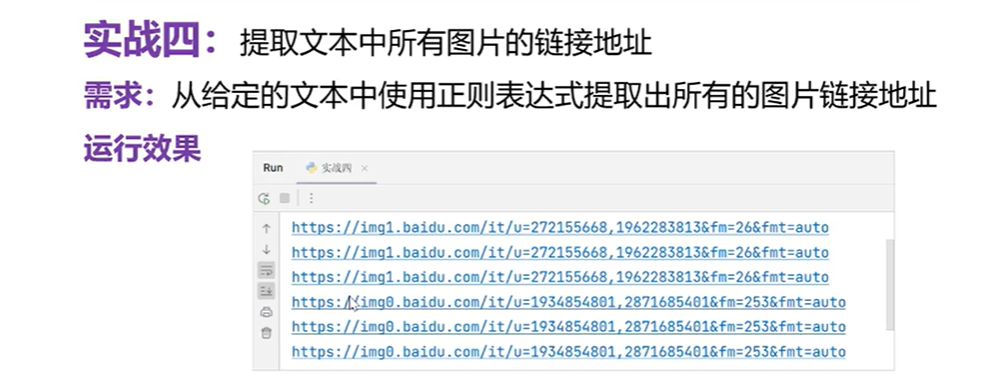
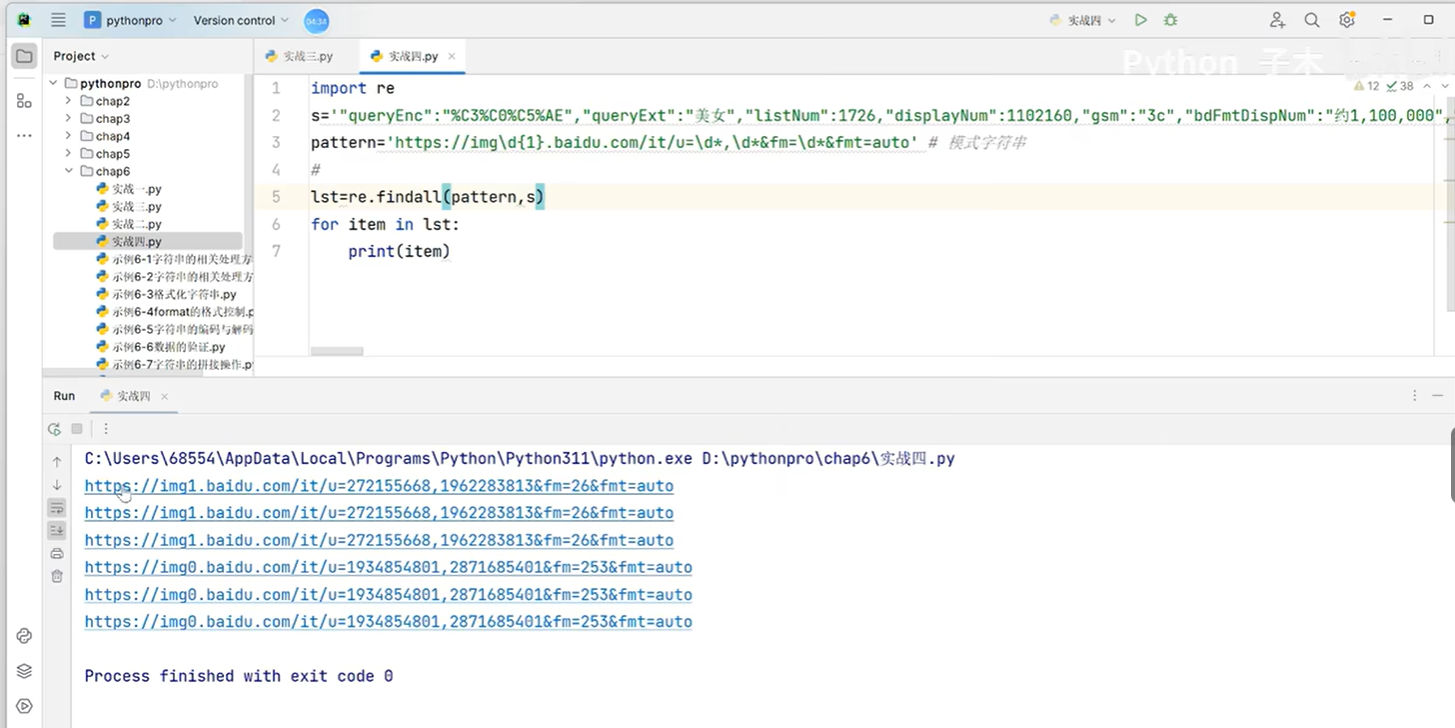
整数的正则表达式是\d,出现几次:{1}。*代表0或者多次
findall结果是列表
四、bug的由来和分类



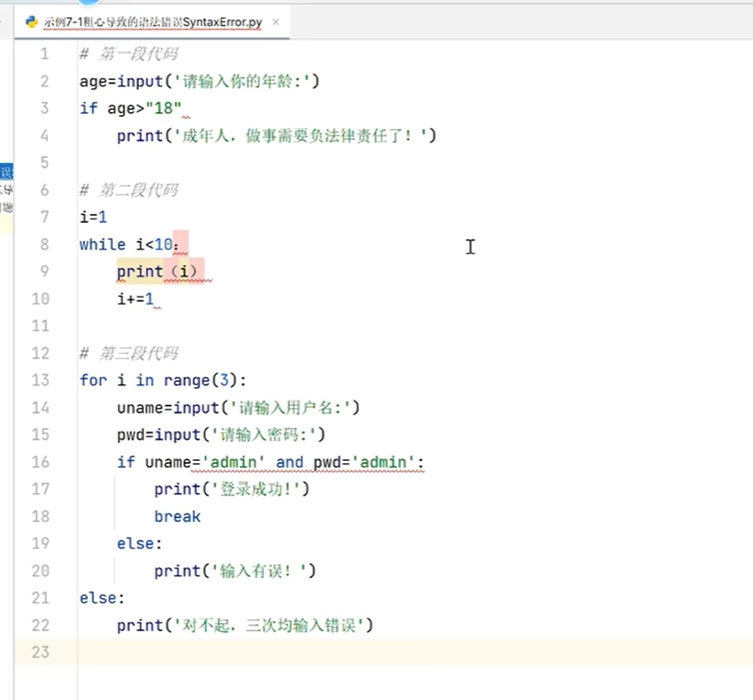
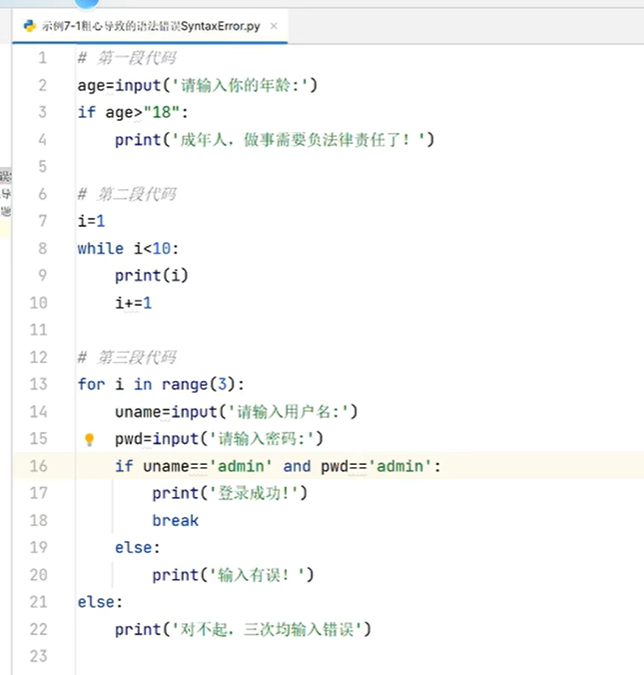
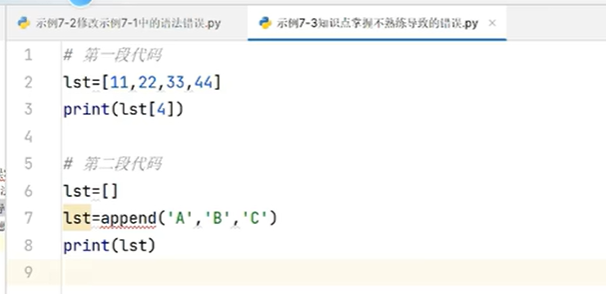
正向递增索引:索引的范围是0—>N-1,append是列表的调用方法,打点调用
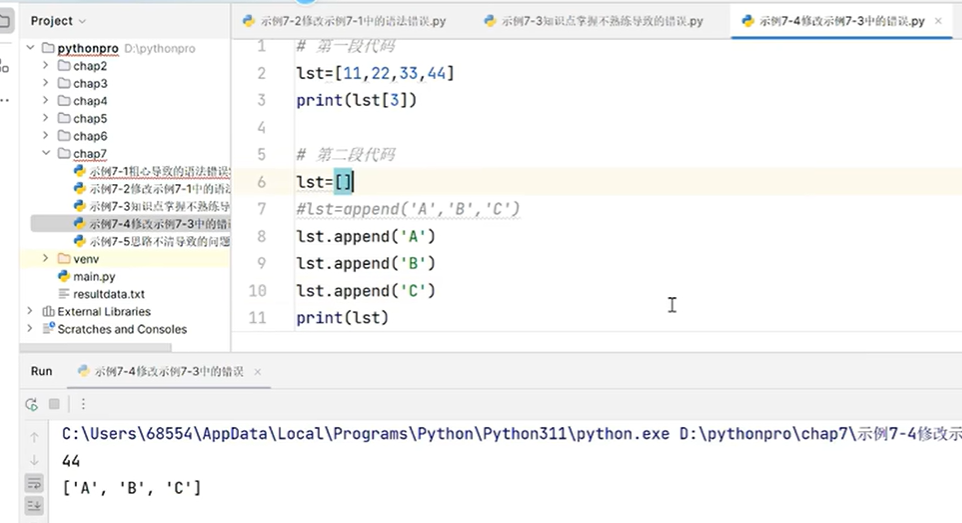
字符串的切片是整数
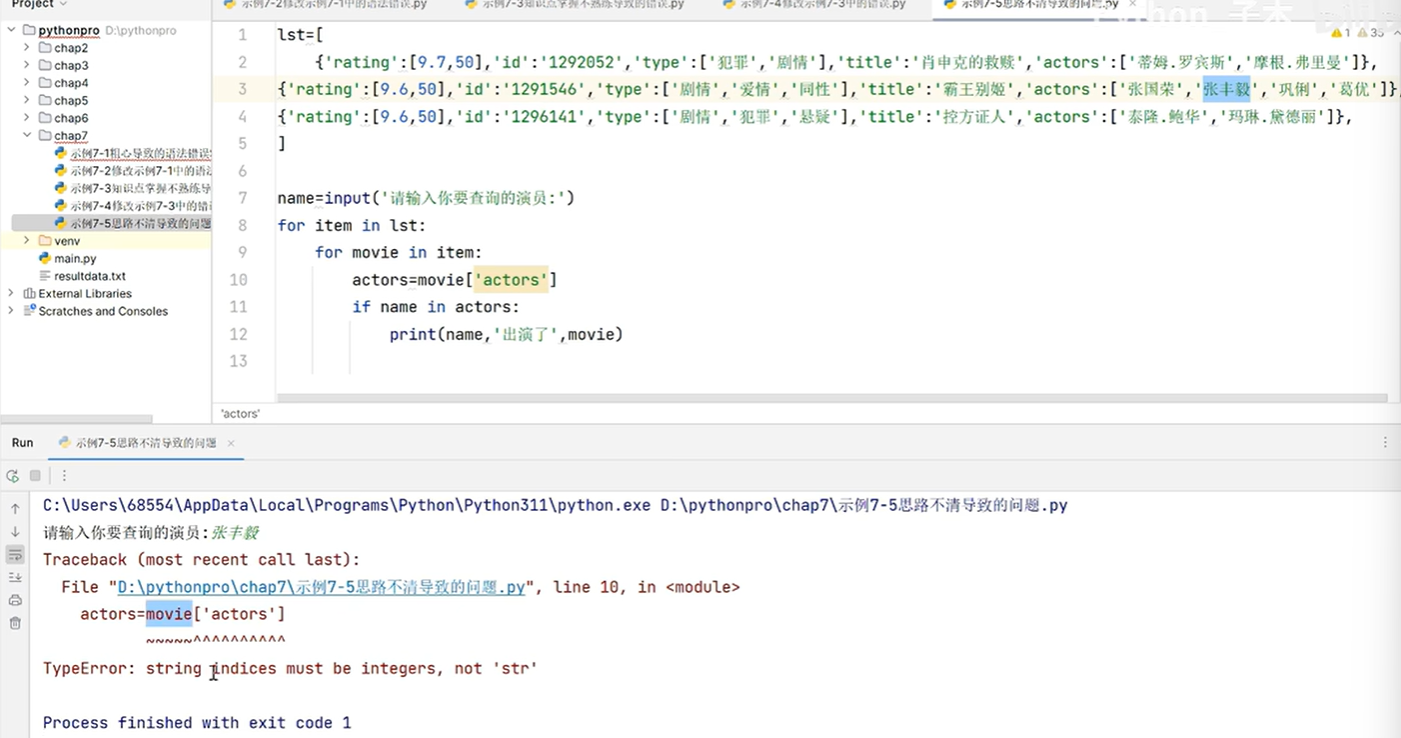
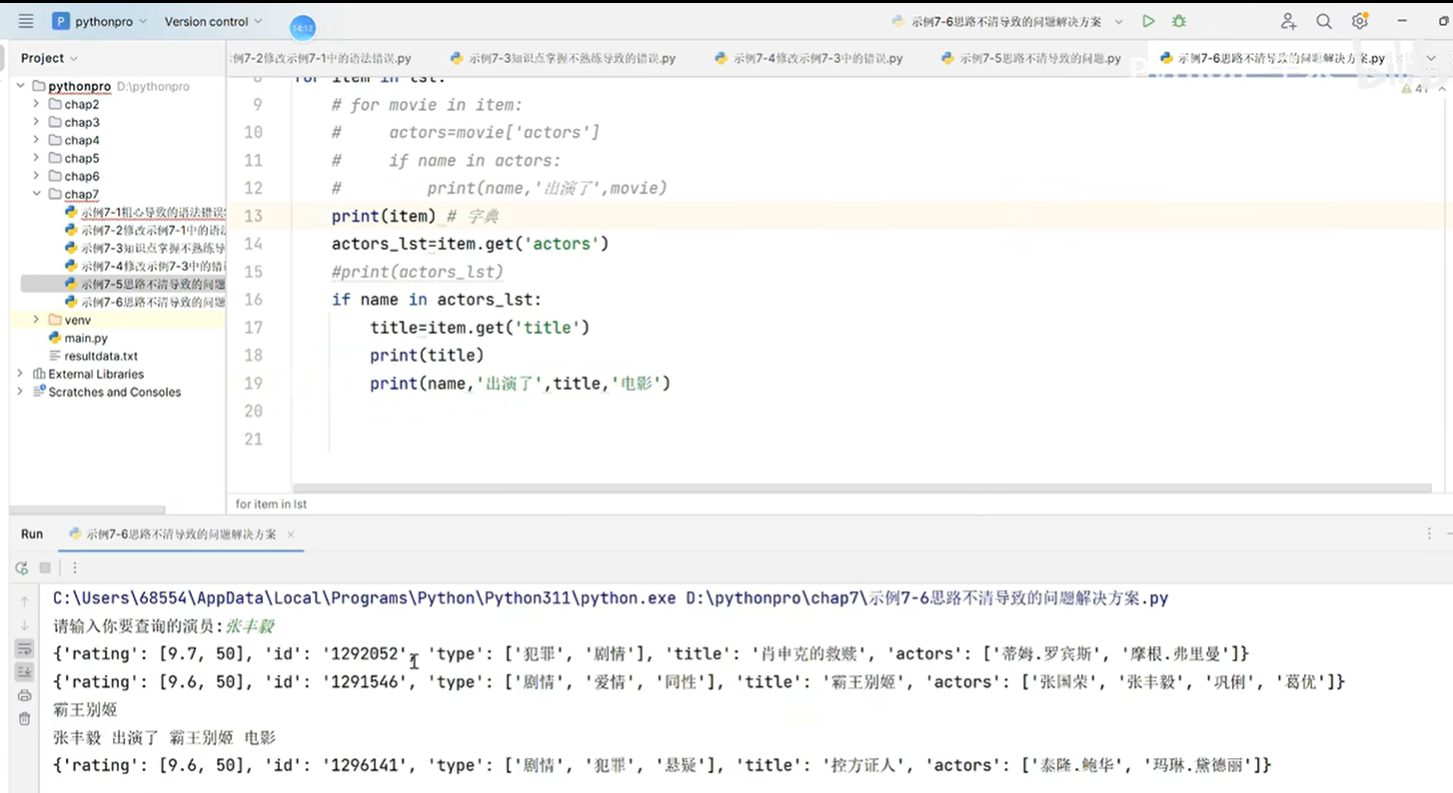
4.1 Python中异常处理机制

try:num1 = int(input("输入一个整数:"))num2 = int(input("输入另一个整数:"))result = num1 / num2print('结果', result)
except ZeroDivisionError:print('除数为0')
4.2多个except结构
try:num1 = int(input("输入一个整数:"))num2 = int(input("输入另一个整数:"))result = num1 / num2print('结果', result)
except ZeroDivisionError:print('除数为0')
except ValueError:print('不能将字符串转成整数')
except BaseException:print('未知异常')
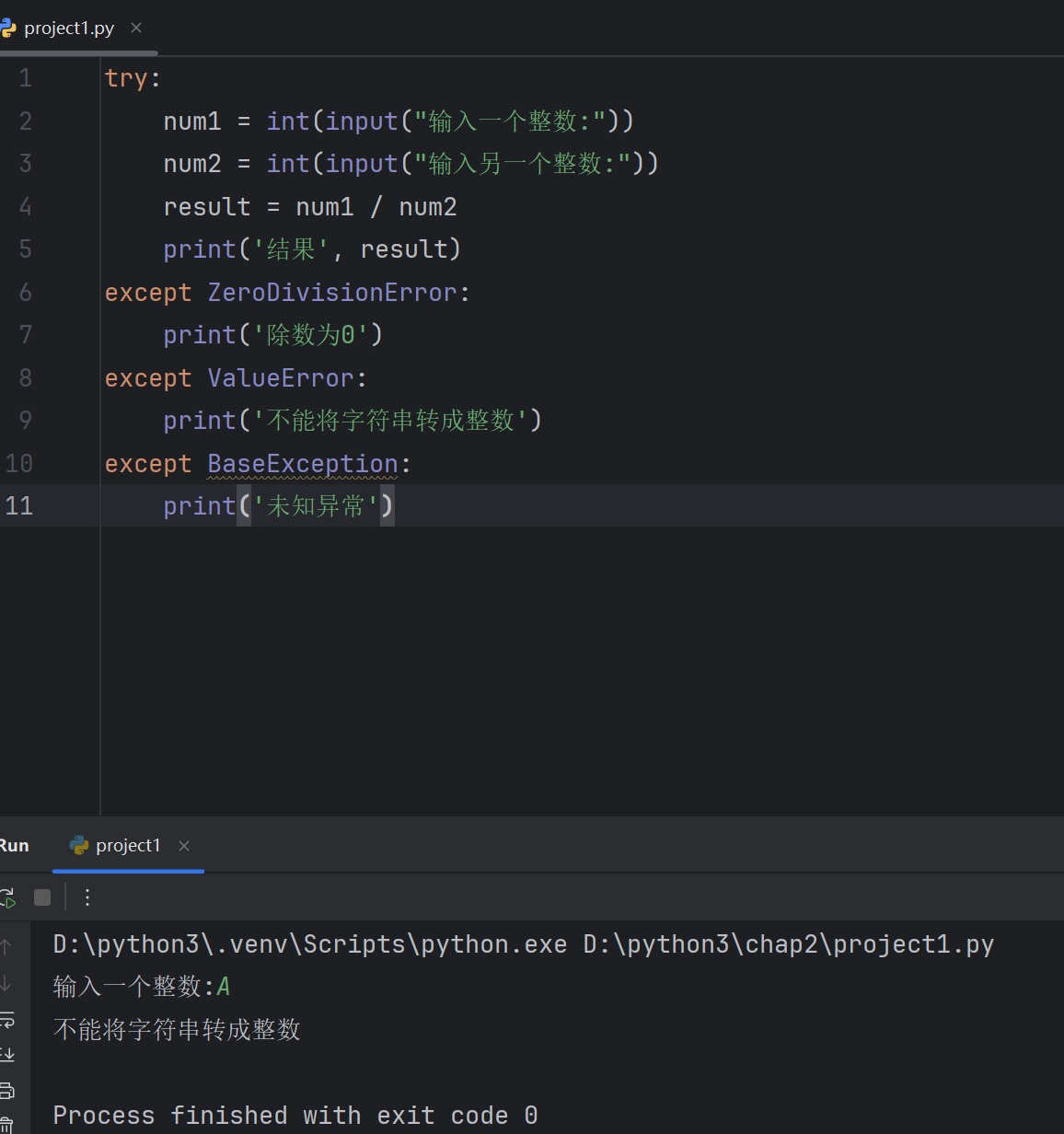

finally无论程序是否异常都会执行的代码
try:num1 = int(input("输入一个整数:"))num2 = int(input("输入另一个整数:"))result = num1 / num2print('结果', result)
except ZeroDivisionError:print('除数为0')
except ValueError:print('不能将字符串转成整数')
except BaseException:print('未知异常')
else:print('结果:',result)
finally:print('程序执行结束')
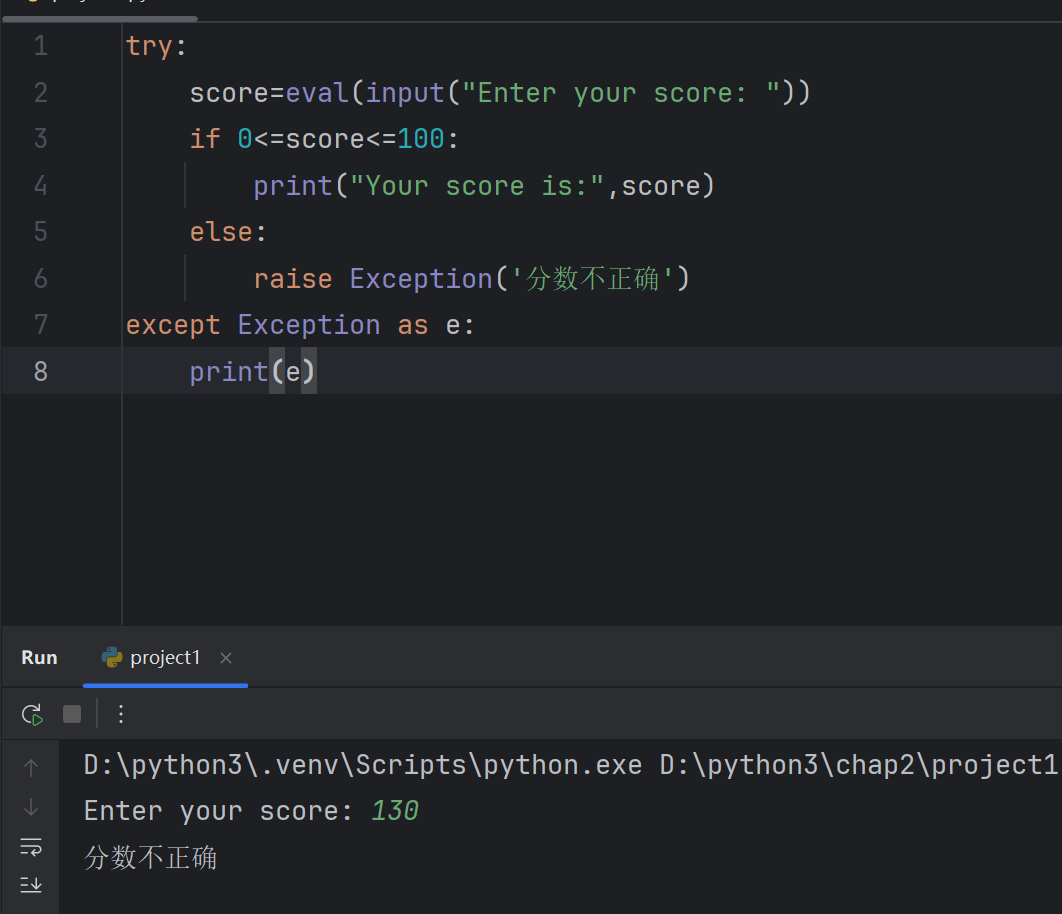
4.3 raise关键字的使用

try:gender=input("Enter your gender: ")if gender!="Male"and gender!="Female":raise Exception('性别只能是男或者女')#第三行判断条件为True,会抛出异常对象else:print('您的性别是',gender)
except Exception as e:print(e)
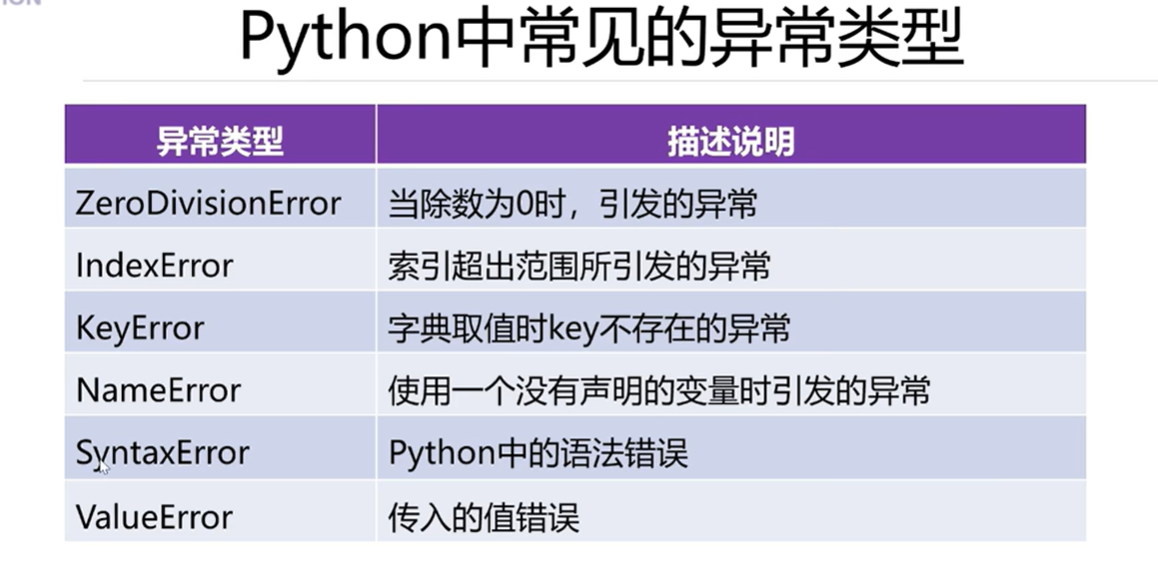
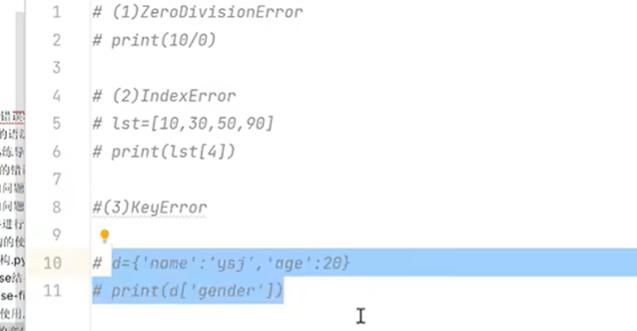
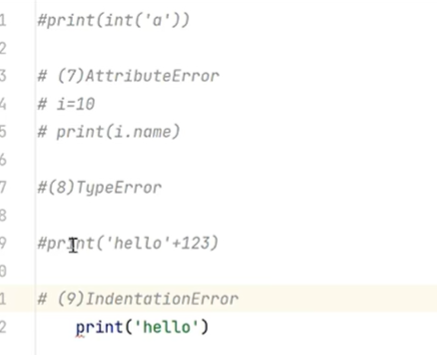
4.4 python中常用的异常类型


4.5 PyCharm的程序调试
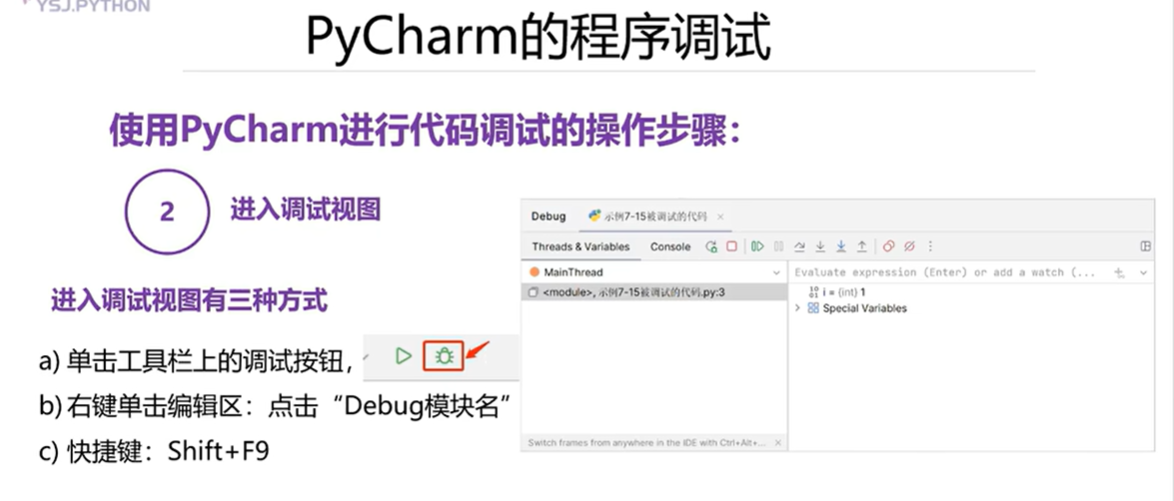
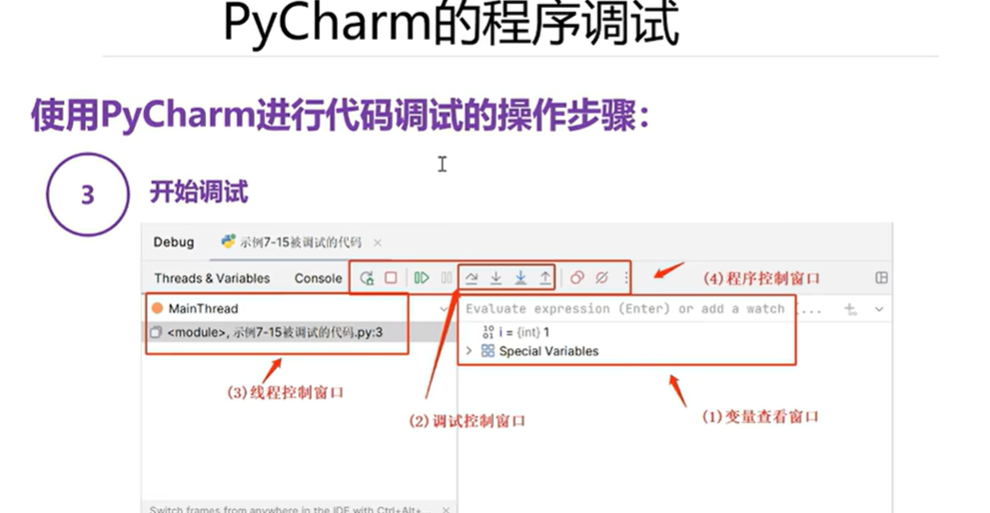
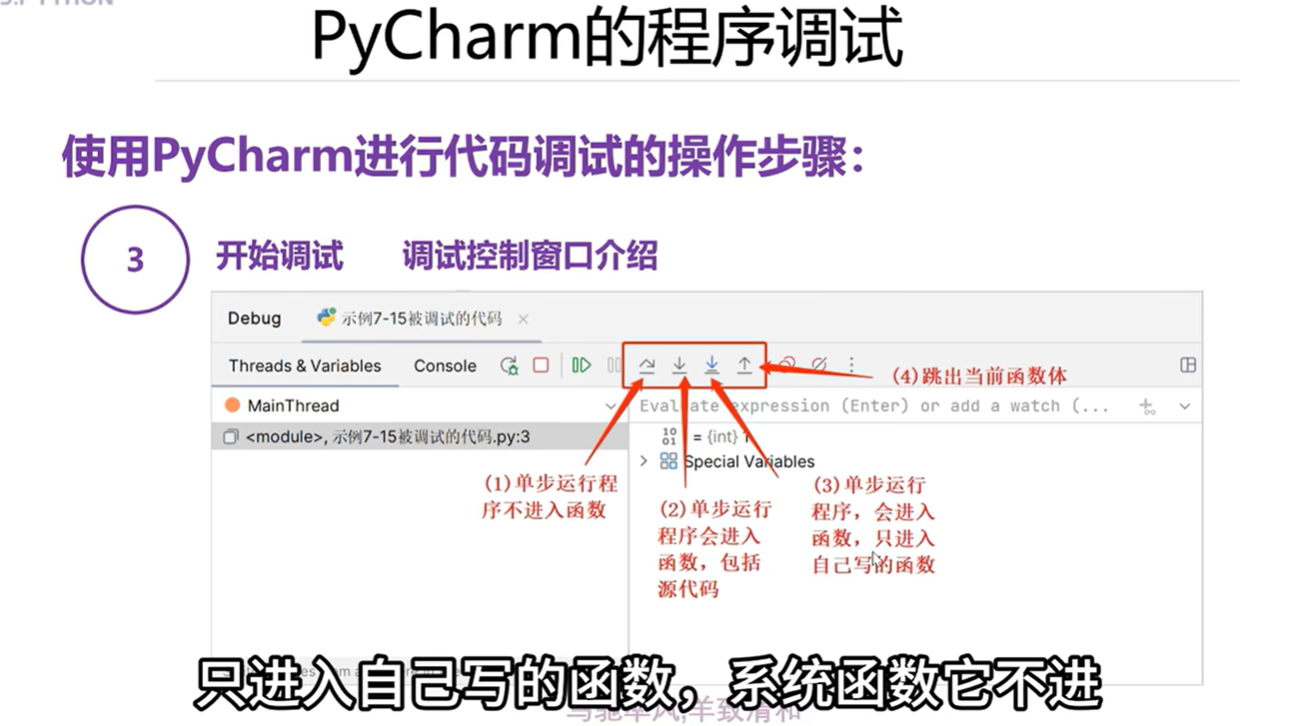
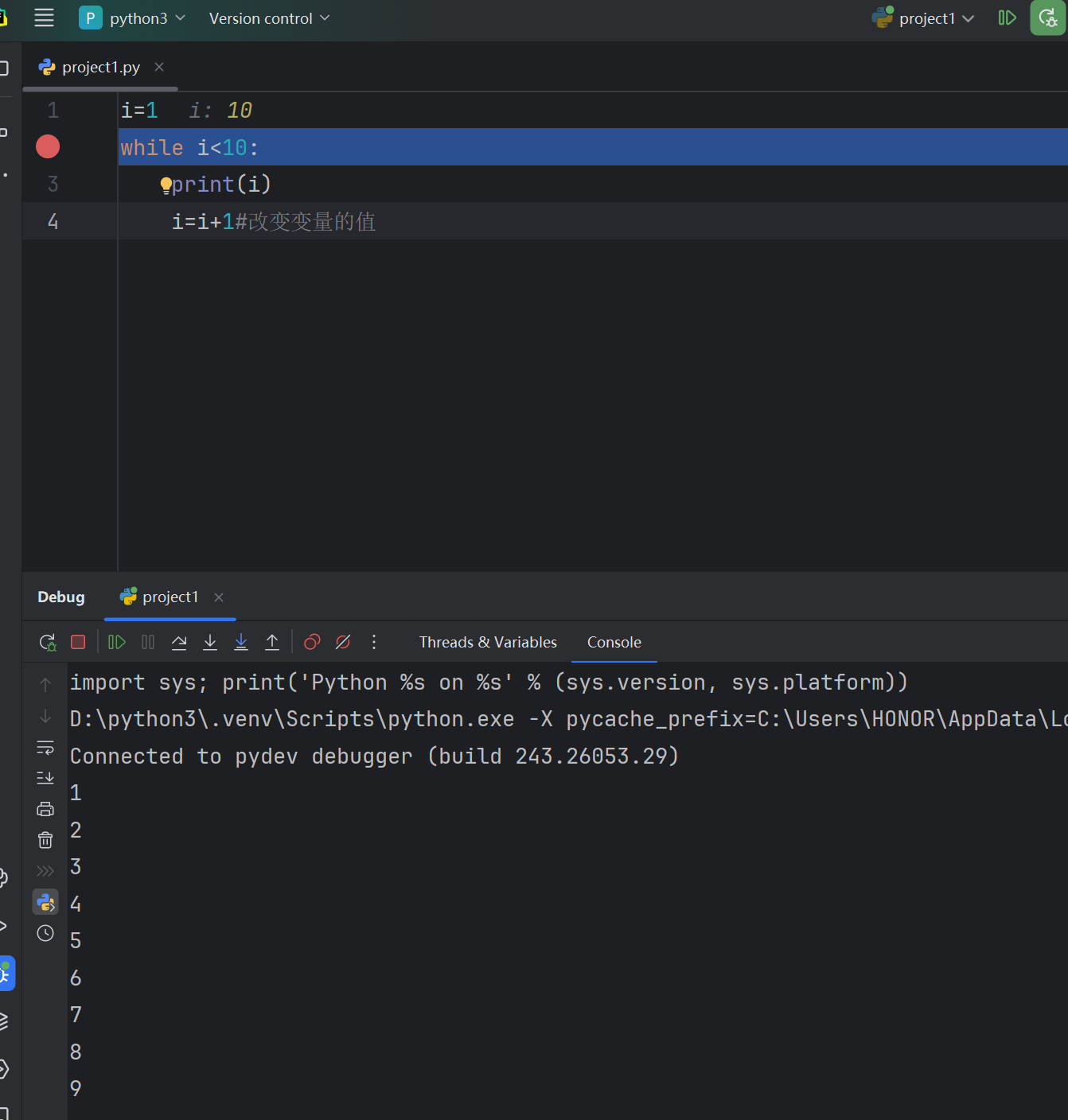
本章总结

如果没有出现异常执行try-else结构,在最后一个结果中,没有异常执行try-else-finally,出现异常执行try-except-finally

设置断点:在变量定义,循环处





finally无论是否异常都会执行




章节习题
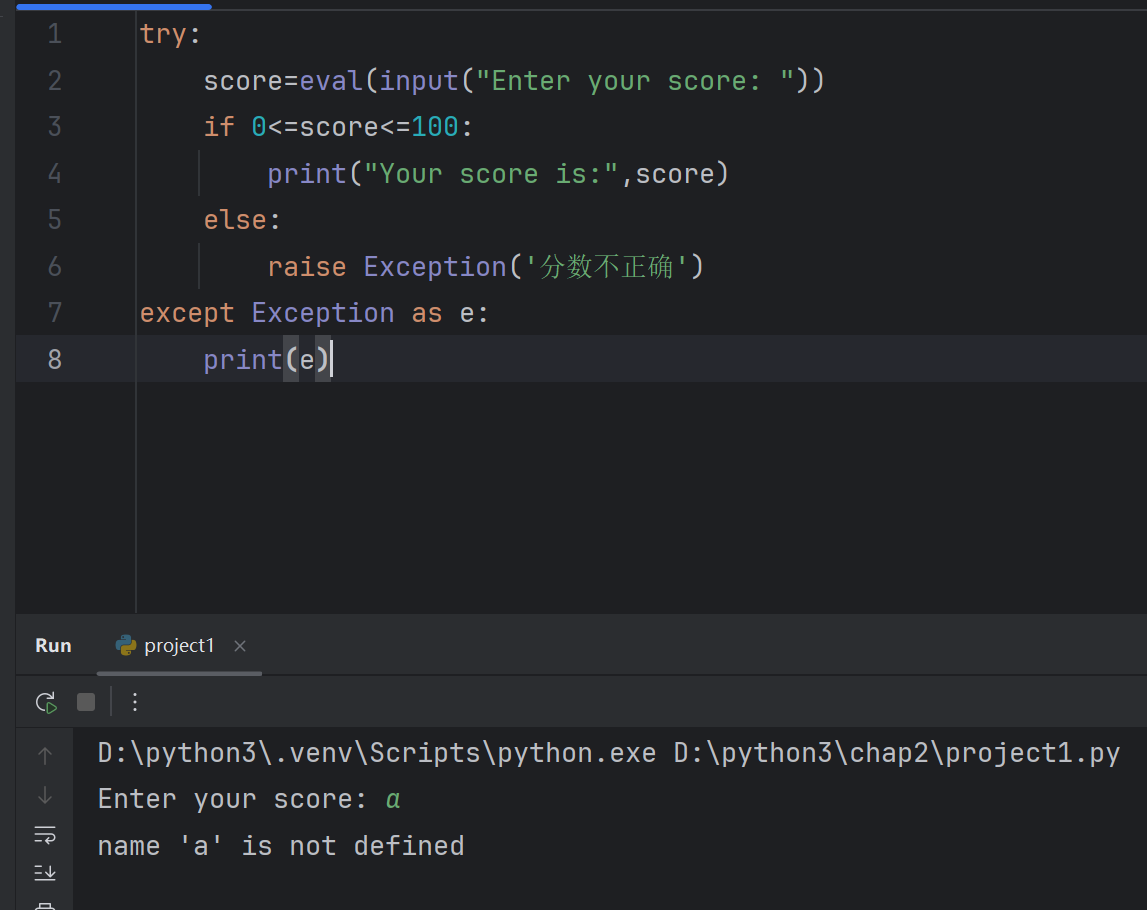
try:score=eval(input("Enter your score: "))if 0<=score<=100:print("Your score is:",score)else:raise Exception('分数不正确')
except Exception as e:print(e)
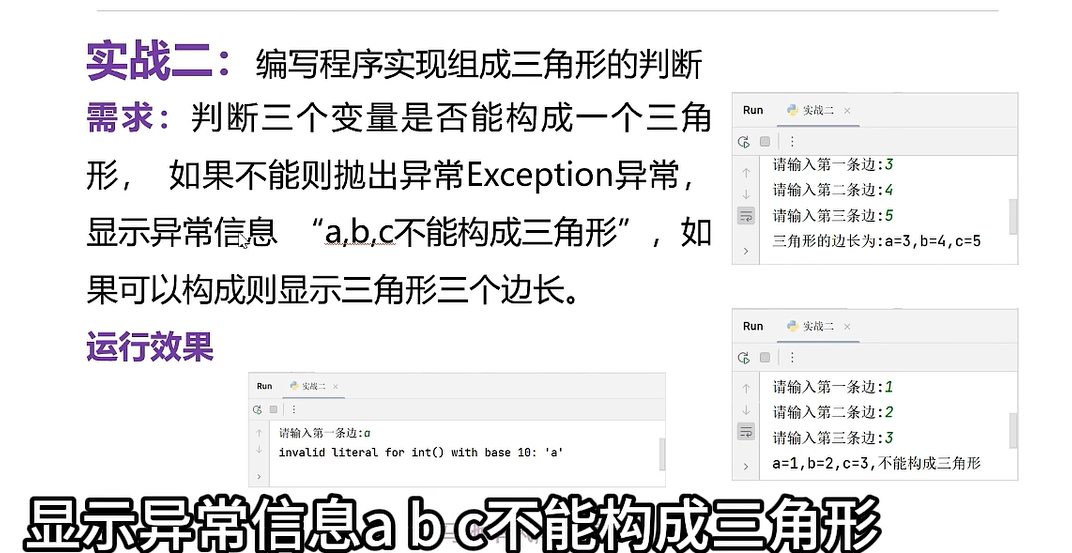
try:a = int(input("请输入第一条边: "))b = int(input("请输入第二条边: "))c = int(input("请输入第三条边: "))if a+b>c and b+c>a:print(f'三角形的边长:,{a},{b},{c}')else:raise Exception(f'{a},{b},{c},不能构成三角形')# 格式化处理
except Exception as e:print(e)
五、函数及常用的内置函数


def get_sum(num):#num叫做形式参数(函数定义处)s=0for i in range(1,num+1):s=s+iprint(f'1到{num}之间的累加和为:{s}')#函数的调用处
get_sum(10)#1-10之间的累加和 10是实际参数值
get_sum(100)#1-100之间的累加和 100是实际参数值
get_sum(1000)#1-100之间的累加和 1000是实际参数值


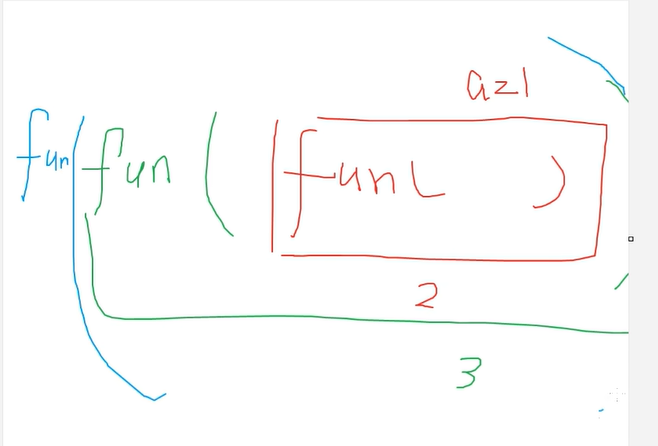
函数的参数传递-位置参数和关键字参数

def happy_birthday(name,age):print('祝'+name+'生日快乐')print(str(age)+'生日快乐')#调用
happy_birthday('张三',18)#调用时调用的参数个数和顺序必须与定义的参数的个数和顺序相同关键字传参
def happy_birthday(name,age):print('祝'+name+'生日快乐')print(str(age)+'生日快乐')
#关键字传参
happy_birthday(age=18,name='张三')
#happy_birthday(age=18,name1='张三')
#定义形参为name,TypeError: happy_birthday() got an unexpected keyword arguhappy_birthday('陈梅梅',age=18)#正常执行,位置传参,也可以使用关键字传参#happy_birthday(name='陈梅梅',18)#SyntaxError: positional argument follows keyword argument
#位置参数在前,关键字传参在后,不然会报错5.1 函数的参数传递–默认值参数

def happy_birthday(name='张三',age=18):print('祝'+name+'生日快乐')print(str(age)+'生日快乐')#调用
happy_birthday()#不用传参
happy_birthday('陈梅梅')#位置传参
happy_birthday(age=19)#关键字传参(函数调用处传参),name采用默认值#happy_birthday(19)# 19会赋值给哪个变量,如果使用位置传参的方式,19被传给了name
def fun(a,b=20):pass#def fun2(a=20,b):# 语法报错,当位置参数和默认参数(在函数定义时)同时存在的时候,位置参数在后会报错# pass# 当位置参数和关键字参数同时存在,应该遵循位置参数在前,默认参数在后5.2 函数的参数传递–可变参数

# 个数可变的位置参数
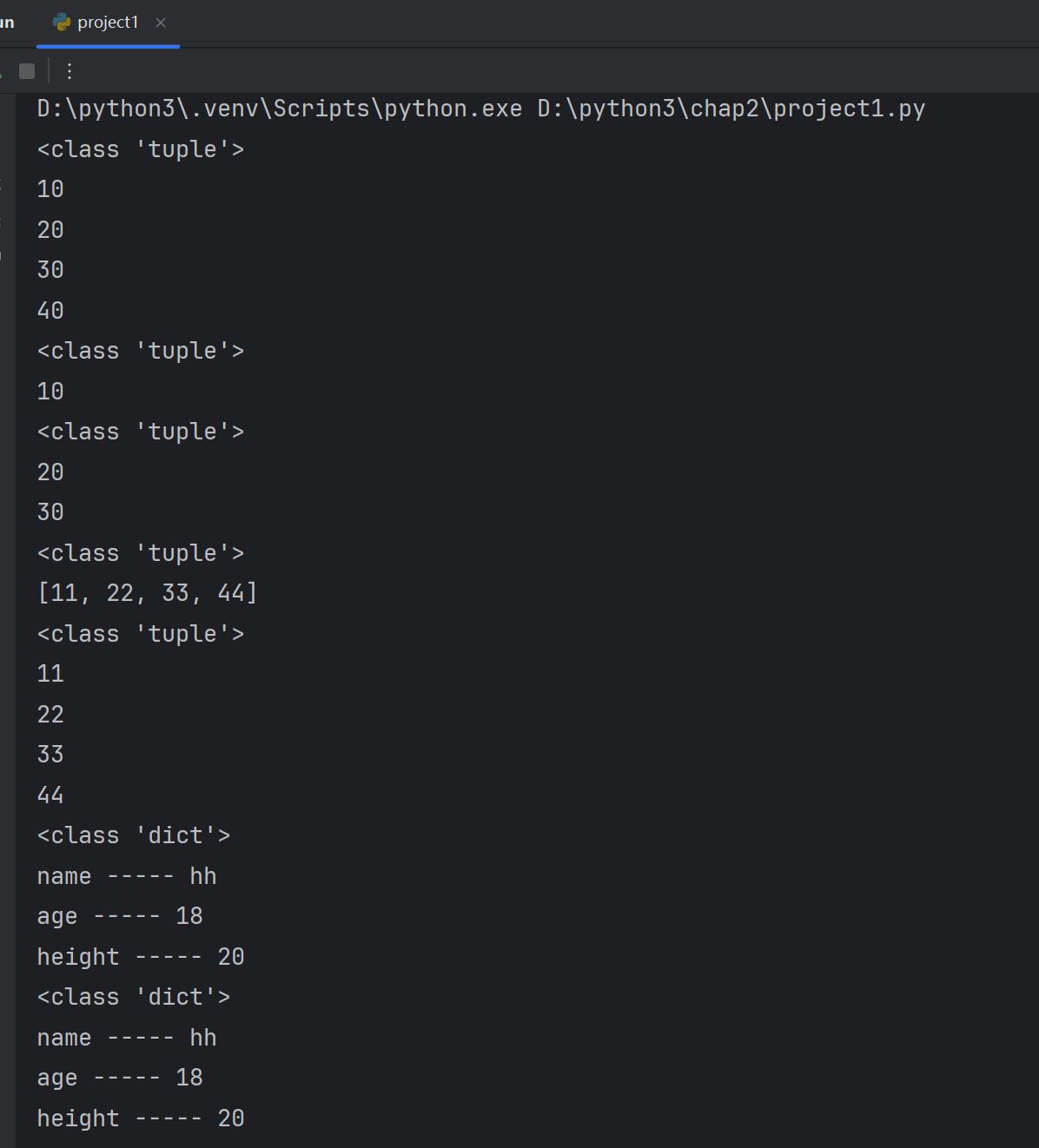
def fun(*data):print(type(data))for item in data:print(item)#调用
fun(10,20,30,40)
fun(10)
fun(20,30)
fun([11,22,33,44])#实际传递的是一个参数
#在调用时,参数前加一颗星,分将列表进行解包
fun(*[11,22,33,44])#个数可变的关键字参数
def fun2(**kwpara):#定义需要两颗星print(type(kwpara))for key,value in kwpara.items():print(key,'-----',value)#调用
fun2(name='hh',age=18,height=20)#关键字参数d={'name':'hh','age':18,'height':20}
#fun2(d)#不可以将字典传入做参数, fun2() takes 0 positional arguments but 1 was given
fun2(**d)# 如果参数是字典,前面加上两颗星进行系列解包
5.3 函数的返回值

# 函数的返回值
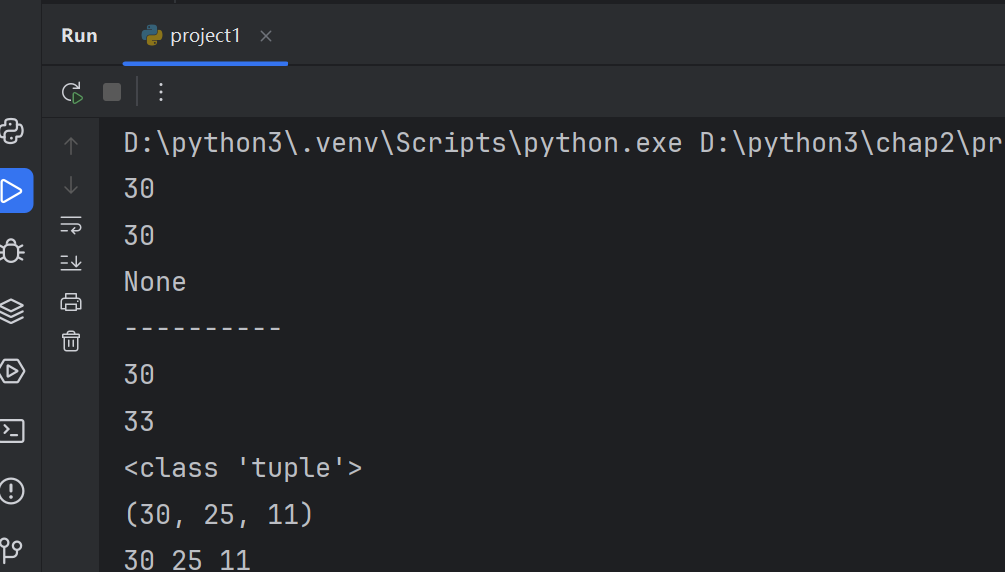
def calc(a,b):print(a+b)calc(10,20)
print(calc(10,20))#Nonedef calc2(a,b):s=a+breturn s #将s返回函数的调用处处理print('-'*10)
get_s=calc2(10,20)#存储到变量当中
print(get_s)get_s2=calc2(calc2(10,20),3)#先去执行calc2(10,20),返回结果是30,再去执行calc2(30,30)
print(get_s2)#返回值可以是多个
def get_sum(num):s=0#累加和for i in range(1,num+1):s=s+iodd_sum=0#奇数和even_sum=0#偶数和for i in range(1,num+1):if i%2==0:odd_sum=odd_sum+ielse:even_sum=even_sum+is+=1return odd_sum,even_sum,s#三个值result=get_sum(10)
print(type(result))
print(result)#系列解包赋值
a,b,c=get_sum(10)
print(a,b,c)
5.4 变量的作用域

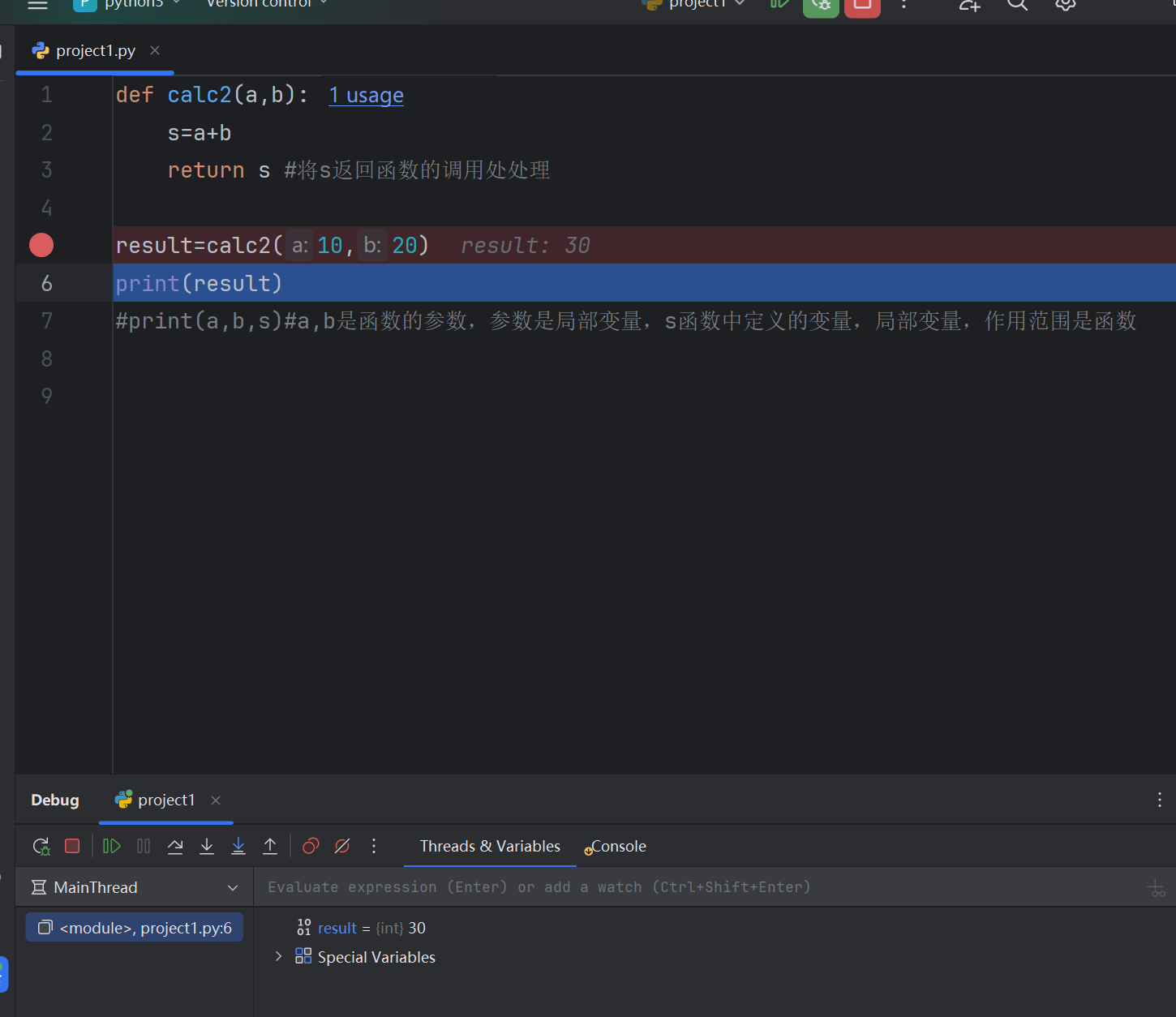
def calc2(a,b):s=a+breturn s #将s返回函数的调用处处理result=calc2(10,20)
print(result)
#print(a,b,s)#a,b是函数的参数,参数是局部变量,s函数中定义的变量,局部变量,作用范围是函数
a=100#全局变量
def calc(x,y):return a+x+y
print(a)
print(calc(10,20))
print('-'*30)def calc2(x,y):a=200#局部变量,局部变量的名称和全局变量的名称相同return a+x+y# a是局部变量还是全局变量?局部变量,当全局变量和局部变量名称相同时,局部变量的优先级高
print(calc2(10,20))
print(a)
print('-'*30)
def calc3(x,y):global s#s是在函数中定义的变量,但是使用了global关键字声明,这个变量s变成了全局变量s=300# 声明和赋值,必须分开执行return s+x+yprint(calc3(10,20))
print(s)
print('-'*30)
5.5 匿名函数的使用

from ctypes import HRESULTdef calc(a,b):return a+b
print(calc(10,20))
#匿名函数
s=lambda a,b:a+b#s表示的是一个匿名函数
print(type(s))
#调用匿名函数
print(s(10,20))
print('*'*50)#
lst=[10,20,30,40,50]
for i in range(len(lst)):# i表示索引print(lst[i])
print()for i in range(len(lst)):result=lambda x:x[i]#根据索引取值,result的是函数(function)类型,x是形式参数print(result(lst))# lst是实际参数student_scores=[#列表,列表里面四个元素{'name':'张三','score':98},{'name':'李四','score':96},{'name':'王五','score':98},{'name':'赵六','score':65}
]
# 对列表进行排序,排序规则:字典中的成绩
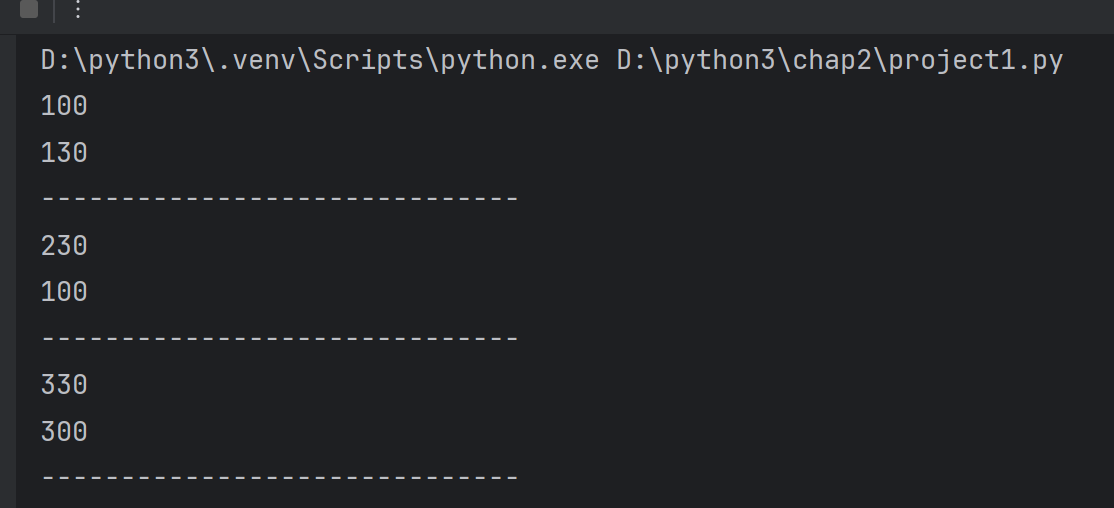
student_scores.sort(key=lambda x:x.get('score'), reverse=True)#x是字典,降序、
print(student_scores)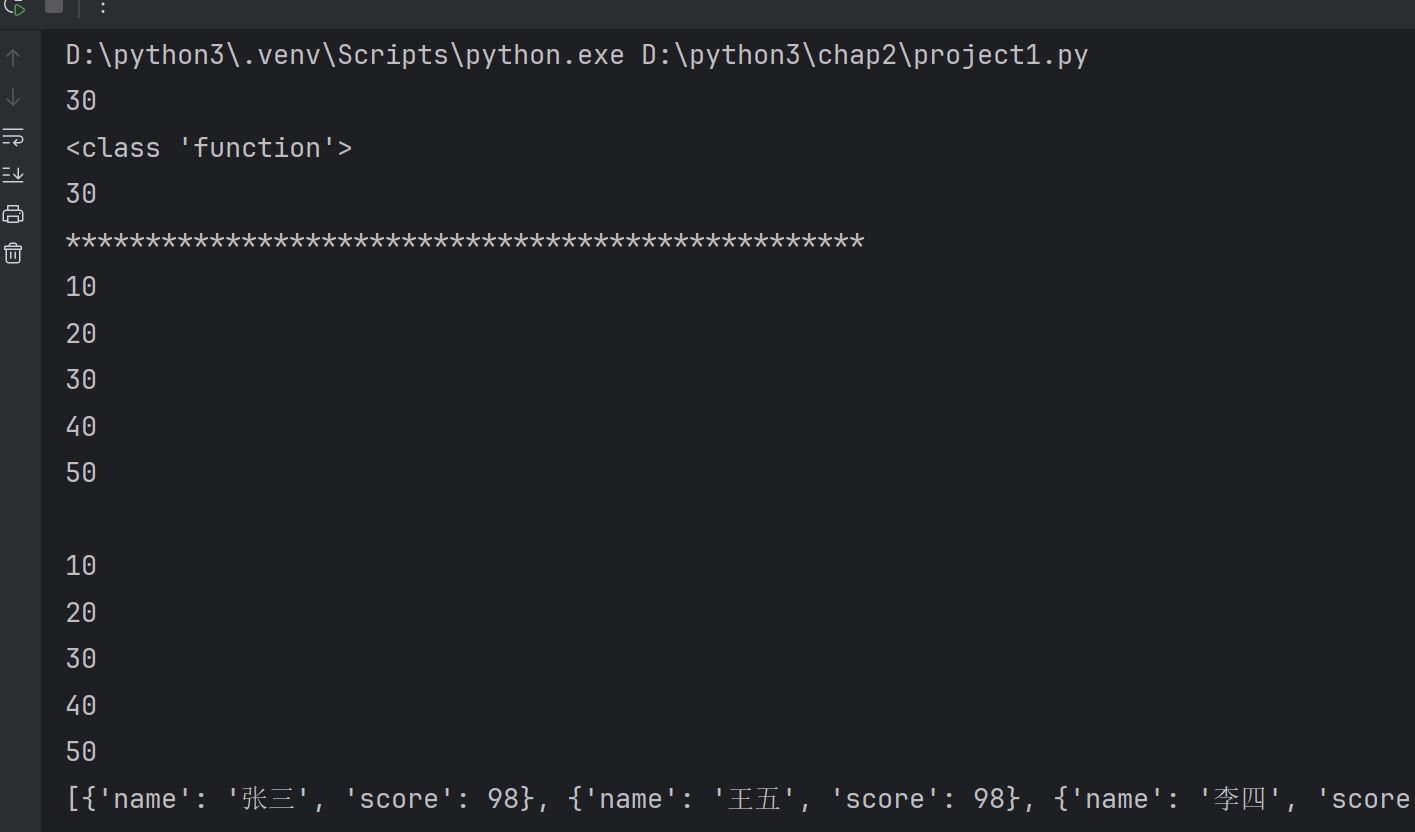
5.6 函数的递归操作

def fac(n):#n的阶乘 N!=N*(N-1)!....1! N=5if n == 1:return 1else:return n * fac(n - 1)# 自己调用自己
print(fac(5))
5.7斐波那契数列
递归每调一次会开辟一个栈

def fac(n):if n == 1 or n == 2:return 1else:return (n - 1)+fac(n-2)print(fac(9))
for i in range(1,9):print(fac(i),end="\t")#不换行
print()
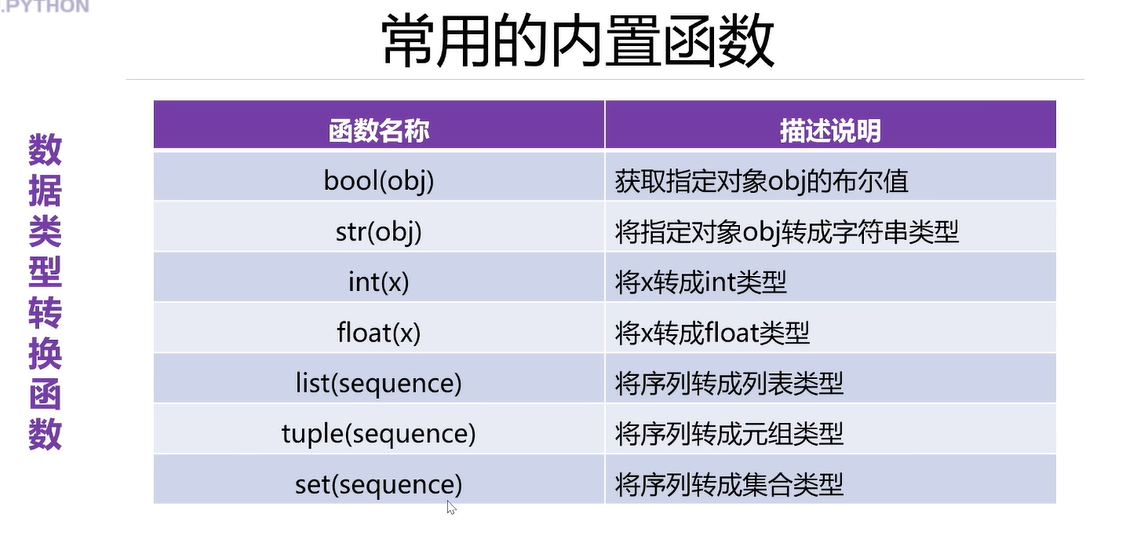
5.8常用的内置函数–类型转换函数
还有转成字典类型的dict
print('非空字符串的布尔值',bool('hello'))
print('空字符串布尔值',bool(''))# 空字符串不是空格字符串
print('空列表布尔值',bool([]))
print('空列表布尔值',bool(list()))
print('空元组布尔值',bool(()))
print('空元组布尔值',bool(tuple()))
print('空集合布尔值',bool(set()))
print('空字典布尔值',bool({}))
print('空字典布尔值',bool(dict()))
print('-'*30)
print('非0数值型布尔值',bool(123))
print('整数0的布尔值',bool(0))
print('浮点数0.0的布尔值',bool(0.0))#将其他类型转成字符型
lst=[10,20,30]
print(type(lst),lst)
print()
s=str(lst)
print(type(s),s)# float类型和str类型转成int类型
print('-'*30,'float类型和str类型转成int类型','-'*30)
print(int(98.7)+int('90'))
# 注意事项
#print(int('98.7'))#ValueError: invalid literal for int() with base 10: '98.7'
#字符串里面的浮点串不可以转
#print(int('a'))ValueError: invalid literal for int() with base 10: 'a'
print('-'*30,'int,str类型转成float类型','-'*30)
print(float(98.7)+float('3.14'))
s='hello'
print(list(s))
seq=range(1,10)#
print(tuple(seq))#创建元组
print(set(seq))#添加到集合中
print(list(seq))
print('-'*30)
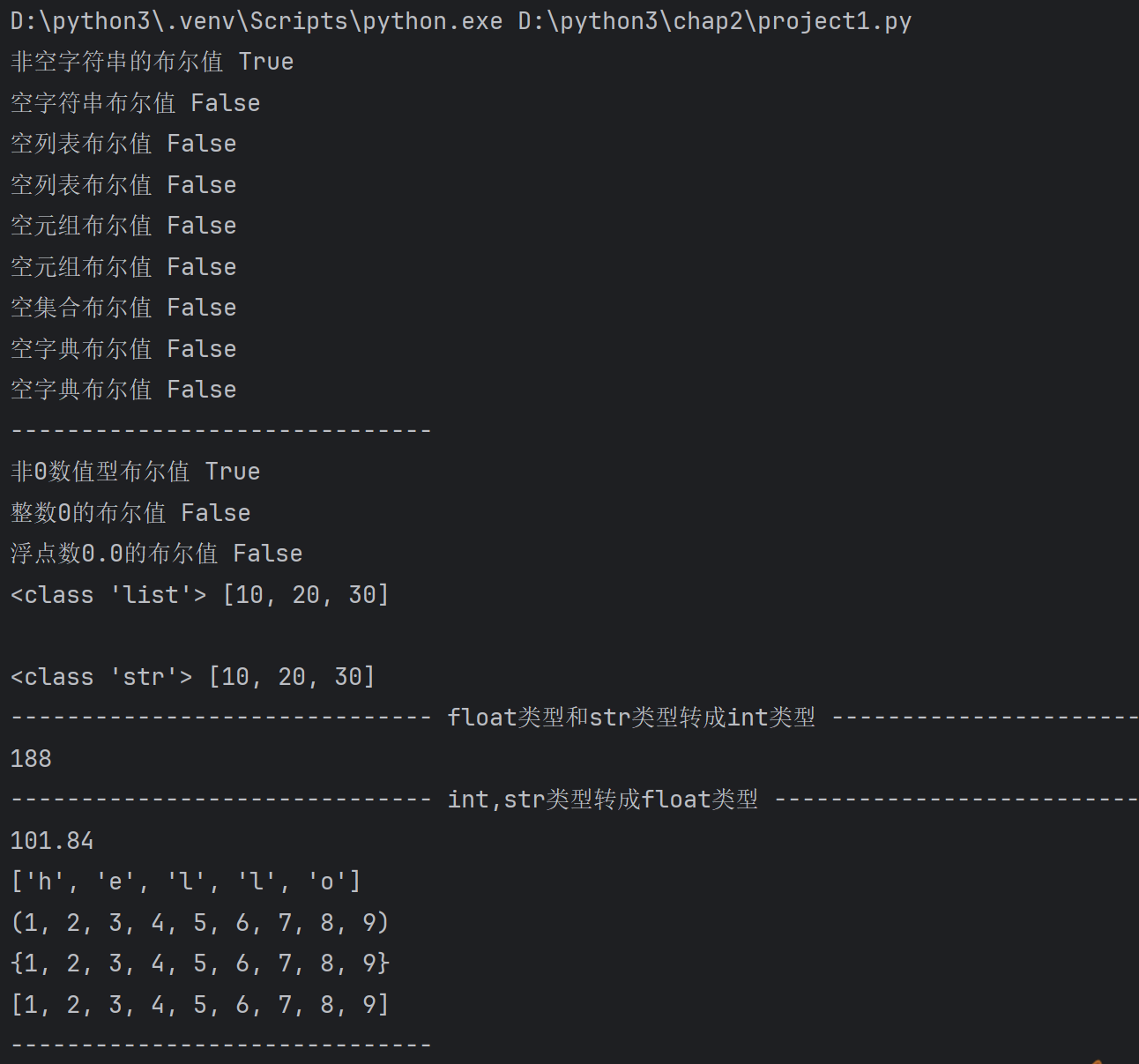
常见的内置函数–数学函数
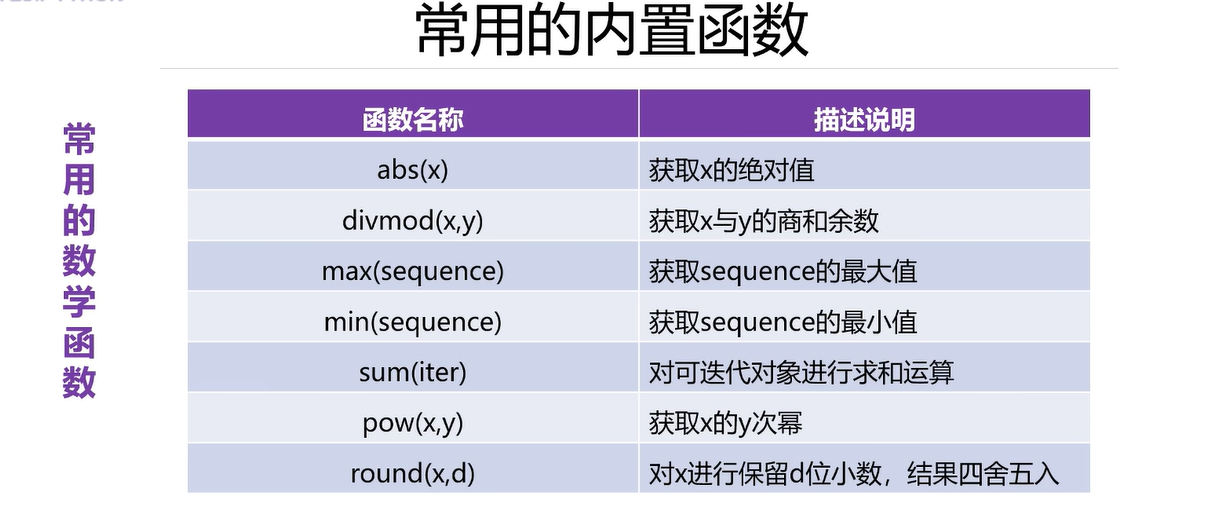
print('绝对值',abs(100),abs(-100),abs(0))
print('商和余数',divmod(13,4))
print('最大值',max('hello'))
print('最大值',max([10,4,56,78,4]))
print('最小值',min('hello'))
print('最小值',min([10,4,56,78,4]))
print('求和',sum([10,34,45]))
print('x的y次幂',pow(2,3))#四舍五入
print(round(3.1415926))# round函数只有一个参数,保留整数
print(round(3.9415926))#4
print(round(3.1415926,2))# 2表示保留两位小数
print(round(314.15926,-1))# 314 ,-1位,个位进行四舍五入
print(round(314.15926,-2))# 300 ,-2位,十位进行四舍五入
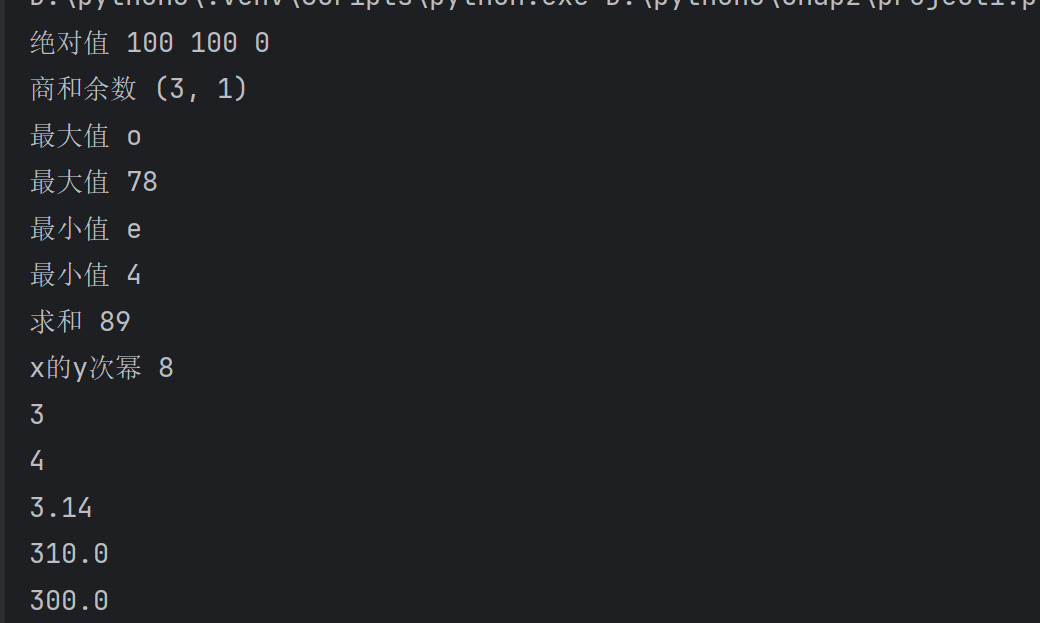
5.9 迭代器操作函数
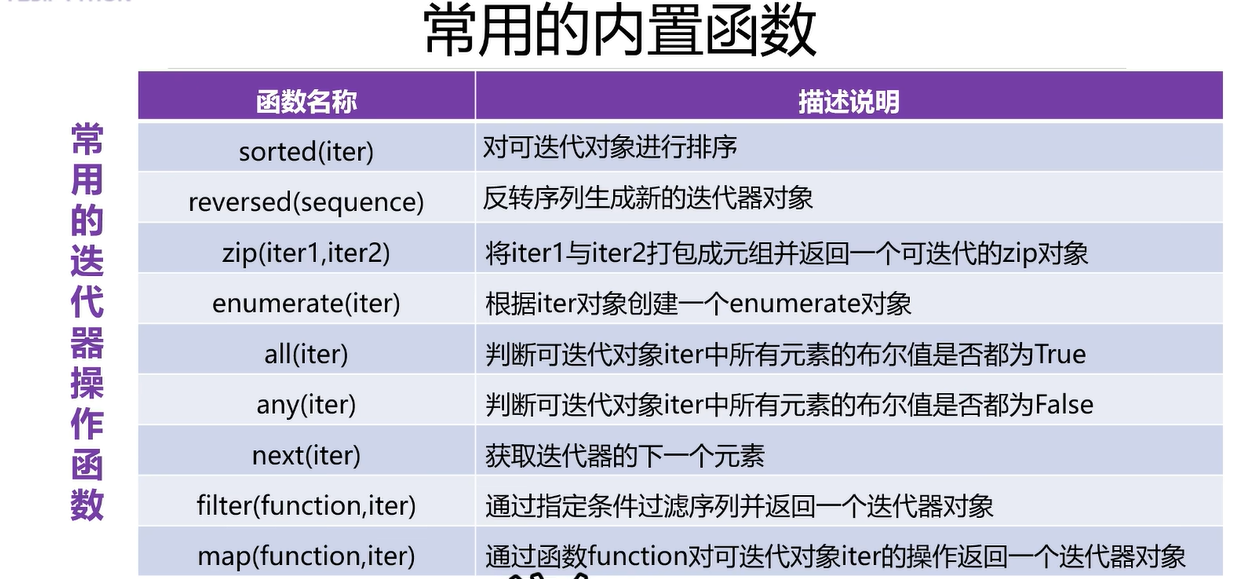
lst=[54,66,43,65,88]
#1.排序
asc_lst=sorted(lst)#升序
desc_lst=sorted(lst,reverse=True)#降序
print('原列表',lst)
print('升序',asc_lst)
print('降序',desc_lst)# 2.reversed反向
new_lst=reversed(lst)
print(type(new_lst))#<class 'list_reverseiterator'> 迭代器对象,结果不是列表
print(list(new_lst))# 3.zip
x=['a','b','c','d','e']
y=[10,20,30,40,50]
zipobj=zip(x,y)
print(type(zipobj))#<class 'zip'>
#print(list(zipobj))# 4.enumerate
enum=enumerate(y,start=1)
print(type(enum))#<class 'enumerate'>
print(tuple(enum))#转成元组#5.all
lst2=[10,20,'',30]
print(all(lst2))#空字符串布尔值是false
print(all(lst))# 6.any
print(any(lst))#True#7.
print(next(zipobj))
print(next(zipobj))
print(next(zipobj))#filter和map第一个参数都是函数
def fun(num):return num*2==1#可能是True,Falseobj=filter(fun,range(10))#函数作为参数
# 将range(10),0-9的整数都执行一次fun操作
print(list(obj))# [1,3,5,7,9]def upper(x):return x.upper()new_lst2=['hello','world','python']
obj=map(upper,new_lst2)
print(list(obj))#迭代器对象要转成列表或元组5.10 其他内置函数的使用
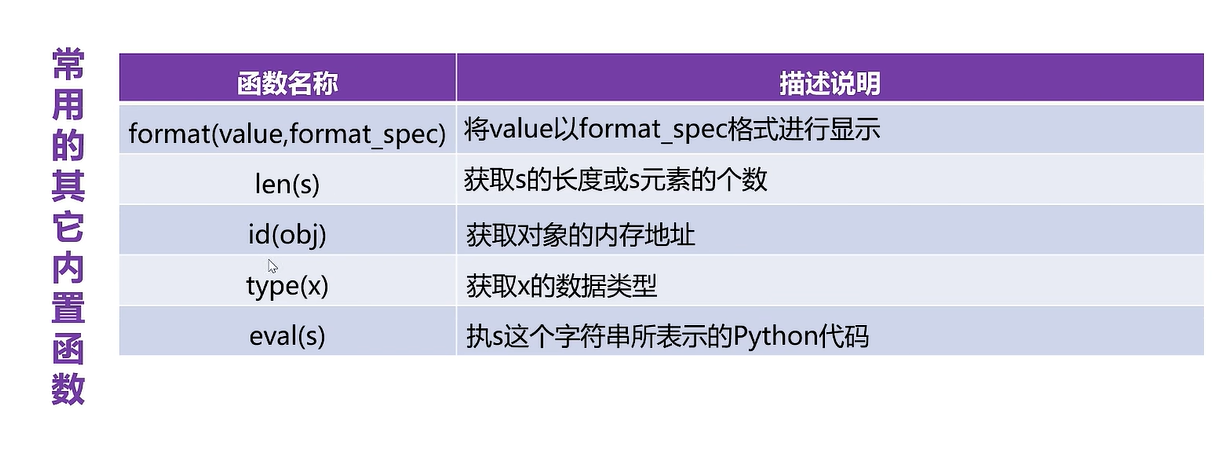
#format()
print(format(3.14,'20'))#默认右对齐
print(format('hello','20'))#默认左对齐
print(format('hello','*<20'))#<左对齐,*表示的填充符,20表示的是显示的宽度
print(format('hello','*^20'))print(format(3.1415926,'.2f'))#3.14
print(format(20,'b'))
print(format(20,'o'))
print(format(20,'x'))
print(format(20,'X'))print('-'*40)
print(len('helloworld'))
print(len([10,20,30,40,50]))print('-'*40)
print(id(10))#查看内存地址
print(id('helloworld'))#查看内存地址
print(type('hello'),type(10))#查看内存地址print(eval('10+30'))
print(eval('10>30'))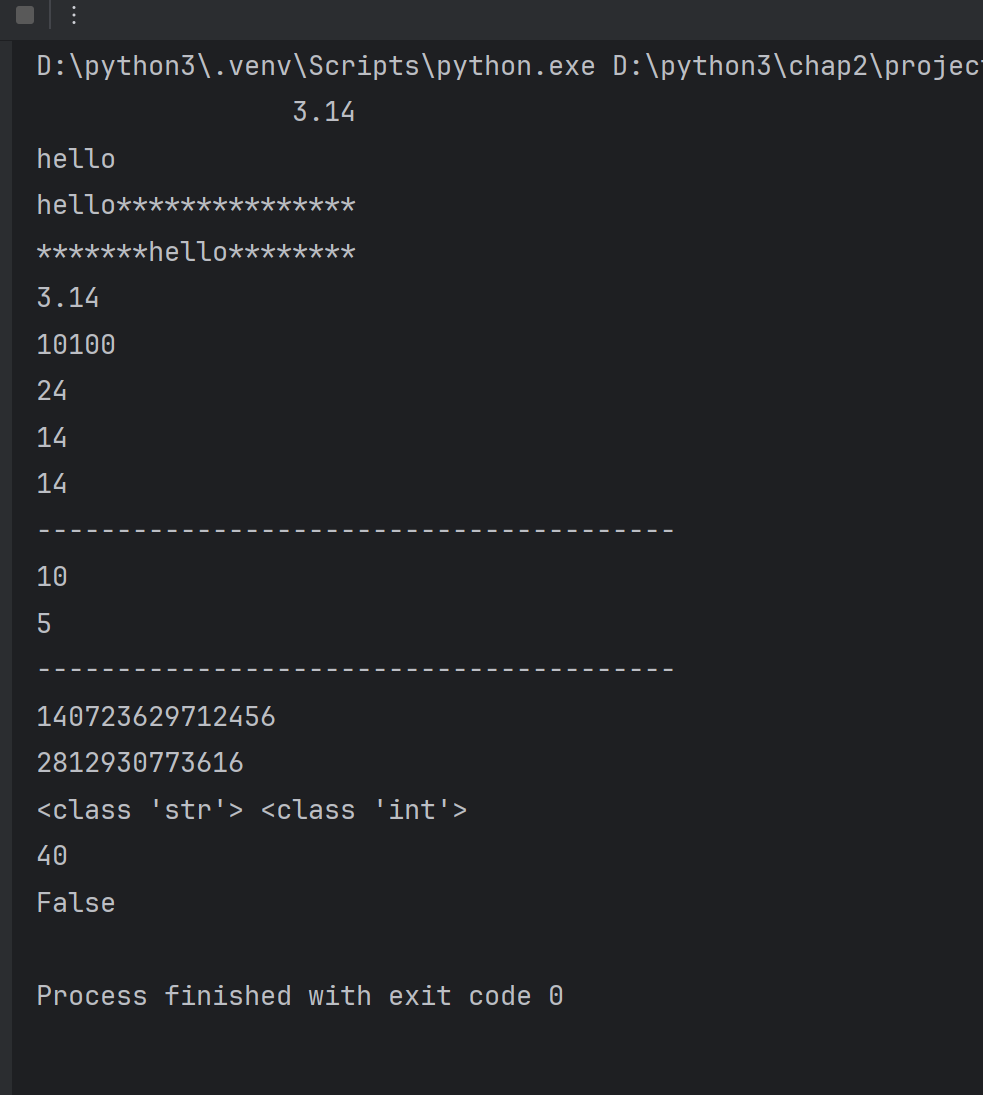
本章总结



章节习题
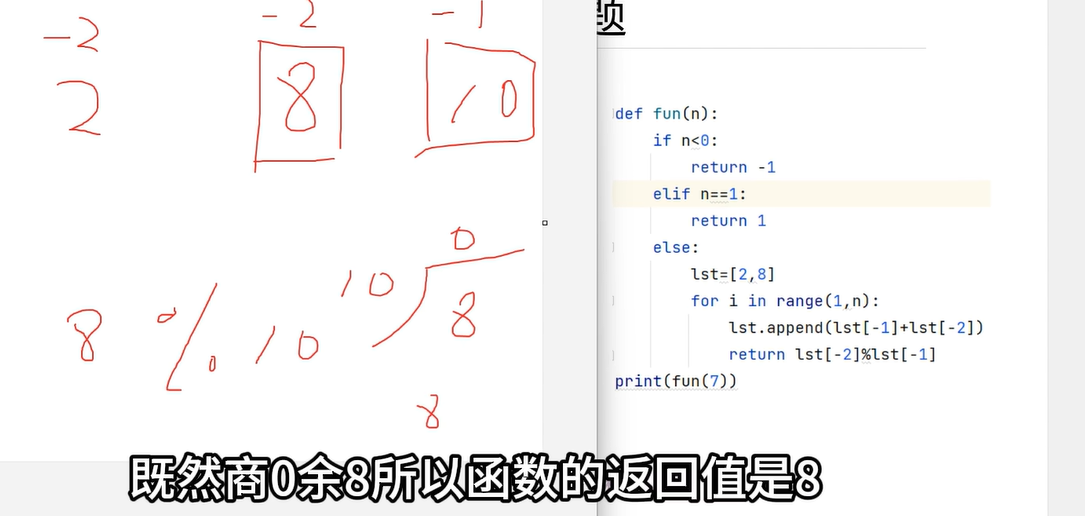
列表用的是-1就是反向递减,8的索引是-1,2的索引是-2,现在有三个元素:2 8 10

函数的返回值可有可无

当全局和局部相同,局部更具有优先级


将第四个元素添加到列表
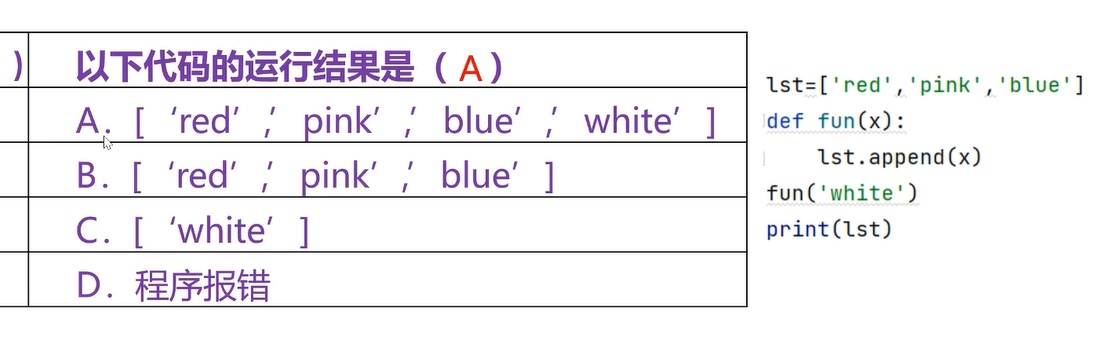
每递归一次规模缩小

3是作为参数传进来的

第一个最内部无返回值

没有返回值类型,结果就是没有

参数可有可无也可以多个

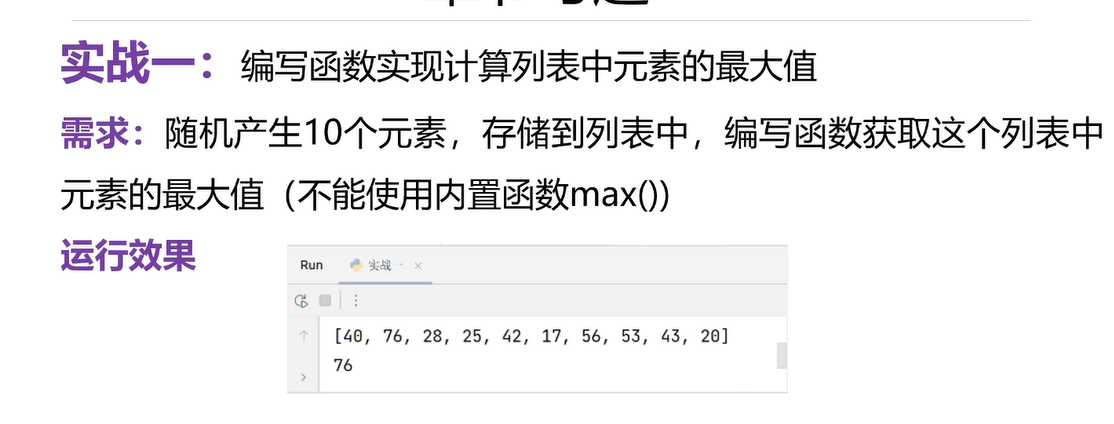
import random
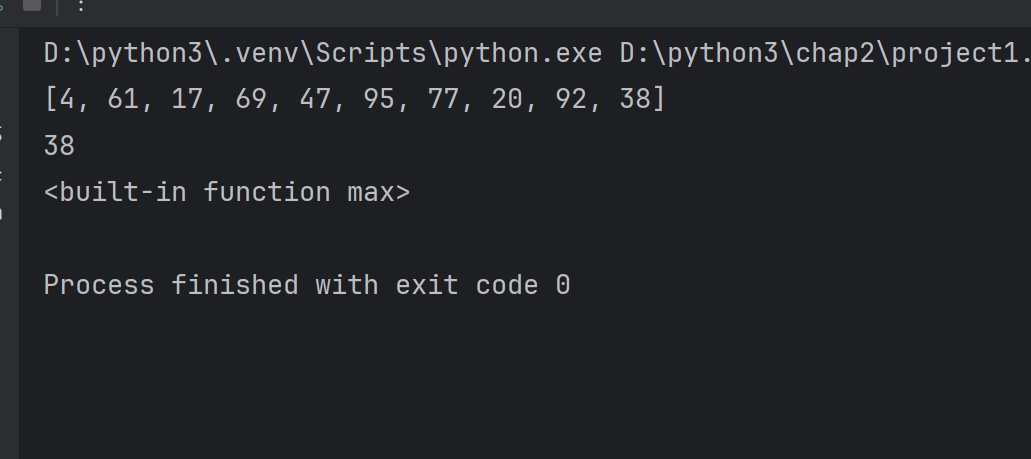
def get_max(lst):x=lst[0]# x存储是元素的最大值#遍历for x in range(1,len(lst)):if lst[x] > x:x=lst[x]# 对最大值进行赋值return x#调用
lst=[random.randint(1,100) for item in range(10)]
print(lst)
#计算列表元素的最大值
print(get_max(lst))
print(max)
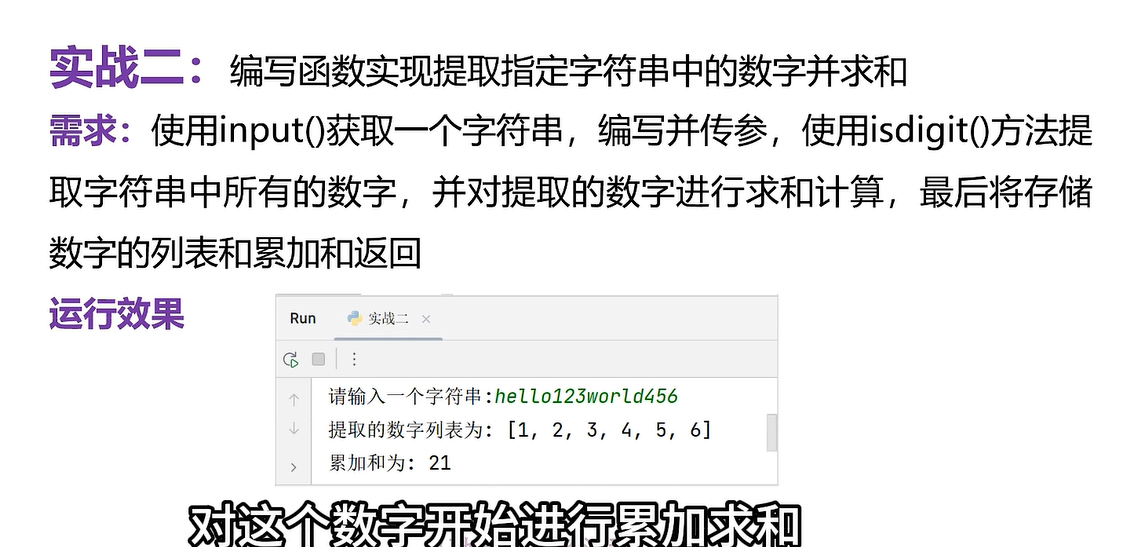
def get_digit(x):s=0 #存储累加和lst=[]#存储提取出来的数字for item in x:if item.isdigit():# 如果是数字lst.append(int(item))#求和s=sum(lst)return lst,s#准备函数的调用
s=input('请输入一个字符串:')
#调用
lst,x=get_digit(s)
print('提取的数字列表为:',lst)
print('累加和为',x)
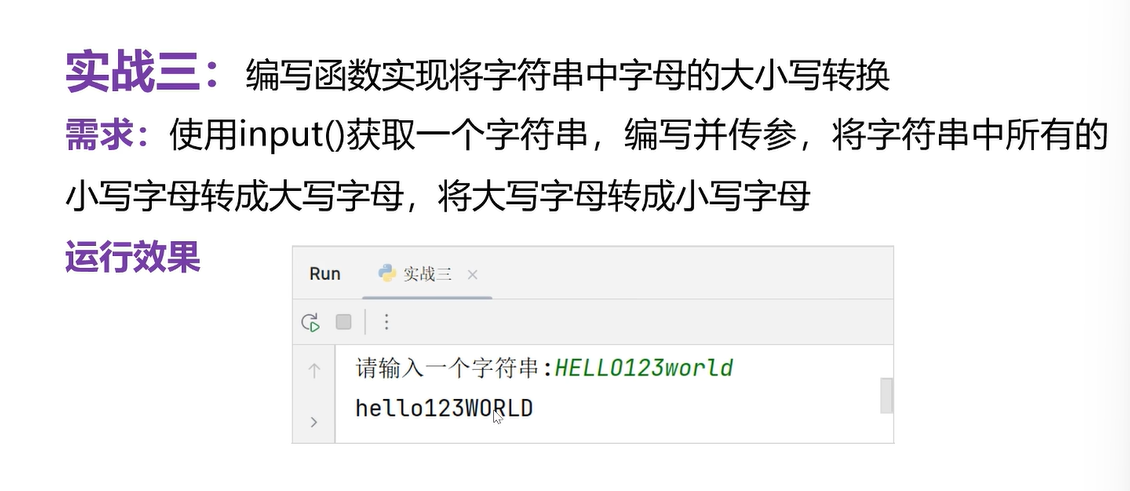
def lower_upper(x):# x是一个字符串,形式参数lst=[]for item in x:if 'A' <= item <= 'Z':lst.append(chr(ord(item)+32))#ord()将字母转成unicode码整数,加上32,chr()整数转成字符elif 'a' <= item <= 'z':lst.append(chr(ord(item)-32))else:lst.append(item)return ''.join(lst)# 准备调用
s=input('请输入一个字符串')
new_s=lower_upper(s)# 函数的调用
print(new_s)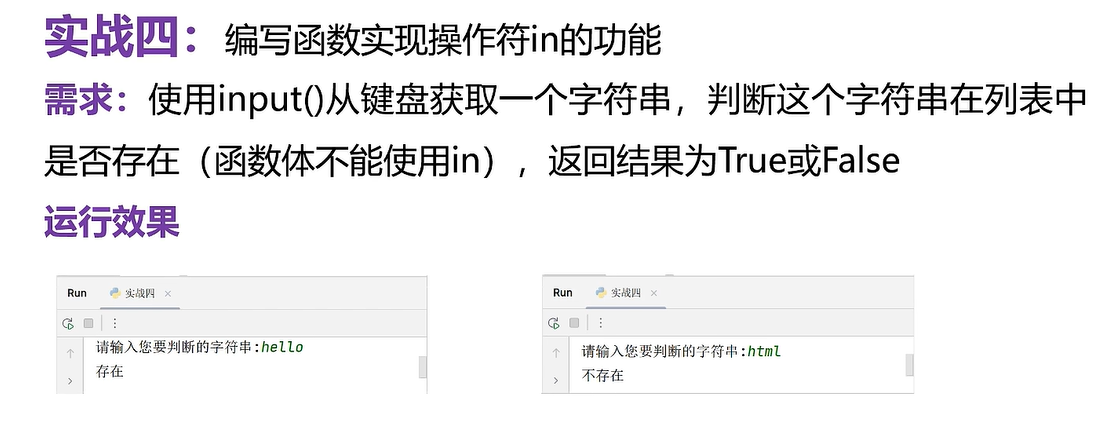
def get_find(s,lst):for item in lst:if s in item:return Truereturn False
lst=['hello','world','python']
s=input('请输入您要判断的字符串')
result=get_find(s,lst)
print('存在'if result else '不存在')# if...else的简写,三元运算符 if result==True if result利用到对象的布尔值六、面向过程和面向对象两大编程思想



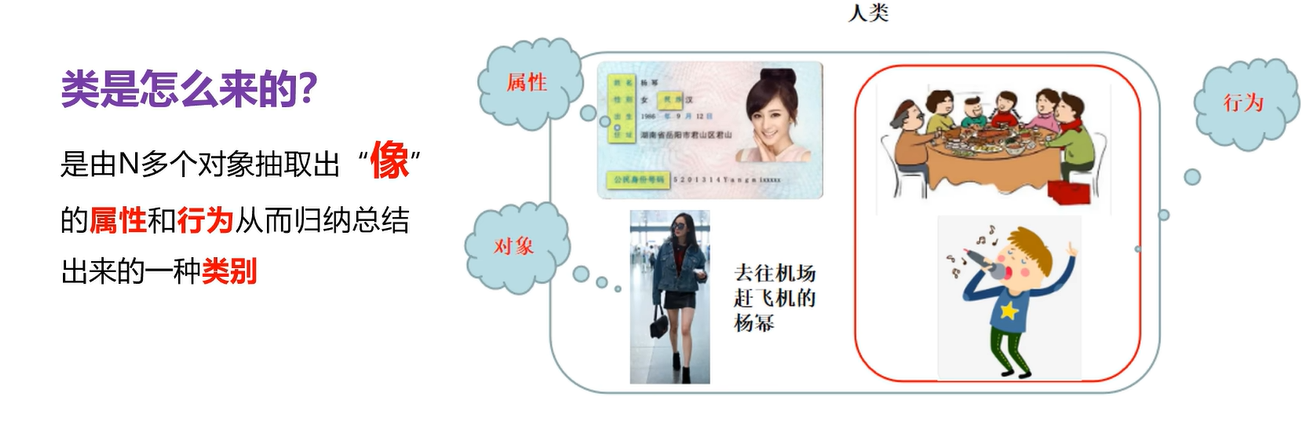
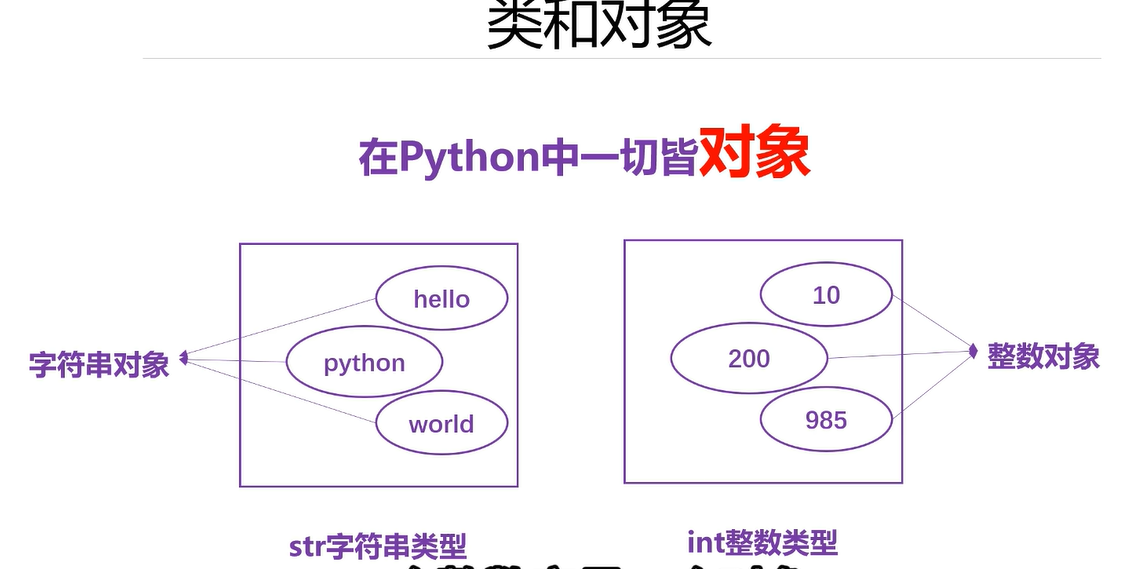
6.1 自定义类和创建自定义类的对象

查看对象的数据类型
a=10
b=8.8
s='hello'
print(type(a))
print(type(b))
print(type(s))
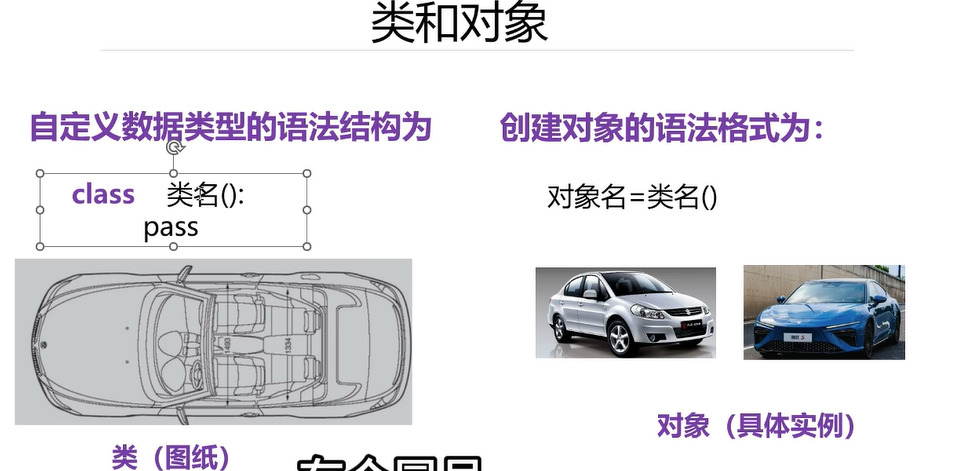
类名大写,冒号可省略,类是抽象的模版,对象是具体的事例
自定义数据类型
#编写一个person
class Person:def __init__(self, name, age):self.name = nameself.age = age# 编写一个Student类
class Student:def __init__(self, name, age):self.name = nameself.age = age
创建自定义类型的对象:
#编写一个person
class Person:pass# 编写一个Student类
class Student:pass#创建一个Person类型对象
per=Person()#per就是Person类型的对象
stu=Student()#stu就是Student类型的对象
print(type(per))
print(type(stu))

class Student:#类属性:定义在类中,方法外的变量school='北京XXX教育'# 初始方法方法,函数称为方法def __init__(self,xm,age):#xm,age是方法的参数,是局部变量,xm,age的作用域是整个__init__方法self.xm=xm#=左侧是实例属性,xm是局部变量,将局部变量的值xm赋值给实例属性self.nameself.age=age#实例的名称和局部变量的名称可以相同#定义在类中的函数,称为方法,自带一个参数selfdef show(self):print(f'我叫:{self.name},今年:{self.age}岁了')#静态方法@staticmethoddef sm():#print(self.name)#self.show()print('这是一个静态方法,不能调用实例属性,也不能调用实例方法')@classmethoddef cm(cls):print('这是一个类方法,不能调用实例属性,也不能调用实例方法')#self.show()#print(self.name)
类方法,类属性,静态方法都是使用类名调用,和实例有关都是使用对象进行打点调用
class Student:#类属性:定义在类中,方法外的变量school='北京XXX教育'# 初始方法方法,函数称为方法def __init__(self,xm,age):#xm,age是方法的参数,是局部变量,xm,age的作用域是整个__init__方法self.name=xm#=左侧是实例属性,xm是局部变量,将局部变量的值xm赋值给实例属性self.nameself.age=age#实例的名称和局部变量的名称可以相同#定义在类中的函数,称为方法,自带一个参数selfdef show(self):print(f'我叫:{self.name},今年:{self.age}岁了')#静态方法@staticmethoddef sm():#print(self.name)#self.show()print('这是一个静态方法,不能调用实例属性,也不能调用实例方法')@classmethoddef cm(cls):print('这是一个类方法,不能调用实例属性,也不能调用实例方法')#self.show()#print(self.name)# 创建类的对象
stu=Student('hh',18)#传了两个参数,因为__init__方法中,有两个参数,self,是自带的参数,无需手动传入
#实例属性,使用对象名打点调用
print(stu.name,stu.age)
#类属性,直接使用类名,打点调用
print(Student.school)
#实例方法,使用对象名进行打点调用
stu.show()
#类方法,@classmethod进行修饰的方法,直接使用类名打点调用
Student.cm()#静态方法 @staticmethod进行修饰的方法,直接使用类名打点调用
Student.sm()
6.2 使用类模版创建N多个对象
class Student:#类属性:定义在类中,方法外的变量school='北京XXX教育'# 初始方法方法,函数称为方法def __init__(self,xm,age):#xm,age是方法的参数,是局部变量,xm,age的作用域是整个__init__方法self.name=xm#=左侧是实例属性,xm是局部变量,将局部变量的值xm赋值给实例属性self.nameself.age=age#实例的名称和局部变量的名称可以相同#定义在类中的函数,称为方法,自带一个参数selfdef show(self):print(f'我叫:{self.name},今年:{self.age}岁了')#根据图纸创建多个对象
stu=Student('hh',18)
stu2=Student('张三',28)
stu3=Student('马丽',21)
stu4=Student('Marry',23)print(type(stu))
print(type(stu2))
print(type(stu3))
print(type(stu4))Student.school='派森教育'#给类属性赋值#将学生对象存储到列表中
lst=[stu,stu2,stu3,stu4]#列表当中的元素是Student类型的对象
for item in lst:# item是列表中的元素,是Student类型的对象item.show()# 对象名打点调用实例方法
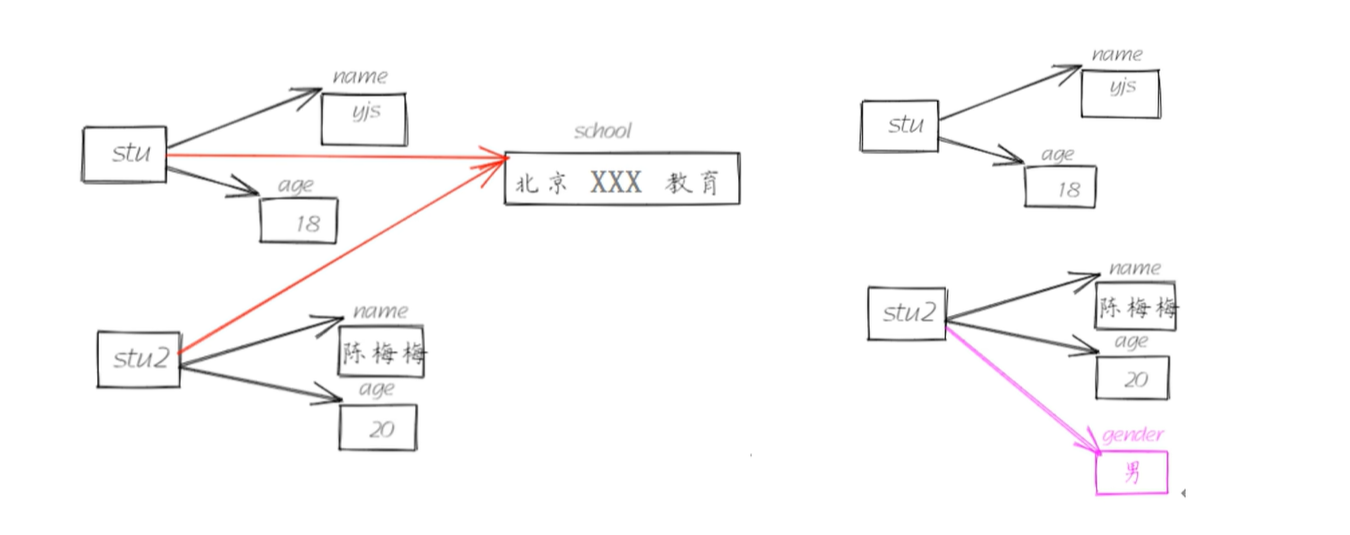
6.3 动态绑定属性和方法
class Student:#类属性:定义在类中,方法外的变量school='北京XXX教育'# 初始方法方法,函数称为方法def __init__(self,xm,age):#xm,age是方法的参数,是局部变量,xm,age的作用域是整个__init__方法self.name=xm#=左侧是实例属性,xm是局部变量,将局部变量的值xm赋值给实例属性self.nameself.age=age#实例的名称和局部变量的名称可以相同#定义在类中的函数,称为方法,自带一个参数selfdef show(self):print(f'我叫:{self.name},今年:{self.age}岁了')# 创建两个Student类型对象
stu=Student('张三',18)
stu2=Student('王五',19)
print(stu.name,stu.age)
print(stu2.name,stu2.age)#为stu2动态绑定一个实例属性
stu2.gender='男'
print(stu2.name,stu2.age,stu2.gender)
#print(stu.gender)#AttributeError: 'Student' object has no attribute 'gender',没有这个属性,没有给stu绑定# 动态绑定方法
def introduce():print('我是一个普通函数,我被动态绑定成了stu2对象方法')
stu2.fun=introduce#函数的赋值
# fun是stu2对象的方法
#调用(实例方法打点调用)
stu2.fun()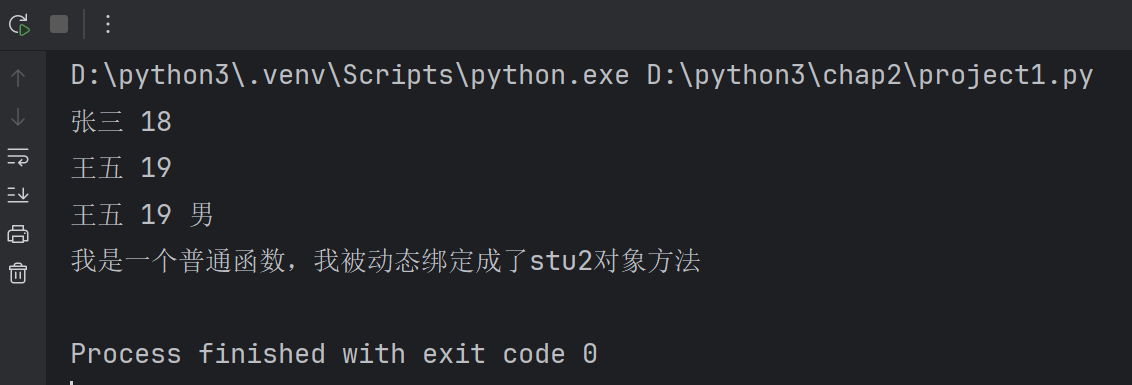
6.4 Python中的权限控制


特殊的:双下划线
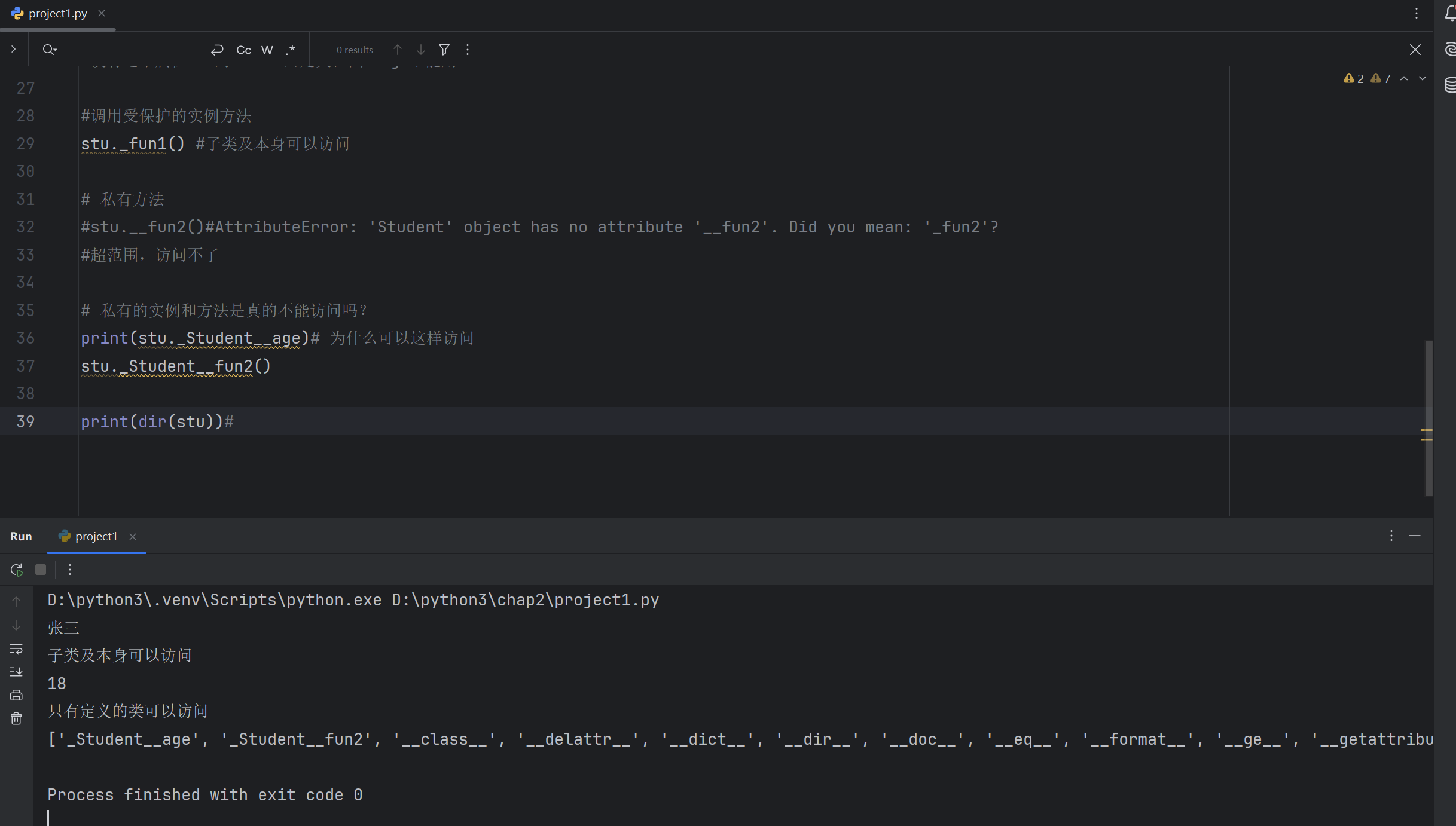
class Student():#首尾双下划线def __init__(self, name,age, gender):self._name = name # self._name受保护的,只能本类和子类访问self.__age = age#self.__age表示私有,只能类本身去访问self.gender=gender# 普通的实例属性,类的内部,外部,及子类都可以访问def _fun1(self):# 受保护的print('子类及本身可以访问')def __fun2(self):# 私有的print('只有定义的类可以访问')def show(self):# 普通的实例方法self._fun1() #类本身访问受保护的方法self.__fun2() #类本身访问私有方法print(self._name)#受保护的实例属性print(self.__age)#私有的实例属性# 创建一个学生类的对象
stu=Student('张三',18 ,'男')#类的外部
print(stu._name)
#print(stu.__age)#AttributeError: 'Student' object has no attribute '__age'. Did you mean: '_name'?
#没有这个属性:出了class的定义范围,age不能用#调用受保护的实例方法
stu._fun1() #子类及本身可以访问# 私有方法
#stu.__fun2()#AttributeError: 'Student' object has no attribute '__fun2'. Did you mean: '_fun2'?
#超范围,访问不了# 私有的实例和方法是真的不能访问吗?
print(stu._Student__age)# 为什么可以这样访问
stu._Student__fun2()print(dir(stu))#
6.5 属性的设置
可以将方法转换成属性使用,访问的时候只能访问属性,不能修改属性的值,可以使用setter方法去修改
class Student():def __init__(self, name,gender):self.name = name#普通实例属性self.__gender=gender#self.__gender是私有的实例属性# 使用@property(属性) 修饰方法,将方法转成属性使用@propertydef gender(self):return self.__gender# 将我们的gender这个属性设置为可写属性@gender.setterdef gender(self,value):if value != '男'and value!='女':print('性别有误,已将性别默认为男')self.__gender='男'else:self.__gender=valuestu=Student('陈梅梅','女')
print(stu.name,'的性别是:',stu.gender)#stu.gender就会去执行syu.gender()
#尝试修改属性值
#stu.gender='男'AttributeError: property 'gender' of 'Student' object has no setterstu.gender='其他'
print(stu.name,'性别是:',stu.gender)

6.6 继承的概念

class Person:# 默认继承了objectdef __init__(self, name, age):self.name = nameself.age = agedef show(self):print(f'大家好,我叫:{self.name},我今年::{self.age}岁')# Student继承Person类
class Student(Person):# 编写初始化的方法def __init__(self, name, age, stuno):super().__init__(name, age) #调用父类的初始化方法self.stuno = stuno
#Doctor继承Person类
class Doctor(Person):# 编写初始化方法def __init__(self, name, age, department):super().__init__(name, age)self.department = department#创建第一个子类对象
stu=Student('陈梅梅',20,'1001')
stu.show()doctor=Doctor('张一一',32,'外科')
doctor.show()
6.7 Python中的多继承
from tkinter.font import namesclass FatherA():def __init__(self,name):self.name=namedef showA(self):print('父类A中的方法')class FatherB():def __init__(self,age):self.age=agedef showB(self):print('父类B中的方法')class Son(FatherA,FatherB):#编写初始化的方法def __init__(self,name,age,gender): # 需要调用两个父类的初始化方法FatherA.__init__(self,name)FatherB.__init__(self,age)self.gender=genderson=Son('陈梅梅',20,'女')
son.showA()
son.showB()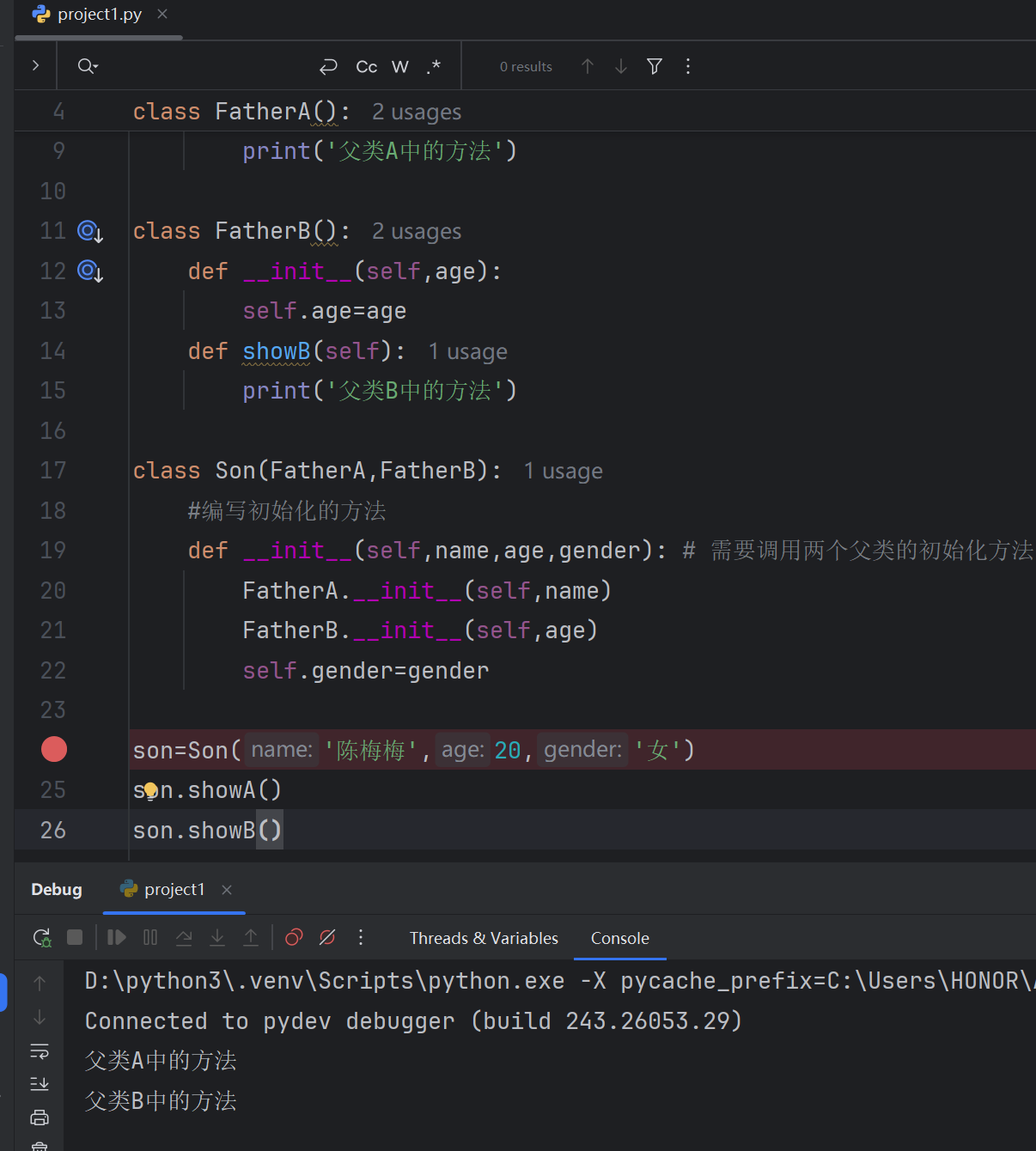
6.8 方法重写
方法的名称必须和父类中相同
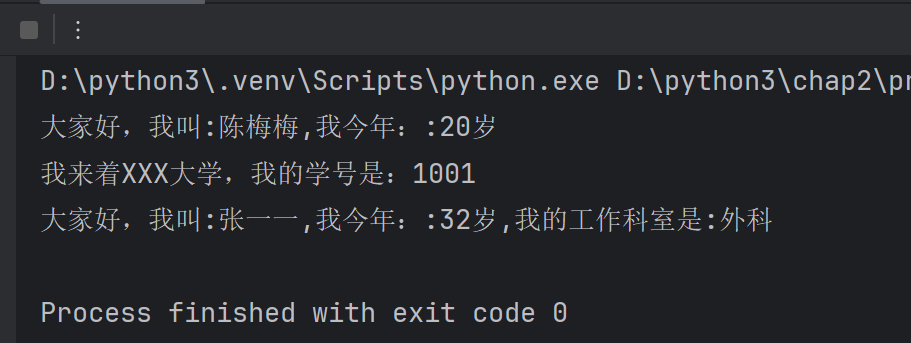
from contextlib import suppressclass Person:# 默认继承了objectdef __init__(self, name, age):self.name = nameself.age = agedef show(self):print(f'大家好,我叫:{self.name},我今年::{self.age}岁')# Student继承Person类
class Student(Person):# 编写初始化的方法def __init__(self, name, age, stuno):super().__init__(name, age) #调用父类的初始化方法self.stuno = stunodef show(self):# 调用父类中的方法super().show()print(f'我来着XXX大学,我的学号是:{self.stuno}')#Doctor继承Person类
class Doctor(Person):# 编写初始化方法def __init__(self, name, age, department):super().__init__(name, age)self.department = departmentdef show(self):print(f'大家好,我叫:{self.name},我今年::{self.age}岁,我的工作科室是:{self.department}')#super().show()#调用父类中show方法#创建第一个子类对象
stu=Student('陈梅梅',20,'1001')
stu.show()#调用子类自己的show方法doctor=Doctor('张一一',32,'外科')
doctor.show()#调用子类自己的show方法
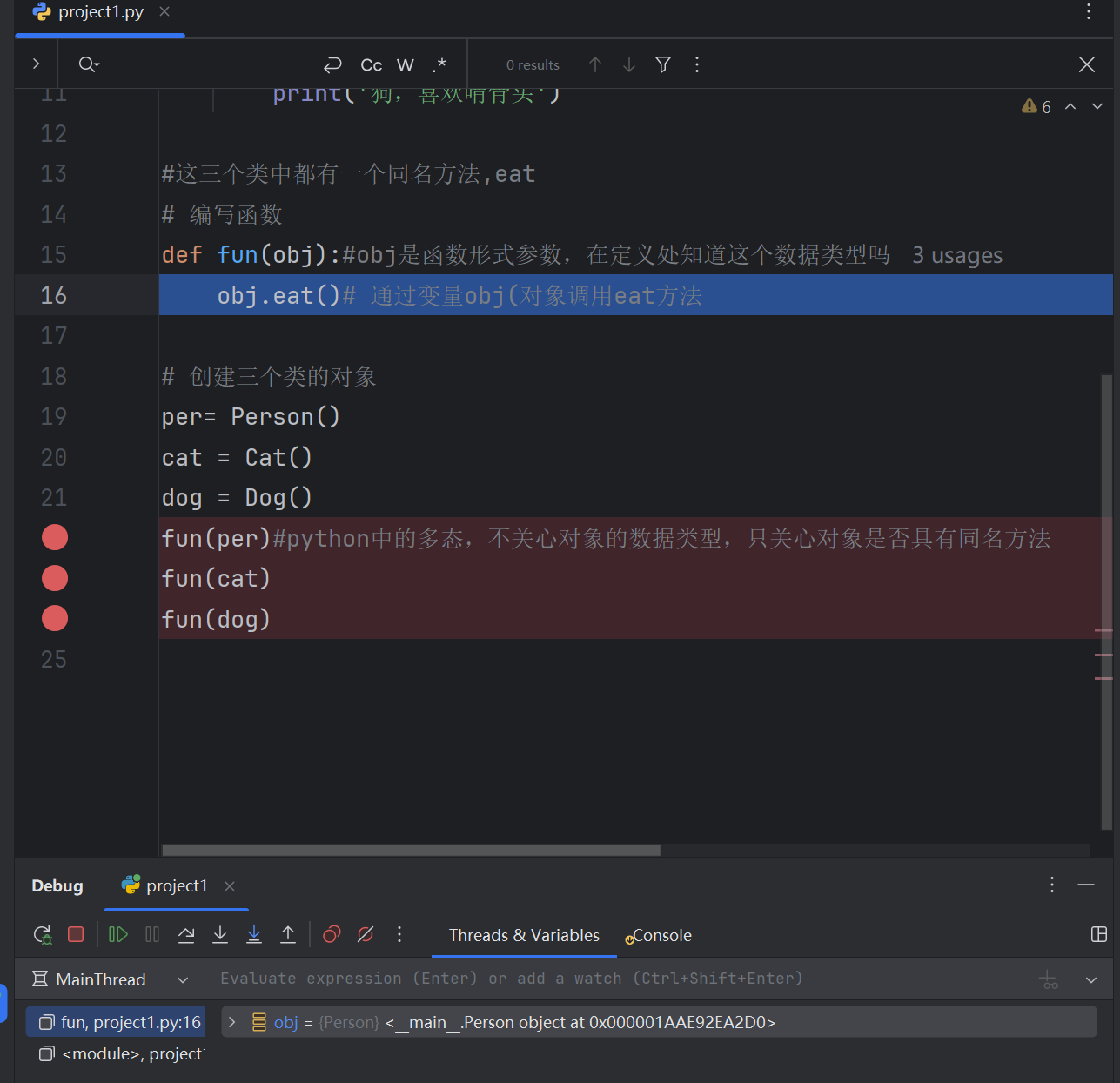
6.9 Python中的多态:值关心对象的行为

class Person():def eat(self):print("人吃五谷杂粮")class Cat():def eat(self):print('猫,喜欢吃鱼')class Dog():def eat(self):print('狗,喜欢啃骨头')#这三个类中都有一个同名方法,eat
# 编写函数
def fun(obj):#obj是函数形式参数,在定义处知道这个数据类型吗obj.eat()# 通过变量obj(对象调用eat方法# 创建三个类的对象
per= Person()
cat = Cat()
dog = Dog()
fun(per)#python中的多态,不关心对象的数据类型,只关心对象是否具有同名方法
fun(cat)
fun(dog)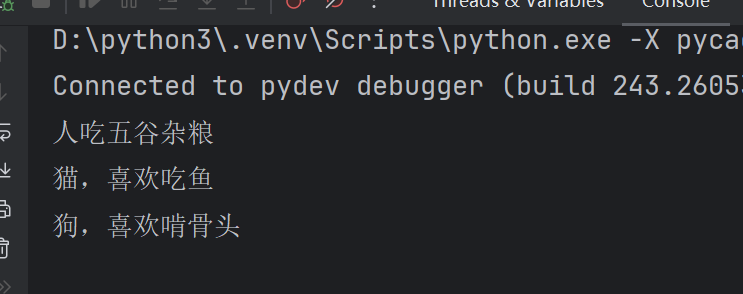
6.10 object类
查看对象属性

class Person(object):def __init__(self,name,age):self.name = nameself.age = agedef show(self):print(f'大家好,我叫:{self.name},我今年:{self.age}岁')# 创建Person类的对象
per=Person('陈梅梅',20) #创建对象的时候会自动调用__init__方法()
print(dir(per))
per.show()
# 先new在inital调用
print(per)#自动调用了__str__方法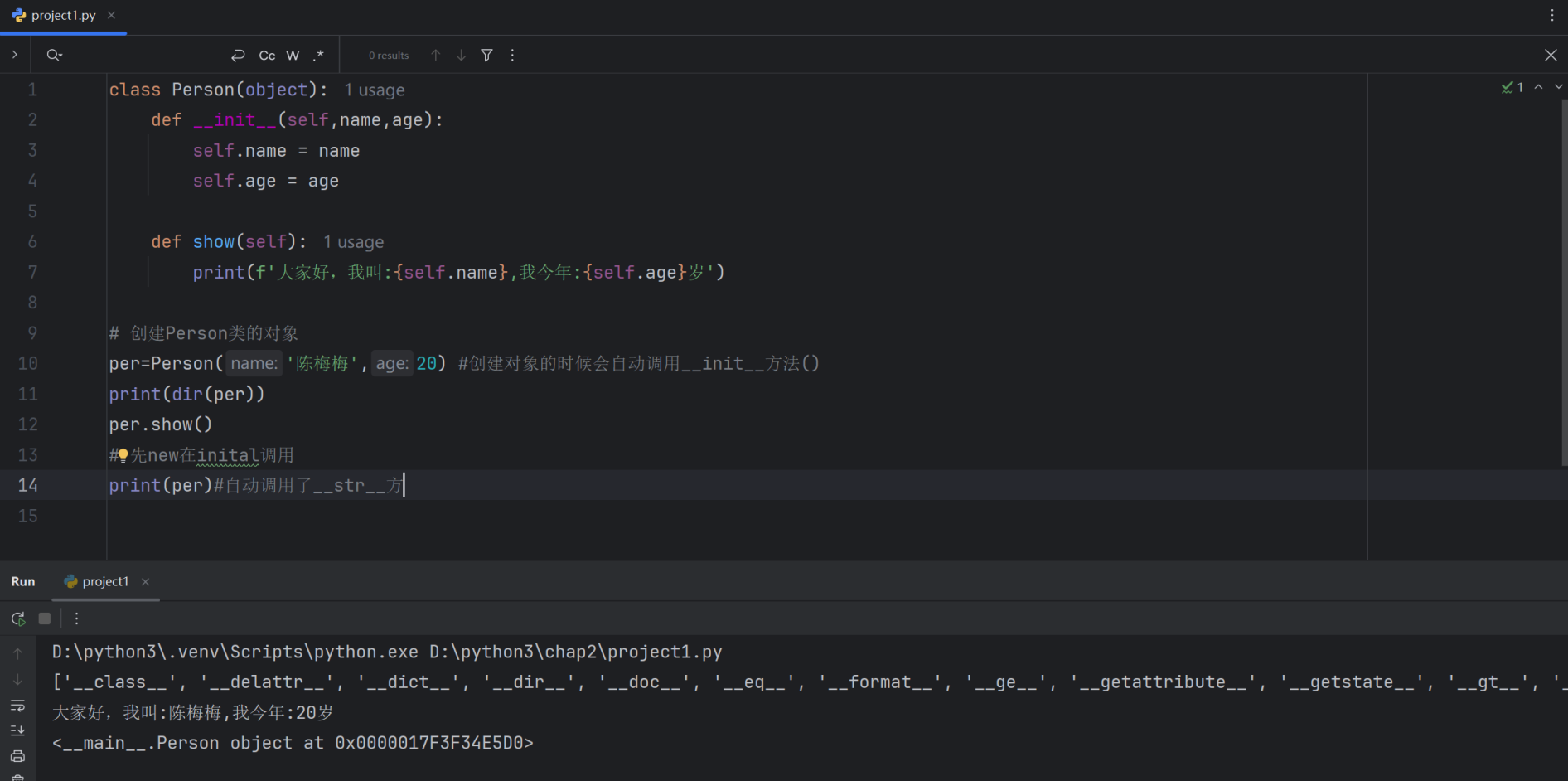
_str_方法重写之前
class Person(object):def __init__(self,name,age):self.name = nameself.age = age# 创建person类的对象
per=Person('陈梅梅',20)
print(per)_str_方法重写之后
class Person(object):def __init__(self,name,age):self.name = nameself.age = age# 方法重写def __str__(self):return '这是一个人类,具有name和age两个实例属性'#返回值是字符串# 创建person类的对象
per=Person('陈梅梅',20)
print(per)# 还是内存地址吗?不是__str__方法中的内容 直接输出对象名,实际上调用__str___方法
print(per.__str__())#手动调用
对象的特殊方法
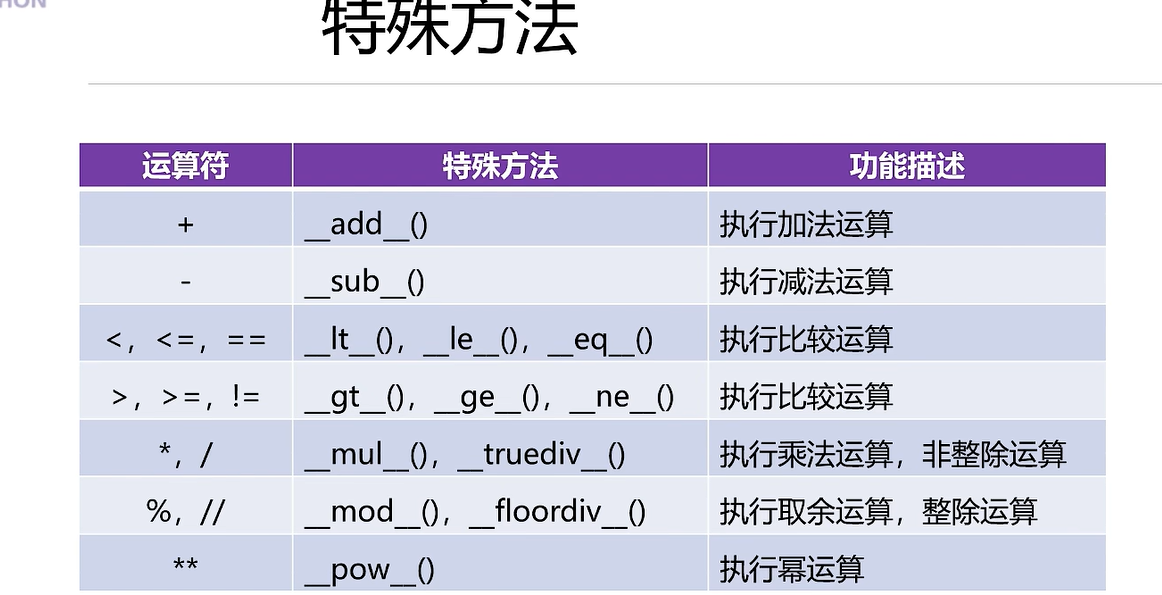
a=10
b=20
print(dir(a))# python中一切皆对象
print(a+b)# 执行加法运算
print(a-b)
print(a.__add__(b))
print(a.__sub__(b)) #执行减法运算
print(f'{a}<{b}吗',a.__lt__(b))
print(f'{a}<={b}吗',a.__le__(b))
print(f'{a}=={b}吗',a.__eq__(b))
print('-'*40)
print(f'{a}>{b}吗',a.__gt__(b))
print(f'{a}>={b}吗',a.__ge__(b))
print(f'{a}!={b}吗',a.__ne__(b))
#
print('-'*40)
print(a.__mul__(b))#乘法
print(a.__truediv__(b))#除法
print(a.__mod__(b))# 取余
print(a.__floordiv__(b))#整除
print(a.__pow__(2))#幂运算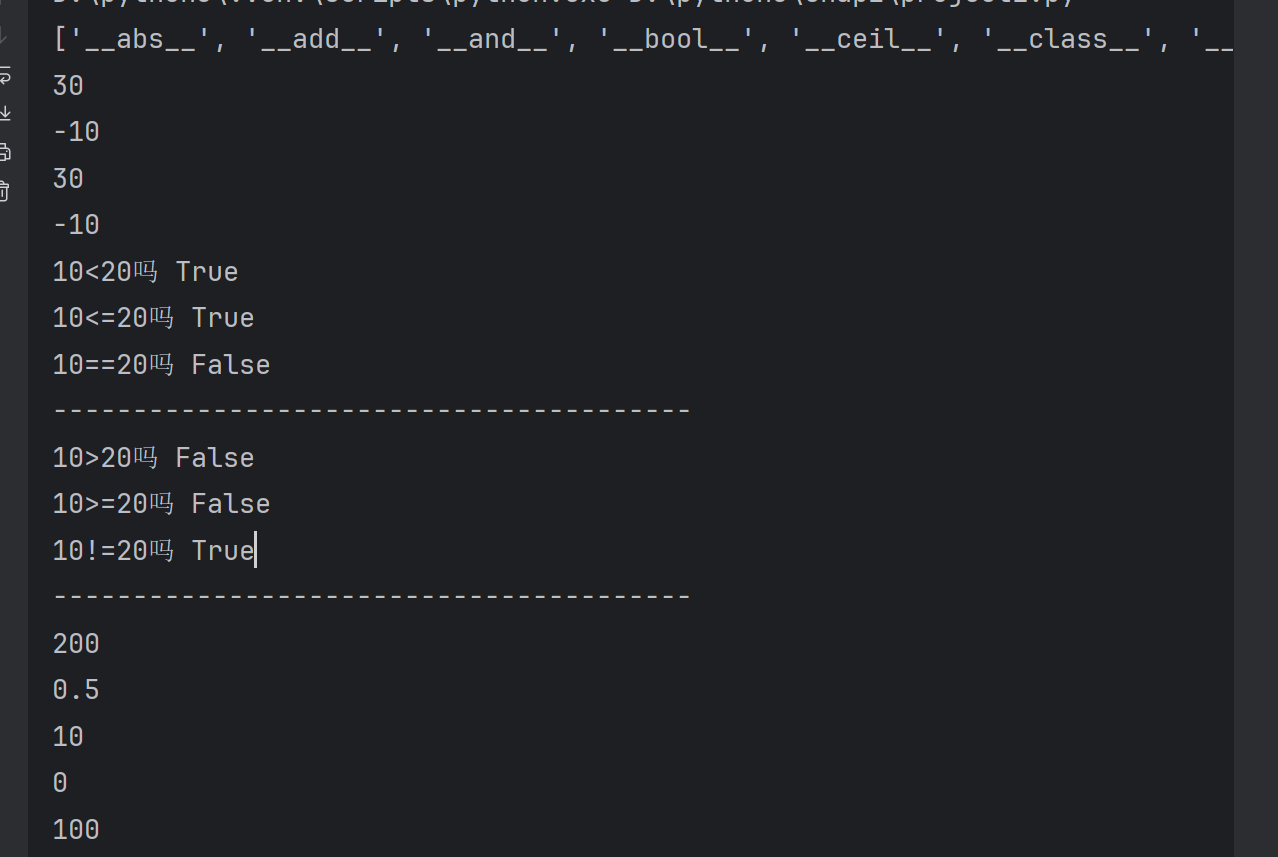
Python的特殊属性
class A:pass
class B:pass
class C(A,B):def __init__(self,name,age):self.name=nameself.age=age# 创建类的对象
a=A()
b=B()
# 创建C类的对象
c=C('陈梅梅',20)print('对象a的属性特点',a.__dict__)#对象的属性字典
print('对象b的属性字典',b.__dict__)
print('对象c的属性字典',c.__dict__)print('对象a的属性特点',a.__class__)#对象的属性字典
print('对象b的属性字典',b.__class__)
print('对象c的属性字典',c.__class__)print('A类的父类的元组',A.__bases__)
print('A类的父类的元组',B.__bases__)
print('A类的父类的元组',C.__bases__)#A类,如果继承了N多个父类,结果只显示一个父类print('A类的层次结构:',A.__mro__)
print('B类的层次结构:',B.__mro__)
print('C类的层次结构:',C.__mro__)#C类继承了A类,B类,间接继承了object类#子类的列表
print('A类的子类列表:',A.__subclasses__())#A的子类是C类
print('B类的子类列表:',B.__subclasses__())
print('C类的子类列表:',C.__subclasses__())
相关文章:
python基础:序列和索引-->Python的特殊属性
一.序列和索引 1.1 用索引检索字符串中的元素 # 正向递增 shelloworld for i in range (0,len(s)):# i是索引print(i,s[i],end\t\t) print(\n--------------------------) # 反向递减 for i in range (-10,0):print(i,s[i],end\t\t)print(\n--------------------------) print(…...

java反射(2)
package 反射;import java.lang.reflect.Constructor; import java.lang.reflect.Field; import java.lang.reflect.Method; import java.util.Arrays;public class demo {public static void main(String[] args) throws Exception {// 通过类的全限定名获取对应的 Class 对象…...

C++核心概念全解析:从析构函数到运算符重载的深度指南
目录 前言一、构析函数1.1 概念1.2 语法格式 1.3 核心特性1.4 调用时机1.5 构造函数 vs 析构函数1.6 代码示例 二、this关键字2.1 基本概念2.2 核心特性2.3 使用场景2.3.1 区分成员与局部变量2.3.2 返回对象自身(链式调用)2.3.3 成员函数间传递当前对象2…...

如何巧妙解决 Too many connections 报错?
1. 背景 在日常的 MySQL 运维中,难免会出现参数设置不合理,导致 MySQL 在使用过程中出现各种各样的问题。 今天,我们就来讲解一下 MySQL 运维中一种常见的问题:最大连接数设置不合理,一旦到了业务高峰期就会出现连接…...

自由学习记录(58)
Why you were able to complete the SpringBoot MyBatisPlus task smoothly: Clear logic flow: Database → Entity → Service → Controller → API → JSON response. Errors are explicit, results are verifiable — you know what’s broken and what’s fixed. Sta…...

ES6 知识点整理
一、变量声明:var、let、const 的区别 作用域 var:函数作用域(函数内有效)。let/const:块级作用域({} 内有效,如 if、for)。 变量提升 var 会提升变量到作用域顶部(值为…...
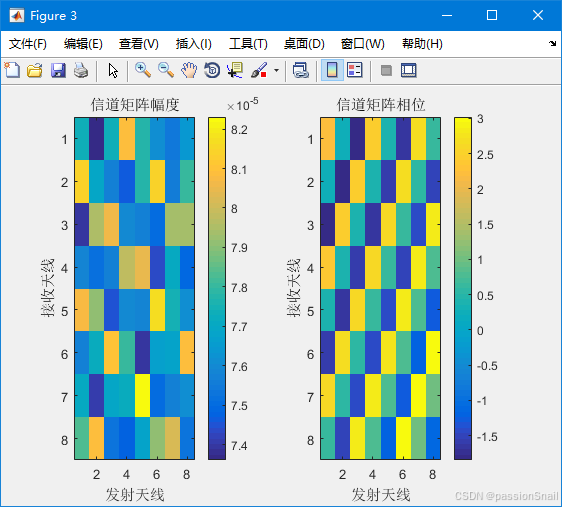
《MATLAB实战训练营:从入门到工业级应用》高阶挑战篇-《5G通信速成:MATLAB毫米波信道建模仿真指南》
《MATLAB实战训练营:从入门到工业级应用》高阶挑战篇-5G通信速成:MATLAB毫米波信道建模仿真指南 🚀📡 大家好!今天我将带大家进入5G通信的奇妙世界,我们一起探索5G通信中最激动人心的部分之一——毫米波信…...

工程师 - 汽车分类
欧洲和中国按字母对汽车分类: **轴距**:简单来说,就是前轮中心点到后轮中心点之间的距离,也就是前轮轴和后轮轴之间的长度。根据轴距的大小,国际上通常把轿车分为以下几类(德国大众汽车习惯用A\B\C\D分类&a…...

57.[前端开发-前端工程化]Day04-webpack插件模式-搭建本地服务器
Webpack常见的插件和模式 1 认识插件Plugin 认识Plugin 2 CleanWebpackPlugin CleanWebpackPlugin 3 HtmlWebpackPlugin HtmlWebpackPlugin 生成index.html分析 自定义HTML模板 自定义模板数据填充 4 DefinePlugin DefinePlugin的介绍 DefinePlugin的使用 5 mode模式配置…...

K8S - 金丝雀发布实战 - Argo Rollouts 流量控制解析
一、金丝雀发布概述 1.1 什么是金丝雀发布? 金丝雀发布(Canary Release)是一种渐进式部署策略,通过逐步将生产流量从旧版本迁移至新版本,结合实时指标验证,在最小化风险的前提下完成版本迭代。其核心逻辑…...

Qt中数据结构使用自定义类————附带详细示例
文章目录 C对数据结构使用自定义类1 QMap使用自定义类1.1 使用自定义类做key1.2 使用自定义类做value 2 QSet使用自定义类 参考 C对数据结构使用自定义类 1 QMap使用自定义类 1.1 使用自定义类做key QMap<key,value>中数据存入时会对存入key值的数据进行比较ÿ…...
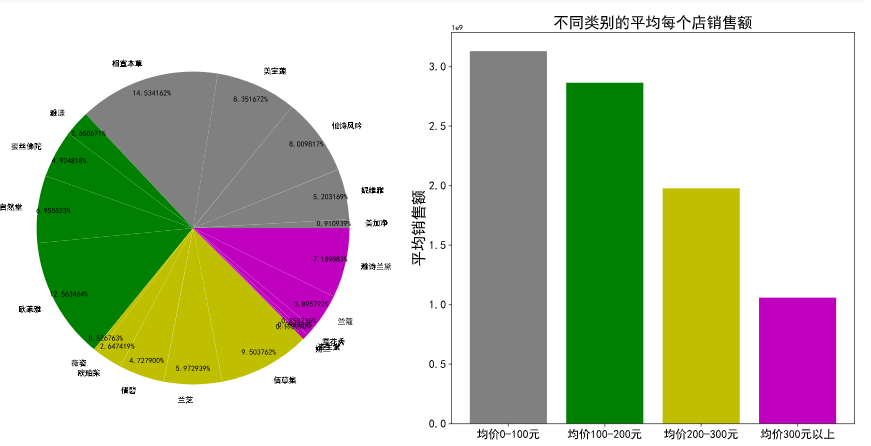
数据可视化与分析
数据可视化的目的是为了数据分析,而非仅仅是数据的图形化展示。 项目介绍 项目案例为电商双11美妆数据分析,分析品牌销售量、性价比等。 数据集包括更新日期、ID、title、品牌名、克数容量、价格、销售数量、评论数量、店名等信息。 1、数据初步了解…...

基于大模型预测的产钳助产分娩全方位研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与方法 二、产钳助产分娩概述 2.1 产钳助产定义与历史 2.2 适用情况与临床意义 三、大模型预测原理与数据基础 3.1 大模型技术原理 3.2 数据收集与处理 3.3 模型训练与验证 四、术前预测与准备 4.1 大模型术前风险预…...

通过混合机器学习和 TOPSIS 实现智能手机身份验证的稳健行为生物识别框架
1. 简介 随着日常工作、个人生活和金融操作对智能手机的依赖性不断增强,对弹性安全身份验证系统的需求也日益增长。尽管 PIN 码、密码和静态生物识别等传统身份验证方法仍可为系统提供一定的安全级别,但事实证明,它们容易受到多种威胁,包括敏感数据泄露、网络钓鱼、盗窃和…...

旅游设备生产企业的痛点 质检系统在旅游设备生产企业的应用
在旅游设备制造行业,产品质量直接关系到用户体验与企业口碑。从景区缆车、观光车到水上娱乐设施,每一件设备的安全性与可靠性都需经过严苛检测。然而,传统质检模式常面临数据分散、流程不透明、合规风险高等痛点,难以满足旅游设备…...

使用ESPHome烧录固件到ESP32-C3并接入HomeAssistant
文章目录 一、安装ESPHome二、配置ESP32-C3控制灯1.主配置文件esp32c3-luat.yaml2.基础通用配置base.yaml3.密码文件secret.yaml4.围栏灯four_light.yaml5.彩灯rgb_light.yaml6.左右柱灯left_right_light.yaml 三、安装固件四、HomeAssistant配置ESPHome1.直接访问2.配置ESPHom…...
【漫话机器学习系列】237. TSS总平方和
深度理解 TSS(总平方和):公式、意义与应用 在机器学习与统计建模领域,评价模型好坏的重要指标之一就是方差与误差分析。其中,TSS(Total Sum of Squares,总平方和)扮演着非常关键的角…...

DeepSeek多尺度数据:无监督与原则性诊断方案全解析
DeepSeek 多尺度数据诊断方案的重要性 在当今的 IT 领域,数据如同石油,是驱动各类智能应用发展的核心资源。随着技术的飞速发展,数据的规模和复杂性呈爆炸式增长,多尺度数据处理成为了众多领域面临的关键挑战。以计算机视觉为例,在目标检测任务中,小目标可能只有几个像素…...

Spring Framework 6:虚拟线程支持与性能增强
文章目录 引言一、虚拟线程支持:并发模型的革命二、AOT编译与原生镜像优化三、响应式编程与可观测性增强四、HTTP接口客户端与声明式HTTP五、性能比较与实际应用总结 引言 Spring Framework 6作为Spring生态系统的基础框架,随着Java 21的正式发布&#…...

用Redisson实现库存扣减的方法
Redisson是一个在Redis基础上实现的Java客户端,提供了许多高级功能,包括分布式锁、计数器、集合等。使用Redisson实现库存扣减可以保证操作的原子性和高效性。本文将详细介绍如何使用Redisson实现一个简单的库存扣减功能。 一、初始化Redisson客户端 首…...

视频转GIF
视频转GIF 以下是一个使用 Python 将视频转换为 GIF 的脚本,使用了 imageio 和 opencv-python 库: import cv2 import imageio import numpy as np """将视频转换为GIF图参数:video_path -- 输入视频的路径gif_path -- 输出GIF的路径fp…...

一场静悄悄的革命:AI大模型如何重构中国产业版图?
一场静悄悄的革命:AI大模型如何重构中国产业版图? 当ChatGPT在2022年掀起全球AI热潮时,很少有人意识到,这场技术变革正在中国产业界掀起更深层次的革命。在浙江宁波,一个纺织企业老板打开"产业链智能创新平台",30秒内就获得了原料采购、设备升级、海外拓客的全…...

kotlin 02flow-sharedFlow 完整教程
一 sharedFlow是什么 SharedFlow 是 Kotlin 协程中 Flow 的一种 热流(Hot Flow),用于在多个订阅者之间 共享事件或数据流。它适合处理 一次性事件(如导航、弹窗、Toast、刷新通知等),而不是持续状态。 ✅ …...
CentOS网络之network和NetworkManager深度解析
文章目录 CentOS网络之network和NetworkManager深度解析1. CentOS网络服务发展历史1.1 传统network阶段(CentOS 5-6)1.2 过渡期(CentOS 7)1.3 新时代(CentOS 8) 2. network和NetworkManager的核心区别3. ne…...

【AI】模型与权重的基本概念
在 ModelScope 平台上,「模型」和「权重」的定义与工程实践紧密结合,理解它们的区别需要从实际的文件结构和加载逻辑入手。以下是一个典型 ModelScope 模型仓库的组成及其概念解析: 1. ModelScope 模型仓库的典型结构 以 deepseek-ai/deepse…...
)
设计模式-基础概念学习总结(继承、多态、虚方法、方法重写)
概念使用例子的方式介绍(继承,多态,虚方法,方法重写),实现代码python 1. 继承(Inheritance) 概念:子类继承父类的属性和方法,可以直接复用父类的代码&#…...

2025年小程序DDoS与CC攻击防御全指南:构建智能安全生态
2025年,小程序已成为企业数字化转型的核心载体,但随之而来的DDoS与CC攻击也愈发复杂化、智能化。攻击者利用AI伪造用户行为、劫持物联网设备发起T级流量冲击,甚至通过漏洞窃取敏感数据。如何在高并发业务场景下保障小程序的稳定与安全&#x…...

当当狸智能天文望远镜 TW2 | 用科技触摸星辰,让探索触手可及
当科技邂逅星空,每个普通人都能成为宇宙的追光者 伽利略用望远镜揭开宇宙面纱的 400 年后,当当狸以颠覆传统的设计,让天文观测从专业领域走入千家万户。当当狸智能天文望远镜 TW2,重新定义「观星自由」—— 无需专业知识ÿ…...

QT实现曲线图缩放、拖拽以及框选放大
.h文件 protected: void saveAxisRange();void wheelEvent(QWheelEvent *event) override;void mousePressEvent(QMouseEvent *event) override;void mouseMoveEvent(QMouseEvent *event) override;void mouseReleaseEvent(QMouseEvent *event) override;private:QPoint m_…...

C# | 基于C#实现的BDS NMEA-0183数据解析上位机
以下是一个基于C#实现的BDS NMEA-0183数据解析上位机的示例代码,包含基础功能和界面: using System; using System.Collections.Generic; using System.IO.Ports; using System.Windows.Forms; using System.Drawing; using System.Globalization;namespace BDS_NMEA_Viewer…...