【算法基础】递归算法 - JAVA
一、递归基础
1.1 什么是递归算法
递归算法是一种通过函数调用自身来解决问题的方法。简单来说,就是"自己调用自己"。递归将复杂问题分解为同类的更简单子问题,直到达到易于直接解决的基本情况。
1.2 递归的核心要素
递归算法由两个关键部分组成:
- 边界条件(终止条件):决定递归何时结束,避免无限递归
- 递归步骤:函数调用自身处理较小规模的问题
1.3 递归的基本结构
public ReturnType recursiveMethod(Parameters params) {// 边界条件(终止条件)if (结束条件) {return 结束值;}// 递归步骤return recursiveMethod(减小规模的参数);
}
1.4 递归的复杂度分析
时间复杂度:递归算法的时间复杂度主要取决于以下因素:
- 递归调用的次数
- 每次递归中的非递归操作耗时
递归算法的时间复杂度通常可以用递推关系表示:
- T(n) = a·T(n/b) + f(n)
- T(n)是规模为n的问题的时间复杂度
- a是每次递归调用的次数
- n/b是子问题的规模
- f(n)是除递归调用外的操作耗时
空间复杂度:递归算法的空间复杂度考虑两部分:
- 递归调用栈空间:与递归深度成正比
- 额外使用的数据结构空间
递归调用的栈空间通常是递归算法空间复杂度的主要部分,对于最大递归深度为D的算法,栈空间复杂度为O(D)。
二、简单递归示例
2.1 计算1到n的和
计算 1+2+3+...+n 的和是理解递归的最佳入门示例。
public class SumExample {public static void main(String[] args) {// 计算1到100的和System.out.println("1到100的和: " + getSum(100));}// 计算从1到n的和的递归方法public static int getSum(int n) {// 边界条件:当n为1时,直接返回1if (n == 1) {return 1;}// 递归步骤:n加上(n-1)的和return n + getSum(n - 1);}
}
递归执行过程详解
以计算getSum(5)为例,让我们看看递归的具体执行过程:
正向递归调用过程(自顶向下):
- 调用
getSum(5),因为5 != 1,执行return 5 + getSum(4),暂停等待getSum(4)的结果 - 调用
getSum(4),因为4 != 1,执行return 4 + getSum(3),暂停等待getSum(3)的结果 - 调用
getSum(3),因为3 != 1,执行return 3 + getSum(2),暂停等待getSum(2)的结果 - 调用
getSum(2),因为2 != 1,执行return 2 + getSum(1),暂停等待getSum(1)的结果 - 调用
getSum(1),满足边界条件n == 1,直接return 1
反向结果返回过程(自底向上):
getSum(1)返回1getSum(2)继续执行计算2 + 1 = 3,返回3getSum(3)继续执行计算3 + 3 = 6,返回6getSum(4)继续执行计算4 + 6 = 10,返回10getSum(5)继续执行计算5 + 10 = 15,返回15,计算完成
可以看到,递归过程包含两个阶段:
- 分解阶段:将问题拆解为更小的子问题
- 回溯阶段:从最简单情况开始,逐层向上计算结果
2.2 计算阶乘
阶乘是另一个简单的递归实例。n的阶乘定义为:n! = n * (n-1) * (n-2) * ... * 2 * 1。
public class FactorialExample {public static void main(String[] args) {int n = 5;System.out.println(n + "的阶乘是: " + factorial(n));}// 计算阶乘的递归方法public static int factorial(int n) {// 边界条件if (n == 0 || n == 1) {return 1;}// 递归步骤return n * factorial(n - 1);}
}
递归执行过程
计算factorial(4)的步骤:
factorial(4)→4 * factorial(3)factorial(3)→3 * factorial(2)factorial(2)→2 * factorial(1)factorial(1)→ 返回1(边界条件)factorial(2)→2 * 1 = 2factorial(3)→3 * 2 = 6factorial(4)→4 * 6 = 24
时间复杂度分析:
- 阶乘递归函数的调用次数与输入n成正比
- 每次函数调用中只有常数级别的操作
- 总时间复杂度:O(n)
空间复杂度分析:
- 递归深度为n,每层递归使用常数级别的空间
- 总空间复杂度:O(n)
2.3 斐波那契数列
斐波那契数列是一个经典递归案例,定义为:F(0)=0, F(1)=1, F(n)=F(n-1)+F(n-2) (n≥2)。
public class FibonacciExample {public static void main(String[] args) {int n = 7;System.out.println("斐波那契数列第" + n + "个数是: " + fibonacci(n));// 打印斐波那契数列的前10个数System.out.print("斐波那契数列前10个数: ");for (int i = 0; i < 10; i++) {System.out.print(fibonacci(i) + " ");}}// 计算斐波那契数列的递归方法public static int fibonacci(int n) {// 边界条件if (n == 0) {return 0;}if (n == 1) {return 1;}// 递归步骤return fibonacci(n - 1) + fibonacci(n - 2);}
}
特别注意
斐波那契数列的简单递归实现存在大量重复计算,效率较低。例如计算fibonacci(5)时,fibonacci(3)会被重复计算多次。这个问题在后面的优化部分会详细讨论。
时间复杂度分析:
- 未优化的递归斐波那契函数时间复杂度为O(2^n)
- 这是因为每个递归调用会产生两个新的递归调用,形成二叉树结构
- 树的高度为n,节点总数约为2^n-1
空间复杂度分析:
- 虽然会有大量函数调用,但递归栈的最大深度为n
- 空间复杂度:O(n)
三、理解递归思维
3.1 递归思维的要点
递归思维的核心是把大问题分解成小问题:
- 相信函数能完成任务:假设对于较小规模的输入,函数已经能正确工作
- 确保边界情况正确:解决最简单的情况作为起点
- 确保递归逐步接近边界:每次递归,问题规模都应该变小
3.2 设计递归函数的步骤
- 确定函数的功能和参数:明确函数要完成什么任务,需要哪些参数
- 确定边界条件:找到最简单的情况,直接给出答案
- 确定递归关系:将原问题分解为更小规模的子问题
- 组合子问题结果:如何从子问题的解得到原问题的解
四、递归的实际应用
4.1 二分查找
二分查找是在有序数组中查找特定元素的高效算法,可以使用递归实现。
public class BinarySearchExample {public static void main(String[] args) {int[] arr = {1, 3, 5, 7, 9, 11, 13, 15, 17, 19};int target = 11;int result = binarySearch(arr, target, 0, arr.length - 1);if (result != -1) {System.out.println("元素 " + target + " 在索引 " + result + " 处");} else {System.out.println("元素 " + target + " 不在数组中");}}// 递归实现的二分查找public static int binarySearch(int[] arr, int target, int left, int right) {// 边界条件:如果查找范围无效,返回-1if (left > right) {return -1;}// 计算中间索引int mid = left + (right - left) / 2;// 找到目标,返回索引if (arr[mid] == target) {return mid;}// 根据中间值与目标值的比较,递归查找左半部分或右半部分if (arr[mid] > target) {return binarySearch(arr, target, left, mid - 1);} else {return binarySearch(arr, target, mid + 1, right);}}
}
递归过程分析
以查找值11为例:
binarySearch(arr, 11, 0, 9),计算mid=4,arr[4]=9 < 11,递归调用右半部分binarySearch(arr, 11, 5, 9),计算mid=7,arr[7]=15 > 11,递归调用左半部分binarySearch(arr, 11, 5, 6),计算mid=5,arr[5]=11 == 11,返回5(找到)
时间复杂度分析:
- 每次递归调用将搜索范围减半
- 对于长度为n的数组,最多需要log₂n次递归调用
- 每次递归中的操作是常数级别的
- 总时间复杂度:O(log n)
空间复杂度分析:
- 递归深度最多为log₂n
- 每层递归使用常数级别的额外空间
- 总空间复杂度:O(log n)
4.2 求解全排列
全排列问题是递归的经典应用。给定一组不同的数字,求其所有可能的排列。
public class PermutationExample {public static void main(String[] args) {String str = "ABC";System.out.println("字符串\"" + str + "\"的全排列:");permute(str.toCharArray(), 0, str.length() - 1);}// 生成全排列的递归方法public static void permute(char[] arr, int start, int end) {// 边界条件:当只剩一个字符时,打印当前排列if (start == end) {System.out.println(String.valueOf(arr));return;}// 递归步骤:固定一个字符,对剩余字符进行全排列for (int i = start; i <= end; i++) {// 交换字符swap(arr, start, i);// 递归生成其余字符的排列permute(arr, start + 1, end);// 恢复原来的顺序(回溯)swap(arr, start, i);}}// 交换字符的辅助方法private static void swap(char[] arr, int i, int j) {char temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}
递归思路解释
以字符串"ABC"为例:
- 首先,我们固定第一个位置(索引0)的字符,然后对剩余字符递归生成全排列
- 固定A:递归处理"BC"的排列
- 固定B:递归处理"AC"的排列
- 固定C:递归处理"AB"的排列
- 当递归到只剩一个字符时,我们已经生成了一个完整的排列
时间复杂度分析:
- 对于长度为n的字符串,共有n!种排列
- 每生成一个排列需要O(n)的时间(打印或存储)
- 总时间复杂度:O(n × n!)
空间复杂度分析:
- 递归深度为n,每层递归使用常数级别的额外空间
- 如果考虑输出存储,需要O(n × n!)的空间
- 仅递归调用栈的空间复杂度:O(n)
4.3 汉诺塔问题
汉诺塔是递归的经典问题,它很好地展示了递归如何简化看似复杂的问题。
public class TowerOfHanoiExample {public static void main(String[] args) {int n = 3; // 盘子数量System.out.println("移动" + n + "个盘子的步骤:");moveDisks(n, 'A', 'B', 'C');}// 移动汉诺塔盘子的递归方法public static void moveDisks(int n, char source, char auxiliary, char target) {// 边界条件:只有一个盘子时,直接从起始柱移到目标柱if (n == 1) {System.out.println("将盘子1从" + source + "移动到" + target);return;}// 递归步骤1:将n-1个盘子从起始柱移到辅助柱moveDisks(n - 1, source, target, auxiliary);// 移动最大的盘子从起始柱到目标柱System.out.println("将盘子" + n + "从" + source + "移动到" + target);// 递归步骤2:将n-1个盘子从辅助柱移到目标柱moveDisks(n - 1, auxiliary, source, target);}
}
递归思路解释
汉诺塔问题的美妙之处在于利用递归,我们可以将复杂的多盘子问题,分解为更简单的子问题:
- 将上面n-1个盘子从起始柱移到辅助柱
- 将最底下的盘子从起始柱移到目标柱
- 将辅助柱上的n-1个盘子移到目标柱
这里的关键是"相信"递归函数能够正确移动n-1个盘子,这样就能将复杂问题简化。
时间复杂度分析:
- 对于n个盘子,总共需要2^n-1步移动
- 每层递归产生两个新的递归调用,直到达到基本情况
- 总时间复杂度:O(2^n)
空间复杂度分析:
- 递归调用的最大深度为n
- 每层递归使用常数级别的额外空间
- 总空间复杂度:O(n)
五、递归优化技巧
5.1 记忆化递归(备忘录法)
斐波那契数列的简单递归实现效率很低,因为有大量重复计算。使用记忆化技术可以显著提高效率。
public class MemoizedFibonacci {public static void main(String[] args) {int n = 40;// 比较普通递归和记忆化递归的时间long startTime = System.currentTimeMillis();System.out.println("斐波那契(" + n + ") = " + fibonacciMemoized(n));long endTime = System.currentTimeMillis();System.out.println("记忆化递归耗时: " + (endTime - startTime) + "毫秒");}// 使用记忆化的斐波那契数列递归方法public static long fibonacciMemoized(int n) {// 创建备忘录数组,保存计算过的结果long[] memo = new long[n + 1];return fibHelper(n, memo);}private static long fibHelper(int n, long[] memo) {// 边界条件if (n <= 1) {return n;}// 如果已经计算过,直接返回结果if (memo[n] != 0) {return memo[n];}// 递归计算并保存结果memo[n] = fibHelper(n - 1, memo) + fibHelper(n - 2, memo);return memo[n];}
}
记忆化递归的关键思想:
- 用数组或HashMap存储已计算的值
- 每次函数调用前先检查是否已计算
- 只计算未知结果并保存
复杂度优化分析:
- 时间复杂度:从指数级O(2^n)降低到线性O(n)
- 每个斐波那契数只计算一次
- 总共计算n+1个数,每次计算是常数时间
- 空间复杂度:O(n)
- 需要额外的长度为n+1的数组存储计算结果
- 递归调用栈深度为O(n)
5.2 尾递归优化
尾递归是一种特殊的递归形式,它在函数返回时不做额外计算,直接返回递归调用的结果。这种形式更容易被编译器优化。
以阶乘计算为例:
public class TailRecursionExample {public static void main(String[] args) {int n = 5;System.out.println(n + "的阶乘: " + factorial(n));System.out.println(n + "的阶乘(尾递归): " + factorialTail(n, 1));}// 普通递归实现阶乘public static int factorial(int n) {if (n <= 1) {return 1;}return n * factorial(n - 1); // 在递归调用后还需要乘以n}// 尾递归实现阶乘public static int factorialTail(int n, int result) {if (n <= 1) {return result;}return factorialTail(n - 1, n * result); // 直接返回递归调用的结果}
}
尾递归的特点:
- 递归调用是函数的最后一个操作
- 递归调用的返回值直接作为函数的返回值
- 不需要额外的计算或状态保存
注意:虽然Java不会自动优化尾递归,但理解尾递归仍有助于编写更高效的代码,尤其是在支持尾递归优化的语言中。
5.3 避免重复计算
在一些递归算法中,避免重复计算是提高效率的关键。以下是几种常见技巧:
- 使用缓存:与记忆化类似,保存中间结果
- 参数传递:通过参数传递已计算的信息,避免重复计算
- 状态记录:使用额外变量记录状态,避免重复检查
六、递归的常见陷阱与解决方法
6.1 无限递归
如果忘记设置正确的终止条件,或递归时参数未正确减小,可能导致无限递归,最终导致栈溢出。
解决方法:
- 确保每次递归都朝着终止条件推进
- 检查边界条件是否全面且正确
- 考虑添加最大递归深度限制
6.2 栈溢出
递归层数过多会导致栈溢出(StackOverflowError)。
解决方法:
- 优化递归算法,减少递归深度
- 将递归转换为迭代
- 使用尾递归优化(在支持的语言中)
- 增大JVM栈大小(-Xss参数)
6.3 重复递归调用
在某些算法中,同一参数的递归调用可能被多次执行,导致不必要的计算。
解决方法:
- 使用记忆化技术(备忘录模式)
- 优化算法结构,避免重复调用
- 考虑使用自底向上的迭代方法
七、递归转迭代
有时,递归算法可能面临效率或栈空间限制,此时可以考虑将递归转换为迭代。
7.1 斐波那契数列的迭代实现
public static long fibonacciIterative(int n) {if (n <= 1) {return n;}long fib = 0;long prev1 = 1;long prev2 = 0;for (int i = 2; i <= n; i++) {fib = prev1 + prev2;prev2 = prev1;prev1 = fib;}return fib;
}
复杂度分析:
- 时间复杂度:O(n) - 只需一次遍历
- 空间复杂度:O(1) - 只使用了常数个变量
7.2 阶乘的迭代实现
public static int factorialIterative(int n) {int result = 1;for (int i = 2; i <= n; i++) {result *= i;}return result;
}
复杂度分析:
- 时间复杂度:O(n) - 需要n-1次乘法运算
- 空间复杂度:O(1) - 只使用了常数个变量
递归转迭代的一般思路:
- 使用栈或其他数据结构模拟递归过程
- 找出算法中的状态变量
- 通过循环代替递归调用
- 手动管理状态变更
转换后的优势:
- 避免栈溢出风险
- 降低函数调用开销
- 通常具有更低的空间复杂度
- 在某些情况下可提高执行速度
八、总结
8.1 递归的核心要点
- 分而治之:将大问题分解为相似的小问题
- 边界条件:解决最基本情况的方法
- 递归关系:大问题与小问题之间的联系
8.2 何时使用递归
适合使用递归的情况:
- 问题可以自然地分解为相似的子问题
- 问题的规模会逐渐减小
- 数据结构具有递归性质(如树、图)
- 代码简洁度比极限性能更重要
不适合使用递归的情况:
- 递归深度可能非常大
- 对执行效率有严格要求
- 问题可以简单地用迭代解决
8.3 递归思维的价值
掌握递归思维不仅是掌握一种编程技巧,更是一种解决问题的思路:
- 学会将复杂问题分解
- 培养"相信函数能工作"的思维方式
- 理解如何从子问题构建完整解决方案
递归是算法设计中的强大工具,掌握它将帮助你解决许多看似复杂的问题。通过从简单例子开始,逐步理解递归的核心概念,再结合优化技巧,你将能够写出既高效又优雅的递归算法。
相关文章:

【算法基础】递归算法 - JAVA
一、递归基础 1.1 什么是递归算法 递归算法是一种通过函数调用自身来解决问题的方法。简单来说,就是"自己调用自己"。递归将复杂问题分解为同类的更简单子问题,直到达到易于直接解决的基本情况。 1.2 递归的核心要素 递归算法由两个关键部…...

触想CX-3588工控主板应用于移动AI数字人,赋能新型智能交互
一、行业发展背景 随着AI智能、自主导航和透明屏显示等技术的不断进步,以及用户对“拟人化”、“沉浸式”交互体验的期待,一种新型交互终端——“移动AI数字人”正在加速实现规模化商用。 各大展厅展馆、零售导购、教学政务甚至家庭场景中,移…...
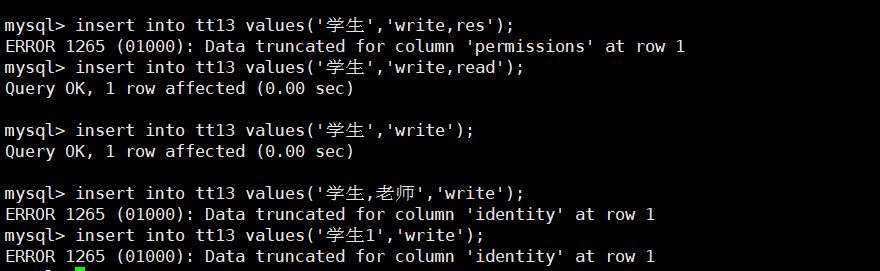
【深入浅出MySQL】之数据类型介绍
【深入浅出MySQL】之数据类型介绍 MySQL中常见的数据类型一览为什么需要如此多的数据类型数值类型BIT(M)类型INT类型TINYINT类型BIGINT类型浮点数类型float类型DECIMAL(M,D)类型区别总结 字符串类型CHAR类型VARCHAR(M)类型 日期和时间类型enum和set类型 …...

Vue3响应式:effect作用域
# Vue3响应式: effect作用域 什么是Vue3响应式? 是一款流行的JavaScript框架,它提供了响应式和组件化的视图组织方式。在Vue3中,响应式是一种让数据变化自动反映在视图上的机制。当数据发生变化时,与之相关的视图会自动更新。 作用…...
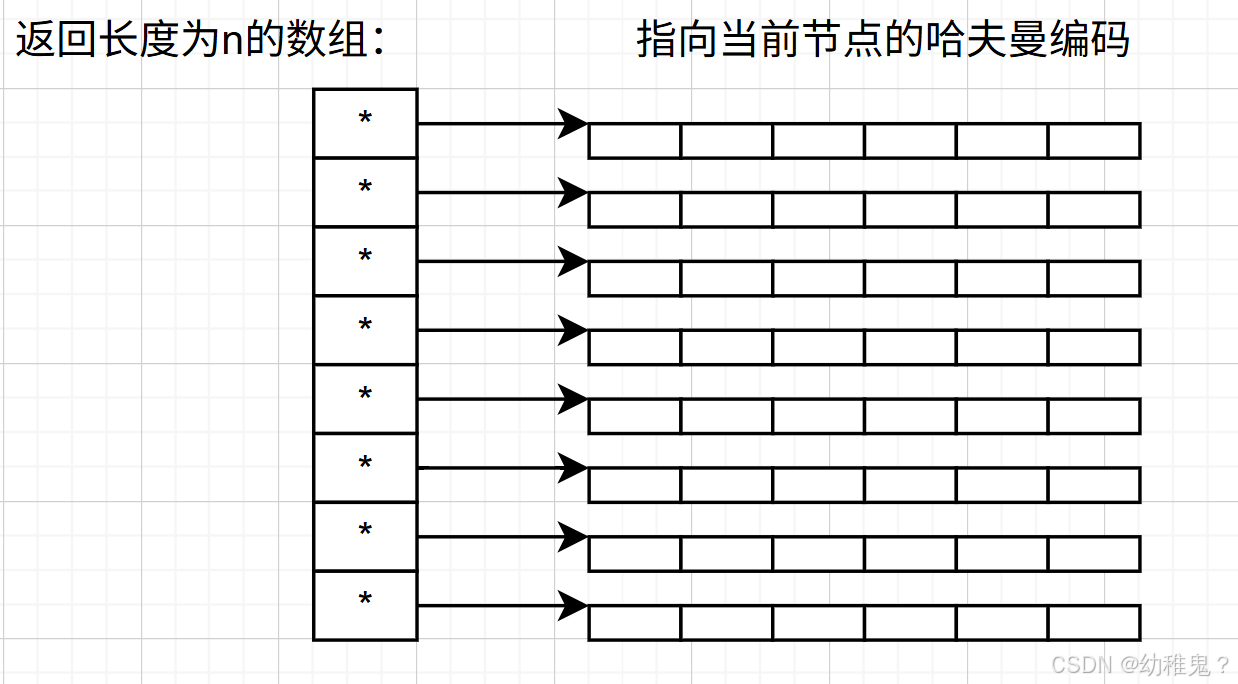
25.5.4数据结构|哈夫曼树 学习笔记
知识点前言 一、搞清楚概念 ●权:___________ ●带权路径长度:__________ WPL所有的叶子结点的权值*路径长度之和 ●前缀编码:____________ 二、构造哈夫曼树 n个带权值的结点,构造哈夫曼树算法: 1、转化成n棵树组成的…...

RabbitMQ 深度解析:从核心组件到复杂应用场景
一.RabbitMQ简单介绍 消息队列作为分布式系统中不可或缺的组件,承担着解耦系统组件、保障数据可靠传输、提高系统吞吐量等重要职责。在众多消息队列产品中,RabbitMQ 凭借其可靠性和丰富的特性,在企业级应用中获得了广泛应用。 二.RabbitMQ …...

Python高级技巧及案例分析:提升编程能力的实践指南
目录 Python高级技巧及案例分析:提升编程能力的实践指南1. Python高级特性概述2. 函数式编程技巧2.1 高阶函数2.2 函数柯里化2.3 不可变数据结构3. 元编程与反射3.1 动态属性访问3.2 类装饰器3.3 元类应用4. 并发与异步编程4.1 多线程与线程池4.2 协程与asyncio4.3 多进程处理…...
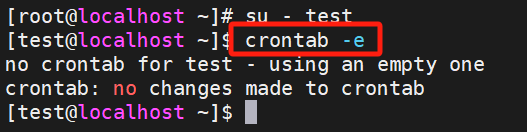
【Linux笔记】系统的延迟任务、定时任务极其相关命令(at、crontab极其黑白名单等)
一、延时任务 1、概念 延时任务(Delayed Jobs)通常指在指定时间或特定条件满足后执行的任务。常见的实现方式包括 at 和 batch 命令,以及结合 cron 的调度功能。 2、命令 延时任务的命令最常用的是at命令,第二大节会详细介绍。…...

转换算子和行动算子的区别
转换算子和行动算子主要是在分布式计算框架(如 Apache Spark)里常用的概念,它们在功能、执行机制、返回结果等方面存在明显区别,以下为你详细介绍: 定义与功能 返回结果 如何在使用转换算子和行动算子时避免出现内存溢…...
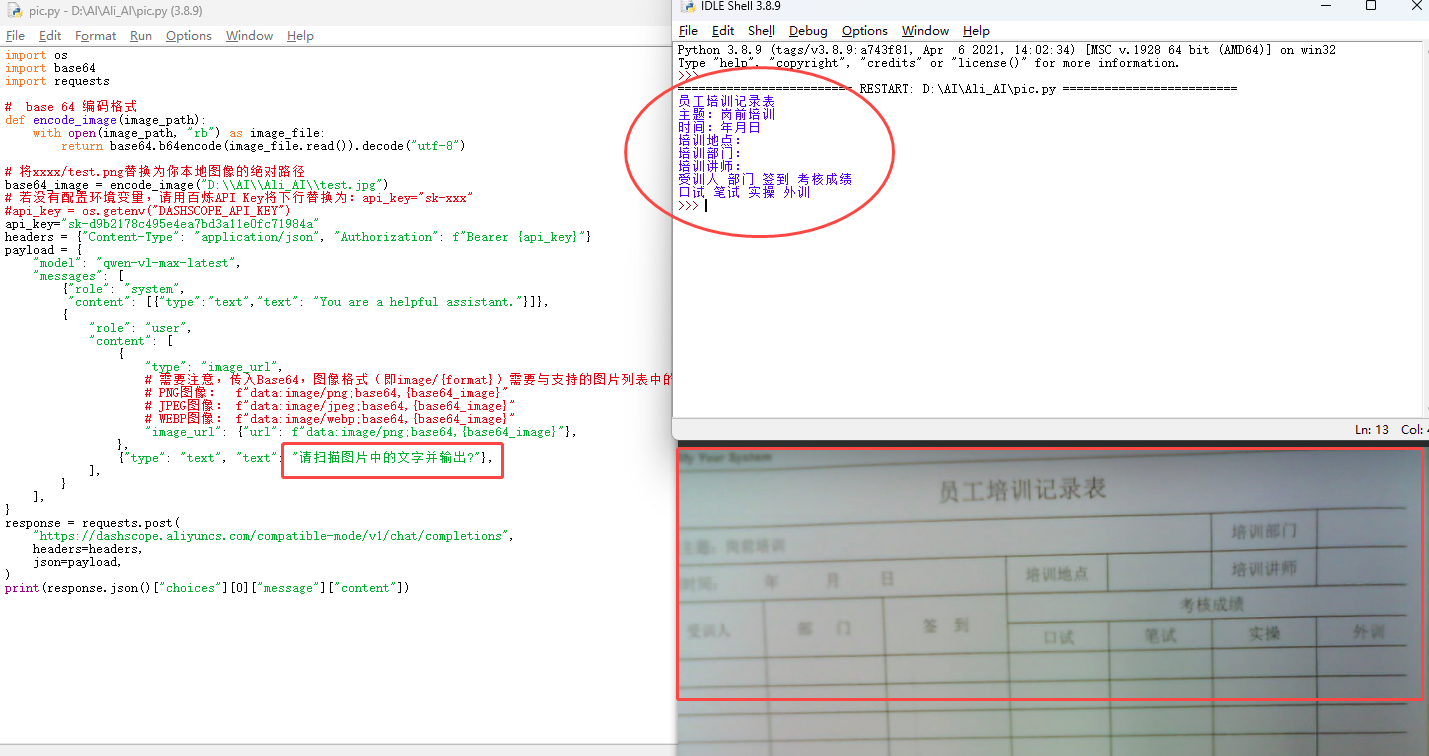
使用阿里AI的API接口实现图片内容提取功能
参考链接地址:如何使用Qwen-VL模型_大模型服务平台百炼(Model Studio)-阿里云帮助中心 在windows下,使用python语言测试,版本:Python 3.8.9 一. 使用QVQ模型解决图片数学难题 import os import base64 import requests# base 64 …...

告别散乱的 @ExceptionHandler:实现统一、可维护的 Spring Boot 错误处理
Spring Boot 的异常处理机制一直都烂得可以。即便到了 2025 年,有了这么多进步和新版本,开发者们发现自己还是在跟 ControllerAdvice、分散各处的 ExceptionHandler 方法以及五花八门的响应结构较劲。这真的是一团糟。 无论你是在构建 REST API、微服务…...

MariaDB 与 MySQL 的关系:从同源到分道扬镳
MariaDB 与 MySQL 的关系:从同源到分道扬镳 1. 起源:MySQL 的辉煌与危机 MySQL 是最流行的开源关系型数据库之一,由瑞典公司 MySQL AB 开发,并于 1995 年 首次发布。由于其高性能、易用性和开源特性,MySQL 迅速成为 L…...
从零开始搭建你的个人博客:使用 GitHub Pages 免费部署静态网站
🌐 从零开始搭建你的个人博客:使用 GitHub Pages 免费部署静态网站 在互联网时代,拥有一个属于自己的网站不仅是一种展示方式,更是一种技术能力的体现。今天我们将一步步学习如何通过 GitHub Pages 搭建一个免费的个人博客或简历…...
C#串口通信
在C#中使用串口通信比较方便,.Net 提供了现成的类, SerialPort类。 本文不对原理啥的进行介绍,只介绍SerialPort类的使用。 SerialProt类内部是调用了CreateFile,WriteFile等WinAPI函数来实现串口通信。 在后期的Windows编程系…...

Qt 显示QRegExp 和 QtXml 不存在问题
QRegExp 和 QtXml 问题 在Qt6 中 已被弃用; 1)QRegExp 已被弃用,改用 QRegularExpression Qt5 → Qt6 重大变更:QRegExp 被移到了 Qt5Compat 模块,默认不在 Qt6 核心模块中。 错误类型解决方法QRegExp 找不到改用 Q…...

【训练】Qwen2.5VL 多机多卡 Grounding Box定位
之前的相关文章: 【深度学习】LLaMA-Factory微调sft Qwen2-VL进行印章识别 https://www.dong-blog.fun/post/1661 使用LLaMA-Factory微调sft Qwen2-VL-7B-Instruct https://www.dong-blog.fun/post/1762 构建最新的LLaMA-Factory镜像 https://www.dong-blog.f…...

服务器配置llama-factory问题解决
在配置运行llama-factory,环境问题后显示环境问题。这边给大家附上连接,我们的是liunx环境但是还是一样的。大家也记得先配置虚拟环境。 LLaMA-Factory部署以及微调大模型_llamafactory微调大模型-CSDN博客 之后大家看看遇到的问题是不是我这样。 AI搜索…...
Spring Boot + Vue 实现在线视频教育平台
一、项目技术选型 前端技术: HTML CSS JavaScript Vue.js 前端框架 后端技术: Spring Boot 轻量级后端框架 MyBatis 持久层框架 数据库: MySQL 5.x / 8.0 开发环境: IDE:Eclipse / IntelliJ IDEA JDK&…...

使用Jmeter进行核心API压力测试
最近公司有发布会,需要对全链路比较核心的API的进行压测,今天正好分享下压测软件Jmeter的使用。 一、什么是Jmeter? JMeter 是 Apache 旗下的基于 Java 的开源性能测试工具。最初被设计用于 Web 应用测试,现已扩展到可测试多种不同的应用程…...
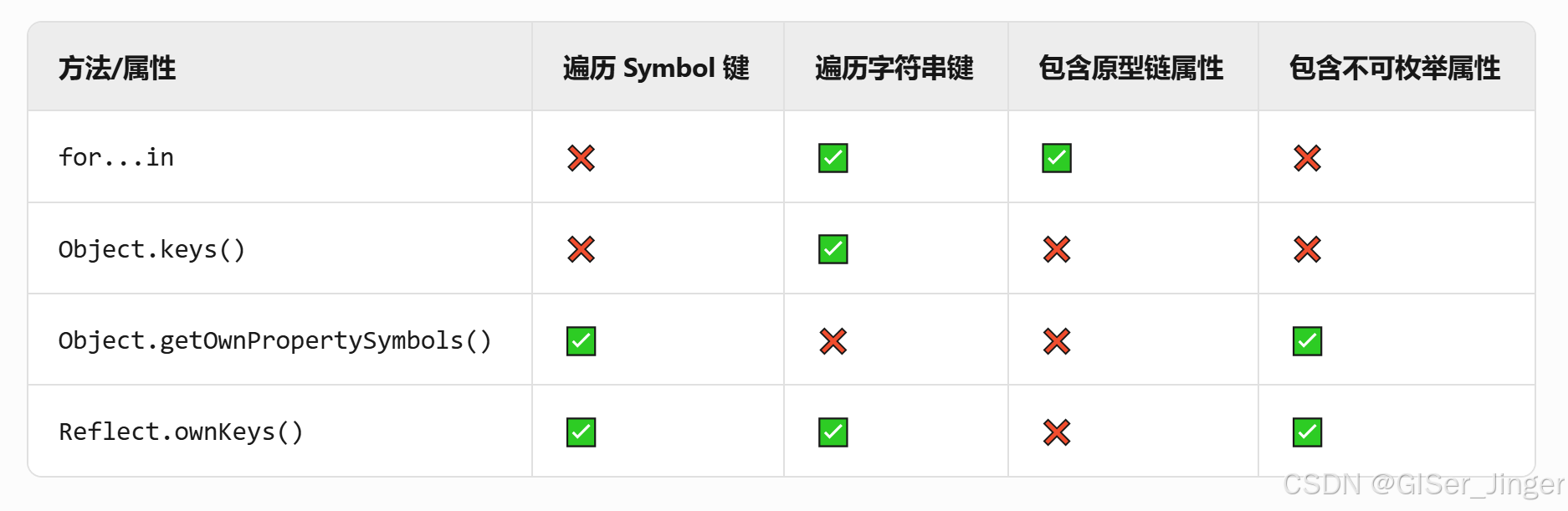
JavaScript中数组和对象不同遍历方法的顺序规则
在JavaScript中,不同遍历方法的顺序规则和适用场景存在显著差异。以下是主要方法的遍历顺序总结: 一、数组遍历方法 for循环 • 严格按数组索引顺序遍历(0 → length-1) • 支持break和continue中断循环 • 性能最优,…...

【机器学习-线性回归-5】多元线性回归:概念、原理与实现详解
线性回归是机器学习中最基础且广泛应用的算法之一,而多元线性回归则是其重要扩展。本文将全面介绍多元线性回归的核心概念、数学原理及多种实现方式,帮助读者深入理解这一强大的预测工具。 1. 多元线性回归概述 1.1 什么是多元线性回归 多元线性回归(…...
)
【软件设计师:数据结构】1.数据结构基础(一)
一 线性表 1.线性表定义 线性表是n个元素的有限序列,通常记为(a1,a2,…,an)。 特点: 存在惟一的表头和表尾。除了表头外,表中的每一个元素均只有惟一的直接前驱。除了表尾外,表中的每一个元素均只有惟一的直接后继。2.线性表的存储结构 (1)顺序存储 是用一组地址连续…...

简单面试提问
Nosql非关系型数据库: Mongodb:开源、json形式储存、c编写 Redis:key-value形式储存,储存在内存,c编写 关系型数据库: sqlite;:轻量型、0配置、磁盘存储、支持多种语言 mysql:开源…...

探秘数据中台:五大核心平台的功能全景解析
数据中台作为企业数据资产的 “智慧中枢”,通过整合数据处理全流程的核心功能,实现数据价值的深度挖掘与高效应用。以下从五大核心平台出发,全面拆解数据中台的功能架构与应用价值。 一、数据可视化平台:让数据 “开口说话” 1.…...

leetcode 3342. 到达最后一个房间的最少时间 II 中等
有一个地窖,地窖中有 n x m 个房间,它们呈网格状排布。 给你一个大小为 n x m 的二维数组 moveTime ,其中 moveTime[i][j] 表示在这个时刻 以后 你才可以 开始 往这个房间 移动 。你在时刻 t 0 时从房间 (0, 0) 出发,每次可以移…...
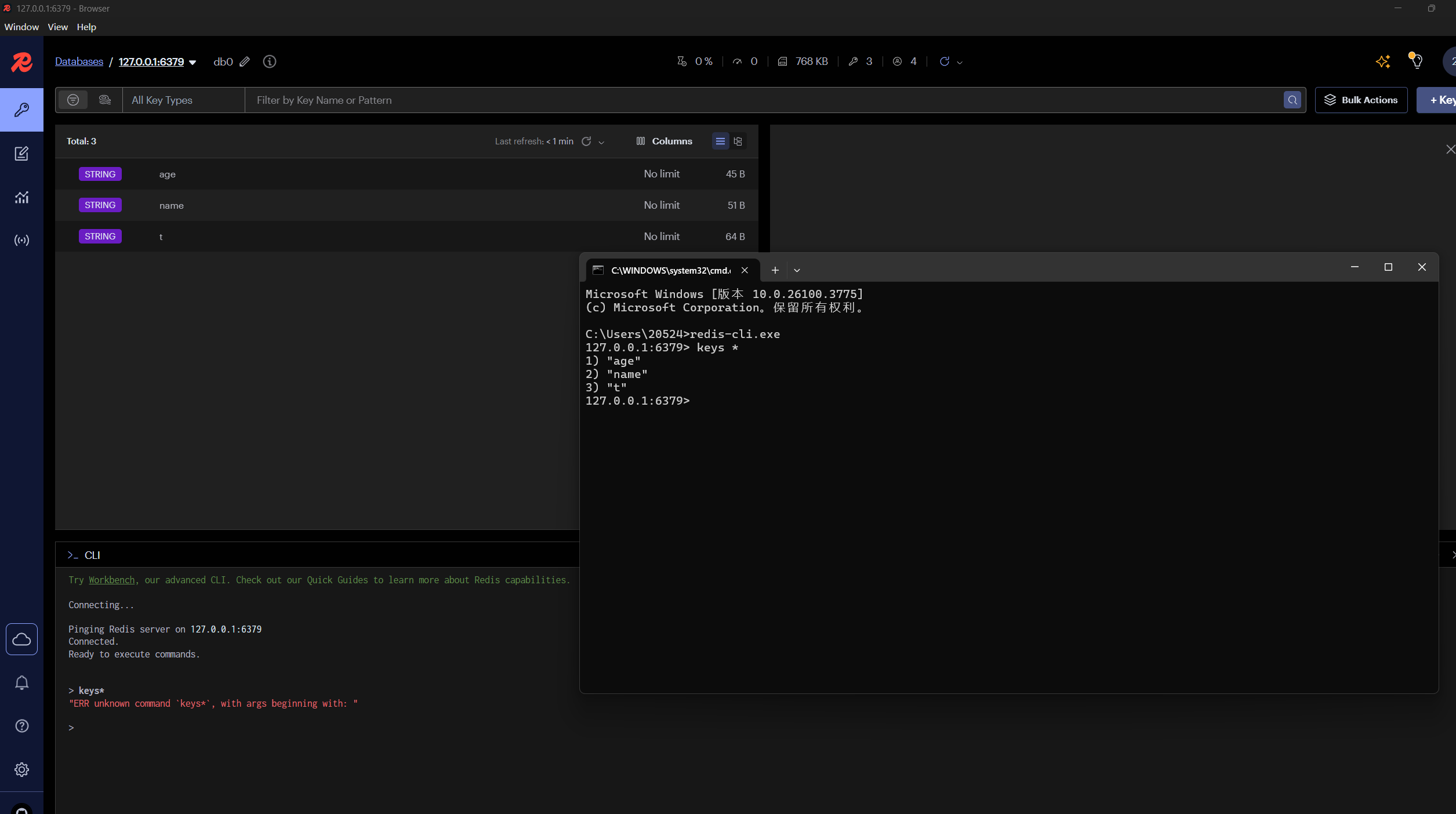
redis----通用命令
文章目录 前言一、运行redis二、help [command]三、通用命令 前言 提示:这里可以添加本文要记录的大概内容: 学习一些通用命令 以下操作在windows中演示 提示:以下是本篇文章正文内容,下面案例可供参考 一、运行redis 我们先c…...

PostgreSQL 查看索引碎片的方法
PostgreSQL 查看索引碎片的方法 在 PostgreSQL 中,索引碎片(Index Fragmentation)是指索引由于频繁的插入、更新和删除操作导致物理存储不连续,从而影响查询性能的情况。以下是几种查看索引碎片的方法: 一 使用 pgstattuple 扩展 1.1 安装…...

pip 常用命令及配置
一、python -m pip install 和 pip install 的区别 在讲解 pip 的命令之前,我们有必要了解一下 python -m pip install 和 pip install 的区别,以便于我们在不同的场景使用不同的方式。 python -m pip install 命令使用 python 可执行文件将 pip 模块作…...
IntelliJ IDEA 保姆级使用教程
文章目录 一、创建项目二、创建模块三、创建包四、创建类五、编写代码六、运行代码注意 七、IDEA 常见设置1、主题2、字体3、背景色 八、IDEA 常用快捷键九、IDEA 常见操作9.1、类操作9.1.1、删除类文件9.1.2、修改类名称注意 9.2、模块操作9.2.1、修改模块名快速查看 9.2.2、导…...
Comfyui 与 SDwebui
ComfyUI和SD WebUI是基于Stable Diffusion模型的两种不同用户界面工具,它们在功能、用户体验和适用场景上各有优劣。 1. 功能与灵活性 ComfyUI:ComfyUI以其节点式工作流设计为核心,强调用户自定义和灵活性。用户可以通过连接不同的模块&…...