人工智能基础知识笔记八:数据预处理
1、简介
在进行数据分析之前,数据预处理是一个至关重要的步骤。它包括了数据清洗、转换和特征工程等过程,以确保数据的质量并提高模型的性能。数据预处理是机器学习和数据分析中至关重要的步骤,其中分类变量的编码是核心任务之一。本文详细讲解四种常用编码方法(One-Hot Encoding、Label Encoding、Frequency Encoding、Target Encoding)。
2、为什么需要编码?
大多数机器学习算法(如线性回归、决策树等)无法直接处理文本型分类变量(如“男/女”、“北京/上海/广州”)。通过编码技术,可将分类变量转换为数值形式,同时保留其语义信息。
3、常用编码方法
3.1、 One-Hot Encoding(独热编码)
One-Hot编码是将分类变量转换为可以提供给机器学习算法的形式的一种方式。通过创建新的二进制列(0或1),每个代表原始类别中的一个可能值。
核心思想
-
将每个类别转换为一个独立的二进制列(0或1)
-
适用于无序分类变量(如城市、颜色)
优点
-
避免人为引入顺序关系
缺点:
-
高基数(类别多)时会导致维度爆炸
示例代码:
import pandas as pd
from sklearn.preprocessing import OneHotEncoder# 示例数据
data = pd.DataFrame({'City': ['北京', '上海', '广州', '北京', '深圳']})# 方法一:使用pandas
df_encoded = pd.get_dummies(data, columns=['City'])# 方法二:使用sklearn
encoder = OneHotEncoder(sparse=False)
encoded_array = encoder.fit_transform(data[['City']])
df_sklearn = pd.DataFrame(encoded_array, columns=encoder.get_feature_names_out(['City']))3.2、 Label Encoding(标签编码)
Label编码是一种将分类变量转换成整数的方法。对于具有自然顺序的类别变量尤其有用。
注意:使用label encoding时要小心,因为某些模型可能会错误地认为这些整数值之间存在某种顺序关系。
核心思想:
-
为每个类别分配一个唯一的整数
-
适用于有序分类变量(如学历:小学<初中<高中)
示例代码:
from sklearn.preprocessing import LabelEncoder# 示例数据
data = pd.DataFrame({'Education': ['小学', '初中', '高中', '大学', '硕士']})# 编码
le = LabelEncoder()
data['Education_encoded'] = le.fit_transform(data['Education'])print(data)
# Education Education_encoded
# 0 小学 0
# 1 初中 1
# 2 高中 2
# 3 大学 3
# 4 硕士 43.3、 Frequency Encoding(频率编码)
频率编码是根据每个类别的出现频率来替换该类别。这种方法有助于捕捉类别与目标变量之间的潜在关系。
核心思想:
-
用类别出现的频率代替原始类别
-
适用于高基数分类变量(如邮政编码)
优点:
-
有效控制维度
缺点:
-
可能丢失重要类别信息
示例代码:
# 计算频率
freq = data['City'].value_counts(normalize=True)# 映射到原始数据
data['City_Freq'] = data['City'].map(freq)# 结果示例:
# 北京 → 0.4, 上海 → 0.2, 广州 → 0.2, 深圳 → 0.23.4、 Target Encoding(目标编码)
目标编码基于每个类别的平均目标值来进行编码。这种方法特别适用于高基数的分类变量。
注意事项:为了避免过拟合,通常会在训练集上计算编码,在验证集/测试集上应用这些编码。同时必须使用交叉验证防止数据泄露,以及需添加平滑处理防止过拟合。
核心思想
-
用目标变量的统计量(如均值)代表类别
-
适用于分类任务中的高基数特征
示例代码:
import numpy as np# 示例数据(含目标变量)
data = pd.DataFrame({'City': ['A','A','B','B','C','C'],'Target': [1,0,1,1,0,0]
})# 计算各城市的目标均值
mean_encoding = data.groupby('City')['Target'].mean().to_dict()# 添加平滑(假设alpha=2,smoothing_factor=10)
n = data.groupby('City').size()
global_mean = data['Target'].mean()
data['City_Target'] = (data['City'].map(mean_encoding)*n + global_mean*10) / (n + 10)# 结果示例:
# City A: (0.5*2 + 0.5*10)/(2+10) = 0.54、方法对比与选择建议
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| One-Hot Encoding | 类别少(<15),无序数据 | 保留完整信息 | 维度爆炸 |
| Label Encoding | 明确有序的分类变量 | 保持顺序关系 | 误导数值关系 |
| Frequency Encoding | 高基数类别 | 降维效果好 | 丢失部分信息 |
| Target Encoding | 监督学习中的高基数特征 | 携带目标信息 | 需防过拟合 |
5、最佳实践建议
-
分类型变量处理流程:
-
类别数 < 10 → 优先考虑One-Hot
-
类别数 ≥ 10 → 尝试Frequency/Target Encoding
-
明确有序 → 使用Label Encoding
-
-
防止Target Encoding过拟合:
-
使用K-Fold交叉验证
-
添加平滑处理(如Bayesian平均)
-
在验证集上计算编码值
-
-
混合使用策略:
1. 对高基数特征使用Target Encoding 2. 对其他特征使用One-Hot Encoding
完整示例代码:
# 综合处理示例
import pandas as pd
from sklearn.model_selection import train_test_split# 加载数据
data = pd.read_csv('your_data.csv')
X = data.drop('target', axis=1)
y = data['target']# 划分数据集
X_train, X_val = train_test_split(X, test_size=0.2)# Target Encoding函数
def target_encode(train, val, col, target, alpha=5):# 计算全局均值global_mean = train[target].mean()# 计算各组的统计量agg = train.groupby(col)[target].agg(['count', 'mean'])counts = agg['count']means = agg['mean']# 计算平滑后的值smooth = (counts * means + global_mean * alpha) / (counts + alpha)# 应用到验证集val[col+'_encoded'] = val[col].map(smooth)return train, val# 对分类变量应用不同编码
categorical_cols = ['city', 'gender', 'education']for col in categorical_cols:if col == 'education': # 有序变量le = LabelEncoder()X_train[col] = le.fit_transform(X_train[col])X_val[col] = le.transform(X_val[col])elif col == 'city': # 高基数变量X_train, X_val = target_encode(X_train, X_val, col, 'target')else: # 普通分类变量X_train = pd.get_dummies(X_train, columns=[col])X_val = pd.get_dummies(X_val, columns=[col])通过合理选择编码方法,可以显著提升模型性能。建议在实践中根据数据特性和业务场景灵活组合使用这些技术。
相关文章:

人工智能基础知识笔记八:数据预处理
1、简介 在进行数据分析之前,数据预处理是一个至关重要的步骤。它包括了数据清洗、转换和特征工程等过程,以确保数据的质量并提高模型的性能。数据预处理是机器学习和数据分析中至关重要的步骤,其中分类变量的编码是核心任务之一。本文…...
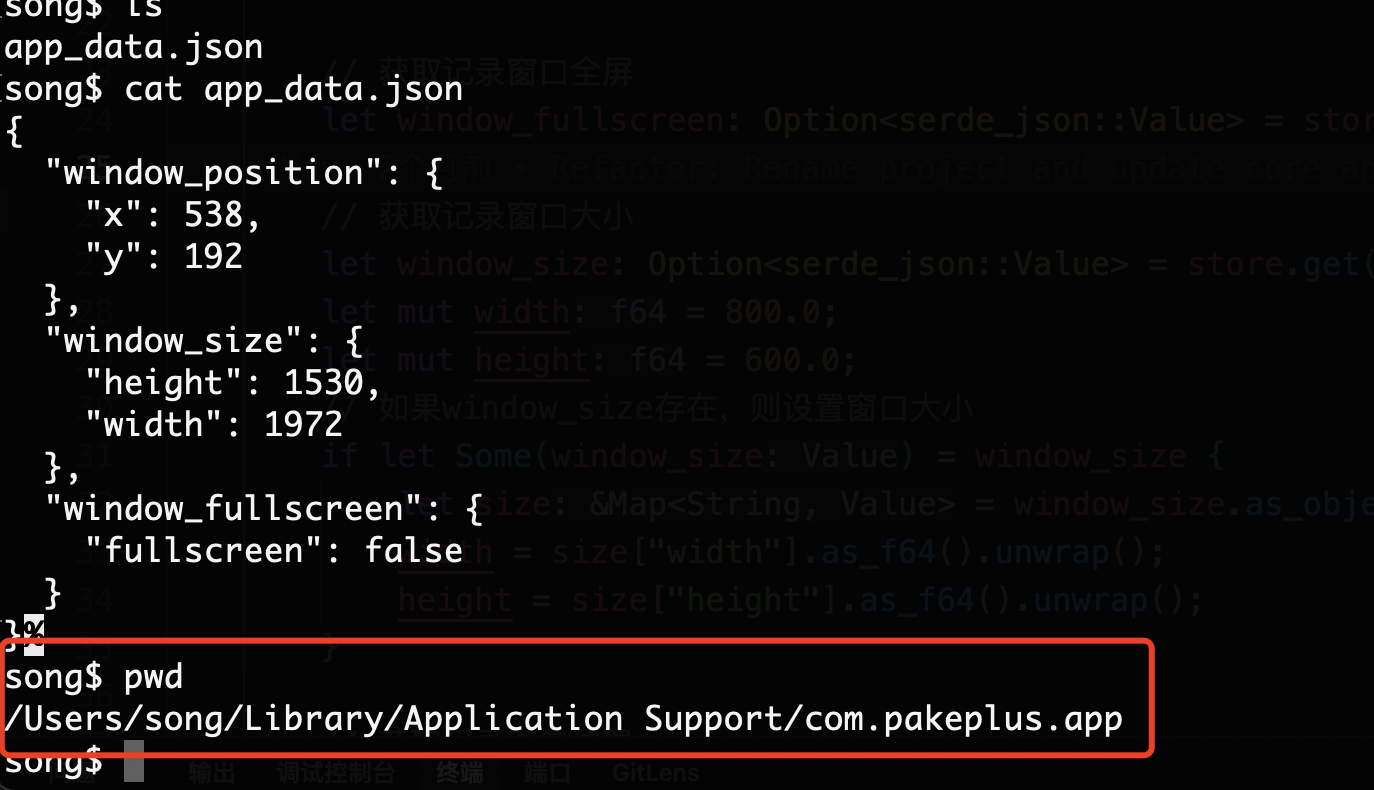
tauri-plugin-store 这个插件将数据存在本地电脑哪个位置
tauri-plugin-store 插件用于在 Tauri 应用中以键值对形式持久化存储数据。它将数据存储在用户本地电脑的一个 JSON 文件中,具体路径取决于操作系统,并且通常位于操作系统的应用数据目录中。 默认存储位置 以默认配置为例(使用 default sto…...

一场陟遐自迩的 SwiftUI + CoreData 性能优化之旅(下)
概述 自从 SwiftUI 诞生那天起,我们秃头码农们就仿佛打开了一个全新的撸码世界,再辅以 CoreData 框架的鼎力相助,打造一款持久存储支持的 App 就像探囊取物般的 Easy。 话虽如此,不过 CoreData 虽好,稍不留神也可能会…...

数字人驱动/动画方向最新顶会期刊论文收集整理 | AAAI 2025
会议官方论文列表:https://ojs.aaai.org/index.php/AAAI/issue/view/624 以下论文部分会开源代码,若开源,会在论文原文的摘要下方给出链接。 语音驱动头部动画/其他 EchoMimic: Lifelike Audio-Driven Portrait Animations through Editabl…...

Java+Selenium+快代理实现高效爬虫
目录 一、前言二、Selenium简介三、环境准备四、代码实现4.1 创建WebDriver工厂类4.2 创建爬虫主类4.3 配置代理的注意事项 六、总结与展望 一、前言 在Web爬虫技术中,Selenium作为一款强大的浏览器自动化工具,能够模拟真实用户操作,有效应对…...
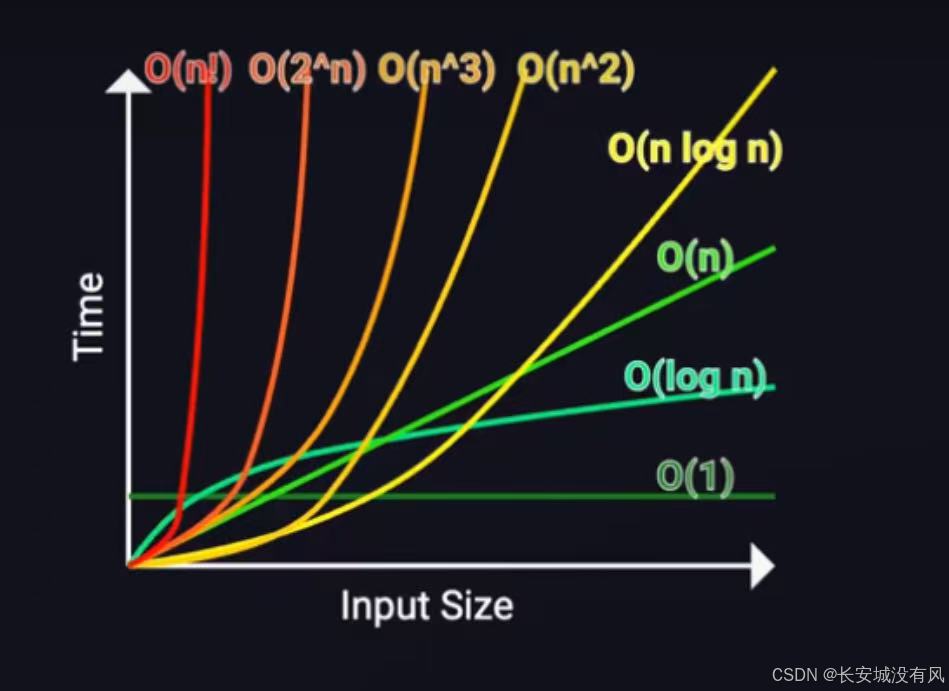
数据结构 集合类与复杂度
文章目录 📕1. 集合类📕2. 时间复杂度✏️2.1 时间复杂度✏️2.2 大O渐进表示法✏️2.3 常见的时间复杂度量级✏️2.4 常见时间复杂度计算举例 📕3. 空间复杂度 📕1. 集合类 Java 集合框架(Java Collection Framework…...
Python学习笔记--Django的安装和简单使用(一)
一.简介 Django 是一个用于构建 Web 应用程序的高级 Python Web 框架。Django 提供了一套强大的工具和约定,使得开发者能够快速构建功能齐全且易于维护的网站。Django 遵守 BSD 版权,初次发布于 2005 年 7 月, 并于 2008 年 9 月发布了第一个正式版本 1…...
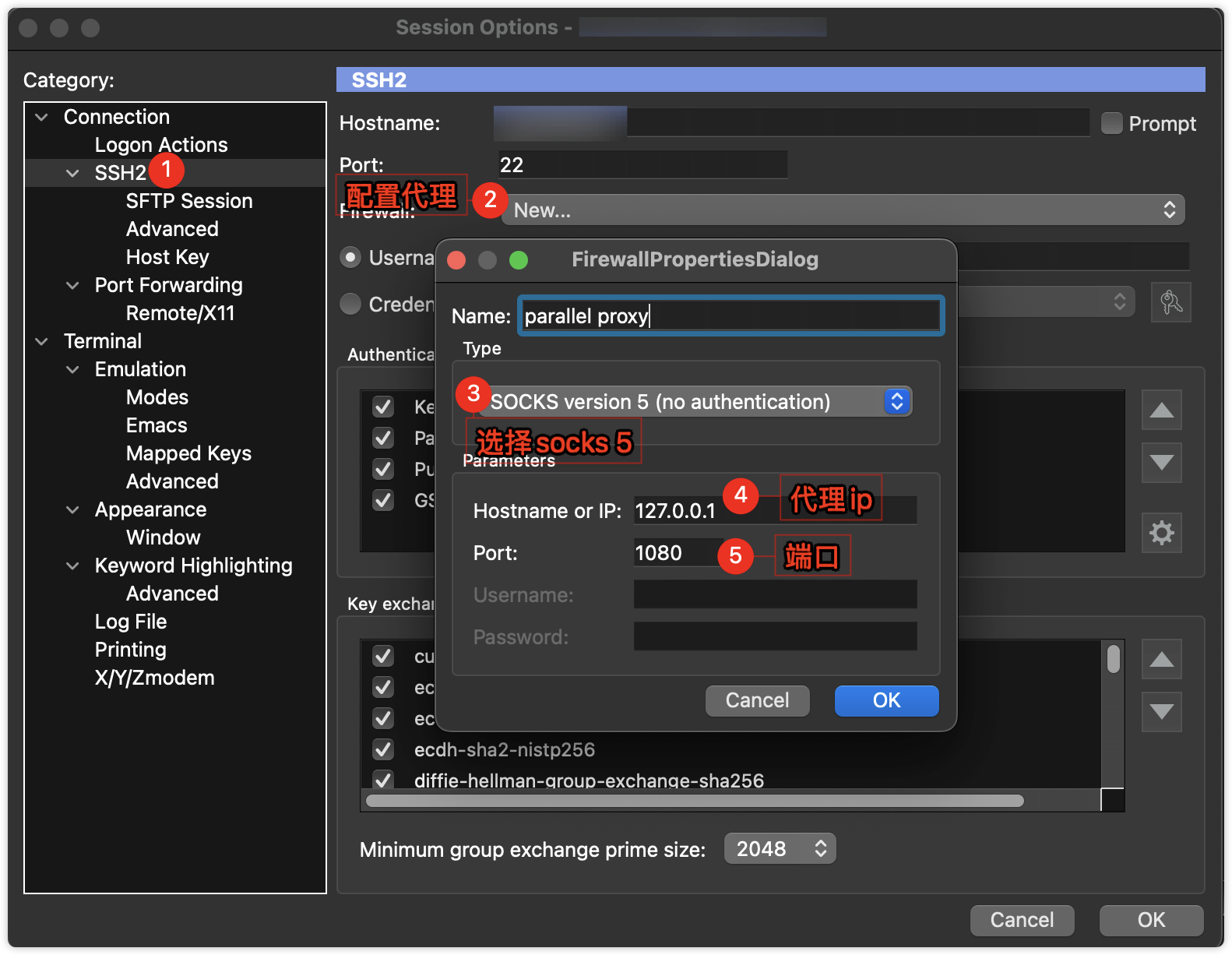
SecureCRT网络穿透/代理
场景 公司的办公VPN软件只有Windows系统版本,没有Macos系统版本,而日常开发过程中需要先登录VPN后,然后才能登录应用服务器。 目的:Macos系统在使用SecureCRT时,登录服务器,需要走Parallels Desktop进行网络…...
视频添加字幕脚本分享
脚本简介 这是一个给视频添加字幕的脚本,可以方便的在指定的位置给视频添加不同大小、字体、颜色的文本字幕,添加方式可以直接修改脚本中的文本信息,或者可以提前编辑好.srt字幕文件。脚本执行环境:windowsmingwffmpeg。本方法仅…...

OrangePi Zero 3学习笔记(Android篇)4 - eudev编译(获取libudev.so)
目录 1. Ubuntu中编译 2. NDK环境配置 3. 编译 4. 安装 这部分主要是为了得到libudev(因为原来的libudev已经不更新了),eudev的下载地址如下: https://github.com/gentoo/eudev 相应的代码最好是在Ubuntu中先编译通过&#…...
)
JavaSE核心知识点02面向对象编程02-04(包和导入)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 JavaSE核心知识点02面向对象编程02-04&#…...

【Git】查看tag
文章目录 1. 查看当前提交是否有tag2. 查看最近的tag3. 查看所有tag 有时候需要基于某个tag拉分支,记录下怎么查看tag。 1. 查看当前提交是否有tag git tag --points-at HEAD该命令可直接检查当前提交(HEAD)是否关联了任何tag。 若当前提交…...

华为昇腾910B通过vllm部署InternVL3-8B教程
前言 本文主要借鉴:VLLM部署deepseek,结合自身进行整理 下载模型 from modelscope import snapshot_download model_dir snapshot_download(OpenGVLab/InternVL3-8B, local_dir"xxx/OpenGVLab/InternVL2_5-1B")环境配置 auto-dl上选择单卡…...
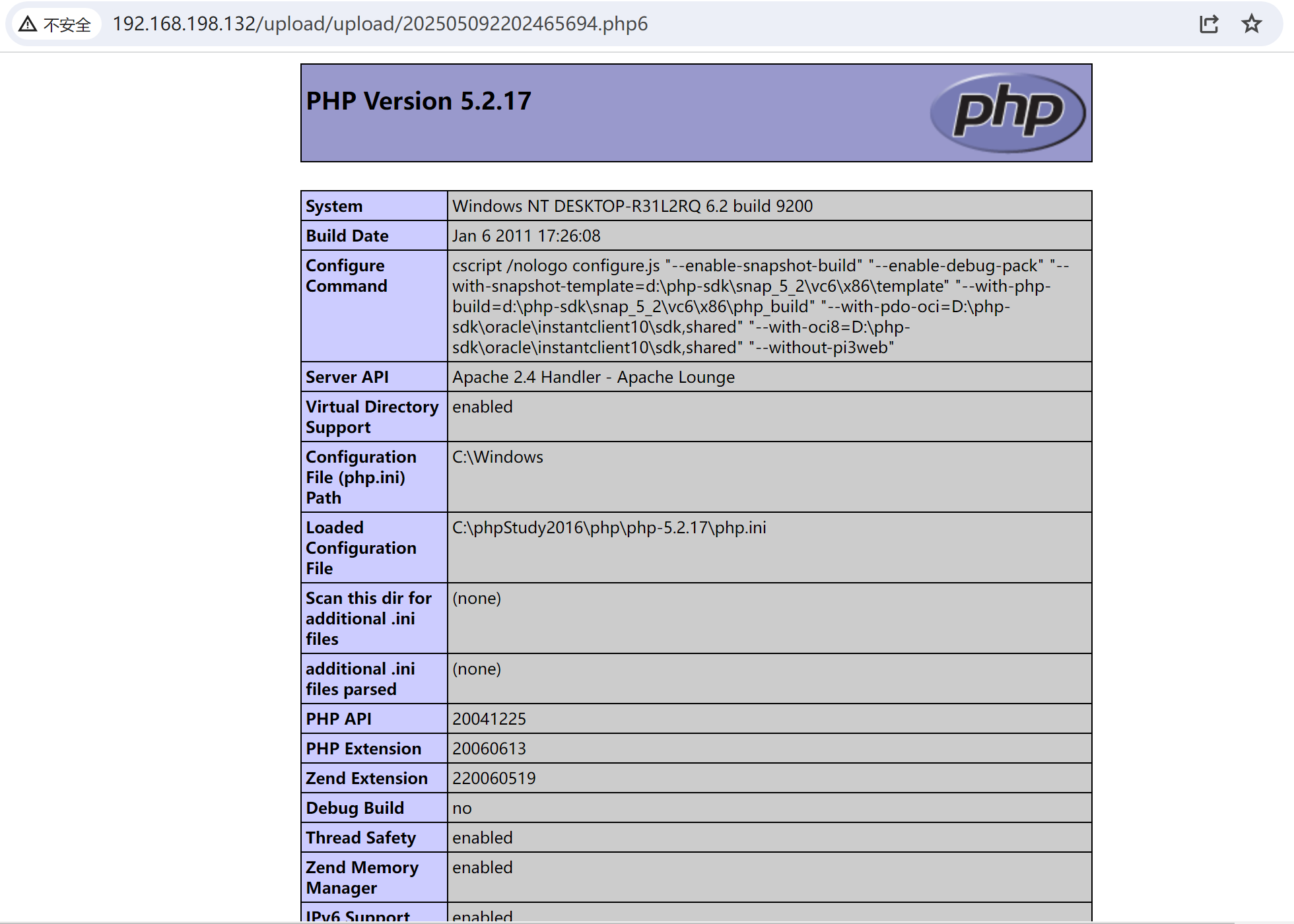
upload-labs靶场通关详解:第三关
一、分析源代码 代码注释如下: <?php // 初始化上传状态和消息变量 $is_upload false; $msg null;// 检查是否通过POST方式提交了表单 if (isset($_POST[submit])) {// 检查上传目录是否存在if (file_exists(UPLOAD_PATH)) {// 定义禁止上传的文件扩展名列表…...
星光云720全景VR系统升级版,720全景,360全景,vr全景,720vr全景
星光云720全景VR系统升级版,720全景,360全景,vr全景,720vr全景 星光云全景系统 系统体验地址 https://720.ailemon.cc 星光云全景新版体验地址 全景系统功能简介 基础设置:作品信息,加载样式ÿ…...
第十六节:图像形态学操作-顶帽与黑帽变换
一、引言:形态学操作的视觉魔法 在数字图像处理领域,形态学操作犹如一柄精巧的解剖刀,能够精准地提取图像特征、消除噪声干扰,并增强关键细节。OpenCV作为计算机视觉的瑞士军刀,提供了一套完整的形态学处理工具。在掌…...

将 iconfont 图标转换成element-plus也能使用的图标组件
在做项目时发现,element-plus的图标组件,不能像文档示例中那样使用 iconfont 的图标。经过研究发现,element-plus的图标封装成了vue组件,组件内容是一个svg,然后以组件的方式引入和调用图标。根据这个思路,…...

大模型系列(四)--- GPT2: Language Models are Unsupervised Multitask Learners
论文链接: Language Models are Unsupervised Multitask Learners 点评: GPT-2采用了与GPT-1类似的架构,将参数规模增加到了15亿,并使用大规模的网页数据集WebText 进行训练。正如GPT-2 的论文所述,它旨在通过无监督语…...
:等保测评的那些事)
等保系列(三):等保测评的那些事
一、等保测评主要做什么 1、测评准备阶段 (1)确定测评对象与范围 明确被测系统的边界、功能模块、网络架构及承载的业务。 确认系统的安全保护等级(如二级、三级)。 (2)签订测评合同 选择具备资质的测…...

ABP vNext + EF Core 实战性能调优指南
ABP vNext EF Core 实战性能调优指南 🚀 目标 本文面向中大型 ABP vNext 项目,围绕查询性能、事务隔离、批量操作、缓存与诊断,系统性地给出优化策略和最佳实践,帮助读者快速定位性能瓶颈并落地改进。 📑 目录 ABP vN…...

高品质办公楼成都国际数字影像产业园核心业务
成都国际数字影像产业园的核心业务,围绕构建专业化的数字影像文创产业生态系统展开,旨在打造高品质、高效率的产业发展平台。 产业集群构建与生态运营 园区核心业务聚焦于吸引和培育数字影像及相关文创领域的企业,形成产业集聚效应。具体包…...
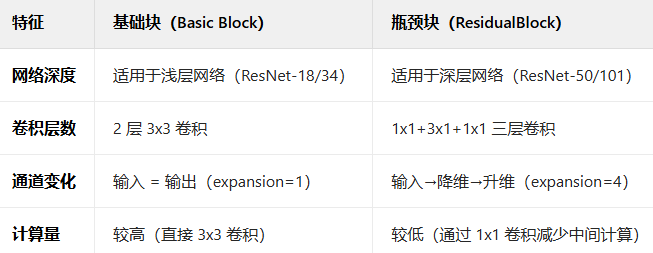
MindSpore框架学习项目-ResNet药物分类-构建模型
目录 2.构建模型 2.1定义模型类 2.1.1 基础块ResidualBlockBase ResidualBlockBase代码解析 2.1.2 瓶颈块ResidualBlock ResidualBlock代码解释 2.1.3 构建层 构建层代码说明 2.1.4 定义不同组合(block,layer_nums)的ResNet网络实现 ResNet组建类代码解析…...

【Spring Boot】Spring Boot + Thymeleaf搭建mvc项目
Spring Boot Thymeleaf搭建mvc项目 1. 创建Spring Boot项目2. 配置pom.xml3. 配置Thymeleaf4. 创建Controller5. 创建Thymeleaf页面6. 创建Main启动类7. 运行项目8. 测试结果扩展:添加静态资源 1. 创建Spring Boot项目 打开IntelliJ IDEA → New Project → 选择M…...

线程中常用的方法
知识点详细说明 Java线程的核心方法集中在Thread类和Object类中,以下是新增整合后的常用方法分类解析: 1. 线程生命周期控制 方法作用注意事项start()启动新线程,JVM调用run()方法多次调用会抛出IllegalThreadStateException(线程状态不可逆)。run()线程的任务逻辑直接调…...
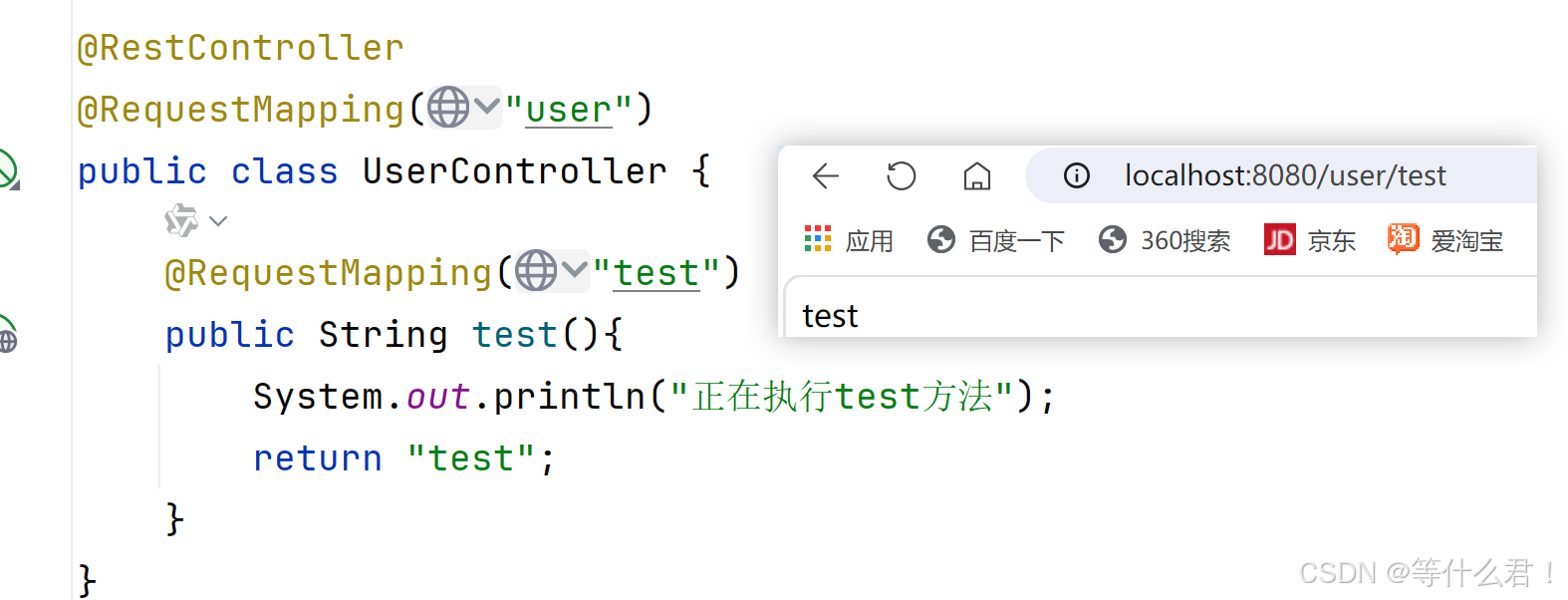
学习spring boot-拦截器Interceptor,过滤器Filter
目录 拦截器Interceptor 过滤器Filter 关于过滤器的前置知识可以参考: 过滤器在springboot项目的应用 一,使用WebfilterServletComponentScan 注解 1 创建过滤器类实现Filter接口 2 在启动类中添加 ServletComponentScan 注解 二,创建…...

为啥大模型一般将kv进行缓存,而q不需要
1. 自回归生成的特点 大模型(如 GPT 等)在推理时通常采用自回归生成的方式: 模型逐个生成 token,每次生成一个新 token 时,需要重新计算注意力。在生成第 t 个 token 时,模型需要基于前 t-1 个已生成的 t…...
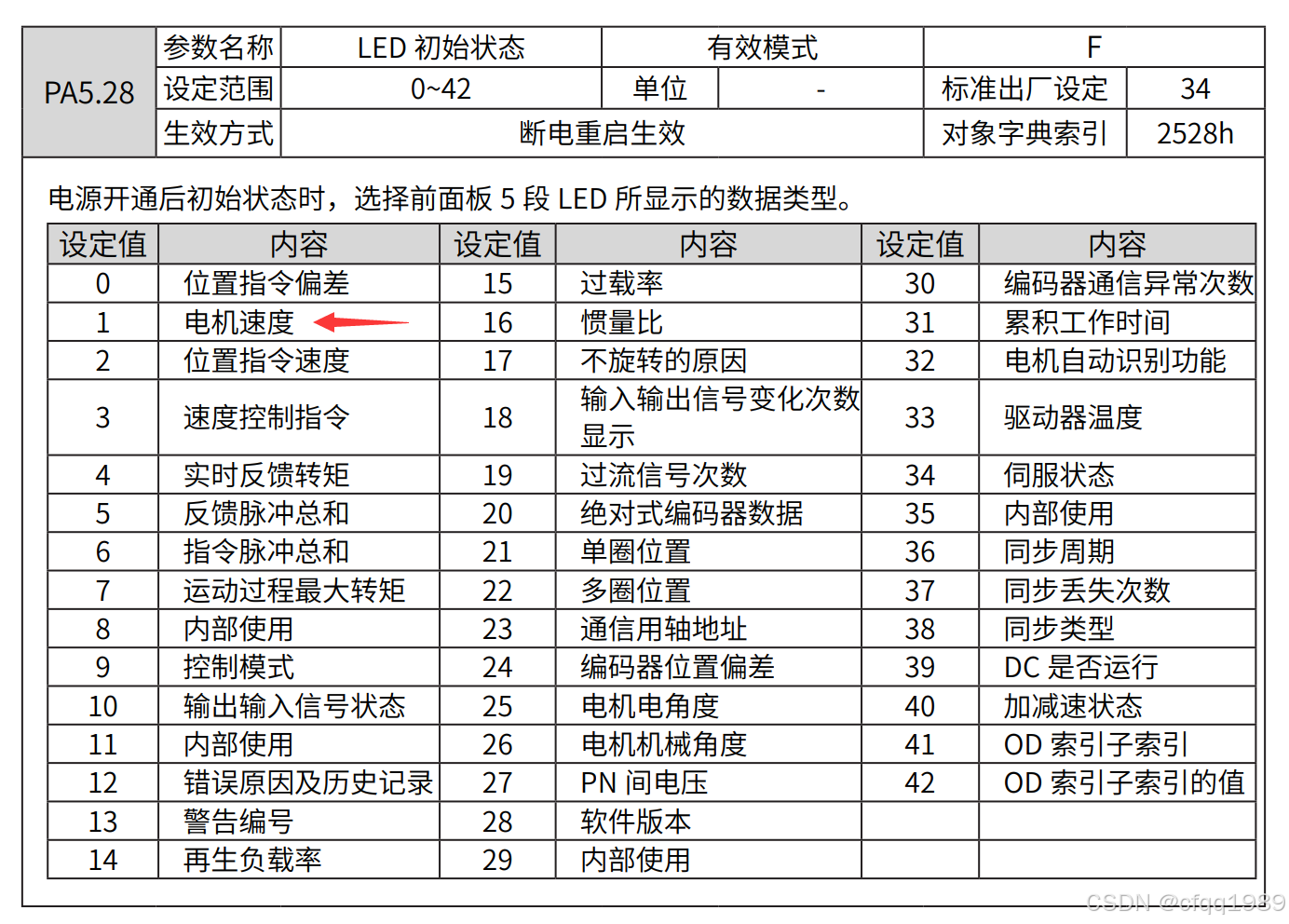
雷赛伺服L7-EC
1电子齿轮比: 电机圈脉冲1万 (pa11的值 x 4倍频) 2电机刚性: pa003 或者 0x2003 // 立即生效的 3LED显示: PA5.28 1 电机速度 4精度: PA14 //默认30,超过3圈er18…...
阅文集团C++面试题及参考答案
能否不使用锁保证多线程安全? 在多线程编程中,锁(如互斥锁、信号量)是实现线程同步的传统方式,但并非唯一方式。不使用锁保证多线程安全的核心思路是避免共享状态、使用原子操作或采用线程本地存储。以下从几个方面详…...
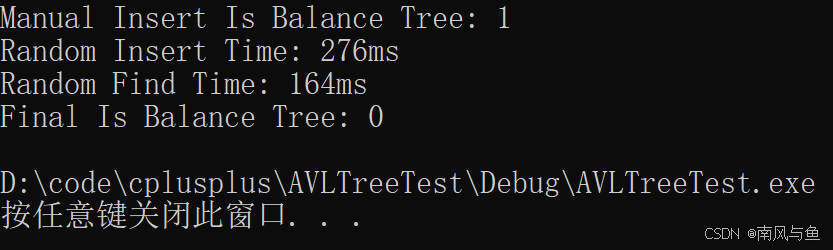
AVL树:保持平衡的高效二叉搜索树
目录 一、AVL树的概念 1. 二叉搜索树的局限性 2. AVL树的定义 二、AVL树节点结构 三、AVL树的插入操作 1. 插入流程 2. 代码实现片段 四、AVL树的旋转调整 1. 左单旋(RR型) 2. 右单旋(LL型) 3. 左右双旋(LR型…...

打造专属AI好友:小智AI聊天机器人详解
打造专属AI好友:小智AI聊天机器人详解 在当下的科技热潮中,AI正迅速改变着我们的生活,成为了科技领域的新宠。而今,借助开源项目的力量,你可以亲手打造一个智能小助手——小智AI聊天机器人。它不仅是一个技术探索的窗…...