【Linux】深入拆解Ext文件系统:从磁盘物理结构到Linux文件管理
目录
1、理解硬件
(1)磁盘
(2)磁盘的物理结构
(3)磁盘的存储结构
(4)磁盘的逻辑结构
(5)CHS && LBA地址
2、引入文件系统
(1)“块”概念
(2)“分区”概念
(3)“inode”概念
3、ext2文件系统
(1)宏观认识
(2)Block Group
(3)块组内部结构
① 超级块(Super Block)
② GDT(Group Descriptor Table)
③ 块位图(Block Bitmap)
④ inode位图(Inode Bitmap)
⑤ i 节点表(Inode Table)
⑥ 数据块(Data Block)
(4)inode和Data Block 映射关系
(5)目录与文件名
(6)路径解析
(7)路径缓存
(8)挂载分区
(9)文件系统总结
4、软硬链接
(1)硬链接
(2)软连接
(3)硬链接局限性
1、理解硬件
(1)磁盘
磁盘是计算机中用于存储数据的硬件设备(外设)。机械磁盘(HDD)是计算机唯一的的机械设备,使用旋转的磁性盘片和机械臂读写数据,特点是容量大、成本低但速度较慢。


★ 有时你可能会听到人们在谈论一些实际上根本不是磁盘的磁盘,比如固态硬盘(SSD)。固态硬盘并没有可以移动的部分,外形也不想唱片那样,并且数据是存储在存储器(闪存)中的。与磁盘唯一的相似之处就是他也存储了大量即使在电源关闭时也不会丢失的数据。
(2)磁盘的物理结构

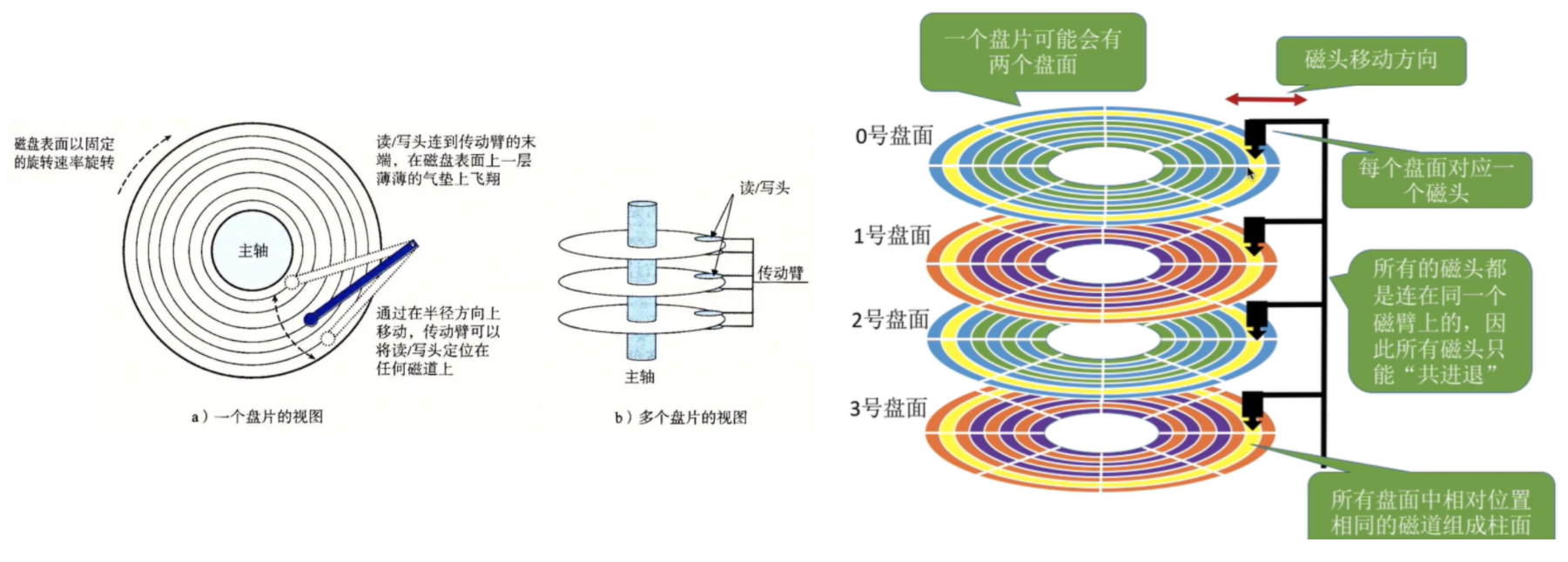
1、马达带动盘片旋转。
2、盘片是数据存储的载体,表面覆盖磁性材料,通过磁化方向记录二进制数据(0和1)。
3、磁头臂将磁头移动到目标磁道上方。
4、磁头通过感应(读)或改变(写)盘片的磁性状态完成数据操作。【读:感应盘片上的磁场变化,转换为电信号。写:通过电磁铁改变盘片上的磁性方向。】
(3)磁盘的存储结构
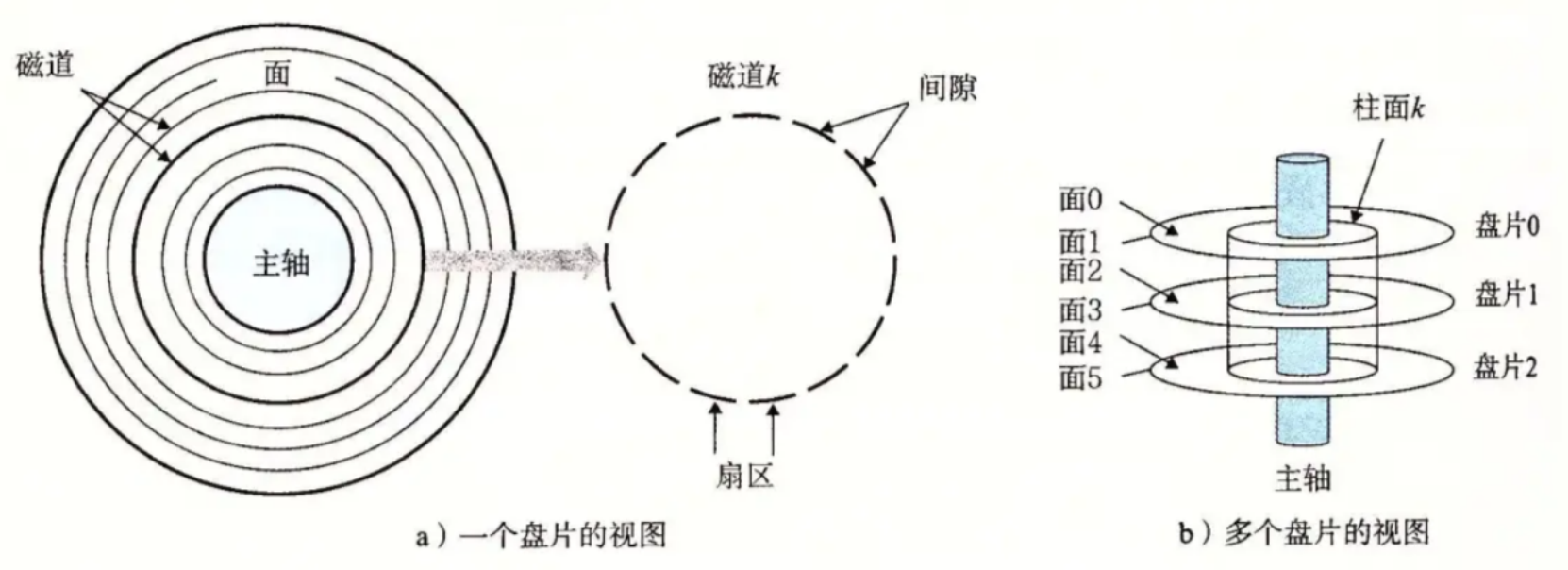
① 单盘片视图:
· 磁道(Track):盘片上的同心圆环,数据存储在磁道上。每个磁道被划分为多个扇区(通常每扇区存储512字节或4KB)。外圈磁道周长更长,但存储密度与内圈相同(现代硬盘可能采用区域位记录技术优化容量)。
· 扇区(Sector):磁道的最小存储单元,是读写数据的基本单位。包含间隙(Gap):分隔扇区的空白区域,用于同步和纠错。扇区头:记录扇区地址和状态信息。
· 主轴(Spindle):驱动所有盘片同步旋转的核心部件。
② 多盘片视图:
· 盘片(Platter):多个磁性盘片叠放在主轴上,正反两面均可存储数据。通常从盘片0开始(对应面0和面1,依此类推)
· 柱面(Cylinder):所有盘片上相同半径的磁道组成的虚拟圆柱体。例如:柱面k = 所有盘片的第k条磁道。
· 磁头(Head):每个盘面对应一个磁头,由磁头臂控制。编号:面0对应磁头0,面1对应磁头1,依此类推。
磁盘容量 = 磁头数×磁道(柱面)数×每道扇区数×每扇区字节数
细节:转动臂上的磁头是共进退的(重要)
类比总结:
盘片 ≈ 一本书的多页。
磁道 ≈ 页面上的一行文字。
扇区 ≈ 行中的一个单词。
柱面 ≈ 所有页面相同行号的集合(如所有书的第10行)。
③ CHS寻址方式
已知柱面、磁头、扇区显然就可以定位数据了,这就是数据定位(寻址)方式之一,CHS寻址。
步骤1:磁头臂移动到目标柱面(所有盘片的同一磁道)。
步骤2:激活对应磁头(选择具体盘面)。
步骤3:等待盘片旋转至目标扇区下方,完成读写。
局限性:CHS模式支持的磁盘容量有限,早期BIOS使用24位存储CHS参数(10位柱面 + 8位磁头 + 6位扇区)。最大支持 504 MiB(≈528MB)的磁盘(1024×255×63×512B)。需预先知道硬盘的实际物理参数(柱面/磁头/扇区数),不同硬盘可能不同。
(4)磁盘的逻辑结构
① 理解过程
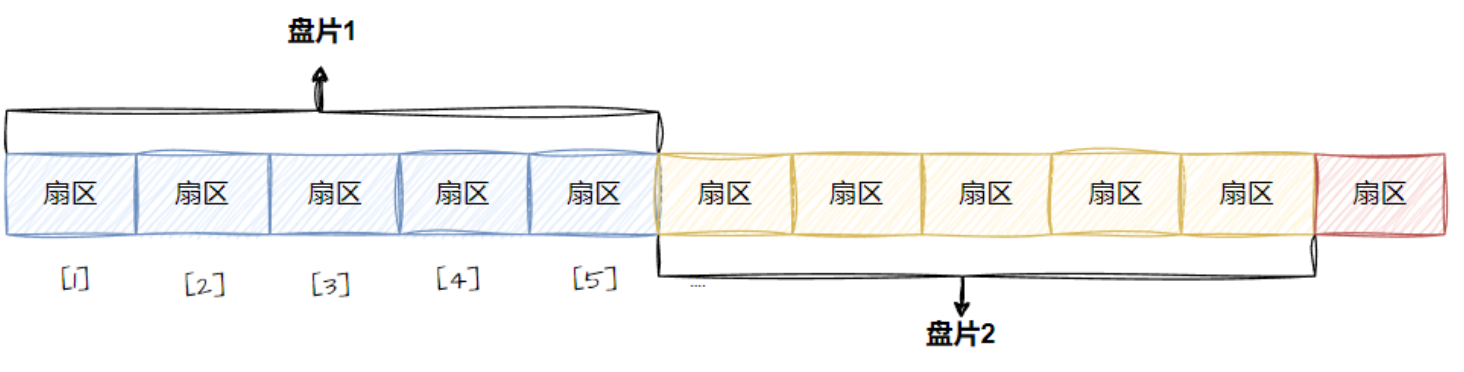
磁带上面可以存储数据,我们可以把磁带“拉直”,形成线性结构!。

那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象为卷在一起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:

这样每一个扇区,就有了一个线性地址(其实就是数组下标),这种地址叫做LBA(逻辑块寻址)。
② 真实过程
已知,转动臂上的磁头是共进退的。柱面是一个逻辑上的概念,其实就是每一面上,相同半径的磁道逻辑上构成柱面。所以磁盘物理上分了很多面(圆柱面),但在我们看来,逻辑上,磁盘整体是由“柱面”卷起来的。
所以,磁盘的真实情况是:
· 磁道:一维数组。某一个盘面的某一磁道展开:

· 柱面:二维数组。柱面上的每个磁道的扇区个数是一样的。柱面展开:
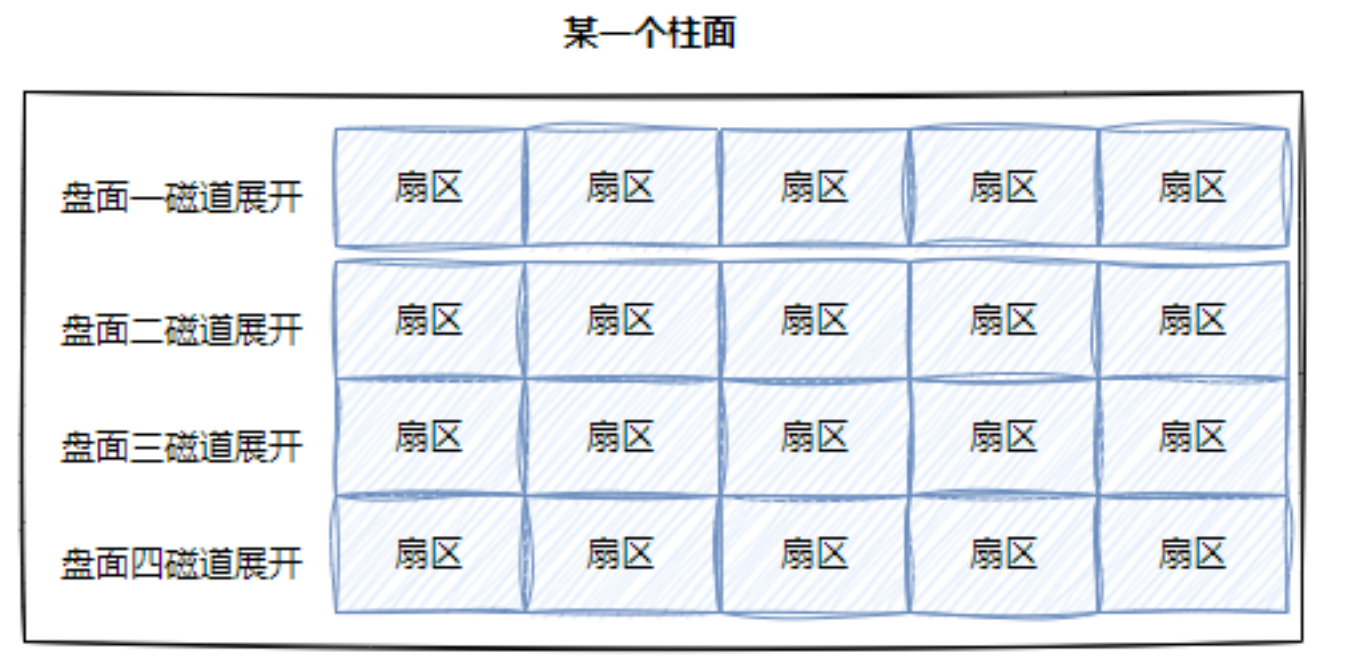
· 整盘:多张二维的扇区数组表。(三维数组)
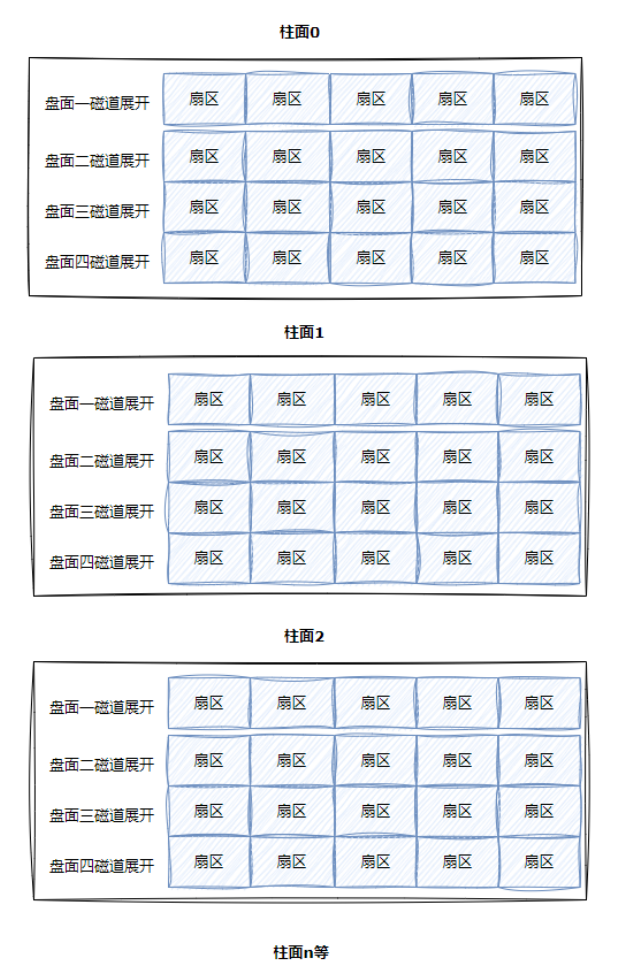
所以,寻找一个扇区:先找到哪一个柱面(Cylinder),再确定柱面内的那一个磁道(其实就是磁头位置Head),然后确定扇区(Sector),所以有了CHS寻址。其实对应的是三维数组中的三个下标。
结合我们之前学过的数组,站在柱面的视角(以柱面为基本单位),我们可以重新将整个磁盘划分成线性结构(一维数组)!

每一个扇区都以一个下标,我们叫做LBA地址,其实就是线性地址。所以怎么计算得到这个LBA地址呢?可以从CHS转换得到LBA。
OS只需要使用LBA就可以了!LBA地址与CHS地址的互相转换由磁盘自己来做!固件(硬件电路,伺服系统)
(5)CHS && LBA地址
CHS 转成 LBA:
• 磁头数 × 每磁道扇区数 = 单个柱面的扇区总数
• LBA = 柱面号 C × 单个柱面的扇区总数 + 磁头号 H × 每磁道扇区数 + 扇区号 S - 1
• 即:LBA = 柱面号 C × (磁头数 × 每磁道扇区数) + 磁头号 H × 每磁道扇区数 + 扇区号 S - 1
• 扇区号通常是从 1 开始的,而在 LBA 中,地址是从 0 开始的
• 柱面和磁道都是从 0 开始编号的
• 总柱面、磁道个数、扇区总数等信息,在磁盘内部会自动维护,上层开机的时候,会获取到这些参数
LBA 转成 CHS:
• 柱面号 C = LBA // (磁头数 × 每磁道扇区数)【就是单个柱面的扇区总数】
• 磁头号 H = (LBA % (磁头数 × 每磁道扇区数)) // 每磁道扇区数
• 扇区号 S = (LBA % 每磁道扇区数) + 1
• "//":表示除取整
所以:从此往后,在磁盘使用者看来,根本就不关心 CHS 地址,而是直接使用 LBA 地址,磁盘内部自己转换。
所以:从现在开始,磁盘就是一个元素为扇区的一维数组,数组的下标就是每一个扇区的 LBA 地址。OS 使用磁盘,就可以用一个数字访问磁盘扇区了。
2、引入文件系统
(1)“块”概念
其实硬盘是典型的“块”设备,操作系统读取硬盘数据的时候,其实是不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个“块”(block)。
硬盘的每个分区是被划分为一个个的“块”。一个“块”的大小是由格式化的时候确定的,并且不可以更改,最常见的是 4KB,即连续八个扇区组成一个“块”。“块”是文件存取的最小单位。
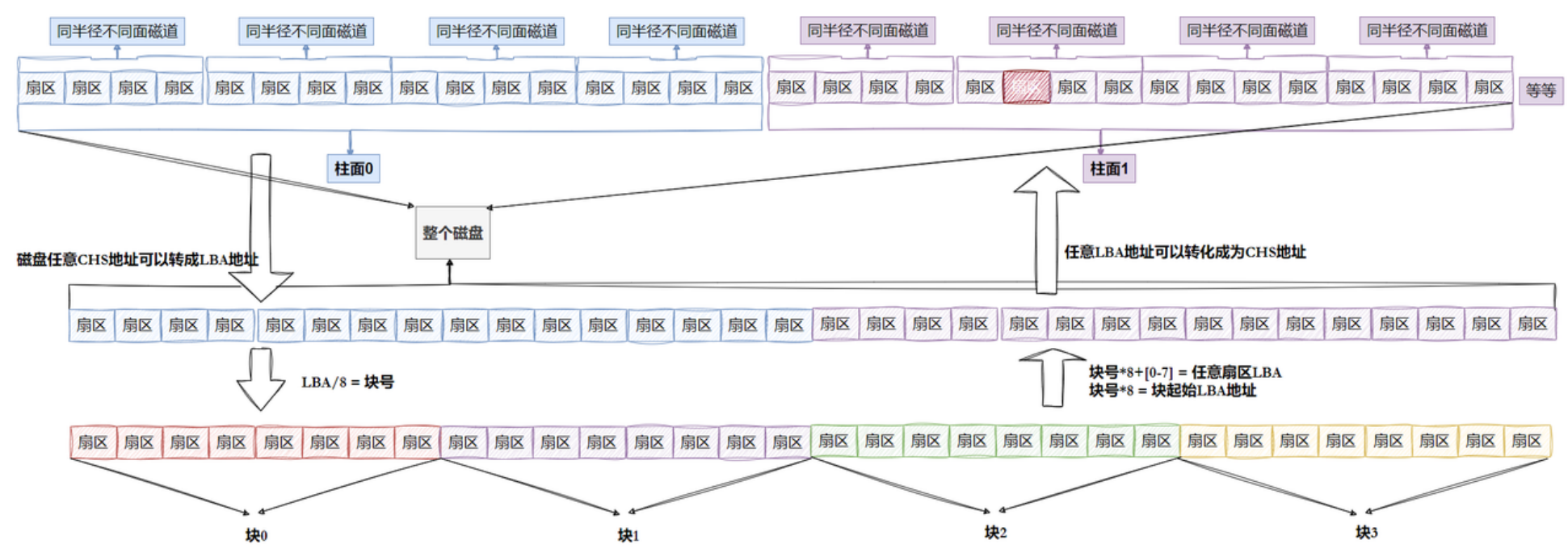
• 磁盘就是一个“一维数组”,数组下标就是LBA,每个元素都是扇区。
• 每个扇区都有LBA,8个扇区一个块,每一个块的地址也能算出来。
• 知道LBA:块号 = LBA/8。
• 知道块号:LBA = 块号 × 8 + n(n是块内第几个扇区)。
(2)“分区”概念
其实磁盘是可以被分成多个分区(partition)的,以Windows观点来看,你可能会有一块磁盘并且将它分区成C、D、E盘。那个C、D、E就是分区。分区从实质上说就是对硬盘的一种格式化。但是Linux的设备都是以文件形式存在,那是怎么分区的呢?
柱面是分区的最小单位,我们可以利用参考柱面号码的方式来进行分区,其本质就是设置每个区的起始柱面和结束柱面号码。此时我们可以将硬盘上的柱面(分区)进行平铺,将其想象成一个大的平面。如图:


注:柱面大小一致,扇区个位一致,那么其实只要知道每个分区的起始和结束柱面号,知道每一个柱面多少个扇区,那么该分区多大,那么就可以直接计算出该分区的LBA范围了:
起始LBA:从磁盘开头到分区起始柱面的扇区总数。
结束LBA:起始LBA + 分区扇区数 - 1。
(3)“inode”概念
以前我们说:【文件 = 内容 + 属性】,我们执行【ls -l】不光能看到文件名,还能看到看到文件元数据(属性)。
[root@localhost linux]# ls -l
总⽤量 12
-rwxr-xr-x. 1 root root 7438 "9⽉ 13 14:56" a.out
-rw-r--r--. 1 root root 654 "9⽉ 13 14:56" test.c【ls -l】读取存储在磁盘上的文件信息,然后显示出来。每行包含7行:模式、硬链接数、文件所有者、组、大小、最后修改时间、文件名。
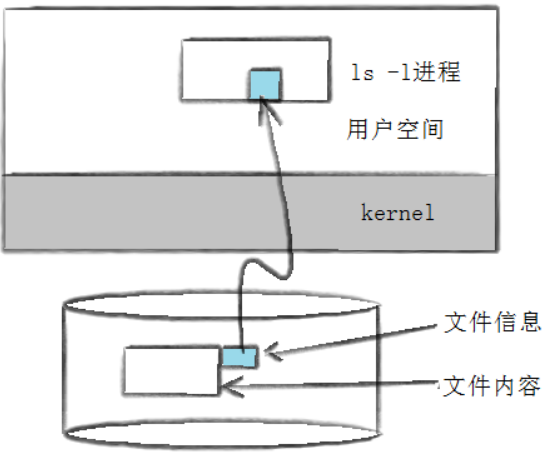
或者用stat命令查看更多信息:
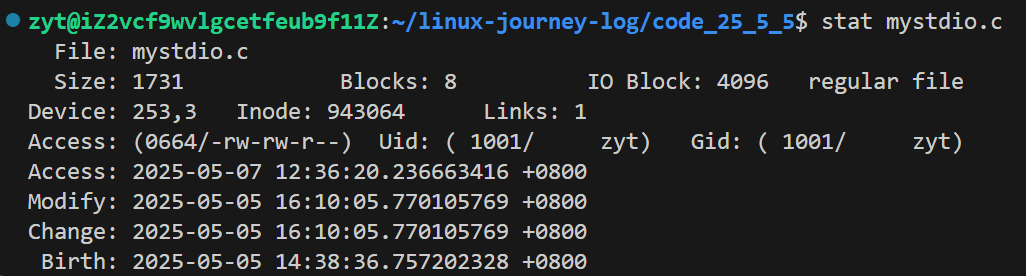
到这我们要思考一个问题,文件数据都储存在“块”中,那么很显然,我们还必须找到一个地方储存文件的元信息(属性信息),比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做 inode,中文译名为“索引节点”。每个文件都有对应的inode,里面包含了与该文件有关的信息。
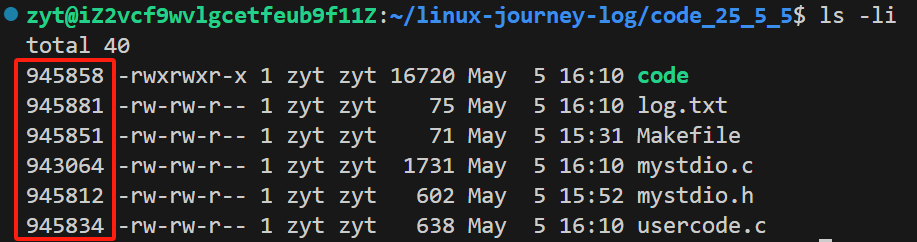
• Linux下文件的属性和内容是分离存储的。
• Linux下,保存文件属性的集合叫做 inode,一个文件,一个 inode,inode内有一个文艺的标识符,叫做 inode 号。
下面展示ext2 文件系统磁盘上的 inode 结构体定义(struct ext2_inode),它描述了 ext2 文件系统中 inode 在磁盘上的物理存储格式。
/** Structure of an inode on the disk (ext2 文件系统的磁盘 inode 结构)*/
struct ext2_inode {__le16 i_mode; /* 文件类型和权限 (16位) */__le16 i_uid; /* 所有者UID的低16位 */__le32 i_size; /* 文件大小 (字节) */__le32 i_atime; /* 最后访问时间 */__le32 i_ctime; /* inode创建/状态变更时间 */__le32 i_mtime; /* 最后修改时间 */__le32 i_dtime; /* 文件删除时间 */__le16 i_gid; /* 所属GID的低16位 */__le16 i_links_count; /* 硬链接计数 */__le32 i_blocks; /* 文件占用的512字节块数 */__le32 i_flags; /* 文件标志 (如immutable、append-only等) *//* 操作系统依赖字段 (OSD) */union {struct {__le32 l_i_reserved1;} linux1;struct {__le32 h_i_translator;} hurd1;struct {__le32 m_i_reserved1;} masix1;} osd1;__le32 i_block[EXT2_N_BLOCKS]; /* 数据块指针数组 (共15个) */__le32 i_generation; /* 文件版本号 (用于NFS) */__le32 i_file_acl; /* 文件ACL块指针 */__le32 i_dir_acl; /* 目录ACL块指针 */__le32 i_faddr; /* 碎片地址 *//* 扩展的OSD字段 */union {struct {__u8 l_i_frag; /* 碎片编号 */__u8 l_i_fsize; /* 碎片大小 */__u16 i_pad1;__le16 l_i_uid_high; /* UID高16位 */__le16 l_i_gid_high; /* GID高16位 */__u32 l_i_reserved2;} linux2;struct {__u8 h_i_frag;__u8 h_i_fsize;__le16 h_i_mode_high;__le16 h_i_uid_high;__le16 h_i_gid_high;__le32 h_i_author;} hurd2;struct {__u8 m_i_frag;__u8 m_i_fsize;__u16 m_pad1;__u32 m_i_reserved2[2];} masix2;} osd2;
};/* 数据块指针类型常量 */
#define EXT2_NDIR_BLOCKS 12 /* 直接块数量 */
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS /* 一级间接块索引 */
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) /* 二级间接块索引 */
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) /* 三级间接块索引 */
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1) /* 总块指针数 (15) */备注:EXT2_N_BLOCKS = 15注意:
• 文件名属性并未纳入到inode数据结构内部
• 文件名保存在当前文件所属目录的数据内容当中,后面会讲
• inode的大小一般是128字节或256,我们后面统一128字节
• 任何文件的内容大小可以不同,但是属性大小一定是相同的
思考:“块” 是硬盘的每个分区下的结构,难道 “块” 是随意的在分区上排布的吗?那要怎么找到 “块” 呢? 还有就是上面提到的存储文件属性的 inode,又是如何放置的呢?
文件系统就是为了组织管理这些的!!
3、ext2文件系统
(1)宏观认识
我们想要在硬盘上存储文件,必须先把硬盘格式化为某种格式的文件系统,才能存储文件。文件系统的目的是组织和管理硬盘中的文件。在 Linux 系统中,最常见的是 ext2 系列的文件系统。其早期版本为 ext2,后来又发展出 ext3 和 ext4。ext3 和 ext4 虽然对 ext2 进行了增强,但是其核心设计并没有发生变化,我们仍以较老的 ext2 作为演示对象。
ext2 文件系统将整个分区划分成若干个同样大小的块组 (Block Group)。只要能管理一个分区就能管理所有分区,也就能管理所有磁盘文件。文件系统的载体是分区!
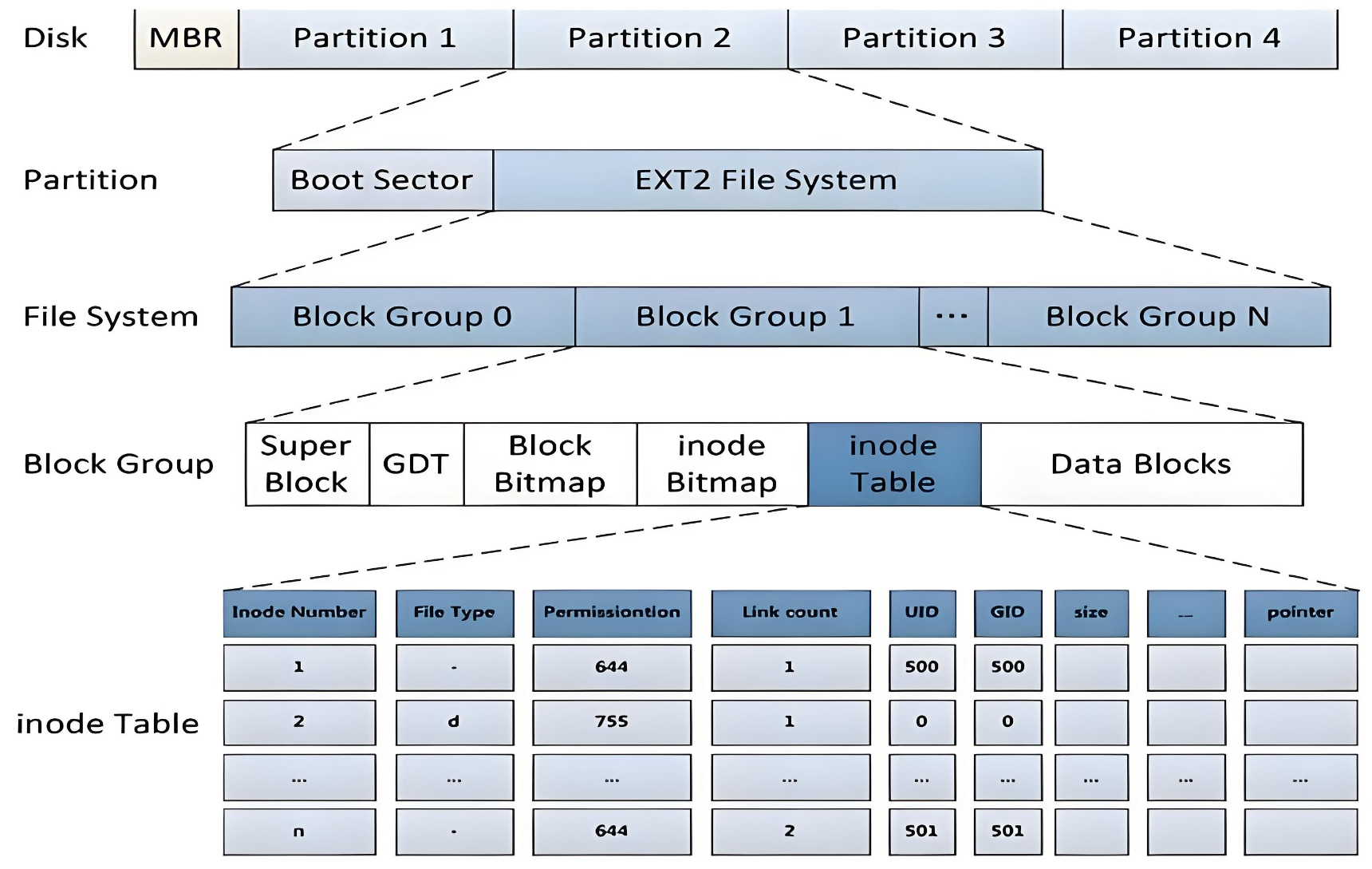
上图中启动块(Boot Block/Sector)的大小是确定的,为 1KB,由 PC 标准规定,用来存储磁盘分区信息和启动信息,任何文件系统都不能修改启动块。启动块之后才是 ext2 文件系统的开始。启动块中的程序将装载该分区中的操作系统。为统一起见,每个分区都从一个启动块开始,即使它不含有一个可启动的操作系统(这个分区未来可能会有一个操作系统)。
(2)Block Group
ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。每个分区可以包含一个文件系统。
(3)块组内部结构
① 超级块(Super Block)
存放文件系统本身的结构信息,描述整个分区的文件系统信息。记录的信息主要有:block 和 inode 的总量,未使用的 block 和 inode 的数量,一个 block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block 的信息被破坏,可以说整个文件系统结构就被破坏了。
超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。为了保证文件系统在磁盘部分扇区出现物理问题的情况下还能正常工作,就必须保证文件系统的 super block 信息在这种情况下也能正常访问。所以一个文件系统的 super block 会在多个 block group 中进行备份,这些 super block 区域的数据保持一致。
/** Structure of the super block*/
struct ext2_super_block {/* 基础文件系统信息 */__le32 s_inodes_count; /* Inodes 总数 */__le32 s_blocks_count; /* 块总数 */__le32 s_r_blocks_count; /* 保留块数(root 保留) */__le32 s_free_blocks_count; /* 空闲块数 */__le32 s_free_inodes_count; /* 空闲 Inodes 数 */__le32 s_first_data_block; /* 第一个数据块号(通常为 1) */__le32 s_log_block_size; /* 块大小(以 2^N 计算,如 0=1KB, 1=2KB, 2=4KB) */__le32 s_log_frag_size; /* 片段大小(通常等于块大小) */__le32 s_blocks_per_group; /* 每块组包含的块数 */__le32 s_frags_per_group; /* 每块组包含的片段数 */__le32 s_inodes_per_group; /* 每块组包含的 Inodes 数 *//* 文件系统状态信息 */__le32 s_mtime; /* 最后一次挂载时间 */__le32 s_wtime; /* 最后一次写入时间 */__le16 s_mnt_count; /* 挂载次数 */__le16 s_max_mnt_count; /* 最大挂载次数(超过需 fsck) */__le16 s_magic; /* 魔数(标识 ext2,值为 0xEF53) */__le16 s_state; /* 文件系统状态(干净/错误) */__le16 s_errors; /* 检测到错误时的行为(继续/只读/panic) */__le16 s_minor_rev_level; /* 次要版本号 *//* 维护信息 */__le32 s_lastcheck; /* 最后一次一致性检查时间 */__le32 s_checkinterval; /* 两次检查的最大间隔时间 */__le32 s_creator_os; /* 创建文件系统的 OS 类型 */__le32 s_rev_level; /* 主版本号(0=原始,1=动态版本) */__le16 s_def_resuid; /* 保留块的默认用户 ID */__le16 s_def_resgid; /* 保留块的默认组 ID *//* 动态版本(EXT2_DYNAMIC_REV)特有字段 */__le32 s_first_ino; /* 第一个非保留 Inode 号(通常为 11) */__le16 s_inode_size; /* Inode 结构大小(字节) */__le16 s_block_group_nr; /* 当前超级块所在的块组号 */__le32 s_feature_compat; /* 兼容性功能标志 */__le32 s_feature_incompat; /* 非兼容性功能标志 */__le32 s_feature_ro_compat; /* 只读兼容性功能标志 */__u8 s_uuid[16]; /* 文件系统 UUID(128 位) */char s_volume_name[16]; /* 卷标名称 */char s_last_mounted[64]; /* 最后一次挂载的目录路径 *//* 性能优化相关 */__le32 s_algorithm_usage_bitmap; /* 压缩算法位图 */__u8 s_prealloc_blocks; /* 预分配的块数 */__u8 s_prealloc_dir_blocks; /* 目录预分配的块数 */__u16 s_padding1; /* 填充对齐 *//* 日志支持(EXT3 特性) */__u8 s_journal_uuid[16]; /* 日志超级块的 UUID */__u32 s_journal_inum; /* 日志文件的 Inode 号 */__u32 s_journal_dev; /* 日志文件的设备号 */__u32 s_last_orphan; /* 待删除 Inode 链表的起始 *//* 哈希和挂载选项 */__u32 s_hash_seed[4]; /* HTREE 哈希种子 */__u8 s_def_hash_version; /* 默认哈希版本 */__u8 s_reserved_char_pad;__u16 s_reserved_word_pad;__le32 s_default_mount_opts; /* 默认挂载选项 */__le32 s_first_meta_bg; /* 第一个元块组号 *//* 保留字段 */__u32 s_reserved[190]; /* 填充至块末尾 */
};★ 新创建的文件系统会写入完整的元数据结构(超级块、块组描述符、位图、inode表等),但数据块区域(用户文件存储区)是空的。部分系统 inode(如根目录)会被初始化,但绝大多数inode和数据块未被占用。★ 格式化:本质是写入文件系统的管理信息(元数据)
② GDT(Group Descriptor Table)
块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储一个块组的描述信息,如在这个块组中从哪里开始是 inode Table,从哪里开始是 Data Blocks,空闲的 inode 和数据块还有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
/** Structure of a block group descriptor (块组描述符结构)* 描述一个块组(Block Group)的元数据分布和状态*/
struct ext2_group_desc {__le32 bg_block_bitmap; /* [块号] 本块组的块位图所在块 */__le32 bg_inode_bitmap; /* [块号] 本块组的inode位图所在块 */__le32 bg_inode_table; /* [块号] 本块组的inode表起始块 */__le16 bg_free_blocks_count; /* 本块组中空闲块的数量 */__le16 bg_free_inodes_count; /* 本块组中空闲inode的数量 */__le16 bg_used_dirs_count; /* 本块组中目录inode的数量(用于orlov算法分配目录) */__le16 bg_pad; /* 填充字段(对齐用途) */__le32 bg_reserved[3]; /* 保留字段(未来扩展用) */
};③ 块位图(Block Bitmap)
Block Bitmap 中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。如果数据块被占用就将对应位图的bit位置为1,释放数据块就将对应位图bit位清0。
100000个数据块可以被 100000 / (8bits * 4096字节) ≈ 3.05 => 4 个位图块表示。
④ inode位图(Inode Bitmap)
每一个bit表示一个inode是否空闲可用。
⑤ i 节点表(Inode Table)
• 存放文件属性,如文件大小,所有者,最近修改时间等。
• 当前分组所有inode属性的集合。
• inode编号以分区为单位,整体划分,不可跨分区。
• 文件内容 通过 inode 的块指针映射到磁盘数据块。块指针它记录了数据块在磁盘上的物理位置。所以拿到inode,就能得到文件的内容和属性。(块指针不是块位图,不要混淆了)
⑥ 数据块(Data Block)
Data Block(数据块) 是存储文件实际内容的最小单位,是以4KB为单位划分的无数个数据块。以4KB为单位把文件内容保存在Data Block若干文件块当中。根据不同的文件类型有以下几种情况:
• 对于普通文件,文件的数据存储在数据块中。
• 对于目录,该目录下的所有文件名和目录名存储在所在目录的数据块中,除了文件名外,ls -l命令看到的其他信息保存在该文件的inode中。
• Block号按照分区划分,不可跨分区。
注意:inode和数据块都是跨组编号,不能跨分区。
---> 同一个分区内,inode与块号是唯一的。
(4)inode和Data Block 映射关系
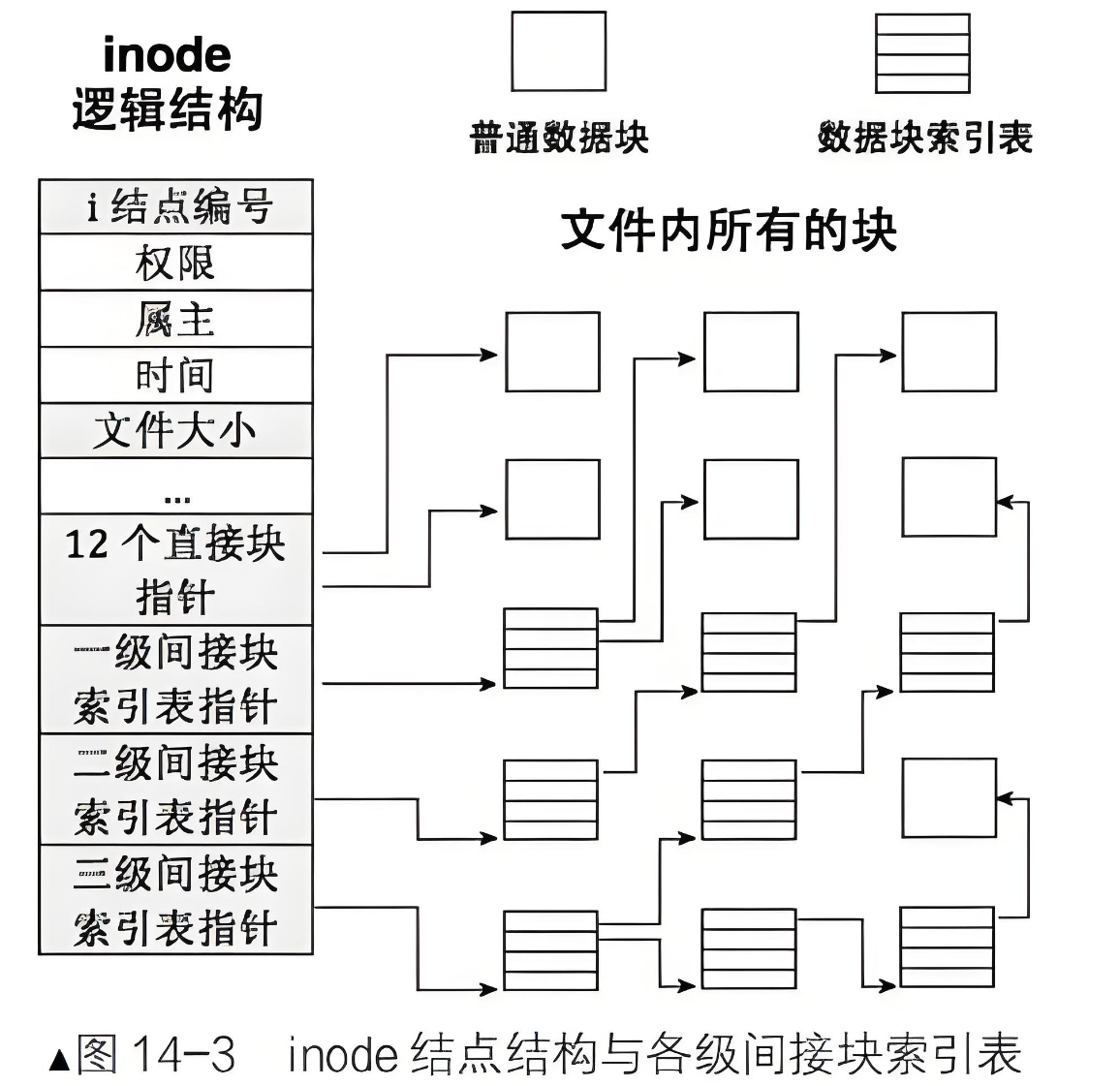
前面我们查看ext2 文件系统磁盘上的 inode 结构体定义(struct ext2_inode),注意到ext2文件系统的inode包含15个数据块指针,分为4种类型:
/* 数据块指针类型常量 */
#define EXT2_NDIR_BLOCKS 12 /* 直接块数量 */
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS /* 一级间接块索引 */
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) /* 二级间接块索引 */
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) /* 三级间接块索引 */
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1) /* 总块指针数 (15) */备注:EXT2_N_BLOCKS = 15
直接块(0-11): 直接指向存储文件数据的物理块
一级间接块(12): 指向一个包含256个(假设块大小1KB)块指针的块
二级间接块(13): 指向一个包含256个一级间接块的块
三级间接块(14): 指向一个包含256个二级间接块的块
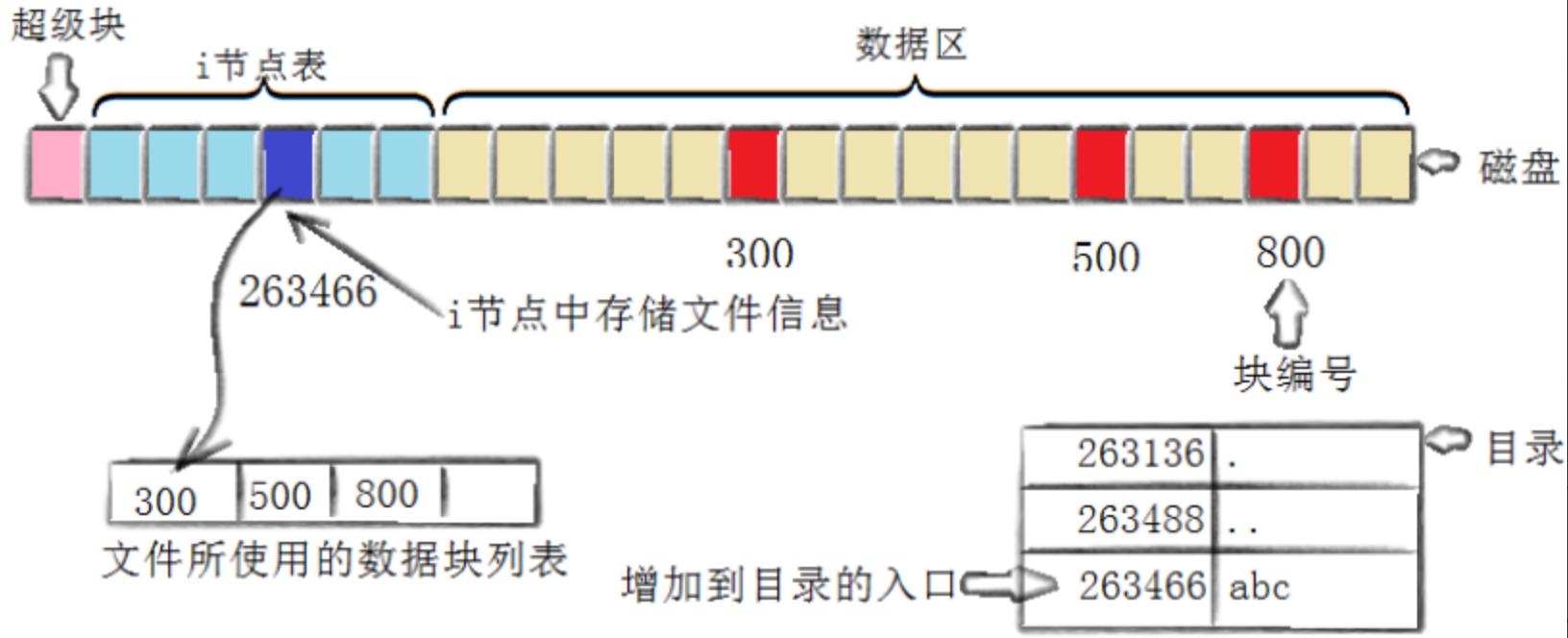
知道inode号的情况下,在指定分区,对文件进行增、删、查、改是在做什么?
结论:
• 分区之后的格式化操作,就是对分区进行分组,在每个分组中写入SB、GDT、Block Bitmap、Inode Bitmap等管理信息,这些管理信息统称:文件系统。
• 只要知道文件的inode号,就能在指定分区中确定是哪一个分组,进而在哪一个分组确定是哪一个inode。
• 拿到inode文件属性和内容就全部都有了。
所以,创建一个新文件主要有以下4个操作:
-
存储属性
内核先找到一个空闲的i节点(这里是263466)。内核把文件信息记录到其中。 -
存储数据
该文件需要存储在三个磁盘块,内核找到了三个空闲块:300, 500, 800。将内核缓冲区的第一块数据复制到300,下一块复制到500,以此类推。 -
记录分配情况
文件内容按顺序300, 500, 800存放。内核在inode上的磁盘分布区记录了上述块列表。 -
添加文件名到目录
新的文件名是abc。Linux如何在当前的目录中记录这个文件?内核将入口(263466,abc)添加到目录文件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。
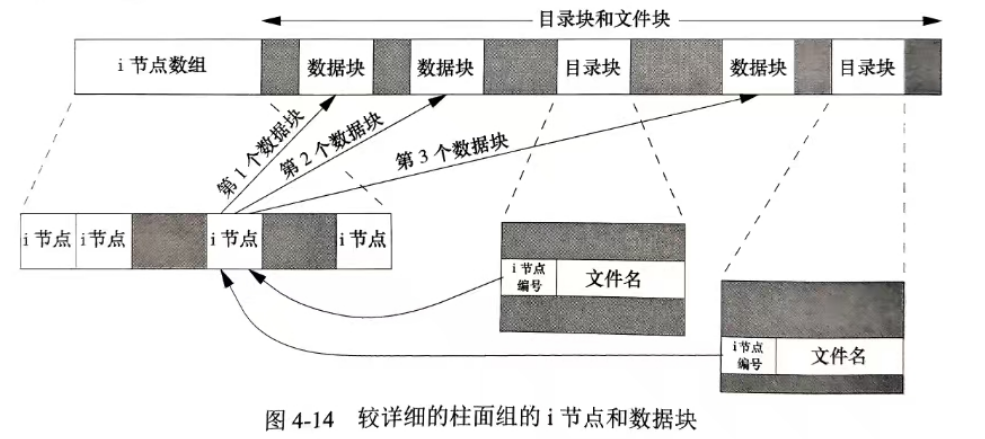
(5)目录与文件名
前面介绍inode时说过,文件名不会作为属性保存在inode中,但是我们查找文件时一直都用的是文件名,没有用过inode查找啊?
其实,目录也是文件,目录也有inode(属性)和数据内容。而目录的数据内容保存的是文件名与inode号的映射关系。所以,在磁盘里面没有目录的概念,文件系统只认inode。
所以用文件名访问文件的流程:先打开文件所处的路径,读取对应目录里面的数据内容,得到文件名和inode的映射关系,文件名 ---> inode ---> inode进行文件查找。
验证代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>int main(int argc, char *argv[]) {// 检查参数数量是否正确if (argc != 2) {fprintf(stderr, "Usage: %s <directory>\n", argv[0]);exit(EXIT_FAILURE);}// 打开目录DIR *dir = opendir(argv[1]); // 系统调用,打开指定目录if (!dir) {perror("opendir");exit(EXIT_FAILURE);}struct dirent *entry;// 遍历目录中的每个条目while ((entry = readdir(dir)) != NULL) { // 系统调用,读取目录条目// 跳过当前目录"."和上级目录".."if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0) {continue;}// 打印文件名和inode号printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino);}// 关闭目录closedir(dir);return 0;
} 程序类似于简化版的ls命令,但额外显示了inode信息。
zyt@iZ2vcf9wvlgcetfeub9f11Z:~/linux-journey-log/code_25_5_9$ ./code ~/linux-journey-log/code_25_5_9/
Filename: code.c, Inode: 946052
Filename: Makefile, Inode: 946062
Filename: code, Inode: 946083zyt@iZ2vcf9wvlgcetfeub9f11Z:~/linux-journey-log/code_25_5_9$ ll
total 32
drwxrwxr-x 2 zyt zyt 4096 May 9 12:38 ./
drwxrwxr-x 22 zyt zyt 4096 May 9 12:33 ../
-rwxrwxr-x 1 zyt zyt 16288 May 9 12:38 code*
-rw-rw-r-- 1 zyt zyt 994 May 9 12:37 code.c
-rw-rw-r-- 1 zyt zyt 57 May 9 12:38 Makefile• 访问文件,必须打开当前目录,根据文件名获得对应的inode号,然后进行文件访问。
• 访问文件必须知道当前工作目录,本质是必须能打开当前工作目录文件,查看目录文件的内容。
(6)路径解析
打开当前工作目录文件,查看当前工作目录文件的内容?当前工作目录不也是文件吗?我们访问当前工作目录不也是只知道当前工作目录的文件名吗?要访问它,不也得知道当前工作目录的inode吗?
而实际上,任何文件,都有路径,访问目标文件,比如:/home/zyt/code/test/test/test.c,都要从根目录开始,依次打开每一个目录,根据目录名,依次访问每个目录下指定的目录,直到访问到test.c。这个过程叫做Linux路径解析。
注意:
• 所以,我们知道了:访问文件必须要有目录+文件名=路径的原因。
• 根目录固定文件名,inode号,无需查找,系统开机之后就必须知道。
可是路径谁提供?
• 你访问文件,都是指令/工具访问,本质是进程访问,进程有CWD!进程提供路径。
• 你open文件,提供了路径。
可是最开始的路径从哪里来?
在计算机系统中,路径是用来定位文件或目录的。路径的起点是根目录(/)。根目录是文件系统树的最顶层,所有其他目录和文件都从根目录开始。当你访问一个文件时,你必须从根目录开始,逐步定位到目标文件。
所以Linux为什么要有根目录,根目录下为什么要有那么多缺省目录?
-
根目录(
/):根目录是文件系统树的最顶层,是所有路径的起点。它必须存在,因为它是文件系统的基础。 -
缺省目录:根目录下有许多缺省目录(如
/bin、/etc、/home、/usr等),这些目录是系统正常运行所必需的。
你为什么要有家目录,你自己可以新建目录?
-
家目录(
/home/username):每个用户都有一个家目录,这是用户的工作空间。家目录是用户存储个人文件和配置的地方。 -
新建目录:用户可以根据需要在自己的家目录或其他有权限的目录下新建目录。这些新建的目录会自动成为文件系统的一部分,并且有唯一的路径。
★ 上面所有行为:本质就是在磁盘文件系统中,新建目录文件。而你新建的任何文件,都在你或者系统指定的目录下新建,这不就是天然就有路径了嘛!
也就是说:当你在某个目录下新建文件或目录时,这些新创建的文件或目录会自动继承其父目录的路径。例如,你在/home/zyt目录下新建一个文件test.txt,它的路径就是 /home/zyt/test.txt。
• 系统+用户共同构建Linux路径结构。
-
系统角色:系统负责创建和管理根目录和缺省目录,确保系统的基本功能和结构。
-
用户角色:用户可以在自己的家目录或其他有权限的目录下创建和管理自己的文件和目录。用户的行为会扩展和丰富文件系统的结构。
(7)路径缓存
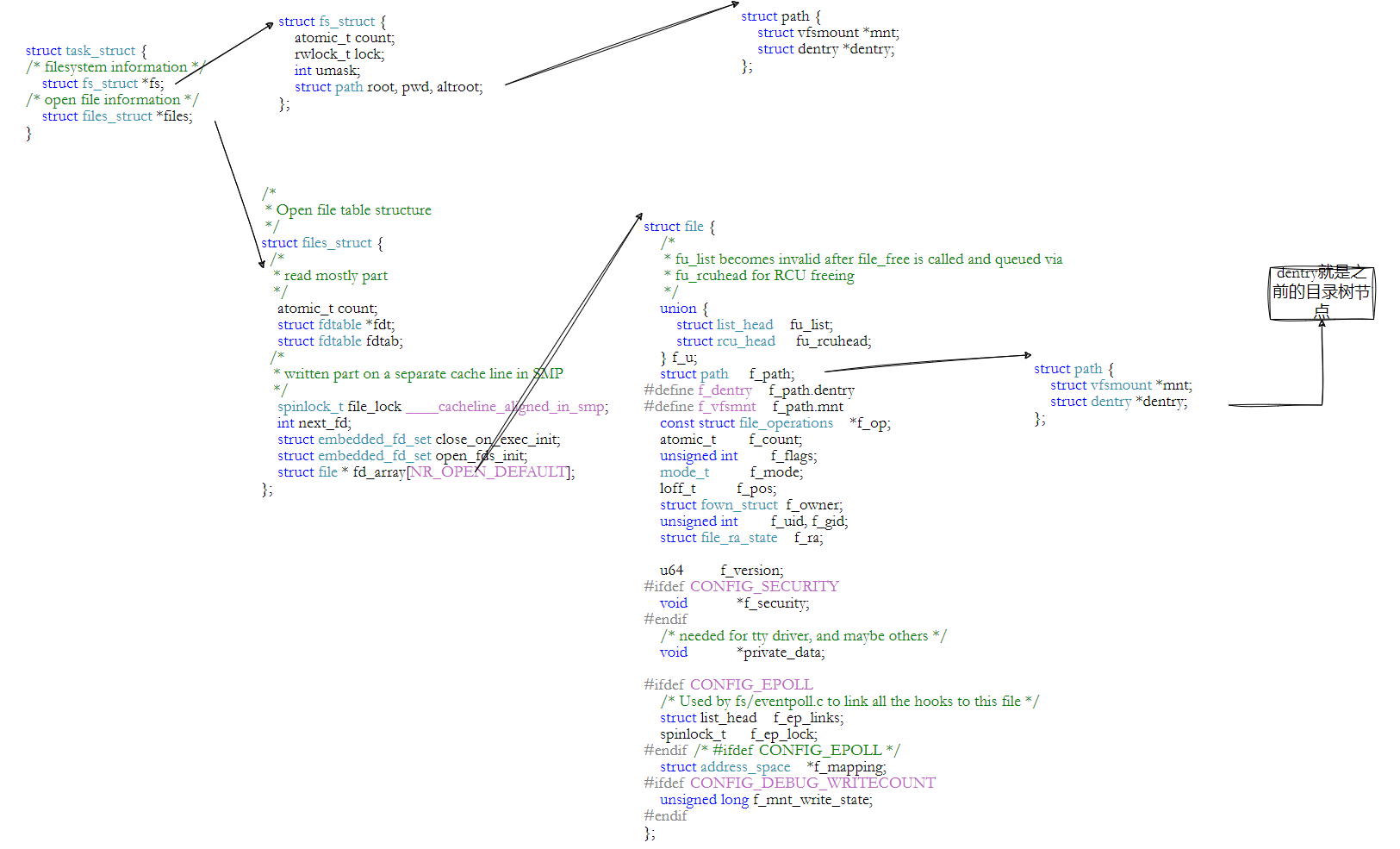
访问任何文件,都要从/目录开始进行路径解析? 原则上是,但是这样太慢,所以Linux会缓存历史路径结构。
Linux目录的概念,怎么产生的? 答案:打开的文件是目录的话,由OS自己在内存中进行路径维护。
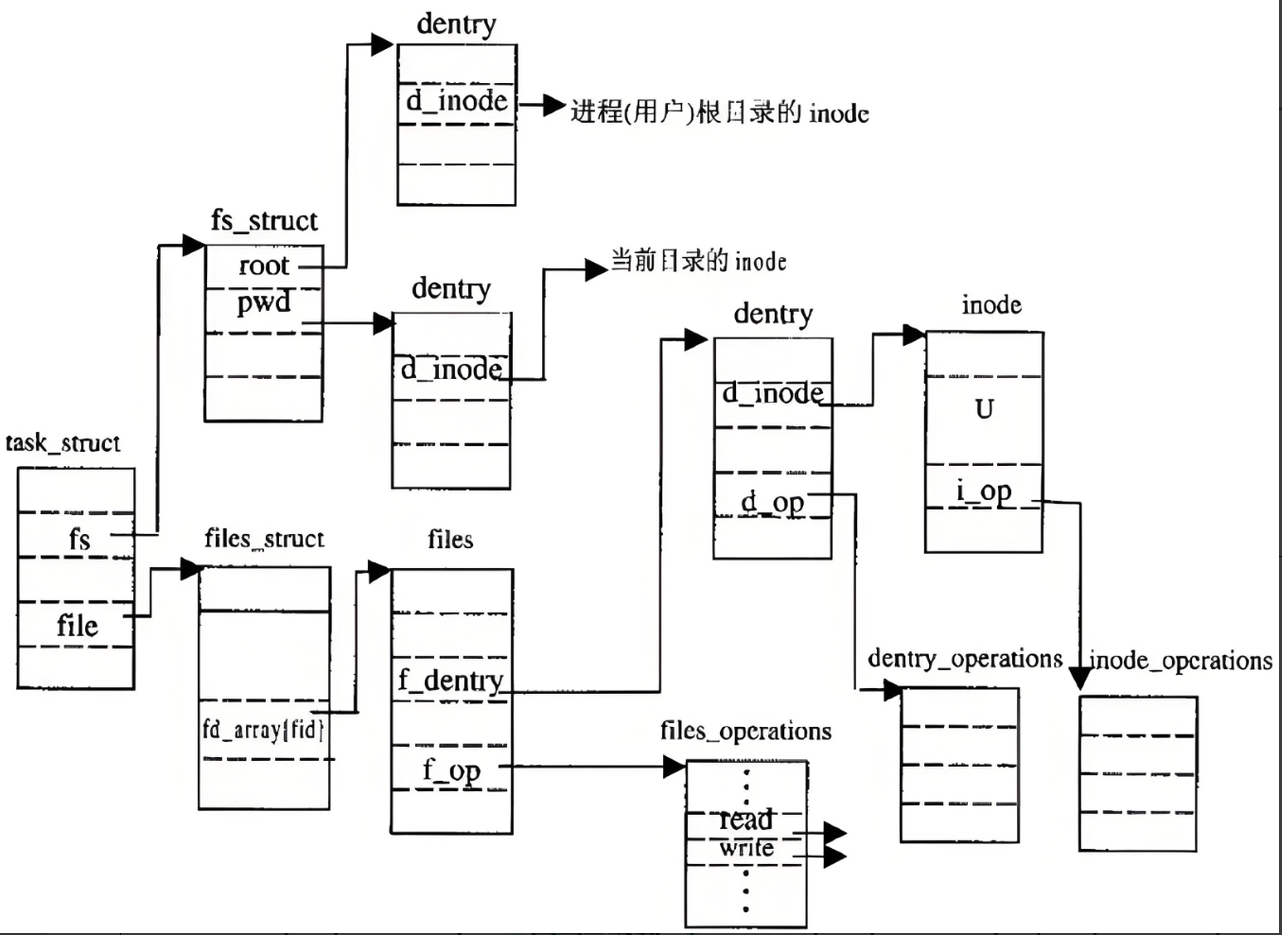
Linux中,在内核中维护树状路径结构的内核结构体叫做: struct dentry
struct dentry {atomic_t d_count; // 引用计数unsigned int d_flags; // 标志位,受 d_lock 保护spinlock_t d_lock; // dentry 自旋锁/* 关联的 inode 结构(NULL 表示负 dentry) */struct inode *d_inode; /* 以下三个字段由 __d_lookup 使用,放在同一缓存行以提高性能 */struct hlist_node d_hash; // 哈希链表节点(用于快速查找)struct dentry *d_parent; // 父目录的 dentrystruct qstr d_name; // 文件名(快速字符串结构)struct list_head d_lru; // LRU 链表节点(用于缓存管理)/* d_child 和 d_rcu 共用内存空间 */union {struct list_head d_child; // 父目录的子 dentry 链表struct rcu_head d_rcu; // RCU 回调头(用于安全释放)} d_u;struct list_head d_subdirs; // 子目录链表(当前目录下的所有 dentry)struct list_head d_alias; // inode 别名链表(硬链接场景)unsigned long d_time; // 用于 d_revalidate 的时间戳struct dentry_operations *d_op; // dentry 操作函数表struct super_block *d_sb; // 所属的超级块(文件系统根)void *d_fsdata; // 文件系统私有数据#ifdef CONFIG_PROFILINGstruct dcookie_struct *d_cookie; // 调试用的 cookie(可选)
#endifint d_mounted; // 是否是挂载点(1=是, 0=否)/* 短文件名内联存储(避免额外分配内存) */unsigned char d_iname[DNAME_INLINE_LEN_MIN];
};• 每个文件其实都要有对应的dentry结构,包括普通文件。这样所有被打开的文件,就可以在内存中形成整个树形结构。
• 整个树形节点也同时会隶属于LRU(Least Recently Used,最近最少使用)结构中,进行节点淘汰。
• 整个树形节点也同时会隶属于Hash,方便快速查找。
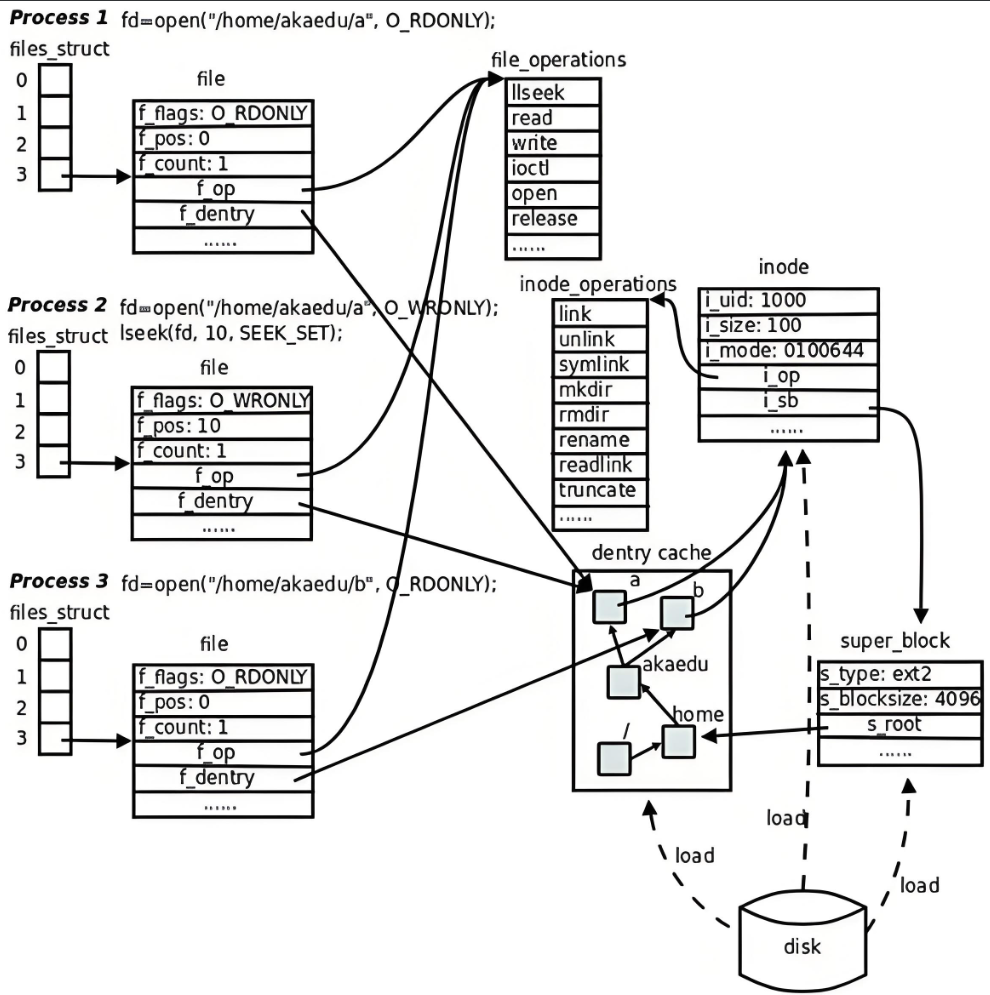
• 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何文件,都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径。
(8)挂载分区
我们已经能够根据inode号在指定分区找文件了,也已经能根据目录文件内容,找指定的inode了,在指定的分区内,我们可以为所欲为了。
可是问题是:inode不是不能跨分区吗?Linux不是可以有多个分区吗?我怎么知道我在哪一个分区?
① 分区必须挂载才能使用
-
原始分区:一个新格式化的分区(如
/dev/sdb1)只是存储设备上的一个“裸容器”,无法直接通过路径访问。 -
挂载(Mount):
将分区关联到文件系统树中的某个目录(称为挂载点)。
mount /dev/sdb1 /mnt/data # 将分区sdb1挂载到目录/mnt/data② 为什么需要挂载?
-
统一命名空间:Linux所有文件(无论来自哪个分区)都必须在单一的目录树下呈现(根目录
/为起点)。 -
隔离与组织:
-
不同分区可以挂载到不同目录(如
/home、/var),实现物理存储的隔离。 -
例如:将SSD挂载到
/,HDD挂载到/home,优化性能与容量。
-
总结:分区写入文件系统无法被直接使用,需要和指定的目录关联,进行挂载才能使用。挂载就是将分区关联到文件系统树中的某个目录,使得目录(路径前缀)成为访问该分区的入口。
③ 如何通过“路径前缀”确定分区?
【df -h】查看当前系统的分区挂载情况,我们来分析如何通过这些信息理解路径前缀与分区的对应关系。
zyt@iZ2vcf9wvlgcetfeub9f11Z:~$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 168M 1.2M 167M 1% /run
efivarfs 256K 7.3K 244K 3% /sys/firmware/efi/efivars
/dev/vda3 49G 6.4G 41G 14% /
tmpfs 839M 0 839M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 197M 6.2M 191M 4% /boot/efi
tmpfs 168M 12K 168M 1% /run/user/0
tmpfs 168M 12K 168M 1% /run/user/1001
| Filesystem | Mounted on(挂载点) | 说明 |
|---|---|---|
/dev/vda3 | / | 根分区,所有未明确挂载的路径默认归属于此(如/etc、/usr) |
/dev/vda2 | /boot/efi | EFI系统分区,存放启动文件 |
tmpfs | /run、/dev/shm等 | 内存虚拟文件系统(非物理分区) |
efivarfs | /sys/firmware/efi/efivars | EFI变量存储 |
通过“路径前缀”确定分区:挂载点是分区在目录树中的“入口”,路径中最长的挂载点前缀决定文件所在分区。示例:
路径
/home/user/file
没有单独挂载
/home,因此匹配最长前缀/→ 属于根分区/dev/vda3。路径
/boot/efi/grub.cfg
匹配前缀
/boot/efi→ 属于/dev/vda2。
内核实现:挂载表(Mount Table):内核维护一个全局挂载表,记录所有分区的挂载点信息。
路径解析时:从根目录(/)开始逐级匹配路径。当遇到某个目录是挂载点时,切换到对应分区的文件系统继续查找。
④ 实验
• 创建虚拟磁盘文件 :【dd if=/dev/zero of=./disk.img bs=1M count=5 】生成一个5MB的空文件,模拟物理磁盘分区。
root@iZ2vcf9wvlgcetfeub9f11Z:~# dd if=/dev/zero of=./disk.img bs=1M count=5
5+0 records in
5+0 records out
5242880 bytes (5.2 MB, 5.0 MiB) copied, 0.00871276 s, 602 MB/s• 格式化为ext4文件系统:【mkfs.ext4 disk.img】
将文件初始化为ext4格式,写入文件系统元数据(超级块、inode表等)。
root@iZ2vcf9wvlgcetfeub9f11Z:~# mkfs.ext4 disk.img
mke2fs 1.47.0 (5-Feb-2023)Filesystem too small for a journal
Discarding device blocks: done
Creating filesystem with 1280 4k blocks and 1280 inodesAllocating group tables: done
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
• 创建挂载点目录 【sudo mkdir /mnt/mydisk】(/mnt目录通常属于root)。
root@iZ2vcf9wvlgcetfeub9f11Z:~# mkdir /mnt/mydisk
root@iZ2vcf9wvlgcetfeub9f11Z:~# df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 168M 1.2M 167M 1% /run
efivarfs 256K 7.3K 244K 3% /sys/firmware/efi/efivars
/dev/vda3 49G 6.4G 41G 14% /
tmpfs 839M 0 839M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 197M 6.2M 191M 4% /boot/efi
tmpfs 168M 12K 168M 1% /run/user/0
tmpfs 168M 12K 168M 1% /run/user/1001• 挂载虚拟磁盘【sudo mount -t ext4 ./disk.img /mnt/mydisk/】
将disk.img挂载到/mnt/mydisk,此时访问该目录即访问虚拟磁盘内容。
root@iZ2vcf9wvlgcetfeub9f11Z:~# sudo mount -t ext4 ./disk.img /mnt/mydisk/
root@iZ2vcf9wvlgcetfeub9f11Z:~# df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 168M 1.2M 167M 1% /run
efivarfs 256K 7.3K 244K 3% /sys/firmware/efi/efivars
/dev/vda3 49G 6.4G 41G 14% /
tmpfs 839M 0 839M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 197M 6.2M 191M 4% /boot/efi
tmpfs 168M 12K 168M 1% /run/user/0
tmpfs 168M 12K 168M 1% /run/user/1001
/dev/loop0 4.7M 24K 4.4M 1% /mnt/mydisk
/dev/loop0 在 Linux 系统中代表第一个循环设备(loop device)。循环设备,也被称为回环设备或者 loopback 设备,是一种伪设备(pseudo-device),它允许将文件作为块设备(block device)来使用。这种机制使得可以将文件(比如 ISO 镜像文件)挂载(mount)为文件系统,就像它们是物理硬盘分区或者外部存储设备一样。
• 卸载虚拟磁盘,解除关联后,/mnt/mydisk恢复为空目录。
root@iZ2vcf9wvlgcetfeub9f11Z:~# sudo umount /mnt/mydisk
root@iZ2vcf9wvlgcetfeub9f11Z:~# df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 168M 1.2M 167M 1% /run
efivarfs 256K 7.3K 244K 3% /sys/firmware/efi/efivars
/dev/vda3 49G 6.4G 41G 14% /
tmpfs 839M 0 839M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 197M 6.2M 191M 4% /boot/efi
tmpfs 168M 12K 168M 1% /run/user/0
tmpfs 168M 12K 168M 1% /run/user/1001
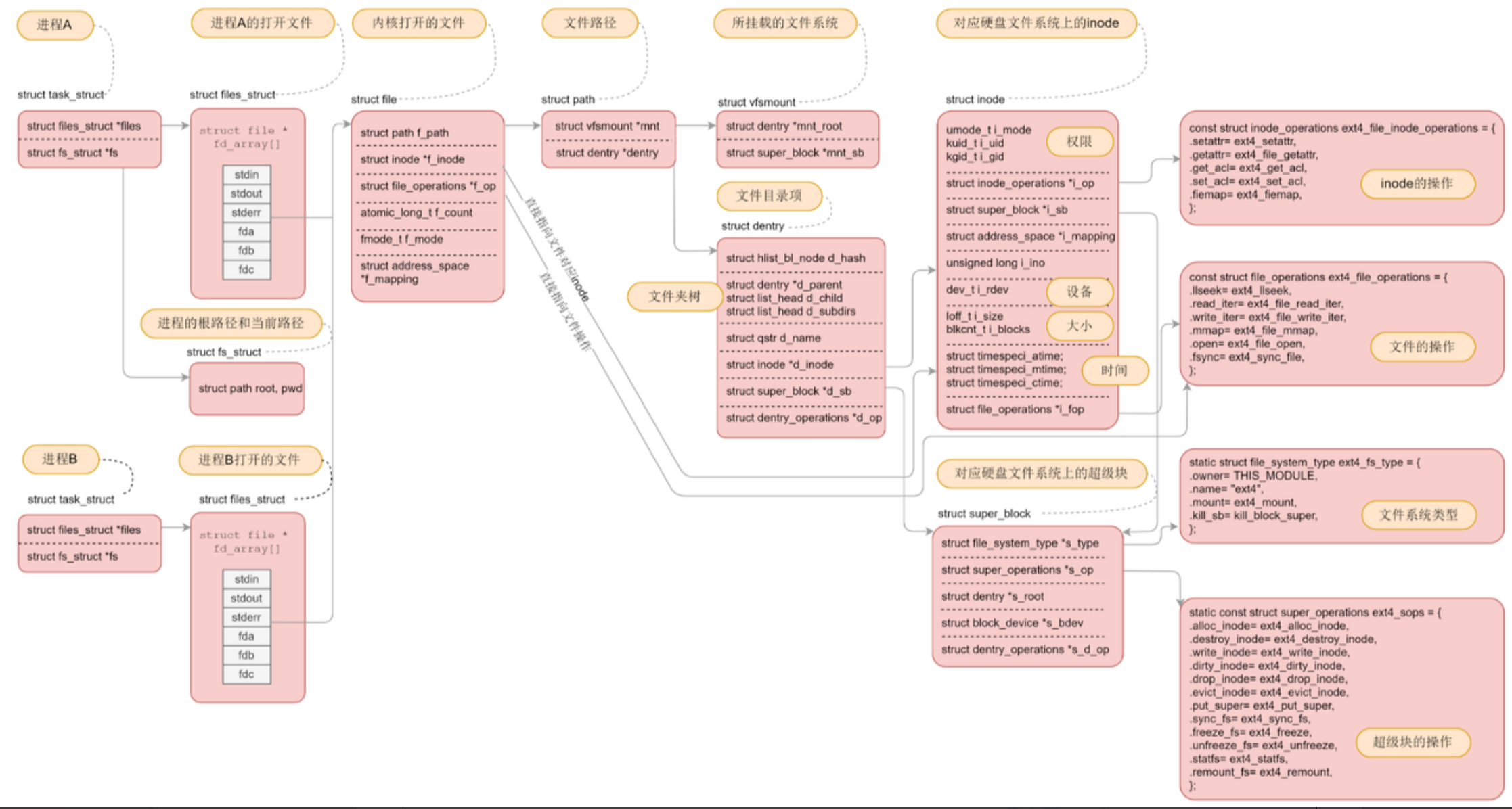
(9)文件系统总结
4、软硬链接
(1)硬链接
硬链接本质不是一个独立的文件,没有独立的inode,而是一组新的的文件名与目标inode nummber的映射关系。【只能链接普通文件,不能链接目录】
abc和def的链接状态完全相同,他们被称为指向文件的硬链接。内核记录了这个连接数,每一个inode节点都有一个链接计数,其值是指向该inode节点的目录项数。inode 946085 的硬连接数为2。
$ ln abc def
$ ls -li
total 0
946085 -rw-rw-r-- 2 zyt zyt 0 May 9 16:00 abc
946085 -rw-rw-r-- 2 zyt zyt 0 May 9 16:00 def★ 我们在删除文件时干了两件事情:1.在目录中将对应的记录删除,2.将硬连接数-1,如果为0,则将对应的磁盘释放。
用途:
① 隐藏文件【.】和【..】就是硬链接② 用于文件备份
只有当链接计数减少至0时,才可以删除该文件(也就是释放该文件占用的数据块),这就是为什么“解除对一个文件的链接”操作并不总是意味着“释放该文件占用的数据块”的原因。这也是为什么删除一个目录项的函数被称为unlink而不是delete的原因。
(2)软连接
软连接是通过inode引用另外一个文件,实际上新文件和被引用的文件的inode不同。也就是说:软链接本质是一个独立的文件,里面的内容是保存目标文件的路径。
用abc.s链接abc后我们发现,它们的inode号是不同的,证明了软链接生成的是一个独立的文件。
$ ln -s abc abc.s # 用abc.s链接abc
$ ls -li
total 0
946085 -rw-rw-r-- 1 zyt zyt 0 May 9 16:00 abc
946086 lrwxrwxrwx 1 zyt zyt 3 May 9 16:00 abc.s -> abc用途:类比成windows下的快捷方式。
(3)硬链接局限性
① 硬链接通常要求链接和文件位于同一个文件系统中。
② 只有超级用户才能创建指向目录的硬链接。(在底层文件系统支持的情况下)
③ 使用软链接可能在文件系统中引入循环。大多数查找路径名的函数在该情况发生时都将出错返回,但都是好消除的,可是对于硬链接就很难了。
$ mkdir foo # 创建一个新目录
$ touch foo/a # 创建一个长度为0的文件
$ ln -s ../foo foo/testdir # 创建一个软链接
$ ls -li foo
total 0
946073 -rw-rw-r-- 1 zyt zyt 0 May 9 17:31 a
946074 lrwxrwxrwx 1 zyt zyt 6 May 9 17:32 testdir -> ../foo
这里我们创建了一个目录foo,它包含了一个名为a的文件以及指向foo的软链接。下图显示了这种结果(圆表示目录,正方形表示一个文件)。
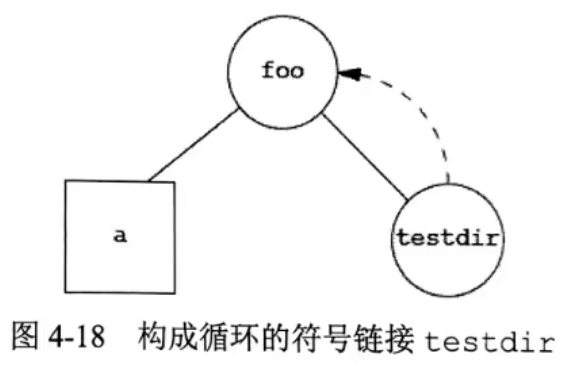
如果我们写一段简单程序,使用ftw(3)函数以降序遍历文件结构,打印每个遇到的路径名,其输出是:
foo
foo/a
foo/testdir
foo/testdir # 进入链接
foo/testdir/a # 重新遍历
foo/testdir/testdir # 再次进入
foo/testdir/testdir/a # 无限循环...
...
[最终因堆栈溢出或 ELOOP (errno) 错误终止]
这样一个循环是很好消除的,因为unlink并不跟随软链接,所以可以unlink文件foo/testdir。但如果创建了一个构成这种循环的硬链接,就很难消除了。这就是为什么link函数不允许构造指向目录的硬链接的原因(除非进程有超级用户权限)。
相关文章:
【Linux】深入拆解Ext文件系统:从磁盘物理结构到Linux文件管理
目录 1、理解硬件 (1)磁盘 (2)磁盘的物理结构 (3)磁盘的存储结构 (4)磁盘的逻辑结构 (5)CHS && LBA地址 2、引入文件系统 (1&…...

基于 Ubuntu 24.04 部署 WebDAV
无域名,HTTP 1. 简介 WebDAV(Web Distributed Authoring and Versioning)是一种基于 HTTP 的协议,允许用户通过网络直接编辑和管理服务器上的文件。本教程介绍如何在 Ubuntu 24.04 上使用 Apache2 搭建 WebDAV 服务,无…...

人工智能基础知识笔记八:数据预处理
1、简介 在进行数据分析之前,数据预处理是一个至关重要的步骤。它包括了数据清洗、转换和特征工程等过程,以确保数据的质量并提高模型的性能。数据预处理是机器学习和数据分析中至关重要的步骤,其中分类变量的编码是核心任务之一。本文…...
tauri-plugin-store 这个插件将数据存在本地电脑哪个位置
tauri-plugin-store 插件用于在 Tauri 应用中以键值对形式持久化存储数据。它将数据存储在用户本地电脑的一个 JSON 文件中,具体路径取决于操作系统,并且通常位于操作系统的应用数据目录中。 默认存储位置 以默认配置为例(使用 default sto…...

一场陟遐自迩的 SwiftUI + CoreData 性能优化之旅(下)
概述 自从 SwiftUI 诞生那天起,我们秃头码农们就仿佛打开了一个全新的撸码世界,再辅以 CoreData 框架的鼎力相助,打造一款持久存储支持的 App 就像探囊取物般的 Easy。 话虽如此,不过 CoreData 虽好,稍不留神也可能会…...

数字人驱动/动画方向最新顶会期刊论文收集整理 | AAAI 2025
会议官方论文列表:https://ojs.aaai.org/index.php/AAAI/issue/view/624 以下论文部分会开源代码,若开源,会在论文原文的摘要下方给出链接。 语音驱动头部动画/其他 EchoMimic: Lifelike Audio-Driven Portrait Animations through Editabl…...

Java+Selenium+快代理实现高效爬虫
目录 一、前言二、Selenium简介三、环境准备四、代码实现4.1 创建WebDriver工厂类4.2 创建爬虫主类4.3 配置代理的注意事项 六、总结与展望 一、前言 在Web爬虫技术中,Selenium作为一款强大的浏览器自动化工具,能够模拟真实用户操作,有效应对…...
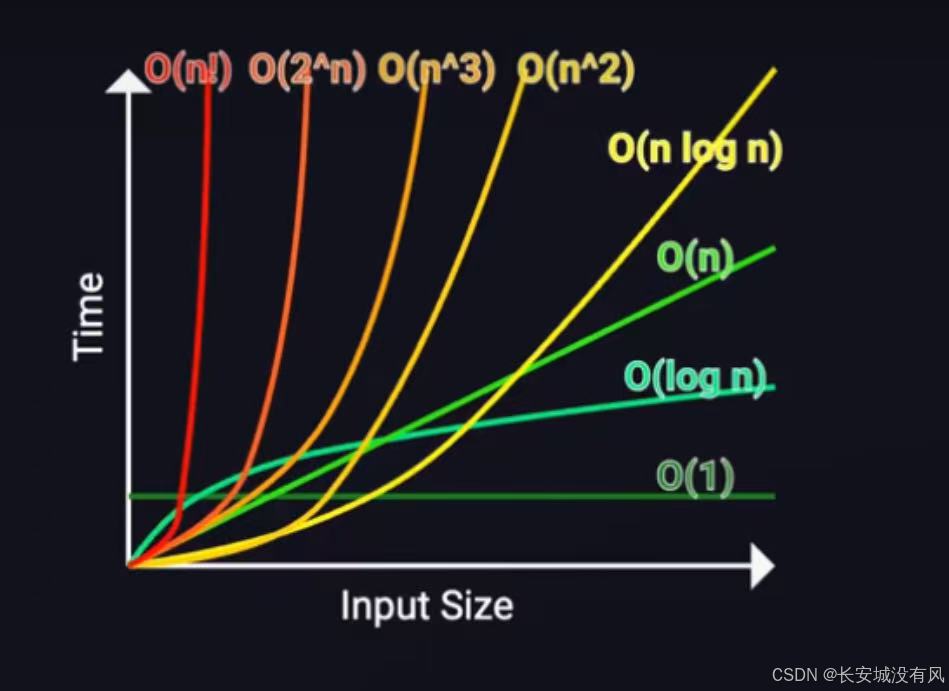
数据结构 集合类与复杂度
文章目录 📕1. 集合类📕2. 时间复杂度✏️2.1 时间复杂度✏️2.2 大O渐进表示法✏️2.3 常见的时间复杂度量级✏️2.4 常见时间复杂度计算举例 📕3. 空间复杂度 📕1. 集合类 Java 集合框架(Java Collection Framework…...
Python学习笔记--Django的安装和简单使用(一)
一.简介 Django 是一个用于构建 Web 应用程序的高级 Python Web 框架。Django 提供了一套强大的工具和约定,使得开发者能够快速构建功能齐全且易于维护的网站。Django 遵守 BSD 版权,初次发布于 2005 年 7 月, 并于 2008 年 9 月发布了第一个正式版本 1…...
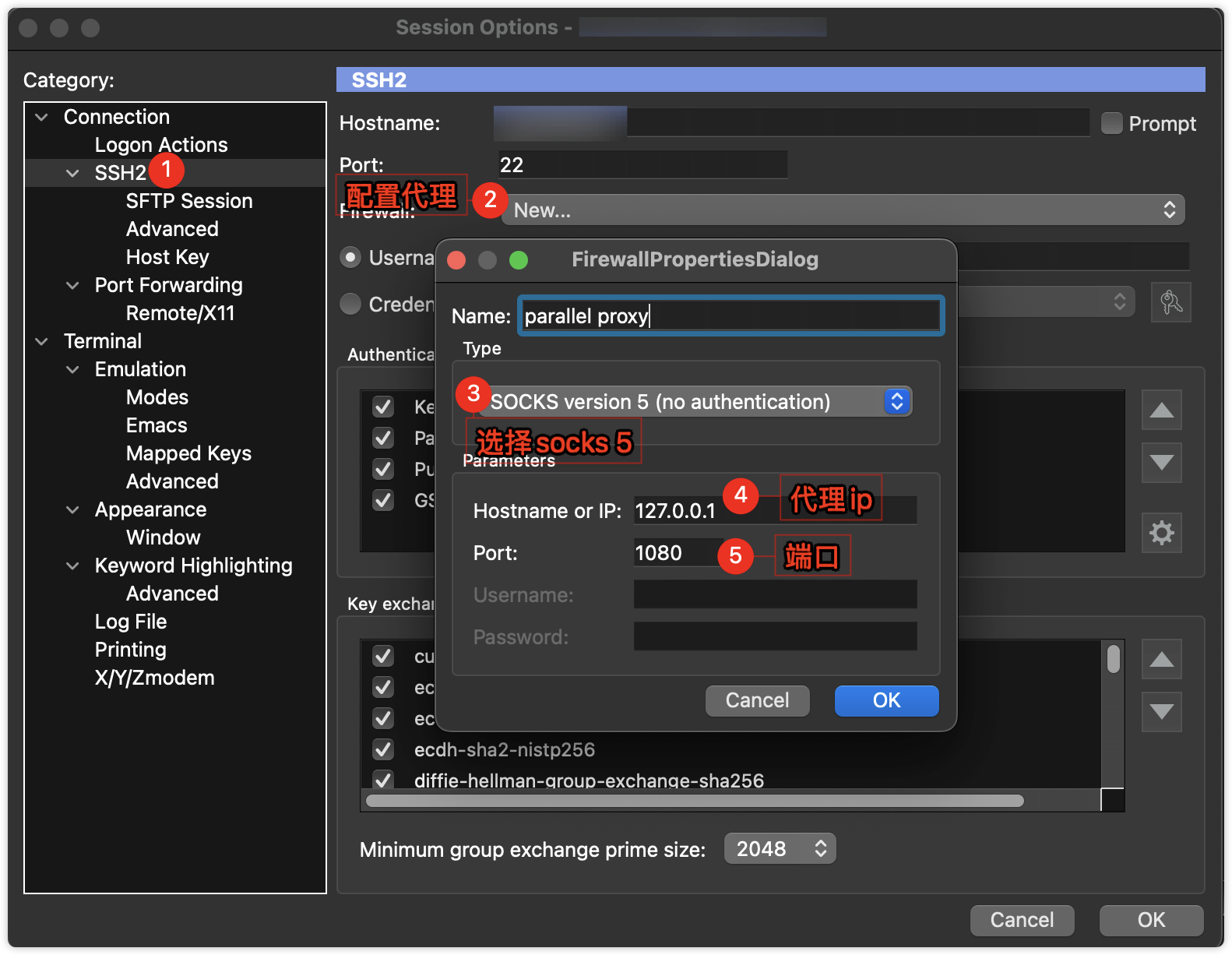
SecureCRT网络穿透/代理
场景 公司的办公VPN软件只有Windows系统版本,没有Macos系统版本,而日常开发过程中需要先登录VPN后,然后才能登录应用服务器。 目的:Macos系统在使用SecureCRT时,登录服务器,需要走Parallels Desktop进行网络…...
视频添加字幕脚本分享
脚本简介 这是一个给视频添加字幕的脚本,可以方便的在指定的位置给视频添加不同大小、字体、颜色的文本字幕,添加方式可以直接修改脚本中的文本信息,或者可以提前编辑好.srt字幕文件。脚本执行环境:windowsmingwffmpeg。本方法仅…...

OrangePi Zero 3学习笔记(Android篇)4 - eudev编译(获取libudev.so)
目录 1. Ubuntu中编译 2. NDK环境配置 3. 编译 4. 安装 这部分主要是为了得到libudev(因为原来的libudev已经不更新了),eudev的下载地址如下: https://github.com/gentoo/eudev 相应的代码最好是在Ubuntu中先编译通过&#…...
)
JavaSE核心知识点02面向对象编程02-04(包和导入)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 JavaSE核心知识点02面向对象编程02-04&#…...

【Git】查看tag
文章目录 1. 查看当前提交是否有tag2. 查看最近的tag3. 查看所有tag 有时候需要基于某个tag拉分支,记录下怎么查看tag。 1. 查看当前提交是否有tag git tag --points-at HEAD该命令可直接检查当前提交(HEAD)是否关联了任何tag。 若当前提交…...

华为昇腾910B通过vllm部署InternVL3-8B教程
前言 本文主要借鉴:VLLM部署deepseek,结合自身进行整理 下载模型 from modelscope import snapshot_download model_dir snapshot_download(OpenGVLab/InternVL3-8B, local_dir"xxx/OpenGVLab/InternVL2_5-1B")环境配置 auto-dl上选择单卡…...
upload-labs靶场通关详解:第三关
一、分析源代码 代码注释如下: <?php // 初始化上传状态和消息变量 $is_upload false; $msg null;// 检查是否通过POST方式提交了表单 if (isset($_POST[submit])) {// 检查上传目录是否存在if (file_exists(UPLOAD_PATH)) {// 定义禁止上传的文件扩展名列表…...
星光云720全景VR系统升级版,720全景,360全景,vr全景,720vr全景
星光云720全景VR系统升级版,720全景,360全景,vr全景,720vr全景 星光云全景系统 系统体验地址 https://720.ailemon.cc 星光云全景新版体验地址 全景系统功能简介 基础设置:作品信息,加载样式ÿ…...
第十六节:图像形态学操作-顶帽与黑帽变换
一、引言:形态学操作的视觉魔法 在数字图像处理领域,形态学操作犹如一柄精巧的解剖刀,能够精准地提取图像特征、消除噪声干扰,并增强关键细节。OpenCV作为计算机视觉的瑞士军刀,提供了一套完整的形态学处理工具。在掌…...

将 iconfont 图标转换成element-plus也能使用的图标组件
在做项目时发现,element-plus的图标组件,不能像文档示例中那样使用 iconfont 的图标。经过研究发现,element-plus的图标封装成了vue组件,组件内容是一个svg,然后以组件的方式引入和调用图标。根据这个思路,…...

大模型系列(四)--- GPT2: Language Models are Unsupervised Multitask Learners
论文链接: Language Models are Unsupervised Multitask Learners 点评: GPT-2采用了与GPT-1类似的架构,将参数规模增加到了15亿,并使用大规模的网页数据集WebText 进行训练。正如GPT-2 的论文所述,它旨在通过无监督语…...
:等保测评的那些事)
等保系列(三):等保测评的那些事
一、等保测评主要做什么 1、测评准备阶段 (1)确定测评对象与范围 明确被测系统的边界、功能模块、网络架构及承载的业务。 确认系统的安全保护等级(如二级、三级)。 (2)签订测评合同 选择具备资质的测…...

ABP vNext + EF Core 实战性能调优指南
ABP vNext EF Core 实战性能调优指南 🚀 目标 本文面向中大型 ABP vNext 项目,围绕查询性能、事务隔离、批量操作、缓存与诊断,系统性地给出优化策略和最佳实践,帮助读者快速定位性能瓶颈并落地改进。 📑 目录 ABP vN…...

高品质办公楼成都国际数字影像产业园核心业务
成都国际数字影像产业园的核心业务,围绕构建专业化的数字影像文创产业生态系统展开,旨在打造高品质、高效率的产业发展平台。 产业集群构建与生态运营 园区核心业务聚焦于吸引和培育数字影像及相关文创领域的企业,形成产业集聚效应。具体包…...
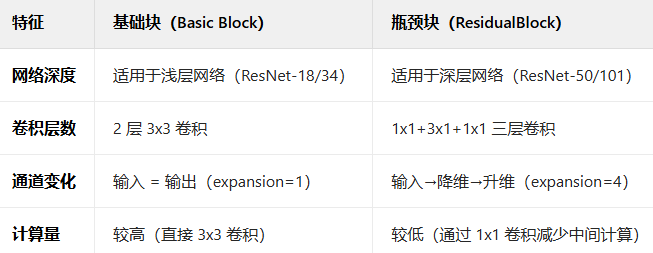
MindSpore框架学习项目-ResNet药物分类-构建模型
目录 2.构建模型 2.1定义模型类 2.1.1 基础块ResidualBlockBase ResidualBlockBase代码解析 2.1.2 瓶颈块ResidualBlock ResidualBlock代码解释 2.1.3 构建层 构建层代码说明 2.1.4 定义不同组合(block,layer_nums)的ResNet网络实现 ResNet组建类代码解析…...

【Spring Boot】Spring Boot + Thymeleaf搭建mvc项目
Spring Boot Thymeleaf搭建mvc项目 1. 创建Spring Boot项目2. 配置pom.xml3. 配置Thymeleaf4. 创建Controller5. 创建Thymeleaf页面6. 创建Main启动类7. 运行项目8. 测试结果扩展:添加静态资源 1. 创建Spring Boot项目 打开IntelliJ IDEA → New Project → 选择M…...

线程中常用的方法
知识点详细说明 Java线程的核心方法集中在Thread类和Object类中,以下是新增整合后的常用方法分类解析: 1. 线程生命周期控制 方法作用注意事项start()启动新线程,JVM调用run()方法多次调用会抛出IllegalThreadStateException(线程状态不可逆)。run()线程的任务逻辑直接调…...
学习spring boot-拦截器Interceptor,过滤器Filter
目录 拦截器Interceptor 过滤器Filter 关于过滤器的前置知识可以参考: 过滤器在springboot项目的应用 一,使用WebfilterServletComponentScan 注解 1 创建过滤器类实现Filter接口 2 在启动类中添加 ServletComponentScan 注解 二,创建…...

为啥大模型一般将kv进行缓存,而q不需要
1. 自回归生成的特点 大模型(如 GPT 等)在推理时通常采用自回归生成的方式: 模型逐个生成 token,每次生成一个新 token 时,需要重新计算注意力。在生成第 t 个 token 时,模型需要基于前 t-1 个已生成的 t…...
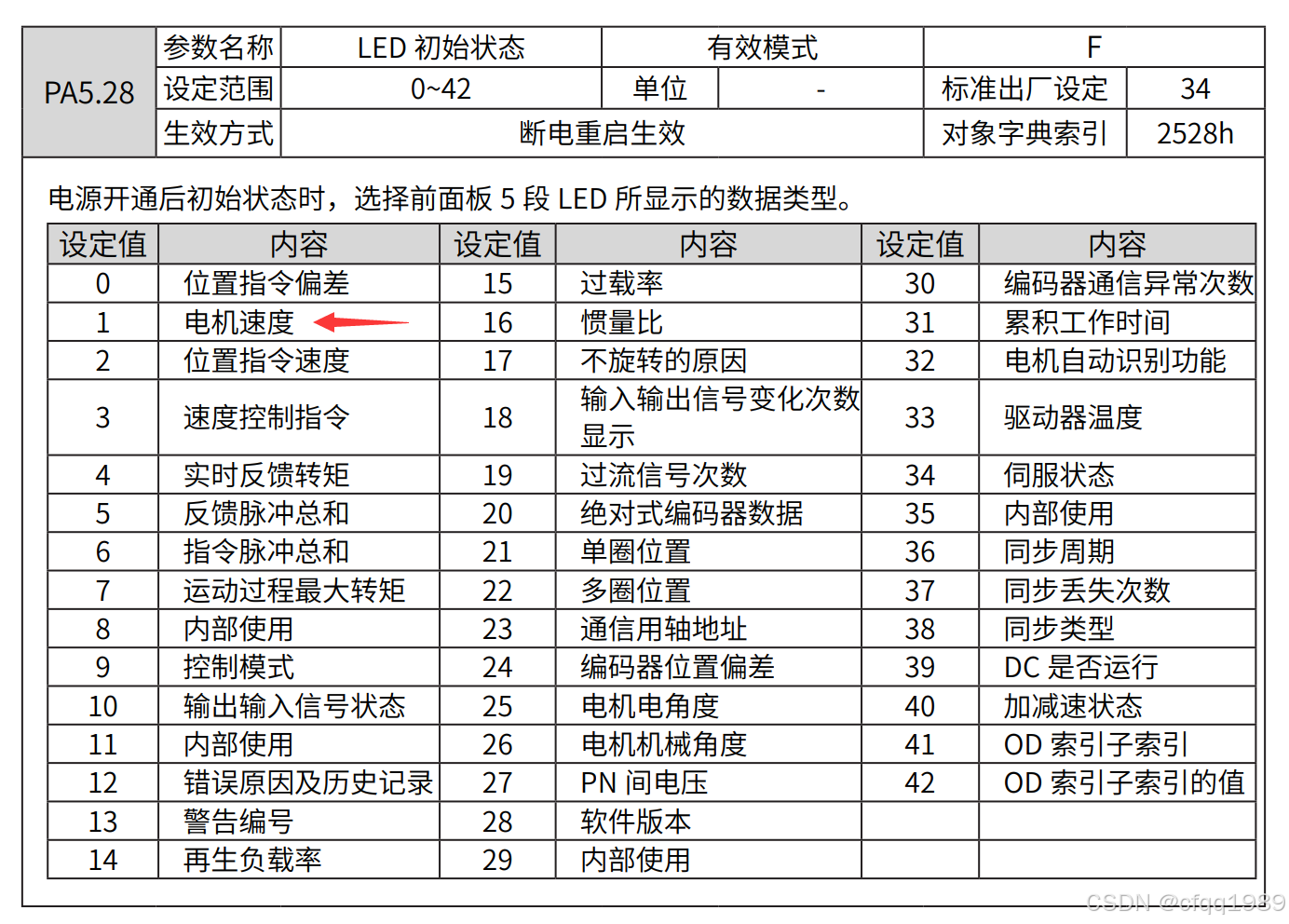
雷赛伺服L7-EC
1电子齿轮比: 电机圈脉冲1万 (pa11的值 x 4倍频) 2电机刚性: pa003 或者 0x2003 // 立即生效的 3LED显示: PA5.28 1 电机速度 4精度: PA14 //默认30,超过3圈er18…...
阅文集团C++面试题及参考答案
能否不使用锁保证多线程安全? 在多线程编程中,锁(如互斥锁、信号量)是实现线程同步的传统方式,但并非唯一方式。不使用锁保证多线程安全的核心思路是避免共享状态、使用原子操作或采用线程本地存储。以下从几个方面详…...