python打卡day20
知识点回顾:
奇异值的应用:
- 特征降维:对高维数据减小计算量、可视化
- 数据重构:比如重构信号、重构图像(可以实现有损压缩,k 越小压缩率越高,但图像质量损失越大)
- 降噪:通常噪声对应较小的奇异值。通过丢弃这些小奇异值并重构矩阵,可以达到一定程度的降噪效果。
- 推荐系统:在协同过滤算法中,用户-物品评分矩阵通常是稀疏且高维的。SVD (或其变种如 FunkSVD, SVD++) 可以用来分解这个矩阵,发现潜在因子 (latent factors),从而预测未评分的项。这里其实属于特征降维的部分。
作业:尝试利用svd来处理心脏病预测,看下精度变化
对于任何矩阵,均可做等价的奇异值SVD分解 A=UΣVᵀ,对于分解后的矩阵,可以选取保留前K个奇异值及其对应的奇异向量,重构原始矩阵,可以通过计算Frobenius 范数相对误差来衡量原始矩阵和重构矩阵的差异。
- U矩阵:描述行之间的关系,列向量来自AAᵀ的特征向量,而AAᵀ计算的是行之间的相似性(因为A的每一行代表一个样本)
- Σ矩阵:告诉我们哪些模式最重要(奇异值越大越重要,是按降序排列的)
- Vᵀ矩阵:描述列之间的关系,列向量来自AᵀA的特征向量,而AᵀA计算的是列之间的相似性(因为A的每一列代表一个特征)
应用:结构化数据中,将原来的m个特征降维成k个新的特征,新特征是原始特征的线性组合,捕捉了数据的主要方差信息,降维后的数据可以直接用于机器学习模型(如分类、回归),通常能提高计算效率并减少过拟合风险。
ps:在进行 SVD 之前,通常需要对数据进行标准化(均值为 0,方差为 1),以避免某些特征的量纲差异对降维结果的影响。
具体说说通过奇异值来降维,本质上通过数学变换创造新特征,这种方法是许多降维算法(如 PCA)和数据处理技术的基础,具体三步搞定:
- 分解:对原始矩阵A做SVD得到 A = UΣVᵀ
- 筛选:选择前k个奇异值(如何选k见下方规则)
- 固定数量法(最简单):直接指定保留前k个(如k=10),适用于对数据维度有明确要求时
- 能量占比法(最常用):计算奇异值平方和(总能量),选择使前k个奇异值平方和占比>阈值(如95%)
- 拐点法(可视化判断):奇异值下降曲线明显变平缓的点作为k
- 重构:用U的前k列、Σ的前k个值、Vᵀ的前k行重构近似矩阵 Aₖ = UₖΣₖVₖᵀ
1.初步理解
下面用一个简单的矩阵实现SVD降维
import numpy as np# 创建一个矩阵 A (5x3)
A = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9],[10, 11, 12],[13, 14, 15]])
print("原始矩阵 A:")
print(A)# 进行 SVD 分解
U, sigma, Vt = np.linalg.svd(A, full_matrices=False)
print("\n奇异值 sigma:")
print(sigma)# 保留前 k=1 个奇异值进行降维
k = 1
U_k = U[:, :k] # 取 U 的前 k 列,因为要保持行数不变
sigma_k = sigma[:k] # 取前 k 个奇异值
Vt_k = Vt[:k, :] # 取 Vt 的前 k 行,因为要保持列数不变# 近似重构矩阵 A,常用于信号or图像筛除噪声
A_approx = U_k @ np.diag(sigma_k) @ Vt_k
print("\n保留前", k, "个奇异值后的近似矩阵 A_approx:")
print(A_approx)# 计算近似误差
error = np.linalg.norm(A - A_approx, 'fro') / np.linalg.norm(A, 'fro')
print("\n近似误差 (Frobenius 范数相对误差):", error)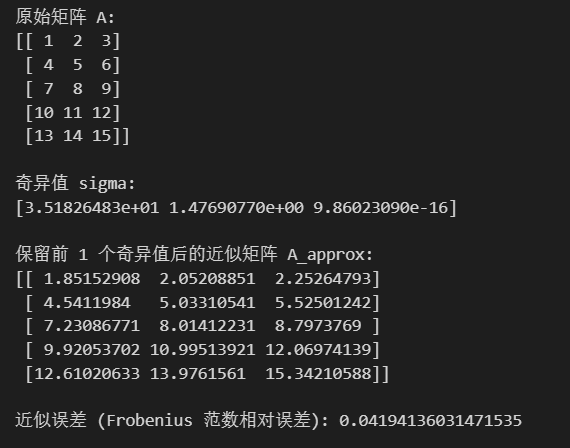
这里的Frobenius 范数相对误差的计算方式有点难理解,举一个更简单的例子说明一下:

2.实际运用到数据集里
难点就是对于测试集要用训练集相同的SVD分解规则,即相同的变换

import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 设置随机种子以便结果可重复
np.random.seed(42)# 模拟数据:1000 个样本,50 个特征
n_samples = 1000
n_features = 50
X = np.random.randn(n_samples, n_features) * 10 # 随机生成特征数据
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 模拟二分类标签# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")# 对训练集进行 SVD 分解
U_train, sigma_train, Vt_train = np.linalg.svd(X_train, full_matrices=False)
print(f"Vt_train 矩阵形状: {Vt_train.shape}")# 选择保留的奇异值数量 k
k = 10
Vt_k = Vt_train[:k, :] # 保留前 k 行,形状为 (k, 50)
print(f"保留 k={k} 后的 Vt_k 矩阵形状: {Vt_k.shape}")# 降维训练集:X_train_reduced = X_train @ Vt_k.T
X_train_reduced = X_train @ Vt_k.T
print(f"降维后训练集形状: {X_train_reduced.shape}")# 使用相同的 Vt_k 对测试集进行降维:X_test_reduced = X_test @ Vt_k.T
X_test_reduced = X_test @ Vt_k.T
print(f"降维后测试集形状: {X_test_reduced.shape}")# 训练模型(以逻辑回归为例)
model = LogisticRegression(random_state=42)
model.fit(X_train_reduced, y_train)# 预测并评估
y_pred = model.predict(X_test_reduced)
accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率: {accuracy}")# 计算训练集的近似误差(可选,仅用于评估降维效果)
X_train_approx = U_train[:, :k] @ np.diag(sigma_train[:k]) @ Vt_k
error = np.linalg.norm(X_train - X_train_approx, 'fro') / np.linalg.norm(X_train, 'fro')
print(f"训练集近似误差 (Frobenius 范数相对误差): {error}")
收获心得:
SVD降维的难点就是数学关系以及维度转换后是否正确,线性代数要学好啊,唉
@浙大疏锦行
相关文章:
python打卡day20
特征降维------特征组合(以SVD为例) 知识点回顾: 奇异值的应用: 特征降维:对高维数据减小计算量、可视化数据重构:比如重构信号、重构图像(可以实现有损压缩,k 越小压缩率越高&#…...

如何使用极狐GitLab 软件包仓库功能托管 ruby?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 软件包库中的 Ruby gems (BASIC ALL) WARNING:Ruby gems 软件包库正在开发中,由于功能有限,尚未准备好…...
数字化转型-4A架构之数据架构
系列文章 数字化转型-4A架构(业务架构、应用架构、数据架构、技术架构) 数字化转型-4A架构之业务架构 数字化转型-4A架构之应用架构 数据架构 Data Architecture(DA) 1. 定义 数据架构,是组织管理数据资产的科学之…...
React 第三十七节 Router 中 useOutlet Hook的使用介绍以及注意事项
React Router 中的 useOutlet 是 v6 版本新增的 Hook,用于在父路由组件中访问当前嵌套的子路由元素。它提供了比 <Outlet> 组件更灵活的控制方式,适合需要根据子路由状态进行动态处理的场景。 一、useOutlet的基本用法 import { useOutlet } fro…...
)
u-boot学习笔记(四)
文章目录 cmd/sub_cmd/exit.cdo_exit()exit.c可提供的命令及使用方式: ext2.cdo_ext2ls()do_ext2load()ext2.c可提供的命令及使用方式: ext4.cdo_ext4_size()do_ext4_load()do_ext4_ls()do_ext4_write()ext4.c可提供的命令及使用方式: fastbo…...

使用React实现调起系统相机功能
前言: 最近在公司推荐研发任务时实现了拍照识别功能,需要调起系统相机,笔者实现之后,将实现的流程分享给各位小伙伴 功能描述: 点击相机icon调起系统相机,同时可以选择是拍摄还是使用相册图片࿰…...

结构性变革与新兴机遇
近年来,全球就业市场正经历深刻的结构性变革。受技术进步、产业升级、人口结构变化及全球经济格局调整的影响,传统就业模式被重塑,新的职业机会不断涌现。本文将分析当前就业市场的主要趋势,并探讨其对劳动者、企业和政策制定者的…...

AGV通信第3期|AGV集群智能应急响应系统:从故障感知到快速恢复
随着智慧工厂物流系统复杂度的提升,AGV运行过程中的异常处理能力已成为保障生产连续性的关键指标。面对突发障碍、设备故障等意外状况,传统依赖人工干预的响应模式已无法满足现代智能制造对时效性的严苛要求。 一、AGV异常应急体系面临的挑战 响应时效瓶…...

军事目标无人机视角坦克检测数据集VOC+YOLO格式4003张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):4003 标注数量(xml文件个数):4003 标注数量(txt文件个数):4003 …...
:大模型商用加速落地 边缘AI开启全域智能新图景)
2025年5月AI科技领域周报(4.28-5.4):大模型商用加速落地 边缘AI开启全域智能新图景
2025年5月AI科技领域周报(4.28-5.4):大模型商用加速落地 边缘AI开启全域智能新图景 一、本周热点回顾1. OpenAI发布GPT-5多模态大模型 开启通用人工智能新纪元2. 谷歌发布安卓15系统 全面集成Gemini大模型重构移动生态3. 百度Apollo发布第六代…...

Flutter 3.29.3 花屏问题记录
文章目录 Flutter 3.29.3 花屏问题记录问题记录解决尝试解决 Flutter 3.29.3 花屏问题记录 问题记录 flutter版本3.29.3,代码大致为: ShaderMask(shaderCallback: (Rect bounds) {return LinearGradient(begin: Alignment.topCenter,end: Alignment.bo…...

【Pandas】pandas DataFrame all
Pandas2.2 DataFrame Computations descriptive stats 方法描述DataFrame.abs()用于返回 DataFrame 中每个元素的绝对值DataFrame.all([axis, bool_only, skipna])用于判断 DataFrame 中是否所有元素在指定轴上都为 True pandas.DataFrame.all() pandas.DataFrame.all() 方…...
软件安全(二)优化shellcode
我们在上一节课中所写的shellcode,其中使用到的相关的API是通过写入其内存地址来实现调用。这种方法具有局限性,如切换其他的操作系统API的内存地址就会发生变化,从而无法正常调用。 所谓的shellcode不过是在目标程序中加一个区段使得程序可…...

RabbitMQ-运维
文章目录 前言运维-集群介绍多机多节点单机多节点 多机多节点下载配置hosts⽂件配置Erlang Cookie启动节点构建集群查看集群状态 单机多节点安装启动两个节点再启动两个节点验证RabbitMQ启动成功搭建集群把rabbit2, rabbit3添加到集群 宕机演示仲裁队列介绍raft算法协议 raft基…...

深度学习基础--目标检测常见算法简介(R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNN、SSD、YOLO)
博主简介:努力学习的22级本科生一枚 🌟;探索AI算法,C,go语言的世界;在迷茫中寻找光芒🌸 博客主页:羊小猪~~-CSDN博客 内容简介:常见目标检测算法简介…...

【Python 元组】
Python 中的元组(Tuple)是一种不可变的有序数据集合,用于存储多个元素的序列。与列表(List)类似,但元组一旦创建后无法修改,这种特性使其在特定场景下具有独特优势。 一、核心特性 不可变性&am…...
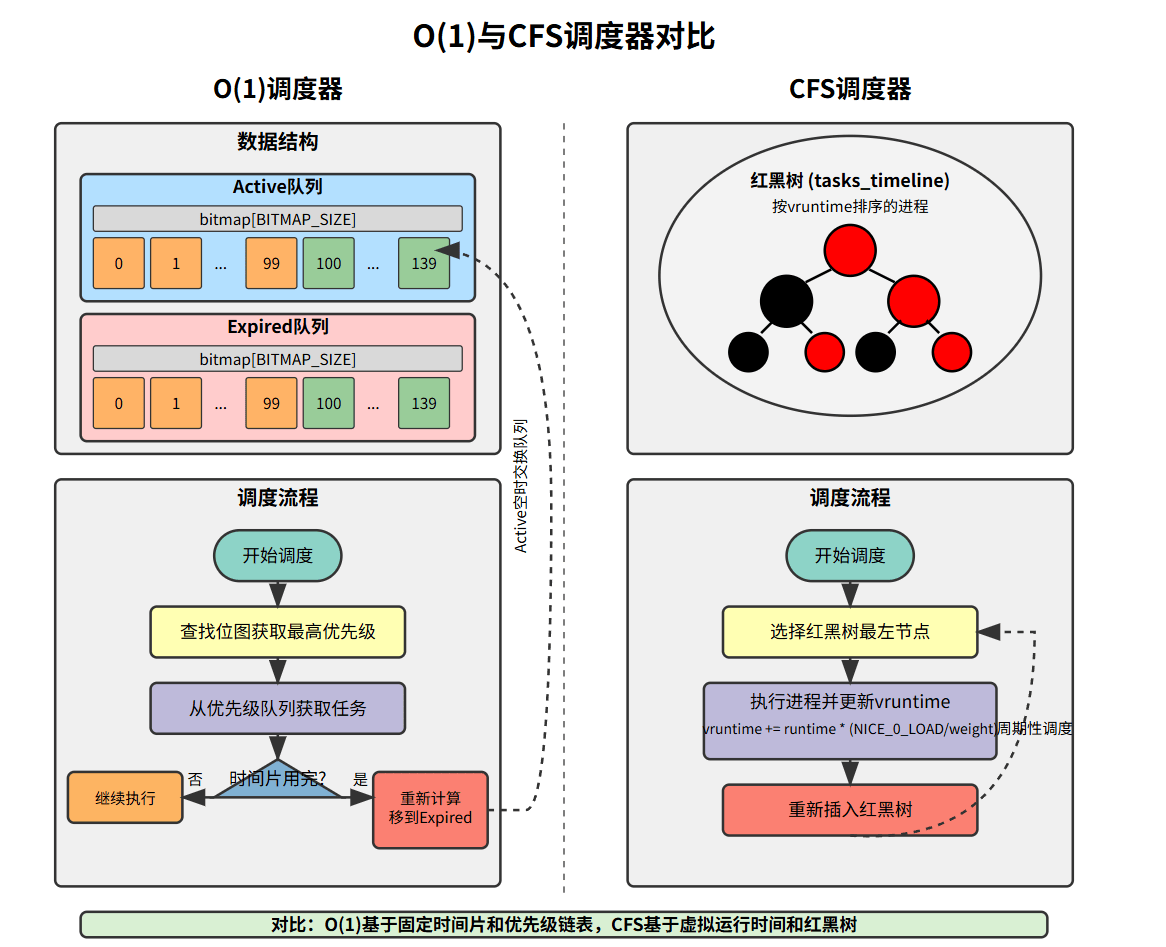
LINUX CFS算法解析
文章目录 1. Linux调度器的发展历程2. CFS设计思想3. CFS核心数据结构3.1 调度实体(sched_entity)3.2 CFS运行队列(cfs_rq)3.3 任务结构体中的调度相关字段 4. 优先级与权重4.1 优先级范围4.2 权重映射表 (prio_to_weight[])优先级计算4.3.1. static_prio (静态优先级)4.3.2. n…...

智能指针笔记
智能指针,利用class类对象销毁的时候自动调用析构函数,去把delete ptr的操作放在析构函数里,去实现自动释放指针里的资源 RAII是ResourceAcquisition Is Initialization的缩写,他是⼀种管理资源的类的设计思想,本质是 …...
软考-软件设计师中级备考 14、刷题 算法
一、考点归纳 1)排序 2、查找 3、复杂度 4、经典问题 0 - 1 背包动态规划0 - 1 背包问题具有最优子结构性质和重叠子问题性质。通过动态规划可以利用一个二维数组来记录子问题的解,避免重复计算,从而高效地求解出背包能装下的最大价值。分…...

Vue3 中 ref 与 reactive 的区别及底层原理详解
一、核心区别 1. 数据类型与使用场景 • ref 可定义基本类型(字符串、数字、布尔值)和对象类型的响应式数据。对于对象类型,ref 内部会自动调用 reactive 将其转换为响应式对象。 语法特点:需通过 .value 访问或修改数据&#…...

豆包:基于多模态交互的智能心理咨询机器人系统设计与效果评估——情感计算框架下的对话机制创新
豆包:基于多模态交互的智能心理咨询机器人系统设计与效果评估——情感计算框架下的对话机制创新 摘要 随着人工智能在心理健康领域的应用深化,本文提出一种融合情感计算与动态对话管理的智能心理咨询机器人系统架构。通过构建“用户状态-情感响应-策略生成”三层模型,结合…...

Baklib实战企业内容与中台管理差异解析
企业内容管理中台本质差异 企业内容管理系统(CMS)与内容中台的核心差异在于战略定位与技术路径的本质性区隔。传统CMS聚焦于内容存储与审批流程的线性管理,而内容中台则构建起全域数据服务中枢,通过API接口实现跨系统内容资产调用…...
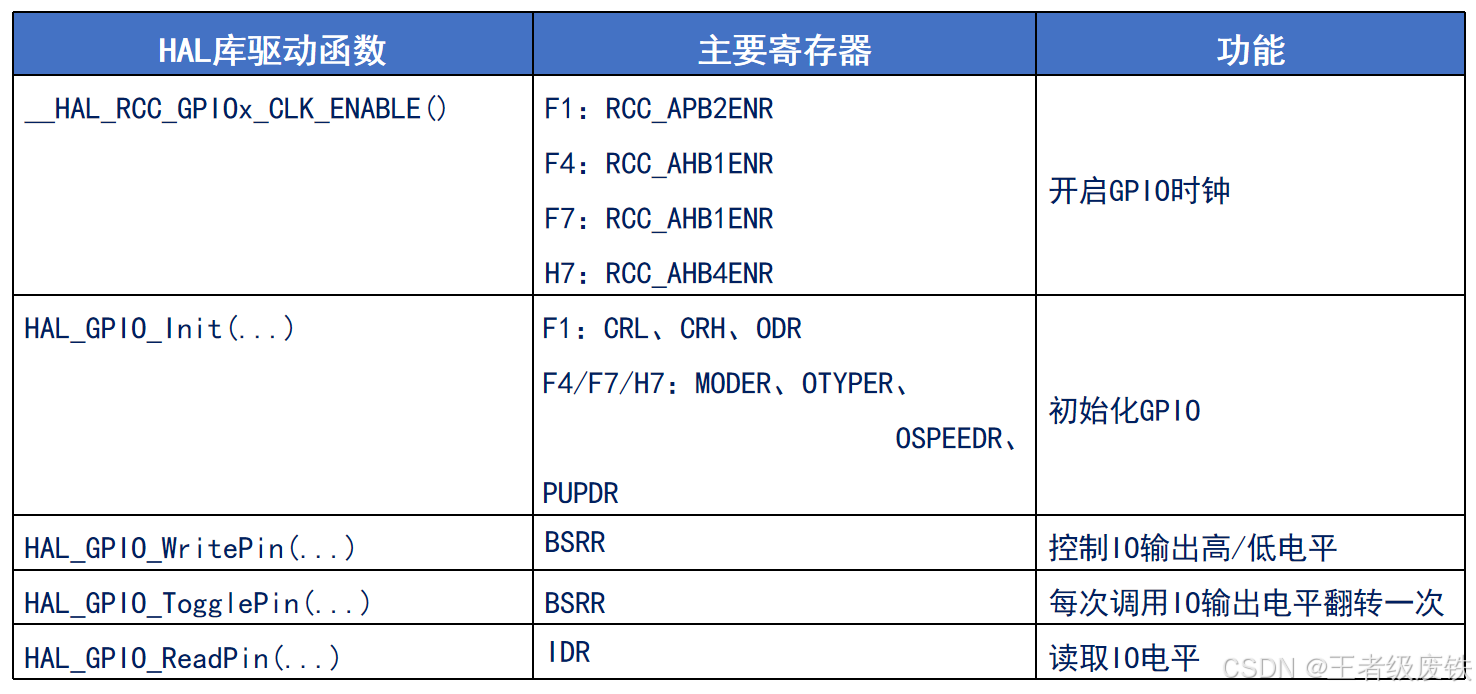
通用外设驱动模型(四步法)
举例:GPIO配置步骤 1、使能时钟 __HAL_RCC_GPIOx_CLK_ENABLE()2、设置工作模式 HAL_GPIO_Init()3、设置输出状态(可选) HAL_GPIO_WritePin() HAL_GPIO_TogglePin()4、读取输入状态(可选) HAL_GPIO_ReadPin()模块…...

IoT无线组网模块,万物互联的底层通信基石
随着物联网(IoT)技术在“快车道”上持续飞驰,一场“交互革命”正在人们的日常出行与工作学习等生活场景中加速爆发。从智能家居到智慧城市,从智慧交通到工业自动化,物联网(IoT)技术凭借着万物互…...
通常指一类现代化的终端工具 工具介绍)
Xterminal(或 X Terminal)通常指一类现代化的终端工具 工具介绍
Xterminal(或 X Terminal)通常指一类现代化的终端工具,旨在为开发者、运维人员提供更高效、更智能的命令行操作体验。 📢提示:文章排版原因,资源链接地址放在文章结尾👇👇ÿ…...
AI 芯片后端 的模块CANN)
OpenCV 中用于支持 华为昇腾(Ascend)AI 芯片后端 的模块CANN
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cannops 是 OpenCV 中用于支持 华为昇腾(Ascend)AI 芯片后端 的模块,全称为 CANN Operations (CANN Operator…...
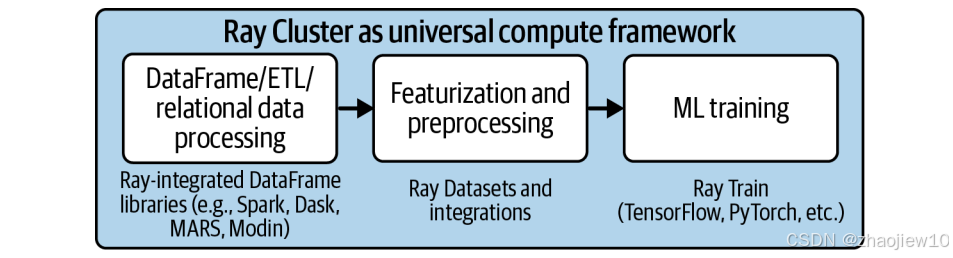
learning ray之ray强化学习/超参调优和数据处理
之前我们掌握了Ray Core的基本编程,我们已经学会了如何使用Ray API。现在,让我们将这些知识应用到一个更实际的场景中——构建一个强化学习项目,并且利用Ray来加速它。 我们的目标是,通过Ray的任务和Actor,将一个简单…...
【Linux】深入拆解Ext文件系统:从磁盘物理结构到Linux文件管理
目录 1、理解硬件 (1)磁盘 (2)磁盘的物理结构 (3)磁盘的存储结构 (4)磁盘的逻辑结构 (5)CHS && LBA地址 2、引入文件系统 (1&…...

基于 Ubuntu 24.04 部署 WebDAV
无域名,HTTP 1. 简介 WebDAV(Web Distributed Authoring and Versioning)是一种基于 HTTP 的协议,允许用户通过网络直接编辑和管理服务器上的文件。本教程介绍如何在 Ubuntu 24.04 上使用 Apache2 搭建 WebDAV 服务,无…...

人工智能基础知识笔记八:数据预处理
1、简介 在进行数据分析之前,数据预处理是一个至关重要的步骤。它包括了数据清洗、转换和特征工程等过程,以确保数据的质量并提高模型的性能。数据预处理是机器学习和数据分析中至关重要的步骤,其中分类变量的编码是核心任务之一。本文…...