LeRobot 项目部署运行逻辑(六)——visualize_dataset_html.py/visualize_dataset.py
可视化脚本包括了两个方法:远程下载 huggingface 上的数据集和使用本地数据集
脚本主要使用两个:
![]()
目前来说,ACT 采集训练用的是统一时间长度的数据集,此外,这两个脚本最大的问题在于不能裁剪,这也是比较好的升级方向;
目录
1 可视化运行
1.1 远程 html
1.2 本地数据集
2 代码详解 visualize_dataset_html.py
2.1 综述
2.2 流程概览
2.3 库引用
2.4 mian() 函数
2.5 关键函数
2.5.1 run_server() —— Flask 应用核心
2.5.2 get_ep_csv_fname(episode_id)
2.5.3 get_episode_data()
2.5.4 get_episode_video_paths
2.5.5 get_episode_language_instruction
2.5.6 get_dataset_info(repo_id)
2.5.7 visualize_dataset_html
3 代码详解 visualize_dataset.py
3.1 综述
3.2 流程概览
3.3 库引用
3.4 mian() 函数
3.5 关键函数
3.5.1 采样器(EpisodeSampler)
3.5.2 图像转换(to_hwc_uint8_numpy)
3.5.3 核心可视化函数(visualize_dataset())
1 可视化运行
1.1 远程 html
对于开源数据集,只需要在 huggingface 上查看 id,比如 aloha_static_coffee 这个:
![]()
点进去选择 use this dataset,可以看到id
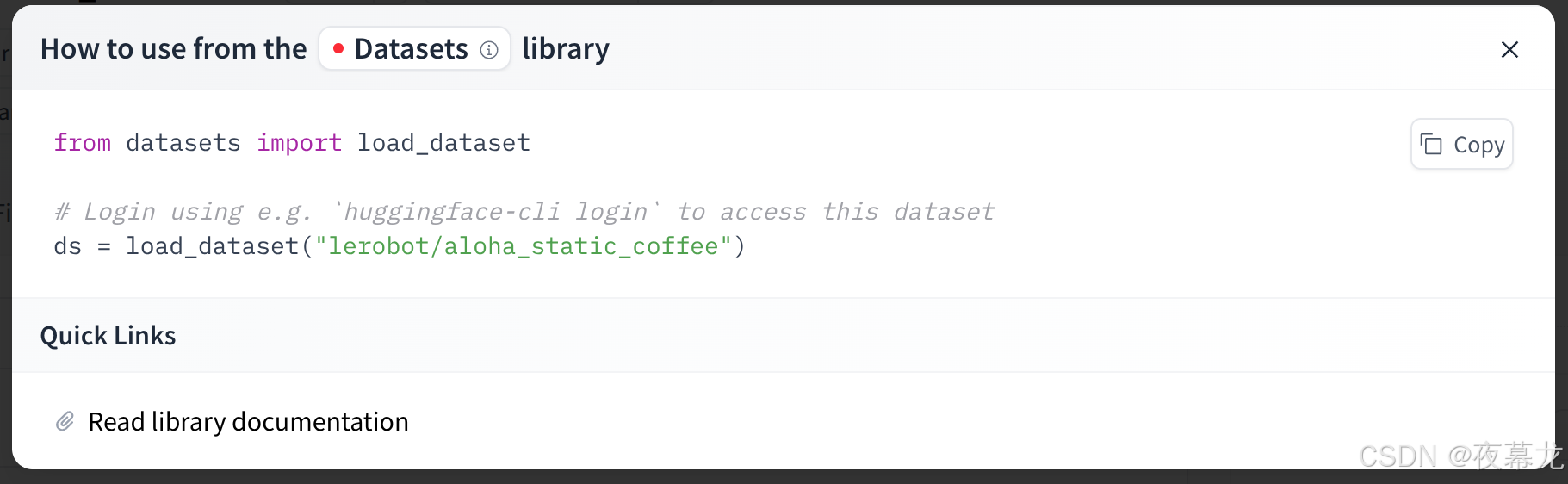
然后运行脚本:
python lerobot/scripts/visualize_dataset_html.py \--repo-id lerobot/aloha_static_coffee下载数据集后生成 web browser:http://127.0.0.1:9090

可以看到采集的各类信息:
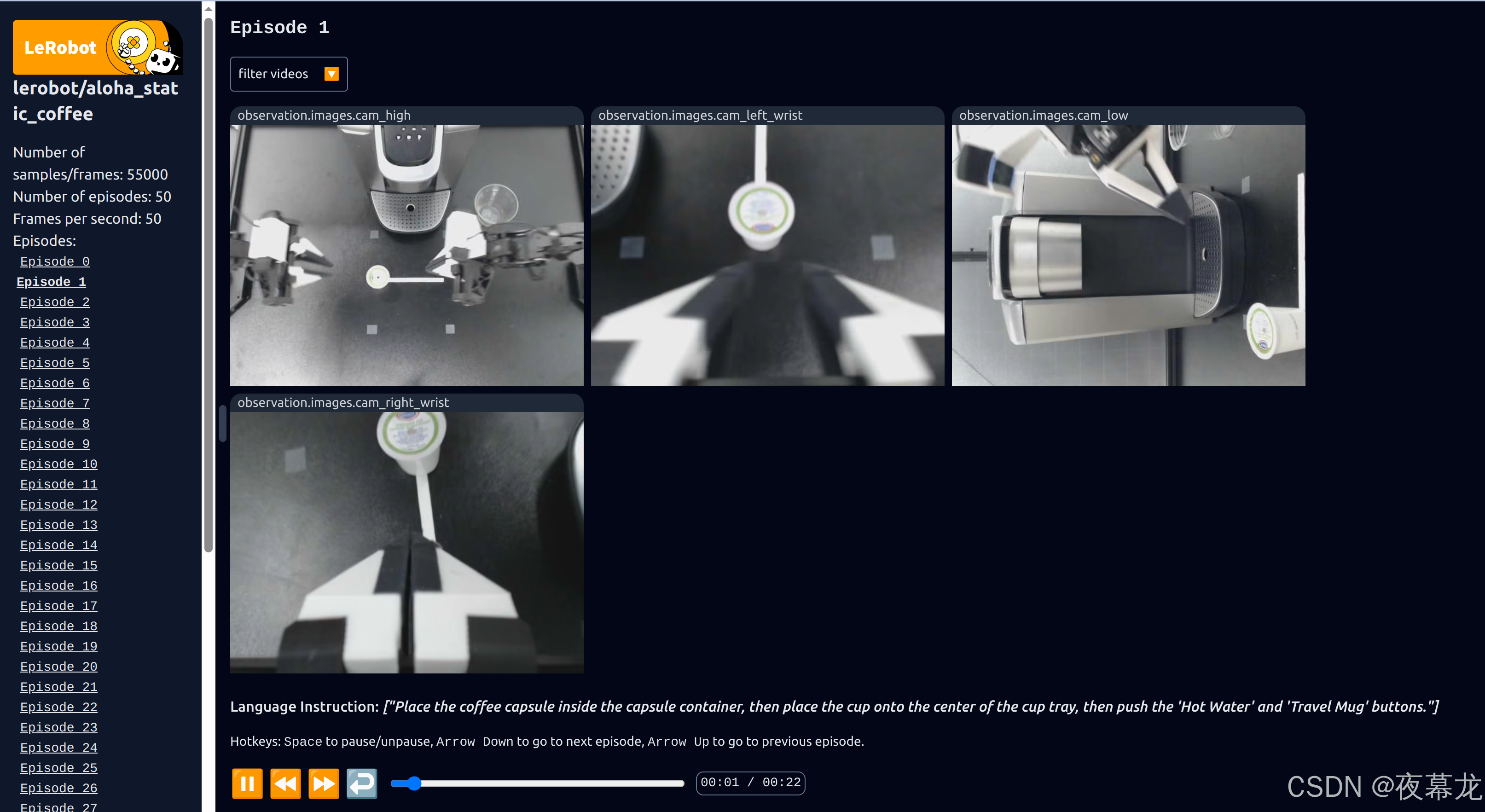
可以看到结果保存地址:

其中,下载的数据集默认存储在了 /home/yejiangchen/.cache/huggingface/lerobot/lerobot

下次再运行会直接调用无需下载
此外,如果想运行本地数据集,则需要指定 --root:
python lerobot/scripts/visualize_dataset_html.py \--root /home/yejiangchen/.cache/huggingface/lerobot/lerobot/aloha_static_coffee \--repo-id lerobot/aloha_static_coffee即可正常运行:

1.2 本地数据集
本地的话可以直接使用 visualize_dataset.py 脚本,测试一下之前下载的数据
python lerobot/scripts/visualize_dataset.py \--repo-id lerobot/aloha_static_coffee \--episode-index 0
2 代码详解 visualize_dataset_html.py
2.1 综述
此脚本将 LeRobotDataset 中的视频+时序传感数据(动作、状态等)渲染成交互式网页,方便快速浏览与排查
-
视频:在浏览器原生 <video> 标签播放
-
时序数值:转成 CSV 字符串,交给前端 Dygraphs JavaScript 库即刻绘制折线图
-
语言任务描述:展示在同一页面
-
部署:内置 Flask 服务器(默认 127.0.0.1:9090)即可本地或经 SSH‑tunnel 远程查看
2.2 流程概览
main() -> visualize_dataset_html() ->(配置、软链接)-> run_server() ->(HTTP 请求)-> get_dataset_info()、get_episode_data()、get_episode_language_instruction() 等
main()└─ 解析 CLI 参数└─ (可选)加载本地/远程数据集 → LeRobotDataset 或 IterableNamespace└─ visualize_dataset_html()├─ 创建/复用输出目录(含模板与静态文件)├─ (本地数据集)软链接视频到 static/videos└─ run_server() ←– 关键:注册所有 Flask 路由├─ "/" : 首页 / 数据集选择页├─ "/<ns>/<name>" : 自动跳到 episode_0└─ "/<ns>/<name>/episode_<id>" : 主可视化页面2.3 库引用
import argparse # 用于解析命令行参数
import csv # 用于生成 CSV 格式字符串
import json # 用于解析和生成 JSON 数据
import logging # 用于日志记录
import re # 用于正则表达式处理
import shutil # 用于文件和目录操作,如复制、删除
import tempfile # 用于创建临时目录
from io import StringIO # 用于将字符串当作文件读写
from pathlib import Path # 用于跨平台路径操作import numpy as np # 数值计算库
import pandas as pd # 数据处理库
import requests # 用于发起 HTTP 请求
from flask import Flask, redirect, render_template, request, url_for # Flask Web 框架核心组件from lerobot import available_datasets # 导入可用数据集列表
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset # LeRobotDataset 类
from lerobot.common.datasets.utils import IterableNamespace # 简单 namespace 类型
from lerobot.common.utils.utils import init_logging # 初始化日志设置2.4 mian() 函数
作为脚本入口,负责解析所有命令行参数并据此准备数据集实例,最后调用 visualize_dataset_html() 启动可视化流程
核心流程:
- 用 argparse 定义并读取参数(如 --repo-id、--root、--episodes、--serve 等)
- 根据 --load-from-hf-hub 决定是实例化完整的 LeRobotDataset(加载本地/缓存数据与视频),还是只拉取元信息 (get_dataset_info)
- 将解析好的 dataset 对象与其它参数传入 visualize_dataset_html()
| 参数 | 作用 | 典型值 |
|---|---|---|
--repo-id | HF Hub 上的数据集 namespace/name | lerobot/pusht |
--root | 本地数据集根目录 | ./data |
--load-from-hf-hub | 整数;为 1 时只下拉 meta / parquet / mp4,不构造完整 LeRobotDataset | 0/1 |
--episodes | 想看的 episode 索引列表 | 0 3 5 |
--host, --port | Flask 服务地址 | 默认 127.0.0.1:9090 |
--tolerance-s | 时间戳容差,保证 fps 一致性 | 1e-4 |
def main():# 入口:解析命令行并调用可视化函数parser = argparse.ArgumentParser()parser.add_argument("--repo-id",type=str,default=None,help="Name of hugging face repositery containing a LeRobotDataset dataset (e.g. `lerobot/pusht`).",)parser.add_argument("--root",type=Path,default=None,help="Root directory for a dataset stored locally (e.g. `--root data`).",)parser.add_argument("--load-from-hf-hub",type=int,default=0,help="Load videos and parquet files from HF Hub rather than local system.",)parser.add_argument("--episodes",type=int,nargs="*",default=None,help="Episode indices to visualize (e.g. `0 1 5 6`).",)parser.add_argument("--output-dir",type=Path,default=None,help="Directory path to write html files and kickoff a web server.",)parser.add_argument("--serve",type=int,default=1,help="Launch web server.",)parser.add_argument("--host",type=str,default="127.0.0.1",help="Web host used by the http server.",)parser.add_argument("--port",type=int,default=9090,help="Web port used by the http server.",)parser.add_argument("--force-override",type=int,default=0,help="Delete the output directory if it exists already.",)parser.add_argument("--tolerance-s",type=float,default=1e-4,help=("Tolerance in seconds used to ensure data timestamps respect the dataset fps value""If not given, defaults to 1e-4."),)args = parser.parse_args() # 解析命令行参数kwargs = vars(args)repo_id = kwargs.pop("repo-id") # 获取 repo-id 并从 kwargs 删除load_from_hf_hub = kwargs.pop("load_from_hf_hub")root = kwargs.pop("root")tolerance_s = kwargs.pop("tolerance_s")dataset = Noneif repo_id:# 根据 load_from_hf_hub 决定实例化 LeRobotDataset 还是只读 metadataset = (LeRobotDataset(repo_id, root=root, tolerance_s=tolerance_s)if not load_from_hf_hubelse get_dataset_info(repo_id))visualize_dataset_html(dataset, **vars(args)) # 调用主可视化入口if __name__ == "__main__":# 脚本直接运行时进入 mainmain()2.5 关键函数
2.5.1 run_server() —— Flask 应用核心
全局配置:app.config["SEND_FILE_MAX_AGE_DEFAULT"] = 0 # 每次刷新都拉最新资源
路由配置:
| 路由 | 功能 |
|---|---|
/ | • 如果脚本在**“单数据集模式”**(已传 dataset),立刻重定向到 episode 0• 否则渲染首页,列出推荐 ( featured_datasets) + 全部可用数据集 (lerobot_datasets) |
/<ns>/<name> | 纯跳转:把 <dataset>/episode_0 作为入口 |
/<ns>/<name>/episode_<id> | 主工作函数: 1.若脚本启动时没载数据,就动态 get_dataset_info()2.检查数据集版本 <2 则拒绝(旧格式) 3.调用 get_episode_data() → CSV + 列信息;拼装 Video‑URL / Tasks‑Text4.把所有信息喂给 visualize_dataset_template.html 渲染 |
def run_server(dataset: LeRobotDataset | IterableNamespace | None,episodes: list[int] | None,host: str,port: str,static_folder: Path,template_folder: Path,
):"""启动 Flask HTTP 服务,渲染可视化页面。参数:- dataset: 已加载的数据集实例或 None- episodes: 要展示的 episode 列表或 None- host, port: 服务监听地址与端口- static_folder: 静态文件目录(视频、JS、CSS)- template_folder: Jinja2 模板目录"""app = Flask(__name__,static_folder=static_folder.resolve(), # 静态资源路径template_folder=template_folder.resolve() # 模板文件路径)app.config["SEND_FILE_MAX_AGE_DEFAULT"] = 0 # 禁用浏览器缓存,确保每次都拉最新的资源@app.route("/")def hommepage(dataset=dataset):"""应用根路由:根据有无 dataset 参数决定重定向或渲染选择页"""if dataset:# 如果在脚本启动时传入 dataset,直接跳转到第 0 集dataset_namespace, dataset_name = dataset.repo_id.split("/")return redirect(url_for("show_episode",dataset_namespace=dataset_namespace,dataset_name=dataset_name,episode_id=0,))# 否则尝试从 query 参数读取 dataset & episode 再跳转dataset_param, episode_param = None, Noneall_params = request.argsif "dataset" in all_params:dataset_param = all_params["dataset"]if "episode" in all_params:episode_param = int(all_params["episode"])if dataset_param:dataset_namespace, dataset_name = dataset_param.split("/")return redirect(url_for("show_episode",dataset_namespace=dataset_namespace,dataset_name=dataset_name,episode_id=episode_param if episode_param is not None else 0,))# 默认渲染首页,列出 featured + 全部 available datasetsfeatured_datasets = ["lerobot/aloha_static_cups_open","lerobot/columbia_cairlab_pusht_real","lerobot/taco_play",]return render_template("visualize_dataset_homepage.html",featured_datasets=featured_datasets,lerobot_datasets=available_datasets,)@app.route("/<string:dataset_namespace>/<string:dataset_name>")2.5.2 get_ep_csv_fname(episode_id)
简单工具,按约定返回某集 CSV 文件名 episode_{id}.csv
def get_ep_csv_fname(episode_id: int):# 根据 episode 索引构造 CSV 文件名ep_csv_fname = f"episode_{episode_id}.csv"return ep_csv_fname2.5.3 get_episode_data()
把单个 episode 的多通道数值数据 -> 二维列表 -> CSV 字符串(返给前端 JS)
1. 列挑选
selected = [col for col, ft in ds.features.items()if ft["dtype"] in ["float32", "int32"]]
selected.remove("timestamp")
2. 过滤高维张量:shape 维度 > 1 的列记入 ignored_columns,避免动态图崩溃
3. 列名展开:如果在 meta 里有 names 用定义好的;否则按 col_0 … col_n 生成
4. 取数据:本地 LeRobotDataset 利用 .episode_data_index 截取 parquet;Hub‑Only 直接 pd.read_parquet(url)
5. 转换为 CSV string(StringIO + csv.writer)
def get_episode_data(dataset: LeRobotDataset | IterableNamespace, episode_index):"""获取 episode 的时序数据,并将其转换为 CSV 字符串返回。Returns:- csv_string: CSV 格式的整个 episode 数据- columns: [{key: 原始列名, value: 展开后子列名列表}, ...]- ignored_columns: 被忽略的高维列名称列表"""columns = [] # 存储展开后列的信息# 选出所有 dtype 为 float32/int32 的数值列selected_columns = [col for col, ft in dataset.features.items() if ft["dtype"] in ["float32", "int32"]]selected_columns.remove("timestamp") # timestamp 先单独处理ignored_columns = [] # 高维列名称for column_name in selected_columns:shape = dataset.features[column_name]["shape"] # 列的原始 shapeshape_dim = len(shape)if shape_dim > 1:# 如果维度 >1,则忽略,不支持 Dygraph 绘多维张量selected_columns.remove(column_name)ignored_columns.append(column_name)# CSV header: timestamp + 各子列名header = ["timestamp"]# 遍历每个一维列,展开成多列子名称for column_name in selected_columns:dim_state = (dataset.meta.shapes[column_name][0]if isinstance(dataset, LeRobotDataset)else dataset.features[column_name].shape[0])if "names" in dataset.features[column_name] and dataset.features[column_name]["names"]:# 如果 meta 中定义了 names,则使用自定义子列名column_names = dataset.features[column_name]["names"]while not isinstance(column_names, list):column_names = list(column_names.values())[0]else:# 否则按 col_0...col_n 展开column_names = [f"{column_name}_{i}" for i in range(dim_state)]columns.append({"key": column_name, "value": column_names})header += column_names # 累加到 CSV header# timestamp 放回最前selected_columns.insert(0, "timestamp")if isinstance(dataset, LeRobotDataset):# 本地模式:根据 index 范围 select pandas DataFramefrom_idx = dataset.episode_data_index["from"][episode_index]to_idx = dataset.episode_data_index["to"][episode_index]data = (dataset.hf_dataset.select(range(from_idx, to_idx)).select_columns(selected_columns).with_format("pandas"))else:# 远程模式:通过 HTTP 拉取 parquet,然后筛列repo_id = dataset.repo_idurl = (f"https://huggingface.co/datasets/{repo_id}/resolve/main/"+ dataset.data_path.format(episode_chunk=int(episode_index) // dataset.chunks_size,episode_index=episode_index))df = pd.read_parquet(url)data = df[selected_columns]# 构造 numpy 二维数组:首列 timestamp,其余为各子列值rows = np.hstack((np.expand_dims(data["timestamp"], axis=1),*[np.vstack(data[col]) for col in selected_columns[1:]],)).tolist()# 写 CSV 到内存字符串csv_buffer = StringIO()csv_writer = csv.writer(csv_buffer)csv_writer.writerow(header)csv_writer.writerows(rows)csv_string = csv_buffer.getvalue()return csv_string, columns, ignored_columns2.5.4 get_episode_video_paths
仅在本地 LeRobotDataset 场景下,获取指定 episode 在底层 HF 数据集中的视频文件路径列表(内部没用到,备用)
- 找到该集第一帧在整表中的行索引
- 针对每个 dataset.meta.video_keys,在对应列读取 ["path"] 字段
def get_episode_video_paths(dataset: LeRobotDataset, ep_index: int) -> list[str]:# hack: 取该 episode 第一帧索引以定位 video pathfirst_frame_idx = dataset.episode_data_index["from"][ep_index].item()return [dataset.hf_dataset.select_columns(key)[first_frame_idx][key]["path"]for key in dataset.meta.video_keys]2.5.5 get_episode_language_instruction
仅在数据集包含 language_instruction 特征时调用,从对应行抽取并清洗掉 Tensor 的包装字符串,返回指令文本
- 判断 dataset.features 是否存在 language_instruction
- 取该集第一帧索引,读取字段,去掉前后缀冗余信息
def get_episode_language_instruction(dataset: LeRobotDataset, ep_index: int) -> list[str]:# 如果数据集含 language_instruction 特征,则提取并清洗字符串if "language_instruction" not in dataset.features:return Nonefirst_frame_idx = dataset.episode_data_index["from"][ep_index].item()language_instruction = dataset.hf_dataset[first_frame_idx]["language_instruction"]# 去除 Tensor 格式冗余包装return language_instruction.removeprefix("tf.Tensor(b'").removesuffix("', shape=(), dtype=string)")2.5.6 get_dataset_info(repo_id)
远程数据辅助:拉 meta/info.json 并包成 IterableNamespace
额外用 episodes.jsonl 找每一集的 tasks 列表
def get_dataset_info(repo_id: str) -> IterableNamespace:# 远程拉取 meta/info.json 并转为 IterableNamespaceresponse = requests.get(f"https://huggingface.co/datasets/{repo_id}/resolve/main/meta/info.json",timeout=5)response.raise_for_status()dataset_info = response.json()dataset_info["repo_id"] = repo_idreturn IterableNamespace(dataset_info)2.5.7 visualize_dataset_html
搭建静态目录结构(HTML 模板 + 静态资源),并根据是否已有数据集对象决定是否创建视频软链接,最后根据 serve 标志调用 run_server()
- 调用 init_logging() 初始化日志设置
- 计算模板目录 templates,创建或清空(若 force_override)输出目录以及 static 子目录
- 若传入本地 LeRobotDataset,在 static/videos 下打软链接指向数据集的 videos 文件夹
- 若 serve 为真,调用 run_server() 启动 Flask 服务
def visualize_dataset_html(dataset: LeRobotDataset | None,episodes: list[int] | None = None,output_dir: Path | None = None,serve: bool = True,host: str = "127.0.0.1",port: int = 9090,force_override: bool = False,
) -> Path | None:# 主函数:准备静态目录 & 启动服务器init_logging() # 配置根日志级别等template_dir = Path(__file__).resolve().parent.parent / "templates"if output_dir is None:# 未指定输出目录时,创建临时目录output_dir = tempfile.mkdtemp(prefix="lerobot_visualize_dataset_")output_dir = Path(output_dir)if output_dir.exists():if force_override:shutil.rmtree(output_dir) # 强制覆盖时先删掉else:logging.info(f"Output directory already exists. Loading from it: '{output_dir}'")output_dir.mkdir(parents=True, exist_ok=True)static_dir = output_dir / "static"static_dir.mkdir(parents=True, exist_ok=True)if dataset is None:# 仅在无本地 dataset 且 serve=True 时进入 run_serverif serve:run_server(dataset=None,episodes=None,host=host,port=port,static_folder=static_dir,template_folder=template_dir,)else:# 本地数据集:在 static/videos 创建软链接到 dataset.root/videosif isinstance(dataset, LeRobotDataset):ln_videos_dir = static_dir / "videos"if not ln_videos_dir.exists():ln_videos_dir.symlink_to((dataset.root / "videos").resolve())# 启动服务器if serve:run_server(dataset, episodes, host, port, static_dir, template_dir)3 代码详解 visualize_dataset.py
3.1 综述
此脚本基于 Rerun SDK,实现对 LeRobotDataset 中单个 episode 进行可视化或记录,主要有三种模式:
- 本地交互模式(mode="local") 直接在当前机器弹出可视化窗口,用于快速调试与观测
- 远端服务模式(mode="distant") 在数据存放的远端机器上启动 WebSocket+HTTP 服务,本地通过 rerun ws://… 连接浏览
- 离线保存模式(--save 1) 将整次会话记录到一个 .rrd 文件,后续可通过 rerun path/to/file.rrd 离线回放
其中,脚本既能实时显示视频帧,也能同步绘制动作、状态、奖励等时序数值
3.2 流程概览
main()├─ 解析 CLI 参数├─ LeRobotDataset(repo_id, root, tolerance_s)└─ visualize_dataset(...)├─ EpisodeSampler(dataset, episode_index)├─ DataLoader(dataset, sampler, batch_size, num_workers)├─ rr.init(namespace, spawn=local_viewer?)├─ gc.collect() # 避免多 worker 卡死├─ (mode=="distant")? rr.serve(web_port, ws_port)├─ for batch in DataLoader:│ ├─ for each frame in batch:│ │ ├─ rr.set_time_sequence/frame_index│ │ ├─ rr.set_time_seconds/timestamp│ │ ├─ rr.log(Image) for each camera│ │ └─ rr.log(Scalar) for each numeric field└─ 会话结束├─ local+save → rr.save(.rrd)└─ distant → 阻塞等待 Ctrl–C3.3 库引用
import argparse # 解析命令行参数模块
import gc # 垃圾回收模块,用于手动触发回收
import logging # 日志记录模块
import time # 时间相关函数模块
from pathlib import Path # 跨平台路径操作
from typing import Iterator # 类型提示:迭代器import numpy as np # 数值计算库
import rerun as rr # Rerun SDK,用于实时可视化
import torch # PyTorch 深度学习库
import torch.utils.data # PyTorch 数据加载工具
import tqdm # 进度条库from lerobot.common.datasets.lerobot_dataset import LeRobotDataset # 自定义 LeRobotDataset 数据集类3.4 mian() 函数
- 强制要求:--repo-id(数据集标识)和 --episode-index(要可视化的集号)
- 可选:数据集根目录、DataLoader 配置(--batch-size、--num-workers)、模式切换(--mode、--save、--output-dir、--web-port、--ws-port)等
- 最终实例化 LeRobotDataset 并调用 visualize_dataset()
def main():# 脚本入口:解析参数并调用可视化函数parser = argparse.ArgumentParser()parser.add_argument("--repo-id",type=str,required=True,help="HF Hub 上数据集标识,例如 `lerobot/pusht`。",)parser.add_argument("--episode-index",type=int,required=True,help="要可视化的 episode 索引。",)parser.add_argument("--root",type=Path,default=None,help="本地数据集根目录,例如 `--root data`。默认使用 HuggingFace 缓存。",)parser.add_argument("--output-dir",type=Path,default=None,help="保存 .rrd 文件的目录,当 `--save 1` 时生效。",)parser.add_argument("--batch-size",type=int,default=32,help="DataLoader 的 batch 大小。",)parser.add_argument("--num-workers",type=int,default=4,help="DataLoader 的并行工作进程数。",)parser.add_argument("--mode",type=str,default="local",help=("可视化模式:'local' 或 'distant'。`"local` 会本地弹出 viewer;`"distant` 则启动服务供远程浏览。"),)parser.add_argument("--web-port",type=int,default=9090,help="`--mode distant` 时的 HTTP 服务端口。",)parser.add_argument("--ws-port",type=int,default=9087,help="`--mode distant` 时的 WebSocket 服务端口。",)parser.add_argument("--save",type=int,default=0,help=("是否保存为 .rrd 文件,启用后会禁用弹窗。""使用 `--output-dir path` 指定目录。"),)parser.add_argument("--tolerance-s",type=float,default=1e-4,help=("时间戳容差,保证与 fps 一致。""传入 LeRobotDataset 构造参数。"),)args = parser.parse_args() # 解析命令行kwargs = vars(args)repo_id = kwargs.pop("repo_id") # 提取 repo_idroot = kwargs.pop("root") # 提取 roottolerance_s = kwargs.pop("tolerance_s") # 提取容差参数logging.info("Loading dataset") # 日志:开始加载数据集dataset = LeRobotDataset(repo_id, root=root, tolerance_s=tolerance_s) # 构造数据集visualize_dataset(dataset, **vars(args)) # 调用可视化主函数if __name__ == "__main__":# 如果脚本被直接执行,则运行 main()main()3.5 关键函数
3.5.1 采样器(EpisodeSampler)
只遍历指定 episode 在底层数据表(Parquet)中的帧索引范围,供 PyTorch DataLoader 使用
class EpisodeSampler(torch.utils.data.Sampler):# 自定义数据采样器,仅遍历指定 episode 的帧索引def __init__(self, dataset: LeRobotDataset, episode_index: int):# 根据 episode_index 从 dataset 中获取起始和结束的全局帧索引from_idx = dataset.episode_data_index["from"][episode_index].item()to_idx = dataset.episode_data_index["to"][episode_index].item()# 保存帧索引范围,用于 DataLoader 的 samplerself.frame_ids = range(from_idx, to_idx)def __iter__(self) -> Iterator:# 返回一个针对帧索引的迭代器return iter(self.frame_ids)def __len__(self) -> int:# 返回此 sampler 的总采样数量(即帧数)return len(self.frame_ids)3.5.2 图像转换(to_hwc_uint8_numpy)
把 PyTorch 的 C×H×W 浮点图像张量(float32, 值域 [0,1])转换为 NumPy 的 H×W×C uint8 数组(值域 [0,255]),以便 Rerun 显示
def to_hwc_uint8_numpy(chw_float32_torch: torch.Tensor) -> np.ndarray:# 将 C×H×W 的 float32 Torch 张量转换为 H×W×C 的 uint8 NumPy 数组assert chw_float32_torch.dtype == torch.float32 # 确保数据类型为 float32assert chw_float32_torch.ndim == 3 # 确保是 3 维c, h, w = chw_float32_torch.shape # 解包通道、高度、宽度assert c < h and c < w, f"expect channel first images, but instead {chw_float32_torch.shape}"# 先乘 255,再转 uint8,然后 permute 到 HWC,最后转换为 NumPyhwc_uint8_numpy = (chw_float32_torch * 255).type(torch.uint8).permute(1, 2, 0).numpy()return hwc_uint8_numpy # 返回处理后的图像数组3.5.3 核心可视化函数(visualize_dataset())
1. 初始化
- 构造 DataLoader(dataset, sampler=EpisodeSampler, batch_size, num_workers)
- 调用 rr.init() 启动 Rerun 会话
- 在远端模式下额外执行 rr.serve() 开启 WebSocket+HTTP 服务
2. 数据记录
- 遍历每个 batch、每帧
- 用 rr.set_time_sequence/rr.set_time_seconds 标注时间信息
- 对所有摄像头键(camera_keys)逐帧 rr.log(Image)
- 逐维 rr.log(Scalar) 记录 action、observation.state、next.reward、next.done、next.success 等数值
3. 会话收尾
- 本地保存模式:rr.save() 写出 .rrd 文件并返回路径
- 远端服务模式:进入阻塞循环以保持 WebSocket 连接,直至 Ctrl–C 退出
def visualize_dataset(dataset: LeRobotDataset,episode_index: int,batch_size: int = 32,num_workers: int = 0,mode: str = "local",web_port: int = 9090,ws_port: int = 9087,save: bool = False,output_dir: Path | None = None,
) -> Path | None:# 主可视化函数,根据模式(Local/Distant)实时或离线记录并展示数据if save:# 如果要保存为 .rrd 文件,必须传入 output_dirassert output_dir is not None, ("Set an output directory where to write .rrd files with `--output-dir path/to/directory`.")repo_id = dataset.repo_id # 获取数据集唯一标识logging.info("Loading dataloader") # 日志:开始加载 DataLoaderepisode_sampler = EpisodeSampler(dataset, episode_index) # 创建只遍历指定 episode 的 samplerdataloader = torch.utils.data.DataLoader(dataset, # 数据集num_workers=num_workers, # 并行加载进程数batch_size=batch_size, # 每个 batch 的帧数sampler=episode_sampler, # 自定义 sampler)logging.info("Starting Rerun") # 日志:启动 Rerun 会话if mode not in ["local", "distant"]:# 不支持其它模式时抛错raise ValueError(mode)# 本地模式且不保存时,自动 spawn viewer;否则不弹出spawn_local_viewer = mode == "local" and not saverr.init(f"{repo_id}/episode_{episode_index}", spawn=spawn_local_viewer)# Rerun v0.16 前的 workaround:触发垃圾回收,避免多进程 DataLoader 卡住gc.collect()if mode == "distant":# 远端模式:启动 WebSocket + HTTP 服务,不自动打开浏览器rr.serve(open_browser=False, web_port=web_port, ws_port=ws_port)logging.info("Logging to Rerun") # 日志:开始写入 Rerun 数据for batch in tqdm.tqdm(dataloader, total=len(dataloader)):# 遍历每个 batch,显示进度条for i in range(len(batch["index"])):# 记录时间序列:帧索引与时间戳rr.set_time_sequence("frame_index", batch["frame_index"][i].item())rr.set_time_seconds("timestamp", batch["timestamp"][i].item())# 遍历所有 camera key,记录图像for key in dataset.meta.camera_keys:rr.log(key, rr.Image(to_hwc_uint8_numpy(batch[key][i])))# 如果存在 action 字段,则按维度记录每个动作值if "action" in batch:for dim_idx, val in enumerate(batch["action"][i]):rr.log(f"action/{dim_idx}", rr.Scalar(val.item()))# 如果存在 observation.state,则按维度记录状态值if "observation.state" in batch:for dim_idx, val in enumerate(batch["observation.state"][i]):rr.log(f"state/{dim_idx}", rr.Scalar(val.item()))# 可选字段:next.done, next.reward, next.successif "next.done" in batch:rr.log("next.done", rr.Scalar(batch["next.done"][i].item()))if "next.reward" in batch:rr.log("next.reward", rr.Scalar(batch["next.reward"][i].item()))if "next.success" in batch:rr.log("next.success", rr.Scalar(batch["next.success"][i].item()))if mode == "local" and save:# 本地保存模式:写入 .rrd 文件并返回路径output_dir = Path(output_dir)output_dir.mkdir(parents=True, exist_ok=True)repo_id_str = repo_id.replace("/", "_")rrd_path = output_dir / f"{repo_id_str}_episode_{episode_index}.rrd"rr.save(rrd_path)return rrd_pathelif mode == "distant":# 远端模式:阻塞当前进程,直到手动按 Ctrl-Ctry:while True:time.sleep(1)except KeyboardInterrupt:print("Ctrl-C received. Exiting.")4 本地数据集效果
python lerobot/scripts/visualize_dataset.py --repo-id loacalhost/square_into_box --root=./collections/square_into_box/ --episode-index 0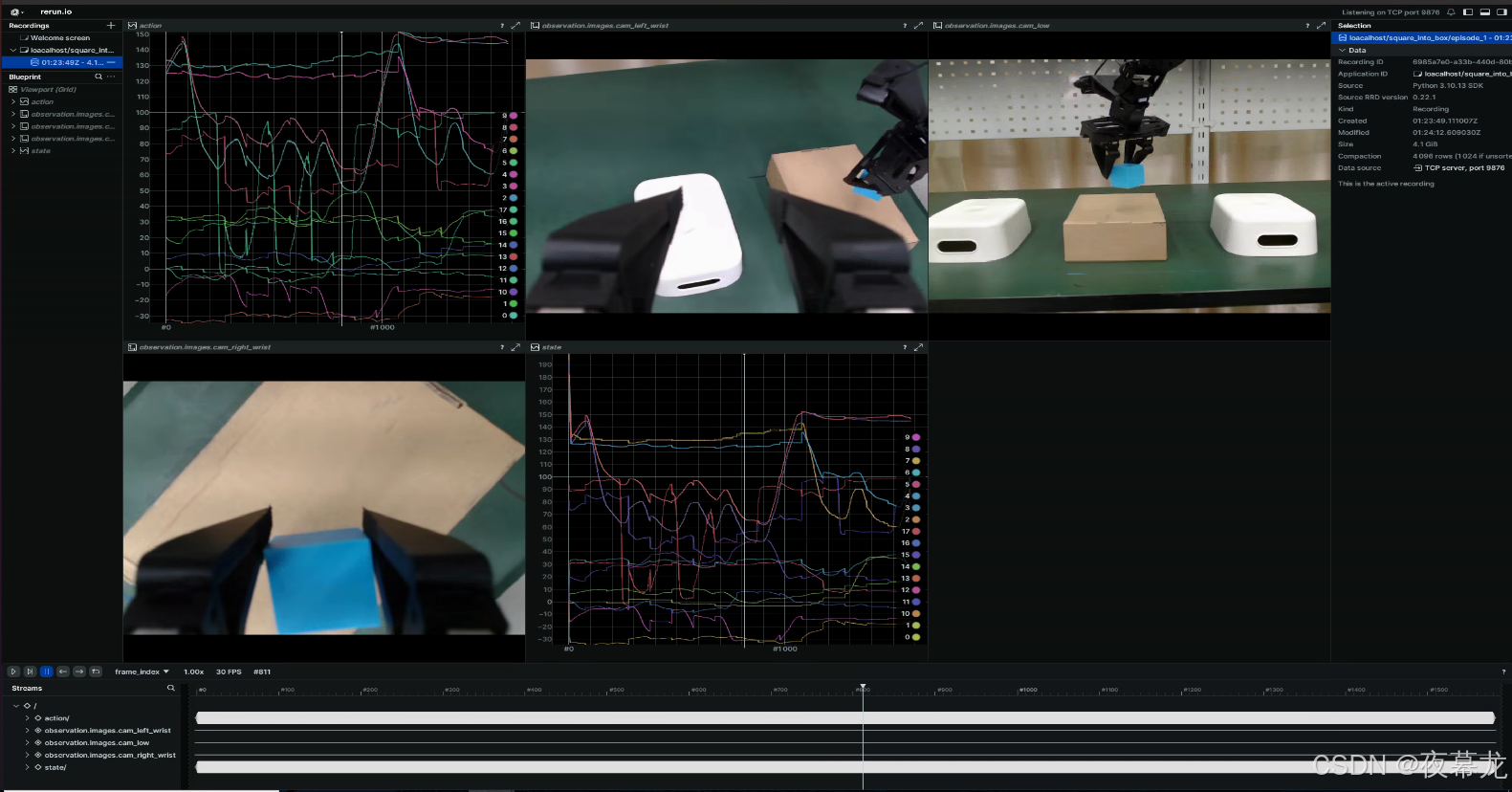
相关文章:
LeRobot 项目部署运行逻辑(六)——visualize_dataset_html.py/visualize_dataset.py
可视化脚本包括了两个方法:远程下载 huggingface 上的数据集和使用本地数据集 脚本主要使用两个: 目前来说,ACT 采集训练用的是统一时间长度的数据集,此外,这两个脚本最大的问题在于不能裁剪,这也是比较好…...
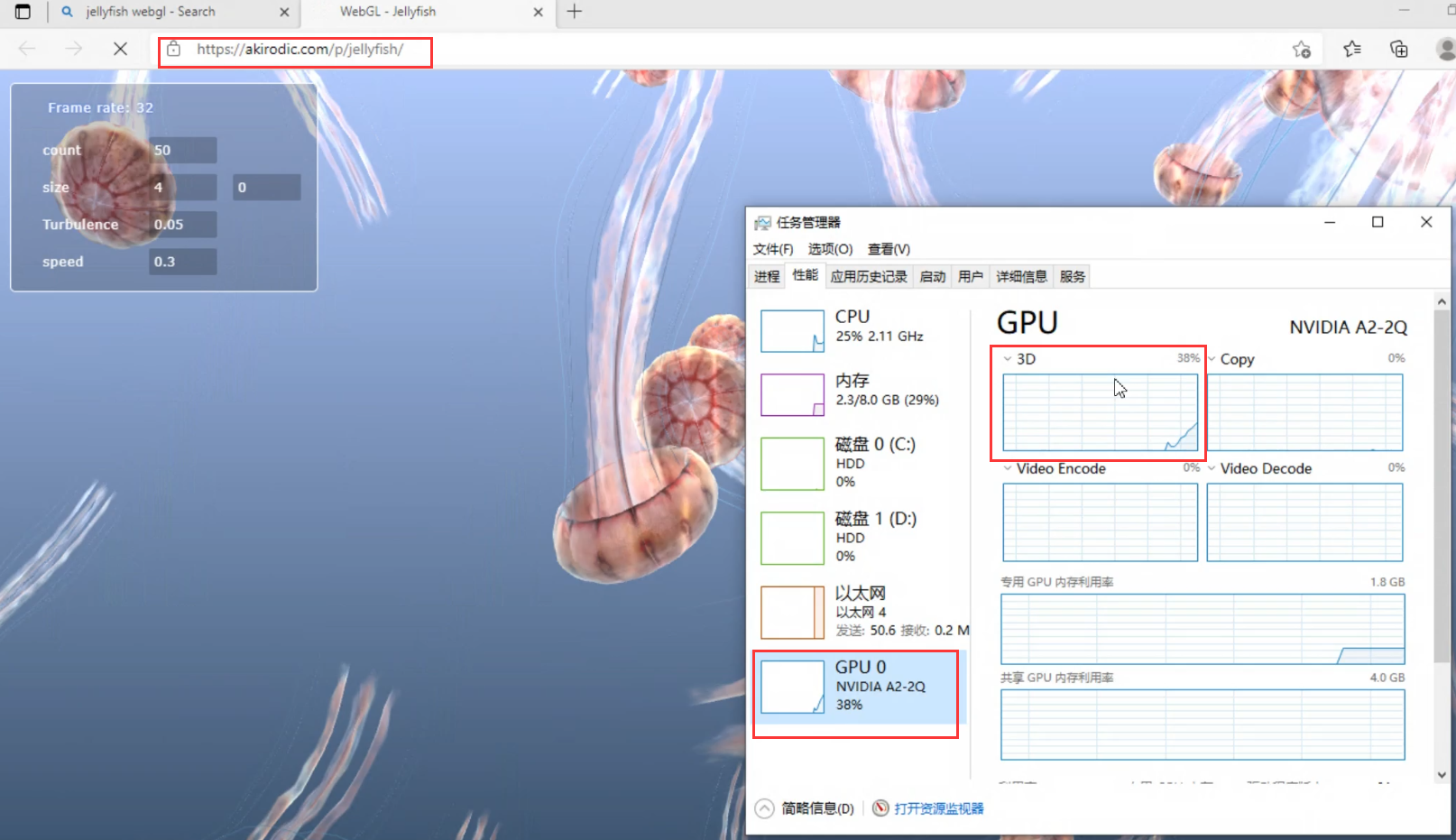
Windows Server 2025开启GPU分区(GPU-P)部署DoraCloud云桌面
本文描述在ShareStation工作站虚拟化方案的部署过程。 将服务器上部署 Windows Server、DoraCloud,并创建带有vGPU的虚拟桌面。 GPU分区技术介绍 GPU-P(GPU Partitioning) 是微软在 Windows 虚拟化平台(如 Hyper-V)中…...
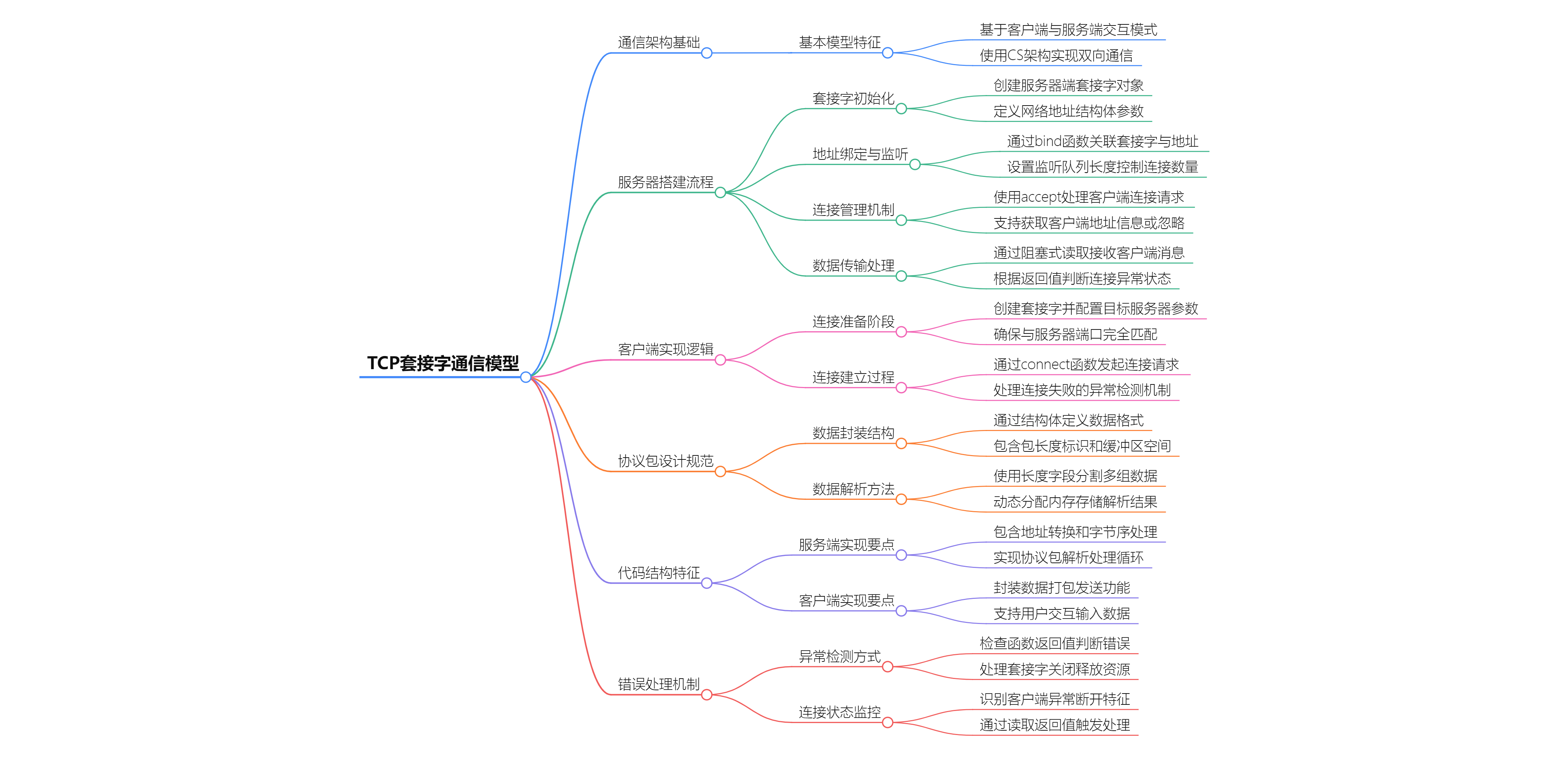
TCP套接字通信核心要点
TCP套接字通信核心要点 通信模型架构 客户端-服务端模型 CS架构:客户端发起请求,服务端响应和处理请求双向通道:建立连接后实现全双工通信 服务端搭建流程 核心步骤 创建套接字 int server socket(AF_INET, SOCK_STREAM, 0); 参数说明&am…...
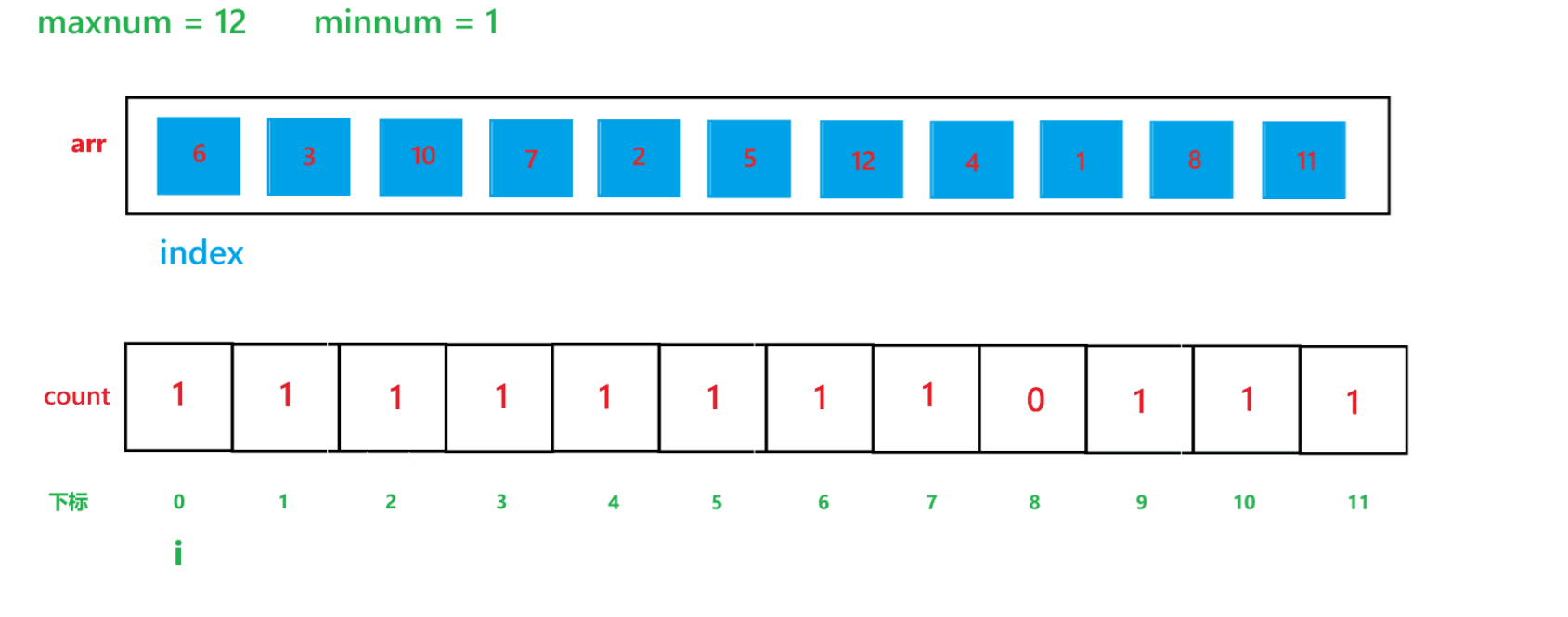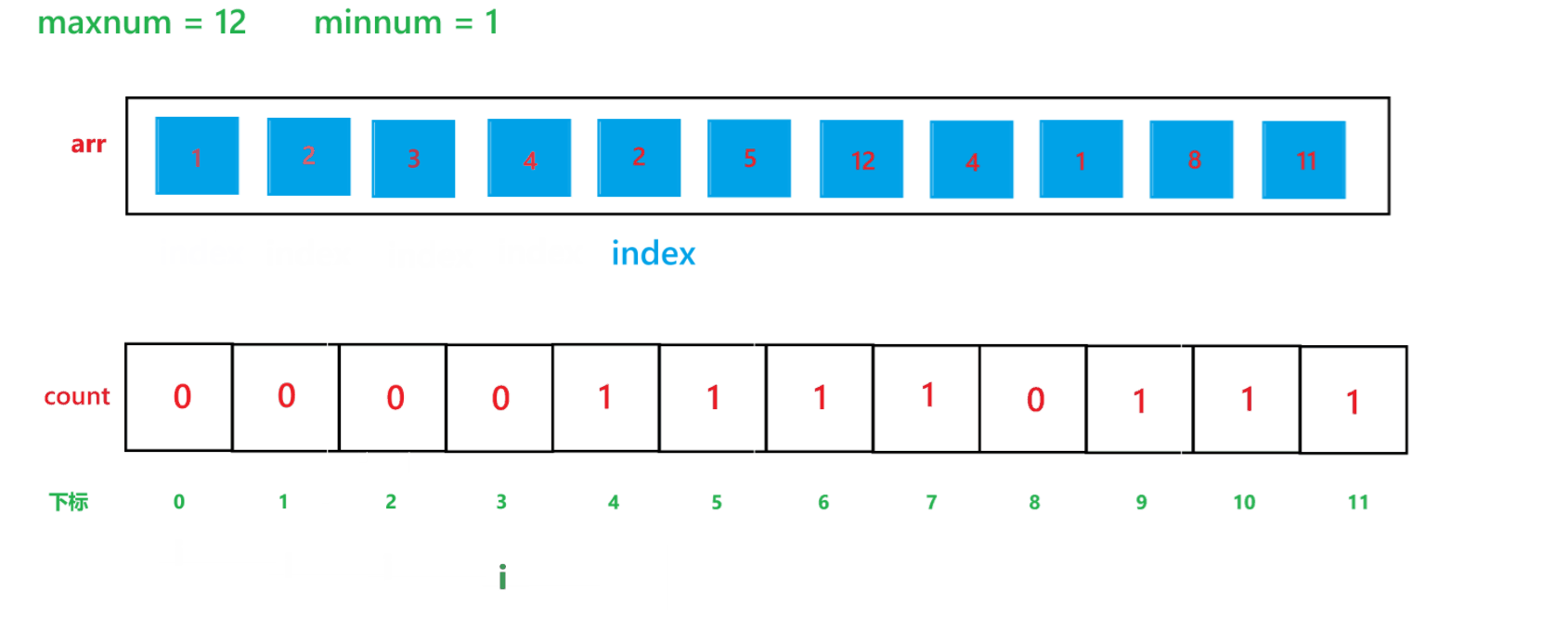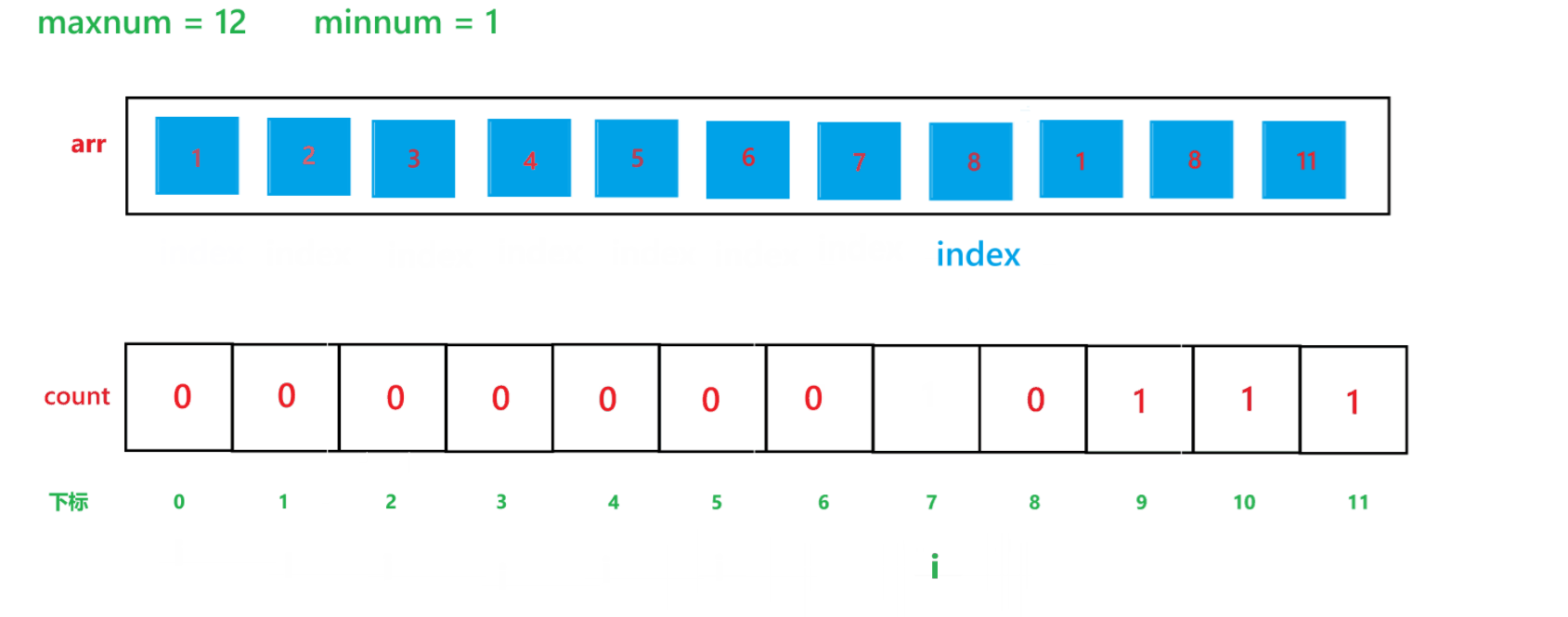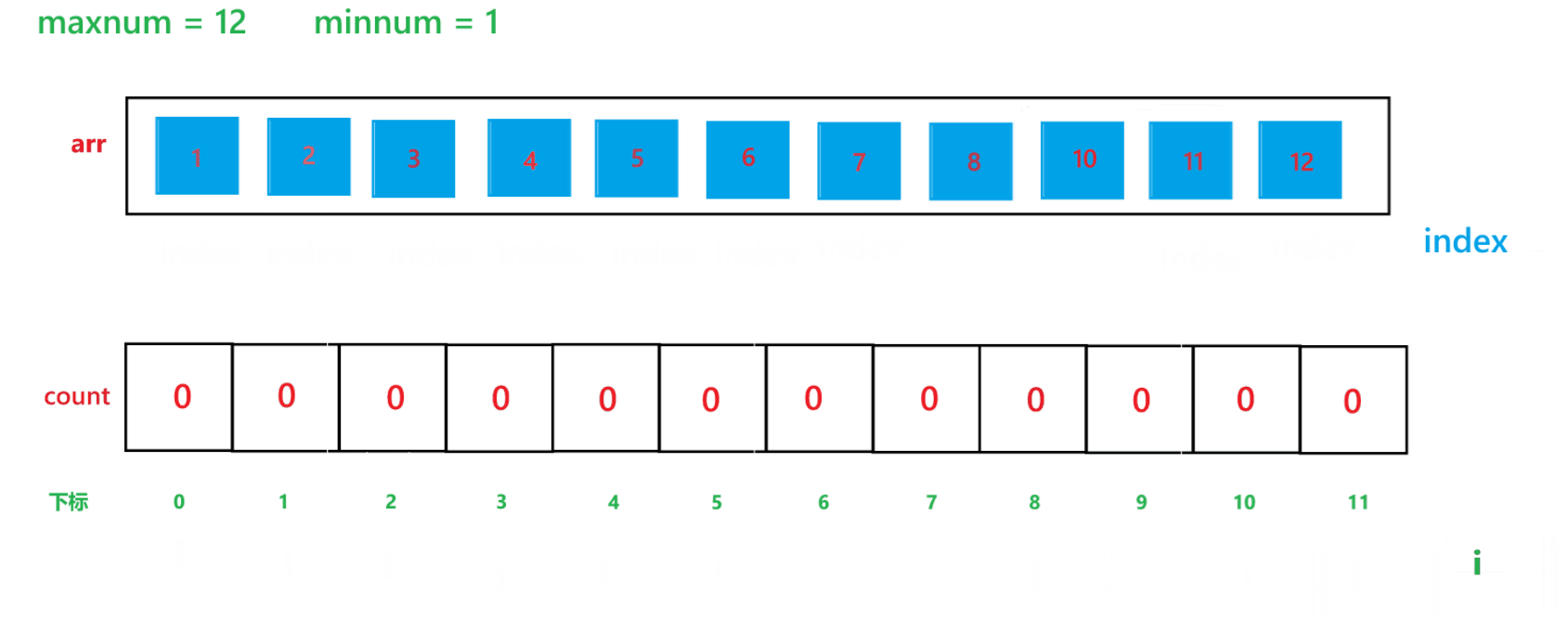
【C】初阶数据结构15 -- 计数排序与稳定性分析
本文主要讲解七大排序算法之外的另一种排序算法 -- 计数排序 目录 1 计数排序 1) 算法思想 2) 代码 3) 时间复杂度与空间复杂度分析 (1) 时间复杂度 (2) 空间复杂度 4) 计…...
高性能Python Web 框架--FastAPI 学习「基础 → 进阶 → 生产级」
以下是针对 FastAPI 的保姆级教程,包含核心概念、完整案例和关键注意事项,采用「基础 → 进阶 → 生产级」的三阶段教学法: 一、FastAPI介绍 FastAPI 是一个现代化的、高性能的 Python Web 框架,专门用于构建 APIs(应…...

Qt QML自定义LIstView
QML ListView组合拳做列表,代码不可直接复制使用,需要小改 先上图看效果 样式1 样式2 样式3 原理:操作:技术点:代码片段: 先上图看效果 样式1 三个表格组合成要给,上下滚动时,三个同时滚动&am…...

C++进阶--红黑树的实现
文章目录 红黑树的实现红黑树的概念红黑树的规则红黑树的效率 红黑树的实现红黑树的结构红黑树的插入变色单旋(变色)双旋(变色) 红黑树的查找红黑树的验证 总结:结语 很高兴和大家见面,给生活加点impetus&a…...
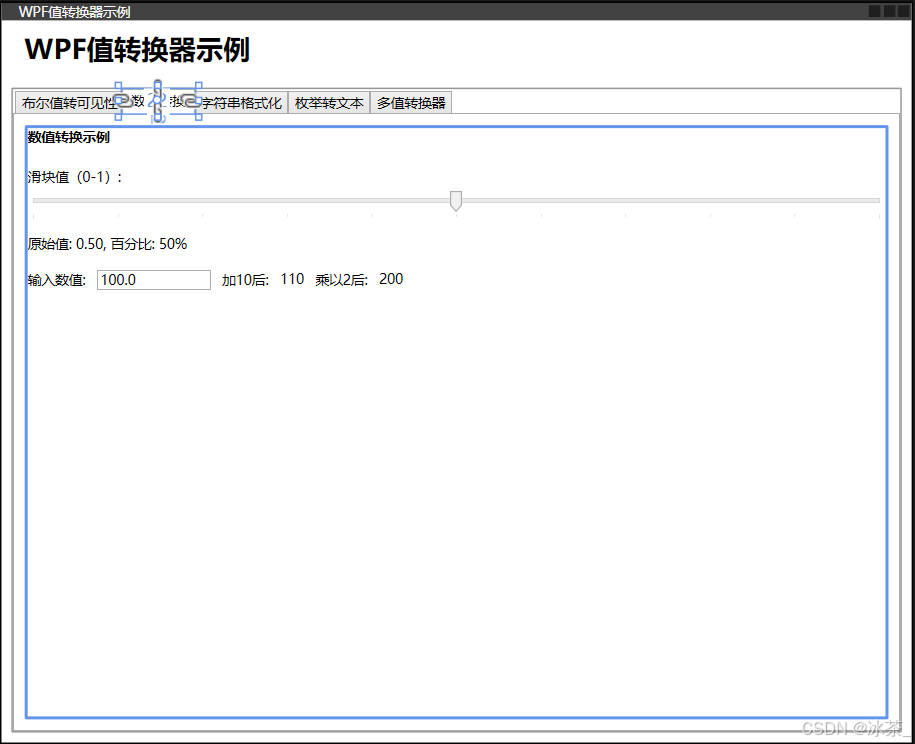
WPF之值转换器
文章目录 目录什么是值转换器IValueConverter接口Convert方法ConvertBack方法 创建和使用值转换器定义转换器类在XAML中使用转换器转换器参数(ConverterParameter) 常用转换器实现布尔值转可见性(BoolToVisibilityConverter)数值转…...

黄金、碳排放期货市场API接口文档
StockTV 提供了多种期货市场的数据接口,包括获取K线图表数据、查询特定期货的实时行情等。以下为对接期货市场的详细接口说明。 一、获取K线图表数据 通过调用/futures/kline接口,您可以获取指定期货合约的历史K线数据(例如开盘价、最高价、…...

云上系统CC攻击如何进行检测与防御?
云上系统遭受CC攻击(Challenge Collapsar,一种针对应用层的DDoS攻击)时,检测与防御需结合流量分析、行为识别和技术手段,以下是核心方法: 一、检测方法 异常流量分析 监控请求量突增&#…...

qml中的TextArea使用QSyntaxHighlighter显示高亮语法
效果图,左侧显示行号,右侧用TextArea显示文本内容,并且语法高亮。 2025年5月8号更新 1、多行文本注释 多行文本注释跟普通的高亮规则代码不太一样,代码需要修改,这里以JavaScript举例。 先制定多行文本注释规则&…...

QuecPython+腾讯云:快速连接腾讯云l0T平台
该模块提供腾讯 IoT 平台物联网套件客户端功能,目前的产品节点类型仅支持“设备”,设备认证方式支持“一机一密”和“动态注册认证”。 BC25PA系列不支持该功能。 初始化腾讯 IoT 平台 TXyun TXyun(productID, devicename, devicePsk, ProductSecret)配置腾讯 IoT…...

RocketMQ 深度解析:架构设计与最佳实践
在分布式系统架构日益复杂的今天,消息中间件作为系统间通信的桥梁,扮演着至关重要的角色。RocketMQ 作为阿里开源的高性能分布式消息中间件,凭借其卓越的性能、丰富的功能以及高可用性,在电商、金融、互联网等众多领域得到广泛应用…...
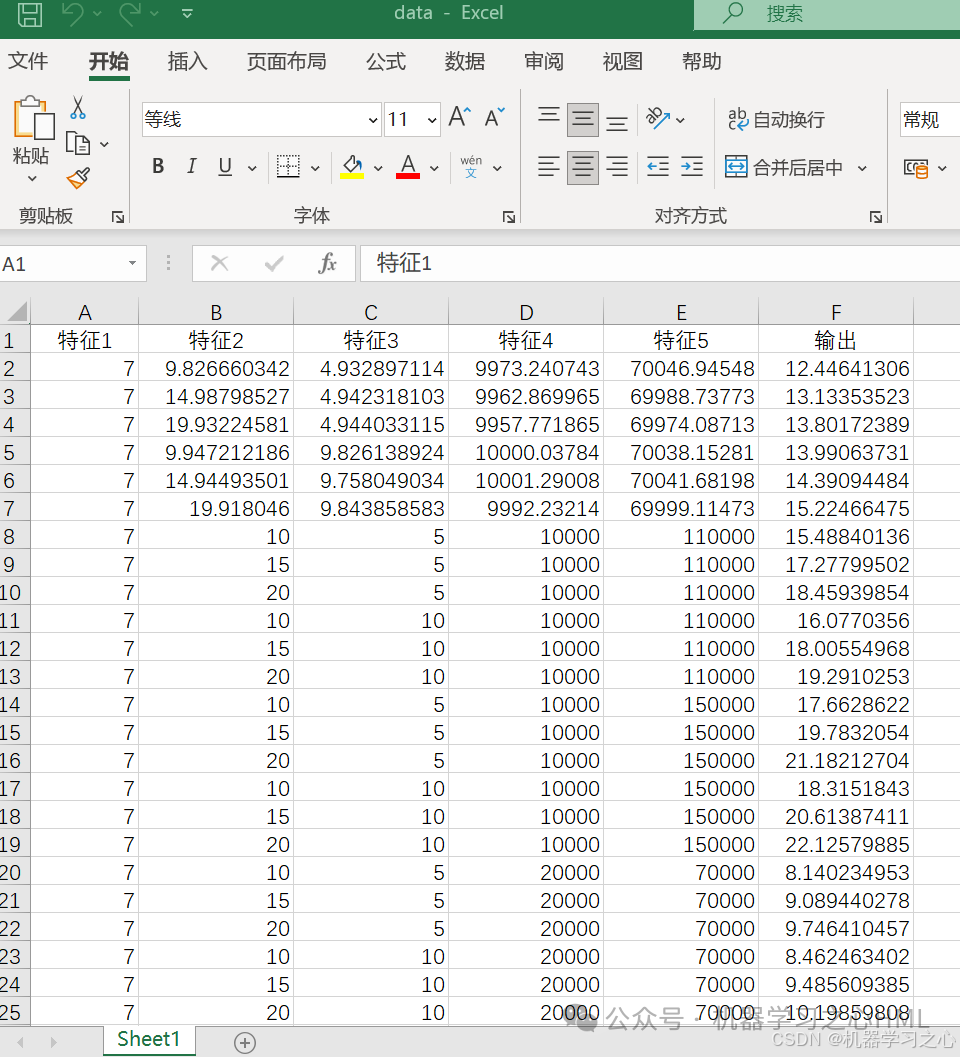
Transformer编码器+SHAP分析,模型可解释创新表达!
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 基本介绍 基于SHAP分析的特征选择和贡献度计算,Matlab2023b代码实现;基于MATLAB的SHAP可解释Transformer编码器回归模型,敏感性分析方法。 详细介绍 引言 在正向渗透(…...

[特殊字符]适合母亲节的SVG模版[特殊字符]
宝藏模版 往期推荐(点击阅读): 趣味效果|高大上|可爱风|年终总结I|年终总结II|循环特效|情人节I|情人节II|情人节IIII|妇女节I&…...

浅蓝色调风格人像自拍Lr调色预设,手机滤镜PS+Lightroom预设下载!
调色教程 浅蓝色调风格人像自拍 Lr 调色是利用 Adobe Lightroom 软件针对人像自拍照进行后期处理的一种调色方式。它通过对照片的色彩、对比度、亮度等参数进行精细调整,将画面的主色调打造为清新、柔和的浅蓝色系,赋予人像自拍独特的清新、文艺风格&…...

isp流程介绍(yuv格式阶段)
一、前言介绍 前面两章里面,已经分别讲解了在Raw和Rgb域里面,ISP的相关算法流程,从前面文章里面可以看到,在Raw和Rgb域里面,很多ISP算法操作,更像是属于sensor矫正或者说sensor标定操作。本质上来说&#x…...

数巅智能携手北京昇腾创新中心深耕行业大模型应用
当前,AI技术正在加速向各行业深度渗透,成为驱动产业转型和社会经济发展的重要引擎。构建开放协作的AI应用生态体系、推动技术和应用深度融合,已成为行业发展的重要趋势。 近日,数巅智能与北京昇腾人工智能计算中心(北京昇腾创新中…...
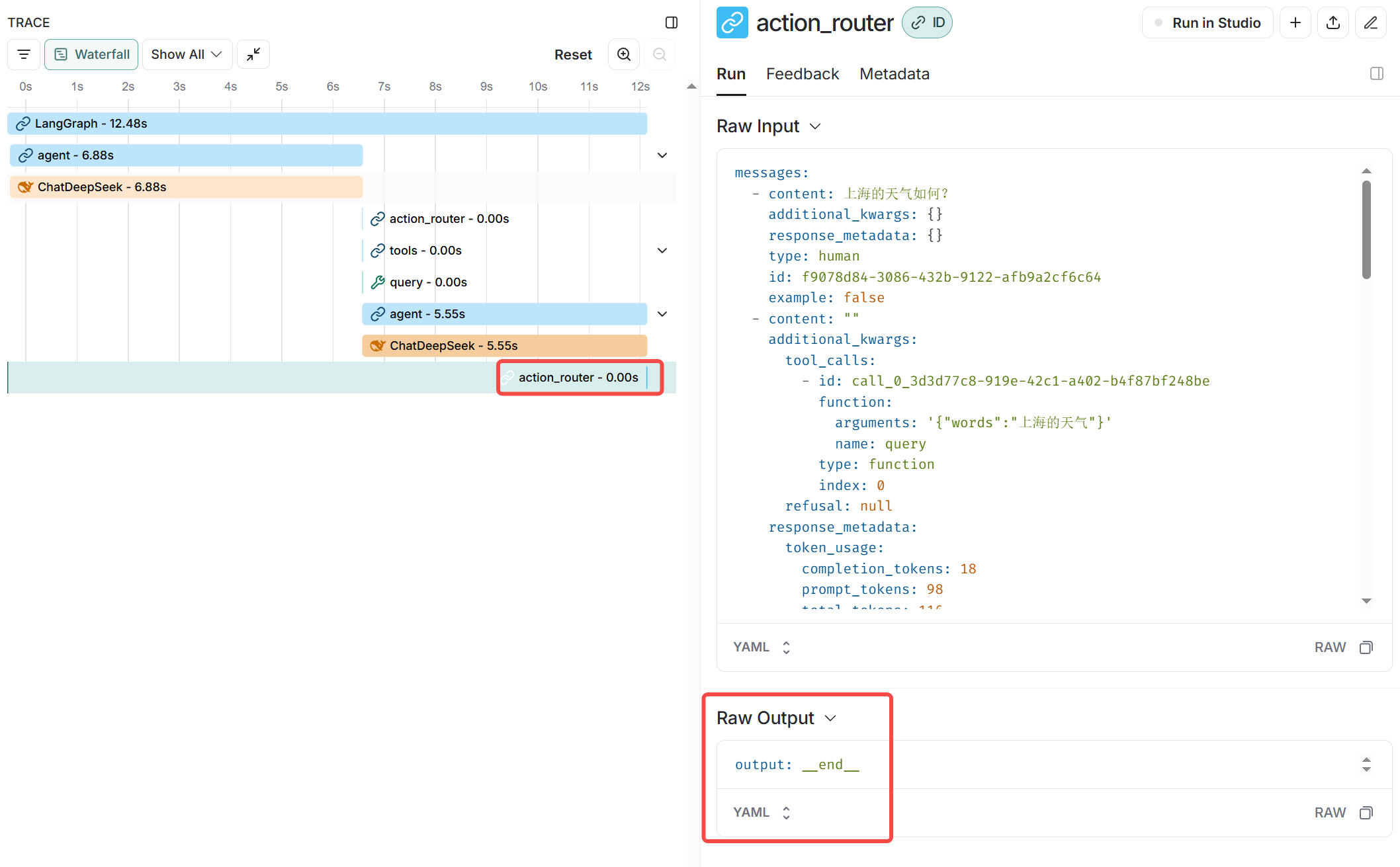
【LangChain高级系列】LangGraph第一课
前言 我们今天直接通过一个langgraph的基础案例,来深入探索langgraph的核心概念和工作原理。 基本认识 LangGraph是一个用于构建具有LLMs的有状态、多角色应用程序的库,用于创建代理和多代理工作流。与其他LLM框架相比,它提供了以下核心优…...
简介)
增强学习(Reinforcement Learning)简介
增强学习(Reinforcement Learning)简介 增强学习是机器学习的一种范式,其核心目标是让智能体(Agent)通过与环境的交互,基于试错机制和延迟奖励反馈,学习如何选择最优动作以最大化长期累积回报。…...
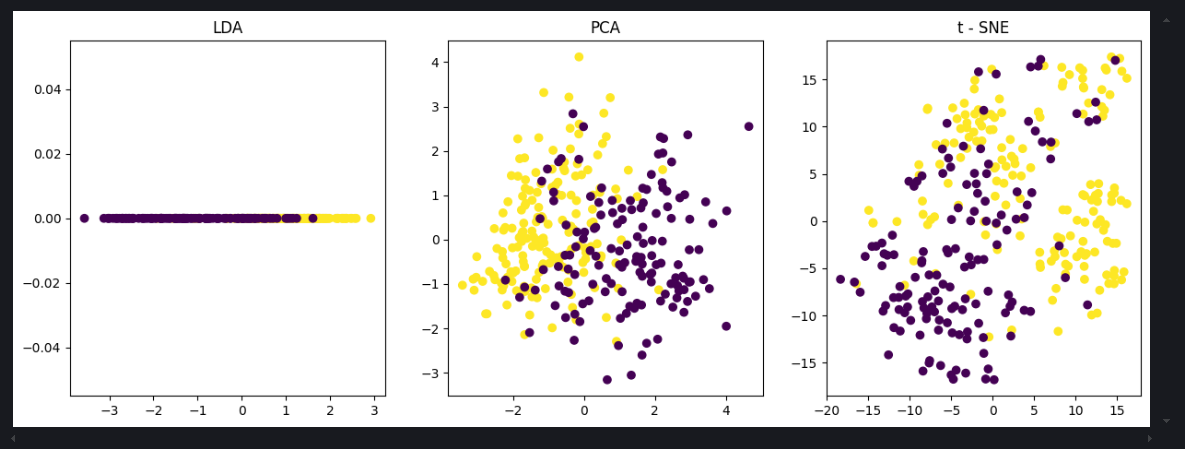
常见降维算法分析
一、常见的降维算法 LDA线性判别PCA主成分分析t-sne降维 二、降维算法原理 2.1 LDA 线性判别 原理 :LDA(Linear Discriminant Analysis)线性判别分析是一种有监督的降维方法。它的目标是找到一个投影方向,使得不同类别的数据在…...

计算机二级(C语言)已过
非线性结构:树、图 链表和队列的结构特性不一样,链表可以在任何位置插入、删除,而队列只能在队尾入队、队头出队 对长度为n的线性表排序、在最坏情况下时间复杂度,二分查找为O(log2n),顺序查找为O(n),哈希查…...

2025年3月,韩先超对国网宁夏进行Python线下培训
大家好,我是韩先超!在2025年3月3号和4号,为 宁夏国网 的运维团队进行了一场两天的 Python培训 ,培训目标不仅是让大家学会Python编程,更是希望大家能够通过这门技术解决实际工作中的问题,提升工作效率。 对…...

ATH12K驱动框架架构图
ATH12K驱动框架架构图 ATH12K驱动框架架构图(分层描述)I. 顶层架构II. 核心数据结构层次关系III. 主要模块详解1. 核心模块 (Core)2. 硬件抽象层 (HAL)3. 无线管理接口 (WMI)4. 主机目标通信 (HTC)5. 复制引擎 (CE)6. MAC层7. 数据路径 (DP)IV. 关键数据流路径1. 发送数据流 …...

pcb样板打样厂家哪家好?
国内在PCB样板加工领域具有较强竞争力的企业主要包括以下几家,综合技术实力、市场份额、客户评价及行业认可度进行推荐: 1. 兴森科技 行业地位:国内最大的PCB样板生产商,细分领域龙头企业,月订单品种数可达25,000种&…...
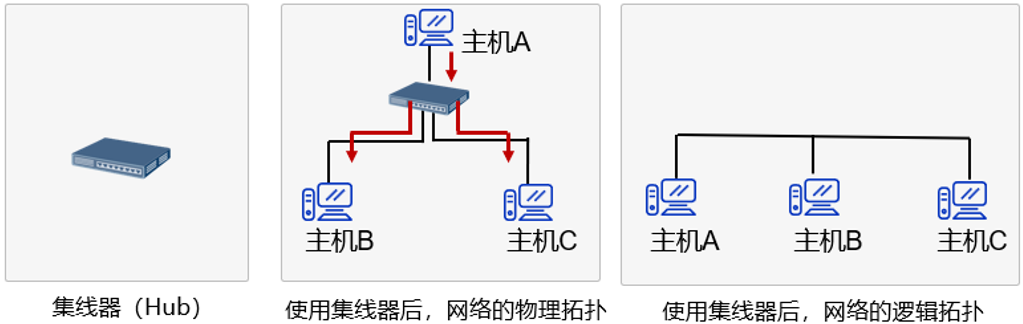
[计算机网络]物理层
文章目录 物理层的概述与功能传输介质双绞线:分类:应用领域: 同轴电缆:分类: 光纤:分类: 无线传输介质:无线电波微波:红外线:激光: 物理层设备中继器(Repeater):放大器:集线器(Hub)&…...
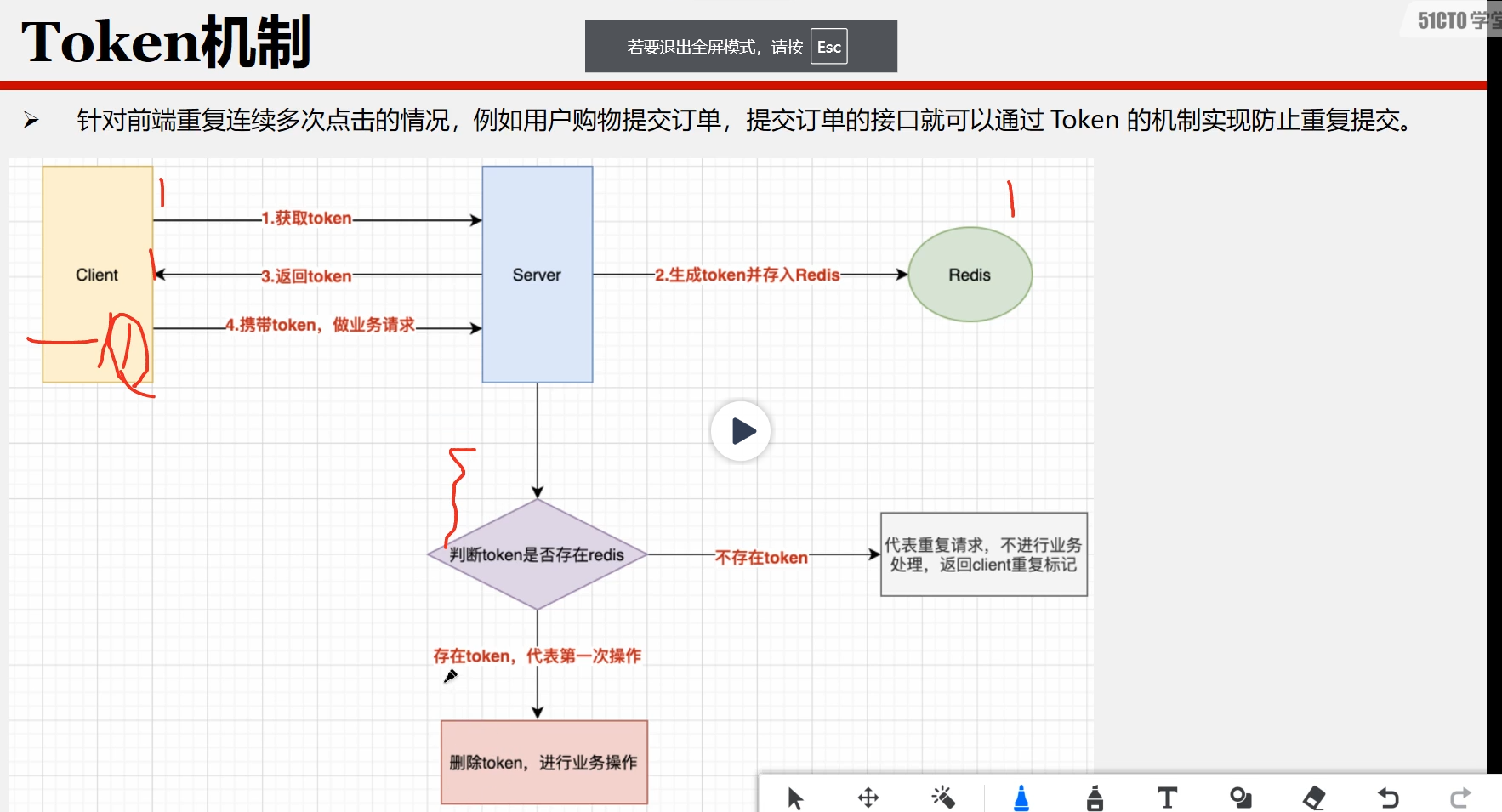
幂等操作及处理措施
利用token模式去避免幂等操作 按以上图所示,除了token,应该也可以把传入的参数用MD5加密,当成key放入redis里面,业务执行完后再删除这个key.如还没有执行完,则请不要重复操作。纯属个人理解...
Matlab 数控车床进给系统的建模与仿真
1、内容简介 Matlab217-数控车床进给系统的建模与仿真 可以交流、咨询、答疑 2、内容说明 略 摘 要:为提高数控车床的加工精度,对数控 车床进给系统中影响加工精度的主要因素进行了仿真分析研 动系统的数学模型,利用MATLAB软件中的动态仿真工具 究:依据机械动力学原理建立了…...
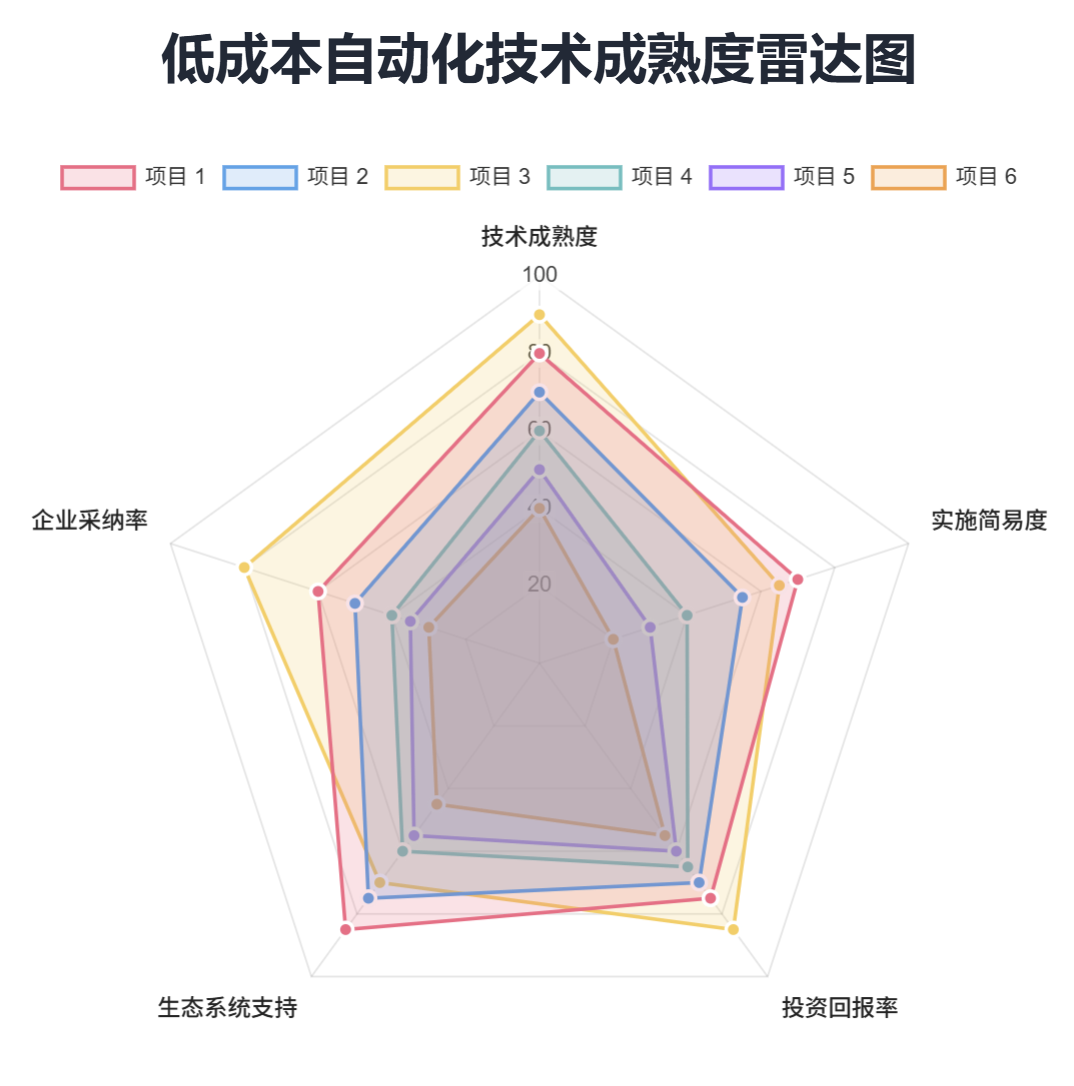
低成本自动化改造的18个技术锚点深度解析
执行摘要 本文旨在深入剖析四项关键的低成本自动化技术,这些技术为工业转型提供了显著的运营和经济效益。文章将提供实用且深入的指导,涵盖老旧设备联网、AGV车队优化、空压机系统智能能耗管控以及此类项目投资回报率(ROI)的严谨…...

【大数据】服务器上部署Apache Paimon
1. 环境准备 在开始部署之前,请确保服务器满足以下基本要求: 操作系统: 推荐使用 Linux(如 Ubuntu、CentOS)。 Java 环境: Paimon 依赖 Java,推荐安装 JDK 8 或更高版本。 Flink 环境: Paimon 是基于 Apache Flink 的…...