多模态大语言模型arxiv论文略读(六十二)

MileBench: Benchmarking MLLMs in Long Context
➡️ 论文标题:MileBench: Benchmarking MLLMs in Long Context
➡️ 论文作者:Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, Benyou Wang
➡️ 研究机构: The Chinese University of Hong Kong, Shenzhen, Shenzhen Research Institute of Big Data
➡️ 问题背景:尽管多模态大语言模型(Multimodal Large Language Models, MLLMs)在各种多模态任务中表现出色,但它们在处理长文本和多图像任务时的实际效果尚不明确。现有的基准测试主要集中在单图像和短文本样本上,未能全面反映现实世界应用的复杂性和多样性。此外,这些基准测试在评估多图像任务时,要么限制图像数量,要么仅关注特定任务,如时间序列描述,这可能导致忽视MLLMs在长文本情境下的幻觉问题。
➡️ 研究动机:为了弥补现有基准测试的不足,研究团队开发了MILEBENCH,这是首个专门设计用于测试MLLMs在多模态长文本情境下能力的基准测试。MILEBENCH旨在系统评估MLLMs在处理长文本和多图像任务时的适应能力和任务完成能力,特别是涉及多轮对话、动作预测、3D空间导航和理解长文档等任务。
➡️ 方法简介:MILEBENCH由两个主要部分组成:现实评估(Realistic Evaluation)和诊断评估(Diagnostic Evaluation)。现实评估侧重于评估MLLMs在多模态长文本情境下的理解、整合和推理能力;诊断评估则侧重于评估MLLMs在长文本情境中检索信息的能力,包括“针在草堆中”(Needle in a Haystack)和图像检索任务。研究团队从21个现有或自建的数据集中收集了6,440个多模态长文本样本,每个样本平均包含15.2张图像和422.3个单词。
➡️ 实验设计:研究团队评估了22个模型,包括5个闭源模型和17个开源模型。实验结果表明,闭源模型GPT-4o在诊断评估和现实评估中表现最佳,分别达到了99.4%和60.3%的准确率。相比之下,大多数开源MLLMs在长文本情境任务中表现不佳,平均得分仅为10.1%。实验还发现,随着图像数量的增加,开源MLLMs的性能下降更为明显,而闭源模型的性能下降幅度较小。
Hallucination of Multimodal Large Language Models: A Survey
➡️ 论文标题:Hallucination of Multimodal Large Language Models: A Survey
➡️ 论文作者:Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
➡️ 研究机构: National University of Singapore, AWS Shanghai AI Lab, Amazon Prime Video
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)在多种多模态任务中展现了显著的进步和卓越的能力,如图像描述、视觉问答等。然而,这些模型在生成输出时经常出现与视觉内容不一致的现象,即“幻觉”(hallucination),这对其实际应用的可靠性和可信度构成了重大挑战。
➡️ 研究动机:尽管多模态大语言模型(MLLMs)在多模态任务中表现出色,但它们生成的输出经常与视觉内容不一致,这种现象被称为“幻觉”。为了深入理解幻觉的成因,并探索有效的检测和缓解方法,研究团队对MLLMs中的幻觉现象进行了全面的分析和综述,旨在为未来的研究和应用提供有价值的见解和指导。
➡️ 方法简介:研究团队对MLLMs中的幻觉现象进行了系统性的分析,包括幻觉的成因、评估基准、度量标准以及缓解策略。研究涵盖了数据、模型、训练和推理四个方面的成因,并提出了针对这些成因的缓解方法。此外,研究还提供了详细的幻觉分类和评估基准,以帮助研究人员更好地理解和评估MLLMs中的幻觉现象。
➡️ 实验设计:研究团队通过分析大量文献,总结了幻觉的多种成因,并提出了相应的评估基准和度量标准。研究还讨论了现有的缓解幻觉的方法,包括数据增强、模型改进、训练策略和推理干预等。通过这些方法,研究旨在为提高MLLMs的可靠性和可信度提供系统性的指导。
What Drives Performance in Multilingual Language Models?
➡️ 论文标题:What Drives Performance in Multilingual Language Models?
➡️ 论文作者:Sina Bagheri Nezhad, Ameeta Agrawal
➡️ 研究机构: Portland State University
➡️ 问题背景:多语言大型语言模型(MLLMs)在自然语言处理领域取得了显著进展,能够支持多种语言的应用,如机器翻译和情感分析。然而,这些模型在不同语言上的表现存在差异,尤其是在资源贫乏的语言上。理解这些模型在不同语言上的表现对于进一步发展至关重要。
➡️ 研究动机:尽管已有研究探讨了影响MLLMs性能的因素,但这些研究通常局限于少数语言、特定任务或训练范式。此外,大多数研究未能区分模型在预训练中见过的语言(SEEN)、完全新的语言(UNSEEN)以及评估数据集中所有语言(ALL)。本研究旨在通过全面分析不同模型和训练设置下的多种因素,为开发更有效和公平的多语言NLP系统提供深入见解。
➡️ 方法简介:研究团队评估了6种MLLMs,包括掩码语言模型、自回归模型和指令调优的大型语言模型,使用SIB-200数据集进行文本分类任务。研究考虑了四个关键因素:预训练数据量、资源可用性水平、语言家族和脚本类型。通过决策树分析,研究团队探讨了这些因素对模型性能的影响。
➡️ 实验设计:实验在SIB-200数据集上进行,该数据集涵盖了204种语言。研究设计了三种训练场景:零样本、两样本上下文学习(ICL)和完全监督。实验分析了不同模型在不同语言类别(SEEN、UNSEEN、ALL)下的表现,重点关注预训练数据量、资源可用性、语言家族和脚本类型等因素的影响。
TableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains
➡️ 论文标题:TableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains
➡️ 论文作者:Yoonsik Kim, Moonbin Yim, Ka Yeon Song
➡️ 研究机构: NAVER Cloud AI
➡️ 问题背景:当前的多模态大语言模型(Multi-Modal Large Language Models, MLLMs)在处理表格视觉问答(TableVQA)任务时,面临缺乏合适的评估数据集的问题。现有的表格问答(TableQA)数据集大多不包含图像或问答对,这限制了它们在TableVQA任务中的应用。因此,构建一个包含图像和问答对的TableVQA数据集对于评估MLLMs在TableVQA任务中的表现至关重要。
➡️ 研究动机:为了填补这一空白,研究团队构建了一个新的TableVQA基准数据集——TableVQA-Bench。该数据集通过整合现有的表格问答(TableQA)和表格结构识别(TSR)数据集,生成了包含图像、HTML文本表示和问答对的综合数据集。研究旨在评估不同MLLMs在TableVQA任务中的表现,并探讨视觉输入与文本输入在性能上的差异。
➡️ 方法简介:研究团队提出了一个系统的方法,通过应用样式表或使用表格渲染系统生成表格图像,并利用大型语言模型(LLM)生成问答对,构建了TableVQA-Bench。该数据集包含1,500个问答对,涵盖了多个表格领域。研究还比较了不同MLLMs在TableVQA-Bench上的表现,并分析了视觉查询数量对模型性能的影响。
➡️ 实验设计:实验在TableVQA-Bench上进行,评估了多个商业和开源MLLMs的性能。实验设计了不同输入格式(视觉和文本)的比较,以及不同模型在处理视觉输入时的性能差异。此外,研究还探讨了两阶段推理方法,即先从图像中提取HTML,再使用LLM进行问答任务,以评估其对模型性能的影响。实验结果表明,GPT-4V在所有模型中表现最佳,但视觉输入的性能普遍低于文本输入。
OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception, Reasoning and Planning
➡️ 论文标题:OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception, Reasoning and Planning
➡️ 论文作者:Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, Jose M. Alvarez
➡️ 研究机构: 北京理工大学、NVIDIA、华中科技大学
➡️ 问题背景:尽管多模态大语言模型(MLLMs)在端到端自动驾驶中的应用展现了强大的推理能力,但将这些能力从2D理解扩展到3D空间的复杂性仍然是一个重大挑战。3D空间的理解对于自动驾驶车辆(AVs)做出明智决策、预测未来状态和安全互动至关重要。此外,处理多视角高分辨率视频输入的需求也是当前2D MLLM架构难以克服的问题。
➡️ 研究动机:为了解决上述挑战,研究团队提出了OmniDrive,这是一个全面的框架,旨在实现3D感知、推理和规划的强对齐。OmniDrive不仅提出了一个新颖的3D MLLM架构,还引入了一个新的基准测试OmniDrive-nuScenes,该基准测试涵盖了全面的视觉问答(VQA)任务,包括场景描述、交通规则、3D定位、反事实推理、决策和规划。
➡️ 方法简介:OmniDrive的核心是一个基于Q-Former的3D MLLM架构,该架构通过将多视角图像特征压缩为稀疏查询,然后将这些查询与3D位置编码结合,输入到大型语言模型中,从而实现3D空间理解。此外,OmniDrive-nuScenes基准测试通过模拟决策和轨迹来评估模型的反事实推理能力,以及在复杂3D场景中的长期规划能力。
➡️ 实验设计:研究团队在nuScenes数据集上进行了广泛的实验,验证了OmniDrive在3D场景中的优秀推理和规划能力。实验包括了场景描述、交通规则理解、3D定位、反事实推理、决策和规划等多个任务,通过多种评估指标(如METEOR、ROUGE、CIDEr、碰撞率和道路边界交叉率等)来全面评估模型的性能。
相关文章:
多模态大语言模型arxiv论文略读(六十二)
MileBench: Benchmarking MLLMs in Long Context ➡️ 论文标题:MileBench: Benchmarking MLLMs in Long Context ➡️ 论文作者:Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, Benyou Wang ➡️ 研究机构: The Chinese Univers…...

现代框架对SEO的深度影响
第8章:现代框架对SEO的深度影响 1. 引言 Next 和 Nuxt 是两个 🔥热度和使用度都最高 的现代 Web 开发框架,它们分别基于 ⚛️React 和 🖖Vue 构建,也代表了这两个生态的 🌐全栈框架。 Next 是由 Vercel 公司…...
密码学--RSA
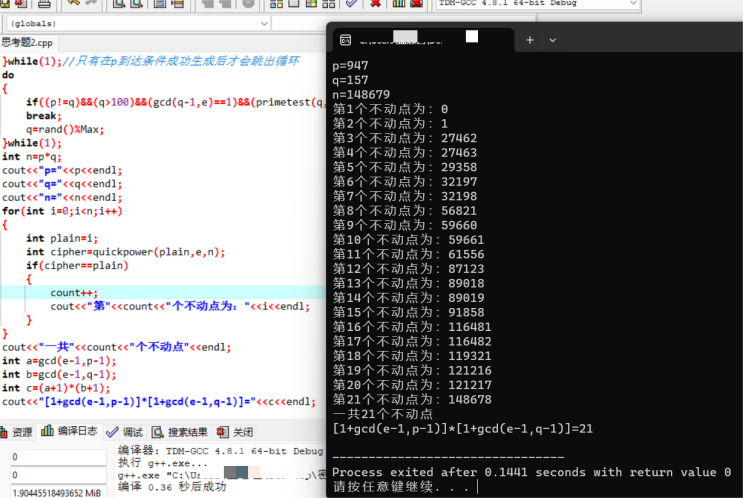
一、实验目的 1.随机生成明文和加密密钥 2.利用C语言实现素数选择(素性判断)的算法 3.利用C语言实现快速模幂运算的算法(模重复平方法) 4.利用孙子定理实现解密程序 5.利用C语言实现RSA算法 6.利用RSA算法进行数据加/解密 …...
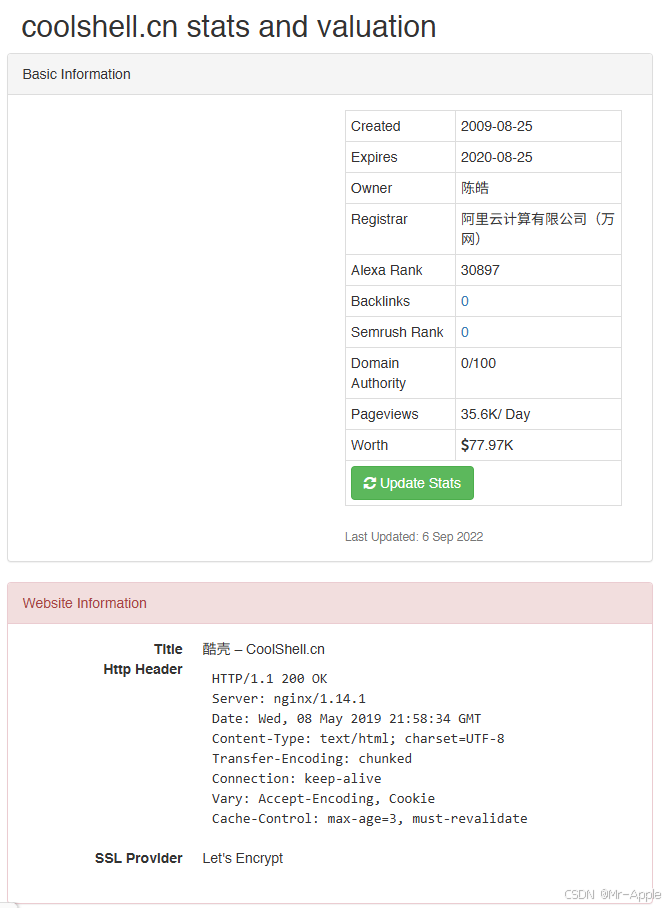
如何选择自己喜欢的cms
选择内容管理系统cms what is cms1.whatcms.org2.IsItWP.com4.Wappalyzer5.https://builtwith.com/6.https://w3techs.com/7. https://www.netcraft.com/8.onewebtool.com如何在不使用 CMS 检测器的情况下手动检测 CMS 结论 在开始构建自己的数字足迹之前,大多数人会…...
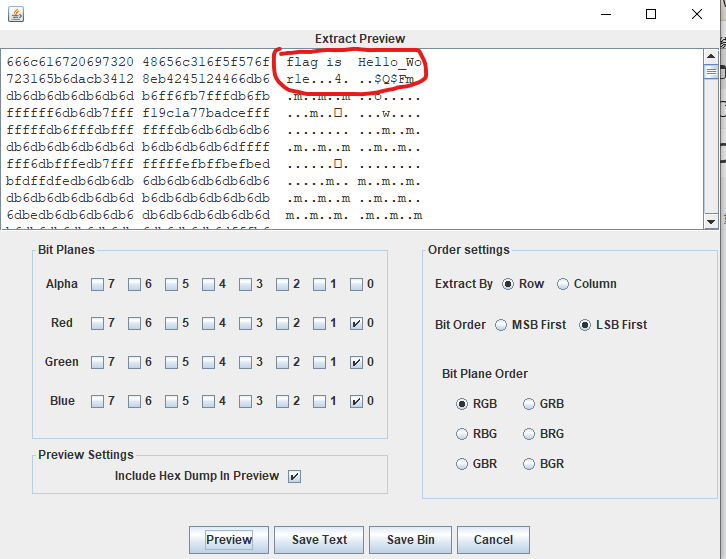
BUUCTF——杂项渗透之赛博朋克
下载附件,是一个txt。打开查看,数据如下: 感觉这个像是用十六进制编辑器打开后的图片数据。为了验证此想法,我用010editor打开,发现文件头的确是png图片的文件头。 把txt文件后缀改成png格式,再双击打开&am…...

【c++】 我的世界
太久没更新小游戏了 给个赞和收藏吧,求求了 要游戏的请私聊我 #include <iostream> #include <vector>// 定义世界大小 const int WORLD_WIDTH 20; const int WORLD_HEIGHT 10;// 定义方块类型 enum BlockType {AIR,GRASS,DIRT,STONE };// 定义世界…...
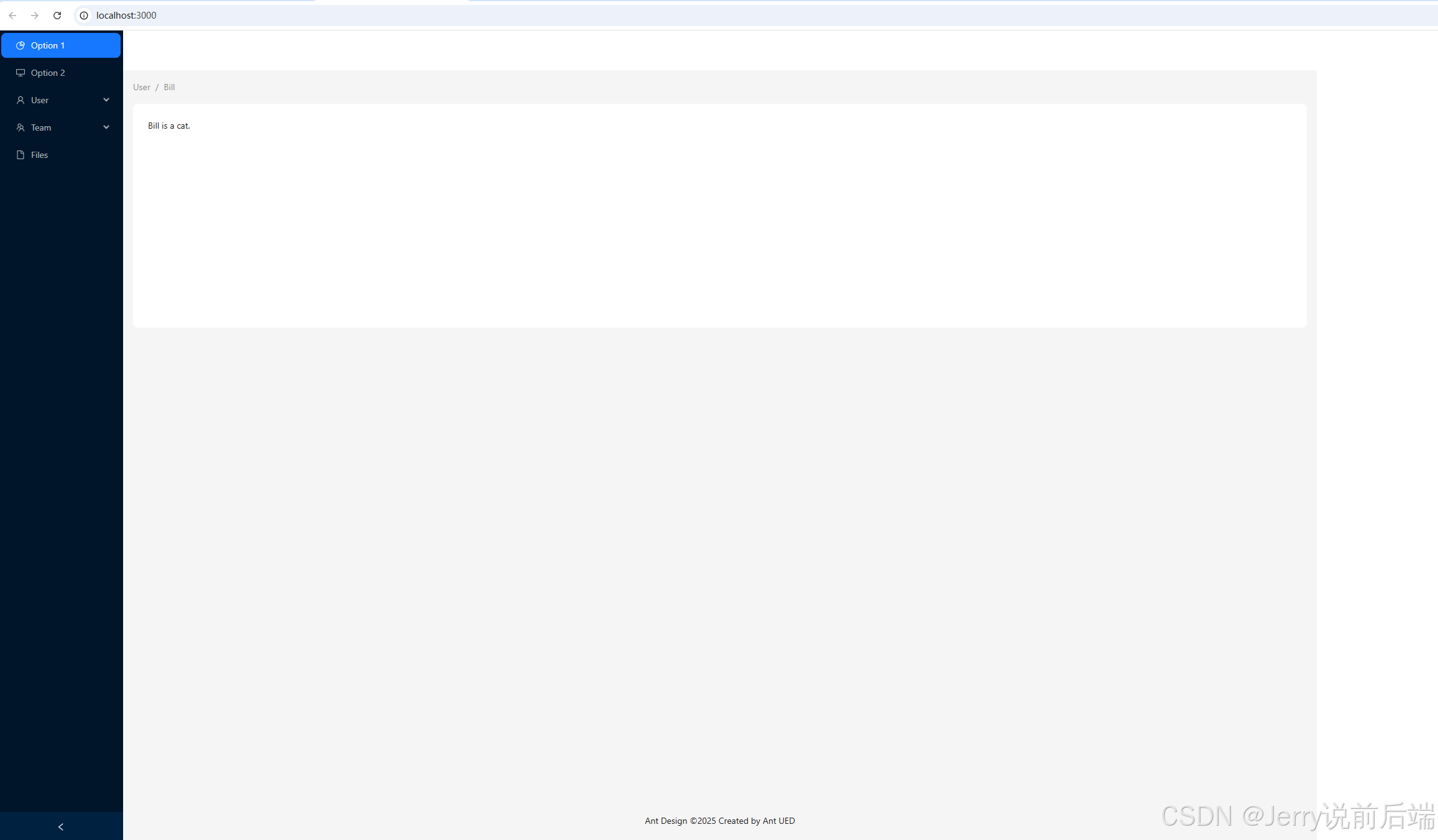
React 中集成 Ant Design 组件库:提升开发效率与用户体验
React 中集成 Ant Design 组件库:提升开发效率与用户体验 一、为什么选择 Ant Design 组件库?二、基础引入方式三、按需引入(优化性能)四、Ant Design Charts无缝接入图标前面提到了利用Redux提供全局维护,但如果在开发时再自己手动封装组件,不仅效率不高,可能开发的组件…...

HunyuanCustom, 腾讯混元开源的多模态定制视频生成框架
HunyuanCustom是一款由腾讯混元团队开发的多模态驱动定制视频生成框架,能够支持图像、音频、视频和文本等多种输入方式。该框架专注于生成高质量的视频,能够实现特定主体和场景的精准呈现。 HunyuanCustom是什么 HunyuanCustom是腾讯混元团队推出的一种…...

Lightweight App Alternatives
The tech industry’s business model thrives on constant churn: new features, fancier designs, and heavier apps — not because they’re essential, but because they keep consumers upgrading. Stripping your phone back to basics is an act of tech self-defense.…...

STM32F103RCT6 + MFC实现网口设备搜索、修改IP、固件升级等功能
资源下载链接:https://download.csdn.net/download/qq_35831134/90712875?spm=1001.2014.3001.5501 一.大概逻辑: // 网口搜索大概逻辑: // ************************************************************************** // 一.环境: // 上位机用MFC下位机用STM32F103R…...

编译原理实验 之 语法分析程序自动生成工具Yacc实验
文章目录 实验环境准备复现实验例子分析总的文件架构实验任务 什么是Yacc Yacc(Yet Another Compiler Compiler)是一个语法分析程序自动生成工具,Yacc实验通常是在编译原理相关课程中进行的实践项目,旨在让学生深入理解编译器的语法分析阶段以及掌握Yac…...

[250504] Moonshot AI 发布 Kimi-Audio:开源通用音频大模型,驱动多模态 AI 新浪潮
目录 Moonshot AI 发布 Kimi-Audio:开源音频基础模型,赋能音频理解、生成与对话新时代核心能力与特性技术基础开放资源与评估行业意义 Moonshot AI 发布 Kimi-Audio:开源音频基础模型,赋能音频理解、生成与对话新时代 Moonshot A…...

从“山谷论坛”看AI七剑下天山
始于2023年的美国山谷论坛(Hill and Valley Forum)峰会,以“国会山与硅谷”命名,寓意连接科技界与国家安全战略。以人工智能为代表的高科技,在逆全球化时代已成为大国的致胜高点。 论坛创办者Jacob Helberg,现在是华府的副国务卿,具体负责经济、环境和能源事务。早先曾任…...

C——数组和函数实践:扫雷
此篇博客介绍用C语言写一个扫雷小游戏,所需要用到的知识有:函数、数组、选择结构、循环结构语句等。 所使用的编译器为:VS2022。 一、扫雷游戏是什么样的,如何玩扫雷游戏? 如图,是一个标准的扫雷游戏初始阶段。由此…...

sui在windows虚拟化子系统Ubuntu和纯windows下的安装和使用
一、sui在windows虚拟化子系统Ubuntu下的安装使用(WindowsWsl2Ubuntu24.04) 前言:解释一下WSL、Ubuntu的关系 WSL(Windows Subsystem for Linux)是微软推出的一项功能,允许用户在 Windows 系统中原生运行…...

智能合约在去中心化金融(DeFi)中的核心地位与挑战
近年来,区块链技术凭借其去中心化、不可篡改等特性,在全球范围内掀起了技术革新浪潮。去中心化金融(DeFi)作为区块链技术在金融领域的重要应用,自 2018 年以来呈现出爆发式增长态势。据 DeFi Pulse 数据显示࿰…...

Femap许可使用数据分析
在当今竞争激烈的市场环境中,企业对资源使用效率和成本控制的关注日益增加。Femap作为一款业界领先的有限元分析软件,其许可使用数据分析功能为企业提供了深入洞察和智能决策的支持。本文将详细介绍Femap许可使用数据分析工具的特点、优势以及如何应用这…...
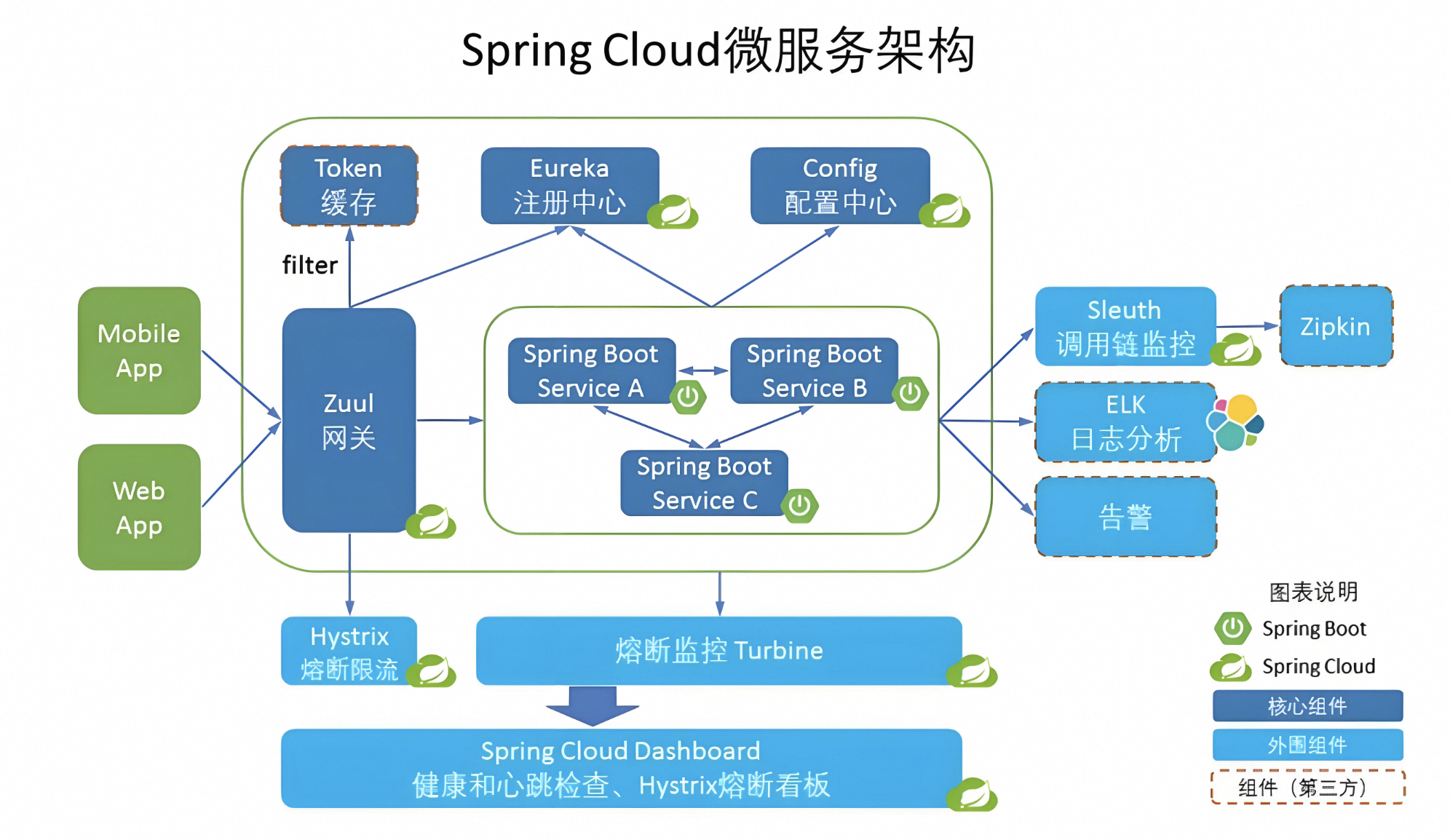
有关SOA和SpringCloud的区别
目录 1. 定义 2. 架构风格 3. 技术栈 4. 服务交互 5. 适用场景 前言 面向服务架构(SOA)是一种软件设计风格,它将应用程序的功能划分为一系列松散耦合的服务。这些服务可以通过标准的通信协议进行交互,通常是HTTP或其他消息传…...
学习搭子,秘塔AI搜索
什么是秘塔AI搜索 《秘塔AI搜索》的网址:https://metaso.cn/ 功能:AI搜索和知识学习,其中学习部分是亮点,也是主要推荐理由。对应的入口:https://metaso.cn/study 推荐理由 界面细节做工精良《今天学点啥》板块的知…...
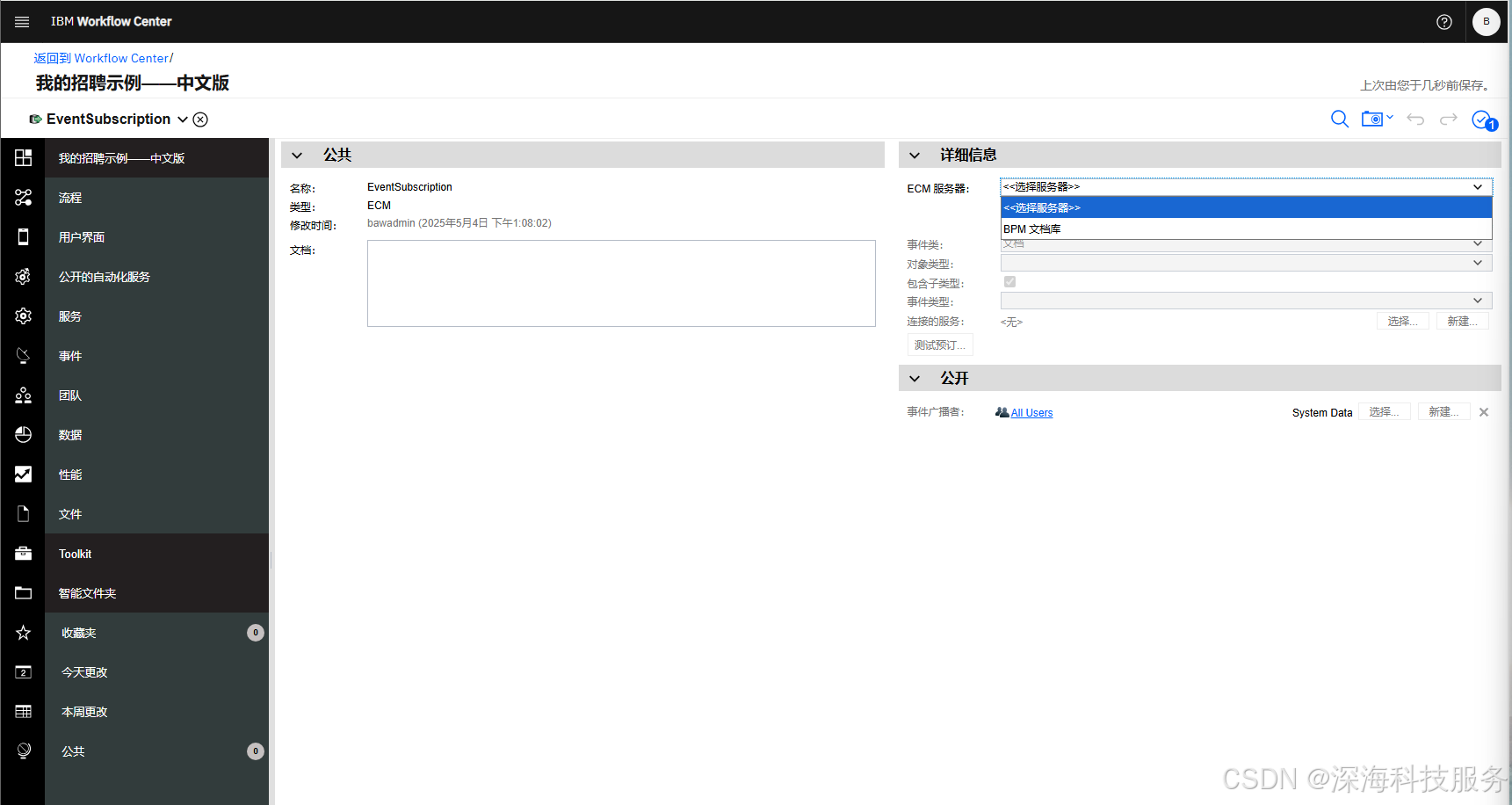
IBM BAW(原BPM升级版)使用教程第六讲
续前篇! 一、事件:Undercover Agent 在 IBM Business Automation Workflow (BAW) 中,Undercover Agent (UCA) 是一个非常独特和强大的概念,旨在实现跨流程或系统的事件处理和触发机制。Undercover Agent 主要用于 事件驱动的流程…...
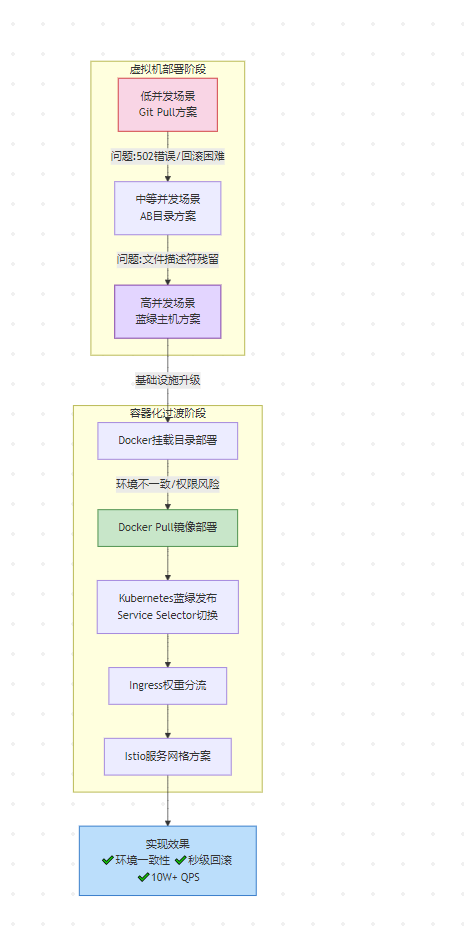
高并发PHP部署演进:从虚拟机到K8S的DevOps实践优化
一、虚拟机环境下的部署演进 1. 低并发场景(QPS<10)的简单模式 # 典型部署脚本示例 ssh userproduction "cd /var/www && git pull origin master" 技术痛点: 文件替换期间导致Nginx返回502错误(统计显示…...
VBA高级应用30例应用4:利用屏蔽事件来阻止自动运行事件
《VBA高级应用30例》(版权10178985),是我推出的第十套教程,教程是专门针对高级学员在学习VBA过程中提高路途上的案例展开,这套教程案例与理论结合,紧贴“实战”,并做“战术总结”,以…...

Centos 7.6 安装 Node.js 20 的环境配置记录
Centos 7.6 安装 Node.js 20 的环境配置记录 Centos 7在 2024 年的 6 月 30 号已经停止维护了,但是由于时代原因,很多服务还是跑在这个系统上。本篇博文记录如何在 Centos 7.6 上安装 Node20。 初步安装 node 下载 node.js 的 Linux 版本 cd ~ curl -O h…...
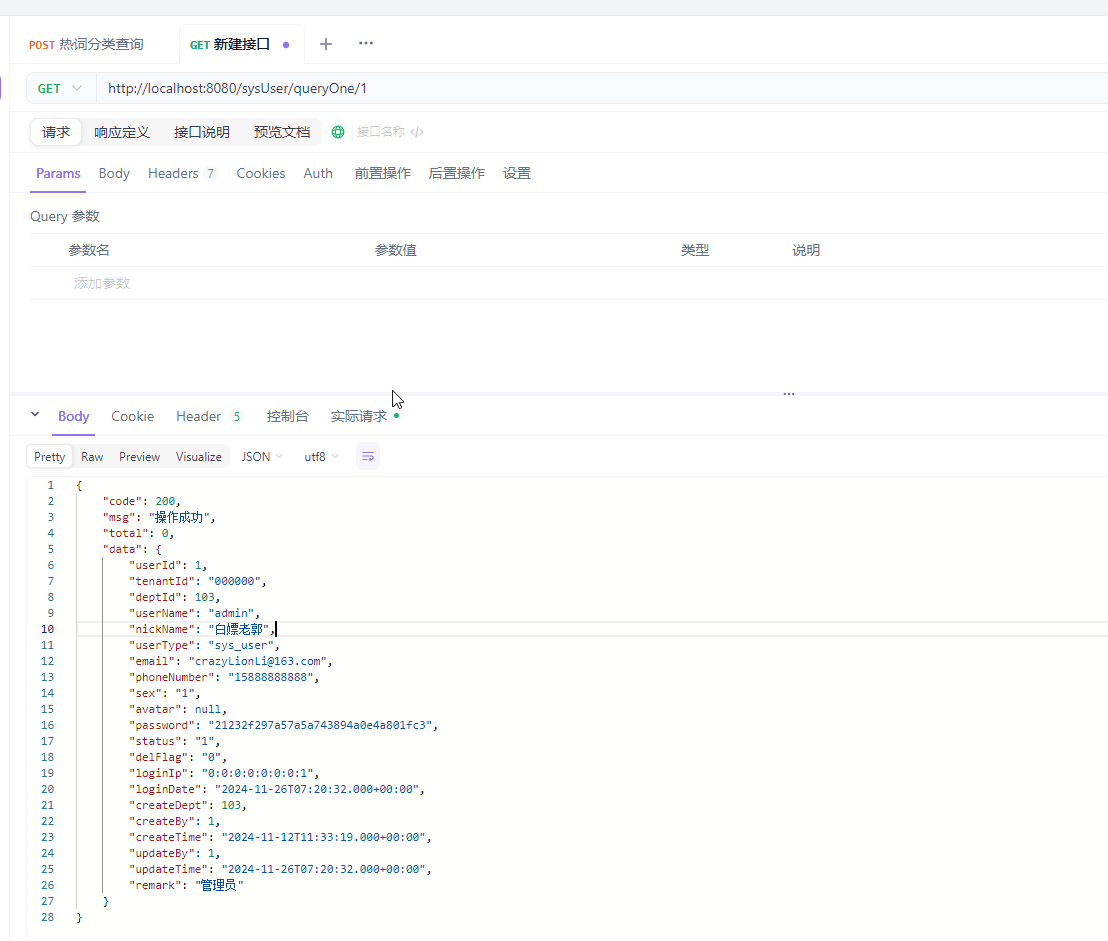
springboot3 + mybatis-plus3 创建web项目实现表增删改查
Idea创建项目 环境配置说明 在现代化的企业级应用开发中,合适的开发环境配置能够极大提升开发效率和应用性能。本文介绍的环境配置为: 操作系统:Windows 11JDK:JDK 21Maven:Maven 3.9.xIDE:IntelliJ IDEA…...

每天批次导入 100 万对账数据到 MySQL 时出现死锁
一、死锁原因及优化策略 1.1 死锁原因分析 批量插入事务过大: Spring Batch 默认将整个 chunk(批量数据块)作为一个事务提交,100 万数据可能导致事务过长,增加锁竞争。 并发写入冲突: 多个线程或批处理作…...
【人工智能学习之动作识别TSM训练与部署】
【人工智能学习之动作识别TSM训练与部署】 基于MMAction2动作识别项目的开发一、MMAction2的安装二、数据集制作三、模型训练1. 配置文件准备2. 关键参数修改3. 启动训练4. 启动成功 ONNX模型部署方案一、环境准备二、执行转换命令 基于MMAction2动作识别项目的开发 一、MMAct…...

ES6/ES11知识点 续五
迭代器【Iterator】 ES6 中的**迭代器(Iterator)**是 JavaScript 的一种协议,它定义了对象如何被逐个访问。迭代器与 for…of、扩展运算符、解构赋值等语法密切相关。 📘 迭代器工作原理 ES6 迭代器的工作原理基于两个核心机制…...
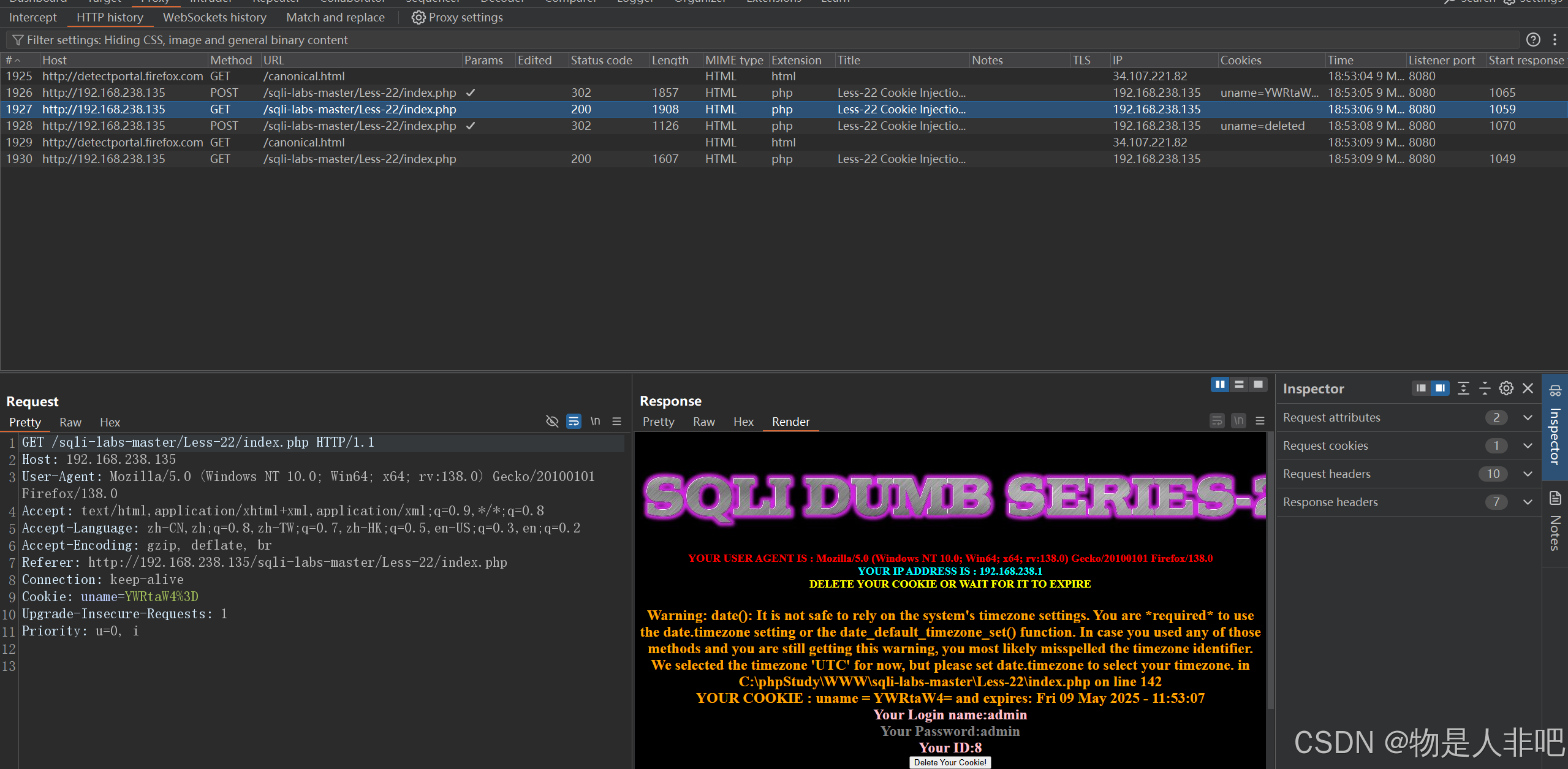
sqli-labs靶场18-22关(http头)
目录 less18(user-agent) less19(referer) less20(cookie) less21(cookie) less22(cookie) less18(user-agent) 这里尝试了多次…...

redhat9 安装pywinrm
看了很多文档,都是有很多限制,还是老老实实用pip 安装: Step1: 安装pip: [rootip-abc ~]# python get-pip.py Collecting pip Downloading pip-25.1.1-py3-none-any.whl.metadata (3.6 kB) Collecting wheel Downloading wheel-0.45.1-py…...
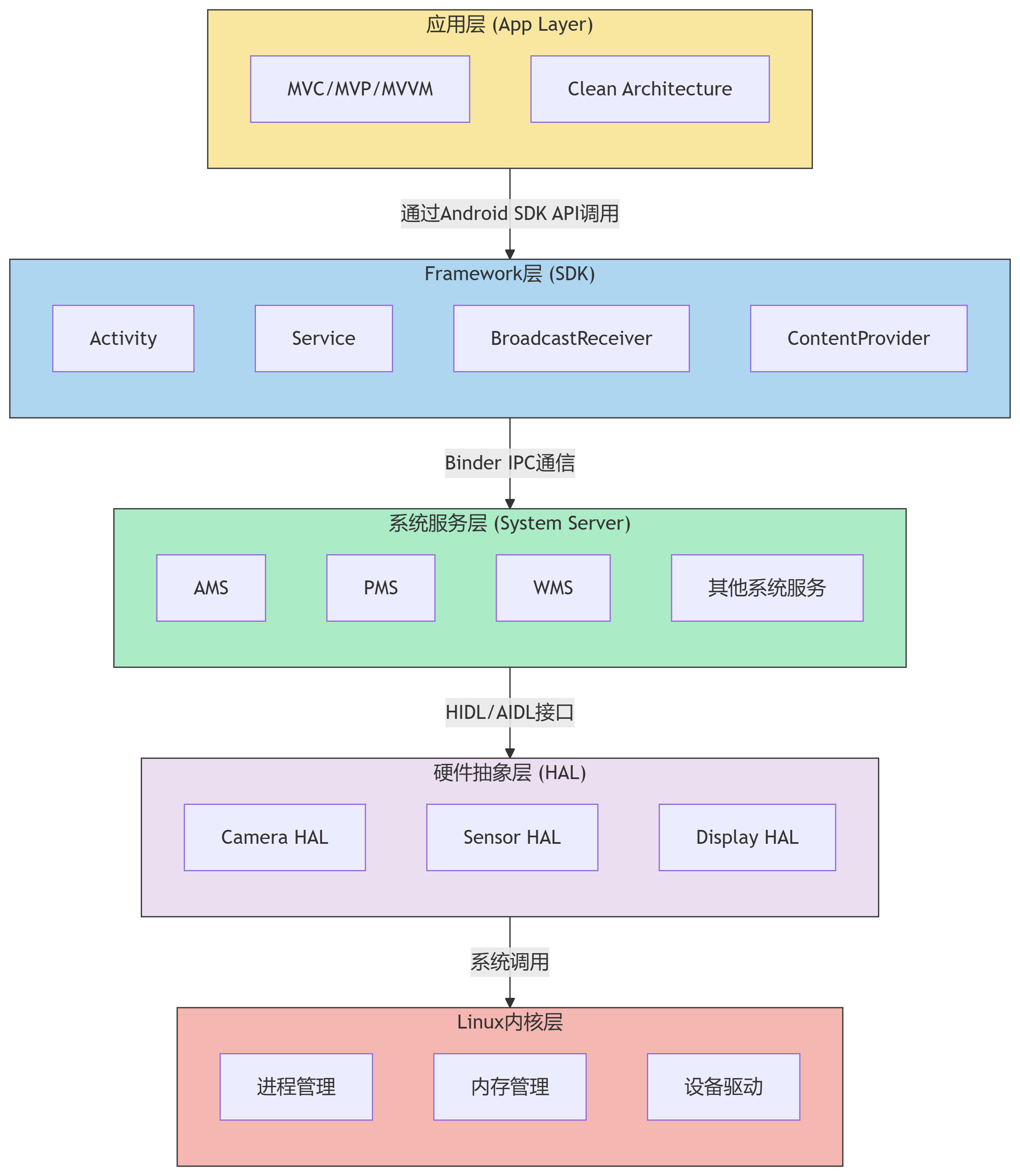
Android系统架构模式分析
本文系统梳理Android系统架构模式的演进路径与设计哲学,希望能够借此探索未来系统的发展方向。有想法的同学可以留言讨论。 1 Android层次化架构体系 1.1 整体分层架构 Android系统采用五层垂直架构,各层之间通过严格接口定义实现解耦: 应用…...