19、HashTable(哈希)、位图的实现和布隆过滤器的介绍
一、了解哈希【散列表】
1、哈希的结构
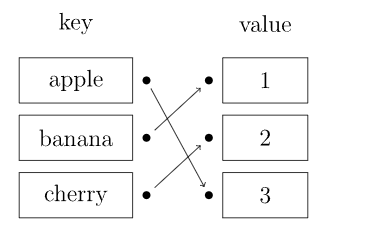
- 在STL中,HashTable是一个重要的底层数据结构, 无序关联容器包括unordered_set, unordered_map内部都是基于哈希表实现
- 哈希表又称散列表,一种以「key-value」形式存储数据的数据结构。
- 哈希函数:负责将任意大小的输入映射到固定大小的输出,即哈希值。
- 这个哈希值作用:是放在在数组中存储键值对的索引。
- 哈希冲突:由于哈希函数的映射不是一对一的,可能会出现两个不同的键映射到相同的索引,即冲突 。
- 解决冲突的方法:
- 链地址法
- 开发寻址法
- 双重哈希
2、哈希函数
- 定义:将键(任意类型)映射为固定大小的整数(哈希值),决定数据在哈希桶中的存储位置。
可能出现的情况
冲突情况 :将两个或两个以上的不同key映射到同一地址。
3、hash操作
- 插入
- 查找
4、哈希的负载因子【重点】
- 负载因子 = 存储的元素个数/数组长度
- 用来形容散列表的存储密度
- 负载因子越小,冲突越小,负载因子越大,冲突越大。
- 描述冲突的程度。
5、哈希冲突的解决方法
5.1、链地址法
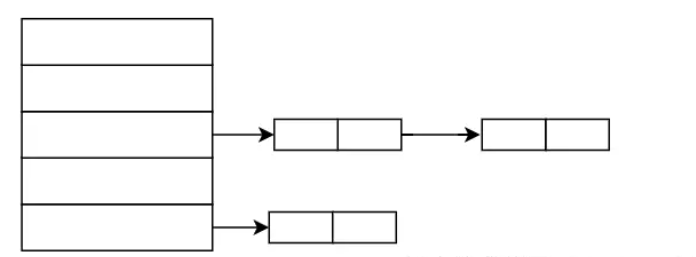
方法一:拉链法 (链表法) 将具有相同的addr的key,可以用链表连接。但是负载因子要在合理范围内。
5.2、开发寻址法
方法二:开发寻址法
- 将所有的数据直接存储在哈希数组中。如果冲突就采用某种算法来改变位置。
- 算法有多种思路:
- 比如 i+1,i+2,i+3等等 或者 i^1, i ^ 2 , i ^3等等。但是他们会出现hash聚集,也就是近似值的hash值很接近,那么位置也接近。聚集的话,就会在一片区域内,查找,这片区域数据太多了,时间复杂从O(1)变O(n)。所以可以使用双重哈希解决。 但是负载因子要在合理范围内。
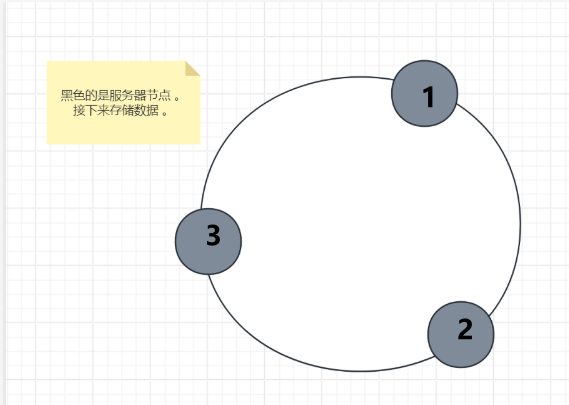
6、分布式一致性哈希
6.1、了解
- 一致性哈希通过环形哈希空间(Hash Ring) 和 虚拟节点(Virtual Nodes) 优化数据分布 。
- 解决传统哈希表在节点数量变化时导致的全局数据迁移问题(例如模运算哈希的 hash(key) % N,当 N 变化时所有数据需重新分布)。
- 一致性哈希,当节点增删时,仅影响环上相邻节点的数据,避免全局数据迁移。
6.2、哈希环
- 将节点和数据通过哈希函数映射到一个环形空间(通常范围为 0 ~ 2^32 - 1)
- 节点和数据的位置由哈希值决定。
每个数据项沿环顺时针查找最近的节点作为存储位置。
6.3、基本原理
- 第一步:
- 创建哈希环 。
- 将节点和数据通过哈希函数映射到一个环形空间
- 第二步:
- 将数据 a 、b 、c 通过哈希函数确定环上的位置,放上去 。
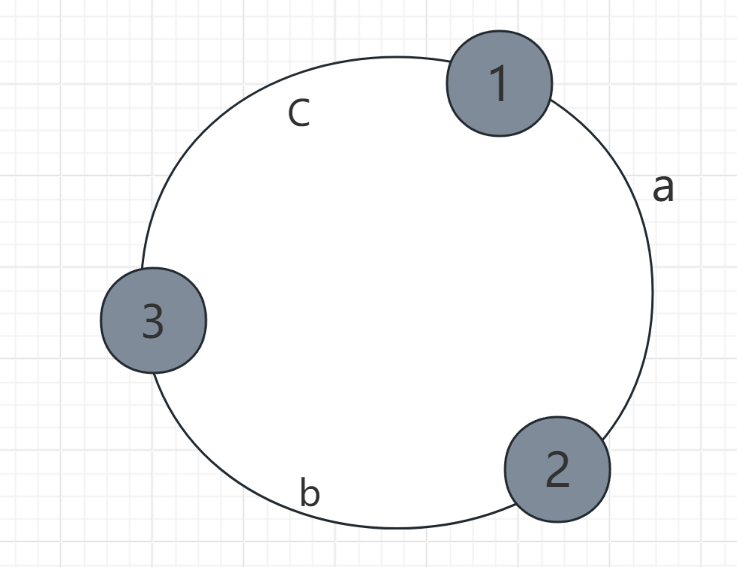
- 第三步
- 确定a、b、c映射到哪一个节点上 。
- 按顺时针顺序,将a、b、c映射到离它们最近的节点。
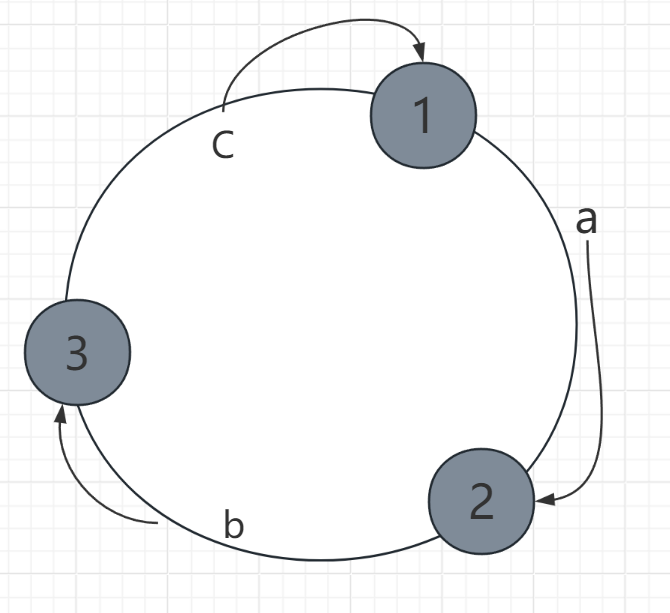
- 第四步
- 新增节点4,放在 1和2之间:仅需将环上相邻节点的部分数据迁移到新节点。
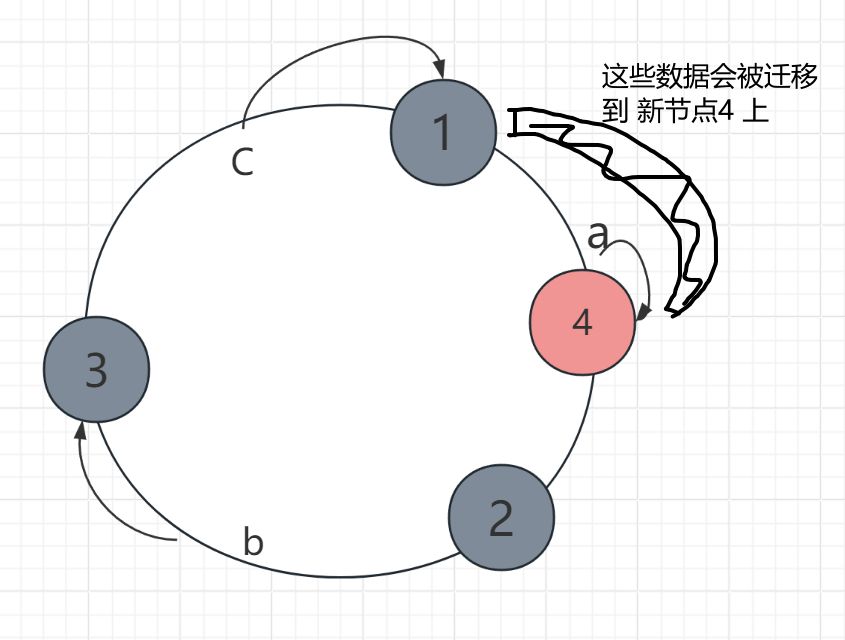
- 第五步
- 删除节点 4 ,把节点4上的数据 a 迁移到 节点2上
-
- 移除节点:该节点的数据顺时针迁移到下一个相邻节点。
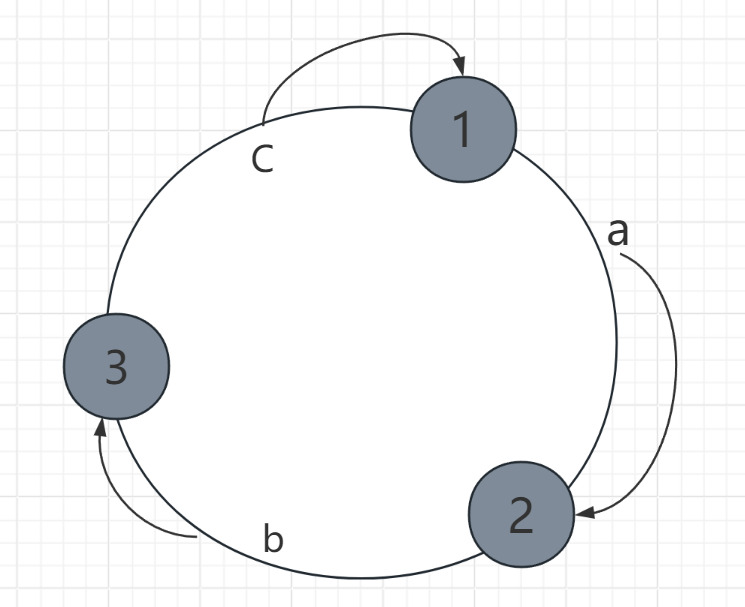
- 移除节点:该节点的数据顺时针迁移到下一个相邻节点。
6.4、虚拟节点
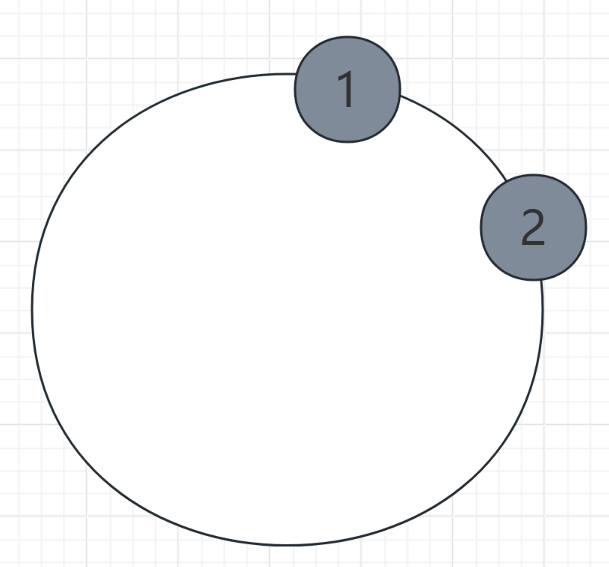
- 问题:
- 若物理节点较少,数据可能分布不均【哈希偏移】, 如上图。
- 哈希偏移:
- 在一致性哈希中,如果节点数量较少,可能会导致数据分布不均匀,某些节点负载过高,而其他节点负载较低。
- 解决:
- 每个物理节点映射多个虚拟节点 。
- 数据最终存储在虚拟节点对应的物理节点。
虚拟节点的优点
- 数据分布均匀
- 虚拟节点将物理节点的负载分散到哈希环的多个位置,避免数据倾斜。
- 动态扩容
- 增加物理节点时,只需为其分配虚拟节点,数据迁移量较少。
- 容错性
- 删除物理节点时,其虚拟节点对应的数据会迁移到其他物理节点,系统仍然保持平衡。
7、哈希的代码
#include<cstddef>
#include<cstdio>
#include<cstdlib>
#include<sstream>
#include<vector>
#include<functional>
#include<utility>
#include<list>
#include<string>
#include<iostream>
#include<algorithm>
using namespace std;
template<class Key,class Value,class Hash=hash<Key>>
class HashTable{class HashNode{public:Key key;Value value;//从key构造节点,Value使用默认构造explicit HashNode(const Key& key):key(key),value(){}//从key和value构造节点HashNode(const Key&key,const Value& value):key(key),value(value){}//比较运算符,只按key来比较bool operator==(const HashNode& other)const{return key==other.key;}bool operator!=(const HashNode& other)const{return key!=other.key;}bool operator<(const HashNode& other)const{return key<other.key;}bool operator>(const HashNode& other)const{return key>other.key;}bool operator==(const Key& key)const{return this->key==key;}//打印void print ()const{cout<<key<<" "<<value<<" ";}};private:using Bucket = list<HashNode>;//定义桶的类型为存储键的链表vector<Bucket> buckets; //存储所有桶的动态数组size_t tableSize; //哈希表的大小,即桶的数量size_t numElements; //哈希中的元素的数量float maxLoadFator = 0.75; //默认最大负载因子Hash hashFunction; //哈希函数对象//计算哈希值,并将其映射到桶的索引size_t hash(const Key& key)const{return hashFunction(key) % tableSize;}//当元素数量超过最大负载因子定义的容量时,增加桶的数量并重新分配所有键void rehash(size_t newSize){vector<Bucket> newBucket(newSize);//创建新的桶组for(Bucket& bucket:buckets){//遍历旧桶//遍历桶中的每一个键for(HashNode& hashNode:bucket){//因为这里是新的newSize计算,所以不能用hash(key)来求size_t newIndex=hashFunction(hashNode.key)%newSize;newBucket[newIndex].push_back(hashNode);//将键重新放入桶中}}buckets = move(newBucket);//使用移动语义更新桶数组tableSize = newSize;}
public://构造函数初始化哈希表HashTable(size_t size = 10,const Hash& hashFunc = Hash()):buckets(size),hashFunction(hashFunc),tableSize(size),numElements(0){}//插入键到哈希表中void insert(const Key&key,const Value& value){if((numElements+1)>maxLoadFator*tableSize){//检查是否需要重哈希//处理clear后再次插入元素时,tableSize = 0 的情况if(tableSize==0)tableSize = 1;rehash(tableSize*2);// 重哈希,桶数量翻倍}size_t index = hash(key); //计算键的索引list<HashNode>& bucket = buckets[index];//获取对应的桶//如果不在桶中,则添加到桶中if(find(bucket.begin(),bucket.end(),key)==bucket.end()){bucket.push_back(HashNode(key,value));++numElements;}}void insertKey(const Key&key){insert(key,Value{});}//从哈希表中移除键void erase(const Key& key){size_t index = hash(key);//计算键的索引auto & bucket = buckets[index];//获取对应的桶auto it = find(bucket.begin(),bucket.end(),key);//查找键if(it!=bucket.end()){bucket.erase(it);//删除键numElements--;//减少元素的数量}}//查找键是否在哈希表中Value* findKey(const Key& key){size_t index = hash(key);//计算键的索引auto & bucket = buckets[index];//获取对应的桶auto it = find(bucket.begin(),bucket.end(),key);//查找键if(it!=bucket.end()){return &it->value;}return nullptr;}//获取哈希表中的元素数量size_t size()const {return numElements;}//打印哈希表中的所有元素void print()const{for(size_t i = 0;i<buckets.size();++i){for(const HashNode& element:buckets[i]){element.print();}}cout<<endl;}void clear(){this->buckets.clear();this->numElements=0;this->tableSize = 0;}
};
int main(int argc, char const *argv[])
{//创建一个哈希表实例HashTable<int, int> hashTable;int n;cin>>n;getchar();string line;for(int i = 0;i<n;i++){getline(cin,line);istringstream iss(line);string command;iss>>command;int key;int value;if(command=="insert"){iss>>key>>value;hashTable.insert(key,value);}if(command == "erase"){if(hashTable.size()==0){continue;}iss>>key;hashTable.erase(key);}if(command=="find"){if(hashTable.size()==0){cout<<"not exist"<<endl;continue;}iss>>key;int* res = hashTable.findKey(key);if(res!=nullptr){cout<<*res<<endl;}else{cout<<"not exist"<<endl;}}if(command=="print"){if(hashTable.size()==0){cout<<"empty"<<endl;}else{hashTable.print();}}if(command=="size"){cout<<hashTable.size()<<endl;}if(command=="clear"){hashTable.clear();}}return 0;
}二、位图
推荐文章
1、问题一
腾讯问题:给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在40亿个数中。【哈希表:每个无符号整数占4字节。40亿占的是16G】
- 1 B是 8 bit 。
- 1GB = 1024MB。
- 1MB = 1024 KB 。
- 1KB = 1024B 。
- 40 亿个 无符号整数是 每个数 4字节。 就有 160 亿字节
- 160亿字节/1024/1024/1024 ≈ 14.9 GB
2、介绍
- 创建一段数组空间,用比特 1 和 0 来表示存在和不存在(1是存在,0是不能存在)。

3、实现位图的计算
void set(size_t x) {size_t index = x / 32; // 定位到哪个 intsize_t pos = x % 32; // 定位到 int 的哪一位bits[index] |= (1 << pos);//更新pos位置的 1
}
- 例如 x = 37:
- index = 37 / 32 = 1(第 2 个 int)
- 假设 bit[index]= 0000 0100
- pos = 37 % 32 = 5(第 5 位)
- 得pos = 0001 0000
- bits[1] |= (1 << 5) 将第 37 位设为 1
- 0000 0100 | 0001 000 = 0001 0100 。保持了原来的位的1,并更新了现在要改的位为 1
- index = 37 / 32 = 1(第 2 个 int)
3、操作
3.1、了解运算符
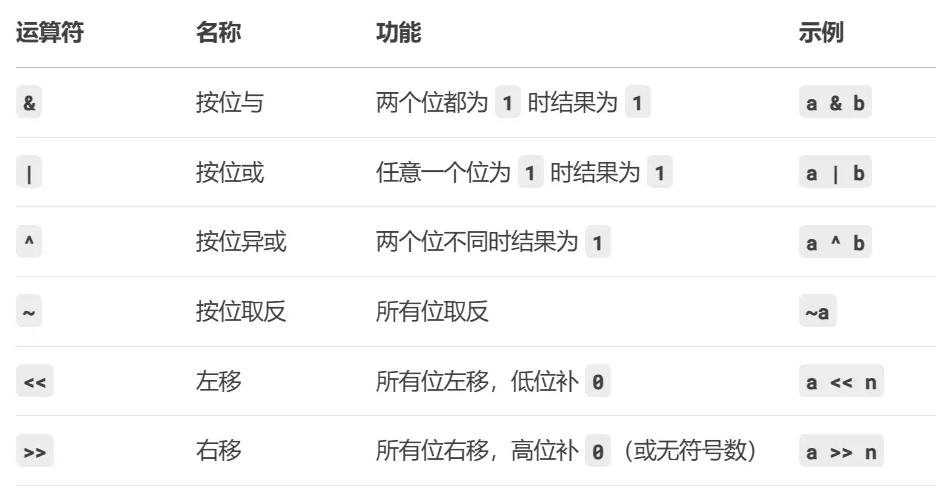
3.2、位图操作

4、位图的优缺点
- 查找很快
- 但是只能用于整型
5、代码实现
#include <cstddef>
#include<vector>
#include<iostream>
using namespace std;
namespace bit{class bitset{public:explicit bitset(size_t N){bits.resize(N/32+1,0);//如果是32的倍数,会多分配一个int}//设置位图void set(size_t x){size_t index = x/32;//算出x映射的位在第几个整型size_t pos = x%32;//算出x在这个整型的第几个位置bits[index]|= (1<<pos);//保留原来的1 ,设置现在需要 位 的1++num;}第pos个位置设置为0void reset(size_t x){size_t index = x/32;//算出x映射的位在第几个整型size_t pos = x%32;//算出x在这个整型的第几个位置bits[index] &= ~(1<<pos);//第pos个位置设置为0}//判断x在不在bool test(size_t x){size_t index = x/32;size_t pos = x%32;return bits[index]&(1<<pos);}private:vector<int> bits;size_t num;//个数};
};
void test_bitset(){using namespace bit;bitset bs(100);bs.set(99);bs.set(98);bs.set(97);for(size_t i =0;i<100;++i){cout<<"[%d]:%d\n"<<i<<static_cast<int>(bs.test(i))<<endl;}
}
int main(int argc, char const *argv[])
{test_bitset();return 0;
}三、布隆过滤器(Bloom Filter)
1、了解
- 用于:只想知道key存在不存在,不想知道内容。(适合去重场景)
- 支持任意数据类型。
- 布隆过滤器将元素进行多个Hash算法计算,都存入位图中,查询时使用同样的Hash算法计算,对应当所有值都为true时,表示存在。这样就可以极大的提升位图的存储效率。
布隆过滤器也有致命的缺陷,即存在误判率,也称为假阳性率。
当数据量不断增大,位图中非true位置越来越少,很可能会出现未插入的数据,查询结果为true。
2、构成
- 哈希+位图
相关文章:
19、HashTable(哈希)、位图的实现和布隆过滤器的介绍
一、了解哈希【散列表】 1、哈希的结构 在STL中,HashTable是一个重要的底层数据结构, 无序关联容器包括unordered_set, unordered_map内部都是基于哈希表实现 哈希表又称散列表,一种以「key-value」形式存储数据的数据结构。哈希函数:负责将…...

函数级重构:如何写出高可读性的方法?
1. 引言:为什么方法级别的重构如此重要? 在软件开发中,方法(函数)是程序逻辑的基本单元。一个高质量的方法不仅决定了程序是否能正常运行,更直接影响到: 代码的可读性:能否让其他开发者快速理解可维护性:未来修改是否容易出错可测试性:是否便于编写单元测试协作效率…...
mysql中int(1) 和 int(10) 有什么区别?
困惑 最近遇到个问题,有个表的要加个user_id字段,user_id字段可能很大,于是我提mysql工单alter table xxx ADD user_id int(1)。领导看到我的sql工单,于是说:这int(1)怕是不够用吧,接下来是一通解…...

FreeRTOS如何实现100%的硬实时性?
实时系统在嵌入式应用中至关重要,其核心在于确保任务在指定时间内完成。根据截止时间满足的严格程度,实时系统分为硬实时和软实时。硬实时系统要求任务100%满足截止时间,否则可能导致灾难性后果,例如汽车安全系统或医疗设备。软实…...

深度学习 ----- 数据预处理
常用的高级数据预处理的方法总结 🧠 一、图像数据高级预处理方法汇总表 方法原理常用参数适用场景图像增强(Augmentation)改变图像外观/几何结构,提升泛化能力翻转、旋转、缩放、色调扰动等分类、检测、分割等Mixup / CutMix合成…...

Cluster Interconnect in Oracle RAC
Cluster Interconnect in Oracle RAC (文档 ID 787420.1)编辑转到底部 In this Document Purpose Scope Details Physical Layout of the Private Interconnect Why Do We Need a Private Interconnect ? Interconnect Failure Interconnect High Availability Private Inte…...

【Spring Boot 注解】@SpringBootApplication
文章目录 SpringBootApplication注解一、简介二、使用1.指定要扫描的包 SpringBootApplication注解 一、简介 SpringBootApplication 是 Spring Boot 提供的一个注解,通常用于启动类(主类)上,它是三个注解的组合: 1.…...

angular的cdk组件库
目录 一、虚拟滚动 一、虚拟滚动 <!-- itemSize相当于每个项目的高度为30px --><!-- 需要给虚拟滚动设置宽高,否则无法正常显示 --> <cdk-virtual-scroll-viewport [itemSize]"40" class"view_scroll"><div class"m…...
element-ui日期时间选择器禁止输入日期
需求解释:时间日期选择器,下方日期有禁止选择范围,所以上面的日期输入框要求禁止输入,但时间输入框可以输入,也就是下图效果,其中日历中的禁止选择可以通过【picker-options】这个属性实现,此属…...

HarmonyOS Next~HarmonyOS应用测试全流程解析:从一级类目上架到二级类目专项测试
HarmonyOS Next~HarmonyOS应用测试全流程解析:从一级类目上架到二级类目专项测试 引言:HarmonyOS生态下的质量保障挑战 在万物互联的智能时代,HarmonyOS作为分布式操作系统,为开发者带来了前所未有的创新空间&#x…...

网络安全体系架构:核心框架与关键机制解析
以下是关于网络安全体系架构设计相关内容的详细介绍: 一、开放系统互联安全体系结构 开放系统互联(OSI)安全体系结构是一种基于分层模型的安全架构,旨在为开放系统之间的通信提供安全保障。它定义了安全服务、安全机制以及它们在…...

一种安全不泄漏、高效、免费的自动化脚本平台
在数字化转型加速的今天,自动化脚本工具已成为提升效率的重要助手。然而,用户在选择这类工具时,往往面临两大核心关切:安全性与成本。冰狐智能辅助(IceFox Intelligent Assistant)作为一款新兴的自动化脚本…...

[论文阅读]Deeply-Supervised Nets
摘要 我们提出的深度监督网络(DSN)方法在最小化分类误差的同时,使隐藏层的学习过程更加直接和透明。我们尝试通过研究深度网络中的新公式来提升分类性能。我们关注卷积神经网络(CNN)架构中的三个方面:&…...

多模态大语言模型arxiv论文略读(六十二)
MileBench: Benchmarking MLLMs in Long Context ➡️ 论文标题:MileBench: Benchmarking MLLMs in Long Context ➡️ 论文作者:Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, Benyou Wang ➡️ 研究机构: The Chinese Univers…...

现代框架对SEO的深度影响
第8章:现代框架对SEO的深度影响 1. 引言 Next 和 Nuxt 是两个 🔥热度和使用度都最高 的现代 Web 开发框架,它们分别基于 ⚛️React 和 🖖Vue 构建,也代表了这两个生态的 🌐全栈框架。 Next 是由 Vercel 公司…...
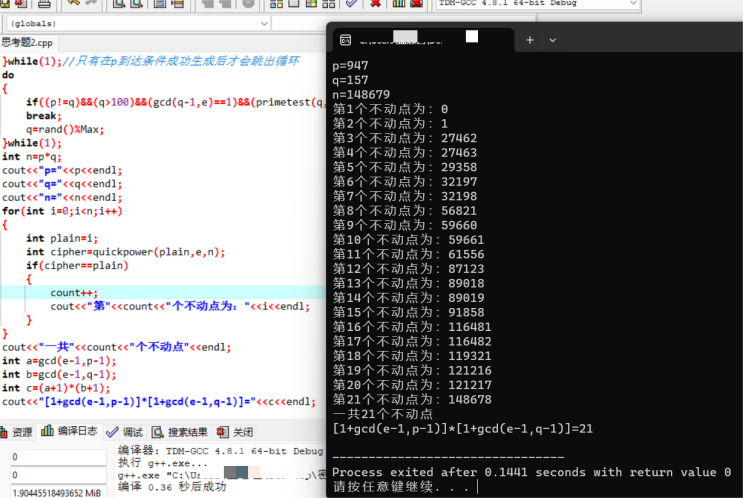
密码学--RSA
一、实验目的 1.随机生成明文和加密密钥 2.利用C语言实现素数选择(素性判断)的算法 3.利用C语言实现快速模幂运算的算法(模重复平方法) 4.利用孙子定理实现解密程序 5.利用C语言实现RSA算法 6.利用RSA算法进行数据加/解密 …...
如何选择自己喜欢的cms
选择内容管理系统cms what is cms1.whatcms.org2.IsItWP.com4.Wappalyzer5.https://builtwith.com/6.https://w3techs.com/7. https://www.netcraft.com/8.onewebtool.com如何在不使用 CMS 检测器的情况下手动检测 CMS 结论 在开始构建自己的数字足迹之前,大多数人会…...
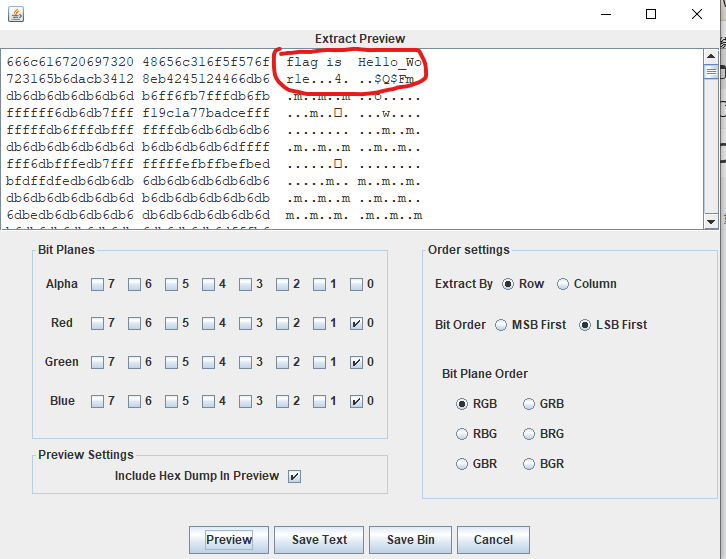
BUUCTF——杂项渗透之赛博朋克
下载附件,是一个txt。打开查看,数据如下: 感觉这个像是用十六进制编辑器打开后的图片数据。为了验证此想法,我用010editor打开,发现文件头的确是png图片的文件头。 把txt文件后缀改成png格式,再双击打开&am…...

【c++】 我的世界
太久没更新小游戏了 给个赞和收藏吧,求求了 要游戏的请私聊我 #include <iostream> #include <vector>// 定义世界大小 const int WORLD_WIDTH 20; const int WORLD_HEIGHT 10;// 定义方块类型 enum BlockType {AIR,GRASS,DIRT,STONE };// 定义世界…...
React 中集成 Ant Design 组件库:提升开发效率与用户体验
React 中集成 Ant Design 组件库:提升开发效率与用户体验 一、为什么选择 Ant Design 组件库?二、基础引入方式三、按需引入(优化性能)四、Ant Design Charts无缝接入图标前面提到了利用Redux提供全局维护,但如果在开发时再自己手动封装组件,不仅效率不高,可能开发的组件…...

HunyuanCustom, 腾讯混元开源的多模态定制视频生成框架
HunyuanCustom是一款由腾讯混元团队开发的多模态驱动定制视频生成框架,能够支持图像、音频、视频和文本等多种输入方式。该框架专注于生成高质量的视频,能够实现特定主体和场景的精准呈现。 HunyuanCustom是什么 HunyuanCustom是腾讯混元团队推出的一种…...

Lightweight App Alternatives
The tech industry’s business model thrives on constant churn: new features, fancier designs, and heavier apps — not because they’re essential, but because they keep consumers upgrading. Stripping your phone back to basics is an act of tech self-defense.…...

STM32F103RCT6 + MFC实现网口设备搜索、修改IP、固件升级等功能
资源下载链接:https://download.csdn.net/download/qq_35831134/90712875?spm=1001.2014.3001.5501 一.大概逻辑: // 网口搜索大概逻辑: // ************************************************************************** // 一.环境: // 上位机用MFC下位机用STM32F103R…...

编译原理实验 之 语法分析程序自动生成工具Yacc实验
文章目录 实验环境准备复现实验例子分析总的文件架构实验任务 什么是Yacc Yacc(Yet Another Compiler Compiler)是一个语法分析程序自动生成工具,Yacc实验通常是在编译原理相关课程中进行的实践项目,旨在让学生深入理解编译器的语法分析阶段以及掌握Yac…...

[250504] Moonshot AI 发布 Kimi-Audio:开源通用音频大模型,驱动多模态 AI 新浪潮
目录 Moonshot AI 发布 Kimi-Audio:开源音频基础模型,赋能音频理解、生成与对话新时代核心能力与特性技术基础开放资源与评估行业意义 Moonshot AI 发布 Kimi-Audio:开源音频基础模型,赋能音频理解、生成与对话新时代 Moonshot A…...

从“山谷论坛”看AI七剑下天山
始于2023年的美国山谷论坛(Hill and Valley Forum)峰会,以“国会山与硅谷”命名,寓意连接科技界与国家安全战略。以人工智能为代表的高科技,在逆全球化时代已成为大国的致胜高点。 论坛创办者Jacob Helberg,现在是华府的副国务卿,具体负责经济、环境和能源事务。早先曾任…...

C——数组和函数实践:扫雷
此篇博客介绍用C语言写一个扫雷小游戏,所需要用到的知识有:函数、数组、选择结构、循环结构语句等。 所使用的编译器为:VS2022。 一、扫雷游戏是什么样的,如何玩扫雷游戏? 如图,是一个标准的扫雷游戏初始阶段。由此…...

sui在windows虚拟化子系统Ubuntu和纯windows下的安装和使用
一、sui在windows虚拟化子系统Ubuntu下的安装使用(WindowsWsl2Ubuntu24.04) 前言:解释一下WSL、Ubuntu的关系 WSL(Windows Subsystem for Linux)是微软推出的一项功能,允许用户在 Windows 系统中原生运行…...

智能合约在去中心化金融(DeFi)中的核心地位与挑战
近年来,区块链技术凭借其去中心化、不可篡改等特性,在全球范围内掀起了技术革新浪潮。去中心化金融(DeFi)作为区块链技术在金融领域的重要应用,自 2018 年以来呈现出爆发式增长态势。据 DeFi Pulse 数据显示࿰…...

Femap许可使用数据分析
在当今竞争激烈的市场环境中,企业对资源使用效率和成本控制的关注日益增加。Femap作为一款业界领先的有限元分析软件,其许可使用数据分析功能为企业提供了深入洞察和智能决策的支持。本文将详细介绍Femap许可使用数据分析工具的特点、优势以及如何应用这…...