TIME - MoE 模型代码 3.2——Time-MoE-main/time_moe/datasets/time_moe_dataset.py
源码:GitHub - Time-MoE/Time-MoE: [ICLR 2025 Spotlight] Official implementation of "Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts"
这段代码定义了一个用于时间序列数据处理的 TimeMoEDataset 类,支持多种数据格式和归一化方法。
1. 类定义与初始化 (__init__)
class TimeMoEDataset(TimeSeriesDataset):def __init__(self, data_folder, normalization_method=None):self.data_folder = data_folderself.normalization_method = normalization_methodself.datasets = [] # 存储子数据集(BinaryDataset/GeneralDataset)self.num_tokens = None # 总时间点数量# 处理归一化方法if normalization_method is None:self.normalization_method = Noneelif isinstance(normalization_method, str):if normalization_method.lower() == 'max':self.normalization_method = max_scaler # 最大值归一化elif normalization_method.lower() == 'zero':self.normalization_method = zero_scaler # 标准化(Z-score)else:raise ValueError(f'未知归一化方法: {normalization_method}')else:self.normalization_method = normalization_method # 自定义归一化函数# 加载数据:支持二进制文件或普通文件/文件夹if BinaryDataset.is_valid_path(self.data_folder):ds = BinaryDataset(self.data_folder)if len(ds) > 0:self.datasets.append(ds)elif GeneralDataset.is_valid_path(self.data_folder):ds = GeneralDataset(self.data_folder)if len(ds) > 0:self.datasets.append(ds)else:# 递归遍历文件夹,加载所有有效文件for root, dirs, files in os.walk(self.data_folder):for file in files:fn_path = os.path.join(root, file)# 跳过二进制元数据文件,加载普通数据集if file != BinaryDataset.meta_file_name and GeneralDataset.is_valid_path(fn_path):ds = GeneralDataset(fn_path)if len(ds) > 0:self.datasets.append(ds)for sub_folder in dirs:folder_path = os.path.join(root, sub_folder)# 检查子文件夹是否为二进制数据集if BinaryDataset.is_valid_path(folder_path):ds = BinaryDataset(folder_path)if len(ds) > 0:self.datasets.append(ds)# 计算累计长度数组,用于快速定位子数据集self.cumsum_lengths = [0]for ds in self.datasets:self.cumsum_lengths.append(self.cumsum_lengths[-1] + len(ds))self.num_sequences = self.cumsum_lengths[-1] # 总序列数- 数据加载:
- 支持两种数据集类型:
BinaryDataset(二进制格式)和GeneralDataset(普通文本 / CSV 等)。 - 通过
os.walk递归遍历文件夹,自动识别有效数据文件,避免手动指定每个文件路径。
- 支持两种数据集类型:
- 归一化处理:
- 内置两种归一化方法:
max_scaler(最大值归一化)和zero_scaler(Z-score 标准化)。 - 支持自定义归一化函数,通过
normalization_method参数传入。
- 内置两种归一化方法:
- 子数据集管理:
cumsum_lengths数组记录每个子数据集的起始索引(类似前缀和),例如cumsum_lengths = [0, 100, 300]表示第一个子数据集有 100 条序列,第二个有 200 条。
2. 序列索引与获取 (__getitem__)
def __getitem__(self, seq_idx):if seq_idx >= self.cumsum_lengths[-1] or seq_idx < 0:raise ValueError(f'索引越界: {seq_idx}')# 二分查找确定子数据集索引和偏移量dataset_idx = binary_search(self.cumsum_lengths, seq_idx)dataset_offset = seq_idx - self.cumsum_lengths[dataset_idx]seq = self.datasets[dataset_idx][dataset_offset] # 获取原始序列# 应用归一化if self.normalization_method is not None:seq = self.normalization_method(seq)return seq- 二分查找:通过
binary_search函数在cumsum_lengths中快速定位序列所属的子数据集(时间复杂度为 \(O(\log N)\))。 - 归一化应用:对获取的序列调用
normalization_method函数,返回归一化后的数据(numpy 数组)。
3. 辅助方法
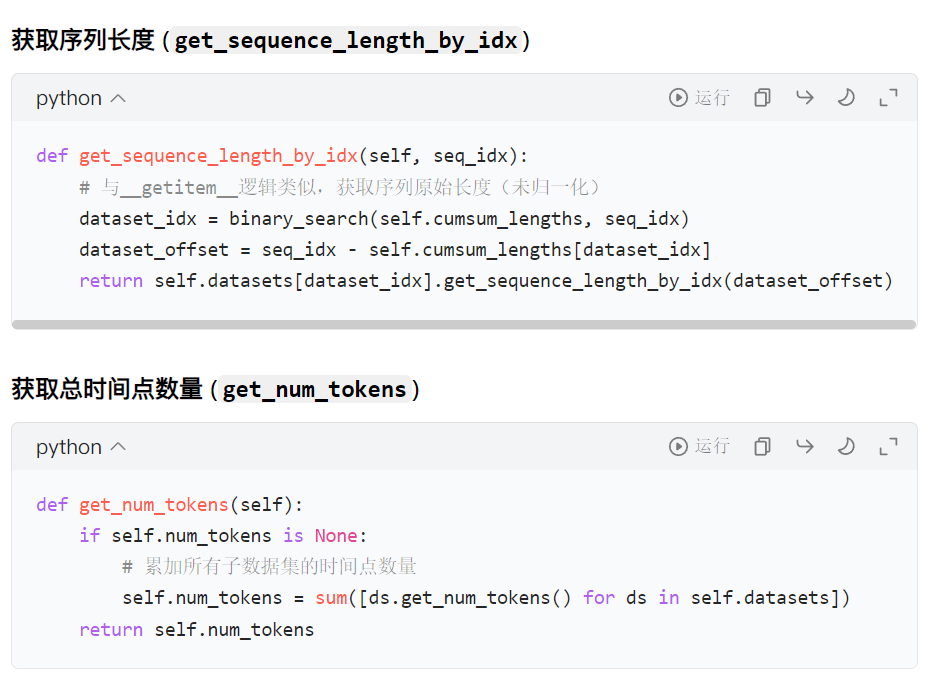
4. 归一化函数实现
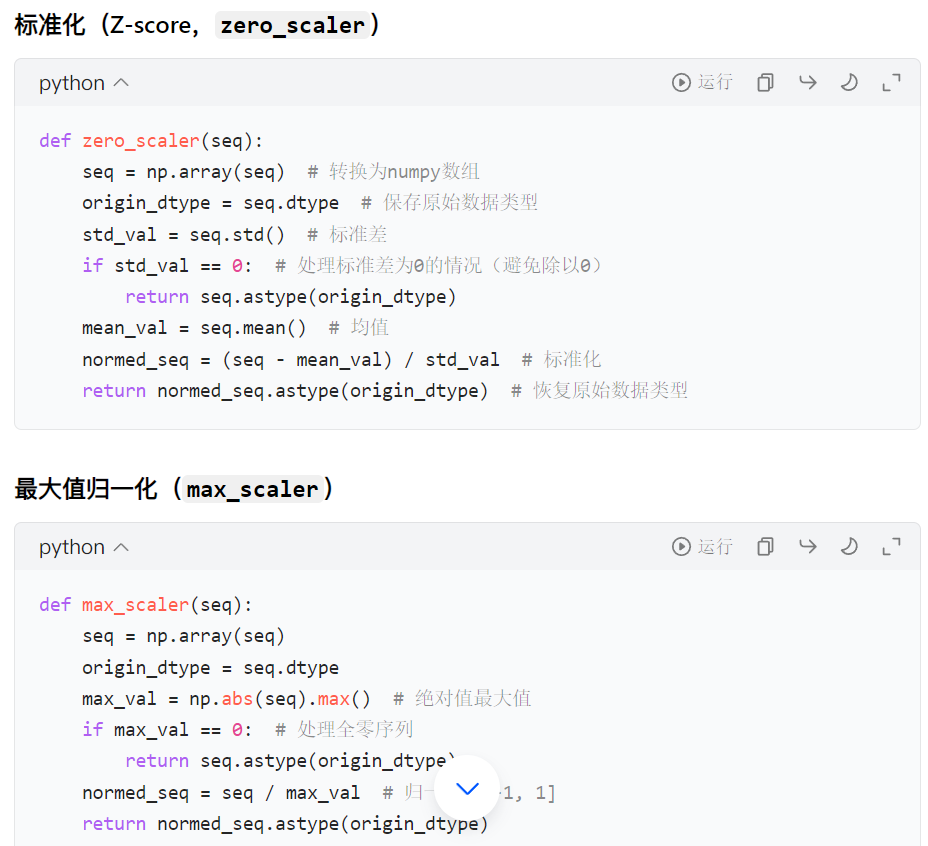
5. 二分查找函数 (binary_search)
def binary_search(sorted_list, value):low, high = 0, len(sorted_list) - 1best_index = -1while low <= high:mid = (low + high) // 2if sorted_list[mid] <= value: # 寻找最大的不超过value的索引best_index = midlow = mid + 1else:high = mid - 1return best_index- 在有序数组
sorted_list(即cumsum_lengths)中查找value所属的区间,返回子数据集索引。例如,若cumsum_lengths = [0, 100, 300],value=150会被定位到索引 1(第二个子数据集,偏移量 50)。
6. 总结
TimeMoEDataset 是一个高效、鲁棒的时间序列数据集加载器,核心功能包括:
- 多格式数据加载:自动识别二进制和普通文件,支持递归遍历文件夹。
- 灵活归一化:内置两种常用归一化方法,支持自定义函数,处理边界情况。
- 高效索引:通过前缀和数组和二分查找,快速定位子数据集,适合大规模数据。
该类为后续模型训练(如 TimeMoeTrainer)提供了统一的数据接口,确保数据预处理的标准化和高效性。
相关文章:
TIME - MoE 模型代码 3.2——Time-MoE-main/time_moe/datasets/time_moe_dataset.py
源码:GitHub - Time-MoE/Time-MoE: [ICLR 2025 Spotlight] Official implementation of "Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts" 这段代码定义了一个用于时间序列数据处理的 TimeMoEDataset 类,支…...
【某OTA网站】phantom-token 1004
新版1004 phantom-token 请求头中包含phantom-token 定位到 window.signature 熟悉的vmp 和xhs一样 最新环境检测点 最新检测 canvas 下的 toDataURL方法较严 过程中 会用setAttribute给canvas 设置width height 从而使toDataURL返回不同的值 如果写死toDataURL的返回值…...
OrangePi Zero 3学习笔记(Android篇)2 - 第一个C程序
目录 1. 创建项目文件夹 2. 创建c/cpp文件 3. 创建Android.mk/Android.bp文件 3.1 Android.mk 3.2 Android.bp 4. 编译 5. adb push 6. 打包到image中 在AOSP里面添加一个C或C程序,这个程序在Android中需要通过shell的方式运行。 1. 创建项目文件夹 首先需…...

DeepResearch深度搜索实现方法调研
DeepResearch深度搜索实现方法调研 Deep Research 有三个核心能力 能力一:自主规划解决问题的搜索路径(生成子问题,queries,检索)能力二:在探索路径时动态调整搜索方向(刘亦菲最好的一部电影是…...
)
使用大语言模型进行机器人规划(Robot planning with LLMs)
李升伟 编译 长期规划在机器人学领域可以从经典控制方法与大型语言模型在现实世界知识能力的结合中获益。 在20世纪80年代,机器人学和人工智能(AI)领域的专家提出了莫雷奇悖论,观察到人类看似简单的涉及移动和感知的任务&#x…...

【论文阅读】基于客户端数据子空间主角度的聚类联邦学习分布相似性高效识别
Efficient distribution similarity identification in clustered federated learning via principal angles between client data subspaces -- 基于客户端数据子空间主角度的聚类联邦学习分布相似性高效识别 论文来源TLDR背景与问题两个子空间之间的主角(Principa…...

Elasticsearch知识汇总之ElasticSearch部署
五 ElasticSearch部署 部署Elasticsearch,可以在任何 Linux、MacOS 或 Windows 机器上运行 Elasticsearch。在Docker 容器 中运行 Elasticsearch 。使用Elastic Cloud on Kubernetes 设置和管理 Elasticsearch、Kibana、Elastic Agent 以及 Kubernetes 上的 Elasti…...
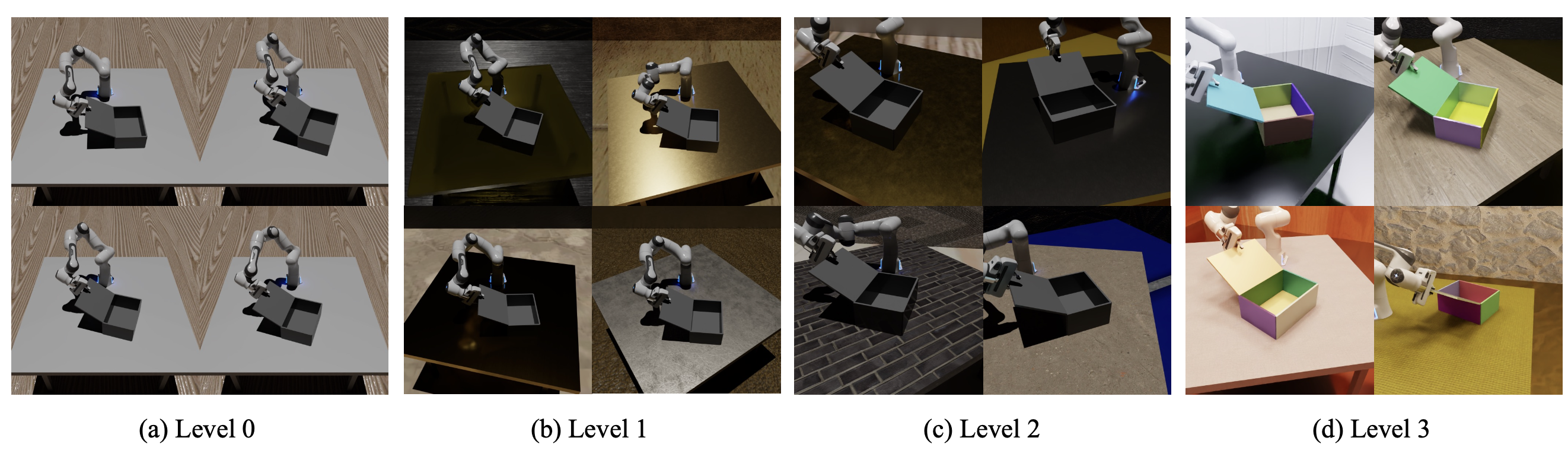
ROBOVERSE:面向可扩展和可泛化机器人学习的统一平台、数据集和基准
25年4月来自UC Berkeley、北大、USC、UMich、UIUC、Stanford、CMU、UCLA 和 北京通用 AI 研究院(BIGAI)的论文“ROBOVERSE: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning”。 数据扩展和标准化评…...

LVGL的核心:lv_timer_handler
文章目录 🧠 一句话总结 LVGL 的运行核心:🔁 1. while(1) 主循环中的 lv_task_handler()⏱️ 2. lv_timer_handler() 定时器调度核心✅ 并发控制✅ 关键行为流程:🌀 任务执行逻辑:🧮 计算下一次…...

(41)VTK C++开发示例 ---qt使用vtk最小示例
文章目录 1. 概述2. CMake链接VTK3. main.cpp文件4. 演示效果 更多精彩内容👉内容导航 👈👉VTK开发 👈 1. 概述 本文演示了在Qt中使用VTK的最小示例程序,使用VTK创建显示一个锥体; 采用Cmake作为构建工具&a…...

⭐️⭐️⭐️【课时1:大模型是什么?】学习总结 ⭐️⭐️⭐️ for《大模型Clouder认证:基于百炼平台构建智能体应用》认证
一、学习目标 概要 通过学习《课时1:大模型是什么?》,全面了解大模型的基础概念、核心特点、发展脉络及阿里云在大模型领域的布局,为后续基于百炼平台构建智能体应用的实践操作打下坚实的理论基础。 具体目标列表 理解人工智能到大模型的演变逻辑,明确大模型在AI发展历…...
OS7.【Linux】基本指令入门(6)
目录 1.zip和unzip 配置指令 使用 两个名词:打包和压缩 打包 压缩 Linux下的操作演示 压缩和解压缩文件 压缩和解压缩目录 -d选项 2.tar Linux下的打包和压缩方案简介 czf选项 xzf选项 -C选项 tzf选项 3.bc 4.uname 不带选项的uname -a选项 -r选项 -v选项…...
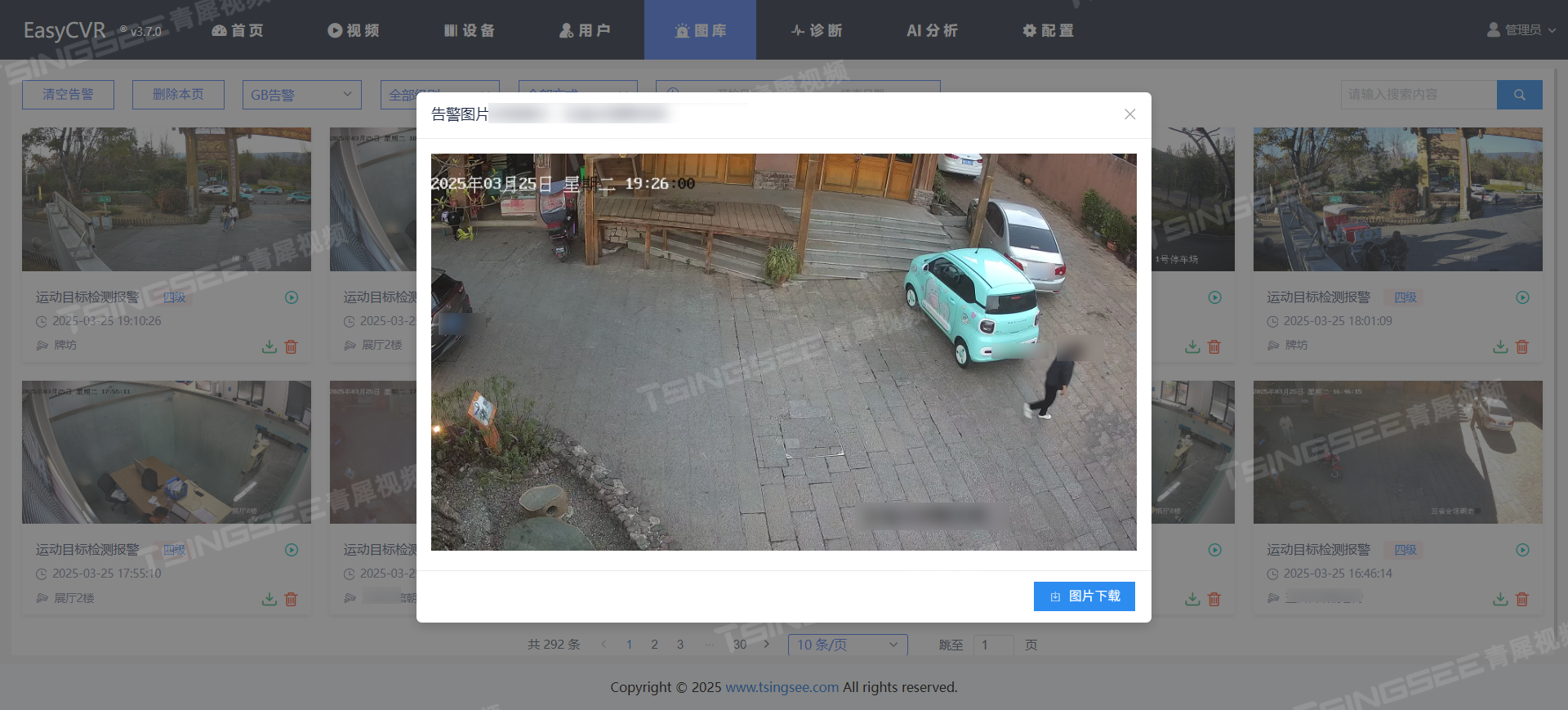
国标GB28181视频平台EasyCVR安防系统部署知识:如何解决异地监控集中管理和组网问题
在企业、连锁机构及园区管理等场景中,异地监控集中管控与快速组网需求日益迫切。弱电项目人员和企业管理者亟需整合分散监控资源,实现跨区域统一管理与实时查看。 一、解决方案 案例一:运营商专线方案 利用运营商专线,连接各分…...
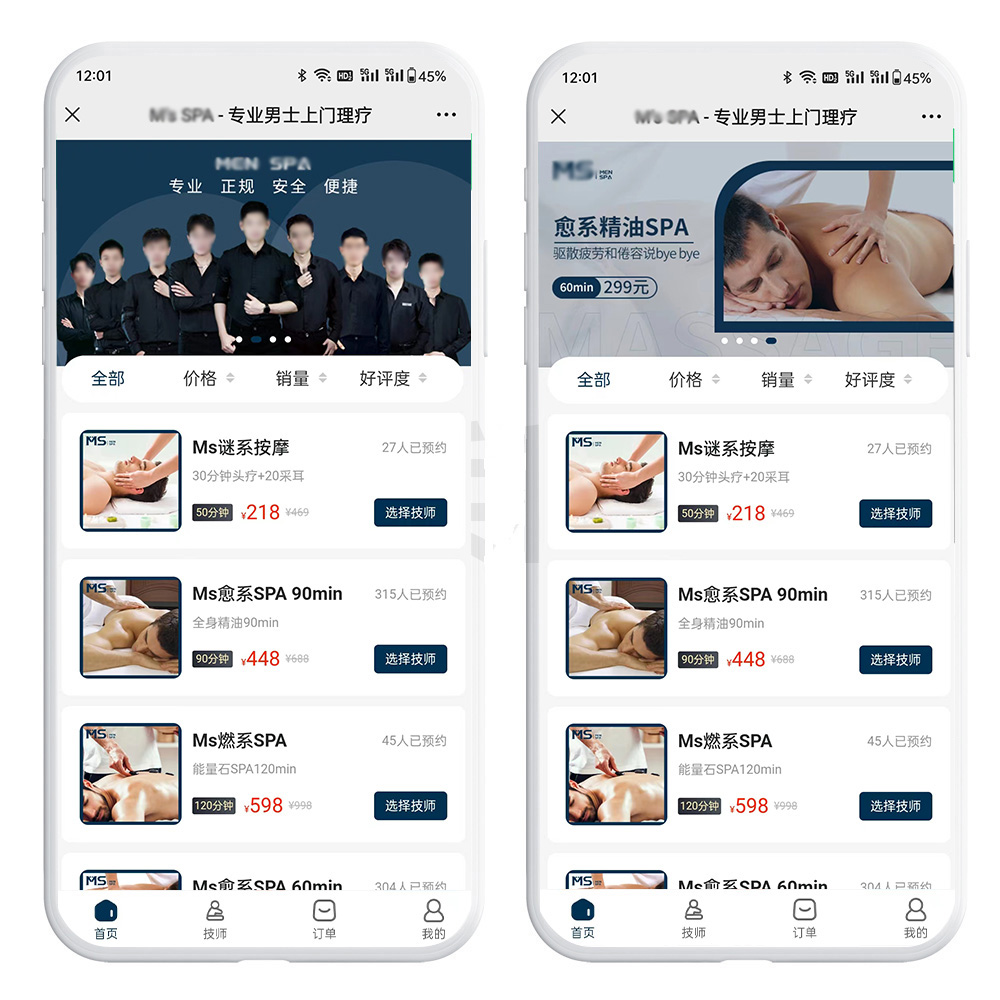
O2O上门服务如何颠覆传统足浴行业?真实案例分析
在湖南经营传统足浴店的张总最近遇到了件让他哭笑不得的事。原本他的门店生意还算稳定,虽然这两年行情不好,但靠着老顾客还能勉强维持。可谁想到,一次好心帮忙,竟让他发现了行业的新天地。 几年前,张总的一位做砂石生意…...

金仓数据库永久增量备份技术原理与操作
先用一张图说明一下常见的备份方式 为什么需要永久增量备份 传统的数据库备份方案通常是间隔7天对数据库做一次全量备份(完整备份),每天会基于全量备份做一次增量备份,如此循环,这种备份方案在全备数据量过大场景下…...

19、HashTable(哈希)、位图的实现和布隆过滤器的介绍
一、了解哈希【散列表】 1、哈希的结构 在STL中,HashTable是一个重要的底层数据结构, 无序关联容器包括unordered_set, unordered_map内部都是基于哈希表实现 哈希表又称散列表,一种以「key-value」形式存储数据的数据结构。哈希函数:负责将…...

函数级重构:如何写出高可读性的方法?
1. 引言:为什么方法级别的重构如此重要? 在软件开发中,方法(函数)是程序逻辑的基本单元。一个高质量的方法不仅决定了程序是否能正常运行,更直接影响到: 代码的可读性:能否让其他开发者快速理解可维护性:未来修改是否容易出错可测试性:是否便于编写单元测试协作效率…...
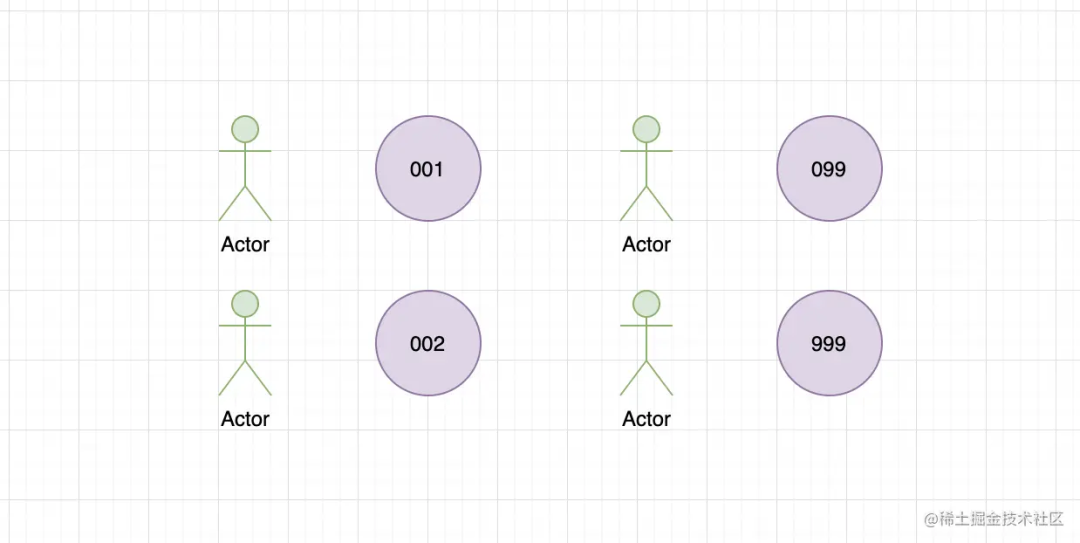
mysql中int(1) 和 int(10) 有什么区别?
困惑 最近遇到个问题,有个表的要加个user_id字段,user_id字段可能很大,于是我提mysql工单alter table xxx ADD user_id int(1)。领导看到我的sql工单,于是说:这int(1)怕是不够用吧,接下来是一通解…...

FreeRTOS如何实现100%的硬实时性?
实时系统在嵌入式应用中至关重要,其核心在于确保任务在指定时间内完成。根据截止时间满足的严格程度,实时系统分为硬实时和软实时。硬实时系统要求任务100%满足截止时间,否则可能导致灾难性后果,例如汽车安全系统或医疗设备。软实…...

深度学习 ----- 数据预处理
常用的高级数据预处理的方法总结 🧠 一、图像数据高级预处理方法汇总表 方法原理常用参数适用场景图像增强(Augmentation)改变图像外观/几何结构,提升泛化能力翻转、旋转、缩放、色调扰动等分类、检测、分割等Mixup / CutMix合成…...

Cluster Interconnect in Oracle RAC
Cluster Interconnect in Oracle RAC (文档 ID 787420.1)编辑转到底部 In this Document Purpose Scope Details Physical Layout of the Private Interconnect Why Do We Need a Private Interconnect ? Interconnect Failure Interconnect High Availability Private Inte…...

【Spring Boot 注解】@SpringBootApplication
文章目录 SpringBootApplication注解一、简介二、使用1.指定要扫描的包 SpringBootApplication注解 一、简介 SpringBootApplication 是 Spring Boot 提供的一个注解,通常用于启动类(主类)上,它是三个注解的组合: 1.…...

angular的cdk组件库
目录 一、虚拟滚动 一、虚拟滚动 <!-- itemSize相当于每个项目的高度为30px --><!-- 需要给虚拟滚动设置宽高,否则无法正常显示 --> <cdk-virtual-scroll-viewport [itemSize]"40" class"view_scroll"><div class"m…...
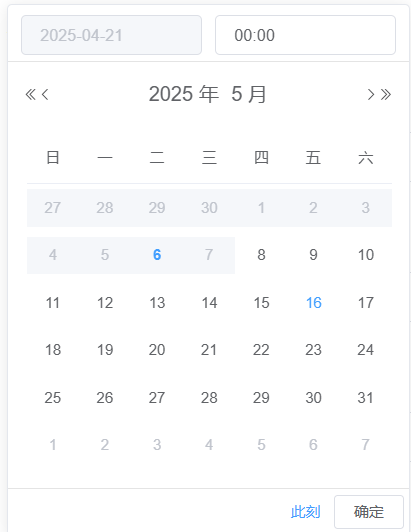
element-ui日期时间选择器禁止输入日期
需求解释:时间日期选择器,下方日期有禁止选择范围,所以上面的日期输入框要求禁止输入,但时间输入框可以输入,也就是下图效果,其中日历中的禁止选择可以通过【picker-options】这个属性实现,此属…...

HarmonyOS Next~HarmonyOS应用测试全流程解析:从一级类目上架到二级类目专项测试
HarmonyOS Next~HarmonyOS应用测试全流程解析:从一级类目上架到二级类目专项测试 引言:HarmonyOS生态下的质量保障挑战 在万物互联的智能时代,HarmonyOS作为分布式操作系统,为开发者带来了前所未有的创新空间&#x…...

网络安全体系架构:核心框架与关键机制解析
以下是关于网络安全体系架构设计相关内容的详细介绍: 一、开放系统互联安全体系结构 开放系统互联(OSI)安全体系结构是一种基于分层模型的安全架构,旨在为开放系统之间的通信提供安全保障。它定义了安全服务、安全机制以及它们在…...

一种安全不泄漏、高效、免费的自动化脚本平台
在数字化转型加速的今天,自动化脚本工具已成为提升效率的重要助手。然而,用户在选择这类工具时,往往面临两大核心关切:安全性与成本。冰狐智能辅助(IceFox Intelligent Assistant)作为一款新兴的自动化脚本…...

[论文阅读]Deeply-Supervised Nets
摘要 我们提出的深度监督网络(DSN)方法在最小化分类误差的同时,使隐藏层的学习过程更加直接和透明。我们尝试通过研究深度网络中的新公式来提升分类性能。我们关注卷积神经网络(CNN)架构中的三个方面:&…...

多模态大语言模型arxiv论文略读(六十二)
MileBench: Benchmarking MLLMs in Long Context ➡️ 论文标题:MileBench: Benchmarking MLLMs in Long Context ➡️ 论文作者:Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, Benyou Wang ➡️ 研究机构: The Chinese Univers…...

现代框架对SEO的深度影响
第8章:现代框架对SEO的深度影响 1. 引言 Next 和 Nuxt 是两个 🔥热度和使用度都最高 的现代 Web 开发框架,它们分别基于 ⚛️React 和 🖖Vue 构建,也代表了这两个生态的 🌐全栈框架。 Next 是由 Vercel 公司…...