Milvus 向量数据库详解与实践指南
一、Milvus 核心介绍
1. 什么是 Milvus?
Milvus 是一款开源、高性能、可扩展的向量数据库,专门为海量向量数据的存储、索引和检索而设计。它支持近似最近邻搜索(ANN),适用于图像检索、自然语言处理(NLP)、推荐系统、语义搜索、智能问答、多模态数据处理等 AI 应用场景。它能够高效处理:
-
嵌入向量(Embeddings)
-
特征向量(Feature Vectors)
-
任何高维数值向量
2. 核心特性
| 特性 | 说明 |
|---|---|
| 多索引支持 | IVF_FLAT、IVF_PQ、HNSW、Annoy 等 |
| 分布式架构 | 支持水平扩展,处理十亿级向量 |
| 多语言 SDK | Python、Java、Go、RESTful API |
| 云原生设计 | Kubernetes 友好,支持多云部署 |
| 混合查询 | 支持向量+标量数据的联合查询 |
3. 典型应用场景
-
图像/视频检索
-
语义文本搜索
-
推荐系统
-
异常检测
-
分子结构搜索
二、详细使用案例:构建电商图像搜索系统
案例背景
为电商平台搭建一个以图搜图系统,用户上传商品图片可找到相似商品。
实施步骤
1. 环境准备
# 安装依赖
pip install pymilvus torch torchvision pillow2. 特征提取模型
import torch
import torchvision.models as models
from torchvision import transforms# 使用ResNet50提取特征
model = models.resnet50(pretrained=True)
model.eval()# 图像预处理
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])def extract_features(img_path):img = Image.open(img_path)img_t = preprocess(img)batch_t = torch.unsqueeze(img_t, 0)with torch.no_grad():features = model(batch_t)return features.numpy().flatten()3. Milvus 集合(Collection)创建
from pymilvus import (connections,FieldSchema, CollectionSchema, DataType,Collection, utility
)# 连接Milvus
connections.connect("default", host="localhost", port="19530")# 定义Schema
fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),FieldSchema(name="product_id", dtype=DataType.VARCHAR, max_length=64),FieldSchema(name="image_vector", dtype=DataType.FLOAT_VECTOR, dim=2048), # ResNet50输出维度FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=128)
]schema = CollectionSchema(fields, description="Product image search collection")
collection = Collection("product_images", schema)# 创建索引
index_params = {"index_type": "IVF_FLAT","metric_type": "L2","params": {"nlist": 128}
}
collection.create_index("image_vector", index_params)4. 数据插入
# 假设已有商品图片数据
product_data = [{"product_id": "1001", "image_path": "path/to/image1.jpg", "category": "electronics"},# 更多商品数据...
]data = [[], # id列表[], # product_id列表[], # 特征向量列表[] # category列表
]for idx, product in enumerate(product_data):features = extract_features(product["image_path"])data[0].append(idx)data[1].append(product["product_id"])data[2].append(features)data[3].append(product["category"])# 批量插入
collection.insert(data)5. 相似搜索
# 用户上传图片搜索
search_img_path = "user_upload.jpg"
search_vector = extract_features(search_img_path)search_params = {"metric_type": "L2","params": {"nprobe": 16}
}results = collection.search(data=[search_vector],anns_field="image_vector",param=search_params,limit=5,output_fields=["product_id", "category"]
)for hits in results:for hit in hits:print(f"产品ID: {hit.entity.get('product_id')}, 距离: {hit.distance}, 类别: {hit.entity.get('category')}")三、关键注意事项
1. 生产环境部署建议
-
集群部署:单机版仅适合开发测试,生产环境使用分布式集群
-
资源规划:
-
向量维度越高,所需资源越多
-
10亿条128维向量 ≈ 500GB内存 + 1TB SSD
-
-
高可用配置:
# docker-compose.yml示例配置 etcd:deploy:replicas: 3 minio:deploy:replicas: 42. 性能优化技巧
-
索引选择:
场景 推荐索引 特点 高精度 IVF_FLAT 召回率高,内存占用大 内存敏感 IVF_PQ 有损压缩,节省内存 超大规模 DISKANN 支持SSD存储 -
查询参数调优:
# 平衡精度与性能的关键参数 search_params = {"nprobe": 32, # 增大值提高精度但降低性能"ef": 64 # HNSW专用参数 }3. 常见问题处理
- 内存不足:
# 调整Milvus配置 docker-compose.yml中增加: milvus-standalone:environment:- QUERY_NODE_GC_INTERVAL=300- QUERY_NODE_GC_THRESHOLD=0.0001
- 数据一致性:
# 插入后立即查询可能看不到数据 collection.flush() # 手动刷新
-
版本升级:
-
备份元数据(etcd)和对象存储(MinIO)
-
使用官方迁移工具
-
4. 安全建议
- 启用身份验证:
# 启动时配置 docker-compose.yml: environment:- MILVUS_AUTHORIZATION_ENABLED=true- MILVUS_ROOT_PASSWORD=YourSecurePassword
- 网络隔离:
# 只允许内网访问 networks:milvus_net:internal: true
四、扩展应用场景
1. 跨模态搜索
# 同时处理文本和图像
multi_modal_collection = CollectionSchema([FieldSchema(name="text_vector", dtype=DataType.FLOAT_VECTOR, dim=768),FieldSchema(name="image_vector", dtype=DataType.FLOAT_VECTOR, dim=2048)
])# 混合查询
expr = "category == 'electronics'"
collection.search(data=[query_vector],anns_field="image_vector",expr=expr, # 结合标量过滤limit=10
)2.实时推荐系统
# 用户行为向量更新
def update_user_vector(user_id, new_behavior_vec):# 获取现有向量current_vec = get_user_vector(user_id)# 加权平均更新updated_vec = 0.9 * current_vec + 0.1 * new_behavior_vec# 更新Milvuscollection.delete(f"id == {user_id}")collection.insert([[user_id], [updated_vec]])五、监控与维护
1. 关键监控指标
| 指标 | 健康值 | 检查命令 |
|---|---|---|
| QPS | < 1000/节点 | show metrics |
| 内存使用 | < 80% | docker stats |
| 查询延迟 | < 50ms | time search... |
2. 备份策略
# 定期备份
docker exec milvus-minio mc alias set myminio http://minio:9000 minioadmin minioadmin
docker exec milvus-minio mc cp --recursive myminio/milvus /backup/通过以上完整案例和注意事项,您可以构建一个高效的向量检索系统。Milvus 2.x 版本相比1.x有显著架构改进,建议新项目直接使用2.x版本。了解更多可以参阅milvus官方文档。安装教程可以参阅下面文章👇:mac 使用 Docker 安装向量数据库Milvus独立版的保姆级别教程-CSDN博客
相关文章:

Milvus 向量数据库详解与实践指南
一、Milvus 核心介绍 1. 什么是 Milvus? Milvus 是一款开源、高性能、可扩展的向量数据库,专门为海量向量数据的存储、索引和检索而设计。它支持近似最近邻搜索(ANN),适用于图像检索、自然语言处理(NLP&am…...

react+ts中函数组件父子通信方式
1. 父组件通过 Props 向子组件传递数据 这是最常见也是最基本的父子组件通信方式。父组件通过 props 将数据或回调函数传递给子组件。 示例代码: // 子组件接收来自父组件的数据 interface ChildProps {message: string; }const ChildComponent: React.FC<Chi…...
VSCode-插件:codegeex:ai coding assistant / 清华智普 AI 插件
一、官网 https://codegeex.cn/ 二、vscode 安装插件 点击安装即可,无需复杂操作,国内软件,无需科学上网,非常友好 三、智能注释 输入 // 或者 空格---后边自动出现注释信息,,按下 Tab 键,进…...

SlideLoss与FocalLoss在YOLOv8分类损失中的应用及性能分析
文章目录 一、引言二、YOLOv8 损失函数概述三、SlideLoss 详解(一)SlideLoss 的原理(二)SlideLoss 的代码实现 四、FocalLoss 分类损失函数详解(一)FocalLoss 的原理(二)FocalLoss 的…...

【AI智能推荐系统】第七篇:跨领域推荐系统的技术突破与应用场景
第七篇:跨领域推荐系统的技术突破与应用场景 提示语:🔥 “打破数据孤岛,实现1+1>2的推荐效果!深度解析美团、亚马逊如何用跨领域推荐技术实现业务协同,知识迁移核心技术全公开!” 目录 跨领域推荐的商业价值跨领域推荐技术体系 2.1 基于共享表征的学习2.2 迁移学习…...
)
ui组件二次封装(vue)
组件二次封装的意义 保证一个系统中ui风格和功能的一致性便于维护 从属性、事件、插槽、ref这几方面考虑 属性和事件的处理:ui组件上绑定$attrs(v-model本质也是一个属性加一个事件,所以也在其列) 在自定义组件中打印$attrs&am…...
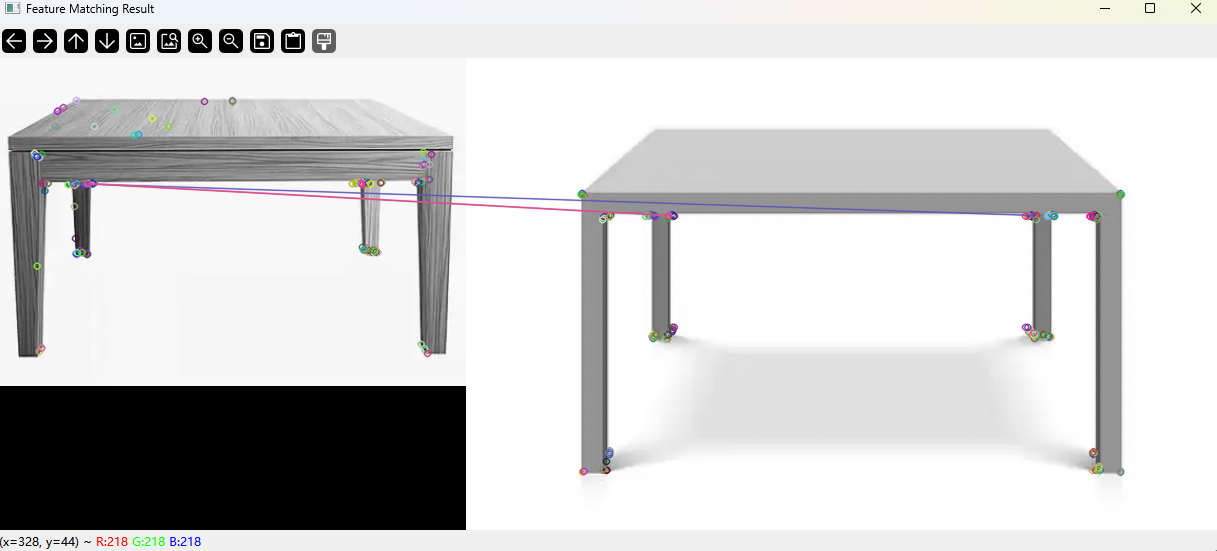
OpenCv实战笔记(4)基于opencv实现ORB特征匹配检测
一、原理作用 ORB 原理(Oriented FAST and Rotated BRIEF): 特征点检测:使用 FAST 算法检测角点(关键点)。 方向计算:为每个关键点分配主方向,增强旋转不变性。 特征描述:…...

PyTorch 线性回归模型构建与神经网络基础要点解析
笔记 1 PyTorch构建线性回归模型 1.1 创建数据集 import torch from torch.utils.data import TensorDataset # 创建x和y张量数据集对象 from torch.utils.data import DataLoader # 创建数据集加载器 import torch.nn as nn # 损失函数和回归函数 from torch.optim impo…...

Android平台FFmpeg音视频开发深度指南
一、FFmpeg在Android开发中的核心价值 FFmpeg作为业界领先的多媒体处理框架,在Android音视频开发中扮演着至关重要的角色。它提供了: 跨平台支持:统一的API处理各种音视频格式完整功能链:从解码、编码到滤镜处理的全套解决方案灵…...
深入解析路由策略:从流量控制到策略实施
一、网络流量双平面解析 在路由策略的设计中,必须明确区分两个关键平面: 1. 控制层面(Control Plane) 定义:路由协议传递路由信息形成的逻辑平面(如OSPF的LSA、RIP的Response报文)…...
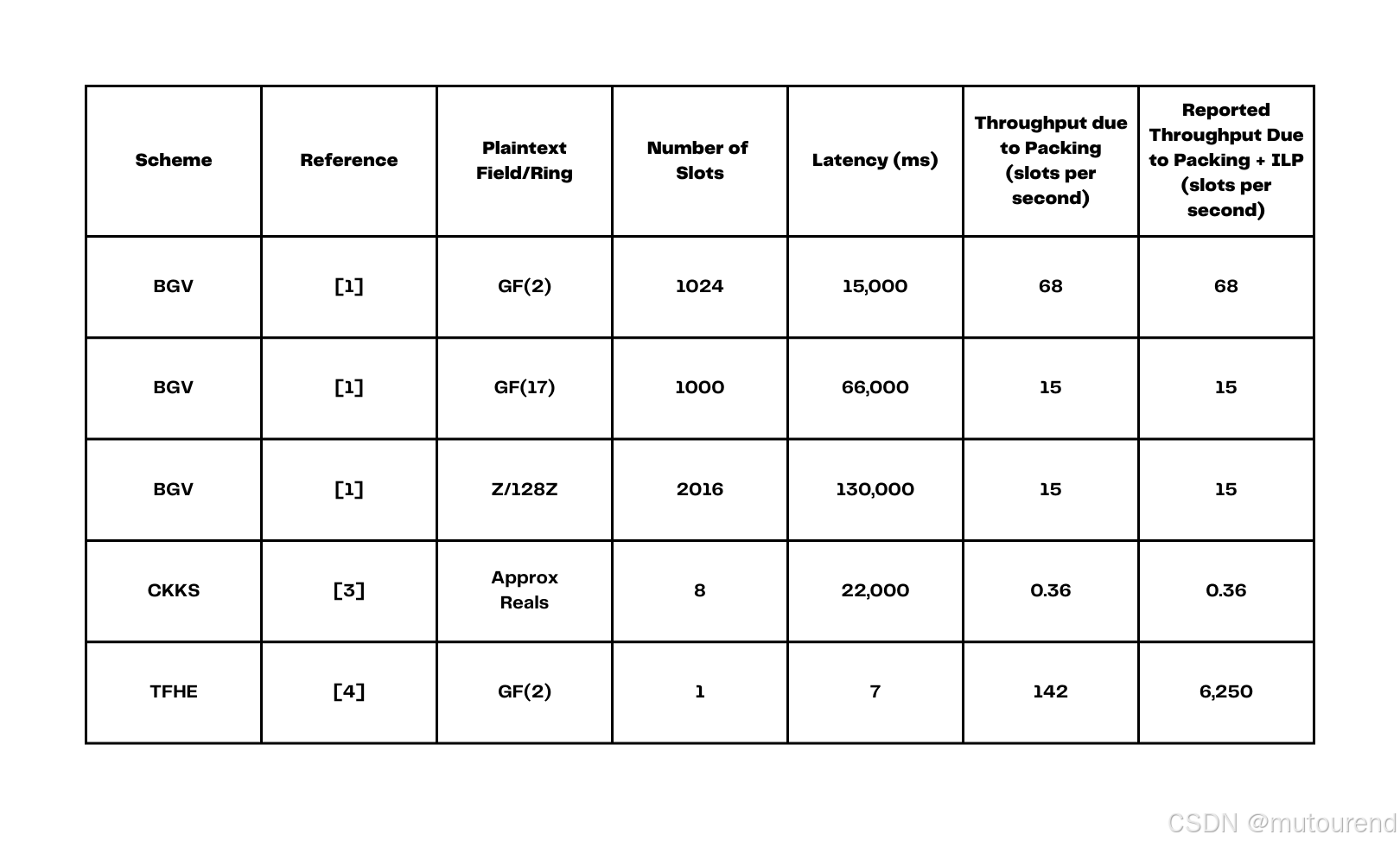
FHE 之 面向小白的引导(Bootstrapping)
1. 引言 FHE初学者和工程师常会讨论的一个问题是; “什么是引导(bootstrapping)?” 从理论角度看,这个问题的答案很简单: 引导就是套用 Gentry 提出的思想——在加密状态下同态地执行解密操作ÿ…...

51单片机入门教程——AT24C02数据存储
前言 本教程基于B站江协科技课程进行个人学习整理,专为拥有C语言基础的零基础入门51单片机新手设计。既帮助解决因时间差导致的设备迭代调试难题,也助力新手快速掌握51单片机核心知识,实现从C语言理论到单片机实践应用的高效过渡 。 目录 …...
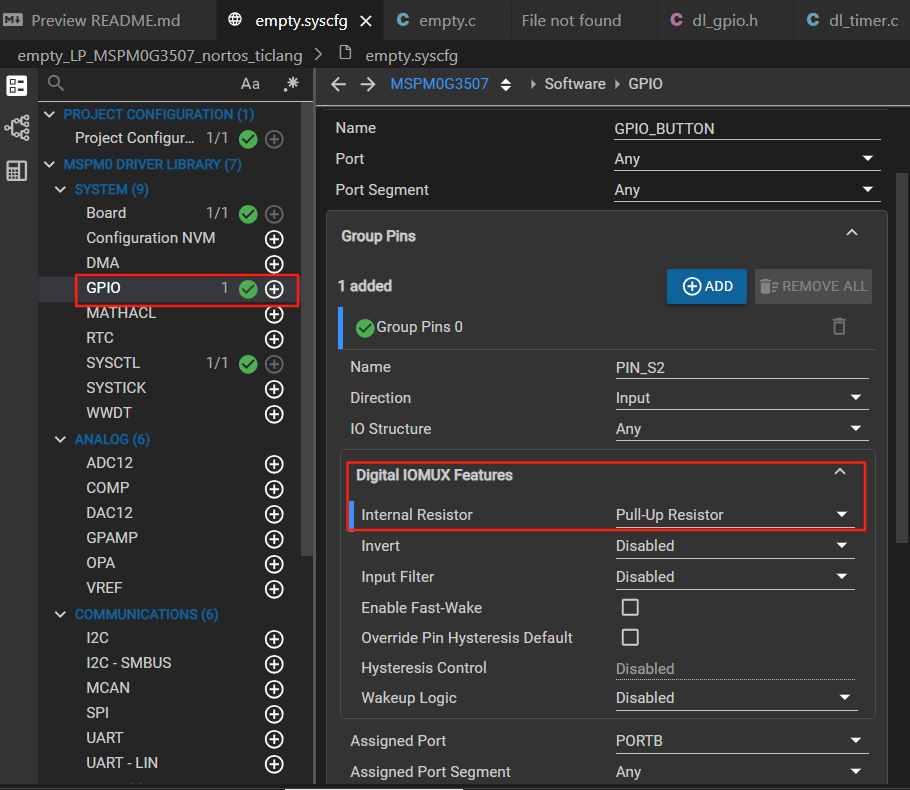
M0的基础篇之PWM学习
一、困惑 上一节课就是单纯的之配置了一个基础的定时器进行计数,计到一定的数值也就是到了一定的时间就进入中断,执行中断里面的任务,也就是一个最基础的定时的功能 这一节课的定时器产生了一个pwm波。也就是我们可以改变里面高电平的持续时间…...
Python----神经网络(基于AlexNet的猫狗分类项目)
一、基于AlexNet的猫狗分类 1.1、项目背景 猫和狗是我们生活中最常见的宠物,它们的图像数据大量存在于互联网上。对此进行分类不仅可以帮助开发自动化宠物识别应用,也可以应用于更广泛的计算机视觉领域。例如,训练良好的模型可以支持流浪动物…...

excel表数据导入数据库
前两天,有个两DB之间的数据导出导入的需求。对方提供的是excel表,我这边是mysql数据库,excel表第一行是字段名,之后的行是记录的值。 其实没有多复杂,我先将exel转成csv,结果mysql导入csv,第一行…...

SMT贴片钢网精密设计与制造要点解析
内容概要 SMT贴片钢网作为电子组装工艺的核心载体,其设计与制造质量直接影响焊膏印刷精度及产品良率。本文系统梳理了钢网全生命周期中的15项关键技术指标,从材料选择、结构设计到工艺控制构建完整技术框架。核心要点涵盖激光切割精度的微米级调控、开口…...

第三节:条件语句与循环:控制程序流程
📌 第三节:条件语句与循环:控制程序流程 目标:熟练运用条件判断、循环结构,实现动态逻辑与重复操作,掌握常见算法的底层实现。 一、条件语句:让程序“聪明”起来 1. if-else 基础语法 作用&am…...

荣耀A8互动娱乐组件部署实录(第1部分:服务端环境搭建)
作者:一位被“只支持安卓”的前端劝退过三次的技术人 前言 这一套组件我拆包已经不止一遍了,老实讲,不支持 iOS 是遗憾,但对于研究 UI 动态加载、资源分离结构和整体架构来说,A8 的这套服务还算完整,服务器…...

流式渲染 Streaming SSR
以下是关于流式渲染(Streaming SSR)的基本知识点总结: 一、流式渲染核心概念 1. 与传统SSR对比 维度传统SSR流式SSR响应方式完整HTML生成后一次性返回分块逐步返回HTML内容首字节时间较慢(需等待所有数据处理完成)极快(立即发送初始HTML结构)内存压力高(需缓存完整页面…...

基于Python Flask的深度学习电影评论情感分析可视化系统(2.0升级版,附源码)
博主介绍:✌IT徐师兄、7年大厂程序员经历。全网粉丝15W、csdn博客专家、掘金/华为云//InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇dz…...

如何减少极狐GitLab 容器镜像库存储?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 减少容器镜像库存储 (BASIC ALL) 未清理的容器镜像库会随着时间的推移而变大。添加大量镜像或标签时: 获取可用标…...
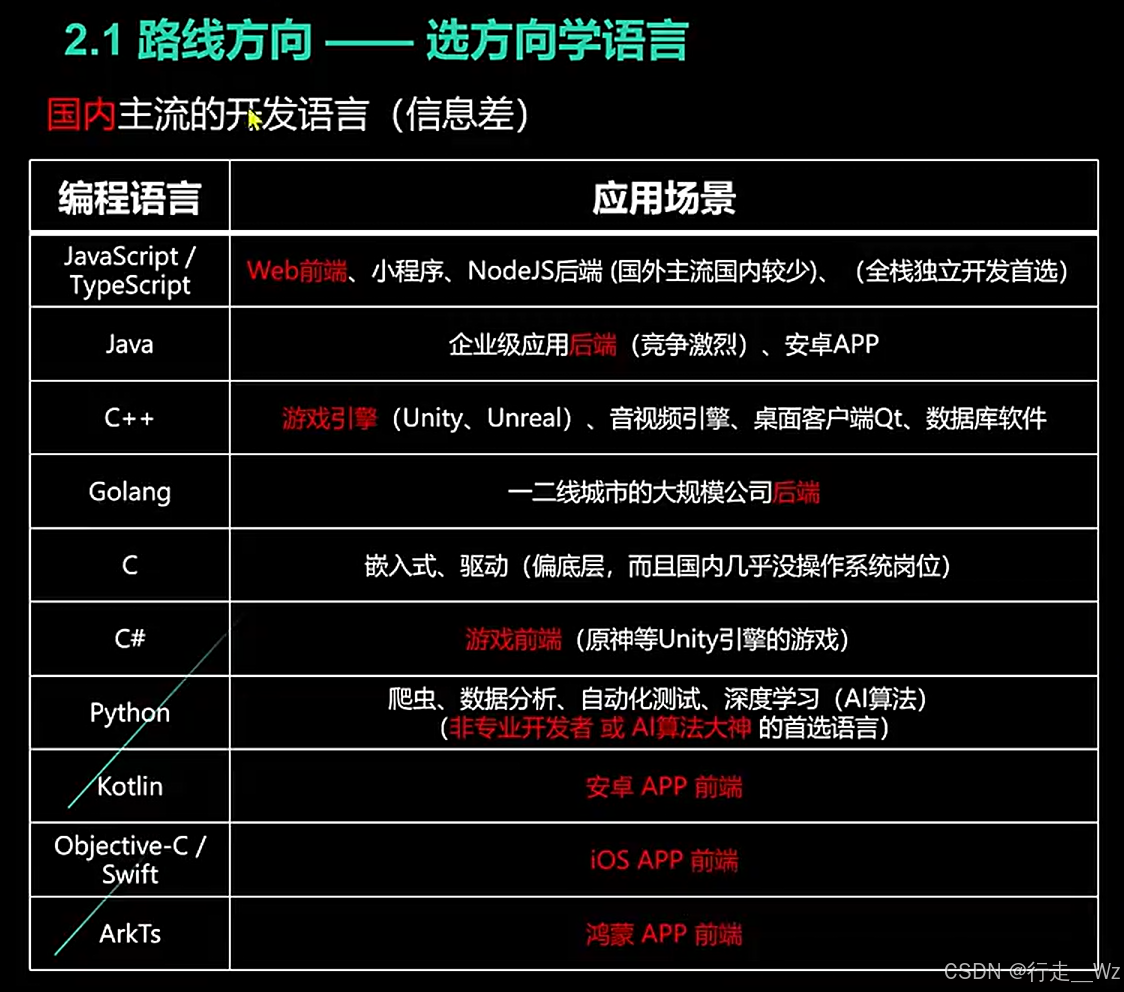
计算机学习路线与编程语言选择(信息差)
——授人以鱼不如授人以渔 计算机学习公式:1/3科班思维 1/3路线选择 1/3工程能力 好工作随便找(来自B站小毛毛熊) 本文主要是路线选择!!!下面开始吧。 面向岗位学习!到招聘网站看看有哪些…...

【redis】redis 手动切换主从
场景一: 测试需要,需要手动切换主从 在redis节点: $ redis-cli -h xx.xx.xx.xx -p XX -a XX shutdown 不要直接关闭redis进程,使用 shutdown ,能在进程关闭前持久化内存中的数据 待主从切换完毕后࿱…...

基于设备指纹识别的反爬虫技术:给设备办 “身份证”
传统的封禁 IP、验证码等反爬虫手段已逐渐失效,基于设备指纹识别的反爬虫技术应运而生,成为守护数据安全的新防线。它如同给每个设备办一张独一无二的 “身份证”,精准区分正常用户与爬虫工具。 一、基础参数采集:构建设备指纹的…...

SpringAI框架中的RAG知识库检索与增强生成模型详解
SpringAI框架中的RAG知识库检索与增强生成模型详解 一、RAG简介 RAG(Retrieval-Augmented Generation)可以通过检索知识库,克服大模型训练完成后参数冻结的局限性,携带知识让大模型根据知识进行回答。 二、SpringAI框架支持的R…...
,图解超赞超详细!!!)
【造包工具】【Xcap】精讲Xcap构造分片包(IPv4、ipv6、4G\5G等pcap均可),图解超赞超详细!!!
目录 前言 1. XCap工具概念介绍 2. Xcap环境说明 2.1 新建报文组 2.2 导入数据包 2.3 查看报文组 2.4 复制删除报文组 3. 构造分片包 3.1 造普通/外层分片步骤: 3.2 造内层分片步骤 3.2.1 建立一个新报文 3.2.2 将组装的新报文分片 3.2.3 替换原始包内层部分 3.2…...
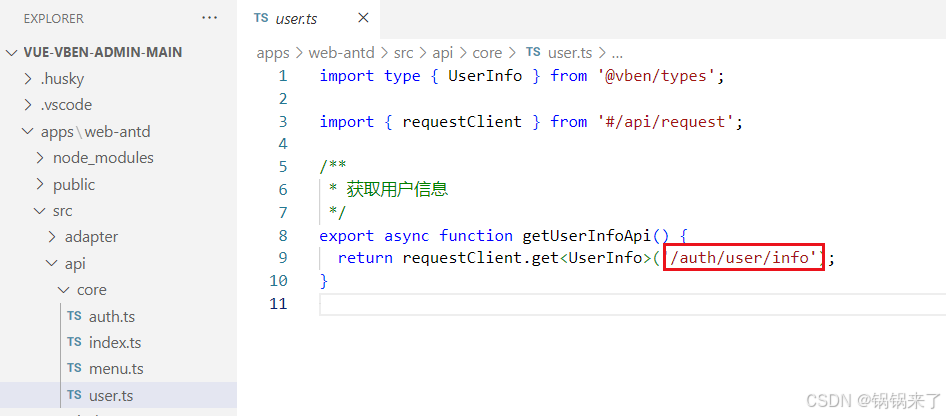
第三节:Vben Admin 最新 v5.0 对接后端登录接口(下)
文章目录 前言一、处理请求头Authorization二、/auth/user/info 接口前端接口后端接口三、/auth/codes 接口1.前端2.后端四、测试接口前言 上一节内容,实现了登录的/auth/login 接口,但是登陆没有完成,还需要完成下面两个接口。才能完成登录。 一、处理请求头Authorizatio…...

爬虫学习————开始
🌿自动化的思想 任何领域的发展原因————“不断追求生产方式的改革,即使得付出与耗费精力越来愈少,而收获最大化”。由此,创造出方法和设备来提升效率。 如新闻的5W原则直接让思考过程规范化、流程化。或者前端框架/后端轮子的…...
Ubuntu18.04搭建samda服务器
一.什么是Samba服务器? Samba服务器是一种基于开源协议实现的网络共享服务软件,主要用于在不同操作系统(如Windows、Linux、Unix)之间实现文件和打印机共享功能。其核心目标是解决跨平台资源共享的兼容性问题,尤其是在…...

K8S扩缩容及滚动更新和回滚
目录: 1、滚动更新1、定义Deployment配置2、应用更新 2、版本回滚1. 使用kubectl rollout undo命令 3、更新暂停与恢复1、暂停更新2、更新镜像(例如,使用kubectl set image命令)3、恢复更新 4、弹性扩缩容1、扩容命令2、缩容命令3…...