【大模型】使用 LLaMA-Factory 进行大模型微调:从入门到精通

使用 LLaMA-Factory 进行模型微调:从入门到精通
- 一、环境搭建:奠定微调基础
- (一)安装依赖工具
- (二)创建 conda 环境
- (三)克隆仓库并安装依赖
- 二、数据准备:微调的基石
- (一)数据集格式
- (二)数据集注册
- 三、模型文件:微调的起点
- (一)从 Hugging Face 下载
- (二)模型文件验证
- 四、代码下载:获取微调工具
- 五、配置更新:掌控微调细节
- (一)微调配置文件详解
- (二)配置文件的灵活应用
- 六、可能会遇到的报错及解决方法:微调的挑战与应对
- (一)CUDA 相关报错
- (二)数据格式错误
- (三)模型加载失败
- (四)训练过程中的其他错误
- 七、相关的论文信息:理论支撑与前沿探索
- (一)LoRA 相关论文
- (二)其他相关论文
- 八、SFT 和 LoRA 的 SH 命令
- (一)SFT 的 SH 命令
- (二)LoRA 的 SH 命令
- 九、快速开始
- 十、LLaMA Board 可视化微调(由 Gradio 驱动)
在人工智能快速发展的当下,大模型微调成为了众多研究人员和开发者关注的焦点。LLaMA-Factory 作为一款简单易用的大模型微调框架,以其高效性和便捷性脱颖而出。本文将详细介绍如何利用 LLaMA-Factory 进行模型微调,从数据准备到模型文件、代码下载、配置更新、配置含义、可能会遇到的报错及解决方法,再到相关的论文信息,全方位为您呈现这一过程。
一、环境搭建:奠定微调基础
(一)安装依赖工具
- 安装 anaconda :访问 Anaconda 官方网站,根据您的操作系统选择对应的安装包进行下载。安装过程中,只需按照安装向导的提示逐步操作,即可完成安装。安装完成后,您可以在命令行中输入
conda --version来验证安装是否成功。 - 安装 git :前往 Git 官方网站,根据您的操作系统下载对应的安装程序。安装完成后,在命令行中输入
git --version,若能显示版本信息,则说明安装成功。
(二)创建 conda 环境
在命令行中输入以下命令:
conda create --name openTreck python=3.8
该命令用于创建一个名为 openTreck 的新环境,并指定 Python 版本为 3.8。激活环境的命令为:
conda activate openTreck
(三)克隆仓库并安装依赖
首先,使用以下命令克隆 LLaMA-Factory 项目仓库到本地:
git clone https://github.com/hiyouga/LLaMA-Factory.git
然后,进入项目目录:
cd LLaMA-Factory
最后,使用以下命令安装所需的 Python 包:
pip install -e ".[torch,metrics]"
二、数据准备:微调的基石
(一)数据集格式
为了确保数据集能够被 LLaMA-Factory 正确读取和处理,您的自定义数据集需要遵循特定的格式。一个典型的指令微调数据集应包含以下字段:
- instruction :表示需要模型执行的指令或任务,例如 “介绍你自己”。
- input :为模型提供执行指令所需的输入信息,在许多情况下可能为空,如前面提到的例子。
- output :展示模型执行指令后应产生的理想输出,比如 “我是 Qwen,一个由月之暗面科技有限公司开发的人工智能助手。”
示例数据集如下:
{"instruction": "介绍人工智能的发展历程","input": "","output": "人工智能的发展历程可以追溯到 20 世纪中叶,当时科学家们开始探索如何使机器模拟人类智能。1956 年,达特茅斯会议的召开标志着人工智能学科的正式诞生。在接下来的几十年里,人工智能经历了多次起伏,包括专家系统的兴起与衰落、机器学习的崛起等。近年来,随着深度学习技术的突破,人工智能迎来了新的发展高潮,自然语言处理、计算机视觉等领域取得了显著的成果。"
}
(二)数据集注册
将准备好的数据集文件(例如命名为 my_dataset.json)放置在 LLaMA-Factory 项目根目录下的 data 文件夹内。接着,您需要在 data_info.json 文件中注册该数据集。编辑 data_info.json 文件,添加以下内容:
{"my_dataset": {"file_name": "my_dataset.json","columns": ["instruction", "input", "output"]}
}
三、模型文件:微调的起点
您可以从 Hugging Face 或 ModelScope 等平台下载所需的模型文件,以 DeepSeek-R1-Distill-Qwen-1.5B 为例。
(一)从 Hugging Face 下载
访问 Hugging Face 模型库,在搜索栏中输入 “DeepSeek-R1-Distill-Qwen-1.5B”,进入模型页面。点击 “Download” 按钮,选择下载整个模型文件夹。下载完成后,将解压后的文件夹放置在 LLaMA-Factory 项目根目录下的 models 文件夹内。
(二)模型文件验证
为了确保下载的模型文件完整且可用,您可以通过 LLaMA-Factory 提供的原始推理 demo 进行验证。在命令行中运行以下命令:
llamafactory-cli inference --model_name_or_path models/DeepSeek-R1-Distill-Qwen-1.5B --prompt "介绍你自己"
若模型能够正确输出类似于 “我是 Qwen,一个由月之暗面科技有限公司开发的人工智能助手。” 的内容,则说明模型文件完整且 transformers 库等依赖软件工作正常。
四、代码下载:获取微调工具
通过前面提到的 git clone https://github.com/hiyouga/LLaMA-Factory.git 命令,您已经成功将 LLaMA-Factory 的代码仓库克隆到本地。这一步骤为您后续进行模型微调提供了必要的代码基础。
五、配置更新:掌控微调细节
(一)微调配置文件详解
LLaMA-Factory 提供了灵活的配置文件来控制微调的各个方面。以下是一个示例配置文件 examples/train_lora/llama3_lora_sft.yaml,我们将对其中的关键参数进行详细解释:
model_name_or_path: models/DeepSeek-R1-Distill-Qwen-1.5B # 指定微调所使用的基座模型路径,这里我们使用之前下载并验证过的 DeepSeek-R1-Distill-Qwen-1.5B 模型。
stage: sft # 指定训练阶段为监督微调(Supervised Fine-Tuning),这是微调过程中的一个关键阶段,主要目的是利用监督数据对模型进行调整,使其更好地适应特定任务。
do_train: true # 设置为 true 以启动训练过程,这是开始微调的必要条件。
finetuning_type: lora # 指定微调方法为 LoRA(Low-Rank Adaptation),这种方法通过在模型原有的权重矩阵上添加一对低秩矩阵来实现微调,具有计算效率高、显存占用少等优点,特别适合在有限资源下对大型模型进行微调。
lora_target: all # 指定 LoRA 微调的目标模块为所有模块,意味着对模型的各个部分都进行微调,以便全面优化模型性能。
dataset: my_dataset # 指定用于微调的数据集名称,这里使用我们在前面准备并注册的自定义数据集 my_dataset。
template: default # 指定数据模板为默认模板,不同的数据模板适用于不同的模型和任务,模板主要定义了如何将数据集中的样本转换为模型可以理解的输入格式,包括提示词(prompt)的构造等。
cutoff_len: 512 # 指定数据的截断长度为 512,防止过长的文本对训练造成影响,如导致显存不足或训练速度过慢等问题。当文本长度超过 512 时,将其截断至该长度。
max_samples: 10000 # 指定最大样本数为 10000,防止数据过多导致训练时间过长,尤其是在资源有限的情况下,可以先使用部分数据进行快速实验和调试。
per_device_train_batch_size: 4 # 指定每个设备上的训练批次大小为 4,批次大小的选择需要综合考虑模型大小、显存容量以及训练效率等因素。较大的批次大小通常可以提高训练效率,但也会增加显存占用。
gradient_accumulation_steps: 2 # 指定梯度累积步数为 2,用于在有限显存下模拟更大的批次大小。例如,当您希望达到批次大小为 8 的效果,但显存不足以支持时,可以将 per_device_train_batch_size 设置为 4,并将 gradient_accumulation_steps 设置为 2,这样每两个步骤累积一次梯度,相当于实现了批次大小为 8 的效果。
learning_rate: 1e-5 # 设置学习率为 1e-5,学习率是控制模型参数更新速度的关键参数。学习率过高可能导致模型参数更新过快,训练过程不稳定,甚至出现 loss 发散的情况;学习率过低则会使训练速度过慢,需要更多的时间才能收敛。通常需要通过实验来确定最佳的学习率。
num_train_epochs: 3 # 设置训练的轮次为 3,表示整个训练数据集将被遍历 3 次。训练轮次的选择需要权衡模型性能和训练成本,过多的轮次可能导致过拟合,而过少的轮次可能无法充分训练模型。
lr_scheduler_type: cosine # 指定学习率调度器类型为 cosine(余弦退火调度器),该调度器会根据余弦函数的形状调整学习率,在训练初期保持较高的学习率以加快收敛速度,然后逐渐降低学习率,以便在训练后期更精细地调整模型参数,提高模型的泛化能力。
output_dir: output/my_model_lora_sft # 指定训练输出目录为 output/my_model_lora_sft,用于保存微调后的模型文件、训练日志以及评估结果等。
(二)配置文件的灵活应用
您可以在 LLaMA-Factory 的 examples 文件夹中找到多个示例配置文件,这些文件涵盖了不同的模型、微调方法和任务场景。通过研究和修改这些示例配置文件,您可以快速掌握如何根据自己的需求定制微调配置。
六、可能会遇到的报错及解决方法:微调的挑战与应对
(一)CUDA 相关报错
- 错误表现 :在训练过程中出现
CUDA out of memory错误,这通常是因为显存不足导致的。 - 解决方法 :
- 减小 batch size :尝试将
per_device_train_batch_size从 4 减小到 2 或更小的值,这样可以减少每次训练迭代所需的显存。 - 使用梯度累积 :适当增加
gradient_accumulation_steps的值,例如从 2 增加到 4,这样可以在不增加显存占用的情况下,模拟更大的批次大小。 - 采用混合精度训练 :在配置文件中添加
fp16: true,开启混合精度训练。混合精度训练利用 GPU 对浮点数运算的优化,使用 16 位浮点数(FP16)进行部分计算,从而减少显存占用并加快训练速度。需要注意的是,在开启混合精度训练时,要确保您的 GPU 和深度学习框架支持此功能,并且对训练过程进行适当的监控,以防止可能出现的数值不稳定问题。
- 减小 batch size :尝试将
(二)数据格式错误
- 错误表现 :在加载数据集时,可能会出现数据格式错误的提示,如
ValueError: Invalid data format。 - 解决方法 :
- 检查数据集文件 :仔细检查您的数据集文件是否符合 LLaMA-Factory 要求的格式,确保每个样本都包含完整的字段(instruction、input、output),且数据类型正确(例如,字符串字段不能包含未转义的特殊字符)。
- 验证数据注册信息 :检查
data_info.json文件中对数据集的注册信息是否准确无误,包括文件名和列名等,确保 LLaMA-Factory 能够正确识别和解析您的数据集。
(三)模型加载失败
- 错误表现 :在运行微调代码时,出现模型加载失败的错误,如
OSError: Error loading model weights。 - 解决方法 :
- 检查模型文件完整性 :重新检查下载的模型文件是否完整,文件大小是否与官方提供的信息一致。如果文件损坏或不完整,重新下载模型文件。
- 验证模型路径 :确保配置文件中指定的
model_name_or_path路径正确无误,且该路径下包含模型所需的全部文件,如配置文件(config.json)、权重文件(pytorch_model.bin 等)和词汇表文件(vocab.json、merges.txt 等)。
(四)训练过程中的其他错误
-
loss 不下降 :
- 原因分析 :可能是因为学习率设置过高或过低,或者数据存在质量问题,如标注不准确、数据分布与模型预训练数据分布差异过大等。
- 解决方法 :尝试调整学习率,如果不确定合适的范围,可以采用学习率范围测试(Learning Rate Range Test)方法,先运行一个学习率范围测试实验,观察 loss 随学习率变化的趋势,找到使 loss 快速下降且未出现发散现象的学习率范围,然后在该范围内选择合适的学习率进行训练。同时,对数据进行仔细检查和清洗,确保数据质量和标注准确性。
-
nan loss :
- 原因分析 :可能是学习率过高,导致模型参数更新过快,梯度出现爆炸现象,从而使 loss 变为 nan;或者是数据中存在异常值,导致模型在计算 loss 时出现数值不稳定的情况。
- 解决方法 :降低学习率,观察 loss 是否恢复正常。同时,对数据进行预处理,检查并处理数据中的异常值,如过大的数值或不合理的文本内容等。
七、相关的论文信息:理论支撑与前沿探索
LLaMA-Factory 所使用的微调方法,如 LoRA 等,都得到了相关学术论文的理论支持和实践验证。
(一)LoRA 相关论文
- 《Low-Rank Adaptation of Large Language Models》 :这篇论文详细介绍了 LoRA 微调方法的原理和优势。论文指出,大型语言模型(LLMs)在各种自然语言处理任务中展现出了强大的性能,但对这些模型进行微调通常需要大量的计算资源和时间。LoRA 提供了一种高效的解决方案,通过在模型原有的权重矩阵上添加一对低秩矩阵(即 rank - decomposition matrices),使得在微调过程中只有这些低秩矩阵需要更新,而模型的原始权重保持不变。这种方法大大减少了需要更新的参数数量,从而降低了计算成本和显存占用。论文还通过实验验证了 LoRA 在多个任务上的有效性,包括文本分类、问答等,证明了 LoRA 能够在保持模型性能的同时,显著提高微调效率。
(二)其他相关论文
-
《Supervised Fine-Tuning for Large Language Models》 :该论文深入探讨了监督微调(SFT)在大型语言模型中的应用。论文分析了 SFT 的目标、方法和挑战,强调了 SFT 在提高模型任务特定性能方面的重要性。论文还比较了不同的 SFT 策略,如直接微调、对比学习等,并探讨了如何设计有效的训练数据集和损失函数来优化 SFT 效果。通过对多个大型语言模型的实验,论文展示了 SFT 在提高模型准确性和相关性方面的显著作用,为 LLaMA-Factory 中采用的 SFT 方法提供了坚实的理论基础和实践指导。
-
《AdamW: A Method for Stochastic Optimization》 :AdamW 优化算法是许多微调过程中常用的优化方法之一。这篇论文介绍了 AdamW 的原理和优势,它在 Adam 优化算法的基础上进行了改进,通过将权重衰减(weight decay)与梯度更新解耦,解决了 Adam 优化器在权重衰减处理上的问题,使得优化过程更加稳定和有效。在 LLaMA-Factory 中,使用 AdamW 作为优化器可以更好地控制模型参数更新,帮助模型更快地收敛并提高模型的泛化能力。
八、SFT 和 LoRA 的 SH 命令
(一)SFT 的 SH 命令
以下是一个用于启动监督微调(SFT)的 SH 命令示例:
llamafactory-cli train examples/sft/single_gpu/baichuan2_sft.yaml
该命令用于执行单 GPU 上的监督微调任务,其中 examples/sft/single_gpu/baichuan2_sft.yaml 是 SFT 的配置文件路径。您需要确保该配置文件中已经正确设置了模型路径、数据集名称、训练参数等信息,以便顺利启动微调过程。
(二)LoRA 的 SH 命令
以下是一个用于启动 LoRA 微调的 SH 命令示例:
llamafactory-cli train examples/lora_multi_gpu/baichuan2_lora_sft.yaml
该命令用于执行多 GPU 上的 LoRA 微调任务,其中 examples/lora_multi_gpu/baichuan2_lora_sft.yaml 是 LoRA 微调的配置文件路径。在进行 LoRA 微调时,您需要确保系统中有多块 GPU,并且已经正确安装和配置了支持多 GPU 训练的深度学习框架和相关依赖库。同时,您也需要在配置文件中正确设置与 LoRA 微调相关的关键参数,如 finetuning_type: lora 等,以确保微调过程按照预期进行。
九、快速开始
下面三行命令分别对 Llama3-8B-Instruct 模型进行 LoRA 微调、推理和合并。
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
高级用法请参考 examples/README_zh.md(包括多 GPU 微调)。
十、LLaMA Board 可视化微调(由 Gradio 驱动)
llamafactory-cli webui
通过以上对 LLaMA-Factory 的详细阐述,您已经掌握了如何利用这一强大工具进行模型微调的全流程。从环境搭建到数据准备,从模型文件选择到代码下载和配置更新,再到应对可能遇到的报错以及了解背后的理论支撑,每一步都为您铺就了通往成功微调的道路。在实际操作过程中,建议您多进行实验和探索,尝试不同的模型、数据集和微调配置,不断提升您的模型性能,挖掘模型在各种应用任务中的潜力。
注 :上文中提及的部分方法(如 LoRA 微调等)的代码实现及参数设置仅供参考,随着 LLaMA-Factory 框架的不断更新,具体的实现方式和最佳实践可能会有所变化。建议您在使用过程中密切关注官方文档和社区动态,以获取最新的信息和指导。
相关文章:
【大模型】使用 LLaMA-Factory 进行大模型微调:从入门到精通
使用 LLaMA-Factory 进行模型微调:从入门到精通 一、环境搭建:奠定微调基础(一)安装依赖工具(二)创建 conda 环境(三)克隆仓库并安装依赖 二、数据准备:微调的基石&#…...

TWAS / FUSION
FUSION 是一套用于执行转录组范围和调控组范围关联研究(TWAS 和 RWAS)的工具。它通过构建功能/分子表型的遗传成分的预测模型,并使用 GWAS 汇总统计数据预测和测试该成分与疾病的关联,目标是识别 GWAS 表型与仅在参考数据中测量的…...

矩阵短剧系统:如何用1个后台管理100+小程序?深度解析多端绑定技术
短剧行业效率革命!一套系统实现多平台内容分发、数据统管与流量聚合 在短剧行业爆发式增长的今天,内容方和运营者面临两大核心痛点:多平台运营成本高与流量分散难聚合。传统模式下,每个小程序需独立开发后台,导致人力…...

使用Python 打造多格式文件预览工具 — 图、PDF、Word、Excel 一站式查看
在日常办公或文件管理场景中,我们经常面临这样的问题:在一个文件夹中短时间内产生了大量不同类型的文件(如图片、PDF、Word、Excel),我们需要快速浏览和筛选这些文件的内容,却不希望一个个打开它们。有没有…...

[docker基础四]容器虚拟化基础之 LXC
目录 一 认识LXC 二 LXC容器操作实战 1)实战目的 2)基础知识 lxc-checkconfig lxc-create lxc-start lxc-ls lxc-info lxc-attach lxc-stop lxc-destory 3)安装LXC(我的是Ubuntu) 4)操作实战 1. 检查 lxc 是否运行…...
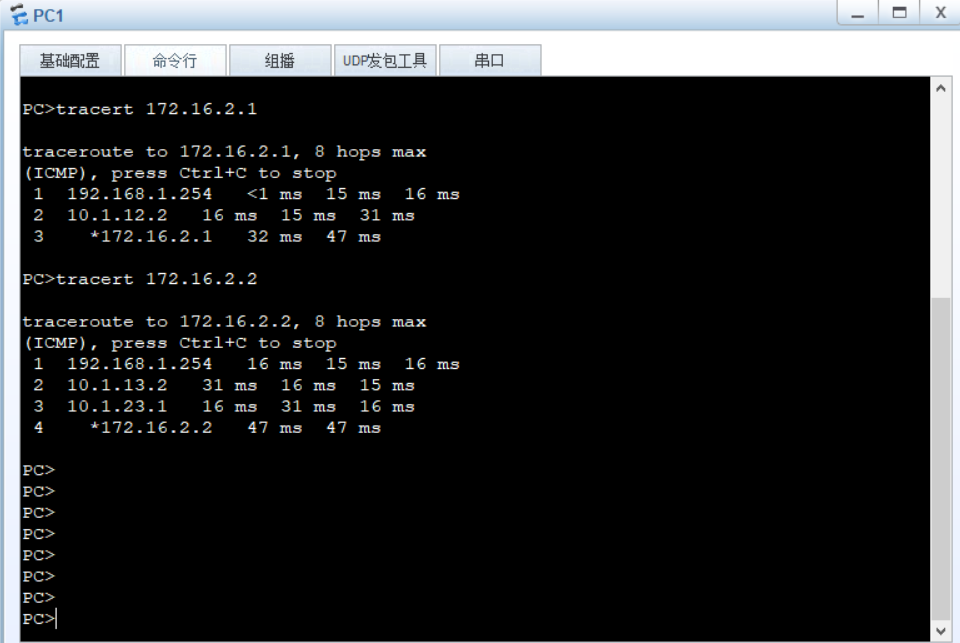
路由策略和策略路由的区别以及配置案例
区别 路由策略:路由策略是通过ACL等方式控制路由发布,让对方学到适当路由条目,比如有20条路由,只想让某个路由器学到10条,可以通过路由策略进行过滤。 策略路由:策略路由是通过定义策略和应用,…...
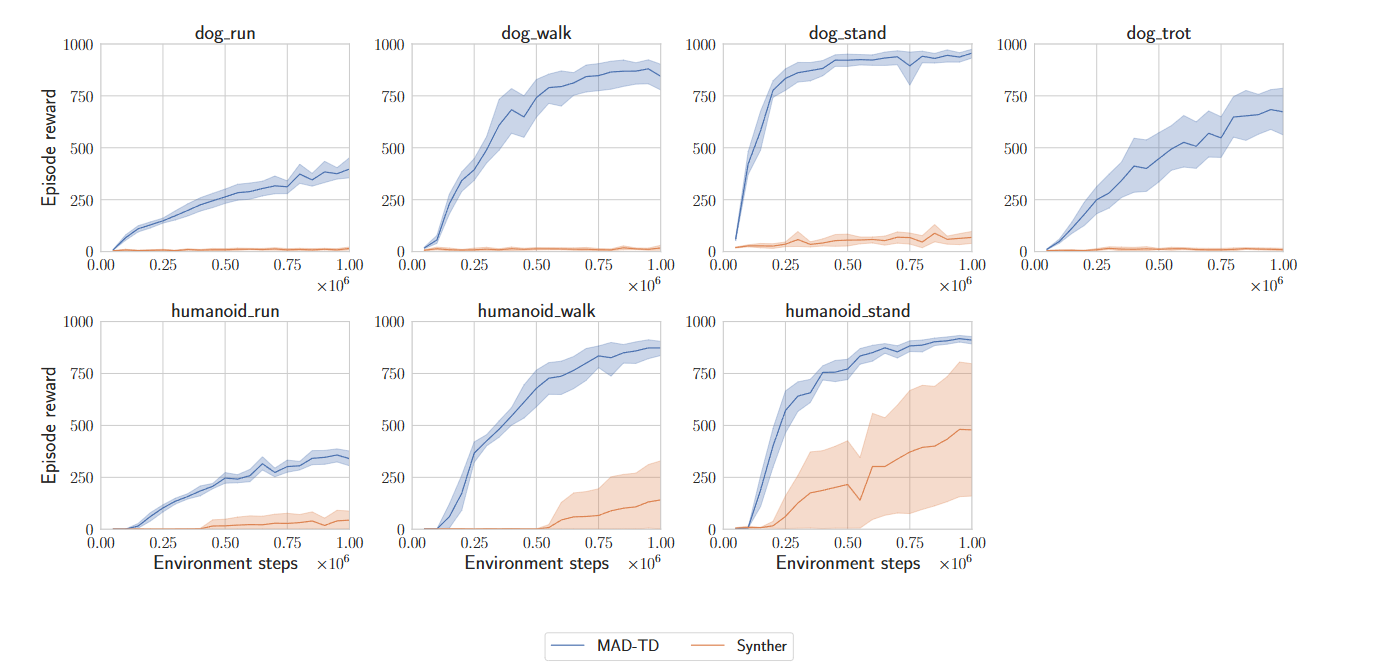
MAD-TD: MODEL-AUGMENTED DATA STABILIZES HIGH UPDATE RATIO RL
ICLR 2025 spotlight paper 构建能够在少量样本下学习出优良策略的深度强化学习(RL)智能体一直是一个极具挑战性的任务。为了提高样本效率,近期的研究尝试在每获取一个新样本后执行大量的梯度更新。尽管这种高更新-数据比(UTD&am…...
PyTorch API 10 - benchmark、data、批处理、命名张量
基于 PyTorch 2.7 文章目录 基准测试工具 - torch.utils.benchmarktorch.utils.bottlenecktorch.utils.checkpointtorch.utils.cpp_extensiontorch.utils.data数据集类型映射式数据集可迭代式数据集 数据加载顺序与采样器加载批处理与非批处理数据自动批处理(默认情…...

后缀表达式+栈(详解)(c++)
前言 很抱歉,上一期没有介绍栈stack的用法,今天简要介绍一下,再讲讲后缀表达式,用stack栈做一些后缀表达式的练习。 栈 栈stack是c中系统给出的栈,有了它,就不用自己创建栈啦! 头文件 栈sta…...

[C++类和对象]构造函数和析构函数
类的6个默认成员函数 如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗? 并不是,任何类在什么都不写时,编译器会自动生成以下6 个默认成员函数。 默认成员函数:用户没有显式实现,编译器会…...
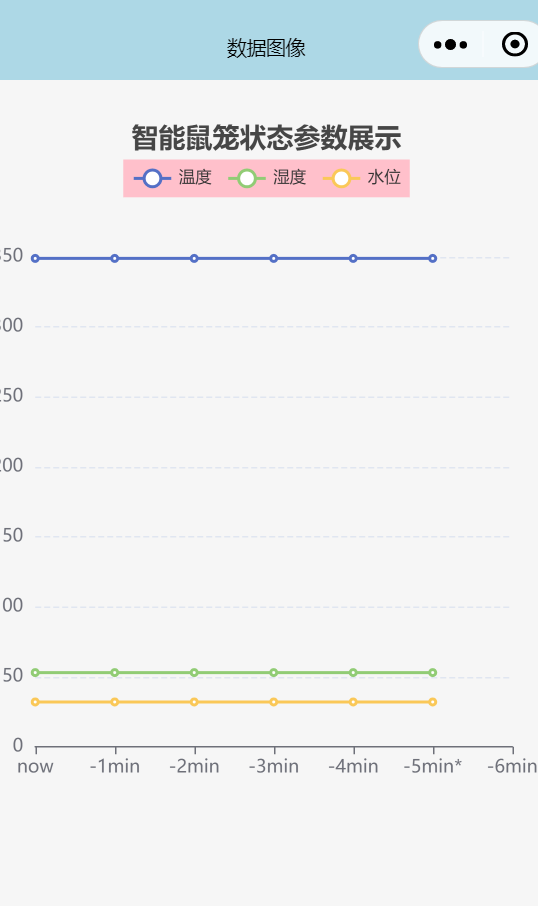
onenet连接微信小程序(mqtt协议)
一、关于mqtt协议 mqtt协议常用于物联网,是一种轻量级的消息推送协议。 其中有三个角色,Publisher设备(客户端)发布主题到服务器,其他的设备通过订阅主题,获取该主题下的消息,Publisher可以发…...

使用 JAX-RS 创建 REST 服务/微服务
REST(表述性状态转移)是一种基于 Web 标准和 HTTP 协议的架构风格,广泛用于构建可扩展、无状态且易于消费的 Web 服务。JAX-RS(Java API for RESTful Web Services)是 Java 提供的标准 API,通过注解简化了 RESTful Web 服务的开发和部署。JAX-RS 允许开发者使用 Java 类和…...

人脸真假检测:SVM 与 ResNet18 的实战对比
在人工智能蓬勃发展的当下,人脸相关技术广泛应用于安防、金融、娱乐等诸多领域。然而,随着人脸合成技术的日益成熟,人脸真假检测成为保障这些应用安全的关键环节。本文将深入探讨基于支持向量机(SVM)结合局部二值模式&…...

如何创建伪服务器,伪接口
创建伪接口一般是用于模拟真实接口的行为,以便在开发和测试过程中进行使用,以下是一些常见的创建伪接口的方法: 使用 Web 框架搭建: Python 和 Flask:Flask 是一个轻量级的 Python Web 框架。示例代码如下:…...

《AI大模型应知应会100篇》第54篇:国产大模型API对比与使用指南
第54篇:国产大模型API对比与使用指南 ——从百度文心到通义千问,一文看懂国内AI平台选型 📌 摘要 随着中国人工智能产业的快速发展,越来越多的国产大模型平台开始崭露头角。本文将系统梳理当前主流国产大模型 API(如…...

质量、重力、引力、惯性 的本质,以及虫洞
1、质量 物体,之所以,有质量源自于其微观结构。物体好比一块海绵,浸没在暗物质的海洋里。随暗物质海洋的涌动而不断移动。海绵微观结构越细密,受到暗物质海洋的裹携力就越大(好比汤勺,与漏勺对汤水的阻碍力。又好比纱窗与船帆对风的阻隔力。) 微观结构越细密,在相同表面积…...
基于ssm+mysql的快递管理系统(含LW+PPT+源码+系统演示视频+安装说明)
系统功能 管理员功能:个人中心、用户管理、订单管理、快递员管理;快递员功能:查看订单、更新快递状态;派单员功能:订单分配、订单管理;客户功能:订单查询、个人信息维护。 作者:计算…...

JVM——即时编译器的中间表达形式
中间表达形式(IR):编译器的核心抽象层 1. IR的本质与作用 在编译原理的体系中,中间表达形式(Intermediate Representation, IR)是连接编译器前端与后端的桥梁。前端负责将源代码转换为IR,而后…...

质心均匀体(引力屏蔽技术)
1、线质心体 陀螺我们都玩过,一个惯性圆盘加一个轴,旋转起来可以独脚而立。(垂直于旋转面的不平衡力,在旋转面旋转180度后,被其自身抵消,故而平衡。可抵消不平衡力的大小,取决于惯性飞轮的质量和旋转的速度)。此时,旋转的陀螺等同于一个轴线质心体(轴线上任意一点提供支…...

深度学习:AI为老年痴呆患者点亮希望之光
引言 随着全球人口老龄化进程的加速,老年痴呆症已成为严重威胁老年人健康和生活质量的公共卫生问题。据世界卫生组织统计,全球每 3 秒钟就有 1 人被诊断为痴呆,预计到 2050 年,全球痴呆患者人数将从目前的约 5000 万激增至 1.52 亿…...

JAVA实战开源项目:健身房管理系统 (Vue+SpringBoot) 附源码
本文项目编号 T 180 ,文末自助获取源码 \color{red}{T180,文末自助获取源码} T180,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...

STM32的SysTick
SysTick介绍 定义:Systick,即滴答定时器,是内核中的一个特殊定时器,用于提供系统级的定时服务。该定时器是一个24位的递减计数器,具有自动重载值寄存器的功能。当计数器到达自动重载值时,它会自动重新加载…...
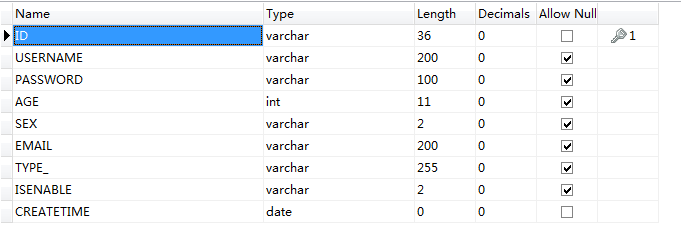
【图书管理系统】深度讲解:图书列表展示的后端实现、高内聚低耦合的应用、前端代码讲解
1.约定前后端交互接口 [请求] /book/getListByPage [参数] currentPage1&pageSize10 [响应] 返回封装的result对象对应的Json数据 2. 整体逻辑 2.1 Controller的逻辑 (1)把接收的参数封装为PageRequest类,里面有属性:curren…...

Github 2025-05-10 Rust开源项目日报 Top10
根据Github Trendings的统计,今日(2025-05-10统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Rust项目10TypeScript项目1Python项目1Zed: 由Atom和Tree-sitter的创建者开发的高性能多人代码编辑器 创建周期:1071 天开发语言:Rust协议类型…...

drf 使用jwt
安装jwt pip install pyJwt 添加登录url path("jwt/login",views.JwtLoginView.as_view(),namejwt-login),path("jwt/order",views.JwtOrderView.as_view(),namejwt-order), 创建视图 from django.contrib.auth import authenticateimport jwt from jw…...

养生:为健康生活添彩
养生是对生活的热爱,是为健康生活注入活力的良方。从饮食、运动到生活习惯,每一个方面都能让我们离健康更近一步。以下是一些实用的养生之道,助你开启健康生活的新旅程。 饮食养生:营养均衡,健康基石 合理的饮食是养…...

在 Vue 3 中使用 canvas-confetti 插件
🎉 在 Vue 3 中使用 canvas-confetti 插件 canvas-confetti 是一个轻量、无依赖的 JavaScript 动画库,用于在网页上展示彩带、庆祝动画。非常适合用于抽奖、支付成功、活动庆祝等场景。 本教程将指导你如何在 Vue 3 项目中集成并使用该插件。 …...

rt-thread+STM32H7移植lwip出现问题解决方法
问题一:ping不通,或有丢帧情况。 问题二:不开启优化一切正常,keil开启优化后就无法联网。 问题三:网络断断续续。 解决方法: 主要是mpu配置和drv_eth驱动的问题,我的配置如下: mpu&…...

Java Spring、Spring MVC、Spring Boot 和 Spring Cloud 的关系与区别
在 Java 开发领域,Spring、Spring MVC、Spring Boot 和 Spring Cloud 这些框架和技术名词频繁出现。对于初学者来说,理解它们之间的关系和区别可能有些困惑。本文将深入浅出地讲解这些概念,帮助你理清它们的联系与差异。 一、Spring 1.1 定义 Spring 是一个轻量级的 Java…...
服务器综合实验(实战详解)
该文章的目录部分 实验内容 实验完成步骤 虚拟机准备 配置两个虚拟机的本地仓库 虚拟机A: 虚拟机B: 配置SSH公钥互信 虚拟机A: 编辑 虚拟机B: 提供基于bind的DNS服务 虚拟机A: 项目需求1: …...