掌握 Kubernetes 和 AKS:热门面试问题和专家解答
1. 在 AKS(Azure Kubernetes 服务)中,集群、节点、Pod 和容器之间的关系和顺序是什么?
在 AKS(Azure Kubernetes 服务)中,集群、节点、Pod 和容器之间的关系和顺序如下:
- 集群:AKS 中的集群是由 Kubernetes 管理的一组节点。集群提供底层基础架构的逻辑表示,并管理容器化应用程序的部署和扩展。
- 节点:节点是运行容器化应用程序的工作器。AKS 中的每个节点都运行一个或多个 Pod,它们是 Kubernetes 中最小的可部署单元。
- Pod:Pod 是 Kubernetes 中最小的可部署单元,代表集群中正在运行的进程的单个实例。一个 Pod 可以包含一个或多个容器,这些容器共享相同的网络命名空间,并可以通过进程间通信 (IPC) 相互通信。
- 容器:容器是一个轻量级、独立的可执行软件包,包含运行应用程序所需的一切,包括代码、库和系统工具。一个 Pod 可以包含一个或多个容器,每个容器运行不同的进程。
总而言之,AKS 中的集群是底层基础架构的逻辑表示,其中包含一个或多个节点。每个节点运行一个或多个 Pod,每个 Pod 可以包含一个或多个容器。
2. 节点是否始终表示单台机器?
在 Kubernetes 和 AKS 的上下文中,节点通常指单台物理机或虚拟机。但是,需要注意的是,节点也可以指一组在调度时充当单个单元的机器。
Kubernetes 旨在实现高度可扩展,可以管理包含数千个节点的集群。在这种情况下,节点可以指一组作为单个单元协同工作以调度和运行容器的机器。这是通过使用专用软件(例如 kubelet)实现的,该软件在每个节点上运行并与 Kubernetes 主服务器通信以管理容器和 Pod。
总而言之,虽然 Kubernetes 和 AKS 中的节点通常指单台机器,但它也可以指一组机器,这些机器在调度时充当一个单元。
3. 容器如何通过进程间通信 (IPC) 相互通信?如果节点有多个容器,那么我们如何识别/引用特定容器?
容器通过进程间通信 (IPC) 机制相互通信,例如共享内存或套接字。在 Kubernetes 和 AKS 中,同一 Pod 内的容器共享相同的网络命名空间,并且可以使用标准的进程间通信机制通过 localhost 相互通信。
如果一个节点正在运行多个容器,则每个容器都由容器运行时生成的唯一名称或 ID 标识。在 Kubernetes 和 AKS 中,容器通常部署在 Pod 中,每个 Pod 都有唯一的名称和 IP 地址。要引用 Pod 中的特定容器,可以使用容器名称或 ID。例如,要访问名为“my-pod”的 Pod 中名为“my-container”的容器,您可以使用以下命令:
kubectl exec -it my-pod -c my-container bash此命令将在“my-pod”Pod 中的“my-container”容器中启动交互式 Shell 会话。“-c”选项用于指定容器名称。
除了容器名称之外,Kubernetes 和 AKS 还支持标签和选择器,允许您根据容器的属性或特征对其进行分组。您可以使用标签和选择器来识别和引用单个 Pod 或多个 Pod 中的容器组。
4. 列出必须部署到容器的所有内容?所有容器之间是否有任何共同点?
必须部署到容器的内容取决于所部署应用程序或服务的具体要求。但是,容器镜像中通常包含一些常见元素:
- 应用程序代码和依赖项:正在部署的应用程序的代码,以及运行应用程序所需的任何依赖项,例如库、框架和运行时环境。
- 操作系统:轻量级操作系统,提供运行应用程序所需的基本系统资源。
- 系统工具和实用程序:一组系统工具和实用程序,例如包管理器、文件系统实用程序和网络工具,用于管理容器并执行基本的系统级任务。
- 配置文件:用于配置容器及其运行的应用程序的配置文件,例如环境变量、网络设置和日志设置。
- 任何其他资产或数据:应用程序所需的任何其他资产或数据,例如静态文件、镜像或其他资源。
- 虽然部署到容器的具体内容因部署的应用程序而异,但所有容器
5. 是否可以拥有混合云或多云集群/pod?如果可以,那么如何配置?
是的,在 Kubernetes(包括 AKS)中可以拥有混合云或多云集群/pod。混合云或多云设置允许您跨多个云提供商或本地数据中心分配工作负载,从而提供更高的灵活性和弹性。
要在 AKS 中配置混合云或多云设置,您可以按照以下步骤操作:
- 在每个云提供商或本地数据中心设置集群:要创建混合云或多云设置,您需要在每个要使用的云提供商或数据中心设置 Kubernetes 集群。您可以使用 AKS 或其他 Kubernetes 管理工具来完成此操作。
- 配置网络:为了允许集群相互通信,您需要在不同集群之间配置网络。这可以使用虚拟专用网络 (VPN) 或其他网络技术(例如服务网格)来实现。
- 配置集群联邦:Kubernetes 提供了一项名为集群联邦的功能,允许您将多个集群作为一个实体进行管理。您可以使用集群联邦跨多个集群部署和管理应用程序,包括位于不同云提供商或数据中心的集群。
- 部署应用程序:设置集群并配置网络和联邦后,您可以使用 Kubernetes 清单或其他部署工具跨不同集群部署应用程序。
6. 列出常用的 kubectl 命令以及开发人员常犯的错误?
以下是一些开发人员常用的 kubectl 命令以及常犯的错误:
- kubectl get:此命令用于检索有关 Kubernetes 资源的信息。一个常见的错误是忘记指定资源类型,例如 Pod 或服务,这可能会导致错误消息或不正确的输出。
- kubectl create:此命令用于创建新的 Kubernetes 资源,例如 Pod 或服务。一个常见的错误是未指定所有必需的参数或选项,例如镜像或容器名称,这可能会导致部署失败。
- kubectl apply:此命令用于将更改应用于现有的 Kubernetes 资源。一个常见的错误是未指定正确的 YAML 文件或配置,这可能会导致部署不正确或失败。
- kubectl logs:此命令用于查看 Kubernetes Pod 的日志。一个常见的错误是未指定正确的 Pod 名称或容器名称,这可能会导致错误消息或不正确的输出。
- kubectl exec:此命令用于在正在运行的 Kubernetes 容器中执行命令。一个常见的错误是未指定正确的 Pod 名称或容器名称,这可能导致错误消息或在错误的容器中执行命令。
- kubectl delete:此命令用于删除 Kubernetes 资源。一个常见的错误是未指定正确的资源类型或名称,这可能导致意外的资源删除。
- kubectl describe:此命令用于查看 Kubernetes 资源的详细信息。一个常见的错误是未指定正确的资源类型或名称,这可能导致错误消息或不正确的输出。
- kubectl rollout:此命令用于管理 Kubernetes 资源的滚动更新。一个常见的错误是未指定正确的部署或副本集,这可能导致更新失败或意外的更改。
7. 列出开发人员在 YAML 文件中最常见的语法错误?
以下是开发人员在 YAML 文件中可能遇到的一些常见语法错误:
- 缩进错误:YAML 语法严重依赖于缩进,任何缩进错误都可能导致问题。常见错误包括空格或制表符数量错误,或者混合使用空格和制表符,这可能导致 YAML 文件解析失败。
- 缺失或多余的引号:YAML 使用引号表示字符串,任何缺失或多余的引号都可能导致问题。常见错误包括忘记关闭引号或在需要双引号的地方使用单引号。
- 缺失或多余的连字符:YAML 使用连字符表示列表或数组,任何缺失或多余的连字符都可能导致问题。常见错误包括忘记在列表项的开头添加连字符,或在不需要连字符的地方添加连字符。
- 括号不匹配:YAML 使用括号来表示对象或字典,任何括号不匹配都可能导致问题。常见错误包括忘记闭合括号或在不需要的地方添加额外的括号。
- 数据类型不正确:YAML 的数据类型非常严格,任何不正确的数据类型都可能导致问题。常见错误包括在需要布尔值的地方使用字符串,或在需要字符串的地方使用整数。
- 拼写错误:YAML 区分大小写,任何拼写错误都可能导致问题。常见错误包括在需要小写字母的地方使用大写字母,或者关键字或值的拼写错误。
- 使用无效字符:YAML 对文件中可以使用的字符有严格的规则,任何无效字符都可能导致问题。常见错误包括在不允许使用特殊字符的地方使用特殊字符,例如“&”符号或美元符号。
8. 当 API 请求到达 AKS 时,它是如何被验证、路由和处理的?请提供所有流程步骤:
当 API 请求到达 Azure Kubernetes 服务 (AKS) 时,它会经过一系列步骤进行验证、路由和处理。以下是一些概要步骤:
- API 请求被发送到 AKS 入口控制器,该控制器负责将传入的请求路由到相应的服务。
- 入口控制器检查请求是否与任何已定义的入口规则匹配。入口规则定义了特定服务的路径和主机。
- 如果请求与入口规则匹配,入口控制器会将请求转发到相应的服务。如果请求与任何入口规则都不匹配,入口控制器将返回错误。
- 然后,服务使用服务帐户或客户端证书对请求进行身份验证。身份验证过程会验证请求是否来自可信来源。
- 如果请求通过身份验证,服务将通过执行相应的代码或命令来处理请求。
- 服务向发出 API 请求的客户端返回响应。
9. 如何使用 Azure Cosmos DB 存储和管理基于 AKS 的应用程序的数据?
Azure Cosmos DB 是一项全球分布式多模型数据库服务,旨在为需要高可扩展性和低延迟的应用程序提供低延迟和高可用性。以下是如何使用 Azure Cosmos DB 存储和管理基于 AKS 的应用程序的数据:
- 选择合适的 Cosmos DB API:Cosmos DB 支持多种 API,包括 SQL API、MongoDB API、Cassandra API、Gremlin API 和 Azure Table API。请选择最符合您应用程序需求的 API。
- 创建 Cosmos DB 帐户:在 Azure 门户中,创建一个新的 Cosmos DB 帐户,并根据您的需求选择合适的 API 和其他设置。
- 配置访问权限:使用 Cosmos DB 连接字符串(包含端点 URL 和授权密钥)配置对 Cosmos DB 帐户的访问权限。
- 创建数据库和集合:在 Cosmos DB 中,为基于 AKS 的应用程序创建一个新的数据库和集合,用于存储和管理数据。您可以根据数据访问模式选择合适的分区键和索引策略。
- 连接基于 AKS 的应用程序:在基于 AKS 的应用程序中,您可以使用合适的 API 和连接字符串连接到 Cosmos DB。然后,您可以使用 API 对数据库和集合执行 CRUD(创建、读取、更新、删除)操作。
- 扩展和复制:Azure Cosmos DB 支持自动扩展和复制,因此您可以根据应用程序的需求轻松地进行扩展或缩减,并跨多个区域复制数据以实现高可用性和低延迟。
- 通过使用 Azure Cosmos DB 存储和管理基于 AKS 的应用程序的数据,您可以利用其全球分布式架构、低延迟和高可扩展性,并确保您的应用程序拥有满足客户需求所需的资源。
10. 当 Kubernetes 中的主节点发生故障时会发生什么?当工作节点发生故障时会发生什么?
当 Kubernetes 中的主节点发生故障时,会发生以下情况:
- Kubernetes 控制平面检测到主节点发生故障。
- Kubernetes 控制平面从集群中的可用节点中选出一个新的主节点。
- Kubernetes 控制平面更新集群状态,并将在故障主节点上运行的所有工作负载重新调度到新的主节点。
- 如果故障主节点是唯一的 etcd 成员,则可能需要重新初始化 etcd 集群或从备份中恢复以恢复数据。
当 Kubernetes 中的工作节点发生故障时,会发生以下情况:
- Kubernetes 控制平面检测到工作节点发生故障。
- Kubernetes 控制平面从集群中移除故障的工作节点并更新集群状态。
- Kubernetes 调度程序将故障工作节点上运行的所有工作负载重新调度到集群中的其他可用节点。
- 如果发生故障的工作节点正在运行具有持久卷的有状态工作负载,Kubernetes 卷控制器将从故障节点分离卷,并将其重新附加到重新调度工作负载的新节点。
- 如果发生故障的工作节点正在运行 DaemonSet 或 hostPath 卷,Kubernetes 控制器管理器将在另一个可用节点上重新调度工作负载。
- 通过这种方式处理主节点和工作节点的故障,Kubernetes 可以确保集群保持高可用性,并确保工作负载持续运行而不中断。
11. 什么是 DaemonSet?请列举一些 DaemonSet 示例(日志记录除外)。
在 Kubernetes 中,DaemonSet 是一种工作负载,用于确保集群中每个节点上都运行一个 Pod 副本。以下是一些 DaemonSet 示例(日志记录除外):
- 监控代理:DaemonSet 可用于在集群中的每个节点上部署监控代理,例如 Prometheus Node Exporter 或 Datadog Agent,用于收集指标并监控系统运行状况。
- 网络:DaemonSet 可用于部署网络组件,例如 CNI(容器网络接口)插件或负载均衡器代理,用于管理所有节点的网络配置。
- 安全:DaemonSet 可用于部署安全组件,例如防病毒代理或入侵检测系统,用于保护每个节点免受攻击。
- 存储:DaemonSet 可用于部署存储组件,例如 CSI(容器存储接口)插件或存储代理,用于管理所有节点的存储并确保每个节点都可以访问持久卷。
总的来说,DaemonSets 是一个强大的工具,用于管理需要部署在集群中每个节点上的工作负载,提供一种可靠且可预测的方式来管理整个 Kubernetes 集群的基础架构组件。
12. 组织或分组节点的最佳方式有哪些?
在 Kubernetes 中,可以使用标签和选择器以不同的方式组织或分组节点。以下是一些常用的选项:
- 可用区域:节点可以使用其运行所在的可用区域进行标记。这对于部署需要高可用性和容错能力的应用程序非常有用。
- 角色:可以根据节点运行的工作负载类型为其标记不同的角色。例如,您可以将节点标记为数据库服务器、Web 服务器或工作节点。
- 硬件规格:可以根据节点的硬件规格(例如 CPU、RAM、存储或 GPU)对节点进行标记。这对于部署需要特定硬件资源的应用程序非常有用。
- 地理位置:可以根据节点的地理位置对节点进行标记。这对于部署需要地理分布的应用程序非常有用。
要根据这些标签对节点进行分组,可以使用选择器来识别符合特定条件的节点。例如,您可以创建一个 Kubernetes 部署或服务,仅选择标记为 Web 服务器的节点来运行特定的工作负载。
13. 我需要每年为某些特殊日期创建 N 个额外的节点。如何在 Kubernetes 中配置?这些日期每年都是固定的。我不想每年都重复同样的事情。
您可以创建一个 Kubernetes cron 作业来运行一个脚本,该脚本会在指定日期扩展节点数量。您可以安排该 cron 作业每年在同一时间运行,以确保在这些日期创建额外的节点。
以下是一个可用于扩展节点的脚本示例:
# set the number of nodes to scale up
node_count=5
# scale up the nodes
kubectl scale --replicas=$node_count deployment/node-deployment然后,您可以创建一个 Kubernetes cron 作业,在指定日期运行该脚本:
apiVersion: batch/v1beta1
kind: CronJob
metadata:name: node-scale-up
spec:schedule: "0 0 1 1 *" # run on 1st January every yearjobTemplate:spec:template:spec:containers:- name: node-scalerimage: <your-image>command: ["/bin/bash"]args: ["-c", "/path/to/script.sh"]restartPolicy: OnFailure
此 cron 作业将在每年 1 月 1 日运行该脚本,并根据指定的日期扩展节点数脚本。您可以修改计划字段,以匹配扩展节点所需的日期。
14. Kubernetes 中的 StatefulSet 是什么?
StatefulSet 是一个 Kubernetes 控制器,用于管理一组有状态 Pod 的部署和扩缩。与管理一组无状态 Pod 的 Deployment 不同,StatefulSet 旨在管理需要稳定网络身份、有序 Pod 初始化和终止以及持久存储的有状态应用程序。
StatefulSet 中的每个 Pod 都拥有基于其在集合中位置的唯一身份和网络主机名,这使得 Pod 能够在重新调度事件中保持其身份和状态。StatefulSet 控制器还确保 Pod 以可预测的顺序启动和停止,以维护 Pod 之间的任何依赖关系。
StatefulSet 通常用于管理有状态应用程序,例如数据库、消息传递系统和其他有状态服务。它们也用于管理需要严格排序和持久性保证的有状态工作负载,例如分布式系统和机器学习工作流。
总体而言,StatefulSets 提供了一种在 Kubernetes 中管理有状态应用程序的方法,这种方法比其他部署选项更可预测、更可靠,从而更容易在 Kubernetes 上操作复杂的有状态工作负载。
15. 请给出一些 StatefulSet 的实际应用示例。
以下是一些可以在 Kubernetes 中使用 StatefulSet 管理的有状态应用程序的实际应用示例:
- 数据库:StatefulSet 可用于管理 MySQL、PostgreSQL、MongoDB 等有状态数据库。每个数据库实例都可以作为具有独立持久卷和网络标识的唯一 Pod 进行管理。
- 流式传输平台:StatefulSet 可用于管理 Apache Kafka、Apache Pulsar 等流式传输平台。集群中的每个 Broker 或节点都可以作为具有独立持久卷和网络标识的唯一 Pod 进行管理。
- 分布式系统:StatefulSet 可用于管理 Apache ZooKeeper、Apache Cassandra 等分布式系统。集群中的每个节点都可以作为具有独立持久卷和网络标识的唯一 Pod 进行管理。
- 机器学习工作流:StatefulSet 可用于管理需要严格排序和持久性保证的机器学习工作流。工作流中的每个步骤都可以作为具有自己的持久卷和网络标识的唯一 pod 进行管理。
16. 什么是命名空间?请列举一些实际用例?它是可选的吗?
在 Kubernetes 中,命名空间是一种将集群资源划分为逻辑命名组的方法。它提供了名称范围,允许多个用户和团队共享集群而不会干扰彼此的资源。每个命名空间可以拥有自己的策略、资源配额和访问控制,这些可用于管理该命名空间内的资源。
命名空间的一些实际用例包括:
- 资源隔离:命名空间可用于隔离不同团队或应用程序使用的资源,这有助于防止冲突并提高安全性。
- 环境隔离:命名空间可用于隔离用于开发、测试和生产的资源,从而更轻松地管理和监控每个环境中的资源。
- 资源配额:命名空间可以拥有自己的资源配额,可用于限制该命名空间内资源使用的 CPU、内存和存储空间。
- 访问控制:命名空间可用于强制执行基于角色的访问控制 (RBAC) 策略,从而限制哪些用户可以访问该命名空间内的资源。
- 多租户:命名空间可用于提供多租户环境,其中不同的团队或应用程序共享同一集群,但彼此隔离。
命名空间在 Kubernetes 中并非可选。Kubernetes 中的每个资源都与一个命名空间关联,如果未指定命名空间,则资源将在默认命名空间中创建。但是,对于小型集群或无需考虑资源管理的简单用例,命名空间并非必需。
17. Kubelet 作为 Kubernetes 中的节点服务组件,主要执行哪些操作?
Kubelet 是 Kubernetes 中的一个节点服务组件,负责管理节点上运行的容器。Kubelet 的一些主要操作包括:
- 容器管理:Kubelet 负责管理节点上运行的容器的生命周期。它会根据需要启动、停止和重启容器,并确保容器正常运行。
- 镜像管理:Kubelet 负责从容器注册表中提取容器镜像,并将其缓存在节点本地。它还会定期检查是否有更新的镜像,并在必要时提取更新的镜像。
- 卷管理:Kubelet 负责管理节点上容器使用的卷。它会创建和挂载卷,并确保容器在必要时可以使用这些卷。
- 健康监控:Kubelet 监控节点上运行的容器的健康状况,并将其状态报告给 Kubernetes 控制平面。如果容器的健康状况不佳,Kubelet 会采取适当的措施来重启该容器。
- 节点状态报告:Kubelet 向 Kubernetes 控制平面报告节点状态,包括节点上运行的容器的状态、可用资源以及其他相关信息。
- Pod 生命周期管理:Kubelet 负责管理节点上 Pod 的生命周期。它会根据需要启动和停止 Pod,并确保 Pod 中的容器正常运行。
总而言之,Kubelet 是 Kubernetes 节点的关键组件,负责管理节点上运行的容器和 Pod,并确保它们健康且正常运行。
18. 多容器 Pod 有哪些不同类型?
在 Kubernetes 中,Pod 是可创建、调度和管理的最小可部署单元。它是一个或多个容器的逻辑主机,Pod 中的所有容器共享相同的网络命名空间、IPC 命名空间和文件系统命名空间。Kubernetes 中有几种类型的多容器 Pod,包括:
- Sidecar 容器:Sidecar 容器是一个辅助容器,与主容器在同一 Pod 中一起运行。它可以执行日志记录、监控或数据处理等任务。Sidecar 容器与主容器共享相同的网络命名空间,这使得它们可以通过本地环回接口相互通信。
- Ambassador 容器:Ambassador 容器充当另一个 Pod 中运行的服务的代理。它可以将流量路由到该服务,并执行负载均衡、服务发现和其他功能。
- Adapter 容器:Adapter 容器是在不同格式或协议之间转换数据的容器。它可用于将数据从一种格式转换为另一种格式,或在不同的 API 之间进行转换。
- Init 容器:Init 容器是一种特殊类型的容器,在 Pod 中的主容器之前运行。它可用于执行初始化任务,例如下载数据、配置环境或等待其他服务可用。
这些不同类型的多容器 Pod 为 Kubernetes 工作负载提供了灵活性和模块化,使其能够根据特定需求进行定制。
19. 如何以特定间隔自动更新 ACR 容器镜像以获取最新的容器镜像?
要以特定间隔自动更新 Azure 容器注册表 (ACR) 容器镜像以获取最新的容器镜像,您可以使用 Azure 容器实例 (ACI) 并设置计划任务。ACI 提供按需运行容器的服务,无需预置或管理任何基础架构。您可以使用 ACI 运行一个容器,该容器会定期检查 ACR 中是否有新的容器镜像,如果有新镜像可用,它会更新 Kubernetes 集群中的部署。
以下是设置此过程的简要步骤:
- 创建一个容器镜像,用于检查 ACR 中镜像的新版本,并在有新镜像可用时更新 Kubernetes 部署。
- 创建一个 Azure 容器注册表 (ACR) 来存储您的容器镜像。
- 创建一个使用您在步骤 1 中创建的容器镜像的 Kubernetes 部署。
- 创建一个 Azure 容器实例 (ACI) 并设置计划任务,以便以特定间隔运行容器镜像。
- 更新计划任务,以便按所需的间隔运行容器镜像。
设置此过程后,容器镜像将自动检查 ACR 中镜像的新版本,并在有新镜像可用时更新 Kubernetes 部署。
以下示例展示了如何创建带有计划任务的 ACI,以运行用于检查 ACR 中镜像新版本的容器:
az container create --resource-group <resource-group-name> --name <aci-name> --image <acr-name>.azurecr.io/<image-name> --registry-username <acr-username> --registry-password <acr-password> --command-line "/bin/bash -c 'while true; do kubectl set image deployment/<deployment-name> <container-name>=<acr-name>.azurecr.io/<image-name>:latest; sleep <interval>; done'" --schedule "*/<interval-in-minutes> * * * *"将 <resource-group-name> 替换为资源组的名称,将 <aci-name> 替换为 ACI 实例的名称,将 <acr-name> 替换为 ACR 注册表的名称,将 <image-name> 替换为容器映像的名称,将 <acr-username> 替换为 ACR 注册表的用户名,将 <acr-password> 替换为 ACR 注册表的密码,将 <deployment-name> 替换为 Kubernetes 部署的名称,将 <container-name> 替换为 Kubernetes 部署中容器的名称,并将 <interval-in-minutes> 替换为所需的间隔(分钟)。
20. AKS 如何使用 Azure 磁盘存储类和pv,pvc,列出主要的步骤
创建自定义存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: managed-premium-custom
provisioner: kubernetes.io/azure-disk
reclaimPolicy: Retain
allowVolumeExpansion: true
parameters:storageAccountType: Premium_LRSkind: Managed
kubectl apply -f storage-class.yaml创建持久卷声明和持久卷
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: azure-managed-disk
spec:accessModes:- ReadWriteOncestorageClassName: managed-premium-customresources:requests:storage: 10Gi
kubectl apply -f Azure-pvc.yaml将持久卷附加到 AKS
apiVersion: v1
kind: Pod
metadata:name: nginx
spec:containers:- name: nginx-frontendimage: nginxvolumeMounts:- mountPath: "/mnt/Azure"name: volumevolumes:- name: volumepersistentVolumeClaim:claimName: azure-managed-disk
相关文章:

掌握 Kubernetes 和 AKS:热门面试问题和专家解答
1. 在 AKS(Azure Kubernetes 服务)中,集群、节点、Pod 和容器之间的关系和顺序是什么? 在 AKS(Azure Kubernetes 服务)中,集群、节点、Pod 和容器之间的关系和顺序如下: 集群&#…...

【MyBatis-7】深入理解MyBatis二级缓存:提升应用性能的利器
在现代应用开发中,数据库访问往往是性能瓶颈之一。作为Java生态中广泛使用的ORM框架,MyBatis提供了一级缓存和二级缓存机制来优化数据库访问性能。本文将深入探讨MyBatis二级缓存的工作原理、配置方式、使用场景以及最佳实践,帮助开发者充分利…...

5.9-selcct_poll_epoll 和 reactor 的模拟实现
5.9-select_poll_epoll 本文演示 select 等 io 多路复用函数的应用方法,函数具体介绍可以参考我过去写的博客。 先绑定监听的文件描述符 int sockfd socket(AF_INET, SOCK_STREAM, 0); struct sockaddr_in serveraddr; memset(&serveraddr, 0, sizeof(struc…...
》阅读笔记:p17-p27)
《算法导论(第4版)》阅读笔记:p17-p27
《算法导论(第4版)》学习第 10 天,p17-p27 总结,总计 11 页。 一、技术总结 1. insertion sort (1)keys The numbers to be sorted are also known as the keys(要排序的数称为key)。 第 n 次看插入排序,这次有两个地方感触比较深&#…...
软考错题集
一个有向图具有拓扑排序序列,则该图的邻接矩阵必定为()矩阵。 A.三角 B.一般 C.对称 D.稀疏矩阵的下三角或上三角部分包含非零元素,而其余部分为零。一般矩阵这个术语太过宽泛,不具体指向任何特定性 质的矩阵。对称矩阵…...

T2I-R1:通过语义级与图像 token 级协同链式思维强化图像生成
文章目录 速览摘要1 引言2 相关工作统一生成与理解的 LMM(Unified Generation and Understanding LMM.)用于大型推理模型的强化学习(Reinforcement Learning for Large Reasoning Models.)3 方法3.1 预备知识3.2 语义级与令牌级 CoT语义级 CoT(Semantic-level CoT)令牌级…...

Dockers部署oscarfonts/geoserver镜像的Geoserver
Dockers部署oscarfonts/geoserver镜像的Geoserver 说实话,最后发现要选择合适的Geoserver镜像才是关键,所以所以所以…🐷 推荐oscarfonts/geoserver的镜像! 一开始用kartoza/geoserver镜像一直提示内存不足,不过还好…...

【脑机接口临床】脑机接口手术的风险?脑机接口手术的应用场景?脑机接口手术如何实现偏瘫康复?
脑机接口的应用 通常对脑机接口感兴趣的两类人群,一类是适应症患者 ,另一类是科技爱好者。 1 意念控制外部设备 常见的外部设备有:外骨骼、机械手、辅助康复设备、电刺激设备、电脑光标、轮椅。 2 辅助偏瘫康复或辅助脊髓损伤患者意念控制…...

扩增子分析|微生物生态网络稳定性评估之鲁棒性(Robustness)和易损性(Vulnerability)在R中实现
一、引言 周集中老师团队于2021年在Nature climate change发表的文章,阐述了网络稳定性评估的原理算法,并提供了完整的代码。自此对微生物生态网络的评估具有更全面的指标,自此网络稳定性的评估广受大家欢迎。本系列将介绍网络稳定性之鲁棒性…...

Client 和 Server 的关系理解
client.py 和 server.py 是基于 MCP(Multi-Component Protocol)协议的客户端-服务端架构,二者的关系如下: 1. 角色分工 server.py:服务端,负责注册和实现各种“工具函数”(如新闻检索、情感分…...
【含文档+PPT+源码】基于微信小程序的社区便民防诈宣传系统设计与实现
项目介绍 本课程演示的是一款基于微信小程序的社区便民防诈宣传系统设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本套…...
)
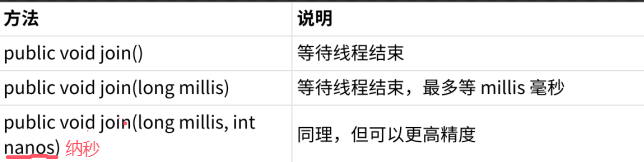
Kafka的核心组件有哪些?简要说明其作用。 (Producer、Consumer、Broker、Topic、Partition、ZooKeeper)
Kafka 核心组件解析 1. 基础架构图解 ┌─────────┐ ┌─────────┐ ┌─────────┐ │Producer │───▶ │ Broker │ ◀─── │Consumer │ └─────────┘ └─────────┘ └────────…...

Java中对象集合转换的优雅实现【实体属性范围缩小为vo】:ListUtil.convert方法详解
1.业务场景 在开发电商系统时,我们经常需要处理订单信息的展示需求。例如:订单详情页需要显示退款信息列表,而数据库中存储的RefundInfo实体类包含敏感字段,直接返回给前端存在安全风险。此时就需要将RefundInfo对象集合转换为Or…...

【MySQL】存储引擎 - ARCHIVE、BLACKHOLE、MERGE详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

代码随想录第41天:图论2(岛屿系列)
一、岛屿数量(Kamacoder 99) 深度优先搜索: # 定义四个方向:右、下、左、上,用于 DFS 中四向遍历 direction [[0, 1], [1, 0], [0, -1], [-1, 0]]def dfs(grid, visited, x, y):"""对一块陆地进行深度…...
详解)
Vue插槽(Slots)详解
文章目录 1. 插槽简介1.1 什么是插槽?1.2 为什么需要插槽?1.3 插槽的基本语法 2. 默认插槽2.1 什么是默认插槽?2.2 默认插槽语法2.3 插槽默认内容2.4 默认插槽实例:创建一个卡片组件2.5 Vue 3中的默认插槽2.6 默认插槽的应用场景 …...

中国古代史1
朝代歌 三皇五帝始,尧舜禹相传。 夏商与西周,东周分两段。 春秋和战国,一统秦两汉。 三分魏蜀吴,二晋前后延。 南北朝并立,隋唐五代传。 宋元明清后,皇朝至此完。 原始社会 元谋人,170万年前…...

vue +xlsx+exceljs 导出excel文档
实现功能:分标题行导出数据过多,一个sheet表里表格条数有限制,需要分sheet显示。 步骤1:安装插件包 npm install exceljs npm install xlsx 步骤2:引用包 import XLSX from xlsx; import ExcelJS from exceljs; 步骤3&am…...

nginx之proxy_redirect应用
一、功能说明 proxy_redirect 是 Nginx 反向代理中用于修改后端返回的响应头中 Location 和 Refresh 字段的核心指令,主要解决以下问题:协议/地址透传错误:当后端返回的 Location 包含内部 IP、HTTP 协议或非标准端口时,需修正为…...

在 Flink + Kafka 实时数仓中,如何确保端到端的 Exactly-Once
在 Flink Kafka 构建实时数仓时,确保端到端的 Exactly-Once(精确一次) 需要从 数据消费(Source)、处理(Processing)、写入(Sink) 三个阶段协同设计,结合 Fli…...

Qt 中基于 spdlog 的高效日志管理方案
在开发 Qt 应用程序时,日志记录是一项至关重要的功能,它能帮助我们追踪程序的运行状态、定位错误和分析性能。本文将介绍如何在 Qt 项目中集成 spdlog 库,并封装一个简单易用的日志管理类 QtLogger,实现高效的日志记录和管理。 为什么选择 spdlog? spdlog 是一个快速、头…...

VUE CLI - 使用VUE脚手架创建前端项目工程
前言 前端从这里开始,本文将介绍如何使用VUE脚手架创建前端工程项目 1.预准备(编辑器和管理器) 编辑器:推荐使用Vscode,WebStorm,或者Hbuilder(适合刚开始练手使用),个…...

Linux 学习笔记2
Linux 学习笔记2 一、定时任务调度操作流程注意事项 二、磁盘分区与管理添加新硬盘流程磁盘管理命令 三、进程管理进程操作命令服务管理(Ubuntu) 四、注意事项 一、定时任务调度 操作流程 创建脚本 vim /path/to/script.sh # 编写脚本内容设置可执行权…...

JS DOM操作与事件处理从入门到实践
对于前端开发者来说,让静态的 HTML 页面变得生动、可交互是核心技能之一。实现这一切的关键在于理解和运用文档对象模型 (DOM) 以及 JavaScript 的事件处理机制。本文将带你深入浅出地探索 DOM 操作的奥秘,并掌握JavaScript 事件处理的方方面面。 目录 …...
Java EE初阶——初识多线程
1. 认识线程 线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。 基本概念:一个进程可以包含多个线程,这些线程共享进程的资源,如内存空间、文件描述符等,但每个线程都有自己独…...
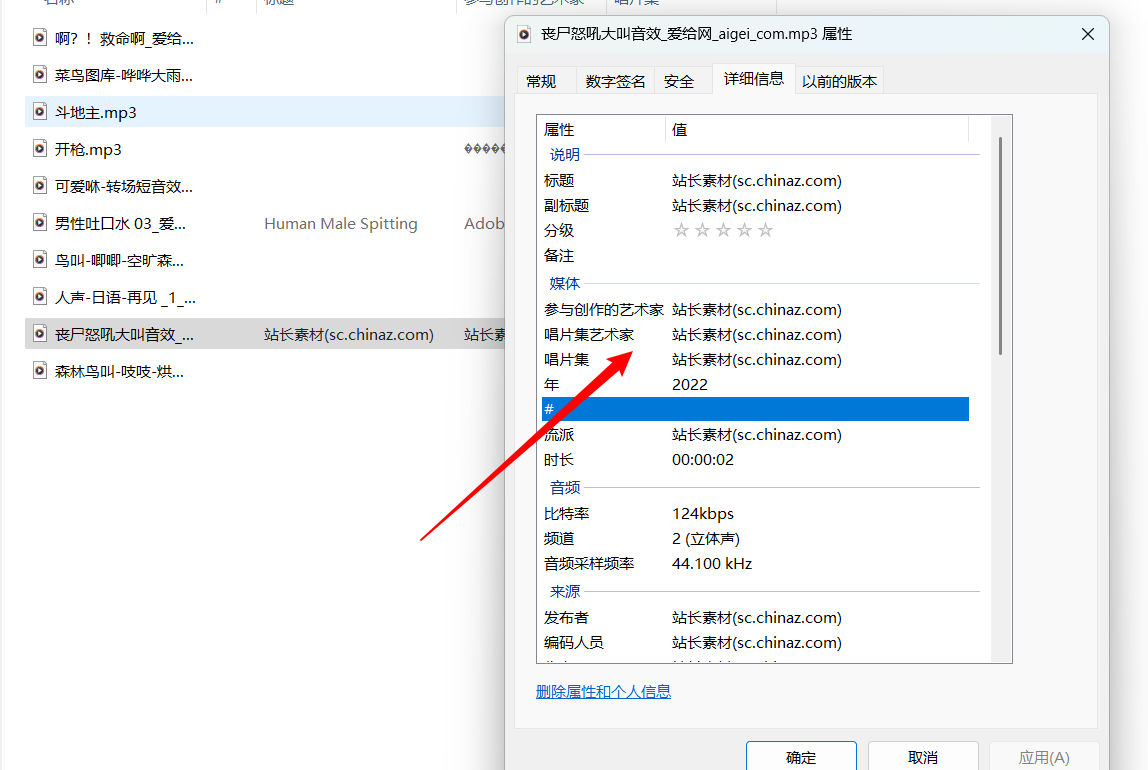
如何删除网上下载的资源后面的文字
这是我在爱给网上下载的音效资源,但是发现资源后面跟了一大段无关紧要的文本,但是修改资源名称后还是有。解决办法是打开属性然后删掉资源的标签即可。...

深入解析C++11委托构造函数:消除冗余初始化的利器
一、传统构造函数的痛点 在C11之前,当多个构造函数需要执行相同的初始化逻辑时,开发者往往面临两难选择: class DataProcessor {std::string dataPath;bool verbose;int bufferSize; public:// 基础版本DataProcessor(const std::string&am…...

Python中的事件循环是什么?事件是怎么个事件?循环是怎么个循环
在Python异步编程中,事件循环(Event Loop)是核心机制,它通过单线程实现高效的任务调度和I/O并发处理。本文将从事件的定义、循环的运行逻辑以及具体实现原理三个维度展开分析。 一、事件循环的本质:协程与任务的调度器…...
FPGA图像处理(5)------ 图片水平镜像
利用bram形成双缓冲,如下图配置所示: wr_flag 表明 buffer0写 还是 buffer1写 rd_flag 表明 buffer0读 还是 buffer1读 通过写入逻辑控制(结合wr_finish) 写哪个buffer ;写地址 进而控制ip的写使能 通过状态缓存来跳转buffer的…...

[python] 类
一 介绍 具有相同属性和行为的事物的通称,是一个抽象的概念 三要素: 类名,属性,方法 格式: class 类名: 代码块 class Pepole:name "stitchcool"def getname(self):return self.name 1.1 创建对象(实例化) 格式: 对象名 类名() p1 Pepole()…...