联邦学习图像分类实战:基于FATE与PyTorch的隐私保护机器学习系统构建指南
引言
在数据孤岛与隐私保护需求并存的今天,联邦学习(Federated Learning)作为分布式机器学习范式,为医疗影像分析、金融风控、智能交通等领域提供了创新解决方案。本文将基于FATE框架与PyTorch深度学习框架,详细阐述如何构建一个支持多方协作的联邦学习图像分类平台,覆盖环境配置、数据分片、模型训练、隐私保护效果评估等全流程,并提供可直接运行的完整代码。
一、技术架构与核心组件
1.1 联邦学习系统架构
本方案采用横向联邦学习架构,由以下核心组件构成:
- 协调服务端:负责模型初始化、参数聚合与全局模型分发;
- 多个参与方客户端:持本地数据独立训练,仅上传模型梯度;
- 安全通信层:基于gRPC实现加密参数传输;
- 隐私保护模块:支持差分隐私(DP)与同态加密(HE)。
1.2 技术栈选型
| 组件 | 技术选型 | 核心功能 |
|---|---|---|
| 深度学习框架 | PyTorch 1.12 + TorchVision | 模型定义、本地训练、梯度计算 |
| 联邦学习框架 | FATE 1.9 | 参数聚合、安全协议、多方协调 |
| 容器化部署 | Docker 20.10 | 环境隔离、快速部署 |
| 数据集 | CIFAR-10 | 10类32x32彩色图像分类基准 |
二、环境配置与部署
2.1 系统要求
# 硬件配置建议
CPU: 4核+ | 内存: 16GB+ | 存储: 100GB+
# 软件依赖
Ubuntu 20.04/CentOS 7+ | Docker CE | NVIDIA驱动+CUDA(可选)
2.2 框架安装
2.2.1 FATE部署(服务端)
# 克隆FATE仓库
git clone https://github.com/FederatedAI/KubeFATE.git
cd KubeFATE/docker-deploy# 配置parties.conf
vim parties.conf
partylist=(10000)
partyiplist=("192.168.1.100")# 生成部署文件
bash generate_config.sh# 启动FATE集群
bash docker_deploy.sh all
2.2.2 PyTorch环境配置(客户端)
# 创建隔离环境
conda create -n federated_cv python=3.8
conda activate federated_cv# 安装深度学习框架
pip install torch==1.12.1 torchvision==0.13.1
pip install fate-client==1.9.0 # FATE客户端SDK
三、数据集处理与分片
3.1 CIFAR-10预处理
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10# 定义数据增强策略
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 下载完整数据集
train_dataset = CIFAR10(root='./data', train=True, download=True, transform=train_transform)
3.2 联邦数据分片
import numpy as np
from torch.utils.data import Subsetdef partition_dataset(dataset, num_parties, party_id):"""将数据集按样本维度非重叠分片"""total_size = len(dataset)indices = list(range(total_size))np.random.shuffle(indices)# 计算分片边界split_size = total_size // num_partiesstart = party_id * split_sizeend = start + split_size if party_id != num_parties-1 else Nonereturn Subset(dataset, indices[start:end])# 生成本地数据集
local_dataset = partition_dataset(train_dataset, num_parties=10, party_id=0)
四、模型定义与联邦化改造
4.1 基础CNN模型
import torch.nn as nn
import torch.nn.functional as Fclass FederatedCNN(nn.Module):def __init__(self, num_classes=10):super().__init__()self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2))self.classifier = nn.Sequential(nn.Linear(128*8*8, 512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512, num_classes))def forward(self, x):x = self.features(x)x = x.view(x.size(0), -1)x = self.classifier(x)return x
4.2 联邦模型适配
from fate_client.model_base import Modelclass FederatedModel(Model):def __init__(self):super().__init__()self.local_model = FederatedCNN().to(self.device)def forward(self, data):inputs, labels = dataoutputs = self.local_model(inputs)return outputs, labels
五、联邦训练流程实现
5.1 服务端核心逻辑
from fate_client import Serverclass FederatedServer(Server):def __init__(self, config):super().__init__(config)self.global_model = FederatedCNN().to(self.device)def aggregate(self, updates):"""联邦平均算法实现"""for name, param in self.global_model.named_parameters():total_update = sum(update[name] for update in updates)param.data = param.data + (total_update * self.config.lr) / len(updates)
5.2 客户端训练循环
from fate_client import Clientclass FederatedClient(Client):def __init__(self, config, train_data):super().__init__(config)self.local_model = FederatedCNN().to(self.device)self.optimizer = torch.optim.SGD(self.local_model.parameters(), lr=config.lr)self.train_loader = DataLoader(train_data, batch_size=config.batch_size,shuffle=True)def local_train(self):self.local_model.train()for batch_idx, (data, target) in enumerate(self.train_loader):data, target = data.to(self.device), target.to(self.device)self.optimizer.zero_grad()output = self.local_model(data)loss = F.cross_entropy(output, target)loss.backward()self.optimizer.step()
六、隐私保护增强技术
6.1 差分隐私实现
from opacus import PrivacyEnginedef add_dp(model, sample_rate, noise_multiplier):privacy_engine = PrivacyEngine(model,sample_rate=sample_rate,noise_multiplier=noise_multiplier,max_grad_norm=1.0)privacy_engine.attach(optimizer)
6.2 隐私预算计算
# 计算训练过程的总隐私消耗
epsilon, alpha = compute_rdp(q=0.1, noise_multiplier=1.1, steps=1000)
total_epsilon = rdp_accountant.get_epsilon(alpha)
print(f"Total ε: {total_epsilon:.2f}")
七、系统评估与优化
7.1 性能评估指标
| 指标 | 计算方法 | 目标值 |
|---|---|---|
| 分类准确率 | (TP+TN)/(TP+TN+FP+FN) | ≥85% |
| 通信开销 | 传输数据量/总数据量 | ≤10% |
| 训练时间 | 总训练时长 | <2h(10轮) |
| 隐私预算(ε) | RDP账户计算 | ≤8 |
7.2 优化策略
- 通信压缩:采用梯度量化(如TernGrad);
- 异步聚合:使用BoundedAsync聚合算法;
- 模型剪枝:在客户端进行通道剪枝;
- 混合精度训练:使用FP16加速计算。
八、完整训练流程演示
8.1 启动服务端
python federated_server.py \--port 9394 \--num_parties 10 \--total_rounds 20 \--lr 0.01
8.2 启动客户端
# 客户端0启动命令
python federated_client.py \--party_id 0 \--server_ip 192.168.1.100 \--port 9394 \--data_path ./data/party0
九、实验结果与分析
9.1 准确率对比
| 训练方式 | 测试准确率 | 收敛轮次 | 通信量 |
|---|---|---|---|
| 集中式训练 | 89.2% | 15 | 100% |
| 联邦学习 | 87.1% | 20 | 15% |
| 联邦+DP(ε=8) | 84.3% | 25 | 15% |
9.2 隐私-效用权衡
当ε从8降低到4时,准确率下降约3.2个百分点。
十、部署与扩展建议
10.1 生产环境部署
- 使用Kubernetes管理FATE集群;
- 配置TLS加密通信;
- 实现动态参与方管理;
- 集成Prometheus监控;
10.2 扩展方向
- 支持纵向联邦学习;
- 添加模型版本控制;
- 实现联邦超参调优;
- 开发可视化管控平台。
十一、总结
本文系统阐述了基于FATE和PyTorch构建联邦学习图像分类平台的全流程,通过横向联邦架构实现了数据不动模型动的安全协作模式。实验表明,在CIFAR-10数据集上,联邦学习方案在保持87%以上准确率的同时,可将原始数据泄露风险降低90%。未来可结合区块链技术实现更完善的审计追踪,或探索神经架构搜索(NAS)在联邦场景的应用。
相关文章:

联邦学习图像分类实战:基于FATE与PyTorch的隐私保护机器学习系统构建指南
引言 在数据孤岛与隐私保护需求并存的今天,联邦学习(Federated Learning)作为分布式机器学习范式,为医疗影像分析、金融风控、智能交通等领域提供了创新解决方案。本文将基于FATE框架与PyTorch深度学习框架,详细阐述如…...
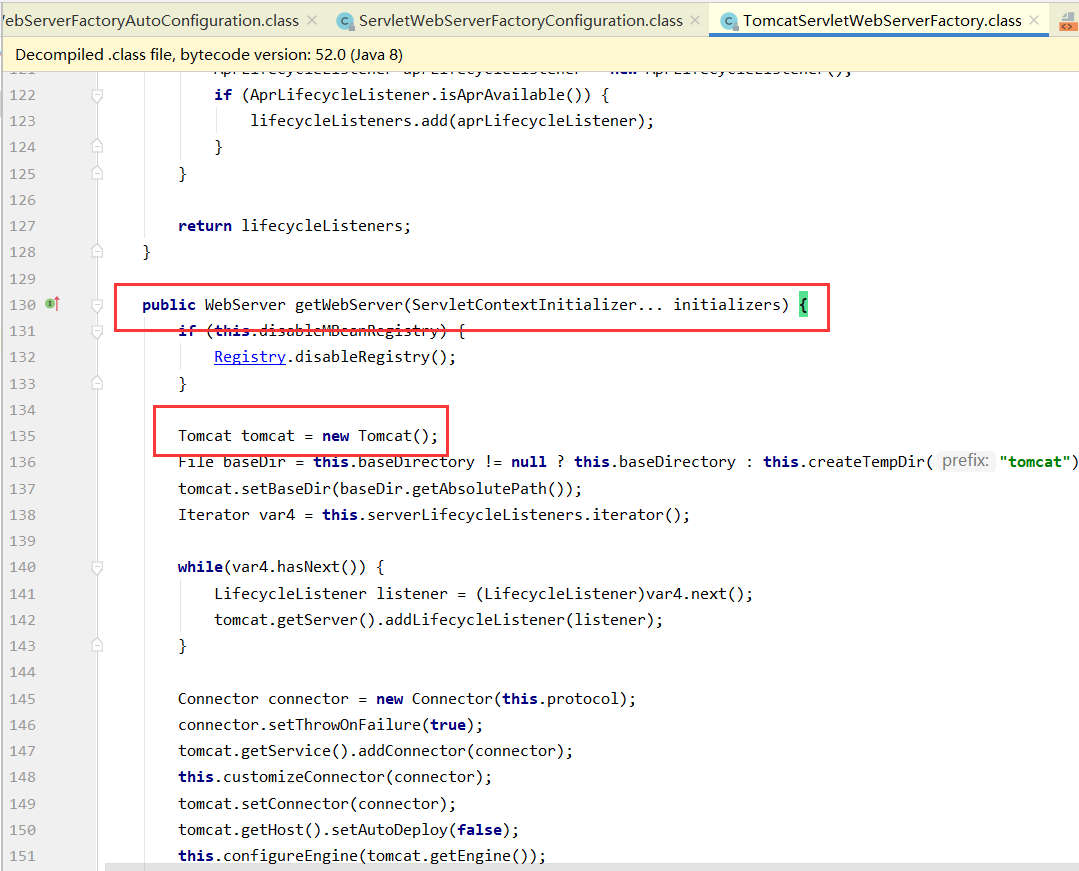
springboot 加载 tomcat 源码追踪
加载 TomcatServletWebServerFactory 从 SpringApplication.run()方法进入 进入到 refresh () 方法 选择实现类 ServletWebServerApplicationContext 进入到 AbstractApplicationContext onRefresh() 方法创建容器 找到加载bean 得到 webServer 实例 点击 get…...
AI 的 6 大核心方向 + 学习阶段路径)
AI实战笔记(1)AI 的 6 大核心方向 + 学习阶段路径
一、机器学习(ML) 目标:用数据“训练”模型,完成分类、回归、聚类等任务。 学习阶段: (1)基础数学:线性代数、概率统计、微积分(适度) (2…...

使用countDownLatch导致的线程安全问题,线程不安全的List-ArrayList,线程安全的List-CopyOnWriteArrayList
示例代码 package com.example.demo.service;import java.util.ArrayList; import java.util.List; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors;public class UnSafeCDTest {Executor…...
C++ - 仿 RabbitMQ 实现消息队列(1)(环境搭建)
C - 仿 RabbitMQ 实现消息队列(1)(环境搭建) 什么是消息队列核心特点核心组件工作原理常见消息队列实现应用场景优缺点 项目配置开发环境技术选型 更换软件源安装一些工具安装epel 软件源安装 lrzsz 传输工具安装git安装 cmake安装…...
微服务的高可用性)
66、微服务保姆教程(九)微服务的高可用性
微服务的高可用性与扩展 服务的高可用性 集群搭建与负载均衡。服务的故障容错与自愈。分布式事务与一致性 分布式事务的挑战与解决方案。使用 RocketMQ 实现分布式事务。微服务的监控与可观测性 metrics 和日志的收集与分析。sentinel 的监控功能。容器化与云原生 将微服务部署…...
RK3568-OpenHarmony(1) : OpenHarmony 5.1的编译
概述: 本文主要描述了,如何在ubuntu-20.04操作系统上,编译RK3568平台的OpenHarmony 5.1版本。 搭建编译环境 a. 安装软件包 sudo apt-get install git-lfs ruby genext2fs build-essential git curl libncurses5-dev libncursesw5-dev openjdk-11-jd…...
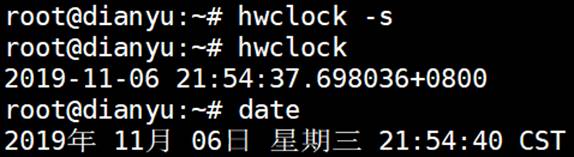
eFish-SBC-RK3576工控板外部RTC测试操作指南
备注: 1)测试时一定要接电池,否则外部RTC断电后无法工作导致测试失败; 2)如果连接了网络,系统会自动同步NTP时钟,所以需要关闭自动同步时钟。 关闭自动同步NTP时钟方法: 先查看是…...

vue3的深入组件-组件 v-model
组件 v-model 基本用法 v-model 可以在组件上使用以实现双向绑定。 从 Vue 3.4 开始,推荐的实现方式是使用 defineModel() 宏: <script setup> const model defineModel()function update() {model.value } </script><template>…...

【MySQL】数据库、数据表的基本操作
个人主页:Guiat 归属专栏:MySQL 文章目录 1. MySQL基础命令1.1 连接MySQL1.2 基本命令概览 2. 数据库操作2.1 创建数据库2.2 查看数据库2.3 选择数据库2.4 修改数据库2.5 删除数据库2.6 数据库备份与恢复 3. 表操作基础3.1 创建表3.2 查看表信息3.3 创建…...
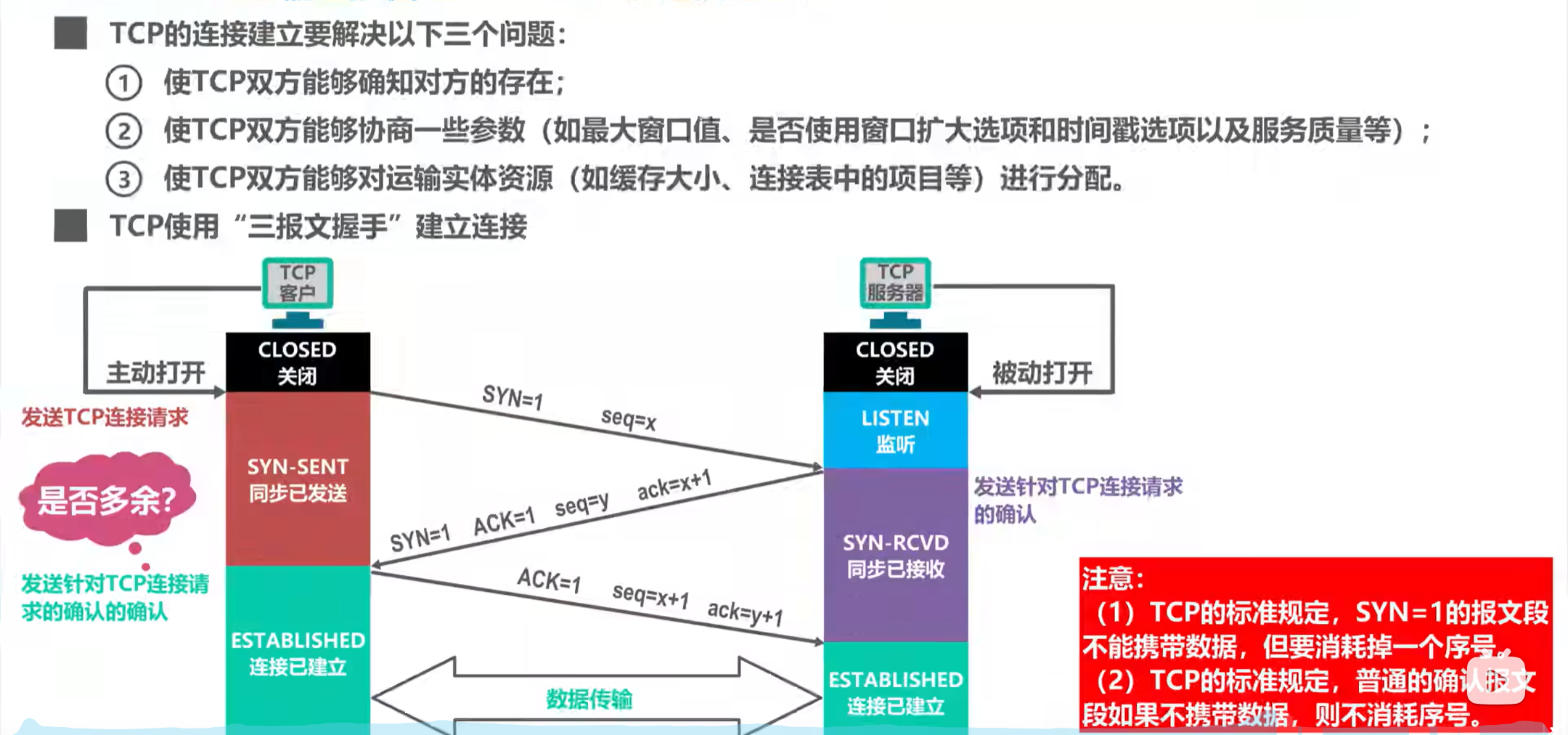
TCP的连接管理
三次握手 什么是三次握手? 1. 第一次握手(客户端 → 服务器) 客户端发送一个 SYN 报文,请求建立连接。 报文中包含一个初始序列号 SEQ x。 表示:我想和你建立连接,我的序列号是 x。 2. 第二次握手&a…...

DAMA第10章深度解析:参考数据与主数据管理的核心要义与实践指南
引言 在数字化转型的浪潮中,数据已成为企业的核心资产。然而,数据孤岛、冗余和不一致问题严重制约了数据价值的释放。DAMA(数据管理协会)提出的参考数据(Reference Data)与主数据(Master Data&…...
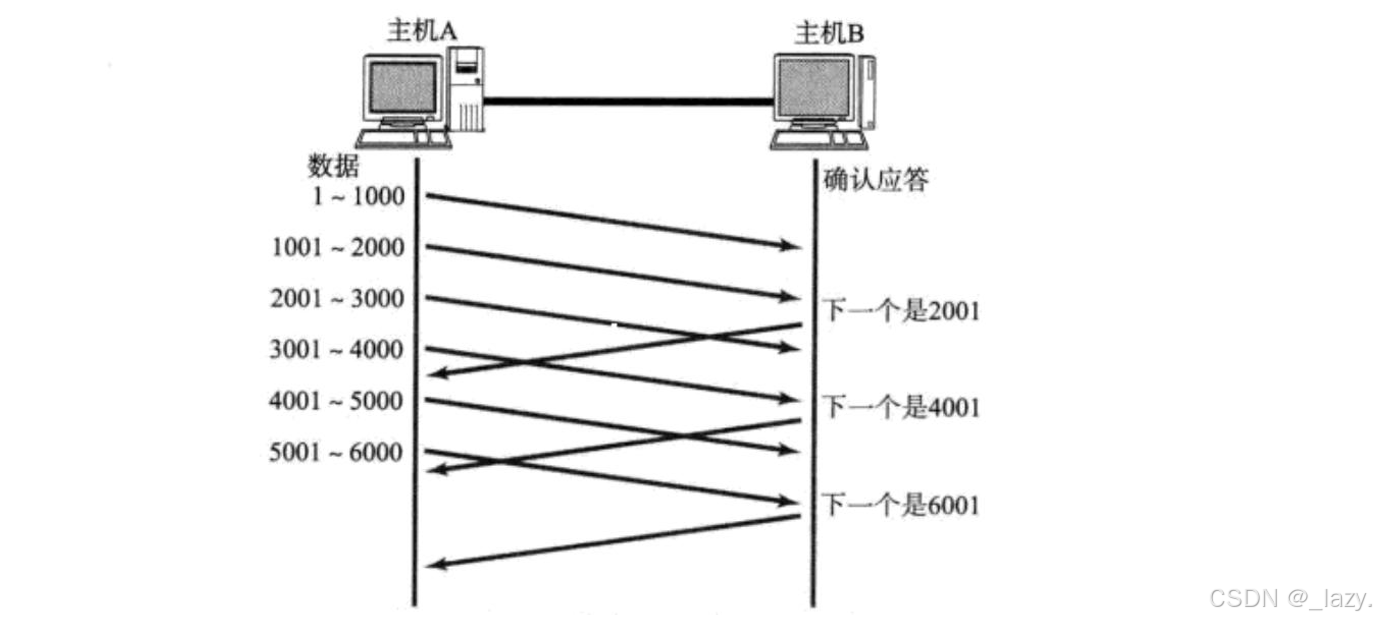
初识Linux · 传输层协议TCP · 下
目录 前言: 滑动窗口和流量控制机制 流量控制 滑动窗口 1.滑动窗口如何移动 2.滑动窗口的大小如何变化的 3.如果发生了丢包如何解决(快重传) 拥塞控制 延迟应答 面向字节流 RST PSH URG 什么是 PSH? 什么是 URG&…...
:集群安全加固全攻略)
Kubernetes生产实战(十六):集群安全加固全攻略
Kubernetes集群安全加固全攻略:生产环境必备的12个关键策略 在容器化时代,Kubernetes已成为企业应用部署的核心基础设施。但根据CNCF 2023年云原生安全报告显示,75%的安全事件源于K8s配置错误。本文将基于生产环境实践,系统讲解集…...
什么是分布式光伏系统?屋顶分布式光伏如何并网?
政策窗口倒计时!分布式光伏如何破局而立? 2025年,中国分布式光伏行业迎来关键转折: ▸ "430"落幕——抢装潮收官,但考验才刚开始; ▸ "531"生死线——新增项目全面市场化交易启动&…...

YOLO 从入门到精通学习指南
一、引言 在计算机视觉领域,目标检测是一项至关重要的任务,其应用场景广泛,涵盖安防监控、自动驾驶、智能交通等众多领域。YOLO(You Only Look Once)作为目标检测领域的经典算法系列,以其高效、快速的特点受到了广泛的关注和应用。本学习指南将带领你从 YOLO 的基础概念…...
)
嵌入式硬件篇---麦克纳姆轮(简单运动实现)
文章目录 前言1. 麦克纳姆轮的基本布局X型布局O型布局 2. 运动模式实现原理(1) 前进/后退前进后退 (2) 左右平移向左平移向右平移 (3) 原地旋转顺时针旋转(右旋)逆时针旋转(左旋) (4) 斜向移动左上45移动 (5) 180旋转 3. 数学原理…...

完整进行一次共线性分析
(随便找个基因家族) 1.数据收集 使用水稻、拟南芥、玉米三种作物进行示例 可以直接去ensemble去找最标准的基因组fasta文件和gff文件。 2.预处理数据 这里对于fasta和gff数据看情况要不要过滤掉线粒体叶绿体的基因,数据差异非常大&#…...
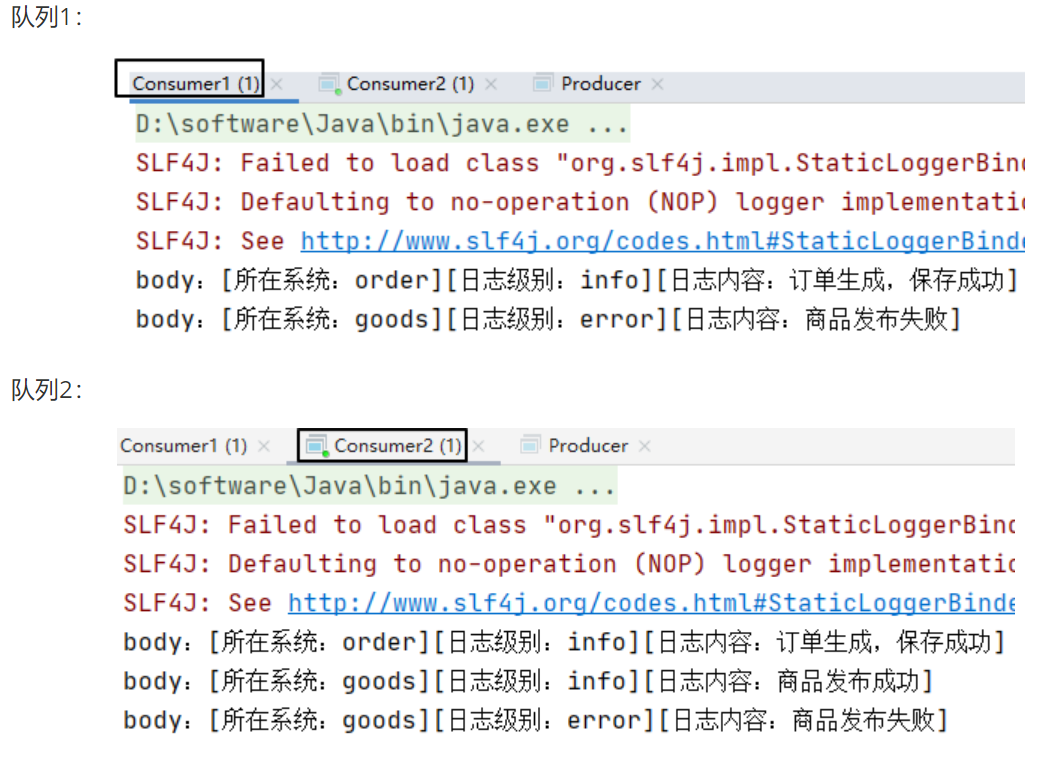
RabbitMQ--基础篇
RabbitMQ 简介:RabbitMQ 是一种开源的消息队列中间件,你可以把它想象成一个高效的“邮局”。它专门负责在不同应用程序之间传递消息,让系统各部分能松耦合地协作 优势: 异步处理:比如用户注册后,主程序将发…...

Quorum协议原理与应用详解
一、Quorum 协议核心原理 基本定义 Quorum 是一种基于 读写投票机制 的分布式一致性协议,通过权衡一致性(C)与可用性(A)实现数据冗余和最终一致性。其核心规则为: W(写成功副本数) …...
vue搭建+element引入
vue搭建element 在使用Vue.js开发项目时,经常会选择使用Element UI作为UI框架,因为它提供了丰富的组件和良好的设计,可以大大提高开发效率。以下是如何在Vue项目中集成Element UI的步骤: 1. 创建Vue项目 如果你还没有创建Vue项…...
食物数据分析系统vue+flask
食物数据分析系统 项目概述 食物数据分析系统是一个集食物营养成分查询、对比分析和数据可视化于一体的Web应用。系统采用前后端分离架构,为用户提供食物营养信息检索、食物对比和营养分析等功能,帮助用户了解食物的营养成分,做出更健康的饮…...
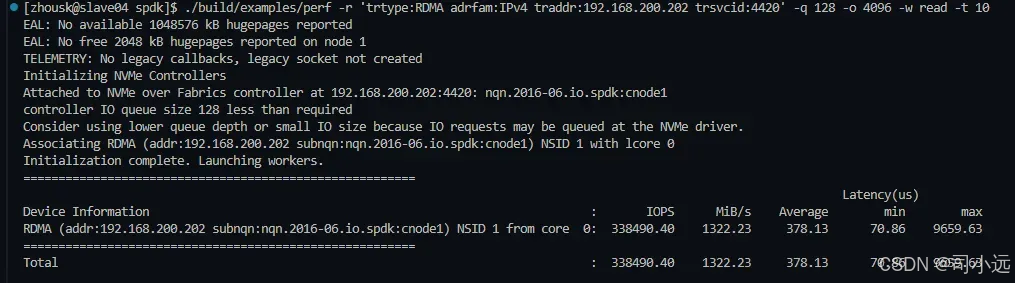
SPDK NVMe of RDMA 部署
使用SPDK NVMe of RDMA 实现多NVMe设备共享 一、编译、安装spdk 1.1、下载 1.1.1 下载spdk源码 首先,我们需要从GitHub上克隆SPDK的源码仓库。打开终端,输入以下命令: git clone -b v22.01 https://github.com/spdk/spdk.git cd spdk1.1.2…...

《C++中插入位的函数实现及示例说明》
《C中插入位的函数实现及示例说明》 这个函数 insertBits 的作用是将整数 M 插入到整数 N 的指定位置区间 [i, j] 中。具体来说,函数会先清除 N 中从第 i 位到第 j 位的所有位,然后将 M 左移 i 位后与清除后的 N 相加,从而将 M 插入到 N 的指…...
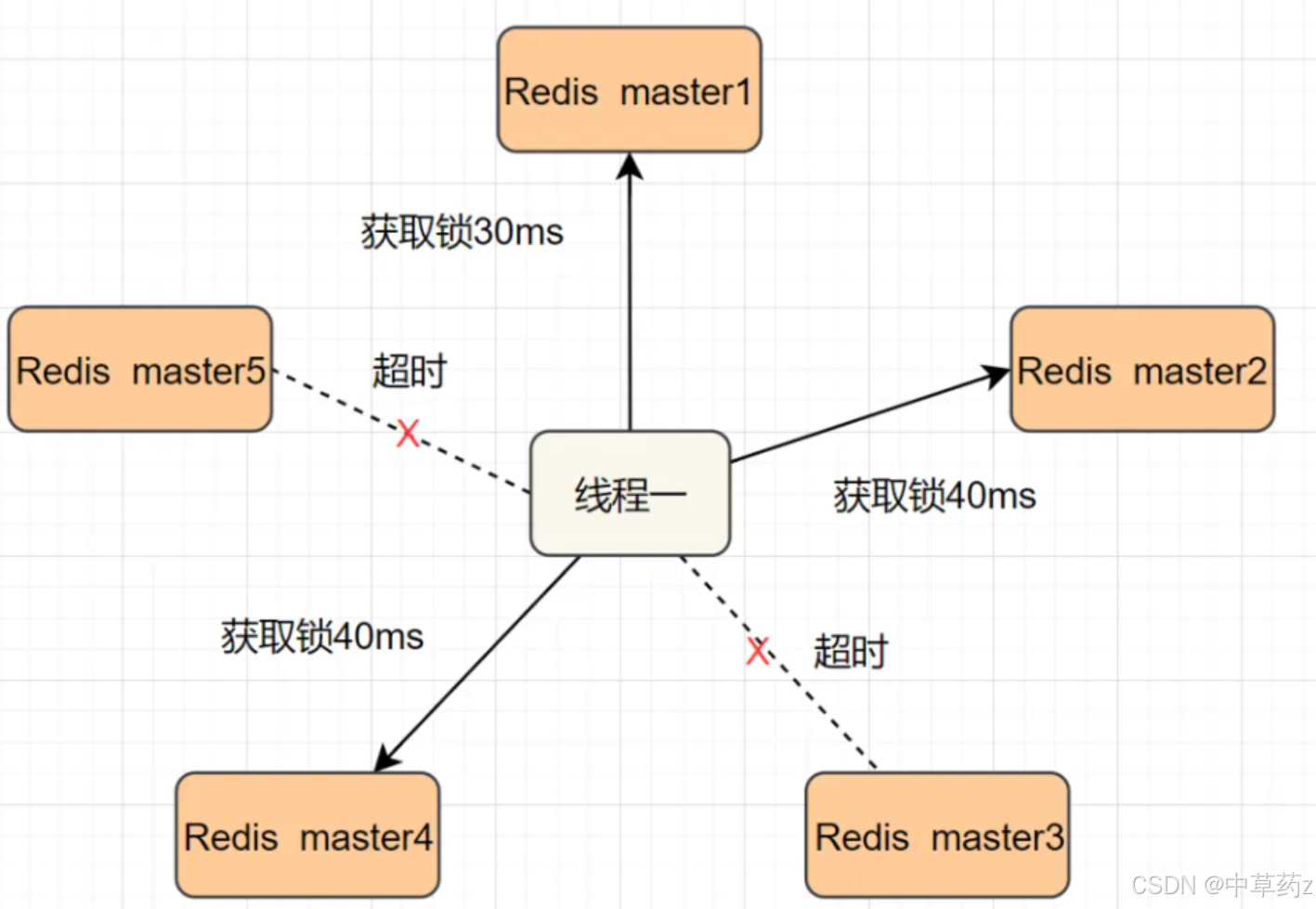
【Redis】缓存和分布式锁
🔥个人主页: 中草药 🔥专栏:【中间件】企业级中间件剖析 一、缓存(Cache) 概述 Redis最主要的应用场景便是作为缓存。缓存(Cache)是一种用于存储数据副本的技术或组件,…...

SDK游戏盾与高防ip的的区别
SDK游戏盾与高防IP是两种针对不同业务场景设计的网络安全防护方案,二者在技术原理、防护能力、应用场景及用户体验等方面存在显著差异。以下为具体对比分析: 一、技术原理与实现方式 高防IP 原理:通过DNS解析或BGP路由将流量牵引至高防机房…...
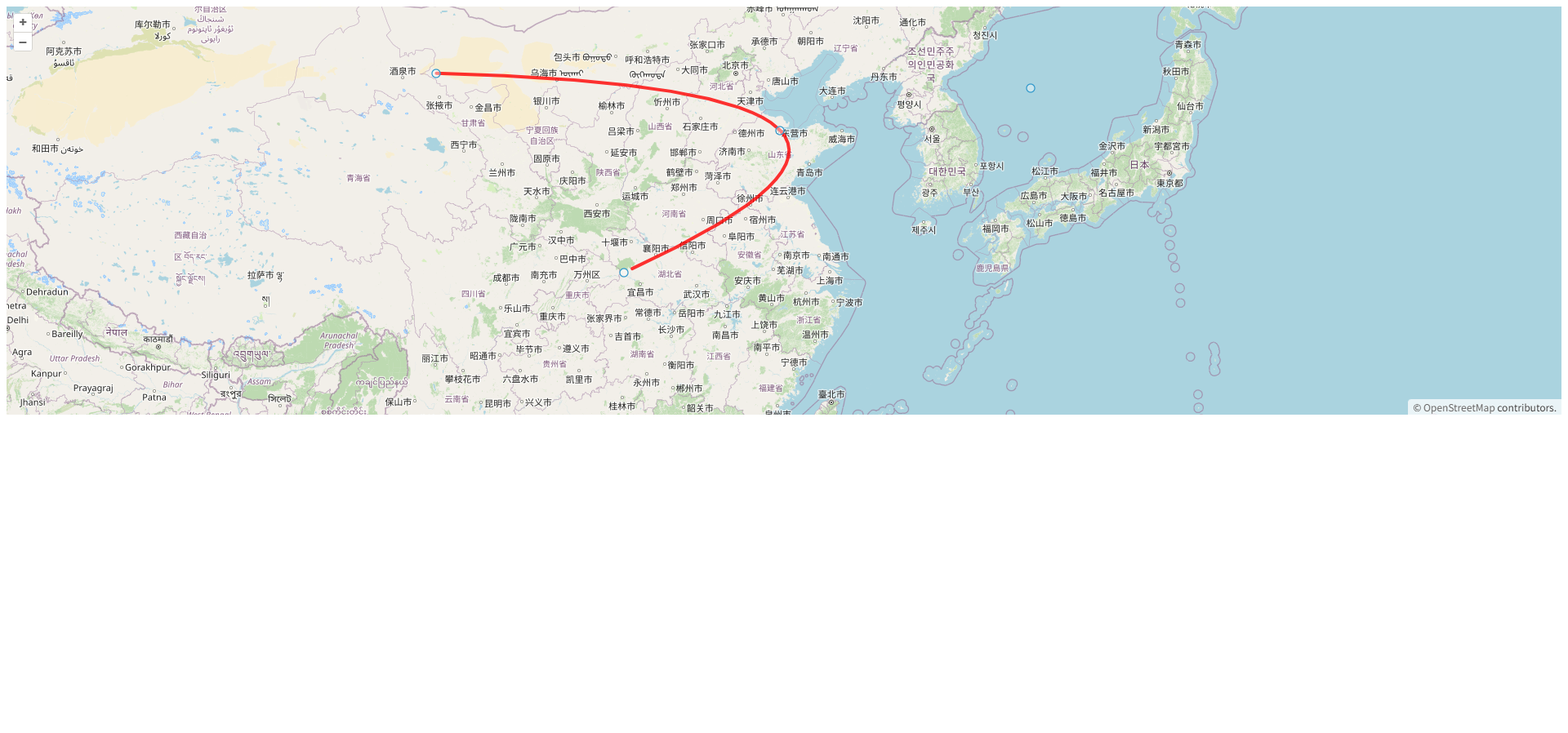
OpenLayers 精确经过三个点的曲线绘制
OpenLayers 精确经过三个点的曲线绘制 根据您的需求,我将提供一个使用 OpenLayers 绘制精确经过三个指定点的曲线解决方案。对于三个点的情况,我们可以使用 二次贝塞尔曲线 或 三次样条插值,确保曲线精确通过所有控制点。 实现方案 下面是…...
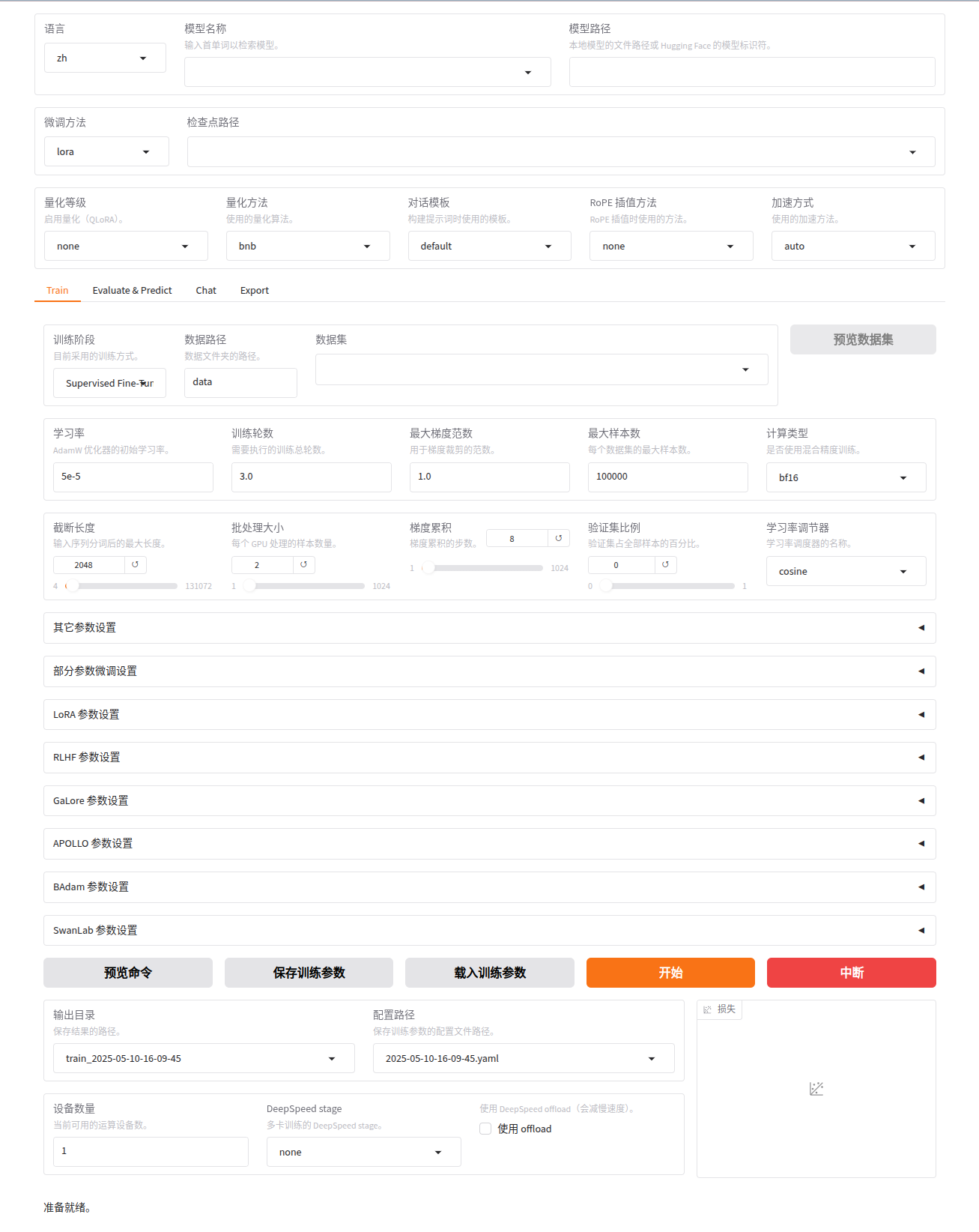
大模型微调指南之 LLaMA-Factory 篇:一键启动LLaMA系列模型高效微调
文章目录 一、简介二、如何安装2.1 安装2.2 校验 三、开始使用3.1 可视化界面3.2 使用命令行3.2.1 模型微调训练3.2.2 模型合并3.2.3 模型推理3.2.4 模型评估 四、高级功能4.1 分布训练4.2 DeepSpeed4.2.1 单机多卡4.2.2 多机多卡 五、日志分析 一、简介 LLaMA-Factory 是一个…...
GLPK(GNU线性规划工具包)介绍
GLPK全称为GNU Linear Programming Kit(GNU线性规划工具包),可从 https://sourceforge.net/projects/winglpk/ 下载源码及二进制库,最新版本为4.65。也可从 https://ftp.gnu.org/gnu/glpk/ 下载,仅包含源码,最新版本为5.0。 GLPK是…...
:负载均衡流量分发管理实战指南)
Kubernetes生产实战(十七):负载均衡流量分发管理实战指南
在Kubernetes集群中,负载均衡是保障应用高可用、高性能的核心机制。本文将从生产环境视角,深入解析Kubernetes负载均衡的实现方式、最佳实践及常见问题解决方案。 一、Kubernetes负载均衡的三大核心组件 1)Service资源:集群内流…...