linux搭建hadoop学习
linux搭建hadoop学习
下载安装包:
海外资源可能需要翻墙或者找国内资源
cd /opt
wget https://dlcdn.apache.org/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz
tar -zxvf hadoop-2.10.2.tar.gz
mv hadoop-2.10.2 hadoop
配置环境变量
# 在/etc/profile文件中添加下面内容
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#生效环境变量
source /etc/profile
测试安装,在命令行中执行
hadoop version
我这里执行后报错,很明显前面提到过hadoop由java开发,所以还需要配置java环境.
[root@win-local-17 ~]# hadoop version
Error: JAVA_HOME is not set and could not be found.
这里可以参考文档: https://blog.csdn.net/qq_42402854/article/details/108164936
如果是原本使用rpm包安装jdk需要注意下,可能你主机上可以执行java命令,但是依然会遇到这个报错.
这时需要我们在手动配置下环境变量:
# 看下java是在哪个目录下,然后配置到/etc/profile文件中
which javaexport JAVA_HOME=/usr/
export PATH=$PATH:$JAVA_HOME/bin
然后再执行:
[root@win-local-17 ~]# hadoop version
Hadoop 2.10.2
Subversion Unknown -r 965fd380006fa78b2315668fbc7eb432e1d8200f
Compiled by ubuntu on 2022-05-24T22:35Z
Compiled with protoc 2.5.0
From source with checksum d3ab737f7788f05d467784f0a86573fe
This command was run using /opt/hadoop/share/hadoop/common/hadoop-common-2.10.2.jar
到这里hadoop的应用程序安装完成了,
接下来我们开始部署单机模型和伪分布式服务.因为是学习阶段所以使用单台主机部署伪分布式就可以了.如果需要多台主机部署分布式可以查看文末的参考文档.
单机模式
先进行一个简单的示例:用来统计分析单词的个数和数量
#首先创建一个目录
cd /opt/hadoop
mkdir input
cd ./intput
然后创建文件,写入一些简单数据
cat test
hadoop yarn
hadoop mapreduce
spark
spark
然后执行一下MapReduce 程序,我们来看下效果:
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.2.jar wordcount input/ wcoutput
程序执行之后会看到有很多输出,此时主机cpu使用率也会升高,主要看有没有明显的报错出现.,执行执行完成之后,在/opt/hadoop下会创建出一个目录: wcoutput
可以看到这里将我们给的测试内容中的单词数量统计出来了.
[root@win-local-17 hadoop]# ll wcoutput
总用量 4
-rw-r--r--. 1 root root 36 5月 8 18:05 part-r-00000
-rw-r--r--. 1 root root 0 5月 8 18:05 _SUCCESS
[root@win-local-17 hadoop]# cat wcoutput/part-r-00000
hadoop 2
mapreduce 1
spark 2
yarn 1
[root@win-local-17 hadoop]# pwd
/opt/hadoop
接下来,我们进行一个nginx日志的统计,上面的测试发现它可以统计简单的单词,那么就可以对指定的日志格式内容进行分析,比如我们让他统计一下nginx日志文件中,请求的客户端IP的数量和状态码的数量.
当然我们不能直接和上面一样运行命令直接进行统计,hadoop还不能直接实现,需要我们对MapReduce 过程进行自定义,分为map过程和Reduce过程;Hadoop Streaming 允许使用任何可执行程序(如 Python 脚本)作为 MapReduce 作业的 mapper 和 reducer。
这里我们自己写两个Python脚本,来实现map过程和Reduce过程.
mapper.py
import sys
import re# 正则表达式用于解析 Nginx 日志行
NGINX_LOG_PATTERN = re.compile(r'^([\d.]+) - - \[(.*?)\] "(.*?)" (\d+) (\d+)')for line in sys.stdin:line = line.strip()match = NGINX_LOG_PATTERN.match(line)if match:# 提取 IP 地址ip = match.group(1)# 提取状态码status_code = match.group(4)# 输出 IP 地址和计数print(f"{ip}\t1")# 输出状态码和计数print(f"{status_code}\t1")
reducer.py
import syscurrent_key = None
current_count = 0for line in sys.stdin:line = line.strip()key, count = line.split('\t', 1)try:count = int(count)except ValueError:continueif current_key == key:current_count += countelse:if current_key:print(f"{current_key}\t{current_count}")current_key = keycurrent_count = countif current_key:print(f"{current_key}\t{current_count}")
这里通过mapper.py对输入的日志内容进行过滤,提取IP和状态码,输入一个键值对。而reducer.py就是对map中输出的键值对,对相同键值进行累计,得到次数。
然后我们在创建目录和日志文件内容:
mkdir nginx-input
cd nginx-input
[root@win-local-17 nginx-input]# ll
总用量 36
-rw-r--r--. 1 root root 502 5月 8 18:34 mapper.py
-rw-r--r--. 1 root root 26326 5月 8 18:48 nginx.log
-rw-r--r--. 1 root root 474 5月 8 18:35 reducer.py
[root@win-local-17 nginx-input]# head nginx.log -n 3
192.168.112.125 - - [03/Apr/2025:20:25:15 +0800] "HEAD /app/psychicai/psychicai_test.ipa HTTP/2.0" 200 0 "-" "com.apple.appstored/1.0 iOS/17.5.1 model/iPhone13,2 hwp/t8101 build/21F90 (6; dt:229) AMS/1" "-"
192.168.112.125 - - [03/Apr/2025:20:25:15 +0800] "GET /app/psychicai/icon_1024@1x.png HTTP/2.0" 200 162747 "-" "com.apple.appstored/1.0 iOS/17.5.1 model/iPhone13,2 hwp/t8101 build/21F90 (6; dt:229) AMS/1" "-"
192.168.112.125 - - [03/Apr/2025:20:25:21 +0800] "GET /app/psychicai/psychicai_test.ipa HTTP/2.0" 200 74397692 "-" "com.apple.appstored/1.0 iOS/17.5.1 model/iPhone13,2 hwp/t8101 build/21F90 (6; dt:229) AMS/1" "-"
文件内容准备好之后,我们执行命令用自定义的脚本去执行两个阶段:(主机需要有Python3的环境)
cd /opt/hadoop/nginx-inputhadoop jar ../share/hadoop/tools/lib/hadoop-streaming-*.jar \
-input ./nginx.log \
-output /output \
-mapper "python3 mapper.py" \
-reducer "python3 reducer.py"
执行期间我们会看到有很对输出,观察里面是否有明显报错.
[root@win-local-17 nginx-input]# hadoop jar ../share/hadoop/tools/lib/hadoop-streaming-*.jar \
> -input ./nginx.log \
> -output /output \
> -mapper "python3 mapper.py" \
> -reducer "python3 reducer.py"
25/05/08 18:50:59 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
25/05/08 18:50:59 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
25/05/08 18:51:19 INFO jvm.JvmMetrics: Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized
25/05/08 18:51:40 INFO mapred.FileInputFormat: Total input files to process : 1
25/05/08 18:51:40 INFO mapreduce.JobSubmitter: number of splits:1
25/05/08 18:51:41 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1405416554_0001
25/05/08 18:51:41 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
25/05/08 18:51:41 INFO mapred.LocalJobRunner: OutputCommitter set in config null
25/05/08 18:51:41 INFO mapreduce.Job: Running job: job_local1405416554_0001
25/05/08 18:51:41 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapred.FileOutputCommitter
25/05/08 18:51:41 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
25/05/08 18:51:41 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
25/05/08 18:51:41 INFO mapred.LocalJobRunner: Waiting for map tasks
25/05/08 18:51:41 INFO mapred.LocalJobRunner: Starting task: attempt_local1405416554_0001_m_000000_0
25/05/08 18:51:42 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
25/05/08 18:51:42 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
25/05/08 18:51:42 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
25/05/08 18:51:42 INFO mapred.MapTask: Processing split: file:/opt/hadoop/nginx-input/nginx.log:0+26326
25/05/08 18:51:42 INFO mapred.MapTask: numReduceTasks: 1
25/05/08 18:51:42 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
25/05/08 18:51:42 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
25/05/08 18:51:42 INFO mapred.MapTask: soft limit at 83886080
25/05/08 18:51:42 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
25/05/08 18:51:42 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
25/05/08 18:51:42 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
25/05/08 18:51:42 INFO streaming.PipeMapRed: PipeMapRed exec [/usr/local/bin/python3, mapper.py]
25/05/08 18:51:42 INFO Configuration.deprecation: mapred.work.output.dir is deprecated. Instead, use mapreduce.task.output.dir
25/05/08 18:51:42 INFO Configuration.deprecation: map.input.start is deprecated. Instead, use mapreduce.map.input.start
25/05/08 18:51:42 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
25/05/08 18:51:42 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
25/05/08 18:51:42 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
25/05/08 18:51:42 INFO Configuration.deprecation: mapred.local.dir is deprecated. Instead, use mapreduce.cluster.local.dir
25/05/08 18:51:42 INFO Configuration.deprecation: map.input.file is deprecated. Instead, use mapreduce.map.input.file
25/05/08 18:51:42 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
25/05/08 18:51:42 INFO Configuration.deprecation: map.input.length is deprecated. Instead, use mapreduce.map.input.length
25/05/08 18:51:42 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
25/05/08 18:51:42 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name
25/05/08 18:51:42 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
25/05/08 18:51:42 INFO streaming.PipeMapRed: R/W/S=1/0/0 in:NA [rec/s] out:NA [rec/s]
25/05/08 18:51:42 INFO streaming.PipeMapRed: R/W/S=10/0/0 in:NA [rec/s] out:NA [rec/s]
25/05/08 18:51:42 INFO streaming.PipeMapRed: R/W/S=100/0/0 in:NA [rec/s] out:NA [rec/s]
25/05/08 18:51:42 INFO streaming.PipeMapRed: Records R/W=100/1
25/05/08 18:51:42 INFO streaming.PipeMapRed: MRErrorThread done
25/05/08 18:51:42 INFO streaming.PipeMapRed: mapRedFinished
.......
在这期间也可以观察到主机cpu和负载会有很明显的升高,
top - 18:51:42 up 2 days, 8:32, 3 users, load average: 0.16, 0.05, 0.06
Tasks: 154 total, 1 running, 153 sleeping, 0 stopped, 0 zombie
%Cpu(s): 12.5 us, 2.8 sy, 0.0 ni, 84.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1867048 total, 211396 free, 249168 used, 1406484 buff/cache
KiB Swap: 1048572 total, 1048404 free, 168 used. 1304388 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND25764 root 20 0 2304916 138548 22392 S 155.5 7.4 0:12.16 java
我这里测试了100条日志数据执行10s左右就结束了,然后我们可以看到执行结果.
[root@win-local-17 nginx-input]# ll /output/
总用量 4
-rw-r--r--. 1 root root 107 5月 8 18:51 part-00000
-rw-r--r--. 1 root root 0 5月 8 18:51 _SUCCESS
[root@win-local-17 nginx-input]# cat /output/part-00000
192.168.112.125 3
192.168.113.187 5
192.168.114.57 1
192.168.115.0 3
192.168.89.136 88
200 53
206 2
405 45
这里他将日志中的客户端IP,以及状态码都统计出来, 我们在用命令去过滤一下,对比一下统计结果
[root@win-local-17 nginx-input]# cat nginx.log | awk '{print $1}' |sort -n | uniq -c3 192.168.112.1255 192.168.113.1871 192.168.114.573 192.168.115.088 192.168.89.136
[root@win-local-17 nginx-input]# cat nginx.log |grep -w '200' |wc -l
53
[root@win-local-17 nginx-input]# cat nginx.log |grep -w '206' |wc -l
2
[root@win-local-17 nginx-input]# cat nginx.log |grep -w '405' |wc -l
45
[root@win-local-17 nginx-input]# wc -l nginx.log
100 nginx.log
通过我们手动对日志文件进行统计可以看到,最终的结果跟上面使用MapReduce的方式一样,通过这种自定义的方式,可以使用多场景化,当然后面再不断地学习中还会有更好工具帮助简化自定义的数据分析方式.
伪分布式模式
伪分布式则是在一台主机上模拟出分布式的各个进程运行状态,方便我们了解学习.
配置集群,修改hadoop的配置文件: /opt/hadoop/etc/hadoop/core-site.xml (该配置文件是 Hadoop 集群的核心配置文件之一,主要用于定义 Hadoop 分布式系统的全局设置和通用属性,控制 Hadoop 各个组件之间的通信、数据传输和基本行为。这个文件决定了 Hadoop 集群如何运行以及各个服务之间如何交互。)
core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property><name>fs.defaultFS</name><!-- namenode主机地址,本地地址 --><value>hdfs://192.168.44.17:8020</value>
</property><!-- 指定Hadoop运行时产生文件的存储目录 -->
<property><name>hadoop.tmp.dir</name><value>/opt/hadoop/data/tmp</value></property>
</configuration>hdfs-site.xml
<configuration><!-- 指定HDFS副本的数量 --><property><name>dfs.replication</name><value>1</value></property>
</configuration>
修改上面的配置后,启动集群
- 格式化 NameNode(第一次启动时格式化,以后就不要总格式化)
hdfs namenode -format
# 执行之后会有很多输出,检查是否有明显异常
25/05/09 11:16:23 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at win-local-17/192.168.44.17
************************************************************/- 启动 NameNode
cd /opt/hadoop/etc/hadoop
[root@win-local-17 hadoop]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/hadoop/logs/hadoop-root-namenode-win-local-17.out
[root@win-local-17 hadoop]# cat /opt/hadoop/logs/hadoop-root-namenode-win-local-17.out
ulimit -a for user root
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7206
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 7206
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
- 启动DataNode
cd /opt/hadoop/etc/hadoop
[root@win-local-17 hadoop]# hadoop-daemon.sh start datanode
starting datanode, logging to /opt/hadoop/logs/hadoop-root-datanode-win-local-17.out
[root@win-local-17 hadoop]# cat /opt/hadoop/logs/hadoop-root-datanode-win-local-17.out
ulimit -a for user root
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7206
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 7206
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
- 查看进程是否启动成功
[root@win-local-17 hadoop]# jps
80615 NameNode
80726 DataNode
80790 Jps
[root@win-local-17 hadoop]# netstat -anltp |grep java
tcp 0 0 192.168.44.17:8020 0.0.0.0:* LISTEN 80615/java
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 80615/java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 80726/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 80726/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 80726/java
tcp 0 0 127.0.0.1:43496 0.0.0.0:* LISTEN 80726/java
tcp 0 0 192.168.44.17:37402 192.168.44.17:8020 ESTABLISHED 80726/java
tcp 0 0 192.168.44.17:8020 192.168.44.17:37402 ESTABLISHED 80615/java
简单介绍上面端口对应的服务:
8020: HDFS 的 NameNode 服务。
50070: NameNode 的 Web UI 服务,可以通过浏览器访问
50010: DataNode 的数据传输端口,DataNode 使用该端口与其他 DataNode 节点或客户端进行数据块的传输。当客户端需要读取或写入数据时,会通过该端口与相应的 DataNode 进行数据交互。
50075: DataNode 的 Web UI 服务。
50020: DataNode 的元数据服务端口。用于 DataNode 与 NameNode 之间进行数据块的元数据信息交换,例如 DataNode 向 NameNode 汇报自己所存储的数据块信息
通过web端访问一下HDFS的系统:
在这里面可以系统的相关信息以及节点和日志的信息



5. 启动 YARN 并运行 MapReduce 程序
修改yarn-site.xml配置文件,添加下面内容
/opt/hadoop/etc/hadoop/yarn-site.xml
<configuration><!-- 指定 NodeManager 节点上运行的辅助服务列表。在 Hadoop 中,mapreduce_shuffle 是一个关键的辅助服务,专门用于处理 MapReduce 作业中的数据混洗(Shuffle)阶段。 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定YARN的ResourceManager的地址,默认端口是8088--><property><name>yarn.resourcemanager.webapp.address</name><value>0.0.0.0:8088</value></property>
</configuration>
mv mapred-site.xml.template mapred-site.xml
修改mapred-site.xml
<configuration><!-- 指定MR运行在YARN上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>- 启动集群
启动前必须保证 NameNode 和 DataNode 已经启动
启动ResourceManager
[root@win-local-17 hadoop]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/hadoop/logs/yarn-root-resourcemanager-win-local-17.out
启动NodeManager启动NodeManager
[root@win-local-17 hadoop]# yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/hadoop/logs/yarn-root-nodemanager-win-local-17.out
查看进程运行:
[root@win-local-17 hadoop]# jps
90321 NodeManager
90593 ResourceManager
80615 NameNode
80726 DataNode
90716 Jps
如果遇到报错: 端口一直报错无法使用,可以将端口改为8098,再重启启动ResourceManager正常运行了.
然后访问web端就能看到:

参考文档:
https://developer.aliyun.com/article/1046126
https://www.cnblogs.com/liugp/p/16607424.html#%E4%BA%8Chadoop-hdfs-ha-%E6%9E%B6%E6%9E%84%E4%B8%8E%E5%8E%9F%E7%90%86
相关文章:
linux搭建hadoop学习
linux搭建hadoop学习 下载安装包: 海外资源可能需要翻墙或者找国内资源 cd /opt wget https://dlcdn.apache.org/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz tar -zxvf hadoop-2.10.2.tar.gz mv hadoop-2.10.2 hadoop配置环境变量 # 在/etc/profile文件中添加下面内…...
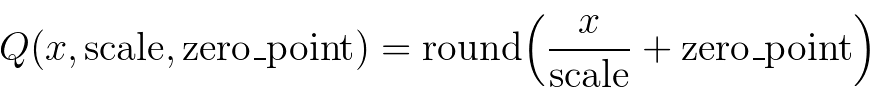
PyTorch API 8 - 工具集、onnx、option、复数、DDP、量化、分布式 RPC、NeMo
文章目录 torch.nn.inittorch.nn.attention工具集子模块 torch.onnx概述基于 TorchDynamo 的 ONNX 导出器基于TorchScript的ONNX导出器贡献与开发 torch.optim如何使用优化器构建优化器每个参数的选项执行优化步骤optimizer.step()optimizer.step(closure) 基类算法如何调整学习…...

0基础 | STM32 | TB6612电机驱动使用
TB6612介绍及使用 单片机通过驱动板连接至电机 原因:单品机I/O口输出电流I小 驱动板:从外部引入高电压,控制电机驱动 电源部分 VM:电机驱动电源输入,输入电压范围建议为3.7~12V GND:逻辑电…...
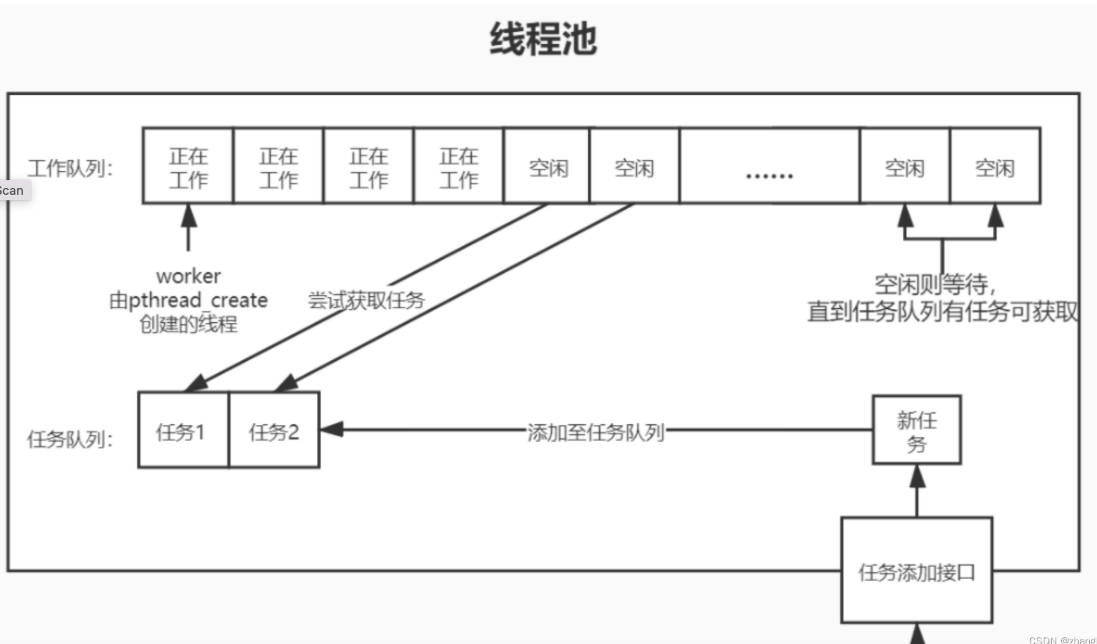
【Linux】POSIX 线程信号量与互斥锁▲
代码要求:高内聚,低耦合 高内聚:元素之间具有很强的关联性,模块的功能单一且集中 低耦合:代码之间的依赖关系尽可能简单,相互之间的影响和交互尽可能少 线程安全问题:多线程访问共享数据&…...

轻松制作高质量视频,实时生成神器LTX-Video重磅登场!
探索LTX-Video:实时视频生成跨越新高度 在如今这个视觉内容主导的数字时代,视频生成成为推动创意表达的关键。而今天,我们将带您深入探索LTX-Video,一个强大的开源项目,致力于通过尖端技术将视频生成提升到一个全新的…...
USR-M100采集数据并提交MQTT服务器
本文为记录备忘,不做过多解释。 模块自身带有2路数字量输入,2路模拟量输入,2路485接口 数字量接报警输入,模拟量接压力传感器,液位传感器,485接口分别接流量计,温湿度传感器。 正确接线&…...
内网穿透系列三:开源本地服务公网映射工具 tunnelmole
以下是对 tunnelmole 简要介绍: tunnelmole 是一款开源的内网穿透工具,一行命令就能把本地http服务映射成公网可访问的链接提供公共免费的网络服务,直接下载运行命令即可使用,也支持自行配置搭建私有客户端、服务端参考开源地址&…...

数据集-目标检测系列- 冥想 检测数据集 close_eye>> DataBall
数据集-目标检测系列- 冥想 检测数据集 close * 相关项目 1)数据集可视化项目:gitcode: https://gitcode.com/DataBall/DataBall-detections-100s/overview 2)数据集训练、推理相关项目:GitHub - XIAN-HHappy/ultralytics-yolo-…...

计算机网络:家庭路由器WiFi信号的发射和手机终端接收信号原理?
WiFi路由器与手机之间的信号传输涉及多个技术层面的协作,以下是其工作原理的详细步骤: 一、数据封装与协议处理 应用层数据生成 用户操作(如浏览网页、视频播放)产生数据包,经TCP/IP协议栈逐层封装,添加IP地址(网络层)和MAC地址(数据链路层)。协议封装 数据包被封装…...

用 NGINX 打造高性能 FastCGI 加速 `ngx_http_fastcgi_module`
一、安装与启用 # 在编译 NGINX 源码时加上: ./configure --with-http_fastcgi_module make && sudo make install# 或确保你使用的二进制已内置(大多数发行版都默认包含) nginx -V | grep fastcgi二、基础转发配置 http {server {…...

深度学习 ———— 迁移学习
迁移学习原理 什么是迁移学习? 迁移学习利用在大规模数据集(如ImageNet)上预训练的模型,改装小数据集(如CIFAR-10)。优势: 减少训练时间:预训练模型已学习通用特征(如边…...

论文精读:YOLOE: Real-Time Seeing Anything
文章目录 前言1、背景2、方法2.1.重参Region-Text对齐模块2.2.VisualPrompt模块2.3.PromptFree 2.4.损失函数3、实验3.1.训练集3.2.实验结果 总结 前言 本文介绍一篇来自清华的开放词汇检测论文:YOLOE;源码链接。 1、背景 本文在yolo-world基础上&#x…...

以影像为笔,劳润智在世界舞台上书写艺术之路
在光影交织中,摄影师劳润智的镜头仿佛能穿透喧嚣,捕捉人类情感最细腻的脉动。从疫情下洛杉矶裁缝日常的温馨瞬间,到象征自由与解脱的飞鸟影像,再到探索时间与空间交错的抽象作品,每一幅作品都展现了他对艺术的深度追求与对生活的温柔洞察。 劳润智的作品为他赢得了多个国际奖项…...

vue3 computed方法传参数
我们对computed的基础用法不陌生,比如前端项目中经常会遇到数据处理的情况,我们就会选择computed方法来实现。但大家在碰到某些特殊场景,比如在template模板中for循环遍历时想给自己的计算属性传参,这个该怎么实现呢,很…...

【ES】Elasticsearch字段映射冲突问题分析与解决
在使用Elasticsearch作为搜索引擎时,经常会遇到一些映射(Mapping)相关的问题。本文将深入分析字段映射冲突问题,并通过原生的Elasticsearch API请求来复现和解决这个问题。 问题描述 在实际项目中,我们遇到以下错误: Transport…...

昇腾NPU容器内 apt 换源
环境 昊算NPU云910b 问题 缺少vim等,同时无法apt安装新的依赖 解决办法 使用vi修改/etc/apt/sources.list.d/debian.sources Types: deb URIs: http://deb.debian.org/debian Suites: bookworm bookworm-updates bookworm-backports Components: main contrib…...
:索引深度解析 —— 性能优化的核心武器)
MySQL 从入门到精通(五):索引深度解析 —— 性能优化的核心武器
目录 一、索引概述:数据库的 “目录” 1.1 什么是索引? 1.2 索引的性能验证:用事实说话 实验环境准备 无索引查询耗时 有索引查询耗时 索引的 “空间换时间” 特性 二、索引的创建:三种核心方式 2.1 方式 1:C…...

spark-Join Key 的基数/rand函数
在数据处理中,Join Key 的基数 是指 Join Key 的唯一值的数量(也称为 Distinct Key Count)。它表示某个字段(即 Join Key)在数据集中有多少个不同的值。 1. Join Key 基数的意义 高基数:Join Key 的唯一值…...
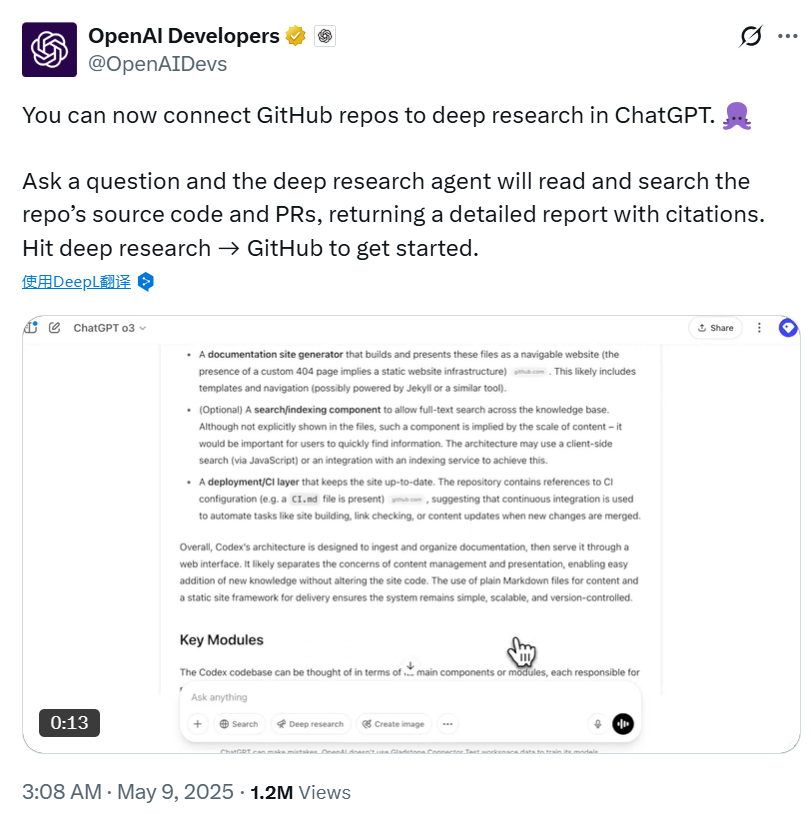
LLMs之ChatGPT:《Connecting GitHub to ChatGPT deep research》翻译与解读
LLMs之ChatGPT:《Connecting GitHub to ChatGPT deep research》翻译与解读 导读:这篇OpenAI帮助文档全面介绍了将GitHub连接到ChatGPT进行深度代码研究的方法、优势和注意事项。通过连接GitHub,用户可以充分利用ChatGPT强大的代码理解和生成…...

【桌面】【输入法】常见问题汇总
目录 一、麒麟桌面系统输入法概述 1、输入法介绍 2、输入法相关组件与服务 3、输入法调试相关命令 3.1、输入法诊断命令 3.2、输入法配置重新加载命令 3.3、启动fcitx输入法 3.4、查看输入法有哪些版本,并安装指定版本 3.5、重启输入法 3.6、查看fcitx进程…...

R语言学习--Day01--数据清洗初了解andR的经典筛选语法
当我们在拿到一份数据时,是否遇到过想要分析数据却无从下手?通过编程语言去利用它时发现有很多报错不是来源于代码而是因为数据里有很多脏数据;在这个时候,如果你会用R语言来对数据进行清洗,这会让你的效率提升很多。 …...
QT的初始代码解读及其布局和弹簧
this指的是真正的当前正在显示的窗口 main函数: Widget w是生成了一个主窗口,QT Designer是在这个主窗口里塞组件 w.show()用来展示这个主窗口 头文件: namespace Ui{class Widget;}中的class Widget和下面的class Widget不是一个东西 Ui…...

Profinet转CanOpen网关,打破协议壁垒的关键技术
在石油化工行业的生产现场,各类自动化设备如同精密运转的神经系统,而通信协议则是传递信号的"语言"。当不同厂商的设备采用Canopen与Profinet这两种主流工业协议时,就像两个使用不同方言的专家需要实时协作,此时开疆智能…...
引用第三方自定义组件——微信小程序学习笔记
1. 使用 npm 安装第三方包 1.1 下载安装Node.js 工具 下载地址:Node.js — Download Node.js 1.2 安装 npm 包 在项目空白处右键弹出菜单,选择“在外部终端窗口打开”,打开命令行工具,输入以下指令: 1> 初始化:…...

Docker、Docker-compose、K8s、Docker swarm之间的区别
1.Docker docker是一个运行于主流linux/windows系统上的应用容器引擎,通过docker中的镜像(image)可以在docker中构建一个独立的容器(container)来运行镜像对应的服务; 例如可以通过mysql镜像构建一个运行mysql的容器,既可以直接进入该容器命…...
SpringAI实现AI应用-使用redis持久化聊天记忆
SpringAI实战链接 1.SpringAl实现AI应用-快速搭建-CSDN博客 2.SpringAI实现AI应用-搭建知识库-CSDN博客 3.SpringAI实现AI应用-内置顾问-CSDN博客 4.SpringAI实现AI应用-使用redis持久化聊天记忆-CSDN博客 5.SpringAI实现AI应用-自定义顾问(Advisor)…...
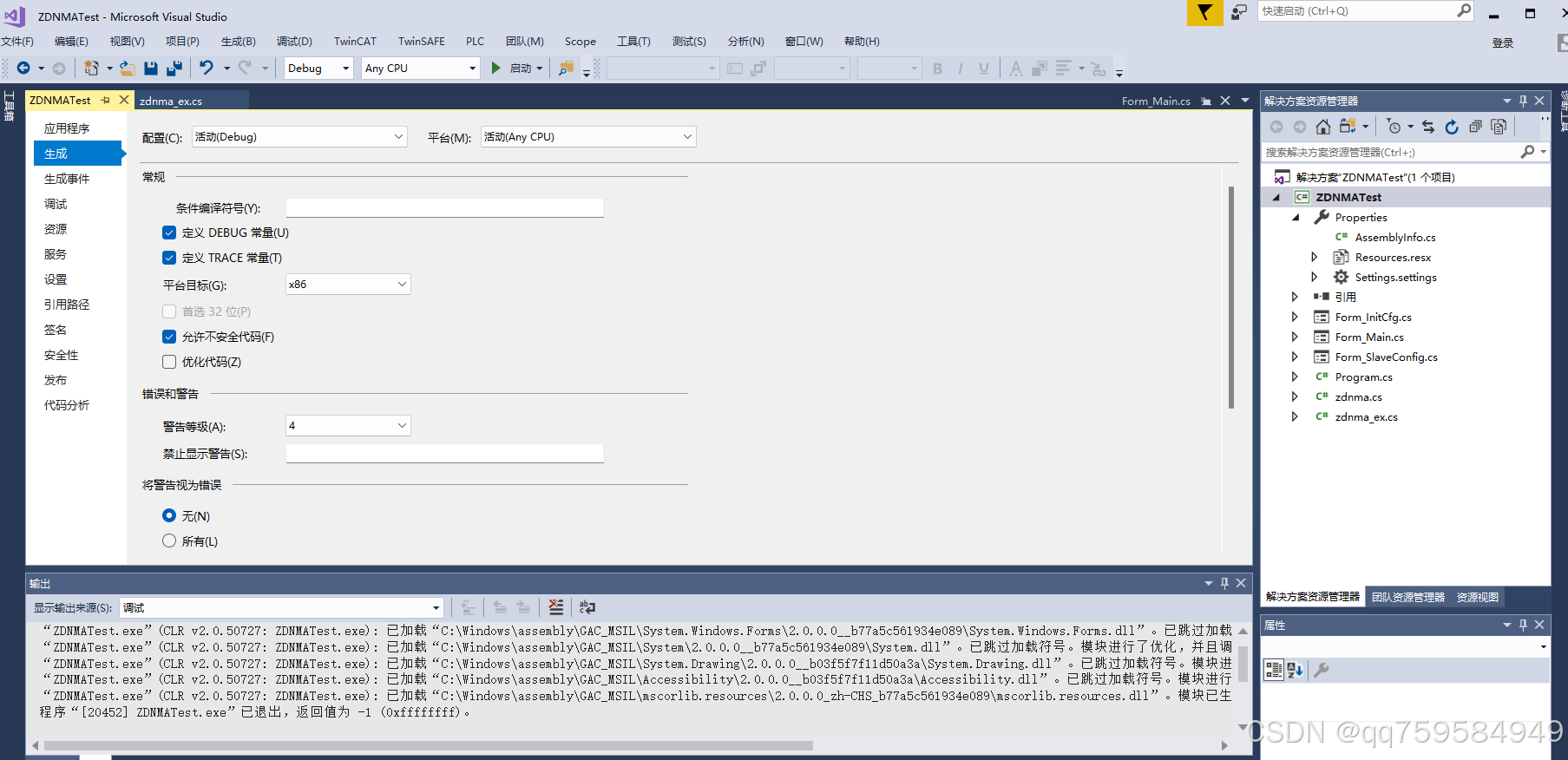
C#问题 加载格式不正确解决方法
出现上面问题 解决办法:C#问题 改成x86 不要选择anycpu...
)
VTK|结合qt创建通用按钮控制显隐(边框、坐标轴、点线面)
文章目录 增加边框BoundingBox添加addBoundingBox添加BoundingBox控制按钮点击按钮之后的槽函数 添加坐标轴增加点线面显隐控制按钮添加控制点线面显隐的按钮到三维显示界面控制面显示槽函数控制线显示槽函数控制点显示槽函数 增加边框BoundingBox 增加边框BoundingBox并通过按…...
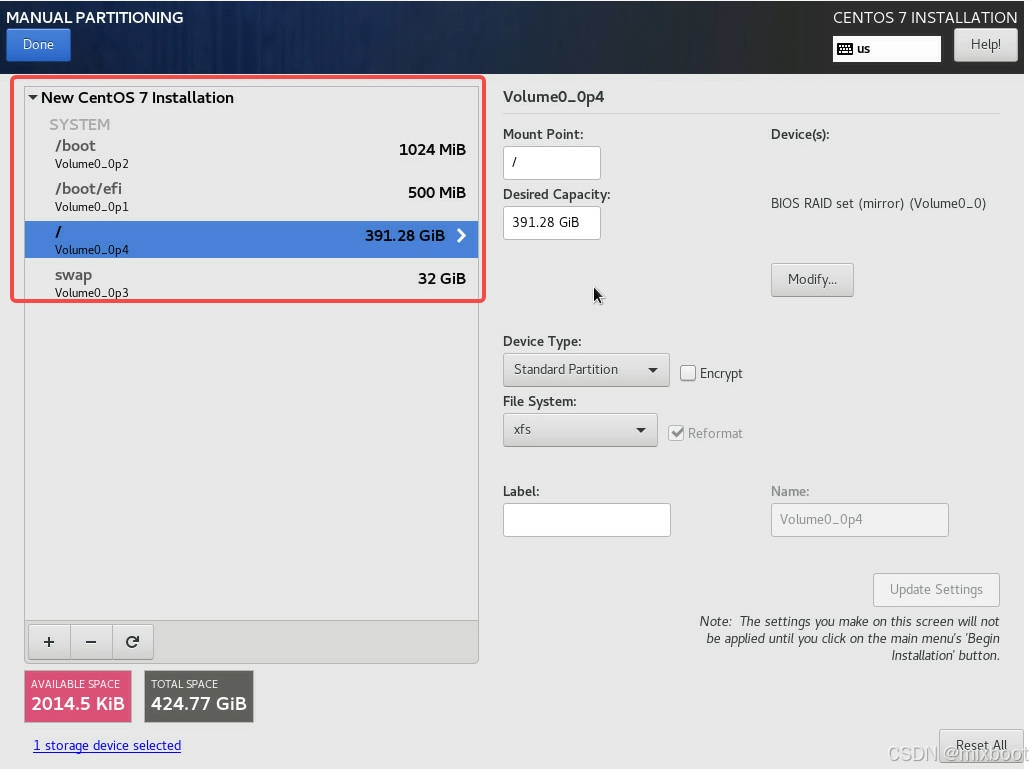
CentOS 7.9 安装详解:手动分区完全指南
CentOS 7.9 安装详解:手动分区完全指南 为什么需要手动分区?CentOS 7.9 基本分区说明1. /boot/efi 分区2. /boot 分区3. swap 交换分区4. / (根) 分区 可选分区(进阶设置)5. /home 分区6. /var 分区7. /tmp 分区 分区方案建议标准…...

在过滤器中获取body中的json数据并且使得后续的controller层也能获取使用
前景提示: ①我需要在filter中获取到json数据->对key名首字母进行排序,然后拼接,进行验签 ②所以就需要在filer获取到json的数据,因为请求数据是一次性读取的流。如果过滤器中调用了request.json或request.get_json()ÿ…...