机器学习-简要与数据集加载
一.机器学习简要
1.1 概念
机器学习即计算机在数据中总结规律并预测未来结果,这一过程仿照人类的学习过程进行。
深度学习是机器学习中的重要算法的其中之一,是一种偏近现代的算法。
1.2 机器学习发展历史
从上世纪50年代的图灵测试提出、塞缪尔开发的西洋跳棋程序,标志着机器学习正式进入发展期。
60年代中到70年代末的发展几乎停滞。
80年代使用神经网络反向传播(BP)算法训练的多参数线性规划(MLP)理念的提出将机器学习带入复兴时期。
90年代提出的“决策树”(ID3算法),再到后来的支持向量机(SVM)算法,将机器学习从知识驱动转变为数据驱动的思路。
21世纪初Hinton提出深度学习(Deep Learning),使得机器学习研究又从低迷进入蓬勃发展期。
从2012年开始,随着算力提升和海量训练样本的支持,深度学习(Deep Learning)成为机器学习研究热点,并带动了产业界的广泛应用。
1.3机器学习分类
1.3.1 监督学习
从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。(标签是训练数据中给定的答案,机器学习的目标就是预测出正确答案)
监督学习主要用于回归和分类:
回归主要用于预测连续的,具体的值(比如房价预测);
分类用于预测非连续的,离散型的数据(比如动物类别预测)。
1.3.2 半监督学习
利用少量标注数据和大量无标注数据进行学习的模式。
1.3.3 无监督学习
从未标注数据中寻找隐含结构的过程。
1.3.4 强化学习
强化学习中,有两个可交互对象:智能体(Agnet)和环境(Environment),还有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的。
这其实就类似于两个AI模型共同进行学习,一个充当环境,一个充当智能体,通过不断的交互,智能体不断学习到最佳策略,从而在环境中获得最大的收益。
1.4 机器学习应用场合
1.4.1 自然语言处理(NLP)
自然语言处理是人工智能中的重要领域之一,涉及计算机与人类自然语言的交互。NLP技术可以实现语音识别、文本分析、情感分析等任务
1.4.2 医疗诊断与影像分析
包括医疗图像分析、疾病预测、药物发现等。深度学习模型在医疗影像诊断中的表现引人注目。
1.4.3 金融风险管理
尤其是在风险管理方面。模型可以分析大量的金融数据,预测市场波动性、信用风险等。
1.4.4 预测与推荐系统
如销售预测、个性化推荐等。协同过滤和基于内容的推荐是常用的技术。
1.4.5 制造业和物联网
物联网(IoT)在制造业中的应用越来越广泛,机器学习可用于处理和分析传感器数据,实现设备预测性维护和质量控制。
1.4.6 能源管理与环境保护
机器学习可以帮助优化能源管理,减少能源浪费,提高能源利用效率。通过分析大量的能源数据,识别优化的机会。
1.4.7 决策支持与智能分析
帮助分析大量数据,辅助决策制定。基于数据的决策可以更加准确和有据可依。
1.4.8 图像识别与计算机视觉
图像识别和计算机视觉是另一个重要的机器学习应用领域,它使计算机能够理解和解释图像。深度学习模型如卷积神经网络(CNN)在图像分类、目标检测等任务中取得了突破性进展。
1.5 机器学习基本步骤
(1)收集数据:无论是来自excel,access,文本文件等的原始数据,这一步(收集过去的数据)构成了未来学习的基础。相关数据的种类,密度和数量越多,机器的学习前景就越好。
(2)准备数据(包含特征提取):任何分析过程都会依赖于使用的数据质量如何。人们需要花时间确定数据质量,然后采取措施解决诸如缺失的数据和异常值的处理等问题。探索性分析可能是一种详细研究数据细微差别的方法,从而使数据的质量迅速提高。
(3)训练模型:此步骤涉及以模型的形式选择适当的算法和数据表示。清理后的数据分为两部分 - 训练和测试(比例视前提确定)。
(4)评估模型:为了测试准确性,使用数据的第二部分(测试数据)。检查模型准确性的更好测试是查看其在模型构建期间根本未使用的数据的性能。
(5)提高性能:此步骤可能涉及选择完全不同的模型或引入更多变量来提高效率。这就是为什么需要花费大量时间进行数据收集和准备的原因。
这五个步骤将贯穿整个机器学习领域,务必记住。
二.scikit-learn工具
(1)Python语言机器学习工具
(2)Scikit-learn包括许多智能的机器学习算法的实现
(3)Scikit-learn官网:https://scikit-learn.org/stable/#
(4)Scikit-learn中文文档:https://scikitlearn.com.cn/
(5)Scikit-learn安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
三.数据集
3.1 玩具数据集
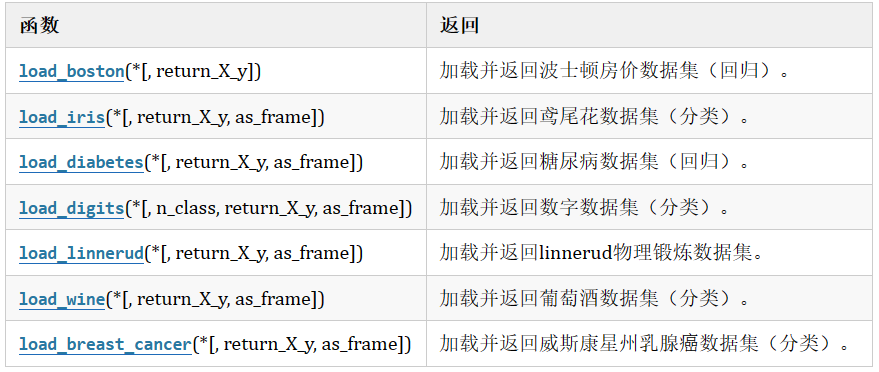
数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取。
注意:回归数据集是没有target_name即标签名属性的,因为回归的预测是一个连续值,不是分类中的0,1,2等就可以表示的东西。
3.2 现实世界数据集

数据量大,但也属于sklearn,数据只能通过网络获取。
3.3 第三方数据集
从网上找的其他数据集或者公司内部的数据集。
3.4 数据集加载
接下来看看sklearn加载数据集:
# 糖尿病数据集分析(回归)
from sklearn.datasets import load_diabetes# 加载数据集
diabetes = load_diabetes()# print(digits),这里可以看出数据集是一个字典# 查看糖尿病的特征数据集,这里提取后是一个二维数组
data = diabetes.data # 这个其实就相当于自变量x
print(data[0:5])
print(type(data))
print(data.shape)
print(data.dtype)
print(diabetes.feature_names) # 这里是特征名称[[ 0.03807591 0.05068012 0.06169621 0.02187239 -0.0442235 -0.03482076
-0.04340085 -0.00259226 0.01990749 -0.01764613]
[-0.00188202 -0.04464164 -0.05147406 -0.02632753 -0.00844872 -0.01916334
0.07441156 -0.03949338 -0.06833155 -0.09220405]
[ 0.08529891 0.05068012 0.04445121 -0.00567042 -0.04559945 -0.03419447
-0.03235593 -0.00259226 0.00286131 -0.02593034]
[-0.08906294 -0.04464164 -0.01159501 -0.03665608 0.01219057 0.02499059
-0.03603757 0.03430886 0.02268774 -0.00936191]
[ 0.00538306 -0.04464164 -0.03638469 0.02187239 0.00393485 0.01559614
0.00814208 -0.00259226 -0.03198764 -0.04664087]]
<class 'numpy.ndarray'>
(442, 10)
float64
['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
# 查看糖尿病的标签数据集,这里是一个一维数组
target = diabetes.target # 这个就相当于因变量y
print(target[0:5])
print(type(target))
print(target.shape)
print(target.dtype)[151. 75. 141. 206. 135.]
<class 'numpy.ndarray'>
(442,)
float64
由于这个数据集是回归数据集,所以是没有标签名的。
# 数字数据集分析(分类)
from sklearn.datasets import load_digits# 加载数据集
digits = load_digits()# print(digits),这里可以看出数据集是一个字典# 查看数字的特征数据集,这里提取后是一个二维数组
data = digits.data
print(data[0:5])
print(type(data))
print(data.shape)
print(data.dtype)
print(digits.feature_names) # 这里是特征名称[[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]
[ 0. 0. 0. 12. 13. 5. 0. 0. 0. 0. 0. 11. 16. 9. 0. 0. 0. 0.
3. 15. 16. 6. 0. 0. 0. 7. 15. 16. 16. 2. 0. 0. 0. 0. 1. 16.
16. 3. 0. 0. 0. 0. 1. 16. 16. 6. 0. 0. 0. 0. 1. 16. 16. 6.
0. 0. 0. 0. 0. 11. 16. 10. 0. 0.]
[ 0. 0. 0. 4. 15. 12. 0. 0. 0. 0. 3. 16. 15. 14. 0. 0. 0. 0.
8. 13. 8. 16. 0. 0. 0. 0. 1. 6. 15. 11. 0. 0. 0. 1. 8. 13.
15. 1. 0. 0. 0. 9. 16. 16. 5. 0. 0. 0. 0. 3. 13. 16. 16. 11.
5. 0. 0. 0. 0. 3. 11. 16. 9. 0.]
[ 0. 0. 7. 15. 13. 1. 0. 0. 0. 8. 13. 6. 15. 4. 0. 0. 0. 2.
1. 13. 13. 0. 0. 0. 0. 0. 2. 15. 11. 1. 0. 0. 0. 0. 0. 1.
12. 12. 1. 0. 0. 0. 0. 0. 1. 10. 8. 0. 0. 0. 8. 4. 5. 14.
9. 0. 0. 0. 7. 13. 13. 9. 0. 0.]
[ 0. 0. 0. 1. 11. 0. 0. 0. 0. 0. 0. 7. 8. 0. 0. 0. 0. 0.
1. 13. 6. 2. 2. 0. 0. 0. 7. 15. 0. 9. 8. 0. 0. 5. 16. 10.
0. 16. 6. 0. 0. 4. 15. 16. 13. 16. 1. 0. 0. 0. 0. 3. 15. 10.
0. 0. 0. 0. 0. 2. 16. 4. 0. 0.]]
<class 'numpy.ndarray'>
(1797, 64)
float64
['pixel_0_0', 'pixel_0_1', 'pixel_0_2', 'pixel_0_3', 'pixel_0_4', 'pixel_0_5', 'pixel_0_6', 'pixel_0_7', 'pixel_1_0', 'pixel_1_1', 'pixel_1_2', 'pixel_1_3', 'pixel_1_4', 'pixel_1_5', 'pixel_1_6', 'pixel_1_7', 'pixel_2_0', 'pixel_2_1', 'pixel_2_2', 'pixel_2_3', 'pixel_2_4', 'pixel_2_5', 'pixel_2_6', 'pixel_2_7', 'pixel_3_0', 'pixel_3_1', 'pixel_3_2', 'pixel_3_3', 'pixel_3_4', 'pixel_3_5', 'pixel_3_6', 'pixel_3_7', 'pixel_4_0', 'pixel_4_1', 'pixel_4_2', 'pixel_4_3', 'pixel_4_4', 'pixel_4_5', 'pixel_4_6', 'pixel_4_7', 'pixel_5_0', 'pixel_5_1', 'pixel_5_2', 'pixel_5_3', 'pixel_5_4', 'pixel_5_5', 'pixel_5_6', 'pixel_5_7', 'pixel_6_0', 'pixel_6_1', 'pixel_6_2', 'pixel_6_3', 'pixel_6_4', 'pixel_6_5', 'pixel_6_6', 'pixel_6_7', 'pixel_7_0', 'pixel_7_1', 'pixel_7_2', 'pixel_7_3', 'pixel_7_4', 'pixel_7_5', 'pixel_7_6', 'pixel_7_7']
# 查看数字的标签数据集,这里是一个一维数组
target = digits.target
print(target[0:5])
print(type(target))
print(target.shape)
print(target.dtype)
print(digits.target_names) # 这里是标签名称[0 1 2 3 4]
<class 'numpy.ndarray'>
(1797,)
int64
[0 1 2 3 4 5 6 7 8 9]
然后是自己的或者第三方数据集:
# 要先导入pandas进行csv读取
import pandas as pd# 读取csv文件
data = pd.read_csv('../datasets/example.csv')
print(data)
name age grade
0 clocky7 18 30
1 jimmy12 17 25
# 读取excel文件
data1 = pd.read_excel('../datasets/example.xlsx')
print(data1)name age grade
0 clocky7 18 30
1 miko 19 40
这里读取excel文件需要下载openpyxl,即
pip install openpyxl
相关文章:
机器学习-简要与数据集加载
一.机器学习简要 1.1 概念 机器学习即计算机在数据中总结规律并预测未来结果,这一过程仿照人类的学习过程进行。 深度学习是机器学习中的重要算法的其中之一,是一种偏近现代的算法。 1.2 机器学习发展历史 从上世纪50年代的图灵测试提出、塞缪尔开发…...
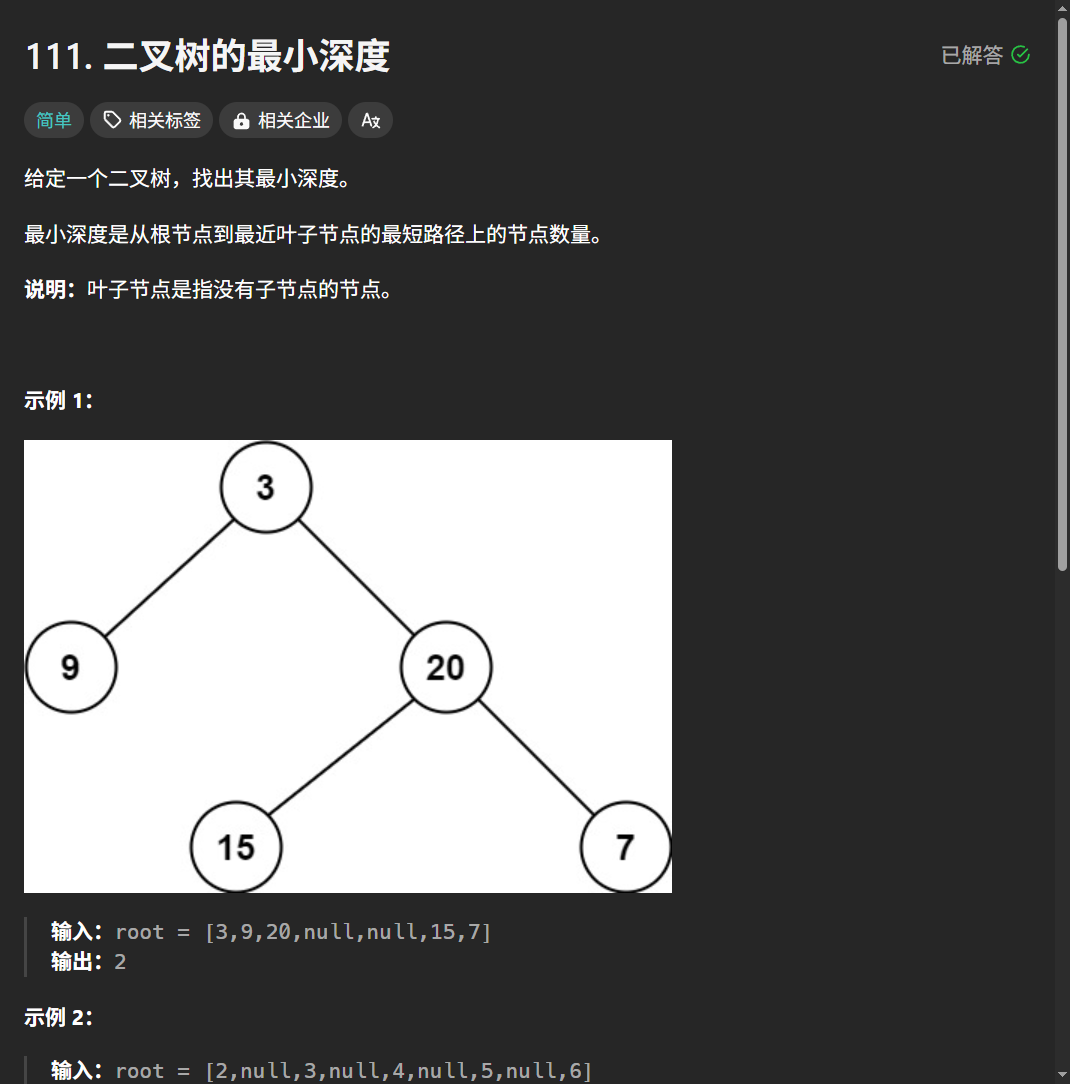
算法训练营第十三天|226.翻转二叉树、101. 对称二叉树、 104.二叉树的最大深度、111.二叉树的最小深度
递归 递归三部曲: 1.确定参数和返回值2.确定终止条件3.确定单层逻辑 226.翻转二叉树 题目 思路与解法 第一想法: 递归,对每个结点进行反转 # Definition for a binary tree node. # class TreeNode: # def __init__(self, val0, le…...
二叉树的遍历与构造
好想回家,我想回家跟馒头酱玩,想老爸老妈。如果上天再给我一次选择的机会,我会选择当一只小动物,或者当棵大树也好,或者我希望自己不要有那么多多余的情绪,不要太被别人影响,开心点,…...

Python+OpenCV实现手势识别与动作捕捉:技术解析与应用探索
引言:人机交互的新维度 在人工智能与计算机视觉技术飞速发展的今天,手势识别与动作捕捉技术正逐步从实验室走向大众生活。通过Python的OpenCV库及MediaPipe等工具,开发者能够以较低门槛实现精准的手部动作识别,为虚拟现实、智能家…...
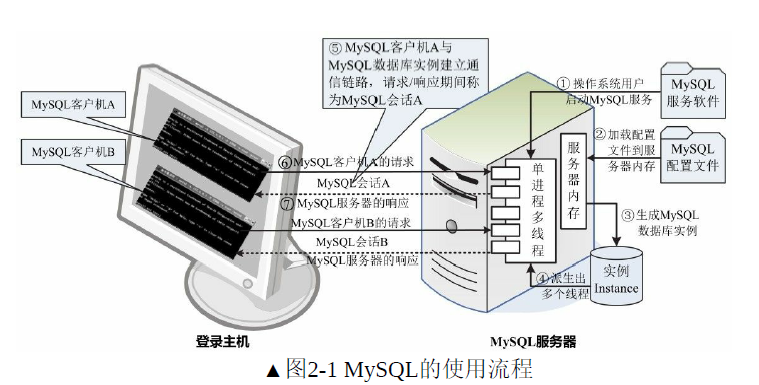
MYSQL服务的使用流程
MYSQL是一个单进程多线程,支持多用户,基于客户机/服务器的关系数据库管理系统。与其他数据库管理系统相比,MYSQL具有体积小,易于安装,运行速度快,功能齐全,成本低廉以及开源等特点。MYSQL可运行…...

华为云API、SDK是什么意思?有什么区别和联系?
目录 一、API:像菜单 + 打电话点餐 📌 本质解释: 🔧 操作方式(偏底层): 🍱 类比举例: 二、SDK:像外卖App(美团/饿了么)自动点餐 📌 本质解释: 🔧 操作方式(偏上层): 🍱 类比举例: 三、联系:SDK 是对 API 的“封装与简化” 四、操作实例对…...
【java】使用iText实现pdf文件增加水印功能
maven依赖 <dependencies><dependency><groupId>com.itextpdf</groupId><artifactId>itext7-core</artifactId><version>7.2.5</version><type>pom</type></dependency> </dependencies>实现代码 前…...

Python爬虫实战:获取艺恩娱数最新电影舆情数据并分析,为影院排片做参考
一、引言 在电影行业蓬勃发展的当下,了解影片的各项指数对于票房宣发排片起着至关重要的作用。艺恩娱数网站作为电影行业重要的数据平台,提供了丰富且有价值的电影相关数据。然而,直接从该网站获取数据面临诸多挑战。Python 作为一种功能强大、应用广泛的编程语言,拥有众多…...

Linux指令入门:DevOps与SRE视角
文章目录 Linux指令入门:DevOps与SRE视角一、Linux基础命令概述二、文件系统操作命令1. 文件与目录基本操作2. 文件查看与编辑3. 文件压缩与归档 三、进程管理命令1. 进程查看与控制2. 服务管理(Systemd) 四、网络管理命令1. 网络连接与诊断2…...
socket套接字-TCP
上一篇:socket套接字-UDP(下)https://blog.csdn.net/Small_entreprene/article/details/147569071?fromshareblogdetail&sharetypeblogdetail&sharerId147569071&sharereferPC&sharesourceSmall_entreprene&sharefromfr…...

Ctrl + D是如何与内核文件结束符对应的?如何模拟文件结束符?数字中间为什么不能插入空格或逗号?丰富多彩的语句结束符或分隔符?语句结束符?
目录 Ctrl D是如何与内核文件结束符对应的? 如何模拟文件结束符? 哪些编程语言支持数值中插入分隔符更容易看清楚? 下划线分隔符 数字中间为什么不能插入空格或逗号? 丰富多彩的语句结束符或分隔符 误用分号 语句结束符 不同语言的结束符 更改语句结束符 Ctrl …...
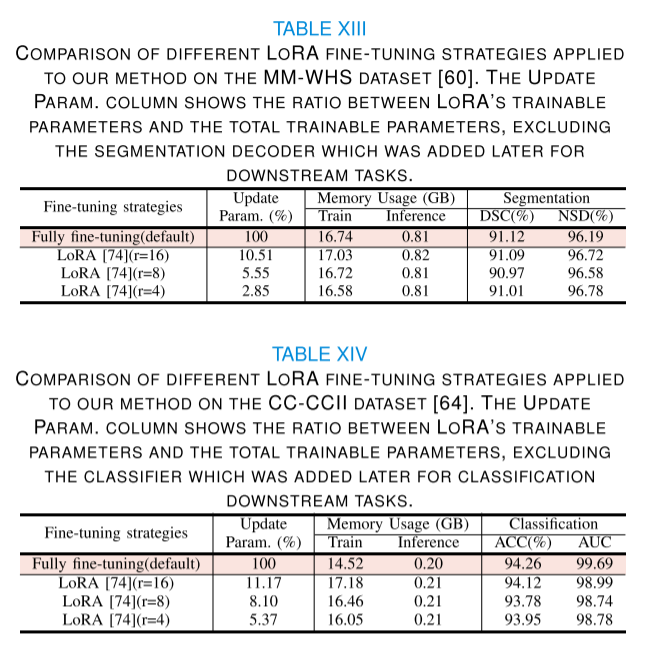
MiM: Mask in Mask Self-SupervisedPre-Training for 3D Medical Image Analysis
Abstract Vision Transformer在3D医学图像分析的自监督学习(Self-Supervised Learning,SSL)中展现了卓越的性能。掩码自编码器(Masked Auto-Encoder,MAE)用于特征预训练,可以进一步释放ViT在各…...
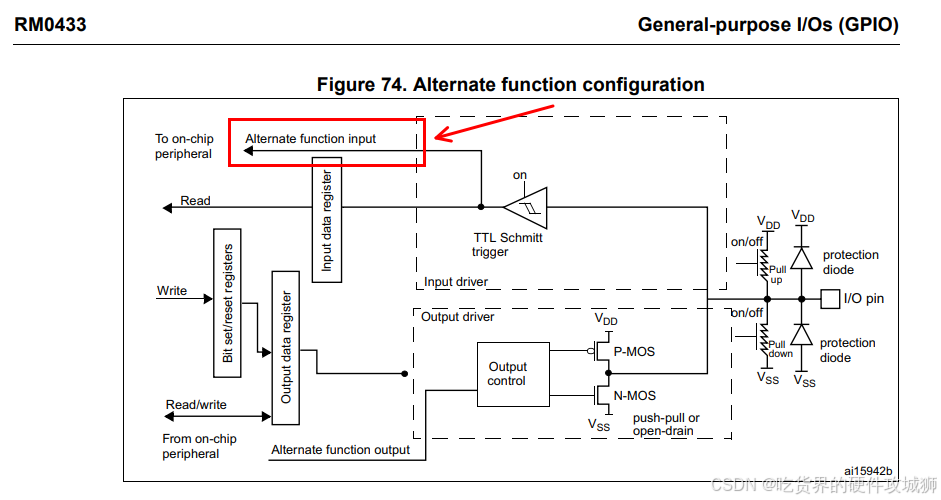
【STM32 学习笔记】I2C通信协议
注:通信协议的设计背景 3:00~10:13 I2C 通讯协议(Inter-Integrated Circuit)是由Phiilps公司开发的,由于它引脚少,硬件实现简单,可扩展性强, 不需要USART、CAN等通讯协议的外部收发设备,现在被广…...

【java】jdk8及以后的时间类总结
目录 1. LocalDate 2. LocalTime 4. ZonedDateTime 5. Duration 6. Period 7. DateTimeFormatter 1. LocalDate 说明:表示不带时区的日期(年、月、日),不可变且线程安全。 import java.time.LocalDate;public class Local…...

深入理解 Istio 的工作原理 v1.26.0
解读最新版本的 Istio 源码确实是一项庞大的工程,但我可以为你梳理出一个清晰的脉络,并指出关键模块和代码路径,帮助你深入理解 Istio 的工作原理。 我们主要关注 Istio 的核心组件 Istiod 和数据平面的 Envoy Proxy。 前提: Go…...

深入理解卷积神经网络的输入层:数据的起点与预处理核心
内容摘要 本文围绕卷积神经网络输入层展开,详细介绍其在网络中的重要作用,包括接收不同领域数据的形式及传递数据的过程。深入解读数据预处理的关键操作,如去均值、归一化和PCA/白化。助力读者透彻理解输入层,为构建高效卷积神经…...
redis bitmap数据类型调研
一、bitmap是什么? redis原文: Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type . This means that bitmaps can be used with string commands, and most importantly with SET and GET. 翻…...

如何用数学思想填报高考志愿
人一辈子有很多四年,但是很少有哪个四年对你一生的影响能超过大学这四年。 从18岁到22岁的这几年,是一个人真正成年的过程,很多人会在这段时间里认识一生的朋友,谈第一次真正的恋爱,第一次离开父母,自己生…...
LabVIEW 2019 与 NI VISA 20.0 安装及报错处理
在使用 Windows 11 操作系统的电脑上,同时安装了 LabVIEW 2019 32 位和 64 位版本的软件。此前安装的 NI VISA 2024 Q1 版,该版本与 LabVIEW 2019 32 位和 64 位不兼容,之后重新安装了 NI VISA 20.0。从说明书来看,NI VISA 20.0 …...
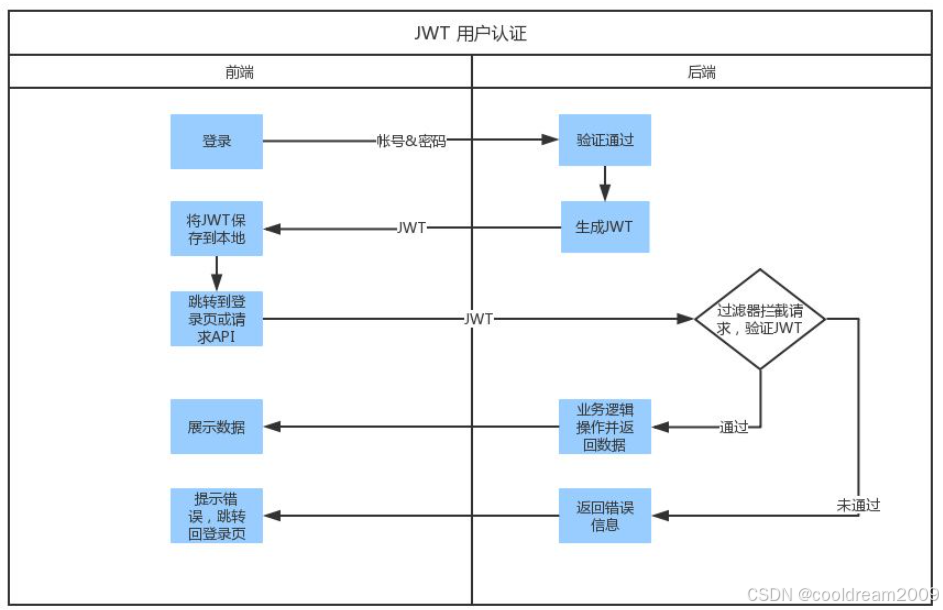
探索 JWT(JSON Web Token):原理、结构与实践应用对比
目录 前言1. 什么是 JWT?2. JWT 的组成结构详解2.1 Header(头部)2.2 Payload(负载)2.3 Signature(签名) 3. JWT 的实际作用3.1 身份认证3.2 信息传递与授权 4. JWT 与 Cookie、API Key 的比较4.…...

互联网大厂Java求职面试:云原生与AI融合下的系统设计挑战-1
互联网大厂Java求职面试:云原生与AI融合下的系统设计挑战-1 在当今云计算和人工智能迅猛发展的背景下,互联网大厂对Java工程师的要求已从传统的单体架构和业务逻辑处理,转向了更复杂的云原生架构设计、AI模型集成以及高并发系统的性能优化能…...

【Redis进阶】持久化
一、MySQL事务特性及Redis持久化需求 (一)MySQL事务特性 MySQL的事务具有四大核心特性,这些特性对于保证数据库操作的准确性和可靠性至关重要。 原子性:事务中的所有操作要么全部成功,要么全部失败…...

[docker基础一]docker简介
目录 一 消除恐惧 1) 什么是虚拟化,容器化 2)案例 3)为什么需要虚拟化,容器化 二 虚拟化实现方式 1)应用程序执行环境分层 2)虚拟化常见类别 3)常见虚拟化实现 一)主机虚拟化(虚拟机)实现 二)容器虚拟化实现 一 消除恐…...
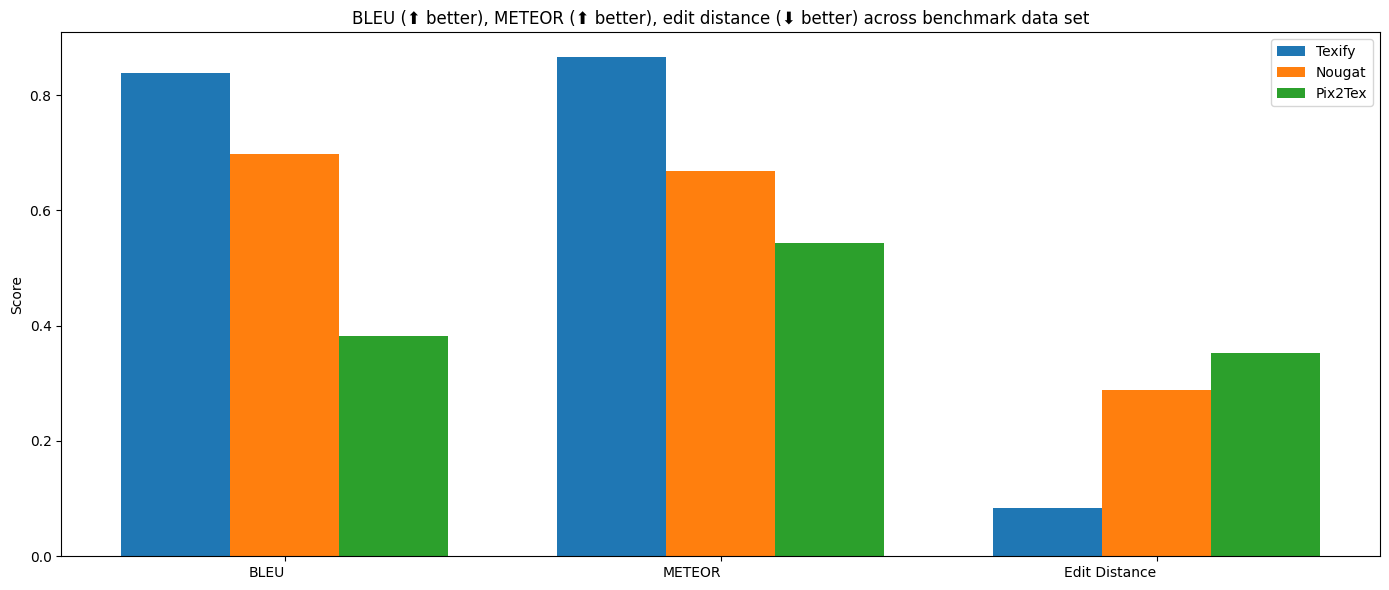
Texify - 数学公式OCR转换工具
文章目录 一、项目概览相关资源核心特性 二、安装指南三、使用示例1、命令行转换2、Python API调用3、交互式应用 四、性能基准运行你自己的基准测试 五、局限性 一、项目概览 Texify 是一个OCR模型,可将包含数学公式的图片或PDF转换为Markdown和LaTeX格式…...
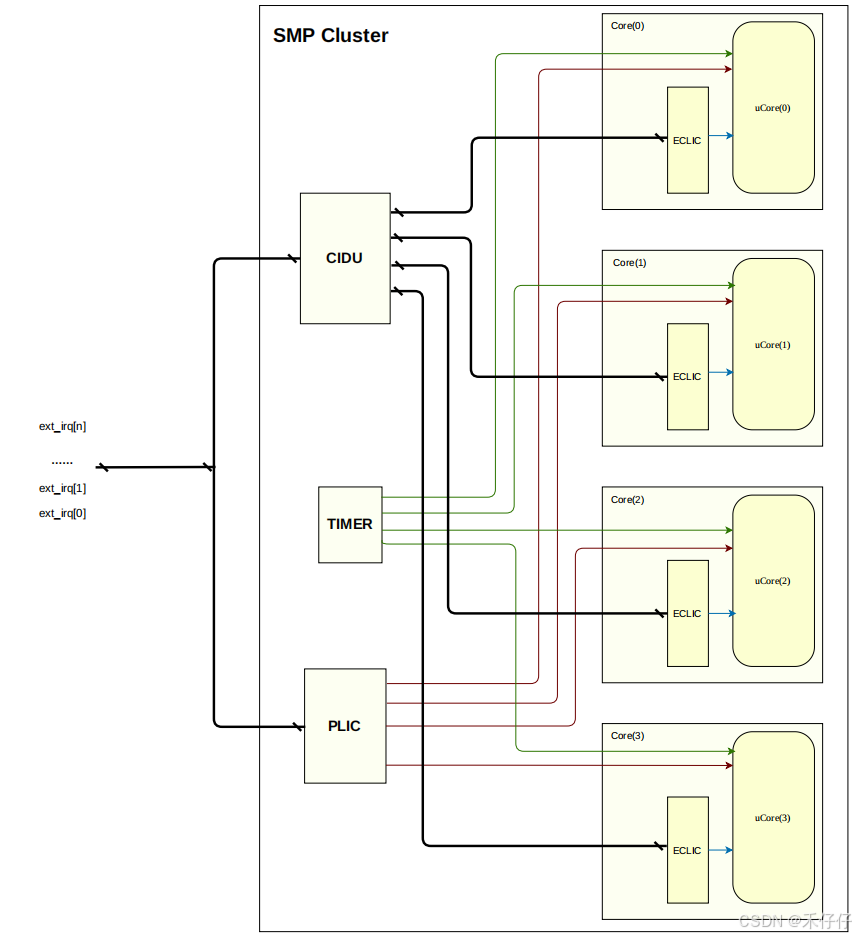
RISC-V CLINT、PLIC及芯来ECLIC中断机制分析 —— RISC-V中断机制(一)
在长期的嵌入式开发实践中,对中断机制的理解始终停留在表面层次,特别当开发者长期局限于纯软件抽象层面时,对中断机制的理解极易陷入"知其然而不知其所以然"的困境,这种认知的局限更为明显;随着工作需要不断…...

时钟晶振锁相环pll方向技术要点和大厂题目解析
本专栏预计更新60期左右。当前第9期。 本专栏不仅适用于硬件的笔试面试,同样也适用于梳理硬件核心的知识点。 通过本文能得到什么? 首先,根据实战经验总结时钟晶振,锁相环的主要知识点,技术要点,面试考点; 然后,列出时钟晶振,锁相环的笔试面试的主要题型真题和模拟题,…...

图像处理篇--- HTTP|RTSP|MJPEG视频流格式
文章目录 前言一、MJPEG (Motion JPEG)基本概念技术特点编码方式传输协议数据格式 优势实现简单低延迟兼容性好容错性强 劣势带宽效率低不支持音频缺乏标准控制 典型应用 二、RTSP (Real Time Streaming Protocol)基本概念技术特点协议栈工作流程传输模式 优势专业流媒体支持高…...

【Harbor v2.13.0 详细安装步骤 安装证书启用 HTTPS】
Harbor v2.13.0 详细安装步骤(启用 HTTPS) 1. 环境准备 系统要求:至少 4GB 内存,100GB 磁盘空间。 已安装组件: Docker(版本 ≥ 20.10)Docker Compose(版本 ≥ v2.0) 域…...

C++中的static_cast:类型转换的安全卫士
C中的static_cast:类型转换的安全卫士 在C编程中,类型转换是不可避免的操作,而static_cast作为C四大强制类型转换运算符之一,是最常用且相对安全的一种转换方式。今天我们就来深入探讨一下这个重要的类型转换工具。 一、static_…...

开源与商业:图形化编程工具的博弈与共生
一、开源生态的破局之路:从技术实验到行业标准 在 2025 年全球开发者生态大会上,iVX 凭借 “全栈代码生成 AI 驱动开发” 的技术架构,被行业权威机构评选为 “年度技术创新典范”。作为 2012 年启动的开源项目,iVX 历经 17 年技…...