大模型项目:普通蓝牙音响接入DeepSeek,解锁语音交互新玩法
本文附带视频讲解
【代码宇宙019】技术方案:蓝牙音响接入DeepSeek,解锁语音交互新玩法_哔哩哔哩_bilibili
目录
效果演示
核心逻辑
技术实现
大模型对话(技术: LangChain4j 接入 DeepSeek)
语音识别(技术:阿里云-实时语音识别)
语音生成(技术:阿里云-语音生成)
效果演示
核心逻辑
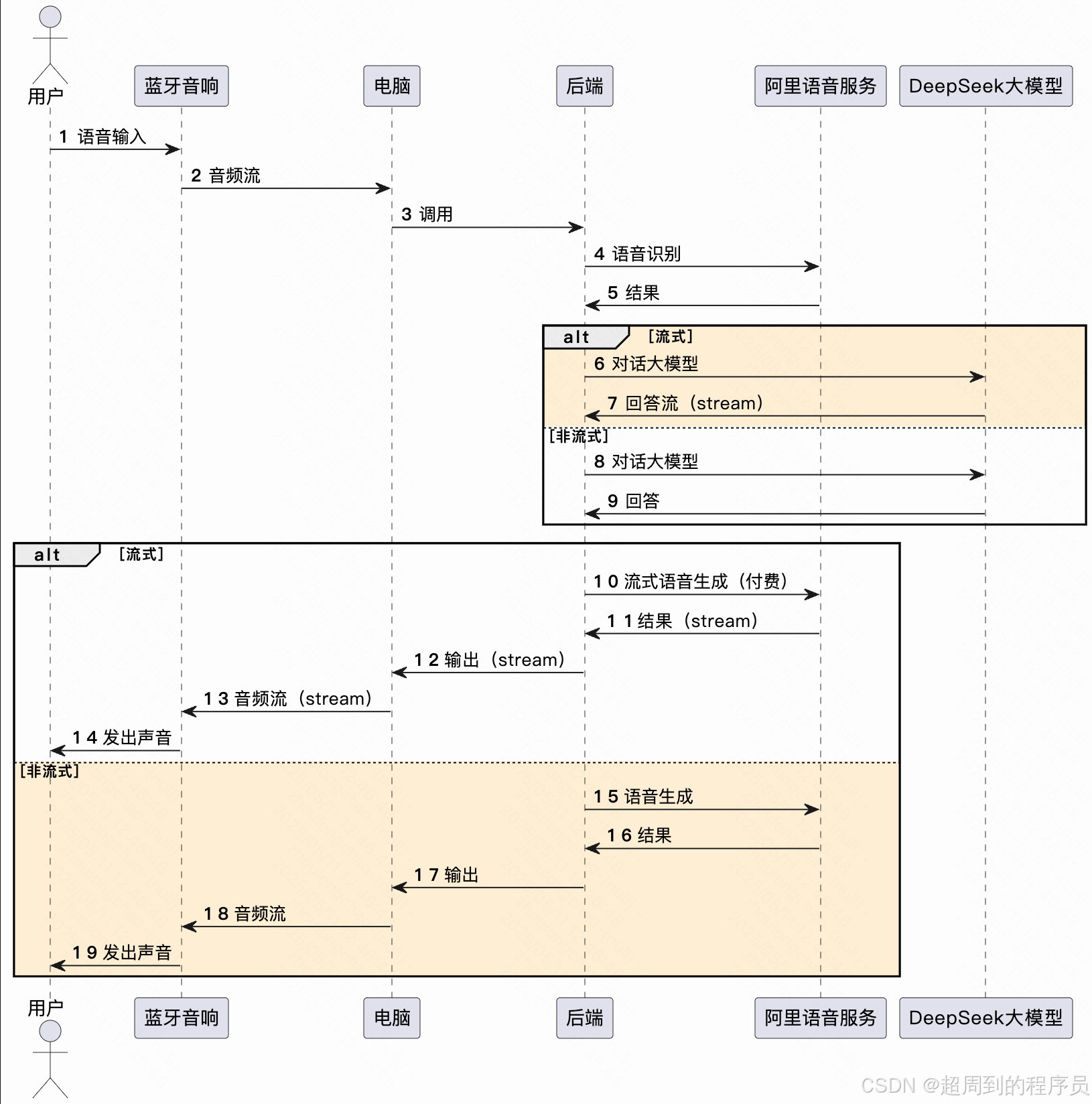
技术实现
大模型对话(技术: LangChain4j 接入 DeepSeek)
常用依赖都在这里(不是最简),DeepSeek 目前没有单独的依赖,用 open-ai 协议的依赖可以兼容,官网这里有说明:OpenAI Official SDK | LangChain4j

<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-open-ai</artifactId><version>1.0.0-beta3</version>
</dependency>
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j</artifactId><version>1.0.0-beta3</version>
</dependency>
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-spring-boot-starter</artifactId><version>1.0.0-beta3</version>
</dependency>请求 ds 的核心类
package ai.voice.assistant.client;/*** @Author:超周到的程序员* @Date:2025/4/25*/import ai.voice.assistant.config.DaemonProcess;
import ai.voice.assistant.service.llm.BaseChatClient;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.SystemMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.response.ChatResponse;
import dev.langchain4j.model.chat.response.StreamingChatResponseHandler;
import dev.langchain4j.model.openai.OpenAiStreamingChatModel;import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;import com.alibaba.fastjson.JSON;@Component("deepSeekStreamClient")
public class DeepSeekStreamClient implements BaseChatClient {private static final Logger LOGGER = LogManager.getLogger(DeepSeekStreamClient.class);@Value("${certificate.llm.deepseek.key}")private String key;@Overridepublic String chat(String question) {if (question.isBlank()) {return "";}OpenAiStreamingChatModel model = OpenAiStreamingChatModel.builder().baseUrl("https://api.deepseek.com").apiKey(key).modelName("deepseek-chat").build();List<ChatMessage> messages = new ArrayList<>();messages.add(SystemMessage.from(prompt));messages.add(UserMessage.from(question));CountDownLatch countDownLatch = new CountDownLatch(1);StringBuilder answerBuilder = new StringBuilder();model.chat(messages, new StreamingChatResponseHandler() {@Overridepublic void onPartialResponse(String answerSplice) {// 语音生成(流式)// voiceGenerateStreamService.process(new String[] {answerSplice});
// System.out.println("== answerSplice: " + answerSplice);answerBuilder.append(answerSplice);}@Overridepublic void onCompleteResponse(ChatResponse chatResponse) {countDownLatch.countDown();}@Overridepublic void onError(Throwable throwable) {LOGGER.error("chat ds error, messages:{} err:", JSON.toJSON(messages), throwable);}});try {countDownLatch.await();} catch (InterruptedException e) {throw new RuntimeException(e);}String answer = answerBuilder.toString();LOGGER.info("chat ds end, answer:{}", answer);return answer;}
}语音识别(技术:阿里云-实时语音识别)
开发参考_智能语音交互(ISI)-阿里云帮助中心
开发日志记录——
这里在我的场景下遇到了会话断连的问题:
- 问题场景:阿里的实时语音识别,第一次对话后 10s 如果不说话那么会断开连接(阿里侧避免过多无用连接占用),本次做的蓝牙音响诉求是让他一直保活不断开,有需要就和它对话并且不想要唤醒词
- 解决方式:因此这里用了 catch 断连异常后再次执行监听方法的方式来兼容这个问题,其实也可以定时发送一个空包过去,但是那样不确定会不会额外增加费用,另外也要处理同时发送空包和人进行语音对话的问题,最终生成的音频文件播放哪个的顺序问题
<dependency><groupId>com.alibaba.nls</groupId><artifactId>nls-sdk-tts</artifactId><version>${ali-vioce-sdk.version}</version>
</dependency>
<dependency><groupId>com.alibaba.nls</groupId><artifactId>nls-sdk-transcriber</artifactId><version>${ali-vioce-sdk.version}</version>
</dependency>package ai.voice.assistant.service.voice;import ai.voice.assistant.config.VoiceConfig;
import ai.voice.assistant.service.llm.BaseChatClient;
import ai.voice.assistant.util.WavPlayerUtil;
import com.alibaba.nls.client.protocol.Constant;
import com.alibaba.nls.client.protocol.InputFormatEnum;
import com.alibaba.nls.client.protocol.NlsClient;
import com.alibaba.nls.client.protocol.SampleRateEnum;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriber;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriberListener;
import com.alibaba.nls.client.protocol.asr.SpeechTranscriberResponse;
import jakarta.annotation.PreDestroy;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;import javax.sound.sampled.AudioFormat;
import javax.sound.sampled.AudioSystem;
import javax.sound.sampled.DataLine;
import javax.sound.sampled.TargetDataLine;/*** @Author:超周到的程序员* @Date:2025/4/23 此示例演示了从麦克风采集语音并实时识别的过程* (仅作演示,需用户根据实际情况实现)*/
@Service
public class VoiceRecognitionService {private static final Logger LOGGER = LoggerFactory.getLogger(VoiceRecognitionService.class);@Autowiredprivate NlsClient client;@Autowiredprivate VoiceConfig voiceConfig;@Autowiredprivate VoiceGenerateService voiceGenerateService;@Autowired
// @Qualifier("deepSeekStreamClient")@Qualifier("deepSeekMemoryClient")private BaseChatClient chatClient;public SpeechTranscriberListener getTranscriberListener() {SpeechTranscriberListener listener = new SpeechTranscriberListener() {//识别出中间结果.服务端识别出一个字或词时会返回此消息.仅当setEnableIntermediateResult(true)时,才会有此类消息返回@Overridepublic void onTranscriptionResultChange(SpeechTranscriberResponse response) {// 重要提示: task_id很重要,是调用方和服务端通信的唯一ID标识,当遇到问题时,需要提供此task_id以便排查LOGGER.info("name: {}, status: {}, index: {}, result: {}, time: {}",response.getName(),response.getStatus(),response.getTransSentenceIndex(),response.getTransSentenceText(),response.getTransSentenceTime());}@Overridepublic void onTranscriberStart(SpeechTranscriberResponse response) {LOGGER.info("task_id: {}, name: {}, status: {}",response.getTaskId(),response.getName(),response.getStatus());}@Overridepublic void onSentenceBegin(SpeechTranscriberResponse response) {LOGGER.info("task_id: {}, name: {}, status: {}",response.getTaskId(),response.getName(),response.getStatus());}//识别出一句话.服务端会智能断句,当识别到一句话结束时会返回此消息@Overridepublic void onSentenceEnd(SpeechTranscriberResponse response) {LOGGER.info("name: {}, status: {}, index: {}, result: {}, confidence: {}, begin_time: {}, time: {}",response.getName(),response.getStatus(),response.getTransSentenceIndex(),response.getTransSentenceText(),response.getConfidence(),response.getSentenceBeginTime(),response.getTransSentenceTime());if (response.getName().equals(Constant.VALUE_NAME_ASR_SENTENCE_END)) {if (response.getStatus() == 20000000) {// 识别完一句话,调用大模型String answer = chatClient.chat(response.getTransSentenceText());voiceGenerateService.process(answer);WavPlayerUtil.playWavFile("/Users/zhoulongchao/Desktop/file_code/project/p_me/ai-voice-assistant/tts_test.wav");}}}//识别完毕@Overridepublic void onTranscriptionComplete(SpeechTranscriberResponse response) {LOGGER.info("task_id: {}, name: {}, status: {}",response.getTaskId(),response.getName(),response.getStatus());}@Overridepublic void onFail(SpeechTranscriberResponse response) {// 重要提示: task_id很重要,是调用方和服务端通信的唯一ID标识,当遇到问题时,需要提供此task_id以便排查LOGGER.info("语音识别 task_id: {}, status: {}, status_text: {}",response.getTaskId(),response.getStatus(),response.getStatusText());}};return listener;}public void process() {SpeechTranscriber transcriber = null;try {// 创建实例,建立连接transcriber = new SpeechTranscriber(client, getTranscriberListener());transcriber.setAppKey(voiceConfig.getAppKey());// 输入音频编码方式transcriber.setFormat(InputFormatEnum.PCM);// 输入音频采样率transcriber.setSampleRate(SampleRateEnum.SAMPLE_RATE_16K);// 是否返回中间识别结果transcriber.setEnableIntermediateResult(true);// 是否生成并返回标点符号transcriber.setEnablePunctuation(true);// 是否将返回结果规整化,比如将一百返回为100transcriber.setEnableITN(false);//此方法将以上参数设置序列化为json发送给服务端,并等待服务端确认transcriber.start();AudioFormat audioFormat = new AudioFormat(16000.0F, 16, 1, true, false);DataLine.Info info = new DataLine.Info(TargetDataLine.class, audioFormat);TargetDataLine targetDataLine = (TargetDataLine) AudioSystem.getLine(info);targetDataLine.open(audioFormat);targetDataLine.start();System.out.println("You can speak now!");int nByte = 0;final int bufSize = 3200;byte[] buffer = new byte[bufSize];while ((nByte = targetDataLine.read(buffer, 0, bufSize)) > 0) {// 直接发送麦克风数据流transcriber.send(buffer, nByte);}transcriber.stop();} catch (Exception e) {LOGGER.info("语音识别 error: {}", e.getMessage());// 临时兼容,用于保持连接在逻辑上不断开,否则默认10s不说话会自动断连process();} finally {if (null != transcriber) {transcriber.close();}}}@PreDestroypublic void shutdown() {client.shutdown();}
}语音生成(技术:阿里云-语音生成)
开发参考_智能语音交互(ISI)-阿里云帮助中心
开发日志记录——
- 非线程安全:在调用完阿里的语音生成能力后,得到了音频文件,和播放打通的方法是建立一个临时文件,生成和播放都路由到这个文件,因为这个项目只是个人方便分阶段单元测试用可以这么写,如果有多个客户端,那么这种方式就不是线程安全的
- 回答延迟:这里我是使用的普通版的语音合成能力,初次接入支持免费体验 3 个月,其实可以使用流式语音合成能力,是另一个 sdk,具体可见文档:流式文本语音合成使用说明_智能语音交互(ISI)-阿里云帮助中心 因为目前流式语音合成能力需要付费,因此没有接入流式,因此每次需要收集完 ds 大模型的回答流之后才可以进行语音生成,会有 8s 延迟
官网有 100 多种音色可以选:
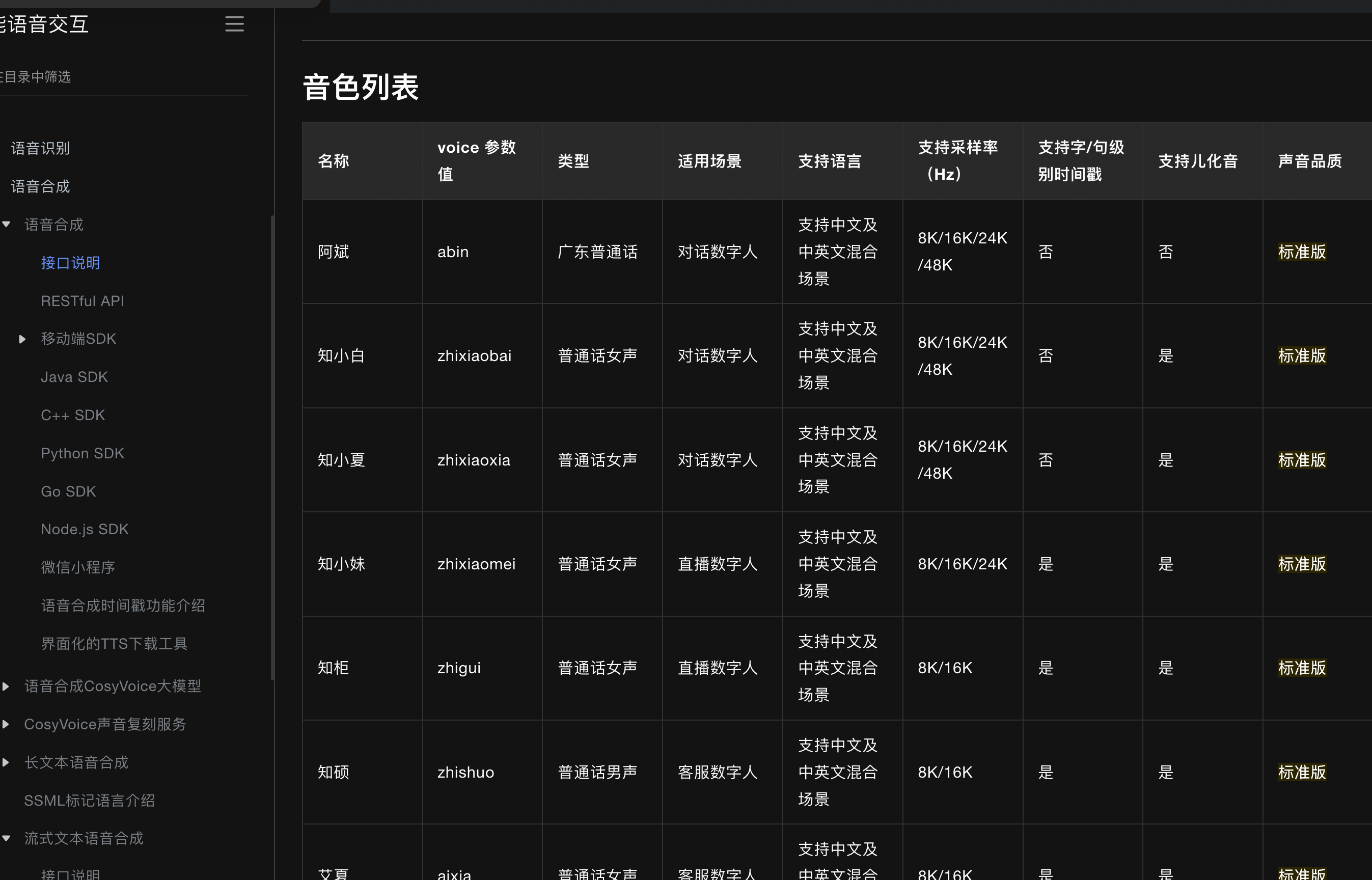
<dependency><groupId>com.alibaba.nls</groupId><artifactId>nls-sdk-tts</artifactId><version>${ali-vioce-sdk.version}</version>
</dependency>
<dependency><groupId>com.alibaba.nls</groupId><artifactId>nls-sdk-transcriber</artifactId><version>${ali-vioce-sdk.version}</version>
</dependency>package ai.voice.assistant.service.voice;import ai.voice.assistant.config.VoiceConfig;
import com.alibaba.nls.client.protocol.NlsClient;
import com.alibaba.nls.client.protocol.OutputFormatEnum;
import com.alibaba.nls.client.protocol.SampleRateEnum;
import com.alibaba.nls.client.protocol.tts.;
import com.alibaba.nls.client.protocol.tts.SpeechSynthesizerListener;
import com.alibaba.nls.client.protocol.tts.SpeechSynthesizerResponse;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.util.concurrent.ScheduledExecutorService;/*** @Author:超周到的程序员* @Date:2025/4/23* 语音合成API调用* 流式合成TTS* 首包延迟计算*/
@Service
public class VoiceGenerateService {private static final Logger LOGGER = LoggerFactory.getLogger(VoiceGenerateService.class);private static long startTime;@Autowiredprivate VoiceConfig voiceConfig;@Autowiredprivate NlsClient client;private static SpeechSynthesizerListener getSynthesizerListener() {SpeechSynthesizerListener listener = null;try {listener = new SpeechSynthesizerListener() {File f = new File("tts_test.wav");FileOutputStream fout = new FileOutputStream(f);private boolean firstRecvBinary = true;//语音合成结束@Overridepublic void onComplete(SpeechSynthesizerResponse response) {// TODO 当onComplete时表示所有TTS数据已经接收完成,因此这个是整个合成延迟,该延迟可能较大,未必满足实时场景LOGGER.info("name:{} status:{} outputFile:{}", response.getStatus(), f.getAbsolutePath(), response.getName());}//语音合成的语音二进制数据@Overridepublic void onMessage(ByteBuffer message) {try {if (firstRecvBinary) {// TODO 此处是计算首包语音流的延迟,收到第一包语音流时,即可以进行语音播放,以提升响应速度(特别是实时交互场景下)firstRecvBinary = false;long now = System.currentTimeMillis();LOGGER.info("tts first latency : " + (now - VoiceGenerateService.startTime) + " ms");}byte[] bytesArray = new byte[message.remaining()];message.get(bytesArray, 0, bytesArray.length);fout.write(bytesArray);} catch (IOException e) {e.printStackTrace();}}@Overridepublic void onFail(SpeechSynthesizerResponse response) {// TODO 重要提示: task_id很重要,是调用方和服务端通信的唯一ID标识,当遇到问题时,需要提供此task_id以便排查LOGGER.info("语音合成 task_id: {}, status: {}, status_text: {}",response.getTaskId(),response.getStatus(),response.getStatusText());}@Overridepublic void onMetaInfo(SpeechSynthesizerResponse response) {
// System.out.println("MetaInfo event:{}" + response.getTaskId());}};} catch (Exception e) {e.printStackTrace();}return listener;}public void process(String text) {SpeechSynthesizer synthesizer = null;try {//创建实例,建立连接synthesizer = new SpeechSynthesizer(client, getSynthesizerListener());synthesizer.setAppKey(voiceConfig.getAppKey());//设置返回音频的编码格式synthesizer.setFormat(OutputFormatEnum.WAV);//设置返回音频的采样率synthesizer.setSampleRate(SampleRateEnum.SAMPLE_RATE_16K);//发音人synthesizer.setVoice("jielidou");//语调,范围是-500~500,可选,默认是0synthesizer.setPitchRate(50);//语速,范围是-500~500,默认是0synthesizer.setSpeechRate(30);//设置用于语音合成的文本synthesizer.setText(text);synthesizer.addCustomedParam("enable_subtitle", true);//此方法将以上参数设置序列化为json发送给服务端,并等待服务端确认long start = System.currentTimeMillis();synthesizer.start();LOGGER.info("tts start latency " + (System.currentTimeMillis() - start) + " ms");VoiceGenerateService.startTime = System.currentTimeMillis();//等待语音合成结束synthesizer.waitForComplete();LOGGER.info("tts stop latency " + (System.currentTimeMillis() - start) + " ms");} catch (Exception e) {e.printStackTrace();} finally {//关闭连接if (null != synthesizer) {synthesizer.close();}}}public void shutdown() {client.shutdown();}
}相关文章:
大模型项目:普通蓝牙音响接入DeepSeek,解锁语音交互新玩法
本文附带视频讲解 【代码宇宙019】技术方案:蓝牙音响接入DeepSeek,解锁语音交互新玩法_哔哩哔哩_bilibili 目录 效果演示 核心逻辑 技术实现 大模型对话(技术: LangChain4j 接入 DeepSeek) 语音识别(…...

C/C++复习--C语言隐式类型转换
目录 什么是隐式类型转换?整型提升 规则与示例符号位扩展的底层逻辑 算术转换 类型层次与转换规则混合类型运算的陷阱 隐式转换的实际应用与问题 代码示例分析常见错误与避免方法 总结与最佳实践 1. 什么是隐式类型转换? 隐式类型转换是C语言在编译阶段…...
 与 Timestamp() 深度解析)
Pandas 时间处理利器:to_datetime() 与 Timestamp() 深度解析
Pandas 时间处理利器:to_datetime() 与 Timestamp() 深度解析 在数据分析和处理中,时间序列数据扮演着至关重要的角色。Pandas 库凭借其强大的时间序列处理能力,成为 Python 数据分析领域的佼佼者。其中,to_datetime() 函数和 Ti…...
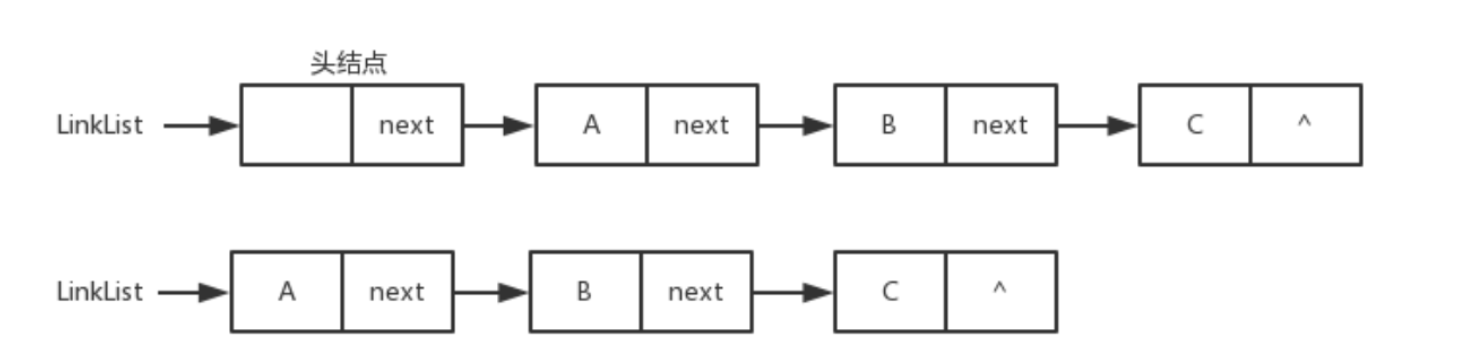
单链表设计与实现
01. 单链表简介 在数据结构中,单链表的实现可以分为 带头结点 和 不带头结点 两种方式,这里我们讨论第二种方式。 头结点:链表第一个节点不存实际数据,仅作为辅助节点指向首元节点(第一个数据节点)。头指…...

JDS-算法开发工程师-第9批
单选题 print(fn.__default__) 哪一个不是自适应学习率的优化算法 (选项:Adagrad,RMSprop,Adam,Momentum,动量法在梯度下降的基础上,加入了“惯性”概念,通过累积历史的梯度更新来加速收敛&…...

Git标签删除脚本解析与实践:轻松管理本地与远程标签
Git 标签删除脚本解析与实践:轻松管理本地与远程标签 在 Git 版本控制系统中,标签常用于标记重要的版本节点,方便追溯和管理项目的不同阶段。随着项目的推进,一些旧标签可能不再需要,此时就需要对它们进行清理。本文将通过一个完整的脚本,详细介绍如何删除本地和远程的 …...

Python中,async和with结合使用,有什么好处?
在Python的异步编程中,async和with的结合使用(即async with)为开发者提供了一种优雅且高效的资源管理模式。这种组合不仅简化了异步代码的编写,还显著提升了程序的健壮性和可维护性。以下是其核心优势及典型应用场景的分析&#x…...
springboot生成二维码到海报模板上
springboot生成二维码到海报模板上 QRCodeController package com.ruoyi.web.controller.app;import com.google.zxing.WriterException; import com.ruoyi.app.domain.Opportunity; import com.ruoyi.app.tool.QRCodeGenerator; import com.ruoyi.common.core.page.TableDat…...

SEO长尾关键词布局优化法则
内容概要 在SEO优化体系中,长尾关键词的精准布局是突破流量瓶颈的关键路径。相较于竞争激烈的核心词,长尾词凭借其高转化率和低竞争特性,成为内容矩阵流量裂变的核心驱动力。本节将系统梳理长尾关键词布局的核心逻辑框架,涵盖从需…...

python:trimesh 用于 STL 文件解析和 3D 操作
python:trimesh 是一个用于处理三维模型的库,支持多种格式的导入导出,比如STL、OBJ等,还包含网格操作、几何计算等功能。 Python Trimesh 库使用指南 安装依赖库 pip install trimesh Downloading trimesh-4.6.8-py3-none-any.w…...

应急响应基础模拟靶机-security2
PS:杰克创建的流量包(result.pcap)在root目录下,请根据已有信息进行分析 1、首个攻击者扫描端口使用的工具是? 2、后个攻击者使用的漏洞扫描工具是? 3、攻击者上传webshell的绝对路径及User-agent是什么? 4、攻击者反弹shell的…...

ROS 2 FishBot PID控制电机代码
#include <Arduino.h> #include <Wire.h> #include <MPU6050_light.h> #include <Esp32McpwmMotor.h> #include <Esp32PcntEncoder.h>Esp32McpwmMotor motor; // 创建一个名为motor的对象,用于控制电机 Esp32PcntEncoder enco…...

Bash 字符串语法糖详解
Bash 作为 Linux 和 Unix 系统中最常用的 Shell 之一,其字符串处理能力是脚本开发者的核心技能之一。为了让字符串操作更高效、更直观,Bash 提供了丰富的语法糖(syntactic sugar)。这些语法糖通过简洁的语法形式,隐藏了…...
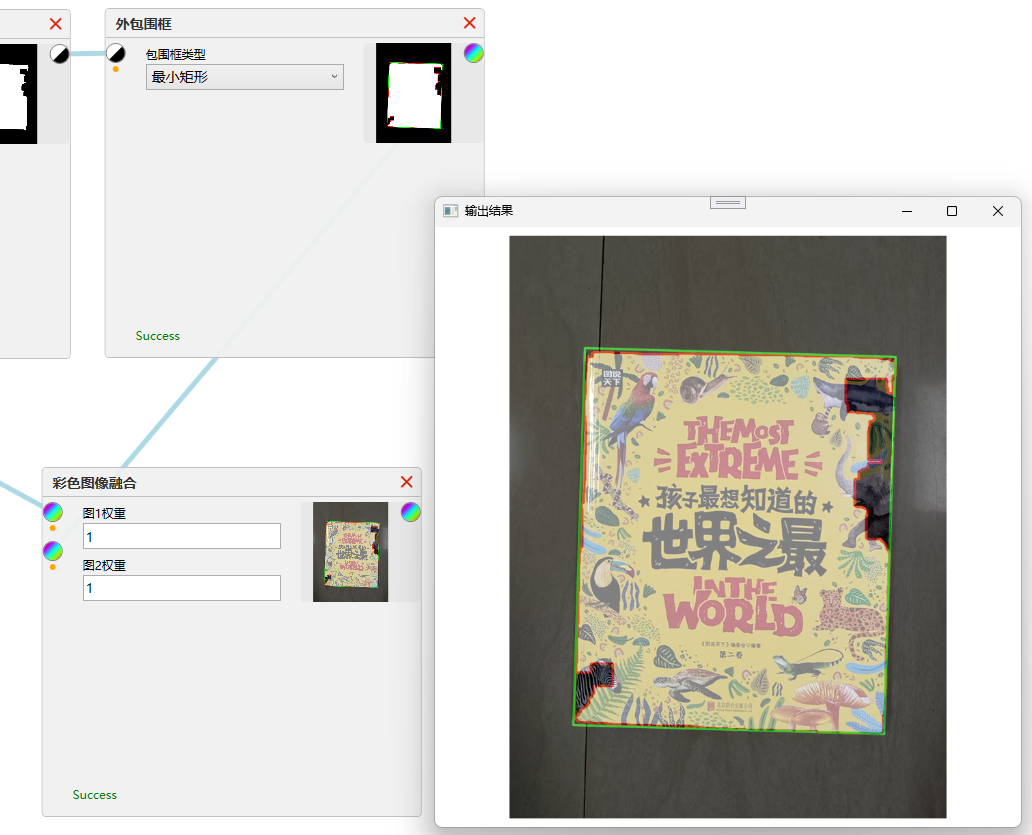
OpenCV定位地板上的书
任务目标是将下面的图片中的书本找出来: 使用到的技术包括:转灰度图、提取颜色分量、二值化、形态学、轮廓提取等。 我们尝试先把图片转为灰度图,然后二值化,看看效果: 可以看到,二值化后,书的…...

C++ string初始化、string赋值操作、string拼接操作
以下介绍了string的六种定义方式,还有很多,这个只是简单举例 #include<iostream>using namespace std;int main() {//1 无参构造string s1;cout << s1 << endl;//2 初始化构造string s2 ({h, h, l, l, o});cout << s2 <<…...

linux动态占用cpu脚本、根据阈值增加占用或取消占用cpu的脚本、自动检测占用脚本状态、3脚本联合套用。
文章目录 说明流程占用脚本1.0版本使用测试占用脚本2.0版本使用测试测试脚本使用测试检测脚本使用测试脚本说明书启动说明停止说明内存占用cpu内存成品任务测试说明 cpu占用实现的功能整体流程 1、先获取当前实际使用率2、设置一个最低阈值30%,一个最高阈值80%、一个需要增加的…...
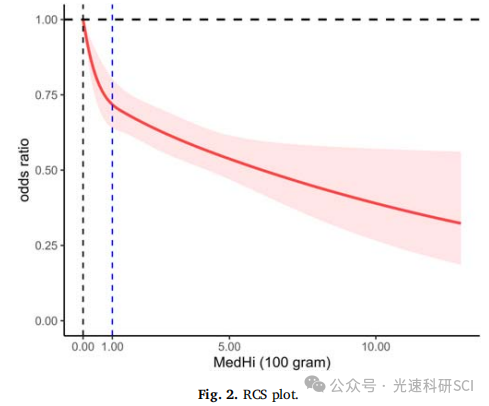
NHANES稀有指标推荐:MedHi
文章题目:Association of dietary live microbe intake with frailty in US adults: evidence from NHANES DOI:10.1016/j.jnha.2024.100171 中文标题:美国成人膳食活微生物摄入量与虚弱的相关性:来自 NHANES 的证据 发表杂志&…...

无人机空中物流优化:用 Python 打造高效配送模型
友友们好! 我是Echo_Wish,我的的新专栏《Python进阶》以及《Python!实战!》正式启动啦!这是专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会…...

关于我在实现用户头像更换时遇到的图片上传和保存的问题
目录 前言 前端更换头像 后端处理 文件系统存储图片 数据库存储图片 处理图片文件 生成图片名 保存图片 将图片路径存储到数据库 完整代码 总结 前言 最近在实现一个用户头像更换的功能,但是因为之前并没有处理过图片的上传和保存,所以就开始…...

10.二叉搜索树中第k小的元素(medium)
1.题目链接: 230. 二叉搜索树中第 K 小的元素 - 力扣(LeetCode)230. 二叉搜索树中第 K 小的元素 - 给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(从 1 开始计数…...
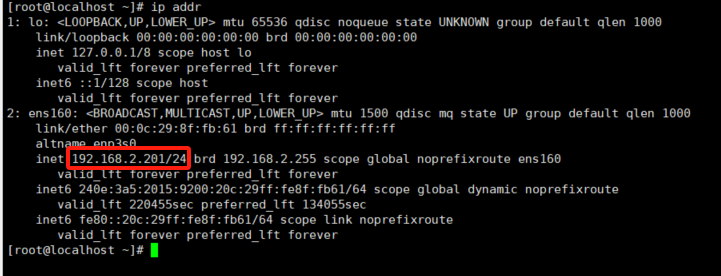
AlimaLinux设置静态IP
通过nmcli命令来操作 步骤 1:确认当前活动的网络接口名称 首先,需要确认当前系统中可用的网络接口名称。可以使用以下命令查看: nmcli device步骤 2:修改配置以匹配正确的接口名称 sudo nmcli connection modify ens160 ipv4.…...
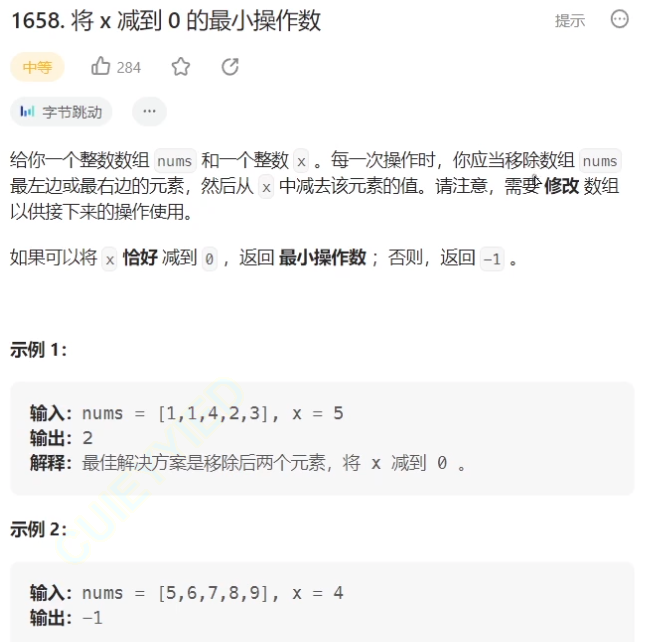
滑动窗口——将x减到0的最小操作数
题目: 这个题如果我们直接去思考方法是很困难的,因为我们不知道下一步是在数组的左还是右操作才能使其最小。正难则反,思考一下,无论是怎么样的,最终这个数组都会分成三个部分左中右,而左右的组合就是我们…...
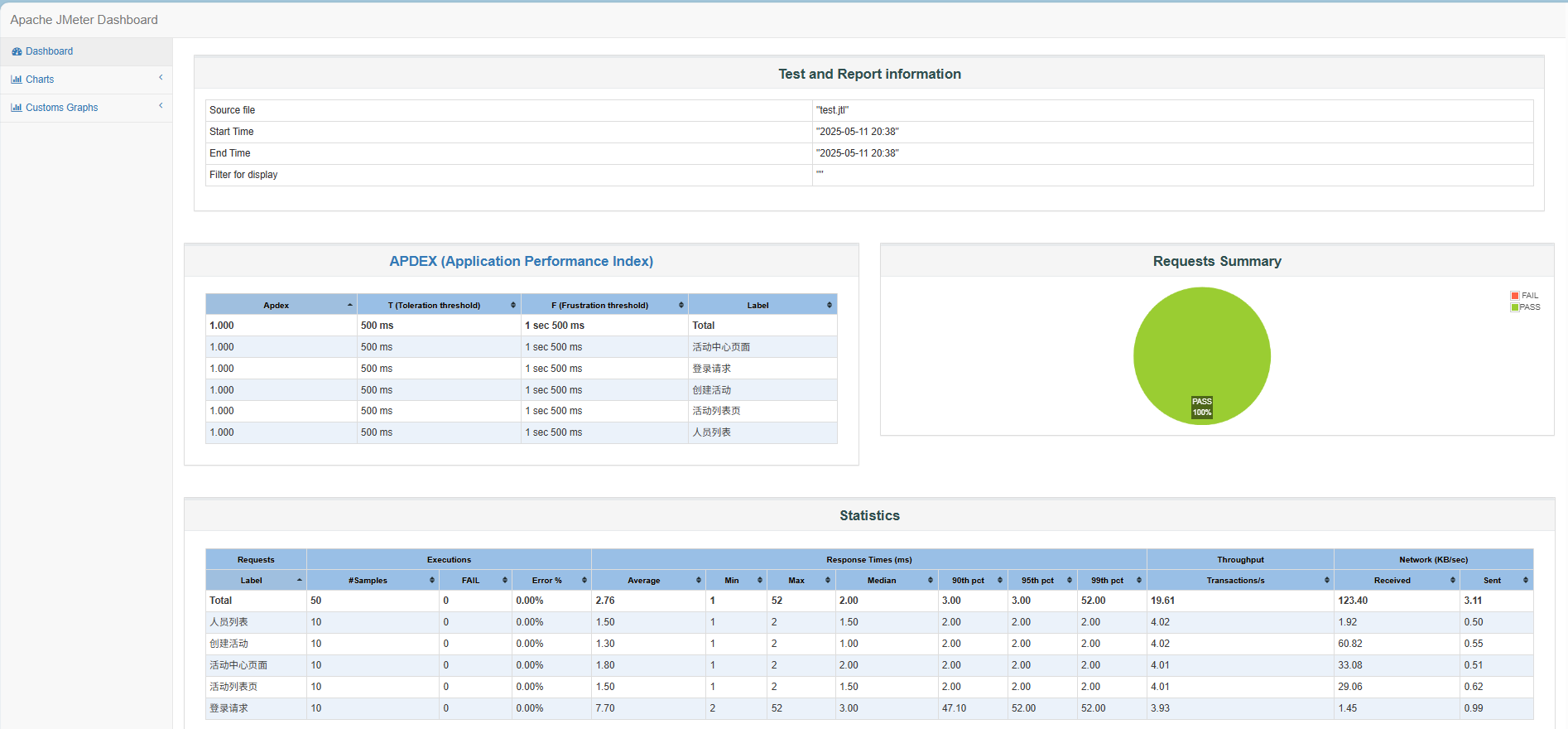
基于SpringBoot的抽奖系统测试报告
一、编写目的 本报告为抽奖系统测试报告,本项目可用于团体抽奖活动,包括了用户注册,用户登录,修改奖项以及抽奖等功能。 二、项目背景 抽奖系统采用前后端分离的方法来实现,同时使用了数据库来存储相关的数据&…...
服务器mysql连接我碰到的错误
搞了2个下午,总算成功了 我在服务器上使用docker部署了java项目与mysql,但mysql连接一直出现问题 1.首先,我使用的是localhost连接,心想反正都在服务器上吧。 jdbc:mysql://localhost:3306/fly-bird?useSSLfalse&serverTime…...
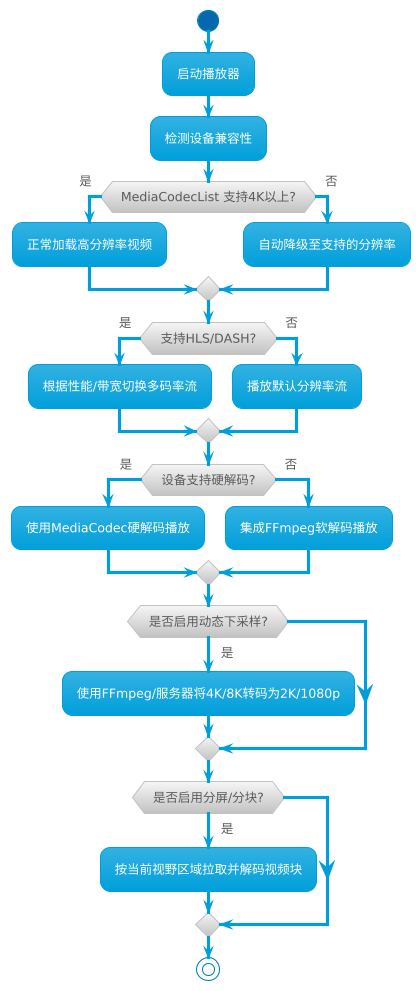
【Part 2安卓原生360°VR播放器开发实战】第四节|安卓VR播放器性能优化与设备适配
《VR 360全景视频开发》专栏 将带你深入探索从全景视频制作到Unity眼镜端应用开发的全流程技术。专栏内容涵盖安卓原生VR播放器开发、Unity VR视频渲染与手势交互、360全景视频制作与优化,以及高分辨率视频性能优化等实战技巧。 📝 希望通过这个专栏&am…...

TIME - MoE 模型代码 4——Time-MoE-main/run_eval.py
源码:https://github.com/Time-MoE/Time-MoE 这段代码是一个用于评估 Time-MoE 模型性能的脚本,它支持分布式环境下的模型评估,通过计算 MSE 和 MAE 等指标来衡量模型在时间序列预测任务上的表现。代码的核心功能包括:模型加载、…...

数字孪生概念
数字孪生(Digital Twin) 是指通过数字技术对物理实体(如设备、系统、流程或环境)进行高保真建模和实时动态映射,实现虚实交互、仿真预测和优化决策的技术体系。它是工业4.0、智慧城市和数字化转型的核心技术之一。 1. …...
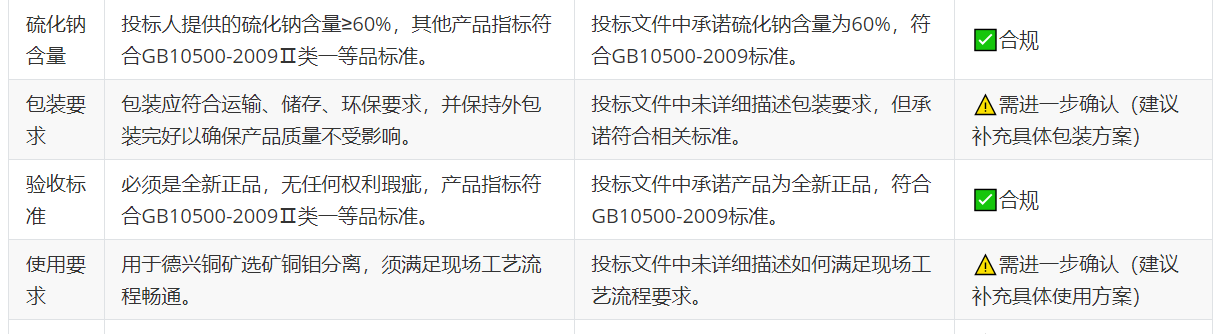
从知识图谱到精准决策:基于MCP的招投标货物比对溯源系统实践
前言 从最初对人工智能的懵懂认知,到逐渐踏入Prompt工程的世界,我们一路探索,从私有化部署的实际场景,到对DeepSeek技术的全面解读,再逐步深入到NL2SQL、知识图谱构建、RAG知识库设计,以及ChatBI这些高阶应…...

DAMA车轮图
DAMA车轮图是国际数据管理协会(DAMA International)提出的数据管理知识体系(DMBOK)的图形化表示,它以车轮(同心圆)的形式展示了数据管理的核心领域及其相互关系。以下是基于用户提供的关键词对D…...
图形化编程革命:iVX携手AI 原生开发范式
一、技术核心:图形化编程的底层架构解析 1. 图形化开发的效率优势:代码量减少 72% 的秘密 传统文本编程存在显著的信息密度瓶颈。以 "按钮点击→条件判断→调用接口→弹窗反馈" 流程为例,Python 实现需定义函数、处理缩进并编写 …...