TIME - MoE 模型代码 4——Time-MoE-main/run_eval.py
源码:https://github.com/Time-MoE/Time-MoE
这段代码是一个用于评估 Time-MoE 模型性能的脚本,它支持分布式环境下的模型评估,通过计算 MSE 和 MAE 等指标来衡量模型在时间序列预测任务上的表现。代码的核心功能包括:模型加载、数据处理、预测生成以及多节点分布式评估。
关键模块与组件
1. 环境初始化与分布式设置
def setup_nccl(rank, world_size, master_addr='127.0.0.1', master_port=9899):dist.init_process_group("nccl", init_method='tcp://{}:{}'.format(master_addr, master_port), rank=rank,world_size=world_size)- 该函数使用 NCCL 后端初始化 PyTorch 分布式训练环境
- 通过 TCP 协议连接主节点,实现多 GPU 或多节点通信
- rank 表示当前进程 ID,world_size 表示总进程数
2. 评估指标体系
class SumEvalMetric:def __init__(self, name, init_val: float = 0.0):self.name = nameself.value = init_valdef push(self, preds, labels, **kwargs):self.value += self._calculate(preds, labels, **kwargs)class MSEMetric(SumEvalMetric):def _calculate(self, preds, labels, **kwargs):return torch.sum((preds - labels) ** 2)class MAEMetric(SumEvalMetric):def _calculate(self, preds, labels, **kwargs):return torch.sum(torch.abs(preds - labels))- 采用面向对象设计,基类 SumEvalMetric 定义了评估指标的基本结构
- MSEMetric 和 MAEMetric 继承自基类,分别实现均方误差和平均绝对误差计算
- push 方法用于累积每个批次的评估结果
3. 模型加载与预测模块
class TimeMoE:def __init__(self, model_path, device, context_length, prediction_length, **kwargs):try:from time_moe.models.modeling_time_moe import TimeMoeForPredictionmodel = TimeMoeForPrediction.from_pretrained(model_path,device_map=device,torch_dtype='auto',)except:model = AutoModelForCausalLM.from_pretrained(model_path,device_map=device,torch_dtype='auto',trust_remote_code=True,)def predict(self, batch):outputs = model.generate(inputs=batch['inputs'].to(device).to(model.dtype),max_new_tokens=prediction_length,)preds = outputs[:, -prediction_length:]labels = batch['labels'].to(device)return preds, labels- 支持两种模型加载方式:原生 Time-MoE 模型或通过 transformers 库加载的通用模型
- 使用
from_pretrained方法加载预训练权重,并自动处理设备映射和数据类型转换 - predict 方法通过 generate 接口生成预测结果,提取最后 prediction_length 个时间步作为预测值
4. 数据处理流程
if args.data.endswith('.csv'):dataset = BenchmarkEvalDataset(args.data,context_length=context_length,prediction_length=prediction_length,)
else:dataset = GeneralEvalDataset(args.data,context_length=context_length,prediction_length=prediction_length,)if torch.cuda.is_available() and dist.is_initialized():sampler = DistributedSampler(dataset=dataset, shuffle=False)
else:sampler = Nonetest_dl = DataLoader(dataset=dataset,batch_size=batch_size,sampler=sampler,shuffle=False,num_workers=2,prefetch_factor=2,
)- 根据数据文件格式选择不同的数据集类
- 支持分布式环境下的数据采样,确保各进程处理不同的数据分片
- 数据加载器配置了多线程数据读取和预取,优化数据处理性能
5. 评估主流程
acc_count = 0
with torch.no_grad():for idx, batch in enumerate(tqdm(test_dl)):preds, labels = model.predict(batch)for metric in metric_list:metric.push(preds, labels)acc_count += count_num_tensor_elements(preds)# 分布式环境下的结果聚合
if is_dist:stat_tensor = torch.tensor(metric_tensors).to(model.device)gathered_results = [torch.zeros_like(stat_tensor) for _ in range(world_size)]dist.all_gather(gathered_results, stat_tensor)all_stat = torch.stack(gathered_results, dim=0).sum(dim=0)
else:all_stat = metric_tensors# 计算最终评估结果
count = all_stat[-1]
for i, metric in enumerate(metric_list):val = all_stat[i] / countitem[metric.name] = float(val.cpu().numpy())- 使用 torch.no_grad () 上下文管理器关闭梯度计算,提高推理速度
- 遍历数据集,累积每个批次的预测结果和评估指标
- 在分布式环境下,使用 all_gather 操作收集所有进程的统计数据
- 最终在主进程上计算并打印全局评估结果
高级特性解析
1. 自适应上下文长度设置
if args.context_length is None:if args.prediction_length == 96:args.context_length = 512elif args.prediction_length == 192:args.context_length = 1024elif args.prediction_length == 336:args.context_length = 2048elif args.prediction_length == 720:args.context_length = 3072else:args.context_length = args.prediction_length * 4- 根据预测长度自动设置合适的上下文长度
- 预测长度越长,所需的历史上下文信息也越多
- 默认使用预测长度的 4 倍作为上下文长度
2. 分布式结果聚合
stat_tensor = torch.tensor(metric_tensors).to(model.device)
gathered_results = [torch.zeros_like(stat_tensor) for _ in range(world_size)]
dist.all_gather(gathered_results, stat_tensor)
all_stat = torch.stack(gathered_results, dim=0).sum(dim=0)- 使用 all_gather 操作将所有进程的统计数据收集到每个进程中
- 对收集到的结果进行求和,得到全局统计数据
- 确保最终评估结果基于所有数据分片
3. 动态设备映射与数据类型处理
model = TimeMoeForPrediction.from_pretrained(model_path,device_map=device,torch_dtype='auto',
)- device_map 参数自动处理模型在多 GPU 间的分布
- torch_dtype='auto' 根据硬件自动选择最优数据类型
- 支持混合精度推理,提高计算效率
使用方法与参数说明
parser = argparse.ArgumentParser('TimeMoE Evaluate')
parser.add_argument('--model', '-m', type=str, default='Maple728/TimeMoE-50M', help='Model path')
parser.add_argument('--data', '-d', type=str, help='Benchmark data path')
parser.add_argument('--batch_size', '-b', type=int, default=32, help='Batch size of evaluation')
parser.add_argument('--context_length', '-c', type=int, help='Context length')
parser.add_argument('--prediction_length', '-p', type=int, default=96, help='Prediction length')--model:指定要评估的模型路径--data:指定评估数据集路径--batch_size:评估时的批次大小--context_length:输入的历史上下文长度--prediction_length:要预测的未来时间步长度
总结
这段代码实现了一个完整的 Time-MoE 模型评估系统,具有以下特点:
- 支持分布式环境下的高效评估
- 提供了 MSE 和 MAE 等常用评估指标
- 能够处理不同格式的时间序列数据
- 自动适应不同的预测长度和上下文长度
- 优化了模型加载和推理过程,支持混合精度计算
这个评估脚本可以帮助研究人员和工程师准确衡量 Time-MoE 模型在各种时间序列预测任务上的性能表现。
我们的实验
print问题
1.输出内容的来源与原因
(1)模型初始化信息
logging.info(f'>>> Model dtype: {model.dtype}; Attention:{model.config._attn_implementation}')
- 位置:
TimeMoE类的__init__方法。 - 原因:记录模型的数据类型(如
float32)和注意力机制实现方式(如eager或flash_attention_2)。
(2)进度条
for idx, batch in enumerate(tqdm(test_dl)):...
- 位置:
evaluate函数的主循环。 - 原因:使用
tqdm库显示评估进度,便于用户了解当前完成情况。
(3)各进程的局部评估结果
print(f'{rank} - {ret_metric}')
- 位置:
evaluate函数的结果聚合前。 - 原因:打印每个进程计算的局部 MSE 和 MAE 指标(分布式环境下每个 GPU 计算一部分数据)。
(4)汇总后的全局评估结果
logging.info(item)
- 位置:
evaluate函数中rank == 0的条件分支。 - 原因:在主进程中汇总所有进程的结果,输出最终的全局评估指标。
3. 输出功能的实现代码
(1)logging 模块的配置与使用
# 隐式配置(未在代码中显示,但transformers库默认配置了logging)
import logging# 使用示例
logging.info(...) # 输出INFO级别的日志
- 特点:日志格式通常包含时间戳、日志级别和消息内容。
(2)print 语句的使用
for idx, batch in enumerate(tqdm(test_dl)):...- 位置:
evaluate函数中,在分布式结果聚合前。 - 原因:记录模型的数据类型(如
float32)和注意力机制实现方式(如eager或flash_attention_2)。
(3)tqdm 进度条
from tqdm import tqdmfor batch in tqdm(test_dl): # 包装数据加载器,显示进度...
- 功能:动态显示评估进度(如
100%|██████████| 100/100 [00:30<00:00])。
4. 分布式环境下的输出规则
- 局部结果:每个进程(GPU)都会打印自己计算的指标(通过
print)。 - 全局结果:仅主进程(
rank == 0)汇总并输出最终指标(通过logging)。 - 示例:
# 分布式环境下(如4卡)可能的输出: 0 - {'mse': tensor(0.0123, device='cuda:0'), 'mae': tensor(0.0987, device='cuda:0')} 1 - {'mse': tensor(0.0119, device='cuda:1'), 'mae': tensor(0.0976, device='cuda:1')} 2 - {'mse': tensor(0.0121, device='cuda:2'), 'mae': tensor(0.0981, device='cuda:2')} 3 - {'mse': tensor(0.0125, device='cuda:3'), 'mae': tensor(0.0993, device='cuda:3')}# 主进程汇总后的结果: INFO: {'model': ..., 'mse': 0.0122, 'mae': 0.0984}
总结
- 输出内容:模型信息、评估进度、各进程局部指标、全局汇总指标。
- 输出原因:监控评估过程、验证模型性能、支持分布式环境调试。
- 实现代码:
logging模块(记录模型配置和最终结果)。print语句(打印各进程局部结果)。tqdm库(显示进度条)。
相关文章:

TIME - MoE 模型代码 4——Time-MoE-main/run_eval.py
源码:https://github.com/Time-MoE/Time-MoE 这段代码是一个用于评估 Time-MoE 模型性能的脚本,它支持分布式环境下的模型评估,通过计算 MSE 和 MAE 等指标来衡量模型在时间序列预测任务上的表现。代码的核心功能包括:模型加载、…...

数字孪生概念
数字孪生(Digital Twin) 是指通过数字技术对物理实体(如设备、系统、流程或环境)进行高保真建模和实时动态映射,实现虚实交互、仿真预测和优化决策的技术体系。它是工业4.0、智慧城市和数字化转型的核心技术之一。 1. …...
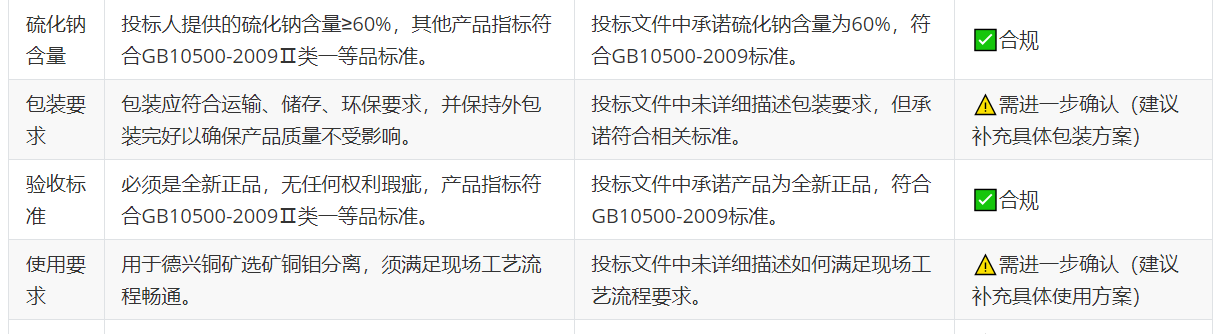
从知识图谱到精准决策:基于MCP的招投标货物比对溯源系统实践
前言 从最初对人工智能的懵懂认知,到逐渐踏入Prompt工程的世界,我们一路探索,从私有化部署的实际场景,到对DeepSeek技术的全面解读,再逐步深入到NL2SQL、知识图谱构建、RAG知识库设计,以及ChatBI这些高阶应…...

DAMA车轮图
DAMA车轮图是国际数据管理协会(DAMA International)提出的数据管理知识体系(DMBOK)的图形化表示,它以车轮(同心圆)的形式展示了数据管理的核心领域及其相互关系。以下是基于用户提供的关键词对D…...
图形化编程革命:iVX携手AI 原生开发范式
一、技术核心:图形化编程的底层架构解析 1. 图形化开发的效率优势:代码量减少 72% 的秘密 传统文本编程存在显著的信息密度瓶颈。以 "按钮点击→条件判断→调用接口→弹窗反馈" 流程为例,Python 实现需定义函数、处理缩进并编写 …...

线程池使用ThreadLocal注意事项
ThreadLocal和线程池都是Java中处理多线程的重要工具,但它们在结合使用时需要特别注意一些问题。 ThreadLocal简介 ThreadLocal提供了线程局部变量,每个线程都有自己独立的变量副本,互不干扰。 基本用法: private static fina…...
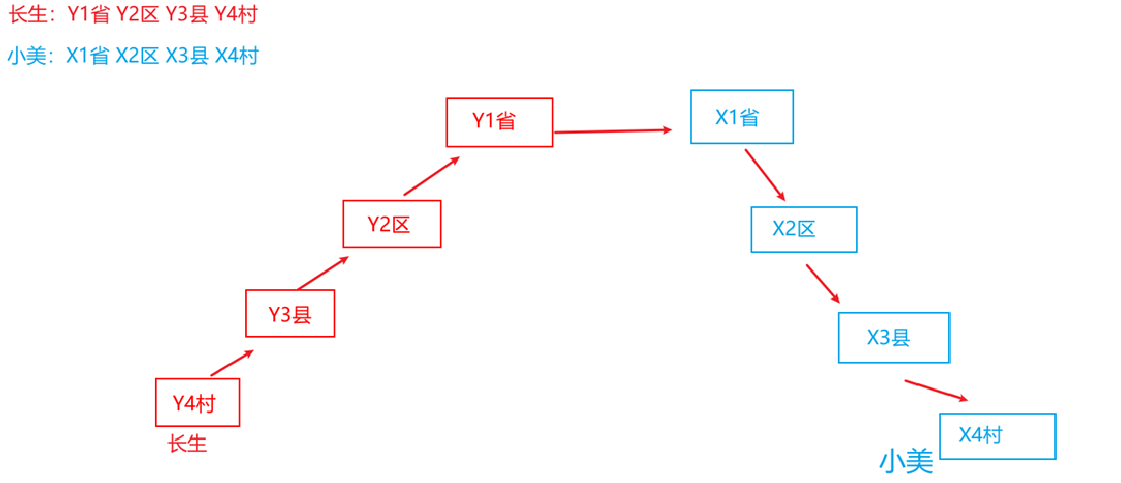
JAVA EE_网络原理_网络层
晨雾散尽,花影清晰。 ----------陳長生. ❀主页:陳長生.-CSDN博客❀ 📕上一篇:数据库Mysql_联…...
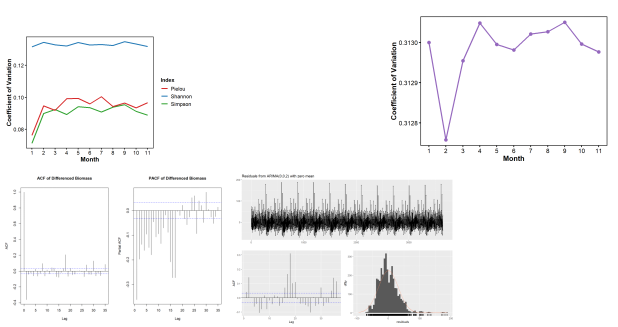
森林生态学研究深度解析:R语言入门、生物多样性分析、机器学习建模与群落稳定性评估
在生态学研究中,森林生态系统的结构、功能与稳定性是核心研究内容之一。这些方面不仅关系到森林动态变化和物种多样性,还直接影响森林提供的生态服务功能及其应对环境变化的能力。森林生态系统的结构主要包括物种组成、树种多样性、树木的空间分布与密度…...
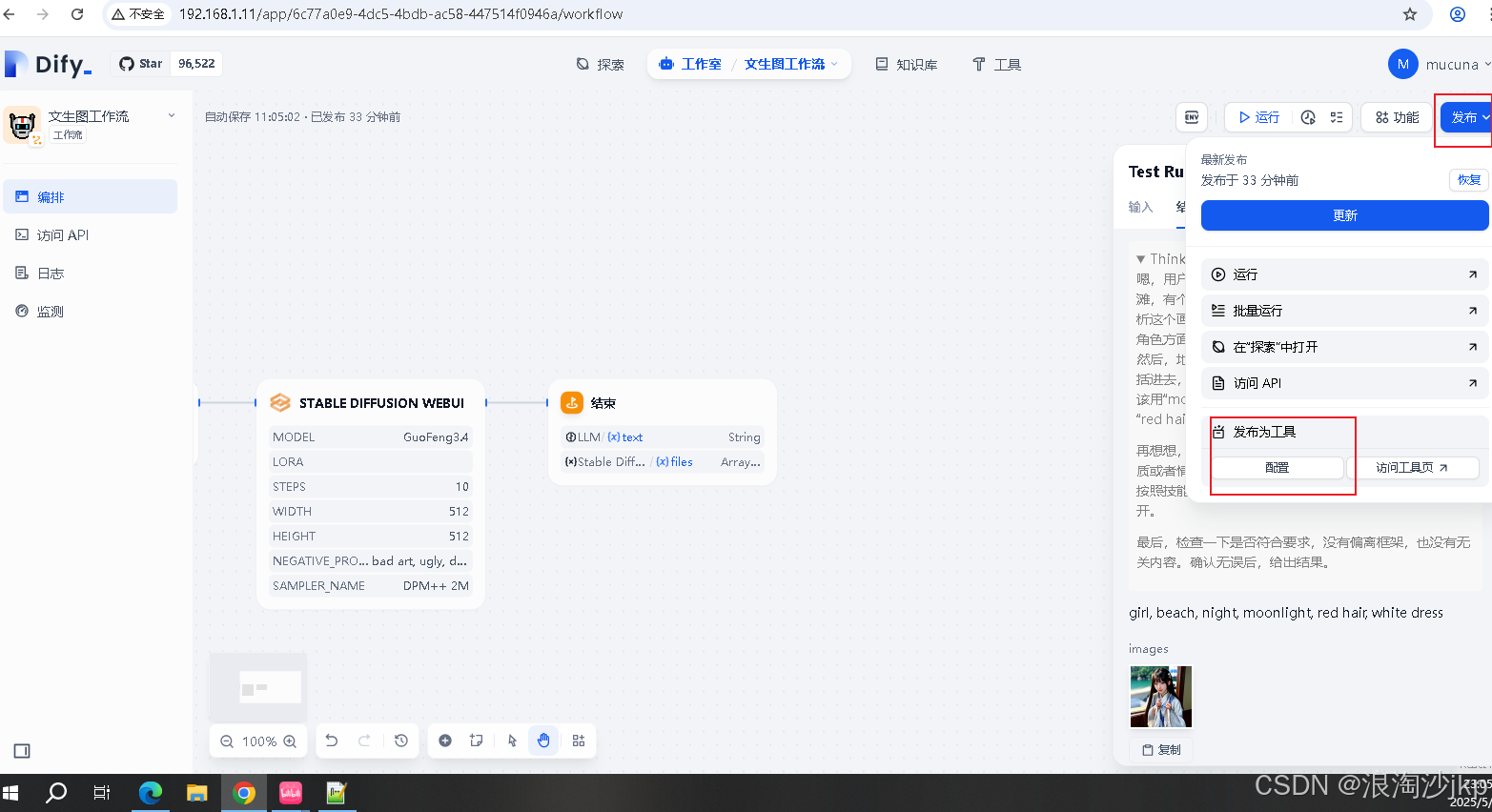
AI大模型学习十八、利用Dify+deepseekR1 +本地部署Stable Diffusion搭建 AI 图片生成应用
一、说明 最近在学习Dify工作流的一些玩法,下面将介绍一下Dify Stable Diffusion实现文生图工作流的应用方法 Dify与Stable Diffusion的协同价值 Dify作为低代码AI开发平台的优势:可视化编排、API快速集成 Stable Diffusion的核心能力:高效…...
关于chatshare.xyz激活码使用说明和渠道指南!
chatshare.xyz和chatshare.biz是两个被比较的平台,分别在其功能特性和获取渠道有所不同。 本文旨在探讨它们的差异,以及提供如何获取并使用的平台信息。此外,还提及其他一些相关资源和模板推荐以满足用户需求。 主要区分关键点 1、chatshar…...

【Python-Day 12】Python列表进阶:玩转添加、删除、排序与列表推导式
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

RAII是什么?
RAII(Resource Acquisition Is Initialization,资源获取即初始化)是C编程中的一项非常重要且经典的设计思想,也是现代C资源管理的基石。它主要解决资源的自动管理与释放问题,从而帮助程序员避免资源泄漏、悬空指针等常…...

Qt开发经验 --- 避坑指南(14)
文章目录 [toc]1 linux下使用linuxdeploy打包2 Qt源码下载3 QtCreator配置github copilot实现AI编程4 使用其它编程AI辅助开发Qt5 Qt开源UI库6 QT6.8以后版本安装QtWebEngine7 清除QtCreator配置 更多精彩内容👉内容导航 👈👉Qt开发经验 &…...

JavaScript 循环语句全解析:选择最适合的遍历方式
循环是编程中处理重复任务的核心工具。JavaScript 提供了多种循环语句,每种都有其适用场景和独特优势。本文将深入解析 JavaScript 的 6 种核心循环语句,通过实际示例帮助你精准选择合适的循环方案。 一、基础循环三剑客 1. for 循环 经典索引控制 ja…...
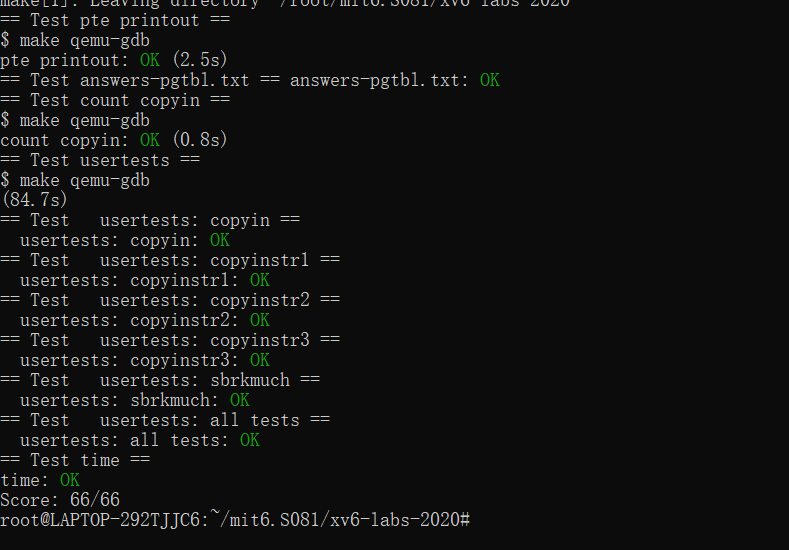
MIT 6.S081 2020 Lab3 page tables 个人全流程
文章目录 零、写在前面1、关于页表2、RISC-V Rv39页表机制3、虚拟地址设计4、页表项设计5、访存流程6、xv6 的页表切换7、页表遍历 一、Print a page table1.1 说明1.2 实现 二、A kernel page table per process2.1 说明2.2 初始化 / 映射相关2.3 用户内核页表的创建和回收2.4…...

Oracle 通过 ROWID 批量更新表
Oracle 通过 ROWID 批量更新表 在 Oracle 数据库中,使用 ROWID 进行批量更新是一种高效的更新方法,因为它直接定位到物理行位置,避免了通过索引查找的开销。 ROWID 基本概念 ROWID 是 Oracle 数据库中每一行的唯一物理地址标识符ÿ…...

webpack 的工作流程
Webpack 的工作流程可以分为以下几个核心步骤,我将结合代码示例详细说明每个阶段的工作原理: 1. 初始化配置 Webpack 首先会读取配置文件(默认 webpack.config.js),合并命令行参数和默认配置。 // webpack.config.js…...

tcpdump 的用法
tcpdump 是一款强大的命令行网络抓包工具,用于捕获和分析网络流量。以下是其核心用法指南: 一、基础命令格式 sudo tcpdump [选项] [过滤表达式]权限要求:需 root 权限(使用 sudo) 二、常用选项 选项说明-i <接口…...

Agent杂货铺
零散记录一些Agent相关的内容。不成体系,看情况是否整理 ReAct ReAct 是一种实践代理模型的高级框架,通过将大语言模型(LLMs)的推理和执行行动的能力结合起来,增强了它们在处理复杂任务时的决策能力、适应性和与外部…...

【Redis】Redis的主从复制
文章目录 1. 单点问题2. 主从模式2.1 建立复制2.2 断开复制 3. 拓扑结构3.1 三种结构3.2 数据同步3.3 复制流程3.3.1 psync运行流程3.3.2 全量复制3.3.3 部分复制3.3.4 实时复制 1. 单点问题 单点问题:某个服务器程序,只有一个节点(只搞一个…...

第04章—技术突击篇:如何根据求职意向进行快速提升与复盘
经过上一讲的内容阐述后,咱们定好了一个与自身最匹配的期望薪资,接着又该如何准备呢? 很多人在准备时,通常会选择背面试八股文,这种做法效率的确很高,毕竟能在“八股文”上出现的题,也绝对是面…...

Quantum convolutional nerual network
一些问答 1.Convolution: Translationally Invariant Quasilocal Unitaries 理解? Convolution(卷积): 在量子信息或量子多体系统中,"卷积"通常指一种分层、局部操作的结构,类似于经典卷积神经网…...

RL之ppo训练
又是一篇之前沉在草稿箱的文章,放出来^V^ PPO原理部分这两篇就够了: 图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读人人都能看懂的RL-PPO理论知识 那些你或多或少听过的名词 actor-critic: actor表示策略,critic表示价值…...

AI云防护真的可以防攻击?你的服务器用群联AI云防护吗?
1. 传统防御方案的局限性 静态规则缺陷:无法应对新型攻击模式(如HTTP慢速攻击)资源浪费:固定带宽采购导致非攻击期资源闲置 2. AI云防护技术实现 动态流量调度算法: # 智能节点选择伪代码(参考群联防护…...

Docker封装深度学习模型
1.安装Docker Desktop 从官网下载DockerDesktop,安装。(默认安装位置在C盘,可进行修改) "D:\Program Files (x86)\Docker\Docker Desktop Installer.exe" install --installation-dir"D:\Program Files (x86)\Do…...

11、参数化三维产品设计组件 - /设计与仿真组件/parametric-3d-product-design
76个工业组件库示例汇总 参数化三维产品设计组件 (注塑模具与公差分析) 概述 这是一个交互式的 Web 组件,旨在演示简单的三维零件(如带凸台的方块)的参数化设计过程,并结合注塑模具设计(如开模动画)与公…...

4.4 os模块
os模块: chdir:修改工作路径 --- 文件所在位置的标识 getcwd():返回当前路径,如果修改了则显示修改后的路径 curdir:获取当前目录的表示形式 cpu_count():返回当前cpu的线程数 getppid(): 获取当前进程编号 getppid():获取当前进程的父进…...
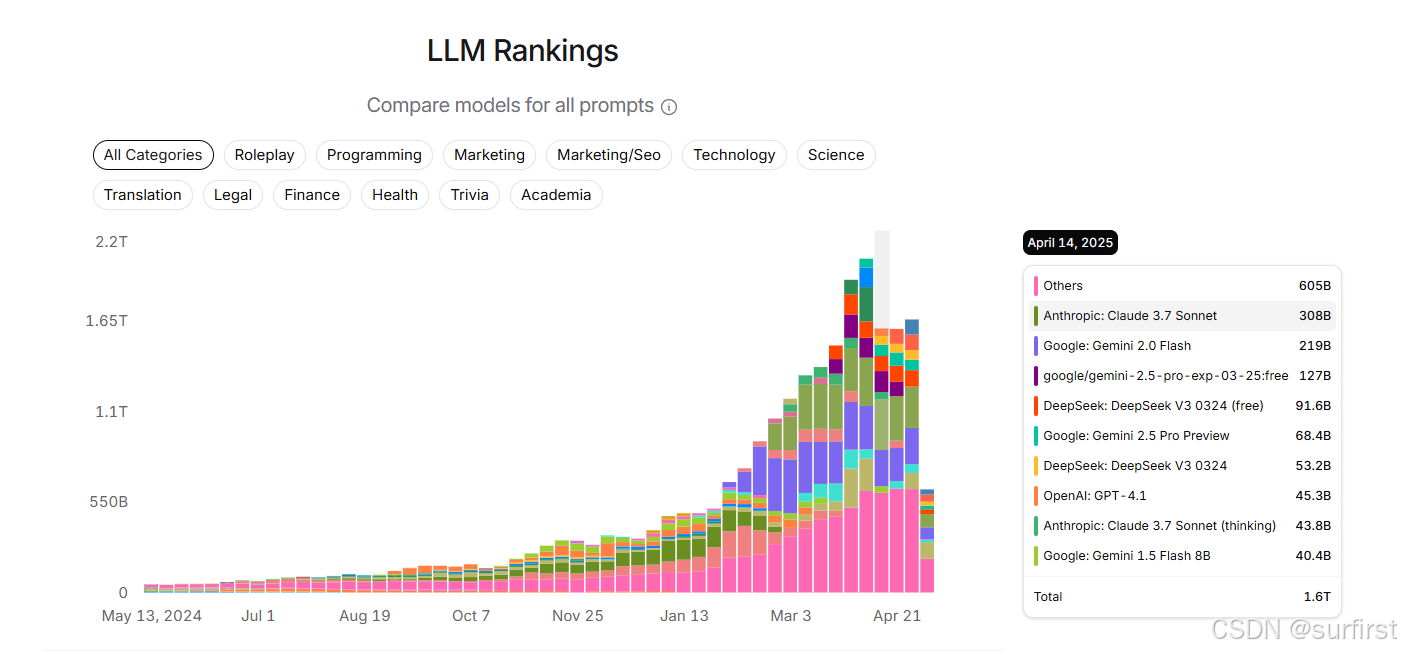
OpenAI 30 亿收购 Windsurf:AI 编程助手风口已至
导语: 各位开发者同仁、产品经理伙伴们,从2024年起,一场由AI驱动的研发范式革命已然来临。Cursor等AI代码编辑器凭借与大语言模型的深度集成,正以前所未有的态势挑战,甚至颠覆着IntelliJ、VS Code等传统IDE的固有疆域。根据OpenRouter的API使用数据,Anthropic的Claude 3.…...

材料创新与工艺升级——猎板PCB引领高频阻抗板制造革命
在5G通信、AI服务器和自动驾驶的推动下,高频电路对信号完整性的要求日益严苛。猎板PCB作为国内高端PCB制造的标杆企业,通过材料创新与工艺革新,实现了阻抗控制的突破性进展,为行业树立了新标杆。 1. 高频材料的突破 传统FR-4基材…...

协议路由与路由协议
协议路由”和“路由协议”听起来相似,但其实是两个完全不同的网络概念。下面我来分别解释: 一、协议路由(Policy-Based Routing,PBR) ✅ 定义: 协议路由是指 根据预设策略(策略路由࿰…...