【Python-Day 12】Python列表进阶:玩转添加、删除、排序与列表推导式
Langchain系列文章目录
01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南
02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖
03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南
04-玩转 LangChain:从文档加载到高效问答系统构建的全程实战
05-玩转 LangChain:深度评估问答系统的三种高效方法(示例生成、手动评估与LLM辅助评估)
06-从 0 到 1 掌握 LangChain Agents:自定义工具 + LLM 打造智能工作流!
07-【深度解析】从GPT-1到GPT-4:ChatGPT背后的核心原理全揭秘
08-【万字长文】MCP深度解析:打通AI与世界的“USB-C”,模型上下文协议原理、实践与未来
Python系列文章目录
PyTorch系列文章目录
机器学习系列文章目录
深度学习系列文章目录
Java系列文章目录
JavaScript系列文章目录
Python系列文章目录
01-【Python-Day 1】告别编程恐惧:轻松掌握 Python 安装与第一个程序的 6 个步骤
02-【Python-Day 2】掌握Python基石:变量、内存、标识符及int/float/bool数据类型
03-【Python-Day 3】玩转文本:字符串(String)基础操作详解 (上)
04-【Python-Day 4】玩转文本:Python 字符串常用方法深度解析 (下篇)
05-【Python-Day 5】Python 格式化输出实战:%、format()、f-string 对比与最佳实践
06- 【Python-Day 6】从零精通 Python 运算符(上):算术、赋值与比较运算全解析
07-【Python-Day 7】从零精通 Python 运算符(下):逻辑、成员、身份运算与优先级规则全解析
08-【Python-Day 8】从入门到精通:Python 条件判断 if-elif-else 语句全解析
09-【Python-Day 9】掌握循环利器:for 循环遍历序列与可迭代对象详解
10-【Python-Day 10】Python 循环控制流:while 循环详解与 for 循环对比
11-【Python-Day 11】列表入门:Python 中最灵活的数据容器 (创建、索引、切片)
12-【Python-Day 12】Python列表进阶:玩转添加、删除、排序与列表推导式
文章目录
- Langchain系列文章目录
- Python系列文章目录
- PyTorch系列文章目录
- 机器学习系列文章目录
- 深度学习系列文章目录
- Java系列文章目录
- JavaScript系列文章目录
- Python系列文章目录
- 前言
- 一、列表元素的添加
- 1.1 `append()`:在列表末尾添加元素
- 1.1.1 方法说明
- 1.1.2 代码示例
- (1) 输出结果
- (2) 注意事项
- 1.2 `insert()`:在指定位置插入元素
- 1.2.1 方法说明
- 1.2.2 代码示例
- (1) 输出结果
- 1.3 `extend()`:将一个可迭代对象的元素逐个添加到列表末尾
- 1.3.1 方法说明
- 1.3.2 代码示例
- (1) 输出结果
- 1.3.3 `append()` vs `extend()`
- 二、列表元素的删除
- 2.1 `remove()`:删除列表中第一个匹配的指定元素
- 2.1.1 方法说明
- 2.1.2 代码示例
- (1) 输出结果
- (2) 场景应用与问题排查
- 2.2 `pop()`:移除并返回指定位置的元素(默认为末尾)
- 2.2.1 方法说明
- 2.2.2 代码示例
- (1) 输出结果
- (2) `pop()` 的应用场景
- 2.3 `del` 语句:根据索引或切片删除元素
- 2.3.1 语句说明
- 2.3.2 代码示例
- (1) 输出结果
- (2) `del` vs `pop()` vs `remove()`
- 2.4 `clear()`:清空列表中的所有元素
- 2.4.1 方法说明
- 2.4.2 代码示例
- (1) 输出结果
- (2) `clear()` vs `del list[:]` vs `list = []`
- 三、列表元素的查找与计数
- 3.1 `index()`:查找指定元素第一次出现的索引
- 3.1.1 方法说明
- 3.1.2 代码示例
- (1) 输出结果
- (2) 使用 `in` 运算符进行安全查找
- 3.2 `count()`:统计指定元素在列表中出现的次数
- 3.2.1 方法说明
- 3.2.2 代码示例
- (1) 输出结果
- (2) 注意 `True` 和 `1`,`False` 和 `0` 的相等性
- 四、列表的排序与反转
- 4.1 `sort()`:对列表进行原地排序
- 4.1.1 方法说明
- 4.1.2 代码示例
- (1) 输出结果
- 4.2 `reverse()`:原地反转列表中的元素顺序
- 4.2.1 方法说明
- 4.2.2 代码示例
- (1) 输出结果
- 4.3 `sorted()`:返回一个新的已排序列表(内建函数)
- 4.3.1 函数说明
- 4.3.2 代码示例
- (1) 输出结果
- (2) `sort()` vs `sorted()`
- 五、获取列表长度
- 5.1 `len()` 函数
- 5.1.1 函数说明
- 5.1.2 代码示例
- (1) 输出结果
- 六、列表推导式 (List Comprehension) - 初步介绍
- 6.1 什么是列表推导式?
- 6.2 基本语法
- 6.3 代码示例
- 6.3.1 简单示例:生成数字序列
- (1) 输出结果
- 6.3.2 带条件过滤的示例
- (1) 输出结果
- 6.3.3 表达式应用示例
- (1) 输出结果
- 6.4 列表推导式的优点
- 七、总结
前言
在上一篇 【Python-Day 11】数据容器之王 - 列表 (List) 详解 (上) 中,我们初步认识了 Python 中的列表,了解了它的创建、访问、切片和修改等基本操作。列表作为 Python 中最为重要和最常用的数据结构之一,其强大之处远不止于此。本篇我们将继续深入探索列表的“十八般武艺”,详细学习列表的常用方法,包括元素的添加、删除、查找、排序等,并初步接触强大的列表推导式。掌握这些内容,将使你在处理序列数据时更加得心应手,为后续更复杂的编程任务打下坚实的基础。
一、列表元素的添加
向列表中添加新元素是常见的操作需求。Python 列表提供了多种方法来实现这一目标,每种方法都有其特定的应用场景。
1.1 append():在列表末尾添加元素
append() 方法用于将一个元素添加到列表的末尾。这是最常用的添加元素的方式。
1.1.1 方法说明
append() 方法直接修改原始列表,不返回任何值 (或者说返回 None)。
list.append(obj)
obj:要添加到列表末尾的对象,可以是任何数据类型。
1.1.2 代码示例
# 创建一个空列表
my_list = []
print(f"初始列表: {my_list}")# 添加数字
my_list.append(10)
print(f"添加 10 后: {my_list}")# 添加字符串
my_list.append("hello")
print(f"添加 'hello' 后: {my_list}")# 添加另一个列表(作为单个元素)
another_list = [20, 30]
my_list.append(another_list)
print(f"添加列表 [20, 30] 后: {my_list}")
(1) 输出结果
初始列表: []
添加 10 后: [10]
添加 'hello' 后: [10, 'hello']
添加列表 [20, 30] 后: [10, 'hello', [20, 30]]
(2) 注意事项
append() 总是将元素作为一个整体添加到列表末尾。如果添加的是一个列表,那么这个列表会成为新列表中的一个元素(即嵌套列表)。
1.2 insert():在指定位置插入元素
如果你需要在列表的特定位置插入元素,而不是仅仅在末尾添加,那么 insert() 方法就派上用场了。
1.2.1 方法说明
insert() 方法将一个元素插入到列表的指定索引位置。它同样直接修改原始列表,不返回值。
list.insert(index, obj)
index:要插入元素的目标索引位置。如果索引超出范围,若为正数且大于列表长度,则元素会插入到末尾;若为负数且绝对值大于列表长度,则元素会插入到开头。obj:要插入的对象。
1.2.2 代码示例
fruits = ["apple", "banana", "cherry"]
print(f"初始水果列表: {fruits}")# 在索引 1 的位置插入 "orange"
fruits.insert(1, "orange")
print(f"在索引 1 插入 'orange' 后: {fruits}")# 在列表开头插入 "mango" (索引 0)
fruits.insert(0, "mango")
print(f"在索引 0 插入 'mango' 后: {fruits}")# 在列表末尾插入 "grape" (使用大于当前最大索引的索引)
fruits.insert(10, "grape") # 列表长度为5,10 超出范围,插入到末尾
print(f"在索引 10 插入 'grape' 后: {fruits}")# 使用负数索引插入
fruits.insert(-1, "pear") # 插入到倒数第一个元素之前
print(f"在索引 -1 插入 'pear' 后: {fruits}")
(1) 输出结果
初始水果列表: ['apple', 'banana', 'cherry']
在索引 1 插入 'orange' 后: ['apple', 'orange', 'banana', 'cherry']
在索引 0 插入 'mango' 后: ['mango', 'apple', 'orange', 'banana', 'cherry']
在索引 10 插入 'grape' 后: ['mango', 'apple', 'orange', 'banana', 'cherry', 'grape']
在索引 -1 插入 'pear' 后: ['mango', 'apple', 'orange', 'banana', 'cherry', 'pear', 'grape']
1.3 extend():将一个可迭代对象的元素逐个添加到列表末尾
extend() 方法用于将另一个可迭代对象(如列表、元组、字符串等)中的所有元素逐个添加到当前列表的末尾。
1.3.1 方法说明
与 append() 不同,extend() 不会将可迭代对象作为一个整体添加,而是将其“打散”后逐个添加。它直接修改原始列表,不返回值。
list.extend(iterable)
iterable:一个可迭代对象,其元素将被添加到列表中。
1.3.2 代码示例
list_a = [1, 2, 3]
list_b = [4, 5, 6]
print(f"初始列表 A: {list_a}")
print(f"初始列表 B: {list_b}")# 使用 extend 将 list_b 的元素添加到 list_a
list_a.extend(list_b)
print(f"extend list_b 到 list_a 后: {list_a}")# extend 也可以用于其他可迭代对象,如元组或字符串
list_c = ["x", "y"]
tuple_d = ("z", "w")
string_e = "uv"list_c.extend(tuple_d)
print(f"extend 元组 {tuple_d} 到 list_c 后: {list_c}")list_c.extend(string_e) # 字符串会被拆分为单个字符
print(f"extend 字符串 '{string_e}' 到 list_c 后: {list_c}")
(1) 输出结果
初始列表 A: [1, 2, 3]
初始列表 B: [4, 5, 6]
extend list_b 到 list_a 后: [1, 2, 3, 4, 5, 6]
extend 元组 ('z', 'w') 到 list_c 后: ['x', 'y', 'z', 'w']
extend 字符串 'uv' 到 list_c 后: ['x', 'y', 'z', 'w', 'u', 'v']
1.3.3 append() vs extend()
理解 append() 和 extend() 的区别非常重要:
graph TDA[列表 L = [1, 2]] --> B{操作};B -- L.append([3, 4]) --> C[结果: L = [1, 2, [3, 4]]];B -- L.extend([3, 4]) --> D[结果: L = [1, 2, 3, 4]];
append()将整个参数视为一个元素。extend()将参数(必须是可迭代对象)的每个元素分别添加到列表中。
二、列表元素的删除
从列表中移除不再需要的元素同样是常见的操作。Python 列表为此提供了多种机制。
2.1 remove():删除列表中第一个匹配的指定元素
remove() 方法用于删除列表中第一个出现的指定值的元素。
2.1.1 方法说明
如果列表中存在多个相同的元素,remove() 只会删除第一个匹配到的。如果指定的元素不存在于列表中,会抛出 ValueError 异常。该方法直接修改原始列表,不返回值。
list.remove(value)
value:要从列表中删除的元素值。
2.1.2 代码示例
numbers = [10, 20, 30, 20, 40]
print(f"初始列表: {numbers}")# 删除元素 20 (第一个匹配到的)
numbers.remove(20)
print(f"删除第一个 20 后: {numbers}")# 尝试删除不存在的元素
try:numbers.remove(50)
except ValueError as e:print(f"删除 50 时出错: {e}")# 删除元素 30
numbers.remove(30)
print(f"删除 30 后: {numbers}")
(1) 输出结果
初始列表: [10, 20, 30, 20, 40]
删除第一个 20 后: [10, 30, 20, 40]
删除 50 时出错: list.remove(x): x not in list
删除 30 后: [10, 20, 40]
(2) 场景应用与问题排查
当你不关心元素的位置,只知道要删除的元素的值时,remove() 非常有用。但请务必注意,如果要删除的元素可能不存在,最好使用 try-except 块来捕获 ValueError,或者先检查元素是否存在(例如使用 in 运算符)。
my_list = [1, 2, 3]
element_to_remove = 4
if element_to_remove in my_list:my_list.remove(element_to_remove)
else:print(f"元素 {element_to_remove} 不在列表中,无法删除。")
2.2 pop():移除并返回指定位置的元素(默认为末尾)
pop() 方法用于移除列表中指定索引位置的元素,并返回被移除的元素。如果未指定索引,则默认移除并返回列表的最后一个元素。
2.2.1 方法说明
pop() 方法直接修改原始列表。如果指定的索引超出了列表的范围,会抛出 IndexError 异常。
list.pop([index])
index(可选):要移除元素的索引。如果省略,则移除并返回最后一个元素。
2.2.2 代码示例
colors = ["red", "green", "blue", "yellow"]
print(f"初始列表: {colors}")# 移除并返回最后一个元素
last_color = colors.pop()
print(f"移除的最后一个元素: {last_color}")
print(f"移除最后一个元素后: {colors}")# 移除并返回索引为 0 的元素
first_color = colors.pop(0)
print(f"移除的索引 0 元素: {first_color}")
print(f"移除索引 0 元素后: {colors}")# 尝试 pop 一个空列表或无效索引
empty_list = []
try:empty_list.pop()
except IndexError as e:print(f"对空列表 pop 时出错: {e}")try:colors.pop(5) # colors 此时长度为 1
except IndexError as e:print(f"pop 超出范围索引时出错: {e}")
(1) 输出结果
初始列表: ['red', 'green', 'blue', 'yellow']
移除的最后一个元素: yellow
移除最后一个元素后: ['red', 'green', 'blue']
移除的索引 0 元素: red
移除索引 0 元素后: ['green', 'blue']
对空列表 pop 时出错: pop from empty list
pop 超出范围索引时出错: pop index out of range
(2) pop() 的应用场景
pop() 非常适合实现栈(Stack LIFO - Last In First Out)或队列(Queue FIFO - First In First Out,配合 pop(0))等数据结构。同时,当你需要获取被删除元素的值进行后续处理时,pop() 是不二之选。
2.3 del 语句:根据索引或切片删除元素
del 是 Python 的一个关键字(不是列表的方法),它可以用来删除列表中的一个或多个元素,甚至可以删除整个列表变量。
2.3.1 语句说明
del 可以通过索引删除单个元素,也可以通过切片删除一段连续的元素。
del list[index] # 删除指定索引的元素
del list[start:end] # 删除指定切片范围的元素
del list # 删除整个列表变量
2.3.2 代码示例
data = [10, 20, 30, 40, 50, 60]
print(f"初始列表: {data}")# 删除索引为 2 的元素 (值为 30)
del data[2]
print(f"删除 data[2] 后: {data}")# 删除索引 1 到 3 (不包含 3) 的元素 (值为 20, 40)
# 注意:此时列表已变为 [10, 20, 40, 50, 60],所以 data[1] 是 20, data[2] 是 40
# 如果基于原始列表,data[1:3] 是 [20, 30]
# 在上一步操作后,data = [10, 20, 40, 50, 60]
# del data[1:3] 将删除 data[1] (20) 和 data[2] (40)
del data[1:3] # 实际删除的是当前列表的索引1和2,即元素20和40
print(f"删除 data[1:3] 后: {data}")# 删除整个列表变量
another_list = ["a", "b", "c"]
print(f"删除前 another_list: {another_list}")
del another_list
# print(another_list) # 取消注释此行会引发 NameError,因为 another_list 已被删除
# print("another_list 已被删除")
(1) 输出结果
初始列表: [10, 20, 30, 40, 50, 60]
删除 data[2] 后: [10, 20, 40, 50, 60]
删除 data[1:3] 后: [10, 50, 60]
删除前 another_list: ['a', 'b', 'c']
(如果取消最后 print(another_list) 的注释并运行,会得到 NameError: name 'another_list' is not defined)
(2) del vs pop() vs remove()
remove(value):按值删除,只删除第一个匹配项,不返回值。pop([index]):按索引删除(默认最后一个),返回被删除的元素。del list[index]/del list[slice]:按索引或切片删除,不返回值。del是更通用的删除操作,不仅限于列表。
2.4 clear():清空列表中的所有元素
如果你想删除列表中的所有元素,使其变为空列表,可以使用 clear() 方法。
2.4.1 方法说明
clear() 方法直接修改原始列表,使其成为一个空列表。它不返回任何值。
list.clear()
2.4.2 代码示例
items = [1, "apple", True, 3.14]
print(f"初始列表: {items}")items.clear()
print(f"clear() 之后: {items}")
(1) 输出结果
初始列表: [1, 'apple', True, 3.14]
clear() 之后: []
(2) clear() vs del list[:] vs list = []
list.clear():原地清空列表,对象 ID 不变。del list[:]:原地清空列表,效果与clear()类似,对象 ID 不变。list = []:将变量list重新指向一个新的空列表对象,原列表如果不再有其他引用则会被垃圾回收,对象 ID 会改变。
list1 = [1, 2, 3]
list2 = list1 # list2 和 list1 指向同一个对象
id_before = id(list1)# 使用 clear()
# list1.clear()
# print(f"list1 after clear: {list1}, id: {id(list1)}") # list1 is [], id 不变
# print(f"list2 after list1.clear: {list2}, id: {id(list2)}") # list2 is [], id 不变# 使用 del list1[:]
# del list1[:]
# print(f"list1 after del list1[:]: {list1}, id: {id(list1)}") # list1 is [], id 不变
# print(f"list2 after del list1[:]: {list2}, id: {id(list2)}") # list2 is [], id 不变# 使用 list1 = []
list1 = []
print(f"list1 after list1 = []: {list1}, id: {id(list1)}") # list1 is [], id 改变
print(f"list2 after list1 = []: {list2}, id: {id(list2)}") # list2 仍是 [1,2,3], id 不变 (是原始对象的id)print(f"Original id: {id_before}")
根据选择的清空方式,list1 的 id 可能会改变。如果希望原地修改,clear() 或 del list[:] 是更好的选择。
三、列表元素的查找与计数
在处理列表数据时,我们经常需要确定某个元素是否存在、它的位置在哪里,或者它在列表中出现了多少次。
3.1 index():查找指定元素第一次出现的索引
index() 方法用于返回列表中指定元素第一次出现的索引位置。
3.1.1 方法说明
如果元素存在于列表中,则返回其第一个匹配的索引。如果元素不存在,则抛出 ValueError 异常。可以指定查找的起始和结束位置。
list.index(value, [start, [end]])
value:要查找的元素。start(可选):开始搜索的索引位置(包含)。end(可选):结束搜索的索引位置(不包含)。
3.1.2 代码示例
letters = ['a', 'b', 'c', 'b', 'd', 'a']
print(f"列表: {letters}")# 查找 'b' 的索引
idx_b = letters.index('b')
print(f"元素 'b' 第一次出现的索引: {idx_b}")# 查找 'a' 从索引 1 开始的第一次出现位置
idx_a_after_0 = letters.index('a', 1)
print(f"元素 'a' 从索引 1 开始第一次出现的索引: {idx_a_after_0}")# 查找 'b' 在索引 2 到 4 (不含) 之间第一次出现的位置
idx_b_slice = letters.index('b', 2, 4)
print(f"元素 'b' 在索引 2 到 4 之间第一次出现的索引: {idx_b_slice}")# 尝试查找不存在的元素
try:idx_z = letters.index('z')
except ValueError as e:print(f"查找 'z' 时出错: {e}")
(1) 输出结果
列表: ['a', 'b', 'c', 'b', 'd', 'a']
元素 'b' 第一次出现的索引: 1
元素 'a' 从索引 1 开始第一次出现的索引: 5
元素 'b' 在索引 2 到 4 之间第一次出现的索引: 3
查找 'z' 时出错: 'z' is not in list
(2) 使用 in 运算符进行安全查找
为了避免 ValueError,通常在调用 index() 之前先用 in 运算符检查元素是否存在。
if 'c' in letters:print(f"'c' 的索引是: {letters.index('c')}")
else:print("'c' 不在列表中。")
3.2 count():统计指定元素在列表中出现的次数
count() 方法用于统计一个指定元素在列表中总共出现了多少次。
3.2.1 方法说明
如果元素不存在于列表中,count() 会返回 0,而不会抛出异常。
list.count(value)
value:要统计出现次数的元素。
3.2.2 代码示例
scores = [100, 90, 85, 90, 70, 90, 60]
print(f"分数列表: {scores}")# 统计 90 分出现的次数
count_90 = scores.count(90)
print(f"90 分出现了 {count_90} 次")# 统计 95 分出现的次数 (不存在)
count_95 = scores.count(95)
print(f"95 分出现了 {count_95} 次")# 统计 True (在Python中 True == 1)
mixed_list = [1, True, 0, False, True, 1.0] # True is 1, False is 0
count_true = mixed_list.count(True)
print(f"True 在 {mixed_list} 中出现了 {count_true} 次") # 注意 True 和 1 会被视为相同
(1) 输出结果
分数列表: [100, 90, 85, 90, 70, 90, 60]
90 分出现了 3 次
95 分出现了 0 次
True 在 [1, True, 0, False, True, 1.0] 中出现了 3 次
(2) 注意 True 和 1,False 和 0 的相等性
在 Python 中,True 等价于整数 1,False 等价于整数 0。因此,count(True) 也会统计列表中的 1 (反之亦然)。
四、列表的排序与反转
对列表中的元素进行排序或反转顺序也是非常常见的需求。
4.1 sort():对列表进行原地排序
sort() 方法用于对列表中的元素进行原地排序,即直接修改原始列表。
4.1.1 方法说明
默认情况下,sort() 按升序排序。可以通过 reverse 参数进行降序排序。对于数字,按大小排序;对于字符串,按字母顺序(字典序)排序。如果要排序的列表中包含不同类型的不可比较元素(如数字和字符串直接比较),会抛出 TypeError。
list.sort(key=None, reverse=False)
key(可选):一个函数,用于从每个列表元素中提取一个用于比较的键。例如key=str.lower可以实现不区分大小写的排序。reverse(可选):布尔值。如果为True,则列表按降序排序;默认为False(升序)。
4.1.2 代码示例
# 数字排序
numbers = [5, 1, 4, 2, 8]
print(f"原始数字列表: {numbers}")
numbers.sort()
print(f"升序排序后: {numbers}")numbers.sort(reverse=True)
print(f"降序排序后: {numbers}")# 字符串排序
names = ["Charlie", "Alice", "Bob", "david"]
print(f"\n原始名称列表: {names}")
names.sort() # 默认区分大小写,大写字母在前
print(f"默认排序后: {names}")names.sort(key=str.lower) # 不区分大小写排序
print(f"不区分大小写升序排序后: {names}")names.sort(key=str.lower, reverse=True) # 不区分大小写降序排序
print(f"不区分大小写降序排序后: {names}")# 按长度排序
words = ["apple", "banana", "kiwi", "pear"]
print(f"\n原始单词列表: {words}")
words.sort(key=len)
print(f"按长度升序排序后: {words}")# 尝试对混合类型排序 (会引发错误)
# mixed_data = [3, "apple", 1, "banana"]
# try:
# mixed_data.sort()
# except TypeError as e:
# print(f"\n混合类型排序错误: {e}")
(1) 输出结果
原始数字列表: [5, 1, 4, 2, 8]
升序排序后: [1, 2, 4, 5, 8]
降序排序后: [8, 5, 4, 2, 1]原始名称列表: ['Charlie', 'Alice', 'Bob', 'david']
默认排序后: ['Alice', 'Bob', 'Charlie', 'david']
不区分大小写升序排序后: ['Alice', 'Bob', 'Charlie', 'david']
不区分大小写降序排序后: ['david', 'Charlie', 'Bob', 'Alice']原始单词列表: ['apple', 'banana', 'kiwi', 'pear']
按长度升序排序后: ['kiwi', 'pear', 'apple', 'banana']
如果取消混合类型排序的注释,会看到类似 TypeError: '<' not supported between instances of 'str' and 'int' 的错误。
4.2 reverse():原地反转列表中的元素顺序
reverse() 方法用于将列表中的元素顺序进行原地反转。
4.2.1 方法说明
该方法不进行排序,仅仅是将当前列表的元素头尾颠倒。它直接修改原始列表,不返回值。
list.reverse()
4.2.2 代码示例
my_list = [1, "two", 3.0, "four"]
print(f"原始列表: {my_list}")my_list.reverse()
print(f"反转后列表: {my_list}")numbers_sorted = [1, 2, 3, 4, 5]
print(f"\n已排序列表: {numbers_sorted}")
numbers_sorted.reverse() # 反转后变成降序
print(f"反转后 (变为降序): {numbers_sorted}")
(1) 输出结果
原始列表: [1, 'two', 3.0, 'four']
反转后列表: ['four', 3.0, 'two', 1]已排序列表: [1, 2, 3, 4, 5]
反转后 (变为降序): [5, 4, 3, 2, 1]
4.3 sorted():返回一个新的已排序列表(内建函数)
与 list.sort() 方法不同,sorted() 是一个内建函数,它可以对任何可迭代对象进行排序,并返回一个新的、已排序的列表,原始的可迭代对象保持不变。
4.3.1 函数说明
sorted() 的参数与 list.sort() 方法的 key 和 reverse 参数类似。
sorted(iterable, key=None, reverse=False)
iterable:任何可迭代对象,如列表、元组、字符串、字典的键等。key(可选):与list.sort()中的key作用相同。reverse(可选):与list.sort()中的reverse作用相同。
4.3.2 代码示例
original_numbers = (5, 1, 4, 2, 8) # 这是一个元组
print(f"原始元组: {original_numbers}")sorted_list = sorted(original_numbers)
print(f"sorted() 返回的新列表 (升序): {sorted_list}")
print(f"原始元组仍保持不变: {original_numbers}")desc_sorted_list = sorted(original_numbers, reverse=True)
print(f"sorted() 返回的新列表 (降序): {desc_sorted_list}")# 对字符串进行排序 (返回字符列表)
text = "Python"
sorted_chars = sorted(text)
print(f"\n原始字符串: {text}")
print(f"sorted() 字符串后得到字符列表: {sorted_chars}")# 对列表使用 sorted()
list_to_sort = ["grape", "apple", "Banana"]
new_sorted_list = sorted(list_to_sort, key=str.lower)
print(f"\n原始列表: {list_to_sort}")
print(f"sorted() 返回的新列表 (不区分大小写): {new_sorted_list}")
print(f"原始列表仍保持不变: {list_to_sort}")
(1) 输出结果
原始元组: (5, 1, 4, 2, 8)
sorted() 返回的新列表 (升序): [1, 2, 4, 5, 8]
原始元组仍保持不变: (5, 1, 4, 2, 8)
sorted() 返回的新列表 (降序): [8, 5, 4, 2, 1]原始字符串: Python
sorted() 字符串后得到字符列表: ['P', 'h', 'n', 'o', 't', 'y']原始列表: ['grape', 'apple', 'Banana']
sorted() 返回的新列表 (不区分大小写): ['apple', 'Banana', 'grape']
原始列表仍保持不变: ['grape', 'apple', 'Banana']
(2) sort() vs sorted()
list.sort():- 是列表对象的方法。
- 原地修改列表。
- 返回
None。 - 只能用于列表。
sorted(iterable):- 是内建函数。
- 不修改原始可迭代对象。
- 返回一个新的排序后的列表。
- 可以用于任何可迭代对象。
选择哪个取决于你是否需要保留原始列表以及是否需要排序后的结果赋给新变量。
五、获取列表长度
len() 是一个内建函数,用于返回序列(如列表、字符串、元组等)或集合中元素的数量。
5.1 len() 函数
5.1.1 函数说明
len(s)
s:一个序列或集合。
5.1.2 代码示例
my_list = [10, 20, 30, 40, 50]
length = len(my_list)
print(f"列表 {my_list} 的长度是: {length}")empty_list = []
length_empty = len(empty_list)
print(f"空列表 {empty_list} 的长度是: {length_empty}")nested_list = [1, [2, 3], 4] # 嵌套列表 [2,3] 算作一个元素
length_nested = len(nested_list)
print(f"嵌套列表 {nested_list} 的长度是: {length_nested}")
(1) 输出结果
列表 [10, 20, 30, 40, 50] 的长度是: 5
空列表 [] 的长度是: 0
嵌套列表 [1, [2, 3], 4] 的长度是: 3
六、列表推导式 (List Comprehension) - 初步介绍
列表推导式是 Python 中一种非常强大且简洁的创建列表的方式。它提供了一种基于现有列表(或其他可迭代对象)生成新列表的优雅语法。
6.1 什么是列表推导式?
列表推导式通常比使用 for 循环和 append() 方法创建列表更加紧凑和易读(一旦你熟悉了它的语法)。它的基本形式是在方括号内包含一个表达式,后跟一个 for 子句,然后是零个或多个 for 或 if 子句。
6.2 基本语法
new_list = [expression for item in iterable if condition]
expression:对item进行处理的表达式,其结果将成为新列表的元素。item:从iterable中取出的每个元素。iterable:一个可迭代对象,如列表、元组、字符串、range()等。condition(可选):一个if语句,用于过滤iterable中的元素。只有满足condition的item才会被expression处理并加入到新列表中。
6.3 代码示例
6.3.1 简单示例:生成数字序列
# 使用 for 循环创建 0-9 的平方列表
squares_loop = []
for x in range(10):squares_loop.append(x**2)
print(f"使用 for 循环: {squares_loop}")# 使用列表推导式创建 0-9 的平方列表
squares_comprehension = [x**2 for x in range(10)]
print(f"使用列表推导式: {squares_comprehension}")
(1) 输出结果
使用 for 循环: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
使用列表推导式: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
6.3.2 带条件过滤的示例
# 使用 for 循环获取一个列表中的所有偶数
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_numbers_loop = []
for num in numbers:if num % 2 == 0:even_numbers_loop.append(num)
print(f"\n原始列表: {numbers}")
print(f"使用 for 循环提取偶数: {even_numbers_loop}")# 使用列表推导式提取偶数
even_numbers_comprehension = [num for num in numbers if num % 2 == 0]
print(f"使用列表推导式提取偶数: {even_numbers_comprehension}")
(1) 输出结果
原始列表: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
使用 for 循环提取偶数: [2, 4, 6, 8, 10]
使用列表推导式提取偶数: [2, 4, 6, 8, 10]
6.3.3 表达式应用示例
# 将列表中的所有字符串转换为大写
words = ["hello", "world", "python"]
uppercase_words = [word.upper() for word in words]
print(f"\n原始单词列表: {words}")
print(f"转换为大写后: {uppercase_words}")
(1) 输出结果
原始单词列表: ['hello', 'world', 'python']
转换为大写后: ['HELLO', 'WORLD', 'PYTHON']
6.4 列表推导式的优点
- 简洁性:代码更短,更易于阅读(对于熟悉其语法的人而言)。
- 效率:通常比等效的
for循环加append更快,因为很多操作在 C 语言层面实现。
列表推导式是 Python 的一个重要特性,我们将在后续的进阶主题中更深入地探讨它以及相关的推导式(如字典推导式、集合推导式)。
七、总结
本篇文章详细介绍了 Python 列表的常用方法和一项高级特性,帮助我们更有效地操作和管理列表数据。核心内容概括如下:
- 添加元素:
append(obj): 在列表末尾添加单个元素。insert(index, obj): 在指定索引位置插入单个元素。extend(iterable): 将一个可迭代对象中的所有元素逐个添加到列表末尾。
- 删除元素:
remove(value): 删除列表中第一个匹配的指定值,值不存在则报错。pop([index]): 移除并返回指定索引的元素(默认末尾),索引不存在或列表为空则报错。del list[index]或del list[slice]: 根据索引或切片删除元素,不返回值。clear(): 清空列表所有元素,列表本身依然存在。
- 查找与计数:
index(value, [start, [end]]): 返回指定元素首次出现的索引,不存在则报错。count(value): 返回指定元素在列表中出现的次数。
- 排序与反转:
sort(key=None, reverse=False): 对列表进行原地排序(修改原列表)。reverse(): 原地反转列表元素顺序(修改原列表)。sorted(iterable, key=None, reverse=False): 内建函数,返回一个新的已排序列表,不修改原可迭代对象。
- 获取长度:
len(list): 内建函数,返回列表中的元素数量。
- 列表推导式 (初步):
- 提供了一种简洁、高效地基于现有可迭代对象创建新列表的语法:
[expression for item in iterable if condition]。
- 提供了一种简洁、高效地基于现有可迭代对象创建新列表的语法:
熟练掌握这些列表方法对于编写高效、简洁的 Python 代码至关重要。列表作为 Python 中用途最广泛的数据结构之一,其灵活性和强大的内置功能使其成为处理各种数据集的理想选择。在接下来的学习中,我们将继续探索 Python 其他重要的数据结构,例如元组和字典。
相关文章:

【Python-Day 12】Python列表进阶:玩转添加、删除、排序与列表推导式
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

RAII是什么?
RAII(Resource Acquisition Is Initialization,资源获取即初始化)是C编程中的一项非常重要且经典的设计思想,也是现代C资源管理的基石。它主要解决资源的自动管理与释放问题,从而帮助程序员避免资源泄漏、悬空指针等常…...

Qt开发经验 --- 避坑指南(14)
文章目录 [toc]1 linux下使用linuxdeploy打包2 Qt源码下载3 QtCreator配置github copilot实现AI编程4 使用其它编程AI辅助开发Qt5 Qt开源UI库6 QT6.8以后版本安装QtWebEngine7 清除QtCreator配置 更多精彩内容👉内容导航 👈👉Qt开发经验 &…...

JavaScript 循环语句全解析:选择最适合的遍历方式
循环是编程中处理重复任务的核心工具。JavaScript 提供了多种循环语句,每种都有其适用场景和独特优势。本文将深入解析 JavaScript 的 6 种核心循环语句,通过实际示例帮助你精准选择合适的循环方案。 一、基础循环三剑客 1. for 循环 经典索引控制 ja…...
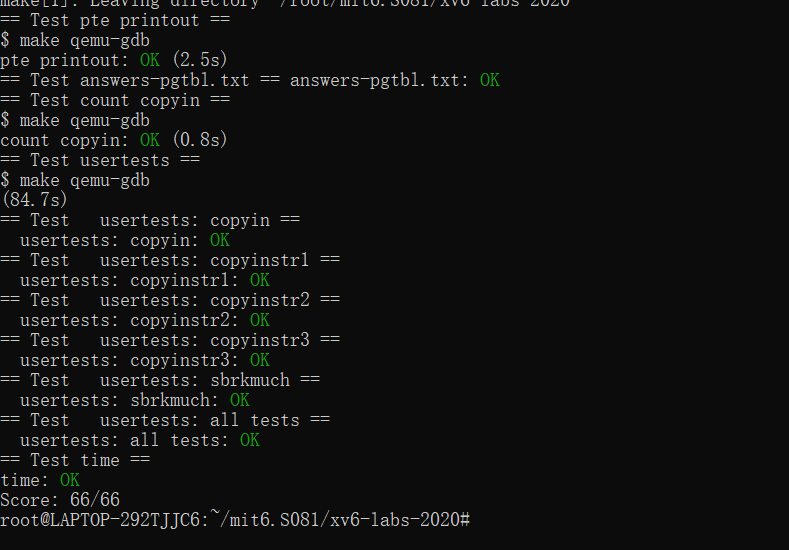
MIT 6.S081 2020 Lab3 page tables 个人全流程
文章目录 零、写在前面1、关于页表2、RISC-V Rv39页表机制3、虚拟地址设计4、页表项设计5、访存流程6、xv6 的页表切换7、页表遍历 一、Print a page table1.1 说明1.2 实现 二、A kernel page table per process2.1 说明2.2 初始化 / 映射相关2.3 用户内核页表的创建和回收2.4…...

Oracle 通过 ROWID 批量更新表
Oracle 通过 ROWID 批量更新表 在 Oracle 数据库中,使用 ROWID 进行批量更新是一种高效的更新方法,因为它直接定位到物理行位置,避免了通过索引查找的开销。 ROWID 基本概念 ROWID 是 Oracle 数据库中每一行的唯一物理地址标识符ÿ…...

webpack 的工作流程
Webpack 的工作流程可以分为以下几个核心步骤,我将结合代码示例详细说明每个阶段的工作原理: 1. 初始化配置 Webpack 首先会读取配置文件(默认 webpack.config.js),合并命令行参数和默认配置。 // webpack.config.js…...

tcpdump 的用法
tcpdump 是一款强大的命令行网络抓包工具,用于捕获和分析网络流量。以下是其核心用法指南: 一、基础命令格式 sudo tcpdump [选项] [过滤表达式]权限要求:需 root 权限(使用 sudo) 二、常用选项 选项说明-i <接口…...

Agent杂货铺
零散记录一些Agent相关的内容。不成体系,看情况是否整理 ReAct ReAct 是一种实践代理模型的高级框架,通过将大语言模型(LLMs)的推理和执行行动的能力结合起来,增强了它们在处理复杂任务时的决策能力、适应性和与外部…...

【Redis】Redis的主从复制
文章目录 1. 单点问题2. 主从模式2.1 建立复制2.2 断开复制 3. 拓扑结构3.1 三种结构3.2 数据同步3.3 复制流程3.3.1 psync运行流程3.3.2 全量复制3.3.3 部分复制3.3.4 实时复制 1. 单点问题 单点问题:某个服务器程序,只有一个节点(只搞一个…...

第04章—技术突击篇:如何根据求职意向进行快速提升与复盘
经过上一讲的内容阐述后,咱们定好了一个与自身最匹配的期望薪资,接着又该如何准备呢? 很多人在准备时,通常会选择背面试八股文,这种做法效率的确很高,毕竟能在“八股文”上出现的题,也绝对是面…...

Quantum convolutional nerual network
一些问答 1.Convolution: Translationally Invariant Quasilocal Unitaries 理解? Convolution(卷积): 在量子信息或量子多体系统中,"卷积"通常指一种分层、局部操作的结构,类似于经典卷积神经网…...

RL之ppo训练
又是一篇之前沉在草稿箱的文章,放出来^V^ PPO原理部分这两篇就够了: 图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读人人都能看懂的RL-PPO理论知识 那些你或多或少听过的名词 actor-critic: actor表示策略,critic表示价值…...

AI云防护真的可以防攻击?你的服务器用群联AI云防护吗?
1. 传统防御方案的局限性 静态规则缺陷:无法应对新型攻击模式(如HTTP慢速攻击)资源浪费:固定带宽采购导致非攻击期资源闲置 2. AI云防护技术实现 动态流量调度算法: # 智能节点选择伪代码(参考群联防护…...

Docker封装深度学习模型
1.安装Docker Desktop 从官网下载DockerDesktop,安装。(默认安装位置在C盘,可进行修改) "D:\Program Files (x86)\Docker\Docker Desktop Installer.exe" install --installation-dir"D:\Program Files (x86)\Do…...

11、参数化三维产品设计组件 - /设计与仿真组件/parametric-3d-product-design
76个工业组件库示例汇总 参数化三维产品设计组件 (注塑模具与公差分析) 概述 这是一个交互式的 Web 组件,旨在演示简单的三维零件(如带凸台的方块)的参数化设计过程,并结合注塑模具设计(如开模动画)与公…...

4.4 os模块
os模块: chdir:修改工作路径 --- 文件所在位置的标识 getcwd():返回当前路径,如果修改了则显示修改后的路径 curdir:获取当前目录的表示形式 cpu_count():返回当前cpu的线程数 getppid(): 获取当前进程编号 getppid():获取当前进程的父进…...
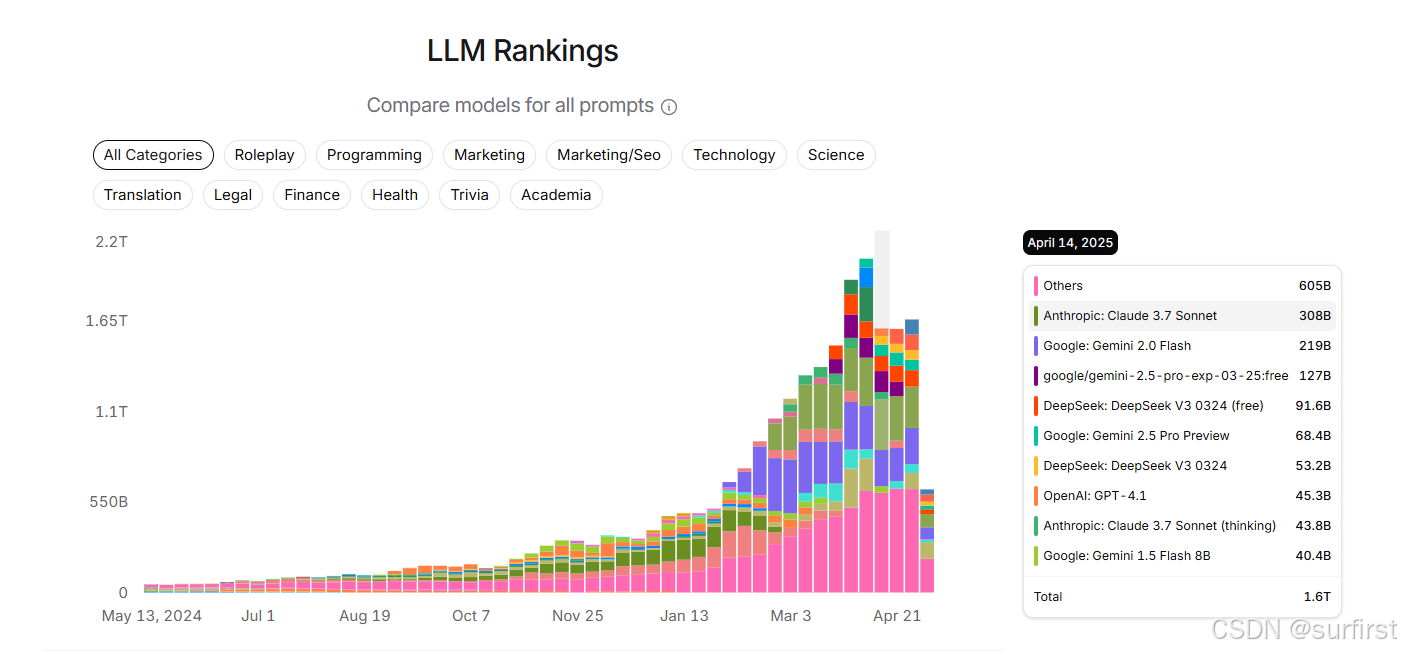
OpenAI 30 亿收购 Windsurf:AI 编程助手风口已至
导语: 各位开发者同仁、产品经理伙伴们,从2024年起,一场由AI驱动的研发范式革命已然来临。Cursor等AI代码编辑器凭借与大语言模型的深度集成,正以前所未有的态势挑战,甚至颠覆着IntelliJ、VS Code等传统IDE的固有疆域。根据OpenRouter的API使用数据,Anthropic的Claude 3.…...

材料创新与工艺升级——猎板PCB引领高频阻抗板制造革命
在5G通信、AI服务器和自动驾驶的推动下,高频电路对信号完整性的要求日益严苛。猎板PCB作为国内高端PCB制造的标杆企业,通过材料创新与工艺革新,实现了阻抗控制的突破性进展,为行业树立了新标杆。 1. 高频材料的突破 传统FR-4基材…...

协议路由与路由协议
协议路由”和“路由协议”听起来相似,但其实是两个完全不同的网络概念。下面我来分别解释: 一、协议路由(Policy-Based Routing,PBR) ✅ 定义: 协议路由是指 根据预设策略(策略路由࿰…...

【linux】倒计时小程序、进度条小程序及其puls版本
小编个人主页详情<—请点击 小编个人gitee代码仓库<—请点击 linux系列专栏<—请点击 倘若命中无此运,孤身亦可登昆仑,送给屏幕面前的读者朋友们和小编自己! 目录 前言一、知识铺垫1. 回车换行2. 缓冲区 二、倒计时小程序1. 实现 三、进度条小…...

HTML难点小记:一些简单标签的使用逻辑和实用化
HTML难点小记:一些简单标签的使用逻辑和实用化 jarringslee 文章目录 HTML难点小记:一些简单标签的使用逻辑和实用化简单只是你的表象标签不是随便用的<div> 滥用 vs 语义化标签的本质嵌套规则的隐藏逻辑SEO 与可访问性的隐形关联 暗藏玄机的表单…...

FastAPI实现JWT校验的完整指南
在现代Web开发中,构建安全的API接口是开发者必须面对的核心挑战之一。随着FastAPI框架的普及,其异步高性能特性与Python类型提示的结合,为开发者提供了构建高效服务的强大工具。本文将深入探讨如何基于FastAPI实现JWT(JSON Web To…...

物流无人机结构与载货设计分析!
一、物流无人机的结构与载货设计模块运行方式 1.结构设计特点 垂直起降与固定翼结合:针对复杂地形(如山区、城市)需求,采用垂直起降(VTOL)与固定翼结合的复合布局,例如“天马”H型无人机&am…...

Linux 常用命令集合
以下是一份 Linux 常用命令集合,涵盖文件操作、系统管理、网络管理、权限管理、进程管理等常见任务,并附上代码示例: 1. 文件与目录操作 命令作用示例ls列出目录内容ls -l(详细列表) ls -a(显示隐藏文件&a…...
原理详解)
LoRA(Low-Rank Adaptation)原理详解
LoRA(Low-Rank Adaptation)原理详解 LoRA(低秩适应)是一种参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)技术,旨在以极低的参数量实现大模型在特定任务上的高效适配。其核心思想基于低秩分解假设,即模型在适应新任务时,参数更新矩阵具有低秩特性,可用少量参…...
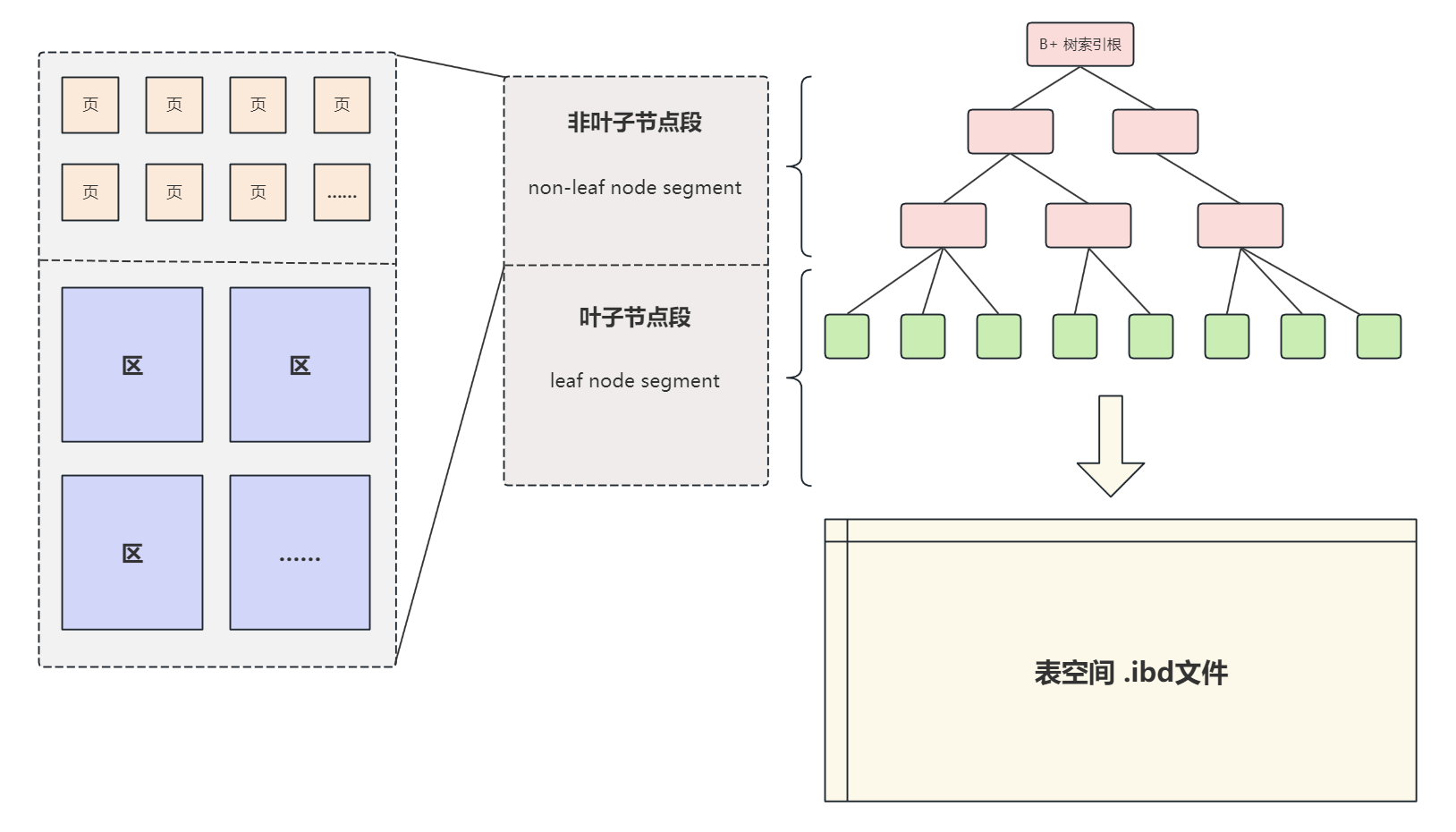
【MySQL】表空间结构 - 从何为表空间到段页详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
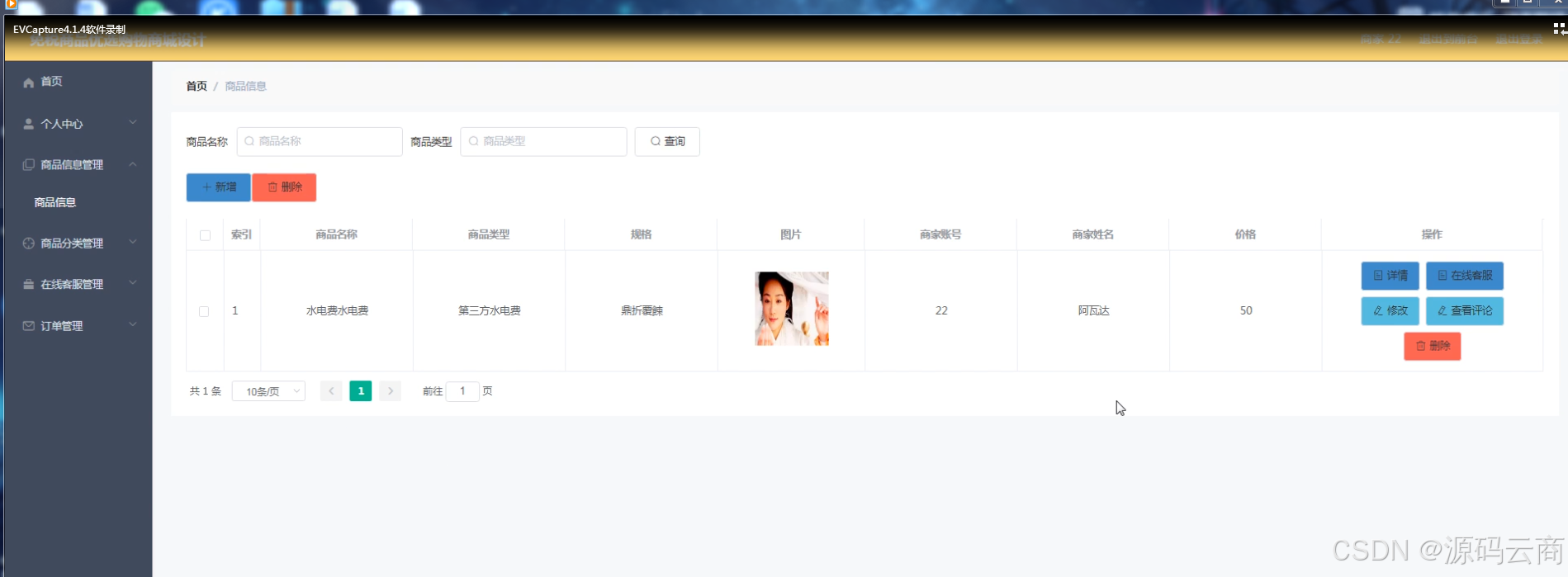
[特殊字符] 免税商品优选购物商城系统 | Java + SpringBoot + Vue | 前后端分离实战项目分享
一、项目简介 本项目为一款功能完备的 免税商品优选购物商城系统,采用 Java 后端 Vue 前端的主流前后端分离架构,支持用户、商家、管理员三类角色,满足商品浏览、下单、商家管理、后台运营等多项功能,适用于实际部署或作为毕业设…...
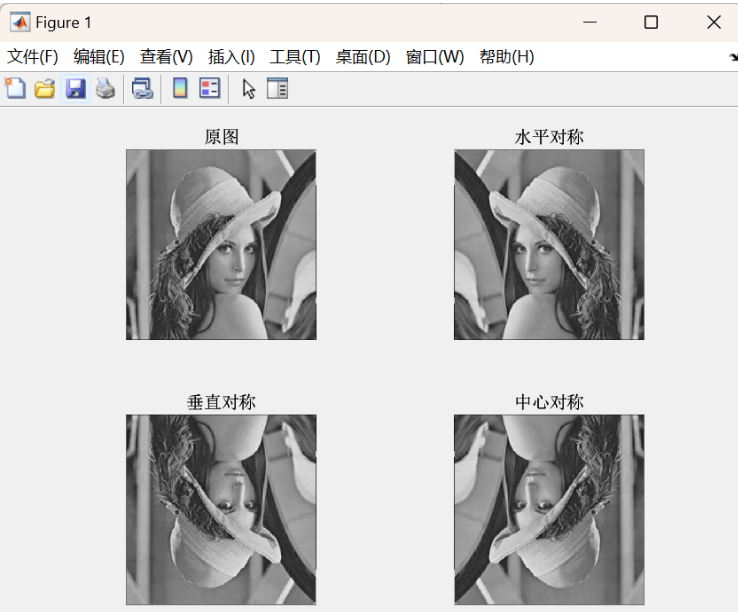
图像处理基础与图像变换
一、目的 通过本次实验,加深对数字图像的理解,熟悉MATLAB中的有关函数;应用DCT对图像进行变换;熟悉图像常见的统计指标,实现图像几何变换的基本方法。 二、内容与设计思想 1、实验内容:选择两幅图像&…...
)
《Effective Python》第1章 Pythonic 思维详解——深入理解 Python 条件表达式(Conditional Expressions)
《Effective Python》第1章 Pythonic 思维详解——深入理解 Python 条件表达式(Conditional Expressions) 在 Python 中,条件表达式(conditional expressions)提供了一种简洁的方式来在一行中实现 if/else 的逻辑。它…...